Abstract
In this study, we propose a new flexible two-parameter continuous distribution with support on the unit interval. It can be identified as a special member of the so-called type I half-logistic-G family of distributions, defined with the Topp–Leone distribution as baseline. Among its features, the corresponding probability density function can be left skewed, right-skewed, approximately symmetric, J-shaped, as well as reverse J-shaped, making it suitable for modeling a wide variety of data sets. It thus provides an alternative to the so-called beta and Kumaraswamy distributions. The mathematical properties of the new distribution are determined, deriving the asymptotes, shapes, quantile function, skewness, kurtosis, some power series expansions, ordinary moments, incomplete moments, moment-generating function, stress strength parameter, and order statistics. Then, a statistical treatment of the related model is proposed. The estimation of the unknown parameters is performed by a simulation study exploring seven methods, all described in detail. Two practical data sets are analyzed, showing the usefulness of the new proposed model.
Keywords:
type I half-logistic distribution; Topp–Leone distribution; estimation methods; data analysis MSC:
60E05; 62E15; 62F10
1. Introduction
Over the past several decades, motivated by the growing demand of statistical models in many applied areas, numerous general families of continuous distributions have been introduced. Most of them consist of adding extra parameters to well-established continuous distributions in order to give them new interesting features. The most notorious of these families are the exponentiated-G family [1], the beta-G family [2], and the gamma-G family [3]. Recent promising families include the Kumaraswamy-G family [4], the type I half-logistic-G family [5], the generalized odd log-logistic family [6], the odd power Cauchy family [7], the exponentiated generalized Topp–Leone-G family [8], and the type II general inverse exponential-G family [9].
The foundation of our study is the type I half-logistic-G (TIHL-G) family [5]. This general family is characterized by the cumulative distribution function (cdf) given by
where and is a baseline cdf of a continuous distribution which may depend on a parameter vector . The corresponding probability density function (pdf) is given by
where denotes the pdf associated to . Also, the corresponding hazard rate function (hrf) is given by
In a former work, Cordeiro et al. [5] studied the main mathematical and statistical properties of the type I half-logistic-G family, with an emphasis on special members with support on the semi-infinite interval . In particular, it is shown that the additional parameter plays a significant role, allowing new features to be reached in terms of flexibility in comparison to the baseline distribution. Applications to two practical data sets are given for the type I half-logistic-G family defined with the Weibull distribution as baseline. Numerical results show great adjustments of the proposed model for both data sets, with the use of the maximum likelihood method to estimate the model parameters.
In this study, we investigate the potential of a new special member of the type I half-logistic-G family with support over the unit interval , defined with the Topp–Leone distribution as baseline. The Topp–Leone distribution was introduced by [10] and has been the object of attention in many studies, mainly thanks to its tractability and various favorable mathematical properties. We refer the interested reader to [11,12], among others. We would also like to mention that the Topp–Leone distribution has inspired some general families, such as [13] for the Topp–Leone-G family, [14] for the Topp–Leone-G exponential power series family, and [15] for the type II Topp–Leone-G family. Here, we aim to profit from the combined features of the type I half-logistic-G family and the Topp–Leone distribution by introducing a new distribution called the type I half-logistic Topp–Leone distribution. As initial motivation, we would like to mention that the corresponding probability density function shows a great flexibility in terms of shape; it can be left-skewed, right-skewed, approximately symmetrical, J-shaped, as well as reverse J-shaped. This is an undeniable plus from a data fitting point of view. Thus, with the same support, the type I half-logistic Topp–Leone distribution provides an alternative to other well-established two-parameter continuous distributions with support on , such as the beta distribution introduced by [16] and the Kumaraswamy distribution introduced by [17]. This study is devoted to the complete mathematical and statistical treatments of this new distribution. An important part presents the estimation of the model parameters, where the following seven methods are investigated: maximum likelihood estimation, least squares and weighted least squares estimation, Cramer–von Mises minimum distance estimation, percentile estimation, as well as Anderson–Darling and right-tail Anderson–Darling estimation. Applications to two practical data sets show the potential of the type I half-logistic Topp–Leone model, with favorable goodness-of-fit results in comparison to the beta and Kumaraswamy models, among others.
The rest of this paper is outlined as follows. In Section 2, we present the type I half-logistic Topp–Leone distribution. Section 3 is devoted to its mathematical properties. The model parameter estimations are investigated in Section 4. The applications are given in Section 5. Concluding remarks are formulated in Section 6.
2. The Type I Half-Logistic Topp–Leone Distribution
As previously mentioned, the type I half-logistic Topp–Leone (TIHLTL) distribution is defined as the special member of the type I half-logistic-G (TIHL-G) family with the Topp–Leone distribution as baseline. Let us recall that the Topp–Leone distribution is characterized by the cdf and pdf given by, respectively,
where . The crucial functions of the TIHLTL distribution are presented below.
The cdf of the TIHLTL distribution is given by
where .
The corresponding probability density function (pdf) is given by
The corresponding hazard rate function (hrf) and cumulative hazard rate function (chrf) are respectively given by:
and
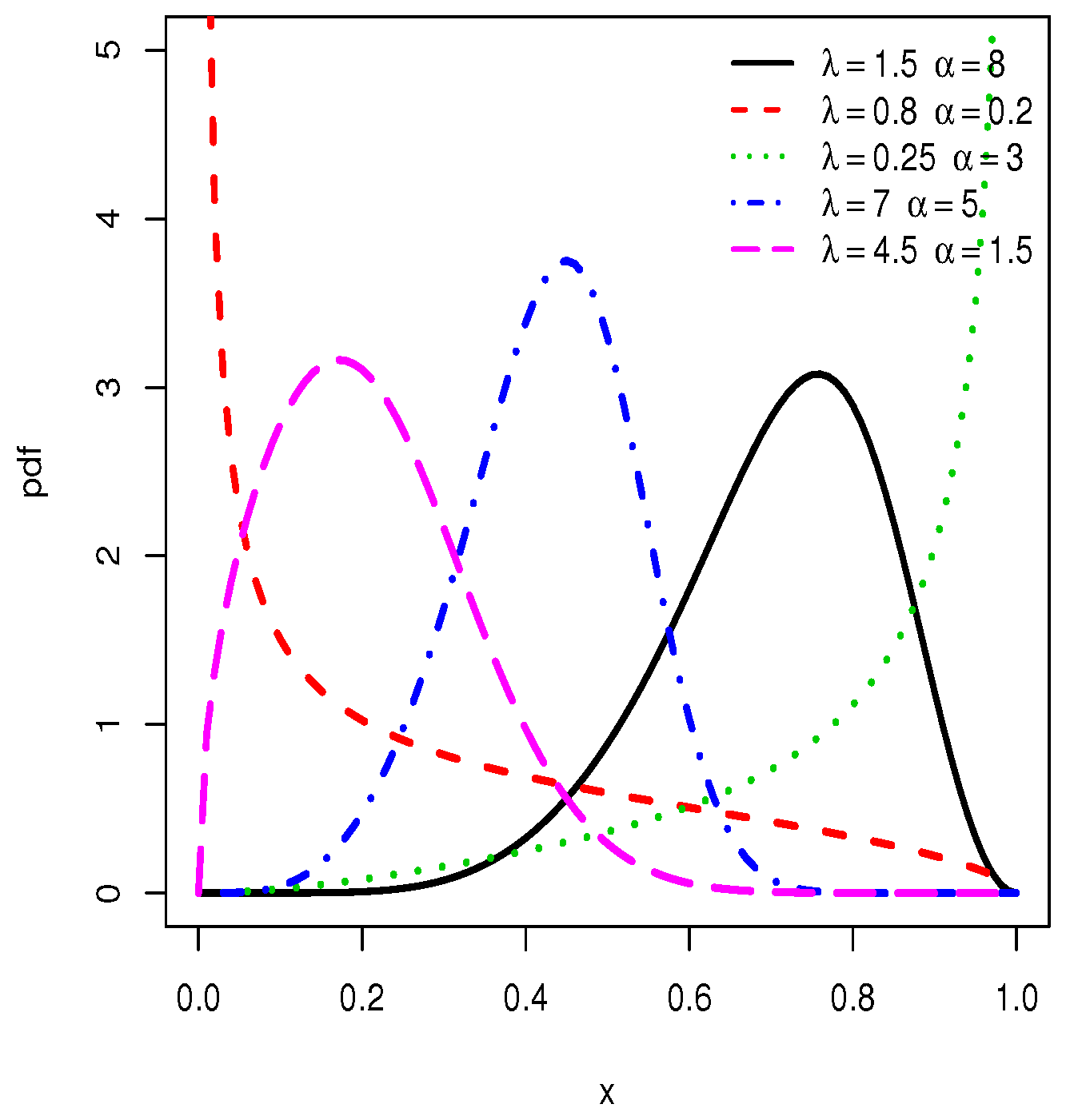
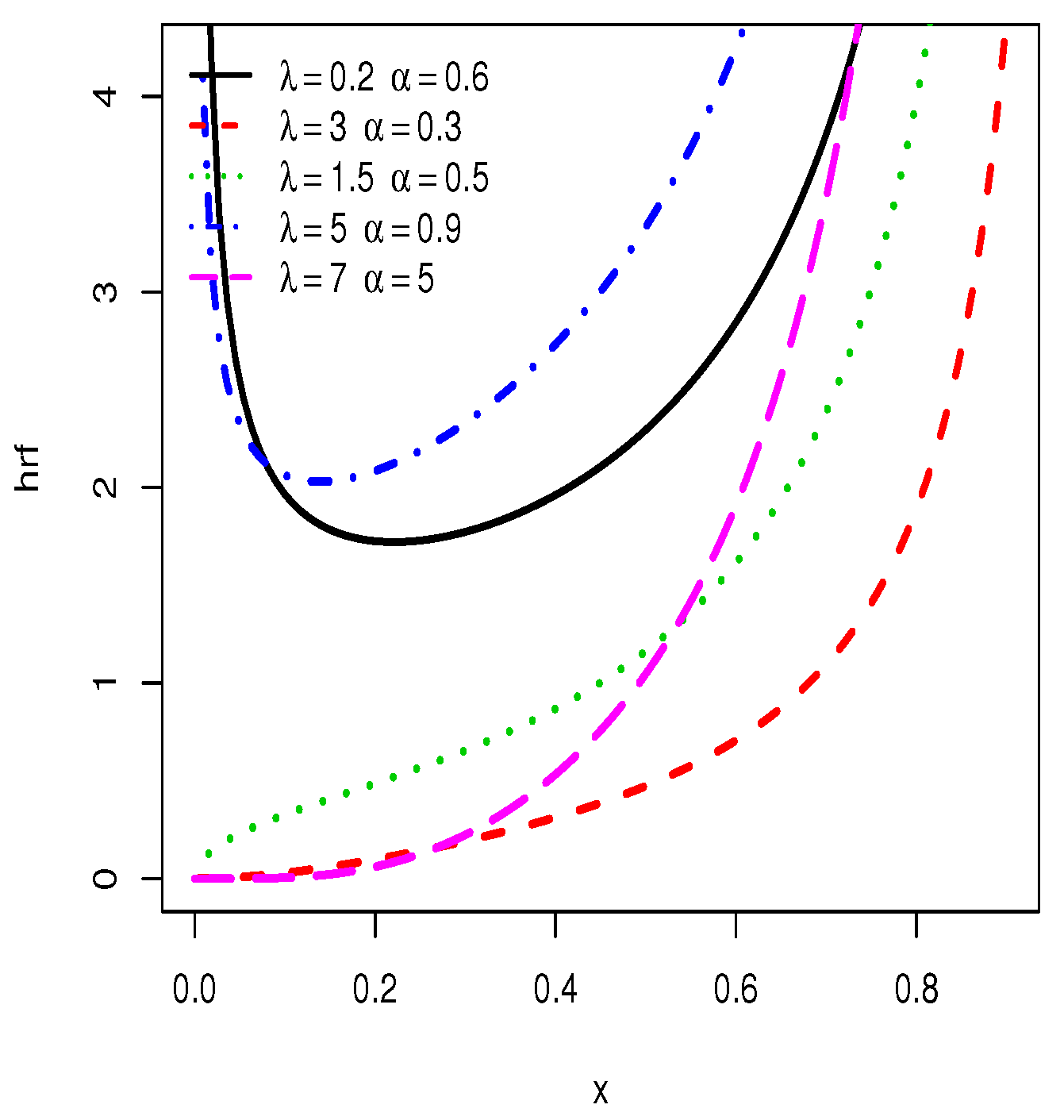
Some plots of the pdf and hrf of the TIHLTL distribution are displayed in Figure 1 and Figure 2, respectively. One can observe that the pdf can be left-skewed, right-skewed, approximate symmetrical, J-shaped, as well as reverse J-shaped, whereas the hrf can be increasing and bathtub shapes. This shows the great flexibility of the TIHLTL distribution and its potential in terms of data fitting.
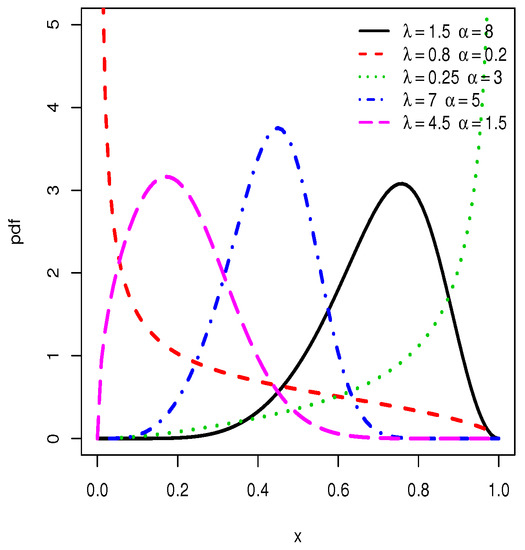
Figure 1.
Plots for probability density functions (pdfs) of the type I half-logistic Topp–Leone (TIHLTL) distribution.
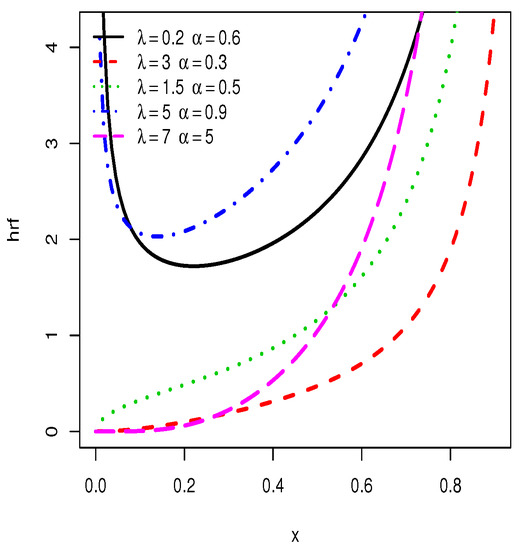
Figure 2.
Plots for hazard rate functions (hrfs) of the type I half-logistic Topp–Leone (TIHLTL) distribution.
3. Mathematical Properties
In this section, some properties of the TIHLTL distribution are discussed.
3.1. Asymptotes and Shapes
Here, we investigate the influence of the parameters and on the asymptotes of the main functions of the TIHLTL distribution. When , we have
Thus, when , we obtain ; when , we get ; and when , we have . The same holds for , under the same conditions.
When , we have
Thus, when , we have ; when , we obtain ; and when , we get . We always have .
The shapes of the pdf and hrf of the TIHLTL distribution can be described analytically. By adopting a common approach, the critical point(s) for is (are) the root(s) of the following equation: , that is,
The analytical expression for the solution(s) is clearly not available. However, for given and , numerical evaluation of this(these) solution(s) is possible by the use of any mathematical software (e.g., Mathematica, R, etc.). As usual, if is a root of this equation, then the study of is useful to identify its nature; it is a local maximum if , a local minimum if , and it is a point of inflection if .
Adopting a similar methodology, the critical point(s) for is(are) the root(s) of the following equation: , that is,
As usual, if is a root of this equation, then the study of is useful to identify its nature.
Hereafter, we consider a random variable (rv) X following the TIHLTL distribution, that is, having the cdf given by (1).
3.2. Quantile Function
The quantile function (qf) of X is given by the function satisfying the equations: , . After some algebraic manipulations, we obtain
In particular, the median of X is given by
Thanks to the qf, the TIHLTL distribution can be simulated as follows. For any rv U following the uniform distribution , the rv follows the TIHLTL distribution. Thus, with this formula, realization of U gives realizations of . This aspect will be developed in Section 4.
Finally, upon differentiation of with respect to y, the quantile density function given by
This function plays an important role in defining some useful statistical tools (see [18]).
3.3. Skewness and Kurtosis
The skewness and kurtosis of the TIHLTL distribution naturally depend on the values of and . The precise effect of these parameters can be measured by the Bowley skewness and the Moors kurtosis, introduced by [19,20], respectively. They are both defined with the qf as, for the Bowley skewness,
and, for the Moors kurtosis,
The Bowley skewness and Moors kurtosis are well-known to be less sensitive to eventual outliers than other measures of skewness and kurtosis. As benchmark, for the standard normal distribution, we inform that the Bowley skewness is equal to 0 and the Moors kurtosis is equal to 1.233.
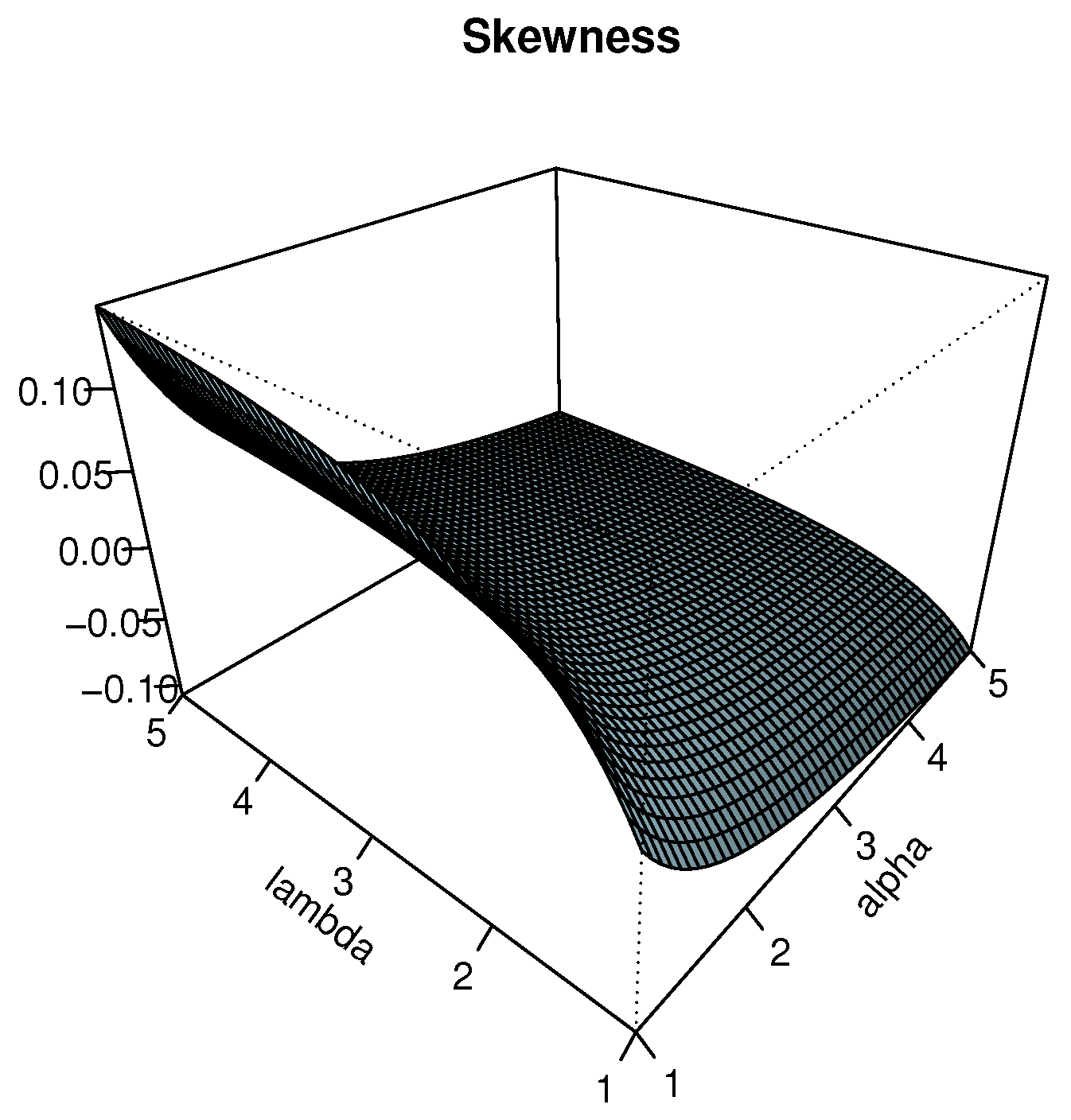
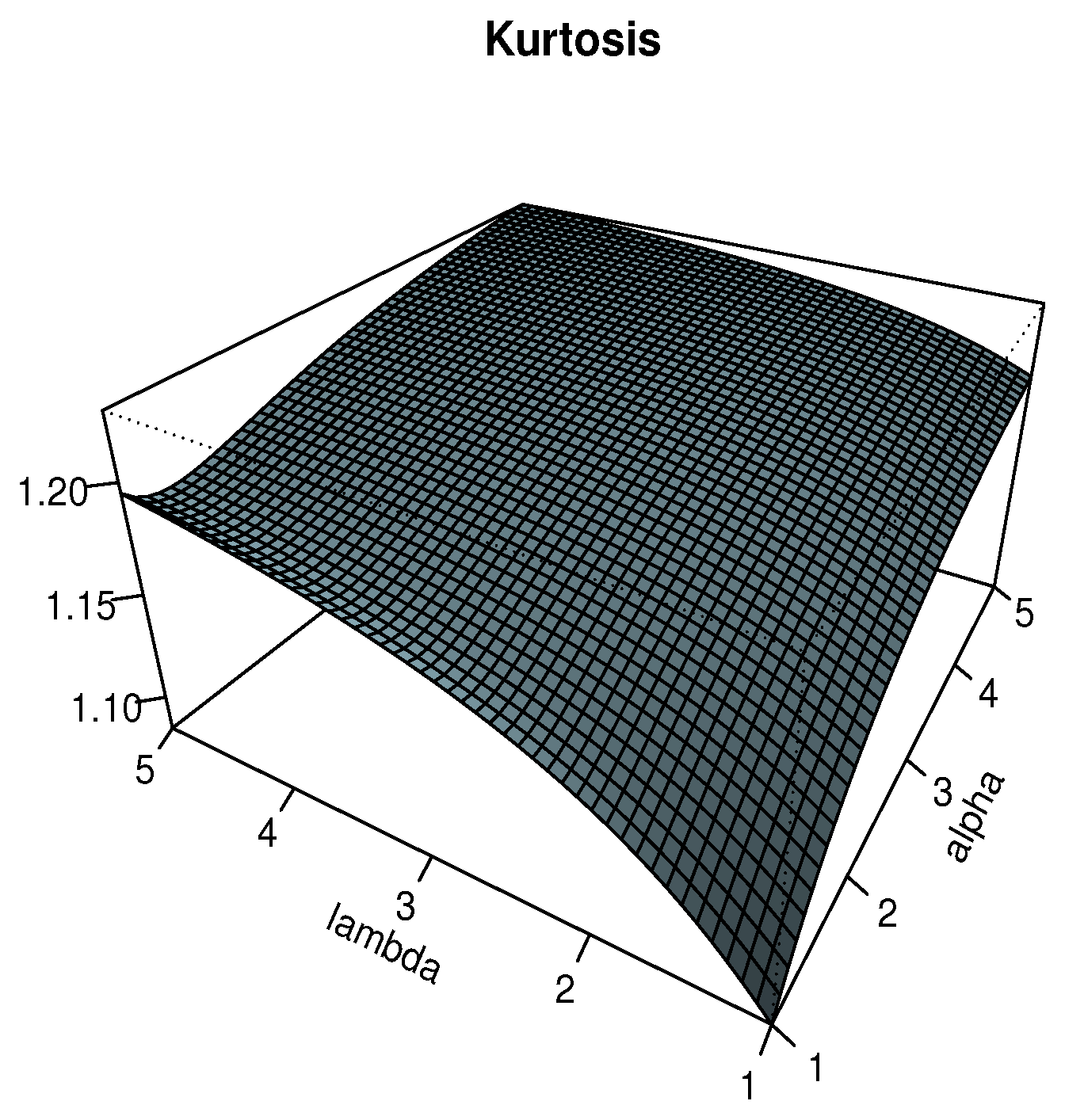
The plots of and are displayed in Figure 3 and Figure 4 for , respectively. In particular, we see that the effects of and on are significant, showing negative and positive values, indicating negative and positive skewness properties, respectively. Also, we observe that the Moors kurtosis increases as and increase.
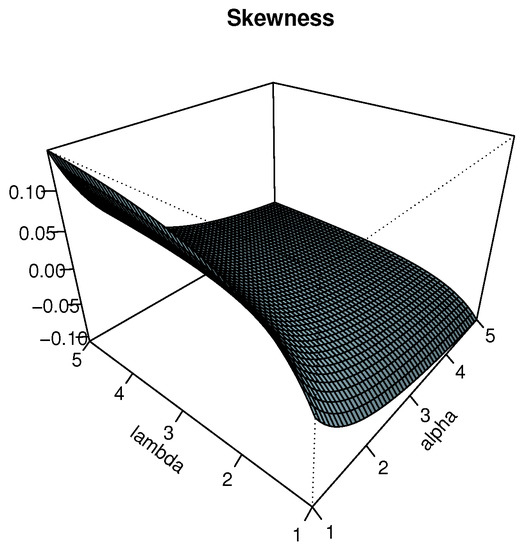
Figure 3.
Plots for the Bowley skewness of the TIHLTL distribution.
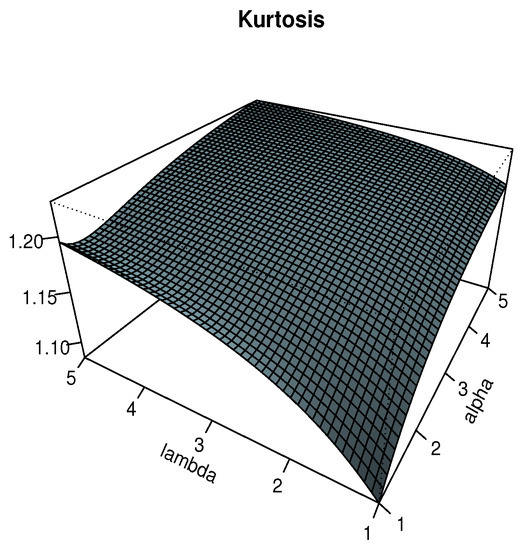
Figure 4.
Plots for the Moors kurtosis of the TIHLTL distribution.
3.4. Power Series Expansion
The following result presents a useful power series expansion for .
Proposition 1.
For any , we have the following power series expansion:
where
(with , such that the sums can be considered without the conjoint value ) and denotes the generalized binomial coefficient defined by .
Proof.
Since , by using the standard geometric formula, we have
Since and , by applying the generalized binomial formula two times in a row, we obtain
By combining the above equalities, we get
Upon differentiation, we obtain the desired result. This ends the proof of Proposition 1. □
The above result will be used to determine some structural properties of the TIHLTL distribution.
3.5. Ordinary Moments
In view of the asymptotes of , for any positive integer r, the r-th ordinary moment of X exists. By using Proposition 1, we can express it as
Owing to this expression, the mean of X can be expressed as
Similarly, the variance of X is given by . Other important quantities can be deduced, such as the r-th central moment of X given by
as well as the skewness and kurtosis coefficients of X based on central moments given by, respectively,
As the Bowley skewness and Moors kurtosis, these two coefficients are of importance because they measure the asymmetry and the peakedness of the TIHLTL distribution, respectively.
3.6. Incomplete Moments
Let A be an event and be the rv such that if the event A is realized, and 0 otherwise. Then, for any , the r-th incomplete moment of X is given by
In particular, the incomplete mean of X is given by
Other important probabilistic quantities include the mean and the mean of X about the median, respectively given by
3.7. Moment-Generating Function
The moment-generating function of X is obtained as, for ,
The last integral term can be calculated in different manners according to the value of t. For instance, if , one can remark that , where denotes the lower incomplete gamma function defined by . Another point of view is to consider the power series of the exponential function: for any , we have
3.8. Stress Strength Parameter
Here, we derive the stress strength parameter defined by , when and are independent rvs following the TIHLTL distribution with the parameters and , respectively. The parameter R is central in reliability theory and deserves special treatment in our context. Further details can be found in [21]. First of all, let and, for any ,
where . Then, by virtue of the expression of given by (4), we have
When and , we have .
3.9. Order Statistics
Many natural phenomena can be modeled by the so-called order statistics, explaining their importance for statisticians. The complete theory can be found in [22]. Here, we provide a contribution to the subject by investigating some properties of the order statistics for the TIHLTL distribution. Let be n independent and identically distributed rvs following the TIHLTL distribution. Then, the i-th order statistic is defined by the i-th rv such that, after reordering of in an ascending manner, . Then, a well-established result states that the pdf of the i-th order statistic is given by
where . As an alternative expression, the binomial formula gives
The following result provides a series expansion for the exponentiated cdf .
Proposition 2.
Let τ be a positive integer. Then, we have the following power series expansion:
where
Proof.
We adopt a different strategy to the proof of Proposition 1. Since , it follows from the (standard and generalized) binomial formula that
Since and , by applying the binomial formula two times in a row, we obtain
By combining the above equalities, we obtain the desired result. This ends the proof of Proposition 2. □
By Proposition 2, upon differentiation of , we obtain the following series expansion:
Therefore, we can write
where
From this expression, one can derive several interesting structural properties on the i-th order statistic, such as the r-th ordinary moment, that is,
4. Parameter Estimation
We now explore the statistical aspect of the TIHLTL distribution and investigate the estimation of the unknown parameters and by seven methods. Hereafter, denote realizations from a random sample of size n from X, and their values in ascending order.
4.1. Method of Maximum Likelihood Estimation
The most useful parametric estimation method is the maximum likelihood method. The reason for its popularity is explained by the theoretical guarantees of the resulting estimators; they enjoy tractable properties such as consistency and asymptotic normality, allowing the construction of reliable objects as confidence interval or statistical tests. See, for instance, [23]. The essential of the method of maximum likelihood estimation in the context of the TIHLTL model is described below. Here, the maximum likelihood estimates (MLEs) of and can be obtained by maximizing, with respect to and , the log-likelihood function for given by
Thus, the maximum likelihood estimates can be determined by solving the following equations simultaneously: and , where
and
Owing to the complexity of these equations, the MLEs do not have analytical expression. However, one can use standard statistical software to solve them (e.g., Mathematica, R, etc.). In this study, R was be used.
4.2. Methods of Least Squares and Weighted Least Squares Estimation
We now consider the methods of least squares and weighted least squares estimation introduced by [24]. The least square estimates (LSEs) of and can be determined by minimizing, with respect to and , the least square function defined by
Thus, the least square estimates can be obtained by solving the following equations simultaneously: and , where
and
where
and
The weighted least square estimates (WLSEs) of and can be obtained by minimizing, with respect to and , the weighted least square function defined by
Then, one can set similar equations developed for .
4.3. Method of Cramer–von Mises Minimum Distance Estimation
The Cramer–von Mises minimum distance estimates (CVEs) of and can be determined by minimizing, with respect to and , the Cramer–von Mises minimum distance function defined by
4.4. Method of Percentile Estimation
The method of percentile estimation was introduced by [26,27] in the context of the Weibull distribution, and has been generalized to other distributions. Here, the percentile estimates (PCEs) of and can be obtained by minimizing, with respect to and , the function defined by
where . Thus, the percentile estimates can be determined by solving the following equations simultaneously: and , where
and
where
and
4.5. Methods of Anderson–Darling and Right-Tail Anderson–Darling Estimation
The method of Anderson–Darling estimation was introduced by [28] in the context of statistical tests. By adapting it to the TIHLTL model, the Anderson–Darling estimates (ADEs) of and can be determined by minimizing, with respect to and , the function given by
Thus, the Anderson–Darling estimates can be obtained by solving the following equations simultaneously: and , where
and
and are given by (5) and (6), respectively. Similarly, the right-tail Anderson–Darling estimates (RTADEs) of and can be determined by minimizing, with respect to and , the function given by
Thus, the right-tail Anderson–Darling estimates can be obtained by solving the following equations simultaneously: and , where
and
4.6. Simulation
Here, we came up with a numerical study to compare the behavior of the previously introduced estimates. We generated N = 1000 random samples of size n = 50, 100, 200 and 1000 from the TIHLTL distribution. Six sets of the parameters were assigned as , , , , , and . The MLE, LSE, WLSE, PCE, CVE, ADE, and RTADE of and were determined for each sample, allowing the calculus of the mean estimates (Est.) for these methods. We also evaluated the mean square errors (MSEs) defined by
where is or , and denotes the corresponding estimates constructed with the i-th random sample. The obtained values are collected in Table 1, Table 2, Table 3, Table 4, Table 5 and Table 6: Table 1 for i, Table 2 for , Table 3 for , Table 4 for , Table 5 for v, and Table 6 for .

Table 1.
Simulations with the seven methods of estimation for and .
Table 2.
Simulations with the seven methods of estimation for and .
Table 3.
Simulations with the seven methods of estimation for and .
Table 4.
Simulations with the seven methods of estimation for and .
Table 5.
Simulations with the seven methods of estimation for and .
Table 6.
Simulations with the seven methods of estimation for and .
From Table 7, and for the parameter combinations, we can conclude that the ML estimation method outperformed all the other estimation methods (with the overall rank of 43.5). Therefore, depending on our study, we can consider that the ML estimation method is the best for the TIHLTL distribution.
Table 7.
Partial and overall ranks of the seven methods of estimation for various combinations of the parameters.
5. Applications
The TIHLTL model aims to provide a suitable alternative to other models available in the literature, in view of deep data analyses. Here, we compare the TIHLTL model with the following:
- The Kumaraswamy (Kum) model with pdf given bywhere ;
- The Topp–Leone (TL) model with pdf given bywhere ;
- The beta (B) model with pdf given bywhere and denotes the gamma function defined by ;
- The Topp–Leone exponential (TLE) model with pdf given bywhere . Further details on this distribution can be found in [29].
As consequence of the simulation study performed in Section 4, we chose to estimate the model parameters by the method of maximum likelihood estimation. Another argument is based on its tractable theoretical guarantees in comparison to other estimation methods. The following goodness-of-fit measures were computed: Akaike Information Criterion (AIC), Bayesian Information Criterion (BIC), Anderson–Darling (A*), and Cramer–von Mises (W*). The lower the values of these criteria, the better the fit. The minus log-likelihood is also indicated. We also offer the value for the Kolmogorov–Smirnov (KS) statistic and its p-value to analyze the goodness of fit of the estimated models to the data. R software was employed for all the implementations.
The first data set. We considered the data from [30] about theordered failure of components. The data are given as follows:
0.0009, 0.004, 0.0142, 0.0221, 0.0261, 0.0418, 0.0473, 0.0834, 0.1091, 0.1252, 0.1404, 0.1498, 0.175, 0.2031, 0.2099, 0.2168, 0.2918, 0.3465, 0.4035, 0.6143
The second data set. The second data set refers to 50 observations on burr (in millimeters), with hole diameter and sheet thickness of 12 mm and 3.15 mm, respectively. We refer to [31] for the technical details behind these measures. The data are given as follows:
0.04, 0.02, 0.06, 0.12, 0.14, 0.08, 0.22, 0.12, 0.08, 0.26, 0.24, 0.04, 0.14, 0.16, 0.08, 0.26, 0.32, 0.28, 0.14, 0.16, 0.24, 0.22, 0.12, 0.18, 0.24, 0.32, 0.16, 0.14, 0.08, 0.16, 0.24, 0.16, 0.32, 0.18, 0.24, 0.22, 0.16, 0.12, 0.24, 0.06, 0.02, 0.18, 0.22, 0.14, 0.06, 0.04, 0.14, 0.26, 0.18, 0.16
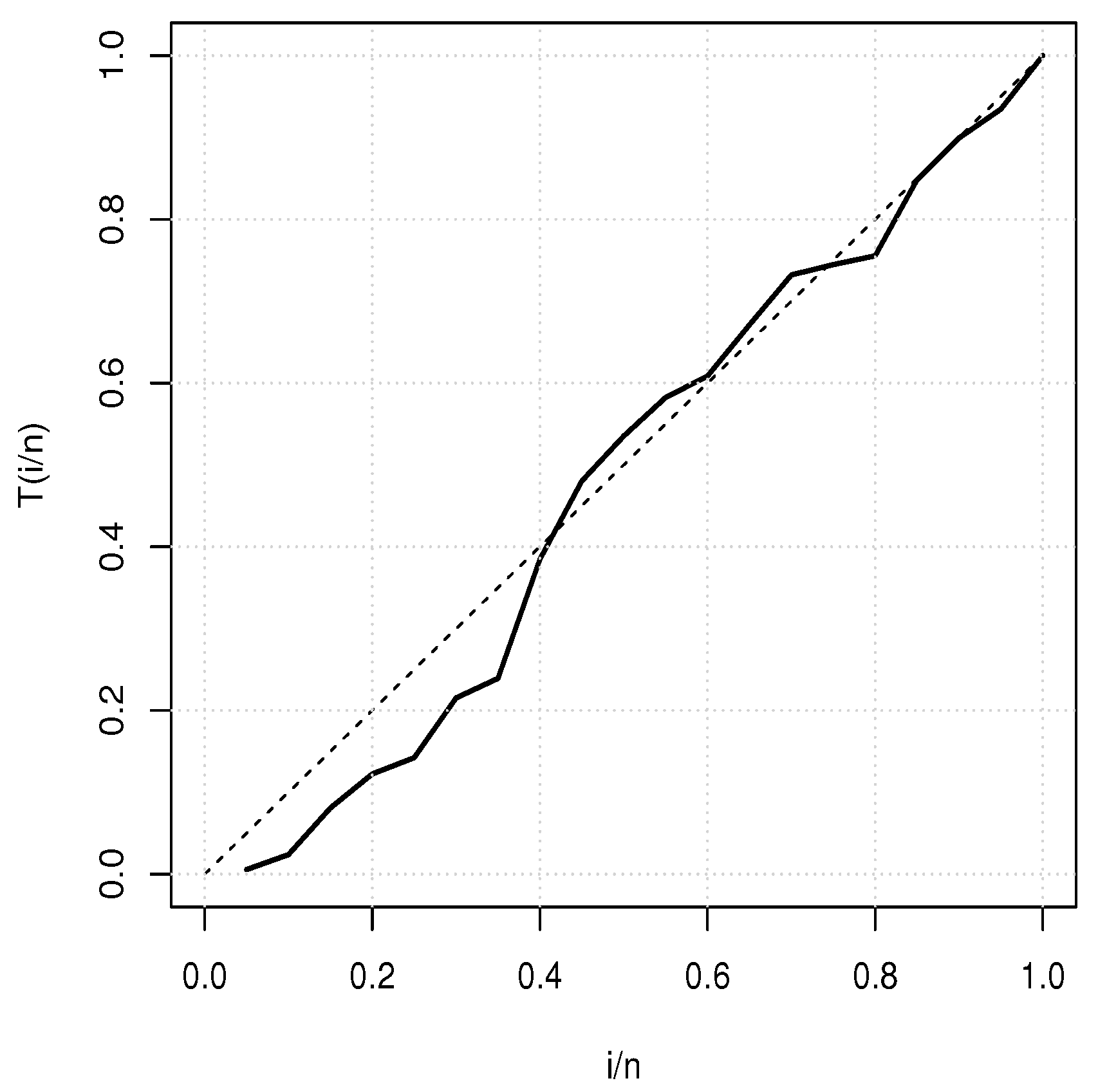
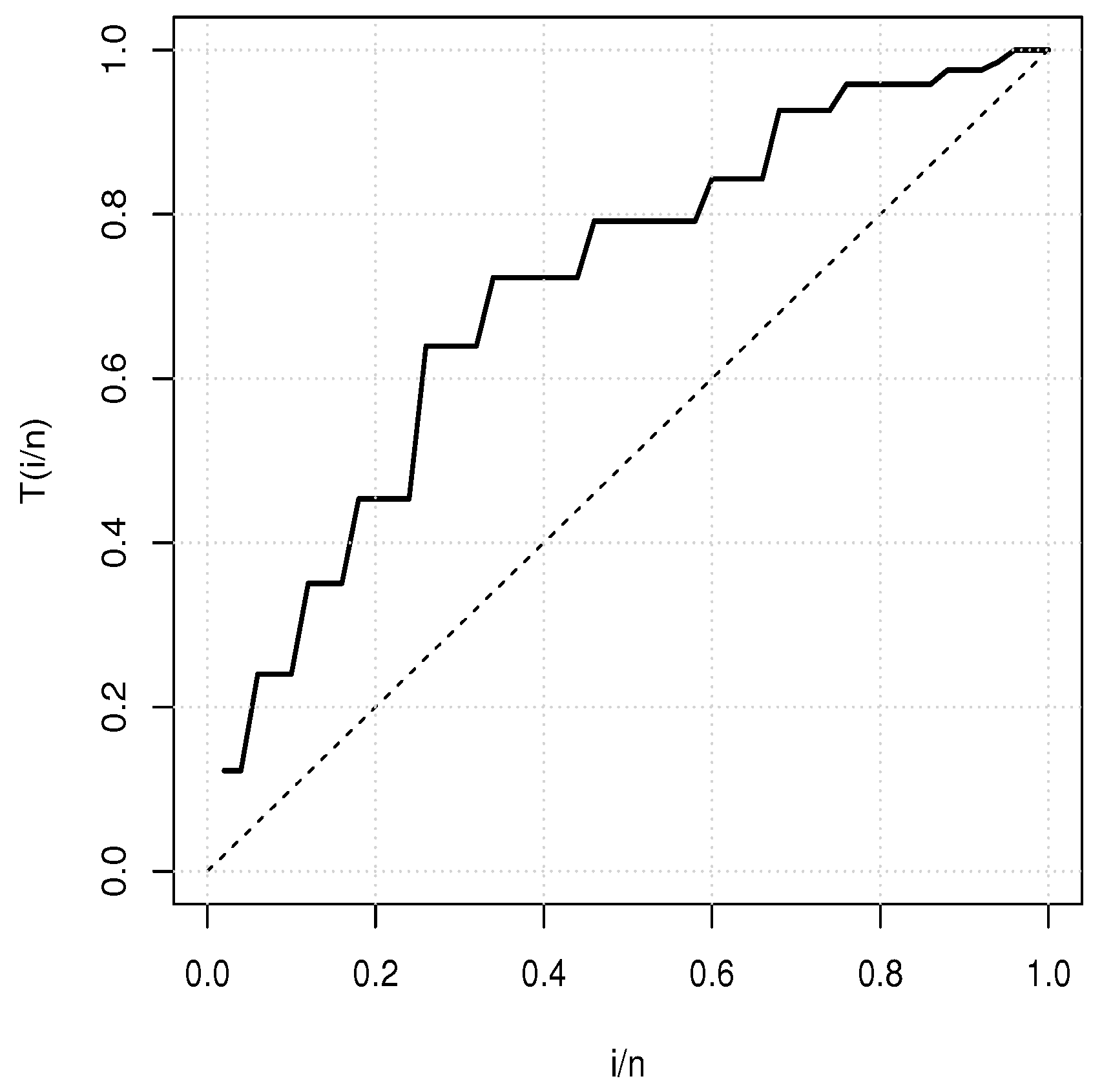
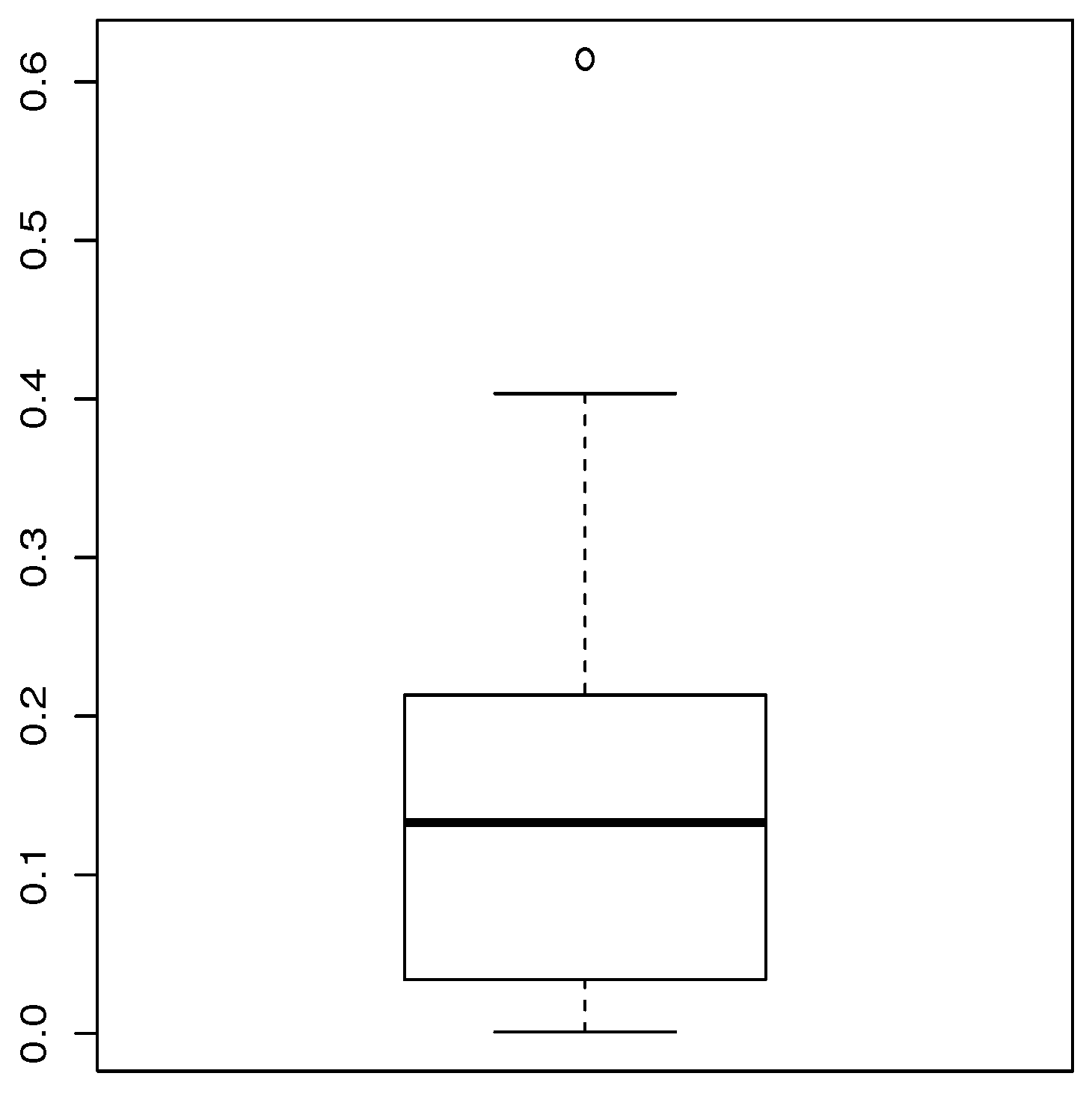
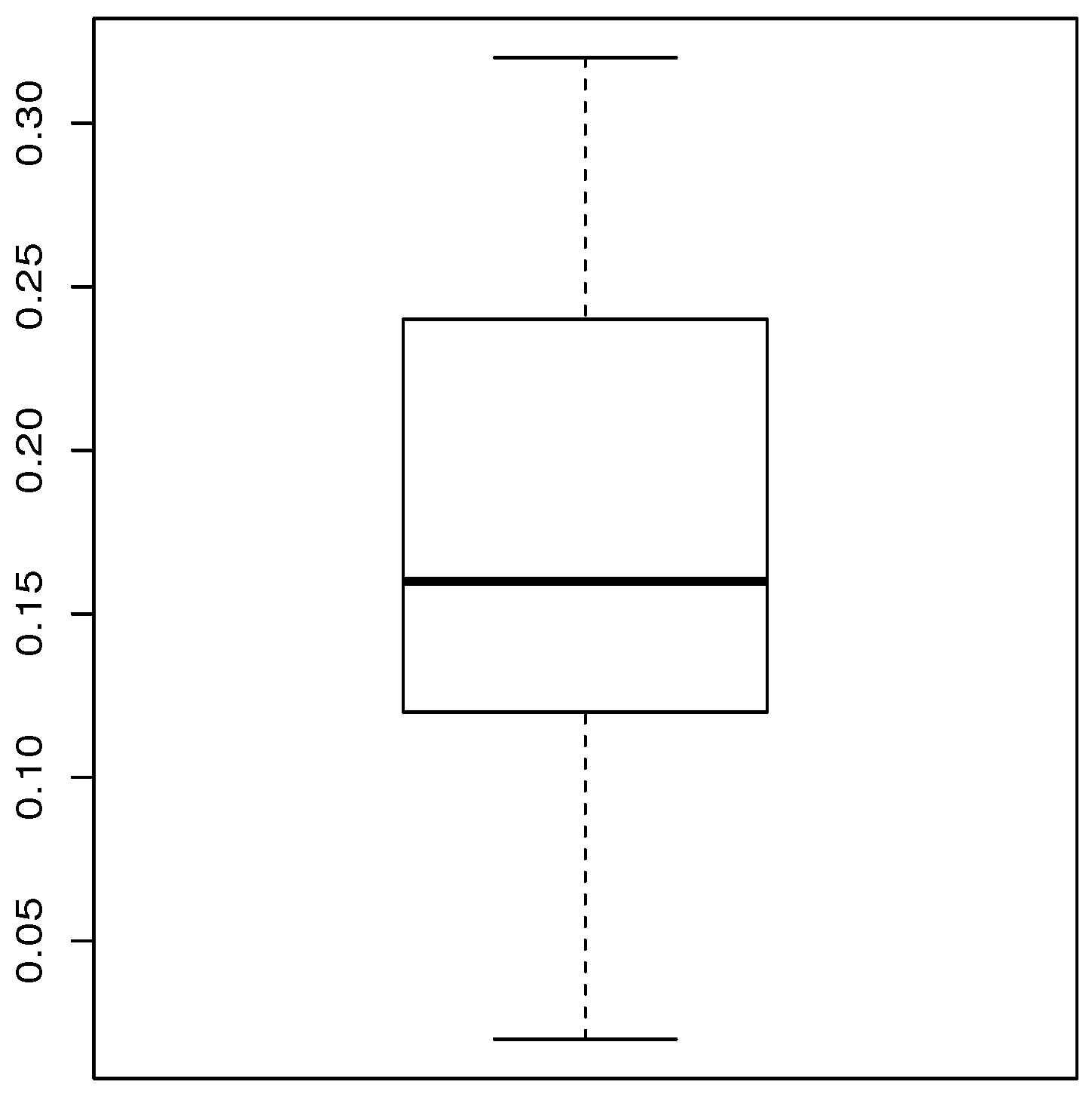
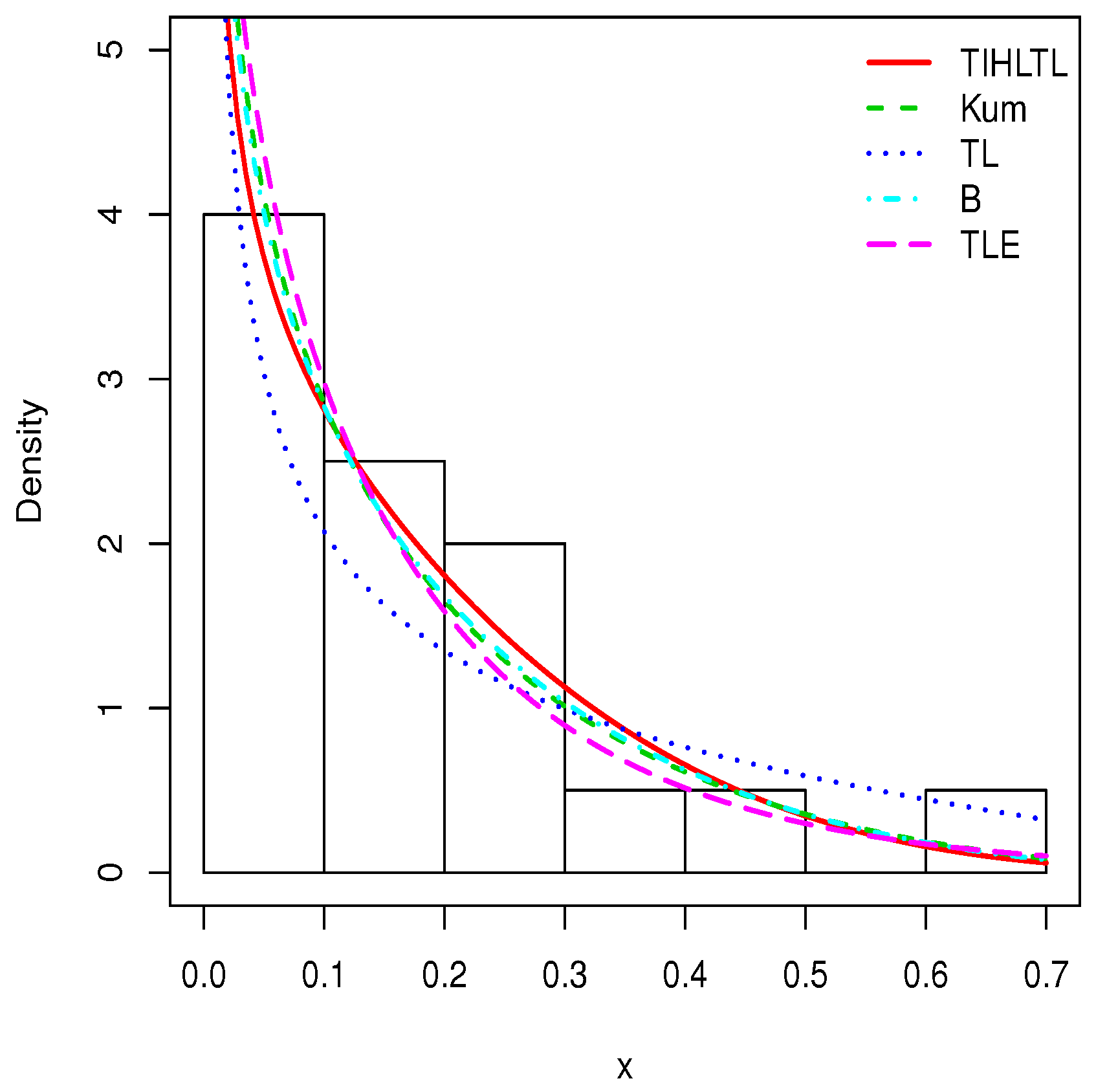
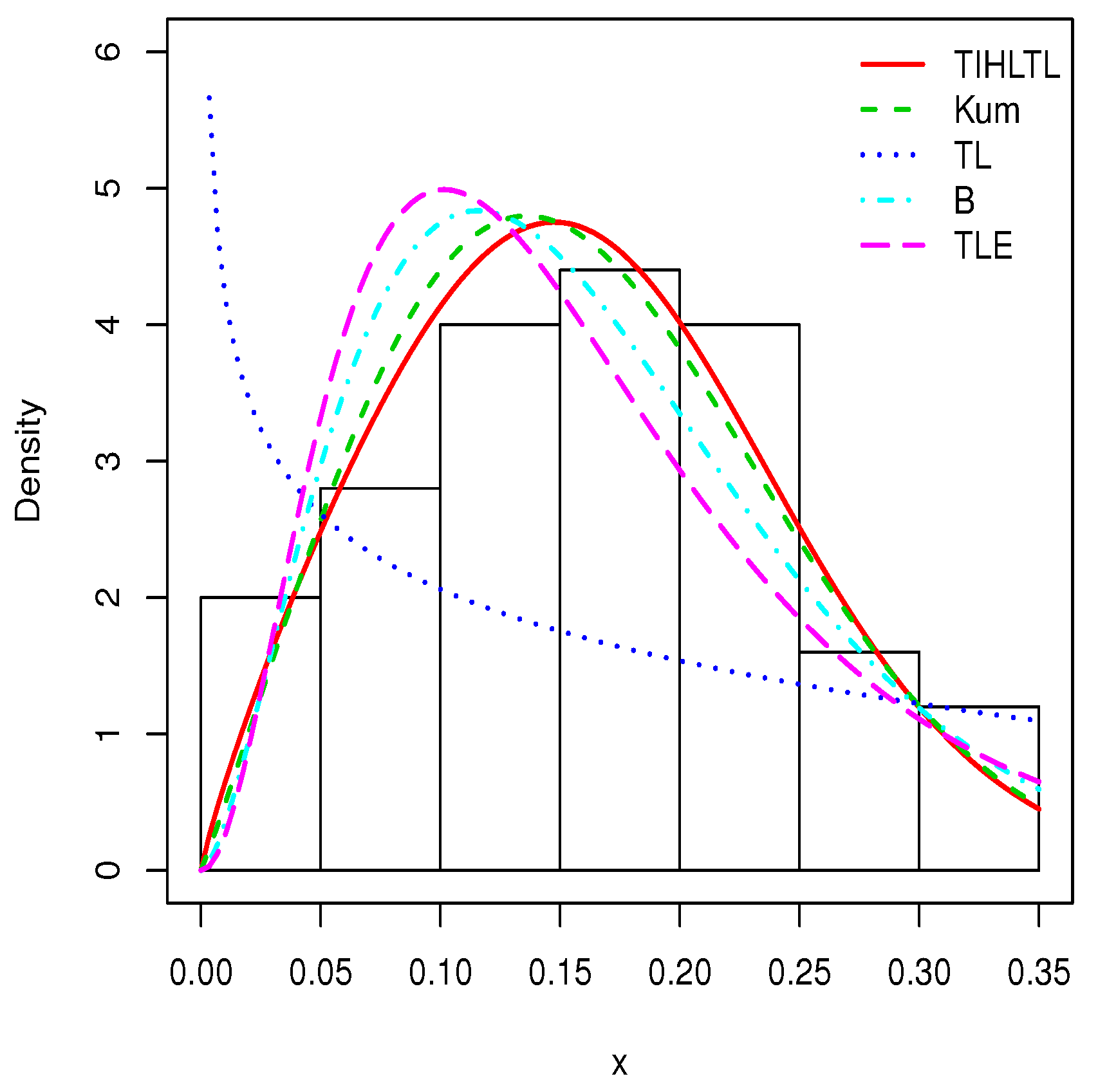
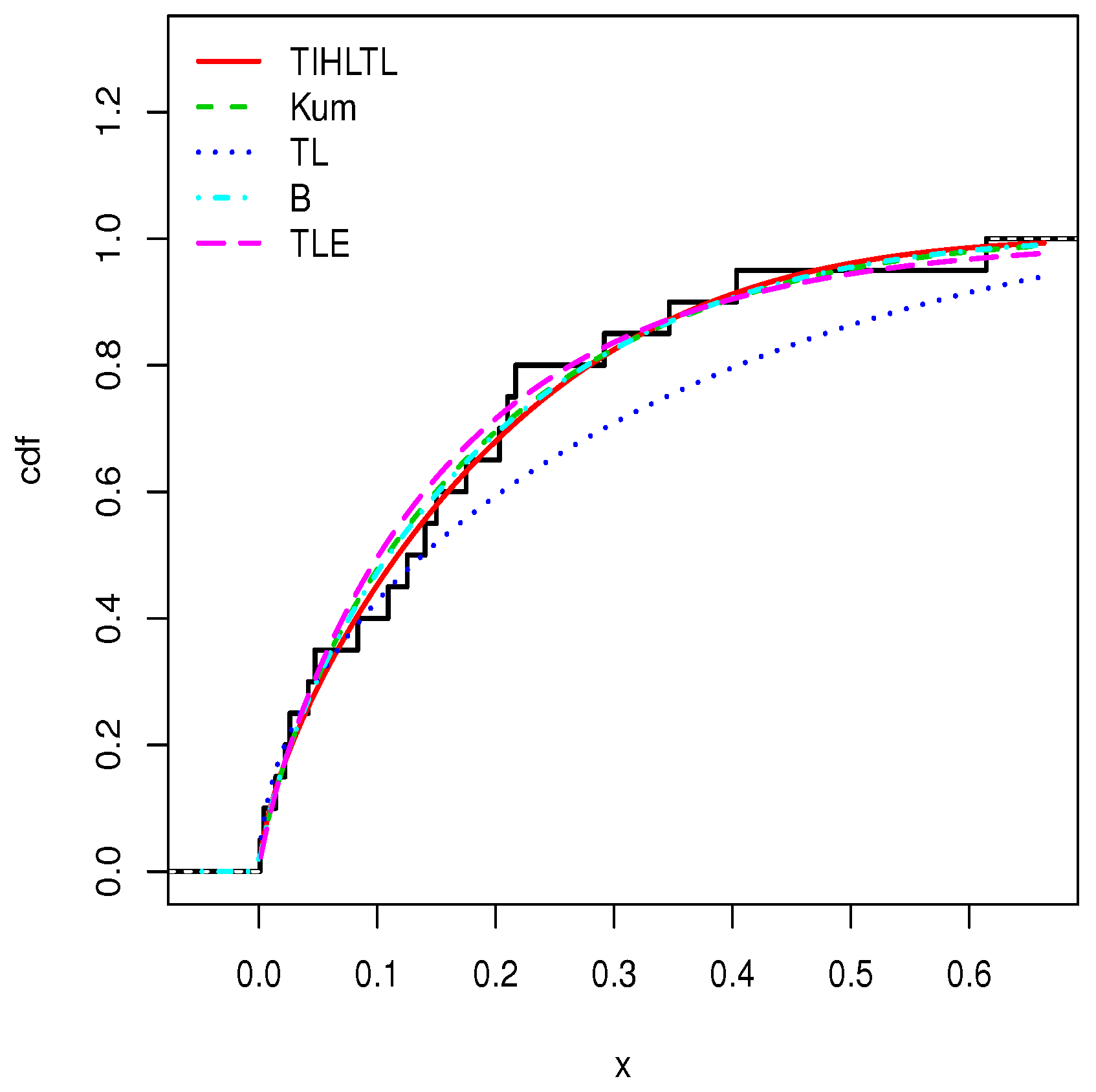
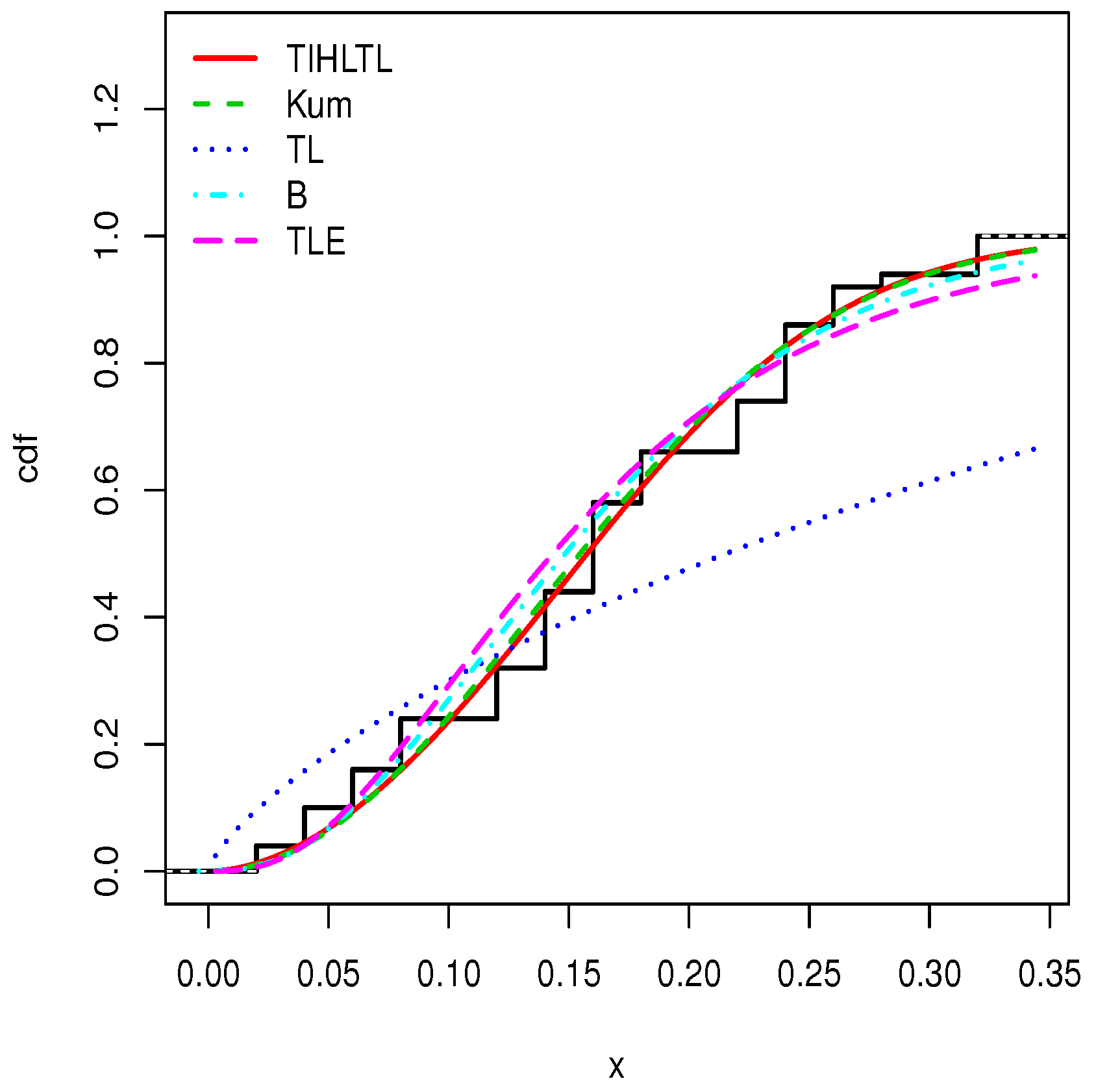
Table 8 provides a basic statistical description of the two data sets. One can remark that data set 1 is highly right skewed, contrary to data set 2. Figure 5 and Figure 6 show the total test time (TTT) plots for data sets 1 and 2, respectively. In particular, the observed curves in the TTT plots are (more or less) concave, implying that a (more or less) monotonic hrf is adequate, giving first signs that the TIHLTL model is appropriate for such data. For more detail on the TTT plot, see [32]. As a complement to this, Figure 7 and Figure 8 present the boxplots for data sets 1 and 2, respectively. The MLEs of the considered models along with their standard errors are given in Table 9 and Table 10 for data sets 1 and 2, respectively. Table 11 and Table 12 contain the values of the goodness-of-fit measures for the considered models. Plots of the estimated pdfs corresponding to data sets 1 and 2 can be observed in Figure 9 and Figure 10, respectively. Plots of the estimated cdfs corresponding to data sets 1 and 2 can be observed in Figure 11 and Figure 12, respectively. Finally, confidence intervals (CIs) for the TIHLTL model parameters are given in Table 13.
Table 8.
First statistical approach of data sets 1 and 2.
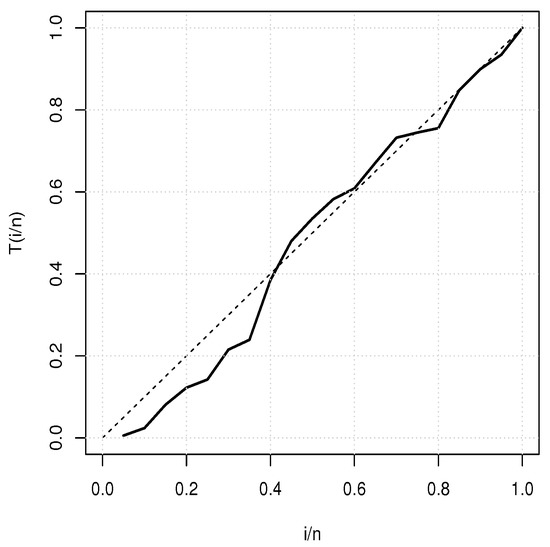
Figure 5.
TTT plot for data set 1.
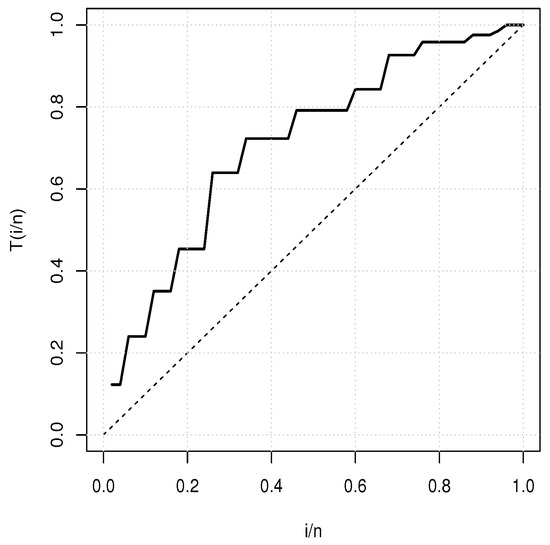
Figure 6.
TTT plot for data set 2.
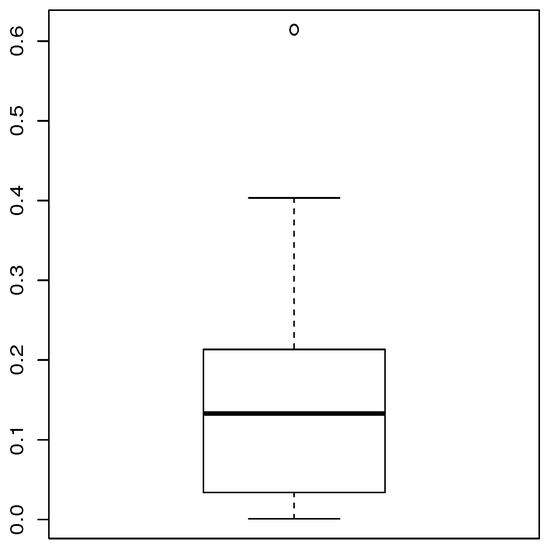
Figure 7.
Boxplot for data set 1.
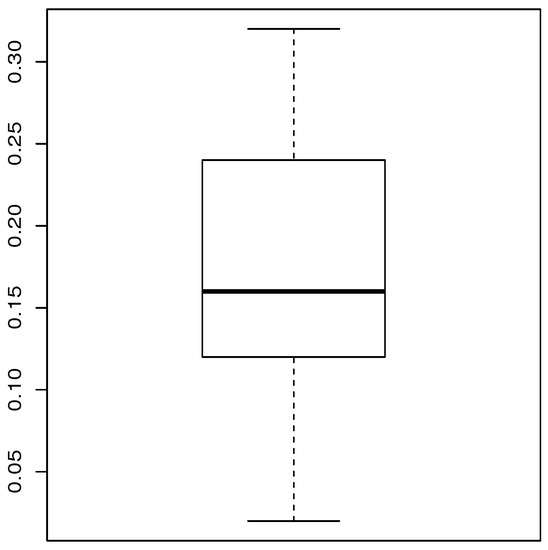
Figure 8.
Boxplot for data set 2.
Table 9.
MLEs and their standard errors (in parentheses) for data set 1. B: beta model; Kum: Kumaraswamy model. TL: Topp–Leone model; TLE: Topp–Leone exponential model.
Table 10.
MLEs along with their standard errors (in parentheses) for data set 2.
Table 11.
Statistical measures for data set 1. A*: Anderson–Darling criterion; AIC: Akaike Information Criterion; BIC: Bayesian Information Criterion; KS: Kolmogorov–Smirnov statistic; W*: Cramer–von Mises criterion.
Table 12.
Statistical measures for data set 2.
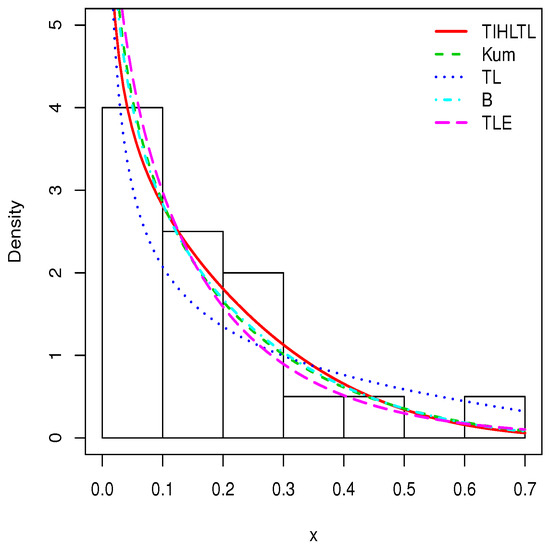
Figure 9.
Plots of estimated probability density functions (pdfs) for data set 1.
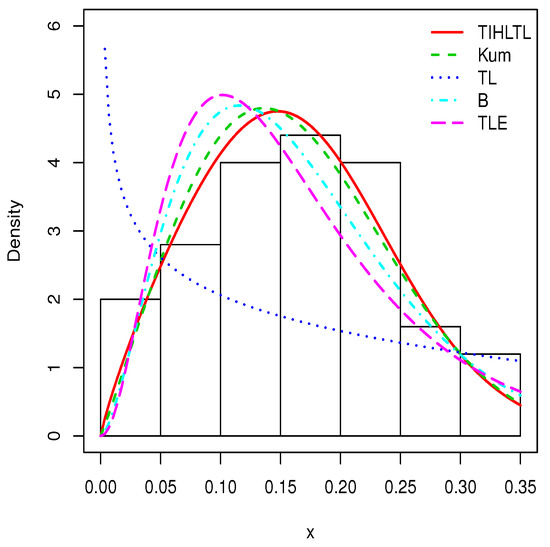
Figure 10.
Plots of estimated probability density functions (pdfs) for data set 2.
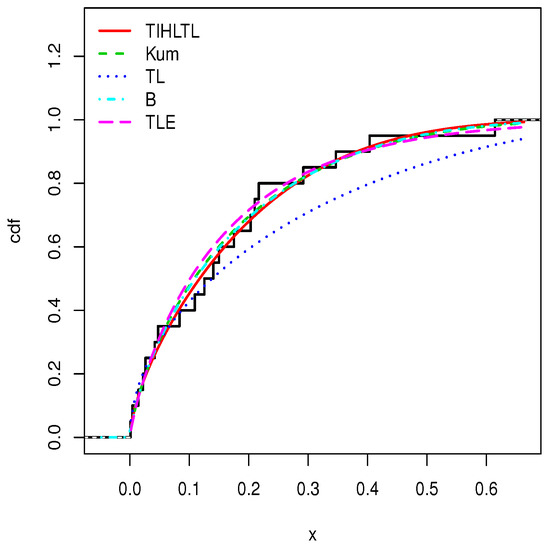
Figure 11.
Plots of estimated cumulative distribution functions (cdfs) for data set 1.
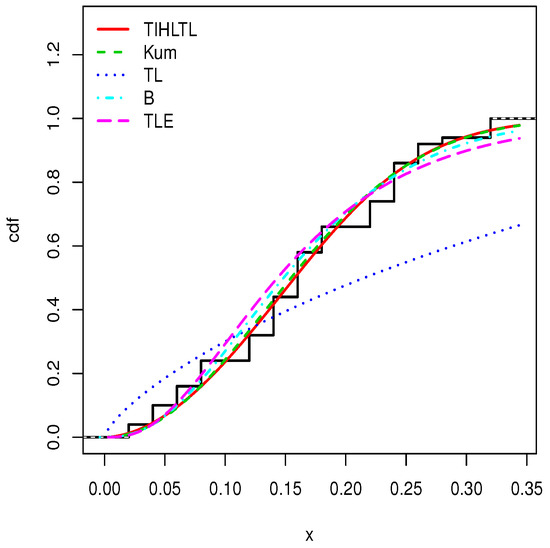
Figure 12.
Plots of estimated cumulative distribution functions (cdfs) for data set 2.
Table 13.
Confidence intervals of the TIHLTL model parameters for data sets 1 and 2, respectively.
6. Concluding Remarks
In this paper, we studied a special member of the type I half-logistic-G family based on the Topp–Leone distribution, constituting a new two-parameter continuous distribution with support in , called the TIHLTL distribution. Among its advantages, a wide variety of shapes are observed for the corresponding pdf and hrf. Some properties of the TIHLTL distribution, such as asymptotes, shapes, quantile function, skewness, kurtosis, some power series expansions, ordinary moments, incomplete moments, moment-generating function, stress strength parameter, and order statistics, were derived. Then, the statistical aspects of the TIHLTL model were explored, assuming that the parameters and were unknown. A simulation study was performed to compare the model performance of seven well-established estimation methods. An application of the TIHLTL model to two practical data sets showed that it is a serious competitor to other well-established models, such as the beta and Kumaraswamy models.
Author Contributions
R.A.Z., C.C., F.J., and M.E. contributed equally to this work.
Funding
This work was funded by the Deanship of Scientific Research (DSR), King AbdulAziz University, Jeddah, under grant No. (DF-283-305-1441).
Acknowledgments
The authors would like to thank the two reviewers for thorough and precise comments which have significantly improved the presentation of the paper. This work was funded by the Deanship of Scientific Research (DSR), King AbdulAziz University, Jeddah, under grant No. (DF-283-305-1441). The authors gratefully acknowledge the DSR technical and financial support.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Gupta, R.D.; Kundu, D. Exponentiated exponential family: An alternative to Gamma and Weibull distributions. Biom. J. 2001, 43, 117–130. [Google Scholar] [CrossRef]
- Eugene, N.; Lee, C.; Famoye, F. Beta-normal distribution and its applications. Commun. Stat.-Theory Methods 2002, 31, 497–512. [Google Scholar] [CrossRef]
- Zografos, K.; Balakrishnan, N. On families of beta- and generalized gamma-generated distributions and associated inference. Stat. Methodol. 2009, 6, 344–362. [Google Scholar] [CrossRef]
- Alizadeh, M.; Emadiz, M.; Doostparast, M.; Cordeiro, G.M.; Ortega, E.M.M.; Pescim, R.R. A new family of distributions: The Kumaraswamy odd log-logistic, properties and applications. Hacet. J. Math. Stat. 2015, 44, 1491–1512. [Google Scholar] [CrossRef]
- Cordeiro, G.M.; Alizadeh, M.; Marinho, E.P.R.D. The type I half-logistic family of distributions. J. Stat. Comput. Simul. 2015, 86, 707–728. [Google Scholar] [CrossRef]
- Cordeiro, G.M.; Alizadeh, M.; Ozel, G. The generalized odd log-logistic family of distributions: Properties, regression models and applications. J. Stat. Comput. Simul. 2017, 87, 908–932. [Google Scholar] [CrossRef]
- Alizadeh, M.; Altun, E.; Cordeiro, G.M.; Rasekhi, M. The odd power Cauchy family of distributions: Properties, regression models and applications. J. Stat. Comput. Simul. 2018, 88, 785–805. [Google Scholar] [CrossRef]
- Reyad, H.M.; Alizadeh, M.; Jamal, F.; Othman, S.; Hamedani, G.G. The Exponentiated Generalized Topp Leone-G Family of Distributions: Properties and Applications. Pak. J. Stat. Oper. Res. 2019, 15, 1–24. [Google Scholar] [CrossRef]
- Jamal, F.; Chesneau, C.; Elgarhy, M. Type II general inverse exponential family of distributions. J. Stat. Manag. Syst. 2019. Available online: https://www.tandfonline.com/toc/tsms20/current (accessed on 15 August 2019).
- Topp, C.W.; Leone, F.C. A family of J-shaped frequency functions. J. Am. Stat. Assoc. 1955, 50, 209–219. [Google Scholar] [CrossRef]
- Nadarajah, S.; Kotz, S. Moments of some J-shaped distributions. J. Appl. Stat. 2003, 30, 311–317. [Google Scholar] [CrossRef]
- Ghitany, M.E.; Kotz, S.; Xie, M. On some reliability measures and their stochastic orderings for the Topp-Leone distribution. J. Appl. Stat. 2005, 32, 715–722. [Google Scholar] [CrossRef]
- Sangsanit, Y.; Bodhisuwan, W. The Topp-Leone generator of distributions: Properties and inferences. Songklanakarin J. Sci. Technol. 2016, 38, 537–548. [Google Scholar]
- Kunjiratanachot, N.; Bodhisuwan, W.; Volodin, A. The Topp-Leone generalized exponential power series distribution with applications. J. Probab. Stat. Sci. 2018, 16, 197–208. [Google Scholar]
- Elgarhy, M.; Nasir, M.A.; Jamal, F.; Ozel, G. The type II Topp-Leone generated family of distributions: Properties and applications. J. Stat. Manag. Syst. 2018, 21, 1529–1551. [Google Scholar] [CrossRef]
- Mauldon, J.M. A Generalization of the Beta-distribution. Ann. Math. Stat. 1959, 30, 509–520. [Google Scholar] [CrossRef]
- Kumaraswamy, P. A generalized probability density function for double-bounded random processes. J. Hydrol. 1980, 46, 79–88. [Google Scholar] [CrossRef]
- Abramowitz, M.; Stegun, I.A. Handbook of Mathematical Functions, National Bureau of Standards; Applied Math. Series 55; Dover Publications: Mineola, NY, USA, 1965. [Google Scholar]
- Galton, F. Inquiries Into Human Faculty and Its Development; Macmillan and Company: London, UK, 1883. [Google Scholar]
- Moors, J.J.A. A quantile alternative for Kurtosis. J. R. Stat. Soc. Ser. D (Stat.) 1988, 37, 25–32. [Google Scholar] [CrossRef]
- Kotz, S.; Lumelskii, Y.; Penskey, M. The Stress-Strength Model and Its Generalizations and Applications; World Scientific: Singapore, 2003. [Google Scholar]
- David, H.A.; Nagaraja, H.N. Order Statistics; John Wiley and Sons: Hoboken, NJ, USA, 2003. [Google Scholar]
- Casella, G.; Berger, R.L. Statistical Inference; Brooks/Cole Publishing Company: Bel Air, CA, USA, 1990. [Google Scholar]
- Swain, J.J.; Venkatraman, S.; Wilson, J.R. Least-squares estimation of distribution functions in johnson’s translation system. J. Stat. Comput. Simul. 1988, 29, 271–297. [Google Scholar] [CrossRef]
- Macdonald, P.D.M. Comment on ‘An estimation procedure for mixtures of distributions’ by Choi and Bulgren. J. R. Stat. Soc. B 1971, 33, 326–329. [Google Scholar]
- Kao, J. Computer methods for estimating Weibull parameters in reliability studies. IRE Trans. Reliab. Qual. Control 1958, 13, 15–22. [Google Scholar] [CrossRef]
- Kao, J. A graphical estimation of mixed Weibull parameters in life testing electron tube. Technometrics 1959, 1, 389–407. [Google Scholar] [CrossRef]
- Anderson, T.W.; Darling, D.A. Asymptotic theory of certain ‘goodness-of- fit’ criteria based on stochastic processes. Ann. Math. Stat. 1952, 23, 193–212. [Google Scholar] [CrossRef]
- Al-Shomrani, A.; Arif, O.; Shawky, K.; Hanif, S.; Shahbaz, M.Q. Topp-Leone family of distributions: Some properties and application. Pak. J. Stat. Oper. Res. 2016, 12, 443–451. [Google Scholar] [CrossRef]
- Nigm, A.M.; AL-Hussaini, E.K.; Jaheen, Z.F. Bayesian one sample prediction of future observations under Pareto distribution. Statistics 2003, 37, 527–536. [Google Scholar] [CrossRef]
- Dasgupta, R. On the distribution of Burr with applications. Sankhya 2011, 73, 1–19. [Google Scholar] [CrossRef]
- Aarset, M.V. How to identify bathtub hazard rate. IEEE Trans. Reliab. 1987, 36, 106–108. [Google Scholar] [CrossRef]
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).