1. Introduction
The Common Vulnerabilities and Exposures list (CVE) [
1] is the largest continuously growing repository of open vulnerabilities, which provides detailed descriptions of vulnerabilities. Cybersecurity staff can refer to this description to promptly identify vulnerabilities in their networks and further find the cause and scope of the vulnerabilities. However, CVE just helps identify and enumerate the vulnerabilities in enterprise networks and does not analyze the relevant attack behaviors that vulnerabilities cause. The Adversarial Tactics, Techniques, and Common Knowledge (ATT&CK) [
2] serves as a comprehensive repository of tactics and techniques, which models the behaviors of attackers in a multi-step attack. A tactic is a high-level concept that describes the goals or intentions of the attacker, while techniques describe in detail the implementation of the tactics, such as the explicit methods, tools, or behaviors. Intuitively, it is possible to establish a mapping between a
Vulnerability in a CVE and an ATT&CK’s
Tactic and
Technique (VTT), where the latter could exploit the former. This is valuable for security staff to re-conceptualize vulnerabilities from an attacker’s perspective in enterprise networks, so that they can develop effective defense strategies to block hidden attacks [
3,
4].
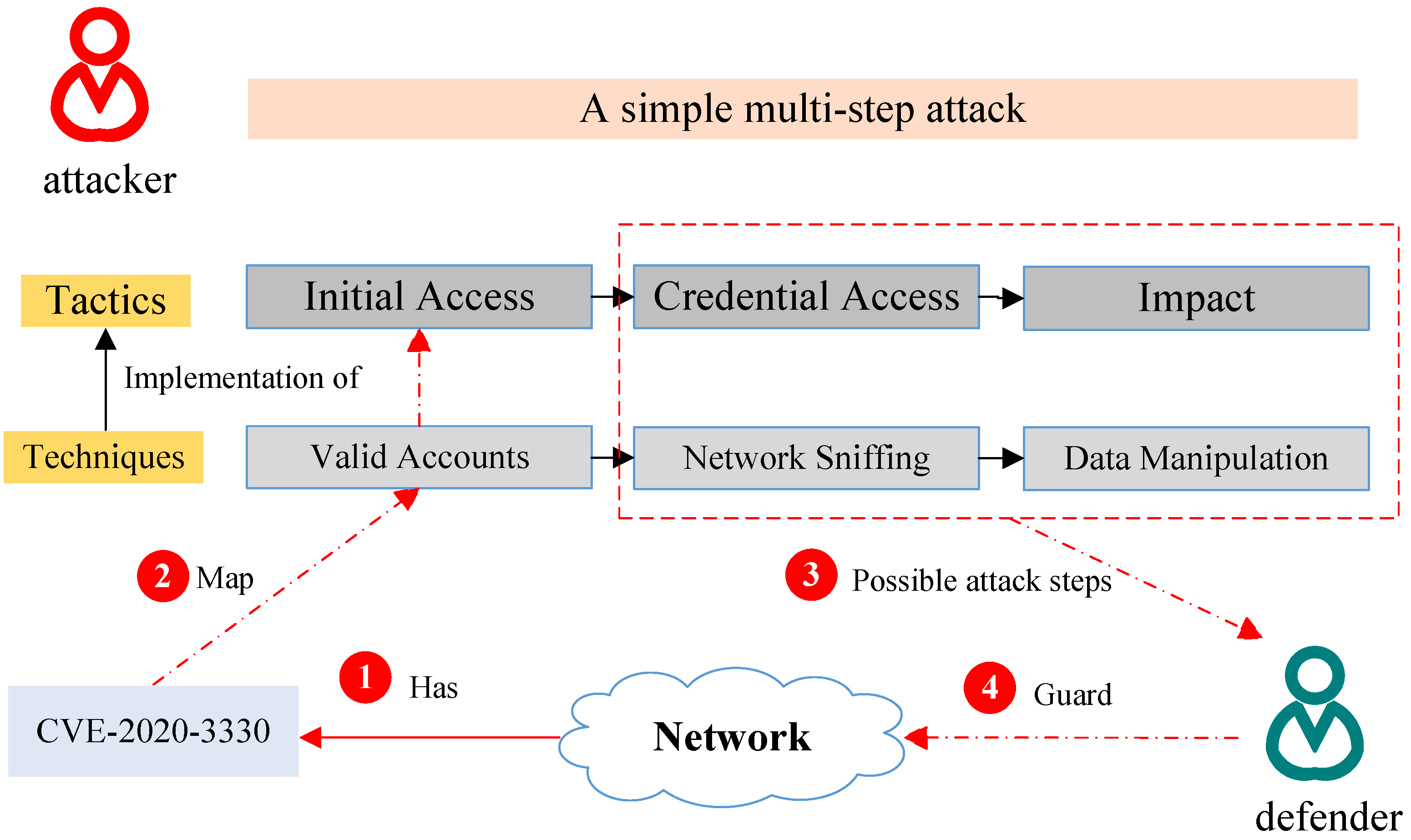
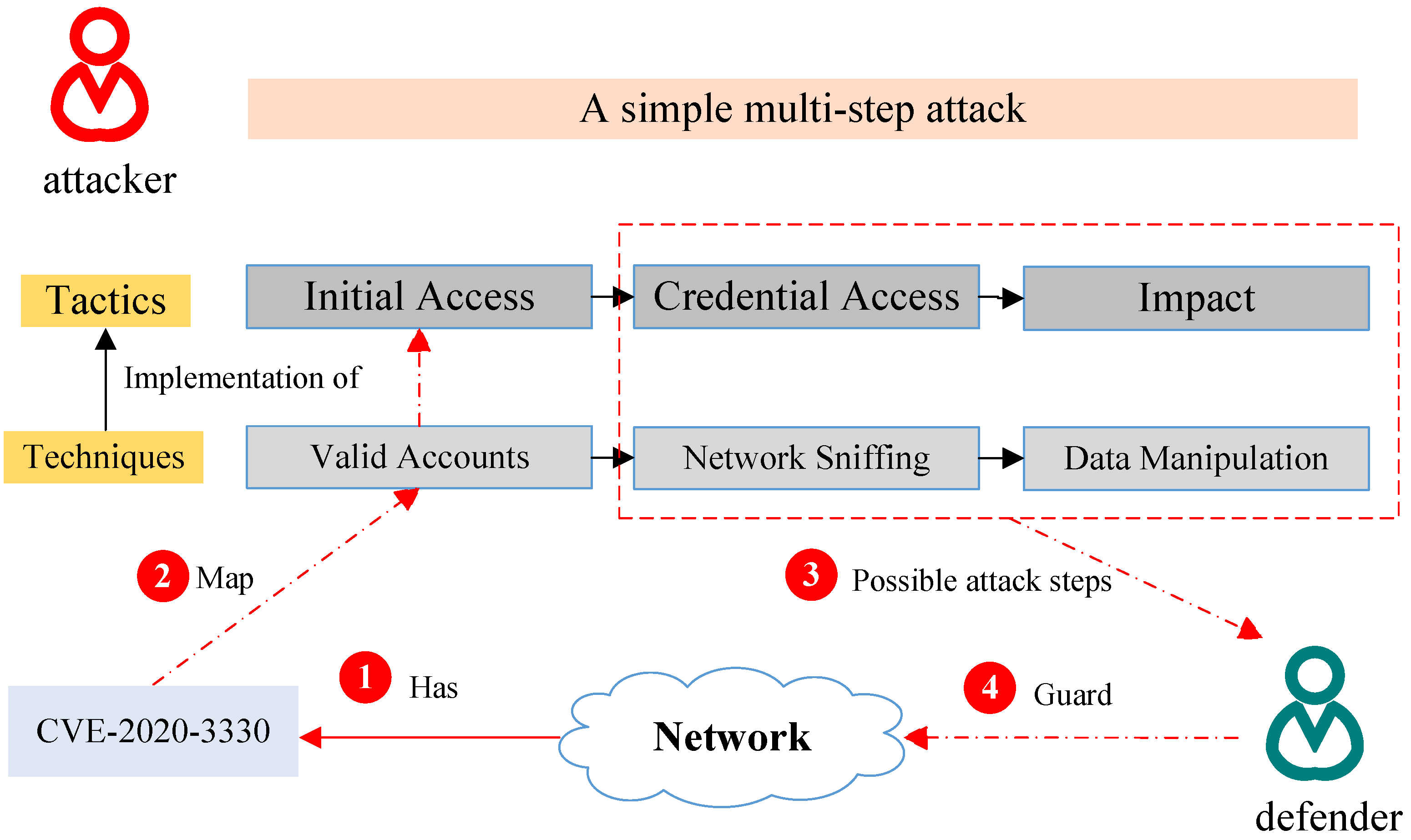
Figure 1 illuminates the scenario. The defender first identifies CVE-2020-3330 in their enterprise network. Then, they infer through VTT that the corresponding tactic of the potential attack is “Initial Access” as well as the technique is “Valid Accounts”. Consequently, they can adopt targeted mitigation such as “Account Locking” to block hidden attacks.
However, manually building a VTT mapping is impractical in the face of emerging vulnerabilities and an ever-expanding category of tactics and techniques, so it is crucial to research automated methods to build a VTT mapping. The core challenge of automating VTT mapping is to extract semantics from lengthy vulnerability descriptions and then map them to multiple categories.
Prior researchers commonly employed language models to establish a VTT mapping, with vulnerability descriptions as input and categories of tactics or techniques as output. Benjamin Ampel and Chen [
5] proposed CVET, which employed a self-knowledge distillation method alongside a fine-tuning process on RoBERTa. CVET was designed to identify key information within CVE descriptions and classify them into one of ten categories of ATT&CK tactics. This method utilized the power of knowledge distillation to achieve a 71.49% tactical accuracy but did not utilize technical and tactical descriptions. Abdeen et al. [
6] introduced SEMT, which automatically mapped CVE entries to ATT&CK techniques based on their textual similarity. SEMT extracted attack vectors from detailed vulnerability descriptions using semantic role labeling and a BERT-based model, then mapped them to 1 of the 41 ATT&CK techniques with a logistic regression model trained by ATT&CK technique descriptions. SEMT utilized technical descriptions but required attack vectors as an intermediate step, which may lose some information. Past works have attempted to establish a static mapping from vulnerability descriptions to technical and tactical categories. The static mapping has to be reconstructed in the face of a category update in ATT&CK, which is generally inefficient.
Large language models (LLMs) are expected to fuel advances in VTT mapping because of their language understanding and generation capabilities. Nevertheless, Liu et al. [
7] states that applying ChatGPT directly to VTT mapping does not work well, achieving a 32.76% tactical accuracy. This suggests that it is difficult for simple queries to utilize the potential of LLMs in solving domain-specific tasks such as the VTT mapping. Therefore, we fine-tuned an LLM to enhance its effectiveness in VTT applications. Many fine-tuning and prompt engineering methods such as Low-Rank Adaptation (LORA) [
8] and chain of thought (CoT) [
9] can unleash the potential of LLMs in the specialized domain. These methods help LLMs improve performance in VTT mapping by fusing more VTT-related information such as that from Common Weakness Enumeration (CWE) [
10] and Common Attack Patterns Enumeration and Classification (CAPEC) [
11]. CWE is a list of software and hardware vulnerability types, while CAPEC catalogs common attack patterns that exploit these types of vulnerabilities. Specifically, many of the attack patterns documented in CAPEC correspond to tactics and techniques outlined in ATT&CK.
In this paper, to automate VTT mapping, we propose a two-step framework called VTT-LLM, which aims to realize the potential of LLMs in VTT mapping, as shown in
Figure 2. Firstly, to leverage the LLM, we extract and craft a chain template to organize instructions from four cybersecurity databases, namely, CVE, CWE, CAPEC, and ATT&CK. These instructions are used to fine-tune the LLM to the specialized domain of the VTT mapping to complete the mapping from vulnerability descriptions to attack technique descriptions. Secondly, we match the attack technique description with the ATT&CK technique description based on text embedding to complete the VTT task. Since the techniques of ATT&CK are implementations of their tactics, mapping vulnerabilities to techniques implies that the VTT task has been implemented. Our contributions are summarized as follows.
We propose a framework called VTT-LLM, which automatically maps vulnerabilities in CVE to techniques in ATT&CK, including mapping to their tactics, thus enabling the mapping of vulnerabilities to attack categories as well as behavior patterns. VTT-LLM significantly improves the accuracy of VTT mapping by 13.69% over the traditional state-of-the-art method, CVET, and 54.42% over the native application of ChatGPT.
To maximize the potential of LLMs in VTT mapping, we propose a novel chain template for generating fine-tuning instructions that combine a priori knowledge of CWE and CAPEC. The method yields an average accuracy increase of 9.24% across different LLMs.
To support future research on VTT mapping and related tasks, we extract knowledge from CWE, CAPEC, and ATT&CK and compile a comprehensible instruction dataset for fine-tuning the LLM, whose effectiveness is promoted in the vertical domain. This dataset includes descriptions of vulnerabilities, weaknesses, attack patterns, and techniques, along with their mappings.
The organization of this paper is as follows. The related work is described in
Section 2. This paper starts with a detailed introduction of the proposed VTT-LLM framework in
Section 3 and verifies the proposed method through experiments and analyses in
Section 4. Limitations are given in
Section 5.
Section 6 summarizes our research and discusses potential future directions. Our fine-tuned model, code, and dataset are available on request for the common research and use of the academic and industrial communities.
2. Related Work
Vulnerability to Tactics and Techniques: Vulnerability to tactics and techniques is important in vulnerability management and cyberhunting [
12,
13,
14,
15]. Few vulnerabilities can map to tactics and techniques based on explicit database information [
2,
11]. Automatically establishing a mapping from vulnerability to tactics and techniques commonly utilize a description of the vulnerability [
5,
6,
16,
17]. These automated methods enable language models to better extract semantics from descriptions of vulnerabilities and techniques, such as information summarization [
6], model distillation [
5], and model fine-tuning [
16]. However, they overlook the benefit of introducing additional information beyond CVE and ATT&CK. VTT-LLM introduces more information including descriptions of weaknesses and attack patterns.
Large language model: General-purpose LLMs exhibit comparatively limited performance when solving complex problems within the professional domain such as the VTT task [
17]. To make LLMs adapt to a professional domain, fine-tuning methods have been proposed [
8,
18,
19,
20]. To improve the ability of LLMs to solve complex problems, researchers transform complex problems into multi-step problems, employing techniques like generating intermediate steps or adopting the chain-of-thought (CoT) approach [
21,
22]. Moreover, fine-tuning with chain-of-thought (CoT) data would be a more effective approach for addressing complex problems in professional domains [
9,
23,
24,
25,
26]. Due to the need for CoT data, these CoT-related fine-tuning methods require the implementation of emerging COT capabilities from fairly large models like GPT-3 (175B) [
25]. In contrast, on the VTT task, we handcrafted a chain template to obtain CoT data, which allowed us to achieve improved results on relatively small LLMs.
3. Method: VTT-LLM Framework
To achieve the goal of VTT mapping, we propose the VTT-LLM framework consisting of a generative module and a mapping module. It should be noted that a vulnerability may correspond to more than one tactic and technique in practice, and our approach aims to identify a correct tactic and technique. The generation module generates the corresponding attack technology description based on the vulnerability description. The mapping module then uses the semantic embedding matching method to map the generated content to the appropriate technology categories. The standard embedding library is built based on the name and description of the category in ATT&CK. In
Section 3.1, we use a concrete example to illustrate how we differ from previous LLM-based studies and elicit our insight. Then, we provide detailed introductions of two modules in
Section 3.2 and
Section 3.3, respectively.
3.1. Motivation
As shown in
Figure 3, previous studies on building a VTT mapping focused on mapping detailed vulnerability descriptions to concise categories, often ignoring or making only limited use of the descriptions of the categories. However, with the introduction of powerful LLMs, there is now the potential to perform more sophisticated long-to-long mappings that capitalize on the categories’ descriptions. Intuitively, allowing the model to see more correct semantic mappings can help improve the accuracy of the VTT task. Furthermore, this inspired us to let the LLM fuse more VTT-related information to improve the effectiveness of the VTT task.
3.2. Generative Module
The generation module is the core component of VTT-LLM. The LLM learns grammar, semantics, and contextual information during the pre-training phase. Consequently, it can fully leverage the semantic information within categories. Moreover, fine-tuning with appropriate instructions and data can unlock the potential of the LLM for VTT mapping. We devised three methods to organize data for fine-tuning instructions to prove the superiority of chain templates.
- (a)
No template
The primary objective of fine-tuning an LLM is to align the model with the specific requirements of the task at hand and the data distribution characteristics of the dataset. Intuitively, we can enhance the performance of the LLM on the VTT task through supervised fine-tuning. This is achieved by organizing instructions and data in a structured manner, as demonstrated in
Table 1. The fine-tuning method without a template can be formulated as
.
- (b)
Intermediate steps’ template
The direct mapping from vulnerabilities to attacker techniques exhibits a stark transition, potentially impeding the inferential capabilities of the LLM. To address this issue, we propose the intermediate steps’ template to create a smoother mapping relationship that incorporates two additional intermediary stages. They are weakness and attack patterns. Weakness come from CWE, which is a community-developed list of common software and hardware weakness types that have security ramifications. Attack pattern is a concept in CAPEC, which is a comprehensive dictionary of known attack patterns that an adversary use to exploit weaknesses. We define a series of functions to articulate the steps’ template.
This function identifies the specific nature and characteristics within the vulnerability description, mapping them to an appropriate weakness type.
This function translates identified weaknesses into specific attack patterns that adversaries might employ.
This function connects attack patterns to precise tactic and techniques within the ATT&CK framework.
This function is to inform the LLM about which tasks to map first and implicitly connect the fine-tuning data knowledge injected into the LLM in steps 1, 2, and 3.
Based on the above function definition, the intermediate steps’ template can be formulated as:
This function represents the composition of the preceding functions, where ∘ symbolizes the sequential composition of these functions, creating a smooth transition from identifying vulnerabilities to determining the corresponding ATT&CK technique. The instructions for these functions are outlined in
Table 2.
- (c)
Chains’ template
The intermediate steps’ template only implicitly captures the relationship between vulnerabilities and attacker techniques. To more effectively leverage the reasoning capabilities of the LLM, utilizing explicit expressions of these relationships could prove more advantageous. The chains’ data structure is shown in
Table 3, which can be formulated as
.
In summary, during training, the LLM undergoes fine-tuning using data organized through the three mentioned methods. This results in the development of a fine-tuned LLM. Consequently, in the inference stage, by inputting instructions and data, the fine-tuned LLM can generate a description of the attacker’s action.

 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}