Abstract
In the realm of medical image processing, the segmentation of dermatological lesions is a pivotal technique for the early detection of skin cancer. However, existing methods for segmenting images of skin lesions often encounter limitations when dealing with intricate boundaries and diverse lesion shapes. To address these challenges, we propose VMPANet, designed to accurately localize critical targets and capture edge structures. VMPANet employs an inverted pyramid convolution to extract multi-scale features while utilizing the visual Mamba module to capture long-range dependencies among image features. Additionally, we leverage previously extracted masks as cues to facilitate efficient feature propagation. Furthermore, VMPANet integrates parallel depthwise separable convolutions to enhance feature extraction and introduces innovative mechanisms for edge enhancement, spatial attention, and channel attention to adaptively extract edge information and complex spatial relationships. Notably, VMPANet refines a novel cross-attention mechanism, which effectively facilitates the interaction between deep semantic cues and shallow texture details, thereby generating comprehensive feature representations while reducing computational load and redundancy. We conducted comparative and ablation experiments on two public skin lesion datasets (ISIC2017 and ISIC2018). The results demonstrate that VMPANet outperforms existing mainstream methods. On the ISIC2017 dataset, its mIoU and DSC metrics are 1.38% and 0.83% higher than those of VM-Unet respectively; on the ISIC2018 dataset, these metrics are 1.10% and 0.67% higher than those of EMCAD, respectively. Moreover, VMPANet boasts a parameter count of only 0.383 M and a computational load of 1.159 GFLOPs.
1. Introduction
Medical image diagnosis plays a crucial role in clinical practice, yet this process heavily relies on the subjective assessment of physicians, which carries a certain risk of misdiagnosis. Misdiagnosis can not only delay patient treatment but also increase mortality and morbidity rates [1]. Artificial intelligence technology has advanced continuously, allowing medical image segmentation to gradually become an essential auxiliary tool to address this issue, which holds significant importance in the medical field. This technology provides a precise image basis for computer-aided diagnosis, helping physicians more accurately identify lesions and determine the type and extent of diseases. Additionally, it can be used to evaluate post-treatment effects by comparing pre- and post-treatment images, visually presenting changes in lesion areas and providing a robust basis for subsequent treatment decisions. In summary, medical image segmentation is a crucial task that underpins computer-aided diagnosis, surgical guidance, and post-treatment evaluation.
In the field of medical image segmentation, the application of machine learning and deep learning technologies has made significant strides. Notably, methods based on Convolutional Neural Networks (CNNs), Transformers, and Mamba have shown impressive performance [2,3,4]. These technologies offer powerful tools for medical image segmentation tasks, greatly advancing the field, yet numerous challenges remain. CNN-based methods excel at capturing local texture details and enhancing feature interaction [5,6]. However, their limited receptive fields restrict their ability to perform global modeling, which may reduce accuracy, as shown in Figure 1a. To address this issue, some studies [7,8,9] have employed dilated convolutions and large kernel convolutions to enhance the model’s ability to capture long-range dependencies, attempting to overcome the limitations of CNNs’ receptive fields. Nevertheless, these methods still face limitations in fully capturing rich global context.
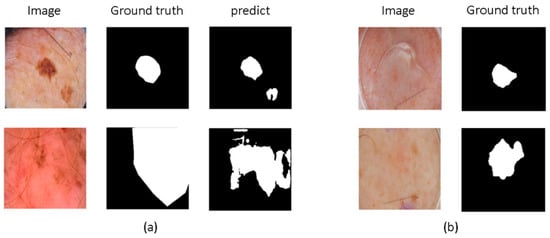
Figure 1.
The challenges in medical image segmentation. (a) The limited receptive field of CNN-based methods restricts their ability to perform global modeling. (b) Medical images exhibit complex edge features, such as blurred boundaries and difficulty in defining boundaries.
On the other hand, Transformers have developed rapidly, leading many researchers to combine them with medical image segmentation methods. Transformer-based methods excel in global modeling and establishing long-range dependencies. Consequently, related research [10] has applied Transformers to medical image segmentation to effectively capture global context, although they are not as effective as CNNs in extracting local details. To address this limitation, some studies [11,12,13] have combined Transformers and CNNs to perform hybrid encoding, aiming to consider both low-level features and global regions of images, thereby maintaining feature richness and consistency. However, these methods often come with high computational costs and large parameter counts. In contrast, Mamba-based architectures offer linear complexity and excel in capturing long-range dependencies [14,15]. For instance, H-vmunet [16] achieves accurate predictions by leveraging CNNs to capture detailed features at lower levels and employing high-order visual Mamba to establish long-range dependencies at deeper levels.
Moreover, as depicted in Figure 1b, medical images exhibit complex edge features. Some methods [17,18] enhance edge information by progressively integrating shallow and deep features or by stacking multiple convolutional layers to continuously extract key information. Additionally, some methods [19,20] extract high-order and low-order features from encoder outputs, capturing high-frequency edge and low-frequency non-edge information and using channel and spatial attention mechanisms to fuse them, enriching edge features. Comparatively, coarse-to-fine registration methods can also capture edge details. Meng et al. [21] designed a correlation-aware window MLP module to capture correlation-aware multi-distance dependencies with different receptive fields, utilizing correlations between images and registration steps to achieve a coarse-to-fine registration process, accurately capturing more details. However, these methods do not account for the diversity of image edge information. Zhou et al. [22] introduced multi-granularity edge detection to capture edge information at different granularities, creating multi-scale feature maps to generate various edge maps. They also decomposed feature maps into low-frequency and high-frequency components to precisely control edge map details. Although these methods are effective, they often incur high computational costs and do not specifically emphasize the details of boundary features.
We analyze the inherent complexity of different edge sizes—namely, the diverse shapes and uneven distribution of skin lesion areas and the complexity of edge structures such as blurred boundaries and difficult-to-define borders—and propose VMPANet, a lightweight network based on the combination of visual Mamba and convolution, contextual self-prompting, and attention mechanisms. Specifically, VMPANet extracts local detail feature information through convolutional layers and establishes long-range dependencies using Mamba. Additionally, it facilitates the propagation and collaboration of features at different depths based on previously generated hint masks. It also extracts multi-scale features through efficient parallel depthwise separable convolutions and adaptively aggregates each feature map at each scale using pointwise convolutions to obtain comprehensive feature representations. By leveraging edge enhancement, spatial attention, and channel attention mechanisms, VMPANet adaptively captures edge details and integrates complex spatial relationships. Furthermore, to combine cross-layer features, we employ a cross-attention mechanism, processing features from the spatial dimension, using high-level semantic cues for saliency guidance and low-level texture information for detail enhancement, dynamically allocating attention to specific regions to facilitate collaboration between cross-layer features.
Our main contributions are summarized as follows:
- We propose a Context Prompt Encoder (PCM) that addresses the inherent complexity of different edge sizes by extracting local detail features using convolution and establishing long-range dependencies with visual Mamba. It enhances feature propagation based on previously generated hint masks, aiding in better localization of salient objects and adding fine-grained details.
- We design a Context-Enhanced Decoder (MCA) that addresses the complexity of edge structures by capturing unified feature representations through multi-scale parallel depthwise separable convolutions. It adaptively emphasizes fine-grained edge information from spatial and channel dimensions, extracting complex spatial relationships to highlight important regions in medical images.
- We introduce a cross-attention mechanism to accurately localize salient targets in deep features while utilizing detail cues from shallow features. The proposed Cross-Attention Fusion (CAF) module employs a single-head self-attention mechanism to effectively enhance the complementarity between semantic information in deep features and texture details in shallow features, which is crucial for accurately localizing salient objects.
To provide a clear roadmap for this paper, the subsequent sections are organized as follows. Section 2 reviews related work on CNN-based, Transformer-based, and Mamba-based models for medical image segmentation. Section 3 details the proposed VMPANet architecture, including the Context Prompt Encoder (PCM), Context-Enhanced Decoder (MCA), and Cross-Attention Fusion (CAF) module, as well as the loss function design. Section 4 presents experimental settings, datasets, evaluation metrics, and comparative results with mainstream methods, along with ablation studies to validate the effectiveness of each component. Finally, Section 5 concludes the paper and outlines future research directions.
2. Related Work
This section summarizes existing research relevant to medical image segmentation, focusing on three mainstream model frameworks: CNN-based, Transformer-based, and Mamba-based approaches. As illustrated in Table 1, each sub-section elaborates on the core principles, advantages, limitations, and representative works of the corresponding framework, laying a foundation for the proposed VMPANet by identifying gaps in current research.
2.1. Medical Image Segmentation Trends
Recent advances in medical image segmentation have witnessed the integration of emerging technologies and interdisciplinary methods, expanding the boundaries of clinical applicability and feature extraction capability. On the one hand, the fusion of cutting-edge technologies such as metaverse with healthcare has opened new avenues for multi-modal data integration and clinical workflow optimization [23]. This trend emphasizes the need for segmentation models to adapt to complex clinical scenarios, such as real-time interaction and multi-source data fusion, which aligns with our goal of enhancing VMPANet’s practical value in clinical settings. On the other hand, rule-based and decision-driven methods remain valuable complements to deep learning approaches, especially in scenarios requiring interpretable feature extraction. For instance, Gupta et al. [24] proposed a fuzzy rule-based system combined with decision trees for breast cancer detection, demonstrating the effectiveness of structured decision logic in capturing discriminative medical image features. This work highlights the importance of targeted feature modeling—an idea we extend in VMPANet through attention mechanisms and edge enhancement, tailored specifically for skin lesion segmentation.

Table 1.
Direct comparative analysis of core frameworks for medical image segmentation.
2.2. CNN-Based Models
Deep learning has developed rapidly, significantly enhancing the performance of models based on Convolutional Neural Networks (CNNs). Rahman et al. [25] proposed an efficient multi-scale convolutional attention decoder that enhances feature maps through unique multi-scale deep convolution blocks. This model utilizes channel, spatial, and group gated attention to capture complex spatial relationships and highlight salient regions. The cascading attention mechanism has also proven to be effective. Wu et al. [26] introduced a high-order spatial interaction model based on recurrent gated convolutions and incorporated a multi-level dimension fusion mechanism, achieving precise segmentation results and better generalization capabilities. However, the limited receptive field of convolutions restricts their ability to focus on global regions. To address this issue, Azad et al. [27] proposed a large kernel attention mechanism that expands the receptive field to capture more contextual information, effectively utilizing both high-frequency and low-frequency information to perform segmentation tasks.
2.3. Transformer-Based Models
Transformers have developed rapidly, leading many researchers to combine them with medical image segmentation methods. Valanarasu et al. [28] used Transformers for medical image segmentation tasks, introducing a gated axial attention mechanism to effectively integrate global contextual information, particularly excelling in handling complex anatomical structures and multimodal data. Cao et al. [10] leveraged the hierarchical architecture and sliding window technique of the Swin Transformer to design a pure Transformer model for medical image segmentation, demonstrating strong capabilities in handling images of different resolutions. Compared to pure Transformer methods, combining Transformers with CNNs can achieve higher performance. Chen et al. [11] combined the powerful encoding capabilities of the Transformer structure with the classic U-Net decoder. They introduced the global feature extraction capability of Transformers, effectively capturing long-range dependencies in complex medical image segmentation tasks and significantly improving segmentation accuracy and robustness. Heidari et al. [13] further expanded the application of Transformers in medical image segmentation by constructing hierarchical multi-scale feature representations, capturing both local details and global contextual information of images, and establishing effective feature fusion between coarse-grained and fine-grained feature representations, achieving excellent performance.
2.4. Mamba-Based Models
State Space Models (SSMs) have developed rapidly, prompting many researchers to combine them with medical image segmentation. Zhu et al. [29] broke through the bottleneck of traditional visual modeling with a bidirectional state space model, achieving linear complexity in global feature extraction. Its unique bidirectional recurrent structure can simultaneously capture forward and backward contextual dependencies of images, significantly enhancing model efficiency and performance. Liu et al. [30] further introduced a cross-scan mechanism and a two-dimensional selective scan module (SS2D) based on visual Mamba. As shown in Figure 2, SS2D achieves multi-scale feature fusion through four-directional scan paths, further improving model performance. Ruan et al. [31] were the first to combine a pure state space model with the classic U-Net structure, designing the Visual State Space (VSS) block as a core component. Its asymmetric encoder and decoder structure reduces the number of convolutional layers while utilizing the global modeling capability of the state space model to capture long-range dependencies. Liu et al. [32] further explored the value of transfer learning in medical image segmentation. This model uses Vmamba [30] as the encoder foundation, combined with a hierarchical feature extraction strategy, and initializes network parameters through ImageNet pretraining, significantly enhancing the model’s generalization ability. Zou et al. [33] proposed a hybrid architecture based on Mamba and CNN, achieving accurate segmentation results on a skin lesion segmentation dataset.
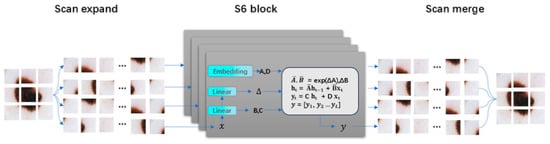
Figure 2.
The scan expanding operation and scan merging operation in SS2D [30].
3. Method
This section comprehensively describes the design of VMPANet, a lightweight network tailored for skin lesion image segmentation. We first introduce the overall architecture of the model, then detail the three core modules (PCM, MCA, CAF), respectively, including their structural designs, working mechanisms, and mathematical formulations. Finally, the loss function adopted in the training process is presented to address the specific challenges of skin lesion segmentation.
To address the issues of varied sizes and shapes of skin lesion areas, uneven distribution, and the difficulty in defining blurred boundaries, we propose VMPANet, a lightweight network that combines visual Mamba and convolution, contextual self-prompting, and attention mechanisms. As illustrated in Figure 3, VMPANet consists of three main modules: the PCM module, the MCA module, and the CAF module.
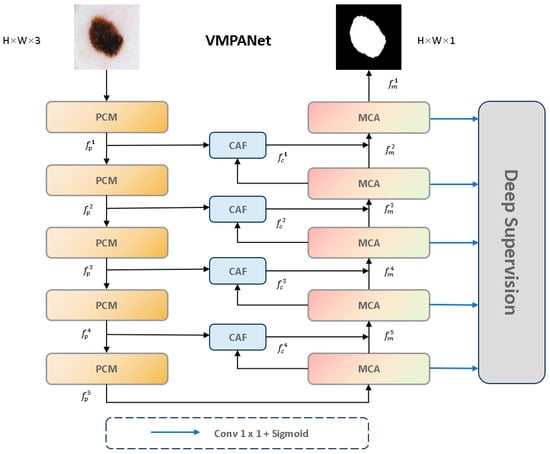
Figure 3.
The overall architecture of VMPANet.
The PCM module is responsible for extracting local features using convolutional layers and performing global modeling with visual Mamba to obtain high-quality encoded features. Subsequently, two sets of hint masks are used to enhance feature propagation and provide target information. The MCA module first uses visual Mamba and the two-dimensional selective scan block (SS2D) to model long-term dependencies of each feature in four directions. Then, convolution operations are employed to aggregate information from the remaining four diagonal directions to enhance feature representation. Additionally, to effectively capture and aggregate multi-scale feature representations, a set of parallel depthwise separable convolutions with different kernel sizes is used to achieve this goal, effectively extracting multi-scale features. It dynamically allocates local attention to specific regions from both spatial and channel dimensions, enabling the capture of edge structures. The CAF module employs a single-head self-attention mechanism to capture global context across spatial dimensions. It uses deep high-level semantic cues from the MCA module as saliency guidance while supplementing shallow low-level texture details generated by the PCM module, thereby thoroughly highlighting globally interesting regions. Furthermore, we introduce a multi-stage supervision mechanism to guide the decoder output at each stage.
3.1. Context Prompt Encoder (PCM)
The challenges in skin lesion image segmentation primarily arise from the inherent complexity of varying edge sizes. Therefore, we need a mechanism that can extract both global and local contextual information while promoting effective feature propagation to fully utilize the features extracted by the encoder.
As shown in Figure 4, the PCM module adopts an inverted pyramid convolution approach to extract both global and local contextual information, effectively transitioning from a large receptive field to a small receptive field. Since the receptive field of convolutional layers is limited and can only handle intra-domain information, failing to capture extra-domain information effectively, we utilized visual Mamba to extract long-range dependencies. To propagate the features extracted by the PCM module effectively, we designed prompts based on previous studies [34,35,36]. Specifically, these prompts generate a hint based on the local detail information extracted by CNN to enhance the model’s localization ability and sensitivity to details. Simultaneously, another hint is generated based on the global contextual information extracted by visual Mamba to guide the model in locating globally salient targets. Additionally, as shown in Figure 4, the input image size is 3 256 256, and the encoder network consists of 5 layers. The output of each encoder block is defined as , where , and .
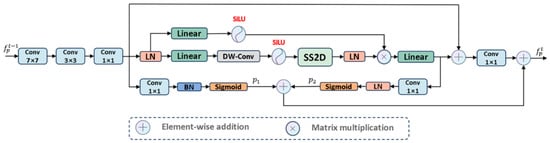
Figure 4.
The architecture of PCM module.
PCM: Extracts information from the feature space in a coarse-to-fine manner. First, we used large kernel convolutions to extract rich global detail prior information and project the input feature map to . Then, we used small kernel convolutions to capture local salient regions from . Finally, convolutions are used to aggregate features from each channel, resulting in a unified feature representation .
Considering the limitations of convolution operations in exploring features within a limited domain, we introduced visual Mamba to capture global long-range dependencies, allowing the extraction of comprehensive feature representations . Subsequently, we applied convolutions to enhance feature expression capability and map to , as shown in Equations (1) and (2):
where and are hyperparameters used to manage the influence of global and local contexts on the results, effectively balancing the two types of information.
Most importantly, to propagate features effectively, we designed self-prompts. Specifically, as shown in Figure 4, based on local features , we established a “many-to-one channel” mapping to generate mask prompt to provide target detail information. Similarly, based on global features , we also established a mapping to generate mask prompt to provide salient region information. To enhance the adaptability and stability of these two mask prompts, we normalized them to obtain standardized mask prompts. These two segmentation masks propagate from shallow to deep layers, and then synergize with , effectively handling contextual features to achieve precise localization of salient targets. The specific process is as follows:
where denotes the number of channels, is used to control the importance of the feature map in the -th channel, represents the feature map of in the -th channel, and represents the feature map of in the -th channel. denotes batch normalization, denotes layer normalization, and is a hyperparameter. is used as the input for the CAF module and the next PCM module.
3.2. Context Enhanced Decoder (MCA)
The challenges in skin lesion image segmentation primarily stem from the complexity of edge structures. To address this issue, Ref. [8] introduced a parallel axial attention mechanism to explore multi-scale information through different convolutional depths and used an uncertainty-enhanced contextual attention mechanism to extract critical information from these features. Another study [25] utilized skip connections to fully integrate high-level salient information with low-level local information, achieving more accurate feature representation. Although these studies considered both global and local contexts, they overlooked the importance of fine-grained edge features in salient regions.
Therefore, there is an urgent need for a method that can extract fine-grained multi-scale contextual information while learning complex tissue edge information, reweighting salient and non-salient information, and maintaining a lightweight model. Based on these considerations, we designed the MCA module, as shown in Figure 5. To effectively capture multi-scale feature representations, the MCA module first uses visual Mamba to establish long-term dependencies. The 2D Selective Scanning Block (SS2D Block) models long-term dependencies for each feature in four directions. To capture multi-scale detail information in hierarchical features and effectively address the direction sensitivity issue in 2D visual data, we used parallel depthwise separable convolutions to extract multi-scale features with different receptive fields and fine granularity, and aggregate information from the remaining four diagonal directions to enhance feature representation. Within each scale, it applies pointwise convolution to adaptively aggregate each feature map at that scale, achieving comprehensive feature representation. This approach aims to capture local texture details while better aggregating long-term dependencies. Next, we used the EASC module to adaptively extract important information from multi-scale features to enhance segmentation performance. Specifically, a combination of Edge Enhancement (EE), Spatial Attention (SA), and Channel Attention (CA) was used to improve the contrast between salient and non-salient regions from spatial and channel dimensions.
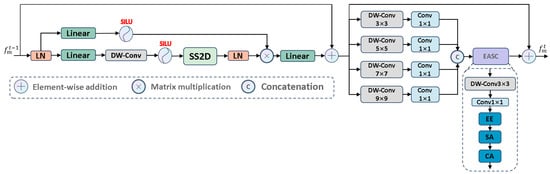
Figure 5.
The architecture of MCA module.
MCA: As shown in Figure 5, it uses four different receptive fields to map features to four different scales , thereby capturing both global context and local fine-grained information simultaneously. To effectively integrate features from different channels, we introduced a convolution to enhance feature representation, defined as follows:
Then, we used a concatenation operation to aggregate the multi-scale features into a unified feature representation, which can contain long-range dependencies and local texture details.
where serves as the input to the EASC module. Considering the impact of complex boundary structures, we improved segmentation accuracy by deeply mining the multi-scale features . Specifically, we used convolutions to extract embedded contextual information from , thereby expanding the interaction between features. This process generates rich contextual clues and salient information, as follows:
where denotes batch normalization, and serves as the subsequent input.
Next, to emphasize salient edges, we propose the EE module, as shown in Figure 6. We used large kernel depthwise separable convolutions to capture global detail information. Then, we analyzed the edge differences between salient and non-salient information to highlight edge features. To prevent excessive edge differences, we normalized these differences to make them smooth. Next, we applied the Sigmoid activation function to estimate edge saliency scores, where higher weights correspond to salient regions and lower weights correspond to non-salient regions. Based on these scores, we further learn the boundary information of salient regions. The specific process is as follows:
where is , denotes element-wise subtraction, denotes
average pooling, and serves as the input to the SA module.
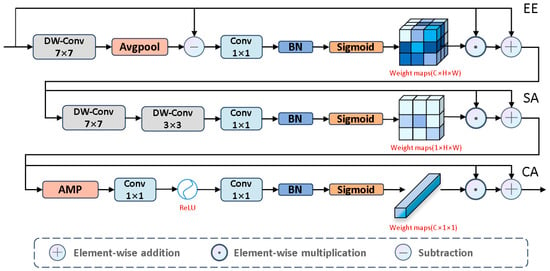
Figure 6.
The architecture of EASC module.
To effectively capture complex spatial relationships, we introduce the SA module, which focuses on the salient regions of the input image, as shown in Figure 6. Specific steps include: first, we use large kernel depthwise separable convolutions to extract key global background information, thereby enhancing the model’s ability to accurately identify salient targets in complex environments. Next, we use small kernel convolutions to focus on local salient features. Finally, through the Sigmoid activation function, these features are converted into spatial saliency scores, assigning higher scores to salient regions and lower scores to background information. The specific process is as follows:
where is , , and serves as the input to the CA module.
Next, we used the CA module, as shown in Figure 6, to assign different levels of importance to each channel, thereby enhancing feature diversity to emphasize valuable features and suppress less important ones. The entire process is as follows:
where is , denotes adaptive max pooling, and is the output of the EASC module. To help the information flow at different depths locate salient regions in complex tissues, we established skip connections to seamlessly integrate into . The specific process is as follows:
where is the output of the t-layer MCA module and serves as the input to the CAF module.
3.3. Cross Attention Fusion Module (CAF)
To accurately locate salient targets in deep features while leveraging detailed cues from shallow features and maintaining the lightweight nature of the model, we need to develop a method that can effectively utilize cross-layer features. Thus, we propose the CAF module. This module employs a single-head self-attention mechanism to capture global context across spatial dimensions, using deep high-level semantic cues from the decoder module as saliency guidance while supplementing shallow low-level texture details generated by the encoder module. This thoroughly highlights globally interesting regions. The CAF module establishes a bidirectional information transmission channel between high-level semantic features (saliency) and low-level detail features (details). Through an attention weight matrix, it dynamically adjusts the spatial and channel dependencies between features, allowing high-level features to supplement detail information and low-level features to receive semantic guidance. The final output is a fused feature that combines spatial details and semantic discriminative power.
CAF: Specifically, we propose the CAF module to process and , as shown in Figure 7. We first performed an upsampling operation and then executed a convolution to map to , while enhancing the CAF module’s ability to learn from . The specific steps are as follows:
where is the query. Simultaneously, we also used a convolution to adaptively learn to enhance its expressive ability and similarly map it to . Specifically:
where is the key (index). Then, to capture important information across the entire spatial dimension, we used as and is , which allows better handling of different features. Specifically, we performed matrix multiplication on and , then applied the SoftMax function to obtain a set of weights that focus on salient regions and suppress non-salient regions. To enhance stability during the training process, we introduced a normalization factor to normalize the attention weights. Specifically:
where , and denotes matrix multiplication. To globally extract deep high-level semantic information and capture shallow texture details, thereby promoting cross-layer feature complementarity, we designed two branches: and . This ensures that the complementary knowledge generated by and can be fully propagated across the branches, establishing connections between the complementary knowledge, and , and focusing on salient regions. Specifically:
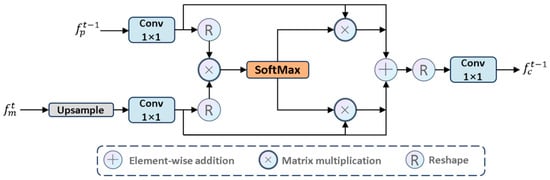
Figure 7.
The architecture of CAF module.
Considering the limitations of the single-head self-attention mechanism in 2D modeling, we integrated feature maps using convolution from a local modeling perspective, balancing high-frequency salient information and low-frequency non-salient information in each feature map. Specifically:
where is the output of the CAF module and serves as the input to the t-layer MCA module.
3.4. Loss Function
During the training phase, we attached pixel-level supervision to each decoder block (i.e., deep supervision strategy). By supervising at different scales, the model can capture abstract features at various levels, thereby improving accuracy and achieving fast convergence. Specifically, we supervise by combining the Binary Cross-Entropy (BCE) loss with the Dice loss, as follows:
where is the total number of samples, represents the ground truth, and is the predicted value. The parameters and are hyperparameters used to adjust the weights between and .
4. Experiments and Results
This section validates the performance of VMPANet through systematic experiments. We first describe the datasets used for evaluation, followed by details of the experimental environment and parameter settings. Then, we present the evaluation metrics employed to assess segmentation quality. Comparative experiments with nine mainstream methods and ablation studies were conducted to verify the superiority and effectiveness of the proposed model, with results analyzed both quantitatively and qualitatively.
4.1. Datasets
We evaluated our proposed method on two datasets: ISIC 2017 and ISIC 2018. The ISIC17 dataset [37] and ISIC18 dataset [38] are publicly available skin lesion segmentation datasets from the International Skin Imaging Collaboration 2017 and 2018 challenges, respectively, containing 2150 and 2694 dermoscopic images with segmentation mask labels. Following previous work [39], as illustrated in Table 2, we split the datasets into training and testing sets in a 7:3 ratio. Specifically, for the ISIC17 dataset, the training set consisted of 1500 images, and the test set consisted of 650 images. For the ISIC18 dataset, the training set contained 1886 images, while the test set contained 808 images.
Table 2.
Composition of ISIC2017 and ISIC2018 datasets.
For the PH2 dataset [40], we acquired 200 images as well as dermatoscope images with segmentation mask labels. All 200 images were used for external validation. The initial size of the images was 768 × 560 pixels, and we standardized the size to 256 × 256 pixels for inputting into the model.
4.2. Experimental Environment
The experiments were implemented using Python 3.8 and Pytorch 1.13.0. All experiments were conducted on a single NVIDIA RTX 3090 (NVIDIA; Santa Clara, CA, USA) with 24 GB of VRAM. To ensure a fair comparison of model performance, the same data augmentation operations were applied, including horizontal and vertical flips, as well as random rotations. The hyperparameter optimizer adopted was AdamW, with the following specific settings: learning rate (lr) = 0.001, betas = (0.9, 0.999), epsilon (eps) = 1 × 10−8, weight decay = 1 × 10−2, and AMSGrad = False. For learning rate scheduling, we used the CosineAn-nealingLR strategy, where the maximum number of iterations (T_max) = 50, the minimum learning rate (eta_min) = 0.00001, and the index of the last epoch (last_epoch) = −1. Each input image was resized to 256 × 256. The training was conducted for 200 epochs, The batch size was set to 8.
Additional Explanation: Definition and Values of Hyperparameters in the Formulas: For the undefined parameters λ and ω in Formulas (1)–(4) and (22)–(24), their values are as follows: Formula (1)–(2) (Global-Local Feature Fusion): Parameters: λ1 (Weight of global Vision Mamba features), λ2 (Weight of local convolutional features); Values: λ1 = 0.5, λ2 = 0.5.
Formula (3) (Mask Hint Generation): Parameters: ωi (Weight of the i-th feature channel); Explanation: These are not manually set hyperparameters, but rather learnable convolutional kernel weights of the 1 × 1 convolutional layers prompt1/prompt2 in the class. End-to-end optimization is performed during training to adaptively emphasize edge/saliency-related channels. Formula (4) (Hint-Feature Fusion): Parameters: λ1 (weight of p1), λ2 (weight of p2); Values: λ1 = λ2 = 1. Formulas (22)–(24) (Loss Functions): Parameters: λ1 (weight of BCE loss), λ2 (weight of Dice loss); Values: λ1 = λ2 = 1.
4.3. Evaluation Metrics
For medical image segmentation, we adopted five widely used evaluation metrics to assess segmentation performance: mean Intersection over Union (mIoU), Dice Similarity Coefficient (DSC), Accuracy (Acc), Specificity (Spe), Sensitivity (Sen), and HD95.
where TP denotes True Positives, FP denotes False Positives, TN denotes True Negatives, and FN denotes False Negatives.
4.4. Results and Analysis
First, to evaluate the impact of different layer weights on deep supervision, we conducted experiments only on a subset of the training set’s validation set. The complete training set was divided into two parts: a sub-training set (80%) used to train the model with different weight combinations (ISIC2017: 1200 images; ISIC2018: 1509 images) and a sub-validation set (20%) used solely for performance evaluation (ISIC2017: 300 images; ISIC2018: 377 images); the test set was not involved in this process.
As shown in Table 3, the model achieves optimal accuracy only when the weights of shallow and deep layers are equal. This indicates that shallow and deep features are equally important during model training. Therefore, we adopted a third parameter setting for training.
Table 3.
Depth supervision weight settings on ISIC17 and ISIC18. Bold text is used to highlight key performance indicators.
Table 4, Table 5 and Table 6 present a comprehensive comparison of performance on the ISIC2017, ISIC2018, and PH2 datasets, while Table 7 compares model size and computational cost.
Table 4.
Performance of the sixteen methods on the ISIC17 dataset. Bold text is used to highlight key performance indicators.
Table 5.
Performance of sixteen methods on ISIC18 dataset. Bold text is used to highlight key performance indicators.
Table 6.
The PH2 dataset was compared with the external validation results of mainstream models. The PH2 dataset is a zero-shot external validation, performed only once, with no standard deviation. Bold text is used to highlight key performance indicators.
Table 7.
Model size comparison (GFLOPs/M). Bold text is used to highlight key performance indicators.
On the ISIC17 dataset, our method achieved the highest values on key metrics. Notably, its Sen value was 1.73 percentage points higher than the closest model, demonstrating superior lesion region identification ability. Similarly, on the ISIC18 dataset, our method also performed well on mIoU, DSC, Acc, and Spe, further validating its generalization ability. Although slightly inferior to some models in Sen value, its overall balance and robustness remain excellent. To verify cross-dataset generalization, we conducted zero-shot transfer experiments: the model was trained solely on ISIC2017 without any fine-tuning, domain adaptation, or parameter updates, and directly deployed for segmentation on PH2 (an independent dataset unrelated to ISIC). As shown in Table 8, our model outperformed other mainstream models on multiple metrics, demonstrating superior generalization ability. Notably, although Ultralight vm-unet [42] has fewer parameters (0.049 M), its mIoU on ISIC2017 (77.59%) and PH2 (84.23%) was 3.13% and 1.37% lower than VMPANet, demonstrating that our model achieves a better balance between efficiency and performance.
Table 8.
Shows the parameters and computational cost of the model’s encoder, decoder, and PH (segmentation head).
Moreover, as shown in Table 7 and Table 8, our proposed method showcased significant advantages in computational resources and model size: it requires only 1.159 GFLOPS of computational power and 0.383 M parameters, yet delivers high-precision performance. Compared to existing mainstream methods, our approach substantially reduces computational overhead and parameter count while sustaining competitive accuracy levels. These results indicate that our model is well-suited for resource-constrained environments and real-time processing scenarios.
We also conducted a visual comparison of our method against sixteen mainstream approaches on the ISIC17 and ISIC18 datasets, as shown in Figure 8. Most methods struggle with segmenting the complex edge structures of lesions, whereas VMPANet demonstrates superior robustness in handling these complexities. Many methods face challenges with low contrast and background interference, but VMPANet effectively addresses these issues, producing smoother and more accurate contours and boundaries. Overall, our method emphasizes both global and local information, as well as multi-scale information at different granularities, to capture significant targets in medical images. While edge enhancement can learn the differences between edge and non-edge regions to complement target contour details, it introduces errors, making it difficult for models to capture fine details in low-contrast and complex edge scenarios. Our spatial and channel attention mechanisms enable the model to adaptively focus on important targets, enhancing robustness against interference. Furthermore, we incorporate a self-attention mechanism to facilitate the complementarity between deep semantic information and shallow detail information, thereby thoroughly identifying significant targets in complex tissues.

Figure 8.
Visual comparison of sixteen methods on ISIC17 and ISIC18 datasets. (In the diagram, red circles indicate oversegmentation, and blue circles indicate undersegmentation).
4.5. Ablation Study
To comprehensively evaluate the effectiveness of our proposed method, we conducted ablation studies on VMPANet using the ISIC17 and ISIC18 datasets, as detailed below.
Table 9 shows the contributions of PCM, MCA, and CAF, while Table 10 further illustrates the ablation effects of more refined components. Clearly, as different component modules are gradually integrated into the network, segmentation performance is significantly improved, fully validating the effectiveness of each component in the model. Specifically, in PCM, convolution and Mamba operations assist the model in extracting rich local and global features, while the Prompt mechanism promotes feature propagation to identify salient targets. In MCA, depthwise separable convolutions extract multi-scale features from different receptive fields, providing rich feature representations for subsequent processing. The EASC module effectively fuses multi-scale features, while the EE module extracts complex edge features to locate salient targets. The SA and CA modules focus on salient regions, extracting key features. The CAF module extracts common salient regions from cross-layer features, promoting complementarity between deep semantic information of salient targets and detailed semantic information of shallow salient targets.
Table 9.
Ablation studies on ISIC17 and ISIC18 datasets.
Table 10.
Component-Level Ablation Results (ISIC2017 & ISIC2018).
5. Conclusions
In this paper, we propose an effective medical image segmentation method, VMPANet. We integrated Progressive Contextual Extraction (PCM), utilizing pixel correlations to gradually extract global and local contextual information and achieve in-depth exploration of salient regions based on visual Mamba. Additionally, we incorporated prompt generation features to create mask prompts that assist in feature propagation, enhancing the model’s ability to accurately identify and refine important targets. Furthermore, we introduced the Multi-scale Contextual Attention (MCA) module, which employs parallel depthwise separable convolutions for multi-scale feature extraction, effectively capturing contextual information and regions of interest from edge, spatial, and channel perspectives. This approach is particularly suitable for handling medical images with complex backgrounds, blurred edges, and intricate targets. We also presented the Cross Attention Fusion (CAF) module, combining single-head self-attention mechanisms with cross-layer feature aggregation techniques across spatial dimensions. This addresses computational redundancy issues and enhances model performance. Experimental results demonstrate that VMPANet outperforms existing mainstream methods, achieving improvements of 1.38% and 0.83% in mIoU and DSC on the ISIC2017 dataset, and 1.10% and 0.67% on the ISIC2018 dataset, with only 0.383M parameters and 1.159 GFLOPs. In future work, we aim to develop more efficient and lightweight models and explore advanced techniques further.
Despite these encouraging results, this study has some inherent limitations that warrant attention: the model adapts poorly to extreme cases (such as very small lesions or severely blurred boundaries) and has not yet been fully integrated into clinical workflows for practical application validation. To address these shortcomings, future work will focus on expanding multi-source clinical data to enhance the model’s generalization ability, optimizing feature modeling for extreme cases, and exploring integration with clinical workflows, thereby further improving the practical value of this approach in clinical practice.
Author Contributions
Conceptualization, S.L. and Z.P.; Methodology, Z.P.; Software, Z.P.; Validation, Z.P. and S.L.; Formal Analysis, Z.P.; Research, Z.P. and C.L.; Resources, S.L.; Data Processing, Z.P. and C.L.; First Draft Writing, Z.P.; Paper Review and Editing, S.L.; Visualization, Z.P.; Monitoring, S.L.; Project Management, S.L.; Funding Acquisition, S.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China (61762085).
Institutional Review Board Statement
Ethical review and approval were waived for this study due to the data used were obtained from the public databases.
Informed Consent Statement
Patient consent was waived due to the data used were obtained from the public databases.
Data Availability Statement
The data presented in this study are openly available in [ISIC] at [https://challenge.isic-archive.com/data/] (accessed on 15 November 2024).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Sonderegger-Lseli, K.; Burger, S.; Muntwyler, J.; Salomon, F. Diagnostic errors in three medical eras: A necropsy study. Lancet 2000, 355, 2027–2031. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Part III 18. Springer International Publishing: Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Vaswani, A. Attention Is All You Need; Advances in Neural Information Processing Systems: San Diego, CA, USA, 2017. [Google Scholar]
- Gu, A.; Dao, T. Mamba: Linear-time sequence modeling with selective state spaces. arXiv 2023, arXiv:2312.00752. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Rahman, M.M.; Marculescu, R. Medical image segmentation via cascaded attention decoding. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 6222–6231. [Google Scholar]
- Li, G.; Liu, Z.; Zeng, D.; Lin, W.; Ling, H. Adjacent context coordination network for salient object detection in optical remote sensing images. IEEE Trans. Cybern. 2022, 53, 526–538. [Google Scholar] [CrossRef]
- Kim, T.; Lee, H.; Kim, D. Uacanet: Uncertainty augmented context attention for polyp segmentation. In Proceedings of the 29th ACM International Conference on Multimedia, New York, NY, USA, 20–24 October 2021; pp. 2167–2175. [Google Scholar]
- Shen, K.; Zhou, X.; Liu, Z. MINet: Multiscale interactive network for real-time salient object detection of strip steel surface defects. IEEE Trans. Ind. Inform. 2024, 20, 7842–7852. [Google Scholar] [CrossRef]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer Nature: Cham, Switzerland, 2022; pp. 205–218. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, H.; Hu, Q. Transfuse: Fusing transformers and cnns for medical image segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, 27 September–1 October 2021; Part I 24. Springer International Publishing: Heidelberg, Germany, 2021; pp. 14–24. [Google Scholar]
- Heidari, M.; Kazerouni, A.; Soltany, M.; Azad, R.; Aghdam, E.K.; Cohen-Adad, J.; Merhof, D. Hiformer: Hierarchical multi-scale representations using transformers for medical image segmentation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 6202–6212. [Google Scholar]
- Ma, J.; Li, F.; Wang, B. U-mamba: Enhancing long-range dependency for biomedical image segmentation. arXiv 2024, arXiv:2401.04722. [Google Scholar]
- Patro, B.N.; Agneeswaran, V.S. Simba: Simplified mamba-based architecture for vision and multivariate time series. arXiv 2024, arXiv:2403.15360. [Google Scholar]
- Wu, R.; Liu, Y.; Liang, P.; Chang, Q. H-vmunet: High-order vision mamba unet for medical image segmentation. Neurocomputing 2025, 624, 129447. [Google Scholar] [CrossRef]
- Zhu, Z.; He, X.; Qi, G.; Li, Y.; Cong, B.; Liu, Y. Brain tumor segmentation based on the fusion of deep semantics and edge information in multimodal MRI. Inf. Fusion 2023, 91, 376–387. [Google Scholar] [CrossRef]
- Bui, N.T.; Hoang, D.H.; Nguyen, Q.T.; Tran, M.T.; Le, N. Meganet: Multi-scale edge-guided attention network for weak boundary polyp segmentation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2024; pp. 7985–7994. [Google Scholar]
- Li, X.; Li, X.; Zhang, L.; Cheng, G.; Shi, J.; Lin, Z.; Tan, S.; Tong, Y. Improving semantic segmentation via decoupled body and edge supervision. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Part XVII 16. Springer International Publishing: Heidelberg, Germany, 2020; pp. 435–452. [Google Scholar]
- Chen, G.; Wang, Q.; Dong, B.; Ma, R.; Liu, N.; Fu, H.; Xia, Y. Em-trans: Edge-aware multimodal transformer for rgb-d salient object detection. IEEE Trans. Neural Netw. Learn. Syst. 2024, 36, 3175–3188. [Google Scholar] [CrossRef] [PubMed]
- Meng, M.; Feng, D.; Bi, L.; Kim, J. Correlation-aware coarse-to-fine mlps for deformable medical image registration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 9645–9654. [Google Scholar]
- Zhou, C.; Huang, Y.; Pu, M.; Guan, Q.; Deng, R.; Ling, H. Muge: Multiple granularity edge detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 25952–25962. [Google Scholar]
- Bhaskar, H.; Raghavan, S. (Eds.) Metaverse Technologies in Healthcare; Academic Press: Cambridge, MA, USA; Elsevier: Amsterdam, The Netherlands, 2024. [Google Scholar] [CrossRef]
- Gupta, V.; Gaur, H.; Vashishtha, S.; Das, U.; Singh, V.K.; Hemanth, D.J. A fuzzy rule-based system with decision tree for breast cancer detection. IET Image Process. 2023, 17, 2083–2096. [Google Scholar] [CrossRef]
- Rahman, M.; Munir, M.; Marculescu, R. Emcad: Efficient multi-scale convolutional attention decoding for medical image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 11769–11779. [Google Scholar]
- Wu, R.; Liang, P.; Huang, X.; Shi, L.; Gu, Y.; Zhu, H.; Chang, Q. Mhorunet: High-order spatial interaction unet for skin lesion segmentation. Biomed. Signal Process. Control. 2024, 88, 105517. [Google Scholar] [CrossRef]
- Azad, R.; Niggemeier, L.; Hüttemann, M.; Kazerouni, A.; Aghdam, E.K.; Velichko, Y.; Bagci, U.; Merhof, D. Beyond self-attention: Deformable large kernel attention for medical image segmentation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2024; pp. 1287–1297. [Google Scholar]
- Valanarasu, J.M.J.; Oza, P.; Hacihaliloglu, I.; Patel, V.M. Medical transformer: Gated axial-attention for medical image segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, 27 September–1 October 2021; Part I 24. Springer International Publishing: Heidelberg, Germany, 2021; pp. 36–46. [Google Scholar]
- Zhu, L.; Liao, B.; Zhang, Q.; Wang, X.; Liu, W.; Wang, X. Vision mamba: Efficient visual representation learning with bidirectional state space model. In Proceedings of the 41st International Conference on Machine Learning (ICML’24), Vienna, Austria, 21–27 July 2024; Volume 235, pp. 62429–62442. [Google Scholar]
- Jiao, J.; Liu, Y.; Liu, Y.; Tian, Y.; Wang, Y.; Xie, L.; Ye, Q.; Yu, H.; Zhao, Y. Vmamba: Visual state space model. Adv. Neural Inf. Process. Syst. 2024, 37, 103031–103063. [Google Scholar]
- Ruan, J.; Li, J.; Xiang, S. Vm-unet: Vision mamba unet for medical image segmentation. arXiv 2024, arXiv:2402.02491. [Google Scholar] [CrossRef]
- Liu, J.; Yang, H.; Zhou, H.Y.; Xi, Y.; Yu, L.; Li, C.; Liang, Y.; Shi, G.; Yu, Y.; Zhang, S.; et al. Swin-umamba: Mamba-based unet with imagenet-based pretraining. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Marrakesh, Morocco, 6–10 October 2024; Springer Nature: Cham, Switzerland, 2024; pp. 615–625. [Google Scholar]
- Zou, S.; Zhang, M.; Fan, B.; Zhou, Z.; Zou, X. SkinMamba: A Precision Skin Lesion Segmentation Architecture with Cross-Scale Global State Modeling and Frequency Boundary Guidance. arXiv 2024, arXiv:2409.10890. [Google Scholar]
- Lee, C.; Lee, S.H.; Kim, C.S. MFP: Making Full Use of Probability Maps for Interactive Image Segmentation. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 4051–4059. [Google Scholar]
- Jiang, Y.; Huang, Z.; Zhang, R.; Zhang, X.; Zhang, S. Zept: Zero-shot pan-tumor segmentation via query-disentangling and self-prompting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 11386–11397. [Google Scholar]
- Sofiiuk, K.; Petrov, I.A.; Konushin, A. Reviving iterative training with mask guidance for interactive segmentation. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 3141–3145. [Google Scholar]
- Berseth, M. ISIC 2017-skin lesion analysis towards melanoma detection. arXiv 2017, arXiv:1703.00523. [Google Scholar]
- Codella, N.; Rotemberg, V.; Tschandl, P.; Celebi, M.E.; Dusza, S.; Gutman, D.; Helba, B.; Kalloo, A.; Liopyris, K.; Marchetti, M.; et al. Skin lesion analysis toward melanoma detection 2018: A challenge hosted by the international skin imaging collaboration (isic). arXiv 2019, arXiv:1902.03368. [Google Scholar] [CrossRef]
- Ruan, J.; Xiang, S.; Xie, M.; Liu, T.; Fu, Y. Malunet: A multi-attention and light-weight unet for skin lesion segmentation. In Proceedings of the 2022 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Las Vegas, NV, USA, 6–8 December 2022; pp. 1150–1156. [Google Scholar]
- Mendonca, T.; Ferreira, P.M.; Marques, J.S.; Marcal, A.R.S.; Rozeira, J. PH 2-A dermoscopic image database for research and benchmarking. In Proceedings of the 2013 35th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Osaka, Japan, 3–7 July 2013; pp. 5437–5440. [Google Scholar]
- Isensee, F.; Jaeger, P.F.; Kohl, S.A.; Petersen, J.; Maier-Hein, K.H. nnU-Net: A self-configuring method for deep learning-based biomedical image segmentation. Nat. Methods 2021, 18, 203–211. [Google Scholar] [CrossRef]
- Wu, R.; Liu, Y.; Ning, G.; Liang, P.; Chang, Q. Ultralight vm-unet: Parallel vision mamba significantly reduces parameters for skin lesion segmentation. Patterns 2024, 6, 101298. [Google Scholar] [CrossRef]
- Hoang, N.-K.; Nguyen, D.-H.; Tran, T.-T.; Pham, V.-T. DermoMamba: A cross-scale Mamba-based model with guide fusion loss for skin lesion segmentation in dermoscopy images. Pattern Anal. Appl. 2025, 28, 128. [Google Scholar] [CrossRef]
- Zhao, W.; Wang, F.; Wang, Y.; Xie, Y.; Wu, Q.; Zhou, Y. UD-Mamba: A pixel-level uncertainty-driven Mamba model for medical image segmentation. arXiv 2025, arXiv:2502.02024. [Google Scholar]
- Yang, M.; Ruhaiyem, N.I.R. MCM-UNet: Mamba convolutional mixing network for skin lesion image segmentation. Biomed. Signal Process. Control. 2026, 112, 108791. [Google Scholar] [CrossRef]








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).