

Community Detection in Multiplex Networks Using Orthogonal Non-Negative Matrix Tri-Factorization Based on Graph Regularization and Diversity


Abstract
1. Introduction
- An orthogonal non-negative matrix tri-factorization model is applied to multiplex networks. It enables the simultaneous detection of common and private communities within the network. The model has enhanced interpretability and feature extraction capabilities.
- For the detected private communities, a graph regularization [15,17] constraint is added. Graph regularization utilizes the topological structure of networks to better capture relationships and connection patterns between nodes. It constrains the formation of community structures. And it aligns more with the actual community partitioning rules in real networks. Finally, it enhances the accuracy and robustness of community detection.
- The Hilbert–Schmidt Independence Criterion (HSIC) [16] term is introduced. Because the private communities in each layer are independent of each other with minimal correlation, an HSIC term is added to the detected private communities [18]. The HSIC effectively imposes independence constraints on the private communities in each layer.
- Weight constraints are applied to the identified shared communities in each layer [19]. Ultimately, the shared communities across all layers are summed, enhancing the accuracy of the detected common communities.
2. Related Works
2.1. Existing Methods
2.2. Multiplex Networks
2.3. Hilbert–Schmidt Independence Criterion (HSIC)
2.4. Community Detection with NMF in Multiplex Networks
3. Notations
4. The Proposed Method
5. Optimization
| Algorithm 1 MX-ONMTF based on graph regularization and diversity. |
|
6. Experiments
6.1. Datasets
6.2. Experimental Settings
6.2.1. Comparison Algorithm Models
6.2.2. Evaluation Metrics
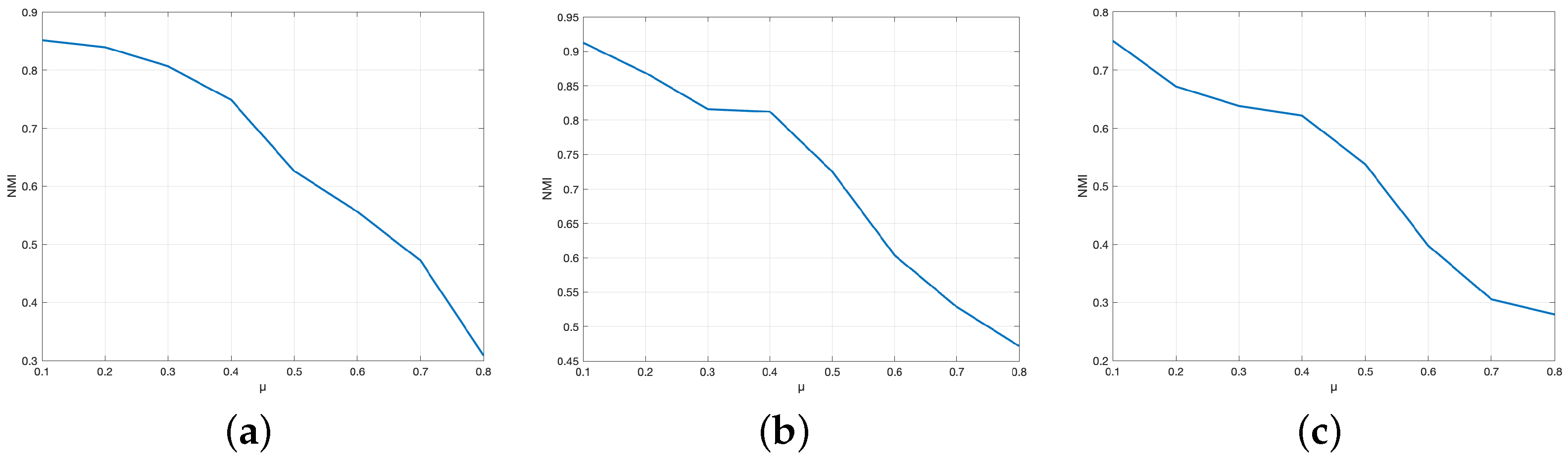
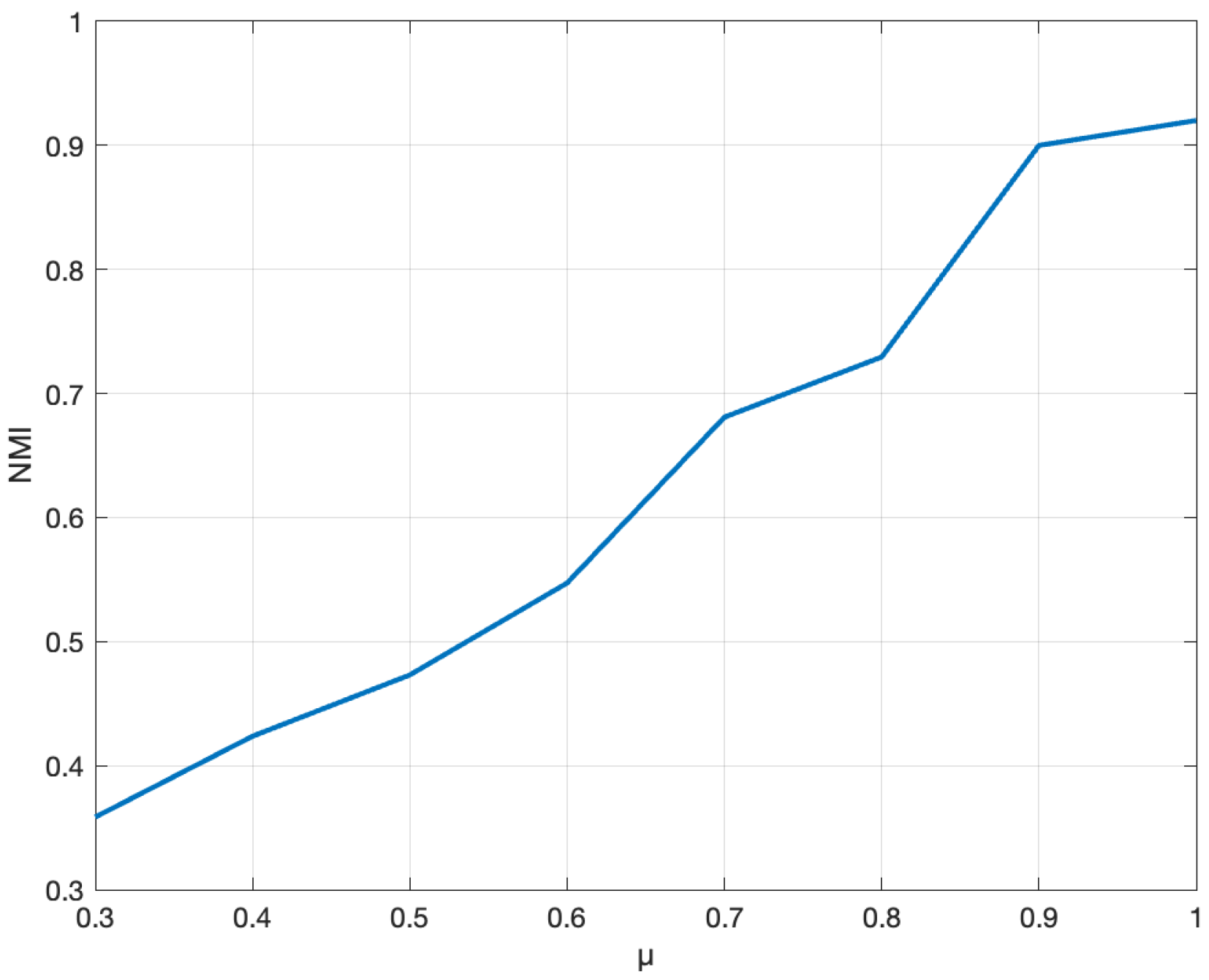
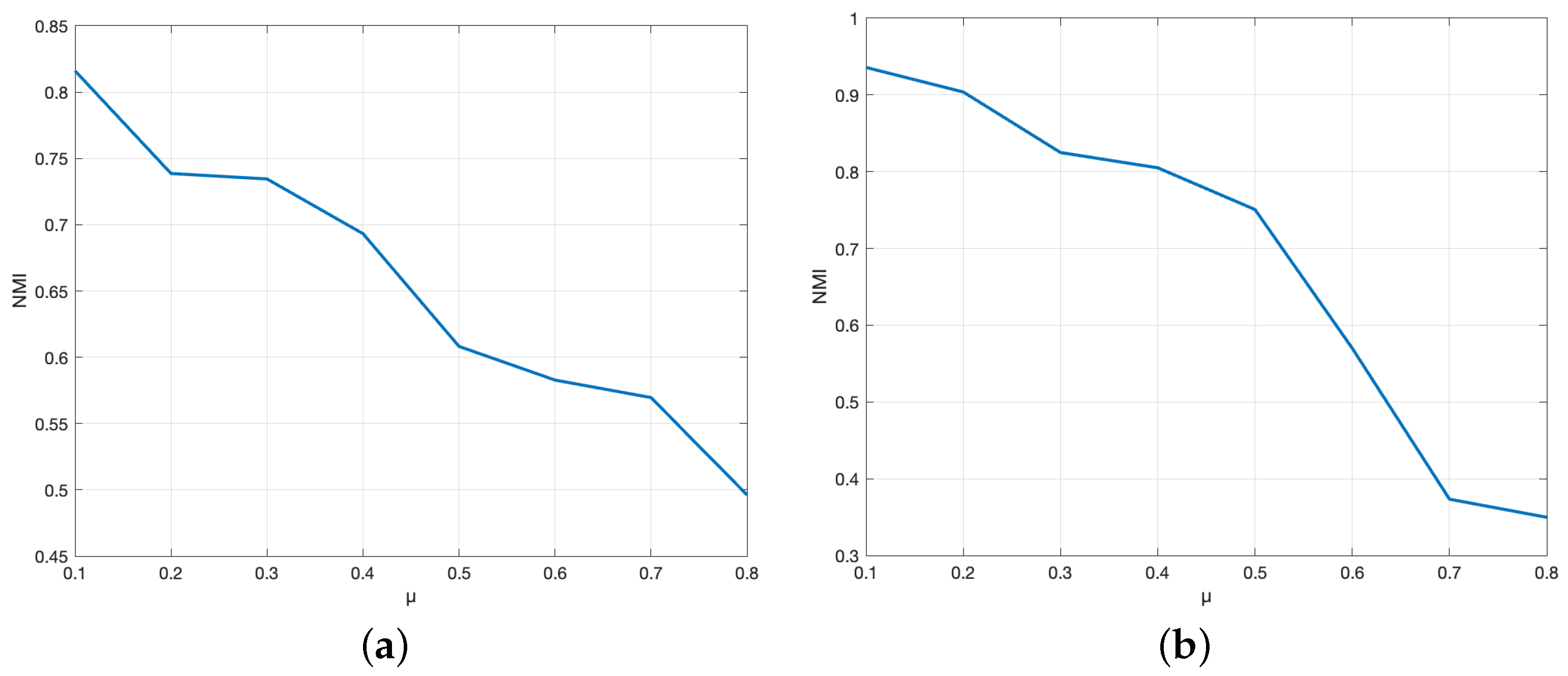
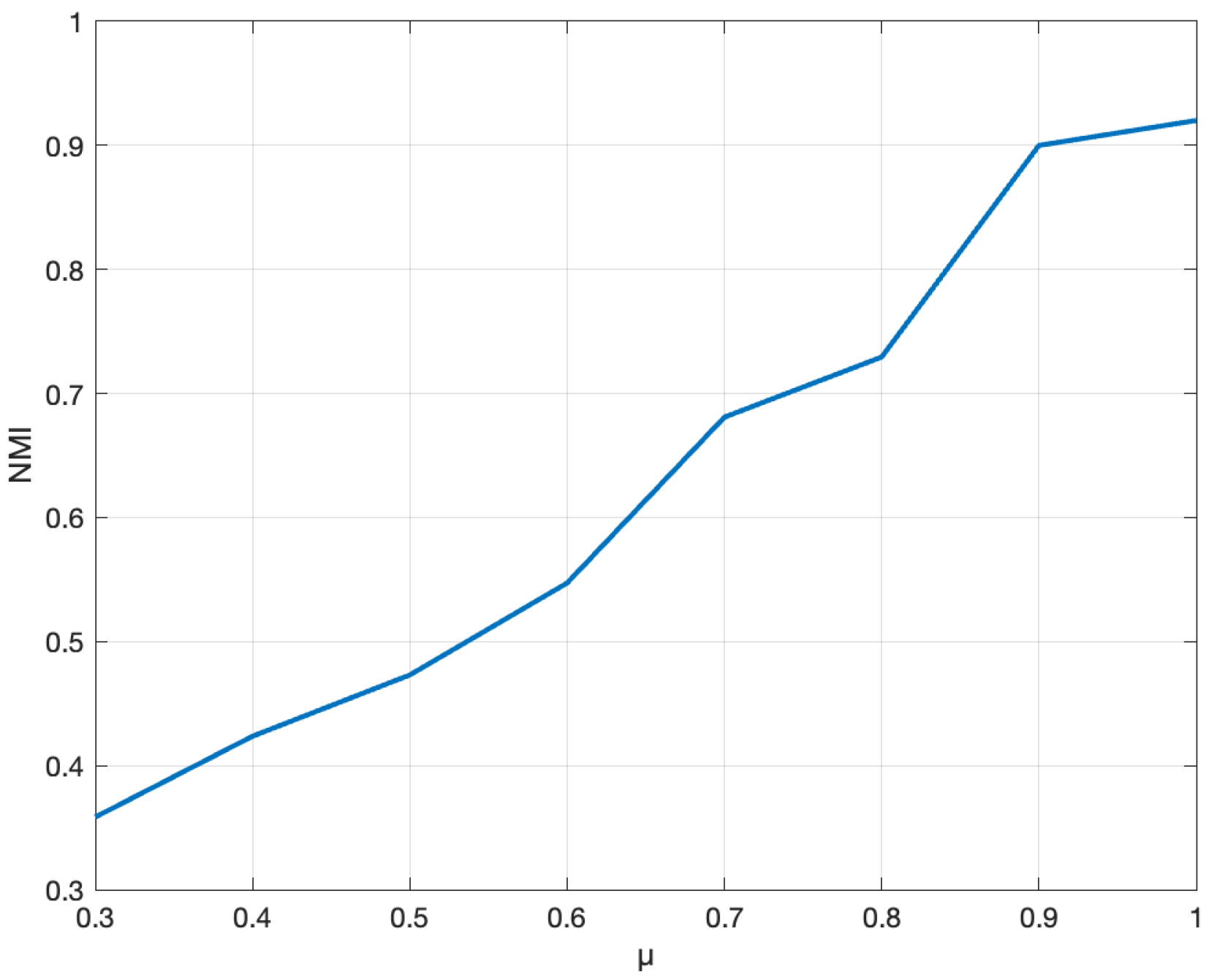
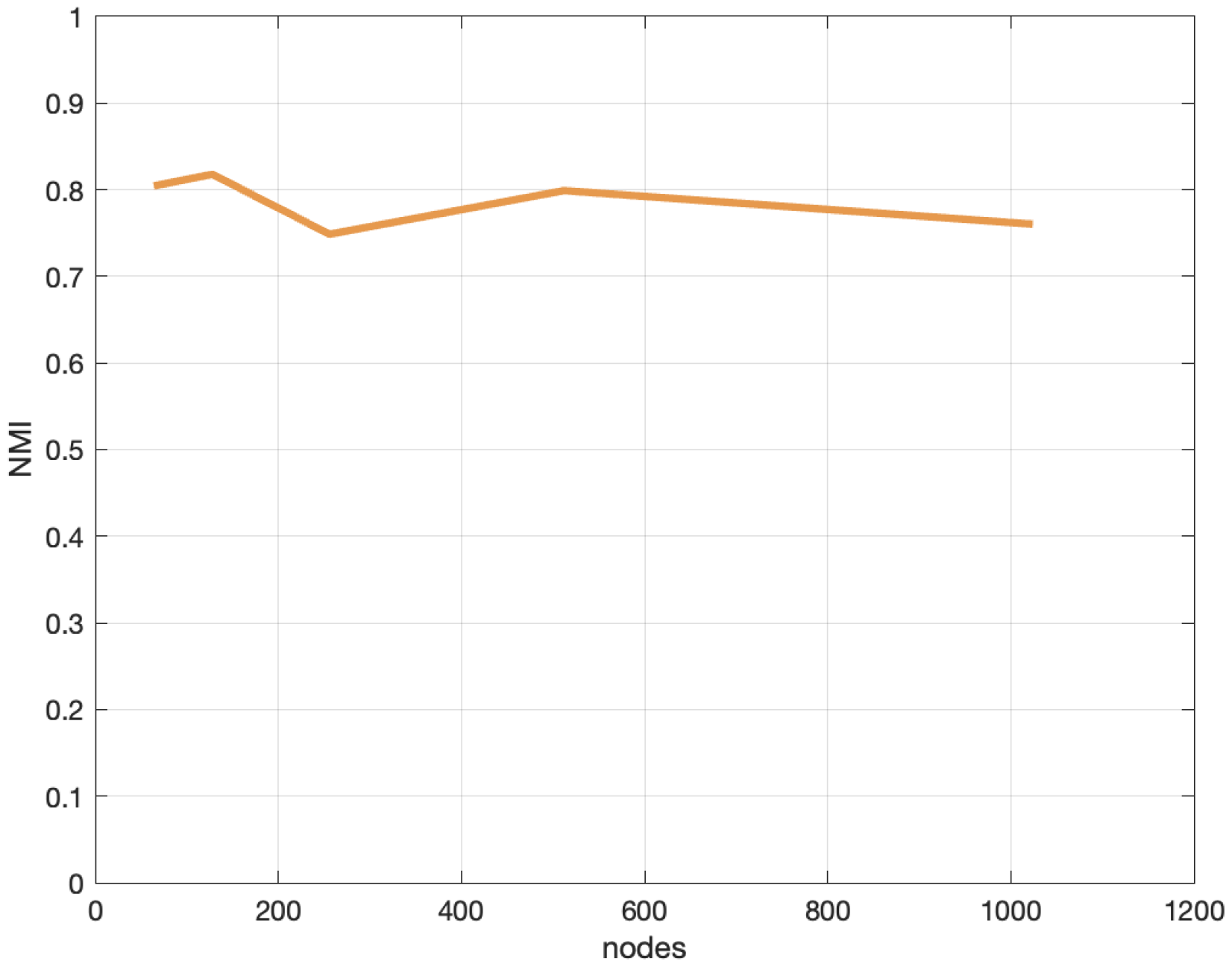
6.3. Analysis
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kivela, M.; Arenas, A.; Barthelemy, M.; Gleeson, J.P.; Moreno, Y.; Porter, M.A. Multilayer networks. J. Complex Netw. 2014, 2, 203–271. [Google Scholar] [CrossRef]
- Berlingerio, M.; Coscia, M.; Giannotti, F. Finding and characterizing communities in multidimensional networks. In Proceedings of the 2011 International Conference on Advances in Social Networks Analysis and Mining ASONAM 2011, Kaohsiung, Taiwan, 25–27 July 2011; IEEE Computer Society: Los Alamitos, CA, USA, 2011; pp. 490–494. [Google Scholar] [CrossRef]
- Chen, P.Y.; Hero, A.O. Multilayer Spectral Graph Clustering via Convex Layer Aggregation: Theory and Algorithms. arXiv 2017, arXiv:stat.ML/1708.02620. [Google Scholar] [CrossRef]
- Dong, X.; Frossard, P.; Vandergheynst, P.; Nefedov, N. Clustering on Multi-Layer Graphs via Subspace Analysis on Grassmann Manifolds. IEEE Trans. Signal Process. 2014, 62, 905–918. [Google Scholar] [CrossRef]
- Kuncheva, Z.; Montana, G. Community detection in multiplex networks using Locally Adaptive Random walks. In Proceedings of the 2015 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM 2015), Paris, France, 25–28 August 2015; pp. 1308–1315. [Google Scholar] [CrossRef]
- De Domenico, M.; Lancichinetti, A.; Arenas, A.; Rosvall, M. Identifying Modular Flows on Multilayer Networks Reveals Highly Overlapping Organization in Interconnected Systems. Phys. Rev. X 2015, 5, 011027. [Google Scholar] [CrossRef]
- Amelio, A.; Pizzuti, C. Community Detection in Multidimensional Networks. In Proceedings of the 2014 IEEE 26th International Conference on Tools with Artificial Intelligence, Limassol, Cyprus, 10–12 November 2014; pp. 352–359. [Google Scholar] [CrossRef]
- Pamfil, A.R.; Howison, S.D.; Lambiotte, R.; Porter, M.A. Relating modularity maximization and stochastic block models in multilayer networks. arXiv 2018, arXiv:cs.SI/1804.01964. [Google Scholar] [CrossRef]
- Mucha, P.J.; Richardson, T.; Macon, K.; Porter, M.A.; Onnela, J.P. Community Structure in Time-Dependent, Multiscale, and Multiplex Networks. Science 2010, 328, 876–878. [Google Scholar] [CrossRef] [PubMed]
- Magnani, M.; Hanteer, O.; Interdonato, R.; Rossi, L.; Tagarelli, A. Community Detection in Multiplex Networks. arXiv 2021, arXiv:cs.SI/1910.07646. [Google Scholar] [CrossRef]
- Wang, H.; Nie, F.; Huang, H.; Ding, C. Nonnegative Matrix Tri-factorization Based High-Order Co-clustering and Its Fast Implementation. In Proceedings of the 2011 IEEE 11th International Conference on Data Mining, Vancouver, BC, Canada, 11–14 December 2011; pp. 774–783. [Google Scholar] [CrossRef]
- Sun, B.J.; Shen, H.; Gao, J.; Ouyang, W.; Cheng, X. A Non-negative Symmetric Encoder-Decoder Approach for Community Detection. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 597–606. [Google Scholar] [CrossRef]
- Gligorijević, V.; Panagakis, Y.; Zafeiriou, S. Non-Negative Matrix Factorizations for Multiplex Network Analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 928–940. [Google Scholar] [CrossRef] [PubMed]
- Yoo, J.; Choi, S. Orthogonal nonnegative matrix tri-factorization for co-clustering: Multiplicative updates on Stiefel manifolds. Inf. Process. Manag. 2010, 46, 559–570. [Google Scholar] [CrossRef]
- Cai, D.; He, X.; Han, J.; Huang, T.S. Graph Regularized Nonnegative Matrix Factorization for Data Representation. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1548–1560. [Google Scholar] [CrossRef] [PubMed]
- Cao, X.; Zhang, C.; Fu, H.; Liu, S.; Zhang, H. Diversity-induced Multi-view Subspace Clustering. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 586–594. [Google Scholar] [CrossRef]
- Che, H.; Pan, B.; Leung, M.F.; Cao, Y.; Yan, Z. Tensor Factorization With Sparse and Graph Regularization for Fake News Detection on Social Networks. IEEE Trans. Comput. Soc. Syst. 2023, 1–11. [Google Scholar] [CrossRef]
- Li, C.; Che, H.; Leung, M.F.; Liu, C.; Yan, Z. Robust multi-view non-negative matrix factorization with adaptive graph and diversity constraints. Inf. Sci. 2023, 634, 587–607. [Google Scholar] [CrossRef]
- Pan, B.; Li, C.; Che, H. Nonconvex low-rank tensor approximation with graph and consistent regularizations for multi-view subspace learning. Neural Netw. 2023, 161, 638–658. [Google Scholar] [CrossRef] [PubMed]
- Cozzo, E.; Kivelä, M.; Domenico, M.D.; Solé-Ribalta, A.; Arenas, A.; Gómez, S.; Porter, M.A.; Moreno, Y. Structure of triadic relations in multiplex networks. New J. Phys. 2015, 17, 073029. [Google Scholar] [CrossRef]
- Gretton, A.; Bousquet, O.; Smola, A.; Schölkopf, B. Measuring Statistical Dependence with Hilbert-Schmidt Norms. In Proceedings of the International Conference on Algorithmic Learning Theory, Singapore, 8–11 October 2005. [Google Scholar]
- Ding, C.; He, X.; Simon, H.D. On the Equivalence of Nonnegative Matrix Factorization and Spectral Clustering. In Proceedings of the 2005 SIAM International Conference on Data Mining (SDM), Newport Beach, CA, USA, 21–23 April 2005; pp. 606–610. [Google Scholar] [CrossRef]
- Dong, Y.; Che, H.; Leung, M.F.; Liu, C.; Yan, Z. Centric graph regularized log-norm sparse non-negative matrix factorization for multi-view clustering. Signal Process. 2024, 217, 109341. [Google Scholar] [CrossRef]
- Wu, W.; Kwong, S.; Zhou, Y.; Jia, Y.; Gao, W. Nonnegative matrix factorization with mixed hypergraph regularization for community detection. Inf. Sci. 2018, 435, 263–281. [Google Scholar] [CrossRef]
- Lu, H.; Sang, X.; Zhao, Q.; Lu, J. Community detection algorithm based on nonnegative matrix factorization and pairwise constraints. Phys. A Stat. Mech. Its Appl. 2020, 545, 123491. [Google Scholar] [CrossRef]
- Kong, Q.; Sun, J.; Xu, Z. Joint orthogonal symmetric non-negative matrix factorization for community detection in attribute network. Knowl.-Based Syst. 2024, 283, 111192. [Google Scholar] [CrossRef]
- Smith Aguilar, S.; Aureli, F.; Busia, L.; Schaffner, C.; Ramos-Fernandez, G. Using multiplex networks to capture the multidimensional nature of social structure. Primates 2018, 60, 277–295. [Google Scholar] [CrossRef] [PubMed]
- Ma, X.; Dong, D.; Wang, Q. Community Detection in Multi-Layer Networks Using Joint Nonnegative Matrix Factorization. IEEE Trans. Knowl. Data Eng. 2019, 31, 273–286. [Google Scholar] [CrossRef]
- Al-Sharoa, E.M.; Aviyente, S. Community Detection in Fully-Connected Multi-layer Networks Through Joint Nonnegative Matrix Factorization. IEEE Access 2022, 10, 43022–43043. [Google Scholar] [CrossRef]
- Ortiz-Bouza, M.; Aviyente, S. Community Detection in Multiplex Networks Based on Orthogonal Nonnegative Matrix Tri-Factorization. IEEE Access 2024, 12, 6423–6436. [Google Scholar] [CrossRef]
- Lazega, E. The Collegial Phenomenon: The Social Mechanisms of Cooperation Among Peers in a Corporate Law Partnership; Oxford University Press: Oxford, UK, 2001. [Google Scholar] [CrossRef]
- Greene, D.; Cunningham, P. A Matrix Factorization Approach for Integrating Multiple Data Views. In Proceedings of the ECML PKDD 2009: Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Bled, Slovenia, 6–10 September 2009. [Google Scholar]
- Rasiwasia, N.; Costa Pereira, J.; Coviello, E.; Doyle, G.; Lanckriet, G.R.; Levy, R.; Vasconcelos, N. A new approach to cross-modal multimedia retrieval. In Proceedings of the 18th ACM International Conference on Multimedia, Firenze, Italy, 25–29 October 2010; pp. 251–260. [Google Scholar] [CrossRef]
- Bazzi, M.; Jeub, L.G.S.; Arenas, A.; Howison, S.D.; Porter, M.A. A framework for the construction of generative models for mesoscale structure in multilayer networks. Phys. Rev. Res. 2020, 2, 023100. [Google Scholar] [CrossRef]
- Pramanik, S.; Tackx, R.; Navelkar, A.; Guillaume, J.L.; Mitra, B. Discovering Community Structure in Multilayer Networks. In Proceedings of the 2017 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Tokyo, Japan, 19–21 October 2017; pp. 611–620. [Google Scholar] [CrossRef]
- Kumar, A.; Rai, P.; Daumé, H. Co-regularized multi-view spectral clustering. In Proceedings of the 24th International Conference on Neural Information Processing Systems, Granada, Spain, 13–15 December 2011; pp. 1413–1421. [Google Scholar]
- Nie, F.; Tian, L.; Li, X. Multiview Clustering via Adaptively Weighted Procrustes. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 2022–2030. [Google Scholar] [CrossRef]
- Zhan, K.; Nie, F.; Wang, J.; Yang, Y. Multiview Consensus Graph Clustering. IEEE Trans. Image Process. 2019, 28, 1261–1270. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations | Meaning |
|---|---|
| Layer l’s adjacency matrix | |
| The shared community membership matrix of layer l | |
| The private community membership matrix of layer l | |
| The shared community member matrix integrating | |
| the shared community member matrix of each layer | |
| The symmetric matrix of the shared community membership matrix | |
| The symmetric matrix of the private community membership matrix | |
| The weight factor added to the shared community membership | |
| matrix for every stratum | |
| The traces of a matrix |
| 3Sources | BBCSport | Wikipedia | |
|---|---|---|---|
| N | 169 | 544 | 693 |
| k | 3 | 2 | 2 |
| c | 6 | 5 | 10 |
| 54, 21, 11, 18, 51, 12 | 62, 104, 193, 124, 61 | 34, 88, 96, 85, 65, 58, 51, 41, 71, 104 |
| Dataset | GL | CoReg | AWP | MCGC | MX-ONMTF | MX-GONMTF |
|---|---|---|---|---|---|---|
| Status | 0.0350 | 0.0468 | 0.0115 | 0.0252 | 0.3902 | 0.4264 |
| Gender | 0.0312 | 0.0019 | 0.0042 | 0.0129 | 0.4100 | 0.1126 |
| Office | 0.5080 | 0.5828 | 0.3235 | 0.1029 | 0.7297 | 0.4216 |
| Seniority | 0.0727 | 0.6946 | 0.6368 | NULL | 0.2192 | 0.3565 |
| Age | 0.0395 | 0.7394 | 0.6997 | NULL | 0.3024 | 0.3363 |
| Practice | 0.5515 | 0.0676 | 0.1857 | 0.0207 | 0.5610 | 0.1143 |
| Law School | 0.0163 | 0.0051 | 0.0070 | 0.0444 | 0.3308 | 0.1249 |
| 3sources | 0.7488 | 0.6584 | 0.6619 | 0.5948 | 0.5265 | 0.5414 |
| BBCSport | 0.7525 | 0.6168 | 0.7223 | 0.7951 | 0.5347 | 0.5082 |
| Wikipedia | 0.5435 | 0.4338 | 0.3249 | 0.1372 | 0.3912 | 0.5573 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Y.; Yu, S.; Pan, B.; Li, C.; Leung, M.-F. Community Detection in Multiplex Networks Using Orthogonal Non-Negative Matrix Tri-Factorization Based on Graph Regularization and Diversity. Mathematics 2024, 12, 1124. https://doi.org/10.3390/math12081124
Yang Y, Yu S, Pan B, Li C, Leung M-F. Community Detection in Multiplex Networks Using Orthogonal Non-Negative Matrix Tri-Factorization Based on Graph Regularization and Diversity. Mathematics. 2024; 12(8):1124. https://doi.org/10.3390/math12081124
Chicago/Turabian StyleYang, Yuqi, Shanshan Yu, Baicheng Pan, Chenglu Li, and Man-Fai Leung. 2024. "Community Detection in Multiplex Networks Using Orthogonal Non-Negative Matrix Tri-Factorization Based on Graph Regularization and Diversity" Mathematics 12, no. 8: 1124. https://doi.org/10.3390/math12081124
APA StyleYang, Y., Yu, S., Pan, B., Li, C., & Leung, M.-F. (2024). Community Detection in Multiplex Networks Using Orthogonal Non-Negative Matrix Tri-Factorization Based on Graph Regularization and Diversity. Mathematics, 12(8), 1124. https://doi.org/10.3390/math12081124