Preliminary Studies on Genetic Profiling of Coffee and Caffeine Consumption


Abstract
1. Introduction
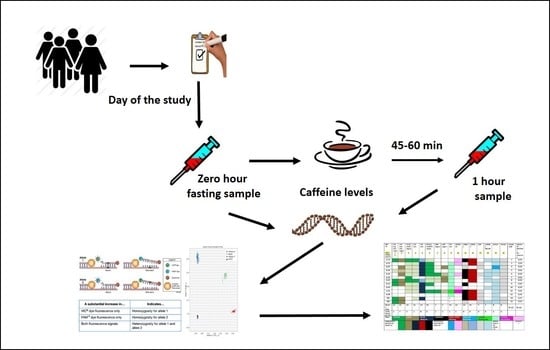
2. Materials and Methods
2.1. Sample Population
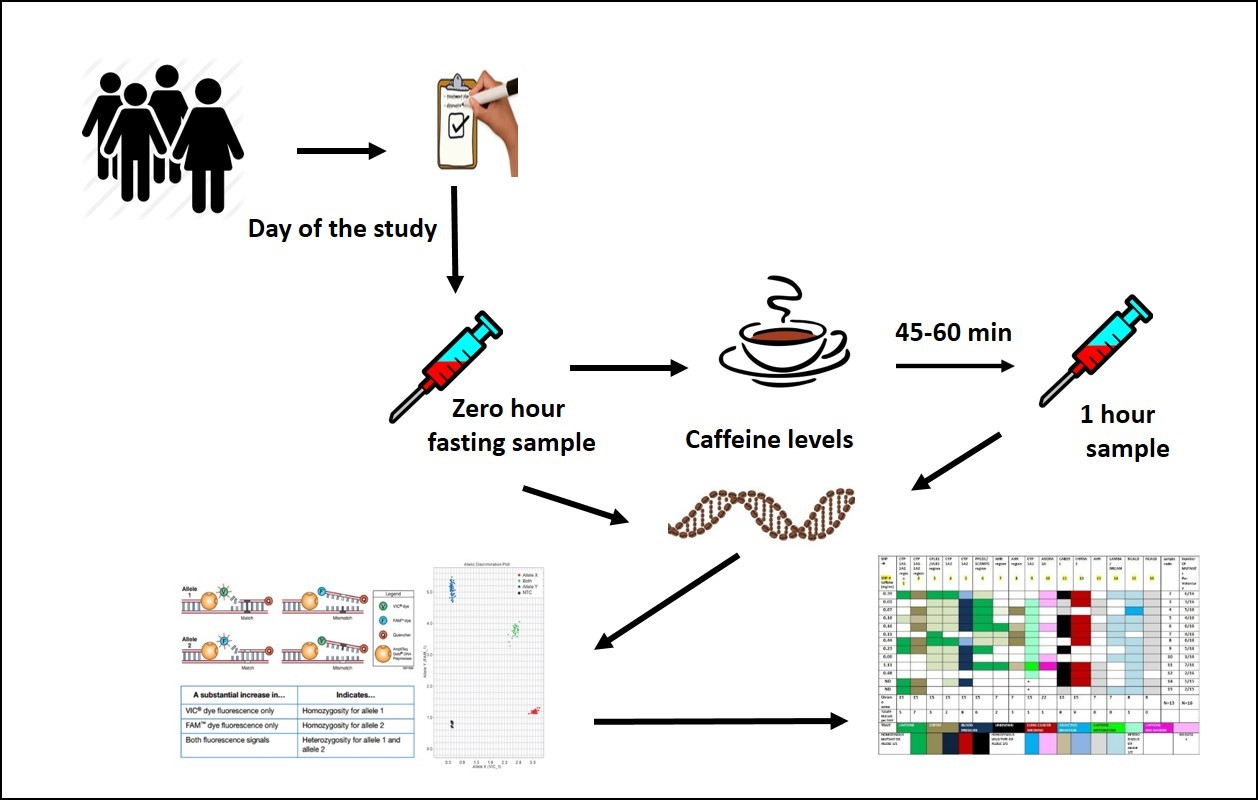
2.2. DNA Preparation and Genotyping
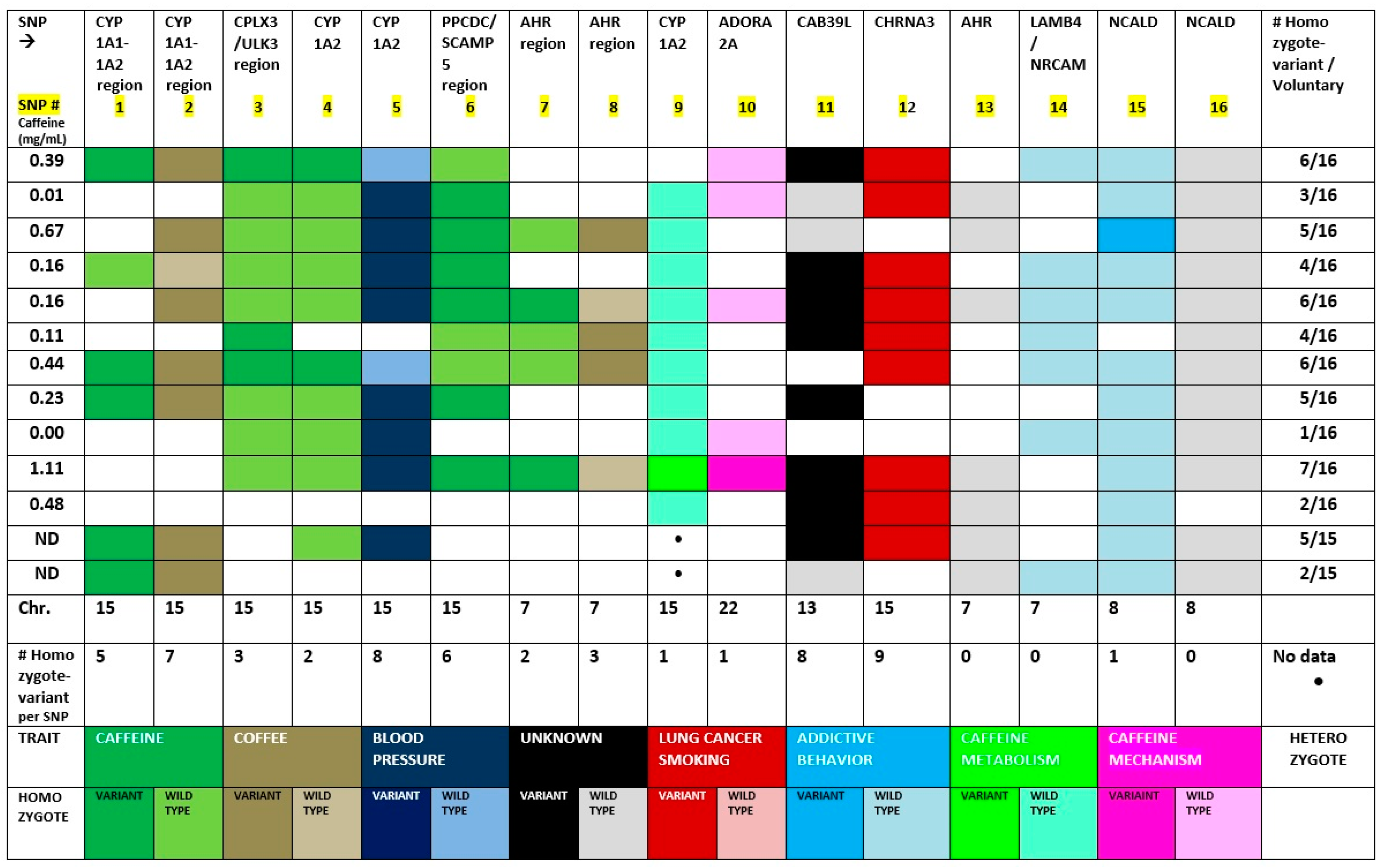
3. Results
4. Discussion
5. Conclusions
6. Patents
Funding
Acknowledgments
Conflicts of Interest
References
- Fredholm, B.B.; Battig, K.; Holmen, J.; Nehlig, A.; Zvartau, E.E. Actions of Caffeine in the Brain with Special Reference to Factors That Contribute to Its Widespread Use. Pharmacol. Rev. 1999, 51, 83–133. [Google Scholar]
- Santos, R.M. Our ‘Black Box’ Cup of Coffee: What Is Inside? Res. Pharm. 2010, 1, 60–63. [Google Scholar]
- Nehlig, A.; Debry, G. Potential Genotoxic, Mutagenic and Antimutagenic Effects of Coffee: A Review. Mutat. Res. 1994, 317, 145–162. [Google Scholar] [CrossRef]
- Butler, M.A.; Iwasaki, M.; Guengerich, F.P.; Kadlubar, F.F. Human Cytochrome P-450pa (P-450ia2), the Phenacetin O-Deethylase, Is Primarily Responsible for the Hepatic 3-Demethylation of Caffeine and N-Oxidation of Carcinogenic Arylamines. Proc. Natl. Acad. Sci. USA 1999, 86, 7696–7700. [Google Scholar] [CrossRef]
- Gu, L.; Gonzalez, F.J.; Kalow, W.; Tang, B.K. Biotransformation of Caffeine, Paraxanthine, Theobromine and Theophylline by Cdna-Expressed Human Cyp1a2 and Cyp2e1. Pharmacogenetics 1992, 2, 73–77. [Google Scholar] [CrossRef]
- Sachse, C.; Brockmoller, J.; Bauer, S.; Roots, I. Functional Significance of a C-->a Polymorphism in Intron 1 of the Cytochrome P450 Cyp1a2 Gene Tested with Caffeine. Br. J. Clin. Pharmacol. 1999, 47, 445–449. [Google Scholar] [CrossRef]
- Santos, R.M.; Cotta, K.; Jiang, S.; Lima, D.R.A. Does Cyp1a2 Genotype Influence Coffee Consumption? Austin J. Pharmacol. Ther. 2014, 3, 1065. [Google Scholar]
- Slatkin, M. Linkage Disequilibrium--Understanding the Evolutionary Past and Mapping the Medical Future. Nat. Rev. Genet. 2008, 9, 477–485. [Google Scholar] [CrossRef]
- HapMap Consortium, T.I. The International Hapmap Project. Nature 2003, 426, 789–796. [Google Scholar] [CrossRef]
- Goldstein, D.B.; Weale Michael, E. Population Genomics: Linkage Desequilibrium Holds the Key. Curr. Biol. 2001, 11, R576–R579. [Google Scholar] [CrossRef]
- Cornelis, M.C.; Byrne, E.M.; Esko, T.; Nalls, M.A.; Ganna, A.; Paynter, N.; Monda, K.L.; Amin, N.; Fischer, K.; Renstrom, F.; et al. Genome-Wide Meta-Analysis Identifies Six Novel Loci Associated with Habitual Coffee Consumption. Mol. Psychiatry 2014, 20, 647. [Google Scholar] [CrossRef]
- Cornelis, M.C. Coffee Intake. Prog. Mol. Biol. Transl. Sci. 2012, 108, 293–322. [Google Scholar]
- Cornelis, M.C.; Monda, K.L.; Yu, K.; Paynter, N.; Azzato, E.M.; Bennett, S.N.; Berndt, S.I.; Boerwinkle, E.; Chanock, S.; Chatterjee, N.; et al. Genome-Wide Meta-Analysis Identifies Regions on 7 p21 (Ahr) and 15 q24 (Cyp1a2) as Determinants of Habitual Caffeine Consumption. PLoS Genet. 2011, 7, e1002033. [Google Scholar] [CrossRef]
- Sulem, P.; Gudbjartsson, D.F.; Geller, F.; Prokopenko, I.; Feenstra, B.; Aben, K.K.; Franke, B.; den Heijer, M.; Kovacs, P.; Stumvoll, M.; et al. Sequence Variants at Cyp1a1-Cyp1a2 and Ahr Associate with Coffee Consumption. Hum. Mol. Genet. 2011, 20, 2071–2077. [Google Scholar] [CrossRef]
- Josse, A.R.; da Costa, L.A.; Campos, H.; El-Sohemy, A. Associations between Polymorphisms in the Ahr and Cyp1a1-Cyp1a2 Gene Regions and Habitual Caffeine Consumption. Am. J. Clin. Nutr. 2012, 96, 665–671. [Google Scholar] [CrossRef]
- Amin, N.; Byrne, E.; Johnson, J.; Chenevix-Trench, G.; Walter, S.; Nolte, I.M.; Vink, J.M.; Rawal, R.; Mangino, M.; Teumer, A.; et al. Genome-Wide Association Analysis of Coffee Drinking Suggests Association with Cyp1a1/Cyp1a2 and Nrcam. Mol. Psychiatry 2012, 17, 1116–1129. [Google Scholar] [CrossRef]
- Blanchard, J.; Mohammadi, J.D.; Conrad, K.A. Improved Liquid-Chromatographic Determination of Caffeine in Plasma. Clin. Chem. 1980, 26, 1351–1354. [Google Scholar]
- Zhang, W.; Ng, H.W.; Shu, M.; Luo, H.; Su, Z.; Ge, W.; Perkins, R.; Tong, W.; Hong, H. Comparing Genetic Variants Detected in the 1000 Genomes Project with Snps Determined by the International Hapmap Consortium. J. Genet. 2015, 94, 731–740. [Google Scholar] [CrossRef]
- Bickmore, W.A.; van Steensel, B. Genome Architecture: Domain Organization of Interphase Chromosomes. Cell 2013, 152, 1270–1284. [Google Scholar] [CrossRef]
- Cremer, T.; Cremer, C. Chromosome Territories, Nuclear Architecture and Gene Regulation in Mammalian Cells. Nat. Rev. Genet. 2011, 2, 292–301. [Google Scholar] [CrossRef]
- Cremer, T.; Cremer, M.; Dietzel, S.; Muller, S.; Solovei, I.; Fakan, S. Chromosome Territories--a Functional Nuclear Landscape. Curr. Opin. Cell Biol. 2006, 18, 307–316. [Google Scholar] [CrossRef]
- Nakagawa-Senda, H.; Hachiya, T.; Shimizu, A.; Hosono, S.; Oze, I.; Watanabe, M.; Matsuo, K.; Ito, H.; Hara, M.; Nishida, Y.; et al. A Genome-Wide Association Study in the Japanese Population Identifies the 12q24 Locus for Habitual Coffee Consumption: The J-Micc Study. Sci. Rep. 2018, 8, 1493. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
| SNP # | Marker (rs) | EA/NEA | CHR | Gene Symbol | Position Kb | Gene Name |
|---|---|---|---|---|---|---|
| 1 | 2470893 | [C/T] | 15 q24 | CYP1A1-1A2 region | 74727108 | Cytochrome P450 family 1A1 |
| 2 | 2472297 | [C/T] | 15 q24 | CYP1A1-1A2 region | 74735539 | Cytochrome P450 family 1A1 |
| 3 | 6495122 | [A/C] | 15 q24 | CPLX3/ULK3/ | 74833304 | Unc-51 like kinase 3 Complexin 3 |
| 4 | 2472304 | [G/A] | 15 q24 | CYP 1A2 | 74751897 | Cytochrome P450 family 1A2 |
| 5 | 1378942 | [A/C] | 15 q24 | CSK | 74785026 | c-src tyrosine kinase microRNA 4513 |
| 6 | 12148488 | [G/T] | 15 q24 | PPCDC/SCAMP5 | 75090201 | Secretory carrier membrane protein 5; phosphor-pantothenoylcysteine decarboxylase |
| 7 | 4410790 | [C/T] | 7 p21 | AHR region | 17244953 | Aryl Hydrocarbon Receptor |
| 8 | 6968865 | [A/T] | 7 p21 | AHR region | 17247645 | Aryl Hydrocarbon Receptor |
| 9 | 762551 | [C/A] | 15 q24 | CYP 1A2 | 74749576 | Cytochrome P450 family 1A2 |
| 10 | 3761422 | [C/T] | 22 q11 | SPECC 1L/ADORA2 | 24430704 | Adenosine Receptor 2A |
| 11 | 9526558 | [A/G] | 13 q14 | CAB39L | 49408376 | Calcium Binding protein g39-like |
| 12 | 1051730 | [A/G] | 15 q25 | CHRNA3 | 78601997 | Cholinergic receptor nicotinic alpha 3/alpha 5 (neuronal) |
| 13 | 2066853 | [A/G] | 7 p21 | AHR | 17339486 | Aryl Hydrocarbon Receptor |
| 14 | 382140 | [A/G] | 7 q31 | LAMB4/NRCAM | 108141755 | Neuronal cell adhesion molecule |
| 15 | 16868941 | [A/G] | 8 q22 | NCALD | 102040149 | Neurocalcin Delta |
| 16 | 17498920 | [A/G] | 8 q22 | NCALD | 102043861 | Neurocalcin Delta |
| SNP # | Homozygote Variant % Frequency | Homozygote Wild-Type % Frequency | Heterozygote % Frequency | Variant-Allele Effect Direction | Marker | Trait (NCBI) |
|---|---|---|---|---|---|---|
| 1 | 38.5 | 7.7 | 53.8 | Subtract | CYP1A1- | Caffeine/Addictive behavior |
| (5/13) | (1/13) | (7/13) | (Negative) | 1A2 region | ||
| 2 | 53.8 | 7.7 | 38.5 | Subtract | CYP1A1- | Coffee |
| (7/13) | (1/13) | (5/13) | (Negative) | 1A2 region | ||
| 3 | 23.1 | 53.8 | 23.1 | CPLX3/ | Caffeine, blood pressure; addictive behavior | |
| (3/13) | (7/13) | (3/13) | No effect | ULK3/ | ||
| 4 | 15.4 | 61.5 | 23.1 | Add | Caffeine | |
| (2/13) | (8/13) | (3/13) | (Positive) | CYP 1A2 | ||
| 5 | 61.5 | 15.4 | 23.1 | Subtract | CSK | Blood Pressure |
| (8/13) | (2/13) | (3/13) | (Negative) | |||
| 6 | 46.2 | 23.1 | 30.8 | Subtract | PPCDC/SC | Caffeine |
| (6/13) | (3/13) | (4/13) | (Negative) | AMP5 | ||
| 7 | 15.4 | 23.1 | 61.5 | Add | AHR | Caffeine |
| (2/13) | (3/13) | (8/13) | (Positive) | region | ||
| 8 | 23.1 | 15.4 | 61.5 | Add | AHR | Coffee |
| (3/13) | (2/13) | (8/13) | (Positive) | region | ||
| 9 * | 9.0 | 81.8 | 9.0 | Add | CYP 1A2 | Caffeine PK |
| (1/11) | (9/11) | (1/11) | (Positive) | |||
| 10 | 7.7 | 30.8 | 61.5 | Add | SPECC | Caffeine PD |
| (1/13) | (4/13) | (8/13) | (Positive) | 1L/ADORA2A | ||
| 11 | 61.5 | 30.8 | 7.7 | Subtract | CAB39L | Unknown |
| (8/13) | (4/13) | (1/13) | (Negative) | |||
| 12 | 69.2 | 0.0 | 30.8 | Subtract | CHRNA3 | Lung cancer Smoking |
| (9/13) | (4/13) | (Negative) | ||||
| 13 | 0.0 | 53.8 | 46.2 | Add | AHR | Unknown |
| (7/13) | (6/13) | (Positive) | ||||
| 14 | 0.0 | 53.8 | 46.2 | Add | LAMB4/ | Addictive behavior |
| (7/13) | (6/13) | (Positive) | NRCAM | |||
| 15 | 7.7 | 84.6 | 7.7 | Add | NCALD | Addictive behavior |
| (1/13) | (11/13) | (1/13) | (Positive) | |||
| 16 | 0.0 | 92.3 | 7.7 | Add | NCALD | Unknown |
| (12/13) | (1/13) | (Positive) |
© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Santos, R.M. Preliminary Studies on Genetic Profiling of Coffee and Caffeine Consumption. Beverages 2019, 5, 41. https://doi.org/10.3390/beverages5030041
Santos RM. Preliminary Studies on Genetic Profiling of Coffee and Caffeine Consumption. Beverages. 2019; 5(3):41. https://doi.org/10.3390/beverages5030041
Chicago/Turabian StyleSantos, Roseane M. 2019. "Preliminary Studies on Genetic Profiling of Coffee and Caffeine Consumption" Beverages 5, no. 3: 41. https://doi.org/10.3390/beverages5030041
APA StyleSantos, R. M. (2019). Preliminary Studies on Genetic Profiling of Coffee and Caffeine Consumption. Beverages, 5(3), 41. https://doi.org/10.3390/beverages5030041