In this section, we provide a detailed description of the dataset we used for SARS-CoV-2 end-to-end video classification and the selection, design, and training of the CNN architecture we employed. Specifically, we focus on data augmentation, transfer learning, training options, and the hyperparameters used to train and fine-tune our video classification networks.
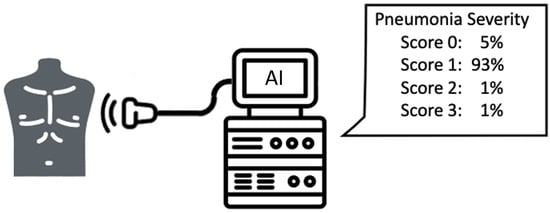
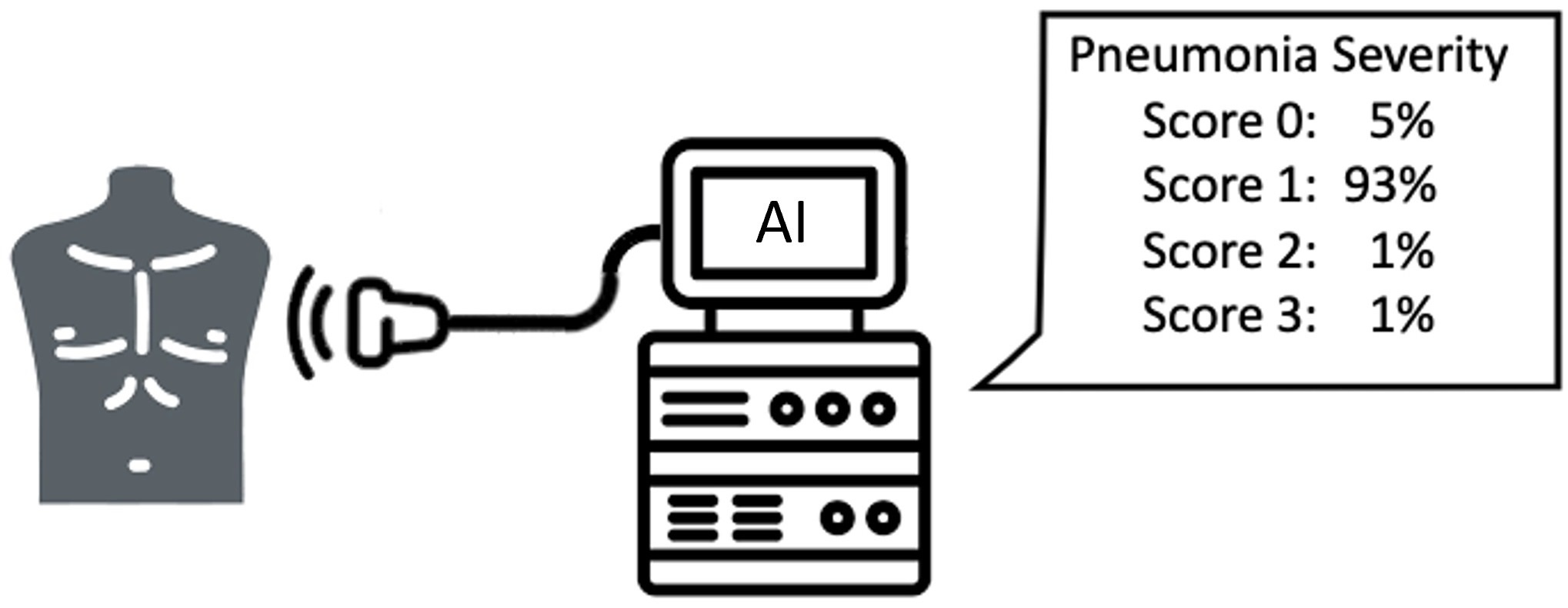
In particular, we addressed end-to-end video classification, since the proposed system takes as input the original clip acquired by the medical instrumentation. Then, the classification system elaborates this video and gives as output the pneumonia severity classification. The elaboration consists of two main steps: the former is the video summarisation, which produces a shorted clip containing only the most informative frames, while the latter is the classification of this summarised video adopting a suitable deep learning architecture.
2.2. SARS-CoV-2 LUS Dataset
Since March 2020, medical personnel at the San Matteo Hospital’s ED have been gathering LUS tests to examine the health of patients with suspected SARS-CoV-2 infection. The doctors operated the Aloka Arietta V70 ultrasound device (Hitachi Medical Systems), which works with convex and linear probes at frequencies of 5 MHz and 12 MHz, respectively. They standardised the procedure by focusing on the pleural line at a depth of 10 cm with the convex probe, and adjusting the gain to optimise the imaging of the pleural line, vertical artifacts, and peripheral consolidations with or without air bronchograms. Longitudinal and transversal scans were performed to examine the full length of the pleural line, with all harmonics and artifact-erasing software disabled.
LUS was performed on patients with suspected SARS-CoV-2 infection due to the potential presence of false negatives in rRT-PCR testing. Specifically, the artefacts observed in the earlier section of the manuscript may be caused by either pulmonary edema or non-cardiac causes of interstitial syndromes [
19]. Even if a swab test is negative, patients with lung involvement have a high likelihood of being SARS-CoV-2 positive. Medical practitioners are trained to distinguish suspected cases from healthy patients using a triaging process that includes LUS examination.
In this study, a “clip” refers to the result of an LUS test, consisting of a set of frames or images. The medical personnel at the hospital collected 12 clips for each patient, all assigned a standardised LUS score according to
Table 1 [
16,
17]. Data was collected from 450 patients treated in Pavia, yielding a total of 5400 clips.
Table 2 lists the subjects classified as SARS-CoV-2 positive and negative, along with their clinical data in the form of median and 25th–75th percentile values. The LUS Score entry indicates the sum of the values obtained from the 12 examinations for each patient.
Nonetheless, different doctors scored the clips, so the ED staff conducted a review to validate the classifications and avoid incorrect severity-scoring issues. This process ensured that each clip had a standardised rank value and that there were no discrepancies in the scores associated with different clips at the same severity stage, as emphasised in other studies [
20].
Accordingly, the dataset operated in this manuscript consisted of 624 clips randomly selected from the initial 5400 clips distribution.
Fondazione IRCCS Policlinico San Matteo Hospital’s Emergency Department physicians oversaw the methodical procedure and ensured that the labeling was accurate. During the first part of the data collection and annotation process, they manually selected all clips from each patient, assessed the quality of each clip, and either proceeded to evaluate it based on the two scoring methodologies or discarded it. They reviewed each clip to assign a score and verify that SARS-CoV-2 pneumonia patterns, as described in
Section 2.1, were present. The patient selection process was random and blinded to reject the hypothesis of biased outcomes. Some subjects may have received fewer LUS exams than others due to the detection of severe lung involvement in the early stages of the procedure. The entire annotation and collection process took longer than one month, resulting in 624 gathered clips based on the initial 5400 clips.
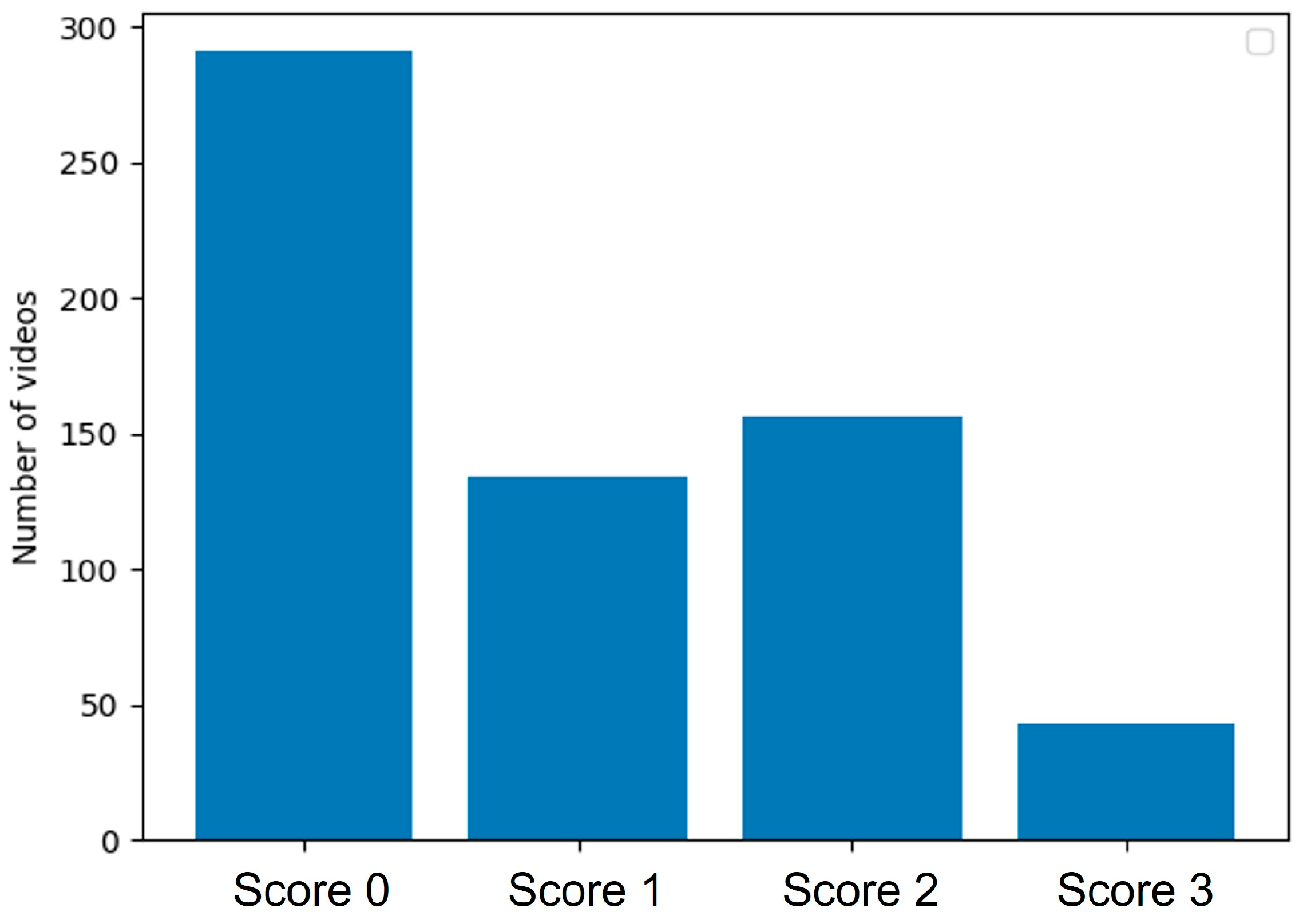
Figure 2 shows the class distribution in the dataset, divided into four tiers.
Finally, this study randomly split the data into training (80%), validation (10%), and testing (10%) sets, following standard deep learning practice [
21] and keeping the training set size as small as possible to reject the overfitting hypothesis.
Similarly, we increased the statistical variance in the training set by applying various data augmentation strategies listed in
Table 2, which forced the networks to focus on relevant information. We applied geometric, filtering, random center cropping, and color transformations to the training frames. The literature demonstrated that these methods are effective when applied to SARS-CoV-2 [
22] and produce strong results in deep learning classification tasks, significantly reducing overfitting [
23]. In addition, we added salt-and-pepper white noise to expand the training set. The X3D pre-trained architecture requires 3 × 32 × 224 × 224 clips in the PyTorch framework, so we converted the grayscale ultrasound frames to RGB to enable color augmentation. Data augmentation modifies the training data numerically, introduces statistically diverse samples, and enables the architectures to robustly classify new frames. The data augmentation process shifts the frame’s point of interest, slightly modifying its shape or color along with noise, preparing the models to expect relevant features to be in a different location. The models also learn to reject disruptions such as probe sensor measurement errors. Therefore, this research applied augmentations to all training images, regardless of the probe used for the LUS examination.
We repeatedly applied augmentations to the training data to exponentially expand the training set.
According to the AI act established by the European Commission, ensuring cybersecurity is crucial in guaranteeing that artificial intelligence applications are resistant to attempts to alter their service, behavior, and performance, or compromise their safety properties through malicious interference by third parties exploiting system vulnerabilities. Cyberattacks on AI systems can leverage assets specific to AI, such as introducing adversarial attacks on trained models, namely providing the optimised architectures with slightly different inputs and confuse their behavior. Consequently, providers of high-risk AI systems should take appropriate measures to ensure an appropriate level of cybersecurity in relation to the risks, taking into account the underlying ICT infrastructure as necessary.
At the end of the training settings management stage, with transfer learning and data augmentation, we collected 29,952, 171, and 171 clips for the training, validation, and test sets.
2.5. Performance Evaluation
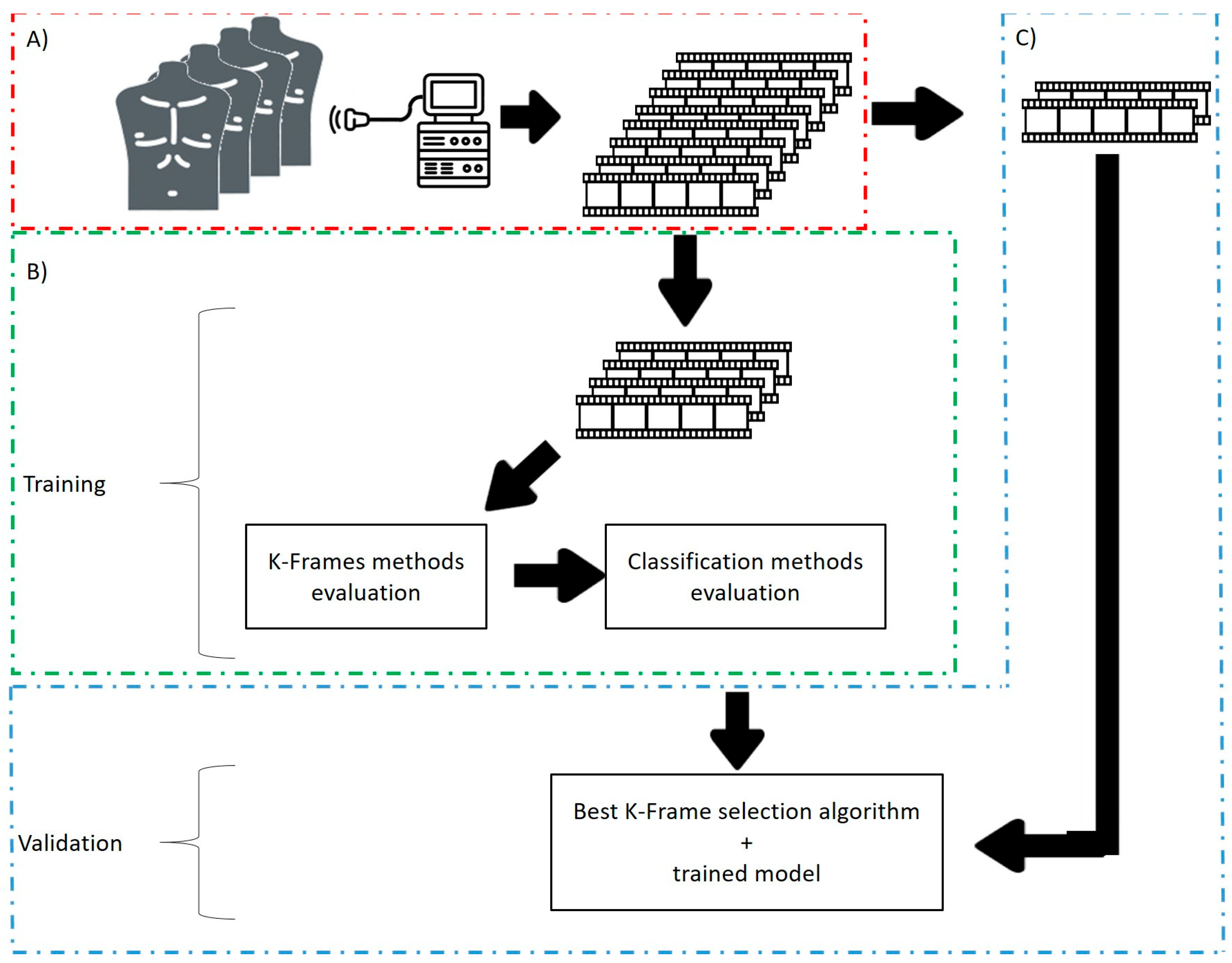
First, we assessed the quality of the key-frame video summary algorithms. This research represents a follow-up of the first study concerning frame classification [
8]. Hence, we have a carefully set of selected frames containing the exact patterns in
Table 1. Nonetheless, video summaries also produce transition frames due to probe movements or noise. Hence, only some of the frames contain patterns. This manuscript aims to deliver end-to-end video classification without manual frame extraction from expert professionals. Hence, we trained residual architectures on the dataset retained from extracting key-frames via all the algorithms described in
Section 2.3. We tested the networks on frames carefully extracted from the Fondazione IRCCS Policlinico San Matteo ED’s medical personnel. We cannot retain 100% accuracy on the test set due to the presence of transition frames. However, good classification performance on the test set implies that it is similar to the training one, thus retaining the patterns in
Table 1.
Similarly, we evaluated the following similarity indexes (Equations (1)–(3)) to compare the datasets originating from the key-frame algorithms (
Section 2.3) and the frames derived from the first study, which laid the grounds for this, carefully selected from San Matteo ED’s skilled physicians.
Equation (1) reports the Structural Similarity Index (SSIM) where
and
are the pixel sample mean of image
and
, respectively. The terms
and
are the variance of image
and
, respectively. Finally,
is the covariance of the two images and
and
are factors used to stabilise the division with a weak denominator [
34].
Equation (2) is the Kullback-Leibler Divergence () where and are two discrete probability distributions over the same probability space .
Finally, Equation (3) defines the Jensen-Shannon divergence as a symmetrised and smoothed version of Equation (2).
It is crucial to decrease false negatives to the maximum extent feasible, particularly when treating an infectious disease such as SARS-CoV-2. A patient’s incorrect diagnosis introduces a false negative, which causes improper care, lack of necessary treatment that reflects cross-contamination among subjects with additional pathologies, and faulty medications that may harm an infected person.
In this research, the performance of the network classifications was evaluated using the validation and test sets. The focus was not only on accuracy, but also on precision, recall, and F1-Score (Equations (4)–(7)) and ROC-AUC [
35]. These metrics, defined in the equations below, were calculated for each category for all classification tasks. The importance of reducing false negatives, particularly in the context of infectious diseases such as SARS-CoV-2, cannot be overemphasised. False negatives can lead to incorrect diagnoses, inadequate treatment, cross-contamination among patients with other pathologies, and potentially harmful medications. True Positive (
TP) refers to correct classifications, False Negative (
FN) refers to incorrect classifications, True Negative (
TN) refers to correct classifications, and False Positive (
FP) refers to incorrect classifications.
Researchers often place a particular emphasis on recall in order to reduce false negatives. Recall measures the performance of correctly identifying frames that do not contain SARS-CoV-2 pneumonia patterns and that belong to either of the considered classes or that display a healthy lung. Precision tells the reader about the classification performance in detecting the considered patterns. Therefore, the F1-Score is considered as a function of the previous two metrics. This parameter provides a more accurate measurement in terms of accuracy, taking into account the trade-off between precision and recall in unbalanced class distributions. Therefore, we need to evaluate recall and F1-Score in order to minimise false negatives while maintaining high precision.
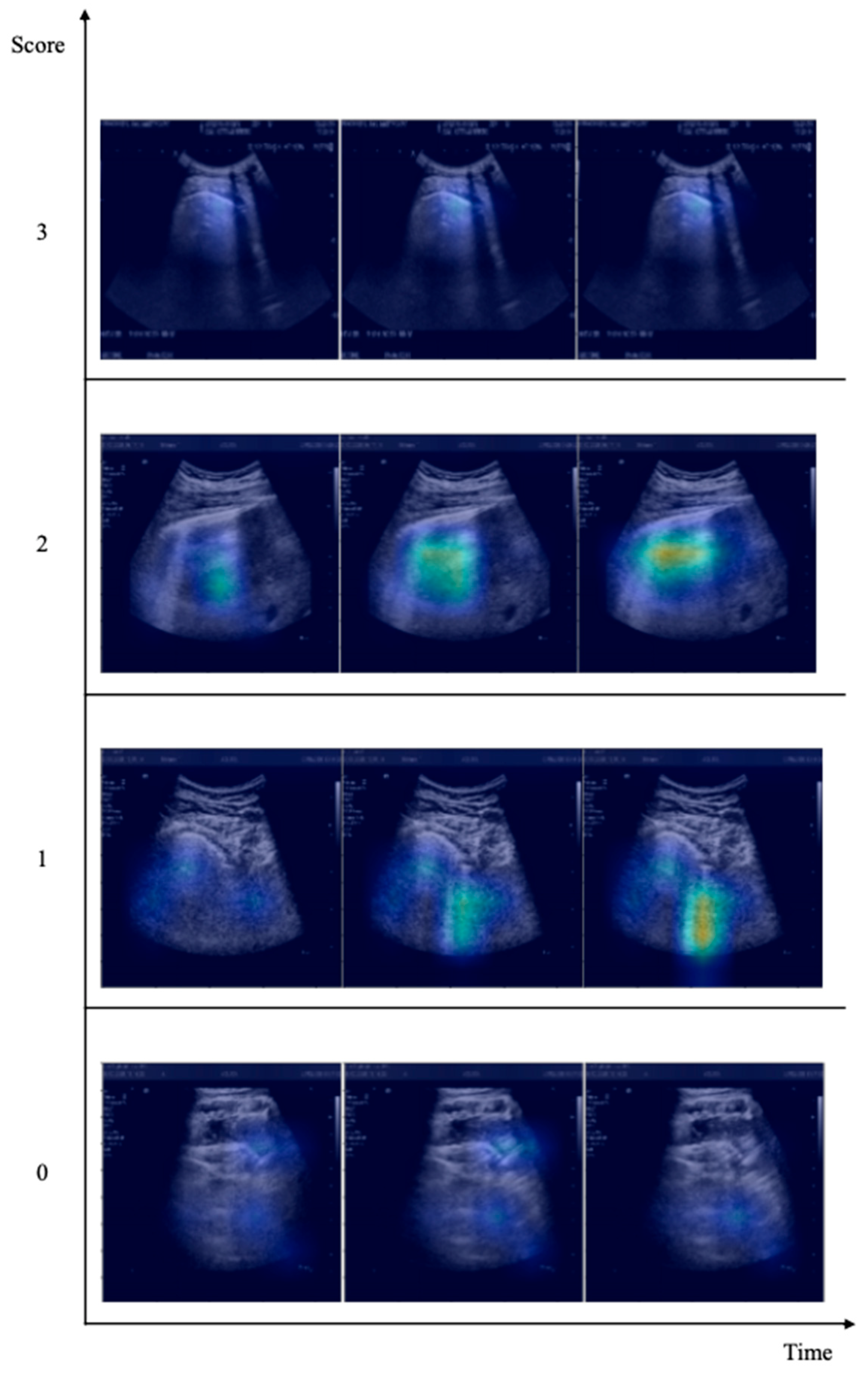
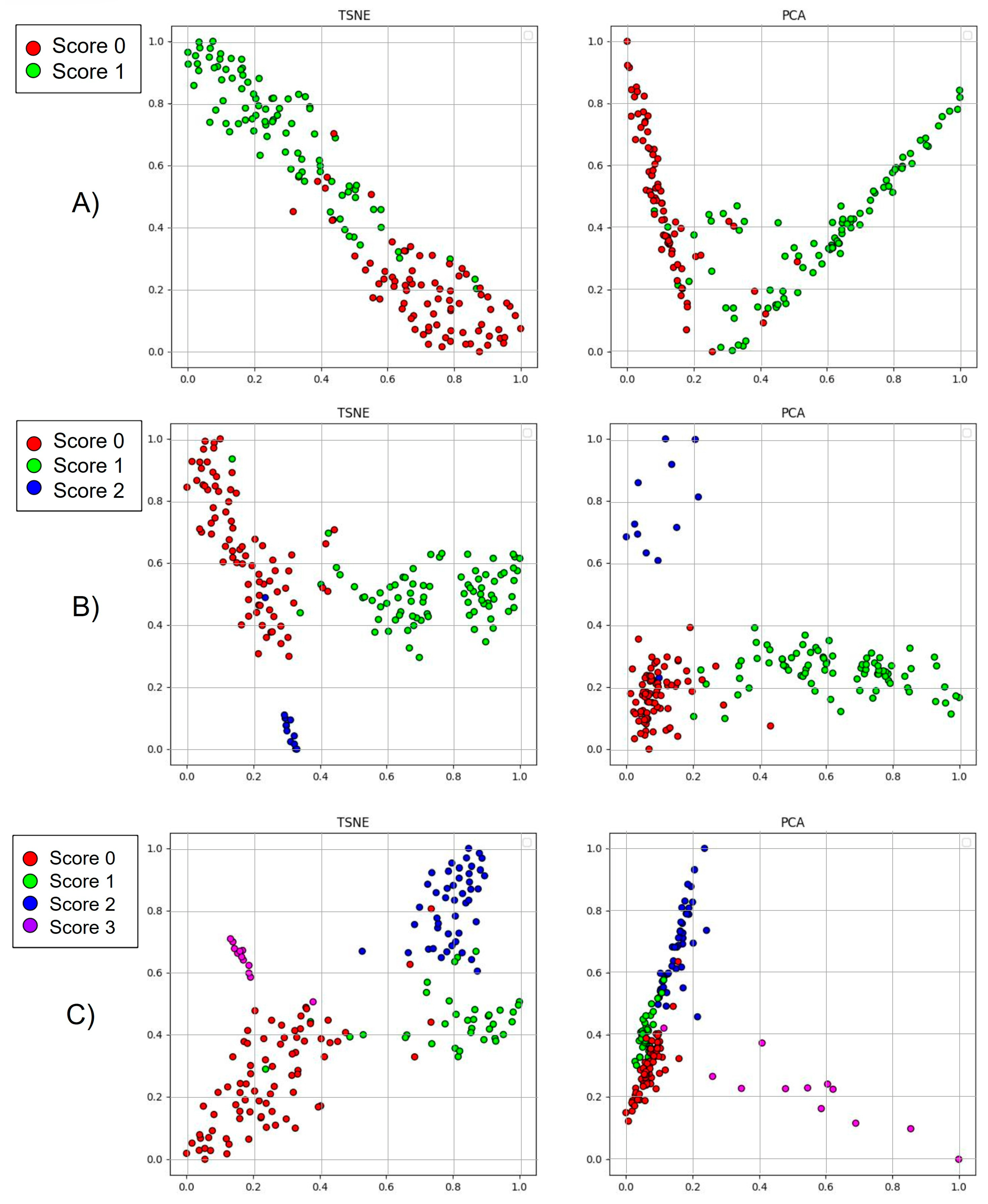
Eventually, this study assessed the quality and robustness of the classification performance through explainable AI strategies. Accordingly, we operated the gradient class activation mapping (Grad-CAM) algorithm and the statistical analysis of features deriving from deep architectural layers to evaluate whether we could clearly identify patterns from LUS clips and how dividable such patterns are in architectural encoded features. The former enables the interpretation of the architecture’s decision-making. Indeed, it emphasises the decisive parts to assign a rank through a heat map. Concerning the latter strategies, we performed PCA and t-SNE over the inner layers of the X3D architecture. Hence, we coloured the clusters according to the clips’ original classes.



 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}