A Simple and Effective Approach for Tackling the Permutation Flow Shop Scheduling Problem



 ,
,  and
and
Abstract
1. Introduction
- Using the continuous values in the approach instead of discrete values, by employing LRV to convert those continuous values into discrete, for tackling PFSSP.
- Combining the uniform crossover and the arithmetic crossover (UAC) to help in increasing the exploitation capability in addition to reducing stuck into local minima.
- Proposing a version of the efficient GA, abbreviated as IEGA, improved by dynamic mutation and crossover probability (DMCP) and UAC for tacking the PFSSP.
- Additionally, IEGA is enhanced by integrating with a LSS and insert-reversed block (IRB) operator for tackling the PFSSP, in a version abbreviated as HIEGA.
- IEGA and HIEGA were tested on the benchmarks Reeves, Carlier, and Heller to check their performance.
2. The Permutation Flow Shop Scheduling Problem
- Each job could be run only one time on each machine.
- Each machine could address only a job at a time,
- Each machine will address a job in a time known as the processing time and abbreviated as PT.
- A completion time c is a time needed by each job on a machine and symbolized as .
- The processing time of each job is a phrase about the running time added with the set-up time of the machine.
- At the start, each job takes time of 0.
- PFSSP is solved with the objective of finding the best permutation that will minimize the makespan that is known as the maximum completion time or until the last job on the final machine was completed.
3. The Proposed Algorithm
3.1. Initialization
3.2. Selection Operator
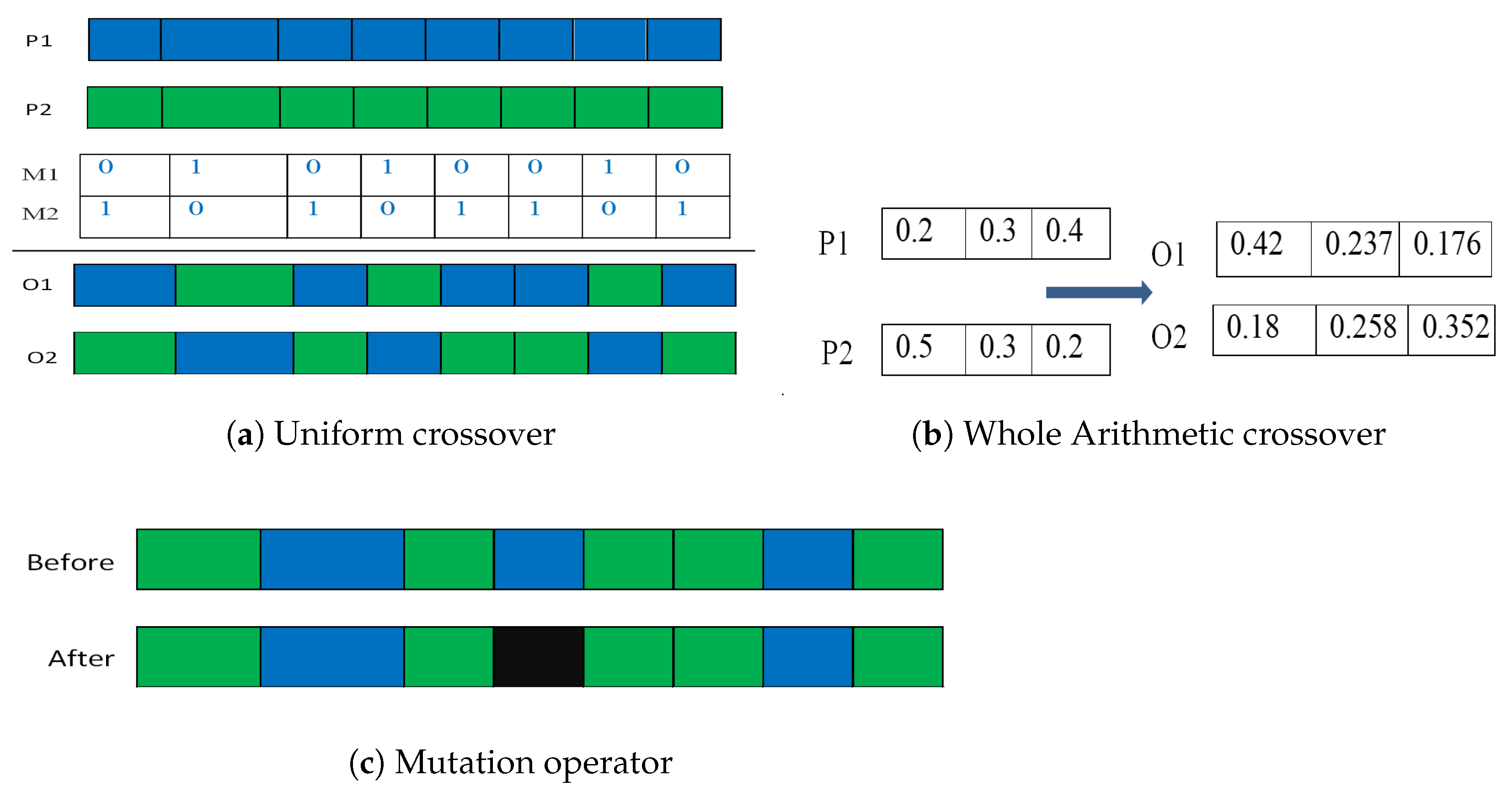
3.3. Crossover Operator
3.4. Mutation Operator
3.5. Combination of Uniform Crossover and Arithmetic Crossover (UAC)
| Algorithm 1 Uniform Arithmetic crossover (UAC) |
|
3.6. Local Search Strategy (LSS)
| Algorithm 2 LSS |
|
| Algorithm 3 HIEGA |
|
3.7. Time Complexity
- The first one is the generating process of offspring that need time complexity of .
- The second one is LRV which will need time complexity of [37] for the Quicksort algorithm. And totally for all population, the time complexity with LRV will be .
- The last one is the LSS that need for single individual. For all individual, the time complexity is as .
3.8. Performance Metric
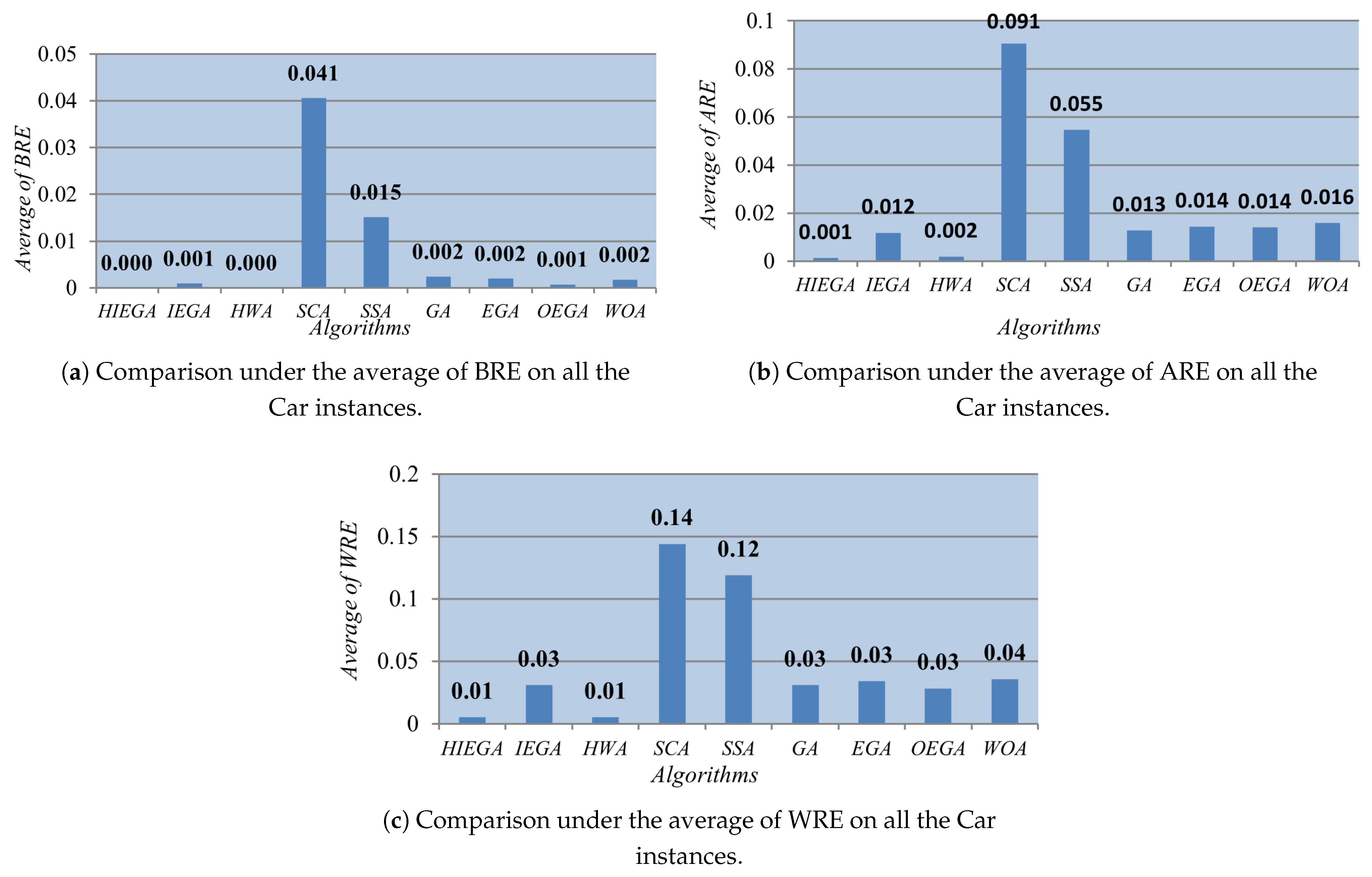
3.9. Comparison under Carlier
3.10. Comparison of Reeves
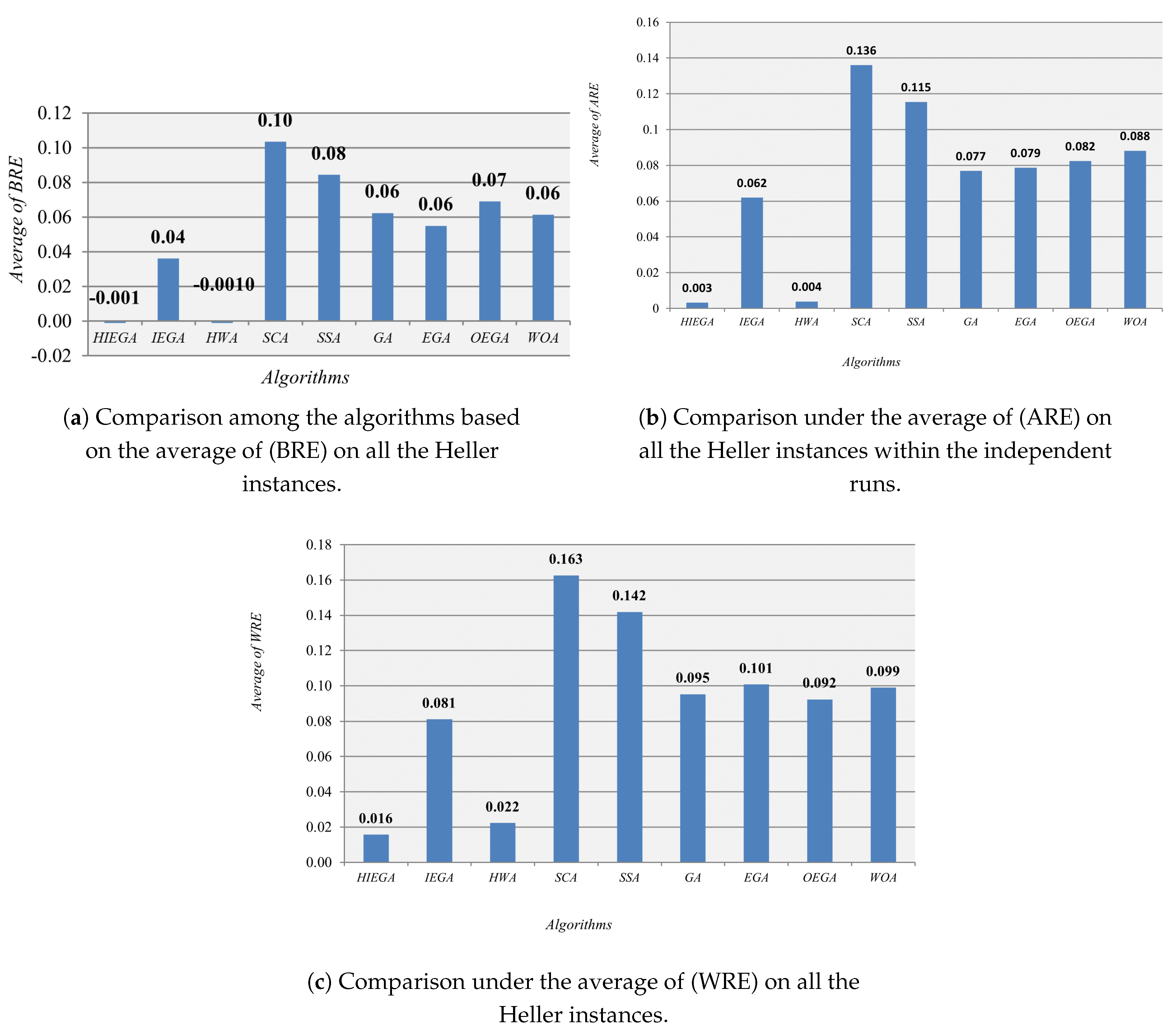
3.11. Comparison of Heller
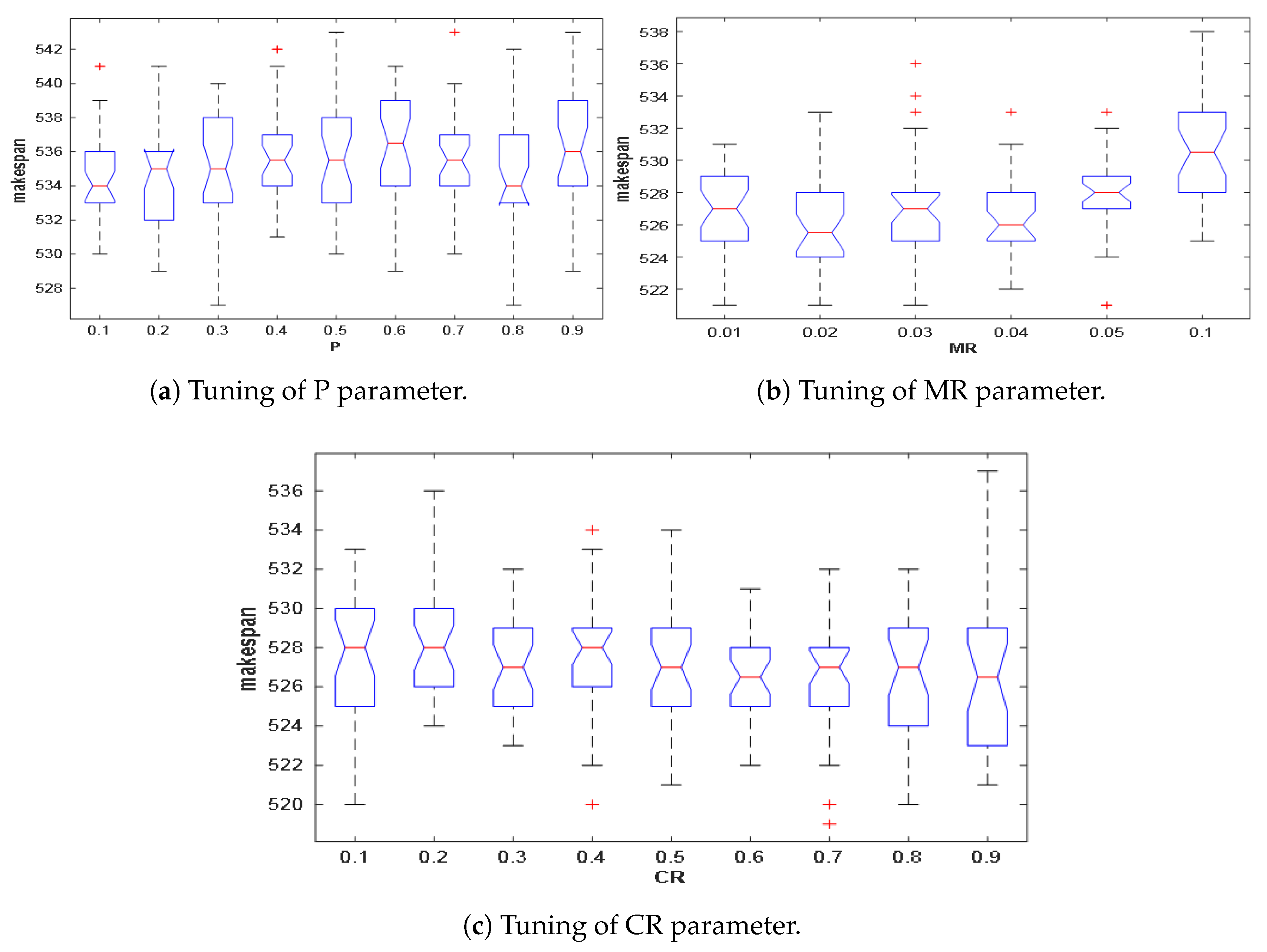
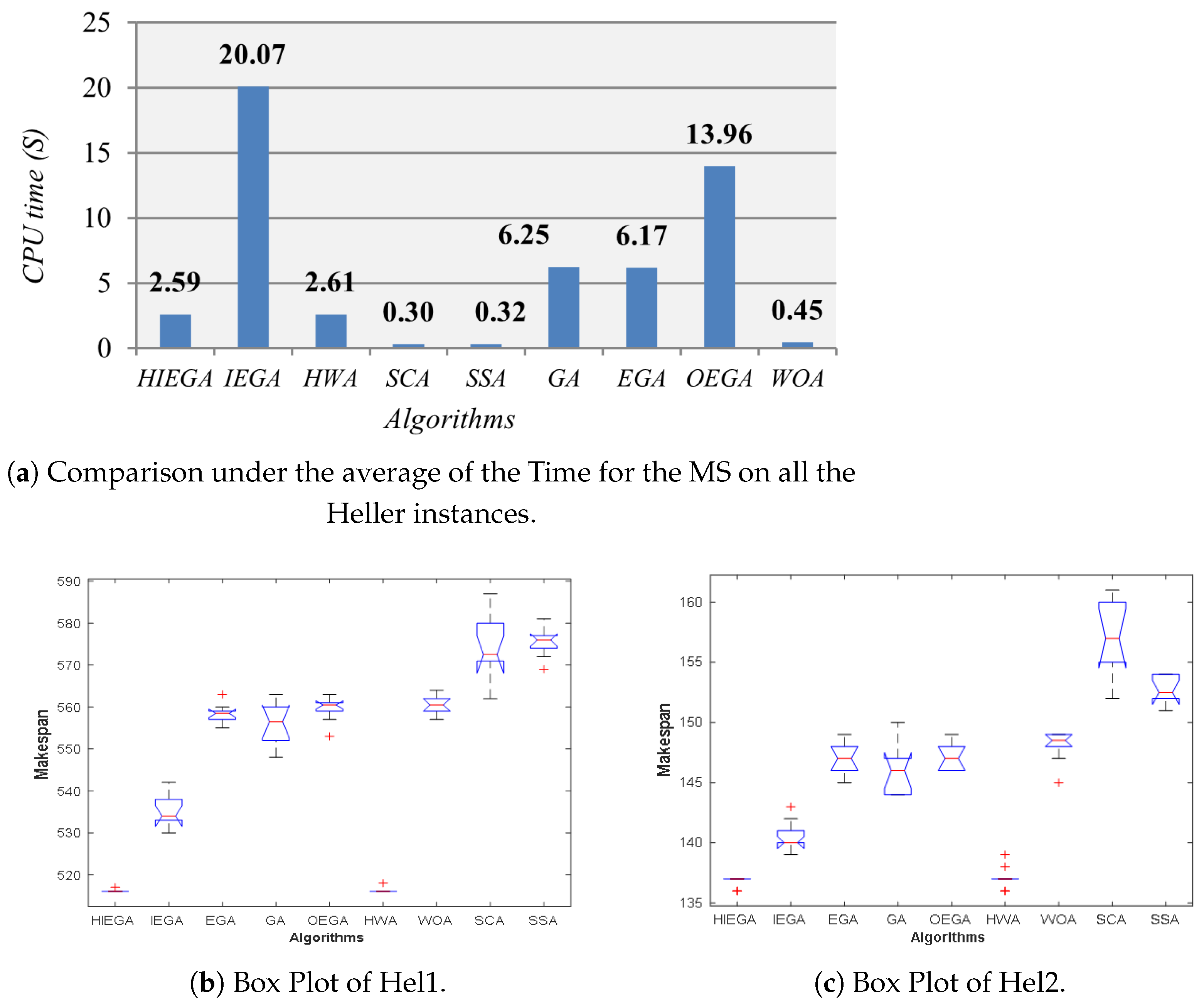
3.12. Comparison under CPU Time and BoxPLot
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Johnson, S.M. Optimal two-and three-stage production schedules with setup times included. Naval Res. Logist. Q. 1954, 1, 61–68. [Google Scholar] [CrossRef]
- Gao, J.; Chen, R. An NEH-based heuristic algorithm for distributed permutation flowshop scheduling problems. Sci. Res. Essays 2011, 6, 3094–3100. [Google Scholar]
- Sauvey, C.; Sauer, N. Two NEH Heuristic Improvements for Flowshop Scheduling Problem with Makespan Criterion. Algorithms 2020, 13, 112. [Google Scholar] [CrossRef]
- Wang, H.; Wang, W.; Sun, H.; Cui, Z.; Rahnamayan, S.; Zeng, S. A new cuckoo search algorithm with hybrid strategies for flow shop scheduling problems. Soft Comput. 2017, 21, 4297–4307. [Google Scholar] [CrossRef]
- Kalczynski, P.J.; Kamburowski, J. An improved NEH heuristic to minimize makespan in permutation flow shops. Comput. Operat. Res. 2008, 35, 3001–3008. [Google Scholar]
- Dong, X.; Huang, H.; Chen, P. An improved NEH-based heuristic for the permutation flowshop problem. Comput. Operat. Res. 2008, 35, 3962–3968. [Google Scholar] [CrossRef]
- Zhang, S.J.; Gu, X.S.; Zhou, F.N. An improved discrete migrating birds optimization algorithm for the no-wait flow shop scheduling problem. IEEE Access 2020, 8, 99380–99392. [Google Scholar]
- Govindan, K.; Balasundaram, R.; Baskar, N.; Asokan, P. A hybrid approach for minimizing makespan in permutation flowshop scheduling. J. Syst. Sci. Syst. Eng. 2017, 26, 50–76. [Google Scholar] [CrossRef]
- Liu, Y.; Yin, M.; Gu, W. An effective differential evolution algorithm for permutation flow shop scheduling problem. Appl. Math. Comput. 2014, 248, 143–159. [Google Scholar] [CrossRef]
- Ding, J.Y.; Song, S.; Zhang, R.; Zhou, S.; Wu, C. A novel block-shifting simulated annealing algorithm for the no-wait flowshop scheduling problem. In Proceedings of the 2015 IEEE Congress on Evolutionary Computation (CEC), IEEE, Sendai, Japan, 25–28 May 2015; pp. 2768–2774. [Google Scholar]
- Sanjeev Kumar, R.; Padmanaban, K.; Rajkumar, M. Minimizing makespan and total flow time in permutation flow shop scheduling problems using modified gravitational emulation local search algorithm. Proc. Instit. Mech. Eng. Part B J. Eng. Manufac. 2018, 232, 534–545. [Google Scholar] [CrossRef]
- Reeves, C.R. A genetic algorithm for flowshop sequencing. Comput. Operat. Res. 1995, 22, 5–13. [Google Scholar] [CrossRef]
- Liu, B.; Wang, L.; Jin, Y.H. An effective PSO-based memetic algorithm for flow shop scheduling. IEEE Trans. Syst. Man Cybern. Part B 2007, 37, 18–27. [Google Scholar] [CrossRef] [PubMed]
- Xie, Z.; Zhang, C.; Shao, X.; Lin, W.; Zhu, H. An effective hybrid teaching–learning-based optimization algorithm for permutation flow shop scheduling problem. Adv. Eng. Softw. 2014, 77, 35–47. [Google Scholar] [CrossRef]
- Zhao, F.; Liu, H.; Zhang, Y.; Ma, W.; Zhang, C. A discrete water wave optimization algorithm for no-wait flow shop scheduling problem. Expert Syst. Appl. 2018, 91, 347–363. [Google Scholar] [CrossRef]
- Shareh, M.B.; Bargh, S.H.; Hosseinabadi, A.A.R.; Slowik, A. An improved bat optimization algorithm to solve the tasks scheduling problem in open shop. Neur. Comput. Appl. 2020, 1–15. [Google Scholar] [CrossRef]
- Li, B.B.; Wang, L.; Liu, B. An effective PSO-based hybrid algorithm for multiobjective permutation flow shop scheduling. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2008, 38, 818–831. [Google Scholar] [CrossRef]
- Priya, A.; Sahana, S.K. Multiprocessor scheduling based on evolutionary technique for solving permutation flow shop problem. IEEE Access 2020, 8, 53151–53161. [Google Scholar] [CrossRef]
- Pang, X.; Xue, H.; Tseng, M.L.; Lim, M.K.; Liu, K. Hybrid Flow Shop Scheduling Problems Using Improved Fireworks Algorithm for Permutation. Appl. Sci. 2020, 10, 1174. [Google Scholar]
- Mishra, A.; Shrivastava, D. A discrete Jaya algorithm for permutation flow-shop scheduling problem. Int. J. Ind. Eng. Comput. 2020, 11, 415–428. [Google Scholar] [CrossRef]
- Mirjalili, S.; Gandomi, A.H.; Mirjalili, S.Z.; Saremi, S.; Faris, H.; Mirjalili, S.M. Salp Swarm Algorithm: A bio-inspired optimizer for engineering design problems. Adv. Eng. Softw. 2017, 114, 163–191. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. The whale optimization algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Mirjalili, S. SCA: A sine cosine algorithm for solving optimization problems. Knowledge-Based Syst. 2016, 96, 120–133. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; Mohamed, R.; Mirjalili, S. A novel Whale Optimization Algorithm integrated with Nelder–Mead simplex for multi-objective optimization problems. Knowl. Based Syst. 2020, 212, 106619. [Google Scholar] [CrossRef]
- Abualigah, L.; Shehab, M.; Alshinwan, M.; Alabool, H. Salp swarm algorithm: A comprehensive survey. Neural Comput. Appl. 2019, 1–21. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; El-Shahat, D.; Deb, K.; Abouhawwash, M. Energy-aware whale optimization algorithm for real-time task scheduling in multiprocessor systems. Appl. Soft Comput. 2020, 93, 106349. [Google Scholar] [CrossRef]
- Zhang, X.; Guo, P.; Zhang, H.; Yao, J. Hybrid Particle Swarm Optimization Algorithm for Process Planning. Mathematics 2020, 8, 1745. [Google Scholar] [CrossRef]
- Ren, T.; Zhang, Y.; Cheng, S.R.; Wu, C.C.; Zhang, M.; Chang, B.Y.; Wang, X.Y.; Zhao, P. Effective Heuristic Algorithms Solving the Jobshop Scheduling Problem with Release Dates. Mathematics 2020, 8, 1221. [Google Scholar] [CrossRef]
- Cosma, O.; Pop, P.C.; Sabo, C. An Efficient Hybrid Genetic Approach for Solving the Two-Stage Supply Chain Network Design Problem with Fixed Costs. Mathematics 2020, 8, 712. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; Manogaran, G.; El-Shahat, D.; Mirjalili, S. A hybrid whale optimization algorithm based on local search strategy for the permutation flow shop scheduling problem. Future Gener. Comput. Syst. 2018, 85, 129–145. [Google Scholar] [CrossRef]
- Goldberg, D.E.; Holland, J.H. Genetic Algorithms. Mach. Learn. 1988, 3, 95–99. [Google Scholar] [CrossRef]
- Holland, J.H. Genetic algorithms. Sci. Am. 1992, 267, 66–73. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; Mohamed, R.; Abouhawwash, M. Balanced multi-objective optimization algorithm using improvement based reference points approach. Swarm Evol. Comput. 2020, 60, 100791. [Google Scholar] [CrossRef]
- Li, X.; Yin, M. An opposition-based differential evolution algorithm for permutation flow shop scheduling based on diversity measure. Adv. Eng. Softw. 2013, 55, 10–31. [Google Scholar] [CrossRef]
- Blickle, T.; Thiele, L. A Mathematical Analysis of Tournament Selection; ICGA Citeseer; Morgan Kaufmann: San Francisco, CA, USA, 1995; Volume 95, pp. 9–15. [Google Scholar]
- Semenkin, E.; Semenkina, M. Self-configuring genetic algorithm with modified uniform crossover operator. In Proceedings of the International Conference in Swarm Intelligence, Brussels, Belgium, 12–14 September 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 414–421. [Google Scholar]
- Xiang, W. Analysis of the time complexity of quick sort algorithm. In Proceedings of the 2011 International Conference on Information Management, Innovation Management and Industrial Engineering, IEEE, Shenzhen, China, 26–27 November 2011; Volume 1, pp. 408–410. [Google Scholar]
- Carlier, J. Ordonnancements a contraintes disjonctives. RAIRO-Operat. Res. 1978, 12, 333–350. [Google Scholar] [CrossRef]
- Heller, J. Some numerical experiments for an M× J flow shop and its decision-theoretical aspects. Operat. Res. 1960, 8, 178–184. [Google Scholar] [CrossRef]
- Ancău, M. On solving flowshop scheduling problems. Proc. Roman. Acad. Ser. A 2012, 13, 71–79. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Carlier, Heller, Reeves Benchmarks | |||||||
|---|---|---|---|---|---|---|---|
| Name | n | m | Name | n | m | ||
| Car01 | 11 | 5 | 7038 | Rec05 | 20 | 5 | 1242 |
| Car02 | 13 | 4 | 7166 | Rec07 | 20 | 10 | 1566 |
| Car03 | 12 | 5 | 7312 | Rec09 | 20 | 10 | 1537 |
| Car04 | 14 | 4 | 8003 | Rec11 | 20 | 10 | 1431 |
| Car05 | 10 | 6 | 7720 | Rec13 | 20 | 15 | 1930 |
| Car06 | 8 | 9 | 8505 | Rec15 | 20 | 15 | 1950 |
| Car07 | 7 | 7 | 6590 | Rec17 | 20 | 15 | 1902 |
| Car08 | 8 | 8 | 8366 | Rec19 | 30 | 10 | 2017 |
| Hel1 | 20 | 10 | 516 | Rec21 | 30 | 10 | 2011 |
| Hel2 | 100 | 10 | 136 | Rec37 | 75 | 20 | 4951 |
| Rec01 | 20 | 5 | 1247 | Rec39 | 75 | 20 | 5087 |
| Rec03 | 20 | 5 | 1109 | Rec41 | 75 | 20 | 4960 |
| GA, EGA, IEGA, OEGA and IEGA | HWA, HIEGA | ||
|---|---|---|---|
| CR | 0.8 | LSP | 0.01 |
| MR | 0.02 | BS P | 5 0.8 |
| Instances | Algorithm | BRE | WRE | ARE | SD | ||
|---|---|---|---|---|---|---|---|
| Car01 | HIEGA | 7038 | 0 | 0 | 0 | 7038 | 0 |
| IEGA | 0 | 0 | 0 | 7038 | 0 | ||
| HWA | 0 | 0 | 0 | 7038 | 0 | ||
| SCA | 0 | 0.171213 | 0.088562 | 7661.3 | 305.406849 | ||
| SSA | 0 | 0.122336 | 0.064303 | 7490.566667 | 226.370593 | ||
| GA | 0 | 0 | 0 | 7038 | 0 | ||
| EGA | 0 | 0.002699 | 0.000090 | 7038.633333 | 3.410604 | ||
| OEGA | 0 | 0 | 0 | 7038 | 0 | ||
| WOA | 0 | 0.042484 | 0.004244 | 7067.866667 | 66.693195 | ||
| Car02 | HIEGA | 7166 | 0 | 0 | 0 | 7166 | 0 |
| IEGA | 0 | 0.029305 | 0.018504 | 7298.6 | 94.769756 | ||
| HWA | 0 | 0 | 0 | 7166 | 0 | ||
| SCA | 0.084706 | 0.171365 | 0.130398 | 8100.433333 | 158.832130 | ||
| SSA | 0.056377 | 0.143734 | 0.099660 | 7880.166667 | 139.553116 | ||
| GA | 0.007257 | 0.055679 | 0.031352 | 7390.666667 | 62.308016 | ||
| EGA | 0 | 0.094334 | 0.037957 | 7438 | 118.735279 | ||
| OEGA | 0 | 0.059029 | 0.033078 | 7403.033333 | 94.837223 | ||
| WOA | 0 | 0.063634 | 0.037687 | 7436.066667 | 119.013146 | ||
| Car03 | HIEGA | 7312 | 0 | 0.011898 | 0.003597 | 7338.3 | 28.709058 |
| IEGA | 0.007385 | 0.049644 | 0.027922 | 7516.166667 | 85.491942 | ||
| HWA | 0 | 0.011898 | 0.006524 | 7359.7 | 34.085334 | ||
| SCA | 0.056483 | 0.184628 | 0.127010 | 8240.7 | 268.999771 | ||
| SSA | 0.035968 | 0.111324 | 0.076067 | 7868.2 | 170.196044 | ||
| GA | 0.011898 | 0.054431 | 0.028679 | 7521.7 | 87.041044 | ||
| EGA | 0.011898 | 0.044037 | 0.026044 | 7502.433333 | 72.344861 | ||
| OEGA | 0.006018 | 0.054431 | 0.032891 | 7552.5 | 65.858308 | ||
| WOA | 0.011898 | 0.056483 | 0.035161 | 7569.1 | 73.710402 | ||
| Car04 | HIEGA | 8003 | 0 | 0 | 0 | 8003 | 0 |
| IEGA | 0 | 0.011746 | 0.001141 | 8012.133333 | 22.399008 | ||
| HWA | 0 | 0 | 0 | 8003 | 0 | ||
| SCA | 0.052480 | 0.148819 | 0.091095 | 8732.033333 | 218.220146 | ||
| SSA | 0.018618 | 0.134699 | 0.070865 | 8570.133333 | 200.441468 | ||
| GA | 0 | 0.025366 | 0.004823 | 8041.6 | 56.202372 | ||
| EGA | 0 | 0.016244 | 0.006702 | 8056.633333 | 58.819772 | ||
| OEGA | 0 | 0.028239 | 0.012475 | 8102.833333 | 67.356803 | ||
| WOA | 0.000625 | 0.052480 | 0.015965 | 8130.766667 | 77.604847 | ||
| Car05 | HIEGA | 7720 | 0 | 0.013083 | 0.002988 | 7743.066667 | 33.402528 |
| IEGA | 0 | 0.034845 | 0.010734 | 7802.866667 | 49.143147 | ||
| HWA | 0 | 0.013083 | 0.003105 | 7743.966667 | 31.594813 | ||
| SCA | 0.038472 | 0.118005 | 0.078001 | 8322.166667 | 164.803536 | ||
| SSA | 0.002332 | 0.118912 | 0.024188 | 7906.733333 | 207.587079 | ||
| GA | 0 | 0.019819 | 0.010289 | 7799.433333 | 40.596948 | ||
| EGA | 0.003886 | 0.017358 | 0.010406 | 7800.333333 | 29.777322 | ||
| OEGA | 0 | 0.013989 | 0.006503 | 7770.2 | 29.221453 | ||
| WOA | 0.001554 | 0.018782 | 0.010622 | 7802 | 43.109937 | ||
| Car06 | HIEGA | 8505 | 0 | 0.007643 | 0.002802 | 8528.833333 | 31.3231366 |
| IEGA | 0 | 0.061023 | 0.021105 | 8684.5 | 147.216337 | ||
| HWA | 0 | 0.007643 | 0.003821 | 8537.5 | 32.5 | ||
| SCA | 0.054321 | 0.144386 | 0.088309 | 9256.066667 | 184.081311 | ||
| SSA | 0.007643 | 0.123691 | 0.044158 | 8880.566667 | 251.156483 | ||
| GA | 0 | 0.058554 | 0.016477 | 8645.133333 | 127.213923 | ||
| EGA | 0 | 0.051382 | 0.019075 | 8667.233333 | 131.723115 | ||
| OEGA | 0 | 0.041152 | 0.016899 | 8648.733333 | 105.884507 | ||
| WOA | 0 | 0.029277 | 0.011515 | 8602.933333 | 96.881004 |
| Instances | Algorithm | BRE | WRE | ARE | SD | ||
|---|---|---|---|---|---|---|---|
| Car07 | HIEGA | 6590 | 0 | 0.008043 | 0 | 6591.766667 | 0 |
| IEGA | 0 | 0.008043 | 0.001877 | 6602.366667 | 22.416487 | ||
| HWA | 0 | 0.008043 | 0.001340 | 6598.833333 | 19.751934 | ||
| SCA | 0.014416 | 0.130197 | 0.071259 | 7059.6 | 195.841024 | ||
| SSA | 0 | 0.145827 | 0.035225 | 6822.133333 | 230.693842 | ||
| GA | 0 | 0.025797 | 0.002155 | 6604.2 | 36.750873 | ||
| EGA | 0 | 0.025797 | 0.002403 | 6605.833333 | 37.018989 | ||
| OEGA | 0 | 0.008346 | 0.002155 | 6604.2 | 23.550513 | ||
| WOA | 0 | 0.008346 | 0.001897 | 6602.5 | 22.662377 | ||
| Car08 | HIEGA | 8366 | 0 | 0.008346 | 0.001897 | 6602.5 | 22.662377 |
| IEGA | 0 | 0 | 0 | 8366 | 0 | ||
| HWA | 0 | 0.035620 | 0.008179 | 8434.433333 | 64.081554 | ||
| SCA | 0 | 0 | 0 | 8366 | 0 | ||
| SSA | 0.010877 | 0.093593 | 0.059527 | 8864 | 169.176239 | ||
| GA | 0.005139 | 0.071002 | 0.025922 | 8582.866667 | 127.503656 | ||
| EGA | 0 | 0.031198 | 0.011017 | 8458.166667 | 65.852909 | ||
| OEGA | 0 | 0.030002 | 0.010774 | 8456.133333 | 53.485658 | ||
| WOA | 0 | 0.012789 | 0.005610 | 8412.933333 | 35.052278 |
| Instances | Algorithm | BRE | WRE | ARE | SD | ||
|---|---|---|---|---|---|---|---|
| Rec01 | HIEGA | 1247 | 0 | 0.019246 | 0.002834 | 1250.533333 | 4.828618 |
| IEGA | 0.052125 | 0.106656 | 0.070783 | 1335.266667 | 14.534862 | ||
| HWA | 0.001604 | 0.051323 | 0.006977 | 1255.7 | 14.744829 | ||
| SCA | 0.109864 | 0.198075 | 0.157017 | 1442.8 | 20.972045 | ||
| SSA | 0.086608 | 0.178027 | 0.137423 | 1418.366667 | 25.921013 | ||
| GA | 0.063352 | 0.100241 | 0.082625 | 1350.033333 | 13.816616 | ||
| EGA | 0.063352 | 0.109864 | 0.082304 | 1349.633333 | 13.352861 | ||
| OEGA | 0.058541 | 0.103448 | 0.081476 | 1348.6 | 15.098786 | ||
| WOA | 0.074579 | 0.120289 | 0.092515 | 1362.366667 | 14.155054 | ||
| Rec03 | HIEGA | 1109 | 0 | 0.021641 | 0.002164 | 1111.4 | 4.644710 |
| IEGA | 0.007214 | 0.061317 | 0.040517 | 1153.933333 | 13.921047 | ||
| HWA | 0 | 0.021641 | 0.002946 | 1112.266667 | 6.065934 | ||
| SCA | 0.102795 | 0.210099 | 0.152901 | 1278.566667 | 32.871146 | ||
| SSA | 0.078449 | 0.167719 | 0.119748 | 1241.8 | 31.186963 | ||
| GA | 0.030658 | 0.067629 | 0.052329 | 1167.033333 | 11.223438 | ||
| EGA | 0.029757 | 0.089269 | 0.056748 | 1171.933333 | 14.449759 | ||
| OEGA | 0.032462 | 0.069432 | 0.052059 | 1166.733333 | 9.688252 | ||
| WOA | 0.038774 | 0.099189 | 0.073129 | 1190.1 | 14.839924 | ||
| Rec05 | HIEGA | 1242 | 0.002416 | 0.018519 | 0.006871 | 1250.533333 | 5.481687 |
| IEGA | 0.012077 | 0.056361 | 0.034568 | 1284.933333 | 11.744313 | ||
| HWA | 0.002416 | 0.011272 | 0.004938 | 1248.133333 | 4.177187 | ||
| SCA | 0.042673 | 0.153784 | 0.115996 | 1386.066667 | 26.293134 | ||
| SSA | 0.045894 | 0.134461 | 0.097236 | 1362.766667 | 26.297888 | ||
| GA | 0.024959 | 0.060387 | 0.043156 | 1295.6 | 9.704295 | ||
| EGA | 0.017713 | 0.070048 | 0.043774 | 1296.366667 | 14.969933 | ||
| OEGA | 0.026570 | 0.058776 | 0.042002 | 1294.166667 | 9.757333 | ||
| WOA | 0.029791 | 0.060387 | 0.048282 | 1301.966667 | 9.809802 | ||
| Rec07 | HIEGA | 1566 | 0 | 0.011494 | 0.007663 | 1578 | 8.485281 |
| IEGA | 0.035759 | 0.087484 | 0.056939 | 1655.166667 | 20.448445 | ||
| HWA | 0 | 0.011494 | 0.007791 | 1578.2 | 8.268011 | ||
| SCA | 0.093231 | 0.188378 | 0.147829 | 1797.5 | 33.795217 | ||
| SSA | 0.082376 | 0.173052 | 0.120945 | 1755.4 | 39.244193 | ||
| GA | 0.042146 | 0.100894 | 0.069199 | 1674.366667 | 18.948146 | ||
| EGA | 0.045338 | 0.101533 | 0.073159 | 1680.566667 | 22.496938 | ||
| OEGA | 0.044699 | 0.084929 | 0.067497 | 1671.7 | 14.512409 | ||
| WOA | 0.051086 | 0.096424 | 0.077203 | 1686.9 | 15.712734 | ||
| Rec09 | HIEGA | 1537 | 0 | 0.063761 | 0.014769 | 1559.7 | 21.506820 |
| IEGA | 0.051399 | 0.116461 | 0.089091 | 1673.933333 | 22.152401 | ||
| HWA | 0 | 0.042290 | 0.017393 | 1563.733333 | 16.958643 | ||
| SCA | 0.130124 | 0.202342 | 0.164867 | 1790.4 | 28.841637 | ||
| SSA | 0.068315 | 0.162004 | 0.118174 | 1718.633333 | 35.250989 | ||
| GA | 0.074171 | 0.117111 | 0.094860 | 1682.8 | 19.482299 | ||
| EGA | 0.062459 | 0.121015 | 0.097636 | 1687.066667 | 20.602481 | ||
| OEGA | 0.065712 | 0.113208 | 0.095316 | 1683.5 | 17.659275 | ||
| WOA | 0.060508 | 0.124268 | 0.099349 | 1689.7 | 22.564205 | ||
| Rec11 | HIEGA | 1431 | 0 | 0.0433263 | 0.014256 | 1451.4 | 17.779388 |
| IEGA | 0.093640 | 0.141858 | 0.117027 | 1598.466667 | 18.990758 | ||
| HWA | 0 | 0.040531 | 0.017353 | 1455.833333 | 17.384060 | ||
| SCA | 0.149545 | 0.220824 | 0.194805 | 1709.766667 | 27.304069 | ||
| SSA | 0.095737 | 0.198462 | 0.156836 | 1655.433333 | 30.650376 | ||
| GA | 0.096436 | 0.145352 | 0.122362 | 1606.1 | 16.213882 | ||
| EGA | 0.082459 | 0.150943 | 0.123526 | 1607.766667 | 19.653130 | ||
| OEGA | 0.100628 | 0.139063 | 0.119613 | 1602.166667 | 14.973495 | ||
| WOA | 0.088050 | 0.136268 | 0.118518 | 1600.6 | 15.632444 |
| Instances | Algorithm | BRE | WRE | ARE | SD | ||
|---|---|---|---|---|---|---|---|
| Rec13 | HIEGA | 1930 | 0 | 0.038342 | 0.015664 | 1960.233333 | 15.683714 |
| IEGA | 0.046632 | 0.118134 | 0.076131 | 2076.933333 | 29.532957 | ||
| HWA | 0.002072 | 0.044559 | 0.019153 | 1966.966667 | 16.592133 | ||
| SCA | 0.122797 | 0.214507 | 0.164162 | 2246.833333 | 35.753865 | ||
| SSA | 0.109844 | 0.182383 | 0.135716 | 2191.933333 | 32.857199 | ||
| GA | 0.078238 | 0.121761 | 0.096269 | 2115.8 | 22.456476 | ||
| EGA | 0.069948 | 0.130569 | 0.094801 | 2112.966667 | 29.238654 | ||
| OEGA | 0.088082 | 0.119171 | 0.100690 | 2124.333333 | 17.376868 | ||
| WOA | 0.096373 | 0.127979 | 0.109706 | 2141.733333 | 14.042633 | ||
| Rec15 | HIEGA | 1950 | 0.004615 | 0.098974 | 0.024290 | 1997.366667 | 35.095567 |
| IEGA | 0.047692 | 0.098974 | 0.068974 | 2084.5 | 19.416058 | ||
| HWA | 0.005128 | 0.042564 | 0.018461 | 1986 | 21.594752 | ||
| SCA | 0.090769 | 0.168205 | 0.141538 | 2226 | 34.466408 | ||
| SSA | 0.070256 | 0.131794 | 0.108085 | 2160.766667 | 30.206713 | ||
| GA | 0.063589 | 0.106666 | 0.084700 | 2115.166667 | 22.764128 | ||
| EGA | 0.061538 | 0.101025 | 0.083641 | 2113.1 | 18.758731 | ||
| OEGA | 0.06 | 0.097948 | 0.080700 | 2107.366667 | 19.027144 | ||
| WOA | 0.055384 | 0.092307 | 0.081982 | 2109.866667 | 14.548157 | ||
| Rec17 | HIEGA | 1902 | 0.017350 | 0.082544 | 0.035173 | 1968.9 | 25.981211 |
| IEGA | 0.067297 | 0.114090 | 0.093305 | 2079.466667 | 24.349857 | ||
| HWA | 0 | 0.058359 | 0.027024 | 1953.4 | 20.878378 | ||
| SCA | 0.127760 | 0.206624 | 0.170347 | 2226 | 32.794308 | ||
| SSA | 0.107781 | 0.179285 | 0.135278 | 2159.3 | 32.444979 | ||
| GA | 0.074658 | 0.121976 | 0.106151 | 2103.9 | 20.932192 | ||
| EGA | 0.088853 | 0.137224 | 0.108307 | 2108 | 19.832633 | ||
| OEGA | 0.090431 | 0.128811 | 0.114335 | 2119.466667 | 16.995555 | ||
| WOA | 0.097791 | 0.136172 | 0.114879 | 2120.5 | 18.067927 | ||
| Rec19 | HIEGA | 2017 | 0.044124 | 0.187902 | 0.058139 | 2134.266667 | 49.683621 |
| IEGA | 0.123946 | 0.163113 | 0.144752 | 2308.966667 | 21.393898 | ||
| HWA | 0.042141 | 0.069410 | 0.055197 | 2128.333333 | 11.950825 | ||
| SCA | 0.176995 | 0.258800 | 0.230325 | 2481.566667 | 36.693944 | ||
| SSA | 0.153197 | 0.238968 | 0.205982 | 2432.466667 | 35.916322 | ||
| GA | 0.143777 | 0.179970 | 0.163427 | 2346.633333 | 19.460187 | ||
| EGA | 0.136836 | 0.184928 | 0.163609 | 2347 | 21.776133 | ||
| OEGA | 0.143777 | 0.174020 | 0.160337 | 2340.4 | 18.045498 | ||
| WOA | 0.134358 | 0.195835 | 0.175260 | 2370.5 | 26.722961 | ||
| Rec21 | HIEGA | 2011 | 0.013426 | 0.019393 | 0.018680 | 2048.566667 | 2.603629 |
| IEGA | 0.074589 | 0.138736 | 0.108238 | 2228.666667 | 28.311756 | ||
| HWA | 0.009945 | 0.019393 | 0.018680 | 2048.566667 | 3.630273 | ||
| SCA | 0.165092 | 0.228741 | 0.196784 | 2406.733333 | 33.423478 | ||
| SSA | 0.128294 | 0.203381 | 0.168788 | 2350.433333 | 34.844113 | ||
| GA | 0.087021 | 0.150174 | 0.126255 | 2264.9 | 24.064288 | ||
| EGA | 0.104922 | 0.148185 | 0.127697 | 2267.8 | 21.487050 | ||
| OEGA | 0.108403 | 0.152163 | 0.129355 | 2271.133333 | 20.170495 | ||
| WOA | 0.109895 | 0.148185 | 0.133731 | 2279.933333 | 19.177996 | ||
| Rec23 | HIEGA | 2011 | 0.004972 | 0.034808 | 0.017918 | 2047.033333 | 14.855937 |
| IEGA | 0.085529 | 0.141223 | 0.110923 | 2234.066667 | 27.282391 | ||
| HWA | 0.004972 | 0.036300 | 0.016194 | 2043.566667 | 14.247066 | ||
| SCA | 0.137245 | 0.220288 | 0.186507 | 2386.066667 | 39.107487 | ||
| SSA | 0.139234 | 0.206365 | 0.165108 | 2343.033333 | 32.162590 | ||
| GA | 0.110890 | 0.158130 | 0.129587 | 2271.6 | 19.491194 | ||
| EGA | 0.104425 | 0.151665 | 0.128244 | 2268.9 | 20.799599 | ||
| OEGA | 0.116360 | 0.146195 | 0.131990 | 2276.433333 | 15.329021 | ||
| WOA | 0.112879 | 0.151168 | 0.131659 | 2275.766667 | 18.322451 | ||
| Rec25 | HIEGA | 2513 | 0.007958 | 0.044966 | 0.026754 | 2580.233333 | 19.095694 |
| IEGA | 0.082371 | 0.121368 | 0.106685 | 2781.1 | 22.530497 | ||
| HWA | 0.014325 | 0.045364 | 0.027616 | 2582.4 | 16.987446 | ||
| SCA | 0.155590 | 0.204934 | 0.176588 | 2956.766667 | 36.271828 | ||
| SSA | 0.108635 | 0.188221 | 0.150245 | 2890.566667 | 41.364786 | ||
| GA | 0.102268 | 0.139673 | 0.122735 | 2821.433333 | 20.817754 | ||
| EGA | 0.092319 | 0.147632 | 0.127749 | 2834.033333 | 25.235534 | ||
| OEGA | 0.097493 | 0.136490 | 0.122708 | 2821.366667 | 19.693456 | ||
| WOA | 0.107043 | 0.149224 | 0.127152 | 2832.533333 | 24.555696 |
| Instances | Algorithm | BRE | WRE | ARE | SD | ||
|---|---|---|---|---|---|---|---|
| Rec27 | HIEGA | 2373 | 0.008006 | 0.036662 | 0.019272 | 2418.733333 | 16.641180 |
| IEGA | 0.096923 | 0.147071 | 0.119047 | 2655.5 | 30.93945 | ||
| HWA | 0.010535 | 0.032027 | 0.019525 | 2419.333333 | 13.842767 | ||
| SCA | 0.170670 | 0.235988 | 0.202612 | 2853.8 | 46.058947 | ||
| SSA | 0.139907 | 0.209860 | 0.179898 | 2799.9 | 40.539980 | ||
| GA | 0.102823 | 0.160977 | 0.136311 | 2696.466667 | 36.165115 | ||
| EGA | 0.115887 | 0.153813 | 0.137772 | 2699.933333 | 20.720253 | ||
| OEGA | 0.088074 | 0.160556 | 0.139120 | 2703.133333 | 34.369301 | ||
| WOA | 0.112937 | 0.156342 | 0.137435 | 2699.133333 | 26.572834 | ||
| Rec29 | HIEGA | 2287 | 0.006121 | 0.042850 | 0.023597 | 2340.966667 | 22.394170 |
| IEGA | 0.101442 | 0.174901 | 0.142661 | 2613.266667 | 37.883974 | ||
| HWA | 0.007870 | 0.050284 | 0.027969 | 2350.966667 | 24.183304 | ||
| SCA | 0.195452 | 0.254044 | 0.225200 | 2802.033333 | 37.867737 | ||
| SSA | 0.157848 | 0.239178 | 0.192042 | 2726.2 | 43.699275 | ||
| GA | 0.140358 | 0.188019 | 0.162789 | 2659.3 | 27.098770 | ||
| EGA | 0.137297 | 0.191954 | 0.162075 | 2657.666667 | 25.819028 | ||
| OEGA | 0.132488 | 0.177962 | 0.159860 | 2652.6 | 25.210579 | ||
| WOA | 0.144731 | 0.186270 | 0.165573 | 2665.666667 | 25.373652 | ||
| Rec31 | HIEGA | 3045 | 0.002627 | 0.027586 | 0.016934 | 3096.566667 | 22.008609 |
| IEGA | 0.104433 | 0.146798 | 0.125473 | 3427.066667 | 39.693772 | ||
| HWA | 0.008867 | 0.037766 | 0.022375 | 3113.133333 | 20.418510 | ||
| SCA | 0.154351 | 0.210837 | 0.186097 | 3611.666667 | 34.852387 | ||
| SSA | 0.134318 | 0.198358 | 0.177329 | 3584.966667 | 42.869167 | ||
| GA | 0.127422 | 0.157635 | 0.140634 | 3473.233333 | 23.531090 | ||
| EGA | 0.122824 | 0.162233 | 0.142200 | 3478 | 23.359509 | ||
| OEGA | 0.122495 | 0.159277 | 0.143940 | 3483.3 | 27.282656 | ||
| WOA | 0.131362 | 0.159277 | 0.147071 | 3492.833333 | 25.139720 | ||
| Rec33 | HIEGA | 3114 | 0.001284 | 0.020231 | 0.008188 | 3139.5 | 10.883473 |
| IEGA | 0.074181 | 0.115606 | 0.098126 | 3419.566667 | 29.809040 | ||
| HWA | 0.001284 | 0.010276 | 0.008295 | 3139.833333 | 4.305681 | ||
| SCA | 0.150610 | 0.198137 | 0.173560 | 3654.466667 | 36.446063 | ||
| SSA | 0.121066 | 0.193962 | 0.162952 | 3621.433333 | 49.127509 | ||
| GA | 0.102761 | 0.136159 | 0.115403 | 3473.366667 | 22.817366 | ||
| EGA | 0.094091 | 0.137443 | 0.113690 | 3468.033333 | 33.271091 | ||
| OEGA | 0.107899 | 0.128131 | 0.118946 | 3484.4 | 18.307739 | ||
| WOA | 0.106294 | 0.140976 | 0.123389 | 3498.233333 | 27.813286 | ||
| Rec35 | HIEGA | 3277 | 0 | 0 | 0 | 3277 | 0 |
| IEGA | 0.044552 | 0.083918 | 0.063452 | 3484.933333 | 29.017159 | ||
| HWA | 0 | 0.000915 | 0.000030 | 3277.1 | 0.538516 | ||
| SCA | 0.105584 | 0.158986 | 0.132478 | 3711.133333 | 42.568950 | ||
| SSA | 0.089105 | 0.145865 | 0.120587 | 3672.166667 | 44.570605 | ||
| GA | 0.064693 | 0.092767 | 0.080327 | 3540.233333 | 25.608180 | ||
| EGA | 0.057064 | 0.101617 | 0.083084 | 3549.266667 | 34.247076 | ||
| OEGA | 0.065913 | 0.091852 | 0.083653 | 3551.133333 | 19.057340 | ||
| WOA | 0.046689 | 0.098870 | 0.085433 | 3556.966667 | 33.488787 | ||
| Rec37 | HIEGA | 4951 | 0.032922 | 0.056756 | 0.042227 | 5160.066667 | 27.546243 |
| IEGA | 0.146435 | 0.182791 | 0.167528 | 5780.433333 | 40.535320 | ||
| HWA | 0.023833 | 0.058372 | 0.044206 | 5169.866667 | 38.933904 | ||
| SCA | 0.185215 | 0.235710 | 0.216064 | 6020.733333 | 62.100957 | ||
| SSA | 0.184407 | 0.213492 | 0.198215 | 5932.366667 | 35.673971 | ||
| GA | 0.157140 | 0.188850 | 0.175708 | 5820.933333 | 35.789135 | ||
| EGA | 0.166229 | 0.191072 | 0.176395 | 5824.333333 | 31.882422 | ||
| OEGA | 0.154918 | 0.188244 | 0.176806 | 5826.366667 | 39.860994 | ||
| WOA | 0.153706 | 0.186225 | 0.176408 | 5824.4 | 31.813623 |
| Instances | Algorithm | BRE | WRE | ARE | SD | ||
|---|---|---|---|---|---|---|---|
| Rec39 | HIEGA | 5087 | 0.013564 | 0.034598 | 0.022980 | 5203.9 | 27.544327 |
| IEGA | 0.113033 | 0.168665 | 0.145888 | 5829.133333 | 71.492066 | ||
| HWA | 0.011401 | 0.039512 | 0.025273 | 5215.566667 | 31.597134 | ||
| SCA | 0.179083 | 0.222528 | 0.198853 | 6098.566667 | 53.726271 | ||
| SSA | 0.159622 | 0.206211 | 0.182412 | 6014.933333 | 57.731524 | ||
| GA | 0.145862 | 0.170434 | 0.15824 | 5891.966667 | 33.412057 | ||
| EGA | 0.141930 | 0.175152 | 0.159229 | 5897 | 47.012055 | ||
| OEGA | 0.140554 | 0.167682 | 0.155527 | 5878.166667 | 35.096137 | ||
| WOA | 0.148810 | 0.177118 | 0.164635 | 5924.5 | 28.965209 | ||
| Rec41 | HIEGA | 4960 | 0.025637 | 0.050806 | 0.039227 | 5154.566667 | 28.312168 |
| IEGA | 0.146572 | 0.194354 | 0.169731 | 5801.866667 | 44.835055 | ||
| HWA | 0.028830 | 0.059072 | 0.043131 | 5173.933333 | 33.260520 | ||
| SCA | 0.197782 | 0.246774 | 0.227210 | 6086.966667 | 54.319108 | ||
| SSA | 0.194354 | 0.237903 | 0.213608 | 6019.5 | 52.392588 | ||
| GA | 0.170161 | 0.208467 | 0.187332 | 5889.166667 | 45.649449 | ||
| EGA | 0.171371 | 0.205040 | 0.187022 | 5887.633333 | 36.043014 | ||
| OEGA | 0.169758 | 0.198790 | 0.186444 | 5884.766667 | 30.707961 | ||
| WOA | 0.178225 | 0.201612 | 0.190732 | 5906.033333 | 29.825585 |
| Instances | Algorithm | BRE | WRE | ARE | SD | ||
|---|---|---|---|---|---|---|---|
| Hel1 | HIEGA | 516 | −0.001938 | 0.001938 | 0.000129 | 516.066666 | 0.442216 |
| IEGA | 0.042635 | 0.081395 | 0.067441 | 550.8 | 4.460194 | ||
| HWA | −0.001938 | 0.007751 | 0.000710 | 516.366666 | 1.079609 | ||
| SCA | 0.089147 | 0.141472 | 0.116085 | 575.9 | 4.928488 | ||
| SSA | 0.094961 | 0.122093 | 0.109043 | 572.266666 | 3.687215 | ||
| GA | 0.065891 | 0.094961 | 0.079715 | 557.133333 | 3.621540 | ||
| EGA | 0.065891 | 0.091085 | 0.079328 | 556.933333 | 3.511251 | ||
| OEGA | 0.071705 | 0.089147 | 0.080943 | 557.766666 | 2.499111 | ||
| WOA | 0.063953 | 0.094961 | 0.086627 | 560.7 | 2.876919 | ||
| Hel3 | HIEGA | 136 | 0 | 0.029411 | 0.006372 | 136.866666 | 0.718022 |
| IEGA | 0.029411 | 0.080882 | 0.056372 | 143.666666 | 1.776388 | ||
| HWA | 0 | 0.036764 | 0.007107 | 136.966666 | 0.982626 | ||
| SCA | 0.117647 | 0.183823 | 0.155882 | 157.2 | 2.150968 | ||
| SSA | 0.073529 | 0.161764 | 0.121813 | 152.566666 | 2.679344 | ||
| GA | 0.058823 | 0.095588 | 0.074019 | 146.066666 | 1.364632 | ||
| EGA | 0.044117 | 0.110294 | 0.077941 | 146.6 | 2.154065 | ||
| OEGA | 0.066176 | 0.095588 | 0.083823 | 147.4 | 1.113552 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdel-Basset, M.; Mohamed, R.; Abouhawwash, M.; Chakrabortty, R.K.; Ryan, M.J. A Simple and Effective Approach for Tackling the Permutation Flow Shop Scheduling Problem. Mathematics 2021, 9, 270. https://doi.org/10.3390/math9030270
Abdel-Basset M, Mohamed R, Abouhawwash M, Chakrabortty RK, Ryan MJ. A Simple and Effective Approach for Tackling the Permutation Flow Shop Scheduling Problem. Mathematics. 2021; 9(3):270. https://doi.org/10.3390/math9030270
Chicago/Turabian StyleAbdel-Basset, Mohamed, Reda Mohamed, Mohamed Abouhawwash, Ripon K. Chakrabortty, and Michael J. Ryan. 2021. "A Simple and Effective Approach for Tackling the Permutation Flow Shop Scheduling Problem" Mathematics 9, no. 3: 270. https://doi.org/10.3390/math9030270
APA StyleAbdel-Basset, M., Mohamed, R., Abouhawwash, M., Chakrabortty, R. K., & Ryan, M. J. (2021). A Simple and Effective Approach for Tackling the Permutation Flow Shop Scheduling Problem. Mathematics, 9(3), 270. https://doi.org/10.3390/math9030270