Semi-Supervised Machine Learning Method for Predicting Observed Individual Risk Preference Using Gallup Data


Abstract
1. Introduction
- Using semi-supervised learning, we expanded the prediction of ORP (collected in 2012) to the Gallup dataset, covering the years 2006–2018.
- –
- We further propose an evaluation step, in addition to traditional evaluation techniques, to ensure the validity of the expansion.
- By integrating a non-linear regression model with the commonly used Ordinary Least Squares (OLS) model, our research opens avenues for uncovering non-linear patterns in predicting general willingness to take risks.
- Our study identifies four factors—health status, optimistic index, social network, and corruption—that were previously overlooked but emerge as potentially significant contributors to determining individual risk tolerance.
2. Literature Review
3. Methodology
3.1. Overview of the Proposed Methodology
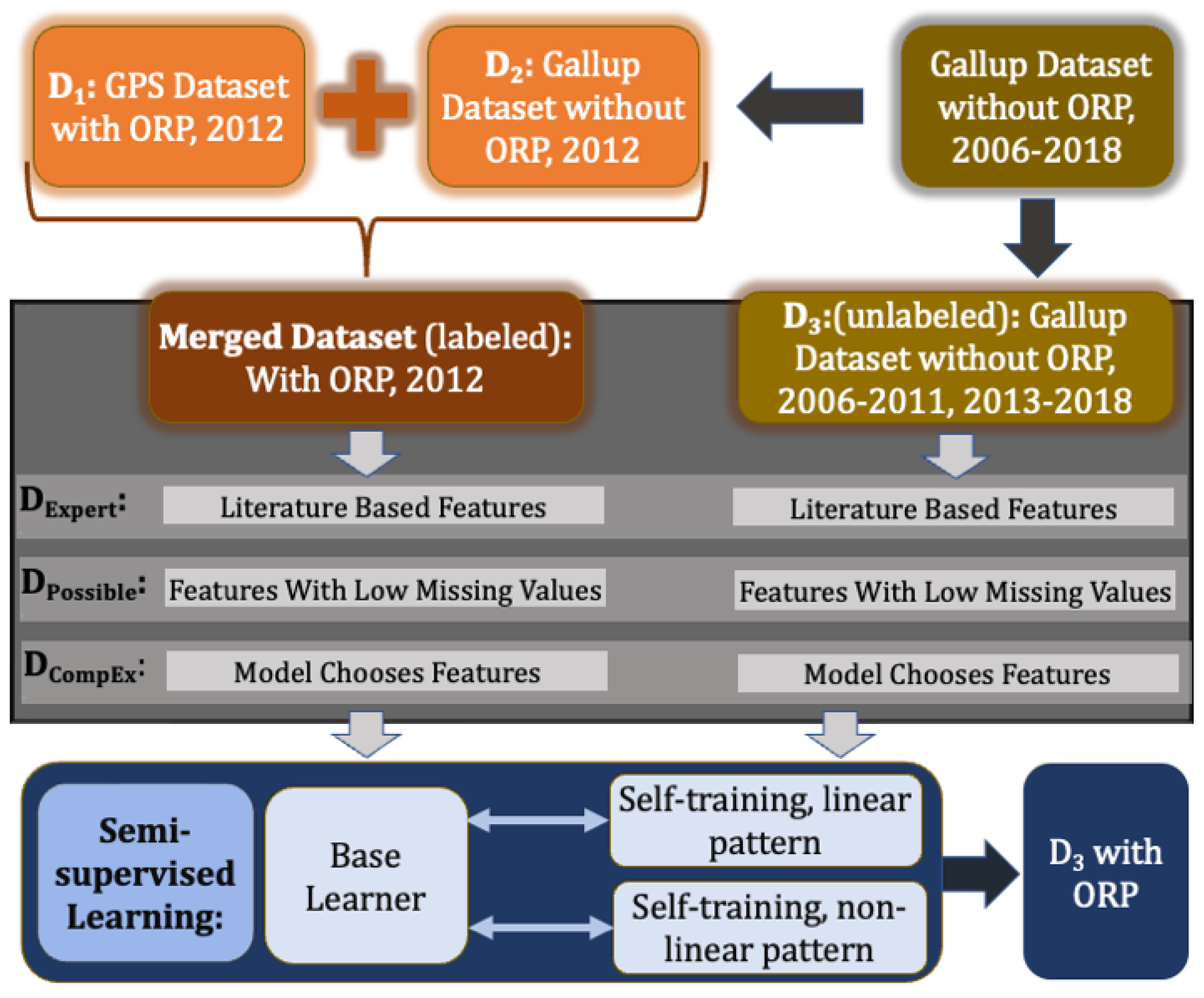
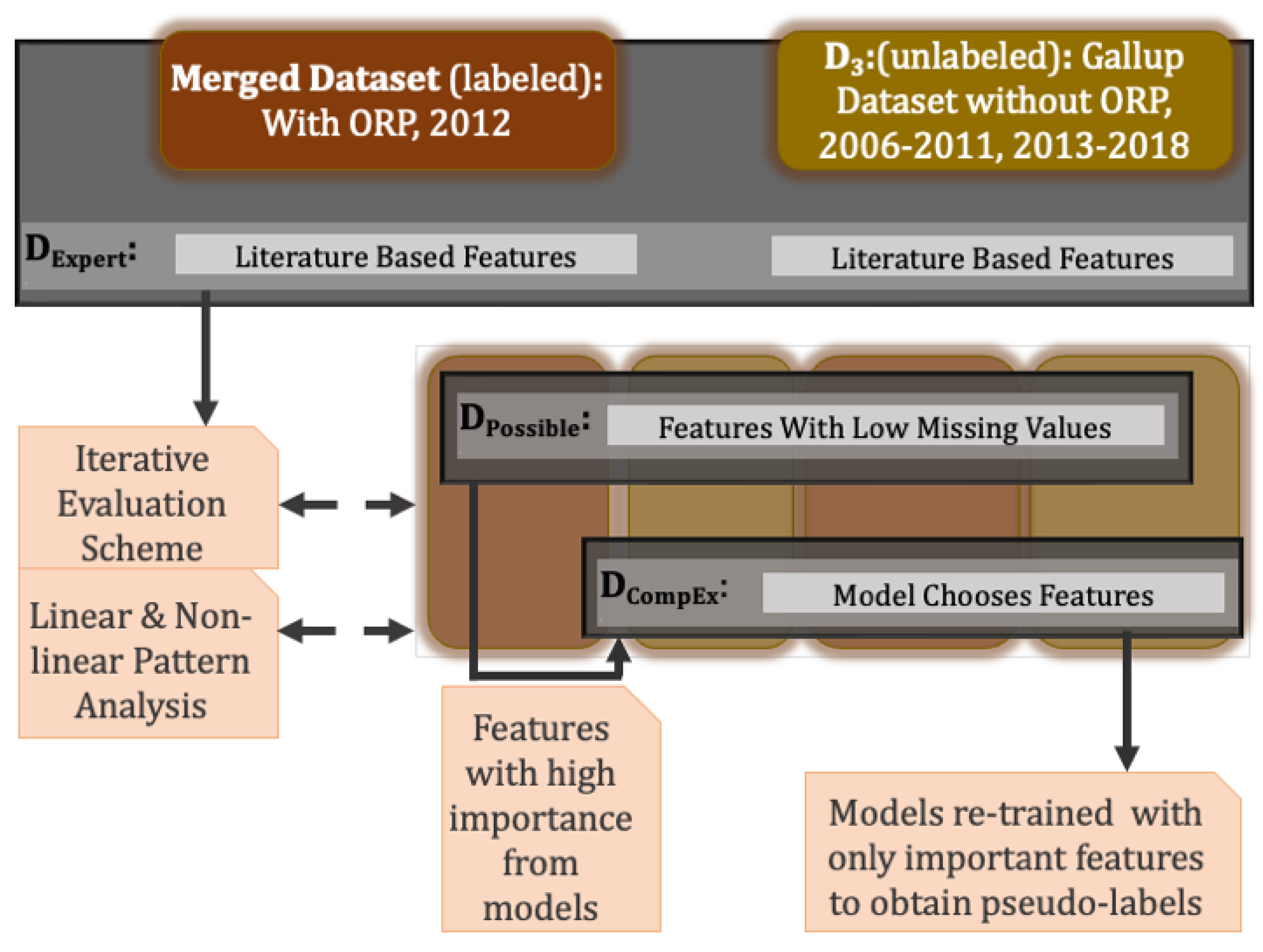
3.2. Dataset Description: GPS, Gallup, Merged
3.3. Data Preprocessing
3.4. Semi-Supervised Learning Using Self-Training Method
- The smoothness assumption: if two instances x and are close together in the input space, their labels y and should display similar proximity
- The low-density assumption: the discriminator/classifier should not pass through high-density regions in the input space
- The manifold assumption: data points on the same low-dimensional manifold should have the same label or similar values.
3.4.1. Base Learners
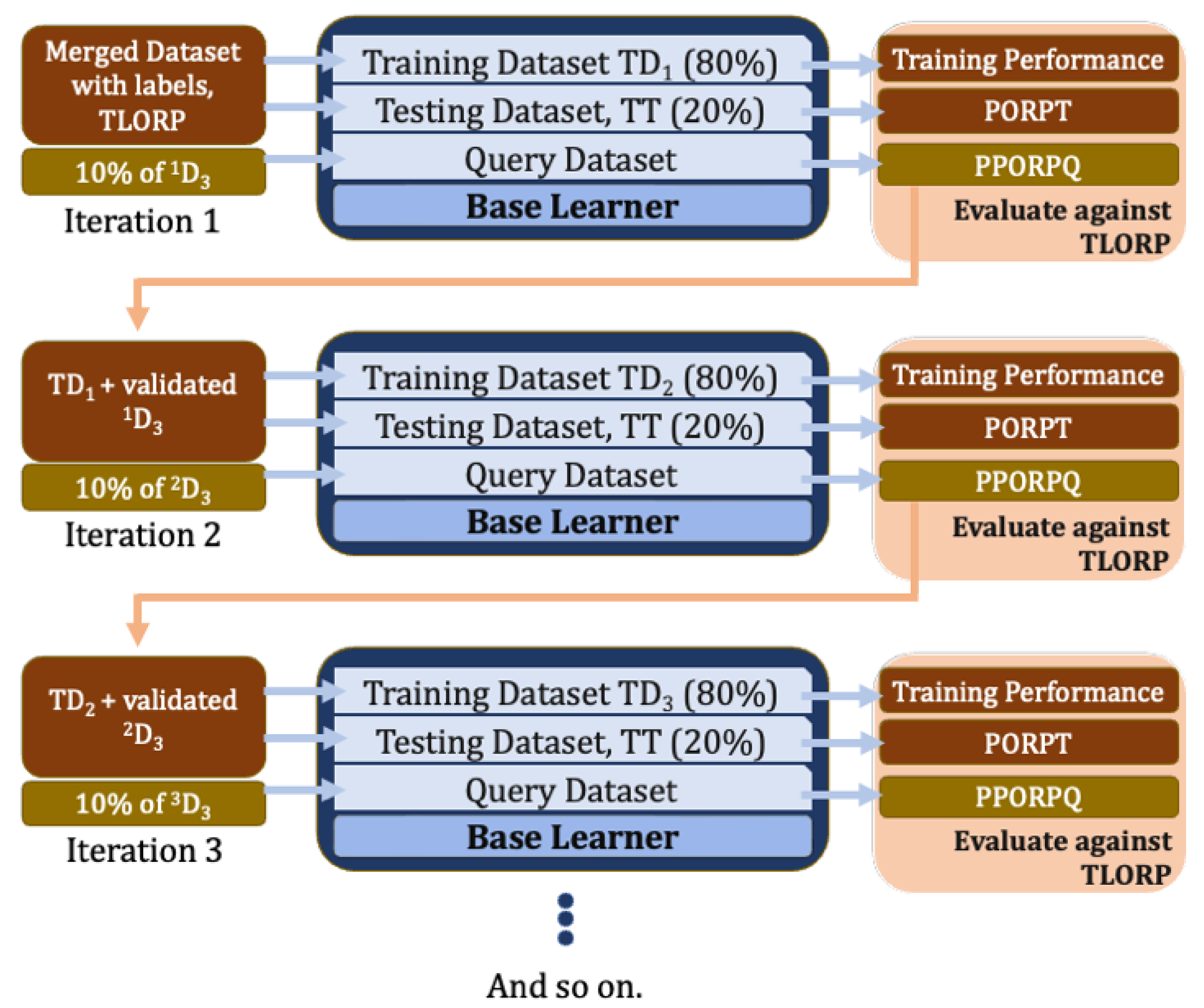
3.4.2. Self-Training—Iterative Training of a Base Learner
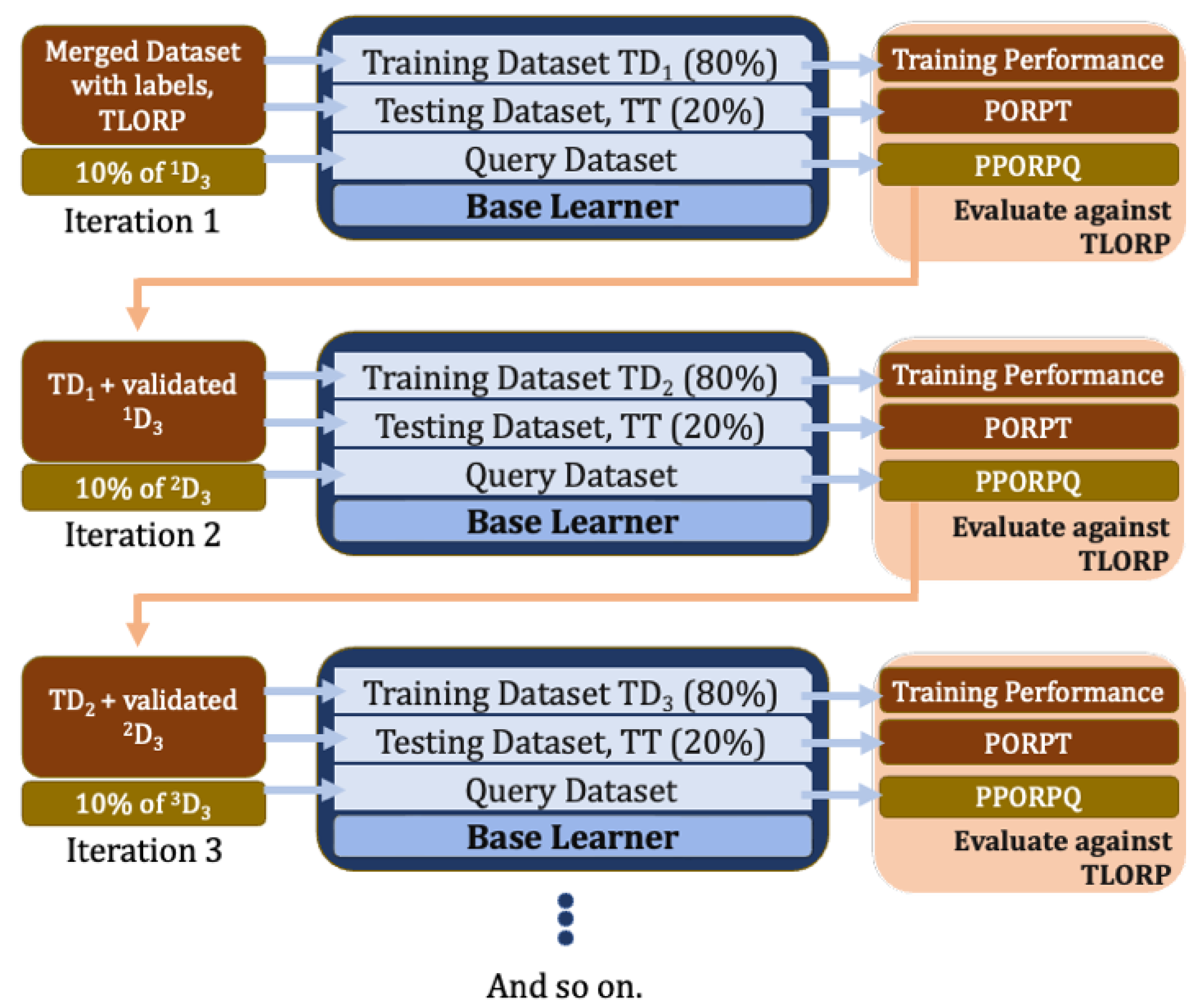
- Step 1: The base learner is trained using the merged training dataset (Figure 4) from D1 and D2, e.g., the one where Gallup data are directly associated with the ORP values from GPS 2012 dataset. Since the 2012 dataset contains authentic ORP values, these values are referred to as True Label ORP (TLORP).
- –
- Using traditional ML evaluation techniques for regression models, we evaluate the base learner on the test dataset (Section 3.5.1) to obtain predicted ORP (PORPT). This involves comparing the TLORP with the PORPT values. These predicted results are recorded for later use in the process.
- Step 2: Next, one of the ten batches from D3 is used as a query to obtain their respective prediction, e.g., the pseudo-ORP values (e.g., PPORPQ) from the base learner.
- –
- Traditional ML evaluation metrics (such as RMSE, etc.) cannot be used to evaluate these predictions, since the query set does not have TLORP against which to calculate the RMSE value. Instead, we use the Proposed Iterative Evaluation Scheme (detailed in Section 3.5.2), a series of tests allowing us to weed out outliers within the query set.
- Step 3: Before going on to the next iteration, the new training set is prepared. The new training set consists of: (i) the training set used in Step 1 of this iteration and (ii) observations in the query set from Step 2 that passed the Proposed Iterative Evaluation Scheme. The testing set remains untouched and is kept constant during each iteration.
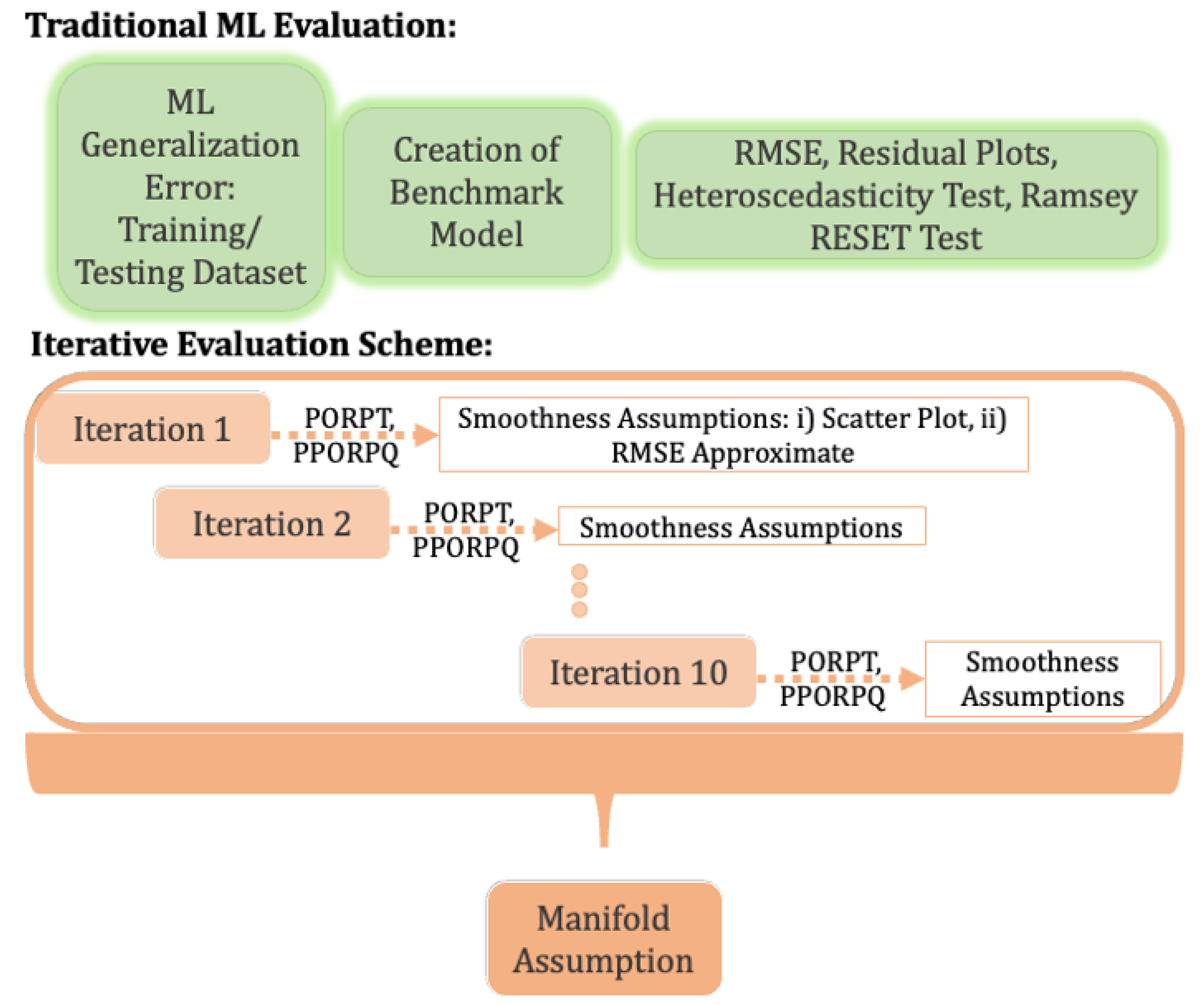
3.5. Evaluation Scheme
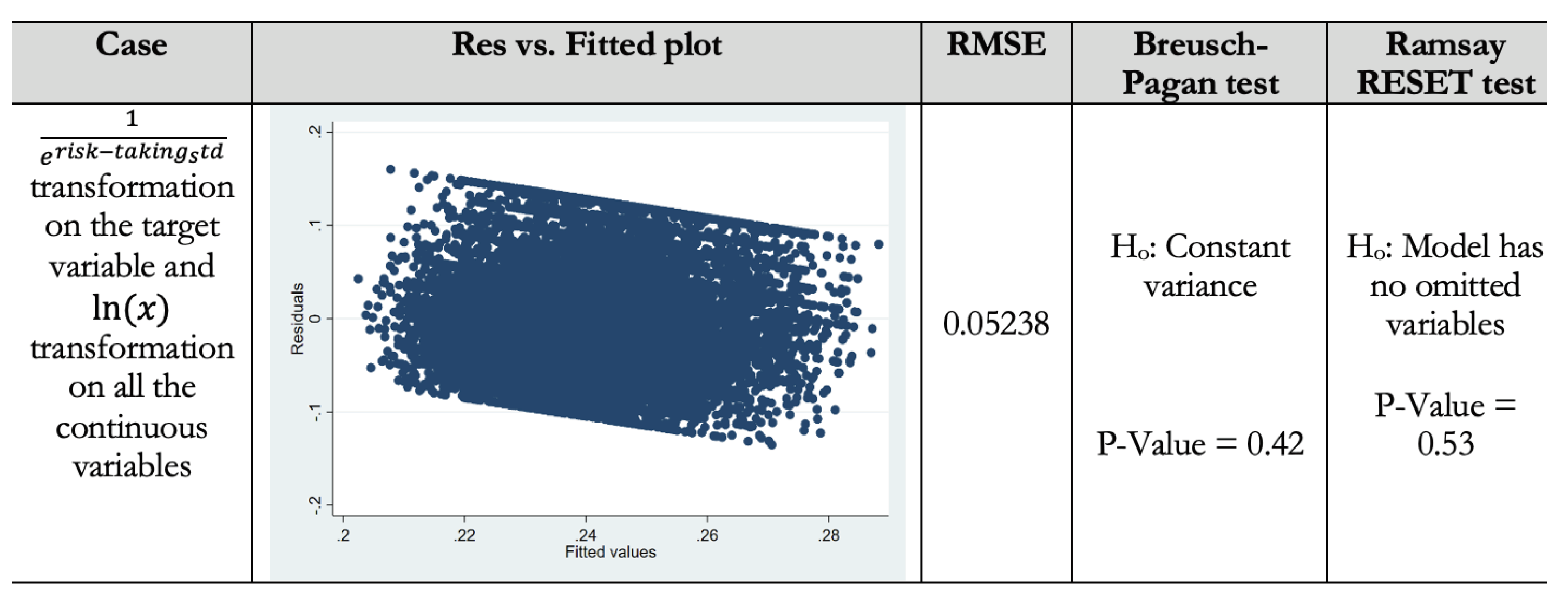
3.5.1. Traditional ML Evaluation
3.5.2. Proposed Iterative Evaluation Scheme
- If the observation passes at least one of the smoothness assumption tests, then it is not excluded; otherwise, they are excluded.
- Next, after the completion of all iterations, if the model passes the manifold assumption, no action is taken; otherwise, we step back and re-run the smoothness assumptions with stricter conditions that if observations do not pass both smoothness assumption tests, they are excluded.
- If the manifold assumption still fails, we conclude that the semi-supervised model should not be trusted, and a different model should be considered.
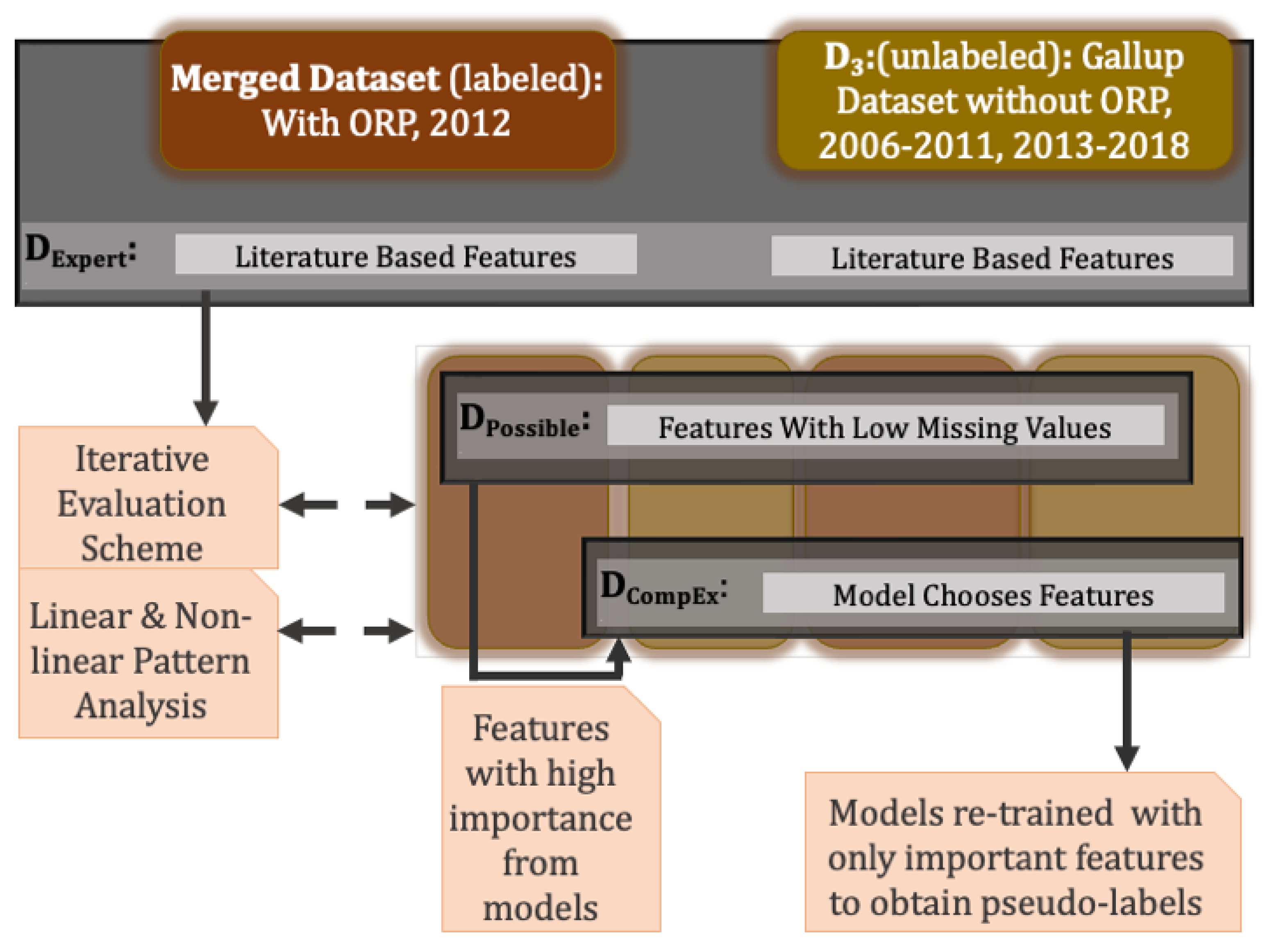
3.6. Feature Exploration and Selection
4. Results
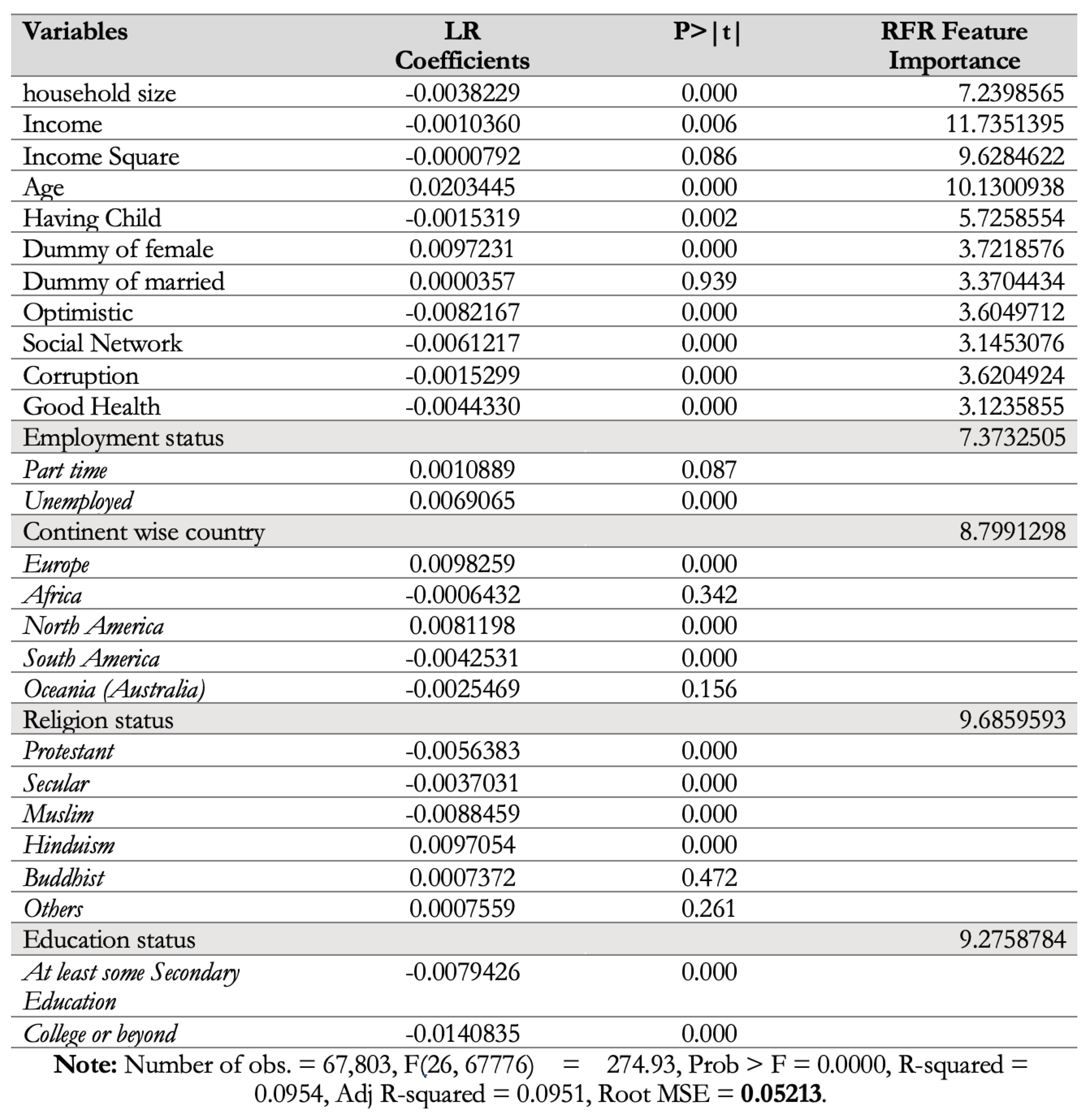
4.1. Benchmark Evaluation: LR, Supervised Paradigm
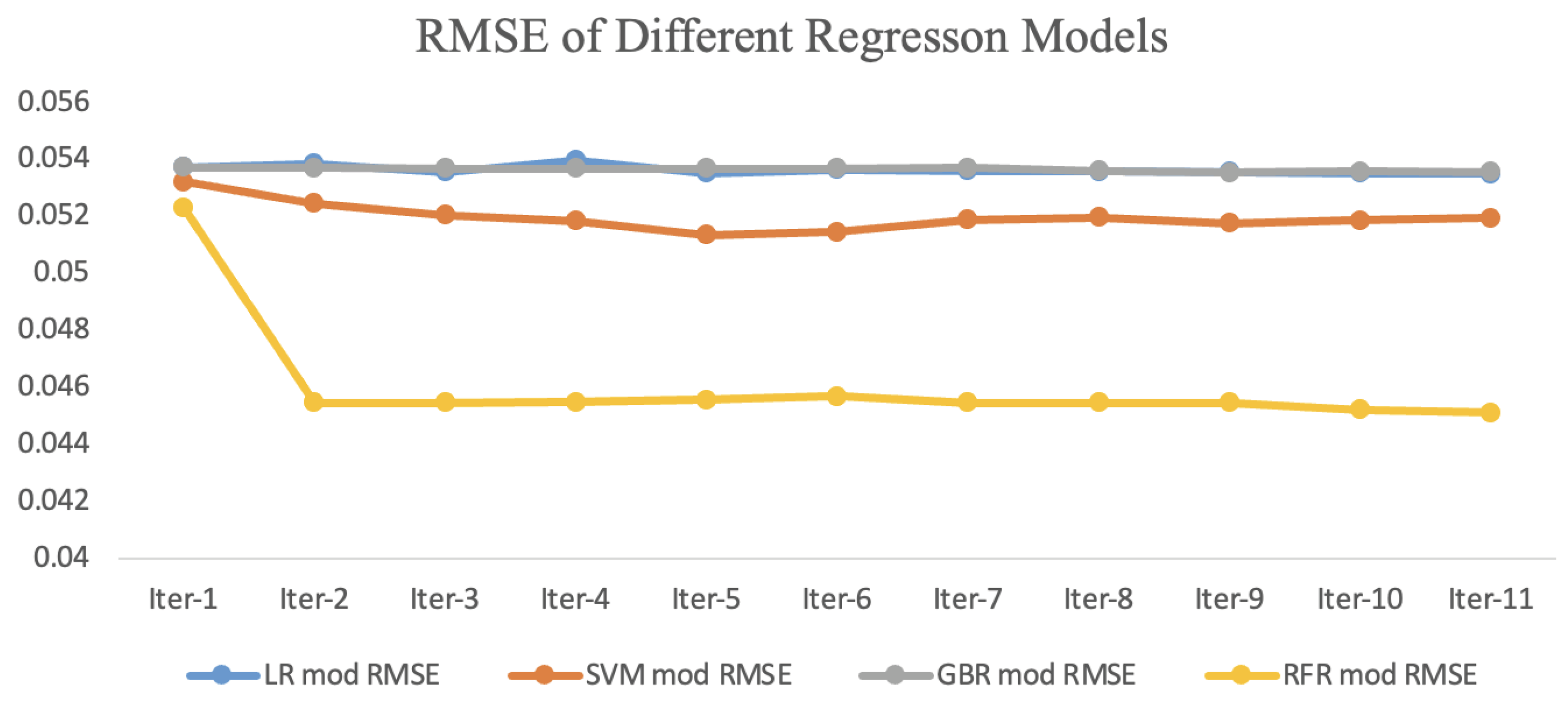
4.2. Self-Training Evaluation: Proposed Iterative Scheme for Semi-Supervised Learning
5. Discussion
5.1. Inference from the Supervised, Linear Model
5.2. Inference from the Semi-Supervised, Non-Linear Model
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| D1 | GPS data with ORP for the year 2012 |
| D2 | Gallup data for the year 2012 |
| D3 | Gallup data without ORP for the year 2005–2011, 2013–2018 |
| TLORP | True Label ORP |
| PORPT | Predicted ORP on labeled test set |
| PPORPQ | Predicted Pseudo ORP from query data (PPORPQ) |
Appendix A
- —this feature set is based on the subject expert’s knowledge and experience in general risk-taking
- —this feature set includes all the features that could be included from the merged dataset (Figure 2).
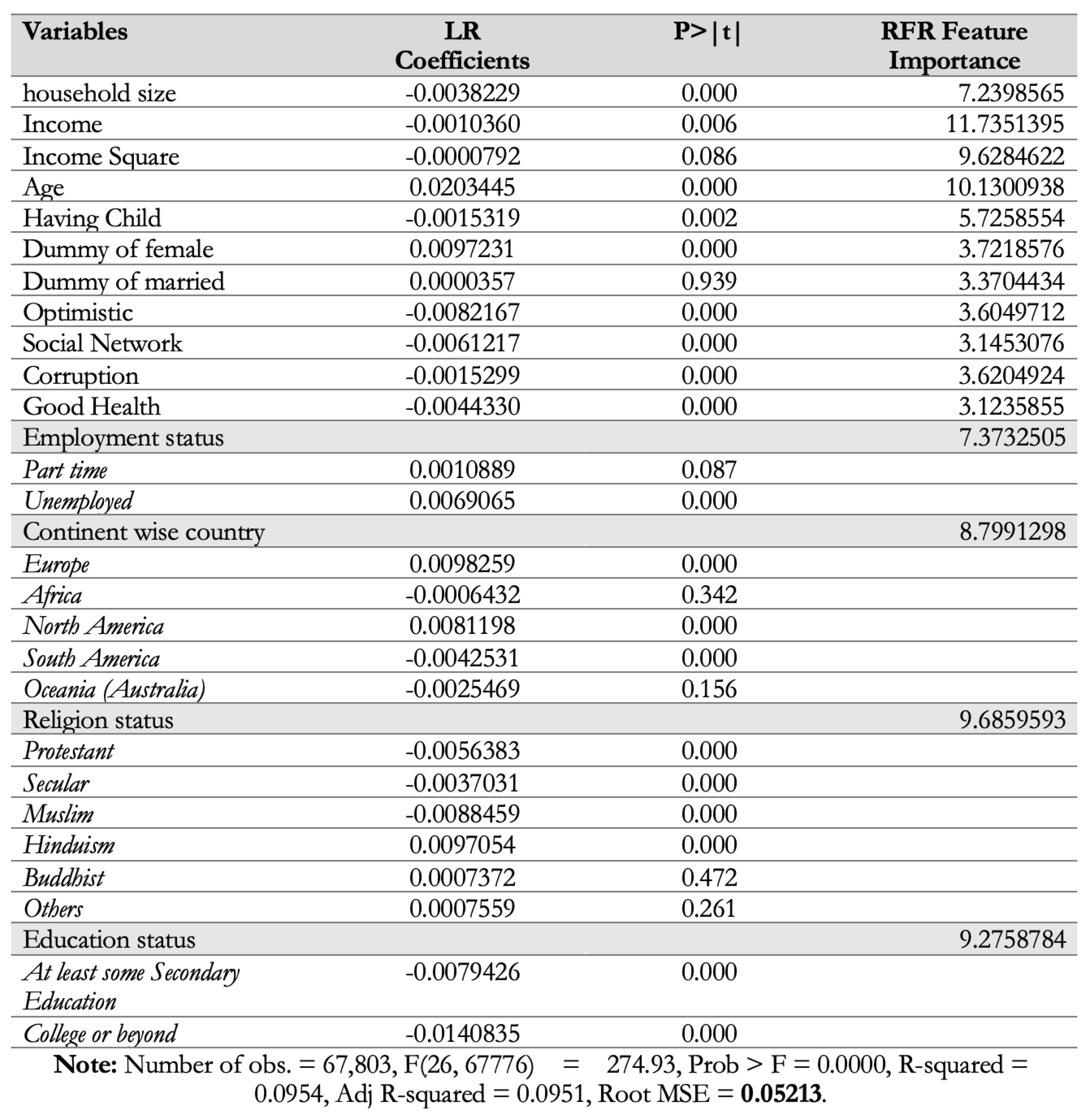
- —this feature set is a proper subset of DPossible, which consists of features that were either found to be significantly important by the LR or given high importance by the RFR. The resulting feature sets are provided in Figure 5, while Figure 11 provides more details about the feature importance obtained for the dataset by the RFR (Column 4), along with the coefficients and p-values from the LR model trained on (Columns 2 and 3).
References
- Dohmen, T.; Quercia, S.; Willrodt, J. Willingness to Take Risk: The Role of Risk Conception and Optimism. In IZA Discussion Paper; IZA: Bonn, Germany, 2018; p. 11642. [Google Scholar]
- Dohmen, T.; Wagner, G.G. ROA Individual Risk Attitudes: Measurement, Determinants and Behavioral Consequences Individual Risk Attitudes: Measurement, Determinants and Behavioral Consequences. J. Eur. Econ. Assoc. 2009, 9, 522–550. [Google Scholar] [CrossRef]
- Frey, R.; Pedroni, A.; Mata, R.; Rieskamp, J.; Hertwig, R. Risk preference shares the psychometric structure of major psychological traits. Sci. Adv. 2017, 3, e1701381. [Google Scholar] [CrossRef]
- Pedroni, A.; Frey, R.; Bruhin, A.; Dutilh, G.; Hertwig, R.; Rieskamp, J. The risk elicitation puzzle. Nat. Hum. Behav. 2017, 1, 803–809. [Google Scholar] [CrossRef]
- Falk, A.; Becker, A.; Dohmen, T.J.; Enke, B.; Huffman, D.; Sunde, U. The Nature and Predictive Power of Preferences: Global Evidence; Centre for Economic Policy Research: London, UK, 2015. [Google Scholar]
- Browne, M.J.; Jäger, V.; Richter, A.; Steinorth, P. Family changes and the willingness to take risks; African Americans. Bioinformatics 2018, 27, 1384–1389. [Google Scholar]
- Dohmen, T.; Falk, A.; Huffman, D.; Sunde, U. The intergenerational transmission of risk and trust attitudes. In IZA Discussion Papers; IZA: Bonn, Germany, 2006; Available online: https://docs.iza.org/dp2380.pdf (accessed on 7 March 2024).
- Dohmen, T.; Falk, A.; Huffman, D.; Sunde, U. The intergenerational transmission of risk and trust attitudes. Rev. Econ. Stud. 2012, 79, 645–677. [Google Scholar] [CrossRef]
- Azar, S.A. Measuring relative risk aversion. Appl. Financ. Econ. Lett. 2006, 2, 341–345. [Google Scholar] [CrossRef]
- Outreville, J.F. Risk Aversion, Risk Behavior, and Demand for Insurance: A Survey. J. Insur. Issues 2014, 37, 158–186. [Google Scholar] [CrossRef]
- Hareli, S.; Elkabetz, S.; Hanoch, Y.; Hess, U. Social perception of risk-taking willingness as a function of expressions of emotions. Front. Psychol. 2021, 12, 655314. [Google Scholar] [CrossRef]
- Falk, A.; Becker, A.; Dohmen, T.; Enke, B.; Huffman, D.; Sunde, U. Global Evidence on Economic Preferences. Q. J. Econ. 2018, 133, 1645–1692. [Google Scholar] [CrossRef]
- Grable, J.E. Financial risk tolerance and additional factors that affect risk taking in everyday money matters. J. Bus. Psychol. 2000, 14, 625–630. [Google Scholar] [CrossRef]
- Yao, R.; Gutter, M.S.; Hanna, S.D. The financial risk tolerance of Blacks, Hispanics and Whites. J. Financ. Couns. Plan. 2005, 16, 51–62. [Google Scholar]
- Schneider, C.R.; Fehrenbacher, D.D.; Weber, E.U. Catch me if I fall: Cross-national differences in willingness to take financial risks as a function of social and state ‘cushioning’. Int. Bus. Rev. 2017, 26, 1023–1033. [Google Scholar] [CrossRef]
- Zhu, X. Semi-Supervised Learning Literature Survey; Technical Report, Computer Sciences; University of Wisconsin-Madison: Madison, WI, USA, 2005. [Google Scholar]
- Van Engelen, J.E.; Hoos, H.H. A survey on semi-supervised learning. Mach. Learn. 2020, 109, 373–440. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote. Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Segal, M.R. Machine Learning Benchmarks and Random Forest Regression; UCSF: San Francisco, CA, USA, 2004. [Google Scholar]
- Kolarik, N.; Shrestha, N.; Caughlin, T.; Brandt, J. Leveraging high resolution classifications and random forests for hindcasting decades of mesic ecosystem dynamics in the Landsat time series. Ecol. Indic. 2024, 158, 111445. [Google Scholar] [CrossRef]
- Myles, A.J.; Feudale, R.N.; Liu, Y.; Woody, N.A.; Brown, S.D. An introduction to decision tree modeling. J. Chemom. J. Chemom. Soc. 2004, 18, 275–285. [Google Scholar] [CrossRef]
- Ardabili, S.; Mosavi, A.; Várkonyi-Kóczy, A.R. Advances in machine learning modeling reviewing hybrid and ensemble methods. In Engineering for Sustainable Future: Selected Papers of the 18th International Conference on Global Research and Education Inter-Academia–2019; Springer: Berlin/Heidelberg, Germany, 2020; Volume 18, pp. 215–227. [Google Scholar]
- Awad, M.; Khanna, R.; Awad, M.; Khanna, R. Support vector regression. In Efficient Learning Machines: Theories, Concepts, and Applications for Engineers and System Designers; Springer: Berlin/Heidelberg, Germany, 2015; pp. 67–80. [Google Scholar]
- Hepp, T.; Schmid, M.; Gefeller, O.; Waldmann, E.; Mayr, A. Approaches to regularized regression—A comparison between gradient boosting and the lasso. Methods Inf. Med. 2016, 55, 422–430. [Google Scholar] [CrossRef]
- Veider, F.M.; Lefebvre, M.; Bouchouicha, R.; Chmura, T.; Hakimov, R.; Krawczyk, M.; Martinsson, P. Common Components of Risk and Uncertainty Attitudes across Contexts and Domains: Evidence from 30 Countries. J. Eur. Econ. Stat. 2015, 13, 421–452. [Google Scholar] [CrossRef]
- Vollenweider, X.; Di Falco, S.; O’Donoghue, C. Risk Preferences and Voluntary Agri-Environmental Schemes: Does Risk Aversion Explain the Uptake of the Rural Environment Protection Scheme? Grantham Research Institute: London, UK, 2011. [Google Scholar]
- Kumar, A.; Page, J.K.; Spalt, O.G. Religious Beliefs, Gambling Attitudes and Financial Market Outcomes. J. Financ. Econ. 2011, 102, 671–708. [Google Scholar] [CrossRef]
- Renneboog, L.; Spaenjers, C. Religion, Economic Attitudes, and Household Finance. Oxf. Econ. Pap. 2012, 64, 103–127. [Google Scholar] [CrossRef]
- Dohmen, T.; Falk, A.; Huffman, D.; Sunde, U.; Schupp, J.; Wagner, G.G. Individual Risk Attitudes: Measurement, Determinants, and Behavioral Consequences. J. Eur. Assoc. 2011, 9, 522–550. [Google Scholar] [CrossRef]
- Croson, R.; Gneezy, U. Gender Differences in Preferences. J. Econ. Lit. 2009, 47, 448–474. [Google Scholar] [CrossRef]
- Weber, C. A modification of Sakaguchi’s reaction for the quantitative determination of arginine. J. Biol. Chem. 1930, 86, 217–222. [Google Scholar] [CrossRef]
- Bartke, S.; Schwarze, R. Risk Averse by Nation or by Religion? Some Insights on the Determinants of Individual Risk Attitudes. SOEPpaper 2008. [Google Scholar] [CrossRef]
- Deole, S.S.; Rieger, M.O. The immigrant-native gap in risk and time preferences in Germany: Levels, socio-economic determinants, and recent changes. J. Popul. Econ. 2023, 36, 743–778. [Google Scholar] [CrossRef]
- Schurer, S. Lifecycle patterns in the socioeconomic gradient of risk preferences. J. Econ. Behav. Organ. 2015, 119, 482–495. [Google Scholar] [CrossRef]
- Bascans, J.M.; Courbage, C.; Oros, C. Means-tested public support and the interaction between long-term care insurance and informal care. Int. J. Health Econ. Manag. 2017, 17, 113–133. [Google Scholar] [CrossRef] [PubMed]
- McKune, S.L.; Stark, H.; Sapp, A.C.; Yang, Y.; Slanzi, C.M.; Moore, E.V.; Omer, A.; Wereme N’Diaye, A. Behavior change, egg consumption, and child nutrition: A cluster randomized controlled trial. Pediatrics 2020, 146, e2020007930. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Transformation |
|---|---|
| Willingness to take a risk (risk-taking) | |
| Age | |
| Gender | Binary |
| Marital status | Binary |
| Income per capita | |
| Income per capita square | |
| Education level | Binary |
| Household size | |
| Having Child | Binary |
| Religion | Binary |
| Employment status | Binary |
| Residence status | Binary |
| Migration status | Binary |
| Continent of respondent | Binary |
| Remittance | Binary |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahmed, F.; Shamsuddin, M.; Sultana, T.; Shamsuddin, R. Semi-Supervised Machine Learning Method for Predicting Observed Individual Risk Preference Using Gallup Data. Math. Comput. Appl. 2024, 29, 21. https://doi.org/10.3390/mca29020021
Ahmed F, Shamsuddin M, Sultana T, Shamsuddin R. Semi-Supervised Machine Learning Method for Predicting Observed Individual Risk Preference Using Gallup Data. Mathematical and Computational Applications. 2024; 29(2):21. https://doi.org/10.3390/mca29020021
Chicago/Turabian StyleAhmed, Faroque, Mrittika Shamsuddin, Tanzila Sultana, and Rittika Shamsuddin. 2024. "Semi-Supervised Machine Learning Method for Predicting Observed Individual Risk Preference Using Gallup Data" Mathematical and Computational Applications 29, no. 2: 21. https://doi.org/10.3390/mca29020021
APA StyleAhmed, F., Shamsuddin, M., Sultana, T., & Shamsuddin, R. (2024). Semi-Supervised Machine Learning Method for Predicting Observed Individual Risk Preference Using Gallup Data. Mathematical and Computational Applications, 29(2), 21. https://doi.org/10.3390/mca29020021