Abstract
This work presents a hybrid model that integrates a mechanistic multicomponent transport scheme in hollow-fiber membranes with an Adaptive Neuro-Fuzzy Inference System (ANFIS). The physical model incorporates pressure drops on the feed and permeate sides (Hagen–Poiseuille), non-ideal gas behavior (Peng–Robinson equation of state), and temperature-dependent viscosity; species permeances are treated as constant for model validation. After validation, a post-validation parametric exploration of permeance variability is carried out by perturbing the methane (CH4) permeance by one decade up and down. From an initial set of 18 variables, 4 key parameters were selected through rigorous statistical analysis (Pearson correlation, variance inflation factor (VIF), and mean absolute error (MAE)); likewise, other physical criteria have been considered: permeance, retentate volume, retentate pressure, and retentate viscosity. Trained with 70% of the simulated data and validated with the remaining 30%, the model achieves a coefficient of determination (R2) close to 0.999 and a root mean square error (RMSE) below 8 × 10−8 m3/h in predicting the methane volume in the retentate, effectively responding to both steady and dynamic fluctuations. The combination of first-principles modeling and adaptive learning captures both steady-state and dynamic behavior, positioning the approach as a viable tool for real-time analysis and supervisory control in petrochemical membrane operations.
1. Introduction
Daily operation of oil and gas production systems requires critical decisions that directly affect production volumes and associated costs [1]. These decisions, made at different organizational levels, converge in the physical production system. In recent years, the industry has evolved toward deeper technological integration, giving rise to the paradigm known as Industry 4.0. This approach promotes the use of intelligent technologies to improve operational efficiency [2].
In the context of natural gas processing, which consists mainly of methane (CH4), one of the most relevant challenges is the removal of carbon dioxide (CO2), as it reduces the calorific value of the gas and accelerates pipeline corrosion. Membrane-based separation technologies, particularly hollow fiber membrane modules (HFMM), have gained importance due to their energy efficiency, modularity, and compactness. These membranes operate through the principle of selective permeation, leveraging differences in solubility and molecular size to separate CH4 from CO2 without the need for chemical solvents.
Gas separation in petrochemical processes has therefore become an active area of research, with CH4/CO2 separation receiving significant attention in recent decades due to the dual objectives of natural gas purification and carbon emission reduction. From a modeling perspective, multiple approaches have been proposed. Chu et al. [3] developed steady-state mass transfer models, while Gu [4] extended this framework by including non-ideal gas effects, concentration profiles, and pressure drops, achieving accurate prediction of experimental data. Later, Ko [5] introduced a dynamic model that considered transient disturbances in operating conditions, enabling more realistic simulations of industrial processes. However, purely physical or “white-box” models require precise estimation of parameters such as permeability, viscosity, and molar volume, which are not always available and often present high uncertainty, particularly in multicomponent systems.
To alleviate these limitations, artificial intelligence (AI) methods have been explored. Artificial neural networks (ANNs) model complex nonlinearities but lack physical interpretability and may generalize poorly beyond the training domain. This motivates hybrid (“gray-box”) strategies that fuse physics with data-driven inference. Among these, the adaptive neuro-fuzzy inference system (ANFIS) stands out by combining the learning capacity of ANNs with fuzzy rule-based reasoning, improving transparency and adaptability [6].
Recent work signals a shift toward hybrid intelligence in gas separation (see Table 1). In polymeric hollow fibers, a GA-optimized ANFIS—genetic algorithm (GA) tuning and ≈7 Gaussian membership functions—predicted permeate-side CO2 for CH4/CO2 separations with near-perfect fit (R2 ≈ 0.9993; RMSE ≈ 0.0064; Average Absolute Relative Deviation (AARD) ≈ 1.25%) [7]. In mixed-matrix membranes (MMMs) comprising fumed silica (FS), polyhedral oligomeric silsesquioxane (POSS), and polydimethylsiloxane (PDMS), differential evolution (DE)–ANFIS was benchmarked against a Crow Search Algorithm–Least-Squares Support Vector Machine (CSA-LSSVM) for single-gas permeation (H2/CH4/CO2/C3H8): DE-ANFIS reached R2 = 0.9981 (overall), while CSA-LSSVM reported R2 = 0.9946/0.9689 (train/test) with MSE = 0.0003/0.0011 and MAE = 0.0114/0.0257 [8]. For silicoaluminophosphate-34 (SAPO-34) MMMs, clustering-guided ANFIS variants—subtractive clustering (SC) and Fuzzy C-Means (FCM)—as well as genetic programming (GP), reproduced CO2 permeability with AARD < 3% and R2 > 0.995 [9]. In polymethylpentene (PMP) modified with nanoparticles, a multilayer perceptron (MLP) with Bayesian regularization (3–8–1) captured “separation capacity” (CO2 permeability) with R = 0.99477, MAE = 6.87, AARD = 5.46%, MSE = 152.75 [10]. By contrast, an empirical-plus-regression HFMM reported a modest R2 ≈ 0.628 for CO2 enrichment/distribution, underscoring the need to embed dynamic multicomponent transport and deliver real-time, explainable responses beyond black-box regression [11].

Table 1.
Comparable studies.
Table 2 widens the lens to adjacent problems with transferable patterns. In electro-assisted ultrafiltration of water, a Takagi–Sugeno–Kang (TSK) fuzzy model predicted Ni2+ removal with R2 ≥ 0.98 and maximum rejections of ≈60% (polyethersulfone, 5 kDa (PBCCS) at ~3.5–4.5 V) and ≈45% (regenerated cellulose, 5 kDa (PLCCS) at 4 V) [12]. For C3H6/C3H8 adsorption in copper benzene-1,3,5-tricarboxylate (Cu-BTC, HKUST-1), particle swarm optimization (PSO)–ANFIS was compared to ANN; ANN yielded the lower MAE (0.111 vs. 0.421) [13]. CO2 solubility in Polystyrene (PS)/ Poly(vinyl acetate) (PVAc)/ Polybutylene succinate (PBS)/ Poly(butylene succinate-co-adipate)(PBSA) was modeled via genetic programming (GP) with R2 > 0.98 and small average relative deviations (ARDs) (≈0.095%, 0.0503%, 0.0312%, 0.039%; 70/30 split; inputs T[K], P[MPa]) [14]. A computational fluid dynamics (CFD) → ANFIS mapping reproduced bubble-column void fraction: with two inputs and eight membership functions (MFs), it attained R ≈ 0.9999, although adding turbulence reduced performance (Rtest ≈ 0.64) [15]. For Cu/H2O nanofluids in a lid-driven square cavity, a grid-partition ANFIS (3 inputs: x, y, T; 4 MFs/input → 64 rules) achieved R ≈ 0.999 (~65% training; up to ~800 iterations); a compact ant colony optimization (ACO) surrogate reached R≈0.92 [16]. CO2 absorption in a closed-vessel nanofluid absorber was learned by an MLP (6–9–1) trained with the Levenberg–Marquardt algorithm (LM), yielding R = 0.9996, MSE = 2.36 × 10−5, MAE% = 0.326 (N = 165) [17]. In forward osmosis (FO) for textile wastewater, combinations of response surface methodology (RSM), ANN (feed-forward backpropagation with Levenberg–Marquardt, FFBP-LM) and ANFIS (Sugeno; five inputs) predicted/optimized water flux (Jw) and reverse salt flux (Js); the ANN evaluation reported Jw: R2 ≈ 0.798, R ≈ 0.8933, MAD ≈ 0.8120, MSE ≈ 1.4800, RMSE ≈ 1.2170; Js: R2 ≈ 0.7807, R ≈ 0.8836, Mean Absolute Deviation (MAD) ≈ 0.7940, MSE ≈ 1.5220, RMSE ≈ 1.2340; a 70/15/15 protocol achieved R2train ≈ 0.998, R2test ≈ 0.997, RMSEtrain/test ≈ 0.0136/0.0194 [18]. In bubble-column CO2 absorption with SiO2/H2O and Fe3O4/H2O, an ANFIS with Fuzzy C-Means (ANFIS-FCM) (3 rules; hybrid learning) produced RMSE ≈ 0.014–0.019; optimal nanoparticle (NP) loadings were 0.025 wt.% SiO2 and 0.015 wt.% Fe3O4, enhancing the mass-transfer enhancement factor (E) to ≈ 1.43 (+43%) and 1.13 (+13.4%), respectively [19]. For sheet-type water permeation, a probabilistic neural network–group method of data handling (PNN–GMDH) with PSO optimized permeate flux, achieving R2 ≈ 0.983, performance index (PI) = 0.723, and Nash–Sutcliffe efficiency (NSE) ≈ 0.984 [20].
Table 2.
Adjacent studies.
CO2 absorption correlations in nanofluids built with GP and GMDH showed GP outperforming GMDH (R2 = 0.9914, AARD = 3.732%, RMSE = 0.0141 vs. R2 = 0.9726, AARD = 8.1134%, RMSE = 0.0231; n = 230; 80/20; inputs t, P, T, dnp, C wt.%, ρnp) [21]. In metal–organic frameworks (MOFs), a random forest (RF) predicted CH4/CO2 biogas separation (main metrics in Supplementary) [22]. Finally, porous liquids (PLs) show a clear AARD ranking for CO2 solubility: 3.17% (CSA-LSSVM) < 6.64% (MLP) < 8.67% (PSO-ANFIS) < 12.98% (ANFIS) [23].
Against this backdrop, our study integrates a mechanistic, multicomponent HFMM model—accounting for pressure drops, non-ideal gas behavior via the Peng–Robinson equation of state (PR-EOS), and temperature-dependent viscosity—with an ANFIS layer trained on statistically paired, physically meaningful inputs (permeance, retentate volume, retentate pressure, retentate mixture viscosity).
This gray-box synthesis delivers near-perfect agreement (R2 ≈ 0.999; RMSE < 8 × 10−8 m3·h−1) for retentate methane volume while retaining interpretability and enabling real-time use, directly addressing the literature gap on dynamic CH4/CO2 separation in HFMM. In doing so, it reduces parameter uncertainty by coupling first-principles transport with data-driven inference; optimizes membrane design and operating conditions to maximize CH4 purity and flow rate; and provides a robust, interpretable, and adaptive system capable of operating under variable conditions—aligning with the principles of Industry 4.0.
To ensure the clarity and reproducibility of the study, it is essential to detail the methodological sequence followed to construct the hybrid model. The starting point was the development of a mechanistic, multicomponent transport model. To ensure its physical fidelity before any subsequent use, this model was rigorously validated against established experimental data from the literature, using the Ko model [5] as a benchmark.
Once the reliability of the mechanistic model was confirmed, it was employed as a “virtual plant” to generate a comprehensive synthetic dataset, thus overcoming the lack of a dedicated experimental dataset for training. Subsequently, to optimize the quality of the inputs for the intelligent model, this synthetic dataset was subjected to a rigorous variable selection process. Based on the statistical criteria detailed in Section 2.2, the initial set of 18 candidate predictors was reduced to the four most informative and statistically independent ones.
Finally, this refined dataset served as the foundation for training and testing the ANFIS layer. The ultimate purpose of this work is for the developed ANFIS model, thanks to its high precision and speed, to serve in a future stage as the predictive core within an advanced optimization and control strategy, whose fundamental structure is illustrated in Figure 1. In such a scheme, the model would predict the system’s behavior, allowing an optimizer, guided by an objective function (specifically, to maximize the amount of methane obtained in the retentate), to determine the optimal control actions for the process.
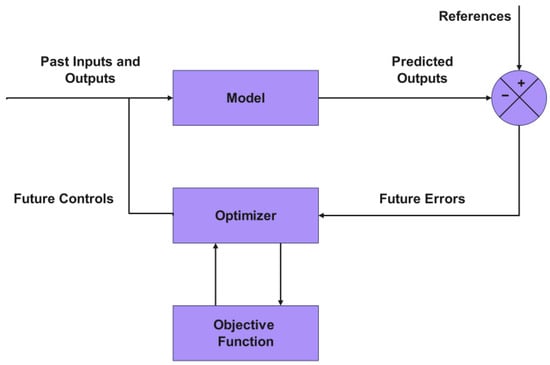
Figure 1.
Basic structure of model-based optimization.
This paper is organized as follows. The Section 2 (Materials and Methods) comprises three subsections: Section 2.1 develops the multicomponent HFMM mechanistic model, including temperature-dependent viscosity and non-ideal gas behavior; Section 2.2 presents the statistical scaffold—data normalization, a normalized multiple linear regression baseline, assumption diagnostics, and multicollinearity/variable selection; and Section 2.3 details the ANFIS layer (membership functions, rule base, hybrid training, and the train/validation/test split). Section 3 presents the results, and Section 4 concludes the paper.
2. Materials and Methods
This section details the methodology used to develop a hybrid model that predicts gas separation in an HFMM. The process begins with the construction of a mathematical model based on first principles, which is rigorously validated. Subsequently, this model is used as a “virtual plant” to generate a synthetic dataset. Finally, the generated data are subjected to a thorough statistical analysis to select the most influential variables, which serve as input for training the intelligent ANFIS model. To further enhance reproducibility, Appendix A (Algorithms A1–A5) provides a series of detailed pseudocodes illustrating the implementation of the mechanistic model, data generation, statistical analysis, and the ANFIS training workflows.
2.1. Mathematical Modeling of HFMM
This model aims to describe the behavior of the separation system through mathematical relationships that account for the gas properties and the membrane’s characteristics. The most critical considerations in this model are described as follows:
- The membrane does not deform under the applied pressure. This is a simplifying assumption [3].
- Pressure drop on the permeate and retentate sides can be calculated using the Hagen-Poiseuille equation.
- Permeance of chemical species is considered constant in model validation (see Section 2.1.3).
This model is based on a set of differential equations that describe the variation of the component flow along the membrane. Equation (1) describes the rate of change in the molar flow of component i on the retentate side of the membrane in the flow direction. Equation (2) represents the rate of change in the molar flow of component i on the permeate side. Equation (3) details the pressure variation along the membrane on the retentate side, considering the dynamic viscosity of the mixture and membrane geometry. Finally, Equation (4) describes pressure variation on the permeate side; see Figure 2 [3,24].
where is permeance of component i , and denote partial pressures of component in the retentate and permeate section, , is the number of tubes or fibers, is component index, is flow rate on the permeate side and is the flow rate on the retentate side ). The internal diameter of the shell is denoted by , while and refer to the internal and external diameter of the fiber , respectively, is the universal gas constant, is the temperature, and is the dynamic viscosity of the mixture . Superscripts and are employed to denote quantities in the retentate and permeate streams, respectively. These notations are consistently applied to other variables in subsequent sections to facilitate further analyses.
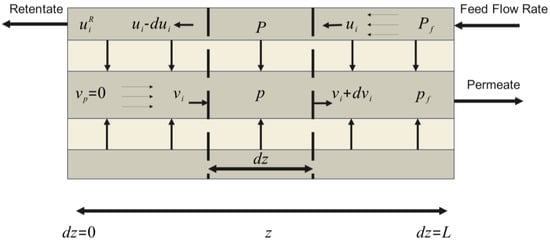
Figure 2.
Countercurrent flow dynamics in an HFMM scheme.
To solve the differential equations, the MATLAB® (version R2025b) function ode15s is used. This function employs an adaptive implicit method based on backward differentiation formulas (BDF). This approach is particularly suitable for stiff systems, as it can handle rapid and slow variations in a stable and efficient manner. First, the model equations and initial conditions were defined (see Table 3 and Table 4). Then, error tolerances and the integration interval were configured. This setup allowed for precise and stable numerical solutions for the system of interest. This model has proven valid with data from studies in [3,25,26].
Table 3.
Initial conditions of the Process.
Table 4.
Initial conditions of chemical species.
2.1.1. Dynamic Determination of Viscosity
According to [27], the viscosity of a pure fluid can be determined using the Chapman-Enskog solution, which is based on the Boltzmann transport equation. This approach assumes that molecular interactions can be approximated by those of Lennard–Jones particles with a potential function. Dynamic viscosity of a gas is calculated using the kinetic theory of gases, which relates this property to temperature , molar mass , collision diameter σ, and collision integral . The pure-component molecular weights used in the Wilke mixing rule are given in Appendix A, Table A1.
Reduced collision integral is calculated by considering the possible trajectories of particles during their approach. An empirical correlation relates to temperature.
where the reduced temperature .
In this expression, is the depth of the Lennard–Jones potential well, and is the Boltzmann constant (1.380649 × 10−23 J/K). The term has units of kelvins, making dimensionless. Physically, represents the ratio of the system temperature to the characteristic energy of intermolecular interactions. The Lennard–Jones parameters adopted for collision-integral evaluations are summarized in Appendix A, Table A3.
According to [28] viscosity of a diluted gas is related to the mole fraction , and the viscosity of the diluted gas component , following Wilke’s equation.
Binary weighting factor expressed as a function of gas viscosity and the molecular weight of component as follows:
2.1.2. Peng–Robinson Equation of State for Non-Ideal Gas Behavior
To accurately represent the non-ideal behavior of gas mixtures within the HFMM, Peng–Robinson (PR) cubic equation of state is implemented in the mathematical model. This approach allows for the calculation of the real molar volume for both the retentate and permeate streams at each spatial position along the membrane, thus providing a more rigorous description of volumetric and transport phenomena, particularly under elevated pressure conditions [29].
The Peng–Robinson equation of state is given by the following:
where is the pressure, is the temperature, is the molar volume, and is the universal gas constant. The parameters and are determined from the critical temperature , critical pressure , and acentric factor of each species.
Computation of the parameters and for Peng–Robinson equation of state in multicomponent mixtures requires the use of appropriate mixing rules, as well as the estimation of temperature-dependent correction factors for each component.
First, for each pure component i, the parameters are defined as follows:
where and are the critical temperature and pressure of component i, respectively. The term introduces temperature dependence, calculated as follows:
For mixtures, global parameters and are obtained by classical mixing rules:
In these equations, and are the mole fractions of components i and j, respectively. Binary interaction parameter is an empirical coefficient used to account for non-ideal interactions between unlike pairs of molecules in the mixture, and it is usually obtained from experimental data or taken as zero in the absence of specific information.
Final values of and are then substituted into the cubic Peng–Robinson equation of state to compute the molar volume or compressibility factor for the mixture under the specified conditions of temperature, pressure, and composition [29].
The Peng–Robinson EoS is widely recognized as a robust model for CH4/CO2 mixtures under the moderate operating conditions (8 atm, 298.15 K) of this study. Its ability to provide an excellent compromise between simplicity and accuracy for CO2-rich systems in the subcritical gas phase, with reported errors for compressibility below 1%, makes it a suitable choice for this application [30]. Furthermore, its successful implementation in recent molecular simulation studies of gas separation in membranes under comparable conditions validates its predictive capabilities [31]. The model’s robustness is also supported by its application in studies under even more demanding conditions of higher pressure [32]. The critical properties and acentric factors employed are listed in Appendix A, Table A2.
2.1.3. Permeance: Baseline Assumption and Post-Validation Exploration
The effective observed in operation can shift with temperature, pressure, and composition (competitive sorption, plasticization), as well as with the architecture/thickness of the selective layer and module non-idealities (pressure drops, film coefficients, non-isothermality). The specialized literature recommends, when reliable parameters are not available, conducting parametric evaluations to bound their impact on module performance and design [33].
At the material/architecture level, hollow-fiber TFC membranes with ultrathin selective layers have reported CO2 permeances on the order of 2.6–2.7 × 103 GPU with CO2/N2 selectivities of ~21; the authors note that thickness estimation assumed constant permeability despite evidence of thickness dependence and operating-condition variability, reinforcing that effective permeance is not static [34].
At the module/process level, performance depends on the integration of the separation unit (areas, stage cut, pressures) and its couplings with other units; these factors modify driving forces and fluxes, explicitly justifying the use of parametric scans when working with tabulated permeances [35].
Regarding constitutive modeling, frameworks that integrate molecular dynamic (MD)+ free-volume theory and pressure/composition-dependent permeability improve agreement with data but require nontrivial parameters; in parallel, non-ideal models (pressure-dependent permeability, substrate resistance, real-gas behavior) have been shown to reduce deviations relative to the ideal approach, supporting parametric evaluation when a full parametrization is not yet available [36].
Adopted protocol. Without introducing a new constitutive model at this stage, a post-validation exploration was carried out by varying only the CH4 permeance in {0.1×, 1×, 10×} relative to its baseline. This approach was chosen as a first-order sensitivity analysis to evaluate the system’s response to perturbations in the less permeable species, a key factor controlling methane purity in the retentate. We acknowledge that a complete analysis would involve co-variation of CO2 permeance to fully map the impact on selectivity, which remains a valuable direction for future studies. The scan reports eighteen outputs spanning: total volumes on each side (retentate and permeate); gas compositions on each side (CO2 and CH4 mole fractions); pressures on each side; component molar flows of CO2 and CH4 on each side; component volumes of CO2 and CH4 on each side; and the mixture viscosity on each side. Together, these metrics quantify the plausible impact on flow splits, compositions, and pressure profiles within a range bounded by the literature.
2.2. Statistical Method
This section details the systematic methodology, illustrated in Figure 3, used to reduce the initial set of 18 candidate predictors to a compact, high-quality subset for ANFIS modeling. The workflow is designed to ensure the final variables are not only statistically powerful but also physically meaningful.
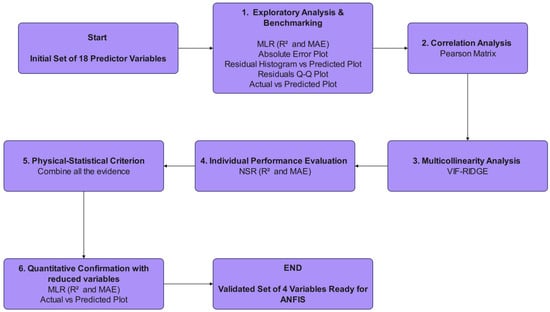
Figure 3.
Statistical analysis framework for predictor dimensionality reduction.
The process begins with an Exploratory Analysis and Benchmarking phase, where a multiple linear regression (MLR) model incorporating all 18 variables is constructed. This initial model serves as a baseline, and its performance is evaluated using the coefficient of determination (R2) and mean absolute error (MAE). Its statistical validity is rigorously checked through a series of diagnostic plots, including residual analysis and Q-Q plots, to assess underlying assumptions like homoscedasticity and normality.
Subsequently, a Correlation and Multicollinearity Analysis is performed. A Pearson correlation matrix is generated to identify strong linear relationships between pairs of variables. This is complemented by a more robust multicollinearity assessment using the Variance Inflation Factor with a Ridge penalty (VIF-Ridge), which quantifies how much the variance of an estimated regression coefficient is increased due to collinearity with other predictors.
In parallel, an Individual Performance Evaluation is conducted for each predictor. By fitting a normalized simple linear regression (NSR) for each variable against the target output, we assess their individual predictive contributions, again using R2 and MAE as key metrics.
The core of the selection process is the Physical-Statistical Criterion, where all the evidence is synthesized. The statistical findings—from the benchmark model, correlation matrix, VIF scores, and individual regressions—are combined with physical knowledge of the membrane separation process. This crucial step ensures that the selected variables are not just statistically independent but also mechanistically relevant.
Finally, a Quantitative Confirmation is performed. A new, reduced MLR model is built using only the four selected variables. Its performance is re-evaluated to confirm that the parsimonious model retains high predictive accuracy. This multi-stage filtering workflow systematically eliminates weak and redundant variables, guaranteeing that the final input set for the ANFIS model is both robust and interpretable.
All measurements are arranged into the standard regression form:
where denotes the number of experimental observations (rows) and is the number of initial predictors (). This succinct representation facilitates matrix-based computations and algorithmic efficiency.
To explore the relationships between variables, scatter plots are employed to visualize ordered pairs (, ). It’s not just a graph but a visual representation of the relationship between the two variables. When most points align closely with a straight line, the correlation is classified as linear. Conversely, the correlation is considered nonlinear if the points follow a curved pattern. However, if no discernible pattern is observed among the ordered pairs, it indicates the absence of a relationship between the two variables. To depict the curve or regression line that best fits the distribution of the ordered pairs, Equation (18) is applied [36].
where is the intercept and are the regression coefficients associated with each predictor.
2.2.1. Data Normalization
To mitigate bias from differing variable scales, all features and the target variable are standardized to zero mean and unit variance:
where and are vectors of column-wise means and standard deviations of the predictor across all samples. and are the mean and standard deviation of the dependent variable .
2.2.2. Normalized Multiple Linear Regression
A normalized multiple linear regression model was fitted to the standardized data:
where is the vector of normalized predicted values. is the normalized design matrix (dimensions ), with each column scaled to zero mean and unit variance, and is the vector (dimensions ).
2.2.3. Parameter Estimation via Gradient Descent
The coefficients were optimized by minimizing the mean squared error (MSE) cost function:
Using stochastic gradient descent (SGD) with Learning rate , Iterations = 1000 (ensuring convergence to local minima) and an update rule according to the following:
where the gradient is computed as follows:
Normalized predictions are transformed back to the original scale for direct comparison with experimental data. We evaluate performance with two metrics: the coefficient of determination (R2), defined in Equation (24), and the mean absolute error (MAE), defined in Equation (25). ∈ [0,1] quantifies the fraction of variance in the target explained by the model, values closer to 1 indicate a better fit. For completeness, the Pearson correlation coefficient ∈ [−1, 1] measures the strength and direction of linear association between variables [34].
Normalized simple linear regression is additionally performed for each independent variable , repeating the same procedure and metric calculations to identify the individual contribution of each variable to the model.
2.2.4. Multicollinearity Analysis
Given that collinearity among predictors can inflate the variance of regression coefficients and undermine the numerical stability of the model. This procedure enabled the systematic elimination of highly collinear and weakly predictive variables, reducing the original pool of 18 candidate predictors to the four most informative and mutually independent inputs for ANFIS training.
Pearson’s correlation coefficients are computed according to [37] on the normalized predictor matrix .
With this, it was also possible to construct a correlation matrix which compacts all the into a single object.
Inspecting the correlation matrix quickly flags pairs with near 1, it remains a subjective heuristic and tells us nothing about how much multicollinearity is affecting our coefficient estimates. To quantify that impact, we turn to the variance inflation factor for predictor , quantifying how much the variance of its estimated coefficient is inflated due to multicollinearity. Formally,
According to [38], is the diagonal element of . Values > 10 indicate severe collinearity. However, when there is severe collinearity, the correlation matrix can become close to singular and lead to extreme or undefined values of . To address this problem, we introduce a Ridge penalty in the collinearity diagnosis. Strictly speaking, we define the “penalized” version of the as follows:
Ridge penalty hyperparameter controls the degree of regularization and was selected (λ = 0.03) via literature . is the identity matrix of size , where is the number of original predictors.
2.2.5. Validation of Model Assumptions via Diagnostic Plots
To ensure that the normalized linear regression satisfies its underlying assumptions prior to ANFIS training, the following diagnostic plots are systematically generated:
- Residuals vs. Predicted Values: Plot the residual against the fitted value yk. This visualization is used to assess homoscedasticity—constancy of error variance across the prediction range—and to detect any funnel-shaped or nonlinear patterns that would indicate model misspecification.
- Q-Q-Plot of Residuals: Construct a quantile-quantile plot comparing the empirical quantiles of the residuals to theoretical quantiles of a standard normal distribution. Close adherence of points to the 45° reference line will validate the assumption of approximate Gaussianity of the errors, which is important for subsequent inferential procedures.
- Histogram of Residuals: Generate a normalized histogram of residuals to examine the shape of their distribution—specifically symmetry, peakedness, and tail behavior. This complements the Q-Q-plot by visually confirming the presence (or absence) of skewness or heavy tails.
- Actual vs. Predicted Values: Plot observed responses versus predicted values alongside the identity line . A tight cluster of points around this line will demonstrate high overall predictive accuracy and minimal systematic bias.
- Absolute Error per Sample: Compute and plot the absolute error for each sample index. This plot helps to identify isolated outliers or regions where the model’s performance deteriorates, thereby guiding further data investigation or model refinement.
By applying these five diagnostic plots, one can confirm the validity of homoscedasticity and normality assumptions, quantify overall goodness-of-fit, and detect any influential observations that may warrant additional scrutiny before proceeding with ANFIS modeling.
2.3. Intelligent Modeling with ANFIS
The technique implemented in this study is the ANFIS, which integrates two intelligent methods: ANNs and fuzzy logic. This hybrid approach combines the learning capacity of ANNs with the interpretability of fuzzy systems, effectively addressing the limitations inherent to each individual technique as a universal approximator [39,40,41].
Classical ANFIS architecture, illustrated in Figure 4, consists of five layers:
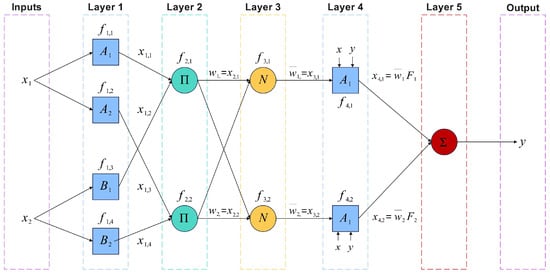
Figure 4.
Architecture scheme of a two-input ANFIS network.
- Layer 1 (Membership Functions): Each input is fuzzified using membership functions (MFs) that transform crisp inputs into membership degrees ranging from 0 to 1. In this work, different membership functions were tested, such as Gaussian, triangular, sigmoidal, and bell functions. After a comparative analysis, the membership function with the best performance was the sigmoidal one, as presented and discussed later in Table 10. The sigmoidal membership function is defined as follows:
where parameters and control the slope and center of the function, respectively.
- Layer 2 (Rule Firing Strength): Computes the firing strength of each fuzzy rule by aggregating membership degrees of all inputs via product:
where is the number of fuzzy rules and is number of inputs.
- Layer 3 (Normalization): Normalizes firing strengths:
- Layer 4 (Consequents): Each rule computes an output as a linear function of inputs weighted by :
where and are consequent parameters.
- Layer 5 (Output Aggregation): Aggregates all outputs to produce final prediction:
Neural network components enable continuous adjustment of weights and parameters during learning. The training method applied is a hybrid algorithm combining least squares estimation for the consequent parameters and gradient descent for nonlinear membership parameters , and [39,40].
The error function minimized during training is the mean squared error:
where and are actual and predicted outputs respectively. Update rule for any parameter follows gradient descent:
with learning rate controlling step size.
To capture temporal dependencies, input vectors include up to 20 previous samples (lags), generating delayed inputs such as the following:
Data for these delayed inputs are generated from white-box membrane transport model and loaded for ANFIS training. Variable selection is performed as previously described using correlation analysis to ensure relevance and reduce redundancy.
To ensure a robust and interpretable ANFIS model, configuration and training parameters are summarized in Table 5. Model uses four selected input variables—permeance , retentate volume , retentate pressure , and retentate mixture viscosity —with methane volume in retentate as output. Temporal dependencies are incorporated by evaluating up to 20 time lags per input, allowing the model to capture the dynamic behavior of the membrane process. Sigmoidal membership functions are primarily used. Each input variable has one membership function, balancing simplicity and expressive power.
Table 5.
Summary of ANFIS Model Configuration and Training Parameters.
While a greater number of membership functions (MFs) can enhance an ANFIS model’s ability to capture complex nonlinearities, this typically comes at the cost of significantly increased processing time. Our findings indicate that for this application, a model with a minimal set of MFs is not only sufficient but optimal. The marginal gains in accuracy from more complex configurations did not justify the exponential increase in computational demand, rendering them impractical for the real-time estimation of CH4 volume in the membrane retentate. Consequently, our chosen architecture strikes a robust balance between high predictive fidelity and operational efficiency.
Dataset is split into 70% training and 30% testing, maintaining strict separation to validate generalization. Training employs a hybrid method combining least squares estimation for linear consequent parameters and gradient descent for nonlinear membership parameters and . Parameters and are initialized randomly within defined ranges. Training proceeds until the mean squared error (MSE) for a maximum of 50 iterations is reached. Likewise, evaluation time (Eval Time) is computed. Performance metrics (Eval Time, MSE, RMSE, MAE, and ) are computed for both training and testing sets to evaluate overall accuracy. Final model selection is based on the lowest test set MSE among all evaluated lag configurations, ensuring optimal predictive performance. Validation includes graphical comparisons of predicted versus actual values and residual analysis to confirm model reliability. This rigorous framework enables ANFIS to effectively capture the nonlinear and temporal characteristics of the HFMM. We propose implementing a real-time control scheme coupled with bio-inspired algorithms (e.g., PSO, Gray Wolf Optimizer (GWO), and DE) for process tuning and optimization [42].
3. Results
This section presents and analyzes the results obtained from the developed hybrid model, which integrates a mechanistic multicomponent transport model for hollow fiber membranes (HFMM) with an Adaptive Neuro-Fuzzy Inference System (ANFIS). The section is organized into three key subsections to demonstrate the model’s validity, the variable selection methodology, and the predictive performance of the final model.
3.1. Mathematical Modeling of HFMM Results and Validation
The accuracy and predictive capacity of the proposed mathematical model are first evaluated by comparing its results against experimental data and the reference Ko model, as shown in Figure 5. Comparison focuses on two primary performance indicators for the membrane system: methane purity (Figure 5a) and methane recovery (Figure 5b), both as functions of feed flow rate.
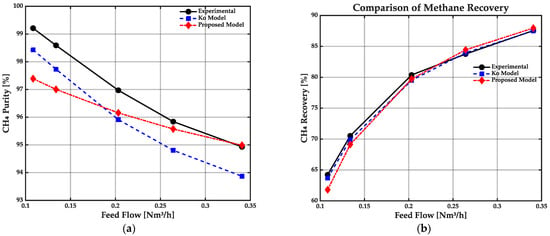
Figure 5.
Validation of the proposed membrane model using experimental results and the Ko model. (a) Methane purity as a function of feed flow rate. (b) Methane recovery as a function of feed flow rate.
As observed in Figure 5a, all models predict a decreasing trend in methane purity with increasing feed flow rate, which is consistent with the expected reduction in separation efficiency at higher feed rates. Notably, the proposed model tracks the experimental data more closely than the Ko model, particularly at intermediate and high feed flow rates. While the Ko model significantly underestimates methane purity under these conditions, the proposed model shows smaller deviations and better alignment with experimental results, indicating a more accurate representation of the underlying transport mechanisms.
In terms of methane recovery (Figure 5b), both models reproduce the expected increasing trend as the feed flow rate rises. However, the proposed model displays improved agreement with experimental data across tested feed rates, especially at low and moderate flow values where the Ko model exhibits more pronounced discrepancies. This consistent agreement highlights the ability of the proposed model to capture both the magnitude and trend of experimental recovery data.
To provide a quantitative assessment of model accuracy, a detailed error analysis was conducted using the relative error and mean absolute error (MAE) metrics for each experimental case (Figure 6 and Figure 7). Relative error distributions for methane purity (Figure 6a) and methane recovery (Figure 6b) show that, although the Ko model achieves lower errors at the lowest feed flow rates, its accuracy diminishes as flow increases. In contrast, the proposed model shows higher errors at low flow but rapidly improves with increasing feed, outperforming the Ko model in the higher range of operational relevance.
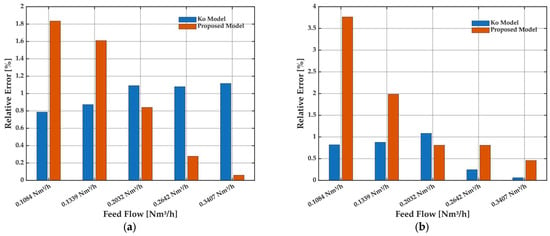
Figure 6.
Relative error of the Ko model and the proposed model for the prediction of (a) methane purity and (b) methane recovery as a function of feed flow rate. Results correspond to the same experimental conditions as in Figure 5.
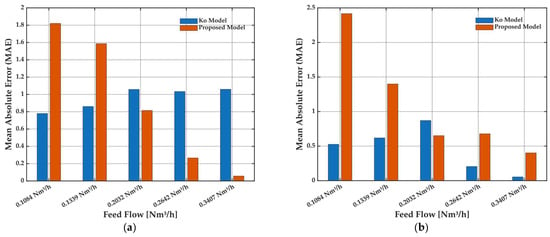
Figure 7.
Mean absolute error (MAE) of the Ko model and the proposed model for the prediction of (a) methane purity and (b) methane recovery as a function of feed flow rate. Results correspond to the same experimental conditions as in Figure 5.
MAE analysis (Figure 7a,b) reinforces this observation: while the Ko model maintains a slight advantage at the lowest feed, the proposed model yields lower MAE values at moderate and high feed flows for both purity and recovery. These results confirm that the proposed model delivers robust and reliable predictions under practical operating conditions, supporting its suitability for process optimization and scale-up in HFMM.
3.2. Statistical Method Results
A comprehensive statistical analysis is carried out to evaluate the predictive performance and interrelationships of all candidate input variables considered for modeling. The objective is to identify informative and least redundant subsets of variables for training a subsequent ANFIS model. Table 6 summarizes the results of individual linear regressions, including coefficient of determination (R2), mean absolute error (MAE) and variance inflation factor .
Table 6.
Initial individual variable regression metrics for model reduction.
Among evaluated variables, Retentate volume and permeate volume showed near-perfect linearity ( ≈ 0.9998–0.9999) and extremely low error (MAE = 5.47 × 10−8). However, their low values (0.52) and very high pairwise correlation (ρ > 0.93), as depicted in the Pearson correlation matrix (Figure 8), revealed significant redundancy. Including both would likely lead to multicollinearity without improving model expressiveness.
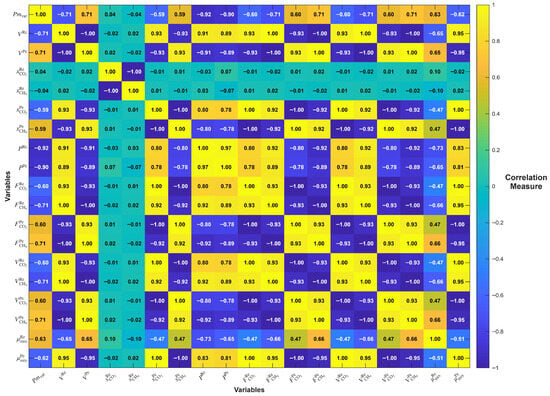
Figure 8.
Pearson correlation matrix between all candidate retentate and permeate variables included in the variable selection procedure. The heatmap indicates the degree of linear relationship between each pair of variables.
Retentate Pressure demonstrated strong predictive ability ( = 0.8356) and moderate (5.62), indicating it brings valuable and relatively unique information. Although its suggests some correlation with other inputs, it remained within an acceptable range for inclusion. On the other hand, permeance had a lower R2 (0.4883) but was favored due to its meaningful physical interpretation, relatively low (3.70), and strong negative correlations with both Retentate Volume and Retentate Pressure (ρ ≈ −0.90), suggesting it captures orthogonal aspects of the system behavior.
Regarding viscosity, Permeate Mix Viscosity achieved a high R2 (0.8992) and low MAE, indicating good predictive potential. However, its strong correlations with other variables (ρ > 0.9) signaled redundancy. Conversely, retentate mix viscosity showed moderate predictive performance ( = 0.4305) and acceptable multicollinearity ( = 2.18) but is retained for its physical relevance and lower correlation with other selected variables (ρ < 0.5), supporting its role in improving model robustness.
The correlation matrix (Figure 8) provides a comprehensive overview of the linear interrelationships among all candidate variables. Several variables exhibited strong pairwise correlations (ρ > 0.93), indicating a high degree of redundancy in the information they convey. Notably, variables such as retentate CH4 flow, permeate CH4 flow, retentate CO2 flow, and permeate CO2 fraction were found to be tightly interrelated with other process variables—particularly retentate volume, permeate volume, and retentate pressure—all of which already captured the principal trends of the system.
Despite achieving near-perfect individual scores in their univariate regressions, these highly correlated variables were not selected for the final model due to their limited marginal contribution to the overall predictive power and their potential to introduce multicollinearity. This decision is further supported by their very low values (typically < 0.60), which mathematically reflect that variance in these predictors can be almost entirely explained by other variables in the model. Including such variables would not only complicate the model unnecessarily but also increase the risk of overfitting and reduce the generalizability of the final predictive tool, particularly in real-world conditions with process noise and variability.
Moreover, from a physical standpoint, flows and fractions are often dependent on the outcomes of pressure, volume, and permeance conditions, and not independent drivers of system behavior. Thus, their high correlation with physically meaningful variables such as retentate pressure and permeance reinforces the decision to exclude them in favor of more mechanistically grounded predictors.
To further validate the reliability of the selected model, residual diagnostics are conducted, as illustrated in Figure 9 and Figure 10. Figure 9a shows the absolute error per sample across the dataset. The majority of errors are small and centered, with some increase observed near sample boundaries. This pattern is consistent with edge effects, where predictive models may exhibit slightly reduced accuracy due to limited data density or extrapolation beyond the core data cloud.
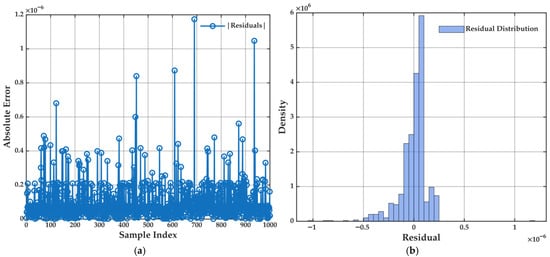
Figure 9.
(a) Absolute error for each sample in the validation dataset for the multiple linear regression model. (b) Histogram of residuals showing the distribution and magnitude of errors across all samples. These visualizations provide a direct assessment of the model’s prediction accuracy and the normality of residuals, which are essential for evaluating regression model assumptions.
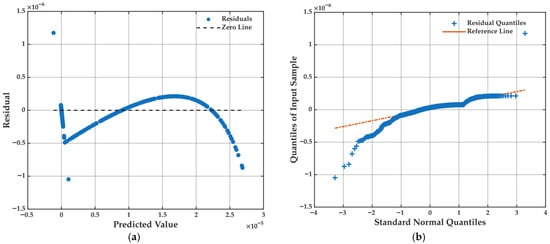
Figure 10.
(a) Residuals as a function of predicted values for a multiple linear regression model, highlighting any trends or heteroscedasticity in model errors. (b) Q-Q plot of residuals, used to assess the normality of errors and the adequacy of linear model assumptions.
Figure 9b presents the histogram of residuals, which exhibits a nearly symmetric bell-shaped distribution, closely approximating normality. This supports the assumption of homoscedastic and unbiased residuals, essential conditions for the validity of linear regression estimators.
Further insight is offered by the residuals vs. predicted plot (Figure 10a), where a slight curvature is observed. While mostly centered around zero, this pattern suggests the presence of mild heteroscedasticity or a weak nonlinear component in data that a linear model may not fully capture. Nevertheless, deviation remains minor and does not compromise the model’s overall fit or its applicability for variable screening.
The scatter plot of actual versus predicted values (Figure 11a) provides a visual confirmation of the regression model’s predictive capability. Most data points align closely with the ideal 1:1 reference line, indicating a strong agreement between observed outputs and those estimated by the model. This tight clustering suggests that the regression model effectively captures dominant trends and intrinsic relationships among selected input variables. Only minimal deviations are observed at the extremes, which is typical in physicochemical models where non-linearities and edge-case behaviors may arise due to unmodeled secondary effects.
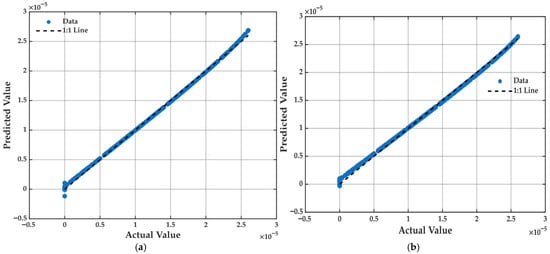
Figure 11.
Comparison of actual vs. predicted values for the multiple linear regression models. (a) Performance of the model with the initial set of 18 variables. (b) Performance of the reduced model with the 4 selected variables. The dashed line indicates the ideal 1:1 relationship.
Statistical performance of regression model is further substantiated by quantitative metrics presented in Table 7. Model achieved a global coefficient of determination of = 0.999, indicating that 99.9% of the variability in the target variable is explained by selected predictors. Additionally, the normalized mean absolute error (MAE) is 1.292, reflecting a very low average deviation between predicted and actual values relative to the output scale. Together, these results support the robustness and high fidelity of regression models.
Table 7.
Comparison of regression model performance metrics.
To complement the visual and numerical analysis, final regression model’s structure, including linear, interaction, and higher-order terms, is presented in Table 8. This table lists the estimated coefficients , which quantifies the relative influence of each term used in the polynomial regression model. Inclusion of higher-order coefficients enables the model to capture subtle nonlinear dependencies without introducing excessive complexity, while preserving interpretability and numerical stability.
Table 8.
The values of .
Following a comprehensive analysis that considered multiple statistical criteria—including , MAE, , and Pearson correlation coefficients—a reduced set of four variables was selected as optimal inputs for the subsequent ANFIS training process: Permeance, retentate volume, retentate pressure, and retentate mix viscosity. These variables were chosen based on their ability to capture complementary aspects of the process. Permeance represents the intrinsic transport property of the membrane, influenced by temperature, pressure, and composition. Retentate volume and retentate pressure reflect the operational state of the feed side and are strongly tied to driving forces for mass transfer. Retentate Mix Viscosity, while having moderate , was retained for its mechanistic relevance and lower correlation with other selected inputs, thus contributing unique variance to the model. Importantly, the selected variables offer a balanced trade-off: they exhibit high predictive power, low to moderate multicollinearity (as evidenced by acceptable values), and are rooted in well-understood physical mechanisms governing membrane-based gas separation. This selection aligns with the principle of model parsimony—minimizing the number of inputs without compromising accuracy or generalizability.
Several other variables, despite exhibiting excellent individual regression metrics (e.g., Permeate Flow CH4, Retentate Flow CO2, Permeate Fraction CH4), were deliberately excluded due to high pairwise correlations (ρ > 0.90), excessively low values (<0.6), or overlapping information content with already selected predictors. Additionally, some variables lacked direct mechanistic interpretability, which could hinder extrapolation or explainability of the model in broader operating domains.
Nonetheless, it is important to recognize that variable selection is inherently context-dependent. Current selection is optimized for the specific objective of training a robust, interpretable ANFIS model for this dataset and operating window. Future studies may consider evaluating alternative or expanded subsets of input variables—such as combinations including permeate mix viscosity or permeate fraction CH4—to explore whether these configurations offer improved performance, particularly under varying process conditions, multicomponent mixtures, or in the presence of dynamic disturbances.
In summary, the selected reduced-input model demonstrates excellent agreement with observed data (see Table 9), both statistically and physically. This outcome provides a strong foundation for training intelligent models like ANFIS, while avoiding pitfalls of overfitting, multicollinearity, and loss of physical meaning.
Table 9.
Criteria and Rationale for Selecting Input Variables for ANFIS Modeling.
3.3. ANFIS Simulation Results
The dataset used for training the ANFIS model is characterized by its high complexity and variability, justifying the choice of an advanced modeling strategy.
Figure 12 presents the output variable used as the target for ANFIS training: for each sample. Much like several of the input variables, the target output displays a highly scattered profile, characterized by frequent peaks and valleys and a lack of clear global trends across the dataset. Distribution is fairly symmetric, with values spanning a broad range; notably, there are no obvious outliers or missing data, though some points fall close to zero—most likely a result of diversity in simulated operating conditions or presence of measurement noise.
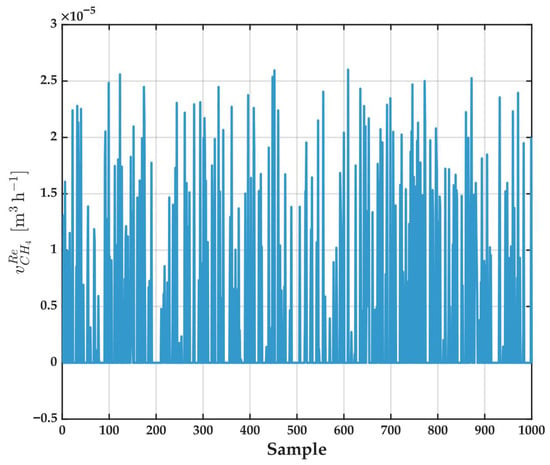
Figure 12.
Experimental values of retentate () for all samples in the dataset. This variable is used as the output (target) in the ANFIS modeling.
This considerable variability in output further increases the challenge for any predictive model, as it must learn to map a set of complexes, nonlinear, and potentially noisy relationships between inputs and target values. When combined with highly variable input variables (as shown in Figure 13), this scattered output underscores the inherent complexity of the modeled gas separation process. Altogether, these figures highlight the necessity for advanced modeling strategies such as ANFIS, which are specifically designed to capture nonlinear dependencies and to provide robust predictions even in the presence of high data dispersion and noise—scenarios where traditional modeling approaches often struggle.
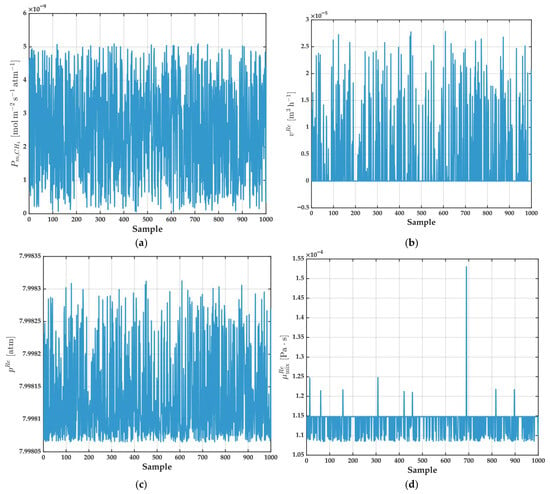
Figure 13.
Input variables used for the ANFIS model: (a) (); (b) (); (c) (); (d) (). Each plot shows the respective variable as a function of sample number for the entire dataset.
Figure 13 provides a comprehensive visualization input variables selected for the ANFIS model: (a) , (b) , (c) , and (d) , each plotted as a function of sample number. This figure serves to illustrate both the dynamic range and variability present in the input dataset used for training and evaluating the ANFIS model.
The input variables depicted in Figure 13 show a combination of highly variable and relatively stable features, reflecting the multifaceted and sometimes unpredictable nature of real-world process data. This diversity underscores the need for robust and flexible modeling strategies—such as ANFIS—that are capable of learning complex, nonlinear, and context-dependent relationships in the presence of noisy or nonstationary inputs.
As shown, the majority of these variables exhibit marked dispersion and apparently random fluctuations throughout the entire sample set, without any discernible temporal trends, periodicities, or seasonality. This high degree of scatter highlights the complexity and nonstationary character of the system, emphasizing the modeling challenge posed by such input data.
Focusing on permeance and retentate volume, both variables display substantial variability and a wide dynamic range. These characteristics may reflect either a broad spectrum of operational scenarios—including changes in membrane properties, feed conditions, or process upsets—or the synthetic or experimental nature of the underlying dataset. The absence of smooth transitions or recurring patterns suggests that the data either samples a wide range of experimental data or intentionally incorporates variability to enhance the generality of the resulting model.
In sharp contrast, retentate pressure remains almost invariant across all samples, presenting only minor fluctuations around a stable mean value. This pattern is typical of processes where pressure is tightly controlled or regulated, ensuring that this variable does not introduce confounding effects in the modeling process. Such stability is often desirable in membrane systems to maintain separation efficiency and process safety.
Finally, retentate mix viscosity displays behavior that is generally stable, with values clustered around a central mean. Nonetheless, several isolated peaks are observed, which could be attributed to specific simulation scenarios, rare measurement anomalies, or occasional transient events in the process. These excursions, though infrequent, might provide a model with valuable information about edge-case behavior or process sensitivity.
Table 10 presents a comparative analysis considering different metrics using several , such as gaussian, sigmoidal, bell, and triangular. Likewise, datasets used are separated into 700 samples for training and 300 samples for validation. Full analysis can be consulted in Appendix A, in Table A4, Table A5 and Table A6. The results obtained show that sigmoidal has better performance. Furthermore, sigmoidal has only two parameters, which allows for a reduction in evaluation time.
Table 10.
Comparative Analysis of Membership Function Performance in an ANFIS Model.
Table 10.
Comparative Analysis of Membership Function Performance in an ANFIS Model.
| Delay | Eval Time (s) | MSETrain | RMSETrain | MAETrain | R2Train | MSETest | RMSETest | MAETest | R2Test | |
|---|---|---|---|---|---|---|---|---|---|---|
| Gaussian | 5 | 3.1722 | 7.4569 × 10−15 | 8.6354 × 10−8 | 4.3155 × 10−8 | 0.9998 | 3.4332 × 10−15 | 5.8594 × 10−8 | 3.6890 × 10−8 | 0.9999 |
| Sigmoidal | 4 | 0.0111 | 6.50 × 10−15 | 8.06 × 10−8 | 4.07 × 10−8 | 0.9998 | 5.83 × 10−15 | 7.64 × 10−8 | 4.39 × 10−8 | 0.9999 |
| Bell | 6 | 4.2737 | 7.2937 × 10−15 | 8.5403 × 10−8 | 4.4189 × 10−8 | 0.9998 | 3.8136 × 10−15 | 6.1755 × 10−8 | 3.9547 × 10−8 | 0.9999 |
| Triangular | 3 | 4.2068 | 5.4029 × 10−11 | 7.3505 × 10−6 | 3.328 × 10−6 | −0.258 | 5.9828 × 10−11 | 7.7348 × 10−6 | 3.5508 × 10−6 | −0.267 |
Once sigmoidal is selected, its graphical results are illustrated. Figure 14a presents a comparison between the experimental values and the predictions generated by the best ANFIS model (with = 4) for the across all samples. The used dataset is clearly divided by a vertical dashed line into two partitions: the initial 70% of samples are assigned to training, while the remaining 30% are reserved for testing and model validation. In both regions, model predictions (dashed lines) exhibit a remarkable alignment with actual experimental data (solid lines), capturing with high accuracy not only the general trends but also the intricate details—such as sharp peaks and deep valleys—that characterize the output signal.
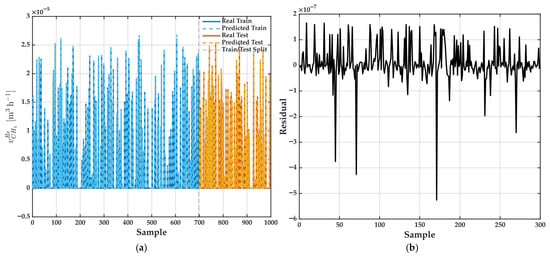
Figure 14.
(a) Comparison between experimental (Real Train: solid blue line; Real Test: solid orange line) and predicted values (Predicted Train: dashed blue line; Predicted Test: dashed orange line) of obtained by the best ANFIS model ( = 4). The model is trained using 70% of the data and tested on the remaining 30%. Vertical dashed line indicates train/test split. (b) Residuals (prediction errors) for test set using best ANFIS model ( = 4).
A closer inspection reveals that the ANFIS model preserves this high fidelity even in segments where the process response is particularly volatile or shows abrupt fluctuations. This is especially noteworthy, as such regions typically pose significant challenges for both conventional and data-driven modeling approaches, often resulting in loss of precision or the introduction of systematic errors. Model’s consistent performance throughout both smooth and highly variable intervals suggests that it is not simply memorizing data (overfitting) but rather learning and internalizing the underlying process dynamics.
Moreover, near-perfect overlap between real and predicted curves in both training and testing subsets underscores the model’s ability to generalize to previously unseen data, which is critical for practical applications in real-world systems. This level of predictive accuracy, even under challenging conditions, highlights the effectiveness of the ANFIS approach when dealing with complex systems where interactions among variables are nonlinear, time-dependent, and potentially obscured by noise.
To complement this visual assessment, Figure 14b provides an in-depth analysis of the model’s predictive accuracy by displaying the residuals— pointwise errors between experimental and predicted values—over the entire test set. The vast majority of these residuals remain tightly clustered around zero, with only isolated instances where more substantial errors occur. Lack of persistent trends, recurring spikes, or clusters of large errors throughout the sample range indicates that the model does not introduce bias, nor does it fail systematically under any particular set of operating conditions. Such a balanced distribution of errors is a desirable attribute, as it suggests that the model’s occasional larger deviations are more likely attributable to inherent data noise or rare process events rather than to structural deficiencies in the model itself.
Another important aspect is that, despite the high degree of scatter and the presence of noise in both input and output variables (as illustrated in Figure 12 and Figure 13), the ANFIS model maintains robustness and does not suffer from degradation in predictive quality as data complexity increases. This robustness is particularly valuable in industrial settings, where sensor noise, process disturbances, and changes in operating regimes are common and can easily compromise the performance of less adaptive models.
Across all tested (see Table 11), ANFIS models achieved outstanding accuracy, with R2 values of 0.999 for both subsets and extremely low error metrics (on the order of 10−15 for MSE and less than 10−7 for RMSE). These results reflect both the suitability of selected variables and the ability of ANFIS to model complex, nonlinear processes.
Table 11.
Performance metrics for ANFIS models at different times, . Metrics Eval Time, MSE, RMSE, MAE, R2 for both the training and test datasets. Best result is highlighted in bold.
As increases from 1 to 20, only minor variations are observed in the error metrics. MSE and MAE remain low and relatively stable for between 1 and 9, with a gradual increase in error from = 10 onward. Best predictive performance in the test set is obtained with a of 4, where the lowest MSE and MAE values are recorded. This indicates that incorporating a moderate memory of previous samples enables the model to optimally capture temporal dependencies without introducing unnecessary complexity or overfitting.
To rigorously evaluate the model’s generalization capability, a cross-validation was performed, with the results summarized in Table 12. This analysis confirms the exceptional predictive performance and stability of the ANFIS architecture.
Table 12.
Performance metrics for ANFIS models with different time using cross-validation. Metrics Eval Time, MSE, RMSE, MAE, R2 for both the training and test datasets. The best result is highlighted in bold.
The results demonstrate outstanding and consistent accuracy for models with short time lags. For delays between = 1 and = 10, the models achieved average R2 values of 0.9998 and Mean Square Errors (MSE) on the order of 10−15, indicating high reliability regardless of the data partition.
However, a drastic degradation in performance is observed for lags greater than 10 ( > 10), where the R2 decreases and errors increase by several orders of magnitude. This behavior suggests that an excess of historical information introduces noise, causing model instability and a loss of its generalization capability.
Based on this analysis, the model with a time lag of = 3 is identified as the optimal configuration. It offers the best balance between near-perfect accuracy, demonstrated by the lowest average MSE (7.256 × 10−15) and computational efficiency, validating its robustness for real-time prediction and control applications.
The architecture of the optimal ANFIS model, corresponding to a time lag of = 3, is illustrated in Figure 15. This structure is notable for its parsimony; although neuro-fuzzy systems can house significant complexity, the preceding statistical analysis demonstrated that a model with a single fuzzy rule (Equation (38)) was sufficient to capture the dynamic process with exceptional precision. The rule follows a first-order Sugeno structure, where if the four input variables (Permeance, Retentate Volume, Retentate Pressure, and Retentate Mix Viscosity) meet their respective membership functions, then the output (methane volume in the retentate) is calculated as a linear combination of those inputs. The fact that such a simple architecture achieves such high performance underscores the effectiveness of the variable selection and the synergy between the mechanistic model and the neuro-fuzzy approach.
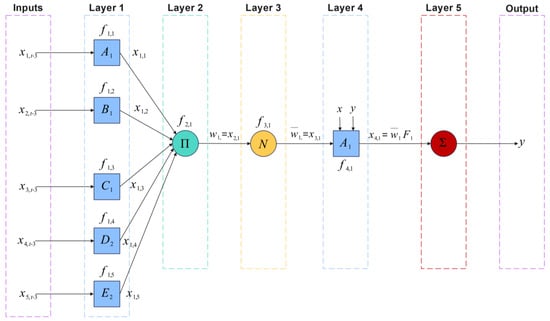
Figure 15.
Architecture of the single-rule ANFIS model for the optimal time lag (d = 3). This title specifies that the diagram represents the structure of the best-performing model identified through cross-validation, which uses a single fuzzy rule and a time delay of three samples.
To conclusively validate the robustness of this optimal model, Table 13 presents a detailed breakdown of the performance metrics for each of the five folds of the cross-validation. The results demonstrate remarkable stability and consistency. Across all folds, the coefficient of determination (R2) remains above 0.999, while the Mean Squared Error (MSE) and Mean Absolute Error (MAE) stay at extremely low orders of magnitude (10−15 and 10−8, respectively). The minimal deviation in these metrics across the different test subsets confirms that the model’s superior performance is not an artifact of a fortunate data partition but the result of a genuine generalization capability.
Table 13.
Cross-validation performance metrics by fold for the optimal ANFIS model ( = 3).
Figure 16a illustrates the evolution of the two main learning algorithm parameters: the step size (k), which is updated using heuristic rules proposed by Jang in [41], and the learning rate (η). Unlike an approach with fixed parameters, a dynamic behavior is observed. The learning rate (η), associated with the gradient descent method for nonlinear parameters, exhibits significant fluctuations throughout the 50 epochs. This indicates that the algorithm actively adjusts the magnitude of the updates to efficiently navigate the error surface. Simultaneously, the step size (k), associated with the adjustment of the linear parameters, decreases in a stepwise fashion, suggesting progressive stabilization as the model approaches the optimal solution.
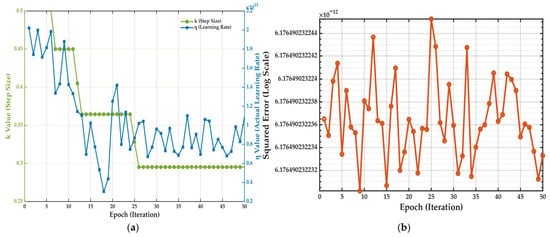
Figure 16.
(a) Evolution of the adaptive step size (k) and learning rate (η) across 50 training epochs. (b) Squared error per epoch, illustrating the model’s convergence behavior.
Meanwhile, Figure 16b shows the evolution of the squared error per epoch. Notably, the error converges almost instantaneously to an extremely low error valley (on the order of 10−12) without showing a typical steep descent curve. The low-amplitude, high-frequency fluctuations observed from that point onward do not indicate instability but are a direct reflection of the micro-adjustments made by the adaptive learning rate shown in Figure 16a. This behavior demonstrates that after a very rapid initial convergence, the algorithm continues a fine-tuning process to ensure the model settles in a deep and stable error minimum.
Taken together, both graphs confirm the efficiency and sophistication of the hybrid training method. The adaptive mechanism allows for swift convergence and precise parameter adjustment, which justifies the superior performance and robustness of the final selected model.
Figure 17 provides a compelling visual validation of the ANFIS model’s performance. It displays a near-perfect superposition of the actual methane volume in the retentate (solid blue line) and the values predicted by the model (dashed yellow line). This exceptional fit is maintained across the entire dataset, capturing with high fidelity not only the general trends but also the abrupt fluctuations and volatility of the process.
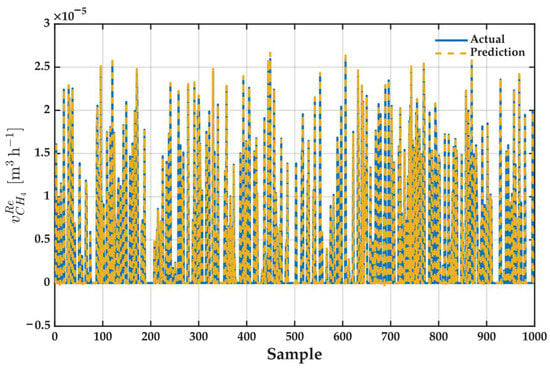
Figure 17.
Validation of the Optimal ANFIS Model’s Predictive Performance. The plot shows the superposition of the actual (solid blue) and model-predicted (dashed yellow) values for the methane volume in the retentate across the entire dataset, demonstrating a near-perfect fit.
The model’s ability to precisely track the sharp peaks and valleys demonstrates that it has successfully learned the complex, nonlinear dynamics of the membrane system. This excellent visual agreement is the graphical representation of the quantitative metrics previously reported, such as a coefficient of determination (R2) close to 0.999. In summary, the plot confirms the model’s robustness and high precision.
The viability of a model for real-time applications depends not only on its accuracy but also on its computational efficiency. Therefore, the inference latency of the optimal ANFIS model was evaluated, and the results are presented in Table 14. This analysis quantifies the time required by the model to generate predictions as a function of the number of samples processed simultaneously (in a batch).
Table 14.
Inference Time Analysis for the Optimal ANFIS Model.
For a single sample, the model demonstrates exceptional responsiveness, generating a prediction in just 0.3930 ms. This speed is fundamental for control systems that require immediate decisions. A key finding is the notable gain in efficiency achieved through batch processing; as the number of samples increases, the average inference time per sample decreases drastically. Specifically, when processing a batch of 100 samples, the average time per prediction is reduced to 0.0085 ms, representing an improvement of over 97% compared to individual processing.
It is observed that performance stabilizes for batches of 100 and 500 samples, indicating that the model’s maximum computational efficiency has been reached under these conditions. In addition to speed, the stability of the performance is notable, as the standard deviation significantly decreases for larger batches, which confirms that the prediction times are highly consistent and reliable. Taken together, these results confirm that the ANFIS model is computationally efficient, validating its implementation in real-time monitoring and control applications where response speed is a critical factor.
4. Conclusions
In this work, it has been demonstrated that combining a first-principles transport model with an ANFIS produces a tool that is both powerful and interpretable for modeling CH4/CO2 separation in HFMM. By systematically reducing eighteen candidate predictors to only four—permeance, retentate volume, retentate pressure, and mixture viscosity of the retentate—via Pearson correlation, VIF (with ridge regularization), and normalized regression diagnostics, it is also ensured a parsimonious input set that balances physical insight and statistical rigor. This hybrid framework not only preserves mechanistic transparency but also injects flexibility of data-driven learning, so that the “fuzzy” part of ANFIS remains strictly in the logic layer—never clouding our understanding of underlying physics!
While an initial analysis training on 70% of the simulated dataset and validating on the remaining 30% suggested the best ANFIS configuration was the one with a time lag of = 4, a more robust cross-validation was performed to get a more reliable estimate of the model’s generalization capability. This more rigorous method revealed that the model with a time lag of = 3 was the true optimum, and this final configuration achieved an R2 of 0.999 and an RMSE below 8 × 10−8 m3/h for retentate methane volume prediction. Such near-perfect agreement, across both smooth regimes and abrupt dynamics, confirms that the model is anything but “fuzzy” in its accuracy.
Validity is restricted by the assumptions and the training domain. For validation, permeances were assumed constant; strong dependencies on T, P, or composition (e.g., competitive sorption, plasticization, aging/moisture) or module non-idealities (maldistribution, external film resistances) not explicitly parameterized can degrade accuracy. The hydrodynamics are 1D and laminar (Hagen–Poiseuille) with non-deformable fibers; deviations are expected under transitional/turbulent flow, slip/Knudsen regimes at very low pressure, or fiber compaction at high pressure drop. PR-EOS and Wilke/Chapman–Enskog viscosity models are adequate across broad ranges but may require corrections near critical regions, under incipient condensation, or for strongly associating/heavy/impure mixtures (e.g., C3+, H2S, high humidity). The ANFIS was trained on physics-generated data. While performance was initially evaluated with a 70/30 train/test split, a cross-validation was also implemented to ensure a more reliable estimate of the model’s generalization capability. To this end, future work will focus on the development of a pilot-scale plant to obtain our own experimental data. This will allow for a direct validation of the model’s generalization to real-world conditions and enable further calibration of the intelligent system, bridging the gap between simulation and industrial application.
From an applied standpoint, this hybrid approach fully aligns with Industry 4.0 objectives: it reduces parameter uncertainty, adapts in real time to process disturbances, and serves as an interpretable “soft sensor” for advanced monitoring and control.
In this context, the interpretability of the ANFIS component provides actionable insight for process engineers in two key ways. First, as a decision-support tool, the ANFIS model distills the complex set of differential equations from the mechanistic model into a single, intuitive “IF-THEN” fuzzy rule. This rule acts as a transparent soft sensor, allowing an operator without modeling expertise to gain a qualitative, cause-and-effect understanding of how input variables (such as permeance or retentate pressure) influence the final methane volume, thereby guiding operational adjustments. Second, its simplicity and high computational speed make it the foundation for advanced process optimization. The model is designed to be integrated into an optimization loop coupled with bio-inspired algorithms, using its predictions within a cost function to determine the optimal operating conditions that maximize methane purity or recovery.
That a single membership function per input sufficed to capture complex nonlinearities underscores the wisdom of marrying white-box equations with neuro-fuzzy learning—delivering high precision without unnecessary model bloat. Moreover, this white-box model can be substituted by a data-collection system in physical plants, enabling empirical calibration and adjustment of the Intelligent Model under real operating conditions.
Looking ahead, integrating this ANFIS-enhanced model into multi-objective optimization routines or closed-loop control schemes promises to further boost the efficiency and resilience of gas separation processes. Specifically, and as a key priority for our next investigation, we will conduct the sensitivity analysis on fiber compaction. This analysis will quantify how potential reductions in fiber diameter impact pressure drop and CH4 recovery, thereby directly addressing the model’s utility for industrial scale-up. Future work could also explore online parameter adaptation under real plant noise, extension to multicomponent mixtures beyond CH4/CO2, and pilot-scale validation.
Author Contributions
Conceptualization, B.J.G.-S. and J.A.R.-H. methodology, J.A.R.-H. and B.J.G.-S.; software, B.J.G.-S.; validation, B.J.G.-S. and J.A.R.-H.; writing—original draft preparation, B.J.G.-S. and J.A.R.-H.; writing—review and editing, J.A.R.-H., A.Y.A., M.A.R.C., J.C.G.G., J.-L.R.-L. and F.J.R.-S. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Acknowledgments
First author acknowledges SECIHTY (formerly CONHACYT) with scholarship number [999970] for its support through a Ph.D. scholarship. The authors also thank the support to UNACAR and U. de G. to establish the academic collaboration network “Sistemas Avanzados, Inteligentes y Bioinspirados Aplicados a la Ingeniería, Tecnología y Control” for providing the facilities, resources, and collaborative environment to carry out this research project.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
| AARD | Average Absolute Relative Deviation |
| ACO | Ant Colony Optimization |
| AI | Artificial Intelligence |
| ANFIS | Adaptive Neuro-Fuzzy Inference System |
| ANN/ANNs | Artificial Neural Network(s) |
| ARD | Average Relative Deviation |
| BDF | Backward Differentiation Formula(s) |
| BR | Bayesian Regularization |
| CFD | Computational Fluid Dynamics |
| CSA-LSSVM | Crow Search Algorithm–Least-Squares Support Vector Machine |
| Cu-BTC | Copper(II) benzene-1,3,5-tricarboxylate (HKUST-1) |
| DE | Differential Evolution |
| dsigmf | Difference-of-Sigmoids Membership Function |
| EUF | Electro-Ultrafiltration (Electro-assisted Ultrafiltration) |
| FCM | Fuzzy C-Means |
| FFBP-LM | Feed-Forward Backpropagation with Levenberg–Marquardt |
| FO | Forward Osmosis |
| FS | Fumed Silica |
| GA | Genetic Algorithm |
| gaussmf | Gaussian membership function |
| GMDH | Group Method of Data Handling |
| GP | Genetic Programming |
| GPU | Gas Permeation Unit |
| GWO | Gray Wolf Optimizer |
| HF | Hollow Fiber |
| HFMM | Hollow Fiber Membrane Module(s) |
| Jw | Water flux |
| Js | Reverse salt flux |
| LM | Levenberg–Marquardt (algorithm) |
| MAE | Mean Absolute Error |
| MAD | Mean Absolute Deviation |
| MD | Molecular dynamic |
| MF/MFs | Membership Function(s) |
| MMM | Mixed-Matrix Membrane |
| MLP | Multilayer Perceptron |
| MOFs | Metal–Organic Frameworks |
| MSE | Mean Square Error |
| NSE | Nash–Sutcliffe Efficiency |
| NP/NPs | Nanoparticle(s) |
| PBCC5 | Polyethersulfone, 5 kDa |
| PBSA | Poly(butylene succinate-co-adipate) |
| PBS | Poly(butylene succinate) |
| PDMS | Polydimethylsiloxane |
| PI | Performance Index |
| PL/PLs | Porous Liquid(s) |
| PLCC5 | Regenerated cellulose, 5 kDa |
| PMP | Polymethylpentene |
| PNN | Probabilistic Neural Network |
| POSS | Polyhedral Oligomeric Silsesquioxane |
| PR | Peng–Robinson |
| PS | Polystyrene |
| PSO | Particle Swarm Optimization |
| PVAc | Poly(vinyl acetate) |
| RF | Random Forest |
| RMSE | Root Mean Square Error |
| RSM | Response Surface Methodology |
| SAPO-34 | Silicoaluminophosphate-34 |
| SC | Subtractive Clustering |
| SGD | Stochastic Gradient Descent |
| TFC | Thin-Film Composite |
| TSK | Takagi–Sugeno–Kang (Sugeno fuzzy model) |
| VIF | Variance Inflation Factor |
Nomenclature
| Latin letters | |||
| PR parameter for pure component i, | |||
| MF slope/shape parameter, | |||
| PR mixture parameter, | |||
| PR parameter for pure component i, | |||
| PR mixture parameter, | |||
| Linear consequent coefficient (rule , input ), | |||
| MF center, | |||
| Consequent offset (rule ), | |||
| Time lag (delay), | |||
| Module (shell) diameter, | |||
| Inner fiber diameter, | |||
| Outer fiber diameter, | |||
| Mean squared error in ANFIS training, | |||
| Molar flow rate of component i, | |||
| Output of rule , | |||
| Identity matrix used in ridge-VIF, | |||
| Regression MSE cost function, | |||
| Number of selected predictors, | |||
| Initial number of candidate predictors (18), | |||
| Boltzmann constant, | |||
| Empirical parameter in , | |||
| Binary interaction parameter, | |||
| Module length, | |||
| Number of fuzzy rules in ANFIS, | |||
| Molar mass of component i, | |||
| Number of observations (samples), | |||
| Number of Hollow Fiber, | |||
| Number of samples (for MSE in ANFIS), | |||
| Pressure on the retentate side, | |||
| Critical pressure of component i, | |||
| Pressure on the permeate side, | |||
| Permeance of component i, | |||
| Number of ANFIS inputs, | |||
| Universal gas constant, | |||
| Coefficient of determination, | |||
| Predictor correlation matrix, | |||
| Time/sample index in ANFIS, | |||
| Temperature, | |||
| Critical temperature of component i, | |||
| Reduced temperature, | |||
| Flow rate on the permeate side of species , | |||
| Flow rate on the retentate side of species , | |||
| Total Volumetric flow rate, | |||
| Volumetric flow rate of component , | |||
| Molar volume, | |||
| Rule firing strength, | |||
| Normalized rule firing strength, | |||
| ANFIS input , | |||
| Value of predictor at observation , | |||
| Normalized predictors, | |||
| ANFIS aggregated output, | |||
| Normalized response, | |||
| Predicted output, | |||
| Predicted output normalized, | |||
| Axial coordinate along the module Length, | |||
| Greek symbols | |||
| Temperature dependence in Peng-Robinson equation, | |||
| Intercept, | |||
| Regression coefficients | |||
| Coefficient vector, | |||
| Depth of the potential well in the Lennard–Jones potential, | |||
| Mole fraction of component , | |||
| Learning rate in ANFIS gradient descent, | |||
| Ridge penalty in ridge-VIF, | |||
| Pure-gas viscosity of component , Pa·s | |||
| Mixture dynamic viscosity, Pa·s | |||
| Column-wise mean vector of X, | |||
| Mean scalar of response y, | |||
| Membership function, | |||
| Lennard–Jones collision diameter, | |||
| Column-wise std. dev. vector of X, | |||
| Std. dev. scalar of response y, | |||
| Pearson correlation between predictors and , | |||
| Binary weighting factor, | |||
| Collision integral, | |||
| Acentric factor of component , | |||
| Subscripts and Superscripts | |||
| Refers to the retentate stream (non-permeated) | |||
| Refers to the permeate stream (permeated) | |||
| Refers to a specific chemical component (e.g., CO2, CH4) | |||
| Refers to a property of the gas mixture | |||
| Refers to a variable parameter in the simulation | |||
Appendix A
For full reproducibility, Appendix A reports the CH4/CO2 parameters used in this work (see Table A1, Table A2 and Table A3). While widely available in the classical literature, they are restated here to avoid ambiguity; we follow Bird, Stewart, and Lightfoot [43].
Table A1.
Molecular weights.
Table A1.
Molecular weights.
| Species | |
|---|---|
| CH4 | 16.04 |
| CO2 | 44.01 |
Table A2.
Critical properties and acentric factor.
Table A2.
Critical properties and acentric factor.
| Species | |||
|---|---|---|---|
| CH4 | 190.7 | 45.8 | 0.011 |
| CO2 | 304.2 | 72.9 | 0.225 |
Table A3.
Lennard–Jones parameters.
Table A3.
Lennard–Jones parameters.
| Species | ||
|---|---|---|
| CH4 | 3.882 | 137 |
| CO2 | 3.996 | 190 |
| Algorithm A1 Gas Separation Membrane Simulation Process and Validation. Pseudocode for the simulation and validation of the mechanistic membrane model. |
| // PHASE 1: SETUP AND INITIALIZATION 1 DEFINE FixedSystemParameters: 2 - Membrane module geometry (Length, Diameters, Number of Fibers) 3 - Operating conditions (Temperature, Inlet Pressures) 4 - Physical and gas constants (R, Molar Masses, etc.) 5 DEFINE MembraneProperties: 6 - Permeance coefficients (Pi) for each gas (CO₂, CH₄) 7 DEFINE StudyCases: 8 - Load list of feed flow rates to simulate 9 LOAD ReferenceData: 10 - Load experimental results (purity, recovery, etc.) 11 - Load results from a comparison model (“Ko Model”) 12 DEFINE 13 Solver Type: ode15s (variable-step method for stiff systems). 14 Relative Tolerance (RelTol): 1 × 10−6. 15 Absolute Tolerance (AbsTol): 1 × 10−12 16 Integration Interval: [0, L] (along the axial axis of the module). 17 INITIALIZE an empty data structure to store the simulation results. // PHASE 2: MAIN SIMULATION LOOP 18 FOR EACH feed_flow_rate IN the list of StudyCases: 19 // a. Prepare initial conditions for the solver 20 CALCULATE the total molar inlet flow based on the feed_flow_rate. 21 CONSTRUCT the initial state vector Q0 at the module inlet (z = 0). 22 // b. Solve the mathematical model along the module length 23 CALL the Ordinary Differential Equation (ODE) Solver with: massPressureModel, range [0, L], and Q0. 24 GET the final state vector Qf at the module outlet. 25 // c. Post-process and store the results for this simulation 26 CALCULATE performance metrics (Purity, Recovery, etc.) from Qf. 27 STORE these calculated metrics in the results structure. 28 END FOR // PHASE 3: RESULTS ANALYSIS AND VISUALIZATION 29 CALCULATE errors (Relative, MAE, and RMSE) by comparing simulation vs. experimental data. 30 GENERATE Performance Plots (Purity and Recovery vs. Flow Rate). 31 GENERATE Error Plots (Bar charts for comparison). 32 END |
| Algorithm A2 Generation of Synthetic Data via Parametric Exploration. Pseudocode for the generation of the synthetic dataset via parametric exploration. |
| // PHASE 1: SETUP AND PARAMETER DEFINITION 1 DEFINE FixedSystemParameters (T, Geometry, Pressures, n_total, etc.). 2 DEFINE SpeciesProperties (Molar fractions, Molar masses M, Pmi_base, etc.). 3 DEFINE RandomSimulationParameters: 4 - Index of the component to vary (var_index = CH₄). 5 - Number of simulations (num_segments). 6 DEFINE 7 Solver Type: ode15s (variable-step method for stiff systems). 8 Relative Tolerance (RelTol): 1 × 10−6. 9 Absolute Tolerance (AbsTol): 1 × 10−12 10 CALCULATE lower and upper limits for the variable permeance (lim_inf_pmi, lim_sup_pmi). 11 GENERATE a vector Pmi_range with num_segments random permeance values within the limits. // PHASE 2: MAIN SIMULATION LOOP 12 INITIALIZE a results matrix ZF (num_segments x 18) with NaN values. 13 FOR EACH Pmi_varied IN the Pmi_range vector: 14 INSIDE a Try-Catch block to handle simulation errors: 15 // a. Configure conditions for the current simulation 16 ASSIGN the Pmi_varied to the permeance vector Pmi. 17 CONSTRUCT the initial state vector Q0 (flows and pressures at z = 0). 18 GROUP all parameters into a ‘sim’ structure for the solver. 20 // b. Solve the mathematical model 21 CALL the ODE Solver (ode15s) with the ‘modeloMasaPresion’ model, Q0, and ‘sim’. 22 GET the solution matrix Qsol. 24 // c. Post-process and calculate performance metrics 25 EXTRACT the final values of flows (FiR, FiP) and pressures from Qsol. 26 CALCULATE the 18 output metrics (volumes, fractions, viscosities, etc.). 27 STORE the calculated metrics as a new row in the ZF matrix. 28 END FOR 29 FILTER ZF to remove any rows containing errors (NaNs). // PHASE 3: STRUCTURING THE FINAL DATASET 30 CONVERT the numerical matrix ZF to a structured table (tabla_ZF) using predefined headers. 31 RETURN tabla_ZF as the synthetic dataset for statistical analysis and ANFIS model training. 32 END |
| Algorithm A3 Statistical Analysis and Multivariate Regression Diagnostics. Pseudocode for the statistical analysis and variable selection workflow. |
| // PHASE 1: SETUP AND PRELIMINARY DIAGNOSTICS 1 LOAD the dataset (tabla_ZF). 2 PROMPT user to select the dependent variable (Y) and independent variables (X). 3 FOR EACH variable in X: 4 CALCULATE and DISPLAY descriptive statistics (standard deviation, min/max). 5 END FOR 6 CALCULATE and DISPLAY the rank of matrix X for an initial multicollinearity check. // PHASE 2: FITTING REGRESSION MODELS 7 // -- Multiple Linear Regression Model -- 8 DEFINE GradientDescentHyperparameters: 9 Learning Rate (alpha): 0.01 10 Number of iterations: 1000 11 NORMALIZE the X and Y matrices. 12 FIT the model coefficients (theta) using Gradient Descent on the normalized data. 13 DENORMALIZE the predictions (Y_pred) back to the original scale. 14 CALCULATE the model's global performance metrics (R², MAE, MAPE). 15 // -- Simple Linear Regression Models -- 16 FOR EACH variable in X: 17 FIT a simple regression model against Y. 18 CALCULATE and STORE its individual performance metrics (R², MAE, MAPE). 19 END FOR // PHASE 3: MULTICOLLINEARITY ANALYSIS 20 CALCULATE the Pearson correlation matrix (Rxx) for the variables in X. 21 FOR EACH variable in X: 22 CALCULATE the Variance Inflation Factor (VIF) using several methods (Classic and with Ridge regularization). 23 Ridge VIF: Using a fixed regularization parameter (lambda = 0.03). 24 END FOR 25 CALCULATE the Condition Index from the eigenvalues of Rxx. 26 GENERATE a summary table with the VIF and Condition Index results. // PHASE 4: GENERATION OF VISUAL DIAGNOSTICS AND REPORTS 27 CALCULATE the residuals of the multiple regression model (resid = Y - Y_pred). 28 GENERATE a Heatmap of the correlation matrix Rxx with labels and values. 29 GENERATE a Residuals vs. Predicted Values plot to check for homoscedasticity. 30 GENERATE a Q-Q plot of the residuals to check for normality. 31 GENERATE a histogram of the residual distribution. 32 GENERATE an Actual vs. Predicted Values plot to evaluate the overall fit. 33 GENERATE an Absolute Error per Sample plot to identify outliers. 34 GENERATE final summary tables with the model coefficients and performance metrics. 35 END |
| Algorithm A4 Optimal Lag Search for ANFIS Model with Fixed Split (Train/Test). Pseudocode for the optimal lag search and training of the ANFIS model. |
| // PHASE 1: INITIAL SETUP 1 LOAD the pre-processed dataset. 2 DEFINE model hyperparameters (I/O indices, max_lags, M, mf_type, k0, max_iters). 3 INITIALIZE Random Number Generator (Seed = 45) for reproducibility. 4 INITIALIZE structures to store metrics, latencies, and parameters for each trained model. // PHASE 2: OPTIMAL LAG SEARCH 5 FOR EACH time lag (lag) FROM 1 TO max_lags: 6 // a. Data Preparation and Splitting 7 GENERATE the input-output dataset by applying the current lag. 8 SPLIT the data into a training set (70%) and a testing set (30%). 9 // b. Model Training 10 INITIALIZE the ANFIS model parameters (a, b, c). 11 FOR EACH epoch FROM 1 TO max_iters: 12 // Step 1: Forward Pass & Least Squares Estimate 13 CALCULATE the consequent parameters (params) using a Least Squares estimate (A\B). 14 // Step 2: Backward Pass & Gradient Descent 15 CALCULATE the error gradient with respect to the premise parameters. 16 UPDATE the premise parameters (a, b, c) using Gradient Descent. 17 // Step 3: Adaptive Learning Rate 18 ADJUST the learning rate (k) based on the error trend of the last 5 epochs (e.g., increase by 10% on steady decrease, decrease by 10% on oscillation)squares and Gradient Descent with an adaptive learning rate). 19 END FOR 20 // c. Evaluation and Storage 21 MAKE predictions on both the training and testing sets. 22 CALCULATE performance metrics (MSE, RMSE, MAE, R²) for both sets. 23 STORE the calculated metrics for the current lag. 24 CALCULATE and STORE the model’s inference latency. 25 SAVE all trained model parameters and results (a, b, c, params, test data, predictions, etc.). 26 END FOR // PHASE 3: RESULTS ANALYSIS AND REPORT GENERATION 27 IDENTIFY the best lag (best_idx) based on the lowest MSE on the test set. 28 // -- General and Best Model Reports -- 29 GENERATE an Error vs. Latency plot to visualize the trade-off of all evaluated models. 30 GENERATE a summary table with the key performance of the best model (lag, MSE, latency). 31 GENERATE a general table with the performance metrics for all evaluated lags. 32 IDENTIFY the top N models (e.g., Top 7) based on the test set MSE. 33 FOR EACH of the top N models: 34 RETRIEVE its saved parameters and results. |
| Algorithm A5 ANFIS Model Training and Cross-Validation. Pseudocode for the ANFIS model training and k-fold cross-validation. |
| // PHASE 1: INITIAL SETUP 1 LOAD the pre-processed dataset. 2 DEFINE model hyperparameters (I/O indices, max_lags, M, mf_type, k_folds, etc.). 3 INITIALIZE structures to store average metrics and standard deviation. 4 INITIALIZE a container (all_lags_fold_metrics) to store the detailed metrics for EACH FOLD. // PHASE 2: OPTIMAL LAG SEARCH VIA CROSS-VALIDATION 5 FOR EACH time lag (lag) FROM 1 TO max_lags: 6 // a. Data Preparation and Partitioning 7 GENERATE the input-output dataset by applying the current lag. 8 CREATE k_folds partitions of the data for cross-validation. 9 // b. Training and Evaluation of the current fold 10 FOR EACH partition (fold) FROM 1 TO k_folds: 11 SPLIT the data into training and testing sets. 12 TRAIN the ANFIS model using the training data. 13 EVALUATE the trained model and CALCULATE performance metrics (MSE, RMSE, MAE, R²). 14 CALCULATE the inference latency and STORE all metrics for this fold. 15 END FOR 16 // c. Consolidation of results for the current lag 17 CALCULATE the average and standard deviation of the metrics from all folds. 18 STORE the consolidated results (average and std. dev.) for the current lag. 19 STORE the complete matrix with the metrics from each fold in ‘all_lags_fold_metrics’. 20 END FOR // PHASE 3: BEST MODEL IDENTIFICATION AND REPORTING 21 IDENTIFY the best lag (best_idx) based on the lowest average MSE on the test set. 22 // -- Generate summary table for the best model -- 23 RETRIEVE the saved test metrics for each fold of the best lag (best_idx) from the container. 24 CALCULATE the average and standard deviation of these retrieved metrics. 25 GENERATE a detailed summary table with the metrics for each fold of the best model. // PHASE 4: REPORT GENERATION 26 GENERATE a summary table comparing the average performance of all evaluated lags. 27 GENERATE an Error vs. Latency plot to visualize the model trade-offs. 28 GENERATE diagnostic plots for the final model (Actual vs. Predicted, error curve, etc.). 29 END |
Table A4.
Performance metrics for ANFIS with Gaussian Membership function models with different time d using cross-validation. Metrics Eval Time, MSE, RMSE, MAE, R2 for both the training and test datasets. Best result is highlighted in bold.
Table A4.
Performance metrics for ANFIS with Gaussian Membership function models with different time d using cross-validation. Metrics Eval Time, MSE, RMSE, MAE, R2 for both the training and test datasets. Best result is highlighted in bold.
| Delay | Eval Time(s) | MSETrain | RMSETrain | MAETrain | R2Train | MSETest | RMSETest | MAETest | R2Test |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 1.4773 | 5.4903 × 10−11 | 7.4097 × 10−6 | 3.4251 × 10−6 | −0.2717 | 5.7991 × 10−11 | 7.6152 × 10−6 | 3.3465 × 10−6 | −0.2393 |
| 2 | 1.8107 | 5.1806 × 10−11 | 7.1976 × 10−6 | 3.1886 × 10−6 | −0.2442 | 6.5415 × 10−11 | 8.0880 × 10−6 | 3.9106 × 10−6 | −0.3051 |
| 3 | 2.2136 | 4.7748 × 10−15 | 6.9100 × 10−8 | 3.4422 × 10−8 | 0.9999 | 1.0148 × 10−14 | 1.0074 × 10−7 | 4.2528 × 10−8 | 0.9998 |
| 4 | 2.6798 | 5.9851 × 10−11 | 7.7364 × 10−6 | 3.5949 × 10−6 | −0.2754 | 4.6392 × 10−11 | 6.8112 × 10−6 | 2.9390 × 10−6 | −0.2288 |
| 5 | 3.1722 | 7.4569 × 10−15 | 8.6354 × 10−8 | 4.3155 × 10−8 | 0.9998 | 3.4332 × 10−15 | 5.8594 × 10−8 | 3.6890 × 10−8 | 0.9999 |
| 6 | 3.6361 | 5.7754 × 10−11 | 7.5996 × 10−6 | 3.4671 × 10−6 | −0.2629 | 5.0826 × 10−11 | 7.1292 × 10−6 | 3.2077 × 10−6 | −0.2538 |
| 7 | 4.0638 | 5.8503 × 10−11 | 7.6487 × 10−6 | 3.5729 × 10−6 | −0.2791 | 4.9241 × 10−11 | 7.0172 × 10−6 | 2.9706 × 10−6 | −0.2183 |
| 8 | 4.6857 | 7.2461 × 10−15 | 8.5124 × 10−8 | 4.4180 × 10−8 | 0.9998 | 4.1107 × 10−15 | 6.4115 × 10−8 | 3.8834 × 10−8 | 0.9999 |
| 9 | 5.0098 | 5.7740 × 10−15 | 7.5987 × 10−8 | 4.0684 × 10−8 | 0.9999 | 7.3984 × 10−15 | 8.6014 × 10−8 | 4.4977 × 10−8 | 0.9999 |
| 10 | 5.4081 | 5.5581 × 10−11 | 7.4553 × 10−6 | 3.3961 × 10−6 | −0.2618 | 5.6650 × 10−11 | 7.5266 × 10−6 | 3.4191 × 10−6 | −0.2600 |
| 11 | 6.4764 | 6.0751 × 10−15 | 7.7943 × 10−8 | 4.1210 × 10−8 | 0.9999 | 6.8112 × 10−15 | 8.2530 × 10−8 | 5.2199 × 10−8 | 0.9999 |
| 12 | 7.0233 | 5.9000 × 10−15 | 7.6811 × 10−8 | 4.1660 × 10−8 | 0.9999 | 6.9338 × 10−15 | 8.3270 × 10−8 | 4.1058 × 10−8 | 0.9998 |
| 13 | 7.1029 | 5.3830 × 10−11 | 7.3369 × 10−6 | 3.2650 × 10−6 | −0.2469 | 6.0972 × 10−11 | 7.8085 × 10−6 | 3.7264 × 10−6 | −0.2949 |
| 14 | 7.7078 | 5.0582 × 10−15 | 7.1121 × 10−8 | 3.9266 × 10−8 | 0.9999 | 1.1384 × 10−14 | 1.0670 × 10−7 | 4.8726 × 10−8 | 0.9997 |
| 15 | 7.9784 | 4.3128 × 10−15 | 6.5672 × 10−8 | 3.6525 × 10−8 | 0.9999 | 1.1275 × 10−14 | 1.0618 × 10−7 | 4.4277 × 10−8 | 0.9998 |
| 16 | 8.4660 | 5.8757 × 10−15 | 7.6653 × 10−8 | 4.3189 × 10−8 | 0.9999 | 6.9371 × 10−15 | 8.3289 × 10−8 | 4.7004 × 10−8 | 0.9998 |
| 17 | 8.8192 | 5.4818 × 10−15 | 7.4039 × 10−8 | 4.0819 × 10−8 | 0.9999 | 9.4202 × 10−15 | 9.7058 × 10−8 | 4.5190 × 10−8 | 0.9998 |
| 18 | 9.3072 | 6.5666 × 10−15 | 8.1035 × 10−8 | 4.6366 × 10−8 | 0.9999 | 5.1686 × 10−15 | 7.1893 × 10−8 | 4.5648 × 10−8 | 0.9999 |
| 19 | 9.7245 | 6.8630 × 10−15 | 8.2843 × 10−8 | 4.6651 × 10−8 | 0.9998 | 4.3345 × 10−15 | 6.5837 × 10−8 | 4.6216 × 10−8 | 0.9999 |
| 20 | 10.4467 | 6.5070 × 10−15 | 8.0666 × 10−8 | 4.5100 × 10−8 | 0.9999 | 5.1161 × 10−15 | 7.1527 × 10−8 | 4.3540 × 10−8 | 0.9999 |
Table A5.
Performance metrics for ANFIS with Bell Membership function models with different time d using cross-validation. Metrics Eval Time, MSE, RMSE, MAE, R2 for both the training and test datasets. Best result is highlighted in bold.
Table A5.
Performance metrics for ANFIS with Bell Membership function models with different time d using cross-validation. Metrics Eval Time, MSE, RMSE, MAE, R2 for both the training and test datasets. Best result is highlighted in bold.
| Delay | Eval Time(s) | MSETrain | RMSETrain | MAETrain | R2Train | MSETest | RMSETest | MAETest | R2Test |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 1.5262 | 5.9250 × 10−15 | 7.6974 × 10−8 | 3.7942 × 10−8 | 0.9999 | 7.3363 × 10−15 | 8.5652 × 10−8 | 4.2986 × 10−8 | 0.9998 |
| 2 | 2.0329 | 6.5181 × 10−15 | 8.0735 × 10−8 | 4.0019 × 10−8 | 0.9999 | 5.7547 × 10−15 | 7.5860 × 10−8 | 3.8586 × 10−8 | 0.9999 |
| 3 | 2.6502 | 5.8358 × 10−11 | 7.6393 × 10−6 | 3.5393 × 10−6 | −0.2733 | 4.9722 × 10−11 | 7.0514 × 10−6 | 3.0590 × 10−6 | −0.2318 |
| 4 | 3.1597 | 1.2387 × 10−13 | 3.5196 × 10−7 | 1.5528 × 10−7 | 0.9967 | 2.1791 × 10−13 | 4.6681 × 10−7 | 2.3510 × 10−7 | 0.9962 |
| 5 | 3.7116 | 2.1288 × 10−13 | 4.6138 × 10−7 | 2.1905 × 10−7 | 0.9950 | 2.6294 × 10−13 | 5.1278 × 10−7 | 2.5875 × 10−7 | 0.9946 |
| 6 | 4.2737 | 7.2937 × 10−15 | 8.5403 × 10−8 | 4.4189 × 10−8 | 0.9998 | 3.8136 × 10−15 | 6.1755 × 10−8 | 3.9547 × 10−8 | 0.9999 |
| 7 | 4.8130 | 8.0846 × 10−15 | 8.9915 × 10−8 | 5.1029 × 10−8 | 0.9998 | 7.0667 × 10−15 | 8.4064 × 10−8 | 5.0239 × 10−8 | 0.9998 |
| 8 | 5.3189 | 4.3471 × 10−14 | 2.0850 × 10−7 | 1.1121 × 10−7 | 0.9991 | 3.4166 × 10−14 | 1.8484 × 10−7 | 9.5496 × 10−8 | 0.9991 |
| 9 | 5.8998 | 6.3681 × 10−15 | 7.9800 × 10−8 | 4.1977 × 10−8 | 0.9999 | 6.1065 × 10−15 | 7.8144 × 10−8 | 4.1437 × 10−8 | 0.9999 |
| 10 | 6.4539 | 2.9457 × 10−13 | 5.4274 × 10−7 | 2.6237 × 10−7 | 0.9934 | 2.8870 × 10−13 | 5.3731 × 10−7 | 2.6382 × 10−7 | 0.9933 |
| 11 | 7.0060 | 5.6392 × 10−11 | 7.5095 × 10−6 | 3.4379 × 10−6 | −0.2640 | 5.4435 × 10−11 | 7.3780 × 10−6 | 3.2942 × 10−6 | −0.2478 |
| 12 | 7.6982 | 3.2737 × 10−7 | 5.7217 × 10−4 | 2.6318 × 10−4 | −7334.3460 | 3.1597 × 10−7 | 5.6211 × 10−4 | 2.5221 × 10−4 | −7229.1041 |
| 13 | 8.3414 | 1.6842 × 10−11 | 4.1039 × 10−6 | 1.8579 × 10−6 | 0.6067 | 1.9071 × 10−11 | 4.3670 × 10−6 | 2.0322 × 10−6 | 0.6026 |
| 14 | 8.9202 | 5.3176 × 10−11 | 7.2922 × 10−6 | 3.3594 × 10−6 | −0.1307 | 4.2280 × 10−11 | 6.5023 × 10−6 | 2.8812 × 10−6 | −0.1087 |
| 15 | 9.3410 | 1.9545 × 10−11 | 4.4210 × 10−6 | 2.0286 × 10−6 | 0.5593 | 1.9552 × 10−11 | 4.4218 × 10−6 | 1.9978 × 10−6 | 0.5625 |
| 16 | 10.0022 | 8.8777 × 10−15 | 9.4222 × 10−8 | 5.5752 × 10−8 | 0.9998 | 9.5581 × 10−15 | 9.7766 × 10−8 | 5.6664 × 10−8 | 0.9998 |
| 17 | 10.5615 | 4.1529 × 10−11 | 6.4443 × 10−6 | 2.9652 × 10−6 | 0.0773 | 3.9082 × 10−11 | 6.2516 × 10−6 | 2.7742 × 10−6 | 0.0947 |
| 18 | 11.0355 | 1.2335 × 10−11 | 3.5121 × 10−6 | 1.6065 × 10−6 | 0.7211 | 1.2656 × 10−11 | 3.5575 × 10−6 | 1.6355 × 10−6 | 0.7197 |
| 19 | 11.5248 | 3.7456 × 10−14 | 1.9353 × 10−7 | 1.0576 × 10−7 | 0.9992 | 3.4843 × 10−14 | 1.8666 × 10−7 | 1.0325 × 10−7 | 0.9992 |
| 20 | 12.2448 | 5.8600 × 10−9 | 7.6551 × 10−5 | 3.4059 × 10−5 | −136.5574 | 7.0564 × 10−9 | 8.4002 × 10−5 | 4.0930 × 10−5 | −143.4051 |
Table A6.
Performance metrics for ANFIS with Triangular Membership function models with different time d using cross-validation. Metrics Eval Time, MSE, RMSE, MAE, R2 for both the training and test datasets. Best result is highlighted in bold.
Table A6.
Performance metrics for ANFIS with Triangular Membership function models with different time d using cross-validation. Metrics Eval Time, MSE, RMSE, MAE, R2 for both the training and test datasets. Best result is highlighted in bold.
| Delay | Eval Time(s) | MSETrain | RMSETrain | MAETrain | R2Train | MSETest | RMSETest | MAETest | R2Test |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2.3089 | 5.2895 × 10−11 | 7.2729 × 10−6 | 3.2705 × 10−6 | −0.2535 | 6.2693 × 10−11 | 7.9179 × 10−6 | 3.7083 × 10−6 | −0.2810 |
| 2 | 3.2791 | 5.6158 × 10−11 | 7.4939 × 10−6 | 3.4448 × 10−6 | −0.2679 | 5.5241 × 10−11 | 7.4324 × 10−6 | 3.3119 × 10−6 | −0.2477 |
| 3 | 4.2068 | 5.4029 × 10−11 | 7.3505 × 10−6 | 3.3286 × 10−6 | −0.2580 | 5.9828 × 10−11 | 7.7348 × 10−6 | 3.5508 × 10−6 | −0.2670 |
| 4 | 5.1379 | 5.7863 × 10−11 | 7.6068 × 10−6 | 3.4970 × 10−6 | −0.2680 | 5.1050 × 10−11 | 7.1449 × 10−6 | 3.1684 × 10−6 | −0.2448 |
| 5 | 6.1085 | 5.4894 × 10−11 | 7.4091 × 10−6 | 3.3714 × 10−6 | −0.2611 | 5.8187 × 10−11 | 7.6280 × 10−6 | 3.4739 × 10−6 | −0.2617 |
| 6 | 7.1356 | 5.5803 × 10−11 | 7.4701 × 10−6 | 3.3211 × 10−6 | −0.2464 | 5.5382 × 10−11 | 7.4419 × 10−6 | 3.5486 × 10−6 | −0.2943 |
| 7 | 8.0671 | 5.5216 × 10−11 | 7.4307 × 10−6 | 3.3730 × 10−6 | −0.2595 | 5.6945 × 10−11 | 7.5462 × 10−6 | 3.4391 × 10−6 | −0.2622 |
| 8 | 8.9672 | 5.4187 × 10−11 | 7.3612 × 10−6 | 3.2155 × 10−6 | −0.2358 | 5.9538 × 10−11 | 7.7161 × 10−6 | 3.8189 × 10−6 | −0.3244 |
| 9 | 10.0539 | 5.4872 × 10−11 | 7.4076 × 10−6 | 3.2907 × 10−6 | −0.2459 | 5.8120 × 10−11 | 7.6236 × 10−6 | 3.6540 × 10−6 | −0.2983 |
| 10 | 10.8480 | 5.7613 × 10−11 | 7.5904 × 10−6 | 3.4500 × 10−6 | −0.2604 | 5.1908 × 10−11 | 7.2047 × 10−6 | 3.2934 × 10−6 | −0.2641 |
| 11 | 12.9791 | 5.3992 × 10−11 | 7.3479 × 10−6 | 3.3587 × 10−6 | −0.2641 | 6.0230 × 10−11 | 7.7608 × 10−6 | 3.4848 × 10−6 | −0.2525 |
| 12 | 13.7962 | 5.7085 × 10−11 | 7.5555 × 10−6 | 3.4768 × 10−6 | −0.2686 | 5.3181 × 10−11 | 7.2926 × 10−6 | 3.2202 × 10−6 | −0.2422 |
| 13 | 15.0747 | 5.7818 × 10−11 | 7.6038 × 10−6 | 3.5455 × 10−6 | −0.2778 | 5.1663 × 10−11 | 7.1877 × 10−6 | 3.0714 × 10−6 | −0.2234 |
| 14 | 15.6277 | 6.1075 × 10−11 | 7.8150 × 10−6 | 3.6762 × 10−6 | −0.2842 | 4.4209 × 10−11 | 6.6490 × 10−6 | 2.7757 × 10−6 | −0.2110 |
| 15 | 16.4818 | 5.8956 × 10−11 | 7.6783 × 10−6 | 3.5931 × 10−6 | −0.2804 | 4.9373 × 10−11 | 7.0266 × 10−6 | 2.9826 × 10−6 | −0.2198 |
| 16 | 16.9554 | 5.5234 × 10−11 | 7.4319 × 10−6 | 3.3770 × 10−6 | −0.2602 | 5.7816 × 10−11 | 7.6037 × 10−6 | 3.4604 × 10−6 | −0.2612 |
| 17 | 18.6361 | 5.5712 × 10−11 | 7.4640 × 10−6 | 3.4169 × 10−6 | −0.2651 | 5.6891 × 10−11 | 7.5426 × 10−6 | 3.3786 × 10−6 | −0.2510 |
| 18 | 18.9670 | 5.6679 × 10−11 | 7.5285 × 10−6 | 3.4563 × 10−6 | −0.2670 | 5.4818 × 10−11 | 7.4040 × 10−6 | 3.2981 × 10−6 | −0.2476 |
| 19 | 19.7371 | 5.4637 × 10−11 | 7.3917 × 10−6 | 3.3915 × 10−6 | −0.2667 | 5.9781 × 10−11 | 7.7318 × 10−6 | 3.4613 × 10−6 | −0.2506 |
| 20 | 20.7408 | 6.0140 × 10−11 | 7.7550 × 10−6 | 3.5966 × 10−6 | −0.2740 | 4.7127 × 10−11 | 6.8649 × 10−6 | 2.9941 × 10−6 | −0.2349 |
References
- Agwu, O.E.; Alatefi, S.; Azim, R.A.; Alkouh, A. Applications of artificial intelligence algorithms in artificial lift systems: A critical review. Flow Meas. Instrum. 2024, 97, 102613. [Google Scholar] [CrossRef]
- Lu, H.; Guo, L.; Azimi, M.; Huang, K. Oil and gas 4.0 era: A systematic review and outlook. Comput. Ind. 2019, 111, 68–90. [Google Scholar] [CrossRef]
- Chu, Y.; Lindbråthen, A.; Lei, L.; He, X.; Hillestad, M. Mathematical modeling and process parametric study of CO2 removal from natural gas by hollow fiber membranes. Chem. Eng. Res. Des. 2019, 148, 45–55. [Google Scholar] [CrossRef]
- Gu, B. Mathematical modelling and simulation of CO2 removal from natural gas using hollow fibre membrane modules. Korean Chem. Eng. Res. 2022, 60, 51–61. [Google Scholar] [CrossRef]
- Ko, D. Development of a dynamic simulation model of a hollow fiber membrane module to sequester CO2 from coalbed methane. J. Membr. Sci. 2018, 546, 258–269. [Google Scholar] [CrossRef]
- Gbadamosi, A.O.; Junin, R.; Manan, M.A.; Agi, A.; Yusuff, A.S. An overview of chemical enhanced oil recovery: Recent advances and prospects. Int. Nano Lett. 2019, 9, 171–202. [Google Scholar] [CrossRef]
- Baghban, A.; Azar, A.A. ANFIS modeling of CO2 separation from natural gas using hollow fiber polymeric membrane. Energy Sources Part A Recovery Util. Environ. Eff. 2017, 40, 193–199. [Google Scholar] [CrossRef]
- Rezakazemi, M.; Azarafza, A.; Dashti, A.; Shirazian, S. Development of hybrid models for prediction of gas permeation through FS/POSS/PDMS nanocomposite membranes. Int. J. Hydrogen Energy. 2018, 43, 17283–17294. [Google Scholar] [CrossRef]
- Alibak, A.H.; Alizadeh, S.M.; Davodi Monjezi, S.; Alizadeh, A.; Alobaid, F.; Aghel, B. Developing a hybrid neuro-fuzzy method to predict carbon dioxide (CO2) permeability in mixed matrix membranes containing SAPO-34 zeolite. Membranes 2022, 12, 1147. [Google Scholar] [CrossRef]
- Abdollahi, S.A.; Ranjbar, S.F. Modeling the CO2 separation capability of poly(4-methyl-1-pentane) membrane modified with different nanoparticles by artificial neural networks. Sci. Rep. 2023, 13, 8812. [Google Scholar] [CrossRef]
- Kim, N.E.; Basak, J.K.; Kim, H.T. Application of hollow fiber membrane for the separation of carbon dioxide from atmospheric air and assessment of its distribution pattern in a greenhouse. Atmosphere 2023, 14, 299. [Google Scholar] [CrossRef]
- Ames, A.; Flores-López, L.Z.; Rogel-Hernandez, E.; Castro, J.R.; Wakida, F.T.; Espinoza-Gomez, H. Electro-cross-flow ultrafiltration system for the rejection of nickel ions from aqueous solution, and Sugeno fuzzy model simulation. Chem. Eng. Commun. 2015, 202, 936–945. [Google Scholar] [CrossRef]
- Fathi, S.; Rezaei, A.; Mohadesi, M.; Nazari, M. PSO-ANFIS and ANN modeling of propane/propylene separation using Cu-BTC adsorbent. J. Chem. Pet. Eng. 2019, 53, 191–201. [Google Scholar] [CrossRef]
- Dashti, A.; Raji, M.; Azarafza, A.; Rezakazemi, M.; Shirazian, S. Computational simulation of CO2 sorption in polymeric membranes using genetic programming. Arab. J. Sci. Eng. 2020, 45, 7655–7666. [Google Scholar] [CrossRef]
- Babanezhad, M.; Nakhjiri, A.T.; Shirazian, S. Changes in the number of membership functions for predicting the gas volume fraction in two-phase flow using grid partition clustering of the ANFIS method. ACS Omega 2020, 5, 16284–16291. [Google Scholar] [CrossRef]
- Pishnamazi, M.; Babanezhad, M.; Nakhjiri, A.T.; Rezakazemi, M.; Marjani, A.; Shirazian, S. ANFIS grid partition framework with difference between two sigmoidal membership functions structure for validation of nanofluid flow. Sci. Rep. 2020, 10, 15395. [Google Scholar] [CrossRef]
- Sodeifian, G.; Niazi, Z. Prediction of CO2 absorption by nanofluids using artificial neural network modeling. Int. Commun. Heat Mass Transf. 2021, 123, 105193. [Google Scholar] [CrossRef]
- Aghilesh, K.; Mungray, A.; Agarwal, S.; Ali, J.; Garg, M.C. Performance optimisation of forward-osmosis membrane system using machine learning for the treatment of textile industry wastewater. J. Clean. Prod. 2021, 289, 125690. [Google Scholar] [CrossRef]
- Ansarian, O.; Beiki, H. Nanofluids application to promote CO2 absorption inside a bubble column: ANFIS and experimental study. Int. J. Environ. Sci. Technol. 2022, 19, 9979–9990. [Google Scholar] [CrossRef]
- Banik, A.; Majumder, M.; Biswal, S.K.; Bandyopadhyay, T.K. Polynomial neural network-based group method of data handling algorithm coupled with modified particle swarm optimization to predict permeate flux (%) of rectangular sheet-shaped membrane. Chem. Pap. 2022, 76, 79–97. [Google Scholar] [CrossRef]
- Nait Amar, M.; Djema, H.; Belhaouari, S.B.; Zeraibi, N. Toward robust models for predicting carbon dioxide absorption by nanofluids. Greenh. Gases Sci. Technol. 2022, 12, 537–551. [Google Scholar] [CrossRef]
- Cooley, I.; Boobier, S.; Hirst, J.D.; Besley, E. Machine learning insights into predicting biogas separation in metal–organic frameworks. Commun. Chem. 2024, 7, 102. [Google Scholar] [CrossRef] [PubMed]
- Amirkhani, F.; Dashti, A.; Abedsoltan, H.; Mohammadi, A.H.; Zhou, J.L.; Altaee, A. Modeling and estimation of CO2 capture by porous liquids through machine learning. Sep. Purif. Technol. 2025, 359, 130445. [Google Scholar] [CrossRef]
- Chen, B.; Dai, Y.; Ruan, X.; Xi, Y.; He, G. Integration of molecular dynamic simulation and free volume theory for modeling membrane VOC/gas separation. Front. Chem. Sci. Eng. 2018, 12, 296–305. [Google Scholar] [CrossRef]
- Medi, B.; Vesali-Naseh, M.; Haddad-Hamedani, M. A generalized numerical framework for solving cocurrent and counter-current membrane models for gas separation. Heliyon 2022, 8, e09053. [Google Scholar] [CrossRef]
- Khalilpour, R.; Abbas, A.; Lai, Z.; Pinnau, I. Analysis of hollow fibre membrane systems for multicomponent gas separation. Chem. Eng. Res. Des. 2013, 91, 332–347. [Google Scholar] [CrossRef]
- Wang, Z.; Han, Y.; Cao, W. Simplified mixing rules for calculating transport coefficients of high-temperature air. Int. J. Aerosp. Eng. 2023, 2023, 7644738. [Google Scholar] [CrossRef]
- Yerumbu, N.; Sahoo, R.K.; Sivalingam, M. Multiobjective optimization of membrane in hybrid cryogenic CO2 separation process for coal-fired power plants. Environ. Sci. Pollut. Res. 2023, 30, 108783–108801. [Google Scholar] [CrossRef]
- Khaghani, A.; Moghaddam, M.S.; Kheshti, M.F. Investigation of the liquid-vapor equilibrium in the mixture of carbon dioxide and normal alkanes in binary systems using the Peng–Robinson equation of state modified with mixing rules. Chem. Thermodyn. Therm. Anal. 2025, 17, 100161. [Google Scholar] [CrossRef]
- Araújo, O.F.; de Medeiros, J.L.; Alves, R.M.B. CO2 Utilization: A Process Systems Engineering Vision. In CO2 Sequestration and Valorization; Morgado, C.R.V., Esteves, V.P.P., Eds.; IntechOpen: London, UK, 2014. [Google Scholar] [CrossRef]
- Dasgupta, S.; Rajasekaran, M.; Roy, P.K.; Thakkar, F.M.; Pathak, A.D.; Ayappa, K.G.; Maiti, P.K. Influence of chain length on structural properties of carbon molecular sieving membranes and their effects on CO2, CH4 and N2 adsorption: A molecular simulation study. J. Membr. Sci. 2022, 664, 121044. [Google Scholar] [CrossRef]
- Castellani, B.; Gambelli, A.M.; Nicolini, A.; Rossi, F. Energy and Environmental Analysis of Membrane-Based CH4-CO2 Replacement Processes in Natural Gas Hydrates. Energies 2019, 12, 850. [Google Scholar] [CrossRef]
- Da Conceicao, M.; Nemetz, L.; Rivero, J.; Hornbostel, K.; Lipscomb, G. Gas separation membrane module modeling: A comprehensive review. Membranes 2023, 13, 639. [Google Scholar] [CrossRef] [PubMed]
- Hillman, F.; Wang, K.; Liang, C.Z.; Seng, D.H.L.; Zhang, S. Breaking the permeance–selectivity tradeoff for post-combustion carbon capture: A bio-inspired strategy to form ultrathin hollow fiber membranes. Adv. Mater. 2023, 35, 2305463. [Google Scholar] [CrossRef] [PubMed]
- Chen, B.; Yang, T.; Xiao, W.; Nizamani, A.K. Conceptual design of pyrolytic oil upgrading process enhanced by membrane-integrated hydrogen production system. Processes 2019, 7, 284. [Google Scholar] [CrossRef]
- Ruz-Hernandez, J.A.; Matsumoto, Y.; Arellano-Valmaña, F.; Pitalúa-Díaz, N.; Cabanillas-López, R.E.; Abril-García, J.H.; Herrera-López, E.J.; Velázquez-Contreras, E.F. Meteorological Variables’ Influence on Electric Power Generation for Photovoltaic Systems Located at Different Geographical Zones in Mexico. Appl. Sci. 2019, 9, 1649. [Google Scholar] [CrossRef]
- Šverko, Z.; Vrankić, M.; Vlahinić, S.; Rogelj, P. Complex Pearson correlation coefficient for EEG connectivity analysis. Sensors 2022, 22, 1477. [Google Scholar] [CrossRef]
- Salmerón Gómez, R.; García Pérez, J.; López Martín, M.D.M.; García, C.G. Collinearity diagnostic applied in ridge estimation through the variance inflation factor. J. Appl. Stat. 2016, 43, 1831–1849. [Google Scholar] [CrossRef]
- Pitalúa-Díaz, N.; Arellano-Valmaña, F.; Ruz-Hernandez, J.A.; Matsumoto, Y.; Alazki, H.; Herrera-López, E.J.; Hinojosa-Palafox, J.F.; García-Juárez, A.; Pérez-Enciso, R.A.; Velázquez-Contreras, E.F. An ANFIS-Based Modeling Comparison Study for Photovoltaic Power at Different Geographical Places in Mexico. Energies 2019, 12, 2662. [Google Scholar] [CrossRef]
- Eliwa, E.H.I.; El Koshiry, A.M.; Abd El-Hafeez, T.; Omar, A. Optimal gasoline price predictions: Leveraging the ANFIS regression model. Int. J. Intell. Syst. 2024, 2024, 8462056. [Google Scholar] [CrossRef]
- Jang, J.S.R.; Sun, C.T.; Mizutani, E. Neuro-fuzzy and soft computing-a computational approach to learning and machine intelligence [Book Review]. IEEE Trans. Autom. Control. 1997, 42, 1482–1484. [Google Scholar] [CrossRef]
- Fetimi, A.; Merouani, S.; Khan, M.S.; Asghar, M.N.; Yadav, K.K.; Jeon, B.-H.; Hamachi, M.; Kebiche-Senhaji, O.; Benguerba, Y. Modeling of textile dye removal from wastewater using innovative oxidation technologies (Fe(II)/chlorine and H2O2/periodate processes): Artificial neural network–particle swarm optimization hybrid model. ACS Omega 2022, 7, 13818–13825. [Google Scholar] [CrossRef]
- Bird, R.B.; Stewart, W.E.; Lightfoot, E.N. Transport Phenomena, 2nd ed.; John Wiley: Hoboken, NJ, USA, 2002. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).