Cognitive Emotional Embedded Representations of Text to Predict Suicidal Ideation and Psychiatric Symptoms

 ,
,
Abstract
1. Introduction
2. Related Work
3. Materials and Methods
3.1. Sampling Methodology and Corpus Description
3.2. Cognitive-Emotional Scoring System and Representation
- If then:
- If and then:
- If and then:
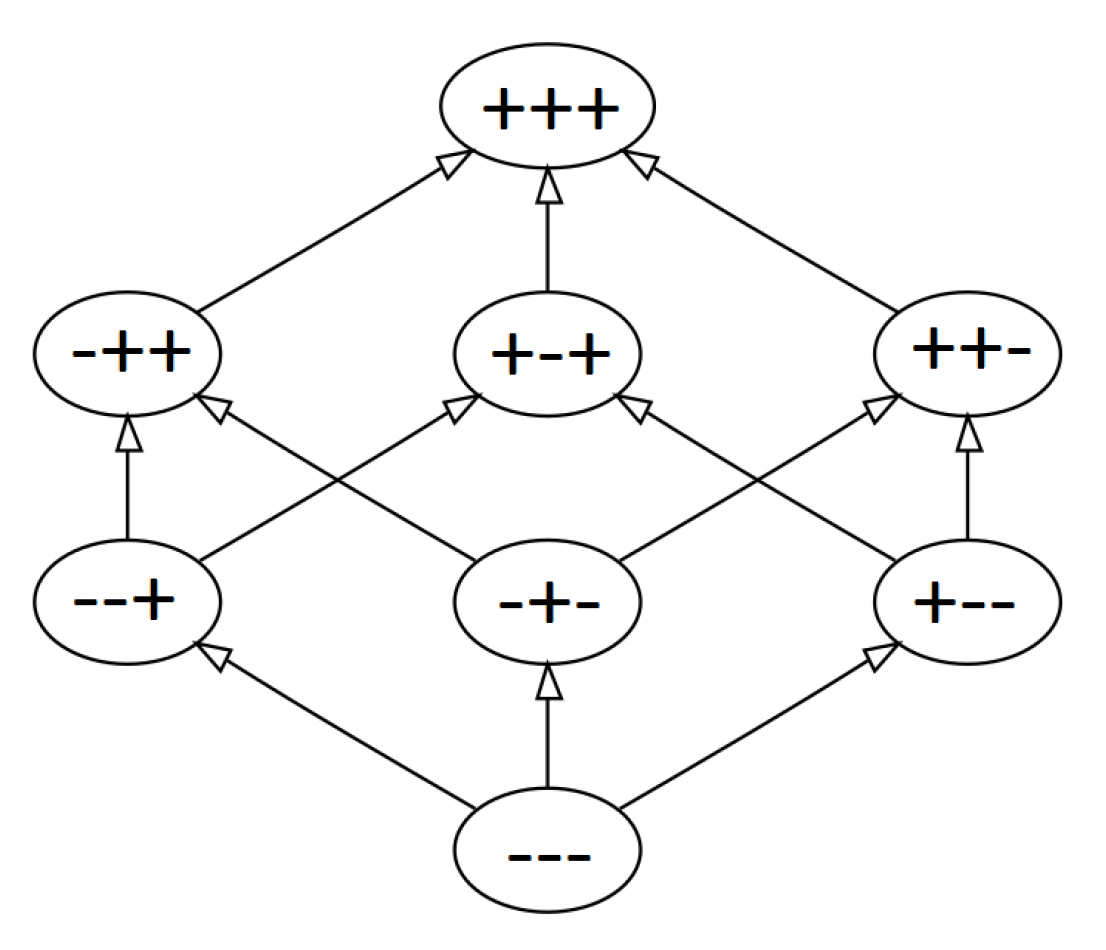
3.3. Topological-Geometrical Clustering and Properties of the Transformation R(w)
3.3.1. Definitions and Preliminary Observations
3.3.2. Hyperoctant Tree Search Clustering Method
- We first choose a density , which will be the minimum density per cluster.
- Now, we perform a Depth-first search on the entire graph starting at the bottom vertex .
- The first time we encounter a vertex in U, we add the word embeddings w in this vertex to a set D, and we write as a short notation meaning that the embedding in that node was added.
- We continue with the search until we encounter another vertex . We add this vertex to D only if
- We now search for each nearest neighbor y of each word in D and add it to D if
- We recursively apply steps 4 and 5, until we encounter a vertex such that its inclusion in D violates the condition in step 4, or a neighbor increases in step 5. In such a case, we create a new cluster and restart the process at step 3 until all vertices and neighbors have been explored.
3.4. Experimental Settings
4. Results
5. Discussion
- of words appear only once in the corpus.
- The vocabulary is rather limited compared to the size of the corpora where word2vec is usually trained. The usual size of such vocabularies is in the order of millions of tokens.
- of the messages consist of only a few words lacking a coherent grammatical structure.
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| NLP | Natural language processing |
| MPQA | Multi-Perspective Question Answering |
| CEIC-FJD | Comité de Ética de la Investigación Clínica de la Fundación Jiménez Díaz |
| PCA | Principal component analysis |
| DBSCAN | Density-based spatial clustering of applications with noise. |
References
- Baca García, E.; Aroca, F. Factores de riesgo de la conducta suicida asociados a trastornos depresivos y ansiedad. Salud Ment. 2014, 37, 373–380. [Google Scholar] [CrossRef]
- Turecki, G. Preventing suicide: Where are we? Lancet. Psychiatry 2016, 3, 597. [Google Scholar] [CrossRef]
- Ge, J.; Vazquez, M.; Gretzel, U. Sentiment analysis: A review. In Advances in Social Media for Travel, Tourism and Hospitality: New Perspectives, Practice and Cases; Routledge: London, UK, 2018; pp. 243–261. [Google Scholar]
- Serrano-Guerrero, J.; Olivas, J.A.; Romero, F.P.; Herrera-Viedma, E. Sentiment analysis: A review and comparative analysis of web services. Inform. Sci. 2015, 311, 18–38. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems-Volume 2, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- Out, C.; Goudbeek, M.; Krahmer, E. Do Speaker’s emotions influence their language production? Studying the influence of disgust and amusement on alignment in interactive reference. Lang. Sci. 2020, 78, 101255. [Google Scholar] [CrossRef]
- Foolen, A. The relevance of emotion for language and linguistics. Moving Ourselves, Moving Others: Motion and Emotion in Intersubjectivity, Consciousness and Language; John Benjamins Publishing Company: Amsterdam, The Netherlands, 2012; pp. 349–369. [Google Scholar]
- Benamara, F.; Taboada, M.; Mathieu, Y. Evaluative Language Beyond Bags of Words: Linguistic Insights and Computational Applications. Comput. Linguist. 2017, 43, 201–264. [Google Scholar] [CrossRef]
- Jatnika, D.; Bijaksana, M.A.; Suryani, A.A. Word2Vec Model Analysis for Semantic Similarities in English Words. Procedia Comput. Sci. 2019, 157, 160–167. [Google Scholar] [CrossRef]
- Tshitoyan, V.; Dagdelen, J.; Weston, L.; Dunn, A.; Rong, Z.; Kononova, O.; Persson, K.A.; Ceder, G.; Jain, A. Unsupervised word embeddings capture latent knowledge from materials science literature. Nature 2019, 571, 95–98. [Google Scholar] [CrossRef]
- Sim, K.; Gopalkrishnan, V.; Zimek, A.; Cong, G. A survey on enhanced subspace clustering. Data Min. Knowl. Discov. 2013, 26, 332–397. [Google Scholar] [CrossRef]
- Bhattacharjee, P.; Mitra, P. A survey of density based clustering algorithms. Front. Comp. Sci. 2020, 15, 151308. [Google Scholar] [CrossRef]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Statistics, Statistical Laboratory of the University of California, Berkeley, CA, USA, 21 June–18 July 1965 and 27 December 1965–7 January 1966; University of California Press: Berkeley, CA, USA, 1967; pp. 281–297. [Google Scholar]
- Dhillon, I.S.; Modha, D.S. Concept decompositions for large sparse text data using clustering. Mach. Learn. 2001, 42, 143–175. [Google Scholar] [CrossRef]
- Tunali, V.; Bilgin, T.; Camurcu, A. An Improved Clustering Algorithm for Text Mining: Multi-Cluster Spherical K-Means. Int. Arab J. Inform. Technol. 2016, 13, 12–19. [Google Scholar]
- Brodinová, Š.; Filzmoser, P.; Ortner, T.; Breiteneder, C.; Rohm, M. Robust and sparse k-means clustering for high-dimensional data. Adv. Data Anal. Classif. 2019, 13, 905–932. [Google Scholar] [CrossRef]
- Gao, J.; Liu, N.; Lawley, M.; Hu, X. An interpretable classification framework for information extraction from online healthcare forums. J. Healthc. Eng. 2017, 2017, 2460174. [Google Scholar] [CrossRef] [PubMed]
- Stewart, R.; Velupillai, S. Applied natural language processing in mental health big data. Neuropsychopharmacology 2020, 46, 252–253. [Google Scholar]
- Mäntylä, M.V.; Graziotin, D.; Kuutila, M. The evolution of sentiment analysis—A review of research topics, venues, and top cited papers. Comp. Sci. Rev. 2018, 27, 16–32. [Google Scholar] [CrossRef]
- Taboada, M.; Brooke, J.; Tofiloski, M.; Voll, K.; Stede, M. Lexicon-Based Methods for Sentiment Analysis. Comput. Linguist. 2011, 37, 267–307. [Google Scholar] [CrossRef]
- Esuli, A.; Sebastiani, F. SentiWordNet: A high-coverage lexical resource for opinion mining. Evaluation 2007, 17, 26. [Google Scholar]
- Thelwall, M.; Buckley, K.; Paltoglou, G. Sentiment strength detection for the social web. J. Am. Soc. Inform. Sci. Technol. 2012, 63, 163–173. [Google Scholar] [CrossRef]
- Abbasi, A.; Chen, H. Affect Intensity Analysis of Dark Web Forums. In Proceedings of the 2007 IEEE Intelligence and Security Informatics, New Brunswick, NJ, USA, 23–24 May 2007; pp. 282–288. [Google Scholar]
- Agarwal, A.; Xie, B.; Vovsha, I.; Rambow, O.; Passonneau, R. Sentiment Analysis of Twitter Data. In Proceedings of the Workshop on Languages in Social Media, LSM ’11, Portland, OR, USA, 23 June 2011; pp. 30–38. [Google Scholar]
- Gautam, G.; Yadav, D. Sentiment analysis of twitter data using machine learning approaches and semantic analysis. In Proceedings of the 2014 Seventh International Conference on Contemporary Computing (IC3), Noida, India, 7–9 August 2014; pp. 437–442. [Google Scholar]
- Tang, D.; Wei, F.; Qin, B.; Yang, N.; Liu, T.; Zhou, M. Sentiment embeddings with applications to sentiment analysis. IEEE Trans. Knowl. Data Eng. 2015, 28, 496–509. [Google Scholar] [CrossRef]
- Li, Y.; Pan, Q.; Yang, T.; Wang, S.; Tang, J.; Cambria, E. Learning word representations for sentiment analysis. Cogn. Comput. 2017, 9, 843–851. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global Vectors for Word Representation. In Proceedings of the Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Volume 14, pp. 1532–1543. [Google Scholar]
- Jabreel, M.; Moreno, A. A deep learning-based approach for multi-label emotion classification in tweets. Appl. Sci. 2019, 9, 1123. [Google Scholar] [CrossRef]
- Appel, O.; Chiclana, F.; Carter, J.; Fujita, H. A hybrid approach to the sentiment analysis problem at the sentence level. Knowl.-Based Syst. 2016, 108, 110–124. [Google Scholar] [CrossRef]
- Zainuddin, N.; Selamat, A.; Ibrahim, R. Hybrid sentiment classification on twitter aspect-based sentiment analysis. Appl. Intell. 2018, 48, 1218–1232. [Google Scholar] [CrossRef]
- Wu, C.S.; Kuo, C.; Su, C.H.; Wang, S.; Dai, H.J. Using text mining to extract depressive symptoms and to validate the diagnosis of major depressive disorder from electronic health records. J. Affect. disord. 2019, 260, 617–623. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Liu, H.; Zhou, T. A Sequential Emotion Approach for Diagnosing Mental Disorder on Social Media. Appl. Sci. 2020, 10, 1647. [Google Scholar] [CrossRef]
- Xue, B.; Fu, C.; Shaobin, Z. A study on sentiment computing and classification of sina weibo with word2vec. In Proceedings of the 2014 IEEE International Congress on Big Data, Anchorage, AK, USA, 27 June–2 July 2014; pp. 358–363. [Google Scholar]
- Turney, P.D.; Littman, M.L. Measuring praise and criticism: Inference of semantic orientation from association. ACM Trans. Inform. Syst. (TOIS) 2003, 21, 315–346. [Google Scholar] [CrossRef]
- Al-Amin, M.; Islam, M.S.; Uzzal, S.D. Sentiment analysis of bengali comments with word2vec and sentiment information of words. In Proceedings of the 2017 International Conference on Electrical, Computer and Communication Engineering (ECCE), Cox’s Bazar, Bangladesh, 16–18 February 2017; pp. 186–190. [Google Scholar]
- Velupillai, S.; Hadlaczky, G.; Baca-Garcia, E.; Gorrell, G.M.; Werbeloff, N.; Nguyen, D.; Patel, R.; Leightley, D.; Downs, J.; Hotopf, M.; et al. Risk assessment tools and data-driven approaches for predicting and preventing suicidal behavior. Front. Psychiatry 2019, 10, 36. [Google Scholar] [CrossRef] [PubMed]
- Corcoran, C.M.; Benavides, C.; Cecchi, G. Natural language processing: Opportunities and challenges for patients, providers, and hospital systems. Psychiatr. Ann. 2019, 49, 202–208. [Google Scholar] [CrossRef]
- Pinker, S. The Stuff of Thought: Language as a Window into Human Nature; Penguin: London, UK, 2007. [Google Scholar]
- Corcoran, C.M.; Cecchi, G. Using language processing and speech analysis for the identification of psychosis and other disorders. Biol. Psychiatry Cogn. Neurosci. Neuroimaging 2020, 5, 770–779. [Google Scholar] [CrossRef] [PubMed]
- Badal, V.D.; Graham, S.A.; Depp, C.A.; Shinkawa, K.; Yamada, Y.; Palinkas, L.A.; Kim, H.C.; Jeste, D.V.; Lee, E.E. Prediction of Loneliness in Older Adults Using Natural Language Processing: Exploring Sex Differences in Speech. Am. J. Geriatr. Psychiatry 2020. [Google Scholar] [CrossRef] [PubMed]
- Goldberg, S.B.; Flemotomos, N.; Martinez, V.R.; Tanana, M.J.; Kuo, P.B.; Pace, B.T.; Villatte, J.L.; Georgiou, P.G.; Van Epps, J.; Imel, Z.E.; et al. Machine learning and natural language processing in psychotherapy research: Alliance as example use case. J. Couns. Psychol. 2020, 67, 438. [Google Scholar] [CrossRef] [PubMed]
- Ni, Y.; Barzman, D.; Bachtel, A.; Griffey, M.; Osborn, A.; Sorter, M. Finding warning markers: Leveraging natural language processing and machine learning technologies to detect risk of school violence. Int. J. Med. Inform. 2020, 139, 104137. [Google Scholar] [CrossRef] [PubMed]
- Coppersmith, G.; Leary, R.; Crutchley, P.; Fine, A. Natural language processing of social media as screening for suicide risk. Biomed. Inform. Insights 2018, 10. [Google Scholar] [CrossRef] [PubMed]
- Cook, B.L.; Progovac, A.M.; Chen, P.; Mullin, B.; Hou, S.; Baca-Garcia, E. Novel use of natural language processing (NLP) to predict suicidal ideation and psychiatric symptoms in a text-based mental health intervention in Madrid. Comput. Math. Methods Med. 2016, 2016, 8708434. [Google Scholar] [CrossRef] [PubMed]
- Pellegrini, A.M.; Chan, S.; Brown, H.E.; Rosenquist, J.N.; Vuijk, P.J.; Doyle, A.E.; Perlis, R.H.; Cai, T. Integrating questionnaire measures for transdiagnostic psychiatric phenotyping using word2vec. PLoS ONE 2020, 15, e0230663. [Google Scholar]
- Zhang, Y.; Li, H.J.; Wang, J.; Cohen, T.; Roberts, K.; Xu, H. Adapting word embeddings from multiple domains to symptom recognition from psychiatric notes. AMIA Summits Transl. Sci. Proc. 2018, 2018, 281. [Google Scholar]
- Cambria, E.; Olsher, D.; Rajagopal, D. SenticNet 3: A Common and Common-Sense Knowledge Base for Cognition-Driven Sentiment Analysis. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, AAAI’14, Québec City, QC, Canada, 27–31 July 2014; pp. 1515–1521. [Google Scholar]
- Mishra, A.; Kanojia, D.; Nagar, S.; Dey, K.; Bhattacharyya, P. Leveraging Cognitive Features for Sentiment Analysis. In Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning, Berlin, Germany, 11–12 August 2016; Association for Computational Linguistics: Berlin, Germany, 2016; pp. 156–166. [Google Scholar]
- Wilson, T.; Wiebe, J.; Hoffmann, P. Recognizing Contextual Polarity in Phrase-Level Sentiment Analysis. In Proceedings of the Conference on Human Language Technology and Empirical Methods in Natural Language Processing, HLT ’05, Vancouver, BC, Canada, 6–8 October 2005; pp. 347–354. [Google Scholar]
- Wiebe, J.; Wilson, T.; Cardie, C. Annotating Expressions of Opinions and Emotions in Language. Lang. Resour. Eval. 2005, 39, 164–210. [Google Scholar] [CrossRef]
- Zucco, C.; Calabrese, B.; Cannataro, M. Sentiment analysis and affective computing for depression monitoring. In Proceedings of the 2017 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Kansas City, MO, USA, 13–16 November 2017; pp. 1988–1995. [Google Scholar]
- Hussein, D.M.E.D.M. A survey on sentiment analysis challenges. J. King Saud Univ. Eng. Sci. 2018, 30, 330–338. [Google Scholar] [CrossRef]
- Witten, D.M.; Tibshirani, R. A framework for feature selection in clustering. J. Am. Stat. Assoc. 2010, 105, 713–726. [Google Scholar] [CrossRef]
- Galimberti, G.; Manisi, A.; Soffritti, G. Modelling the role of variables in model-based cluster analysis. Stat. Comp. 2018, 28, 145–169. [Google Scholar] [CrossRef]
- Houle, M.E.; Kriegel, H.P.; Kröger, P.; Schubert, E.; Zimek, A. Can shared-neighbor distances defeat the curse of dimensionality? In Proceedings of the International Conference on Scientific and Statistical Database Management, Heidelberg, Germany, 31 June–2 July 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 482–500. [Google Scholar]
- Beyer, K.; Goldstein, J.; Ramakrishnan, R.; Shaft, U. When is “nearest neighbor” meaningful? In Proceedings of the International conference on database theory, Jerusalem, Israel, 10–12 January 1999; Springer: Berlin/Heidelberg, Germany, 1999; pp. 217–235. [Google Scholar]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, KDD’96, Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Xu, R.; Wunsch, D. Survey of clustering algorithms. IEEE Trans. Neural Netw. 2005, 16, 645–678. [Google Scholar] [CrossRef] [PubMed]
- Porras-Segovia, A.; Molina-Madueño, R.M.; Berrouiguet, S.; López-Castroman, J.; Barrigón, M.L.; Pérez-Rodríguez, M.S.; Marco, J.H.; Díaz-Oliván, I.; de León, S.; Courtet, P.; et al. Smartphone-based ecological momentary assessment (EMA) in psychiatric patients and student controls: A real-world feasibility study. J. Affect. Disord. 2020, 274, 733–741. [Google Scholar] [CrossRef] [PubMed]
- Berrouiguet, S.; Barrigón, M.L.; Castroman, J.L.; Courtet, P.; Artés-Rodríguez, A.; Baca-García, E. Combining mobile-health (mHealth) and artificial intelligence (AI) methods to avoid suicide attempts: The Smartcrises study protocol. BMC Psychiatry 2019, 19, 277. [Google Scholar] [CrossRef] [PubMed]
- Barrigón, M.L.; Berrouiguet, S.; Carballo, J.J.; Bonal-Giménez, C.; Fernández-Navarro, P.; Pfang, B.; Delgado-Gómez, D.; Courtet, P.; Aroca, F.; Lopez-Castroman, J.; et al. User profiles of an electronic mental health tool for ecological momentary assessment: MEmind. Int. J. Methods Psychiatr. Res. 2017, 26, e1554. [Google Scholar] [CrossRef] [PubMed]
- Deza, M.M.; Deza, E. Encyclopedia of distances. In Encyclopedia of Distances; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1–583. [Google Scholar]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Mnih, A.; Kavukcuoglu, K. Learning word embeddings efficiently with noise-contrastive estimation. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 2265–2273. [Google Scholar]
- Wang, Y.; Rastegar-Mojarad, M.; Komandur-Elayavilli, R.; Liu, H. Leveraging word embeddings and medical entity extraction for biomedical dataset retrieval using unstructured texts. Database 2017, 2017, bax091. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, S.; Afzal, N.; Rastegar-Mojarad, M.; Wang, L.; Shen, F.; Kingsbury, P.; Liu, H. A comparison of word embeddings for the biomedical natural language processing. J. Biomed. Inform. 2018, 87, 12–20. [Google Scholar] [CrossRef]
- Chen, Q.; Peng, Y.; Lu, Z. BioSentVec: Creating sentence embeddings for biomedical texts. In Proceedings of the 2019 IEEE International Conference on Healthcare Informatics (ICHI), Xi’an, China, 10–13 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–5. [Google Scholar]
- Levy, O.; Goldberg, Y.; Dagan, I. Improving distributional similarity with lessons learned from word embeddings. Trans. Assoc. Comput. Linguist. 2015, 3, 211–225. [Google Scholar] [CrossRef]
- Gathigia, M.G.; Wang, R.; Shen, M.; Tirado, C.; Tsaregorodtseva, O.; Khatin-Zadeh, O.; Minervino, R.; Marmolejo-Ramos, F. A cross-linguistic study of metaphors of death. Cogn. Linguist. Stud. 2018, 5, 359–375. [Google Scholar] [CrossRef]
- Zepeda-Mendoza, M.L.; Resendis-Antonio, O. Hierarchical Agglomerative Clustering. In Encyclopedia of Systems Biology; Springer: New York, NY, USA, 2013; pp. 886–887. [Google Scholar]
- Kriegel, H.P.; Kröger, P.; Zimek, A. Clustering High-Dimensional Data: A Survey on Subspace Clustering, Pattern-Based Clustering, and Correlation Clustering. ACM Trans. Knowl. Discov. Data 2009, 3, 1. [Google Scholar] [CrossRef]
- Müller, E.; Günnemann, S.; Assent, I.; Seidl, T. Evaluating Clustering in Subspace Projections of High Dimensional Data. Proc. VLDB Endow. 2009, 2, 1270–1281. [Google Scholar] [CrossRef]
- Levenshtein, V.I. Binary codes capable of correcting deletions, insertions, and reversals. Soviet Physics Doklady 1966, 10, 707–710. [Google Scholar]
- Porras-Segovia, A.; Pérez-Rodríguez, M.M.; López-Esteban, P.; Courtet, P.; López-Castromán, J.; Cervilla, J.A.; Baca-García, E.; Barrigón M, M.L. Contribution of sleep deprivation to suicidal behaviour: A systematic review. Sleep Med. Rev. 2019, 44, 37–47. [Google Scholar] [CrossRef] [PubMed]
- Hashimoto, T.B.; Alvarez-Melis, D.; Jaakkola, T.S. Word embeddings as metric recovery in semantic spaces. Trans. Assoc. Comput. Linguist. 2016, 4, 273–286. [Google Scholar] [CrossRef]
- Mikros, G.K.; Macutek, J. Sequences in Language and Text; De Gruyter Mouton: Berlin, Germany; Boston, MA, USA, 24 April 2015. [Google Scholar]
- González-Espinoza, A.; Martínez-Mekler, G.; Lacasa, L. Arrow of time across five centuries of classical music. Phys. Rev. Res. 2020, 2, 033166. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
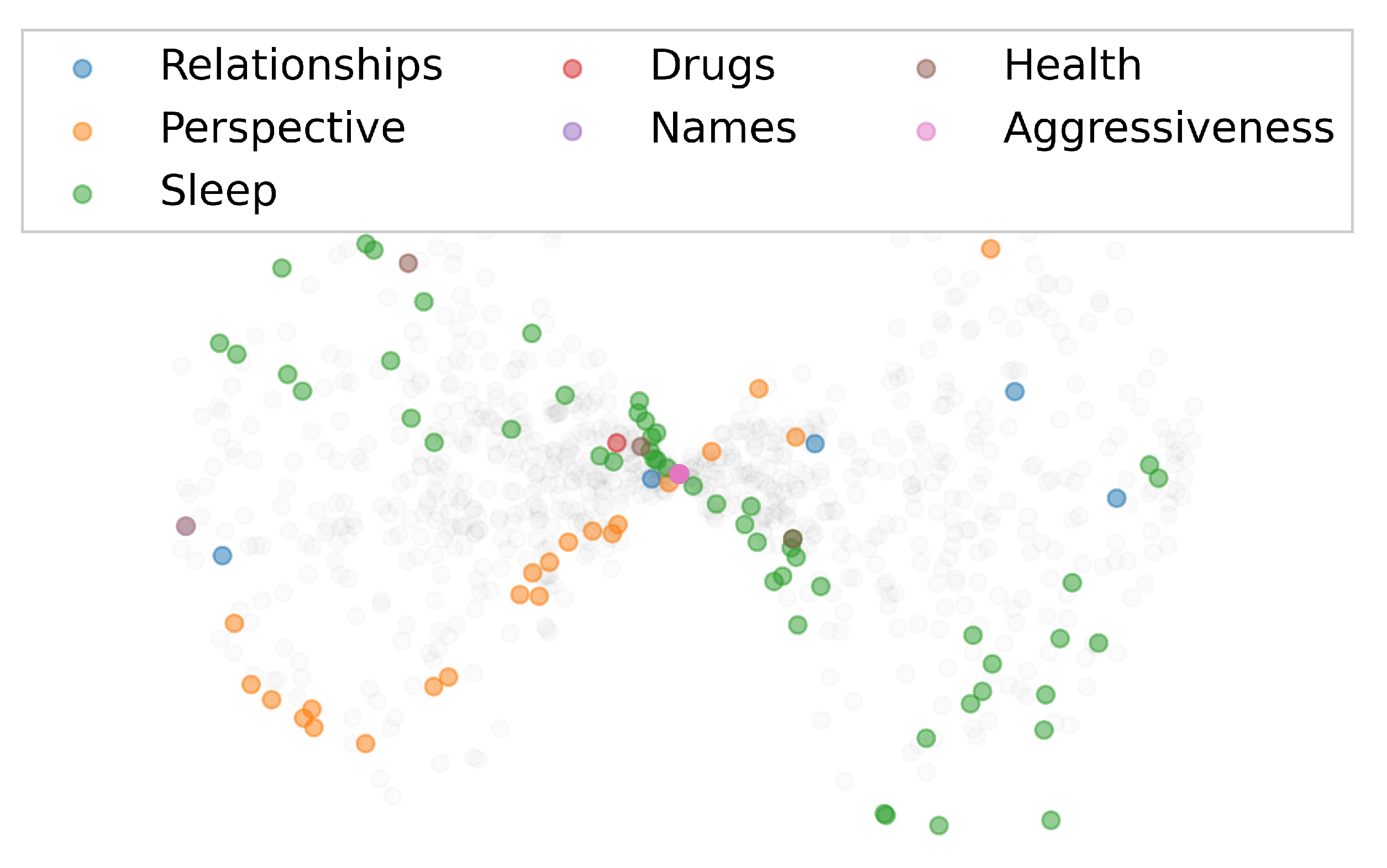
| Cluster/Topic | Topic Description | Some Members |
|---|---|---|
| Relationships | Relationships between members of a family, friends or acquaintances. | brother, sister, mother, grandmother, daughter, son, neighbour. |
| Perspective | Words related to the future or the attitude towards life in general | To live, peace, to abandon, to face, perspective, to hate, frustration. |
| Sleep | Words related to sleep or rest. | sleep, sleepless, asleep, incubate, inactive, rested. |
| Names | Names or last names of people | Luisa, Juan, Yolanda, Teresa, Sánchez. |
| Health | Words regarding injuries, sickness or ailments. | sclerosis, throat, exhaustion, muscular, ocular. |
| Aggressiveness | Words bearing various levels of aggressiveness. | To warn, to trample, excuses, wall, break up, to cheat, to demand, slander, bruise. |
| Drugs | Names and terms related to medications, mainly antidepressants. | Escitalopram, lormetazepam, lorazepam, ibuprofen, orfidal, paroxetine, sycrest. |
| Word | Score | Translation | Word | Score | Translation |
|---|---|---|---|---|---|
| descansada | 1.0 | rested | tenso | −1.0 | tense |
| mejorar | 1.0 | to get better | empeorar | −1.0 | to get worse |
| acompañada | 1.0 | accompanied | muerte | −1.0 | death |
| principio | 1.0 | beginning | peores | −1.0 | worst |
| mejores | 1.0 | best | atrás | −0.9783 | backwards |
| descansado | 1.0 | rested | malo | −0.9726 | bad |
| bienestar | 1.0 | well−being | fin | −0.9655 | end |
| durmiendo | 0.9821 | sleeping | mala | −0.96 | bad |
| adelante | 0.9818 | forward | duro | −0.9583 | rough |
| positivo | 0.9787 | positive | negativo | −0.95 | negative |
| útil | 0.9706 | useful | nervioso | −0.949 | nervous |
| dormido | 0.9684 | asleep | sol | −0.9474 | sun |
| relajada | 0.9661 | relaxed | pasado | −0.947 | past |
| tranquilo | 0.965 | serene | cansado | −0.9423 | tired |
| fácil | 0.96 | easy | triste | −0.9364 | sad |
| tranquila | 0.9583 | serene | librarme | −0.934 | freeing my self |
| contenta | 0.9516 | content | arrepentirme | −0.92 | to regret |
| alegre | 0.95 | happy | cansada | −0.9194 | tired |
| buena | 0.9494 | good | nerviosa | −0.9159 | nervous |
| relajado | 0.9286 | relaxed | concentrándome | −0.915 | focusing |
| Word | Score | Translation | Word | Score | Translation |
|---|---|---|---|---|---|
| bienestar | 1.0 | well−being | empeorar | −1.0 | to worsen |
| acompañada | 1.0 | accompanied | muerte | −1.0 | death |
| descansada | 1.0 | rested | peores | −1.0 | worst |
| mejores | 1.0 | better | tenso | −1.0 | tense |
| descansado | 1.0 | rested | durmiendo | −0.9821 | sleeping |
| principio | 1.0 | beginning | atrás | −0.9783 | backwards |
| mejorar | 1.0 | to get better | despierto | −0.9747 | awake |
| adelante | 0.9818 | forward | malo | −0.9726 | bad |
| positivo | 0.9787 | positive | dormido | −0.9684 | asleep |
| útil | 0.9706 | useful | fin | −0.9655 | end |
| relajada | 0.9661 | relaxed | mala | −0.96 | bad |
| tranquilo | 0.965 | peaceful | duro | −0.9583 | tough |
| fácil | 0.96 | easy | negativo | −0.95 | negative |
| tranquila | 0.9583 | peaceful | nervioso | −0.949 | nervous |
| contenta | 0.9516 | happy | sol | −0.9474 | sun |
| alegre | 0.95 | cheerful | pasado | −0.947 | past |
| buena | 0.9494 | good | cansado | −0.9423 | tired |
| relajado | 0.9286 | relaxed | triste | −0.9364 | sad |
| franca | 0.9209 | frank | librarme | −0.9342 | to get rid of |
| pintando | 0.9195 | painting | despierta | −0.9286 | awake |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Toledo-Acosta, M.; Barreiro, T.; Reig-Alamillo, A.; Müller, M.; Aroca Bisquert, F.; Barrigon, M.L.; Baca-Garcia, E.; Hermosillo-Valadez, J. Cognitive Emotional Embedded Representations of Text to Predict Suicidal Ideation and Psychiatric Symptoms. Mathematics 2020, 8, 2088. https://doi.org/10.3390/math8112088
Toledo-Acosta M, Barreiro T, Reig-Alamillo A, Müller M, Aroca Bisquert F, Barrigon ML, Baca-Garcia E, Hermosillo-Valadez J. Cognitive Emotional Embedded Representations of Text to Predict Suicidal Ideation and Psychiatric Symptoms. Mathematics. 2020; 8(11):2088. https://doi.org/10.3390/math8112088
Chicago/Turabian StyleToledo-Acosta, Mauricio, Talin Barreiro, Asela Reig-Alamillo, Markus Müller, Fuensanta Aroca Bisquert, Maria Luisa Barrigon, Enrique Baca-Garcia, and Jorge Hermosillo-Valadez. 2020. "Cognitive Emotional Embedded Representations of Text to Predict Suicidal Ideation and Psychiatric Symptoms" Mathematics 8, no. 11: 2088. https://doi.org/10.3390/math8112088
APA StyleToledo-Acosta, M., Barreiro, T., Reig-Alamillo, A., Müller, M., Aroca Bisquert, F., Barrigon, M. L., Baca-Garcia, E., & Hermosillo-Valadez, J. (2020). Cognitive Emotional Embedded Representations of Text to Predict Suicidal Ideation and Psychiatric Symptoms. Mathematics, 8(11), 2088. https://doi.org/10.3390/math8112088