Abstract
Reconstruction of 3D objects in various tomographic measurements is an important problem which can be naturally addressed within the mathematical framework of 3D tensors. In Optical Coherence Tomography, the reconstruction problem can be recast as a tensor completion problem. Following the seminal work of Candès et al., the approach followed in the present work is based on the assumption that the rank of the object to be reconstructed is naturally small, and we leverage this property by using a nuclear norm-type penalisation. In this paper, a detailed study of nuclear norm penalised reconstruction using the tubal Singular Value Decomposition of Kilmer et al. is proposed. In particular, we introduce a new, efficiently computable definition of the nuclear norm in the Kilmer et al. framework. We then present a theoretical analysis, which extends previous results by Koltchinskii Lounici and Tsybakov. Finally, this nuclear norm penalised reconstruction method is applied to real data reconstruction experiments in Optical Coherence Tomography (OCT). In particular, our numerical experiments illustrate the importance of penalisation for OCT reconstruction.
1. Introduction
1.1. Motivations and Contributions
3D Image reconstruction from subsamples is a difficult problem at the intersection of the fields of inverse problem, computational statistics and numerical analysis. Following the Compressed Sensing paradigm [1], the problem can be tackled using sparsity priors in the case where sparsity can be proved present in the image to be recovered. Compressed sensing has evolved from the recovery of a sparse vector [2], to the recovery of spectrally sparse matrices [3]. The problem we are considering in the present paper was motivated by Optical Coherence Tomography (OCT), where a 3D volume is to be recovered from a small set of measurements along a ray across the volume, making the problem a kind of tensor completion problem.
The possibility of efficiently addressing the reconstruction problem in Compressed Sensing, Matrix Completion and their avatars greatly depend on formulating it as a problem which can be relaxed as a convex optimisation problem. For example, the sparsity of a vector is measured by the number of non-zero components in that vector. This quantity is a non-convex function of the vector but a surrogate can be easily found in the form the -norm. Spectral sparsity of a matrix is measured by the number of nonzero singular values and, similarly, a convex surrogate is the -norm of the vector of singular values, also called the nuclear norm.
The main problem with tensor recovery is that the spectrum is not a well defined quantity and several approaches have been proposed for defining it [4,5]. Different nuclear norms have also been proposed in the literature, based on the various definitions for the spectrum [6,7,8]. A very interesting approach was proposed in References [9,10]. This approach is interesting in several ways:
- the 3D tensors are considered as matrix of 1D vectors (tubes) and the approach uses a tensor product similar to the classical matrix product, after replacing multiplication of entries by, for example, convolution of the tubes,
- the SVD is fast to compute,
- a specific and natural nuclear norm can be easily defined.
Motivated by the 3D reconstruction problem, our goal in the present paper is to study the natural nuclear norm penalised estimator for tensor completion problem. Our approach extends the method proposed in [11] to the framework developed by [10]. The main contribution of the paper is
- to present the most natural definition of the nuclear norm in the framework of Reference [10],
- to compute the subdifferential of this nuclear norm,
- to present a precise mathematical study of the nuclear norm penalised least-squares reconstruction method,
- to illustrate the efficiency of the approach on the OCT reconstruction problem with real data.
1.2. Background on Tensor Completion
1.2.1. Matrix Completion
After the many successes of Compressed Sensing in inverse problems, Matrix and tensor completion problems have recently taken the stage and become the focus of an extensive research activity. Completion problems have applications in collaborative filtering [12], Machine Learning [13,14], sensor networks [15], subspace clustering [16], signal processing [8], and so forth. The problem is intractable if the matrix to recover does not have any particular structure. An important discovery in References [17,18] is that when the matrix to be recovered has a low rank, then it can be recovered based on a few observations only [18] and using nuclear norm penalised estimation is a reasonably easy problem to solve.
The use of the nuclear norm as a convex surrogate for the rank was first proposed in Reference [19] and further analysed in a series of breakthrough papers [3,11,17,20,21,22].
1.2.2. Tensor Completion
The matrix completion problem was recently generalised to the problem of tensor completion. A very nice overview of tensors and algorithms is given in Reference [23]. Tensors play a fundamental role in statistics [24] and more recently in Machine Learning [13]. It can be used for multidimensional time series [25], analysis of seismic data [6], Hidden Markov Models [13], Gaussian Mixture based clustering [26], Phylogenetics [27], and much more. Tensor completion is however a more difficult problem from many points of view. First, the rank is NP-hard to compute in full generality [5]. Second, many different Singular Value Decompositions are available. The Tucker decomposition [5] extends the useful sum of rank one decomposition to tensors but it is NP-hard to compute in general. An interesting algorithm was proposed in References [28,29]; see also the very interesting Reference [30]. Another SVD was proposed in Reference [31] with the main advantage that the generalized singular vectors form an orthogonal family. The usual diagonal matrix is replaced with a so called “core” tensor with nice orthogonality properties and very simple structure in the case of symmetric [32] or orthogonally decomposable tensors [33].
Another very interesting approach, called the t-SVD was proposed recently in [10] for 3D tensors with applications to face recognition [34] and image deblurring, computerized tomography [35] and data completion [36]. In the t-SVD framework, one dimension is assumed to be of a different nature from the others, such as, for example, time. In this setting, the decomposition resembles the SVD closely by using a diagonal tensor instead of a diagonal matrix as for the standard 2D SVD. The t-SVD was also proved to be amenable to online learning [37]. One other interesting advantage of the t-SVD is that the nuclear norm is well defined and its subdifferential is easy to compute.
The t-SVD proposed in Reference [10] is a very attractive representation of tensors in many settings such as image analysis, multivariate time series, and so forth. Obviously, it is not so attractive for the study of symmetric moment or cumulant tensors as studied in Reference [13], but for large image sequences and times series, this approach seems to be extremely relevant.
1.3. Sparsity
One of the main discoveries of the past decade is that sparsity may help in certain contexts where data are difficult or expensive to acquire [1]. When the object to recover is a vector, the fact that it may be sparse in a certain dictionary will dramatically improve recovery, as demonstrated by the recent breakthroughs in high dimensional statistics on the analysis of estimators obtained via convex optimization, such as the LASSO [38,39,40], the Adaptive LASSO [41] or the Elastic Net [42]. When is a matrix, the property of having a low rank may be crucial for the recovery as proved in References [11,43]. Extensions to the tensor case are studied in References [7,44,45]. Tensor completion using the t-SVD framework has been analyzed in Reference [36]. In particular, our results complement and improve on the results in Reference [36]. Reference [46] deserves special mention for using more advanced techniques based on real algebraic geometry and sums of squares decompositions.
The usual estimator in a sparse recovery problem is a nuclear norm penalized least squares such as the one studied here and defined by (27). Several other types of nuclear norms have been used for tensor estimation and completion. In particular, several nuclear norms can be naturally defined such as in for example, References [7,47,48]. It is interesting to notice that, sparsity promoting penalization of the least squares estimator crucially relies on the structure of the subdifferential of the norm involved. See for instance References [11,49] or Reference [50]. In Reference [7] a subset of the subdifferential is studied and then used in order to establish the efficiency of the penalized least squares approach. Another interesting approach is the one in [48] where an outer approximation of the subdifferential is given. In the matrix setting, the work in References [51,52] are famous for providing a neat characterization of the subdifferential of matrix norms or more generally functions of the matrix enjoying enough symmetries. In the 3D or higher dimensional setting, however, the case is much less understood. The relationship between the tensor norms and the norms of the flattening are intricate although some good bounds relating one to the other can be obtained, as, for example, in Reference [53].
The extension of previous results on low rank matrix reconstruction to the tensor setting is nontrivial but is shown to be relatively easy to obtain once the appropriate background is given. In particular, our theoretical analysis will generalise the analysis in Reference [11]. In order to do this, we provide a complete characterisation of the subdifferential of the nuclear norm. Our results will be illustrated by computational experiments for solving a problem in Optical Coherence Tomography (OCT).
1.4. Plan of the Paper
Section 2 presents the necessary mathematical background about tensors and sparse recovery. Section 3 introduces the measurement model and the present our nuclear-norm penalised estimator. In Section 4 we prove our main theoretical result. In Section 5, our approach is finally illustrated in the context of Optical Coherence Tomography, and some computational results based on real data are presented.
2. Background on Tensors, t-SVD
In this section, we present what is meant by the notion of tensor and the various generalisations of the common objects in linear algebra to the tensor setting. In particular, we will introduce the Singular Value Decomposition proposed in Reference [10] and some associated Schatten norms.
2.1. Basic Notations for Third-Order Tensor
In this section, we recall the framework introduced by Kilmer and Martin [9,10] for a very special class of tensors which is particularly adapted to our setting.
2.1.1. Slices and Transposition
For a third-order tensor A, its th entry is denoted by A.
Definition 1.
The kth-frontal slice of A is defined as
The -transversal slice of A is defined as
A tubal scalar (t-scalar) is an element of and a tubal vector (t-vector) is an element of .
Definition 2
(Tensor transpose). The conjugate transpose of a tensor tensor obtained by conjugate transposing each of the frontal slice and then reversing the order of transposed frontal slices starting from the slide number 2 to the slice number and then appending the conjugate transposed frontal slice .
Definition 3
(The “dot” product). The dot product between two tensors and is the tensor whose slice is the matrix product of the slice with the slice :
We will also need the canonical inner product.
Definition 4
(Inner product of tensors). If and are third-order tensors of same size , then the inner product between A and B is defined as the following (notice the normalization constant of FFT),
2.1.2. Convolution and Fourier Transform
Definition 5
(t-product for circular convolution). The t-product of and is an tensor whose -th tube is given by
where * denotes the circular convolution between two cubes of same size.
Definition 6
(Identity tensor). The identity tensor is defined to be a tensor whose first frontal slice is the identity matrix and all other frontal slices are zero.
Definition 7
(Orthogonal tensor). A tensor is orthogonal if it satisfies
is a tensor which is obtained by taking the Fast Fourier Transform (FFT) along the third dimension and we will use the following convention for Fast Transform along the 3rd dimension
The one-dimensional FFT along the 3th-dimension is given
Naturally, one can compute A from via ifft using the inverse FFT, and is defined:
Definition 8
(Inverse of a tensor). The inverse of a tensor A is written as satisfying
where J is the identity tensor of size .
Remark 1.
It is proved in Reference [10] that for any tensor and , we have
2.2. The t-SVD
We finally arrive at the definition of the t-SVD.
Definition 9
(f-diagonal tensor). Tensor A is called f-diagonal if each frontal slice is a diagonal matrix.
Definition 10
(Tensor Singular Value Decomposition: t-SVD). For M , the t-SVD of M is given by
where U and V are orthogonal tensor of size and respectively. S is a rectangular f-diagonal tensor or size , and the entries in S are called the singular values of M. This SVD can be obtained using the Fourier transform as follows:
This t-SVD is illustrated in Figure 1 below. Notice that the diagonal elements of S, i.e., are tubal scalars as introduced in Definition 1. They will also be called tubal eigenvalues.
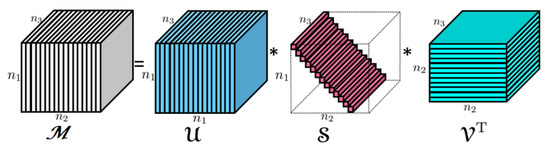
Figure 1.
The t-SVD of a tensor.
Definition 11.
The spectrum of the tensor A is the tubal vector given by
for .
2.3. Some Natural Tensor Norms
Using the previous definitions, it is easy to define some generalisations of the usual matrix norms.
Definition 12
(Tensor Frobenius norm). The induced Frobenius norm from the inner product defined above is given by,
Definition 13
(Tensor spectral norm). The tensor spectral norm is defined as follows:
where is the -norm.
Proposition 1.
Let M be tensor. Therefore
where corresponds to the Fast Fourier Transform.
Definition 14
(Tubal nuclear norm). The tensor nuclear norm of a tensor A denoted as is the sum of singular values of all the frontal slices of A. Moreover,
Note that by Parseval’s inequality
Therefore, it is equivalent to define the tubal-nuclear norm via in the Fourier domain. Recall moreover that the are all non-negative due to the fact that is the SVD of the slice of A.
Proposition 2
(Trace duality property). Let A, B be tensor. Therefore
Proof.
By Cauchy-Schwartz, we have
taking the maximum of and the sum the slices of , and apply (12) and inverse of FFT, we obtain the result. □
Proposition 3.
Given tensor . We have
Proof.
Again by Cauchy-Schwartz, we have
□
Lemma 1.
We have
Proof.
If we take such as is colinear with , i.e, ∀, , …,
This means to solve the equation system to determine the . Thus,
With this result, the remaining of proof follows directly from the proof of Proposition 2. □
2.4. Rank, Range and Kernel
The rank, the range and the kernel are extremely important notions for matrices. They will play a role in our analysis of the penalised least squares tensor recovery procedure as well.
As noticed in Reference [10], a tubal scalar may have all its entrees different from zero but still be non-invertible. According to the definition, a tubal scalar is invertible if there exists a tubal scalar b such that . Equivalently, the Fourier transform of a has no coefficient equal to zero. We can define the tubal rank of as the number of non-zero components of . Then, the easiest way to define the rank of a tensor is by means of the notion of multirank as follows.
Definition 15.
The multirank of a tensor is the vector where r is the number of nonzero tubal vectors , .
We now define the range of a tensor.
Definition 16.
Let j denote the number of invertible tubal eigenvalues and let k denote the number of nonzero noninvertible tubal eigenvalues. The range of a tensor is defined as
Definition 17.
Let j denote the number of invertible tubal eigenvalues. The kernel of a tensor is defined as
3. Measurement Model and the Estimator
3.1. The Observation Model
In the model considered hereafter, the observed data are , …, given by the following model
where the notation stands for the canonical scalar product of tensors. This can be seen as a tensor regression problem , are some tensors in and , are some independent zero mean random variables. Assume that the frontal faces are i.i.d uniformly distributed on the set
where are the canonical basis vectors in .
Our goal is to recover the tensor based on the data , only for n as small as possible.
Definition 18.
For any tensors , we define the scalar product
and the bilinear form
Here , where denotes the distribution of . The corresponding semi-norm is given by
and will denote by M the tensor given by
3.2. The Estimator
The approach proposed in Reference [11] for low rank matrix estimation which will be extended to tensor estimation in the present paper consists in minimising
where
where is a tubal tensor nuclear norm that we will introduce in Definition 14.
Recall that nuclear norm penalisation is widely used in sparse estimation when the matrix to be recovered is low rank [1]. Following the success of the application of sparsity to low rank matrix recovery, several extensions of the matrix nuclear norm were proposed in the literature [7,8,47], etc. Another type of nuclear norm was proposed in Reference [36] based on the tubal framework of Kilmer [10]. Our estimator is another nuclear norm penalisation based estimator. As it will be explained in Section 2 below, the nuclear norm used in the present paper has some advantages over other norms in the context of tubal low rank tensors and the resulting estimator is most relevant in many applications where we want to recover a tensor which is the sum of a small number of rank-one tensors.
4. Main Results
In this section, we provide our main results. First, in Section 4.2, we give a complete characterisation of the subdifferential of the nuclear norm (Definition 14). Then, we propose a statistical study of the nuclear-norm penalised estimator in Section 4.3.
4.1. Preliminary Remarks
4.1.1. Orthogonal Invariance
It is easy to see that the t-nuclear norm is orthogonally invariant. Indeed, consider two orthogonal tensors , , . Since the product of two orthogonal tensors is itself orthogonal, we have
4.1.2. Support of a Tensor
Given that the t-svd of a tensor is
with is a family of orthonormal matrix in , and a family of orthonormal matrix in and are the spectrum of A.
The support of A is the couple of linear vector spaces of tubal tensors, where
- is the linear span of and
- is the linear span of .
We also let to be the orthogonal complements of and by , the projector on linear vector subspace S of tubal tensors.
4.2. The Subdifferential of the t-nuclear Norm
Our first result is a characterisation of the subdifferential of . Recall first the particular case of the matrix nuclear norm . By Corollary 2.5 in [52], we have
This result is established in [52] using the Von-Neumann inequality and in particular the equality case of this inequality.
4.2.1. Von-Neumann’s Inequality for Tubal Tensors
Theorem 1.
Let A, B be tensor. Therefore
where is a rectangular f-diagonal tensor, contains all the singular values of A.
Equality holds in (21) if and only if A, B have the same singular tensors.
Proof.
Let denote the Fast Fourier Transform. We have
Thus, using the Von Neumann inequality for matrices, we get
where the last equality stems from the isometry property of Fast Fourier Transform. □
Notice that the Von-Neumann inequality was extended in [54] to general tensors and exploited in [55] for the computation of the subdifferential of some tensor norms. In comparison, the case of the t-nuclear norm only need an appropriate use of the matrix Von Neumann inequality.
4.2.2. Lewis’s Characterization of the Subdifferential
Theorem 2.
Let be a function convex, so:
The proof is exactly the same as in [52], Theorem 2.4.
Theorem 3.
Let us suppose that the function is convex. Then, the tensor
The proof is the same as in [52], Corollary 2.5 where the matrix Von Neumann inequality (and more precisely, the exact characterization of the equality case) is replaced with Von Neumann inequality for tubal tensors given by Theorem 4.1.
Theorem 4.
Let r denote the number of which are non-zero. The subdifferential of the t-nuclear norm is given by
Proof.
We only need to rewrite (22) using the well-known formula for the subdifferential of the Euclidean norm. We provide the details for the sake of completeness.
Let be a t-vector in .
where in second equality we use the result of [56], Chapter 16,l Section 1, Proposition 16.8.
As is well known, the subgradient of the -norm is
and plugg this formula into (24). Therefore
Let T be the set of indices j which tubal scalar . Thus,
Moreover,
Therefore, is of the form
with and
So we have,
□
4.3. Error Bound
Our error bound on tubal-tensor recovery using the approach of Koltchinskii, Lounici and Tsybakov [11] is given in the following theorem.
Theorem 5.
Let be a convex set of tensors. Let be defined by
where we recall that denotes the tensor nuclear norm (see Definition 14). Assume that there exists a constant such that, for all tensor ,
Let , then
Proof.
We follow the proof of Reference [11]. We provide all the details for the sake of the completeness.
Let us compute the directional derivative of at .
The optimality condition of implies . Thus
for all (the tangent cone to at ). Taking , we have,
On the other hand,
by compacity of ; see [57]. Combining (31) with (26), we obtain
Consider an arbitrary tensor of tubal rank r with spectral representation
where , and with support . Using that
it thus follows from (32) that
with
By the monotonicity of subdifferentials of convex functions, we have (cf. [58], Chapter 4, Section 3, Proposition 9). Therefore
Furthermore, by (23), the following representations holds
where W is an arbitrary tensor with and
and using Lemma 3, we can choose W such that
where in the first equality we used that A has support For this particular choice of W, (36) implies that
Using the identity
and the fact that
we deduce from (37) that
Now, to find an upper bound on , we use the following decomposition:
where . This implies, due to the trace duality,
where
Using that
we have with
Thus,
Due to Proposition 3, we have
and using the assumption (28), it follows from (38) and (40) that
Using
we deduce from (42) that
□
5. Numerical Experiments
The proposed methods were numerically validated using 3D OCT images. OCT is widely studied as a medical imaging system in many clinical applications and fundamental research. In numerous clinical purposes, OCT is considered as a very interesting technique for in situ tissue characterization known as “optical biopsy” (in opposition to the conventional physical biopsy). OCT is operating under the principle of low coherence interferometry providing micro-meter spatial resolution at several MHz A-scan (1D optical core in z direction) acquisition rate. In these experiments, we found that depth was a different coordinate from the two other coordinates and the tubal SVD approach appeared particularly relevant. One way of circumventing the problem in the case where the three coordinates have the same properties is to perform the reconstruction three times using the proposed method and take the average of the results.
5.1. Benefits of Subsampling for OCT
The OCT imaging device, as the case of the most medical imaging systems, obeys two key requirements for successful application of compressed sensing methods: (1) medical imaging is naturally compressible by sparse coding in an appropriate transform domain (e.g., wavelet, shearlet transforms, etc.) and (2) OCT scanning system (e.g., Spectral-Domain OCT, the most used) naturally acquire encoded samples, rather than direct pixel samples (e.g., in spatial-frequency encoding). Therefore, the images resulting from Spectral-Domain OCT are sparse in native representation, hence yielding themselves well to various implementations of the ideas from Compressed Sensing theory.
Certainly, OCT enables high-speed A-scan and B-scan acquisitions (Figure 2B) but presents a serious issue when it comes to acquiring a C-scan volume. Therefore, especially in case of biological sample/tissue examination, using OCT volumes poses the problem of frame-rate acquisition (generating artifacts) as well as the data transfer i.e., several hundred Mo for each volume (Figure 2B).
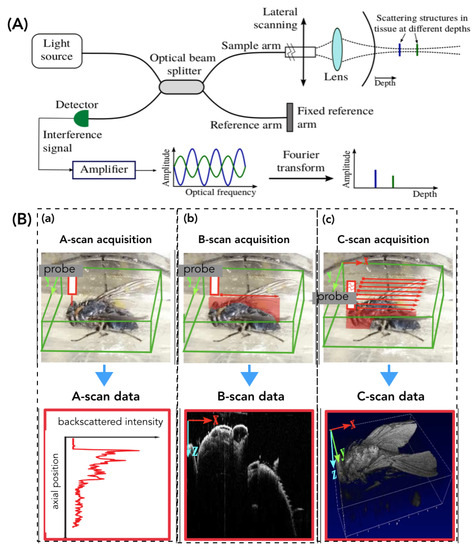
Figure 2.
Illustration of the Fourier-Domain Optical Coherence Tomography (OCT) operating. (A) the optical principle and (B) the different available acquisition modes: A-scan (1D optical core), B-Scan (2D image), and C-scan (volume).
Indeed, OCT volume data can be considered as a tensor of voxels. Thereby, the mathematical methods and materials related to tensors study are well suited for 3D OCT data.
5.2. Experimental Set-Up
An OCT imaging system (Telesto-II 1325 nm spectral domain OCT) from Thorlabs (Figure 3), is used to validate the proposed distortion models. Axial (resp. lateral) resolution is 5.5 m (resp. 7 m) and up to 3.5 mm depth. The Telesto-II allows a maximum field-of-view of 10 × 10 × 3.5 mm with a maximum A-Scan (optical core) acquisition rate of 76 kHz.
Figure 3.
Global view of the OCT acquisition setup.
5.3. Validation Scenario
The method proposed in this paper was implemented in a MatLab framework without taking into account the code optimization aspects as well as the time-computation. In order to validate experimentally the approach presented here, we acquired different OCT volumes (C-Scan images) of realistic biological samples: for example, a part of a grape (Figure 4 (left)) and a part of a fish eye retina (Figure 4 (right)). The size of the OCT volume used in these numerical validations, for both samples, is voxels.

Figure 4.
Examples of the OCT volumes of biological samples used to validate the proposed method. (first row) the initial OCT volumes and (second row), B-scan images (100th vertical slice) taken from the initial volumes.
To access the performance of the proposed algorithm, we constructed several undersampled 3D volume using 30%, 50%, 70%, and 90% of the original OCT volume. To do this, we created two types of 3D masks. The first consists of a pseudo-random binary masks using a density random sampling in which the data are selected in a vertical manner (Figure 5 (left)). For the second type of mask, instead of a vertical subsampling of the data, we designed oblique masks as shown in Figure 5 (right)) which are more appropriate in the case of certain imaging systems such as Magnetic Resonance Imaging (MRI), Computerized Tomography scan (CT-scan), and in certain instances, OCT imaging systems as well.
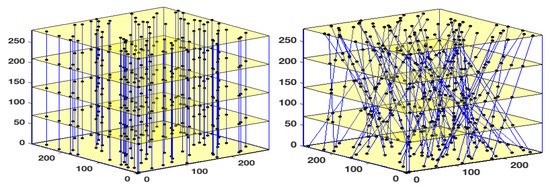
Figure 5.
Illustration of the implemented 3D masks used to subsampled the data and creating the 3D masks. (Left) a 3D mask allowing a vertical and random selection of the data, and (right) a 3D mask allowing an oblique selection of the subsampled data.
5.4. Obtained Results
The validation scenarios were carried out as follows—the studied method was applied to each OCT volume (i.e., grape or fish eye) using various subsampling rates (i.e., 30%, 50%, 70%, and 90%). Also, in each case, the vertical or the oblique 3D binary masks were used. The results obtained with our nuclear norm penalised reconstruction approach are discussed below.
5.4.1. Grape Sample
Figure 6 and Figure 7 depict the different reconstructed OCT volumes using the oblique and the vertical binary masks. Instead of illustrating the fully reconstructed OCT volume, we choose to show 2D images (the 100th slice of the reconstructed volumes) for a better visualization, with the naked eye, of the quality of the obtained results. It can be highlighted that the sharpness of the boundary is well preserved; however, it loses some features in the zones where the image has low intensity. This is a common effect of most of the compressed sensing and inpainting methods. In order to improve the quality of the recovered data, conventional filters based post-processing could be also be used in order to enhance contrast.
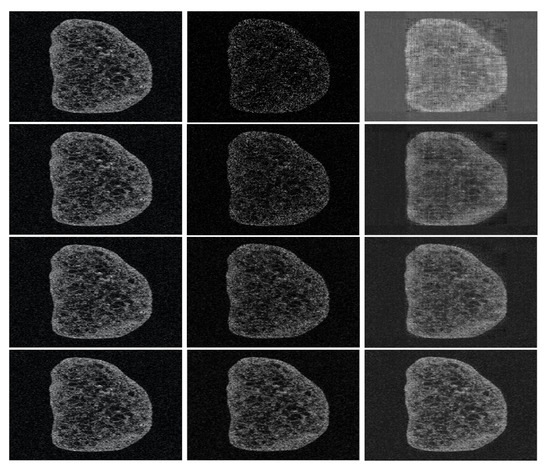
Figure 6.
[sample: grape, mask: vertical]—Reconstructed OCT images (only a 2D slice is shown in this example). Each row corresponds to an under-sampling rate: 30% (1st row), 50% (2nd row), 70% (3th row), and 90% (4th row). The first column represents the initial OCT image, the second column the under-sampled data used for the reconstruction, and the third column, the recovered OCT images.
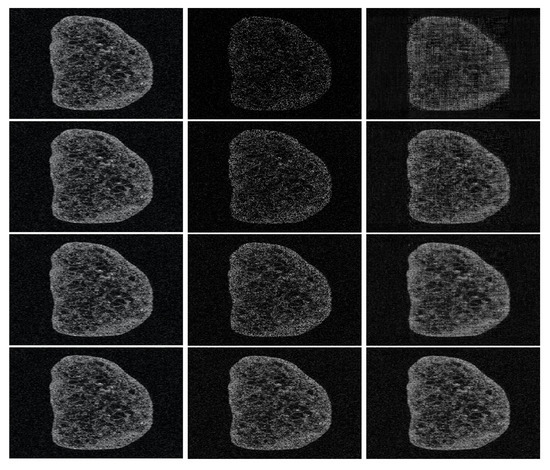
Figure 7.
[sample: grape, mask: oblic]—Reconstructed OCT images (only a 2D slice is shown in this example). Each row corresponds to an under-sampling rate: 30% (1st row), 50% (2nd row), 70% (3th row), and 90% (4th row). The first column represents the initial OCT image, the second column the under-sampled data used for the reconstruction, and the third column, the recovered OCT images.
5.4.2. Fish Eye Sample
we also performed validation experiments using an optical biopsy of a fish eye (see the images sequence depicted in Figure 8 and Figure 9).

Figure 8.
[sample: fish eye retina, mask: vertical]—Reconstructed OCT images (only a 2D slice is shown in this example). Each row corresponds to an under-sampling rate: 30% (1st row), 50% (2nd row), 70% (3th row), and 90% (4th row). The first column represents the initial OCT image, the second column the under-sampled data used for the reconstruction, and the third column, the recovered OCT images.

Figure 9.
[sample: fish eye retina, mask: oblic]—Reconstructed OCT images (only a 2D slice is shown in this example). Each line corresponds to an under-sampling rate: 30% (1st line), 50% (2nd line), 70% (3th line), and 90% (4th line). The first column represents the initial OCT image, the second column the under-sampled data used for the reconstruction, and the third column, the recovered OCT images.
5.5. The Singular Value Thresholding Algorithm
In this section, we describe the algorithm used for the computation of our estimator, namely a tubal tensor version of the fixed point algorithm of Reference [59]. This algorithm is a very simple and scalable iterative scheme which converges to the solution of (17). Each iteration consists of two successive steps:
- a singular value thresholding step where all tubal singular values with norm below the level are set to zero and the remaining larger singular values are being removed an offset .
- a relaxed gradient step.
In mathematical terms, the algorithms works as follows:
In the setting of our algorithm, the Shrinkage operator operates as follows:
- compute the circular Fourier transform of the tubal components of ,
- compute the SVD of all the slices of and forms the tubal singular values,
- sets to zero the tubal singular values whose -norm lies below the level and shrink the other by ,
- recompose the spectrally thresholded matrix and take the inverse Fourier transform of the tubal components.
On the other hand, is the operator that assigns to the entries indexed by the observed values and leaves the other values unchanged.
The convergence analysis of [59] directly applies to our setting.
5.6. Analysis of the Numerical Results
In order to quantitatively assess the obtained results using different numerical validation scenarios and OCT images, we implemented two images similarity scores extensively employed in the image processing community. In particular, we use
- the Peak Signal Noise Ratio (PSNR) computed as followswhere d is the maximal pixel value in the initial OCT image and the (mean-squared error) is obtained bywith and represent an initial 2D OCT slice (selected from the OCT volume) and the recovered one, respectively.
- The second image similarity score consists of the Structural Similarity Index (SIMM) which allows measuring the degree of similarity between two images. It is based on the computation of three values namely the luminance l, the contrast c and the structural aspect s. It is given bywhere,with , , , , and are the local means, standard deviations, and cross-covariance for images , . The variables , , are used to stabilize the division with weak denominator.
5.6.1. Illustrating the Rôle of the Nuclear Norm Penalisation
In order to understand the rôle of the nuclear norm penalisation in the reconstruction, we have performed several experiments with different values of the hyper-parameter which are reported in Figure 10. This figure shows the performance of the estimator as a function of the ratio between the largest singular value and the smallest selected singular value. This ratio is an implicit function of , which is more intuitive than for interpreting the results. The smaller the ratio, the smaller the number of singular values incorporated in the estimation.
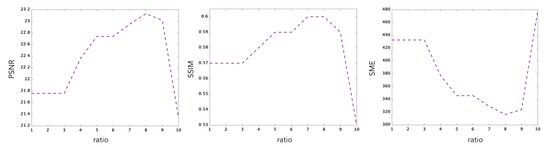
Figure 10.
Evolution of the PSNR, SSIM and SME performance criteria as a function of the ratio between the largest singular value and the smallest singular value selected by the penalised estimator.
The corresponding values are reported in Table 1.

Table 1.
SME, PSNR, SSIM for various values of the ratio.
The results of these experiments show that different weights for the nuclear norm penalisation imply different erros. In these experiments, one sees that the SME is optimised at a ration equal to 8 and the PSNR is maximised at 8 as well. The SSIM is maximum for values of the ratio equal to 7 and 8. Estimation which does not account for the intrinsic complexity of the object to recover will clearly fail to reconstruct the 3D images properly.
5.6.2. Performance Results
Table 2 and Table 3 summarise the numerical values of MSE, PSNR, SSIM computed for each test, that is, using different undersampling rates and masks, for our two different test samples (grape or fish eye retina). The parameter was chosen using the simple and efficient method proposed in [60]. As expected the error decreases as a function of the percentage of observed pixels. The results also show that the estimator is not very sensitive to the orientation of the mask. There seems to be a phase transition after the 70% level, above which the reconstruction accuracy is suddenly improved in terms of PSNR and SSIM, but the method still works satisfactorily at smaller sampling rates.
Table 2.
[sample: grape]: Numerical values of the different image similarities (between initial image and reconstructed one): MSE, PSNR and SSIM.
Table 3.
[sample: fish eye retina]: Numerical values of the different image similarities (between initial image and recontructed one): MSE, PSNR and SSIM.
6. Conclusions and Perspectives
In this paper, we studied tensor completion problems based on the framework proposed by Kilmer et al. [10]. We provided some theoretical analysis of the nuclear norm penalised estimator. These theoretical results are validated numerically using realistic OCT data (volumes) of biological samples. These encouraging results with real datasets demonstrate the relevance of the low rank assumption for practical applications. Further research will be undertaken in devising fast algorithms and incorporating other penalties such as, e.g., based on sparsity of the shearlet transform [61].
Author Contributions
Data curation, B.T.; Formal analysis, S.C. and B.T.; Investigation, M.I.A., S.C. and B.T.; Methodology, S.C.; Project administration, B.T.; Supervision, S.C.; Validation, B.T.; Visualization, B.T.; Writing—original draft, M.I.A.; Writing—review and editing, B.T. All authors have read and agreed to the published version of the manuscript.
Funding
This work has been supported by ANR NEMRO (ANR-14-CE17-0013).
Acknowledgments
The authors would like to thank S. Aeron from Tufts University for interesting discussions and for kindly sharing his code at an initial stage of this research. They would also like to thank the reviewers for their help in improving the paper by their numerous comments and criticisms.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Some Technical Results
Appendix A.1. Calculation of ρ and a value of λ such that ‖M‖S∞ ≤ λ with high probability
Appendix A.1.1. Computation of ρ
Using the fact where m is the number of pixels considered, we have with
Thus we can set
Appendix A.1.2. Control of the Stochastic Error ‖M‖S∞
In this part, we will show that a possible value for the coefficient can be taken as
In order to prove this bound, we will need a large deviation inequality given by the following result
Proposition A1
(Theorem 1.6 in [62]). Let be independant random variables with dimension that satisfy and U almost surely for some constant U and all . We define
Then, for all , with probability at least , we have
where .
The next lemma gives a bound of the stochastic error for tensor completion.
Lemma A1.
Let be i.i.d uniformly distributed on . Then for any with probability at least , we have
In order to prove this lemma, we will need the following lemma
Lemma A2.
We draw with a uniform random position on with null entries everywhere except one input equals 1 at the position . Observe that
Proof.
Let of the form
Determine its Fourier transform and spectral norm of expectation of . Thus,
Moreover,
with
So, we have , and
□
Proof of Lemma A1.
Consider the tensor completion under uniform sampling at random with Gaussian error. Recall that in this case we assume that the pairs are i.i.d. Using the fact and , we have
In the following, we treat the terms and separately in the lemma and proposition below. Before proceeding, notice that is the Schatten norm of a quadratic function of . Furthermore, is the Fourier Transform of the tube for the frequency . Using the Property 1, we have
□
Define the operator which takes the slice j of a tensor (i.e tensor ) and puts it in the same place in a zero tensor. The following proposition
Proposition A2.
Let T be a null tensor except at slice j. Therefore
Using (A7), we have
Lemma A3.
Let be i.i.d a uniform random position on . Then, for all , with probability at least , we have
Proof.
To prove this lemma, we apply the Proposition A1 for the random variables
.
Moreover, using the facts
- andUsing the duality trace and Jensen’s inequality, we have
Now, we study the bound of . For this purpose, we use the proposition below is an immediate consequence of the matrix Gaussian’s inequality of Theorem 1.6 of [62].
Proposition A3.
Let be independent random variables with dimensions , and be a finite sequence of independent standart normal. Define
Then, for all ,
where
Using this fact and (A7), we have
References
- Candès, E.J. Mathematics of sparsity (and a few other things). In Proceedings of the International Congress of Mathematicians, Seoul, Korea, 13–21 August 2014. [Google Scholar]
- Candès, E.J.; Romberg, J.; Tao, T. Robust uncertainty principles: Exact signal reconstruction from highly incomplete frequency information. IEEE Trans. Inf. Theory 2006, 52, 489–509. [Google Scholar] [CrossRef]
- Recht, B.; Fazel, M.; Parrilo, P.A. Guaranteed minimum-rank solutions of linear matrix equations via nuclear norm minimization. SIAM Rev. 2010, 52, 471–501. [Google Scholar] [CrossRef]
- Hackbusch, W. Tensor Spaces and Numerical Tensor Calculus; Springer Science & Business Media: Berlin, Germany, 2012; Volume 42. [Google Scholar]
- Landsberg, J.M. Tensors: Geometry and Applications; American Mathematical Society: Providence, RI, USA, 2012; Volume 128. [Google Scholar]
- Sacchi, M.D.; Gao, J.; Stanton, A.; Cheng, J. Tensor Factorization and its Application to Multidimensional Seismic Data Recovery. In SEG Technical Program Expanded Abstracts; Society of Exploration Geophysicists: Houston, TX, USA, 2015. [Google Scholar]
- Yuan, M.; Zhang, C.H. On tensor completion via nuclear norm minimization. Found. Comput. Math. 2016, 16, 1031–1068. [Google Scholar] [CrossRef]
- Signoretto, M.; Van de Plas, R.; De Moor, B.; Suykens, J.A. Tensor versus matrix completion: A comparison with application to spectral data. Signal Process. Lett. IEEE 2011, 18, 403–406. [Google Scholar] [CrossRef]
- Kilmer, M.E.; Martin, C.D. Factorization strategies for third-order tensors. Linear Algebra Its Appl. 2011, 435, 641–658. [Google Scholar] [CrossRef]
- Kilmer, M.E.; Braman, K.; Hao, N.; Hoover, R.C. Third-order tensors as operators on matrices: A theoretical and computational framework with applications in imaging. SIAM J. Matrix Anal. Appl. 2013, 34, 148–172. [Google Scholar] [CrossRef]
- Koltchinskii, V.; Lounici, K.; Tsybakov, A.B. Nuclear-norm penalization and optimal rates for noisy low-rank matrix completion. Ann. Stat. 2011, 39, 2302–2329. [Google Scholar] [CrossRef]
- Candes, E.J.; Plan, Y. Matrix completion with noise. Proc. IEEE 2010, 98, 925–936. [Google Scholar] [CrossRef]
- Anandkumar, A.; Ge, R.; Hsu, D.; Kakade, S.M.; Telgarsky, M. Tensor decompositions for learning latent variable models. J. Mach. Learn. Res. 2014, 15, 2773–2832. [Google Scholar]
- Signoretto, M.; Dinh, Q.T.; De Lathauwer, L.; Suykens, J.A. Learning with tensors: A framework based on convex optimization and spectral regularization. Mach. Learn. 2014, 94, 303–351. [Google Scholar] [CrossRef]
- So, A.M.C.; Ye, Y. Theory of semidefinite programming for sensor network localization. Math. Program. 2007, 109, 367–384. [Google Scholar] [CrossRef]
- Eriksson, B.; Balzano, L.; Nowak, R. High-rank matrix completion and subspace clustering with missing data. arXiv 2011, arXiv:1112.5629. [Google Scholar]
- Candès, E.J.; Recht, B. Exact matrix completion via convex optimization. Found. Comput. Math. 2009, 9, 717–772. [Google Scholar] [CrossRef]
- Singer, A.; Cucuringu, M. Uniqueness of low-rank matrix completion by rigidity theory. SIAM J. Matrix Anal. Appl. 2010, 31, 1621–1641. [Google Scholar] [CrossRef]
- Fazel, M. Matrix Rank Minimization with Applications. Ph.D. Thesis, Stanford University, Stanford, CA, USA, 2002. [Google Scholar]
- Gross, D. Recovering low-rank matrices from few coefficients in any basis. Inf. Theory IEEE Trans. 2011, 57, 1548–1566. [Google Scholar] [CrossRef]
- Recht, B. A simpler approach to matrix completion. J. Mach. Learn. Res. 2011, 12, 3413–3430. [Google Scholar]
- Candès, E.J.; Tao, T. The power of convex relaxation: Near-optimal matrix completion. Inf. Theory IEEE Trans. 2010, 56, 2053–2080. [Google Scholar] [CrossRef]
- Kolda, T.G.; Bader, B.W. Tensor decompositions and applications. SIAM Rev. 2009, 51, 455–500. [Google Scholar] [CrossRef]
- McCullagh, P. Tensor Methods in Statistics; Chapman and Hall: London, UK, 1987; Volume 161. [Google Scholar]
- Rogers, M.; Li, L.; Russell, S.J. Multilinear Dynamical Systems for Tensor Time Series. Adv. Neural Inf. Process. Syst. 2013, 26, 2634–2642. [Google Scholar]
- Ge, R.; Huang, Q.; Kakade, S.M. Learning mixtures of gaussians in high dimensions. arXiv 2015, arXiv:1503.00424. [Google Scholar]
- Mossel, E.; Roch, S. Learning nonsingular phylogenies and hidden Markov models. In Proceedings of the Thirty-Seventh Annual ACM Symposium on Theory of Computing, Baltimore, MD, USA, 22–24 May 2005; pp. 366–375. [Google Scholar]
- Jennrich, R. A generalization of the multidimensional scaling model of Carroll and Chang. UCLA Work. Pap. Phon. 1972, 22, 45–47. [Google Scholar]
- Kroonenberg, P.M.; De Leeuw, J. Principal component analysis of three-mode data by means of alternating least squares algorithms. Psychometrika 1980, 45, 69–97. [Google Scholar] [CrossRef]
- Bhaskara, A.; Charikar, M.; Moitra, A.; Vijayaraghavan, A. Smoothed analysis of tensor decompositions. In Proceedings of the 46th Annual ACM Symposium on Theory of Computing, New York, NY, USA, 1–3 June 2014; pp. 594–603. [Google Scholar]
- De Lathauwer, L.; De Moor, B.; Vandewalle, J. A multilinear singular value decomposition. SIAM J. Matrix Anal. Appl. 2000, 21, 1253–1278. [Google Scholar] [CrossRef]
- Kolda, T.G. Symmetric Orthogonal Tensor Decomposition is Trivial. arXiv 2015, arXiv:1503.01375. [Google Scholar]
- Robeva, E.; Seigal, A. Singular Vectors of Orthogonally Decomposable Tensors. arXiv 2016, arXiv:1603.09004. [Google Scholar] [CrossRef]
- Hao, N.; Kilmer, M.E.; Braman, K.; Hoover, R.C. Facial recognition using tensor-tensor decompositions. SIAM J. Imaging Sci. 2013, 6, 437–463. [Google Scholar] [CrossRef]
- Semerci, O.; Hao, N.; Kilmer, M.E.; Miller, E.L. Tensor-based formulation and nuclear norm regularization for multienergy computed tomography. Image Process. IEEE Trans. 2014, 23, 1678–1693. [Google Scholar] [CrossRef]
- Zhang, Z.; Aeron, S. Exact tensor completion using t-svd. IEEE Trans. Signal Process. 2017, 65, 1511–1526. [Google Scholar] [CrossRef]
- Pothier, J.; Girson, J.; Aeron, S. An algorithm for online tensor prediction. arXiv 2015, arXiv:1507.07974. [Google Scholar]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. Methodol. 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Bickel, P.J.; Ritov, Y.; Tsybakov, A.B. Simultaneous analysis of Lasso and Dantzig selector. Ann. Stat. 2009, 37, 1705–1732. [Google Scholar] [CrossRef]
- Candès, E.J.; Plan, Y. Near-ideal model selection by l1 minimization. Ann. Stat. 2009, 37, 2145–2177. [Google Scholar] [CrossRef]
- Zou, H. The adaptive lasso and its oracle properties. J. Am. Stat. Assoc. 2006, 101, 1418–1429. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. Stat. Methodol. 2005, 67, 301–320. [Google Scholar] [CrossRef]
- Gaïffas, S.; Lecué, G. Weighted algorithms for compressed sensing and matrix completion. arXiv 2011, arXiv:1107.1638. [Google Scholar]
- Xu, Y. On Higher-order Singular Value Decomposition from Incomplete Data. arXiv 2014, arXiv:1411.4324. [Google Scholar]
- Raskutti, G.; Yuan, M. Convex Regularization for High-Dimensional Tensor Regression. arXiv 2015, arXiv:1512.01215. [Google Scholar] [CrossRef]
- Barak, B.; Moitra, A. Noisy Tensor Completion via the Sum-of-Squares Hierarchy. arXiv 2015, arXiv:1501.06521. [Google Scholar]
- Gandy, S.; Recht, B.; Yamada, I. Tensor completion and low-n-rank tensor recovery via convex optimization. Inverse Probl. 2011, 27, 025010. [Google Scholar] [CrossRef]
- Mu, C.; Huang, B.; Wright, J.; Goldfarb, D. Square Deal: Lower Bounds and Improved Convex Relaxations for Tensor Recovery. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014. [Google Scholar]
- Amelunxen, D.; Lotz, M.; McCoy, M.B.; Tropp, J.A. Living on the edge: Phase transitions in convex programs with random data. Inf. Inference 2014, 3, 224–294. [Google Scholar] [CrossRef]
- Lecué, G.; Mendelson, S. Regularization and the small-ball method I: Sparse recovery. arXiv 2016, arXiv:1601.05584. [Google Scholar] [CrossRef]
- Watson, G.A. Characterization of the subdifferential of some matrix norms. Linear Algebra Its Appl. 1992, 170, 33–45. [Google Scholar] [CrossRef]
- Lewis, A.S. The convex analysis of unitarily invariant matrix functions. J. Convex Anal. 1995, 2, 173–183. [Google Scholar]
- Hu, S. Relations of the nuclear norm of a tensor and its matrix flattenings. Linear Algebra Its Appl. 2015, 478, 188–199. [Google Scholar] [CrossRef]
- Chrétien, S.; Wei, T. Von Neumann’s inequality for tensors. arXiv 2015, arXiv:1502.01616. [Google Scholar]
- Chrétien, S.; Wei, T. On the subdifferential of symmetric convex functions of the spectrum for symmetric and orthogonally decomposable tensors. Linear Algebra Its Appl. 2018, 542, 84–100. [Google Scholar] [CrossRef]
- Heinze, H.; Bauschke, P.L. Convex Analysis and Monotone Operator Theory in Hilbert Spaces; Canada Mathematical Society: Ottawa, ON, Canada, 2011. [Google Scholar]
- Borwein, J.; Lewis, A.S. Convex Analysis and Nonlinear Optimization: Theory and Examples; Springer Science & Business Media: Berlin, Germany, 2010. [Google Scholar]
- Jean-Pierre Aubin, I.E. Applied Nonlinear Analysis; Dover Publications: Mineola, NY, USA, 2006; Volume 518. [Google Scholar]
- Ma, S.; Goldfarb, D.; Chen, L. Fixed point and Bregman iterative methods for matrix rank minimization. Math. Program. 2011, 128, 321–353. [Google Scholar] [CrossRef]
- Chrétien, S.; Lohvithee, M.; Sun, W.; Soleimani, M. Efficient hyper-parameter selection in Total Variation- penalised XCT reconstruction using Freund and Shapire’s Hedge approach. Mathematics 2020, 8, 493. [Google Scholar] [CrossRef]
- Guo, W.; Qin, J.; Yin, W. A new detail-preserving regularization scheme. SIAM J. Imaging Sci. 2014, 7, 1309–1334. [Google Scholar] [CrossRef]
- Tropp, J.A. User-Frindly tail bounds for sums of random matrices. arXiv 2010, arXiv:1004.4389v7. [Google Scholar]










© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).