


Deep Learning Based Target Tracking Algorithm Model for Athlete Training Trajectory
Abstract
:1. Introduction
2. Related Works
3. Deep Learning-Based Target Long-Time Tracking Algorithm Model Design
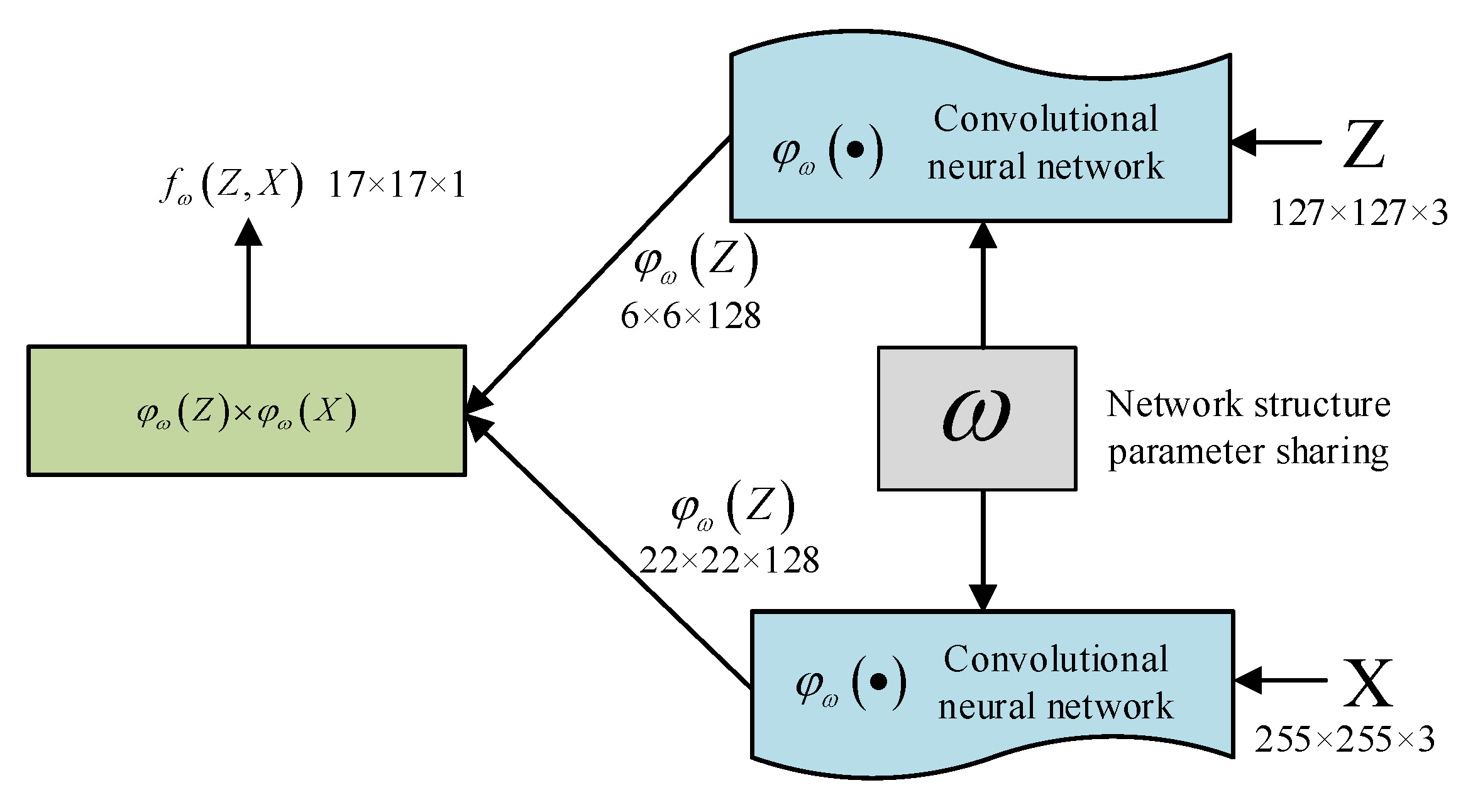
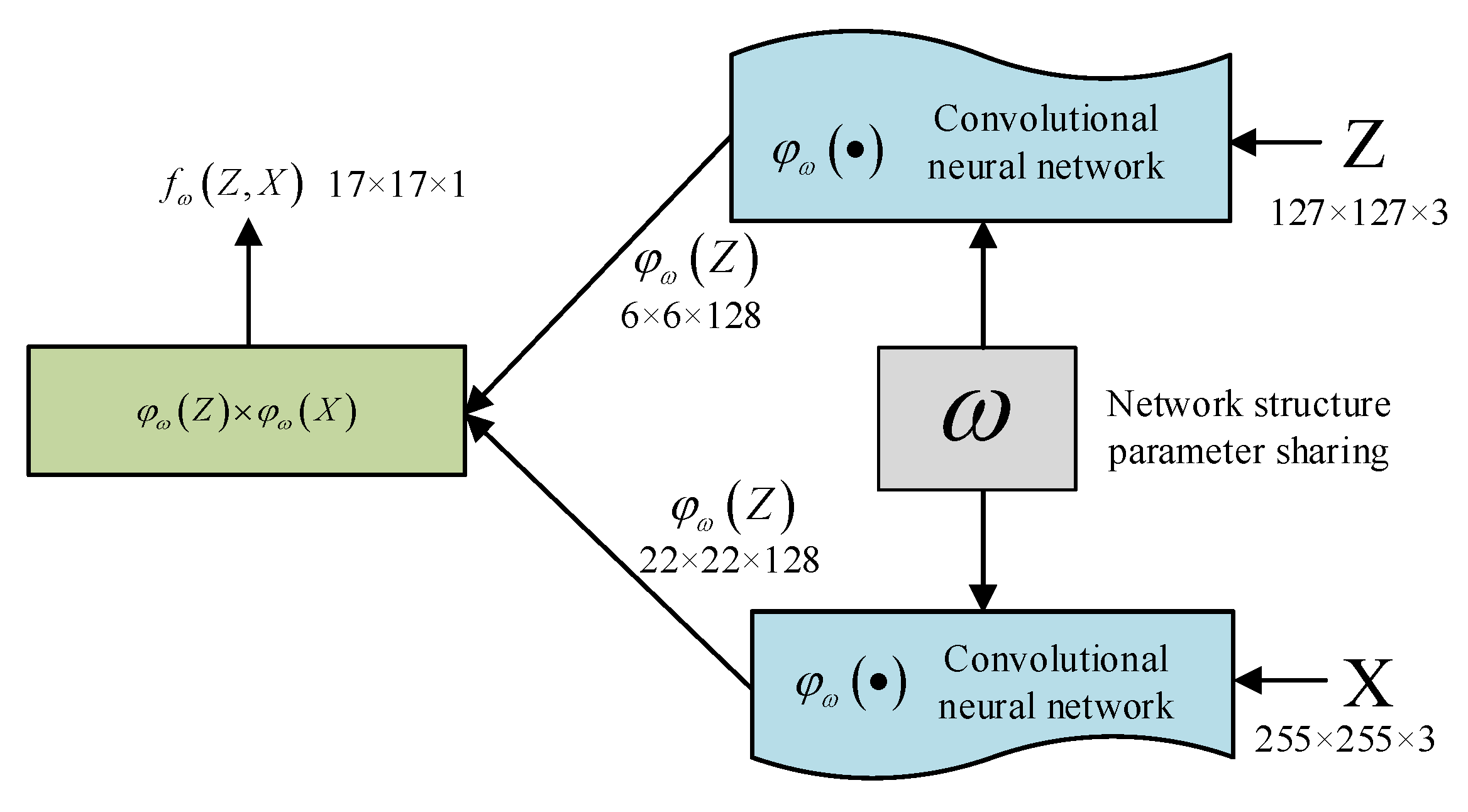
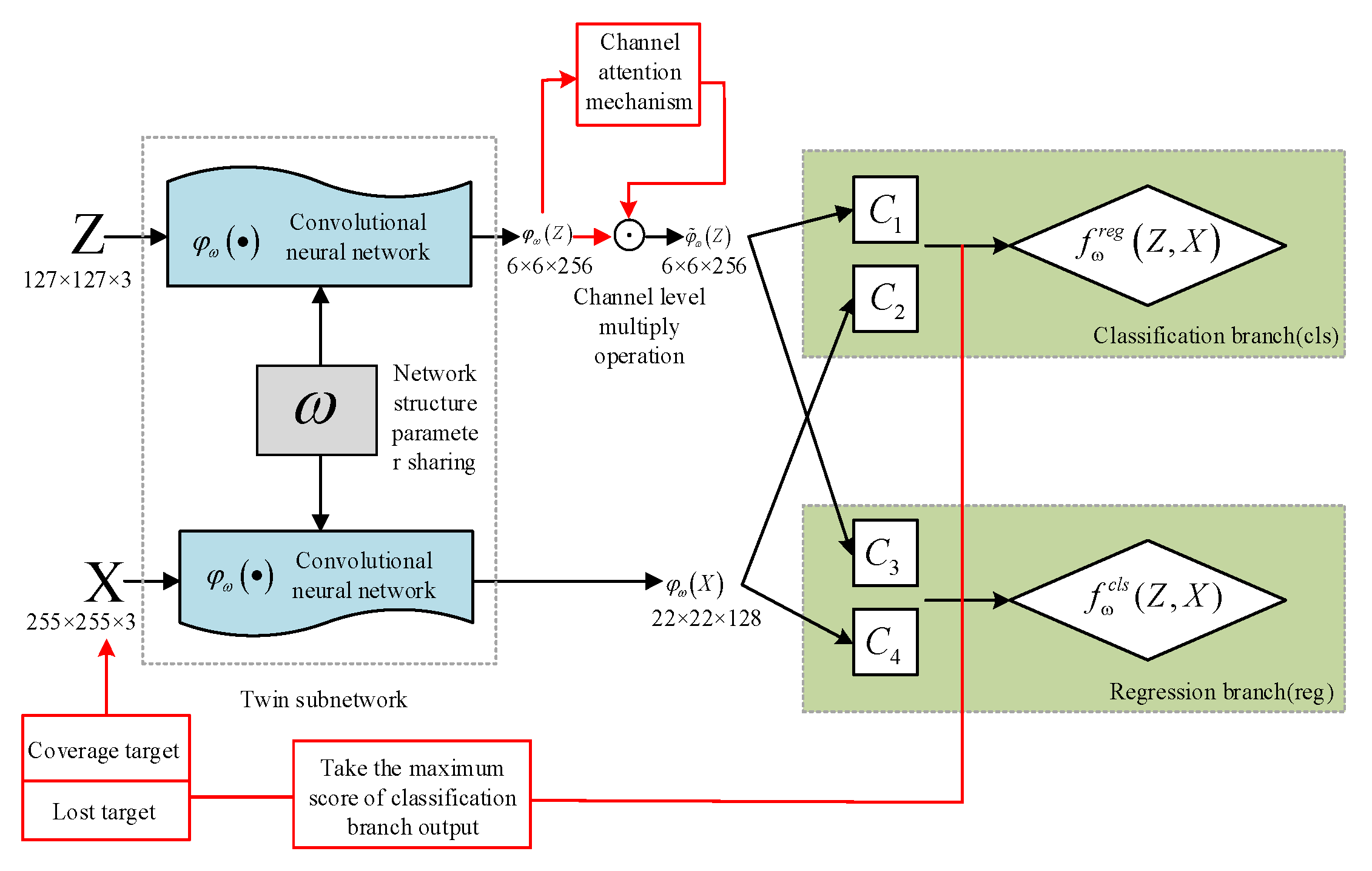
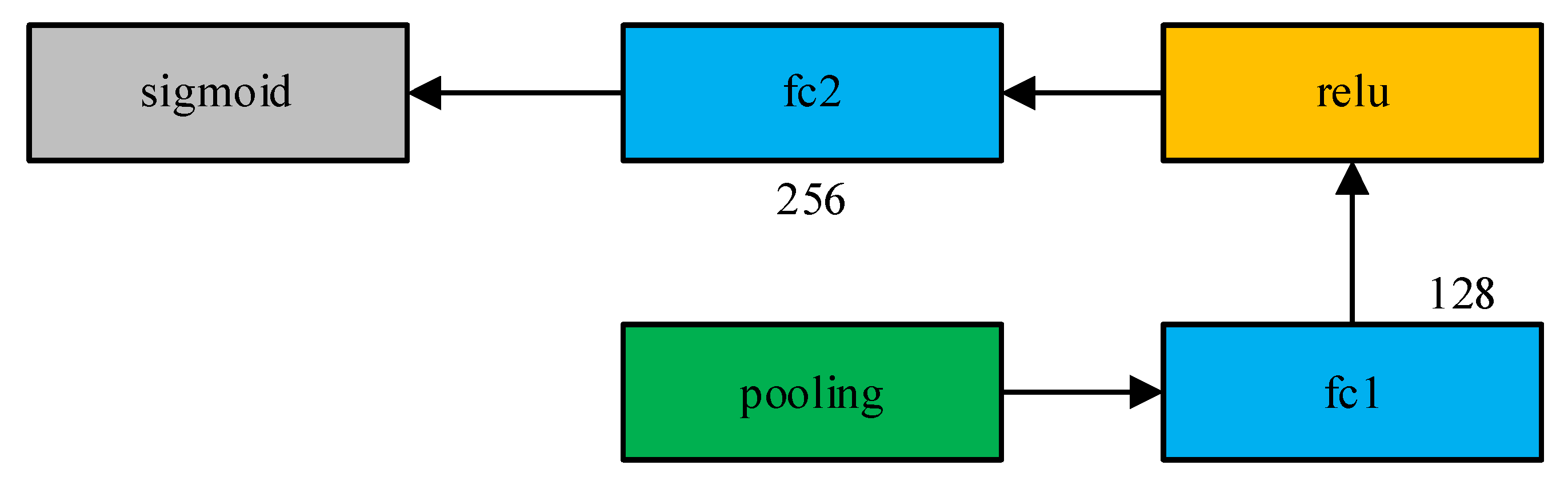
3.1. Deep Learning Tracking Algorithm Model Based on Offline Training
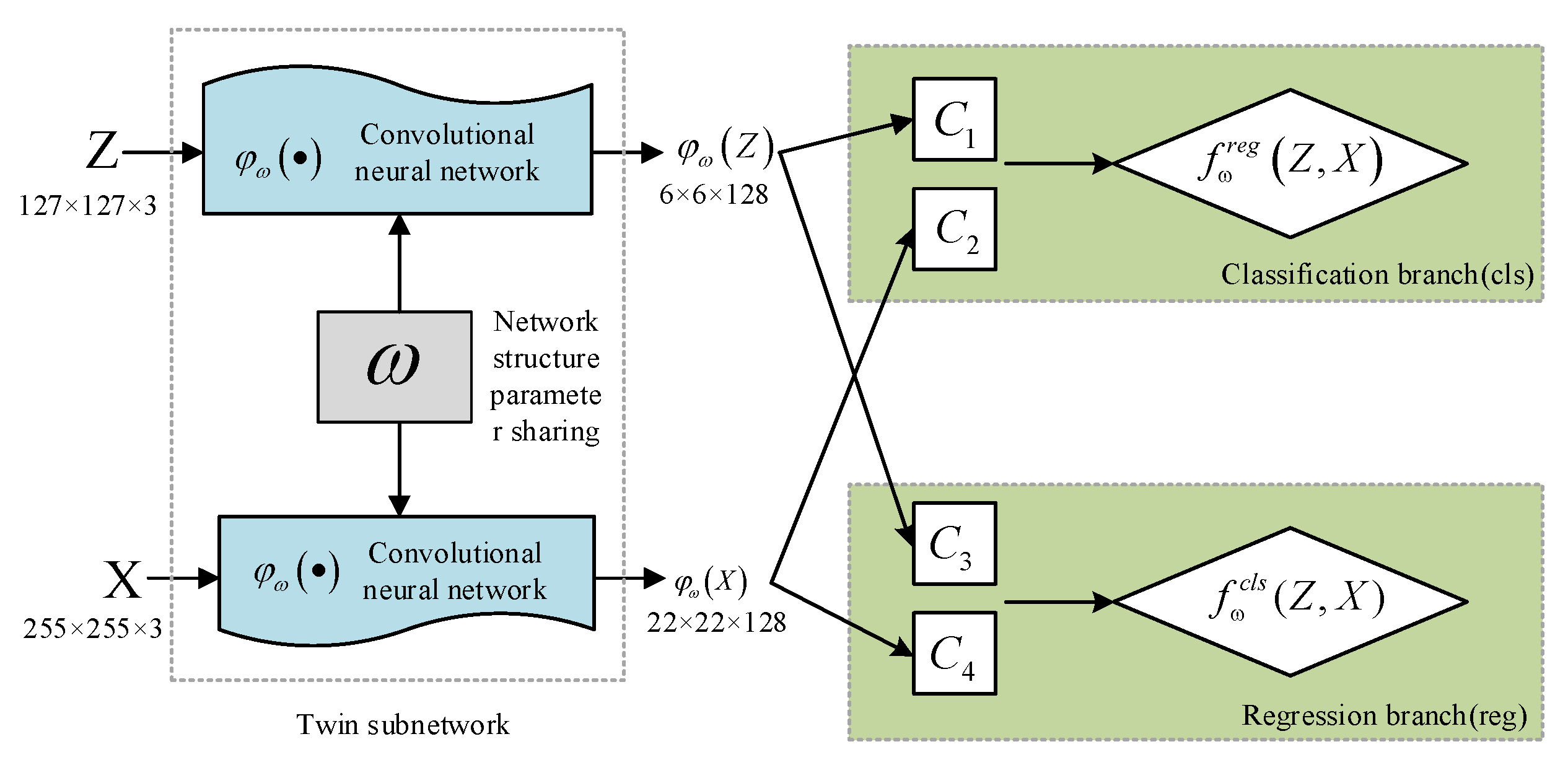
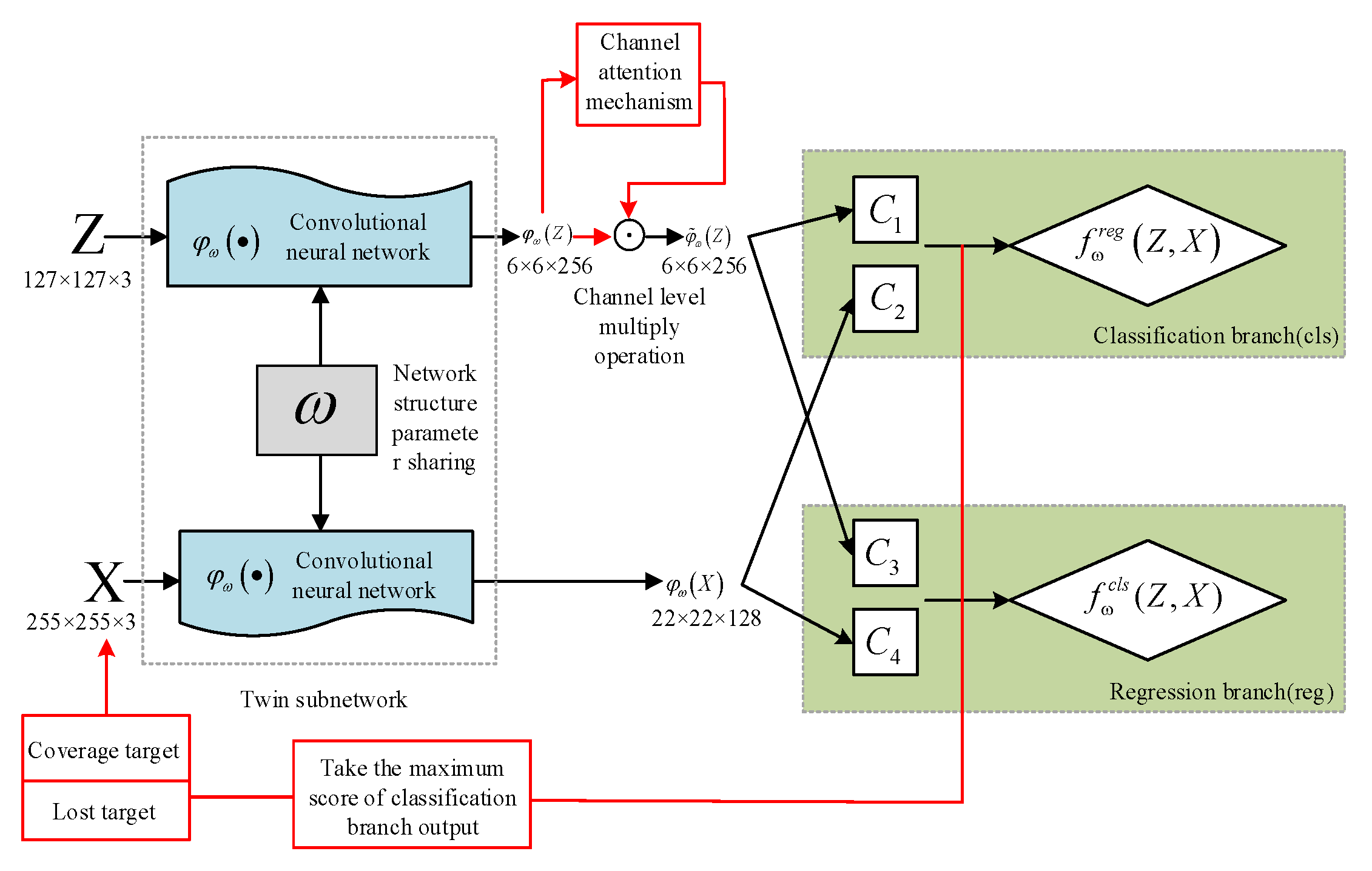
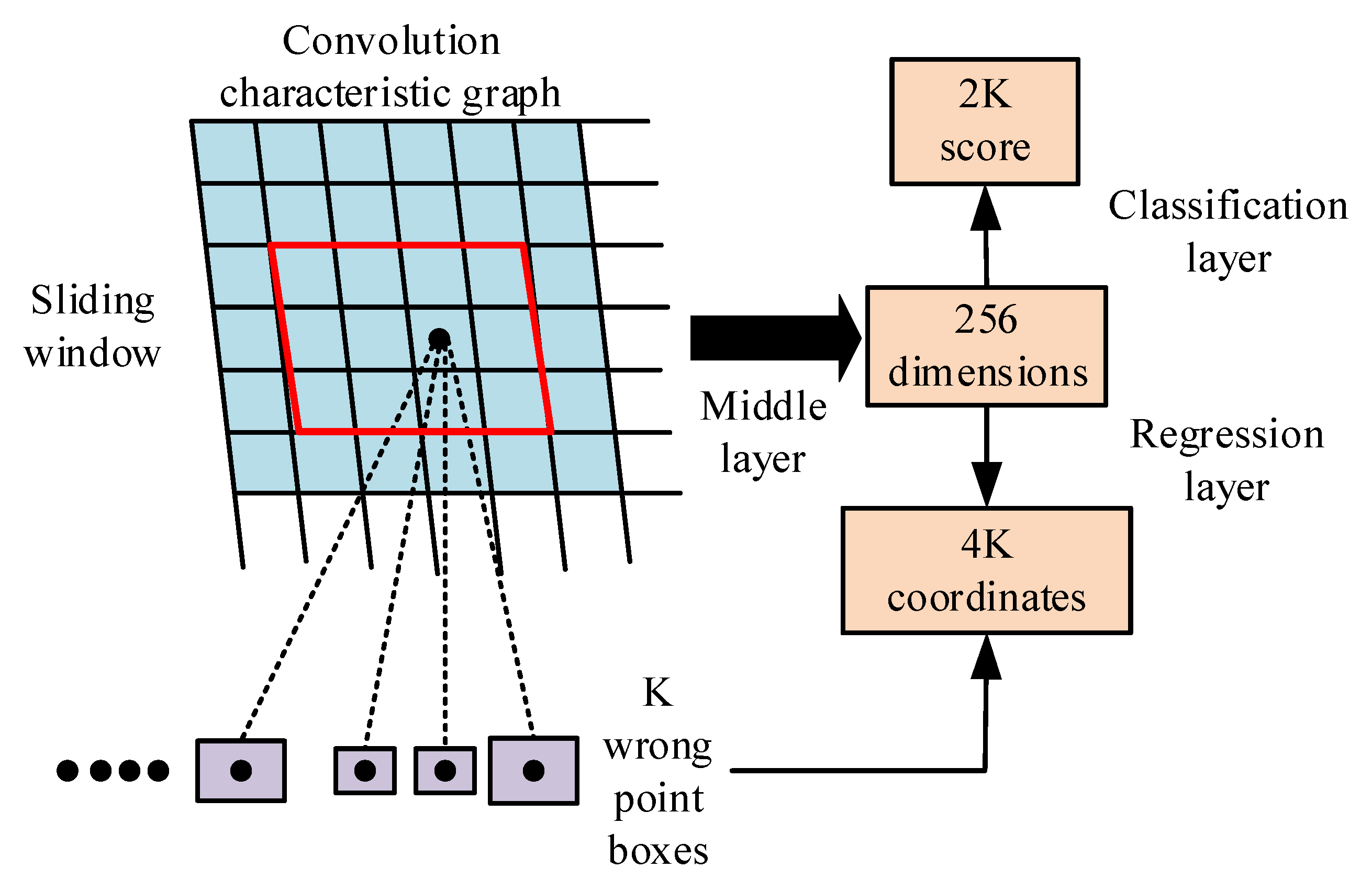
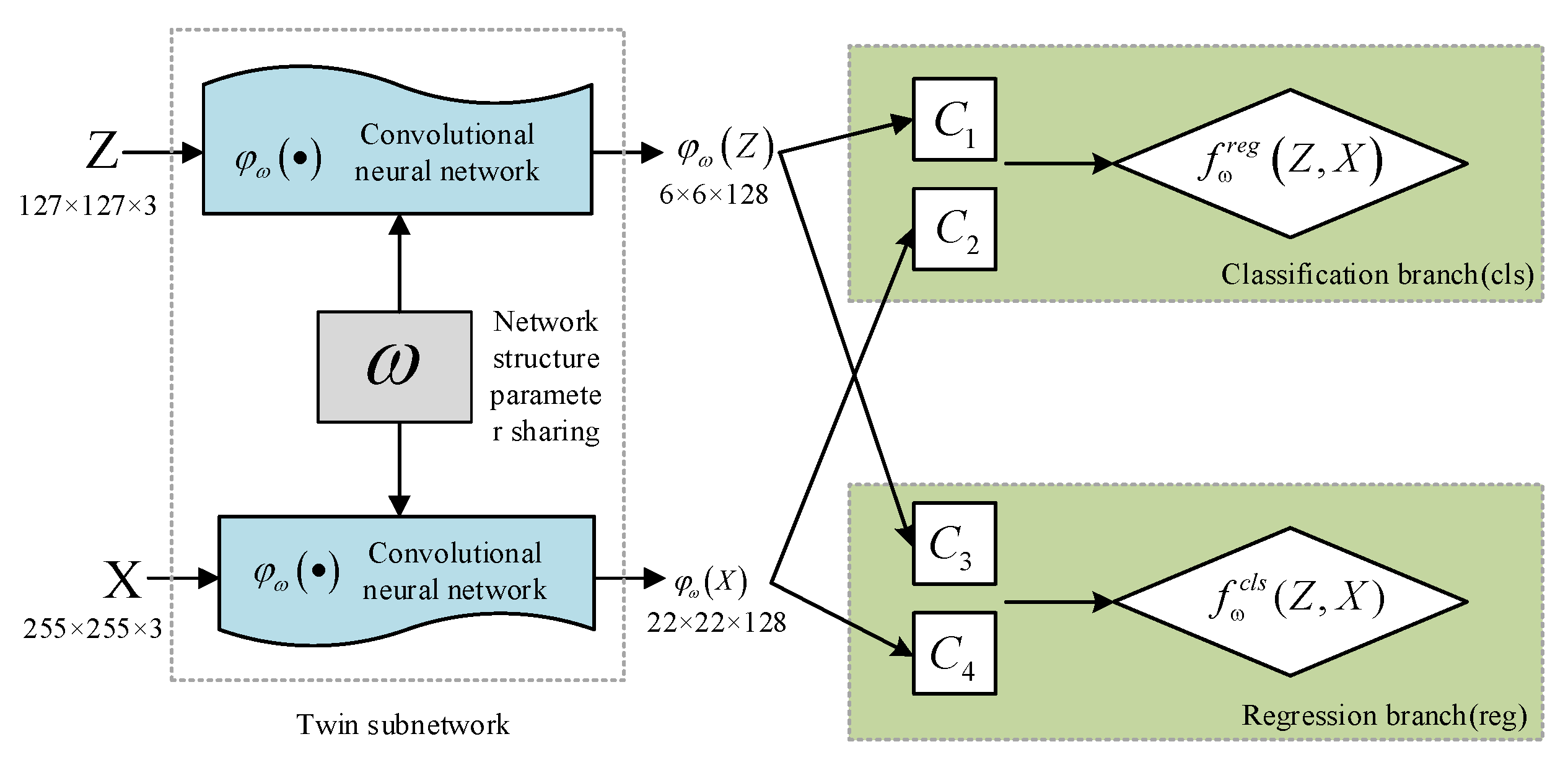
3.2. A SingleTarget Long-Time Tracking Framework Based on Improved SiamRPN
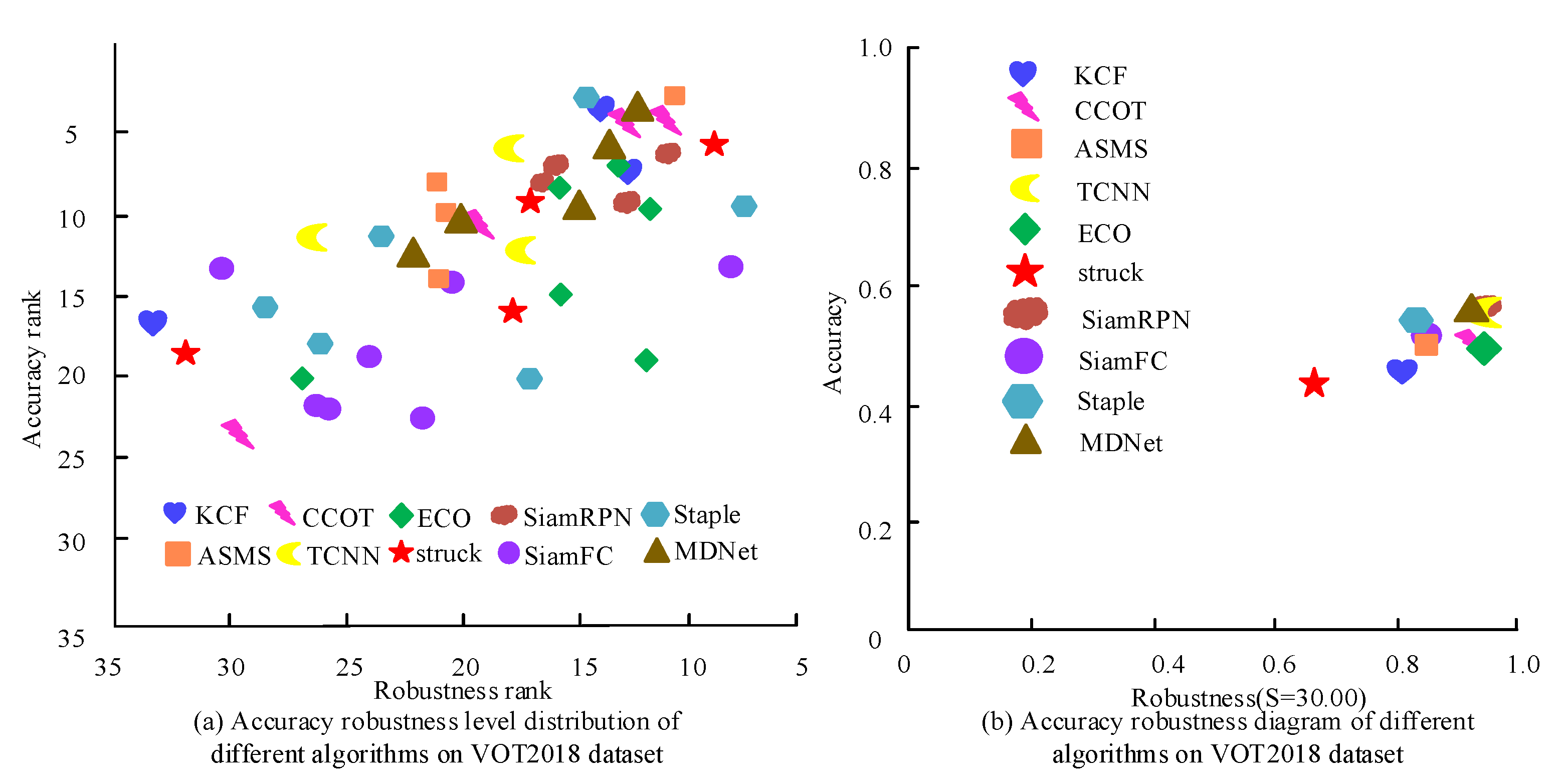
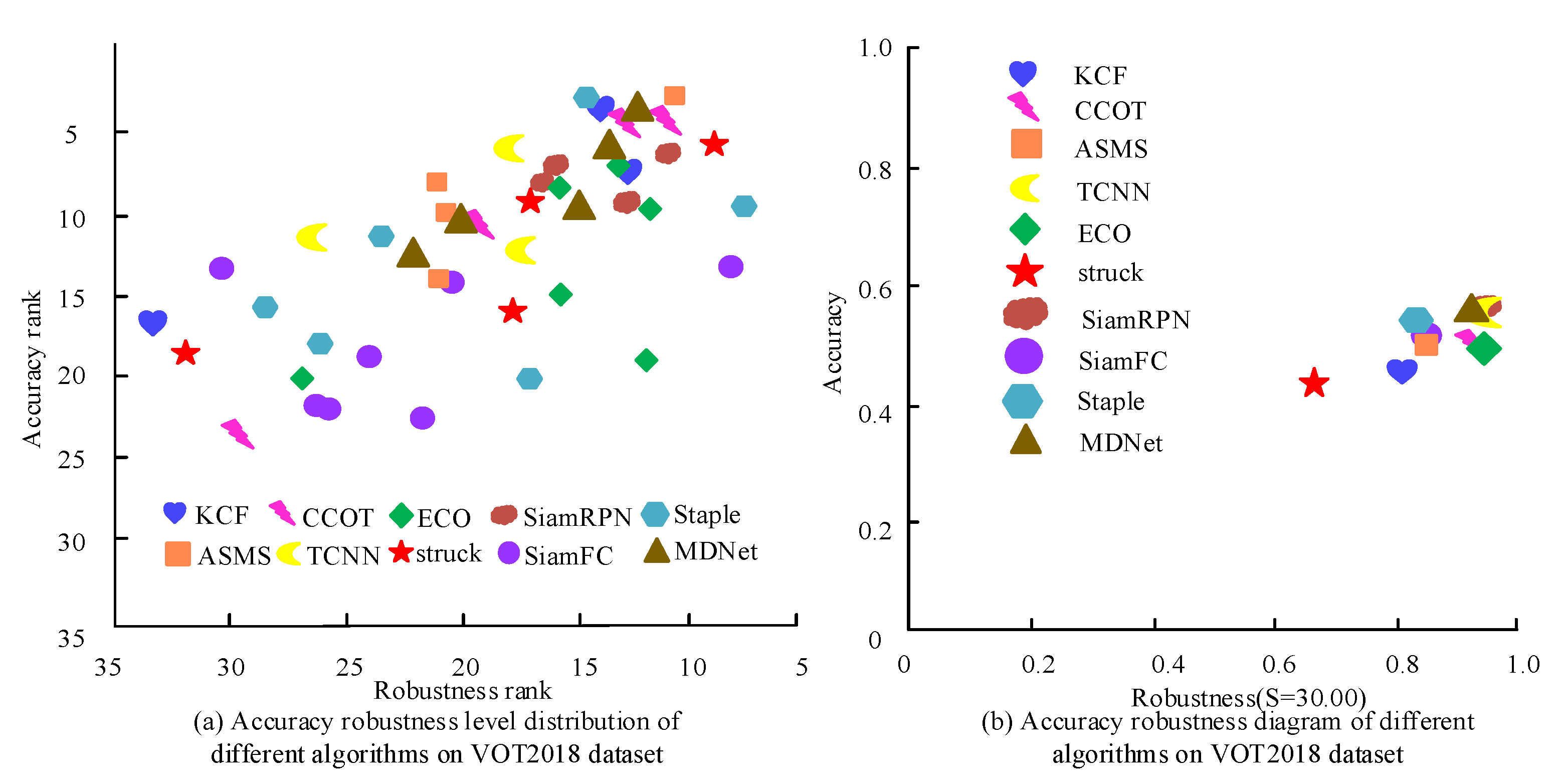
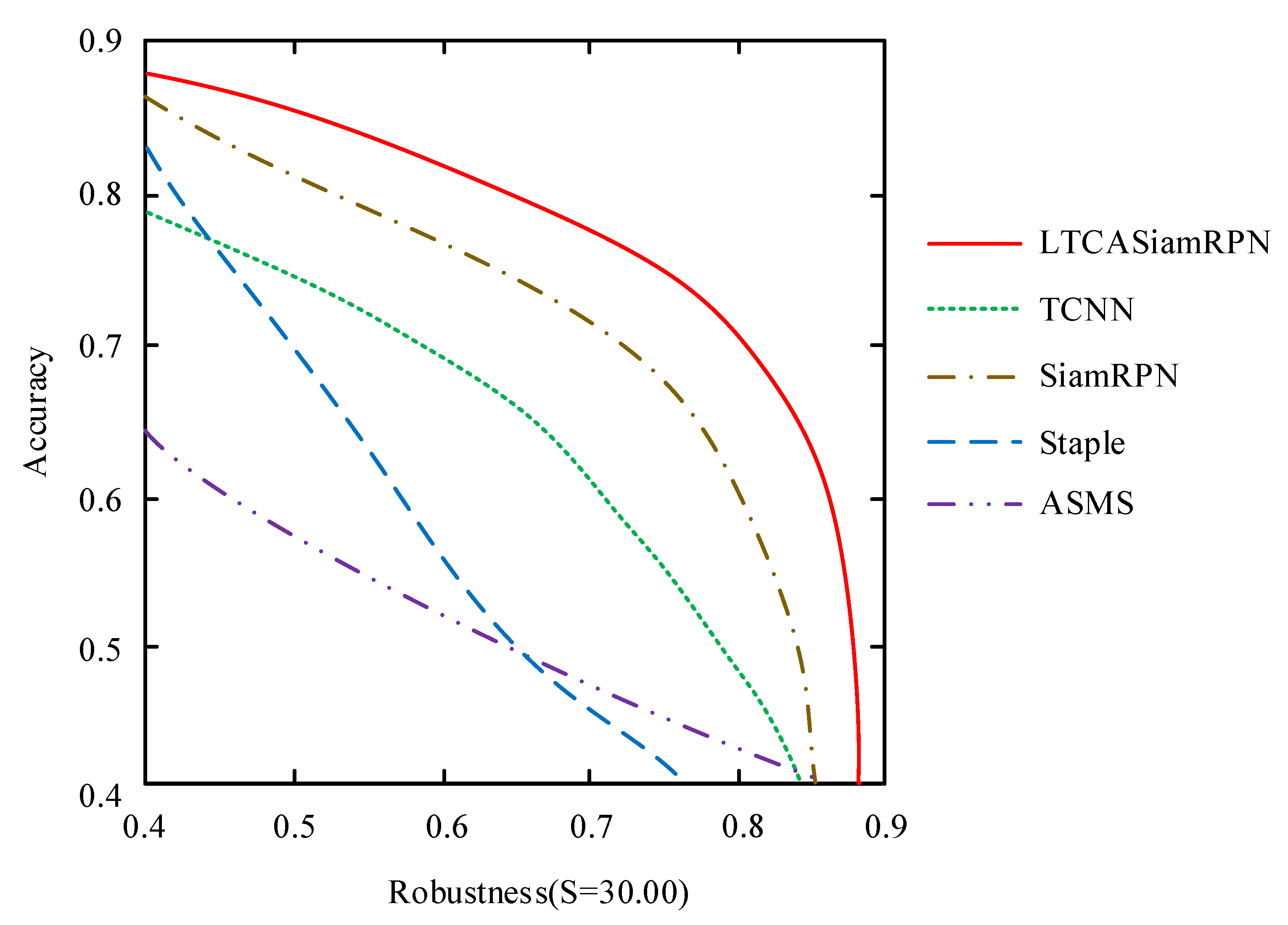
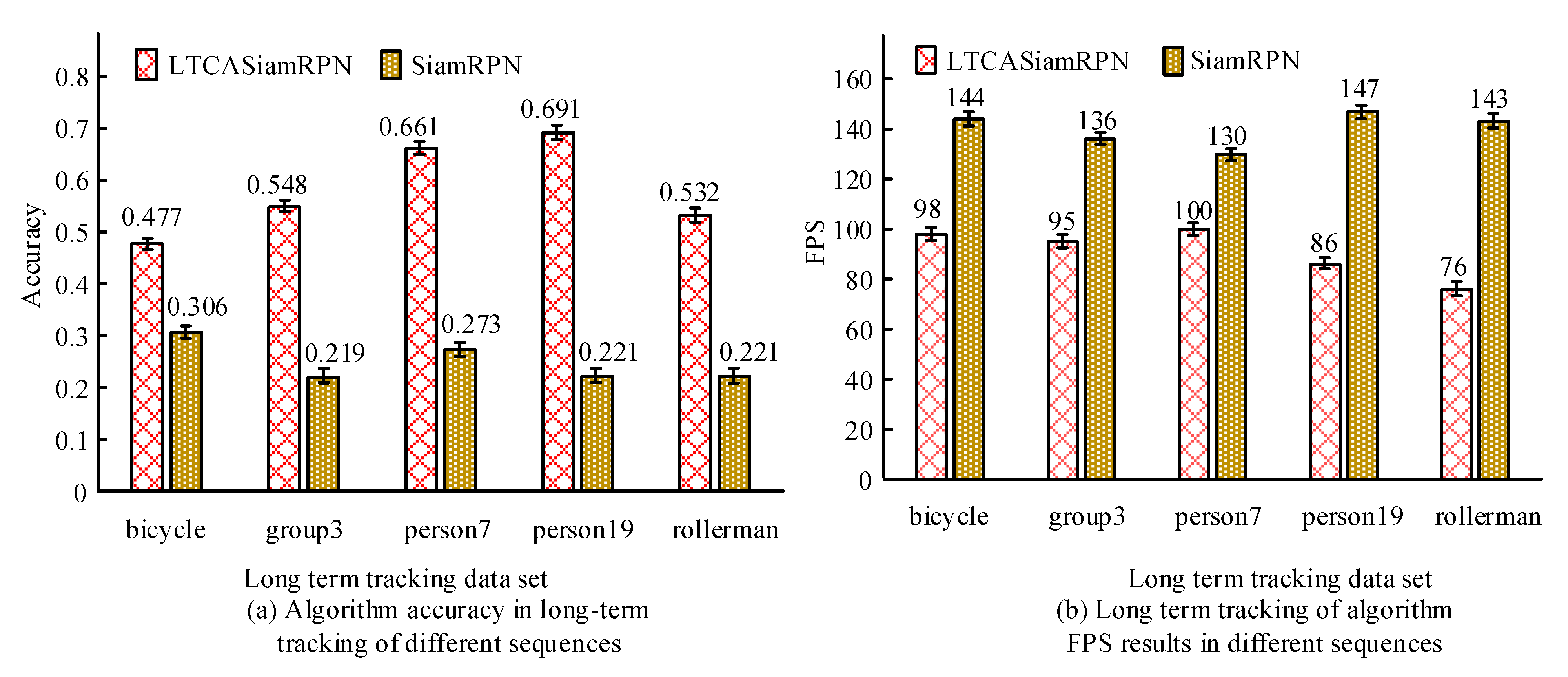
4. Performance Testing of the Target Long-Time Tracking Algorithm Model
5. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dergaa, I.; Saad, H.B.; Souissi, A.; Musa, S.; Abdulmalik, M.A.; Chamari, K. Olympic Games in COVID-19 times: Lessons learned with special focus on the upcoming FIFA World Cup Qatar 2022. Br. J. Sport. Med. 2022, 56, 654–656. [Google Scholar] [CrossRef] [PubMed]
- Bianco, S.; Napoletano, P.; Raimondi, A.; Rima, M. U-WeAr: User Recognition on Wearable Devices through Arm Gesture. IEEE Trans. Hum. Mach. Syst. 2022, 52, 713–724. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, P.; Chan, S.; Fang, K.; Fang, J. Densely connected Siamese network visual tracking. Ind. Robot. Int. J. Robot. Res. Appl. 2021, 48, 680–687. [Google Scholar]
- Xing, R.; Zhang, W.; Shu, L.; Zhang, B. An Autonomous Moving Target Tracking System for Rotor UAV 2021 International Conference on Robotics and Control Engineering; ACM: New York, NY, USA, 2021; pp. 48–53. [Google Scholar]
- Wu, C.; Fu, T.; Wang, Y.; Lin, Y.; Wang, Y.; Ai, D.; Fan, J.; Song, H.; Yang, J. Fusion Siamese network with drift correction for target tracking in ultrasound sequences. Phys. Med. Biol. 2022, 67, 045018. [Google Scholar] [CrossRef] [PubMed]
- Reddy, B.M.; Rahman, M. Novel Segmentation Technique for Target Tracking in Synthetic Aperture Radars. Int. J. Comput. Intell. Theory Pract. 2021, 16, 113–119. [Google Scholar]
- Kent, J.S.; Wamsley, C.C.; Flateau, D.; Ferguson, A. Unsupervised learning for target tracking and background subtraction in satellite imagery. SPIE 2021, 11746, 2021–2030. [Google Scholar]
- Koteswara, R.S.; Omkar Lakshmi Jagan, B.; Kavitha, L.M. Underwater target tracking in three-dimensional environment using intelligent sensor technique. Int. J. Pervasive Comput. Commun. 2022, 18, 319–334. [Google Scholar]
- Jang, J.; Lee, C.; Kim, J. Ambiguity Resolution Between Constant Velocity and Coordinated Turn Models for Multimodel Target Tracking. IEEE Sens. Lett. 2022, 6, 1–4. [Google Scholar] [CrossRef]
- Farahmand, S.; Fernandez, A.I.; Ahmed, F.S.; Rimm, D.L.; Chuang, J.H.; Reisenbichler, E.; Zarringhalam, K. Deep learning trained on hematoxylin and eosin tumor region of Interest predicts HER2 status and trastuzumab treatment response in HER2+ breast cancer. Mod. Pathol. 2022, 35, 44–51. [Google Scholar] [CrossRef]
- Sato, H.; Igarashi, H. Deep learning-based surrogate model for fast multi-material topology optimization of IPM motor. COMPEL Int. J. Comput. Math. Electr. Electron. Eng. 2022, 41, 900–914. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; Hawash, H.; Chakrabortty, R.K.; Ryan, M.; Elhoseny, M.; Song, H. ST-DeepHAR: Deep Learning Model for Human Activity Recognition in IoHT Applications. IEEE Internet Things J. 2021, 8, 4969–4979. [Google Scholar] [CrossRef]
- Kuutti, S.; Bowden, R.; Jin, Y.; Barber, P.; Fallah, S. A Survey of Deep Learning Applications to Autonomous Vehicle Control. IEEE Trans. Intell. Transp. Syst. 2021, 22, 712–733. [Google Scholar] [CrossRef]
- Duan, S.; Xiang, J.; Yu, X. A model-driven robust deep learning wireless transceiver. IET Commun. 2021, 15, 2252–2258. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, J.; Fan, R. An underwater single target tracking method using SiamRPN++ based on inverted residual bottleneck block. IEEE Access 2021, 99, 25148–25157. [Google Scholar] [CrossRef]
- An, N.; Yan, W.Q. Multitarget tracking using Siamese neural networks. ACM Trans. Multimed. Comput. Commun. Appl. 2021, 17, 1–16. [Google Scholar] [CrossRef]
- Subrahmanyam, K.; Kavitha, L.M.; Rao, S.K. Shifted Rayleigh filter: A novel estimation filtering algorithm for pervasive underwater passive target tracking for computation in 3D by bearing and elevation measurements. Int. J. Pervasive Comput. Commun. 2022, 18, 272–287. [Google Scholar]
- Ramkumar, M.; Yadav, R.; Yadav, S. Deep Learning Approach for Radical Sound Valuation of Fetal Weight. ECS Trans. 2022, 107, 2735–2747. [Google Scholar]
- Han, Y.; Lam, J.C.; Li, V.O.; Zhang, Q. A Domain-Specific Bayesian Deep-Learning Approach for Air Pollution Forecast. IEEE Trans. Big Data 2022, 8, 1034–1046. [Google Scholar] [CrossRef]
- Delande, E.; Houssineau, J.; Franco, J.; Frueh, C.; Clark, D.; Jah, M. A new multi-target tracking algorithm for a large number of orbiting objects. Adv. Space Res. 2019, 64, 645–667. [Google Scholar] [CrossRef]
- Yu, X.; Jin, G.; Li, J. Target Tracking Algorithm for System with Gaussian/Non-Gaussian Multiplicative Noise. IEEE Trans. Veh. Technol. 2019, 69, 90–100. [Google Scholar] [CrossRef]
- Ankel, V.; Shribak, D.; Chen, W.Y.; Heifetz, A. Classification of computed thermal tomography images with deep learning convolutional neural network. J. Appl. Phys. 2022, 131, 244901. [Google Scholar] [CrossRef]
- Alshra’a, A.S.; Farhat, A.; Seitz, J. Deep Learning Algorithms for Detecting Denial of Service Attacks in Software-Defined Networks. Procedia Comput. Sci. 2021, 191, 254–263. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Years | Research Contents |
|---|---|---|
| Reddy B.M. et al. [6] | 2021 | Application of image enhancement and sar image speckle suppression and automatic region segmentation extraction system |
| Kent J.S. et al. [7] | 2021 | Unsupervised machine learning in satellite images and its application in target tracking and background suppression |
| Abdel-Basset M. et al. [12] | 2021 | Application of supervised dual-channel model in human activity recognition |
| Jin Y. et al. [13] | 2021 | Application of deep learning methods in various complex driving and traffic environments |
| Duan S. et al [14]. | 2021 | Application of wireless transceiver in digital communication based on new deep learning |
| Wang Z. et al. [15] | 2021 | Application of SiamRPN++based on convolution neural network in underwater singletarget tracking |
| An N. et al. [16] | 2021 | Test of SiamRPN in multi-target tracking based on deep neural network |
| Koteswara R.S. et al. [8] | 2022 | Application of unscented Kalman filtering algorithm in ocean target tracking and environmental monitoring |
| Jang J. et al. [9] | 2022 | Application of probability density function and numerical model in multi-mode target tracking |
| Sato H. et al. [11] | 2022 | Agent model based on convolution neural network and prediction of multi-material topology optimization based on genetic algorithm |
| Subrahmanyam K. [17] | 2022 | Application of 3D target tracking technology in long-distance underwater target tracking |
| Tracking Algorithm | Robustness | Accuracy | FPS |
|---|---|---|---|
| ASMS | 35 | 0.476 | 132 |
| TCNN | 15 | 0.534 | 1 |
| struck | 80 | 0.405 | 15 |
| Staple | 42 | 0.522 | 45 |
| MDNet | 23 | 0.531 | 1 |
| ECO | 16 | 0.463 | 3 |
| KCF | 50 | 0.440 | 63 |
| CCOT | 22 | 0.475 | 0.3 |
| SiamFC | 37 | 0.502 | 88 |
| SiamRPN | 18 | 0.548 | 158 |
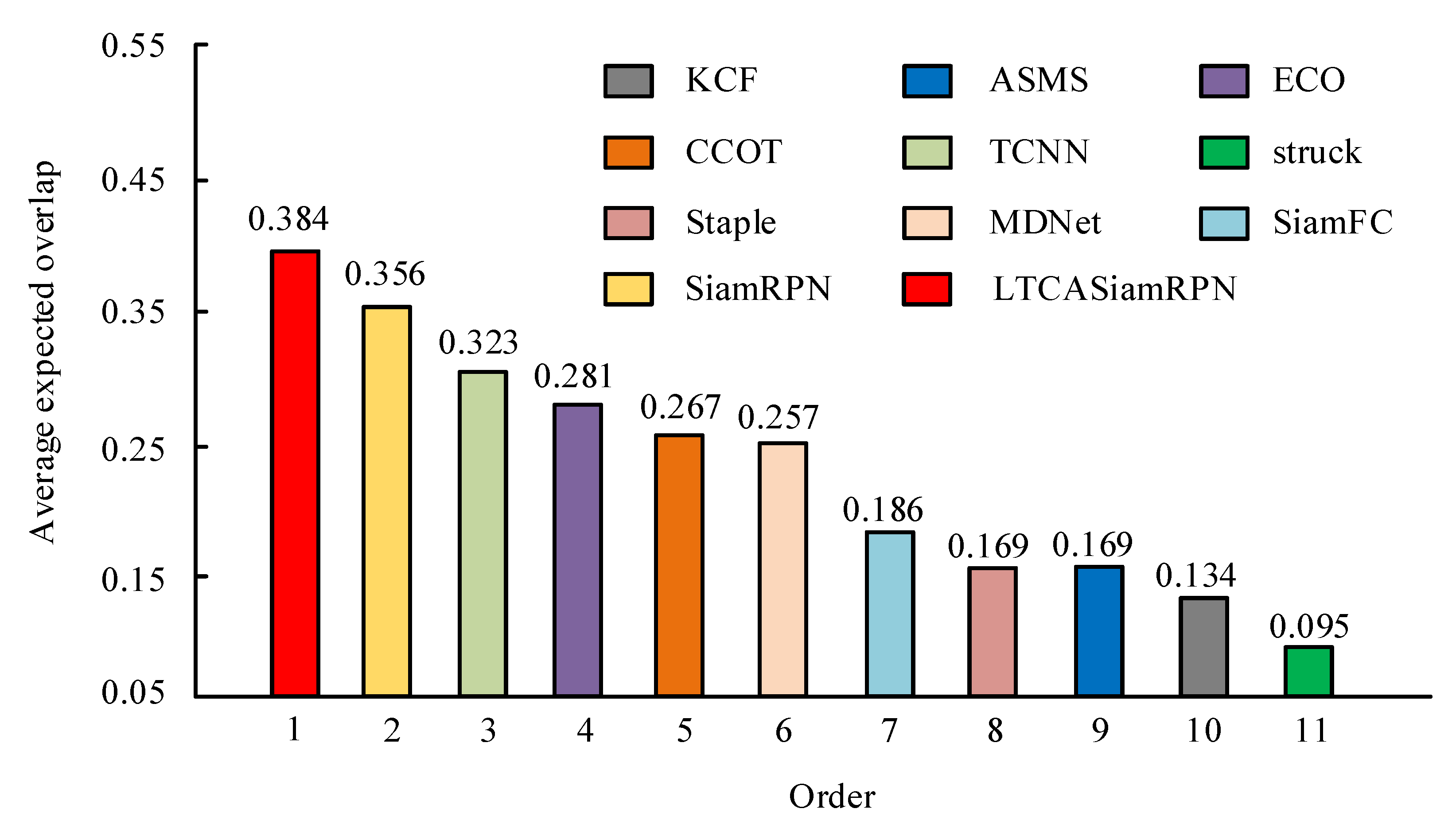
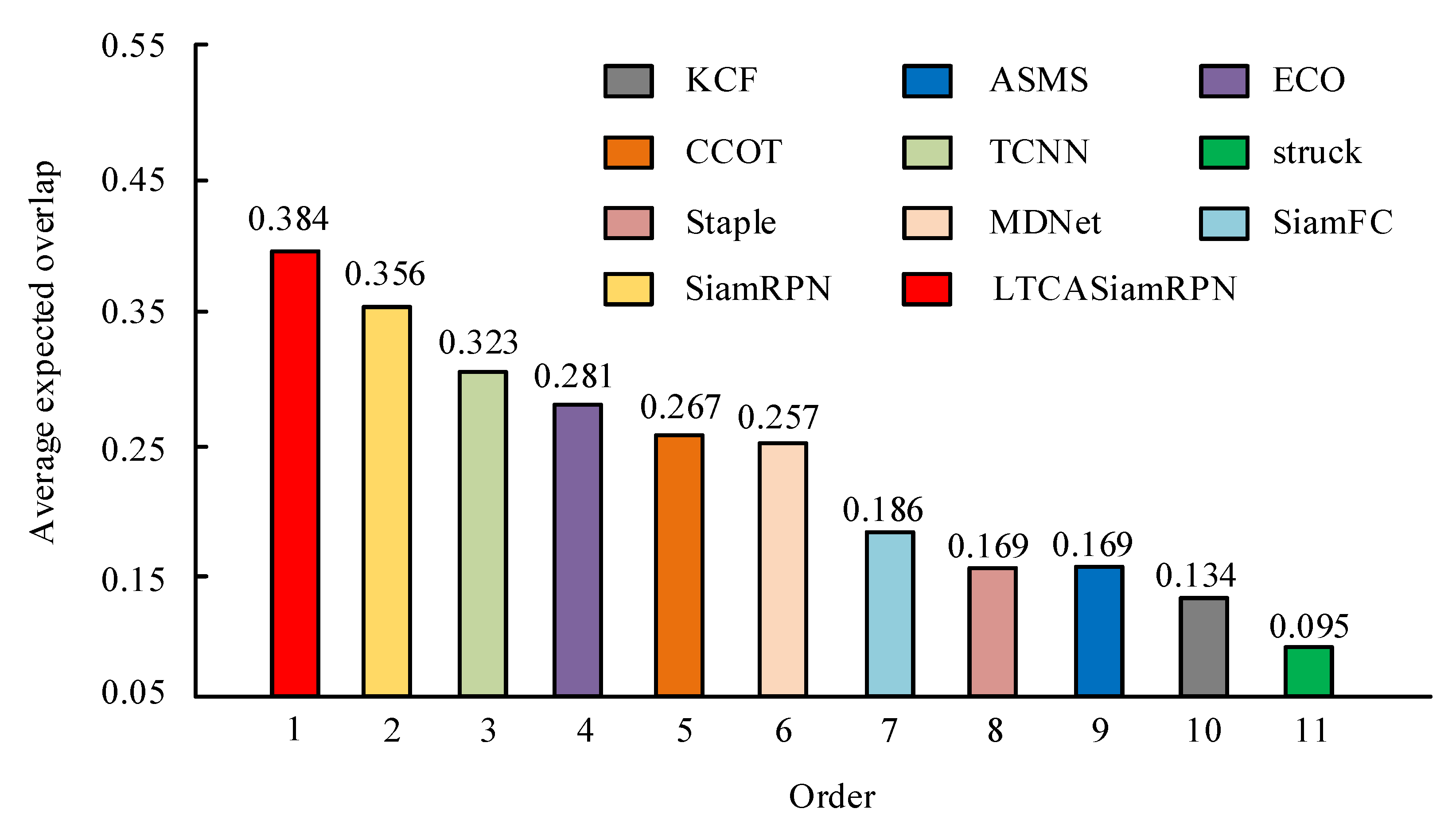
| Tracking Algorithm | Robustness | Accuracy | FPS | EAO |
|---|---|---|---|---|
| ASMS | 35 | 0.476 | 132 | 0.169 |
| TCNN | 15 | 0.534 | 1 | 0.323 |
| struck | 80 | 0.405 | 15 | 0.095 |
| Staple | 42 | 0.522 | 45 | 0.169 |
| MDNet | 23 | 0.531 | 1 | 0.257 |
| ECO | 16 | 0.463 | 3 | 0.281 |
| KCF | 50 | 0.440 | 63 | 0.134 |
| CCOT | 22 | 0.475 | 0.3 | 0.267 |
| SiamFC | 37 | 0.502 | 88 | 0.186 |
| SiamRPN | 18 | 0.548 | 158 | 0.356 |
| improved SiamRPN | 17 | 0.578 | 118 | 0.384 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y. Deep Learning Based Target Tracking Algorithm Model for Athlete Training Trajectory. Processes 2022, 10, 2710. https://doi.org/10.3390/pr10122710
Wang Y. Deep Learning Based Target Tracking Algorithm Model for Athlete Training Trajectory. Processes. 2022; 10(12):2710. https://doi.org/10.3390/pr10122710
Chicago/Turabian StyleWang, Yue. 2022. "Deep Learning Based Target Tracking Algorithm Model for Athlete Training Trajectory" Processes 10, no. 12: 2710. https://doi.org/10.3390/pr10122710
APA StyleWang, Y. (2022). Deep Learning Based Target Tracking Algorithm Model for Athlete Training Trajectory. Processes, 10(12), 2710. https://doi.org/10.3390/pr10122710