1. Introduction
In industrial processes [
1], the nonsharp distillation sequences are widely used for obtaining nonsharp separated products. Compared to sharp separation sequences, nonsharp sequences are relatively understudied. Sequences with nonsharp separation have the features of the general distillation sequences, but with more options in terms of the choice of sequence and columns, which make their optimization complicated and computationally intensive. The distillation sequence is usually optimized by adjusting the discrete variables of the separation sequence and the continuous design/operation parameters of each column in the sequence. Column-associated equations contribute to the nonlinear part. All these make the problem a nonconvex MINLP problem with a discontinuous feasible region, making it difficult to find the global optimum.
Optimization algorithms based on numerical searching have been focused on solving the optimization problem of the distillation sequence. Floquet et al. [
2] applied a simulated annealing algorithm on sequence synthesis, and their attention was focused on the definition and evolution of a local solution. Henrich et al. [
3] combined an evolutionary algorithm with the rigorous modelling capabilities of Aspen Plus to optimize the distillation sequence. Similarly, Leboreiro et al. [
4] combined the genetic algorithm with a sequential process simulator. Both Henrich’s and Leboreiro’s research combined numerical searching with a modelling tool. The convergence rate of numerical searching is fast, but global optimum solution could not be guaranteed.
Rather than random searching in the solution space, enumeration-like algorithms have been used to optimize distillation sequences. Xu et al. [
5] improved 0–1 matrices into code matrices, but the information conveyed by code matrices is insufficient to describe the details of columns. Ni et al. [
6] used a process simulation automation server to realize the optimization of heat-integrated sequences at both the sequence level and the column level. Proios et al. [
7] proposed an improved generalized modular framework that can overcome the structural complexities of thermally-coupled columns, including dividing wall columns, through systematic and highly detailed structural models. However, the involved models significantly limit the scope of problems the framework can handle. None of the above-mentioned studies have considered nonsharp distillation sequences.
Heat exchanging within sequences has also been introduced to the research of distillation sequence optimization. Jain et al. [
8] studied the synthesis of a heat-integrated thermally coupled distillation sequence with energy-capital economic trade-offs, thus enhancing the economy of the sequence. Caballero et al. [
9] also synthesized the sequence in common with Jain’s via the Underwood–Fenske–Gilliland equations for column design and used a generalized disjunctive program (GDP) for model formulation, thus making the model more flexible. Zhang et al. [
10] optimized the heat integrated nonsharp thermally coupled distillation sequence through an improved simulated annealing algorithm, thus increasing the searching efficiency. The energy is saved by heat integration in the heat exchanger network of the distillation sequence, but heat integration can only be used when there is a large pressure difference between the columns in the sequence [
10]. Furthermore, thermal coupling or heat integration increase the complexity and instability of the system. Specific examples of heat integration and thermal coupling for energy saving were considered in the research of Jain, Caballero and Zhang, but their work is highly dependent on the corresponding configuration considered.
Optimization including a non-sharp distillation sequence has gradually received the attention of researchers. Among the relevant studies, Nath et al. [
11] proposed a material allocation diagram, but this was not suitable for the optimization problem when the considered component number is more than three. Bamopoulos et al. [
12,
13] improved the material allocation diagram and combined the empirical rules with a depth-first search strategy, but the physical meaning of each element in the component recovery matrix is lost as the corresponding vector of each product is normalized every time the matrix is transformed. Muraki et al. [
14] proposed a two-stage evolutionary method based on the achievements of Nath, but the computational load increases rapidly when this method is used to handle large-scale problems. The research of Nath, Bamopoulos and Muraki were based on material distribution diagrams, which are specified for each sequence.
Sargent and Gaminibandara [
15] proposed a representation method for superstructures including nonsharp separation to make the whole MINLP problem for distillation sequence optimization modelled in a rigorous mathematical expression, and more details of a specific sequence can be optimized by this method. Compared to the achievements of Sargent and Gaminibandara, Floudas et al. [
16] refined the representation method of the superstructure and proposed the MINLP model for superstructure optimization. Based on the mature representation of the superstructure, Yeomans and Grossmann [
17,
18] proposed two methods, the state task network (STN) and the state equipment network (SEN), to establish the superstructure; GDP was used to model the superstructure optimization problem, but structures which cannot be exclusively represented by Boolean variables are difficult to support in this method, e.g., side rectifiers and side strippers. Gaballero and Grossmann [
19] used GDP to model the STN superstructure, verifying the feasibility of the method proposed by Yeomans and Grossmann. The methods based on the MINLP model needs complex solving algorithms, and the existing solving algorithms possibly fall into local optimum.
As distillation sequence optimization based on the superstructure representation method requires a rigorous mathematical foundation, optimization methods with simplified mathematical operations have been applied in distillation sequence optimization research. Rong et al. have proposed a series of heuristic and mathematically simplified methods for synthesis of sequences including dividing wall columns [
20] and process intensification of sequences with respect to thermal couplings and heat integration [
21,
22,
23,
24,
25,
26], promoting optimization efficiency, improving the theoretical foundation of the optimization method and proposing new energy saving configurations of the sequence. Shah and Kokossis [
27] proposed a method combining knowledge rules with mathematical programming to construct the search space. However, due to the limitation of empirical rules, some feasible distillation sequences have not been considered by this method, and the real optimal distillation sequence may not be obtained. Agrawal et al. [
28,
29] proposed a systematic mathematical method optimizing nonsharp distillation sequences with thermal coupling; however, with the increase of component number, the number of feasible distillation sequences is becoming larger and larger, resulting in unfeasible calculations.. In addition to the above conventional methods, Ulaganathan et al. [
30] used a sequential minimization algorithm to optimize 3–5 components nonsharp distillation sequence, including complex columns, but when the component number is more than three, global optimization is hard to guarantee.
It can be observed that the representation of superstructures, the modelling of problems, the thermal coupled distillation sequences and the optimization algorithm have been investigated in previous research, which made the optimization of distillation sequence a very popular topic in process system engineering area. As Gibran said, we already walked too far, down to we had forgotten why embark. No matter how complicate the problem can be, the optimization of distillation sequence itself is still obtained via a good choice of column sequence with all columns optimized. Hendry et al. [
31] proposed dynamic programming to optimize the distillation sequence. Based on the distillation sequence optimization method of Hendry, dividing wall columns were considered into the sharp distillation sequence by Zhang et al. [
32]. By method used by Hendy, Zhang and Ni, the optimization problem is divided into two sub-problems at the sequence level and the column level, effectively separating the superstructure and column optimization. The solution is found by searching possible subsequences and ruling out the non-optimal ones sequentially to avoid random searching within non-continuous feasible domain. The optimization of individual columns is easy to obtained with the wide availability of commercial software such as Aspen Plus, while the ruling out is relatively hard for nonsharp distillation sequences as there are no unique subsequence in this situation any more, but the idea of ruling out significantly saves computational load if a proper strategy for ruling out can be proposed. Both the divide-and-conquer strategy and reliable column model are implied in the dynamic programing method, inspiring a way for this work.
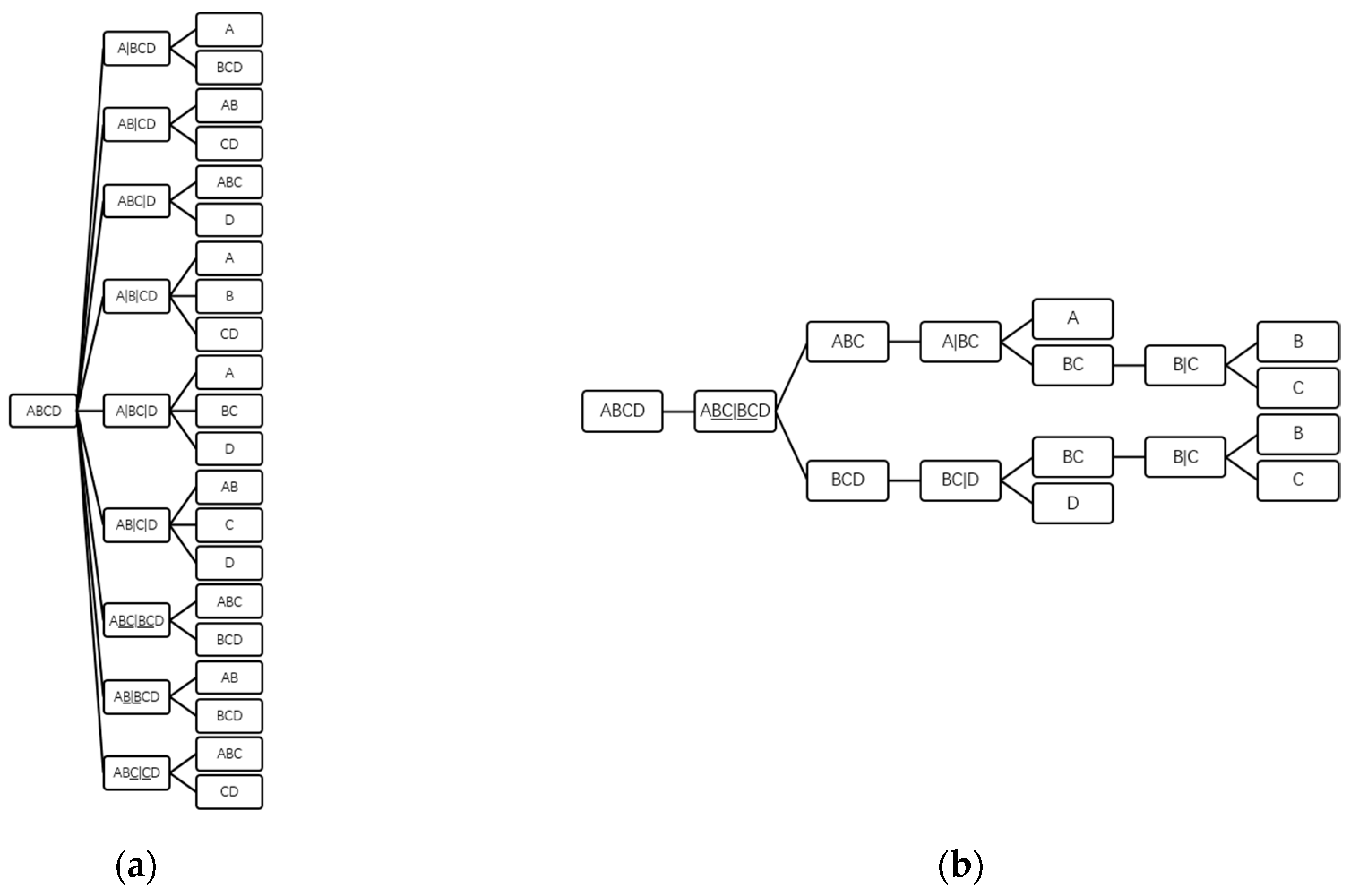
In this work, the differences of subsequences in both sharp and nonsharp distillation sequences are illustrated in
Section 2. A framework for separating the superstructure of nonsharp distillation problems is proposed in
Section 3, in which modified ruling out is applied to speed up the sequence-level searching. Two cases are studied in
Section 4 and conclusions are drawn at the end.
3. Methodology
Inspired by the dynamic programing method for sharp distillation sequences, a bi-level distillation sequence optimization algorithm is proposed in this work to decompose the MINLP into an IP problem in the upper level and NLP problems in the lower level, by which the optimization of the separation sequence is implemented at the upper level and the single column within the sequence is simulated and optimized at the lower level.
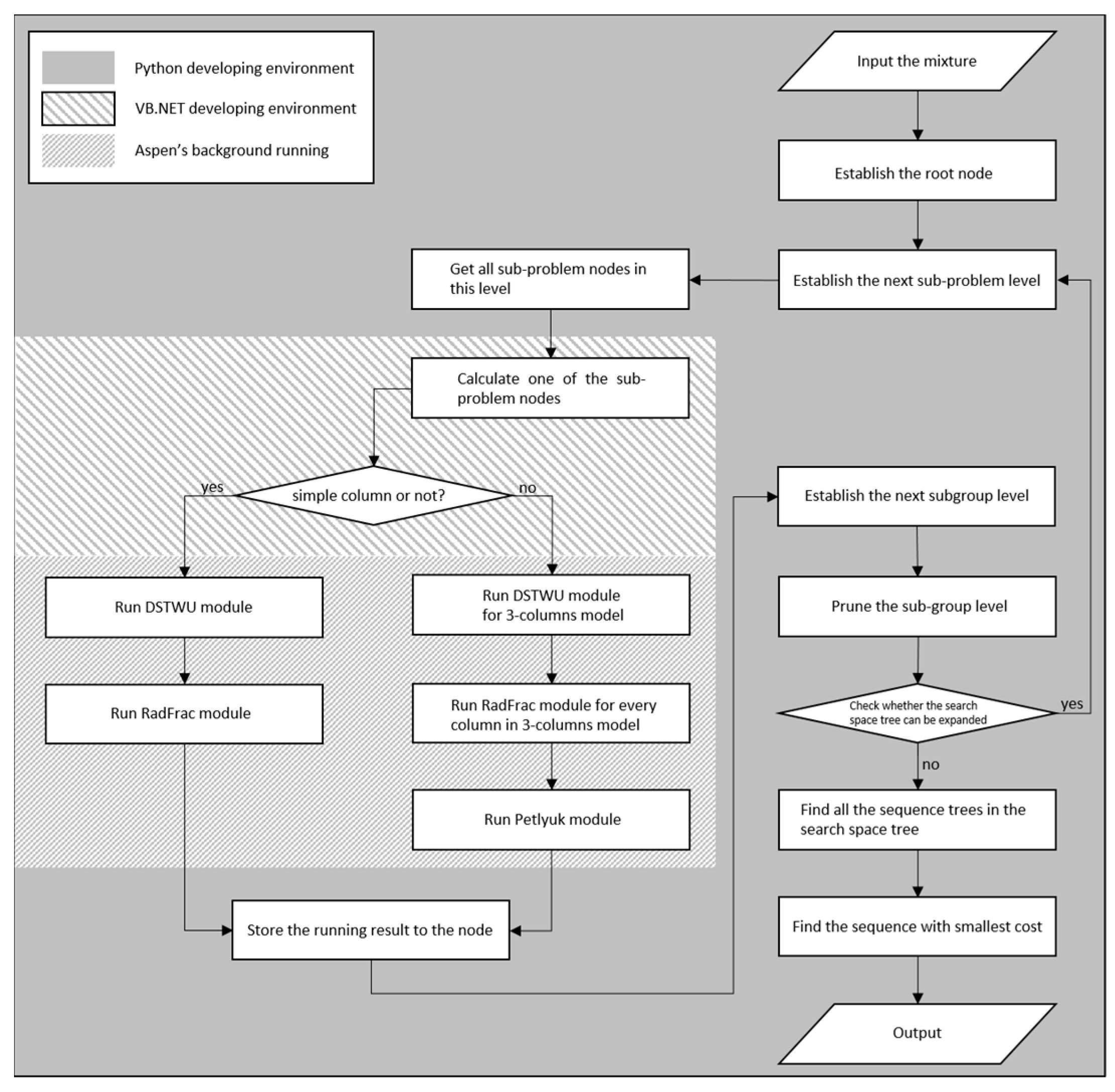
3.1. The Framework with Aspen
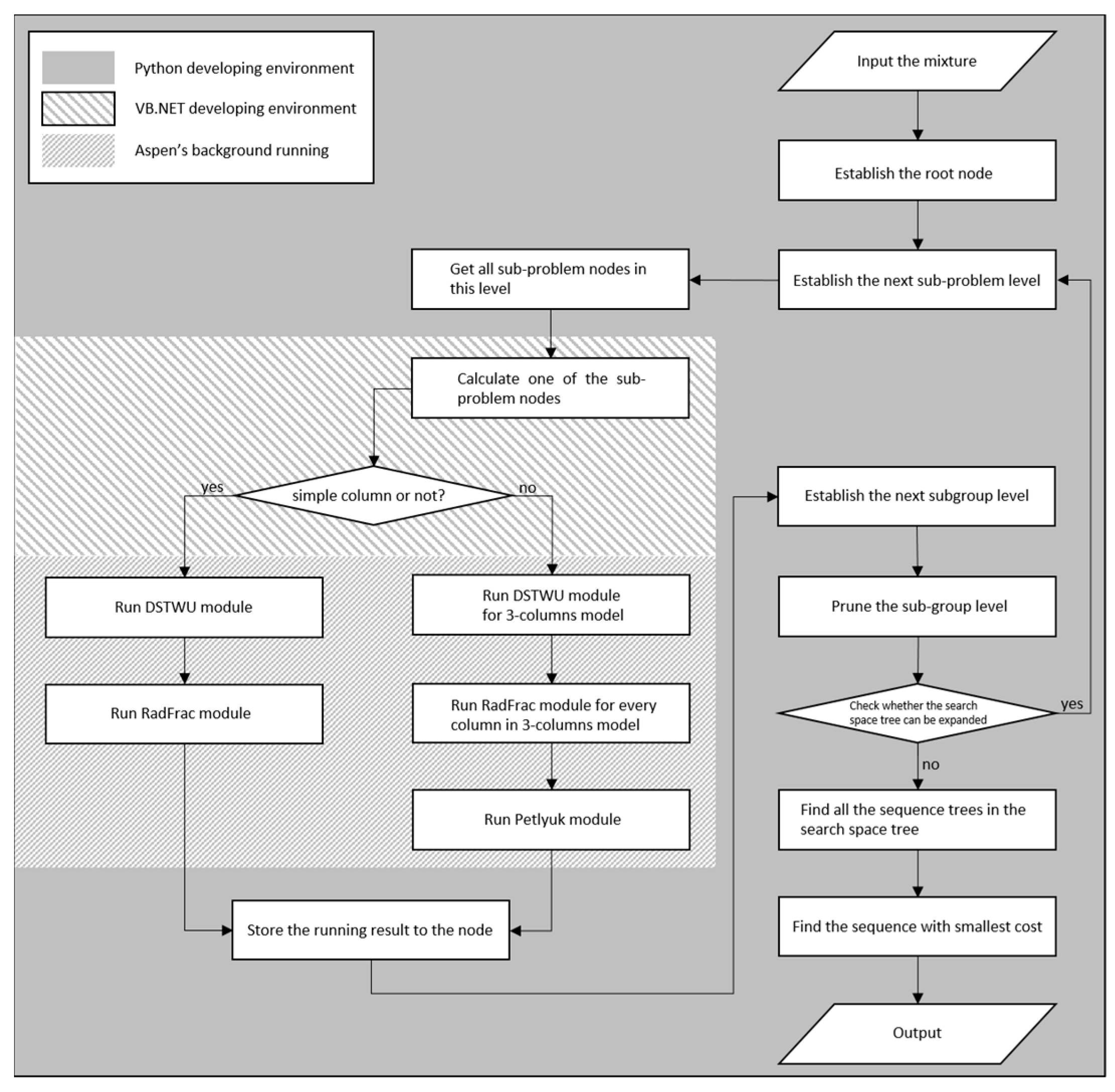
The framework in
Figure 4 is divided into three parts. The grey part, where the sequence is optimized, is edited by Python. The sparse oblique-line part, where column is optimized, is edited by VB.NET. The dense oblique-line part for the simulation and optimization of the column is the Aspen modules running in the background. The relationship among the three parts of the framework is shown in
Figure 5.
The VB.NET program (column optimization plug-in program) is applied to connect the Python program and the Aspen Plus background-running modules by manipulating the ActiveX interface of Aspen Plus. The Python language is an integrated language with many modules and functions encapsulated into packets, making the coding for sequence-level optimization easier.
There are two options to call and manipulate the Aspen modules automatically through the ActiveX interface. One is to code in Python language with a packet; the other is to code in VB.NET language. The later one is adopted in this work, because the Aspen help file [
33] illustrates only the formats of VB.NET codes for manipulating the ActiveX interface, making coding in VB.NET rather than Python to operate Aspen modules more user-friendly.
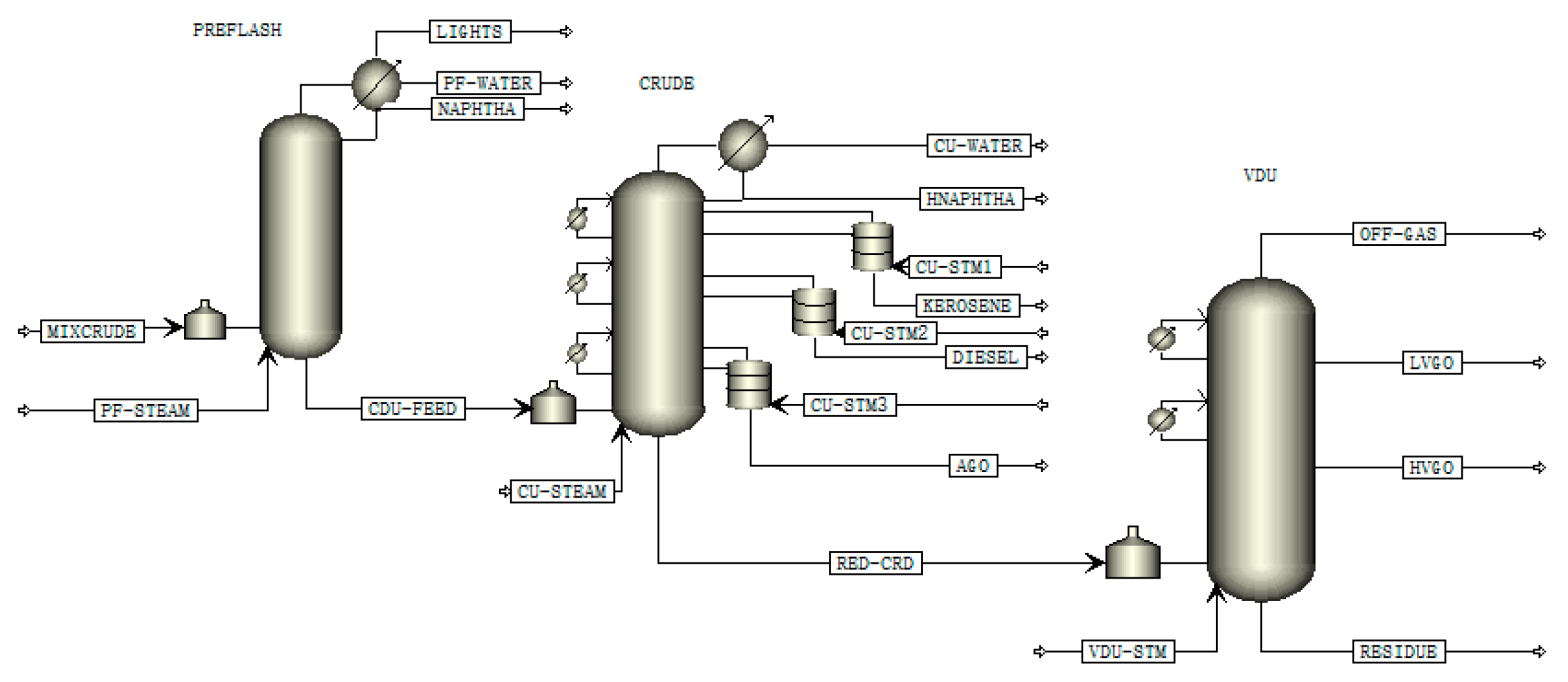
The modules of Aspen used in this work can be divided into two categories. For simple columns and dividing wall columns (three outflows) respectively, as shown in the grey part of
Figure 3, one includes the DSTWU (distillation-Winn-Underwood) module and RadFrac module, a module for rigorous distillation design, while another includes the DSTWU module, RadFrac module and Petlyuk module. The DSTWU module uses the Winn–Underwood–Gilliland (WUG) method for a short-cut. The Winn equations are cited as Equations (6) and (7).
where subscripts
D,
B,
LK,
HK and
x represent the top product, bottom product, light key component, heavy key component and liquid mole fraction, respectively. The minimum stage number
Nmin can be obtained by using Winn equations. The Underwood equations are cited as Equations (8) and (9).
where
αj,
fj,
φ,
F,
q,
ξj and
D represent the relative volatility of component
j, flow rate of component
j, the root of Underwood equations, the feed flow rate, the feed thermal state, the recovery of component
j at the top of the column and the distillate flow rate, respectively. The minimum reflux ratio
Rmin can be obtained by using Underwood equations. The Gilliland correlation is cited as Equation (10).
The theoretical stage number Nt can be obtained by using the Gilliland correlation.
Many distillation sequence optimization works depend on using only the WUG method to simulate a single column. Based on the WUG method, a more rigorous module called RadFrac is used in this work to improve the simulation of a single column. The RadFrac module solves material balance, energy balance and phase equilibrium simultaneously by using two nested iteration loops and the Newton algorithm to converge.
The Petlyuk module can be regarded as a three-columns module with complete thermal coupling and it converges in the same way as the RadFrac module does. The prefractionator of the Petlyuk module is a nonsharp column, but the whole Petlyuk module is designed only for sharp separation. As the Petlyuk module is thermodynamically equivalent to the ideal dividing wall column, the dividing wall column is also for sharp separation only.
The Aspen Plus ActiveX automation server is used in this work as an interface to connect theVB.NET program and the Aspen Plus modules. This server exposes objects of Aspen Plus through the COM (component object model), and the vast majority of parameters are stored in a tree structure. Using VB.NET code in a specific format can navigate this tree structure and change the data on it. With this interface, the inputs and the results of Aspen Plus simulations can be connected to other applications.
In addition, this program framework can be further expanded to optimize distillation sequences with more complex structures.
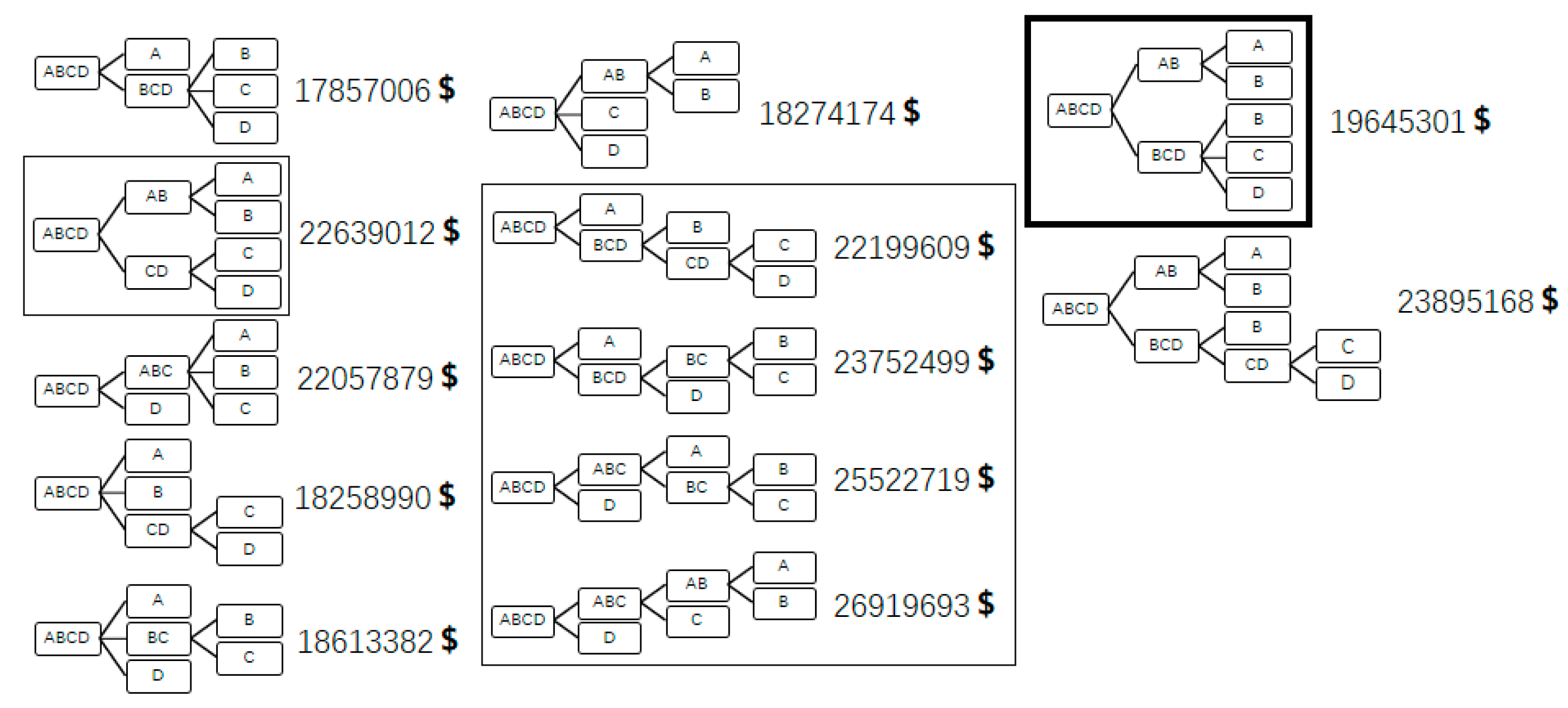
3.2. The Search Space and the Pruning Operation
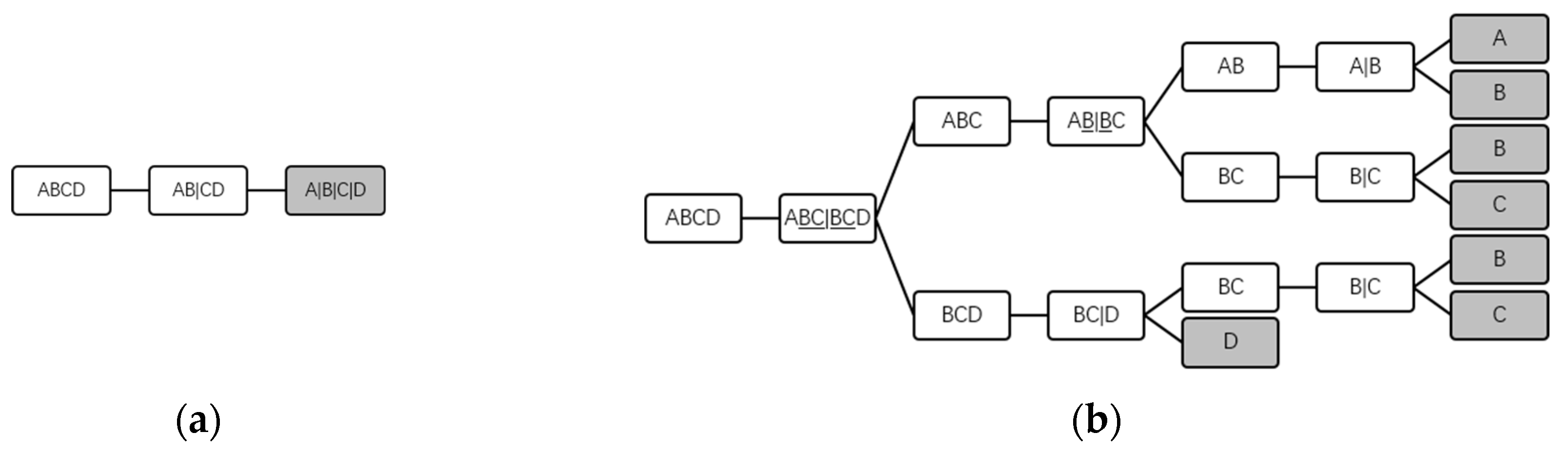
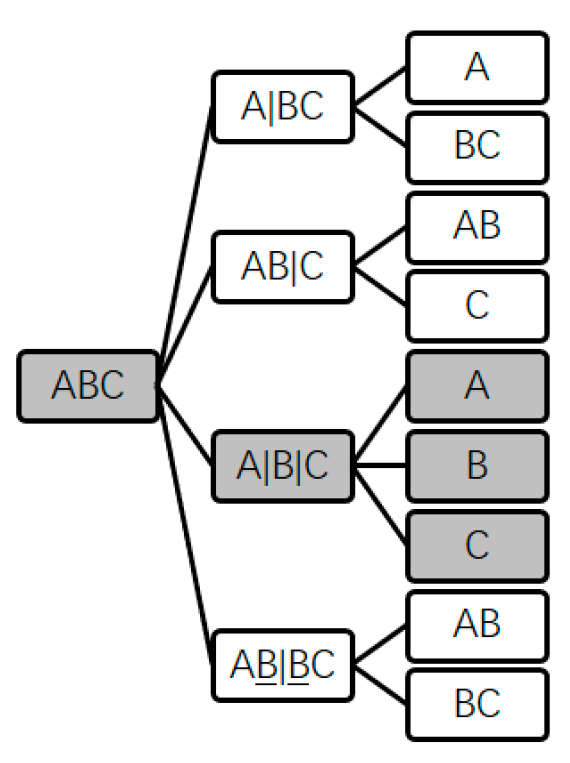
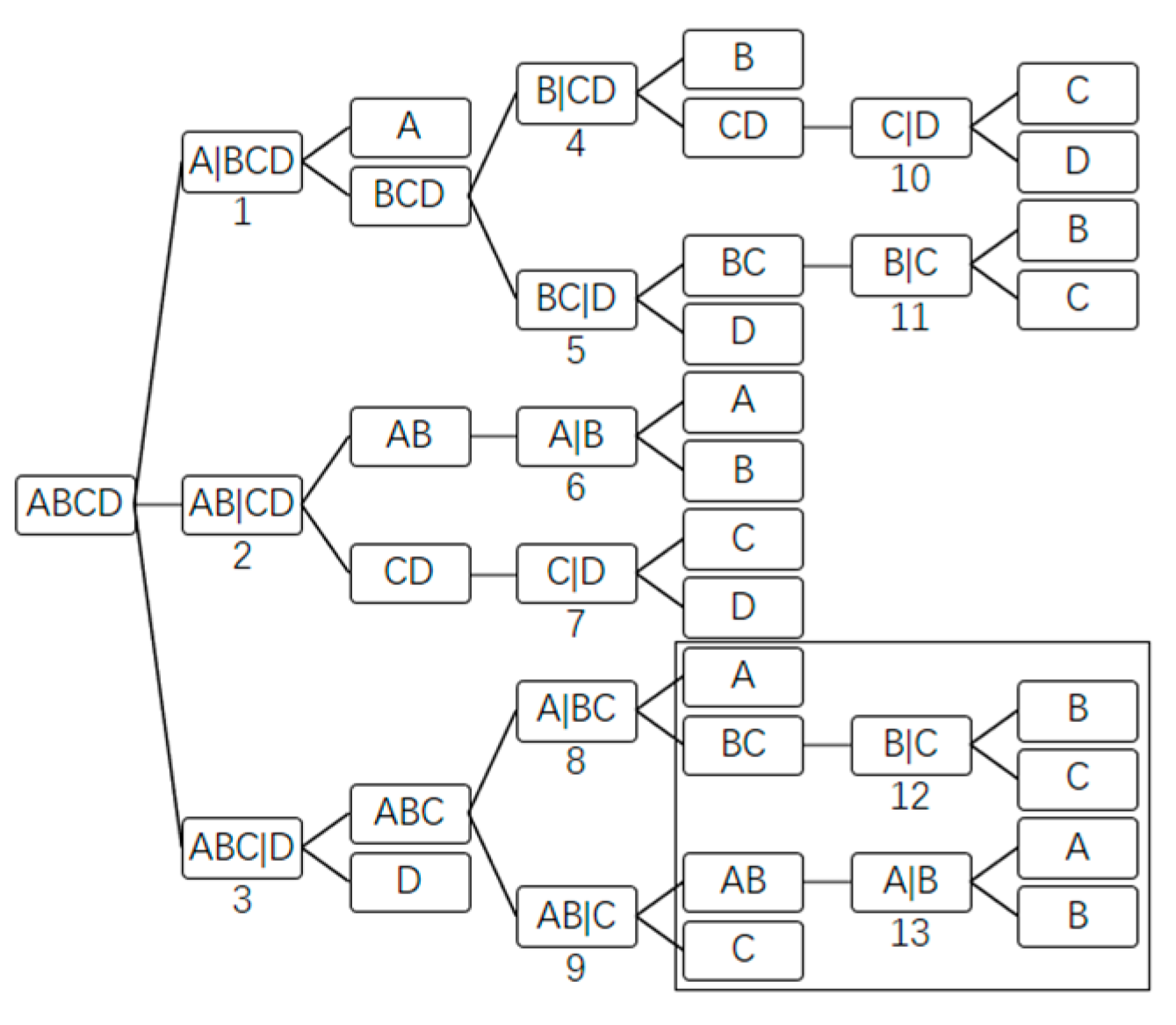
The scale of the solution space tree can be huge, and expanding the whole solution space tree consumes too much computing resource, therefore, a pruning method is proposed. The method can be implemented in two basic steps: first, once a subgroup level is finished, whether completed sequence trees are contained in the current incomplete solution space tree is determined; second, if there are completed sequence trees in the current incomplete solution space tree, the best one of them will be selected. All sequence trees contained in the current incomplete solution space tree will be compared with the best completed sequence tree while the ones worse than this one will not be expanded by deleting the nodes of the newest subgroup levels of them. In this method, the search space is generated. If the solution space tree is not pruned, the search space is equivalent to the solution space.
In
Figure 6, after finishing the second subgroup level of the solution space tree, the black nodes make up a completed sequence tree earliest. If the cost of sequence tree ABC//AB|C//AB/C is greater than that of the black-nodes tree, the subgroup nodes AB and C of this sequence tree will be removed.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}