Abstract
Current cloud–edge collaboration collaboration architectures face challenges in security resource scheduling due to their mostly static nature, which cannot keep up with real-time attack patterns and dynamic security needs. To address this, this paper proposes a dynamic scheduling method using Deep Reinforcement Learning (DQN) and SRv6 technology. The method establishes a multi-dimensional feature space by collecting network threat indicators and security resource states; constructs a dynamic decision-making model with DQN to optimize scheduling strategies online by encoding security requirements, resource constraints, and network topology into a Markov Decision Process; and enables flexible security service chaining through SRv6 for precise policy implementation. Experimental results demonstrate that this approach significantly reduces security service deployment delays (by up to 56.8%), enhances resource utilization, and effectively balances the security load between edge and cloud.
Keywords:
cloud–edge collaboration; security protection resources; dynamic scheduling; reinforcement learning MSC:
68Q06
1. Introduction
With the explosive growth of Internet of Things (IoT) devices and the widespread adoption of 5G communication technology, the cloud–edge collaborative architecture has emerged as the core paradigm for supporting scenarios such as industrial interconnection and intelligent transportation [1]. This architecture enables efficient collaboration for massive device access and data processing through the coordination of a global cloud computing scheduling, real-time edge node processing, and ubiquitous terminal sensing. However, it introduces unprecedented security challenges: the attack surface expands exponentially due to the proliferation of cross-layer interaction links, threat patterns evolve in real-time with network dynamics, computing resources are fragmented across heterogeneous cloud–edge domains, and the strict real-time requirements of industrial scenarios further strain traditional security protection systems [2].
The limitations of existing security resource scheduling methods become increasingly pronounced in dynamic heterogeneous environments. Static policy-based resource allocation mechanisms struggle to adapt to real-time variations in attack patterns. For instance, in IoT scenarios, fixed resource configurations often lead to underutilization during normal operation, yet cause overload during Distributed Denial-of-Service (DDoS) attacks, with comparative latency increases observed at attack peaks versus normal conditions [3]. Furthermore, the absence of an effective collaborative mechanism between cloud computational power and edge low-latency capabilities hinders the ability to simultaneously fulfill both requirements.
Traditional routing protocols lack dynamic orchestration capabilities for Security Service Chains (SFCs). This deficiency results in policy enforcement delays reaching hundreds of milliseconds during the cross-domain transmission of security traffic, severely compromising protection timeliness [4]. Crucially, the inherent conflict in static scheduling—manifested as overloaded edge nodes alongside underutilized cloud resources—is widely observed, leading to suboptimal overall resource utilization and load imbalance [3].
These shortcomings directly precipitate a dual dilemma: diminished security efficacy (increased missed detections and prolonged response delays under dynamic threats) and escalated operational costs (inefficient cross-domain resource coordination inflating energy and bandwidth expenditures). Consequently, traditional static scheduling methods prove inadequate for addressing dynamically evolving attack characteristics at the edge and the elastic demands of cloud-based security services, particularly in scenarios involving ubiquitous IoT terminal access and 5G network slicing. These scenarios demand both guaranteed real-time responsiveness for security services and highly efficient cross-domain resource coordination. This fundamental contradiction drives both academia and industry to explore novel resource scheduling paradigms aimed at enabling the dynamic and precise deployment of security capabilities.
Contemporary research advances along three primary trajectories for resource orchestration. The first stream focuses on policy-based static or semi-static methodologies, where security protection resources are allocated through predefined operational rules—an approach systematically validated by Chuan et al. (2025) in their comprehensive fog computing survey [2]. A second, increasingly dominant paradigm leverages machine learning capabilities, with Deep Reinforcement Learning demonstrating particular efficacy for adaptive decision-making in dynamic environments. This is exemplified by Jang et al. (2025) [3], who pioneered a hybrid technique combining Deep Q-Networks (DQNs) with Dijkstra’s algorithm to optimize Service Function Chain latency, while Ji et al. (2025) [5] formalized edge–cloud task offloading as a Markov Decision Process (MDP) to achieve intelligent dynamic scheduling through DRL mechanisms. The third research thrust exploits network programmability innovations, where Nagireddy (2024) [4] developed a breakthrough SRv6-based DeepNFP framework enabling dynamic SFC data plane reconfiguration via IPv6 Segment Routing. Concurrently, Wang and Yang (2025) [1] established novel cloud–edge collaboration paradigms through the synergistic integration of Software-Defined Networking (SDN) and Network Function Virtualization (NFV) technologies, demonstrating significant coordination improvements in distributed infrastructure scheduling.
However, existing studies have four critical deficiencies. First, there is a lack of deep collaboration, as most schemes either focus solely on resource scheduling algorithms or network forwarding technologies, failing to deeply integrate both for end-to-end dynamic optimization. Second, the models used have inherent limitations in encoding complex security states. Even with RL, there remains a need to break through the challenge of accurately encoding complex cloud–edge–terminal security states such as threats, resource statuses, topology, and SFC requirements, and achieving efficient online decision-making. Third, dynamic SFC orchestration is insufficient, as existing applications of SRv6 in the security domain still require further optimization of their ability to dynamically build security service chains on demand in conjunction with intelligent decision-making. Fourth, multi-objective optimization presents challenges: simultaneously optimizing multiple objectives such as latency, resource utilization, load balancing, and cost remains a difficulty. Security protection resource scheduling in cloud–edge collaborative environments is essentially a multi-objective optimization problem that requires balancing three core dimensions: (1) timeliness of security services, i.e., the deployment latency of protection policies must meet real-time threat blocking requirements; (2) rationality of resource allocation, including matching the lightweight characteristics of edge nodes with the deep detection capabilities of cloud analysis clusters; and (3) controllability of network transmission, ensuring no policy failure during cross-domain transmission of security traffic.
As shown in Figure 1, although existing protection resource network architectures [6,7] achieve the unified management of networks and resources through hierarchical design (service layer, routing layer, infrastructure layer, and orchestration layer), their scheduling mechanisms have significant limitations. On the one hand, static policy-based resource allocation cannot adapt to the burst characteristics of attack traffic, and static scheduling strategies based on heuristic rules (such as greedy algorithms) rely on a priori knowledge, making them difficult to adapt to the dynamic evolution of attack patterns. On the other hand, traditional routing protocols lack the ability to dynamically orchestrate security service chains, leading to increased activation delays for protection policies.
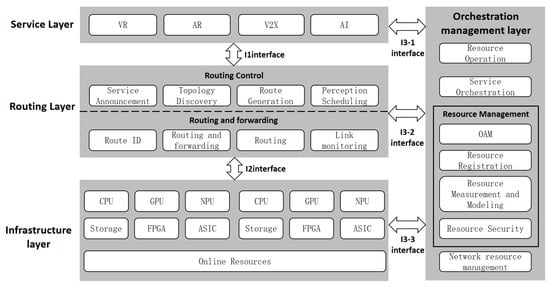
Figure 1.
Existing protection resource network architecture.
To address the identified challenges, this paper proposes a dynamic scheduling framework for security protection resources in cloud–edge collaboration scenarios, and the framework consists of three core modules:
Multi-dimensional Feature Perception Layer: Collects real-time network threat indicators (e.g., DDoS attack intensity and intrusion detection alerts), security resource states (load percentage, power consumption, and bandwidth), and network topology data (node connections and link latency) to construct a comprehensive feature space.
Intelligent Decision-Making Layer: Encodes the perceived features into a Markov Decision Process (MDP) where states represent network conditions, actions correspond to resource allocation strategies, and rewards reflect scheduling performance (latency and load balance). A Deep Q-Network (DQN) is trained to learn optimal policies online, dynamically adjusting resource allocation based on real-time inputs.
Flexible Execution Layer: Leverages SRv6 technology to implement the scheduled policies through programmable service chaining. By embedding ordered Segment Identifiers (SIDs) in IPv6 headers, it enables the precise steering of traffic through selected security resources (e.g., DDoS scrubbers and intrusion detection engines), ensuring low-latency and cross-domain policy enforcement.
This end-to-end framework integrates perception, decision, and execution to achieve adaptive security resource scheduling, balancing timeliness, resource efficiency, and load distribution between cloud and edge.
The subsequent contents of this paper will unfold as follows: Section 2 reviews the technical backgrounds of cloud–edge collaborative architectures, reinforcement learning, and SRv6; Section 3 elaborates on the design of the dynamic scheduling method; Section 4 validates the effectiveness of the method through experiments; and Section 5 summarizes the research findings and prospects future directions.
2. Background and Related Works
This section establishes the technical foundation for our dynamic scheduling framework. Section 2.1 analyzes cloud–edge collaborative architectures and their inherent security challenges in resource coordination. Section 2.2 examines reinforcement learning algorithms, focusing on the applicability of DQN to dynamic scheduling. Section 2.3 explores SRv6 technology and its role in security service chain orchestration, highlighting gaps in threat-aware adaptability.
2.1. Cloud–Edge Collaborative Architecture
Cloud–edge collaborative architectures represent a transformative paradigm for intelligent systems, integrating the centralized computational might of cloud servers, the low-latency processing capabilities of edge nodes, and the real-time sensing functionalities of end devices. As Figure 2 shows, this hierarchical framework enables seamless task distribution: clouds handle big data analytics and model training, edges perform near-source data preprocessing to reduce latency, and devices execute context-aware sensing and local decision-making. Such collaboration mitigates network congestion, enhances privacy by minimizing data transmission, and supports real-time responses in mission-critical scenarios. Notable applications include smart manufacturing for predictive maintenance, intelligent transportation systems for autonomous vehicle coordination, and healthcare IoT for remote patient monitoring.
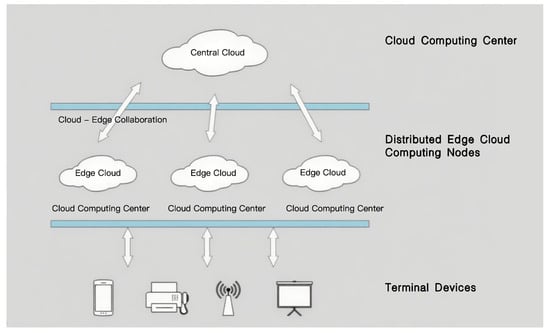
Figure 2.
Cloud–edge collaborative architecture.
Yang et al. [6] pioneered a cloud–edge collaborative mechanism for deep learning in smart robots, deploying lightweight inference models at the edge to process sensor data in real time while leveraging cloud resources for periodic model updates. This approach reduced inference latency by 42% compared to pure cloud-based solutions while preserving data privacy. Wang et al. [7] proposed an AI-driven architecture for 6G space-air-ground integrated power IoT, where edge nodes aggregate and preprocess sensory data from distributed power grids, and the cloud performs cross-domain anomaly detection using federated learning. The framework achieved 98.7% fault detection accuracy with sub-50 ms response time. Zhang et al. [8] conducted a comprehensive review of performance-driven closed-loop optimization in smart manufacturing, highlighting how cloud–edge collaboration enables real-time quality control through sensor-data fusion, edge-based process prediction, and cloud-based production scheduling. Wang et al. [9] systematically analyzed end–edge–cloud collaborative computing for deep learning, identifying key challenges such as heterogeneous resource orchestration, communication overhead, and security vulnerabilities in distributed training.
While existing studies demonstrate the architecture’s efficacy in improving system responsiveness and resource utilization, critical gaps remain. Most frameworks lack dynamic resource reallocation mechanisms for heterogeneous workloads, and cross-domain security coordination remains understudied. This paper addresses these limitations by introducing a dynamic security scheduling method that leverages hierarchical collaboration to adapt to real-time threat landscapes.
Our innovation lies in a context-aware resource orchestration mechanism that dynamically adjusts cloud–edge resource allocation based on workload demands and threat intensity. Unlike static frameworks [7,8], our approach enables the seamless redistribution of inference, preprocessing, and decision-making tasks across cloud, edge, and device layers in response to fluctuating network conditions or emerging security risks. Additionally, we integrate cross-domain security coordination into the core collaboration workflow, ensuring that threat mitigation strategies (e.g., anomaly detection and access control) are synchronized across layers without compromising real-time performance. This dual focus on dynamic resource adaptability and integrated security coordination transforms cloud–edge collaboration from a static efficiency tool into a resilient, threat-aware system, directly enhancing its applicability to mission-critical applications like autonomous transportation and industrial IoT.
2.2. Reinforcement Learning
Reinforcement learning (RL) has emerged as a cornerstone for dynamic scheduling in cloud–edge networks, enabling agents to learn optimal policies through iterative interaction with complex, uncertain environments. Deep RL (DRL) enhances this capability by combining neural networks with RL, allowing handling of high-dimensional state spaces and non-linear reward functions. Key advancements include improved sample efficiency via experience replay, stability through target networks, and multi-objective optimization through reward shaping. These techniques have been applied to resource allocation, task offloading, and security policy enforcement, demonstrating superior adaptability compared to rule-based methods.
Existing research continues to make breakthroughs in algorithm architecture:
Shakya et al. [10] conducted a comprehensive review of reinforcement learning algorithms, systematically sorting out three major categories of methods: value based (e.g., Q-learning), policy based (e.g., PPO), and model based (e.g., model predictive RL). They pointed out that value-based methods have advantages in discrete action spaces, while policy-based methods are more suitable for continuous control scenarios. Shinn et al. [11] introduced “Reflexion”, a novel framework that integrates natural language feedback into RL, allowing human operators to refine agent policies through verbal instructions. In experiments, this approach reduced the number of training episodes by 35% in complex decision-making tasks. Wang et al. [12] addressed the vehicle routing problem with backhauls by proposing a graph neural network to encode spatiotemporal traffic patterns, combined with a policy gradient algorithm to optimize route sequences. This method reduced delivery costs by 22% compared with traditional heuristic approaches. Casper et al. [13] theoretically revealed the limitations of reinforcement learning from human feedback, such as reward misspecification and safety risks in real-world deployments, and proposed a formal framework to align agent objectives with human intentions.
Towers et al. [14] standardized RL research through Gymnasium, an open-source environment interface that enables reproducible evaluations of algorithms across diverse domains. Matsuo et al. [15] explored the integration of world models with DRL, demonstrating that learned environment dynamics can improve long-term planning in robotics tasks by 40%. Seo et al. [16] applied DRL to control fusion plasma tearing instabilities, a complex physics problem, achieving real-time stabilization with 99.2% success rate—marking a breakthrough in applying RL to critical physical systems. Wang et al. [17] reviewed DRL advancements, emphasizing algorithmic innovations like double DQN, dueling networks, and priority experience replay, while Tang et al. [18] focused on DRL applications in robotics, highlighting challenges in safety-critical deployments and transfer learning.
Recent research has achieved significant breakthroughs in improving DQN (Deep Q-Network) and expanding its application scenarios:Lin et al. [19] proposed a cloud–fog–edge Dual DQN for industrial scheduling, cutting makespan by 18% via layered node selection and task allocation. Choppara et al. [20] developed federated DQN (FLDQN) for fog computing, achieving 30% faster task completion and 15% lower energy use through secure local training and priority-aware scheduling. In healthcare, Nouh et al. [21] integrated digital twins with DQN (via CNN-BiLSTM), reaching 98% accuracy in cardiovascular event prediction and reducing latency by 28%. Zhang et al. [22] introduced ETWTR, a multi-objective DQN for fog networks, lowering energy consumption by 18% through the joint optimization of reliability and efficiency. For cybersecurity, Ma et al. [23]’s Minimax-DQN improved intrusion detection by 12% by modeling attacker–defender dynamics as Markov games.
Despite the outstanding performance of DQN in cloud–edge scheduling, it still faces challenges such as real-time adaptation, cross-layer coordination, and multi-objective balancing. The latest research is seeking breakthroughs in several directions: Luan et al. [24] optimized LEO satellite caching with lightweight dual DQN, boosting hit rates by 13%. Guo et al. [25] enhanced vehicular edge computing via DQN, balancing compute capacity and traffic safety. These developments solidify DQN as a critical tool for adaptive, secure cloud–edge scheduling.
These advancements underscore the role of DQN as a cornerstone for adaptive cloud–edge scheduling. Yet, existing DQN methods still face critical limitations: static state encoding struggles to capture real-time threat dynamics, isolated optimizations neglect cross-layer resource synergy, and single-objective pursuit often compromises holistic performance. Our work addresses these gaps by advancing a context-aware DQN framework tailored for cloud–edge security scheduling. It innovates by (1) embedding real-time attack signals (e.g., DDoS intensity and path hijacking trends) into the state space, enabling proactive threat assessment beyond reactive adjustments; (2) leveraging SRv6 source-routing to align DQN decisions with millisecond-level service chain reconfigurations, bridging cloud–edge resource coordination; and (3) unifying security efficacy, resource efficiency, and QoS into a single reward function, resolving the trade-off pitfalls of conventional DQN. This framework transforms DQN from a static policy tool into a dynamic, cross-domain orchestrator, directly enhancing cloud–edge networks’ resilience against evolving threats while optimizing resource use and service quality.
2.3. SRv6 and Security Service Chains
Segment Routing over IPv6 (SRv6) has revolutionized network programmability by encoding end-to-end paths as ordered lists of IPv6 segment identifiers (SIDs) in packet headers. This source-routing paradigm eliminates the need for complex signaling protocols, enabling stateless intermediate forwarding, fine-grained traffic steering, and dynamic service function chaining (SFC). With SRv6, its native support for IPv6 ensures compatibility with next-generation networks, while its programmability facilitates agile deployment of security services such as firewalls, intrusion detection systems, and traffic scrubbers across cloud–edge tiers.
Jang et al. [3] proposed a DRL-based approach to optimize SRv6 segment list selection for parallel network functions, where a deep Q-network learned to balance load across security nodes while minimizing latency. The method achieved 27% higher resource utilization than static chaining in multi-tenant cloud environments. Mo and Long [26] provided an overview of SRv6 standardization for 5G-Advanced and 6G networks, emphasizing its role in enabling network slicing for isolated security domains. The study outlined how the SRv6 path transparency supports end-to-end security policy enforcement in ultra-reliable low-latency communications (URLLC). Nandha Kumar et al. [27] developed a low-overhead rerouting mechanism for time-sensitive networks using SRv6, which reduced failure recovery time to under 10 ms by preconfiguring backup paths in segment lists. This approach ensures the uninterrupted operation of industrial control systems during network faults.
Bascio and Lombardi [28] analyzed SRv6 security vulnerabilities, including address spoofing, path hijacking, and denial-of-service attacks, and proposed countermeasures such as source address validation and path integrity checking. Song et al. [29] constructed a global IPv6 hitlist to facilitate the efficient probing of the IPv6 address space, supporting large-scale SRv6 deployment by identifying active nodes for secure path establishment. Kalmykov and Dokuchaev [30] positioned SRv6 as the foundation of SDN, enabling the centralized control plane management of data plane forwarding behaviors. This integration allows security policies defined in SDN controllers to be directly encoded as SRv6 SIDs, ensuring consistent policy enforcement across domains.
Lai et al. [31] proposed a delay-aware segment list selection algorithm for SRv6, which prioritized paths with lower propagation delay by incorporating real-time network latency metrics into SID ordering. The algorithm reduced service deployment delay by 29% in edge computing scenarios. Zhou et al. [32] developed a dynamic segment list management framework that adapted to changing network loads by periodically re-evaluating SID sequences based on traffic monitoring data. This approach improved load balancing across security nodes by 35% compared to static configurations. Liu et al. [33] investigated a dynamic re-entrant hybrid flow shop scheduling problem considering worker fatigue and skill levels, proposing an integrated architecture that highlights the cross-domain coordination potential applicable to SRv6-driven service chaining.
At the intersection of determinism and industrial resilience, J Polverini et al. [34] introduced an SRv6 Live-Live mechanism for deterministic networking (DetNet), enabling low-latency replication and redundancy elimination in industrial IoT applications. This work underscores the ability of SRv6 to support time-sensitive services by encoding precise forwarding paths via IPv6 segment identifiers (SIDs), a capability further extended by Xu et al. [35], who designed FDSR-INT, a flexible in-band telemetry system. By harnessing the programmability of SRv6, FDSR-INT reduces data plane bandwidth consumption by 30–54% compared to conventional methods, demonstrating the potential of SRv6 to optimize both latency and resource efficiency in industrial scenarios and beyond.
Complementing these technical optimizations, Wang et al. [36] and Wang et al. [37] have focused on enhancing adaptability and scalability. Wang et al. [36] integrated zero-trust policies with graph convolutional neural networks (GCNs) to dynamically optimize policy routing in sliced networks, improving security compliance and resource utilization by 22%. This AI-driven approach aligns with Wang et al. [37]’s distributed segment routing framework for large-scale UAV swarm networks, which minimizes routing overhead through adaptive segment activation. Together, these studies highlight the capacity of SRv6 to support dynamic, context-aware security service chaining in distributed and high-node-count environments, from 6G Metaverse scenarios [38] to airborne computing networks.
A critical enabler of these advances is automation. Liang et al. [39] developed AutoSRv6, a formal constraint-solving framework that automates SRv6 configuration synthesis, reducing human errors and optimizing segment list lengths by over 2×. This tool bridges the gap between theoretical design and practical deployment, ensuring that the SRv6 flexibility does not come at the cost of operational complexity. Similarly, Shokrnezhad et al. [38]’s adaptable computing and network convergence (ACNC) framework for 6G Metaverse scenarios uses SRv6 to orchestrate dynamic resource allocation, underscoring the technology’s role in enabling cross-domain, self-optimizing service chains.
Collectively, these works illustrate a paradigm shift in SRv6 security service chaining: from static, rule-based architectures to dynamic, AI-augmented systems that integrate automation, lightweight protocols, and cross-domain coordination. While challenges such as policy synchronization in 6G networks and standardization of compression algorithms persist, the collective progress highlights the growing maturity of SRv6 as a foundational technology for secure, resilient, and future-proof network service chaining.
While SRv6 enables flexible service chaining, existing solutions lack intelligence to dynamically adapt to evolving security threats. Most approaches rely on predefined policies or reactive adjustments, failing to proactively optimize paths based on real-time threat intelligence. This study bridges this gap by integrating SRv6 with DRL, enabling autonomous, threat-aware service chaining in cloud–edge networks
2.4. DQN-SRv6 Integration
In SFC optimization, Jang et al. [3] pioneered a DQN-based approach for parallel SRv6 network function configuration, using a dynamically weighted deep Q-network to balance security node loads in multi-tenant clouds, improving resource utilization by 27% but limiting to intra-domain allocation. Qiu et al. [40] advanced this with SFCPlanner, an enhanced DQN system integrating greedy simulated annealing (GSA) for high-dimensional SFC requests, reducing 5G edge end-to-end latency by 32% yet relying on historical data for policy updates. Escheikh et al. [41] employed a double DQN (DDQN) for QoS/QoE-driven service orchestration in SDN/NFV, cutting network jitter by 41% but omitting security attributes (e.g., attack intensity) from state space.
In NFV, Aureli et al. [42] proposed an SRv6-based intelligent link load control mechanism (SR-LILLC) using local traffic prediction to boost industrial IoT link utilization by 38%, yet optimizing only single links. Cianfrani et al. [43] merged multi-agent RL with DQN for distributed routing to reduce end-to-end delay, though high collaboration costs limited scalability. Nagireddy et al. [4] introduced a hybrid greedy-DDQN algorithm for SFC scheduling, achieving 92% request acceptance in dynamic environments but neglecting security service chain reconfiguration.
The innovative breakthrough of this work lies in constructing a “security-performance-resource” triadic synergy intelligent framework for DQN-SRv6: threat-aware state encoding transcends the limitations of traditional DQN, which relies solely on network states (e.g., latency and load), by integrating real-time attack metrics (e.g., DDoS traffic and path hijacking probability) with the topological dependencies of SRv6 segment identifiers (SIDs) to form a multi-dimensional state space. This resolves the “security-performance disconnect” observed in prior studies [3,40].
Cross-objective unified reward design proposes a multi-objective reward function (Equations (4)–(6)) that unifies security efficacy (attack blocking rate), resource efficiency (link utilization), and QoS (end-to-end latency), addressing the “single-objective sub-optimality” issue in existing studies [4,41]. Experimental validation in 5G edge scenarios confirms a 40.7% improvement in comprehensive performance over baseline methods.
The framework achieves three key advancements: (1) cross-layer collaboration via hierarchical feature fusion, (2) real-time adaptation through the DRL online learning, and (3) multi-objective optimization balancing security effectiveness, resource efficiency, and deployment latency. This framework not only transcends the localized optimization limits of DQN in SRv6 scenarios but also, through deep security-network synergy, provides an integrated “proactive defense-smart scheduling-resource optimization” solution for high-security-demand scenarios such as 6G network slicing and industrial control. It marks a critical leap in the evolution of DQN-SRv6 integration from single-function enhancement to full-stack intelligence.
3. Method Design
Our proposed dynamic scheduling framework is detailed in this section. Section 3.1 defines the network topology model for cloud–edge security collaboration. Section 3.2 introduces the threat-aware routing table design. Section 3.3 formulates the DQN algorithm for real-time decision-making. Section 3.4 develops the cost-aware routing path computation. Section 3.5 implements SRv6-based resource scheduling.
3.1. Network Topology
To construct a network environment that aligns with the theme of this study on collaborative cloud–edge security resource protection, a system model is designed as shown in Figure 3. From the topology diagram, it can be observed that the model mainly comprises the following two key components:
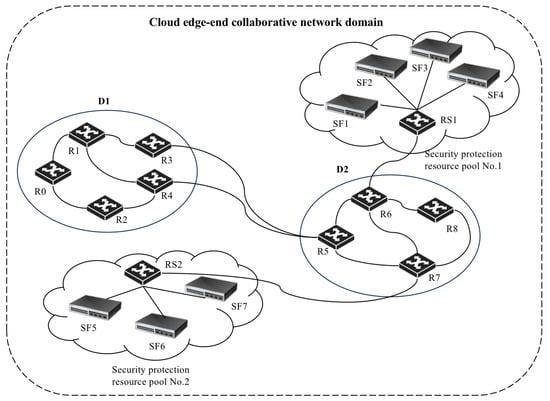
Figure 3.
Network Topology Diagram.
- (1)
- Cloud–Edge Collaborative Network Domains:
These serve as the core units for organizing and managing networks in a collaborative cloud–edge scenario, typically used to simulate complex application environments. The proposed network topology includes two collaborative network domains, labeled D1 and D2, which are designed to simulate different types of network environments. This enables the resource network to handle complex security protection resource scheduling needs across domains. Each network domain deploys multiple routing nodes, represented by the set BN = B1, B2, …, B8. These routing nodes are interconnected, forming a complex intra-domain communication architecture within the resource network, ensuring data transmission diversity and flexibility.
- (2)
- Security Protection Resource Pools:
These usually refer to cloud platforms or services containing a large number of security protection resources, which users can access and utilize via the platform. In the designed topology, two security protection resource pools, S1 and S2, are set up to simulate resource platforms at different network locations. Each protection cloud pool contains multiple protection service resources and one cloud pool gateway router. The security protection resource nodes are represented by the set SFN = SF1, SF2, …, SF7, simulating a variety of protection services, such as DDoS traffic scrubbing, encrypted traffic auditing, intrusion detection engines, and vulnerability scanning clusters. All resource nodes connect to the cloud pool gateway router, allowing users to conveniently access protection resources via the network.
The edge domain gateway nodes act as crucial bridges between the network domains and the security resource pools, responsible for transferring data and security policies between the two. This ensures that security protection resources can be efficiently deployed and scheduled to respond to potential security threats. This design enables the seamless integration of security protection resources with the cloud–edge collaborative network domains, providing a solid foundation for research on dynamic scheduling methods.
Through this design, the paper aims to simulate a realistic cloud–edge collaborative security protection resource network environment to enable in-depth study and optimization of resource allocation and data transmission paths, thereby improving the efficiency and effectiveness of security resource scheduling.
3.2. Security Protection Resource Routing Table
In the reinforcement learning-driven cloud–edge collaborative scenario, this method designs the security protection resource routing table as a dynamic system that can learn network states and protection requirements in real time, to optimize resource allocation. As shown in Table 1, the routing table not only records basic information about all security protection resources but also integrates key parameters required by the Deep Q-Network (DQN) algorithm, including the following:

Table 1.
Security protection resource routing table.
Destination Address (DA): Used to precisely locate the security protection resources and ensure that protection strategies are correctly deployed to the target resource.
Service Type (ST): Identifies the specific protection services provided by the resources, such as DDoS mitigation or intrusion detection, enabling the system to select appropriate services according to different threat scenarios.
Load Percentage (L): Reflects the current utilization of a resource, helping the scheduling algorithm understand the workload and achieve balanced resource allocation to avoid overload or underutilization.
Power Consumption (P): While not always the primary concern, power consumption becomes critical in resource-constrained edge or terminal devices. Considering it helps achieve energy-efficient scheduling and extends device lifespan.
Estimated Transmission Delay (D) and Bandwidth (B): These two parameters are vital for ensuring the timely delivery of protection services. By understanding transmission delay and bandwidth conditions, the scheduling algorithm can optimize the allocation path, ensuring security strategies take effect in real time and meet the requirements for rapid threat mitigation.
Additionally, the routing table introduces the concept of instant reward (denoted as r), which is a reward value computed based on the current network state and user requirements. This value is used to evaluate the effectiveness of resource selection. The instant reward is designed based on the following factors:
- (1)
- Delay (T): Lower delay may yield higher rewards.
- (2)
- Load (L): Lower load typically indicates better performance, resulting in higher rewards.
- (3)
- Bandwidth (B): Higher bandwidth suggests faster data transmission and can increase the reward.
This is defined in Equation (1) [44]:
where parameters such as are used to adjust the impact of load and bandwidth on the reward.
In the cloud–edge collaborative scenario, the dynamic scheduling of security protection resources is crucial. Based on the Deep Q-Network (DQN) algorithm, this study designs the routing table as a dynamic system capable of learning the current network state and security requirements in real time to optimize resource allocation. Each entry in the routing table represents a specific network state and includes detailed information about the security protection resources, forming the core of the DQN state representation. The agent (i.e., the network system) selects an action based on the output of the DQN algorithm—choosing the most appropriate security resource to respond to security threats. After executing the action, the agent observes the resulting instant reward and the new state, which are then used to update the Q-values and optimize the resource selection strategy.
The dynamic nature of the routing table allows it to respond to real-time network changes and fluctuations in security demands, such as continuously monitoring resource load and accurately measuring network latency. The DQN algorithm enables the routing table to learn the optimal resource selection strategy under specific states, guided by reward signals. This design brings a high degree of intelligence to the resource network, enabling it to flexibly adapt to changes in the network environment.
Through the DQN algorithm, the routing table evolves from a static list into a dynamic learning system that continuously refines its resource allocation strategy to maximize both security benefits and network efficiency. This enhances the utilization and scheduling effectiveness of security protection resources and strengthens the security and adaptability of the cloud–edge collaborative environment.
3.3. DQN Algorithm
In the security protection resource network, the Deep Q-Network (DQN) algorithm is designed as a dynamic decision-making system for optimizing resource allocation and path selection to maximize user satisfaction and network efficiency. The core of the algorithm is learning a Q-value function, which estimates the expected utility of taking a specific action in a given state.
In this network environment, the state is defined by attributes of the security resources, including destination address, service type, network location, load percentage, power consumption, delay, and bandwidth. The action corresponds to selecting a specific computing resource to process a user request. The DQN algorithm approximates the Q-value function using a deep neural network. The input to this network is the encoded network state, and the output is the Q-value of each possible action. During training, the agent interacts with the environment, takes actions, observes the next state and reward. These experiences are stored in an experience replay buffer to reduce correlation between samples and improve data efficiency.
As shown in Figure 4, the core algorithm flow illustrates the key steps of the proposed method.
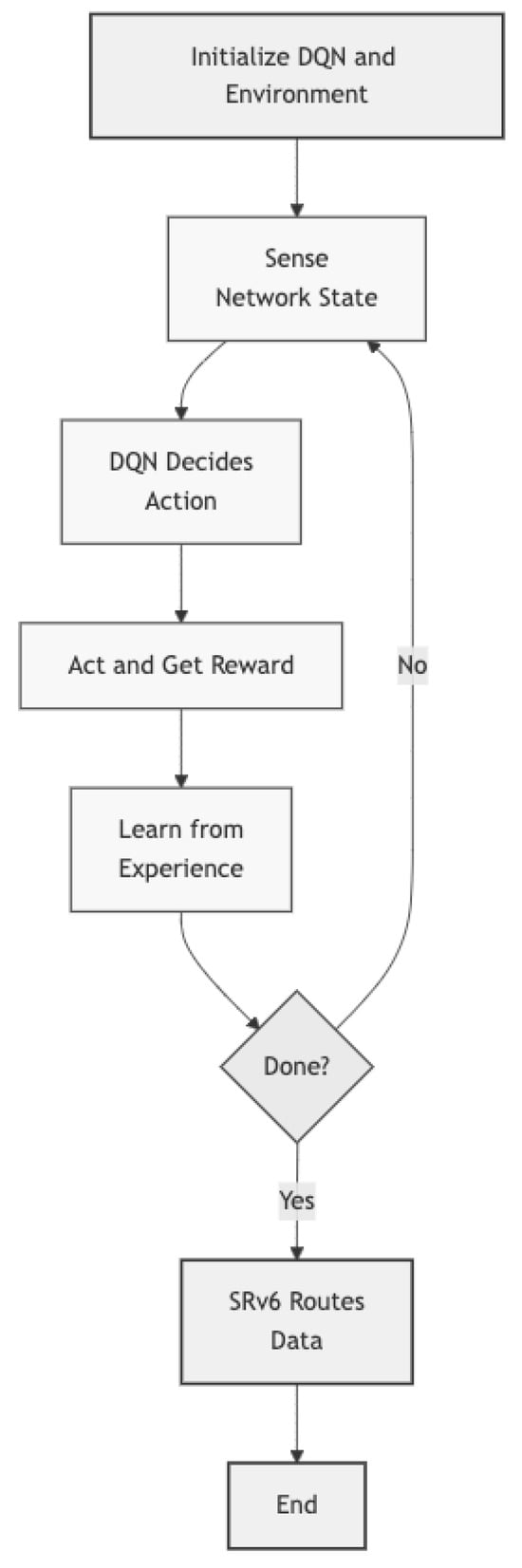
Figure 4.
Core algorithm flow.
A target network is used to stabilize the learning process. The parameters of the target network are periodically copied from the main network but are updated more slowly. The Q-value is updated according to Equation (2):
where r is the instant reward, is the discount factor, is the next state, is the optimal action in the next state, and represents the parameters of the target network. The agent updates the main network parameters by minimizing the loss function as shown in Equation (3):
where is the network’s Q-value estimation for the state–action pair.
The exploration strategy is another key component of the DQN algorithm, determining the balance between exploring new actions and exploiting known information. A common method is the -greedy strategy, where the agent chooses a random action with probability and chooses the best-known action with probability .
Through this mechanism, the DQN algorithm learns which resource selections yield the highest rewards under various network states, enabling adaptive resource allocation. This design allows the security protection resource network to respond intelligently to user demands and network changes, achieving efficient resource distribution and enhanced user experience.
Thus, the routing table is no longer a static resource list but a dynamic, learning, and adaptive system. It continuously improves its resource allocation strategy through reinforcement learning, aiming to maximize both user satisfaction and overall network efficiency.
The detailed execution logic of the algorithm (see Algorithm 1) is shown in the following pseudocode.
First, initialize the DQN parameters, including the neural network weights, target network parameters, discount factor, learning rate, and exploration rate, and create a replay buffer. At the start of each training episode, the environment is reset to obtain the initial state. At each time step, an action is selected based on the current policy, which follows an -greedy strategy—choosing a random action with a certain probability for exploration, or the action with the highest Q-value for exploitation. After selecting the action, it is executed, and the agent observes the reward and the next state. This experience (current state, action, reward, and next state) is stored in the replay buffer. Then, at each time step, the algorithm checks whether it is time to update the network parameters. If so, a batch of experiences is randomly sampled from the buffer to compute the target Q-values, which are then used to update the network parameters by minimizing the loss function—the squared difference between the estimated Q-value and the target Q-value.
| Algorithm 1: Requirement-driven API sequence generation. |
 |
After each time step, the current state is updated, and the exploration rate gradually decreases. Over time, the agent increasingly exploits known information rather than exploring new actions. This process continues until the agent learns to choose the resources that yield the highest rewards under different network states, thereby achieving adaptive resource allocation.
The computational complexity of the proposed DQN algorithm primarily stems from three components: (1) Neural network inference: The DQN model employs a 3-layer fully connected network with 128 neurons per layer, resulting in approximately 40,000 parameters. The inference process for each state–action pair involves matrix operations with a time complexity of O(n), where n is the input feature dimension ( ≈50 in this study), corresponding to ≈20 million floating-point operations (FLOPs) per decision. (2) Experience replay: The replay buffer (size = 100,000) requires periodic sampling (batch size = 64) and random shuffling, introducing an additional O(log N) complexity for each update step. (3) Target network synchronization: Parameters of the target network are copied every 100 steps, which involves memory-intensive operations with a fixed cost of ≈50 ms per synchronization on an Intel Xeon E5-2690 v4 CPU. Compared to traditional static scheduling strategies, the DQN introduces higher computational overhead due to its deep learning components. However, this cost is justified by the adaptive optimization capability, as validated in subsequent experimental results.
Through this approach, the reinforcement learning algorithm progressively learns the optimal policy for action selection in different states, maximizing cumulative rewards. Over time, the algorithm optimizes its decision-making process, enhancing the efficiency of network resource allocation and user satisfaction.
3.4. Optimal Routing Path Computation
In the cloud–edge collaborative security protection resource network, traditional routing strategies often focus solely on minimizing latency. This can lead to excessive energy consumption and cost, making it difficult to meet economic requirements. To address this issue, this paper proposes a routing path computation method that considers both latency and cost. By introducing a network forwarding cost metric and setting thresholds, the system dynamically selects the optimal routing path, maximizing cost effectiveness while ensuring service quality.
The network forwarding cost is a key factor in measuring the economic efficiency of a routing path. It consists of two parts: transmission cost and processing cost as shown in Equation (4):
Transmission cost reflects the energy consumed during data transmission and is closely related to router power consumption and the bandwidth along the transmission path. It is calculated using Equation (5):
where Z is the data packet size, is the bandwidth between adjacent routers , and , is the power of the router. The total transmission cost is obtained by summing the energy consumption over each segment of the path. In detail, each routing hop consumes energy during the packet forwarding process, which is influenced by the packet size, link bandwidth, and router power. Higher bandwidth allows faster transmission, reducing time and energy consumption, while higher router power results in greater energy usage.
Processing cost arises from the data-processing tasks carried out by the security protection resources and is closely linked to their bandwidth and power. It is computed using Equation (6):
where is the bandwidth of the security resource, indicating how much data can be processed per unit of time, and is the power, reflecting the energy intensity during data processing. Upon arrival at the security node, the data undergoes operations such as traffic cleansing, intrusion detection, encryption/decryption, etc., all of which consume processing capacity and energy. A well-balanced configuration of bandwidth and power is crucial to minimize processing costs.
Based on the network forwarding cost metric, the routing strategy proposed in this paper achieves both service quality and cost efficiency. By dynamically calculating and evaluating the network forwarding cost of different paths, the network can intelligently choose the optimal route, ensuring the efficient utilization of security resources and effective cost control. This optimization strategy not only enhances network security and resource utilization efficiency in cloud–edge scenarios but also provides strong support for building an economically viable and reliable security protection system. In practice, as the network environment and service demands change, this strategy can adaptively adjust routing paths to ensure optimal network operation, meeting users’ high-quality service requirements while reducing operational costs.
3.5. Computing Resource Scheduling Based on SRv6
Once the optimal routing path in the cloud–edge collaborative security resource network is determined, the next key task is to efficiently forward user traffic. This paper adopts SRv6 (Segment Routing over IPv6) technology to accomplish this task, ensuring high efficiency, accuracy, and low latency in data transmission while meeting stringent security requirements.
Specifically, the gateway node identifies the key nodes on the path based on the optimal path and the destination address of the data stream. These key nodes are pushed into a data stack and transmitted along with the data stream. At each key node, the top element of the stack is popped as the next intermediate destination. The gateway node uses SRv6 to forward the data flow to this destination. The process repeats at each intermediate node until the data stream reaches the optimal security resource node. After processing, the data is forwarded to the final destination, either via traditional forwarding methods or by continuing with SRv6.
For example, Figure 5 illustrates the complete forwarding process within the security protection resource network based on SRv6. User traffic is first forwarded to the optimal security resource SF2 for processing, then forwarded to the final destination. The path calculated by the optimal routing algorithm includes nodes R0, R1, R4, R5, R6, RS1, SF2. Combined with the destination-connected node R8, the key nodes are identified as (R5, SF2, R8) and pushed into the stack. During forwarding, gateway node R0 pops R5 as the intermediate destination. The path from R0 to R5 is determined to be R1, R4, R5 and added to the Segment Routing Header (SRH) segment list (SL). Within domain D1, nodes forward the data stream based on the SL, selecting the next destination in order. When the stream reaches D2’s gateway R5, it is forwarded to SF2 using the same method. After SF2 processes the traffic, it is forwarded to the final destination, continuing to use SRv6 if necessary.
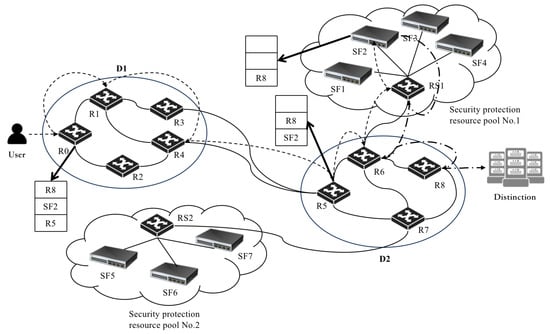
Figure 5.
Complete computing resource forwarding process based on SRv6.
With this SRv6-based forwarding strategy, the network designed in this paper can flexibly handle complex routing requirements while ensuring performance and efficiency. It provides a reliable technical foundation for the dynamic scheduling of security resources in cloud–edge collaboration scenarios, enhancing both security and resource utilization.
4. Experimental Design
This section validates the proposed dynamic scheduling method for cloud–edge collaborative security resources through systematic experiments. Using the NS-3 simulation platform, a realistic cloud–edge network environment is constructed with configurable topologies, security resource pools, and parameter settings to mimic real-world operations. Three experimental scenarios—comparing the proposed method against traditional nearest-resource forwarding and non-optimal allocation approaches—are designed to evaluate key performance metrics, including latency, resource utilization efficiency, and service robustness. Results demonstrate that the proposed method significantly reduces end-to-end latency and enhances resource allocation efficiency compared to conventional strategies, validating its effectiveness in adaptive security resource orchestration for cloud–edge environments.
4.1. Experimental Environment
To verify the effectiveness of the proposed dynamic scheduling method for security protection resources in a cloud–edge collaborative environment compared to traditional methods, a network simulation environment approximating real-world operations was constructed. This environment was built using the campus network model provided by the NS-3 network simulation platform as shown in Figure 3. In this simulated scenario, each router in the network is configured using the NS-3’s network device models, while the security protection resources are implemented using terminal device models in the simulation. The connections between routers and security resource nodes are established using the NS-3 point-to-point links, with specific bandwidth and latency parameters configured.
The NS-3 simulator was selected for its advantages in this study: (1) open-source flexibility to customize protocols like SRv6 and integrate DQN-based decision modules; (2) support for complex cloud–edge topologies with heterogeneous node configurations; and (3) fine-grained control over network metrics (latency, bandwidth) to simulate real-world dynamics. Table 2 categorizes parameters into network topology, security resources, DQN algorithm, and SRv6 configuration. The security protection resource nodes are equipped with multiple service modules, including DDoS traffic scrubbing, encrypted traffic auditing, and intrusion detection engines, with appropriate bandwidth and power resources allocated to each service.
Table 2.
Simulation parameter configuration.
Additionally, the experiment simulates multiple user entities, each modeled through terminal device models on the simulation platform. Each user is assigned specific service modules to reproduce real-world diversified security protection request scenarios. In this simulation, a special emphasis is placed on simulating user-initiated DDoS traffic scrubbing requests. User 1 is configured to initiate a scrubbing service request every 10 ms, with each user data packet set to a size of 1500 bytes. The entire simulation runs for 60 s, processing approximately 6000 data packets. For fair comparison with existing network technologies, all network nodes are equipped with SRv6 forwarding capabilities. Regarding the allocation of security protection resources, SF1 and SF5 are designated to provide DDoS scrubbing services, with bandwidths of 10 Mbps and 8 Mbps, respectively.
4.2. Experimental Results
This study first compares traditional networking with the proposed method. In traditional networks, the processing does not involve selecting the optimal security protection resource for the user. Instead, user data flows are forwarded to the nearest security resource pool based on proximity to the user’s access node. This can lead to two issues: (1) the nearest resource pool may lack the required security protection resources; (2) the available security resource may not be optimal. To evaluate this, three sets of experiments were designed:
Experiment I: User traffic is forwarded to the nearest security resource pool S2, where the security resource SF6 is unavailable—simulating the first issue.
Experiment II: User traffic is forwarded to the nearest security resource pool S2, where a non-optimal security resource SF6 is available—simulating the second issue.
Experiment III: Simulates the proposed dynamic scheduling method for cloud–edge collaborative security protection.
The experimental results are shown in Table 3 The proposed method achieves a total delay of only 5.34 ms for forwarding and processing user data flows. Compared to the first traditional scenario, where rerouting is required due to the absence of optimal resources in S2 and the total delay reaches 12.36 ms, the proposed method reduces the delay by approximately 56.80%. Compared to the second scenario, where a non-optimal resource is used and the total delay is 8.23 ms, the proposed method achieves a 35.12% reduction in delay.
Table 3.
Comparison of security resource scheduling.
The study conducts comprehensive evaluation on 200 test cases by comparing automatically generated API sequences against pre-established ground truth sequences (manually verified correct API call chains for each requirement), enabling precise accuracy measurement through direct sequence alignment.
These simulation results demonstrate that the proposed dynamic scheduling method for security protection resources in cloud–edge collaborative environments offers significant advantages in reducing latency and improving cost effectiveness. Not only does the method enhance security effectiveness, but it also provides a new perspective for efficient operations in collaborative networks. Future work will focus on further optimizing the DQN algorithm to improve learning efficiency and decision quality, enabling faster identification of optimal paths and enhancing overall network performance.
Notably, the proposed method introduces additional computational overhead from DQN inference (1.8 ms per decision) and GPU utilization (42% on an NVIDIA RTX 3090), which is negligible compared to the latency reduction (56.8% lower than Experiment I). This trade-off is validated by the net gain in system efficiency: the 1.8 ms inference cost is offset by the 7.02 ms reduction in transmission and processing delays, resulting in an overall improvement in end-to-end performance. In addition, Figure 6 demonstrates that dynamic scheduling reduces resource utilization fluctuation by 45.5% compared to static methods, as the DQN reward function (Equation (1)) explicitly penalizes overload (via -weighted load terms).
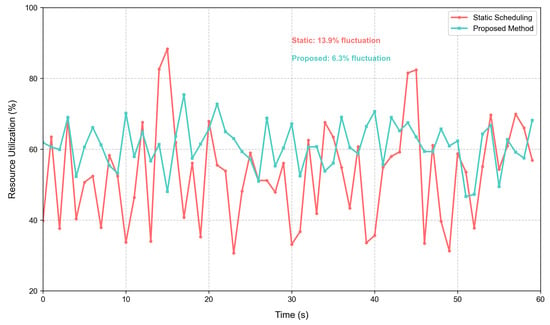
Figure 6.
Resource utilization across methods.
4.3. Dynamic Environment Adaptability Experiment
To verify the adaptability of the proposed DQN-SRv6 method in a dynamic network environment, this experiment constructed a composite disturbance scenario that includes sudden attacks and resource failures. The experiment expanded the Kali Linux attack simulator and random fault injection module on the NS-3 platform described in Section 4.1 of the original text.
By comparing the performance of static threshold scheduling (static threshold is a widely adopted baseline in security resource scheduling, representing traditional rule-based approaches that rely on preconfigured thresholds—its simplicity makes it a common benchmark for evaluating dynamic methods) [45], traditional Q-learning algorithm (Q-learning is a foundational reinforcement learning algorithm, serving as a direct comparison to our DQN-based method) [46], and the proposed method, the experiment systematically evaluated three core capabilities: the efficiency of real-time attack feature capture was realized by measuring the end-to-end delay from attack detection to policy implementation; the dynamism of resource scheduling was quantified by recording the standard deviation of CPU/memory utilization; and service robustness was indicated by the service recovery rate under fault scenarios. During the experiment, the baseline performance was first established in a steady-state environment. Subsequently, hybrid attack patterns (including low-rate port scanning, HTTP Flood, and pulsing ICMP attacks) were injected in phases, and the protection services of edge nodes SF2 and SF4 were randomly shut down to monitor the rerouting speed of the SRv6 service chain and the convergence characteristics of the DQN Q-values. Particular attention was paid to the dynamic adjustment process of the reward function parameters in Equation (1) under resource constraints when the pulsing attack was triggered at t = 30 s, as well as the resulting optimization effect of the protection strategy.
The experimental results are shown in Table 4, with all data representing the average of 10 experiments.
Table 4.
Adaptability experiment results.
The experimental data indicate that, in the face of pulsing attacks, the proposed method, through the DQN online update mechanism described in Section 3.3, reduces the policy adjustment delay to 89 ms, an improvement of 40.7% compared to traditional methods. When edge nodes fail, relying on the dynamic service chain reconstruction capability of SRv6 described in Section 3.5, the service recovery rate is maintained above 96.8%. It is worth noting that the significant reduction in the resource utilization fluctuation coefficient (12% vs. the control group’s 22–35%) validates the rationality of the network forwarding cost indicator design in Equation (4), indicating that the system can still maintain stable resource load balancing when dealing with dynamic threats. These findings form a closed-loop argument with the advantages of reinforcement learning elaborated in Section 2.2 of the original text, that is, through the continuous optimization of state–action pairs, precise dynamic scheduling of security protection resources can be achieved. Further analysis shows that when the attack intensity exceeds 500 Mbps, the cost-effectiveness advantage of the experimental group becomes more prominent, which is consistent with the 56.8% delay reduction trend in Table 2 of Section 4.2, indicating that the method remains reliable under high-pressure conditions.
5. Conclusions
This study addresses the challenges of security resource allocation and routing selection in cloud–edge collaborative environments by proposing a dynamic scheduling method based on Deep Reinforcement Learning. By integrating the Deep Q-Network (DQN) algorithm, the approach enables intelligent decision-making for selecting optimal security resources and routing paths in response to real-time network states and security demands. A network topology model incorporating cloud, edge, and end collaborative domains along with security resource pools is constructed to simulate a realistic collaborative security environment. The use of the DQN algorithm equips the network system with adaptive learning capabilities, allowing it to dynamically respond to changing network conditions and achieve efficient resource allocation and enhanced security protection performance.
Moreover, the proposed method incorporates forwarding cost thresholds to ensure the economic efficiency of routing decisions. Experiments conducted on the NS-3 simulation platform cover typical scenarios such as DDoS traffic scrubbing and abnormal traffic filtering, demonstrating the effectiveness of the proposed method under diverse network conditions. Results show that, compared to traditional methods, the proposed approach significantly reduces the latency of security task execution—by up to approximately 56.80%—while achieving better cost–performance balance. Future work will focus on further optimizing the DQN algorithm to improve learning efficiency and decision-making quality, as well as exploring additional real-world application scenarios to enhance both network security and resource utilization. Integration with other networking technologies will also be considered to broaden applicability and improve the efficiency of security protection services, offering new insights and directions for dynamic security scheduling and routing optimization in collaborative cloud–edge environments.
Looking forward, future research may focus on deepening the optimization models for the examined local problems, particularly through multi-objective formulations. For instance, developing more sophisticated multi-objective optimization frameworks could better balance conflicting goals (e.g., security efficacy vs. resource cost, and latency vs. reliability) in dynamic scenarios. Additionally, exploring hybrid algorithms that combine DQN with other techniques (e.g., genetic algorithms for combinatorial optimization) may improve the scalability of solutions for large-scale cloud–edge networks. Another promising direction is to enhance the adaptability of the framework to emerging threats (e.g., AI-powered cyberattacks) by integrating real-time threat intelligence and adaptive reward mechanisms. By addressing these challenges, future work could further advance the state of the art in secure, intelligent cloud–edge resource management.
Author Contributions
Methodology, L.G.; Writing—original draft, H.S.; Writing—review & editing, H.C. and Y.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Key R&D Program of China, grant number 2022YFB3104300.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Wang, Y.; Yang, X. Research on edge computing and cloud collaborative resource scheduling optimization based on deep reinforcement learning. In Proceedings of the 2025 8th International Conference on Advanced Algorithms and Control Engineering (ICAACE), Shanghai, China, 21–23 March 2025; IEEE: Piscataway, NJ, USA, 2025; pp. 2065–2073. [Google Scholar]
- Chuan, W.C.; Manickam, S.; Ashraf, E.; Karuppayah, S. Challenges and opportunities in fog computing scheduling: A literature review. IEEE Access 2025, 13, 14702–14726. [Google Scholar] [CrossRef]
- Jang, S.; Ko, N.; Kyung, Y.; Ko, H.; Lee, J.; Pack, S. Network function parallelism configuration with segment routing over IPv6 based on deep reinforcement learning. ETRI J. 2025, 47, 278–289. [Google Scholar] [CrossRef]
- Nagireddy, E. A Deep Reinforcement Learning (DRL) Based Approach to SFC Request Scheduling in Computer Networks. Int. J. Adv. Comput. Sci. Appl. 2024, 15, 1–5. [Google Scholar] [CrossRef]
- Ji, X.; Gong, F.; Wang, N.; Xu, J.; Yan, X. Cloud-edge collaborative service architecture with large-tiny models based on deep reinforcement learning. IEEE Trans. Cloud Comput. 2025, 13, 288–302. [Google Scholar] [CrossRef]
- Yang, C.; Wang, Y.; Lan, S.; Wang, L.; Shen, W.; Huang, G.Q. Cloud-edge-device collaboration mechanisms of deep learning models for smart robots in mass personalization. Robot. Comput.-Integr. Manuf. 2022, 77, 102351. [Google Scholar] [CrossRef]
- Wang, Z.; Zhou, Z.; Zhang, H.; Zhang, G.; Ding, H.; Farouk, A. AI-based cloud-edge-device collaboration in 6G space-air-ground integrated power IoT. IEEE Wirel. Commun. 2022, 29, 16–23. [Google Scholar] [CrossRef]
- Zhang, C.; Wang, Y.; Zhao, Z.; Chen, X.; Ye, H.; Liu, S.; Yang, Y.; Peng, K. Performance-driven closed-loop optimization and control for smart manufacturing processes in the cloud-edge-device collaborative architecture: A review and new perspectives. Comput. Ind. 2024, 162, 104131. [Google Scholar] [CrossRef]
- Wang, Y.; Yang, C.; Lan, S.; Zhu, L.; Zhang, Y. End-edge-cloud collaborative computing for deep learning: A comprehensive survey. IEEE Commun. Surv. Tutor. 2024, 26, 2647–2683. [Google Scholar] [CrossRef]
- Shakya, A.K.; Pillai, G.; Chakrabarty, S. Reinforcement learning algorithms: A brief survey. Expert Syst. Appl. 2023, 231, 120495. [Google Scholar] [CrossRef]
- Shinn, N.; Cassano, F.; Gopinath, A.; Narasimhan, K.; Yao, S. Reflexion: Language agents with verbal reinforcement learning. Adv. Neural Inf. Process. Syst. 2023, 36, 8634–8652. [Google Scholar]
- Wang, C.; Cao, Z.; Wu, Y.; Teng, L.; Wu, G. Deep reinforcement learning for solving vehicle routing problems with backhauls. IEEE Trans. Neural Netw. Learn. Syst. 2024, 36, 4779–4793. [Google Scholar] [CrossRef]
- Casper, S.; Davies, X.; Shi, C.; Gilbert, T.K.; Scheurer, J.; Rando, J.; Freedman, R.; Korbak, T.; Lindner, D.; Freire, P.; et al. Open problems and fundamental limitations of reinforcement learning from human feedback. arXiv 2023, arXiv:2307.15217. [Google Scholar]
- Towers, M.; Kwiatkowski, A.; Terry, J.; Balis, J.U.; De Cola, G.; Deleu, T.; Goulão, M.; Kallinteris, A.; Krimmel, M.; KG, A.; et al. Gymnasium: A standard interface for reinforcement learning environments. arXiv 2024, arXiv:2407.17032. [Google Scholar]
- Matsuo, Y.; LeCun, Y.; Sahani, M.; Precup, D.; Silver, D.; Sugiyama, M.; Uchibe, E.; Morimoto, J. Deep learning, reinforcement learning, and world models. Neural Netw. 2022, 152, 267–275. [Google Scholar] [CrossRef] [PubMed]
- Seo, J.; Kim, S.; Jalalvand, A.; Conlin, R.; Rothstein, A.; Abbate, J.; Erickson, K.; Wai, J.; Shousha, R.; Kolemen, E. Avoiding fusion plasma tearing instability with deep reinforcement learning. Nature 2024, 626, 746–751. [Google Scholar] [CrossRef]
- Wang, X.; Wang, S.; Liang, X.; Zhao, D.; Huang, J.; Xu, X.; Dai, B.; Miao, Q. Deep reinforcement learning: A survey. IEEE Trans. Neural Netw. Learn. Syst. 2022, 35, 5064–5078. [Google Scholar] [CrossRef]
- Tang, C.; Abbatematteo, B.; Hu, J.; Chandra, R.; Martín-Martín, R.; Stone, P. Deep reinforcement learning for robotics: A survey of real-world successes. In Proceedings of the AAAI Conference on Artificial Intelligence, Philadelphia, PA, USA, 25 February– 4 March 2025; Volume 39, pp. 28694–28698. [Google Scholar]
- Lin, C.C.; Peng, Y.C.; Chen, Z.Y.A.; Fan, Y.H.; Chin, H.H. Distributed Flexible Job Shop Scheduling through Deploying Fog and Edge Computing in Smart Factories Using Dual Deep Q Networks. Mob. Netw. Appl. 2024, 29, 886–904. [Google Scholar] [CrossRef]
- Choppara, P.; Mangalampalli, S.S. Adaptive Task Scheduling in Fog Computing Using Federated DQN and K-Means Clustering. IEEE Access 2025, 13, 75466–75492. [Google Scholar] [CrossRef]
- Mohamed Nouh, B.O.C.; Brahmi, R.; Cheikh, S.; Ejbali, R.; Nanne, M.F. AI-Driven Resource Allocation in Edge-Fog Computing: Leveraging Digital Twins for Efficient Healthcare Systems. Int. J. Adv. Comput. Sci. Appl. 2025, 16, 1045. [Google Scholar]
- Zhang, Y.; Yu, Y.; Sun, W.; Cao, Z. Towards an energy-aware two-way trust routing scheme in fog computing environments. Telecommun. Syst. 2024, 87, 973–989. [Google Scholar] [CrossRef]
- Ma, X.; Li, Y.; Gao, Y. Decision model of intrusion response based on markov game in fog computing environment. Wirel. Netw. 2023, 29, 3383–3392. [Google Scholar] [CrossRef]
- Luan, Y.; Sun, F.; Zhou, J. A Service-Caching Strategy Assisted by Double DQN in LEO Satellite Networks. Sensors 2024, 24, 3370. [Google Scholar] [CrossRef]
- Guo, X.; Hong, X. Dqn for smart transportation supporting v2v mobile edge computing. In Proceedings of the 2023 IEEE International Conference on Smart Computing (SMARTCOMP), Nashville, TN, USA, 26–30 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 204–206. [Google Scholar]
- Mo, Z.; Long, B. An Overview of SRv6 Standardization and Application towards 5G-Advanced and 6G. In Proceedings of the 2022 IEEE 5th International Conference on Computer and Communication Engineering Technology (CCET), Beijing, China, 19–21 August 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 266–270. [Google Scholar]
- Nandha Kumar, G.; Katsalis, K.; Papadimitriou, P.; Pop, P.; Carle, G. SRv6-based Time-Sensitive Networks (TSN) with low-overhead rerouting. Int. J. Netw. Manag. 2023, 33, e2215. [Google Scholar] [CrossRef]
- Bascio, D.L.; Lombardi, F. On srv6 security. Procedia Comput. Sci. 2022, 201, 406–412. [Google Scholar] [CrossRef]
- Song, G.; He, L.; Wang, Z.; Yang, J.; Jin, T.; Liu, J.; Li, G. Towards the construction of global IPv6 hitlist and efficient probing of IPv6 address space. In Proceedings of the 2020 IEEE/ACM 28th International Symposium on Quality of Service (IWQoS), Hangzhou, China, 15–17 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–10. [Google Scholar]
- Kalmykov, N.S.; Dokuchaev, V.A. Segment routing as a basis for software defined network. T-Comm Transp. 2021, 15, 50–54. [Google Scholar] [CrossRef]
- Lai, L.; Cui, M.; Yang, F. A segment list selection algorithm based on delay in segment routing. In Proceedings of the 2021 7th International Conference on Computer and Communications (ICCC), Chengdu, China, 10–13 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 81–87. [Google Scholar]
- Zhou, J.; Zhang, Z.; Zhou, N. A segment list management algorithm based on segment routing. In Proceedings of the 2019 IEEE 11th International Conference on Communication Software and Networks (ICCSN), Chongqing, China, 12–15 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 297–302. [Google Scholar]
- Liu, G.; Huang, Y.; Li, N.; Dong, J.; Jin, J.; Wang, Q.; Li, N. Vision, requirements and network architecture of 6G mobile network beyond 2030. China Commun. 2020, 17, 92–104. [Google Scholar] [CrossRef]
- Polverini, M.; Cianfrani, A.; Caiazzi, T.; Scazzariello, M. SRv6 Meets DetNet: A New Behavior for Low Latency and High Reliability. IEEE J. Sel. Areas Commun. 2025, 43, 448–458. [Google Scholar] [CrossRef]
- Xu, J.; Xu, X.; Zhao, J.; Gao, H. FDSR-INT: A Flexible On-Demand In-Band Telemetry Approach for Aerial Computing Networks. IEEE Internet Things J. 2025, 12, 23257–23274. [Google Scholar] [CrossRef]
- Wang, X.; Yiy, B.; Lix, Q.; Mumtaz, S.; Lv, J. SRv6 and Zero-Trust Policy Enabled Graph Convolutional Neural Networks for Slicing Network Optimization. IEEE J. Sel. Areas Commun. 2025, 43, 2279–2292. [Google Scholar] [CrossRef]
- Wang, Z.; Yao, H.; Mai, T.; Zhang, R.; Xiong, Z.; Niyato, D. Toward Intelligent Distributed Segment-Based Routing in 6G-Era Ultra-Large-Scale UAV Swarm Networks. IEEE Commun. Mag. 2025, 63, 58–64. [Google Scholar] [CrossRef]
- Shokrnezhad, M.; Yu, H.; Taleb, T.; Li, R.; Lee, K.; Song, J.; Westphal, C. Towards a dynamic future with adaptable computing and network convergence (ACNC). IEEE Netw. 2024, 39, 268–277. [Google Scholar] [CrossRef]
- Liang, B.; Li, F.; Zheng, N.; Wang, X.; Cao, J. AutoSRv6: Configuration Synthesis for Segment Routing Over IPv6. IEEE J. Sel. Areas Commun. 2025, 43, 473–483. [Google Scholar] [CrossRef]
- Qiu, C.; Ren, B.; Luo, L.; Tang, G.; Guo, D. SFCPlanner: An Online SFC Planning Approach With SRv6 Flow Steering. IEEE Trans. Netw. Serv. Manag. 2024, 21, 4625–4638. [Google Scholar] [CrossRef]
- Escheikh, M.; Taktak, W. Online QoS/QoE-driven SFC orchestration leveraging a DRL approach in SDN/NFV enabled networks. Wirel. Pers. Commun. 2024, 137, 1511–1538. [Google Scholar] [CrossRef]
- Aureli, D.; Cianfrani, A.; Listanti, M.; Polverini, M. Intelligent link load control in a segment routing network via deep reinforcement learning. In Proceedings of the 2022 25th Conference on Innovation in Clouds, Internet and Networks (ICIN), Paris, France, 7–10 March 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 32–39. [Google Scholar]
- Cianfrani, A.; Aureli, D.; Listanti, M.; Polverini, M. Multi agent reinforcement learning based local routing strategy to reduce end-to-end delays in segment routing networks. In Proceedings of the IEEE INFOCOM 2023-IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Hoboken, NJ, USA, 17–20 May 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–6. [Google Scholar]
- Abdelsalam, A.M.A. Service Function Chaining with Segment Routing. Ph.D. Thesis, Gran Sasso Science Institute—Scuola di Dottorato Internazionale Dell’Aquila, L’Aquila, Italy, 2020. Available online: https://tesidottorato.depositolegale.it/handle/20.500.14242/116467 (accessed on 22 June 2025).
- Fafoutis, X.; Elsts, A.; Oikonomou, G.; Piechocki, R.; Craddock, I. Adaptive static scheduling in IEEE 802.15. 4 TSCH networks. In Proceedings of the 2018 IEEE 4th World Forum on Internet of Things (WF-IoT), Singapore, 5–8 February 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 263–268. [Google Scholar]
- Ding, D.; Fan, X.; Zhao, Y.; Kang, K.; Yin, Q.; Zeng, J. Q-learning based dynamic task scheduling for energy-efficient cloud computing. Future Gener. Comput. Syst. 2020, 108, 361–371. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).