Abstract
Objectives: The present cross-sectional analysis aimed to investigate whether Large Language Model-based chatbots can be used as reliable sources of information in orthodontics by evaluating chatbot responses and comparing them to those of dental practitioners with different levels of knowledge. Methods: Eight true and false frequently asked orthodontic questions were submitted to five leading chatbots (ChatGPT-4, Claude-3-Opus, Gemini 2.0 Flash Experimental, Microsoft Copilot, and DeepSeek). The consistency of the answers given by chatbots at four different times was assessed using Cronbach’s α. Chi-squared test was used to compare chatbot responses with those given by two groups of clinicians, i.e., general dental practitioners (GDPs) and orthodontic specialists (Os) recruited in an online survey via social media, and differences were considered significant when p < 0.05. Additionally, chatbots were asked to provide a justification for their dichotomous responses using a chain-of-through prompting approach and rating the educational value according to the Global Quality Scale (GQS). Results: A high degree of consistency in answering was found for all analyzed chatbots (α > 0.80). When comparing chatbot answers with GDP and O ones, statistically significant differences were found for almost all the questions (p < 0.05). When evaluating the educational value of chatbot responses, DeepSeek achieved the highest GQS score (median 4.00; interquartile range 0.00), whereas CoPilot had the lowest one (median 2.00; interquartile range 2.00). Conclusions: Although chatbots yield somewhat useful information about orthodontics, they can provide misleading information when dealing with controversial topics.
1. Introduction
Online Health Information Seeking Behavior (OHISB) identifies a general behavioral pattern of using the Internet as a primary tool to search for health information [1]. As communication and information technologies improve, OHISB is increasingly becoming a global trend [2]. Indeed, searching for health information online has become a preferred method because of its accessibility, comprehensive coverage, ease of use, low cost, interactivity, and anonymity [3,4].
OHISB is thought to positively influence health information consumers by improving their knowledge of health-related topics, influencing opinion formation, and resulting in desirable behavior, as patients are more likely to adhere to treatment after receiving sufficient information about their health conditions [5,6]. However, the reliability and accuracy of health information sources on the Internet remain a major concern [7]. Notably, several investigations have found inaccurate and misleading health-related content on social media, which represents the most appealing source of medical and dental information for laypeople [8,9,10,11]. Such inaccurate information may negatively affect awareness and attitudes of patients towards health-related topics [12,13].
The introduction of Large Language Models (LLMs) has offered a new way for Internet users to access health information [14,15]. LLMs are artificial intelligence (AI) systems that are pre-trained on large volumes of text from datasets, books, articles, and web sources through various word prediction tasks [16]. Through further fine-tuning, including varying levels of human feedback, LLMs develop Natural Language Processing (NLP) capabilities and can generate relevant text responses in plain language to free-text prompts [17,18]. Early data suggests that these AI-powered chatbots can even provide empathetic responses to patients [19]. These chatbots are also able to address patients’ queries and provide answers in an easy-to-understand manner [17,20].
Patients have shown interest in seeking medical advice from chatbots [21], leading to a rapid increase in studies evaluating their ability to provide reliable health advice to both physicians and patients [22]. These investigations have focused on the ability of chatbots to synthesize evidence and provide accurate health guidance on topics such as screening, diagnosis, treatment, and disease prevention [23]. However, chatbots are generally not designed for medical use, and there is currently no regulatory oversight for their use in healthcare [24]. In addition, generative AI-powered chatbots pose unique risks, including the potential to confidently generate incorrect responses and disseminate misleading information and advice [25]. As a result, the aforementioned studies found low levels of chatbot performance, highlighting concerns about their limitations and associated risks [26].
Previous studies have shown that LLMs have promising potential as an aid in the implementation of evidence-based dentistry. However, models occasionally exhibit inaccuracies, outdated content, and a lack of source references. With regard to orthodontics, recent investigations found that AI-based chatbots can be useful for patient education and guidance [27,28]. However, these studies shared the limitations of categorizing the responses of chatbots as true and false, whereas the quality of chatbots’ detailed explanations was not evaluated.
Therefore, the aim of the present study was to assess the accuracy and consistency of AI-based chatbots as a source of information on orthodontics by comparing the answers they provided to orthodontic questions with those given by general dental practitioners (GDPs) and orthodontic specialists (Os) and by rating the educational value of their detailed explanations.
2. Materials and Methods
2.1. Study Design
The present study was developed following the Strengthening the Reporting of Observational Studies in Epidemiology (STROBE) guidelines [29] and adhering to ethical guidelines for research involving human participants in the use of AI in dentistry. Ethical approval was waived for this study since no patient data was used and clinicians voluntarily self-enrolled.
Data collection was carried out between March 2024 and January 2025 from two different sources:
- Artificial Intelligence-based chatbots, including ChatGPT-4, Claude-3-Opus, Gemini 2.0 Flash Experimental, Microsoft Copilot, and DeepSeek 1.0.0.
- Clinicians, including general practitioners and orthodontists (i.e., practitioners who have obtained a specialty in orthodontics).
To generate a set of frequently asked orthodontic questions, the Google Trends website (freely available at https://trends.google.com/trends/, accessed on 24 February 2024) was searched to determine the most frequently used search term related to orthodontics worldwide in the past five years on Google. The term with the highest search volume was “malocclusion”. Accordingly, the most frequently searched queries associated with “malocclusion” were identified through Google (“Frequently Asked Questions about Malocclusion”) and chatbots (“What are 10 frequently asked questions with the word “malocclusion”?). Two orthodontic specialists (S.M. and M.G.) eliminated duplicates and unscientific inquiries and selected only dichotomous questions. Identified questions were clarified if needed, and an 8-item yes/no questionnaire was created (Table 1).

Table 1.
Eight-item questionnaire developed on the basis of most frequently Internet-searched queries associated with “malocclusion”.
2.2. Survey Dissemination
The 8-item yes/no questionnaire was released as an online survey created using Google Forms (http://www.google.com/forms/about/, accessed on 27 February 2024). It was distributed through a standardized recruitment email that included a link to the survey and a cover letter explaining the aim of the study, assuring participants of the anonymity of their responses, and requesting participation. There was no financial incentive to participate in the survey.
Clinicians were recruited via Facebook (Meta Platforms), as this has proven to be a cost-effective means of recruiting for online survey research.
The electronic message was disseminated through various modalities supported by the Facebook platform, including public posts on dental network group pages and private messages.
Participants could only respond once to the survey, and it was not possible to change responses after successful submission. It was made clear to all participants that participation was entirely voluntary, and that they could choose to stop filling out the questionnaire at any time and for any reason, without facing any penalties.
At the beginning of the survey, participants were asked if they were orthodontists (i.e., with a specialty in orthodontics) or general dentists in order to enable a comparison of answers across the two categories, as well as to determine how long they had been in the dental profession.
The target sample size was estimated using R. Software, version 4.1.0 (May 2021, R Foundation for Statistical Computing, Vienna, Austria), with Cochran’s sample size formula for prevalence studies [30]. Since the total number of dental practitioners in Italy is approximately 60,000 according to Eurostat data (https://ec.europa.eu/eurostat/data/database; accessed on 27 February 2024), the target sample size for the survey was estimated to be 382 participants, at a 95% confidence level and 3% margin of error.
The initial dissemination of the standardized recruitment message and survey link occurred on the Facebook platform on 3 March 2024. The first messages were sent on the same day, and follow-up reminders (messages and posts) were sent at one, two, and four weeks.
2.3. Chatbot Analysis Process
A standardized prompt-template using a chain-of-thought prompting approach was developed and used for all LLM questions [31,32]. The prompts used are detailed in Table 2.
Table 2.
Standardized prompts using chain-of-thought prompting approach.
To evaluate the consistency of the chatbots, two users experienced in chatbot use (D.C. and V.S.) asked each question in four different attempts, each time starting a new conversation after clearing the browser history and cache. Moreover, the questions were resubmitted to the chatbots from different computer systems, with a cleared history and cache, after three, six, and nine days, for a total of 20 attempts. Chatbots were set as follows: memory and model improvement disabled; no preference in customization.
The same users then asked the chatbots the same questions again, requiring them to justify their answers, and rated the chatbots’ responses educational value according to the five-point Global Quality Scale (GQS) criteria [33,34]:
- Score 1: Poor quality, very unlikely to be of any use to patients.
- Score 2: Poor quality, but some information present; of very limited use to patients.
- Score 3: Suboptimal flow, some information covered but important topics missing; somewhat useful to patients.
- Score 4: Good quality and flow, most important topics covered; useful to patients.
- Score 5: Excellent quality and flow; highly useful to patients.
To address potential sources of bias, the responses of chatbots were evaluated independently and blindly by two certified orthodontic dentists (S.M. and M.G.) against the generated list of answers. Any discrepancies were resolved through consensus.
2.4. Data Collection and Statistical Analysis
Data collected from the questionnaire and the responses of the chatbot were qualitatively synthesized by means of descriptive statistics analysis using Microsoft Excel software 2019 (Microsoft Corporation, Redmond, WA, USA), and frequencies and percentages were calculated for each item.
Cronbach’s α was calculated to assess chatbot consistency in answering questions, with a threshold value of 0.80 indicating excellent reliability.
Chi-squared test or Fisher’s exact test, depending on the observed frequencies, was performed to assess differences in the answers given by Os and GPs to different items of the questionnaire, as well as differences in the responses of dentists and chatbots to the various questionnaire items.
To assess the quality of the responses provided by chatbots, the median and interquartile range (IQR) were calculated for the GQS values assigned to responses given by individual chatbots to all questions and to individual questions for all chatbots.
Statistical analysis was carried out using the IBM SPSS Statistics 29.0.0 software (IBM Corporation, Armonk, NY, USA). A significance level of p < 0.05 was considered statistically significant.
3. Results
3.1. Dentists’ Responses to the Most Frequently Internet Searched Queries Associated with “Malocclusion”
A total of 458 dentists participated in the present study, notably 284 GDPs (62.0%), and 174 Os (38.0%). GDPs and Os were similar in terms of years in the dental profession (less than 10 years: 146 GDPs, 96 Os, p = 0.434; 10–20 years: 92 GDPs, 54 Os, p = 0.762; more than 20 years: 46 GDPs, 24 Os, p = 0.488). Between groups, differences were found in the responses to the questions Q3 and Q4, suggesting that, on average, GDPs were more likely to support the relationships between malocclusion and temporomandibular disorder (TMD) signs and symptoms, as well as malocclusion and posture, compared to Os, as shown in Table 3. Indeed, 61.2% of GDPs (174) believed that malocclusion can affect posture, whereas only 46.5 % of Os (81) believed the same (p = 0.002). Similarly, most GDPs (54,9%) considered malocclusion a risk factor for the onset of TMDs, while only 25.9% of Os agreed with this statement (p < 0.001). No other differences were found between the two groups’ answers.
Table 3.
Responses to the most frequently Internet searched queries associated with “malocclusion” of general dental practitioners (GDP) and orthodontists (O). Between-group differences were measured with the Chi-squared test.
3.2. Chatbot Analysis Results
The analysis of Cronbach’s α revealed a high degree of consistency in chatbot responses, ranging from 0.93 to 0.99.
When compared with GDPs’ and Os’ ones, all chatbots’ responses to the questionnaire were found to be statistically different, except for Q6, as shown in Table 4 and Table 5.
Table 4.
Responses to the most frequently Internet searched queries associated with “malocclusion” of general dental practitioners (GDPs) and chatbots (Cs). Between-group differences were measured with Fisher’s exact test.
Table 5.
Responses to the most frequently Internet searched queries associated with “malocclusion” of orthodontists (Os) and chatbots (Cs). Between-group differences were measured with Fisher’s exact test.
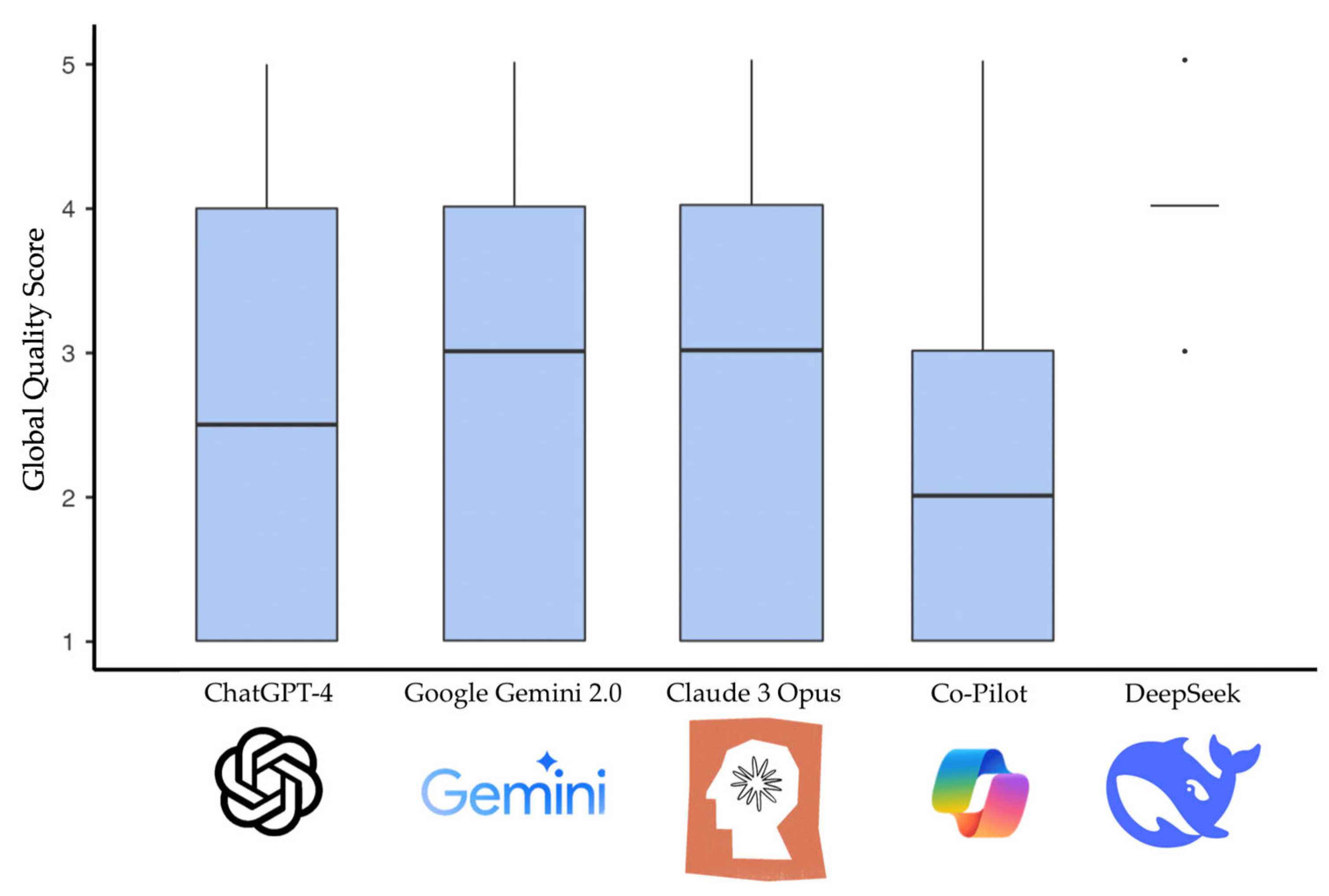
When evaluating the chatbots using the GQS, DeepSeek achieved the highest median score (median 4.00; IQR 0.00), whereas CoPilot had the lowest median (median 2.00; IQR 2.00). Figure 1 shows the distribution of the GQS scores among the different chatbots.

Figure 1.
Distribution of the GQS scores among the different chatbots.
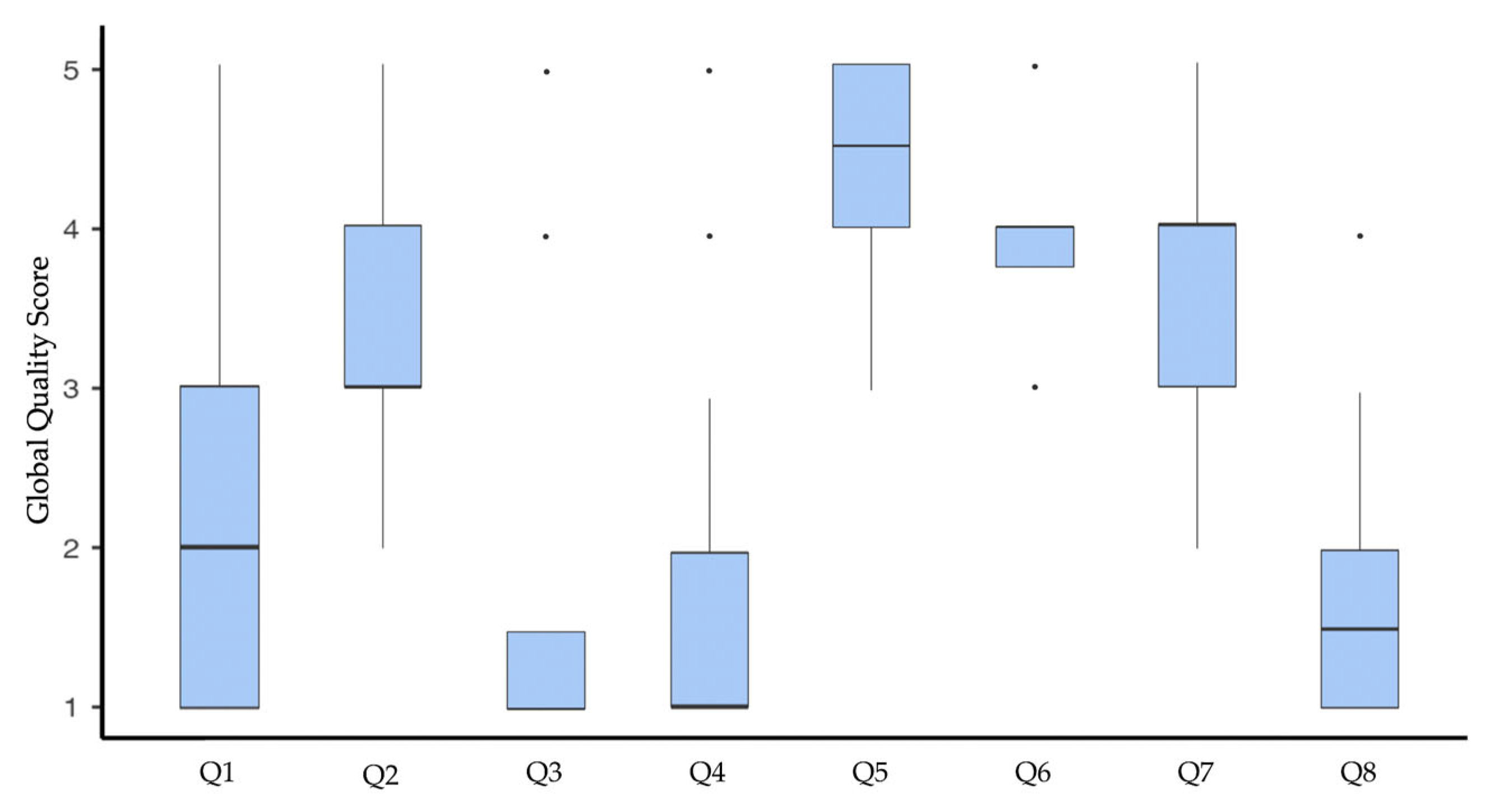
Regarding the GQS evaluation of individual questions, the highest-quality responses were observed for Q6 (median 4.00; IQR 0.25). In contrast, the lowest performance was associated with Q3 and Q4 (median 1.00; IQR 1.00). Figure 2 shows the distribution of the GQS scores for the different questions.

Figure 2.
Distribution of the GQS scores among the different questions.
4. Discussion
The present cross-sectional study aimed to compare the performance of several prominent AI chatbots—namely ChatGPT-4, Claude-3-Opus, Gemini 2.0 Flash Experimental, Microsoft Copilot, and DeepSeek—assessing their reliability and consistency in answering a set of orthodontic questions and comparing them with that of general dental practitioners and orthodontists.
The analysis of the responses to the questionnaire found that both Os and GDPs did not support the causal role of the lower third molar in the onset of malocclusion (Table 2), in accordance with recent investigations on the topic [35]. Instead, the chatbots provided answers that support the potential of a third molar eruption in determining malocclusion, notably anterior dental crowding (Table 3 and Table 4). Actually, the effect of mandibular third molars on crowding of mandibular teeth remains an ongoing topic of discussion among researchers and clinicians. Indeed, some studies found a significant association between impacted third molars with insufficient mesiodistal distance and dental crowding, resulting from the force applied by the molars to other teeth [36]. However, evidence supporting the contribution of lower third molars to mandibular crowding and lower arch constriction is weak, marred by the absence of randomized studies and the presence of uncontrollable confounding factors, such as growth-related changes, muscular factors, periodontal ligament traction, bone adaptation, masticatory force, dental agenesis, and previous dental extractions in the studied populations. Additionally, the low methodological quality of the existing studies further weakens the evidence [37]. The information provided by chatbots in supporting the role of third molars in the pathogenesis of malocclusions may influence the patients’ perception of the scientifically unsupported need for asymptomatic molars extraction to prevent dental crowding, which could be misleading. Overall, in relation to the current literature, the quality of information provided by chatbots to justify their response to Q1 was considered poor.
The possibility of malocclusions affecting chewing, speech patterns, and swallowing was supported by Os, GPDs, and chatbots (Table 1, Table 3 and Table 4). On this topic, there is a general consensus in the literature that certain malocclusions, such as an open bite, may affect the pattern of phonation and swallowing [38], and, similarly, severe malocclusions are potentially capable of altering muscle function and thus chewing [39]. However, the questionnaire presented in this study did not distinguish between different types of malocclusions, and thus clinicians’ responses that deviate from the majority must be interpreted given the impossibility of generalizing the association between malocclusion and functional problems. The strength of the evidence in the literature regarding these topics was also reflected in the ability of chatbots to provide adequate arguments to justify their responses, resulting in good quality, useful information for Internet users, according to the findings of the GQS analysis (Q4: median 4.50, IQR 1.00; Q2: median 3.00, IQR 1.00; Figure 2).
An agreement between dental practitioners and chatbots was also found in recognizing heritability among the factors contributing to the determination of malocclusion, as well as in acknowledging the potential for untreated malocclusion to worsen over time (Table 1, Table 2 and Table 3). This agreement stems from the consensus in the literature on the genetic component underlying malocclusions [40] and on the possibility of dentofacial deformities to worsen with growth [41], which is reflected in the good-quality information provided by the chatbots (Q6: median 4.00; IQR 0.25; Q7: median 4.00; IQR 1.00; Figure 2).
The association between occlusion and posture was denied by Os, whereas general practitioners indicated a possible link (Table 3), which is also supported by chatbot responses (Table 4 and Table 5). This could be explained by the ambiguity of the scientific literature related to this topic. Indeed, although some recent reviews reported evidence of a possible association between sagittal malocclusion and head and body posture [42,43], primitive study design, methodological heterogeneity, small sample sizes, and definition and analysis of outcomes severely limit the generalizability of these results. Coherently, the only existing meta-analysis on the topic found no sufficiently robust evidence supporting an association between head and neck posture with sagittal malocclusion [44]. Despite the ambiguity of the relevant literature, chatbots support the link between occlusion and posture, though with poor-quality, low evidence-based information (Q3: GQS median 1.00, IQR 1.00; Figure 2), potentially leading to inappropriate management of both postural problems and malocclusions. Furthermore, it is crucial for patients to seek consultation with a specialist rather than a GDP, as this can potentially result in inappropriate management of the underlying postural issue through orthodontic interventions.
Similarly, chatbots claimed a relationship between malocclusion and TMD signs and symptoms (Table 3 and Table 5). General dental practitioners also supported the etiopathogenetic role of malocclusion in TMD development or progression, whereas specialists did not (Table 3). For instance, a recent web-based analysis on TMD-related content showed that the existing online information ascribes TMD to occlusal problems, including malocclusion, and recommends addressing these problems to manage TMD [45,46]. Although a recent meta-analysis suggested a higher prevalence of TMD in subjects with malocclusion, notably Class II and posterior unilateral crossbite [47], the lack of standardized TMD diagnostic criteria, malocclusion classifications, and representative sampling methods across available studies makes it impossible to establish a clear correlation or to know if and when a malocclusion may unbalance the stomatognathic system and cause TMD signs and symptoms. After all, the role of occlusion in the TMD has been downplayed in favor of cognitive, emotional, and behavioral factors [48,49]. Therefore, the literature does not support orthodontic treatment as a therapy for TMD management and suggests routinely performing TMD-related examinations before and throughout the duration of orthodontic treatment in order to start treatment only in patients without pain and to temporarily discontinue treatment if pain occurs [50]. However, the inaccurate information provided by chatbots (Q4: GQS median 1.00, IQR 1.00; Figure 2) may influence patients’ attitudes, leading them to seek orthodontic treatment to address their pain or dysfunctional symptoms. Since the level of knowledge on this topic is low even among clinicians, especially general dentists, there is a risk of going against proper TMD management.
Lastly, the ability of malocclusion to result in the onset of headaches is supported by both clinicians and chatbots (Table 2, Table 3 and Table 4). Although a recent systematic review suggested that certain malocclusions, notably Class II malocclusion, might be associated with a higher headache prevalence [51], the level of evidence is very low. Moreover, due to the heterogeneity of headaches described in the most recent International Classification of Headache Disorders (ICHD-3) [52], it is not possible to formulate a definitive answer to this question. In fact, most studies on this topic either do not specify the type of headache or assume that it is a headache attributable to TMD. In addition, it is unclear whether the headache is a direct consequence of the malocclusion, resulting from adaptations of the stomatognathic system to the occlusal imbalances that might stimulate the trigeminal nerve, potentially leading to central sensitization [53], or rather the result of the malocclusion’s impact on the patient’s quality of life [54]. The information provided by chatbots on this topic was misleading. However, DeepSeek exhibited a noticeably higher GQS than other chatbots since it mentioned the possible implication of the psychosocial impact of malocclusions.
Based on the above, the accuracy of chatbots as public sources of information on orthodontics appeared to be influenced by the level of evidence available in the literature relative to the topic analyzed since the greater the consensus in the literature, the more accurate the answer provided proved to be. Indeed, it must be considered that chatbots answer questions by integrating information from external sources such as databases, scientific articles, and websites. When there is a high degree of agreement among these sources, the resulting answer will have greater accuracy, so much so that they can be equated with those of clinicians, as also shown by previous studies [55]. Instead, when there is no agreement on a topic, AI-based chatbots were prone to generate plausible-sounding but inaccurate content [24].
The significant differences seen between the chatbot and clinician responses for most questions, except for heritability, matched the findings of Metin and Goymen [27]. Their research showed that AI-driven chatbots had higher accuracy compared to dental students and general dentists but generally performed worse than orthodontists. Salmanpour et al. confirmed this claim, demonstrating that expert responses are consistently better than those of chatbots in complex areas of orthodontics [28].
However, Zhou et al. suggested that ChatGPT-4 might provide more accurate answers than specialists when handling common questions about orthodontics [56]. Similarly, Hassan et al. found that Google Gemini reached 100% accuracy in answering questions about TMD [57]. These contradictions indicate that generalizing the performance of AI is not possible, depending on many factors such as the specific model, the type of question, and the evaluation criteria.
Differences in accuracy observed among the different chatbots highlighted that not all LLMs are equally proficient in handling specialized medical or dental information. Differences in their training datasets, underlying model architectures, and the specific fine-tuning techniques employed likely contribute to these variations in their ability to accurately and comprehensively address questions related to malocclusion. DeepSeek’s superior performance could potentially be attributed to specific characteristics of its training data or model architecture that make it particularly well-suited for processing and responding to the types of questions included in this study. A key strength of DeepThink was its open-source nature, which allowed users to access and modify the source code based on their needs. This learning process used data from public sources, enabling the model to update itself continuously with the latest scientific and medical findings. As a result, this approach helped it keep up with new trends in health care and made it more effective over time [58]. This noted diversity in performance exists throughout literature. For example, Dermata et al. found that ChatGPT-4 ranked highest in pediatric dentistry among six LLMs, closely followed by Gemini Advanced and ChatGPT-4o [59]. In addition, Özbay et al. further found that ChatGPT-4 outperformed ChatGPT-3.5 and Google Bard in endodontics [60]. Hassan et al. found that ChatGPT-4o was much more complete and more accurate than other models for TMD questions [57]. On the other hand, Makrygiannakis et al. reported that the best performance in orthodontics came from Microsoft Bing Chat and was followed by ChatGPT-4 [61]. This finding indicates that the "best" chatbot is dependent upon the specific area and evaluation method.
Interestingly, the results of the present study found excellent inter-chatbot reliability. When the same chatbot was asked the same question several times, by different users and at different times, the answer was always the same, and the quality of the related argument was almost always consistent. This finding was in contrast with those of previous studies, which reported that chatbots may generate different responses to the same prompt if asked multiple times or asked by different users or at different times.
This study offers several notable strengths. The study simultaneously evaluates four different LLMs, which is a rare approach, as most existing research focuses on a single model—typically ChatGPT, which was the first to be publicly available and remains the most widely known. Another strength of this study is that it includes not only quantitative findings but also qualitative results, such as evaluators’ detailed comments, which provide deeper insights into the LLMs’ performance and reveal some of their limitations.
The main limitation of the study relates to the content of the questions asked of the chatbots. Since the questions were identified based on Internet search trends, it was not possible to establish a consensus “gold standard” against which to compare the artificial intelligence responses, and thus experts had to rely solely on their own subjective judgment to assess the correctness and completeness of the answers. However, as the same study highlighted, experts also disagree on some of the issues analyzed. Nevertheless, considering the purpose of the study, selecting frequently asked questions provided a more accurate representation of the actual usefulness of chatbots as a source of information for Internet users. However, it should be considered that it was impossible to know who conducted the searches through the identified search terms—doctors, students, or patients—limiting the ability to contextualize and correctly interpret data. Secondarily, a potential selection bias of survey participants should be considered, since they were geographically homogeneous, limiting the generalizability of the results. Another major limitation concerns the operators’ judgment of the quality of chatbot responses, whose inadequate or incomplete content may have been camouflaged through fluid and articulate language, according to the concept of hallucination of LLMs. Another selection bias concerns the choice of questions arbitrarily conducted by operators, including questions the answer to which may be contained in the gray literature that is not consulted by chatbots. Lastly, it is important to highlight that the responses reflect the performance of the LLMs at the time the research was conducted, and this may evolve over time, which is an inherent limitation of studies focused on technological advancements.
5. Conclusions
The results of the present study found that AI-based chatbots provide information about orthodontics with excellent reproducibility. According to GQS, this information has a medium level of accuracy, with DeepSeek showing the statistically significant highest performance and proving to be somewhat useful to patients. However, when dealing with controversial topics, the accuracy of chatbots was weak compared to clinicians’ opinions on the same topics.
Author Contributions
Conceptualization, M.G. and S.M.; methodology, D.C.; software, M.G.; validation, S.M. and F.G.; formal analysis, F.G.; investigation, S.M.; resources, S.M.; data curation, V.S.; writing—original draft preparation, T.P.; writing—review and editing, D.C. and S.M.; visualization, V.S.; supervision, M.G.; project administration, S.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Ethical review and approval were deemed unnecessary for this study, as it was conducted using data voluntarily provided by participants. No personally identifiable information was collected during the survey, including, but not limited to, names, identification numbers, location data, online identifiers, or any attributes that could lead to the identification of an individual, in accordance with the definition of personal data outlined in Article 4 of the General Data Protection Regulation (GDPR, Regulation EU 2016/679). All participants provided informed consent for the processing of their data through a written declaration, formulated in clear and comprehensible language, in compliance with Article 7 of the GDPR.
Informed Consent Statement
Written informed consent has been obtained from all subjects involved in this study.
Data Availability Statement
The datasets used and analyzed during the current study are available from the corresponding author upon reasonable request.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AI | Artificial Intelligence |
| C | Chatbot |
| GQS | Global Quality Score |
| ICHD-3 | International Classification of Headache Disorders |
| IQR | Interquartile Range |
| LLM | Large Language Model |
| NLP | Natural Language Processing |
| O | Orthodontic specialists |
| OHISB | Online Health Information Seeking Behavior |
| Q | Question |
| STROBE | Strengthening the Reporting of Observational Studies in Epidemiology |
| TMD | Temporomandibular Disorder |
References
- Jia, X.; Pang, Y.; Liu, L.S. Online Health Information Seeking Behavior: A Systematic Review. Healthcare 2021, 9, 1740. [Google Scholar] [CrossRef] [PubMed]
- Di Spirito, F.; Giordano, F.; Di Palo, M.P.; Cannatà, D.; Orio, M.; Coppola, N.; Santoro, R. Reliability and Accuracy of YouTube Peri-Implantitis Videos as an Educational Source for Patients in Population-Based Prevention Strategies. Healthcare 2023, 11, 2094. [Google Scholar] [CrossRef] [PubMed]
- Di Spirito, F.; Amato, A.; D’Ambrosio, F.; Cannatà, D.; Di Palo, M.P.; Coppola, N.; Amato, M. HPV-Related Oral Lesions: YouTube Videos Suitability for Preventive Interventions Including Mass-Reach Health Communication and Promotion of HPV Vaccination. Int. J. Environ. Res. Public Health 2023, 20, 5972. [Google Scholar] [CrossRef] [PubMed]
- Di Spirito, F.; Di Palo, M.P.; Garofano, M.; Del Sorbo, R.; Allegretti, G.; Rizki, I.; Bartolomeo, M.; Giordano, M.; Amato, M.; Bramanti, A. Effectiveness and Adherence of Pharmacological vs. Non-Pharmacological Technology-Supported Smoking Cessation Interventions: An Umbrella Review. Healthcare 2025, 13, 953. [Google Scholar] [CrossRef] [PubMed]
- Nangsangna, R.D.; da-Costa Vroom, F. Factors Influencing Online Health Information Seeking Behaviour among Patients in Kwahu West Municipal, Nkawkaw, Ghana. Online J. Public Health Inform. 2019, 11, e13. [Google Scholar] [CrossRef] [PubMed]
- Peng, Y.; Malin, B.A.; Rousseau, J.F.; Wang, Y.; Xu, Z.; Xu, X.; Weng, C.; Bian, J. From GPT to DeepSeek: Significant Gaps Remain in Realizing AI in Healthcare. J. Biomed. Inform. 2025, 163, 104791. [Google Scholar] [CrossRef] [PubMed]
- Reddy, S. Generative AI in Healthcare: An Implementation Science Informed Translational Path on Application, Integration and Governance. Implement. Sci. 2024, 19, 27. [Google Scholar] [CrossRef] [PubMed]
- Cannatà, D.; Galdi, M.; Russo, A.; Scelza, C.; Michelotti, A.; Martina, S. Reliability and Educational Suitability of TikTok Videos as a Source of Information on Sleep and Awake Bruxism: A Cross-Sectional Analysis. J. Oral Rehabil. 2025, 52, 434–442. [Google Scholar] [CrossRef] [PubMed]
- Lena, Y.; Dindaroğlu, F. Lingual Orthodontic Treatment: A YouTubeTM Video Analysis. Angle Orthod. 2018, 88, 208–214. [Google Scholar] [CrossRef] [PubMed]
- Sezici, Y.L.; Gediz, M.; Dindaroğlu, F. Is YouTube an Adequate Patient Resource about Orthodontic Retention? A Cross-Sectional Analysis of Content and Quality. Am. J. Orthod. Dentofac. Orthop. 2022, 161, e72–e79. [Google Scholar] [CrossRef] [PubMed]
- Fortuna, G.; Schiavo, J.H.; Aria, M.; Mignogna, M.D.; Klasser, G.D. The Usefulness of YouTubeTM Videos as a Source of Information on Burning Mouth Syndrome. J. Oral Rehabil. 2019, 46, 657–665. [Google Scholar] [CrossRef] [PubMed]
- Yilmaz, H.; Aydin, M. YouTubeTM Video Content Analysis on Space Maintainers. J. Indian Soc. Pedod. Prev. Dent. 2020, 38, 34. [Google Scholar] [CrossRef] [PubMed]
- Pisano, M.; Bramanti, A.; Di Spirito, F.; Di Palo, M.P.; De Benedetto, G.; Amato, A.; Amato, M. Reviewing Mobile Dental Apps for Children with Cognitive and Physical Impairments and Ideating an App Tailored to Special Healthcare Needs. J. Clin. Med. 2025, 14, 2105. [Google Scholar] [CrossRef] [PubMed]
- Ayers, J.W.; Poliak, A.; Dredze, M.; Leas, E.C.; Zhu, Z.; Kelley, J.B.; Faix, D.J.; Goodman, A.M.; Longhurst, C.A.; Hogarth, M.; et al. Comparing Physician and Artificial Intelligence Chatbot Responses to Patient Questions Posted to a Public Social Media Forum. JAMA Intern. Med. 2023, 183, 589–596. [Google Scholar] [CrossRef] [PubMed]
- Najeeb, M.; Islam, S. Artificial Intelligence (AI) in Restorative Dentistry: Current Trends and Future Prospects. BMC Oral Health 2025, 25, 592. [Google Scholar] [CrossRef] [PubMed]
- Singhal, K.; Azizi, S.; Tu, T.; Mahdavi, S.S.; Wei, J.; Chung, H.W.; Scales, N.; Tanwani, A.; Cole-Lewis, H.; Pfohl, S.; et al. Large Language Models Encode Clinical Knowledge. Nature 2023, 620, 172–180. [Google Scholar] [CrossRef] [PubMed]
- Khurana, D.; Koli, A.; Khatter, K.; Singh, S. Natural Language Processing: State of the Art, Current Trends and Challenges. Multimed. Tools Appl. 2023, 82, 3713–3744. [Google Scholar] [CrossRef] [PubMed]
- Al-Dhubaibi, M.S.; Mohammed, G.F.; Atef, L.M.; Bahaj, S.S.; Al-Dhubaibi, A.M.; Bukhari, A.M. Artificial Intelligence in Aesthetic Medicine: Applications, Challenges, and Future Directions. J. Cosmet. Dermatol. 2025, 24, e70241. [Google Scholar] [CrossRef] [PubMed]
- Battineni, G.; Baldoni, S.; Chintalapudi, N.; Sagaro, G.G.; Pallotta, G.; Nittari, G.; Amenta, F. Factors Affecting the Quality and Reliability of Online Health Information. Digit. Health 2020, 6, 2055207620948996. [Google Scholar] [CrossRef] [PubMed]
- Wah, J.N.K. Revolutionizing E-Health: The Transformative Role of AI-Powered Hybrid Chatbots in Healthcare Solutions. Front. Public Health 2025, 13, 1530799. [Google Scholar] [CrossRef] [PubMed]
- Shahsavar, Y.; Choudhury, A. User Intentions to Use ChatGPT for Self-Diagnosis and Health-Related Purposes: Cross-Sectional Survey Study. JMIR Hum. Factors 2023, 10, e47564. [Google Scholar] [CrossRef] [PubMed]
- Temsah, M.-H.; Altamimi, I.; Jamal, A.; Alhasan, K.; Al-Eyadhy, A. ChatGPT Surpasses 1000 Publications on PubMed: Envisioning the Road Ahead. Cureus 2023, 15, e44769. [Google Scholar] [CrossRef] [PubMed]
- Lee, P.; Bubeck, S.; Petro, J. Benefits, Limits, and Risks of GPT-4 as an AI Chatbot for Medicine. N. Engl. J. Med. 2023, 388, 1233–1239. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Dada, A.; Puladi, B.; Kleesiek, J.; Egger, J. ChatGPT in Healthcare: A Taxonomy and Systematic Review. Comput. Methods Programs Biomed. 2024, 245, 108013. [Google Scholar] [CrossRef] [PubMed]
- Meskó, B.; Topol, E.J. The Imperative for Regulatory Oversight of Large Language Models (or Generative AI) in Healthcare. NPJ Digit. Med. 2023, 6, 120. [Google Scholar] [CrossRef] [PubMed]
- Sallam, M. ChatGPT Utility in Healthcare Education, Research, and Practice: Systematic Review on the Promising Perspectives and Valid Concerns. Healthcare 2023, 11, 887. [Google Scholar] [CrossRef] [PubMed]
- Metin, U.; Goymen, M. Information from Digital and Human Sources: A Comparison of Chatbot and Clinician Responses to Orthodontic Questions. Am. J. Orthod. Dentofac. Orthop. 2025, in press. [Google Scholar] [CrossRef]
- Salmanpour, F.; Camcı, H.; Geniş, Ö. Comparative Analysis of AI Chatbot (ChatGPT-4.0 and Microsoft Copilot) and Expert Responses to Common Orthodontic Questions: Patient and Orthodontist Evaluations. BMC Oral Health 2025, 25, 896. [Google Scholar] [CrossRef] [PubMed]
- Cuschieri, S. The STROBE Guidelines. Saudi J. Anaesth. 2019, 13, S31–S34. [Google Scholar] [CrossRef] [PubMed]
- Pourhoseingholi, M.A.; Vahedi, M.; Rahimzadeh, M. Sample Size Calculation in Medical Studies. Gastroenterol. Hepatol. Bed Bench 2013, 6, 14–17. [Google Scholar] [PubMed]
- Nori, H.; Lee, Y.T.; Zhang, S.; Carignan, D.; Edgar, R.; Fusi, N.; King, N.; Larson, J.; Li, Y.; Liu, W.; et al. Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine. arXiv 2023, arXiv:2311.16452. [Google Scholar]
- Vassis, S.; Powell, H.; Petersen, E.; Barkmann, A.; Noeldeke, B.; Kristensen, K.D.; Stoustrup, P. Large-Language Models in Orthodontics: Assessing Reliability and Validity of ChatGPT in Pretreatment Patient Education. Cureus 2024, 16, e68085. [Google Scholar] [CrossRef] [PubMed]
- Naz, R.; Akacı, O.; Erdoğan, H.; Açıkgöz, A. Can Large Language Models Provide Accurate and Quality Information to Parents Regarding Chronic Kidney Diseases? J. Eval. Clin. Pract. 2024, 30, 1556–1564. [Google Scholar] [CrossRef] [PubMed]
- Büker, M.; Mercan, G. Readability, Accuracy and Appropriateness and Quality of AI Chatbot Responses as a Patient Information Source on Root Canal Retreatment: A Comparative Assessment. Int. J. Med. Inform. 2025, 201, 105948. [Google Scholar] [CrossRef] [PubMed]
- Guldiken, I.N.; Gulsever, S.; Malkoc, Y.; Yilmaz, Z.C.; Ozcan, M. Prophylactic Third Molar Removal: Are Oral Surgeons and Orthodontists Aligned in Preventive Approaches? BMC Oral Health 2024, 24, 1072. [Google Scholar] [CrossRef] [PubMed]
- Esan, T.; Schepartz, L.A. Third Molar Impaction and Agenesis: Influence on Anterior Crowding. Annu. Hum. Biol. 2017, 44, 46–52. [Google Scholar] [CrossRef] [PubMed]
- Palikaraki, G.; Mitsea, A.; Sifakakis, I. Effect of Mandibular Third Molars on Crowding of Mandibular Teeth in Patients with or without Previous Orthodontic Treatment: A Systematic Review and Meta-Analysis. Angle Orthod. 2024, 94, 122–132. [Google Scholar] [CrossRef] [PubMed]
- Tashkandi, N.E.; AlDosary, R.; Zamandar, H.; Alalwan, M.; Alwothainani, M.; Aljoaid, H.; Alghazhmri, D.; Allam, E.; Marya, A.; Adel, S.M. The Relationship between Malocclusion and Speech Patterns: A Cross-Sectional Study. BMC Oral Health 2025, 25, 65. [Google Scholar] [CrossRef] [PubMed]
- Alshammari, A.; Almotairy, N.; Kumar, A.; Grigoriadis, A. Effect of Malocclusion on Jaw Motor Function and Chewing in Children: A Systematic Review. Clin. Oral Investig. 2022, 26, 2335–2351. [Google Scholar] [CrossRef] [PubMed]
- Di Spirito, F.; Cannatà, D.; Schettino, V.; Galdi, M.; Bucci, R.; Martina, S. Perceived Orthodontic Needs and Attitudes towards Early Evaluation and Interventions: A Survey-Based Study among Parents of Italian School-Aged Children. Clin. Pract. 2024, 14, 1159–1170. [Google Scholar] [CrossRef] [PubMed]
- Grippaudo, M.M.; Quinzi, V.; Manai, A.; Paolantonio, E.G.; Valente, F.; La Torre, G.; Marzo, G. Orthodontic Treatment Need and Timing: Assessment of Evolutive Malocclusion Conditions and Associated Risk Factors. Eur. J. Paediatr. Dent. 2020, 21, 203–208. [Google Scholar] [CrossRef] [PubMed]
- Różańska-Perlińska, D.; Potocka-Mitan, M.; Rydzik, Ł.; Lipińska, P.; Perliński, J.; Javdaneh, N.; Jaszczur-Nowicki, J. The Correlation between Malocclusion and Body Posture and Cervical Vertebral, Podal System, and Gait Parameters in Children: A Systematic Review. J. Clin. Med. 2024, 13, 3463. [Google Scholar] [CrossRef] [PubMed]
- Álvarez Solano, C.; González Camacho, L.; Castaño Duque, S.; Cortés Velosa, T.; Vanoy Martin, J.; Chambrone, L. To Evaluate Whether There Is a Relationship between Occlusion and Body Posture as Delineated by a Stabilometric Platform: A Systematic Review. CRANIO® 2023, 41, 368–379. [Google Scholar] [CrossRef] [PubMed]
- Peng, H.; Liu, W.; Yang, L.; Zhong, W.; Yin, Y.; Gao, X.; Song, J. Does Head and Cervical Posture Correlate to Malocclusion? A Systematic Review and Meta-Analysis. PLoS ONE 2022, 17, e0276156. [Google Scholar] [CrossRef] [PubMed]
- Kim, M.J.; Kim, J.R.; Jo, J.H.; Kim, J.S.; Park, J.W. Temporomandibular Disorders-Related Videos on YouTube Are Unreliable Sources of Medical Information: A Cross-Sectional Analysis of Quality and Content. Digit. Health 2023, 9, 20552076231154377. [Google Scholar] [CrossRef] [PubMed]
- Cannatà, D.; Giordano, F.; Bartolucci, M.L.; Galdi, M.; Bucci, R.; Martina, S. Attitude of Italian Dental Practitioners toward Bruxism Assessment and Management: A Survey-Based Study. Orthod. Craniofacial Res. 2023, 46, 228–236. [Google Scholar] [CrossRef] [PubMed]
- Huang, L.; Xu, Y.; Xiao, Z.; Liu, Y.; Luo, F. Temporomandibular Disorder Prevalence in Malocclusion Patients: A Meta-Analysis. Head Face Med. 2025, 21, 13. [Google Scholar] [CrossRef] [PubMed]
- Michelotti, A.; Rongo, R.; D’Antò, V.; Bucci, R. Occlusion, Orthodontics, and Temporomandibular Disorders: Cutting Edge of the Current Evidence. J. World Fed. Orthod. 2020, 9, S15–S18. [Google Scholar] [CrossRef] [PubMed]
- Cannatà, D.; Galdi, M.; Caggiano, M.; Acerra, A.; Amato, M.; Martina, S. Prevalence of Signs and Symptoms of Temporomandibular Disorders and Their Association with Emotional Factors and Waking-State Oral Behaviors on University Students: A Cross-Sectional Study. Healthcare 2025, 13, 1414. [Google Scholar] [CrossRef] [PubMed]
- Aldayel, A.M.; AlGahnem, Z.J.; Alrashidi, I.S.; Nunu, D.Y.; Alzahrani, A.M.; Alburaidi, W.S.; Alanazi, F.; Alamari, A.S.; Alotaibi, R.M. Orthodontics and Temporomandibular Disorders: An Overview. Cureus 2023, 15, e47049. [Google Scholar] [CrossRef] [PubMed]
- Tavares, L.F.; Friesen, R.; Köning, P.; Neuhaus, M.; von Piekartz, H.; Armijo-Olivo, S. Are Orthodontic Interventions Associated With Headaches in Children and Adolescents? A Systematic Review and Meta-Analysis. Orthod. Craniofacial Res. 2025, 28, 656–669. [Google Scholar] [CrossRef] [PubMed]
- Headache Classification Committee of the International Headache Society (IHS) The International Classification of Headache Disorders, 3rd Edition (Beta Version). Cephalalgia 2013, 33, 629–808. [CrossRef] [PubMed]
- Komazaki, Y.; Fujiwara, T.; Ogawa, T.; Sato, M.; Suzuki, K.; Yamagata, Z.; Moriyama, K. Association between Malocclusion and Headache among 12- to 15-Year-Old Adolescents: A Population-Based Study. Community Dent. Oral Epidemiol. 2014, 42, 572–580. [Google Scholar] [CrossRef] [PubMed]
- Çınar, B.K.; Bucci, R.; D’Antò, V.; Cascella, S.; Rongo, R.; Valletta, R. Parental Perceptions and Family Impact on Adolescents’ Oral Health-Related Quality of Life in Relation to the Severity of Malocclusion and Caries Status. Children 2025, 12, 425. [Google Scholar] [CrossRef] [PubMed]
- Hswen, Y.; Rubin, R. An AI Chatbot Outperformed Physicians and Physicians Plus AI in a Trial-What Does That Mean? JAMA 2025, 333, 273–276. [Google Scholar] [CrossRef] [PubMed]
- Zhou, X.; Chen, Y.; Abdulghani, E.A.; Zhang, X.; Zheng, W.; Li, Y. Performance in Answering Orthodontic Patients’ Frequently Asked Questions: Conversational Artificial Intelligence versus Orthodontists. J. World Fed. Orthod. 2025, in press. [Google Scholar] [CrossRef]
- Hassan, M.G.; Abdelaziz, A.A.; Abdelrahman, H.H.; Mohamed, M.M.Y.; Ellabban, M.T. Performance of AI-Chatbots to Common Temporomandibular Joint Disorders (TMDs) Patient Queries: Accuracy, Completeness, Reliability and Readability. Orthod. Craniofacial Res. 2025, in press. [Google Scholar] [CrossRef]
- Temsah, A.; Alhasan, K.; Altamimi, I.; Jamal, A.; Al-Eyadhy, A.; Malki, K.H.; Temsah, M.-H. DeepSeek in Healthcare: Revealing Opportunities and Steering Challenges of a New Open-Source Artificial Intelligence Frontier. Cureus 2025, 17, e79221. [Google Scholar] [CrossRef] [PubMed]
- Dermata, A.; Arhakis, A.; Makrygiannakis, M.A.; Giannakopoulos, K.; Kaklamanos, E.G. Evaluating the Evidence-Based Potential of Six Large Language Models in Paediatric Dentistry: A Comparative Study on Generative Artificial Intelligence. Eur. Arch. Paediatr. Dent. 2025, 26, 527–535. [Google Scholar] [CrossRef] [PubMed]
- Özbay, Y.; Erdoğan, D.; Dinçer, G.A. Evaluation of the Performance of Large Language Models in Clinical Decision-Making in Endodontics. BMC Oral Health 2025, 25, 648. [Google Scholar] [CrossRef] [PubMed]
- Makrygiannakis, M.A.; Giannakopoulos, K.; Kaklamanos, E.G. Evidence-Based Potential of Generative Artificial Intelligence Large Language Models in Orthodontics: A Comparative Study of ChatGPT, Google Bard, and Microsoft Bing. Eur. J. Orthod. 2024, 46, cjae017. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).