



A Bayesian Optimization Approach for Tuning a Grouping Genetic Algorithm for Solving Practically Oriented Pickup and Delivery Problems

Abstract
1. Introduction
2. Related Work
2.1. Pickup and Delivery Problems
2.2. Parameter Tuning Problems
3. Problem Definition
3.1. Mathematical Model for the Multi-Depot Pickup and Delivery Problem with Time Windows and Heterogeneous Vehicle Fleets
3.2. Parameter Tuning Problem
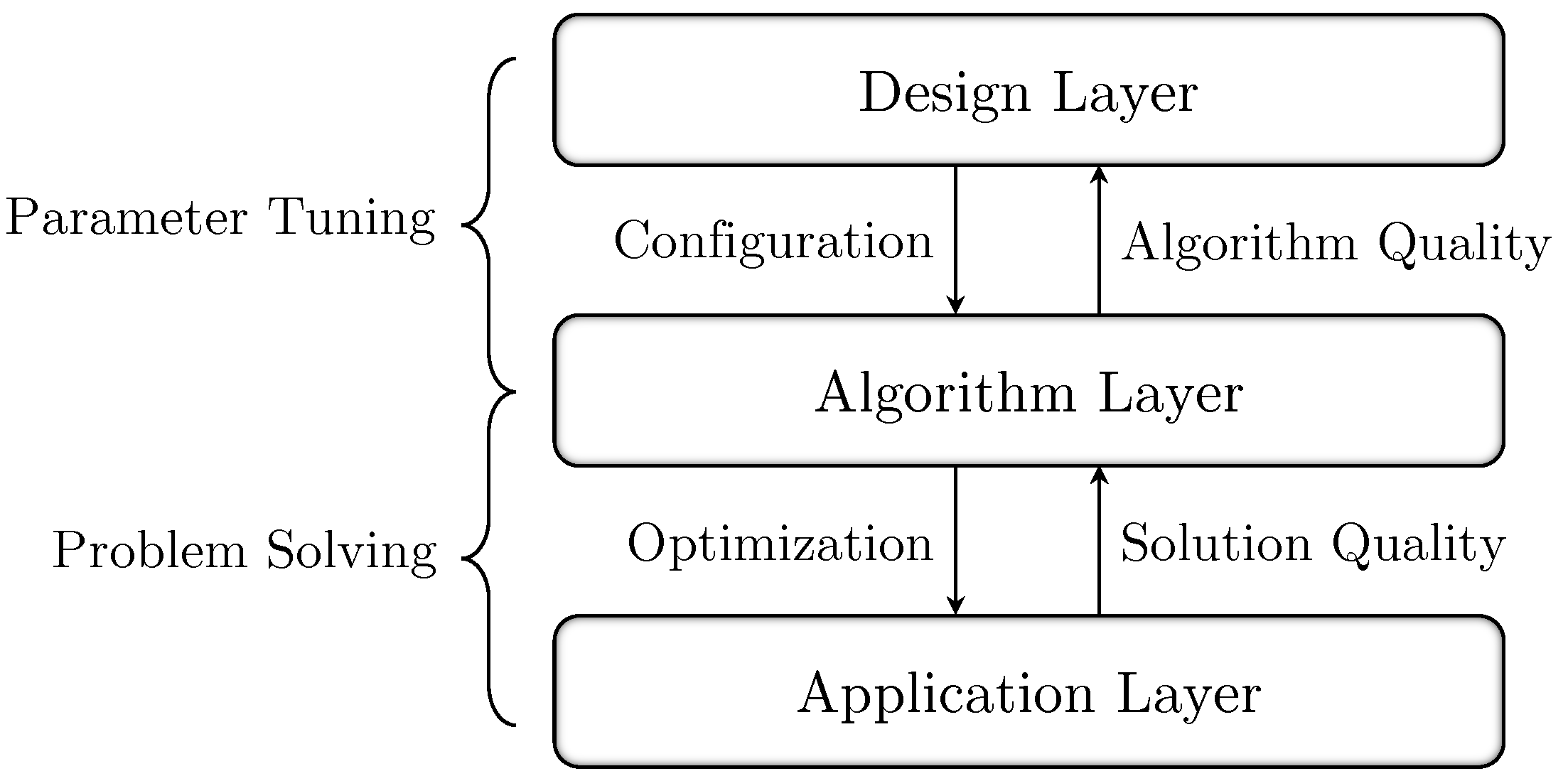
4. Proposed Methods
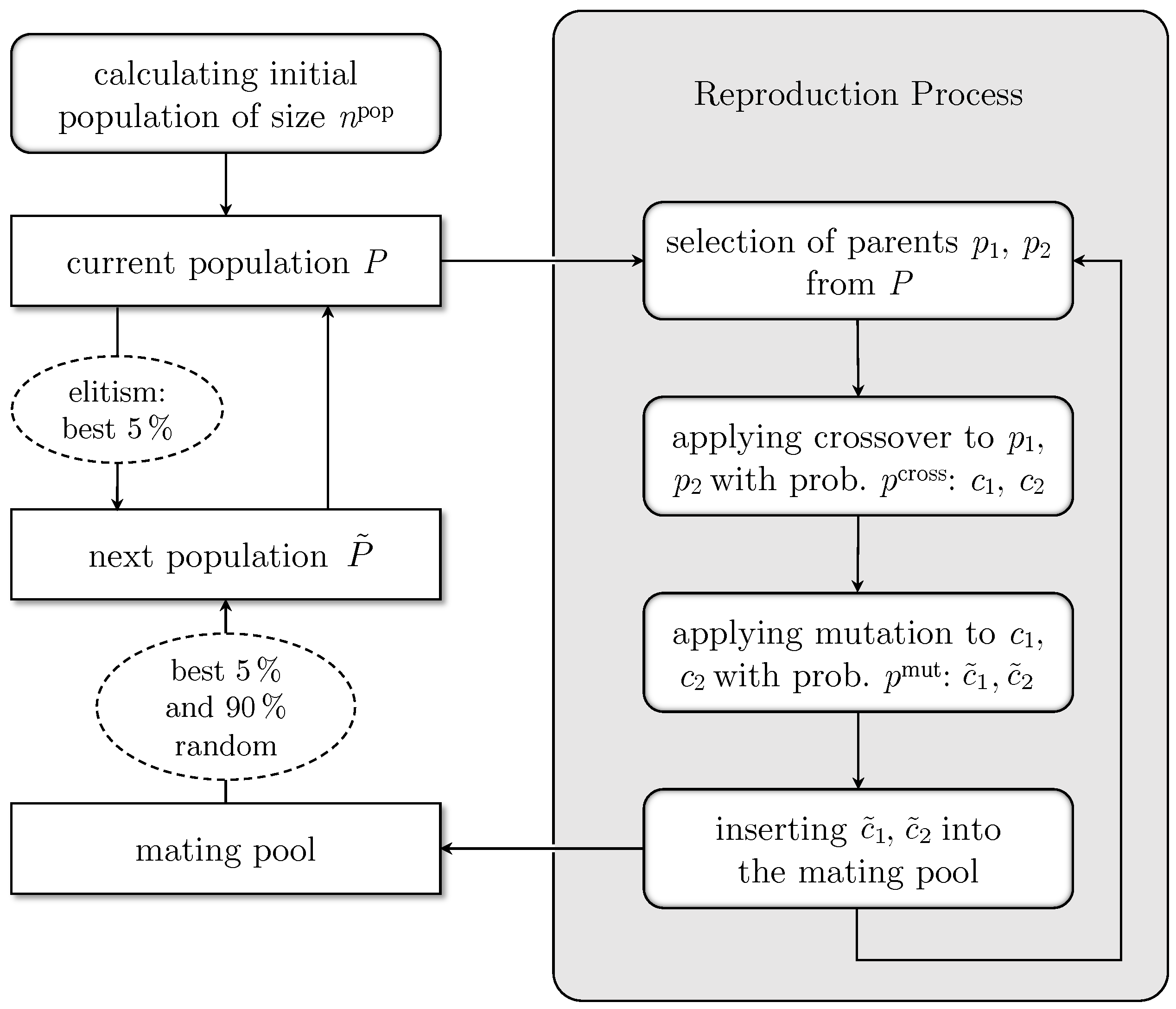
4.1. Grouping Genetic Algorithm Framework
4.1.1. Population Management
4.1.2. Selection
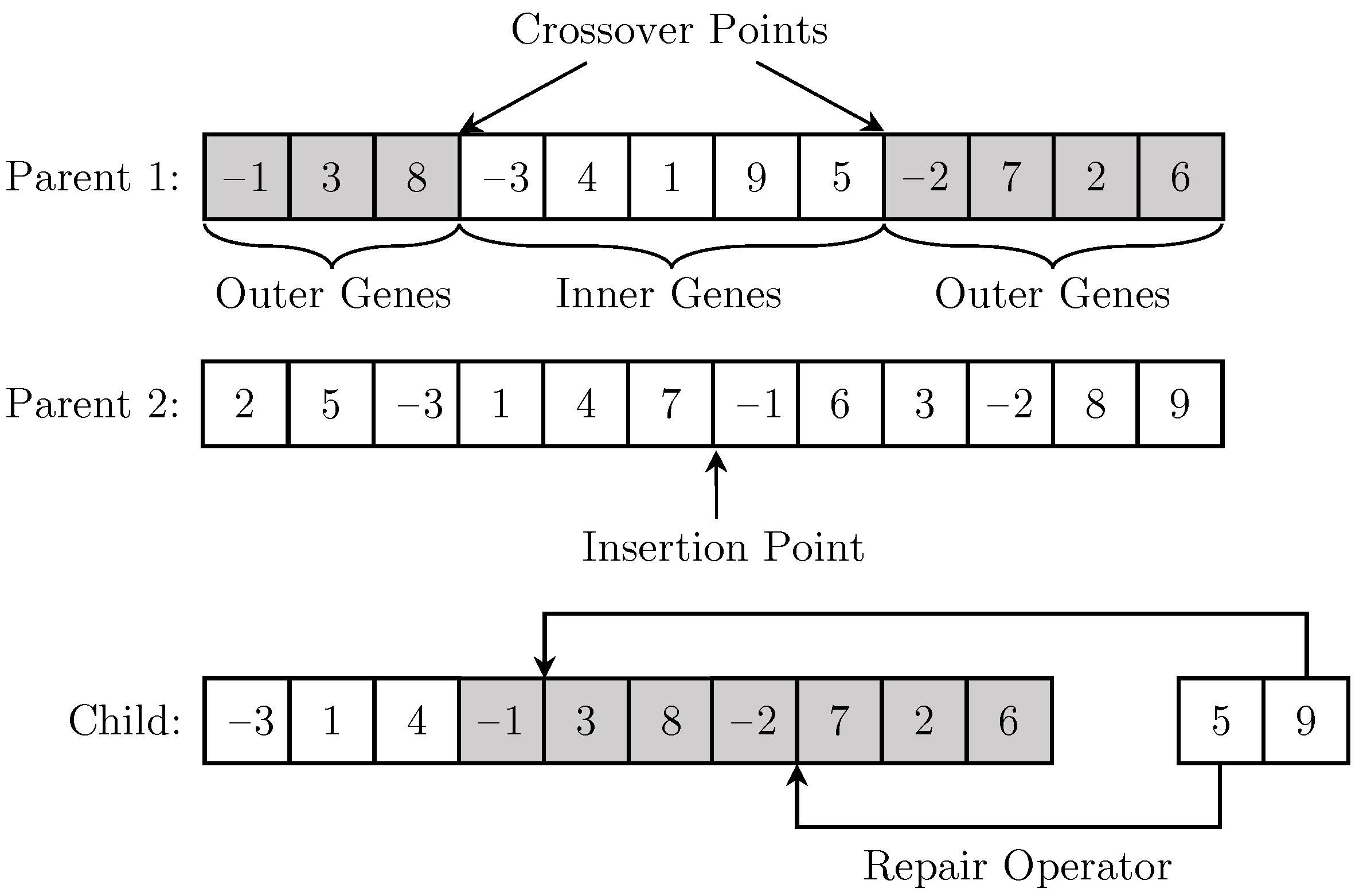
4.1.3. Crossover Operator
4.1.4. Mutation Operators
- Costs/Number-of-Request Ratio. The ratio of route costs and the number of served requests is calculated for each vehicle and used to generate a roulette wheel. By spinning the roulette wheel, a vehicle index is selected. In particular, expensive routes with a small number of requests are preferred for removal.
- Number of Requests. The vehicle with the minimum number of requests is used for deletion.
- Random Vehicle Index. Here, a random vehicle index is selected, thus all vehicles are equally likely to be chosen.
- Random Genotype Position. The variant chooses a random position within the genotype and selects the respective vehicle index. Hence, vehicles with many requests are preferred.
- Historical Request Pair. This concept is adopted from the approach of [17] and uses a matrix of weights for all requests . The matrix stores how promising a combination of two requests on the same vehicle is. To do so, the elite is evaluated after each generation and a matrix element is increased by one if the requests i and j are served together on one vehicle. The matrix can be interpreted as long-term memory. Since combinations with high quality in a certain generation do not necessarily have to be globally optimal, the matrix is adjusted during each generation through reducing by a factor , i.e., . To determine the requests to be eliminated, a score is specified in which values are summed up if request j is served with i on the same vehicle in the considered individual. Requests with low are non-promising combinations on the same vehicle and, consequently, are removed from the individual.
- Similarity Measure. The variant is derived from the similarity-measure-based removal operator of [16]. Here, the first request is chosen randomly and, additionally, those requests are removed which are similar with respect to the measure from Equation (29), i.e., those that have the smallest values. Please note that and request i have pickup customer i and delivery customer (see Section 3.1).
4.1.5. Repair Operator
- Greedy Insertion. For each request, the insertion costs for all possible positions in each vehicle are calculated and the position with the lowest costs is chosen (cf. [1]).
- Regret- Insertion. For each request r, the difference in how much worse it is to insert a request in the k-th best vehicle instead of the best one is calculated, while the differences from the best to the k-th best vehicle are summed up. The request with the maximum value is supposed to be inserted into its best position in the current iteration, since, later on, the insertion costs increase (cf. [16]). Formally, this can be written as in (30):
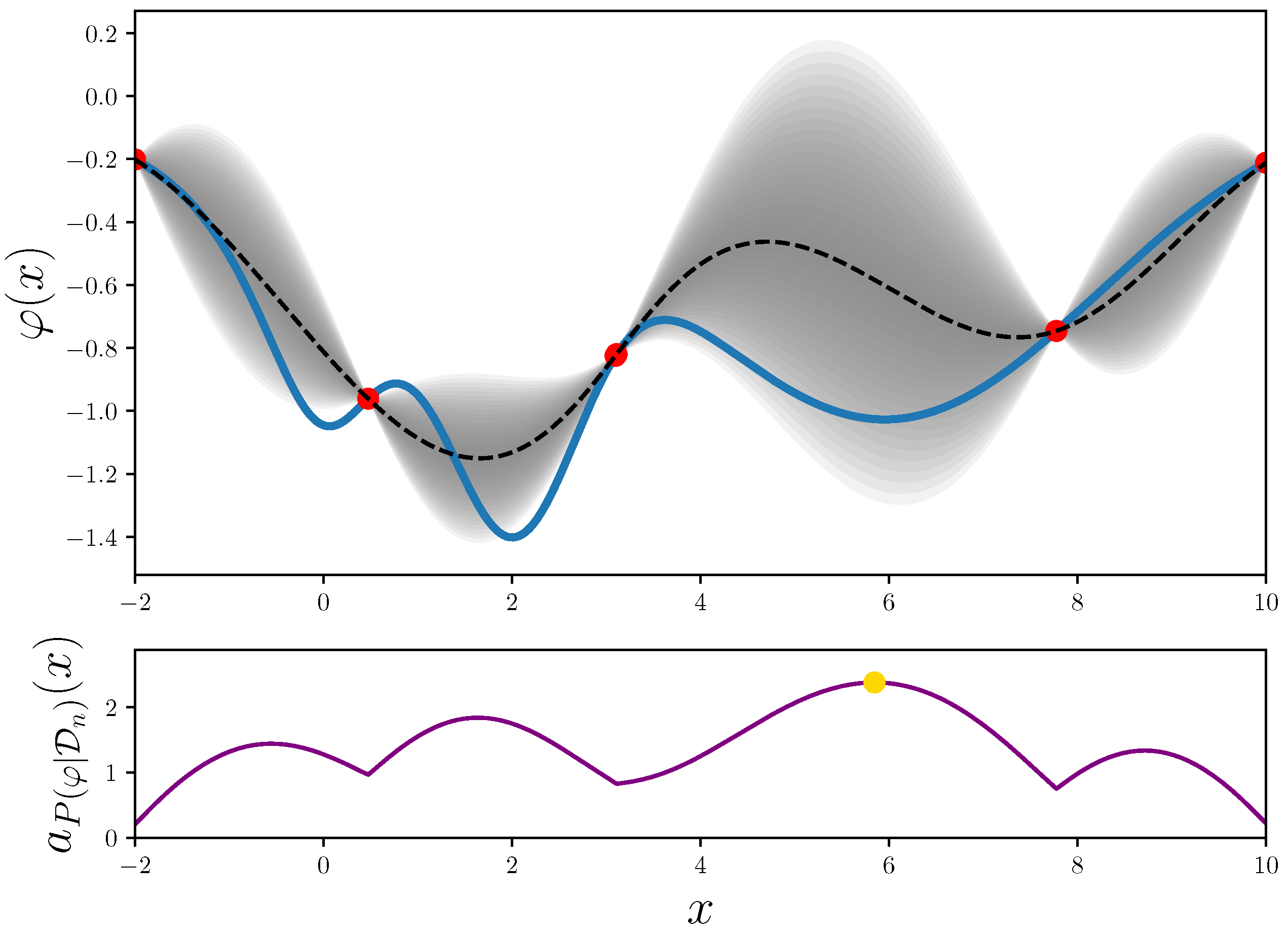
4.2. Bayesian Optimization for Tuning the Parameters of the Grouping Genetic Algorithm
- Find the next configuration whose evaluation is most promising, i.e., which maximizes the acquisition function under the condition of the known data points :
- Determine with possible noise and add to the previous data points: .
- Update the probability model and, consequently, the acquisition function .
4.2.1. Gaussian Processes
4.2.2. Acquisition Function
5. Results and Discussion
5.1. Data Generation
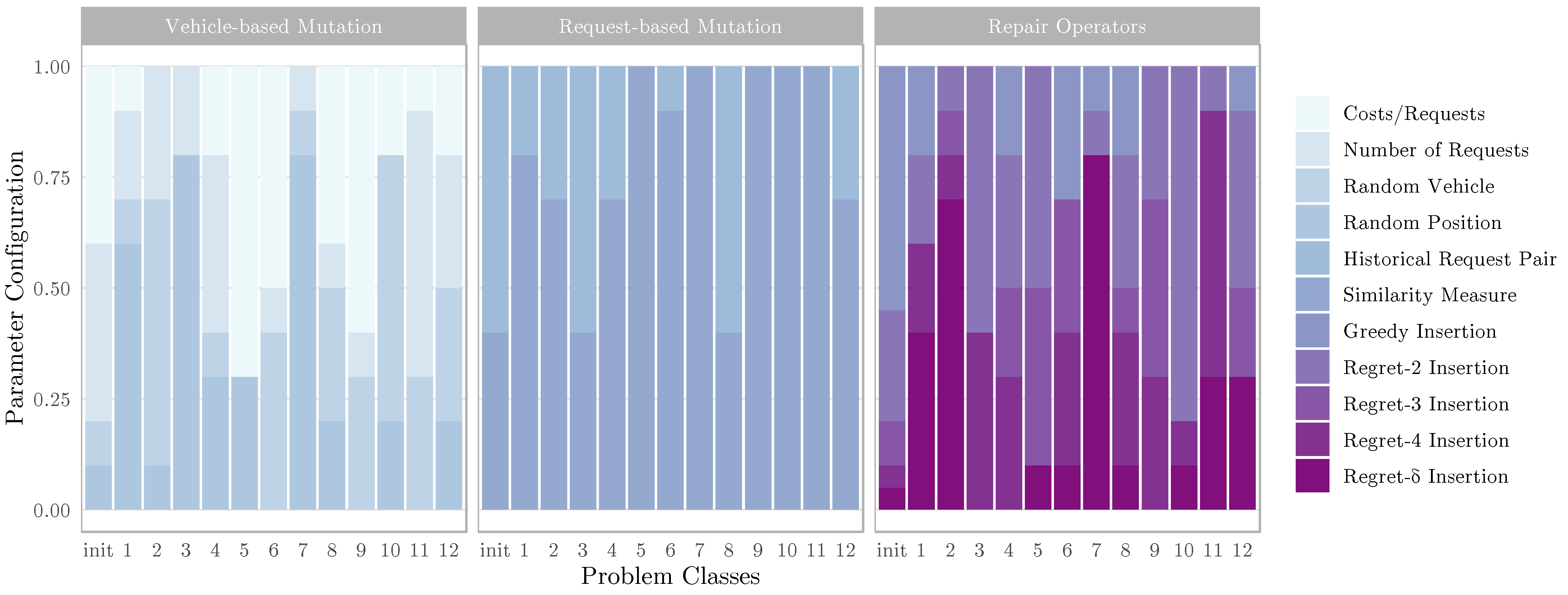
5.2. Parameter Configuration
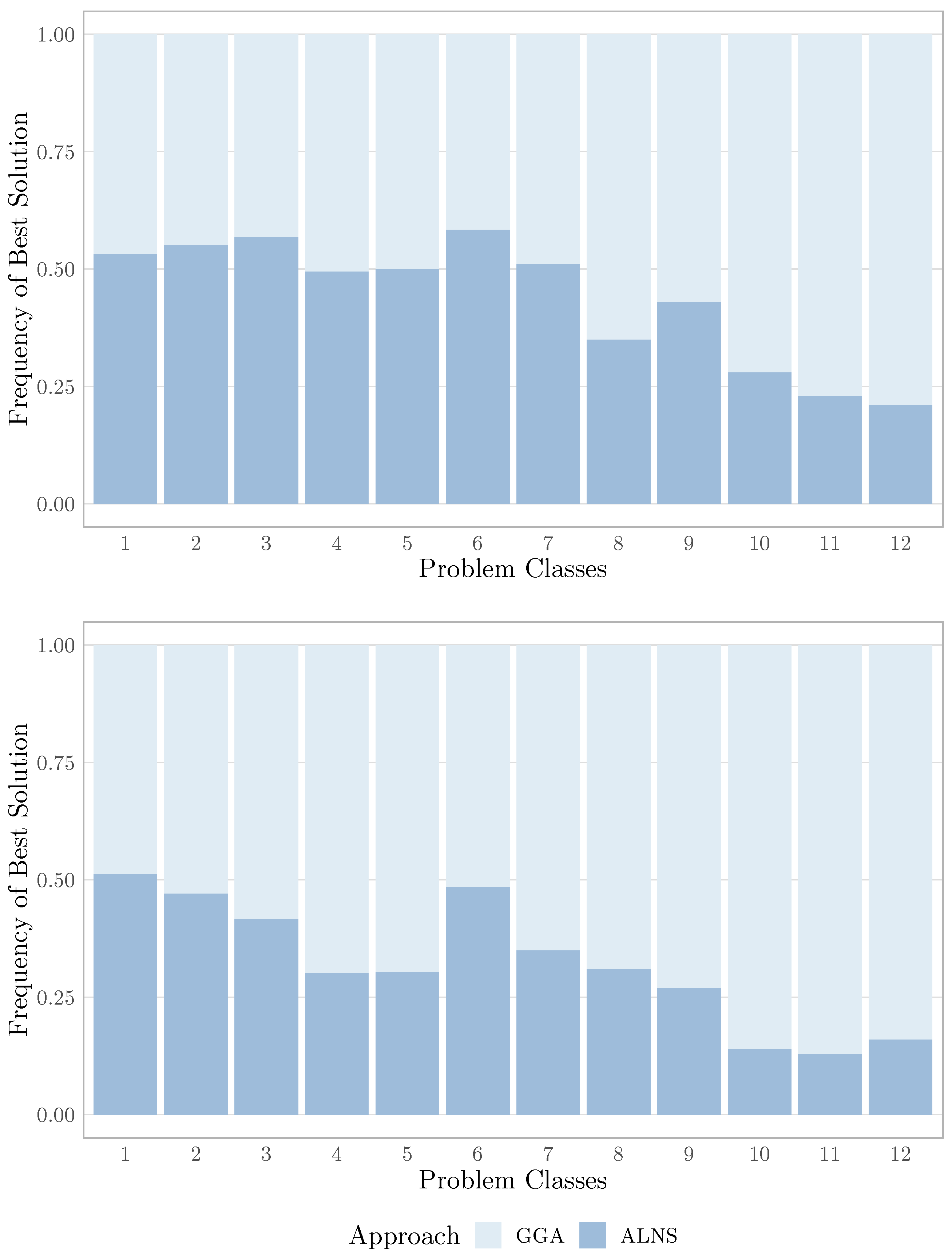
5.3. Evaluation and Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Rüther, C.; Rieck, J.A. Grouping Genetic Algorithm for Multi Depot Pickup and Delivery Problems with Time Windows and Heterogeneous Vehicle Fleets. In Evolutionary Computation in Combinatorial Optimization (EvoCOP); Paquete, L., Zarges, C., Eds.; Springer: Cham, Switzerland, 2020; pp. 148–163. [Google Scholar]
- Huang, C.; Li, Y.; Yao, N.X. A Survey of Automatic Parameter Tuning Methods for Metaheuristics. IEEE Trans. Evol. Comput. 2020, 24, 201–216. [Google Scholar] [CrossRef]
- Jones, D.R.; Schonlau, M.; Welch, W.J. Efficient Global Optimization of Expensive Black-Box Functions. J. Glob. Optim. 1998, 13, 455–492. [Google Scholar] [CrossRef]
- Mockus, J. Bayesian Global Optimization. In Encyclopedia of Optimization; Floudas, C.A., Pardalos, P.M., Eds.; Springer: Berlin/Heidelberg, Germany, 2001; pp. 123–127. [Google Scholar]
- Berbeglia, G.; Cordeau, J.-F.; Gribkovskaia, I.; Laporte, G. Static Pickup and Delivery Problems: A Classification Scheme and Survey. Top 2007, 15, 1–31. [Google Scholar] [CrossRef]
- Parragh, S.N.; Doerner, K.F.; Hartl, R.F. A Survey on Pickup and Delivery Problems—Part II: Transportation Between Pickup and Delivery Locations. J. Betriebswirtschaft 2008, 58, 81–117. [Google Scholar] [CrossRef]
- Smit, S.K.; Eiben, A.E. Comparing Parameter Tuning Methods for Evolutionary Algorithms. In Proceedings of the IEEE Congress on Evolutionary Computation, Trondheim, Norway, 18–21 May 2009; pp. 399–406. [Google Scholar]
- Drake, J.H.; Kheiri, A.; Özcan, E.; Burke, E.K. Recent advances in selection hyper-heuristics. Eur. J. Oper. Res. 2019, 285, 405–428. [Google Scholar] [CrossRef]
- Hosny, M.I.; Mumford, C.L. Constructing Initial Solutions for the Multiple Vehicle Pickup and Delivery Problem with Time Windows. J. King Saud Univ. Comput. Inf. Sci. 2012, 24, 59–69. [Google Scholar] [CrossRef]
- Li, H.; Lim, A. A Metaheuristic for the Pickup and Delivery Problem with Time Windows. Int. J. Art. Intell. Tools 2001, 12, 160–167. [Google Scholar]
- Lu, Q.; Dessouky, M.M. A New Insertion-Based Construction Heuristic for Solving the Pickup and Delivery Problem with Time Windows. Eur. J. Oper. Res. 2006, 175, 672–687. [Google Scholar] [CrossRef]
- Irnich, S. A Unified Modeling and Solution Framework for Vehicle Routing and Local Search-Based Metaheuristics. INFORMS J. Comp. 2008, 20, 270–287. [Google Scholar] [CrossRef]
- Nanry, W.P.; Barnes, J.W. Solving the Pickup and Delivery Problem with Time Windows using Reactive Tabu Search. Transport. Res B-Meth. 2000, 34, 107–121. [Google Scholar] [CrossRef]
- Hosny, M.I.; Mumford, C.L. The Single Vehicle Pickup and Delivery Problem with Time Windows: Intelligent Operators for Heuristic and Metaheuristic Algorithms. J. Heuristics 2010, 16, 417–439. [Google Scholar] [CrossRef]
- Bent, R.; Hentenryck, P.V. A Two-Stage Hybrid Algorithm for Pickup and Delivery Vehicle Routing Problems with Time Windows. Comp. Oper. Res. 2006, 33, 875–893. [Google Scholar] [CrossRef]
- Ropke, S.; Pisinger, D. An Adaptive Large Neighborhood Search Heuristic for the Pickup and Delivery Problem with Time Windows. Trans. Sci. 2006, 40, 455–472. [Google Scholar] [CrossRef]
- Pisinger, D.; Ropke, S. A General Heuristic for Vehicle Routing Problems. Comput. Oper. Res. 2007, 34, 2403–2435. [Google Scholar] [CrossRef]
- Masson, R.; Lehuédé, F.; Péton, O. An Adaptive Large Neighborhood Search for the Pickup and Delivery Problem with Transfers. Trans. Sci. 2013, 47, 344–355. [Google Scholar] [CrossRef]
- Qu, Y.; Bard, J.F. The Heterogeneous Pickup and Delivery Problem with Configurable Vehicle Capacity. Trans. Res. Part C Emerg. Tech. 2013, 32, 1–20. [Google Scholar] [CrossRef]
- Jung, S.; Haghani, A. Genetic Algorithm for a Pickup and Delivery Problem with Time Windows. Transp. Res. Record 2000, 1733, 1–7. [Google Scholar] [CrossRef]
- Pankratz, G. A Grouping Genetic Algorithm for the Pickup and Delivery Problem with Time Windows. OR Spectr. 2005, 27, 21–41. [Google Scholar] [CrossRef]
- Alaia, E.B.; Dridi, I.H.; Borne, P.; Bouchriha, H. A Comparative Study of the PSO and GA for the m-MDPDPTW. Int. J. Comput. Commun. Control 2018, 13, 8–23. [Google Scholar] [CrossRef]
- Wang, H.F.; Chen, Y.Y. A Genetic Algorithm for the Simultaneous Delivery and Pickup Problems with Time Window. Comp. Ind. Eng. 2012, 62, 84–95. [Google Scholar] [CrossRef]
- Crèput, J.-C.; Koukam, A.; Kozlak, J.; Lukasik, J. An evolutionary approach to pickup and delivery problem with time windows. In Proceedings of the Computational Science (ICCS 2004), Kraków, Poland, 6–9 June 2004; Bubak, M., van Albada, G.D., Sloot, P.M.A., Dongarra, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2004; pp. 1102–1108. [Google Scholar]
- Nannen, V.; Eiben, A.E. Relevance Estimation and Value Calibration of Evolutionary Algorithm Parameters. In Proceedings of the IJCAI International Joint Conference on Artificial Intelligence, Hyderabad, India, 6–12 January 2007; pp. 975–980. [Google Scholar]
- Hansen, N. The CMA evolution strategy: A comparing review. In Towards a New Evolutionary Computation: Advances in the Estimation of Distribution Algorithms; Lozano, J.A., Larranaga, P., Inza, I., Bengoetxea, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 75–102. [Google Scholar]
- Balaprakash, P.; Birattari, M.; Stützle, T. Improvement strategies for the F-race algorithm: Sampling design and iterative refinement. In Hybrid Metaheuristics; Bartz-Beielstein, T., Blesa Aguilera, M.J., Blum, C., Naujoks, B., Roli, A., Rudolph, G., Sampels, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 108–122. [Google Scholar]
- Roman, I.; Ceberio, J.; Mendiburu, A.; Lozano, J.A. Bayesian Optimization for Parameter Tuning in Evolutionary Algorithms. In Proceedings of the IEEE Congress on Evolutionary Computation (CEC), Vancouver, BC, Canada, 24–29 July 2016; pp. 4839–4845. [Google Scholar]
- Hutter, F.; Hoos, H.H.; Leyton-Brown, K.; Stützle, T. ParamILS: An Automatic Algorithm Configuration Framework. J. Artif. Int. Res. 2009, 36, 267–306. [Google Scholar] [CrossRef]
- Hutter, F.; Hoos, H.H.; Leyton-Brown, K. Sequential model-based optimization for general algorithm configuration. In Learning and Intelligent Optimization; Coello, C.A., Ed.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 507–523. [Google Scholar]
- López-Ibáñez, M.; Dubois-Lacoste, J.; Pérez Cáceres, L.; Birattari, M.; Stützle, T. The Irace Package: Iterated Racing for Automatic Algorithm Configuration. Oper. Res. Perspect. 2016, 3, 43–58. [Google Scholar] [CrossRef]
- Ramasamy, S.; Mondal, M.S.; Reddinger, J.-P.F.; Dotterweich, J.M.; Humann, J.D.; Childers, M.A.; Bhounsule, P.A. Heterogenous Vehicle Routing: Comparing Parameter Tuning Using Genetic Algorithm and Bayesian Optimization. In Proceedings of the International Conference on Unmanned Aircraft Systems (ICUAS), Dubrovnik, Croatia, 21–24 June 2022; pp. 104–113. [Google Scholar]
- Rasku, J.; Musliu, N.; Kärkkäinen, T. On Automatic Algorithm Configuration of Vehicle Routing Problem Solvers. J. Veh. Rout. Alg. 2019, 2, 1–22. [Google Scholar] [CrossRef]
- Wolpert, D.H.; Macready, W.G. No Free Lunch Theorems for Optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef]
- Huang, C.; Yuan, B.; Li, Y.; Yao, X. Automatic Parameter Tuning using Bayesian Optimization Method. In Proceedings of the IEEE Congress on Evolutionary Computation (CEC), Wellington, New Zealand, 10–13 June 2019; pp. 2090–2097. [Google Scholar]
- Rieck, J.; Zimmermann, J. A New Mixed Integer Linear Model for a Rich Vehicle Routing Problem with Docking Constraints. Ann. Oper. Res. 2010, 181, 337–358. [Google Scholar] [CrossRef]
- Furtado, M.G.S.; Munari, P.; Morabito, R. Pickup and Delivery Problem with Time Windows: A New Compact Two-index Formulation. Oper. Res. Lett. 2017, 45, 334–341. [Google Scholar] [CrossRef]
- Feillet, D. A Tutorial on Column Generation and Branch-and-Price for Vehicle Routing Problems. 4OR 2010, 8, 407–424. [Google Scholar] [CrossRef]
- Calvet, L.; Juan, A.A.; Serrat, C.; Ries, J. A Statistical Learning Based Approach for Parameter Fine-tuning of Metaheuristics. Stat. Oper. Res. Trans. 2016, 40, 201–224. [Google Scholar]
- Eiben, A.E.; Hinterding, R.; Michalewicz, Z. Parameter Control in Evolutionary Algorithms. IEEE Trans. Evol. Comput. 1999, 3, 124–141. [Google Scholar] [CrossRef]
- Karimi-Mamaghan, M.; Mohammadi, M.; Meyer, P.; Karimi-Mamaghanb, A.M.; Talbi, E.-G. Machine learning at the service of meta-heuristics for solving combinatorial optimization problems: A state-of-the-art. Eur. J. Oper. Res. 2022, 296, 393–422. [Google Scholar] [CrossRef]
- Hussein, A.A.; Yassen, E.T.; Rashid, A. Learnheuristics in routing and scheduling problems: A review. Samarra J. Pure Appl. Sci. 2023, 5, 60–90. [Google Scholar] [CrossRef]
- Aleti, A.; Moser, I. A Systematic Literature Review of Adaptive Parameter Control Methods for Evolutionary Algorithms. ACM Comput. Surv. 2016, 49, 1–35. [Google Scholar] [CrossRef]
- Holland, J.H. Adaptation in Natural and Artificial Systems; University of Michigan Press: Ann Arbor, MI, USA, 1975. [Google Scholar]
- Eiben, A.E.; Smith, J.E. Introduction to Evolutionary Computing, 2nd ed.; Natural Computing Series; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Michalewicz, Z.; Fogel, D.B. How to Solve It: Modern Heuristics, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2004. [Google Scholar]
- Brochu, E.; Cora, V.M.; de Freitas, N. A Tutorial on Bayesian Optimization of Expensive Cost Functions, with Application to Active User Modeling and Hierarchical Reinforcement Learning. arXiv 2010, arXiv:1012.2599. [Google Scholar]
- Frazier, P.I. A Tutorial on Bayesian Optimization. arXiv 2018, arXiv:1807.02811. [Google Scholar]
- Shahriari, B.; Swersky, K.; Wang, Z.; Adams, R.P.; de Freitas, N. Taking the Human Out of the Loop: A Review of Bayesian Optimization. Proc. IEEE 2016, 104, 148–175. [Google Scholar] [CrossRef]
- Klein, A.; Falkner, S.; Bartels, S.; Hennig, P.; Hutter, F. Fast Bayesian Hyperparameter Optimization on Large Datasets. Electron. J. Stat. 2017, 11, 4945–4968. [Google Scholar] [CrossRef]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning; Series Adaptive Computation and Machine Learning; MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Duvenaud, D.K. Automatic Model Construction with Gaussian Processes. Ph.D. Thesis, University of Cambridge, Cambridge, UK, 2014. [Google Scholar]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical Bayesian Optimization of Machine Learning Algorithms. arXiv 2012, arXiv:1206.2944. [Google Scholar]
- Betriebswirtschaft und Operations Research Homepage. Available online: https://www.uni-hildesheim.de/fb4/institute/bwl/betriebswirtschaft-und-operations-research/ (accessed on 23 December 2023).
- Rüther, C.; Chamurally, S.; Rieck, J. An a-priori parameter selection approach to enhance the performance of genetic algorithms solving pickup and delivery problems. In International Conference on Operations Research; Trautmann, N., Gnägi, M., Eds.; Lecture Notes in Operations Research; Springer: Cham, Switzerland, 2022; pp. 66–72. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| indices and sets: | |
| set of depots, whereas each vehicle is modeled as an artificial depot with a start depot and end depot ; is the number of depots (and vehicles) ⇒ set of start depots , set of end depots | |
| set of customer nodes, | |
| set of pickup locations, | |
| set of delivery locations, | |
| set of nodes, ; in addition, and are declared | |
| parameters: | |
| time window at node in which the service has to start | |
| variable costs (distance) for travelling from i to | |
| delivery demand at customer , where and ; note that holds | |
| fixed costs for using a vehicle associated with depot | |
| capacity of vehicle at depot | |
| maximum capacity of all vehicles, i.e., | |
| l | load factor for vehicle loading measured in time per quantity unit |
| additional loading time to model preparations before service | |
| M | big M for linearization of time window constraints |
| reciprocal speed of the vehicle at depot | |
| max. reciprocal speed of all vehicles, i.e., | |
| pickup demand at customer , where and | |
| service time at node holding , and | |
| decision variables: | |
| current load of the visiting vehicle after serving node | |
| beginning of the service at node | |
| route number on which customer is assigned | |
| capacity of the vehicle which serves customer | |
| reciprocal speed of the vehicle which serves customer | |
| binary variable which indicates whether a vehicle uses the arc between nodes i and () or not () | |
| Param. | Value | Description |
|---|---|---|
| 50 | population size | |
| 1.0 | crossover rate | |
| 0.3 | mutation rate | |
| 250 | maximum number of generations | |
| 1.5 | relative mating pool size with respect to population size (i.e., results in 75 individuals) | |
| 0.05 | proportion of the elite within the population | |
| 0.5 | probability of applying one of the crossover variants, | |
| 0.4 | probability of applying vehicle-based mutation Costs/Number-of-Request Ratio | |
| 0.4 | probability of applying vehicle-based mutation Number of Requests | |
| 0.1 | probability of applying vehicle-based mutation Random Vehicle Index | |
| 0.1 | probability of applying vehicle-based mutation Random Genotype Position | |
| 0.6 | probability of applying request-based mutation Historical Request Pair | |
| 0.4 | probability of applying request-based mutation Similarity Measure Selection | |
| 0.55 | probability for using the Greedy Insertion Repair Operator | |
| 0.25 | probability for using the Regret-2 Repair Operator | |
| 0.10 | probability for using the Regret-3 Repair Operator | |
| 0.05 | probability for using the Regret-4 Repair Operator | |
| 0.05 | probability for using the Regret- Repair Operator |
| Approach | |||||||
|---|---|---|---|---|---|---|---|
| 1D | GGA | BO | 0.79% | 1.48% | 0.89% | 1.31% | 15.49 s |
| Random | 0.99% | 1.39% | 14.67 s | ||||
| ALNS | 1.08% | 1.48% | 1.99% | 1.95% | 17.49 s | ||
| 4D | GGA | BO | 0.48% | 1.06% | 0.61% | 1.08% | 17.48 s |
| Random | 0.66% | 1.12% | 17.45 s | ||||
| ALNS | 0.86% | 1.42% | 1.50% | 1.91% | 19.10 s | ||
| 6D | GGA | BO | 0.63% | 1.34% | 0.66% | 1.11% | 34.82 s |
| Random | 0.80% | 1.24% | 33.15 s | ||||
| ALNS | 1.01% | 1.51% | 2.00% | 2.15% | 48.07 s | ||
| 8D | GGA | BO | 0.79% | 1.49% | 0.72% | 1.19% | 66.77 s |
| Random | 0.88% | 1.23% | 55.56 s | ||||
| ALNS | 0.97% | 1.40% | 2.18% | 2.24% | 100.05 s | ||
| 9D | GGA | BO | 0.84% | 1.55% | 0.78% | 1.25% | 83.64 s |
| Random | 0.91% | 1.30% | 73.14 s | ||||
| ALNS | 1.00% | 1.48% | 2.26% | 2.23% | 135.94 s | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rüther, C.; Rieck, J. A Bayesian Optimization Approach for Tuning a Grouping Genetic Algorithm for Solving Practically Oriented Pickup and Delivery Problems. Logistics 2024, 8, 14. https://doi.org/10.3390/logistics8010014
Rüther C, Rieck J. A Bayesian Optimization Approach for Tuning a Grouping Genetic Algorithm for Solving Practically Oriented Pickup and Delivery Problems. Logistics. 2024; 8(1):14. https://doi.org/10.3390/logistics8010014
Chicago/Turabian StyleRüther, Cornelius, and Julia Rieck. 2024. "A Bayesian Optimization Approach for Tuning a Grouping Genetic Algorithm for Solving Practically Oriented Pickup and Delivery Problems" Logistics 8, no. 1: 14. https://doi.org/10.3390/logistics8010014
APA StyleRüther, C., & Rieck, J. (2024). A Bayesian Optimization Approach for Tuning a Grouping Genetic Algorithm for Solving Practically Oriented Pickup and Delivery Problems. Logistics, 8(1), 14. https://doi.org/10.3390/logistics8010014