Abstract
A sequential scheduling method for multi-objective, flexible job-shop scheduling problem (FJSP) work calendars is proposed. Firstly, the sequential scheduling problem for the multi-objective FJSP under mixed work calendars was described. Secondly, two key technologies to solve such a problem were proposed: one was a time-reckoning technology based on the machine’s work calendar, the other was a sequential scheduling technology. Then, a non-dominated sorting genetic algorithm with an elite strategy (NSGA-II) was designed to solve the problem. In the algorithm, a two-segment encoding method was used to encode the chromosome. A two-segment crossover and mutation operator were used with an improved strategy of genetic operators therein to ensure feasibility of the chromosomes. Time-reckoning technology was used to calculate start and end time of each process. The sequential scheduling technology was used to implement sequential scheduling. The case study shows that the proposed method can obtain an effective Pareto set of the sequential scheduling problem for multi-objective FJSP under mixed work calendars within an acceptable time.
1. Introduction
In recent years, researchers have shown an increased interest in the field of the flexible job-shop scheduling problem (FJSP), and there have been a large number of related research results. However, there is a phenomenon of mixed work calendars in manufacturing companies, i.e., different machines in the same company or workshop may run under different work calendars. Most of the existing research results cannot be applied when mixed work calendars are considered. Nowadays, because of the increasing pressure in manufacturing companies, more than one objective should be often considered in the process of production scheduling. Just for this reason, multi-objective optimization is more suitable for scheduling requirements. It is often possible to arrange the next batch of scheduling tasks before the completion of the previous one in the production process. This work is called sequential scheduling in this paper. Based on the above reasons, the sequential scheduling for FJSP with multi-objectives under the mixed work calendars has become a new research topic.
There are three main ways to deal with a work calendar in job-shop scheduling: not considering a work calendar, considering a work calendar after scheduling, considering a work calendar in scheduling. Most of the researches belong to the first case [1,2,3]. Although the calculative complexity is lowest, the scheduling scheme is not associated with the work calendar and is obviously out of touch with practice. A part of the research has been devoted to the second case. The work calendar is not considered in scheduling. After the scheduling scheme is obtained, the time is mapped to the calendar time through “integral translation” [4]. Although the calculative complexity is low, it is only suitable when the machines operate under the same work calendar. In the third case, the start and stop time of process is arranged according to the work calendar of each machine in scheduling. Although calculative complexity is large, it can ensure that the scheduling scheme is in accordance with practice. Just for this reason, it is suitable for occasions when the machines operate under mixed work calendars. Existing research results on job-shop scheduling with mixed work calendars are rare and there are some shortcomings. Wu Zhijun et al. [5] proposed an implementation strategy and key algorithms of a dynamic work calendar, but did not consider work shift. Huang Yuyue et al. [6] considered work shift in scheduling, but did not consider work system. Stefan et al. [7] considered work system in scheduling, but did not consider work shift. Wan Chunhui et al. [8] not only considered work system but also work shift in scheduling, but there are some shortcomings, such as low operability and large amount of calculation.
In the sequential scheduling process for FJSP with multi-objectives, the scheduling scheme selected by the previous batch of scheduling will affect the machines’ initial time status of the next batch of scheduling. In order to maximize utilization of machines and shorten production cycle when arranging the processes, it is necessary to arrange the processes by means of “extrusion insertion”. Therefore, how to update the machines’ time status according to the selected scheduling scheme, how to construct the machines’ initial time status according to the machines’ time status and the scheduling start time, and how to arrange the processes by means of “extrusion insertion” based on the machines’ work calendars are the three key issues to solve the sequential scheduling for FJSP with multi-objectives under mixed work calendars.
There are two methods to solve FJSP with multi-objectives: indirect method and direct method. The former refers to the method to solve the problem after it is transformed into single objective problem by some means, mainly including the minimax method, linear weighted sum method [9], ideal point method, main object method [10], efficacy coefficient method [11], hierarchical ordering method [12], etc. But this method cannot obtain the entire optimal solution set. The latter refers to the method to obtain the optimal solution set directly in multi-objective space, in which the optimization method based on Pareto optimization thought is most widely used, including the multi-objective genetic algorithm (MOGA) [13], niched pareto genetic algorithm (NPGA) [14], strength Pareto genetic algorithm (SPGA) [15,16], non-dominated sorting genetic algorithm (NSGA) [17], etc. Some research [18,19] has obtained the conclusion that NSGA is superior to other algorithms. With the expansion of the research scope, the shortcomings of NSGA are exposed in the multi-objective optimization algorithms. In order to better solve the multi-objective optimization problem, some scholars proposed a genetic algorithm with non-dominated sorting with elite strategy (NSGA-II). NSGA-II reduces the complexity of NSGA and has the advantages of fast running and good convergence of the solution set. It is one of the most popular multi-objective genetic algorithms at present.
Based on above analysis, a sequential scheduling method for FJSP with multi-objectives under mixed work calendars is proposed in this paper.
2. Problem Description
A batch of workpieces needs to be arranged on several machines. Assumptions: ① Each machine runs under the specified work calendar. The work calendar considered in this paper is a combination of work system and work shifts. ② Each workpiece has multiple processes, and there may be more than one feasible machine for each process. ③ The process flow of each workpiece, the adjusting and processing time of each process on the feasible machines, are determined beforehand. ④ When a machine is shut down under its work calendar, the machine stops adjusting, and the process stops processing. The unfinished work will be continued when the machine begins to work again. ⑤ Once a process is started, it should not be interrupted to perform another one. ⑥ When two adjacent batches of workpieces are scheduled, the next schedule should take the machines’ time occupation status of the selected scheduling scheme as the initial state. ⑦ The scheduling runs from the specified scheduling start time. ⑧ The scheduling start time of the next batch is not earlier than that of the previous one. Requirements: to reasonably arrange the processes so as to minimize production cycle and total cost under the above assumptions.
Obviously, the above problem belongs to a sequential scheduling problem for FJSP with multi-objectives under mixed work calendars. Because different machines may operate under different work calendars, the problem is a highly complex NP-hard problem. It can be solved by an intelligent search algorithm. In view of the advantages of a genetic algorithm, taking Excel as the designed platform, this paper designs a non-dominated sorting genetic algorithm with elite strategy (NSGA-II) to solve it.
3. Definition of Types, Variables and Arrays
A set of types, variables, and arrays are defined. The types are proc, job, chr, mach, as shown in Figure 1. The variables are shown in Table 1. The arrays are shown in Table 2. chr.R is an array of tpnum × 12. Columns 1 to 12 are used to store task No., workpiece No., process No., machine No., adjustment time, processing time, adjusting start time, adjusting end time, processing start time, processing end time, adjusting cost and processing cost. MA is used to store parameters of each machine. JB is used to store parameters of each workpiece. MMB is used to store the machines’ time status before scheduling.

Figure 1.
Custom type.

Table 1.
Variables.
Table 2.
Arrays.
4. Key Technologies
4.1. Time Reckoning Technology Based on the Machine’s Work Calendar
4.1.1. Design and Configuration of Work Calendar
A worksheet “work system” is designed for setting up work systems. In Figure 2, from left to right, every two columns correspond to a work system. The cells of the odd column in the first row are names of work systems. The cells of the odd column in the other rows are days off on the non-weekend. The cells of even columns are work days on the weekend. The dispatcher can also add other work systems to the right as needed.
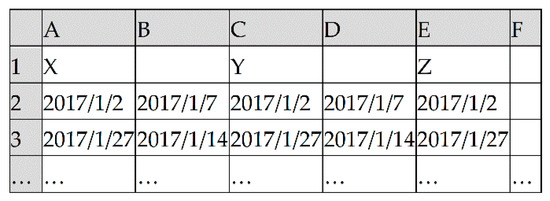
Figure 2.
Worksheet “work systems”.
A worksheet “work shifts” is designed for setting up work shifts. In Figure 3, columns A to G are setting content of work shift A. Cell A1 is the name of work shift A. Columns A2 to G2 are number of work periods per day from Monday to Sunday. The other rows in each column are used to set up work periods of each day. Taking column A as an example, columns A3 to A8 indicate that the three work periods on Monday are 8:00 to 12:00, 13:00 to 17:00 and 18:00 to 22:00. The dispatcher can also add other work shifts to the right, such as B, C… as needed.
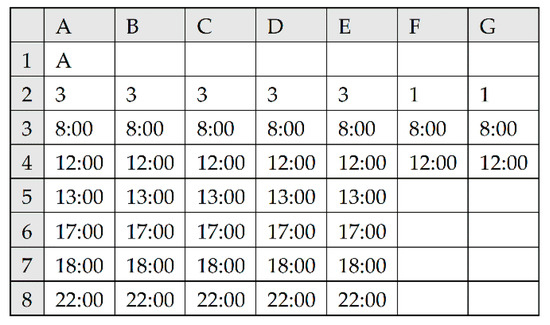
Figure 3.
Worksheet “work shifts”.
A worksheet “machines” is designed for configuring the work calendar for each machine. In Figure 4, work system Z and work shift A are assigned to machine “300T”, and work system Y and work shift B are assigned to machine “200T”.
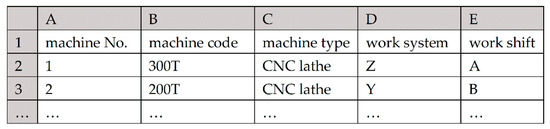
Figure 4.
Worksheet “machines”.
4.1.2. Design of Time-Reckoning Function Based on Work Calendar
Based on the design and configuration of the work calendar, six functions were designed to realize time reckoning, namely Isworkday, Nextworkday, Getsd, Forwardwd, Backwd and Getat.
Isworkday: This function has two parameters: md (date) and wds (string). It is used to judge whether the date md is work day or not according to the machine’s work system wds. If so, return 1, otherwise, return 0. Figure 5 is flow of this function.
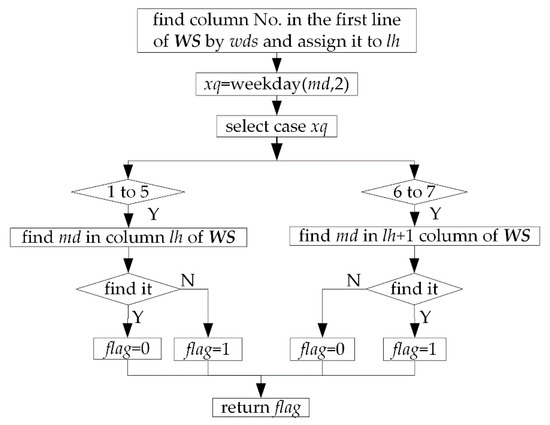
Figure 5.
Flow of function Isworkday.
Nextworkday: This function has three parameters: md (date), t (integer) and wds (string). It is used to get the work day after t days from date md according to work system wds. t > 0 indicates forward reckoning, and t < 0 indicates backward reckoning. Figure 6 is the flow of this function.
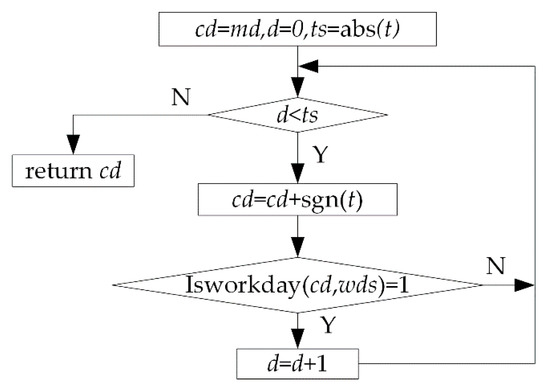
Figure 6.
Flow of function Nextworkday.
Getsd: This function has three parameters: md (date), t (double), and mn (integer). It is used to get the position of time t on the date md according to work shift of machine mn. Its return value is an array A. A contains 2 elements. A (2) is the flag element. A (2) = 0 indicates that time t belongs to the A (1)th non-work period on the date md of machine mn. A (2) = 1 indicates that time t belongs to the A (1)th work period on the date md of machine mn. In Figure 7, 0:00~24:00 is split into 5 time periods, including 2 work periods 8:00~12:00 (No. 1),13:00~17:00 (No. 2), and 3 non-work periods 0:00~8:00 (No. 0), 12:00~13:00 (No. 1), 17:00~24:00 (No. 2). Figure 8 is flow of this function. The for loop I is used to judge whether time t belongs to the ith work period of the date md. If so, let A (1) = i, A (2) = 1, and return A. The for loop II and if statement III are used to judge whether time t belongs to the ith non-work period of the date md. If so, let A (1) = i, A (2) = 0, and return A. It is necessary to be pointed that if condition of if statement III is not met, it means that time t does not belong to any of the work periods and non-work periods of 1~wtn, so it can only belong to the 0th non-work period. In this case, the function will return array A, in which A (1) = 0, A (2) = 0.

Figure 7.
Work and non-work periods on one day of a machine.
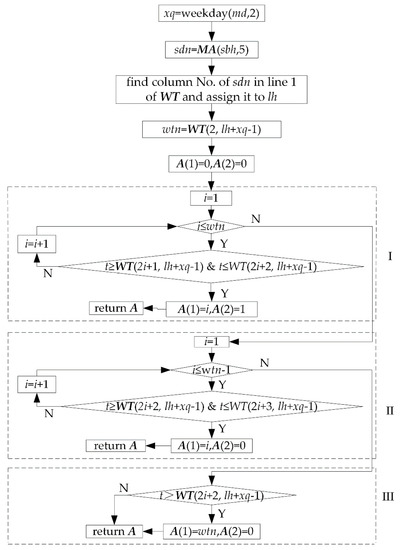
Figure 8.
Flow of function Getsd.
Forwardwd: This function has three parameters: mdt (date), t (double), and mn (integer). It is used to get the work time after t hours from work time mdt according to work calendar of machine mn by forward reckoning. Figure 9 is a schematic diagram of reckoning process. Figure 10 is flow of this function. In Figure 9, the work period is simply referred to as wp.
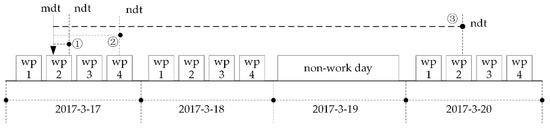
Figure 9.
Schematic diagram of forward reckoning.
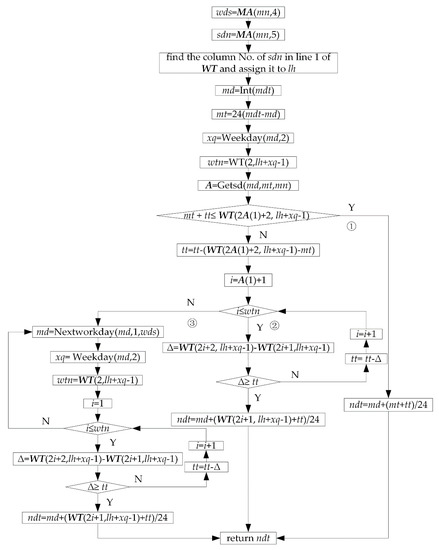
Figure 10.
Flow of function forward.
Backwd: This function has three parameters: mdt (date), t (double) and mn (integer). It is used to get the work time before t hours from work time mdt according to work calendar of machine mn by backward reckoning. The function Backwd is similar to the function Forwardwd in calculation principle and flow, no more repeat here.
Getat: This function has two parameters: mdt (date) and mn (integer). It is used to get the earliest work time from time mdt according to work calendar of machine mn by forward reckoning. Figure 11 is a schematic diagram of the reckoning process, and Figure 12 is the flow of this function. In Figure 11, the work period is simply referred to as wp.
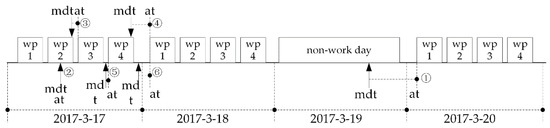
Figure 11.
Getting the earliest work time.
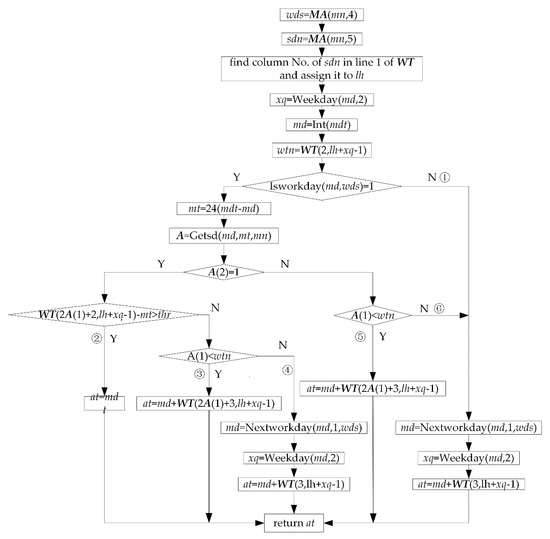
Figure 12.
Flow of function Getat.
4.2. Sequential Scheduling Technology
As mentioned in the introduction, how to construct the machines’ initial time status according to the machines’ time status and the scheduling start time, and how to arrange the processes by means of “extrusion insertion” based on the machines’ work calendars, are the key issues to solve the sequential scheduling for FJSP with multi-objectives under mixed calendars. The technical steps to solve these key issues in this paper are as follows.
Step 1: Construct machines’ initial time status before scheduling and assign them to array MMB according to worksheet “machines’ time status” and the given scheduling start time.
Construct a worksheet “machines’ time status” as shown in Figure 13. Each row is used to store time status information of a machine. Column A is machine No. Columns B and C are start and end time of the first idle period of each machine. Columns C to G are adjusting start time, adjusting end time, details of a process, processing start time, and processing end time of the first process. Columns G and H are start and end time of the second idle period of each machine. Columns H to L are adjusting start time, adjusting end time, details of the second process, processing start time, and processing end time of the second process; and so on.
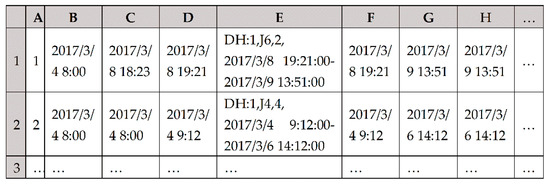
Figure 13.
Worksheet “machines’ time status”.
Schematic diagram of constructing the machines’ time status before scheduling is shown in Figure 14. Take machine i as an example. If the given scheduling start time is in the kth idle period of machine i (a), let the start time of the first idle period of machine i be equal to the given scheduling start time, and the end time of the first idle period of machine i be equal to the end time of the kth idle period. The subsequent idle periods are taken back in turn. If the given scheduling start time is between the start and end time of a certain process (b), let the start time of the first idle period of machine i be equal to the end time of the process, and let the end time of the first idle period of machine i be equal to the end time of the first idle period after the process. The subsequent idle periods are taken back in turn.
Figure 14.
Constructing machines’ time status before scheduling.
Step 2: Assign MMB to the individual’s attribute MMA.
Step 3: Arrange the processes by means of “extrusion insertion” when the individual is decoded.
The detailed steps are as follows (Figure 15). Firstly, find the first feasible idle period k according to time status of machine i. Then, insert process a into the idle period k. Finally, update time status of machine i. The method of finding the first feasible idle period is as follows. Determine whether each idle period is enough for process a from left to right. If enough, find the first feasible idle period k, otherwise continue to search backward. The steps of judging whether the idle period k is enough is as follows. Reckon processing end time of process a according to the earliest adjustable time, adjusting time, processing time of process a and work calendar of the machine. Judge whether the end time of process a is not more than the end time of idle period k. If so, idle period k is a feasible idle period. The steps of updating the time status of machine i is as follows. Firstly, increase length of ch.MMA (R (i, 4)). TS by 5. Then, move data from the second datum of kth idle period back 5 positions so as to obtain 5 empty positions. Finally, fill adjusting start time, adjusting end time, process details, processing start time, and processing end time of the current process in the 5 empty positions.
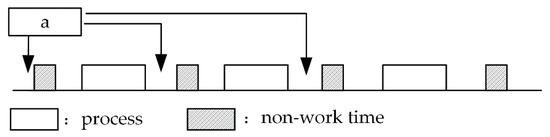
Figure 15.
Process arrangement by means of extrusion insertion.
Step 4: Output scheduling matrix R and the machines’ time status array MMA of each Pareto solution to worksheet “pareto solution set” at the end of the evolution. Worksheet “pareto solution set” is shown in Figure 16.
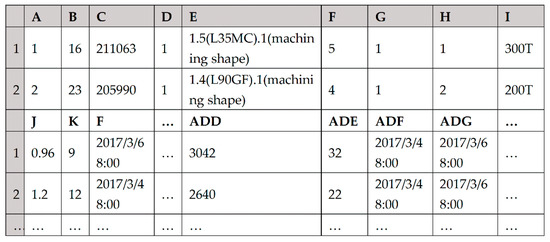
Figure 16.
Worksheet “Pareto solution set”.
If a scheduling scheme has two optimization objectives, the columns in worksheet “pareto solution set” are described as follows. Columns A to ADE are data of the Pareto solution. Among them, columns A to D are sequence No., objective 1, objective 2, Pareto frontier value. Columns E to ADD are data of scheduling matrix R of the Pareto solution, namely process details, workpiece No., process No., machine No., machine code, adjusting time, processing time, adjusting start time, adjusting end time, processing start time, processing end time, adjusting cost, processing cost. Column ADE is data number of time status of machine 1. The next 32 cells after column ADE are data of time status of machine 1; and so on.
Step 5: Extract scheduling matrix into worksheet “Pareto Solution”, and machines’ time status into worksheet “machines’ time status” from the row double clicked when the dispatcher selects a Pareto solution by double click.
5. Non-Dominated Sorting Genetic Algorithm with an Elite Strategy (NSGA-II) Design
5.1. Algorithm Flow
Take popsize as an even number, the designed algorithm flow is shown in Figure 17.
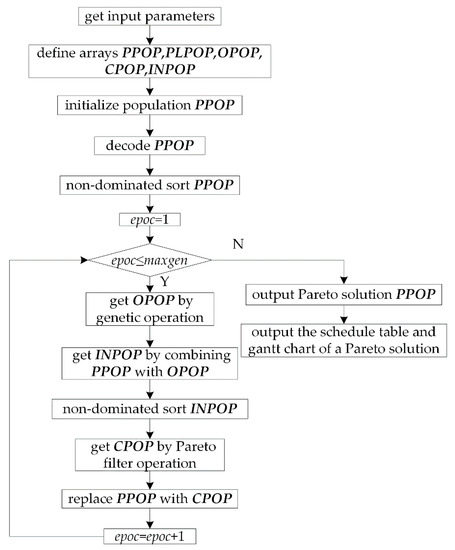
Figure 17.
Algorithm flowchart.
5.2. Obtaining Input Parameters
Firstly, design worksheet “workpiece”, “scheduling workpiece”, “process flow” and “other parameters” for the dispatcher to set up input parameters. Then, obtain input parameters by the following steps in the algorithm. Read parameters from worksheet “other parameters” and assign them to variables whose type are input parameters in Table 1. Read data from the second row to last row of worksheet “machine” and assign them to array MA. Assign value to array MMB by step (1) in Section 4.2. Assign value to JB by loop: take workpiece i as an example. Firstly, read name, type and number of processes of workpiece i from worksheet “workpiece” and assign them to JB (i).name, JB (i).type and JB (i).pnum. Then, redefine each dimension of JB (i).PR by Redim JB (i).PR (JB (i).pnum). Finally, read parameters of processes of workpiece i from worksheet “process flow” and assign them to JB (i).PR (i)~JB (i).PR (JB (i).pnum) by for loop.
5.3. Encoding Method
Encode processes and their processing machines separately by means of “segmentation” as shown in Formula (1). PPOP (i).R is an array of tpnum × 12, in which the second and fourth column are used for encoding, and the other columns are used for auxiliary or decoding. Each gene value of column 2 is a natural number between 1 and jnum. This represents the workpiece No. The number of occurrences of each natural number is equal to the number of processes of the workpiece. Each gene value of column 4 is the No. of feasible machines for each process.
5.4. Population Initialization
Randomly generate popsize individuals and store them in population PPOP by flow shown in Figure 18. In Figure 18, the flow to assign feasible machine No. to column 4 of R is shown in Figure 19. As can be seen from Figure 18 and Figure 19, the randomly generated individuals are feasible individuals.
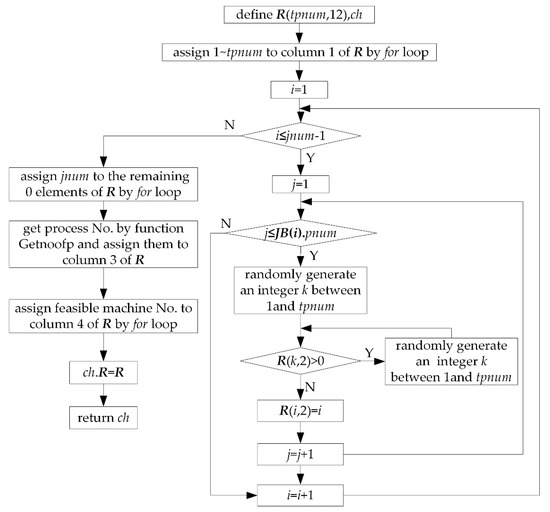
Figure 18.
Flow of population initialization.
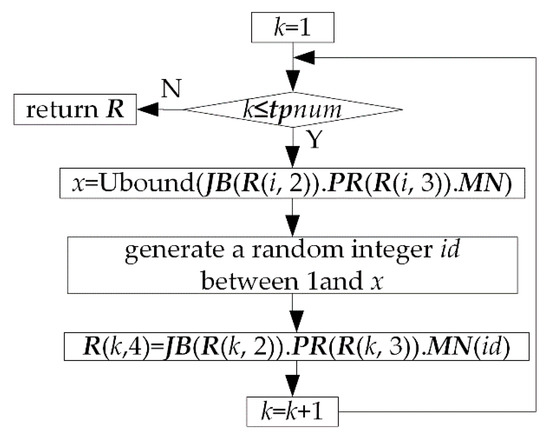
Figure 19.
Assigning machine No. to column 4 of R.
5.5. Select Operation
Select “excellent” individuals from parent population PPOP by “league mechanism” and form a pairing pool PLPOP made up of popsize/2 individuals by for loop. Suppose league size is ts. Randomly select ts individuals from parent population PPOP and select an “excellent” individual from them by each individual’s frontier value rank and congestion degree cd into pairing pool PLPOP in each loop. Finally, return PLPOP.
5.6. Genetic Operation
Generate offspring population OPOP made up of popsize individuals by selection, crossover, and mutation operation from parent population PPOP through a genetic operation. The flow is shown in Figure 20.
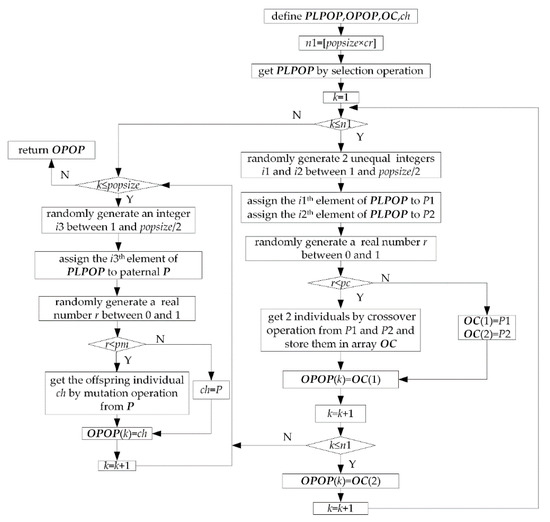
Figure 20.
Flow of genetic operation.
5.7. Crossover Operation
• Crossover operation of processes
Based on an improved strategy of a genetic operator, adopt a kind of crossover method is based on process No. in crossover operation of processes to ensure feasibility of the offspring individuals [20]. Because there is a sequence between processes of the same workpiece, adopt the following measure to ensure this sequence not to be destroyed. Fix the row (workpiece No., process No., and machine No.) of a certain workpiece No. of a parent, and replace the remaining rows of this parent with the other parent’s rows except that of this workpiece No. from top to bottom. Take Formula (2) as an example. Fix workpiece 1 in P1.R, fix workpiece 3 in P2.R, the result of crossover operation between P1.R and P2.R is shown in Formula (3).
• Crossover operation of processing machines
Adopt a kind of two-point crossover method in crossover operation of processing machines. Randomly generate two different integers mp1 and mp2 between 1 and tpnum. If mp1 > mp2, swamp them to make mp1 < mp2. Take parent P1′ as an example. Let k change from mp1 to mp2. For each k, find row No. h in P2′. R where the workpiece No. is equal to P1′. R (k, 2) and the process No. is equal to P1′.R (k, 3). Let P1′. R (k, 4) = P2′. R (h, 4). Deal with parent P2′ by similar method. After crossover operation of processing machines, re-decode P1′, P2′ and assign them to OC (1) and OC (2). For example, if mp1 = 3, mp2 = 5, the result of crossover operation from P1′ and P2′ in Formula (3) is shown in Formula (4).
Obviously, the above crossover operation can ensure feasibility of the offspring individuals.
5.8. Mutation Operation
• Mutation operation of processes
Based on an improvement strategy of genetic operator, adopt a kind of sliding mutation method in mutation operation of processes to ensure feasibility of the offspring individuals. Take parent P as an example. Randomly generate an integer mp b9etween 1 and tpnum as the mutation point. Find the nearest index id where P′R(id,2) = P′R(mp,2) from mp upwards and assign it to s1. If id is null, let s1 = 0. Find the nearest index id where P′R (id,2) = P′R (mp,2) from mp downwards and assign it to s2. If id is null, let s2 = tpnum + 1. Let k1 = s1 + 1. Let k2 = s2 − 1. Randomly generate an integer between k1 and k2, and assign it to k. Then slip workpiece No., process No. and machine No. of the mpth row to the kth row. Take Formula (5) as an example. If mp = 3, k1 = 2, k2 = 8, k = 6, the result of mutation operation is shown in Formula (6).
• Mutation operation of processing machines
Adopt a kind of single-point mutation method in mutation operation of processing machines. Randomly generate an integer mp between 1 and tpnum as the mutation point. Let k = Ubound (JB (P′.R (mp, 2). PR (P′.R (mp, 3).MN). Randomly generate an integer between 1 and k as index of the new processing machine No. and assign it to id. Then, let P′.R (mp,4) =JB (P′.R(mp,2)).PR (P′.R (mp,3)).MN (id).
Re-decode individual P′ and assign it to ch after mutation operation.
5.9. Decoding Operation
The flow of decoding operation is shown in Figure 21.
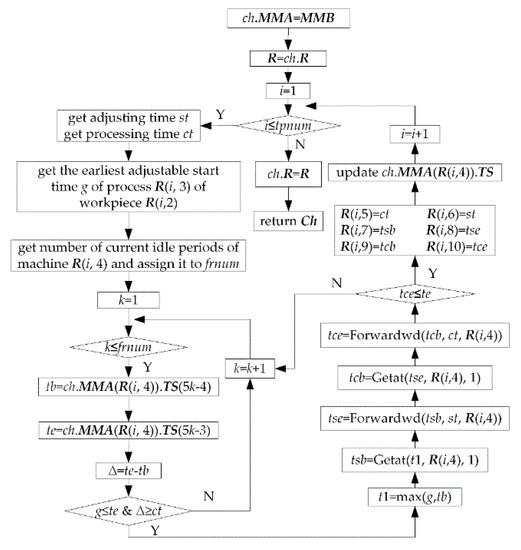
Figure 21.
Decoding operation.
There are three steps in the decoding operation. Firstly, assign MMB to ch.MMA and ch.R to R. Then, let i change from 1 to tpnum, arrange processes in sequence and determine columns 5~12 of R. Finally, let ch.R = R. The following three points need to be explained.
Method of getting machines’ adjusting time st and processing time ct is as follows. Obtain index of machine No. R (i, 4) in JB (R (i, 2). PR (R (i, 3). MN and assign it to id. Let st = JB (R (i, 2). PR (R (i, 3)). st (id). Let ct = JB (R (i, 2)). PR (R (i, 3)). ct (id).
The method of getting the earliest adjustable start time g of process R (i, 3) of workpiece R (i, 2) is as follows. There are three cases, as shown in Figure 22. Case 1: When R (i, 3) = 1, let g = bt. Case 2: When R (i, 3) ≠ 1, process R (i, 3) and R (i, 3) − 1 of workpiece R (i, 2) are arranged on the same machine p. In this case, process R (i, 3) of workpiece R (i, 2) cannot be adjusted until process R (i, 3) − 1 is completed. So, we can assign the processing end time of process R (i, 3) − 1 of workpiece R (i, 2) to g. Assume that row No. of process R (i, 3) − 1 of workpiece R (i, 2) in R is h, let g = R (h, 10). Case 3: When R (i, 3) ≠ 1, process R (i, 3) and R (i, 3) − 1 of workpiece R (i, 2) are arranged on different machines. In this case, process R (i, 3) can start its adjusting st hours earlier than processing end time of process R (i, 3) − 1 of workpiece R (i, 2). Thus process R (i, 3) can be processed immediately once process R (i, 3) − 1 is finished. Assume that row No. of process R (i, 3) − 1 of workpiece R (i, 2) in R is h, the method to get g is as follows. Firstly, get work time t according to work calendar of machine R (i, 4) through the forward reckoning function Getat, namely let t = Getat (R (h, 10), R (i, 4)). Then, let g = Backwd (t, st, R (i,4)).
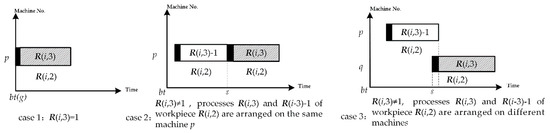
Figure 22.
Obtaining the earliest adjustable start time g for process R (i, 3) of workpiece R (i, 2).
The method of updating ch.MMA (R (i, 4)).TS is as follows. In Figure 23, if machine R (i, 4) has been arranged one process a in the initial state, initial length of ch.MMA (R(i,4)).TS is 7. Namely there are only 7 elements in ch.MMA (R (i, 4)).TS which are scheduling start time bt, tsba (adjusting start time of process a), tsea (adjusting end time of process a), and jca (details of process a), tcba (processing start time of process a), tcea (processing end time of process a), large time number tln. There are two idle periods (Here frnum = 2), namely bt~tsba, tcea~tln. After process b is arranged on machine R (i, 4) (Assume that process b is arranged after processing end time of process a), five elements are inserted between tcea and tln, namely tsbb (adjusting start time of process b), tsbe (adjusting end time of process b), jcb (details of process b), tcbb (processing start time of process b) and tceb (processing end time of process b). Length of ch.MMA (R (i, 4).TS is added to 12. bt~tln is split further into 3 idle periods (Here frnum = 3), namely bt~tsba, tcea~tsbb, tceb~tln. By above method, with continuous arrangement of each process, the length of ch.MMA (R (i, 4)).TS is dynamically changed and its elements is dynamically updated. Assume that the insertion period is the kth idle period of machine R (i, 4), then update ch.MMA (R (i, 4)).TS as follows. Firstly, increase length of ch.MMA (R (i, 4)).TS by 5. Then, move data from the second datum of the kth idle period back 5 positions so as to obtain 5 empty positions. Finally, fill the adjusting start time, adjusting end time, process details, processing start time, and processing end time of the current process in the 5 empty positions.
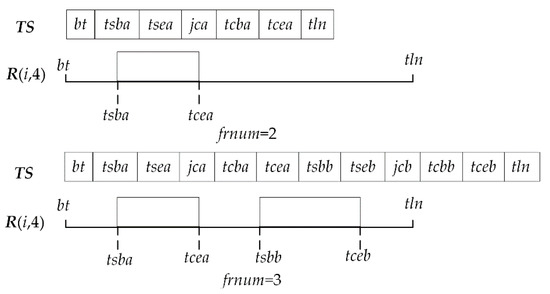
Figure 23.
Updating ch.MMA (R (i, 4)).TS.
5.10. Calculating Objectives
• Production cycle (ch.O (1))
Production cycle is the time span between processing start time and adjusting end time of the scheduled workpieces. Find the minimum value in column 7 of ch.R and assign it to s1. Find the maximum value in column 10 of ch.R and assign it to s2. Let ch.O (1) = s2 − s1.
• Total cost (ch.O(2))
Total cost is the sum of production cost c1, earlier completion cost c2, and delayed completion cost c3.
Production cost (c1): Production cost is the sum of adjusting cost and processing cost for all processes of scheduled workpieces. Because column 11 and column 12 of ch.R are the adjusting cost and processing cost of each process, sum column 11 and column 12, and assign it to c1.
Earlier completion cost (c2): The earlier completion cost of a workpiece is cost produced when the last process of it is finished earlier than its delivery time. It mainly represents storage cost. Sum earlier completion cost of each workpiece to obtain the total earlier completion cost of the scheduled workpieces. Assign it to c2. The earlier completion cost of workpiece i is equal to the product of earlier completion time and earlier completion fee rate. The method to get earlier completion time of workpiece i is as follows: Obtain the difference between delivery time of workpiece i and processing end time of the last process of workpiece i in column 10 of ch.R. Let earlier completion time of workpiece i be equal to the maximum value of the difference and 0.
Delayed completion cost (c3): The delayed completion cost of a workpiece is cost produced when the last process of it is finished later than its delivery time. It mainly represents penalty fine, crush cost and so on. Sum delayed completion cost of each workpiece to get total delayed completion cost of the scheduled workpieces. Assign it to c3. The delayed completion cost of workpiece i is equal to the product of delayed completion time and delayed completion rate. The method to get delayed completion time of workpiece i is as follows: Obtain the difference between processing end time of the last process of workpiece i in column 10 of ch.R and delivery time of workpiece i. Let delayed completion time of workpiece i be equal to the maximum value of the difference and 0.
After getting c1, c2, and c3, sum them to ch.O (2).
6. Case Study
The information of the workpieces to be produced in a job shop is shown in Table 3. The process flow is shown in Table 4. There are 18 machines. The information of the machines is shown in Table 5. There are 3 work systems for the machines which are work system X, Y and Z. Their settings are shown in Figure 24. There are 3 work shifts for the machines which are work shift A, B and C. Their settings are shown in Figure 25.
Table 3.
The information of the workpieces.
Table 4.
Process flow.
Table 5.
The information of the machines.
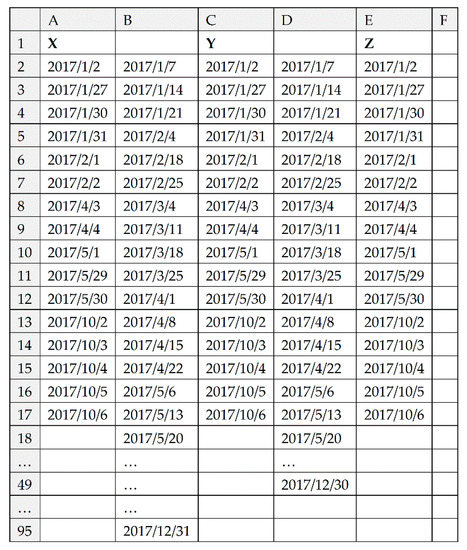
Figure 24.
Settings of worksheet “work system”.
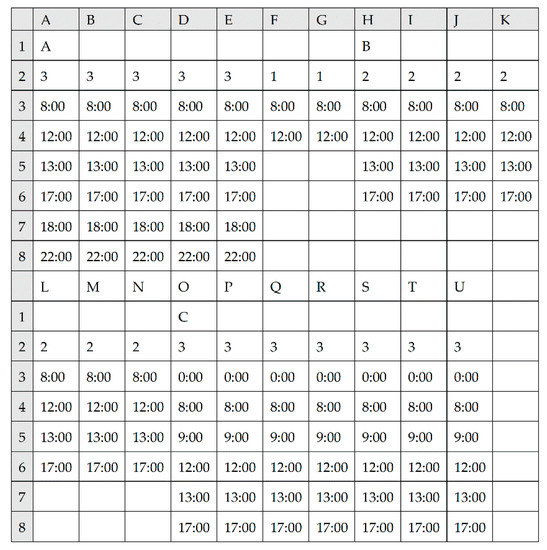
Figure 25.
Settings of worksheet “work shifts”.
• No. 1 schedule
Start time of No. 1 schedule is 2017/3/4 8:00:00. It aims to arrange processing tasks of three workpieces on 18 machines. The information of the scheduled workpieces is shown in Table 6. Initial time status of the machines is shown in Figure 26. Other parameters are shown in Table 7.
Table 6.
The information of the scheduled workpieces of No. 1 schedule.
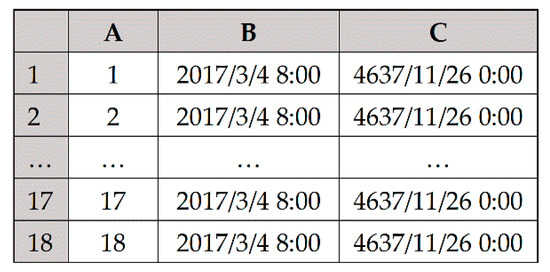
Figure 26.
Setting of worksheet “initial time status of the machines”.
Table 7.
Other parameters.
Let the algorithm run independently 20 times. The calculation time of each evolutionary calculation is about 40 s. Each evolutionary calculation can obtain almost the same and uniform Pareto solution set. This shows that convergence effect is good. The Pareto solution set obtained by one of the evolutionary calculations is shown in Figure 27. The dispatcher can select one of the Pareto solutions to arrange production. The schedule table of a Pareto solution (production cycle is 12.28 days, total cost is 105,226.84 yuan) is shown in Table 8. A Gantt chart of the scheduled workpieces and a Gantt chart of the machines are shown in Figure 28 and Figure 29.
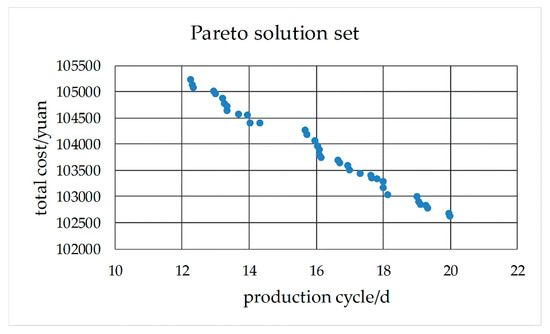
Figure 27.
Pareto solution set of No. 1 schedule.
Table 8.
Schedule table of a Pareto solution.
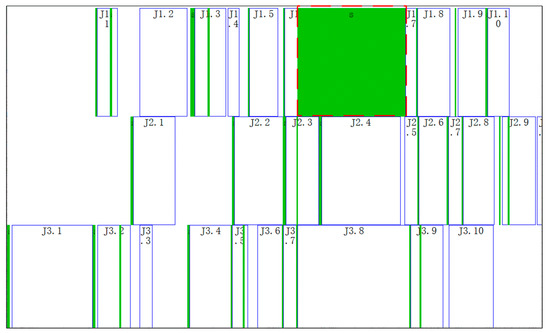
Figure 28.
Gantt chart of the scheduled workpieces of No. 1 schedule.
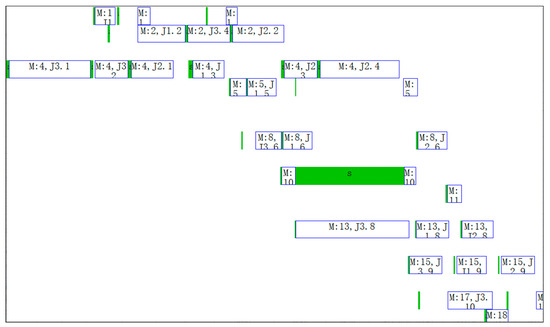
Figure 29.
Gantt chart of the machines of No.1 schedule.
In Figure 28 and Figure 29, the boxes with s identifier indicate adjusting start-end periods of processes, and the boxes with M or J identifier indicate processing start-end periods of processes. For example, the dotted box in Figure 28 indicates adjusting the start-end period of the 7th process of workpiece 1. The righthand box close to it indicates processing the start-end period of the 7th process of workpiece 1 (In row 19 of Table 8). As can be seen from row 19 of Table 8, this process is arranged on machine 10 and the adjusting start time, adjusting end time, processing start time and processing end time of this process is respectively 2017/3/10 21:45, 2017/3/13 8:23, 2017/3/13 8:23 and 2017/3/13 15:00. According to work calendar of machine 10 (M5515), we can know that calendar time between 2017/3/10 21:45 and 2017/3/13 8:23 is 58.64 h, but work time is only 0.64 h; Calendar time between 2017/3/13 8:23 and 2017/3/13 15:00 is 6.625 h, but work times are 5.625 h. 0.64 h and 5.625 h consistent with adjusting time st and processing time ct in Table 8. This shows that the result of time reckoning according to the machines’ work calendars in the algorithm is correct.
In Table 8 the sequence of processes on machine 4 (T42) is J3.1, J3.2, J2.1, J2.3, J1.3 and J2.4 can be seen to be in ascending order by No. However, it can be seen from Figure 29 that the sequence of processes on machine 4 from left to right is J3.1, J3.2, J2.1, J1.3, J2.3 and J2.4. The above two sequences are not consistent. The reason for this phenomenon is that “extrusion insertion” method is adopted in decoding operation. This method can reduce idle time of the machines as much as possible and shorten production cycle.
• No.2 schedule
The information of scheduled workpieces of No.2 schedule is shown in Table 9. The start time of No.2 schedule is 2017/3/10 8:00:00. Another condition is the same as No.1 schedule. The Pareto solution set is shown in Figure 30. Calculation time is about 40 s. The dispatcher can select one of the Pareto solutions to arrange production. The Gantt chart of the scheduled workpieces and Gantt chart of the machines of the Pareto solution (Production cycle is 16.64 days and total cost is 131,805.00 yuan) are shown in Figure 31 and Figure 32. After the No.1 and No. 2 schedules, the Gantt chart of the machines is shown in Figure 33.
Table 9.
The information of the scheduling workpieces of No.2 schedule.
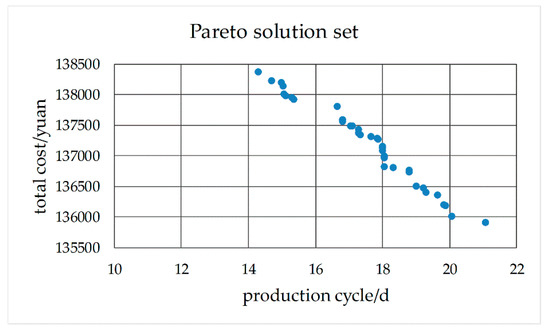
Figure 30.
Pareto solution set of No. 2 schedule.
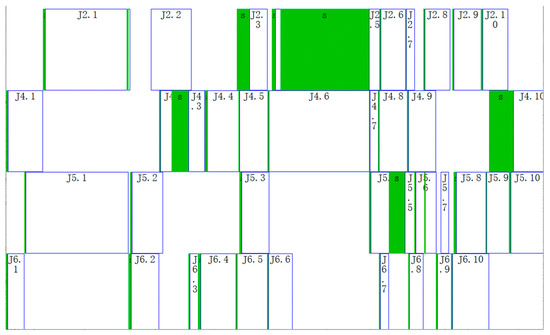
Figure 31.
Gantt chart of the scheduled workpieces of No.2 schedule.
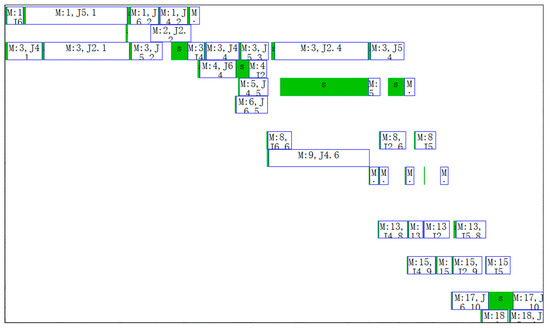
Figure 32.
Gantt chart of the machines of No.2 schedule.
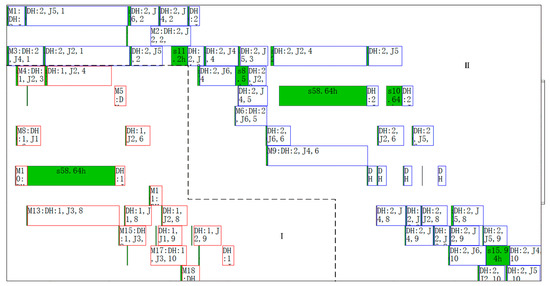
Figure 33.
Gantt chart of the machines after No.1 and No.2 schedule.
The dotted box I is a part of the Gantt chart of the No.1 schedule. The dotted box II is the Gantt chart of the No.2 schedule. It can be seen from Figure 33 that this is a typical sequential scheduling process based on the machines’ work calendars.
7. Discussion
Because NSGA-II has a fast non-dominated sorting algorithm, elite strategy, congestion degree and congestion degree comparison operator, it retains the best of all individuals in the offspring, which improves the precision of the optimization result, the operation speed and robustness of the algorithm.
However, the case study shows that the speed of operation needs to be further increased, and the calculation time is further reduced for actual production. The algorithm considers the mixed work calendars phenomenon in actual production, so that it is consistent with reality. Meanwhile, the algorithm results are more practical, and the method can also shorten the production cycle. The scheduling scheme proposed in this paper is not the best, but it is most suitable for the actual production process.
The next step is to continue to optimize the algorithm, further reduce the computation time and algorithm complexity, and obtain a better Pareto solution set.
8. Conclusions
In order to solve the sequential scheduling problem for FJSP with multi-objectives under mixed work calendars, an optimization method based on NSGA-II is proposed. The research conclusions are as follows.
- The algorithm can ensure feasibility of the scheduling scheme by accurately calculating adjusting start and end time, processing start and end time of each process through time reckoning functions in the process of arranging processes.
- The algorithm can increase the utilization rate of the machines in the sequential scheduling by the following two technologies. One is taking the time status of the machines of the previous schedule as the initial status of the machines of the next schedule. The other is adopting the “extrusion insertion” method to arrange each process.
- The proposed method can help to obtain an effective Pareto solution set of the sequential scheduling problem for FJSP with multi-objectives under mixed work calendars for the dispatcher to make decisions in acceptable time.
Author Contributions
Q.Z. designed and performed the experiments; L.S. provided analysis software; H.S. and M.W. analyzed the data; M.W. organized the data and wrote the paper.
Funding
This research was funded by the Research Fund for universities of Henan Province (grant number: 19A410001), and the Research Fund for Doctoral Program of Henan Polytechnic University (grant number: B2011-088).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Gao, L.; Pan, Q.K. A shuffled multi-swarm micro-migrating birds optimizer for a multi-resource-constrained flexible job shop scheduling problem. Inf. Sci. 2016, 372, 655–676. [Google Scholar] [CrossRef]
- Amirghasemi, M.; Zamani, R. An effective asexual genetic algorithm for solving the job shop scheduling problem. Comput. Ind. Eng. 2015, 83, 123–138. [Google Scholar] [CrossRef]
- Kundakci, N.; Kulak, O. Hybrid genetic algorithms for minimizing makespan in dynamic job shop scheduling problem. Comput. Ind. Eng. 2016, 96, 31–51. [Google Scholar] [CrossRef]
- Xiong, W.; Li, Z.B.; Hao, J.B. Research on methods to solve key problems of dynamic job shop scheduling. Modul. Mach. Tool Autom. Manuf. Tech. 2008, 7, 105–108, 112. [Google Scholar]
- Wu, Z.J.; Ning, R.X.; Wan, C.H. Research and Implementation of Dynamic Workday System in Job Shop Scheduling. Manuf. Autom. 2006, 4, 46–48, 75. [Google Scholar]
- Huang, Y.Y.; Li, K.Q.; Zheng, X.F. Job Shop Equal-Scale Batch Scheduling Algorithm Considering Shift Constraints. Sci. Technol. Eng. 2013, 1, 1–7, 16. [Google Scholar]
- Stefan, K.; Julia, R.; Jürgen, Z. Models and solution procedures for the resource-constrained project scheduling problem with general temporal constraints and calendars. Eur. J. Oper. Res. 2016, 251, 387–403. [Google Scholar]
- Wan, C.H.; Yan, Y.; Wu, Z.J.; Wang, G.X. Research on Dynamic Workday System for Dynamic Scheduling of Workshop Production. Modul. Mach. Tool Autom. Manuf. Tech. 2006, 3, 102–104. [Google Scholar]
- Wu, X.L.; Sun, S.D.; Yu, J.J.; Zhang, H.F. Research on Multi-Objective Flexible Job Shop Scheduling Optimization. Comput. Integr. Manuf. Syst. 2006, 5, 731–736. [Google Scholar]
- He, G.X. The application of multi-objective programming in the problem of transshipment of railway partial load freight. China Railw. Sci. 2007, 4, 111–116. [Google Scholar] [CrossRef]
- Zhou, G.G. Efficiency coefficient method for solving multi-objective optimization problems. J. Shanghai Inst. Meenanical Eng. 1987, 3, 103–108. [Google Scholar]
- Song, L.F.; Wei, G.; Wang, Q.S. Segmentation of Video Objects by Multi-Objective Optimization of Contour Positioning. J. Electron. Inf. Technol. 2002, 11, 1551–1558. [Google Scholar]
- Wang, B.G.; Rao, Y.Q.; Shao, X.Y.; Xu, C. A MOGA-based Algorithm for Sequencing a Mixed-model Fabrication/Assembly System. China Mech. Eng. 2009, 20, 1434–1438. [Google Scholar]
- Liu, A.J.; Yang, Y.; Xing, Q.S.; Lu, H.; Zhang, Y.D. Research on Niche Genetic Annealing Algorithm with Elite Strategy and Its Applications. China Mech. Eng. 2012, 23, 556–563. [Google Scholar]
- Zitzler, E.; Thiele, L. Multi-objective evolutionary algorithms: A comparative case study and the strength pareto approach. IEEE Trans. Evolut. Comput. 1993, 3, 257–271. [Google Scholar] [CrossRef]
- Zitzler, E.; Laumanns, M.; Thiele, L. SPEA2: Improving the strength pareto evolutionary algorithm for multi-objective optimization. In Proceedings of the Evolutionary Methods for Design, Optimization and Control with Applications to Industrial Problems (EUROGEN’2001), Athens, Greece, 19–21 September 2001; pp. 95–100. [Google Scholar]
- Ju, L.Y.; Yang, J.J.; Zhang, J.B.; Guo, L.L.; Li, S.B. Improved NSGA for Multi-Objective Flexible Job-Shop Scheduling Problem. Comput. Eng. Appl. 2019, 55, 260–265, 270. [Google Scholar]
- Qiu, Z.P.; Zhang, Y.X. Application of Improved Genetic Algorithm in Aircraft Overall Parameter Optimization. J. Beijing Univ. Aeronaut. Astronaut. 2008, 10, 1182–1185. [Google Scholar]
- Bekkar, A.; Guemri, O.; Bekrar, A.; Aissani, N.; Beldjilali, B.; Trentesaux, D. An Iterative Greedy Insertion Technique for Flexible Job Shop Scheduling Problem. IFAC-Pap. Online 2016, 12, 1956–1961. [Google Scholar] [CrossRef]
- Chen, H.P.; Gu, F.; Lu, B.Y.; Gu, C.S. Application of Self-Adaptive Multi-Objective Genetic Algorithm in Flexible Job Shop Scheduling. J. Syst. Simul. 2006, 18, 2271–2274, 2288. [Google Scholar]
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).