Abstract
Globally, there is a substantial unmet need to diagnose various diseases effectively. The complexity of the different disease mechanisms and underlying symptoms of the patient population presents massive challenges in developing the early diagnosis tool and effective treatment. Machine learning (ML), an area of artificial intelligence (AI), enables researchers, physicians, and patients to solve some of these issues. Based on relevant research, this review explains how machine learning (ML) is being used to help in the early identification of numerous diseases. Initially, a bibliometric analysis of the publication is carried out using data from the Scopus and Web of Science (WOS) databases. The bibliometric study of 1216 publications was undertaken to determine the most prolific authors, nations, organizations, and most cited articles. The review then summarizes the most recent trends and approaches in machine-learning-based disease diagnosis (MLBDD), considering the following factors: algorithm, disease types, data type, application, and evaluation metrics. Finally, in this paper, we highlight key results and provides insight into future trends and opportunities in the MLBDD area.
1. Introduction
In medical domains, artificial intelligence (AI) primarily focuses on developing the algorithms and techniques to determine whether a system’s behavior is correct in disease diagnosis. Medical diagnosis identifies the disease or conditions that explain a person’s symptoms and signs. Typically, diagnostic information is gathered from the patient’s history and physical examination [1]. It is frequently difficult due to the fact that many indications and symptoms are ambiguous and can only be diagnosed by trained health experts. Therefore, countries that lack enough health professionals for their populations, such as developing countries like Bangladesh and India, face difficulty providing proper diagnostic procedures for their maximum population of patients [2]. Moreover, diagnosis procedures often require medical tests, which low-income people often find expensive and difficult to afford.
As humans are prone to error, it is not surprising that a patient may have overdiagnosis occur more often. If overdiagnosis, problems such as unnecessary treatment will arise, impacting individuals’ health and economy [3]. According to the National Academics of Science, Engineering, and Medicine report of 2015, the majority of people will encounter at least one diagnostic mistake during their lifespan [4]. Various factors may influence the misdiagnosis, which includes:
- lack of proper symptoms, which often unnoticeable
- the condition of rare disease
- the disease is omitted mistakenly from the consideration
Machine learning (ML) is used practically everywhere, from cutting-edge technology (such as mobile phones, computers, and robotics) to health care (i.e., disease diagnosis, safety). ML is gaining popularity in various fields, including disease diagnosis in health care. Many researchers and practitioners illustrate the promise of machine-learning-based disease diagnosis (MLBDD), which is inexpensive and time-efficient [5]. Traditional diagnosis processes are costly, time-consuming, and often require human intervention. While the individual’s ability restricts traditional diagnosis techniques, ML-based systems have no such limitations, and machines do not get exhausted as humans do. As a result, a method to diagnose disease with outnumbered patients’ unexpected presence in health care may be developed. To create MLBDD systems, health care data such as images (i.e., X-ray, MRI) and tabular data (i.e., patients’ conditions, age, and gender) are employed [6].
Machine learning (ML) is a subset of AI that uses data as an input resource [7]. The use of predetermined mathematical functions yields a result (classification or regression) that is frequently difficult for humans to accomplish. For example, using ML, locating malignant cells in a microscopic image is frequently simpler, which is typically challenging to conduct just by looking at the images. Furthermore, since advances in deep learning (a form of machine learning), the most current study shows MLBDD accuracy of above 90% [5]. Alzheimer’s disease, heart failure, breast cancer, and pneumonia are just a few of the diseases that may be identified with ML. The emergence of machine learning (ML) algorithms in disease diagnosis domains illustrates the technology’s utility in medical fields.
Recent breakthroughs in ML difficulties, such as imbalanced data, ML interpretation, and ML ethics in medical domains, are only a few of the many challenging fields to handle in a nutshell [8]. In this paper, we provide a review that highlights the novel uses of ML and DL in disease diagnosis and gives an overview of development in this field in order to shed some light on this current trend, approaches, and issues connected with ML in disease diagnosis. We begin by outlining several methods to machine learning and deep learning techniques and particular architecture for detecting and categorizing various forms of disease diagnosis.
Motivation
The purpose of this review is to provide insights to recent and future researchers and practitioners regarding machine-learning-based disease diagnosis (MLBDD) that will aid and enable them to choose the most appropriate and superior machine learning/deep learning methods, thereby increasing the likelihood of rapid and reliable disease detection and classification in diagnosis. Additionally, the review aims to identify potential studies related to the MLBDD. In general, the scope of this study is to provide the proper explanation for the following questions:
- 1.
- What are some of the diseases that researchers and practitioners are particularly interested in when evaluating data-driven machine learning approaches?
- 2.
- Which MLBDD datasets are the most widely used?
- 3.
- Which machine learning and deep learning approaches are presently used in health care to classify various forms of disease?
- 4.
- Which architecture of convolutional neural networks (CNNs) is widely employed in disease diagnosis?
- 5.
- How is the model’s performance evaluated? Is that sufficient?
In this paper, we summarize the different machine learning (ML) and deep learning (DL) methods utilized in various disease diagnosis applications. The remainder of the paper is structured as follows. In Section 2, we discuss the background and overview of ML and DL, whereas in Section 3, we detail the article selection technique. Section 4 includes bibliometric analysis. In Section 5, we discuss the use of machine learning in various disease diagnoses, and in Section 6, we identify the most frequently utilized ML methods and datatypes based on the linked research. In Section 7, we discuss the findings, anticipated trends, and problems. Finally, Section 9 concludes the article with a general conclusion.
2. Basics and Background
Machine learning (ML) is an approach that analyzes data samples to create main conclusions using mathematical and statistical approaches, allowing machines to learn without programming. Arthur Samuel presented machine learning in games and pattern recognition algorithms to learn from experience in 1959, which was the first time the important advancement was recognized. The core principle of ML is to learn from data in order to forecast or make decisions depending on the assigned task [9]. Thanks to machine learning (ML) technology, many time-consuming jobs may now be completed swiftly and with minimal effort. With the exponential expansion of computer power and data capacity, it is becoming simpler to train data-driven ML models to predict outcomes with near-perfect accuracy. Several papers offer various sorts of ML approaches [10,11].
The ML algorithms are generally classified into three categories such as supervised, unsupervised, and semisupervised [10]. However, ML algorithms can be divided into several subgroups based on different learning approaches, as shown in Figure 1. Some of the popular ML algorithms include linear regression, logistic regression, support vector machines (SVM), random forest (RF), and naïve Bayes (NB) [10].
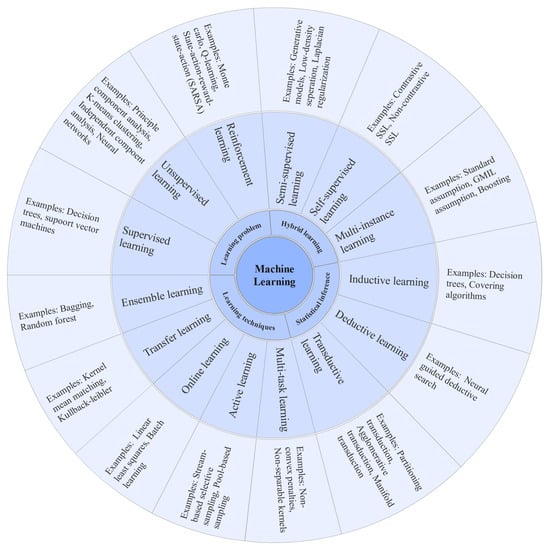
Figure 1.
Different types of machine learning algorithms.
2.1. Machine Learning Algorithms
This section provides a comprehensive review of the most frequently used machine learning algorithms in disease diagnosis.
2.1.1. Decision Tree
The decision tree (DT) algorithm follows divide-and-conquer rules. In DT models, the attribute may take on various values known as classification trees; leaves indicate distinct classes, whereas branches reflect the combination of characteristics that result in those class labels. On the other hand, DT can take continuous variables called regression trees. C4.5 and EC4.5 are the two famous and most widely used DT algorithms [12]. DT is used extensively by following reference literature: [13,14,15,16].
2.1.2. Support Vector Machine
For classification and regression-related challenges, support vector machine (SVM) is a popular ML approach. SVM was introduced by Vapnik in the late twentieth century [17]. Apart from disease diagnosis, SVMs have been extensively employed in various other disciplines, including facial expression recognition, protein fold, distant homology discovery, speech recognition, and text classification. For unlabeled data, supervised ML algorithms are unable to perform. Using a hyperplane to find the clustering among the data, SVM can categorize unlabeled data. However, SVM output is not nonlinearly separable. To overcome such problems, selecting appropriate kernel and parameters is two key factors when applying SVM in data analysis [11].
2.1.3. K-Nearest Neighbor
K-nearest neighbor (KNN) classification is a nonparametric classification technique invented in 1951 by Evelyn Fix and Joseph Hodges. KNN is suitable for classification as well as regression analysis. The outcome of KNN classification is class membership. Voting mechanisms are used to classify the item. Euclidean distance techniques are utilized to determine the distance between two data samples. The projected value in regression analysis is the average of the values of the KNN [18].
2.1.4. Naïve Bayes
The naïve Bayes (NB) classifier is a Bayesian-based probabilistic classifier. Based on a given record or data point, it forecasts membership probability for each class. The most probable class is the one having the greatest probability. Instead of predictions, the NB classifier is used to project likelihood [11].
2.1.5. Logistic Regression
Logistic regression (LR) is an ML approach that is used to solve classification issues. The LR model has a probabilistic framework, with projected values ranging from 0 to 1. Examples of LR-based ML include spam email identification, online fraud transaction detection, and malignant tumor detection. The cost function, often known as the sigmoid function, is used by LR. The sigmoid function transforms every real number between 0 and 1 [19].
2.1.6. AdaBoost
Yoav Freund and Robert Schapire developed Adaptive Boosting, popularly known as AdaBoost. AdaBoost is a classifier that combines multiple weak classifiers into a single classifier. AdaBoost works by giving greater weight to samples that are harder to classify and less weight to those that are already well categorized. It may be used for categorization as well as regression analysis [20].
2.2. Deep Learning Overview
Deep learning (DL) is a subfield of machine learning (ML) that employs multiple layers to extract both higher and lower-level information from input (i.e., images, numerical value, categorical values). The majority of contemporary DL models are built on artificial neural networks (ANN), notably convolutional neural networks (CNN), which may be integrated with other DL models, including generative models, deep belief networks, and the Boltzmann machine. Deep learning may be classified into three types: supervised, semisupervised, and unsupervised. Deep neural networks (DNN), reinforcement learning, and recurrent neural networks (RNN) are some of the most prominent DL architectures (RNN) [21].
Each level in DL learns to convert its input data to the succeeding layers while learning distinct data attributes. For example, the raw input may be a pixel matrix in image recognition applications, and the first layers may detect the image’s edges. On the other hand, the second layer will construct and encode the nose and eyes, and the third layer may recognize the face by merging all of the information gathered from the previous two layers [6].
In medical fields, DL has enormous promise. Radiology and pathology are two well-known medical fields that have widely used DL in disease diagnosis over the years [22]. Furthermore, collecting valuable information from molecular state and determining disease progression or therapy sensitivity are practical uses of DL that are frequently unidentified by human investigations [23].
Convolutional Neural Network
Convolutional neural networks (CNNs) are a subclass of artificial neural networks (ANNs) that are extensively used in image processing. CNN is widely employed in face identification, text analysis, human organ localization, and biological image detection or recognition [24]. Since the initial development of CNN in 1989, a different type of CNN has been proposed that has performed exceptionally well in disease diagnosis over the last three decades. A CNN architecture comprises three parts: input layer, hidden layer, and output layer. The intermediate levels of any feedforward network are known as hidden layers, and the number of hidden layers varies depending on the type of architecture. Convolutions are performed in hidden layers, which contain dot products of the convolution kernel with the input matrix. Each convolutional layer provides feature maps used as input by the subsequent layers. Following the concealed layer are more layers, such as pooling and fully connected layers [21]. Several CNN models have been proposed throughout the years, and the most extensively used and popular CNN models are shown in Figure 2.
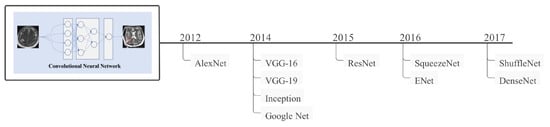
Figure 2.
Some of the most well-known CNN models, along with their development time frames.
In general, it may be considered that ML and DL have grown substantially throughout the years. The increased computational capability of computers and the enormous number of data available inspire academics and practitioners to employ ML/DL more efficiently. A schematic overview of machine learning and deep learning algorithms and their development chronology is shown in Figure 3, which may be a helpful resource for future researchers and practitioner.
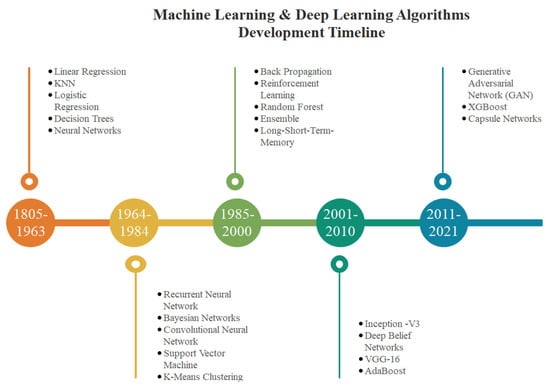
Figure 3.
Illustration of machine learning and deep learning algorithms development timeline.
2.3. Performance Evaluations
This section describes the performance measures used in reference literature. Performance indicators, including accuracy, precision, recall, and F1 score, are widely employed in disease diagnosis. For example, lung cancer can be categorized as true positive () or true-negative () if individuals are diagnosed correctly, while it can be categorized into false positive () or false negative () if misdiagnosed. The most widely used metrics are described below [10].
Accuracy (Acc): The accuracy denotes total correctly identifying instances among all of the instances. Accuracy can be calculated using following formulas:
Precision (): Precision is measured as the proportion of precisely predicted to all expected positive observations.
Recall (): The proportion of overall relevant results that the algorithm properly recognizes is referred to as recall.
Sensitivity (): Sensitivity denotes only true positive measure considering total instances and can be measured as follows:
Specificity (): It identifies how many true negatives are appropriately identified and calculated as follows:
F-measure: The F1 score is the mean of accuracy and recall in a harmonic manner. The highest F score is 1, indicating perfect precision and recall score.
Area under curve (AUC): The area under the curve represents the models’ behaviors in different situations. The AUC can be calculated as follows:
where and denotes positive and negative data samples and is the rating of the ith positive samples.
3. Article Selection
3.1. Identification
The Scopus and Web of Science (WOS) databases are utilized to find original research publications. Due to their high quality and peer review paper index, Scopus and WOS are prominent databases for article searching, as many academics and scholars utilized them for systematic review [25,26]. Using keywords along with Boolean operators, the title search was carried out as follows:
“disease” AND (“diagnsois” OR “Supprot vector machine” OR “SVM” OR “KNN” OR “K-nearest neighbor” OR “logistic regression” OR “K-means clustering” OR “random forest” OR “RF” OR “adaboost” OR “XGBoost”, “decision tree” OR “neural network” OR “NN” OR “artificial neural network” OR “ANN” OR “convolutional neural network” OR “CNN” OR “deep neural network” OR “DNN” OR “machine learning" or “adversarial network” or “GAN”).
The initial search yielded 16,209 and 2129 items, respectively, from Scopus and Web of Science (WOS).
3.2. Screening
Once the search period was narrowed to 2012–2021 and only peer-reviewed English papers were evaluated, the total number of articles decreased to 9117 for Scopus and 1803 for WOS, respectively.
3.3. Eligibility and Inclusion
These publications were chosen for further examination if they are open access and are journal articles. There were 1216 full-text articles (724 from the Scopus database and 492 from WOS). Bibliographic analysis was performed on all 1216 publications. One investigator (Z.S.) imported the 1216 article information as excel CSV data for future analysis. Excel duplication functions were used to identify and eliminate duplicates. Two independent reviewers (M.A. and Z.S.) examined the titles and abstracts of 1192 publications. Disagreements were settled through conversation. We omitted studies that were not relevant to machine learning but were relevant to disease diagnosis or vice versa.
After screening the titles and abstracts, the complete text of 102 papers was examined, and all 102 articles satisfied all inclusion requirements. Factors that contributed to the article’s exclusion from the full-text screening includes:
- 1.
- Inaccessibility of the entire text
- 2.
- Nonhuman studies, book chapters, reviews
- 3.
- Incomplete information related to test result
Figure 4 shows the flow diagram of the systematic article selection procedure used in this study.
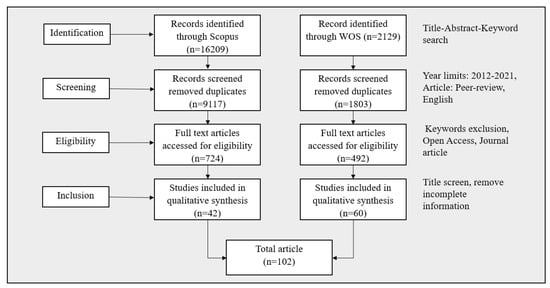
Figure 4.
MLBDD article selection procedure used in this study.
4. Bibliometric Analysis
The bibliometric study in this section was carried out using reference literature gathered from the Scopus and WOS databases. The bibliometric study examines publications in terms of the subject area, co-occurrence network, year of publication, journal, citations, countries, and authors.
4.1. Subject Area
Many research disciplines have uncovered machine learning-based disease diagnostics throughout the years. Figure 5 depicts a schematic representation of machine learning-based disease detection spread across several research fields. According to the graph, computer science (40%) and engineering (31.2%) are two dominating fields that vigorously concentrated on MLBDD.
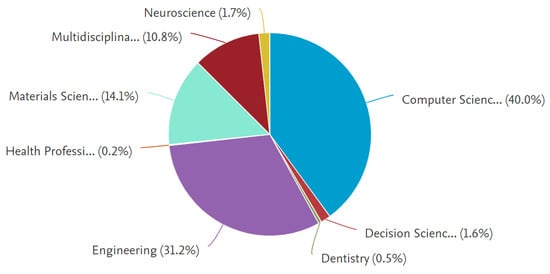
Figure 5.
Distribution of articles by subject area.
4.2. Co-Occurrence Network
Co-occurrence of keywords provides an overview of how the keywords are interconnected or used by the researchers. Figure 6 displays the co-occurrence network of the article’s keywords and their connection, developed by VOSviewer software. The figure shows that some of the significant clusters include neural networks (NN), decision trees (DT), machine learning (ML), and logistic regression (LR). Each cluster is also connected with other keywords that fall under that category. For instance, the NN cluster contains support vector machine (SVM), Parkinson’s disease, and classification.
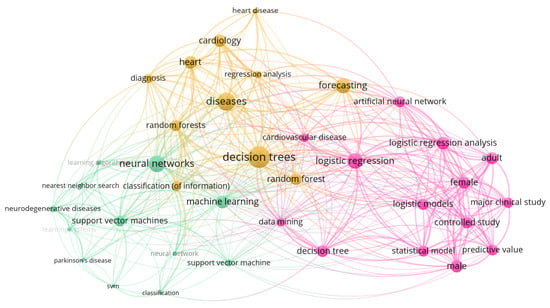
Figure 6.
Bibliometric map representing co-occurrence analysis of keywords in network visualization.
4.3. Publication by Year
The exponential growth of journal publications is observed from 2017. Figure 7 displays the number of publications between 2012 to 2021 based on the Scopus and WOS data. Note that while the image may not accurately depict the MLBDD’s real contribution, it does illustrate the influence of MLBDD over time.
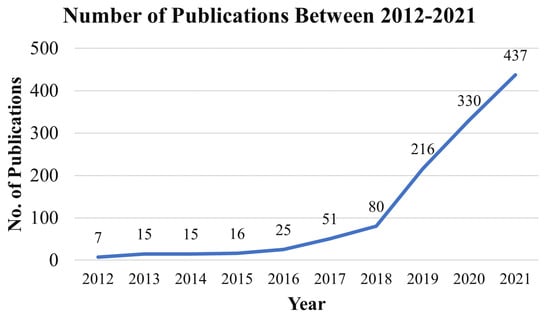
Figure 7.
Publications of machine-learning-based disease diagnosis (MLBDD) by year.
4.4. Publication by Journal
We investigated the most prolific journals in MLBDD domains based on our referred literature.The top ten journals and the number of articles published in the last ten years are depicted in Figure 8. IEEE Access and Scientific Reports are the most productive journals that published 171 and 133 MLBDD articles, respectively.
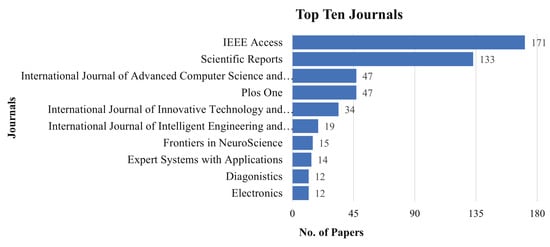
Figure 8.
Publications by journals.
4.5. Publication by Citations
Citations are one of the primary indicators of an article’s effect. Here, we have identified the top ten cited articles using the R Studio tool. Table 1 summarizes the top articles that achieved the highest citation during the year between 2012 to 2021. Note that Google Scholar and other online databases may have various indexing procedures and times; therefore, the citations in this manuscript may differ from the number of citations shown in this study. The table shows that published articles by [27] earned the most citations (257), with 51.4 citations per year, followed by Gray [28]’s article, which obtained 218 citations. It is assumed that all the authors included in Table 1 are among those prominent authors that contributed to MLBDD.

Table 1.
Top ten cited papers published in MLBDD in between 2012–2021 based on Scopus and WOS database.
4.6. Publication by Countries
Figure 9 displayed that China published the most publications in MLBDD, total 259 articles. USA and India are placed 2nd and 3rd, respectively, as they published 139 and 103 papers related to MLBDD. Interestingly, four out of the top ten productive countries are from Asia: China, India, Korea, and Japan.
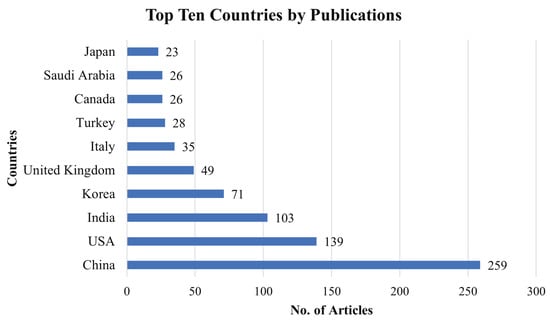
Figure 9.
Top ten countries that contributed to MLBDD literature.
4.7. Publication by Author
According to Table 2, author Kim J published the most publications (20 out of 1216). Wang Y and Li J Ranked 2nd and 3rd by publishing 19 and 18 articles, respectively. As shown in Table 2, the number of papers produced by the top 10 authors ranges between 15–20.
Table 2.
Top ten authors based on total number of publications.
5. Machine Learning Techniques for Different Disease Diagnosis
Many academics and practitioners have used machine learning (ML) approaches in disease diagnosis. This section describes many types of machine-learning-based disease diagnosis (MLBDD) that have received much attention because of their importance and severity. For example, due to the global relevance of COVID-19, several studies concentrated on COVID-19 disease detection using ML from 2020 to the present, which also received greater priority in our study. Severe diseases such as heart disease, kidney disease, breast cancer, diabetes, Parkinson’s, Alzheimer’s, and COVID-19 are discussed briefly, while other diseases are covered briefly under the “other disease”.
5.1. Heart Disease
Most researchers and practitioners use machine learning (ML) approaches to identify cardiac disease [37,38]. Ansari et al. (2011), for example, offered an automated coronary heart disease diagnosis system based on neurofuzzy integrated systems that yield around 89% accuracy [37]. One of the study’s significant weaknesses is the lack of a clear explanation for how their proposed technique would work in various scenarios such as multiclass classification, big data analysis, and unbalanced class distribution. Furthermore, there is no explanation about the credibility of the model’s accuracy, which has lately been highly encouraged in medical domains, particularly to assist users who are not from the medical domains in understanding the approach.
Rubin et al. (2017) uses deep-convolutional-neural-network-based approaches to detect irregular cardiac sounds. The authors of this study adjusted the loss function to improve the training dataset’s sensitivity and specificity. Their suggested model was tested in the 2016 PhysioNet computing competition. They finished second in the competition, with a final prediction of 0.95 specificity and 0.73 sensitivity [39].
Aside from that, deep-learning (DL)-based algorithms have lately received attention in detecting cardiac disease. Miao and Miao et al. (2018), for example, offered a DL-based technique to diagnosing cardiotocographic fetal health based on a multiclass morphologic pattern. The created model is used to differentiate and categorize the morphologic pattern of individuals suffering from pregnancy complications. Their preliminary computational findings include accuracy of 88.02%, a precision of 85.01%, and an F-score of 0.85 [40]. During that study, they employed multiple dropout strategies to address overfitting problems, which finally increased training time, which they acknowledged as a tradeoff for higher accuracy.
Although ML applications have been widely employed in heart disease diagnosis, no research has been conducted that addressed the issues associated with unbalanced data with multiclass classification. Furthermore, the model’s explainability during final prediction is lacking in most cases. Table 3 summarizes some of the cited publications that employed ML and DL approaches in the diagnosis of cardiac disease. However, further information about machine-learning-based cardiac disease diagnosis can be found in [5].
Table 3.
Referenced literature that considered machine-learning-based heart disease diagnosis.
5.2. Kidney Disease
Kidney disease, often known as renal disease, refers to nephropathy or kidney damage. Patients with kidney disease have decreased kidney functional activity, which can lead to kidney failure if not treated promptly. According to the National Kidney Foundation, 10% of the world’s population has chronic kidney disease (CKD), and millions die each year due to insufficient treatment. The recent advancement of ML- and DL-based kidney disease diagnosis may provide a possibility for those countries that are unable to handle the kidney disease diagnostic-related tests [49]. For instance, Charleonnan et al. (2016) used publicly available datasets to evaluate four different ML algorithms: K-nearest neighbors (KNN), support vector machine (SVM), logistic regression (LR), and decision tree classifiers and received the accuracy of 98.1%, 98.3%, 96.55%, and 94.8%, respectively [50]. Aljaaf et al. (2018) conducted a similar study. The authors tested different ML algorithms, including RPART, SVM, LOGR, and MLP, using a comparable dataset, CKD, as used by [50], and found that MLP performed best (98.1 percent) in identifying chronic kidney disease [51]. To identify chronic kidney disease, Ma et al. (2020) utilizes a collection of datasets containing data from many sources [52]. Their suggested heterogeneous modified artificial neural network (HMANN) model obtained an accuracy of 87–99%.
Table 4 summarizes some of the cited publications that employed ML and DL approaches to diagnose kidney disease.
Table 4.
Referenced literature that considered machine-learning-based kidney disease diagnosis.
5.3. Breast Cancer
Many scholars in the medical field have proposed machine-learning (ML)-based breast cancer analysis as a potential solution to early-stage diagnosis. Miranda and Felipe (2015), for example, proposed fuzzy-logic-based computer-aided diagnosis systems for breast cancer categorization. The advantage of fuzzy logic over other classic ML techniques is that it can minimize computational complexity while simulating the expert radiologist’s reasoning and style. If the user inputs parameters such as contour, form, and density, the algorithm offers a cancer categorization based on their preferred method [57]. Miranda and Felipe (2015)’s proposed model had an accuracy of roughly 83.34%. The authors employed an approximately equal ratio of images for the experiment, which resulted in improved accuracy and unbiased performance. However, as the study did not examine the interpretation of their results in an explainable manner, it may be difficult to conclude that accuracy, in general, indicates true accuracy for both benign and malignant classifications. Furthermore, no confusion matrix is presented to demonstrate the models’ actual prediction for the each class.
Zheng et al. (2014) presented hybrid strategies for diagnosing breast cancer disease utilizing k-means clustering (KMC) and SVM. Their proposed model considerably decreased the dimensional difficulties and attained an accuracy of 97.38% using Wisconsin Diagnostic Breast Cancer (WDBC) dataset [58]. The dataset is normally distributed and has 32 features divided into 10 categories. It is difficult to conclude that their suggested model will outperform in a dataset with an unequal class ratio, which may contain missing value as well.
To determine the best ML models, Asri et al. (2016) applied various ML approaches such as SVM, DT (C4.5), NB, and KNN on the Wisconsin Breast Cancer (WBC) datasets. According to their findings, SVM outperformed all other ML algorithms, obtaining an accuracy of 97.13% [59]. However, if a same experiment is repeated in a different database, the results may differ. Furthermore, experimental results accompanied by ground truth values may provide a more precise estimate in determining which ML model is the best or not.
Mohammed et al. (2020) conducted a nearly identical study. The authors employ three ML algorithms to find the best ML methods: DT (J48), NB, and sequential minimal optimization (SMO), and the experiment was conducted on two popular datasets: WBC and breast cancer datasets. One of the interesting aspects of this research is that they focused on data imbalance issues and minimized the imbalance problem through the use of resampling data labeling procedures. Their findings showed that the SMO algorithms exceeded the other two classifiers, attaining more than 95% accuracy on both datasets [60]. However, in order to reduce the imbalance ratio, they used resampling procedures numerous times, potentially lowering the possibility of data diversity. As a result, the performance of those three ML methods may suffer on a dataset that is not normally distributed or imbalanced.
Assegie (2021) used the grid search approach to identify the best k-nearest neighbor (KNN) settings. Their investigation showed that parameter adjustment had a considerable impact on the model’s performance. They demonstrated that by fine-tuning the settings, it is feasible to get 94.35% accuracy, whereas the default KNN achieved around 90% accuracy [61].
To detect breast cancer, Bhattacherjee et al. (2020) employed a backpropagation neural network (BNN). The experiment was carried out in the WBC dataset with nine features, and they achieved 99.27% accuracy [62]. Alshayeji et al. (2021) used the WBCD and WDBI datasets to develop a shallow ANN model for classifying breast cancer tumors. The authors demonstrated that the suggested model could classify tumors up to 99.85% properly without selecting characteristics or tweaking the algorithms [63].
Sultana et al. (2021) detect breast cancer using a different ANN architecture on the WBC dataset. They employed a variety of NN architectures, including the multilayer perceptron (MLP) neural network, the Jordan/Elman NN, the modular neural network (MNN), the generalized feedforward neural network (GFFNN), the self-organizing feature map (SOFM), the SVM neural network, the probabilistic neural network (PNN), and the recurrent neural network (RNN). Their final computational result demonstrates that the PNN with 98.24% accuracy outperforms the other NN models utilized in that study [64]. However, this study lacks the interpretability as of many other investigations because it does not indicate which features are most important during the prediction phase.
Deep learning (DL) was also used by Ghosh et al. (2021). The WBC dataset was used by the authors to train seven deep learning (DL) models: ANN, CNN, GRU, LSTM, MLP, PNN, and RNN. Long short-term memory (LSTM) and gated recurrent unit (GRU) demonstrated the best performance among all DL models, achieving an accuracy of roughly 99% [65]. Table 5 summarizes some of the referenced literature that used ML and DL techniques in breast cancer diagnosis.
Table 5.
Referenced literature that considered machine-learning-based breast cancer disease diagnosis.
5.4. Diabetes
According to the International Diabetes Federation (IDF), there are currently over 382 million individuals worldwide who have diabetes, with that number anticipated to increase to 629 million by 2045 [71]. Numerous studies widely presented ML-based systems for diabetes patient detection. For example, Kandhasamy and Balamurali (2015) compared ML classifiers (J48 DT, KNN, RF, and SVM) for classifying patients with diabetes mellitus. The experiment was conducted on the UCI Diabetes dataset, and the KNN (K = 1) and RF classifiers obtained near-perfect accuracy [72]. However, one disadvantage of this work is that it used a simplified Diabetes dataset with only eight binary-classified parameters. As a result, getting 100% accuracy with a less difficult dataset is unsurprising. Furthermore, there is no discussion of how the algorithms influence the final prediction or how the result should be viewed from a nontechnical position in the experiment.
Yahyaoui et al. (2019) presented a Clinical Decision Support Systems (CDSS) to aid physicians or practitioners with Diabetes diagnosis. To reach this goal, the study utilized a variety of ML techniques, including SVM, RF, and deep convolutional neural network (CNN). RF outperformed all other algorithms in their computations, obtaining an accuracy of 83.67%, while DL and SVM scored 76.81% and 65.38% accuracy, respectively [73].
Naz and Ahuja (2020) employed a variety of ML techniques, including artificial neural networks (ANN), NB, DT, and DL, to analyze open-source PIMA Diabetes datasets. Their study indicates that DL is the most accurate method for detecting the development of diabetes, with an accuracy of approximately 98.07% [71]. The PIMA dataset is one of the most thoroughly investigated and primary datasets, making it easy to perform conventional and sophisticated ML-based algorithms. As a result, gaining greater accuracy with the PIMA Indian dataset is not surprising. Furthermore, the paper makes no mention of interpretability issues and how the model would perform with an unbalanced dataset or one with a significant number of missing variables. As is widely recognized in healthcare, several types of data can be created that are not always labeled, categorized, and preprocessed in the same way as the PIMA Indian dataset. As a result, it is critical to examine the algorithms’ fairness, unbiasedness, dependability, and interpretability while developing a CDSS, especially when a considerable amount of information is missing in a multiclass classification dataset.
Ashiquzzaman et al. (2017) developed a deep learning strategy to address the issue of overfitting in diabetes datasets. The experiment was carried out on the PIMA Indian dataset and yielded an accuracy of 88.41%. The authors claimed that performance improved significantly when dropout techniques were utilized and the overfitting problems were reduced [74]. Overuse of the dropout approach, on the other hand, lengthens overall training duration. As a result, as they did not address these concerns in their study, assessing whether their proposed model is optimum in terms of computational time is difficult.
Alhassan et al. (2018) introduced the King Abdullah International Research Center for Diabetes (KAIMRCD) dataset, which includes data from 14k people and is the world’s largest diabetic dataset. During that experiment, the author presented a CDSS architecture based on LSTM and GRU-based deep neural networks, which obtained up to 97% accuracy [75]. Table 6 highlights some of the relevant publications that employed ML and DL approaches in the diagnosis of diabetic disease.
Table 6.
Referenced literature that considered machine-learning-based diabetic disease diagnosis.
5.5. Parkinson’s Disease
Parkinson’s disease is one of the conditions that has received a great amount of attention in the ML literature. It is a slow-progressing chronic neurological disorder. When dopamine-producing neurons in certain parts of the brain are harmed or die, people have difficulty speaking, writing, walking, and doing other core activities [80]. There are several ML-based approaches have been proposed. For instance, Sriram et al. (2013) used KNN, SVM, NB, and RF algorithms to develop intelligent Parkinson’s disease diagnosis systems. Their computational result shows that, among all other algorithms, RF shows the best performance (90.26% accuracy), and NB demonstrate the worst performance (69.23% accuracy) [81].
Esmaeilzadeh et al. (2018) proposed a deep CNN-based model to diagnose Parkinson’s disease and achieved almost 100% accuracy on train and test set [82]. However, there was no mention of any overfitting difficulties in the trial. Furthermore, the experimental results do not provide a good interpretation of the final classification and regression, which is now widely expected, particularly in CDSS. Grover et al. (2018) also used DL-based approaches on UCI’s Parkinson’s telemonitoring voice dataset. Their experiment using DNN has achieved around 81.67% accuracy in diagnosing patients with Parkinson’s disease symptoms [80].
Warjurkar and Ridhorkar (2021) conducted a thorough study on the performance of the ML-based approach in decision support systems that can detect both brain tumors and diagnose Parkinson’s patients. Based on their findings, it was obvious that, when compared to other algorithms, boosted logistic regression surpassed all other models, attaining 97.15% accuracy in identifying Parkinson’s disease patients. In tumor segmentation, however, the Markov random technique performed best, obtaining an accuracy of 97.4% [83]. Parkinson’s disease diagnosis using ML and DL approaches is summarized in Table 7, which includes a number of references to the relevant research.
Table 7.
Referenced literature that considered machine-learning-based Parkinson’s disease diagnosis.
5.6. COVID-19
The new severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2), also known as COVID-19, pandemic has become humanity’s greatest challenge in contemporary history. Despite the fact that a vaccine had been advanced in distribution because to the global emergency, it was unavailable to the majority of people for the duration of the crisis [88]. Because of the new COVID-19 Omicron strain’s high transmission rates and vaccine-related resistance, there is an extra layer of concern. The gold standard for diagnosing COVID-19 infection is now Real-Time Reverse Transcription-Polymerase Chain Reaction (RT-PCR) [89,90]. Throughout the epidemic, the researcher advocated other technologies including as chest X-rays and Computed Tomography (CT) combined with Machine Learning and Artificial Intelligence to aid in the early detection of people who might be infected. For example, Chen et al. (2020) proposed a UNet++ model employing CT images from 51 COVID-19 and 82 non-COVID-19 patients and achieved an accuracy of 98.5% [91]. Ardakani et al. (2020) used a small dataset of 108 COVID-19 and 86 non-COVID-19 patients to evaluate ten different DL models and achieved a 99% overall accuracy [92]. Wang et al. (2020) built an inception-based model with a large dataset, containing 453 CT scan images, and achieved 73.1% accuracy. However, the model’s network activity and region of interest were poorly explained [93]. Li et al. (2020) suggested the COVNet model and obtain 96% accuracy utilizing a large dataset of 4356 chest CT images of Pneumonia patients, 1296 of which were verified COVID-19 cases [94].
Several studies investigated and advised screening COVID-19 patients utilizing chest X-ray images in parallel, with major contributions in [95,96,97]. For example, Hemdan et al. (2020) used a small dataset of only 50 images to identify COVID-19 patients from chest X-ray images with an accuracy of 90% and 95%, respectively, using VGG19 and ResNet50 models [95]. Using a dataset of 100 chest X-ray images, Narin et al. (2021) distinguished COVID-19 patients from those with Pneumonia with 86% accuracy [97].
In addition, in order to develop more robust and better screening systems, other studies considered larger datasets. For example, Brunese et al. (2020) employed 6505 images with a data ratio of 1:1.17, with 3003 images classified as COVID-19 symptoms and 3520 as “other patients” for the objectives of that study [98]. With a dataset of 5941 images, Ghoshal and Tucker (2020) achieved 92.9% accuracy [99]. However, neither study looked at how their proposed models would work with data that was severely unbalanced and had mismatched class ratios. Apostolopoulos and Mpesiana (2020) employed a CNN-based Xception model on an imbalanced dataset of 284 COVID-19 and 967 non-COVID-19 patient chest X-ray images and achieved 89.6% accuracy [100].
The following Table 8 summarizes some of the relevant literature that employed ML and DL approaches to diagnose COVID-19 disease.
Table 8.
Referenced literature that considered machine-learning-based COVID-19 disease diagnosis.
5.7. Alzheimer’s Disease
Alzheimer is a brain illness that often begins slowly but progresses over time, and it affects 60–70% of those who are diagnosed with dementia [103]. Alzheimer’s disease symptoms include language problems, confusion, mood changes, and other behavioral disorders. Body functions gradually deteriorated, and the usual life expectancy is three to nine years after diagnosis. Early diagnosis, on the other hand, may assist to avoid and take required actions to enter into suitable treatment as soon as possible, which will also raise the possibility of life expectancy. Machine learning and deep learning have shown promising outcomes in detecting Alzheimer’s disease patients throughout the years. For instance, Neelaveni and Devasana (2020) proposed a model that can detect Alzheimer patients using SVM and DT, and achieved an accuracy of 85% and 83% respectively [104]. Collij et al. (2016) also used SVM to detect single-subject Alzheimer’s disease and mild cognitive impairment (MCI) prediction and achieved an accuracy of 82% [105].
Multiple algorithms have been adopted and tested in developing ML based Alzheimer disease diagnosis. For example, Vidushi and Shrivastava (2019) experimented using Logistic Regression (LR), SVM, DT, ensemble Random Forest (RF), and Boosting Adaboost and achieved an accuracy of 78.95%, 81.58%, 81.58%, 84.21%, and 84.21% respectively [106]. Many of the study adopted CNN based approach to detect Alzheimer patients as CNN demonstrates robust results in image processing compared to other existing algorithms. As a consequence, Ahmed et al. (2020) proposed a CNN model for earlier diagnosis and classification of Alzheimer disease. Within the dataset consists of 6628 MRI images, the proposed model achieved 99% accuracy [107]. Nawaz et al. (2020) proposed deep feature-based models and achieved an accuracy of 99.12% [108]. Additionally, Studies conducted by Haft-Javaherian et al. (2019) [109] and Aderghal et al. (2017) [110] are some of the CNN based study that also demonstrates the robustness of CNN based approach in Alzheimer disease diagnosis. ML and DL approaches employed in the diagnosis of Alzheimer’s disease are summarized in Table 9.
Table 9.
Referenced literature that considered Machine Learning-based Alzheimer disease diagnosis.
5.8. Other Diseases
Beyond the disease mentioned above, ML and DL have been used to identify various other diseases. Big data and increasing computer processing power are two key reasons for this increased use. For example, Mao et al. (2020) used Decision Tree (DT) and Random Forest (RF) to disease classification based on eye movement [114]. Nosseir and Shawky (2019) evaluated KNN and SVM to develop automatic skin disease classification systems, and the best performance was observed using KNN by achieving an accuracy of 98.22% [115]. Khan et al. (2020) employed CNN-based approaches such as VGG16 and VGG19 to classify multimodal Brain tumors. The experiment was carried out using publicly available three image datasets: BraTs2015, BraTs2017, and BraTs2018, and achieved 97.8%, 96.9%, and 92.5% accuracy, respectively [116]. Amin et al. (2018) conducted a similar experiment utilizing the RF classifier for tumor segmentation. The authors achieved 98.7%, 98.7%, 98.4%, 90.2%, and 90.2% accuracy using BRATS 2012, BRATS 2013, BRATS 2014, BRATS 2015, and ISLES 2015 dataset, respectively [117].
Dai et al. (2019) proposed a CNN-based model to develop an application to detect Skin cancer. The authors used a publicly available dataset, HAM10000, to experiment and achieved 75.2% accuracy [118]. Daghrir et al. (2020) evaluated KNN, SVM, CNN, Majority Voting using ISIC (International Skin Imaging Collaboration) dataset to detect Melanoma skin cancer. The best result was found using Majority Voting (88.4% accuracy) [119]. Table 10 summarizes some of the referenced literature that used ML and DL techniques in various disease diagnosis.
Table 10.
Referenced literature that considered Machine Learning on various disease diagnoses.
6. Algorithm and Dataset Analysis
Most of the referenced literature considered multiple algorithms in MLBDD approaches. Here we have addressed multiple algorithms as hybrid approaches. For instance, Sun et al. (2021) used hybrid approaches to predict coronary Heart disease using Gaussian Naïve Bayes, Bernoulli Naïve Bayes, and Random Forest (RF) algorithms [111]. Bemando et al. (2021) adopted CNN and SVM to automate the diagnosis of Alzheimer’s disease and mild cognitive impairment [41]. Saxena et al. (2019) used KNN and Decision Tree (DT) in Heart disease diagnosis [131]; Elsalamony (2018) employed Neural Networks (NN) and SVM in detecting Anaemia disease in human red blood cells [132]. One of the key benefits of using the hybrid technique is that it is more accurate than using single ML models.
According to the relevant literature, the most extensively utilized induvial algorithms in developing MLBDD models are CNN, SVM, and LR. For instance, Kalaiselvi et al. (2020) proposed CNN based approach in Brain tumor diagnosis [123]; Dai et al. (2019) used CNN in developing a device inference app for Skin cancer detection [118]; Fathi et al. (2020) used SVM to classify liver diseases [121]; Sing et al. (2019) used SVM to classify the patients with Heart disease symptoms [43]; and Basheer et al. (2019) used Logistic Regression to detect Heart disease [133].
Figure 10 depicts the most commonly used Machine Learning algorithms in disease diagnosis. The bolder and larger font emphasizes the importance and frequency with which the algorithms in MLBDD are used. Based on the Figure, we can observe that Neural Networks, CNN, SVM, and Logistic Regression are the most commonly employed algorithms by MLBDD researchers.

Figure 10.
Word cloud for most frequently used ML algorithms in MLBDD publications.
Most MLBDD researchers utilize publically accessible datasets since they do not require permission and provide sufficient information to do the entire study. Manually gathering data from patients, on the other hand, is time-consuming; yet, numerous research utilized privately collected/owned data, either owing to their special necessity based on their experiment setup or to produce a result with actual data [46,55,56,68,70]. The Cleveland Heart disease dataset, PIMA dataset, and Parkinson dataset are the most often utilized datasets in disease diagnosis areas. Table 11 lists publicly available datasets and sources that may be useful to future academics and practitioners.
Table 11.
Most widely used disease diagnosis dataset URL along with the referenced literature (accessed on 16 December 2021).
7. Discussion
In the last 10 years, Machine Learning (ML) and Deep Learning (DL) have grown in prominence in disease diagnosis, which the annotated literature has strengthened in this study. The review began with specific research questions and attempted to answer them using the reference literature. According to the overall research, CNN is one of the most emerging algorithms, outperforming all other ML algorithms due to its solid performance with both image and tabular data [94,123,128,137]. Transfer learning is also gaining popularity since it does not necessitate constructing a CNN model from scratch and produces better results than typical ML methods [47,91]. Aside from CNN, the reference literature lists SVM, RF, and DT as some of the most common algorithms utilized widely in MLBDD. Furthermore, several researchers are emphasizing ensemble techniques in MLBDD [127,130]. Nonetheless, when compared to other ML algorithms, CNN is the most dominating. VGG16, VGG19, ResNet50, and UNet++ are among of the most prominent CNN architectures utilized widely in disease diagnosis.
In terms of databases, it was discovered that UCI repository data is the preferred option of academics and practitioners for constructing a Machine Learning-based Disease Diagnosis (MLBDD) model. However, while the current dataset frequently has shortcomings, several researchers have recently relied on additional data acquired from the hospital or clinic (i.e., imbalance data, missing data). To assist future researchers and practitioners interested in studying MLBDD, we have included a list of some of the most common datasets utilized in the reference literature in Table 11, along with the link to the repository.
As previously indicated, there were several inconsistencies in terms of assessment measures published by the literature. For example, some research reported their results with accuracy [45]; others provided with accuracy, precision, recall, and F1-score [42]; while a few studies emphasized sensitivity, specificity, and true positive [67]. As a result, there were no criteria for the authors to follow in order to report their findings correctly and genuinely. Nonetheless, of all assessment criteria, accuracy is the most extensively utilized and recognized by academics.
With the emergence of COVID-19, MLBDD research switched mostly on Pneumonia and COVID-19 patient detection beginning in 2020, and COVID-19 remains a popular subject as the globe continues to battle this disease. As a result, it is projected that the application of ML and DL in the medical sphere for disease diagnosis would expand significantly in this domain in the future as well. Many questions have been raised due to the progress of ML and DL-based disease diagnosis. For example, if a doctor or other health practitioner incorrectly diagnoses a patient, he or she will be held accountable. However, if the machine does, who will be held accountable? Furthermore, fairness is an issue in ML because most ML models are skewed towards the majority class. As a result, future research should concentrate on ML ethics and fairness.
Model interpretation is absent in nearly all investigations, which is surprising. Interpreting machine learning models used to be difficult, but explainable and interpretable XAI have made it much easier. Despite the fact that the previous MLBDD lacked sufficient interpretations, it is projected that future researchers and practitioners would devote more attention to interpreting the machine learning model due to the growing demand for model interpretability.
The idea that ML alone will enough to construct an MLBDD model is a flawed one. To make the MLBDD model more dynamic, it may be anticipated that the model will need to be developed and stored on a cloud system, as the heath care industry generates a lot of data that is typically kept in cloud systems. As a result, the adversarial attack will focus on patients’ data, which is very sensitive. For future ML-based models, the data bridge and security challenges must be taken into consideration.
It is a major issue to analyze data if there is a large disparity in the data. As the ML-based diagnostic model deals with human life, every misdiagnosis is a possible danger to one’s health. However, despite the fact that many study used the imbalance dataset to perform their experiment, none of the cited literature highlights issues related to imbalance data. Thus, future work should demonstrate the validity of any ML models while developing with imbalanced data.
Within the many scopes this review paper also have some limitations which can be summarized as follows:
- 1.
- The study first searched the Scopus and WOS databases for relevant papers and then examined other papers that were pertinent to this investigation. If other databases like Google Scholar and Pubmed were used, the findings might be somewhat different. As a result, our study may provide some insight into MLBDD, but there is still a great deal of information that is outside of our control.
- 2.
- ML algorithms, DL algorithms, dataset, disease classifications, and evaluation metrics are highlighted in the review. Though the suggested ML process is thoroughly examined in reference literature, this paper does not go into that level of detail.
- 3.
- Only those publications that adhered to a systematic literature review technique were included in the study’s paper selection process. Using a more comprehensive range of keywords, on the other hand, might lead to higher search activity. However, our SLR approach will provide researchers and practitioners with a more thorough understanding of MLBDD.
8. Research Challenges and Future Agenda
While machine learning-based applications have been used extensively in disease diagnosis, researchers and practitioners still face several challenges when deploying them as a practical application in healthcare. In this section, the key challenges associated with ML in disease diagnosis have been summarized as follows:
8.1. Data Related Challenges
- 1.
- Data scarcity: Even though many patients’ data has been recorded by different hospitals and healthcare, due to the data privacy act, real-world data is not often available for global research purposes.
- 2.
- Noisy data: Frequently, the clinical data contains noise or missing values; therefore, such kind of data takes a reasonable amount of time to make it trainable.
- 3.
- Adversarial attack: Adversarial attack is one of the key issues in the disease dataset. Adversarial attack means the manipulation of training data, testing data, or machine learning model to result in wrong output from ML.
8.2. Disease Diagnosis-Related Challenges
- 1.
- Misclassification: While the machine learning model can be used to develop as a disease diagnosis model, any misclassification for a particular disease might bring severe damage. For instance, if a patient with stomach cancer is diagnosed as a non-cancer patient, it will have a huge impact.
- 2.
- Wrong image segmentation: One of the key challenges with the ML model is that the model often identifies the wrong region as an infected region. For instance, author Ahsan et al. (2020) shows that even though the accuracy is around 100% in detecting COVID-19 and non-COVID-19 patients, the pre-trained CNN models such as VGG16 and VGG19 often pay attention to the wrong region during the training process [2]. As a result, it also raises the question of the validity of the MLBDD.
- 3.
- Confusion: Some of the diseases such as COVID-19, pneumonia, edema in the chest often demonstrate similar symptoms; in these particular cases, many CNN models detect all of the data samples into one class, i.e., COVID-19.
8.3. Algorithm Related Challenges
- 1.
- Supervised vs. unsupervised: Most ML models (Linear regression, logistic regression) performed very well with the labeled data. However, similar algorithms’ performance was significantly reduced with the unlabeled data. On the other hand, popular algorithms that can perform well with unlabeled data such as K-means clustering, SVM, and KNNs performance also degraded with multidimensional data.
- 2.
- Blackbox-related challenges: One of the most widely used ML algorithms is convolutional neural networks. However, one of the key challenges associated with this algorithm is that it is often hard to interpret how the model adjusts internal parameters such as learning rate and weights. In healthcare, implementing such an algorithm-related model needs proper explanations.
8.4. Future Directions
The challenges addressed in the above section might give some future direction to future researchers and practitioners. Here we have introduced some of the possible algorithms and applications that might overcome existing MLBDD challenges.
- 1.
- GAN-based approach: Generative adversarial network is one of the most popular approaches in deep learning fields. Using this approach, it is possible to generate synthetic data which looks almost similar to the real data. Therefore, GAN might be a good option for handling data scarcity issues. Moreover, it will also reduce the dependency on real data and also will help to follow the data privacy act.
- 2.
- Explainable AI: Explainable AI is a popular domain that is now widely used to explain the algorithms’ behavior during training and prediction. Still, the explainable AI domains face many challenges; however, the implementation of interpretability and explainability clarifies the ML models’ deployment in the real world.
- 3.
- Ensemble-based approach: With the advancement of modern technology, we can now capture high resolutions and multidimensional data. While the traditional ML approach might not perform well with high-quality data, a combination of several machine learning models might be an excellent option to handle such high-dimensional data.
9. Conclusions and Potential Remarks
This study reviewed the papers published between 2012–2021 that focused on Machine Learning-based Disease Diagnosis (MLBDD). Researchers are particularly interested in some diseases, such as Heart disease, Breast cancer, Kidney disease, Diabetes, Alzheimer’s, and Parkinson’s diseases, which are discussed considering machine learning/deep learning-based techniques. Additionally, some other ML-based disease diagnosis approaches are discussed as well. Prior to that, A bibliometric analysis was performed, taking into account a variety of parameters such as subject area, publication year, journal, country, and identifying the most prominent contributors in the MLBDD field. According to our bibliometric research, machine learning applications in disease diagnosis have grown at an exponential rate since 2017. In terms of overall number of publications over the years, IEEE Access, Scientific Reports, and the International Journal of advanced computer science and applications are the three most productive journals. The three most-cited publications on MLBDD are those by Motwani et al. (2017), Gray et al. (2013), and Mohan et al. (2019). In terms of overall publications, China, the United States, and India are the three most productive countries. Kim J, the most influential author, published around 20 publications between 2012 and 2021, followed by Wang Y and Li J, who came in second and third place, respectively. Around 40% of the publication are from computer science domains and around 31% from engineering fields, demonstrating their domination in the MLBDD field.
Finally, we have systematically selected 102 papers for in-depth analysis. Our overall findings were highlighted in the discussion sections. Because of its remarkable performance in constructing a robust model, our primary conclusion implies that deep learning is the most popular method for researchers. Despite the fact that deep learning is widely applied in MLBDD fields, the majority of the research lacks sufficient explanations of the final predictions. As a result, future research in MLBDD needs focus on pre and post hoc analysis and model interpretation in order to use the ML model in healthcare.
Physical patient services are increasingly dangerous as a result of the emergence of COVID-19. At the same time, the health-care system must be maintained. While telemedicine and online consultation are becoming more popular, it is still important to consider an alternate strategy that may also highlight the importance of in-person health facilities. Many recent studies recommend home-robot service for patient care rather than hospitalization [138].
Many countries are increasingly worried about the privacy of patients’ data. Many nations have also raised legal concerns about the ethics of AI and ML when used with real-world patient data [139]. As a result, rather of depending on data gathering and processing, future study could try producing synthetic data. Some of the techniques that future researchers and practitioners may be interested in to produce synthetic data for the experiment include generative adversarial networks, ADASYN, SMOTE, and SVM-SMOTE.
Cloud systems are becoming potential threats as a result of data storage in it. As a result, any built ML models must safeguard patient access and transaction concerns. Many academics exploited blockchain technology to access and distribute data [140,141]. As a result, blockchain technology paired with deep learning and machine learning might be a promising study subject for constructing safe diagnostic systems.
We anticipate that our review will guide both novice and expert research and practitioners in MLBDD. It would be interesting to see some research work based on the limitations addressed in the discussion and conclusion section. Additionally, future works in MLBDD might focus on multiclass classification with highly imbalanced data along with highly missing data, explanation and Interpretation of multiclass data classification using XAI, and optimizing the big data containing numerical, categorical, and image data.
Author Contributions
Conceptualization—M.M.A.; methodology—M.M.A. and Z.S.; software—M.M.A.; validation—Z.S. and S.A.L.; formal analysis—S.A.L.; investigation—Z.S.; writing—original draft preparation—M.M.A.; writing—review and editing—M.M.A., S.A.L., Z.S.; supervision—Z.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Conflicts of Interest
The authors declare no conflict of interest.
References
- McPhee, S.J.; Papadakis, M.A.; Rabow, M.W. (Eds.) Current Medical Diagnosis & Treatment; McGraw-Hill Medical: New York, NY, USA, 2010. [Google Scholar]
- Ahsan, M.M.; Ahad, M.T.; Soma, F.A.; Paul, S.; Chowdhury, A.; Luna, S.A.; Yazdan, M.M.S.; Rahman, A.; Siddique, Z.; Huebner, P. Detecting SARS-CoV-2 From Chest X-ray Using Artificial Intelligence. IEEE Access 2021, 9, 35501–35513. [Google Scholar] [CrossRef] [PubMed]
- Coon, E.R.; Quinonez, R.A.; Moyer, V.A.; Schroeder, A.R. Overdiagnosis: How our compulsion for diagnosis may be harming children. Pediatrics 2014, 134, 1013–1023. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Balogh, E.P.; Miller, B.T.; Ball, J.R. Improving Diagnosis in Health Care; National Academic Press: Washington, DC, USA, 2015. [Google Scholar] [CrossRef]
- Ahsan, M.M.; Siddique, Z. Machine Learning-Based Heart Disease Diagnosis: A Systematic Literature Review. arXiv 2021, arXiv:2112.06459. [Google Scholar]
- Ahsan, M.M.; E Alam, T.; Trafalis, T.; Huebner, P. Deep MLP-CNN model using mixed-data to distinguish between COVID-19 and Non-COVID-19 patients. Symmetry 2020, 12, 1526. [Google Scholar] [CrossRef]
- Stafford, I.; Kellermann, M.; Mossotto, E.; Beattie, R.; MacArthur, B.; Ennis, S. A systematic review of the applications of artificial intelligence and machine learning in autoimmune diseases. NPJ Digit. Med. 2020, 3, 1–11. [Google Scholar] [CrossRef]
- Ahsan, M.M.; Gupta, K.D.; Islam, M.M.; Sen, S.; Rahman, M.; Shakhawat Hossain, M. COVID-19 symptoms detection based on nasnetmobile with explainable ai using various imaging modalities. Mach. Learn. Knowl. Extr. 2020, 2, 490–504. [Google Scholar] [CrossRef]
- Samuel, A.L. Some studies in machine learning using the game of checkers. IBM J. Res. Dev. 1959, 3, 210–229. [Google Scholar] [CrossRef]
- Brownlee, J. Machine learning mastery with Python. Mach. Learn. Mastery Pty Ltd. 2016, 527, 100–120. [Google Scholar]
- Houssein, E.H.; Emam, M.M.; Ali, A.A.; Suganthan, P.N. Deep and machine learning techniques for medical imaging-based breast cancer: A comprehensive review. Expert Syst. Appl. 2021, 167, 114161. [Google Scholar] [CrossRef]
- Brijain, M.; Patel, R.; Kushik, M.; Rana, K. A survey on decision tree algorithm for classification. Int. J. Eng. Dev. Res. 2014. Available online: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.673.2797 (accessed on 10 December 2021).
- Walse, R.S.; Kurundkar, G.D.; Khamitkar, S.D.; Muley, A.A.; Bhalchandra, P.U.; Lokhande, S.N. Effective Use of Naïve Bayes, Decision Tree, and Random Forest Techniques for Analysis of Chronic Kidney Disease. In Proceedings of the International Conference on Information and Communication Technology for Intelligent Systems, Ahmedabad, India, 15–16 May 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 237–245. [Google Scholar]
- Rajendran, K.; Jayabalan, M.; Thiruchelvam, V. Predicting breast cancer via supervised machine learning methods on class imbalanced data. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 54–63. [Google Scholar] [CrossRef]
- Tsao, H.Y.; Chan, P.Y.; Su, E.C.Y. Predicting diabetic retinopathy and identifying interpretable biomedical features using machine learning algorithms. BMC Bioinform. 2018, 19, 111–121. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nurrohman, A.; Abdullah, S.; Murfi, H. Parkinson’s disease subtype classification: Application of decision tree, logistic regression and logit leaf model. In AIP Conference Proceedings; AIP Publishing LLC: Melville, NY, USA, 2020; Volume 2242, p. 030015. [Google Scholar]
- Drucker, H.; Wu, D.; Vapnik, V.N. Support vector machines for spam categorization. IEEE Trans. Neural Netw. 1999, 10, 1048–1054. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fix, E.; Hodges, J.L. Discriminatory analysis. Nonparametric discrimination: Consistency properties. Int. Stat. Rev. Int. De Stat. 1989, 57, 238–247. [Google Scholar] [CrossRef]
- Wright, R.E. Logistic regression. In Reading and Understanding Multivariate Statistics; American Psychological Association: Washington, DC, USA, 1995. [Google Scholar]
- Schapire, R.E. Explaining adaboost. In Empirical Inference; Springer: Berlin/Heidelberg, Germany, 2013; pp. 37–52. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Hayashi, Y. The right direction needed to develop white-box deep learning in radiology, pathology, and ophthalmology: A short review. Front. Robot. AI 2019, 6, 24. [Google Scholar] [CrossRef]
- Akkus, Z.; Galimzianova, A.; Hoogi, A.; Rubin, D.L.; Erickson, B.J. Deep learning for brain MRI segmentation: State of the art and future directions. J. Digit. Imaging 2017, 30, 449–459. [Google Scholar] [CrossRef] [Green Version]
- Yap, M.H.; Pons, G.; Martí, J.; Ganau, S.; Sentís, M.; Zwiggelaar, R.; Davison, A.K.; Marti, R. Automated breast ultrasound lesions detection using convolutional neural networks. IEEE J. Biomed. Health Inform. 2017, 22, 1218–1226. [Google Scholar] [CrossRef] [Green Version]
- Malviya, R.K.; Kant, R. Green supply chain management (GSCM): A structured literature review and research implications. Benchmarking Int. J. 2015, 22, 1360–1394. [Google Scholar] [CrossRef]
- Fahimnia, B.; Sarkis, J.; Davarzani, H. Green supply chain management: A review and bibliometric analysis. Int. J. Prod. Econ. 2015, 162, 101–114. [Google Scholar] [CrossRef]
- Motwani, M.; Dey, D.; Berman, D.S.; Germano, G.; Achenbach, S.; Al-Mallah, M.H.; Andreini, D.; Budoff, M.J.; Cademartiri, F.; Callister, T.Q.; et al. Machine learning for prediction of all-cause mortality in patients with suspected coronary artery disease: A 5-year multicentre prospective registry analysis. Eur. Heart J. 2017, 38, 500–507. [Google Scholar] [CrossRef]
- Gray, K.R.; Aljabar, P.; Heckemann, R.A.; Hammers, A.; Rueckert, D.; Initiative, A.D.N. Random forest-based similarity measures for multi-modal classification of Alzheimer’s disease. NeuroImage 2013, 65, 167–175. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mohan, S.; Thirumalai, C.; Srivastava, G. Effective heart disease prediction using hybrid machine learning techniques. IEEE Access 2019, 7, 81542–81554. [Google Scholar] [CrossRef]
- Yadav, S.S.; Jadhav, S.M. Deep convolutional neural network based medical image classification for disease diagnosis. J. Big Data 2019, 6, 1–18. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Dong, Z.; Phillips, P.; Wang, S.; Ji, G.; Yang, J.; Yuan, T.F. Detection of subjects and brain regions related to Alzheimer’s disease using 3D MRI scans based on eigenbrain and machine learning. Front. Comput. Neurosci. 2015, 9, 66. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Austin, P.C.; Tu, J.V.; Ho, J.E.; Levy, D.; Lee, D.S. Using methods from the data-mining and machine-learning literature for disease classification and prediction: A case study examining classification of heart failure subtypes. J. Clin. Epidemiol. 2013, 66, 398–407. [Google Scholar] [CrossRef] [Green Version]
- Sharmila, A.; Geethanjali, P. DWT based detection of epileptic seizure from EEG signals using naive Bayes and k-NN classifiers. IEEE Access 2016, 4, 7716–7727. [Google Scholar] [CrossRef]
- Lebedev, A.; Westman, E.; Van Westen, G.; Kramberger, M.; Lundervold, A.; Aarsland, D.; Soininen, H.; Kłoszewska, I.; Mecocci, P.; Tsolaki, M.; et al. Random Forest ensembles for detection and prediction of Alzheimer’s disease with a good between-cohort robustness. NeuroImage Clin. 2014, 6, 115–125. [Google Scholar] [CrossRef] [Green Version]
- Luz, E.J.d.S.; Nunes, T.M.; De Albuquerque, V.H.C.; Papa, J.P.; Menotti, D. ECG arrhythmia classification based on optimum-path forest. Expert Syst. Appl. 2013, 40, 3561–3573. [Google Scholar] [CrossRef] [Green Version]
- Challis, E.; Hurley, P.; Serra, L.; Bozzali, M.; Oliver, S.; Cercignani, M. Gaussian process classification of Alzheimer’s disease and mild cognitive impairment from resting-state fMRI. NeuroImage 2015, 112, 232–243. [Google Scholar] [CrossRef] [Green Version]
- Ansari, A.Q.; Gupta, N.K. Automated diagnosis of coronary heart disease using neuro-fuzzy integrated system. In Proceedings of the 2011 World Congress on Information and Communication Technologies, Mumbai, India, 11–14 December 2011; pp. 1379–1384. [Google Scholar]
- Ahsan, M.M.; Mahmud, M.; Saha, P.K.; Gupta, K.D.; Siddique, Z. Effect of data scaling methods on machine Learning algorithms and model performance. Technologies 2021, 9, 52. [Google Scholar] [CrossRef]
- Rubin, J.; Abreu, R.; Ganguli, A.; Nelaturi, S.; Matei, I.; Sricharan, K. Recognizing abnormal heart sounds using deep learning. arXiv 2017, arXiv:1707.04642. [Google Scholar]
- Miao, J.H.; Miao, K.H. Cardiotocographic diagnosis of fetal health based on multiclass morphologic pattern predictions using deep learning classification. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Bemando, C.; Miranda, E.; Aryuni, M. Machine-Learning-Based Prediction Models of Coronary Heart Disease Using Naïve Bayes and Random Forest Algorithms. In Proceedings of the 2021 International Conference on Software Engineering & Computer Systems and 4th International Conference on Computational Science and Information Management (ICSECS-ICOCSIM), Pekan, Malaysia, 24–28 August 2021; pp. 232–237. [Google Scholar]
- Kumar, R.R.; Polepaka, S. Performance Comparison of Random Forest Classifier and Convolution Neural Network in Predicting Heart Diseases. In ICCII 2018, Proceedings of the Third International Conference on Computational Intelligence and Informatics; Springer: Singapore, 2020; pp. 683–691. [Google Scholar] [CrossRef]
- Singh, H.; Navaneeth, N.; Pillai, G. Multisurface Proximal SVM Based Decision Trees For Heart Disease Classification. In Proceedings of the TENCON 2019–2019 IEEE Region 10 Conference (TENCON), Kerala, India, 17–20 October 2019; pp. 13–18. [Google Scholar]
- Desai, S.D.; Giraddi, S.; Narayankar, P.; Pudakalakatti, N.R.; Sulegaon, S. Back-propagation neural network versus logistic regression in heart disease classification. In Advanced Computing and Communication Technologies; Springer: Berlin/Heidelberg, Germany, 2019; pp. 133–144. [Google Scholar]
- Patil, D.D.; Singh, R.; Thakare, V.M.; Gulve, A.K. Analysis of ECG Arrhythmia for Heart Disease Detection using SVM and Cuckoo Search Optimized Neural Network. Int. J. Eng. Technol. 2018, 7, 27–33. [Google Scholar] [CrossRef] [Green Version]
- Liu, N.; Lin, Z.; Cao, J.; Koh, Z.; Zhang, T.; Huang, G.B.; Ser, W.; Ong, M.E.H. An intelligent scoring system and its application to cardiac arrest prediction. IEEE Trans. Inf. Technol. Biomed. 2012, 16, 1324–1331. [Google Scholar] [CrossRef]
- Acharya, U.R.; Oh, S.L.; Hagiwara, Y.; Tan, J.H.; Adam, M.; Gertych, A.; San Tan, R. A deep convolutional neural network model to classify heartbeats. Comput. Biol. Med. 2017, 89, 389–396. [Google Scholar] [CrossRef]
- Yang, W.; Si, Y.; Wang, D.; Guo, B. Automatic recognition of arrhythmia based on principal component analysis network and linear support vector machine. Comput. Biol. Med. 2018, 101, 22–32. [Google Scholar] [CrossRef]
- Levey, A.S.; Coresh, J. Chronic kidney disease. Lancet 2012, 379, 165–180. [Google Scholar] [CrossRef]
- Charleonnan, A.; Fufaung, T.; Niyomwong, T.; Chokchueypattanakit, W.; Suwannawach, S.; Ninchawee, N. Predictive analytics for chronic kidney disease using machine learning techniques. In Proceedings of the 2016 Management and Innovation Technology International Conference, Bang-Saen, Chonburi, Thailand, 12–14 October 2016; pp. MIT-80–MIT-83. [Google Scholar]
- Aljaaf, A.J.; Al-Jumeily, D.; Haglan, H.M.; Alloghani, M.; Baker, T.; Hussain, A.J.; Mustafina, J. Early prediction of chronic kidney disease using machine learning supported by predictive analytics. In Proceedings of the 2018 IEEE Congress on Evolutionary Computation (CEC), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–9. [Google Scholar]
- Ma, F.; Sun, T.; Liu, L.; Jing, H. Detection and diagnosis of chronic kidney disease using deep learning-based heterogeneous modified artificial neural network. Future Gener. Comput. Syst. 2020, 111, 17–26. [Google Scholar] [CrossRef]
- Nithya, A.; Appathurai, A.; Venkatadri, N.; Ramji, D.; Palagan, C.A. Kidney disease detection and segmentation using artificial neural network and multi-kernel k-means clustering for ultrasound images. Measurement 2020, 149, 106952. [Google Scholar] [CrossRef]
- Al Imran, A.; Amin, M.N.; Johora, F.T. Classification of chronic kidney disease using logistic regression, feedforward neural network and wide & deep learning. In Proceedings of the 2018 International Conference on Innovation in Engineering and Technology (ICIET), Dhaka, Bangladesh, 27–28 December 2018; pp. 1–6. [Google Scholar]
- Navaneeth, B.; Suchetha, M. A dynamic pooling based convolutional neural network approach to detect chronic kidney disease. Biomed. Signal Process. Control 2020, 62, 102068. [Google Scholar] [CrossRef]
- Brunetti, A.; Cascarano, G.D.; De Feudis, I.; Moschetta, M.; Gesualdo, L.; Bevilacqua, V. Detection and segmentation of kidneys from magnetic resonance images in patients with autosomal dominant polycystic kidney disease. In Proceedings of the International Conference on Intelligent Computing, Nanchang, China, 3–6 August 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 639–650. [Google Scholar]
- Miranda, G.H.B.; Felipe, J.C. Computer-aided diagnosis system based on fuzzy logic for breast cancer categorization. Comput. Biol. Med. 2015, 64, 334–346. [Google Scholar] [CrossRef]
- Zheng, B.; Yoon, S.W.; Lam, S.S. Breast cancer diagnosis based on feature extraction using a hybrid of K-means and support vector machine algorithms. Expert Syst. Appl. 2014, 41, 1476–1482. [Google Scholar] [CrossRef]
- Asri, H.; Mousannif, H.; Al Moatassime, H.; Noel, T. Using machine learning algorithms for breast cancer risk prediction and diagnosis. Procedia Comput. Sci. 2016, 83, 1064–1069. [Google Scholar] [CrossRef] [Green Version]
- Mohammed, S.A.; Darrab, S.; Noaman, S.A.; Saake, G. Analysis of breast cancer detection using different machine learning techniques. In Proceedings of the International Conference on Data Mining and Big Data, Belgrade, Serbia, 14–20 July 2020; Springer: Berlin/Heidelberg, Gemany, 2020; pp. 108–117. [Google Scholar]
- Assegie, T.A. An optimized K-Nearest Neighbor based breast cancer detection. J. Robot. Control (JRC) 2021, 2, 115–118. [Google Scholar] [CrossRef]
- Bhattacherjee, A.; Roy, S.; Paul, S.; Roy, P.; Kausar, N.; Dey, N. Classification approach for breast cancer detection using back propagation neural network: A study. In Deep Learning and Neural Networks: Concepts, Methodologies, Tools, and Applications; IGI Global: Hershey, PA, USA, 2020; pp. 1410–1421. [Google Scholar]
- Alshayeji, M.H.; Ellethy, H.; Gupta, R. Computer-aided detection of breast cancer on the Wisconsin dataset: An artificial neural networks approach. Biomed. Signal Process. Control 2022, 71, 103141. [Google Scholar] [CrossRef]
- Sultana, Z.; Khan, M.R.; Jahan, N. Early breast cancer detection utilizing artificial neural network. WSEAS Trans. Biol. Biomed. 2021, 18, 32–42. [Google Scholar] [CrossRef]
- Ghosh, P.; Azam, S.; Hasib, K.M.; Karim, A.; Jonkman, M.; Anwar, A. A performance based study on deep learning algorithms in the effective prediction of breast cancer. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Online, 18–22 July 2021; pp. 1–8. [Google Scholar]
- Abdel-Nasser, M.; Rashwan, H.A.; Puig, D.; Moreno, A. Analysis of tissue abnormality and breast density in mammographic images using a uniform local directional pattern. Expert Syst. Appl. 2015, 42, 9499–9511. [Google Scholar] [CrossRef]
- Sharma, S.; Khanna, P. Computer-aided diagnosis of malignant mammograms using Zernike moments and SVM. J. Digit. Imaging 2015, 28, 77–90. [Google Scholar] [CrossRef]
- Moon, W.K.; Chen, I.L.; Chang, J.M.; Shin, S.U.; Lo, C.M.; Chang, R.F. The adaptive computer-aided diagnosis system based on tumor sizes for the classification of breast tumors detected at screening ultrasound. Ultrasonics 2017, 76, 70–77. [Google Scholar] [CrossRef]
- Lo, C.M.; Chan, S.W.; Yang, Y.W.; Chang, Y.C.; Huang, C.S.; Jou, Y.S.; Chang, R.F. Feasibility testing: Three-dimensional tumor mapping in different orientations of automated breast ultrasound. Ultrasound Med. Biol. 2016, 42, 1201–1210. [Google Scholar] [CrossRef]
- Venkatesh, S.S.; Levenback, B.J.; Sultan, L.R.; Bouzghar, G.; Sehgal, C.M. Going beyond a first reader: A machine learning methodology for optimizing cost and performance in breast ultrasound diagnosis. Ultrasound Med. Biol. 2015, 41, 3148–3162. [Google Scholar] [CrossRef] [PubMed]
- Naz, H.; Ahuja, S. Deep learning approach for diabetes prediction using PIMA Indian dataset. J. Diabetes Metab. Disord. 2020, 19, 391–403. [Google Scholar] [CrossRef] [PubMed]
- Kandhasamy, J.P.; Balamurali, S. Performance analysis of classifier models to predict diabetes mellitus. Procedia Comput. Sci. 2015, 47, 45–51. [Google Scholar] [CrossRef] [Green Version]
- Yahyaoui, A.; Jamil, A.; Rasheed, J.; Yesiltepe, M. A decision support system for diabetes prediction using machine learning and deep learning techniques. In Proceedings of the 2019 1st International Informatics and Software Engineering Conference (UBMYK), Ankara, Turkey, 6–7 November 2019; pp. 1–4. [Google Scholar]
- Ashiquzzaman, A.; Tushar, A.K.; Islam, M.; Shon, D.; Im, K.; Park, J.H.; Lim, D.S.; Kim, J. Reduction of overfitting in diabetes prediction using deep learning neural network. arXiv 2017, arXiv:1707.08386. [Google Scholar]
- Alhassan, Z.; McGough, A.S.; Alshammari, R.; Daghstani, T.; Budgen, D.; Al Moubayed, N. Type-2 diabetes mellitus diagnosis from time series clinical data using deep learning models. In Proceedings of the 2019 International Conference on Artificial Neural Networks, Rhodes, Greece, 4–7 October 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 468–478. [Google Scholar]
- Fitriyani, N.L.; Syafrudin, M.; Alfian, G.; Rhee, J. Development of disease prediction model based on ensemble learning approach for diabetes and hypertension. IEEE Access 2019, 7, 144777–144789. [Google Scholar] [CrossRef]
- Fernández-Edreira, D.; Liñares-Blanco, J.; Fernandez-Lozano, C. Machine Learning analysis of the human infant gut microbiome identifies influential species in type 1 diabetes. Expert Syst. Appl. 2021, 185, 115648. [Google Scholar] [CrossRef]
- Ali, A.; Alrubei, M.A.; Hassan, L.F.M.; Al-Ja’afari, M.A.; Abdulwahed, S.H. Diabetes Diagnosis based on KNN. IIUM Eng. J. 2020, 21, 175–181. [Google Scholar] [CrossRef] [Green Version]
- Qtea, H.; Awad, M. Using Hybrid Model of Particle Swarm Optimization and Multi-Layer Perceptron Neural Networks for Classification of Diabete. Int. J. Intell. Eng. Syst. 2021, 14, 11–22. [Google Scholar]
- Grover, S.; Bhartia, S.; Yadav, A.; Seeja, K.R. Predicting severity of Parkinson’s disease using deep learning. Procedia Comput. Sci. 2018, 132, 1788–1794. [Google Scholar] [CrossRef]
- Sriram, T.V.; Rao, M.V.; Narayana, G.S.; Kaladhar, D.; Vital, T.P.R. Intelligent Parkinson disease prediction using machine learning algorithms. Int. J. Eng. Innov. Technol. (IJEIT) 2013, 3, 1568–1572. [Google Scholar]
- Esmaeilzadeh, S.; Yang, Y.; Adeli, E. End-to-end Parkinson disease diagnosis using brain mr-images by 3d-cnn. arXiv 2018, arXiv:1806.05233. [Google Scholar]
- Warjurkar, S.; Ridhorkar, S. A Study on Brain Tumor and Parkinson’s Disease Diagnosis and Detection using Deep Learning. In Proceedings of the 3rd International Conference on Integrated Intelligent Computing Communication & Security (ICIIC 2021), Online, 27–28 August 2021; Atlantis Press: Amsterdam, The Netherlands, 2021; pp. 356–364. [Google Scholar]
- Sherly Puspha Annabel, L.; Sreenidhi, S.; Vishali, N. A Novel Diagnosis System for Parkinson’s Disease Using K-means Clustering and Decision Tree. In Communication and Intelligent Systems; Springer: Berlin/Heidelberg, Germany, 2021; pp. 607–615. [Google Scholar]
- Asmae, O.; Abdelhadi, R.; Bouchaib, C.; Sara, S.; Tajeddine, K. Parkinson’s disease identification using KNN and ANN Algorithms based on Voice Disorder. In Proceedings of the 2020 1st International Conference on Innovative Research in Applied Science, Engineering and Technology (IRASET), Meknes, Morocco, 19–20 March 2020; IEEE: Manhattan, NY, USA, 2020; pp. 1–6. [Google Scholar]
- Gürüler, H. A novel diagnosis system for Parkinson’s disease using complex-valued artificial neural network with k-means clustering feature weighting method. Neural Comput. Appl. 2017, 28, 1657–1666. [Google Scholar] [CrossRef]
- Shetty, S.; Rao, Y. SVM based machine learning approach to identify Parkinson’s disease using gait analysis. In Proceedings of the 2016 International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 26–27 August 2016; IEEE: Manhattan, NY, USA, 2016; Volume 2, pp. 1–5. [Google Scholar]
- Ahsan, M.M.; Nazim, R.; Siddique, Z.; Huebner, P. Detection of COVID-19 patients from ct scan and chest X-ray data using modified mobilenetv2 and lime. Healthcare 2021, 9, 1099. [Google Scholar] [CrossRef]
- Haghanifar, A.; Majdabadi, M.M.; Choi, Y.; Deivalakshmi, S.; Ko, S. Covid-cxnet: Detecting COVID-19 in frontal chest X-ray images using deep learning. arXiv 2020, arXiv:2006.13807. [Google Scholar]
- Tahamtan, A.; Ardebili, A. Real-time RT-PCR in COVID-19 detection: Issues affecting the results. Expert Rev. Mol. Diagn. 2020, 20, 453–454. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, J.; Wu, L.; Zhang, J.; Zhang, L.; Gong, D.; Zhao, Y.; Chen, Q.; Huang, S.; Yang, M.; Yang, X.; et al. Deep learning-based model for detecting 2019 novel coronavirus pneumonia on high-resolution computed tomography. Sci. Rep. 2020, 10, 19196. [Google Scholar] [CrossRef] [PubMed]
- Ardakani, A.A.; Kanafi, A.R.; Acharya, U.R.; Khadem, N.; Mohammadi, A. Application of deep learning technique to manage COVID-19 in routine clinical practice using CT images: Results of 10 convolutional neural networks. Comput. Biol. Med. 2020, 121, 103795. [Google Scholar] [CrossRef]
- Wang, L.; Lin, Z.Q.; Wong, A. Covid-net: A tailored deep convolutional neural network design for detection of COVID-19 cases from chest X-ray images. Sci. Rep. 2020, 10, 19549. [Google Scholar] [CrossRef]
- Li, L.; Qin, L.; Xu, Z.; Yin, Y.; Wang, X.; Kong, B.; Bai, J.; Lu, Y.; Fang, Z.; Song, Q.; et al. Artificial intelligence distinguishes COVID-19 from community acquired pneumonia on chest CT. Radiology 2020. [Google Scholar] [CrossRef]
- Hemdan, E.E.D.; Shouman, M.A.; Karar, M.E. Covidx-net: A framework of deep learning classifiers to diagnose COVID-19 in X-ray images. arXiv 2020, arXiv:2003.11055. [Google Scholar]
- Sethy, P.K.; Behera, S.K. Detection of Coronavirus Disease (COVID-19) Based on Deep Features and Support Vector Machine. 2020. Available online: https://pdfs.semanticscholar.org/9da0/35f1d7372cfe52167ff301bc12d5f415caf1.pdf (accessed on 10 December 2021).
- Narin, A.; Kaya, C.; Pamuk, Z. Automatic detection of coronavirus disease (COVID-19) using X-ray images and deep convolutional neural networks. Pattern Anal. Appl. 2021, 24, 1207–1220. [Google Scholar] [CrossRef] [PubMed]
- Brunese, L.; Mercaldo, F.; Reginelli, A.; Santone, A. Explainable deep learning for pulmonary disease and coronavirus COVID-19 detection from X-rays. Comput. Methods Programs Biomed. 2020, 196, 105608. [Google Scholar] [CrossRef] [PubMed]
- Ghoshal, B.; Tucker, A. Estimating uncertainty and interpretability in deep learning for coronavirus (COVID-19) detection. arXiv 2020, arXiv:2003.10769. [Google Scholar]
- Apostolopoulos, I.D.; Mpesiana, T.A. COVID-19: Automatic detection from X-ray images utilizing transfer learning with convolutional neural networks. Phys. Eng. Sci. Med. 2020, 43, 635–640. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Song, Y.; Zheng, S.; Li, L.; Zhang, X.; Zhang, X.; Huang, Z.; Chen, J.; Wang, R.; Zhao, H.; Chong, Y.; et al. Deep learning enables accurate diagnosis of novel coronavirus (COVID-19) with CT images. IEEE/ACM Trans. Comput. Biol. Bioinform. 2021, 18, 2775–2780. [Google Scholar] [CrossRef] [PubMed]
- Jin, C.; Chen, W.; Cao, Y.; Xu, Z.; Tan, Z.; Zhang, X.; Deng, L.; Zheng, C.; Zhou, J.; Shi, H.; et al. Development and evaluation of an artificial intelligence system for COVID-19 diagnosis. Nat. Commun. 2020, 11, 5088. [Google Scholar] [CrossRef]
- Graham, N.; Warner, J. Alzheimer’s Disease and Other Dementias; Family Doctor Publications Limited: Northampton, UK, 2009. [Google Scholar]
- Neelaveni, J.; Devasana, M.G. Alzheimer disease prediction using machine learning algorithms. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 6–7 March 2020; IEEE: Manhattan, NY, USA, 2020; pp. 101–104. [Google Scholar]
- Collij, L.E.; Heeman, F.; Kuijer, J.P.; Ossenkoppele, R.; Benedictus, M.R.; Möller, C.; Verfaillie, S.C.; Sanz-Arigita, E.J.; van Berckel, B.N.; van der Flier, W.M.; et al. Application of machine learning to arterial spin labeling in mild cognitive impairment and Alzheimer disease. Radiology 2016, 281, 865–875. [Google Scholar] [CrossRef] [Green Version]
- Vidushi, A.R.; Shrivastava, A.K. Diagnosis of Alzheimer disease using machine learning approaches. Int. J. Adv. Sci. Technol. 2019, 29, 7062–7073. [Google Scholar]
- Ahmed, S.; Kim, B.C.; Lee, K.H.; Jung, H.Y.; Initiative, A.D.N. Ensemble of ROI-based convolutional neural network classifiers for staging the Alzheimer disease spectrum from magnetic resonance imaging. PLoS ONE 2020, 15, e0242712. [Google Scholar] [CrossRef]
- Nawaz, H.; Maqsood, M.; Afzal, S.; Aadil, F.; Mehmood, I.; Rho, S. A deep feature-based real-time system for Alzheimer disease stage detection. Multimed. Tools Appl. 2020, 1–19. [Google Scholar] [CrossRef]
- Haft-Javaherian, M.; Fang, L.; Muse, V.; Schaffer, C.B.; Nishimura, N.; Sabuncu, M.R. Deep convolutional neural networks for segmenting 3D in vivo multiphoton images of vasculature in Alzheimer disease mouse models. PLoS ONE 2019, 14, e0213539. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Aderghal, K.; Benois-Pineau, J.; Afdel, K. Classification of sMRI for Alzheimer’s disease diagnosis with CNN: Single Siamese networks with 2D+? Approach and fusion on ADNI. In Proceedings of the 2017 ACM on International Conference on Multimedia Retrieval, Bucharest, Romania, 6–9 June 2017; pp. 494–498. [Google Scholar]
- Sun, M.; Huang, Z.; Guo, C. Automatic Diagnosis of Alzheimer’s Disease and Mild Cognitive Impairment Based on CNN+ SVM Networks with End-to-end Training. In Proceedings of the 2021 13th International Conference on Advanced Computational Intelligence (ICACI), Wanzhou, Chongqing, China, 14–16 May 2021; IEEE: Manhattan, NY, USA, 2021; pp. 279–285. [Google Scholar]
- Kuang, J.; Zhang, P.; Cai, T.; Zou, Z.; Li, L.; Wang, N.; Wu, L. Prediction of transition from mild cognitive impairment to Alzheimer’s disease based on a logistic regression–artificial neural network–decision tree model. Geriatr. Gerontol. Int. 2021, 21, 43–47. [Google Scholar] [CrossRef] [PubMed]
- Manzak, D.; Çetinel, G.; Manzak, A. Automated Classification of Alzheimer’s Disease using Deep Neural Network (DNN) by Random Forest Feature Elimination. In Proceedings of the 2019 14th International Conference on Computer Science & Education (ICCSE), Bandung, Indonesia, 14–15 October 2019; IEEE: Manhattan, NY, USA, 2019; pp. 1050–1053. [Google Scholar]
- Mao, Y.; He, Y.; Liu, L.; Chen, X. Disease classification based on eye movement features with decision tree and random forest. Front. Neurosci. 2020, 14, 798. [Google Scholar] [CrossRef]
- Nosseir, A.; Shawky, M.A. Automatic classifier for skin disease using k-NN and SVM. In Proceedings of the 2019 8th International Conference on Software and Information Engineering, Cairo, Egypt, 9–12 April 2019; pp. 259–262. [Google Scholar]
- Khan, M.A.; Ashraf, I.; Alhaisoni, M.; Damaševičius, R.; Scherer, R.; Rehman, A.; Bukhari, S.A.C. Multimodal brain tumor classification using deep learning and robust feature selection: A machine learning application for radiologists. Diagnostics 2020, 10, 565. [Google Scholar] [CrossRef] [PubMed]
- Amin, J.; Sharif, M.; Raza, M.; Yasmin, M. Detection of brain tumor based on features fusion and machine learning. J. Ambient Intell. Human. Comput. 2018, 1–17. [Google Scholar] [CrossRef]
- Dai, X.; Spasić, I.; Meyer, B.; Chapman, S.; Andres, F. Machine learning on mobile: An on-device inference app for skin cancer detection. In Proceedings of the 2019 Fourth International Conference on Fog and Mobile Edge Computing (FMEC), Rome, Italy, 10–13 June 2019; IEEE: Manhattan, NY, USA, 2019; pp. 301–305. [Google Scholar]
- Daghrir, J.; Tlig, L.; Bouchouicha, M.; Sayadi, M. Melanoma skin cancer detection using deep learning and classical machine learning techniques: A hybrid approach. In Proceedings of the 2020 5th International Conference on Advanced Technologies for Signal and Image Processing (ATSIP), Sfax, Tunisia, 2–5 September 2020; IEEE: Manhattan, NY, USA, 2020; pp. 1–5. [Google Scholar]
- Dhaliwal, J.; Erdman, L.; Drysdale, E.; Rinawi, F.; Muir, J.; Walters, T.D.; Siddiqui, I.; Griffiths, A.M.; Church, P.C. Accurate Classification of Pediatric Colonic Inflammatory Bowel Disease Subtype Using a Random Forest Machine Learning Classifier. J. Pediatr. Gastroenterol. Nutr. 2021, 72, 262–269. [Google Scholar] [CrossRef]
- Fathi, M.; Nemati, M.; Mohammadi, S.M.; Abbasi-Kesbi, R. A machine learning approach based on SVM for classification of liver diseases. Biomed. Eng. Appl. Basis Commun. 2020, 32, 2050018. [Google Scholar] [CrossRef]
- Wang, A.; An, N.; Xia, Y.; Li, L.; Chen, G. A logistic regression and artificial neural network-based approach for chronic disease prediction: A case study of hypertension. In Proceedings of the 2014 IEEE International Conference on Internet of Things (iThings), and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom), Taipei, Taiwan, 1–3 September 2014; IEEE: Manhattan, NY, USA, 2014; pp. 45–52. [Google Scholar]
- Kalaiselvi, T.; Padmapriya, S.; Sriramakrishnan, P.; Somasundaram, K. Deriving tumor detection models using convolutional neural networks from MRI of human brain scans. Int. J. Inf. Technol. 2020, 1–6. [Google Scholar] [CrossRef]
- Usman, K.; Rajpoot, K. Brain tumor classification from multi-modality MRI using wavelets and machine learning. Pattern Anal. Appl. 2017, 20, 871–881. [Google Scholar] [CrossRef] [Green Version]
- Waheed, Z.; Waheed, A.; Zafar, M.; Riaz, F. An efficient machine learning approach for the detection of melanoma using dermoscopic images. In Proceedings of the 2017 International Conference on Communication, Computing and Digital Systems (C-CODE), Islamabad, Pakistan, 8–9 March 2017; IEEE: Manhattan, NY, USA, 2017; pp. 316–319. [Google Scholar]
- Kamboj, A. A color-based approach for melanoma skin cancer detection. In Proceedings of the 2018 First International Conference on Secure Cyber Computing and Communication (ICSCCC), Jalandhar, India, 15–17 December 2018; IEEE: Manhattan, NY, USA, 2018; pp. 508–513. [Google Scholar]
- Magalhaes, C.; Tavares, J.M.R.; Mendes, J.; Vardasca, R. Comparison of machine learning strategies for infrared thermography of skin cancer. Biomed. Signal Process. Control 2021, 69, 102872. [Google Scholar] [CrossRef]
- Chen, M.; Zhang, B.; Topatana, W.; Cao, J.; Zhu, H.; Juengpanich, S.; Mao, Q.; Yu, H.; Cai, X. Classification and mutation prediction based on histopathology H&E images in liver cancer using deep learning. NPJ Precis. Oncol. 2020, 4, 14. [Google Scholar]
- Das, A.; Acharya, U.R.; Panda, S.S.; Sabut, S. Deep learning based liver cancer detection using watershed transform and Gaussian mixture model techniques. Cogn. Syst. Res. 2019, 54, 165–175. [Google Scholar] [CrossRef]
- Wang, Y.; Ji, C.; Wang, Y.; Ji, M.; Yang, J.J.; Zhou, C.M. Predicting postoperative liver cancer death outcomes with machine learning. Curr. Med Res. Opin. 2021, 37, 629–634. [Google Scholar] [CrossRef] [PubMed]
- Saxena, R.; Johri, A.; Deep, V.; Sharma, P. Heart diseases prediction system using CHC-TSS Evolutionary, KNN, and decision tree classification algorithm. In Emerging Technologies in Data Mining and Information Security; Springer: Berlin/Heidelberg, Germany, 2019; pp. 809–819. [Google Scholar]
- Elsalamony, H.A. Detection of anaemia disease in human red blood cells using cell signature, neural networks and SVM. Multimed. Tools Appl. 2018, 77, 15047–15074. [Google Scholar] [CrossRef]
- Basheer, S.; Mathew, R.M.; Devi, M.S. Ensembling Coalesce of Logistic Regression Classifier for Heart Disease Prediction using Machine Learning. Int. J. Innov. Technol. Explor. Eng. 2019, 8, 127–133. [Google Scholar]
- Bharti, R.; Khamparia, A.; Shabaz, M.; Dhiman, G.; Pande, S.; Singh, P. Prediction of heart disease using a combination of machine learning and deep learning. Comput. Intell. Neurosci. 2021, 2021, 8387680. [Google Scholar] [CrossRef] [PubMed]
- Saw, M.; Saxena, T.; Kaithwas, S.; Yadav, R.; Lal, N. Estimation of Prediction for Getting Heart Disease Using Logistic Regression Model of Machine Learning. In Proceedings of the 2020 International Conference on Computer Communication and Informatics (ICCCI), Da Nang, Vietnam, 30 November–3 December 2020; IEEE: Manhattan, NY, USA, 2020; pp. 1–6. [Google Scholar]
- Gill, N.S.; Mittal, P. A computational hybrid model with two level classification using SVM and neural network for predicting the diabetes disease. J. Theor. Appl. Inf. Technol 2016, 87, 1–10. [Google Scholar]
- Sun, G.; Hakozaki, Y.; Abe, S.; Vinh, N.Q.; Matsui, T. A novel infection screening method using a neural network and k-means clustering algorithm which can be applied for screening of unknown or unexpected infectious diseases. J. Infect. 2012, 65, 591–592. [Google Scholar] [CrossRef]
- Yang, G.; Pang, Z.; Deen, M.J.; Dong, M.; Zhang, Y.T.; Lovell, N.; Rahmani, A.M. Homecare robotic systems for healthcare 4.0: Visions and enabling technologies. IEEE J. Biomed. Health Inform. 2020, 24, 2535–2549. [Google Scholar] [CrossRef]
- Ngiam, K.Y.; Khor, W. Big data and machine learning algorithms for health-care delivery. Lancet Oncol. 2019, 20, e262–e273. [Google Scholar] [CrossRef]
- Zhang, P.; Schmidt, D.C.; White, J.; Lenz, G. Blockchain technology use cases in healthcare. In Advances in Computers; Elsevier: Amsterdam, The Netherlands, 2018; Volume 111, pp. 1–41. [Google Scholar]
- Engelhardt, M.A. Hitching healthcare to the chain: An introduction to blockchain technology in the healthcare sector. Technol. Innov. Manag. Rev. 2017, 7. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).