Abstract
In this paper, data consistency in the three-option Davidson model is investigated. Starting out with the usual consistency definition in pairwise matrices-based methods, we examine its consequences. We formulate an equivalent statement based on the usual PCM-based consistency definition for evaluation results, which aligns with the statement found in the two-option model and establishes a connection between the evaluation results based on PCM and those obtained from the three-option Davidson model. The theoretical results are complemented by findings based on random simulations, through which we also demonstrate the connections: the optimal comparison structures are identical to those in the PCM-based methods and in the two-option Bradley–Terry model.
Keywords:
paired comparison; Davidson model; incomplete comparisons; consistency; optimal graph structure MSC:
62C86; 90B50; 62J15
1. Introduction
Comparisons in pairs is a very useful method for collecting data. It is particularly beneficial in such cases where it is difficult to compare objects to a scale value but it is much easier to determine which is better or worse in relation to each other. Such decisions are much more reliable than the scale values. It is applied in various fields of life: risk analysis [1], psychology [2], decision making in business [3], marketing [4], group decision making [5], architecture [6], sports [7,8,9], politics [10], education [11], environmental studies [12], social sciences [13,14], artificial intelligence [15], and we could continue the list extensively [16,17]. The main goal is rating and ranking the compared objects based on the results of the comparisons. As the primary comparison results are relationships instead of numbers on a scale, the evaluation of paired comparison data requires special evaluation methods.
Two main branches of evaluation methods can be distinguished: the pairwise comparison matrices-based methods (PCMs) and the Thurstone motivated methods (THMMs). An outstanding member of the former family of methods is the Analytic Hierarchy Process (AHP), associated with Saaty’s name [18,19]. The starting point of PCMs is a real squared reciprocal symmetric matrix with dimension , where n is the number of objects to evaluate. Although the decisions between the objects are verbal (equal, better, much better, extremely better, etc.), these decisions are converted into numbers, and these numbers are the elements of the matrices. The conversion methods are different, starting from the usual 1, 3, 5, 7, and 9 elements and the reciprocal numbers to the ratios of the numbers of types of decisions [8]. The evaluation methods are also varied: the most commonly used is the eigenvector method (EM) [20], but the logarithmic least squares method (LLSM) is also frequently applied [21]. The result of the evaluation is a normalized vector with positive coordinates; it is usually called the priority vector. Its coordinates represent the weights (strengths) of the individual objects to be evaluated.
Another branch of the paired comparison models is the stochastic models. In this case, the relations themselves are not converted directly into numbers. Thurstone’s idea that latent probabilistic variables underlie the objects to be evaluated and that decisions depend on the current values of these probabilistic variables holds great potential. Thurstone dealt with the Gauss distribution allowing two options [22], and applied the least squares parameter estimation method. Later, logistic distribution was applied with maximum likelihood estimation (MLE) [23]. The number of options has been extended to three, allowing option ‘equal’ next to options ‘worse’, and ‘better’ [24,25]. More than 3 options were analyzed in [26], applying the least squares estimation method, and in [27], applying MLE and allowing a wide class of distributions.
It is always an exciting challenge in research to recognize the connections between models based on different foundations. In the area of research in the field of comparisons in pairs, it is an interesting question what the relationship between PCMs and stochastic paired comparison methods can be. Based on empirical evidence, a connection was presented between them in the publication [28]. Recently, a theoretical relationship was proved for the two-option Bradley–Terry model and PCM-based methods [29]. The key of the relation was the concept of consistency, i.e., the absence of contradiction among the data [19]. It has been proved that in the case of data consistency, the two-option Bradley–Terry model with MLE parameter estimation and PCMs with LLSM or eigenvector methods provide the same priority vectors. If data are inconsistent, then the optimal comparison structures are proved to be the same structures in the case of 4, 5, and 6 objects to evaluate. However, the relation between the three-option stochastic models and the PCM-based models has not been revealed. This gap is filled in the current paper in the case of a three-option stochastic model.
In this paper, we investigate a stochastic three-option model from the aspects of data consistency. This model is a modified version of the three-option Bradley–Terry model. The modification was performed by Davidson in [30] in order for Luce’s choice axiom to be satisfied in the stochastic model even in the case of three options. In the case of the Bradley–Terry model that allows two options (BT2), Luce’s choice axiom is satisfied. Luce’s choice axiom expresses that the probabilities of the comparison results between two objects depend only on their strengths and are not affected by other objects [31,32], but in the case of the Bradley–Terry model allowing three options in choices (BT3), it is not. However, in Davidson’s modified model, Luce’s choice axiom holds.
Our article is structured as follows. In Section 2, the investigated Davidson model is presented. In Section 3, the concept of consistency in PCM models and the concept of consistency in the Davidson model is detailed, along with their relationship, based on the theoretical considerations. The connection between the Davidson model and PCM-based models is also supported by the simulation results in Section 4. The methodology of the simulation is described in Section 4.1, and in Section 4.2 and Section 4.3, the results of the simulations are presented. Finally, the paper is closed with a brief summary.
2. The Investigated Model: Davidson Model
To ensure that Luce’s choice axiom is satisfied in the model, Davidson introduced a modified three-option model as follows [30].
Consider a vector , that satisfies . The probabilities of the options ‘worse’, ‘equal’, and ‘better’ are assumed to be
with some
It is easy to see that if , we return to BT2.
In this model, the Luce’s choice axiom [31,32] is fulfilled as
Data are contained in a three-dimensional matrix A. Its element represents the number of decisions according to the comparison of object i and object j, and the result of the decision belongs to option k ( stands for ‘worse’, stands for ‘equal’ and stands for option ‘better’). Of course, and , and due to the symmetry, and .
The likelihood function represents the probability of the data as a function of unknown parameters. Assuming an independent sample, it can be written as follows:
The log-likelihood function is its logarithm
The maximum likelihood estimation of the parameters (MLEP) is the argument of the maximum value of the function (8), i.e.,
Note that the parameters can be multiplied by a positive constant without changing (8). This multiplication possibility is eliminated by requiring that the sum of the coordinates equals 1. Moreover, if all data are multiplied by the same positive constant, the maximum value would also be multiplied by it, but the argument of the maximum value, i.e., the estimate MLEP, would not change.
To investigate the evaluability of the data, i.e., the existence of the maximum value and the uniqueness of its argument, we need the following graph definitions and theorem.
Definition 1
(graph of comparisons ). Let the objects to be evaluated be assigned the nodes of the graph. Let there be an edge between i and j () if there is a comparison between i and j, i.e.,
Let the set of edges be denoted by E. This graph is denoted by .
Definition 2
(directed graph ). Let the objects to be evaluated be assigned the nodes of the graph. Let there be a directed edge from i to j (i → j) if there is a decision that i is considered to be ’better’ than j, that is, . Let there be bi-directed edges from i to j () if i is considered equal to j according to a decision, that is . This graph is denoted by .
Theorem 1
([33]). The maximum value of the log-likelihood function (8) exists and the argument is unique under the conditions and , if and only if data matrix A satisfies the following set of conditions:
- (A)
- There is at least one index pair for which .
- (B)
- For any partition S and , , , there is at least one element and , for which , or there are two (not necessarily different) pairs , , , for which and .
- (C)
- With the graph definition given in Definition 2, there exists such a directed cycle , where are nodes, in which the number of the directed ’better’ edges exceeds the number of the bi-directed ‘equal’ edges.
The proof of Theorem 1 can be found in [33].
3. Consistency and Its Theoretical Consequences
3.1. Consistency of Data in the Case of PCM-Based Methods
The concept of consistency and the degree of data inconsistency are central issues in PCMs. The most commonly used concept of consistency is the following: denote by , the elements of the (multiplicative) pairwise comparison matrix , . If the comparison is complete, (every object is compared to any other object, i.e., , ), then consistency means the following relations:
In the case of incomplete comparisons, in matrix , the elements corresponding to the missing comparisons will remain empty. In such cases, the following generalized consistency definition is given [34]. For all cycles () in the graph of comparisons, the following equality holds:
Even in complete and incomplete cases, assuming a consistent data matrix , the result of the evaluation is a priority vector , with properties , and , then
and relation (13) guarantees the consistency.
Numerous metrics have been developed to measure inconsistency [18,35,36]. Recently, the case of incomplete comparisons has become the subject of research; see, for example, [37].
3.2. Consistency in Davidson Model
The concept of consistency is rarely examined in the case of the models with a stochastic background. In the publication [29], the two-option Bradley–Terry model was scrutinized, and the consistency of the data was defined within it. In the conference paper [38], the three-option Davidson model was investigated, and now these examinations will be extended.
First, we prove that if we start with a parameter set and we define data as the probabilities given by (1)–(3), moreover, the graph of comparisons is connected, then the maximum likelihood estimation of the parameters coincides with the starting parameter set.
Theorem 2.
Let be a starting initial vector with and , and . Let be computed from this parameter set applying formulas (1), (2), and (3). Fix a graph of comparisons, incomplete or complete , the set of its edges is denoted by E. Let the data be defined as follows:
If the graph of comparisons is connected, then the log-likelihood function (8) attains its maximum value at , and , i.e.,
Proof.
First of all, we note that if , then , , and . In other words, for a fixed pair , all data for are positive, or all data for are equal to zero. Therefore, the connection of the comparison graph belonging to the data set guarantees that conditions (A), (B), and (C) are satisfied. Consequently, if the data are defined by (14), the necessary and sufficient condition for a unique maximizer is the connectedness of the graph .
Let us define the following function:
for the regions , and Here, is the number of compared pairs, and there is a one-to-one correspondence between the indices s and the elements of the set of vertices in E. Moreover, in the log-likelihood function (8), , and . To find the maximum value, take the partial derivative with respect to and , , and we obtain
and
Using the Hesse matrix, we can check that at this point, the extreme value exists, and it is the maximum.
Now the question is whether there exists such a parameter set () for which
and
We know that the starting parameter set () satisfies Equations (20) and (21). Moreover, as the argument of the maximum value is unique, we can conclude that
□
Now, we will show that the priority vectors obtained using the LLSM and EM methods with PCM match the evaluation results obtained in the Davidson model if the elements of the PC matrix are defined based on the probabilities from the previous statement.
Theorem 3.
Let us define the data by (14), and let the elements of the PCM be
Assume that the graph of comparison is connected. Then, the results of the evaluation of PCM by LLSM and also by EM coincide with the MLEP in the Davidson model, i.e., .
Proof.
Due to the definition of , the PCM is consistent; therefore, if the result of the evaluation is , then . This property holds for . As the sums of the coordinates equal 1 in both cases, the equality of the vectors is guaranteed. □
The following statement expresses the equivalence between the concept of consistency used for PCMs (see (12)) and the data ratio written as the ratio of the coordinates of the priority vector in the Davidson model.
Theorem 4.
Let and be the graph of comparisons defined by the edges in E. Suppose that is connected. Assume that the data satisfy the following requirements.
If , then
and moreover,
with a common value . Let us introduce the notation
Proof.
It can be checked that the extreme value at this point is the maximum. We verify whether there exists such a vector , , , and ,
To satisfy the equalities (31)–(33), the equalities
and
have to be satisfied for every . (35) is satisfied due to (25), that is, in (35).
Let us turn to (34). If is a spanning tree, then start from object 1, and suppose that . Now, walking along the edges in , the coordinate of can be defined by
There is no cycle in a spanning tree, therefore, every coordinate is reached once and only once. Taking
we obtain an appropriate vector in the case of a spanning tree.
Turn to the case where is not a spanning tree. Take an edge . Let I be a spanning tree in , . Define the parameter vector as in the case of spanning trees. If is an edge in the tree I, then (34) holds. If is not contained among the edges of I, then there exists a path from i to j in the spanning tree ; let it be (. Consider the cycle . As (27) holds, and
and so on, we can conclude that
i.e.,
So, one can see that (34) is true for every edge in .
Now, let us consider the opposite direction of the equivalence. If (28) holds, then multiply these values in the case of the edges in a cycle. After performing the simplifications, it is obvious that the product would be 1. □
The presented analogy, the properties of PCM models, and the Davidson model are used to define data consistency in the Davidson model as follows.
Definition 3.
Data A are said to be consistent in the Davidson model if (24) and (25) are satisfied and with the notation (26), for every cycle .
Here, E is the set of pairs , where there is a comparison between i and j.
Data are inconsistent if they are not consistent.
Remark 2.
The requirement (25) requires some explanation. Since the geometric mean property holds for probabilities, and relative frequencies are close to probabilities in the case of many comparisons, requiring the geometric mean property for the data does not seem to be a very strict constraint.
Remark 3.
The equivalence of (27) and (28) coincides with the same results in the case of PCMs [34] and this result is true in a three-option model. Consequently, a connection can be established not only between two-option models and PCM-based models but also between the three-option Davidson model and PCM-based models through the concept of consistency given for incomplete PCM in [34]. Theorem 4 states a perfect analogy between the consistent BT2, PCMs, and three-option Davidson model through the priority vectors and through
To summarize the similarities among the different models, see Table 1 below.

Table 1.
Similarities between paired comparison models concerning the concept of consistency.
Finally, we present an interesting property of the consistent data in the Davidson model. This is the following: in the case of a consistent data set, if we multiply the data of any pairs in comparisons by a positive constant, the evaluation result will not change. It obviously holds in the case of PCMs too but is not true in the case of inconsistent data in the Davidson model. To demonstrate this, let us see the following examples. Consider data matrix as follows (Table 2).
Table 2.
Data matrix .
One can easily check that is consistent with . The result of the evaluation is
As a consequence of Theorem 4, the same vector will be the result of the evaluation if we consider
We mention that in the case of consistent data, there is no need to reduce the effect of non-equal comparison numbers [39], as this has no impact on the evaluation result.
The PCM matrix, defined by
is contained in Table 3. The results of the evaluation by LLSM and EM equal .
Table 3.
PCM data matrix defined by the ratios of data belonging to options ‘better’ and ‘worse’ from the data of Table 2. * denotes that there is no comparison between the objects.
It is obvious that the PCM matrix does not change if data belonging to a fixed pair are multiplied by a positive constant, so the evaluation result by LLSM or EM does not change either.
Next, let be another data matrix modified as follows:
In this case, the MLEP is
4. Connections in the Case of Inconsistent Data, Based on Simulations
In Section 3, we presented the concept of consistent and inconsistent data in the case of PCMs and we defined the concept of consistent data in the case of the Davidson model. Moreover, based on theoretical considerations, we could set up a link between the PCMs and three-option Davidson model, and also BT2 and the three-option Davidson model in the case of consistent data. If data are inconsistent, this type of relation cannot be proved, but we can present some common features of the mentioned models by computer simulations.
4.1. Method of Simulations
Due to the complexity of the analytical calculations, we perform Monte Carlo simulations, similar to those in [29], to examine information retrieval from incomplete comparisons in the Davidson model. This section describes the simulation methodology.
The steps of the simulations are described as follows:
- Generate a normalized random n-length vector, and assign a positive value. The coordinates of and are uniformly distributed random values in the interval . These will be the initial parameter values for the Davidson model. is referred to as the initial priority vector.
- As we know from Theorem 2, in the case of consistent comparison data, MLE recovers the initial values in all (complete or incomplete) cases. For this reason, perturbations are performed on the consistent data set as follows: each probability value is modified by adding independent, uniformly distributed random numbers in the range [, ]. The value can be set between 0 and 1, but we use between 0 and 0.1. We guarantee that the resulting perturbed probability values are also between 0 and 1, then we normalize them by dividing their sum. These data serve as an inconsistent complete data set.
- Using the above perturbed probability values as a data set, the estimated vector and value are calculated using MLE. The vector is referred to as an estimated priority vector based on the complete comparison and is denoted by .
- In the next step, we calculate the estimated priority vectors for different graph structures as follows. We omit data from the complete data set. For each fixed connected graph, we keep only the data that belong to the comparison structure associated with the graph. The remaining data set is incomplete and inconsistent. After performing MLE, the estimated priority vector is called the priority vector belonging to the incomplete data set and is denoted by . We want to determine how much information is retained from the initial priority vector, on the one hand, and from the estimated priority vector based on the complete comparison, on the other hand.
- The differences between the priority vectors computed from the complete and incomplete data sets for the fixed graph structure are determined using various measures.To analyze the similarities of the rankings, we use two rank correlations and two additional distance measures:
- Spearman rank correlationwhere is the difference in rankings of the ith object;
- Kendall rank correlationwhere is the number of concordant pairs, and is the number of discordant pairs.
- Further used distances are the Pearson correlation coefficientwhere is the i-th coordinate of the estimated priority vector from the incomplete comparison and is the i-th coordinate of the estimated priority vector from the complete comparison and the upper line denotes the arithmetic average of the coordinates.Each type of the correlation coefficients is in the interval . The closer the result is to 1, the more information is recovered about the rank or about the coordinates of the priority vector.
- The Euclidean distance of the estimated parameter vectors
The Euclidean distance is always non-negative. It can be larger than 1. Its largest value is , if the Euclidean norms of the vectors equal 1. In this case, the smaller value represents better information retrieval. - It is also interesting to see how much information is retained from the initial priority vector in the case of different comparison structures. In this case, both the perturbation and the omission of part of the data may cause information loss. The same similarity measures as in the previous step are used for the initial parameter set and the estimated parameter vector based on incomplete comparison. More specifically, the same similarity measures as in Step 6 are calculated according to Formulae (53)–(56), but is substituted with .
- Repeat the above-described steps N times, where N is the number of simulations. The similarity measures described in Step 6 are random, due to the random initial parameter vector and the random perturbation value. Therefore, we take their average over the simulations for each fixed comparison structure. These average values characterize the information retrieval measures associated with the fixed comparison structures.
4.2. Results of Simulations in the Case of Uniformly Distributed Random Perturbation Values
As in the article [29], the numbers of objects to be compared are n = 4, 5, and 6. For four objects, six different graphs can be distinguished, including the complete comparison. For five objects, this means 21 different graphs, while for six objects, 112 different graph structures exist. The number of simulations is . The random coordinates of the initial priority vector are uniformly distributed. The perturbation values are uniformly distributed random values from the intervals , , , and .
In summary, we can conclude that the same conclusions can be drawn in the three-option Davidson model as in PCMs and in the two-option Bradley–Terry model. We illustrate these observations with a few figures.
The independence of the rankings from the similarity measures can be observed as shown in Figure 1. We experience this for all investigated ranges of the random perturbation values. This is true even if the similarity measure is computed from the initial parameter vector and the estimated parameter vector based on complete comparison. This observation confirms that most of the information retrieval is related to the graph structure.
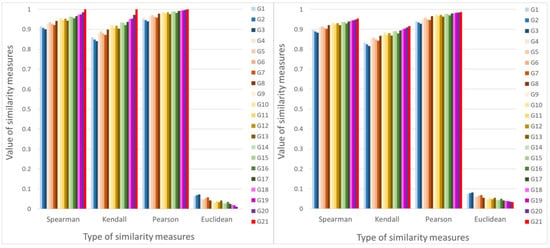
Figure 1.
Average correlations defined by (53) (Spearman), (54) (Kendall), (55) (Pearson), and Euclidean average distance defined by (56) for objects, with uniformly distributed perturbation values in applied. The difference in the comparison of the priority vector computed from the perturbed complete data set is shown on the left, and from the initial priority vector on the right.
It is important to highlight that the closer the result is to one, the more information is recovered, except for Euclidean distance, where this relationship is reversed.
We examine how the similarity measures change as a function of the range of random perturbation values when the graph structure is fixed. We find that as perturbation increases, Euclidean distances become larger, while correlations become smaller as expected. The presentation of the data for the star-graph illustrates this observation as shown in Figure 2.
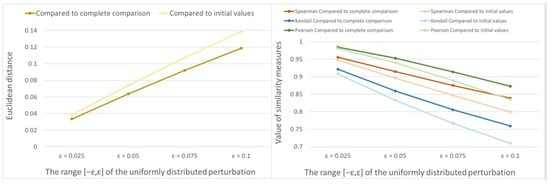
Figure 2.
The Euclidean distance (on the left) and correlation values (on the right) for the star-graph are presented for different ranges of the random perturbation values, comparing the initial priority vector to the estimated priority vector from the complete data set, for objects.
In the case of and , Table 4 and Table 5 present the computed average similarity measures for each comparison (graph) structure with uniformly distributed random perturbation values in . The rows represent the graph structures, and the columns represent the similarity measures, with the left side showing the comparison to the estimated priority vector from the complete comparison data, and the right side showing the comparison to the initial priority vector. We can establish that every similarity measure designates the same structure as the best in the case of each comparison structure if we compare the priority vector from incomplete comparison either to the initial priority vector or to the one estimated based on the complete comparison data. In the case of the optimal comparison structures the graph structures are also represented.
Table 4.
Average similarity measures when the distance is related to the priority vector from the complete comparison data and to the initial priority vector for objects and uniformly distributed random perturbation values in .
Table 5.
Average similarity measures when the distance is related to the priority vector from the complete comparison data and to the initial priority vector for n = 5 objects and uniformly distributed random perturbation values in .
The same conclusions can be stated if . Table 6 contains the data only for the optimal graph structures, as the number of comparison structures is high. It is a very important observation that the optimal comparison structures are the same in the Davidson model, PCMs, and the BT2 model for n = 4, 5, and 6. This supports the idea that the optimal comparison structures do not depend on either the model selection or the number of options.
Table 6.
Optimal comparison structures and the average similarity measures belonging to them when the distance is related to the priority vector from the complete comparison data and to the initial priority vector for n = 6 objects and uniformly distributed random perturbation values in .
The simulations show that when using the best comparison structure for a given number of edges, a higher number of edges leads to better information retrieval. This holds true for all object numbers (n = 4, 5, and 6), all ranges of the uniformly distributed perturbation values, and all tested measurements.
For fixed edge numbers, Figure 3 shows the Pearson correlation and Euclidean distance belonging to the optimal structures, comparing both to the initial parameter vector and estimated parameter vector from complete comparison. Although the values differ, the tendencies coincide. It is clearly seen that the correlation values increase monotonically, while the Euclidean distances decrease monotonically as a function of the number of edges as expected. On the right side of Figure 3, the topmost value in blue is obviously zero.
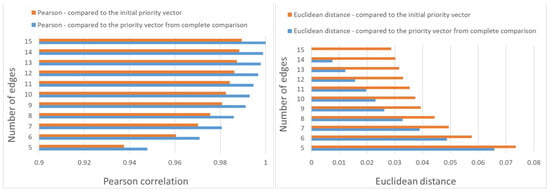
Figure 3.
Pearson correlation and Euclidean distance between the estimated priority vector belonging to the optimal graph structures and belonging to the complete graph and to the initial priority vector in the function of the number of graph’s edges in the case of n = 6 objects and random perturbation values uniformly distributed from the interval .
As it was already established in the previous research for the BT2 model [29], although the best graph structures with k edges are always weaker than the best graph structures with edges, we can still find cases where the best graph structure with k edges is better than the worst graph structure with edges. For the Davidson model, we observe similar behavior in the data. Figure 4 illustrates this for each indicator by comparing the best graph with seven edges () and the worst graph with eight edges (). The situation is the same if we compare estimated parameters arising from the incomplete and complete data, or we compare the estimated parameters arising from the incomplete comparisons to the initial parameter vector. This observation is highly significant because it supports the idea that the structure of the comparisons used to collect data matters. Therefore, using optimal comparison structures is worthwhile for better information retrieval.
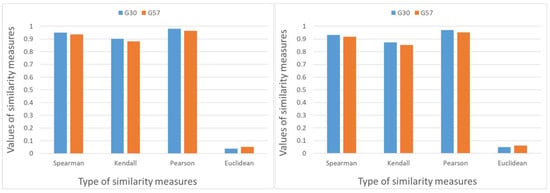
Figure 4.
Comparison of the best graph structure with 7 edges () and the worst graph structure with 8 edges () in the case of n = 6 objects to compare and random perturbation values, uniformly distributed in . Differences in comparison with the estimated priority vector based on complete data on the left, differences from the initial priority vector on the right.
We also test what can be stated for additional object numbers. Based on the simulations, we observe that for objects and compared pairs, the star graph always proves to be the best structure, while for n compared pairs, the best structure is the cycle. We suggest using these structures for as well.
4.3. Results of Simulations in the Case of Gaussian-Distributed Random Perturbation Values
In order to make our model more realistic, we also perform the perturbation applying Gaussian distribution. The only modification in the simulation process is made in step 3: uniformly distributed random values are changed to Gaussian-distributed random values.
In the case of , Table 7 presents the computed average similarity measures for each comparison (graph) structure applying Gaussian-distributed perturbation values in . First, similarly to the uniformly distributed random perturbed values, the expectation of the perturbations is zero, but the dispersion is . In this case, the possible values of the Gaussian-distributed random perturbation values are almost always (i.e., with probability 0.997) in the interval . The results are contained in Table 7.
Table 7.
Average similarity measures when the distance is related to the priority vector from the complete comparison data and to the initial priority vector for n = 5 objects and Gaussian-distributed random perturbation values with expectation 0 and dispersion 1/30.
The structure of Table 7 is the same as the structure of Table 5. The observations coincide with the observations in the case of uniformly distributed random perturbation, but the similarity measures are better. More precisely, Euclidean distances are smaller, and correlations are higher than in the case of uniformly distributed perturbations. In each number of compared pairs, the optimal comparison structures coincide, regardless of whether the perturbations are Gaussian-distributed or uniformly distributed random values. This observation also holds in the cases of objects.
We also investigate the case where the perturbation follows a certain tendency: its expectation is increased from zero, while the dispersion is kept at 1/30. Table 8 presents the results in the case of Gaussian-distributed random perturbed values with mean 0.01 and standard deviation 1/30. Comparing the measurements in Table 7 and Table 8, we can see that, although the distances are usually larger and the correlations are smaller, the optimal graph structures do not change if we increase the expectation of the perturbation from zero to a positive value. Every conclusion drawn in Section 4.2 can also be repeated in the case of Gaussian-distributed perturbation with nonzero expectation. This supports the robustness of optimal graph structures.
Table 8.
Average similarity measures, when the distance is related to the priority vector from the complete comparison data and to the initial priority vector for n = 5 objects and Gaussian-distributed random perturbation values with expectation 0.01 and dispersion 1/30.
5. Summary
The main finding of the paper is a relation between two main branches of paired comparison methods: a three-option paired comparison model with stochastic background and the multiplicative pairwise comparison matrix-based model. The key moment was the definition of consistency in PCM models. Starting with Luce’s choice axiom, we characterized the data consistency in the Davidson model. We proved that, similarly to the two-option Bradley–Terry model, in the case of consistent data in the Davidson model, the priority vector coincides with the priority vector provided by PCM, and also with the priority vector in BT2. This is not true in the case of inconsistent data. If the data are not consistent, investigating the comparison structures by simulations, we established that the same conclusions can be drawn in the case of Davidson model and the two-option Bradley–Terry model: the optimal graph structures coincide with those investigating PCMs, and these structures form a sequence presented in [29,40]. This is true both when comparing the evaluation results derived from incomplete comparisons after the perturbation to the initial priority vector, and when comparing the evaluation results derived from complete and incomplete comparisons after the perturbation, independently of the distribution of the perturbed values. Therefore, the optimal information retrieval structure does not depend on the number of options and the model.
Based on simulations for , we observed that the best comparison structure is the star graph when only pairs are allowed for comparison, and the cycle when n pairs are allowed. Therefore, we suggest using these comparison structures when dealing with a large number n of objects and or n compared pairs. Further investigations would be performed in the case of the three-option Bradley–Terry and Thurstone–Mosteller models when Luce’s choice axiom is not fulfilled.
Author Contributions
Conceptualization, C.M. and É.O.-M.; methodology, A.T.-M. and L.G.; software, A.T.-M. and L.G.; validation, C.M.; writing—original draft preparation, É.O.-M. and A.T.-M. writing—review and editing, A.T.-M. and É.O.-M.; visualization, A.T.-M.; supervision, C.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
All of the data are generated randomly by computer.
Acknowledgments
This work has been implemented by the TKP2021-NVA-10 project with the support provided by the Ministry of Culture and Innovation of Hungary from the National Research, Development and Innovation Fund, financed under the 2021 Thematic Excellence Programme funding scheme. The authors are grateful to Zsombor Szádoczki for providing them with the equivalent graph structures.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| PCM | Paired Comparison Matrices-based Method |
| THMM | Thurstone motivated method |
| AHP | Analytic Hierarchy Process |
| EM | Eigenvector method |
| LLSM | logarithmic least squares method |
| MLE | maximum likelihood estimation |
| BT2 | Bradley–Terry model that allows two options |
| BT3 | Bradley–Terry model allowing three options in choices |
| MLEP | maximum likelihood estimate of the parameters |
| GRC | graph of comparisons |
| GRDIR | directed graph |
References
- Mangla, S.K.; Kumar, P.; Barua, M.K. Risk analysis in green supply chain using fuzzy AHP approach: A case study. Resour. Conserv. Recycl. 2015, 104, 375–390. [Google Scholar] [CrossRef]
- Shi, W. Construction and evaluation of college students’ psychological quality evaluation model based on Analytic Hierarchy Process. J. Sens. 2022, 2022, 3896304. [Google Scholar] [CrossRef]
- Koczkodaj, W.W.; LeBrasseur, R.; Wassilew, A.; Tadeusziewicz, R. About business decision making by a consistency-driven pairwise comparisons method. J. Appl. Comput. Sci. 2009, 17, 55–70. [Google Scholar]
- Wind, Y.; Saaty, T.L. Marketing applications of the analytic hierarchy process. Manag. Sci. 1980, 26, 641–658. [Google Scholar] [CrossRef]
- Brunelli, M. A study on the anonymity of pairwise comparisons in group decision making. Eur. J. Oper. Res. 2019, 279, 502–510. [Google Scholar] [CrossRef]
- Amorocho, J.A.P.; Hartmann, T. A multi-criteria decision-making framework for residential building renovation using pairwise comparison and TOPSIS methods. J. Build. Eng. 2022, 53, 104596. [Google Scholar] [CrossRef]
- Baker, R.D.; McHale, I.G. A dynamic paired comparisons model: Who is the greatest tennis player? Eur. J. Oper. Res. 2014, 236, 677–684. [Google Scholar] [CrossRef]
- Bozóki, S.; Csató, L.; Temesi, J. An application of incomplete pairwise comparison matrices for ranking top tennis players. Eur. J. Oper. Res. 2016, 248, 211–218. [Google Scholar] [CrossRef]
- Baker, R.D.; McHale, I.G. Estimating age-dependent performance in paired comparisons competitions: Application to snooker. J. Quant. Anal. Sports 2024, 20, 113–125. [Google Scholar] [CrossRef]
- Gisselquist, R.M. Paired comparison and theory development: Considerations for case selection. PS Polit. Sci. Polit. 2014, 47, 477–484. [Google Scholar] [CrossRef]
- Crompvoets, E.A.; Béguin, A.A.; Sijtsma, K. Adaptive pairwise comparison for educational measurement. J. Educ. Behav. Stat. 2020, 45, 316–338. [Google Scholar] [CrossRef]
- Williamson, T.B.; Watson, D.O.T. Assessment of community preference rankings of potential environmental effects of climate change using the method of paired comparisons. Clim. Change 2010, 99, 589–612. [Google Scholar] [CrossRef]
- Verschuren, P.; Arts, B. Quantifying influence in complex decision making by means of paired comparisons. Qual. Quant. 2005, 38, 495–516. [Google Scholar] [CrossRef]
- Tarricone, P.; Newhouse, C.P. A study of the use of pairwise comparison in the context of social online moderation. Aust. Educ. Res. 2016, 43, 273–288. [Google Scholar] [CrossRef]
- Oliveira, I.F.; Ailon, N.; Davidov, O. A new and flexible approach to the analysis of paired comparison data. J. Mach. Learn. Res. 2018, 19, 1–29. [Google Scholar]
- Saaty, T.L.; Vargas, L.G. The Logic of Priorities: Applications of Business, Energy, Health and Transportation; Springer Science & Business Media: Dordrecht, The Netherlands, 2013. [Google Scholar]
- Vaidya, O.S.; Kumar, S. Analytic hierarchy process: An overview of applications. Eur. J. Oper. Res. 2006, 169, 1–29. [Google Scholar] [CrossRef]
- Saaty, T.L. The Analytic Hierarchy Process: Planning, Priority Setting, Resource, Allocation; McGraw-Hill: New York, NY, USA, 1980. [Google Scholar]
- Saaty, T.L. How to make a decision: The analytic hierarchy process. Eur. J. Oper. Res. 1990, 48, 9–26. [Google Scholar] [CrossRef]
- Saaty, T.L. Decision-making with the AHP: Why is the principal eigenvector necessary. Eur. J. Oper. Res. 2003, 145, 85–91. [Google Scholar] [CrossRef]
- Bozóki, S.; Fülöp, J.; Rónyai, L. On optimal completion of incomplete pairwise comparison matrices. Math. Comput. Model. 2010, 52, 318–333. [Google Scholar] [CrossRef]
- Thurstone, L.L. A law of comparative judgment. Psychol. Rev. 1927, 34, 273–286. [Google Scholar] [CrossRef]
- Bradley, R.A.; Terry, M.E. Rank analysis of incomplete block designs: I. The method of paired comparisons. Biometrika 1952, 39, 324–345. [Google Scholar] [CrossRef]
- Glenn, W.A.; David, H.A. Ties in paired-comparison experiments using a modified Thurstone-Mosteller model. Biometrics 1960, 16, 86–109. [Google Scholar] [CrossRef]
- Rao, P.V.; Kupper, L.L. Ties in paired-comparison experiments: A generalization of the Bradley-Terry model. J. Am. Stat. Assoc. 1967, 62, 194–204. [Google Scholar] [CrossRef]
- Agresti, A. Analysis of ordinal paired comparison data. J. R. Stat. Soc. Ser. C Appl. Stat. 1992, 41, 287–297. [Google Scholar] [CrossRef]
- Orbán-Mihálykó, É.; Mihálykó, C.; Koltay, L. Incomplete paired comparisons in case of multiple choice and general log-concave probability density functions. Cent. Eur. J. Oper. Res. 2019, 27, 515–532. [Google Scholar] [CrossRef]
- Orbán-Mihálykó, É.; Koltay, L.; Szabó, F.; Csuti, P.; Kéri, R.; Schanda, J. A new statistical method for ranking of light sources based on subjective points of view. Acta Polytech. Hung. 2015, 12, 195–214. [Google Scholar]
- Gyarmati, L.; Orbán-Mihálykó, É.; Mihálykó, C.; Szádoczki, Z.; Bozóki, S. The incomplete Analytic Hierarchy Process and Bradley–Terry model: (In)consistency and information retrieval. Expert Syst. Appl. 2023, 229, 120522. [Google Scholar] [CrossRef]
- Davidson, R.R. On Extending the Bradley-Terry Model to Accommodate Ties in Paired Comparison Experiments. J. Am. Stat. Assoc. 1970, 65, 317–328. [Google Scholar] [CrossRef]
- Luce, R.D. Individual Choice Behavior; Wiley: New York, NY, USA, 1959; Volume 4. [Google Scholar]
- Luce, R.D. The choice axiom after twenty years. J. Math. Psychol. 1977, 15, 215–233. [Google Scholar] [CrossRef]
- Mihálykó, C.; Gyarmati, L.; Orbán-Mihálykó, É.; Mihálykó, A. Evaluability of paired comparison data in stochastic paired comparison models: Necessary and sufficient condition. arXiv 2025, arXiv:2502.13617. [Google Scholar]
- Bozóki, S.; Tsyganok, V. The (logarithmic) least squares optimality of the arithmetic (geometric) mean of weight vectors calculated from all spanning trees for incomplete additive (multiplicative) pairwise comparison matrices. Int. J. Gen. Syst. 2019, 48, 362–381. [Google Scholar] [CrossRef]
- Kazibudzki, P.T. Redefinition of triad’s inconsistency and its impact on the consistency measurement of pairwise comparison matrix. J. Appl. Math. Comput. Mech. 2016, 15, 71–78. [Google Scholar] [CrossRef][Green Version]
- Brunelli, M. A survey of inconsistency indices for pairwise comparisons. Int. J. Gen. Syst. 2018, 47, 751–771. [Google Scholar] [CrossRef]
- Ágoston, K.C.; Csató, L. Inconsistency thresholds for incomplete pairwise comparison matrices. Omega 2022, 108, 102576. [Google Scholar] [CrossRef]
- Mihálykó, C.; Orbán-Mihálykó, É.; Gyarmati, L. Consistency and Inconsistency in the Case of a Stochastic Paired Comparison Model. In Proceedings of the 2024 IEEE 3rd Conference on Information Technology and Data Science (CITDS), Debrecen, Hungary, 26–28 August 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Chartier, T.P.; Harris, J.; Hutson, K.R.; Langville, A.N.; Martin, D.; Wessell, C.D. Reducing the effects of unequal number of games on rankings. IMAGE Bull. Int. Linear Algebra Soc. 2014, 52, 15–23. [Google Scholar]
- Bozóki, S.; Szádoczki, Z. Optimal sequences for pairwise comparisons: The graph of graphs approach. arXiv 2022, arXiv:2205.08673. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).