2.1. Common Correlated Estimator in Panel Unit Root Testing
In this part, we introduce a practical way to refine the CCE estimator of [
8]. In the author’s well-known paper, he introduces an auxiliary regression to remedy cross-sectional dependency. In line with [
8], we consider the following heterogeneous panel ADF regression:
where
is the unobserved common factor assumed to be a stationary process,
is factor loadings, and
is the individual specific error terms. For the moment, we assume that idiosyncratic error terms
are independently distributed across both
and
.
The common factor
can be proxied by the cross-sectional mean of
and
following [
8,
27]. To see this, first re-write Equation (1) as follows:
Taking the cross-section average of both sides, we obtain the following equation:
Assuming that
does not vanish, the common factor
can be written as
which suggests that the common factor can be proxied by a linear combination of
and
. Therefore, in order to filter out the effects of the common factor, we run the following modified test regression:
Then, the test of the null hypothesis of the unit root ( in Equation (1) above) is based on ratio of the OLS estimate of in Equation (6).
In Equation (1) and hence in Equation (6), it was assumed that the error terms are not serially correlated. In order to allow for serial correlation in the error terms, we ran the following augmented regression:
and we compute the test statistic from Equation (7) (see [
8]).
Ref. [
28] demonstrated that the CCE estimator provides consistent and asymptotically normal estimates of slope coefficients in panel data models, even with a multifactor error structure. In this section, we aim to explore additional properties by using the CSD test to determine whether the CCE estimator truly remedies the CSD issue. To carry out this, we employ the
test from [
30]. First, we need to verify if this test performs well across different levels of CSD.
2.2. The Behavior or Performance of the Test
In this section, we first conduct a Monte Carlo study to test whether the
test works properly with DGP given in Equation (3). The features of this DGP are described in [
8,
27], where CSD is introduced into the panel data using a factor structure, as shown in Equation (3). First, we compute the
test directly on the DGP to verify if the test detects CSD. In the second stage, we use the same DGP but apply the factor structure to remedy the CSD during the testing process. We expect to observe severe CSD in the first Monte Carlo setup and no CSD in the second. If these expectations hold, the
test can be used to assess the CCE estimator proposed by [
8,
27]. Previous studies [
28] have shown that the CCE estimator effectively remedies CSD and produces unbiased estimates. While our analysis complements theirs, our findings suggest a new direction for developing a more efficient estimator. In the final stage, we propose a new estimator based on these new insights.
The Monte Carlo design used in this study can be summarized as follows: First, we generate data using Equation (3) with factor loadings
ranging from −1.0 to 3.0, as suggested by the authors of [
8,
27], who classify this range as strong CSD. In our study, we compute the
test for each factor loading in this interval at 0.1 increments. These computations are performed for
and
. For each point, we calculate the
test 1000 times to examine the distribution and the minimum and maximum values of the test. For example, with
and
, we generate 40 intervals representing the probability of detecting CSD when imposed or, conversely, detecting no CSD. For
and
values as described, this results in 360 cells (
), which can be displayed in 27 tables for each
and
. To simplify interpretation, we present the results visually through figures. In these figures, we also include the 10% significance interval for the z-test, ranging from −2.0 to 2.0.
We consider the following panel regression model,
for
cross-sectional units and
time periods. The sample estimate of the pair-wise correlation of the residuals is given by
where
is the OLS estimates of
defined as
. Ref. [
30] suggests that the
test statistic can be computed as
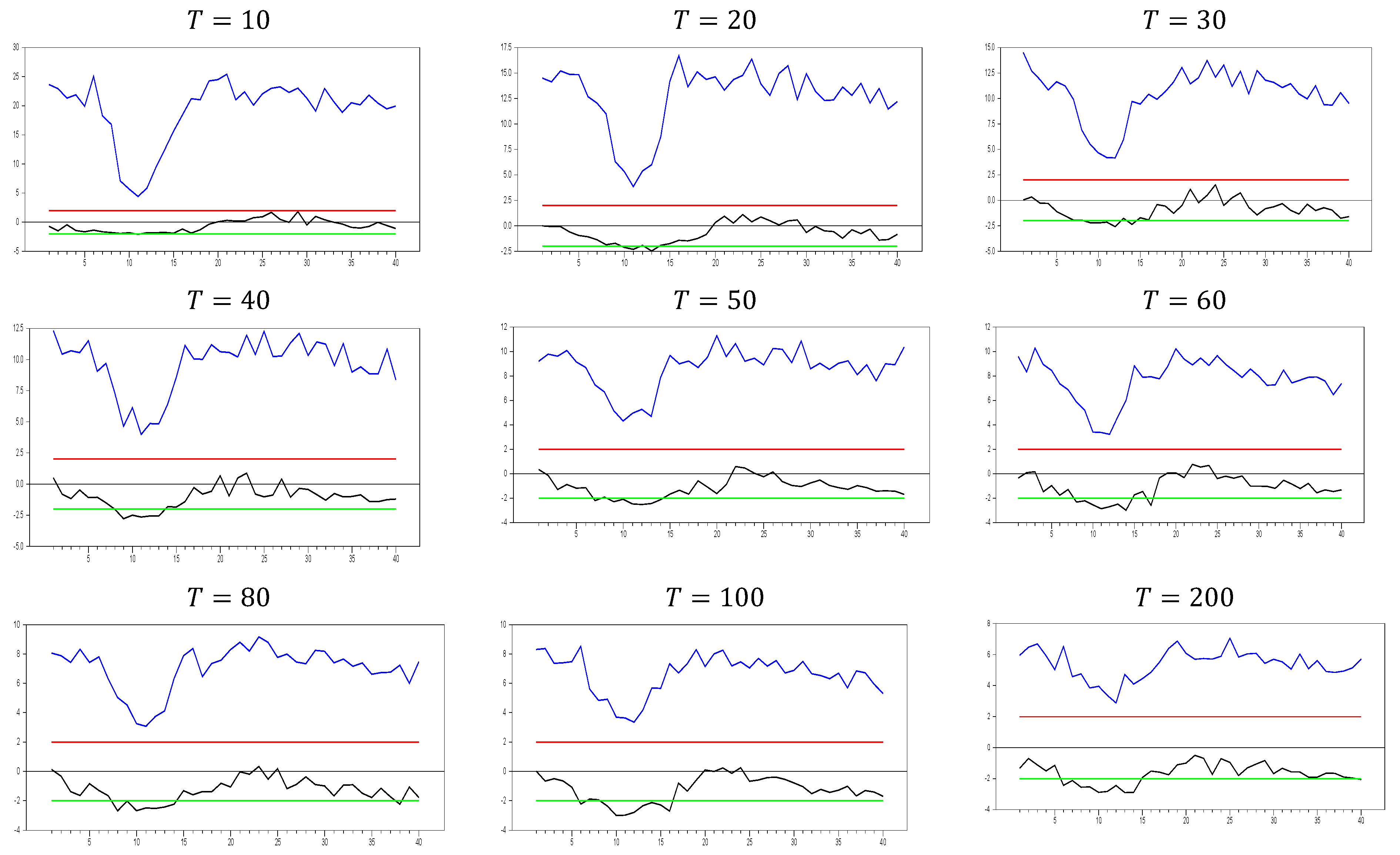
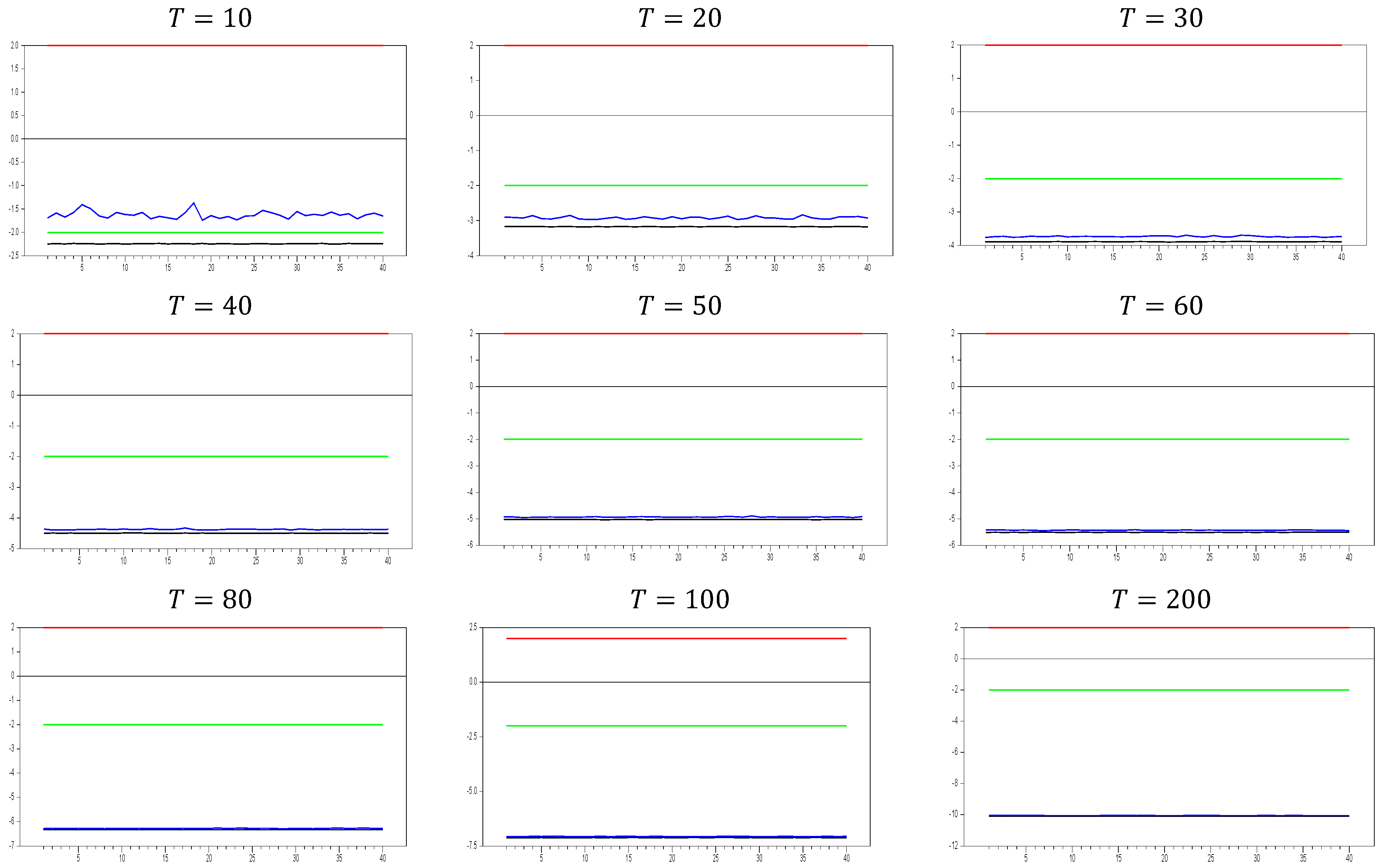
2.2.1. The Behavior of the Without Imposing the CCE Estimator
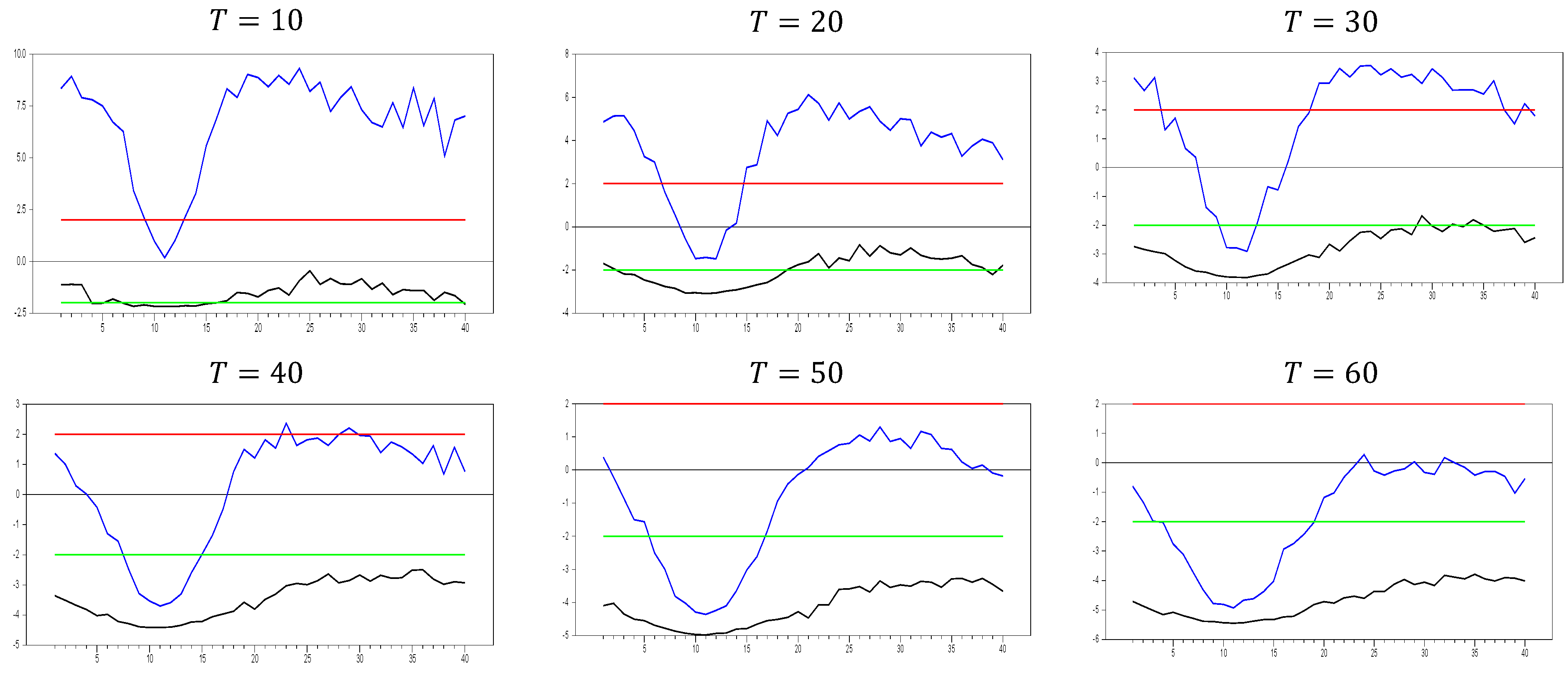
For the first Monte Carlo study, we use the DGP from Equation (3) without imposing any remedy. The results are shown in
Figure 1,
Figure 2 and
Figure 3.
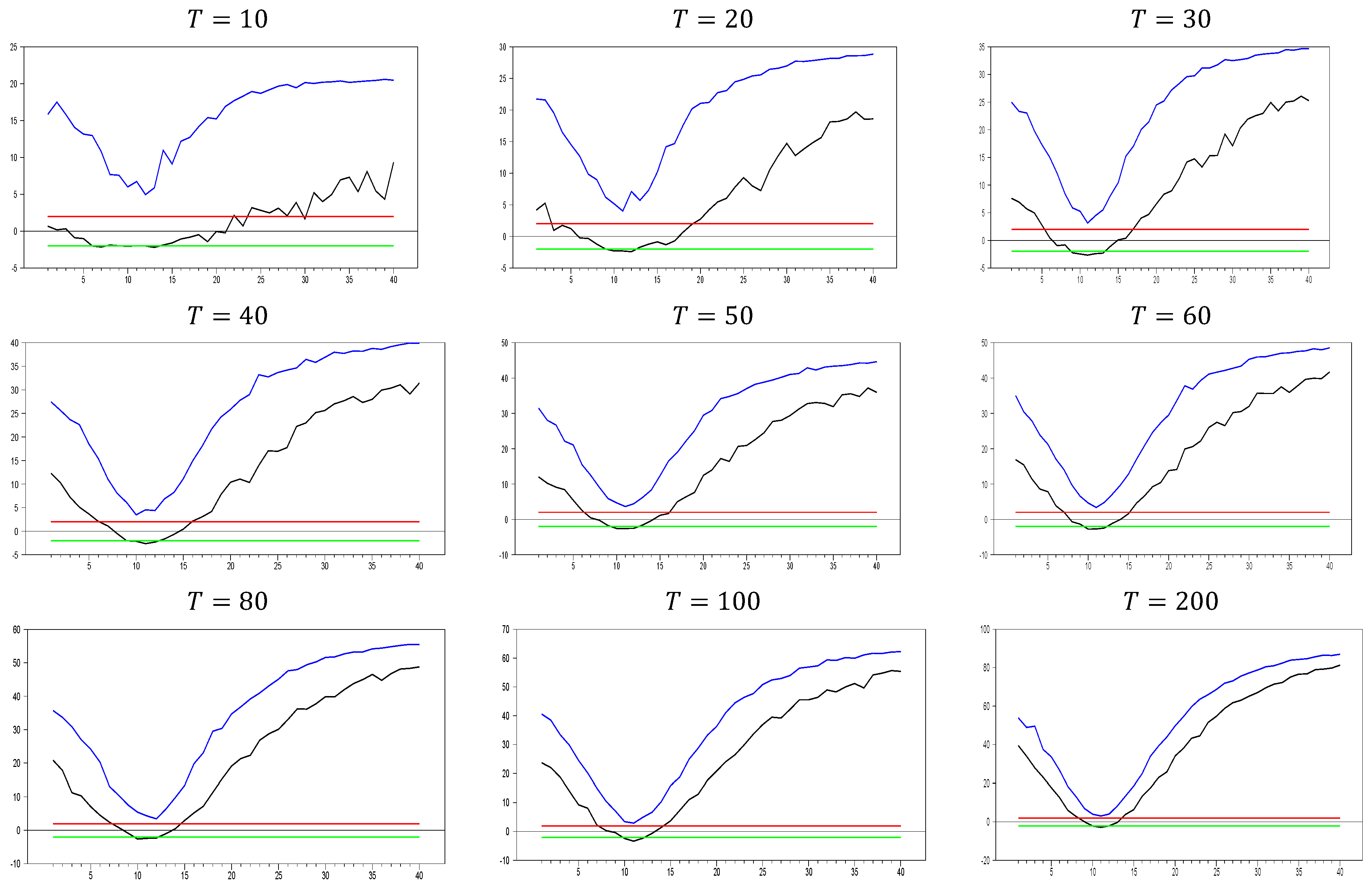
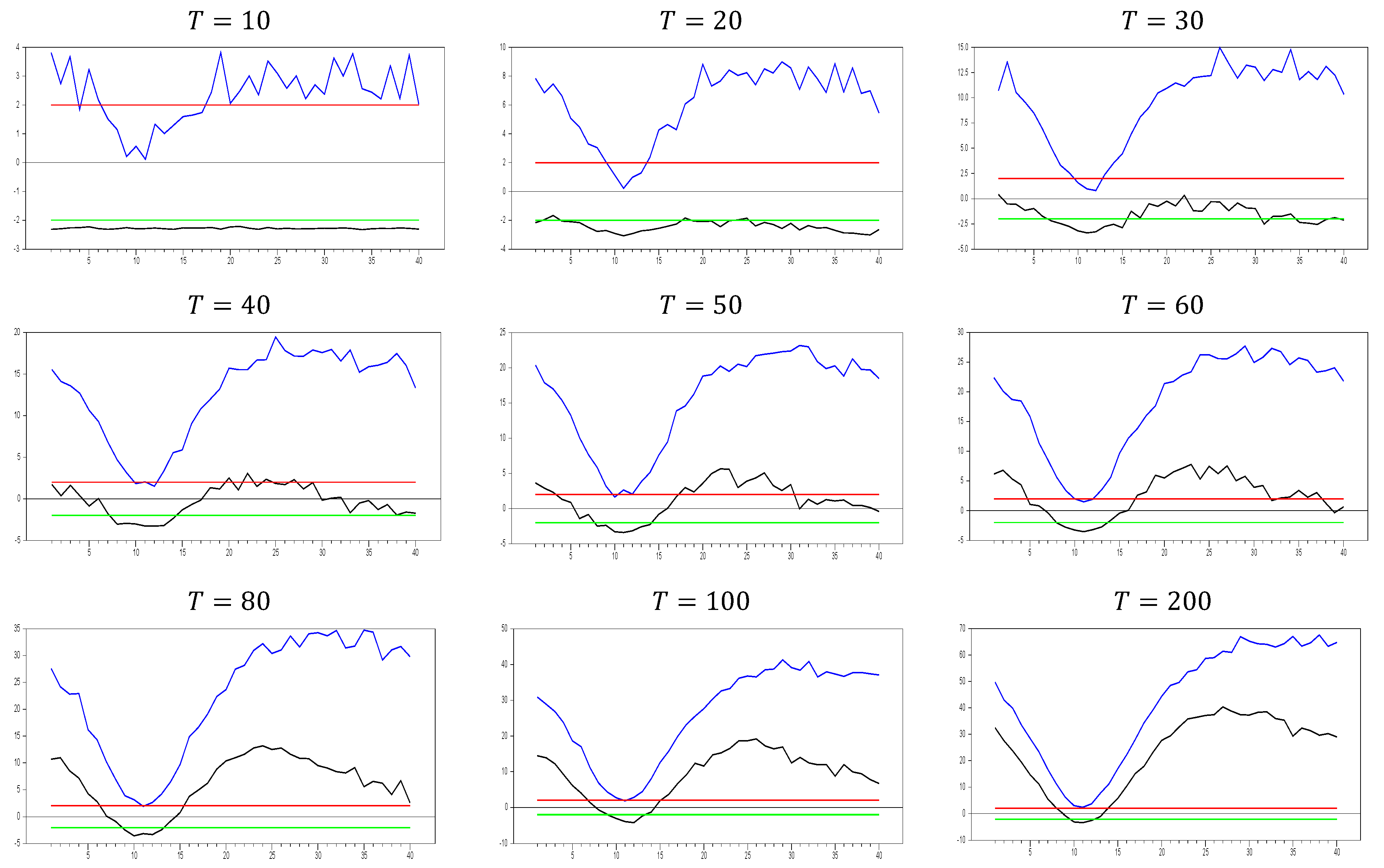
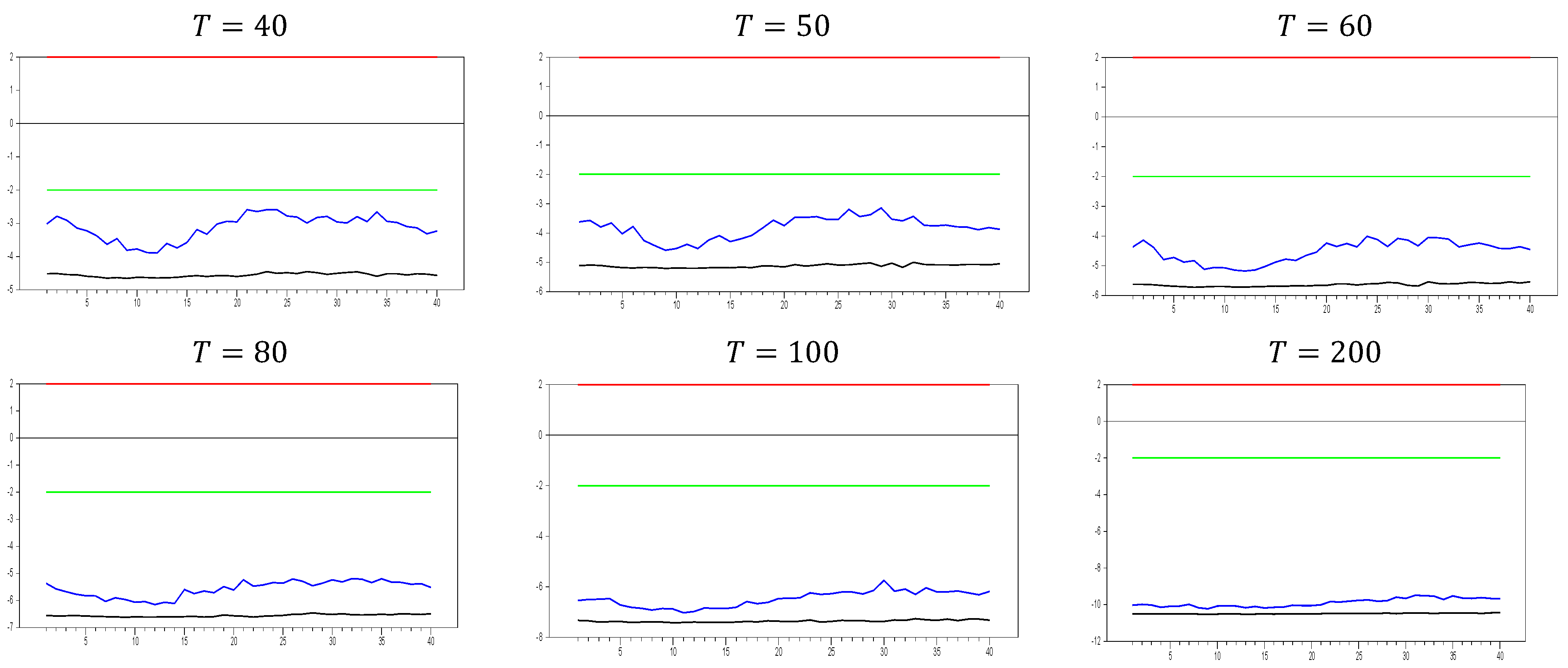
As shown in
Figure 1, the
test effectively captures CSD for
. The test becomes more sensitive as the
dimension increases. This can be observed in the figures, where for
, the maximum
test value approaches 20.0, while for
, it increases to around 50. A similar pattern is seen for the minimum values. As
increases, the initially u-shaped
test results become skewed, with the tangency points of the curve shortening. This indicates that the
test detects CSD for smaller factor loadings as
grows. For
, the range of test statistics is approximately (
0.1, 0.4), indicating almost no CSD, while for
, the range is wider at (−1.0, 2.4). These results suggest that it is not straightforward to categorize the range (0.0, 0.2) as weak CSD, as some effects are still present when
increases. However, our primary goal is to confirm whether the
test is working or not. Based on
Figure 1, we conclude that it works well for small
values.
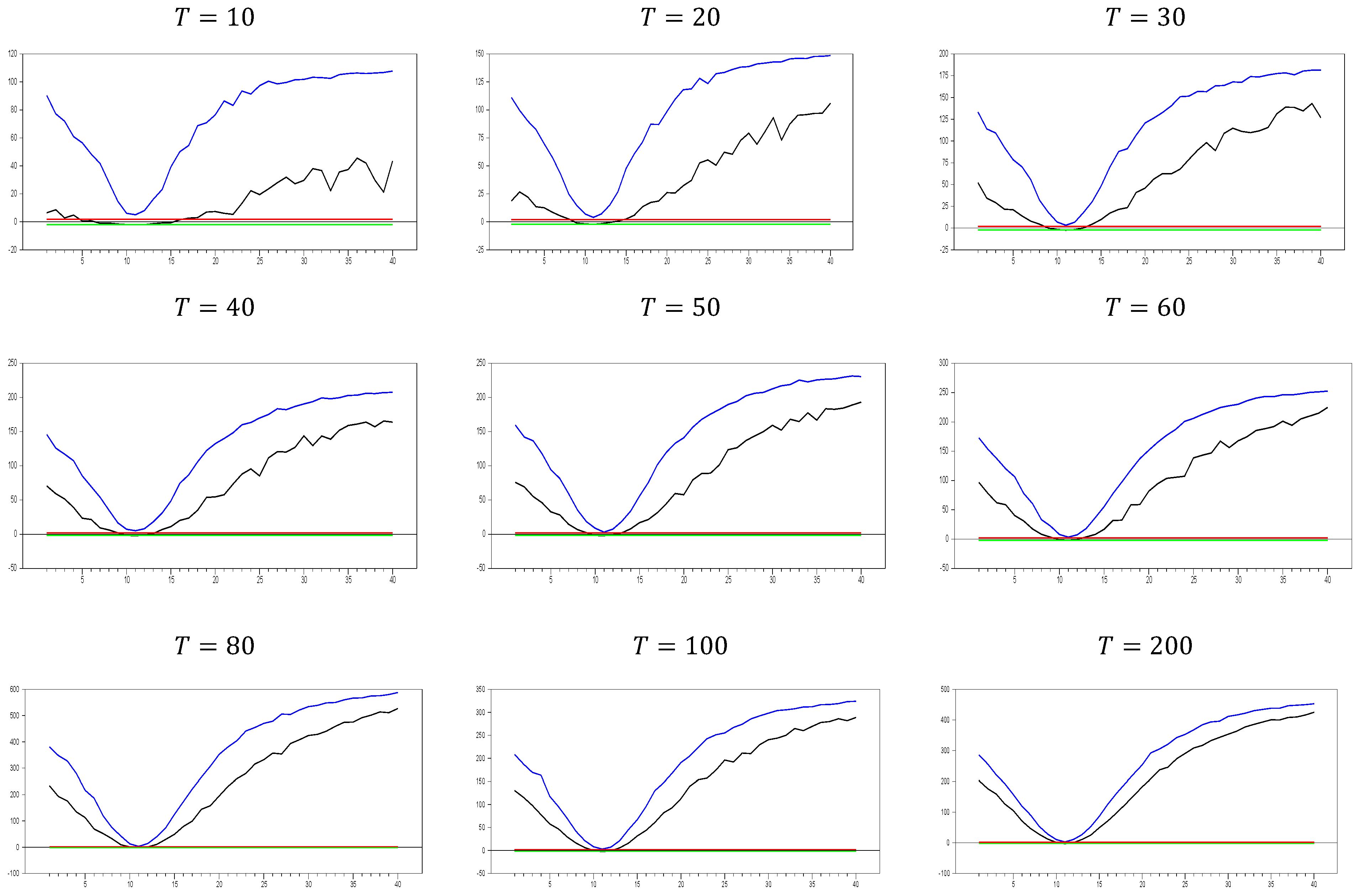
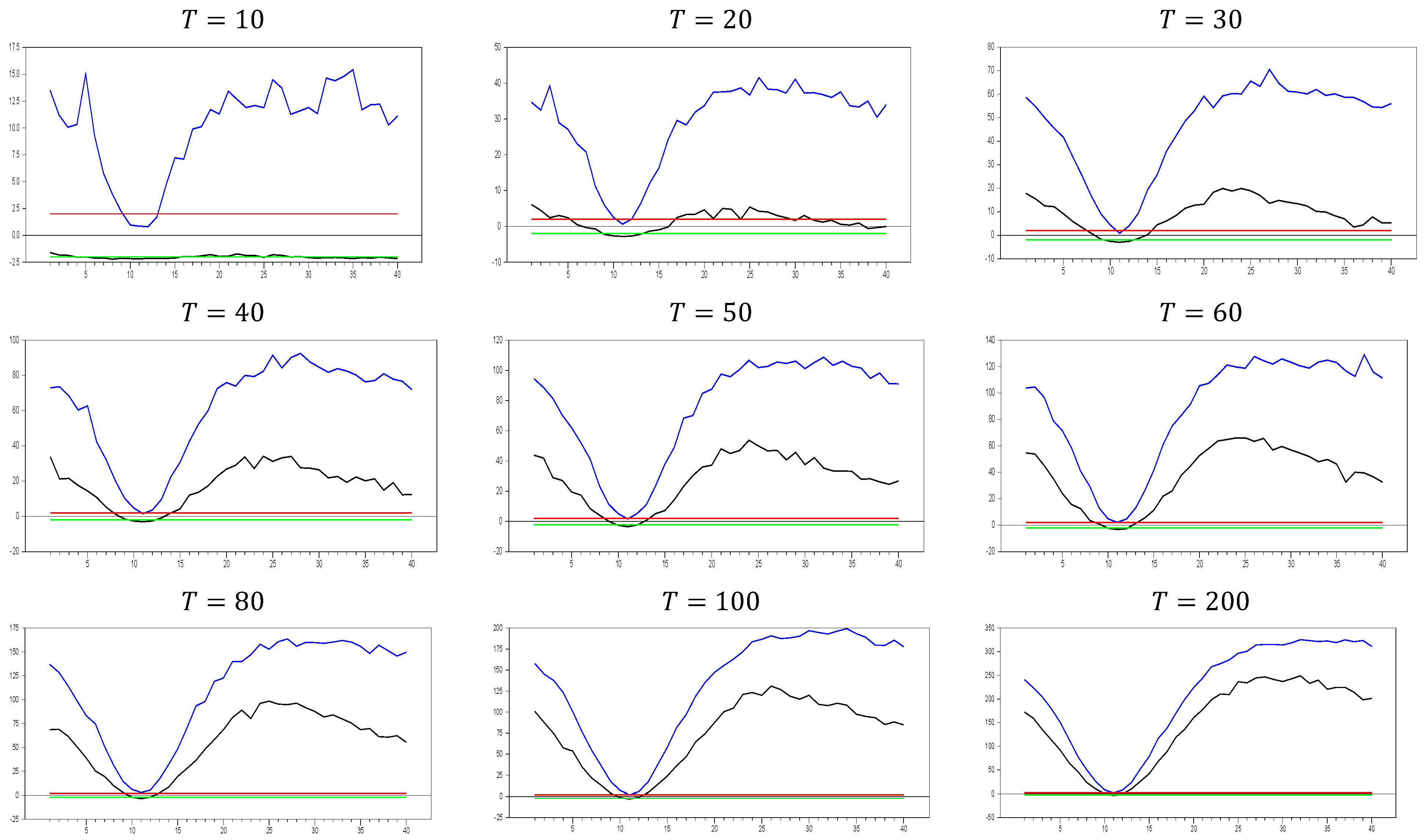
We now move on to test the performance with a larger
value, selecting
, and the corresponding results are given in
Figure 2. As shown in
Figure 2, the pattern observed is consistent with that in
Figure 1. This confirms that increasing the
dimension does not cause any issues with the
test results. Therefore, these simulation results provide evidence of the test’s consistency in small samples. As the
dimension increases, both the maximum and minimum values of the
test also increase. For example, with
and
, the maximum
test value approaches 20.0, but for
and
, this maximum value rises to approximately 100.0. Similarly, for
0 and
, the maximum value is around 50, while for
and
, it increases to 450.0. A similar pattern is observed for the minimum values. Furthermore, as the
dimension increases, the tangency points of the u-shaped figure become shorter, indicating that the
test detects CSD for smaller factor loadings.
For
and
, the test produces a range of (−0.1, 0.4), indicating almost no CSD, while for
and
, the range narrows to (0.0, 0.1). Once again, this confirms that it is difficult to classify the range (0.0, 0.2) as weak CSD for all values of
and
, as claimed by [
8,
27]. However, for large values of
and
, factor loadings in the range
can indeed be categorized as weak CSD.
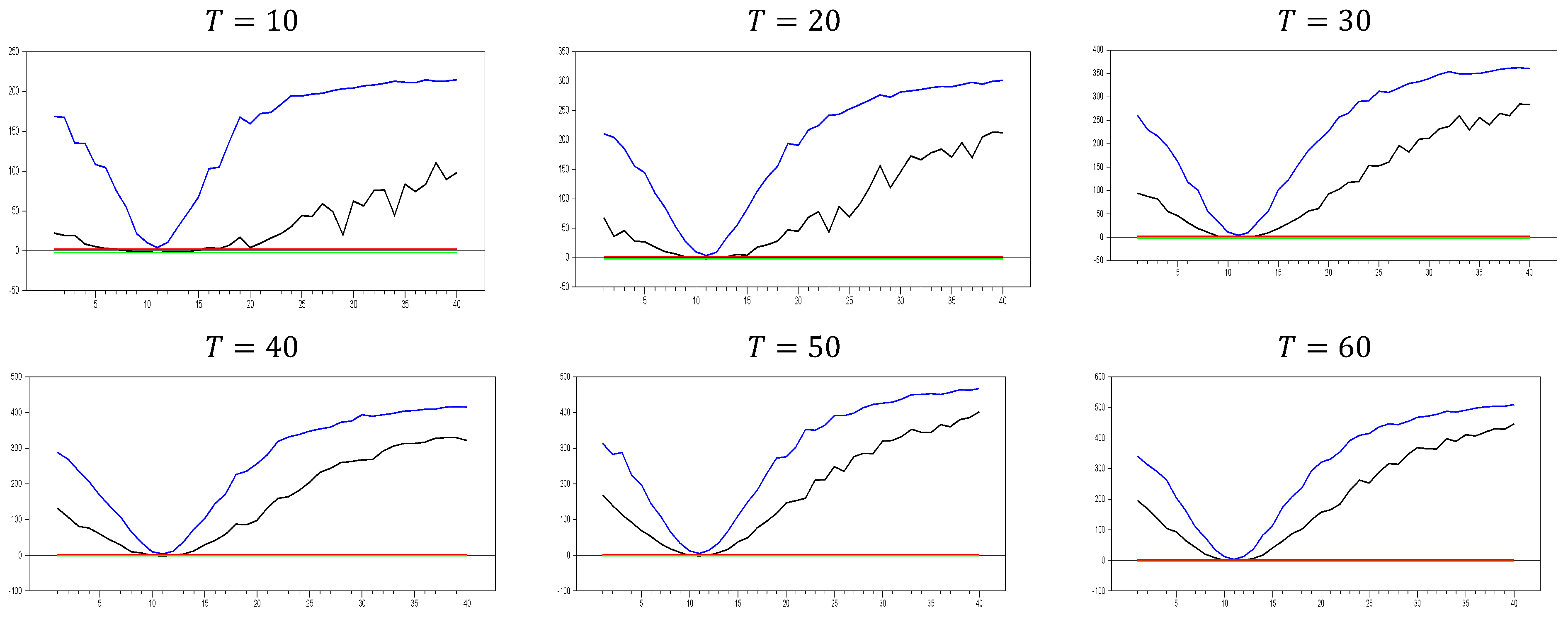
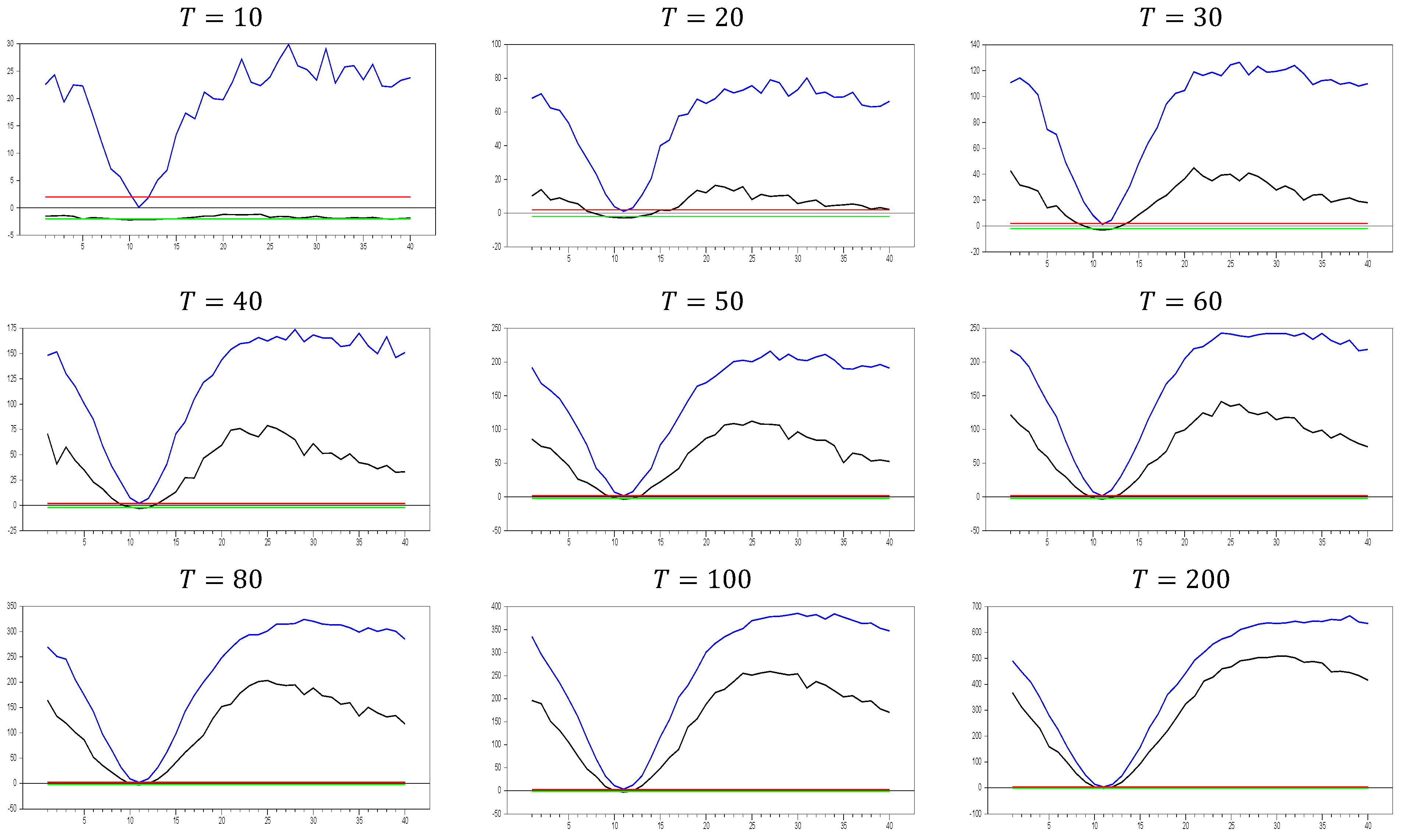
Up until here in
Figure 2 and
Figure 3, we have deal with
and
with
. In order to see the large sample features, we performed simulations for
and
.
Figure 4 shows the behavior of the
test in large samples.
Figure 4 confirms the expected pattern of
Figure 1,
Figure 2 and
Figure 3. All the explanations for the comparison of
Figure 1,
Figure 2 and
Figure 3 are valid. Hence, these simulation results provide evidence of the consistency of the test for catching CSD in small samples.
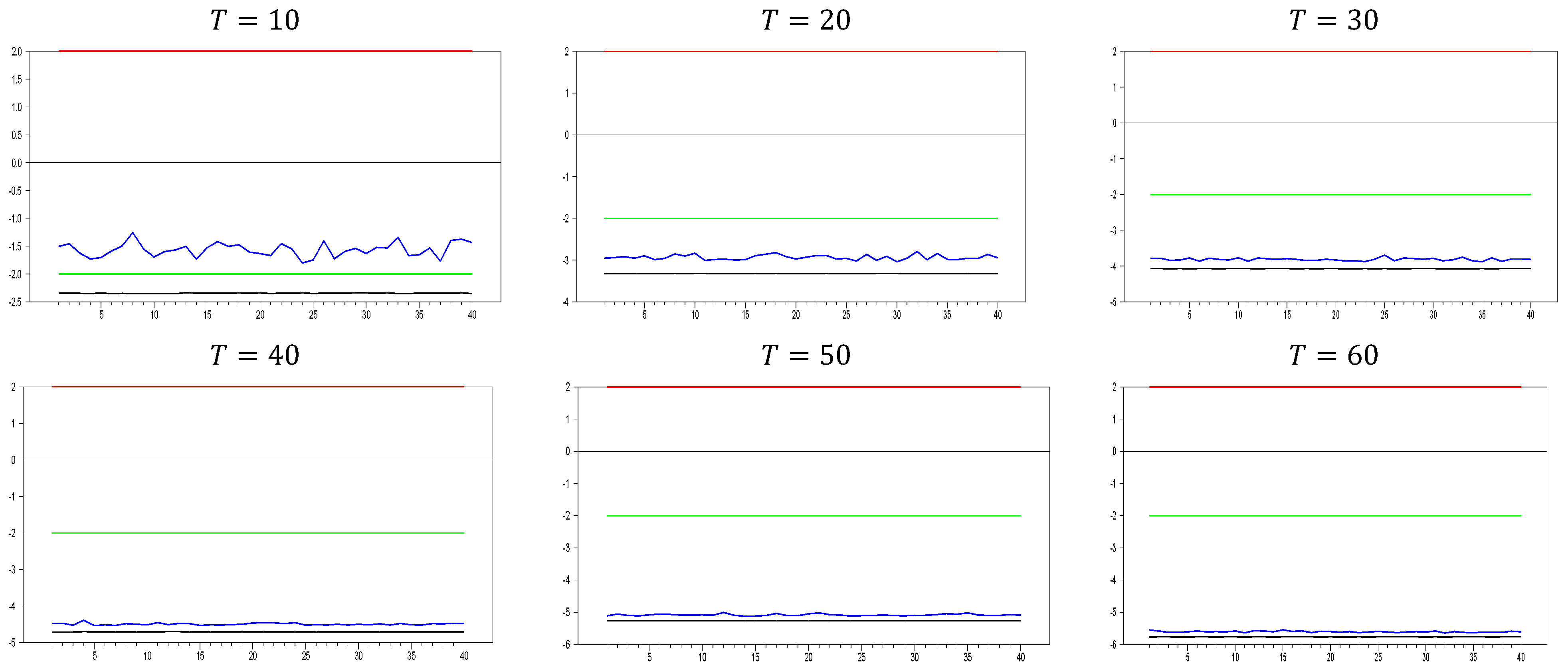
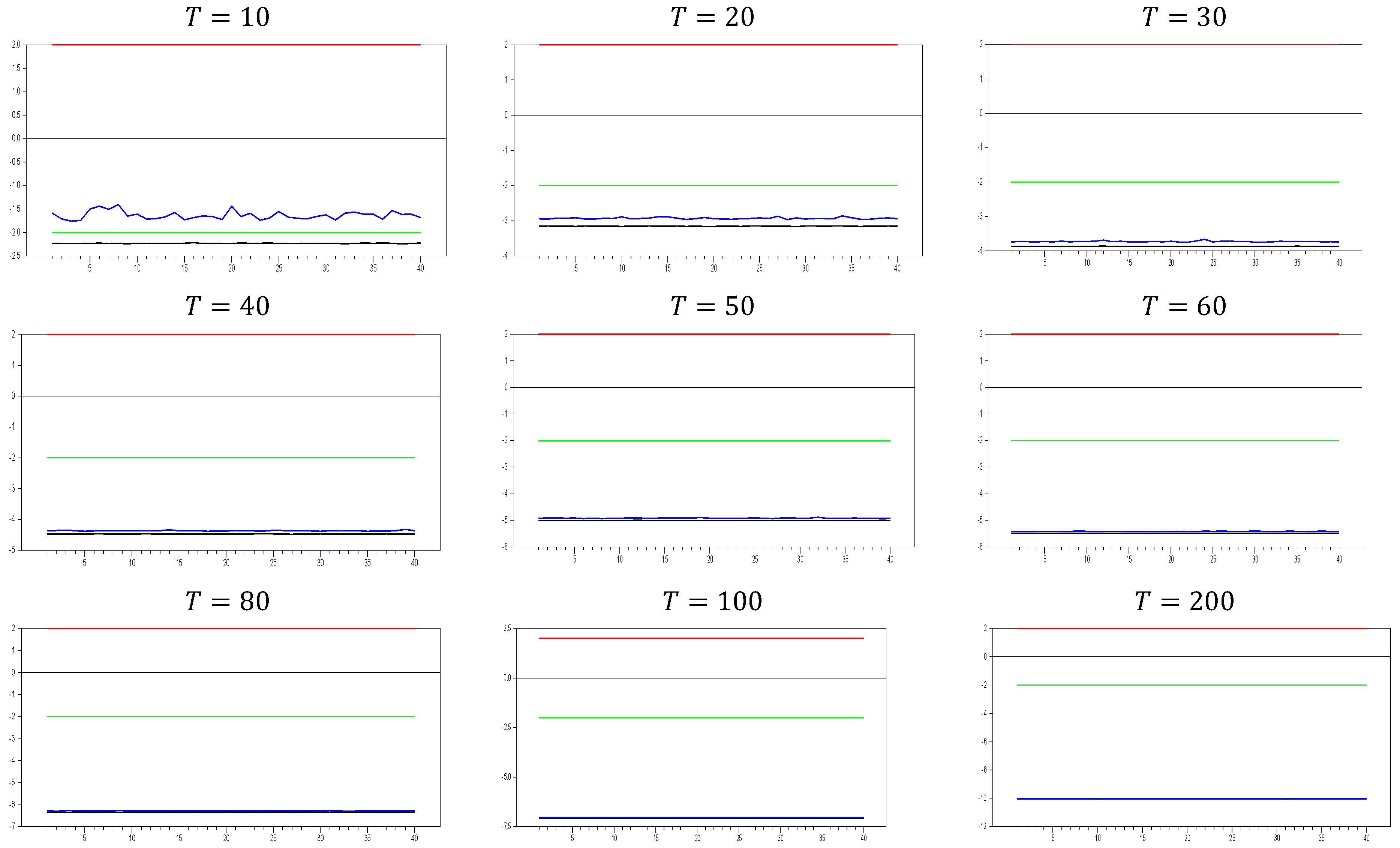
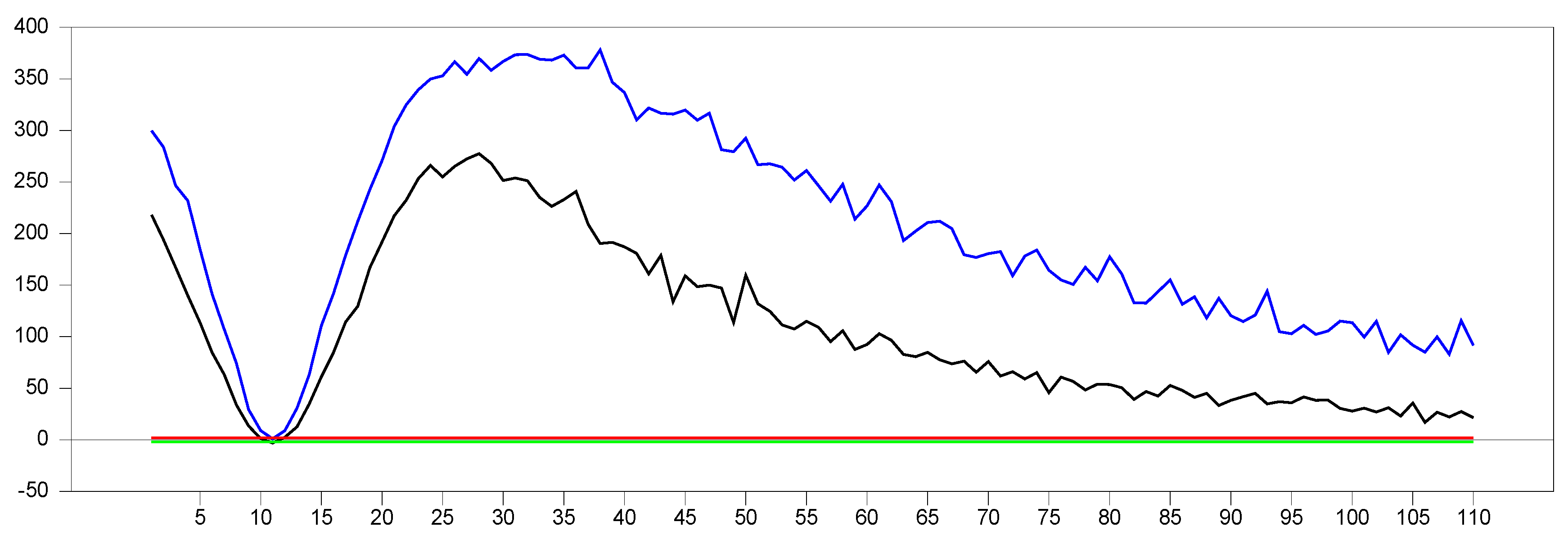
2.2.2. The Behavior of the with Imposing the Factor Variable
We now investigate the consistency of the
test by imposing a factor variable into the testing process, which induces CSD in the DGP. If the
test is working correctly, the inclusion of the factor variable should eliminate the CSD, and the
test should indicate no remaining CSD. The resulting
values will fall between the z-test thresholds of −2.0 and 2.0, as shown in the graphics. The first results are given in
Figure 5 for
.
From
Figure 5, we observe that the calculated minimum and maximum values fall within the 10% significance level of the z-test, confirming that the
test successfully captures the CSD imposed in the DGP of Equation (3). This result meets our expectations and provides a benchmark for evaluating proxies used to remedy CSD. A valid proxy should follow this pattern for small
and
dimensions. If the test shows no CSD for any factor loading, the proxy can be considered an efficient factor variable. In
Figure 5, we can see how increasing the
dimension affects the results. The test statistics range between approximately −2.0 and 7.0 for
, and between −3.0 and 4.0 for
. As
increases, the band of calculated test statistics narrows and shifts downward, with the maximum values decreasing more significantly than the minimum values. This suggests that while the original factor effectively remedies CSD, it still has some limitations in handling very small probabilities. To better understand the
test’s behavior, it would be useful to analyze the results with a larger
dimension.
From
Figure 6, we can observe that for
and
, the calculated
test statistics range between approximately −1.5 and 15.0, compared to a range of −2.0 to 7.0 for
and
. As
increases, the band of the
test statistics shifts upward and widens, with the maximum values increasing more than the minimum values. When
and
, the band narrows to a range of −2.0 to 4.0, whereas for
and
, the range is approximately −3.0 to 4.0. This narrowing of the band as both
and
increase suggests that the original factor more effectively remedies CSD in the DGP. These simulations highlight the power of the
test, which proves to be highly effective in detecting CSD based on the test results. The second set of simulations further demonstrates the effectiveness of the method in remedying CSD, building on the first simulation’s results. Therefore, we can conclude that both simulations confirm the power of the
test and the method used to remedy CSD.
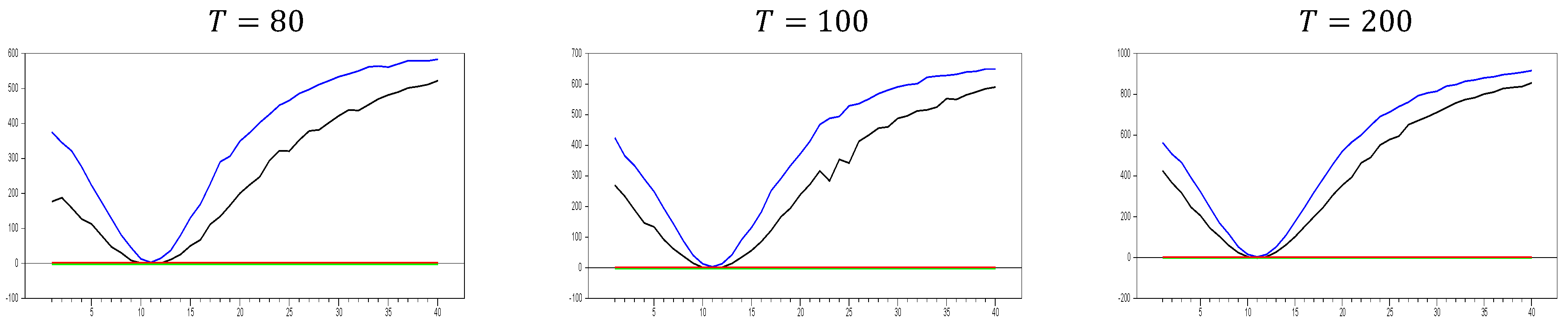
To explore this further, we now examine the impact of increasing the
dimension in
Figure 7. In
Figure 7, a new phenomenon emerges. When the factor loadings are low, the original factor remedies CSD more effectively than at higher factor loadings. This behavior may also appear in approximation methods like the CCE estimator.
Up until here in
Figure 5,
Figure 6 and
Figure 7, we have deal with
,
and
with
. To explore the behavior in larger samples, we conducted a simulation with
and
.
Figure 8 illustrates how the
test performs in remedying CSD using the original factor in these large-sample settings.
We now have solid benchmark simulations to assess whether the proxy variables are effective. The results from the first simulation help us evaluate whether the proxy can remedy part of CSD. The second set of simulations further demonstrates the efficiency of the proposed method in addressing CSD.
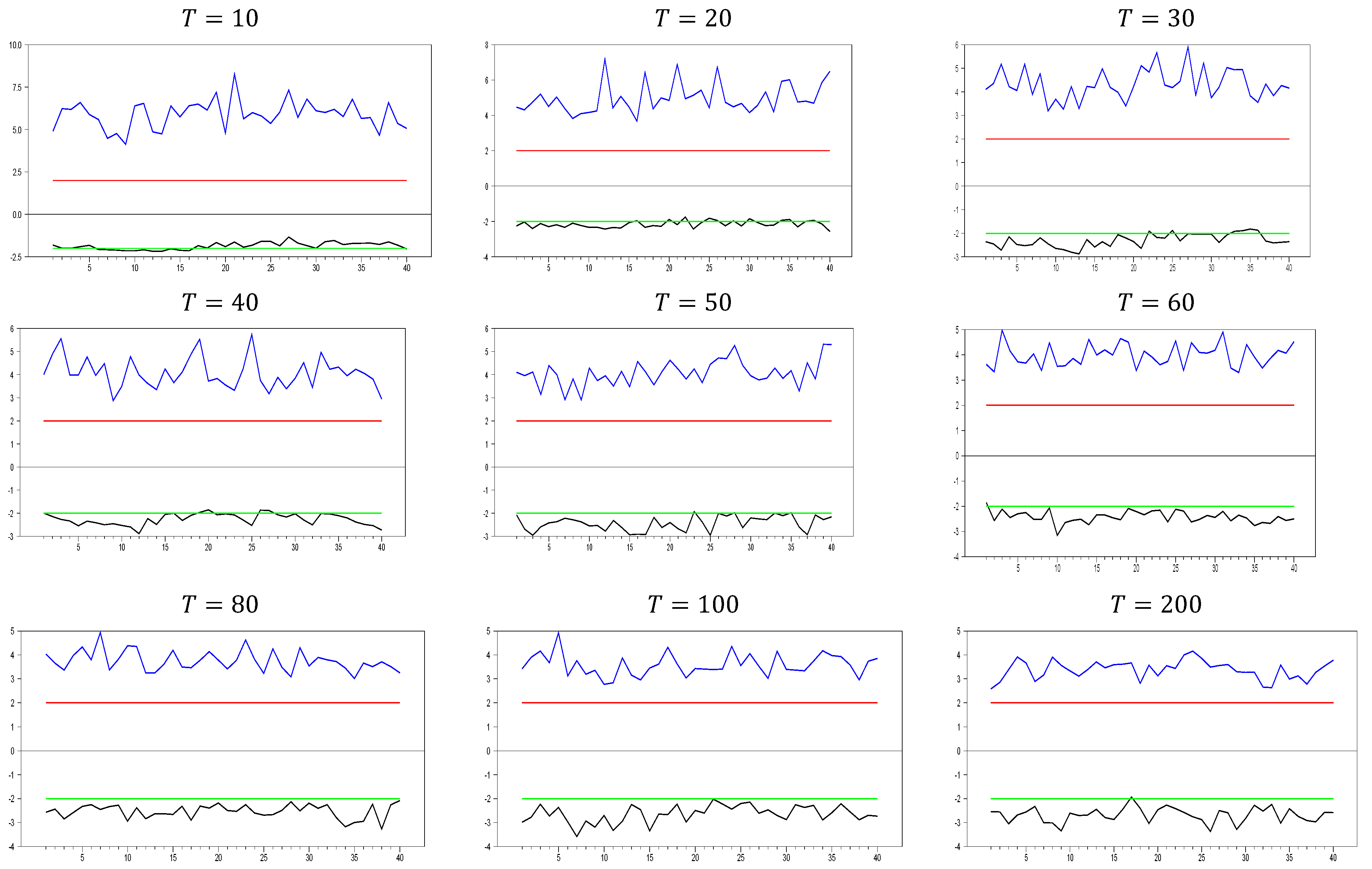
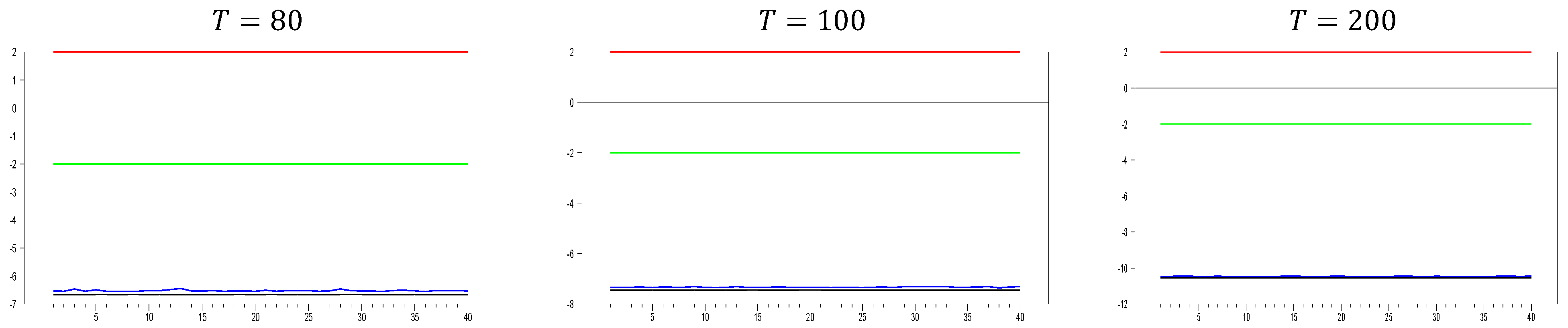
2.2.3. The Behavior of the with Imposing the CCE Estimator
In light of these arguments, we can assess performances of the CCE estimator proposed by [
8,
27]. In
Figure 9, we observe some unexpected results for what would typically be considered a good proxy. However, only for
and
do we see the expected results for a proxy that remedies CSD, as indicated by simulations 1 and 2. The computed
values range between approximately −2.4 and −1.5, demonstrating that the CCE estimator effectively remedies CSD. Additionally, for
, the computed values quickly move out of the CSD rejection region, and the band between the minimum and maximum
values narrows as the
dimension increases. By
, the minimum and maximum values of the
test are approximately
10.25 and −10.15, respectively. Now, we can further explore the effects of increasing the
dimension.
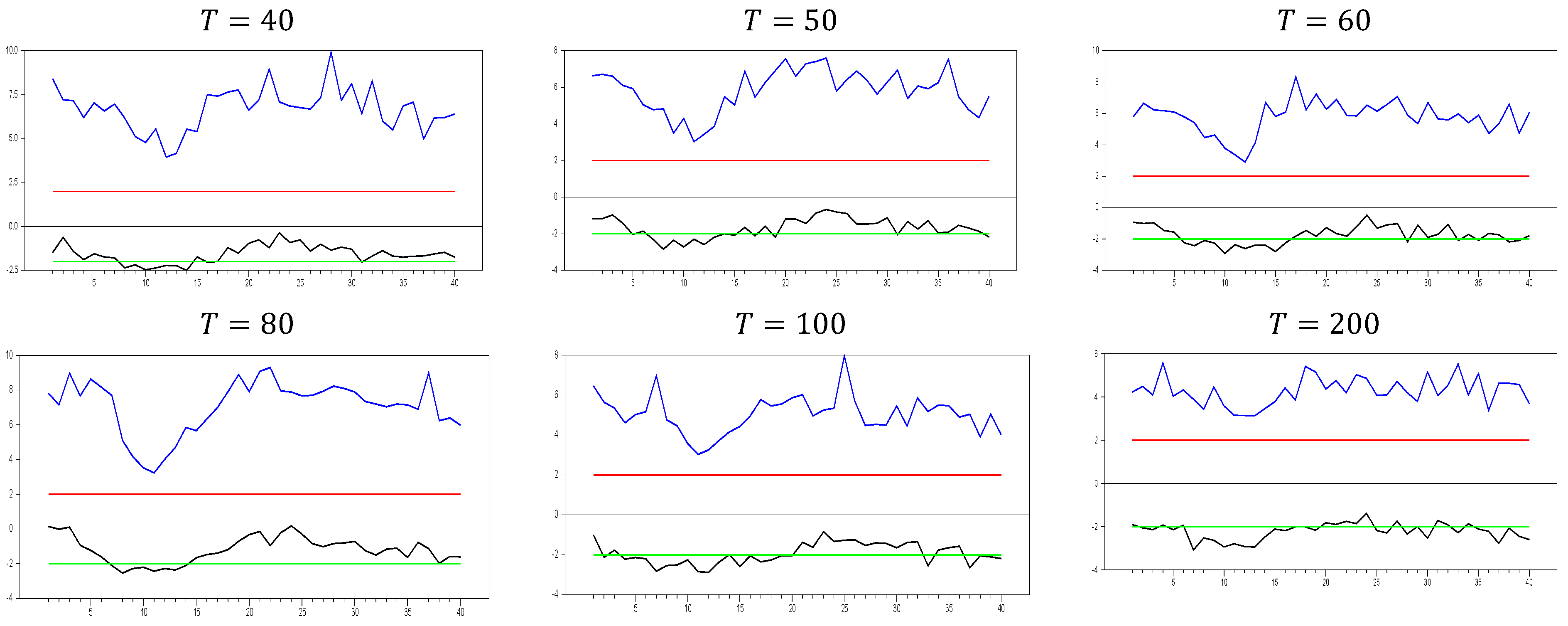
In
Figure 10, we observe that only for
and
we obtain the expected results for a good proxy that remedies CSD, as indicated by simulations 1 and 2. The computed
values range between approximately −2.2 and −1.4, confirming that the CCE estimator effectively remedies CSD. However, as the
dimension increases, the band between the minimum and maximum
values narrows. For
and
, the minimum and maximum
values for
are approximately
and
, respectively. These results show that increasing
reduces the
test values and narrows the band, while increasing
further narrows the range. The key finding from these simulations, in line with simulations 1 and 2, is that the CCE estimator remedies CSD most effectively when
is small. However, as
increases, the proxies
and
correct the factor’s effect in the residual term but introduce additional CSD in the opposite direction. These simulations focus solely on CSD, so we cannot yet determine how they impact bias reduction in the
parameter in Equation (3). Nonetheless, there remains scope for developing a better estimator for addressing CSD in panel unit root testing, in line with the approaches of [
8,
27]. Before further investigating this, it is beneficial to examine the effects of increasing both
and
dimensions.
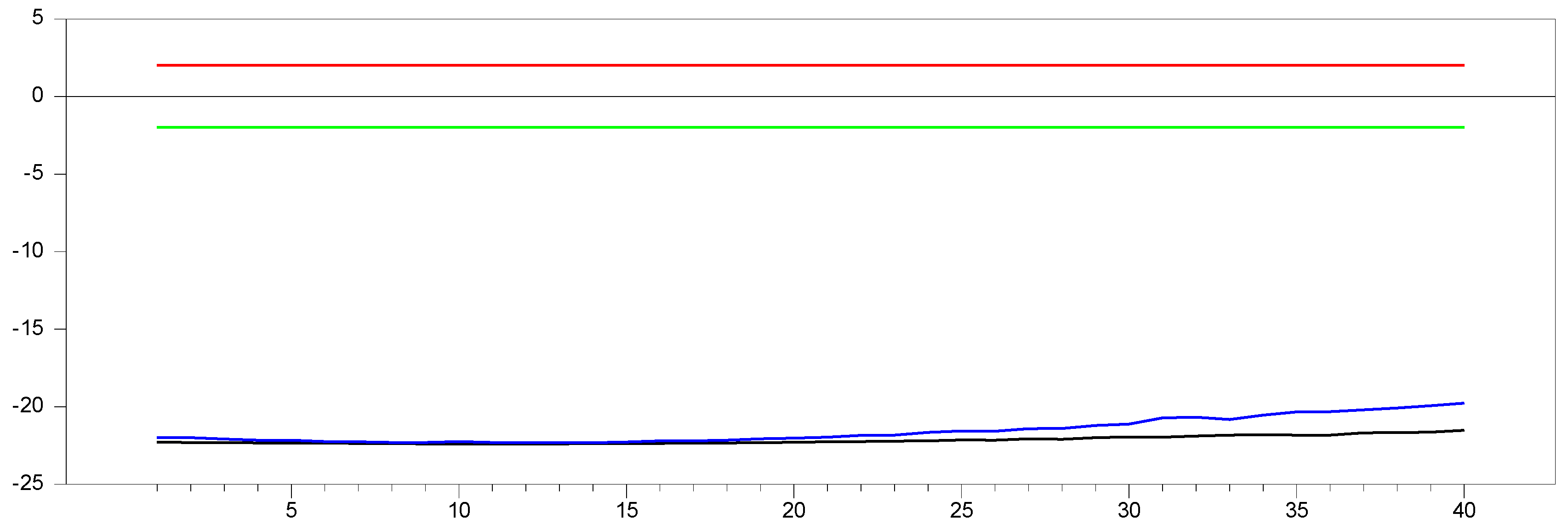
In
Figure 11, we observe that the results are similar to those in
Figure 9 and
Figure 10. The only difference is that for
and
, no band appears, and the minimum and maximum values are fixed at 10.0. This indicates that the bands in
Figure 11 are narrower than those in
Figure 9 and
Figure 10. To further explore the behavior in large samples, we conducted a simulation for
and
.
Figure 12 illustrates how the
test performs when remedying CSD using the CCE estimator proposed by [
27] in large samples. In
Figure 12, we observe that as the
dimension increases, the
test values reach 22.0. Additionally, increasing both the
and
dimensions together eliminate the band between the minimum and maximum values of the
test.
2.3. The Refinement of the Common Correlated Estimator by Using the Test Results
In light of these findings, we now can investigate for a more efficient estimator for remedying CSD in small samples.
Proposition 1. and
proxies can be expressed by
.
Proof. with some algebra can show that
where
and
is taken:
Now, we can re-write Equation (12),
Showing that
we prove that
□
Using this variable,
, may provide a more effective proxy factor to address cross-sectional dependency compared to [
27]’s CCE estimator. In the CCE estimator, we use two variables to proxy the factor; now, we have only one parameter to estimate, which may increase the efficiency.
Figure 13 clearly demonstrates that, for small
values, the newly proposed estimator or proxy closely mimics the original factor variable. Specifically, for
and
, the new proxy closely replicates the original factor variable based on the
test results shown in
Figure 5. However, as the
dimension increases, both the minimum and maximum
test values rise, and the band widens. By
, the
test results for the proxy estimator indicate that it no longer provides an effective remedy. To further examine the effect of increasing the
dimension, we performed a simulation for
. The results are shown in
Figure 14.
Figure 14 shows that the effectiveness of the newly proposed estimator in remedying CSD diminishes as the
dimension increases. Thus, we can conclude that this proxy is only effective for very small
dimensions.
To further examine the impact of increasing the
dimension, we conducted a simulation for
. The results are presented in
Figure 15. Fortunately, as seen in
Figure 15, the
test results for
and
show that the test values converge to 1000.0, while the new estimator’s
test values converge to 600.0. This indicates that the new estimator remedies part of the CSD, but a significant portion of the induced CSD still remains, leading to biased estimates. Additionally, the
test values start to decrease around a factor loading of
, opposite to the trend in
Figure 15. Therefore, it may be useful to examine the behavior of the
test for higher factor loadings.
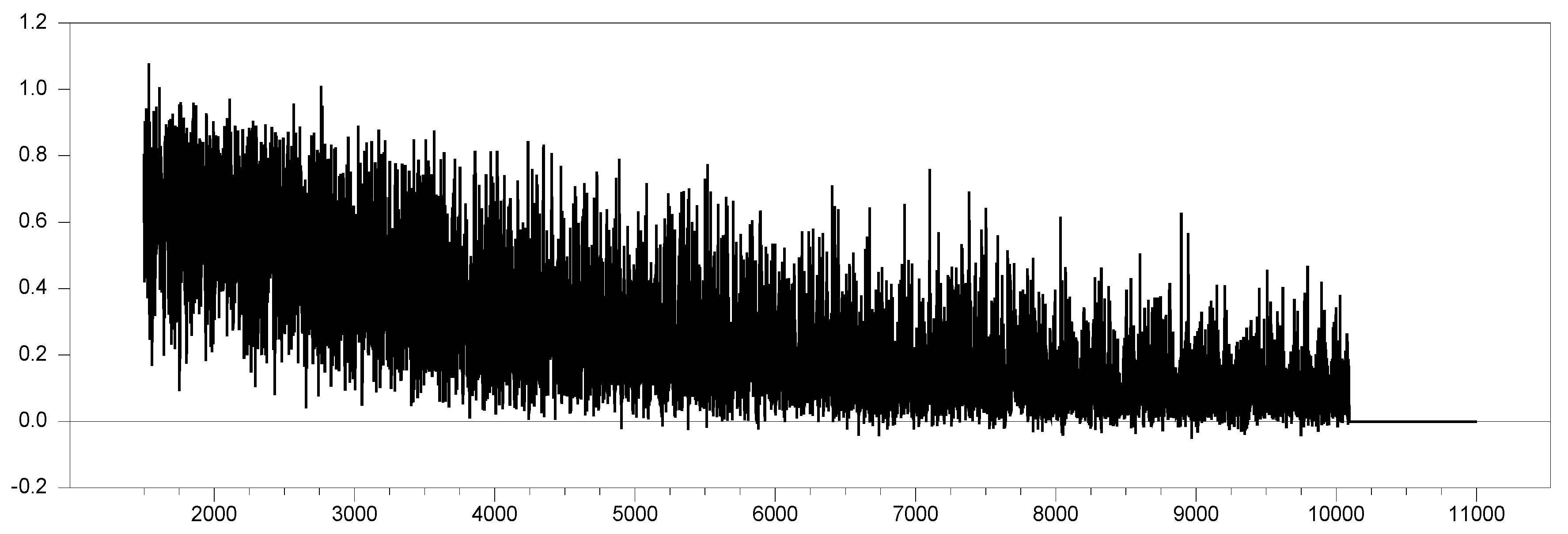
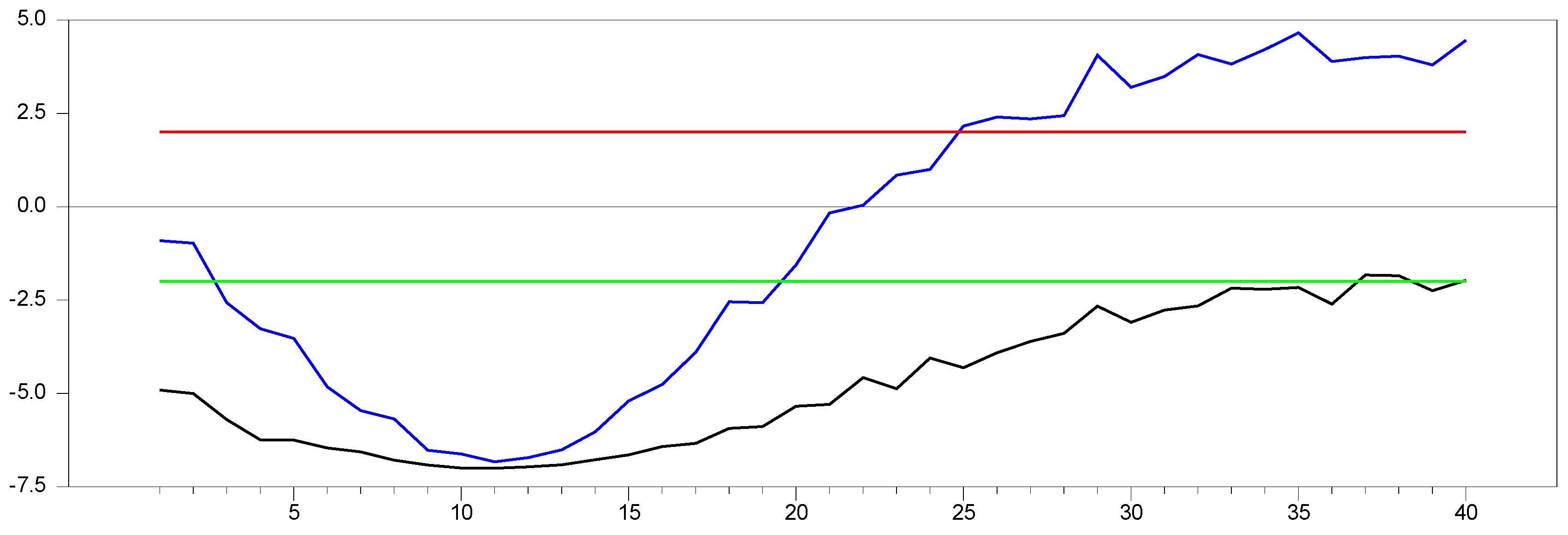
Figure 16 presents the simulation results for
and
with factor loadings ranging from
in 0.1 increments. As the factor loadings increase, the new proxy
adjusts within the range of
. To better understand the behavior without any remedy applied, we simulated the same values, as shown in
Figure 17 below.
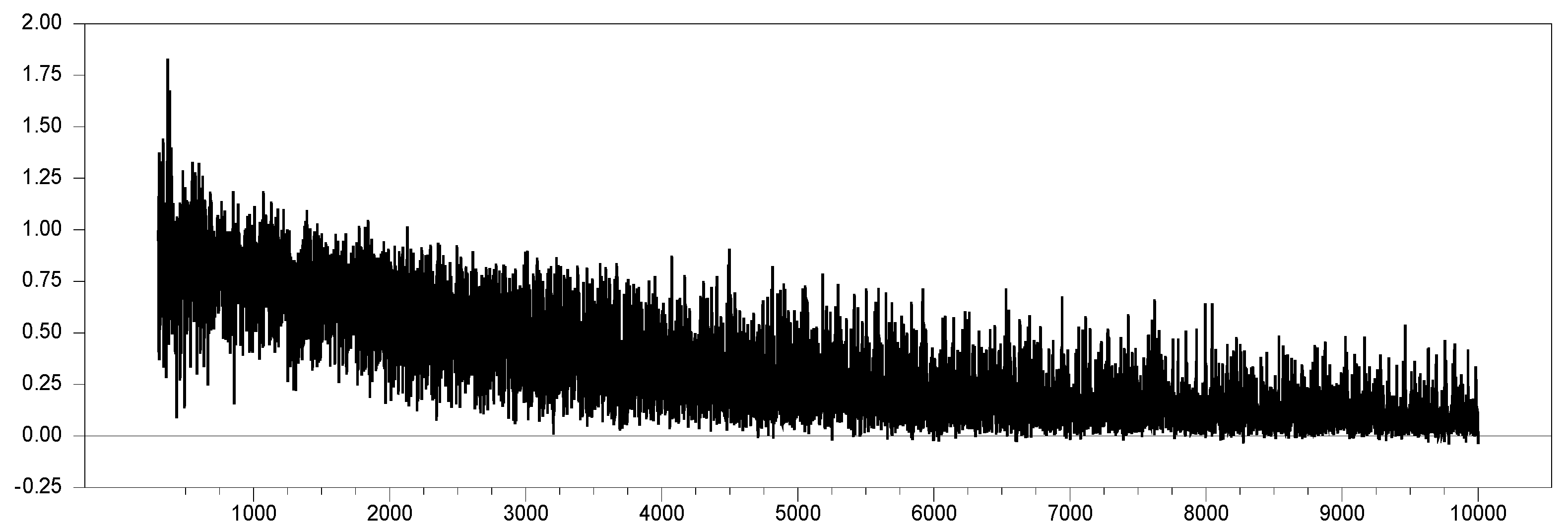
Comparing
Figure 16 and
Figure 17, we can observe that the
proxy remedies CSD across all factor loadings and converges to the results obtained by the original factor variable. To further examine the parameter estimates of both the original factor and the
variable, we performed simulations for
and
within the factor loading range
. The simulated values are shown in
Figure 18 below (the simulations were performed by the 50-entity 100 factor loading interval for 10 trials; hence, the simulated values are 50,000).
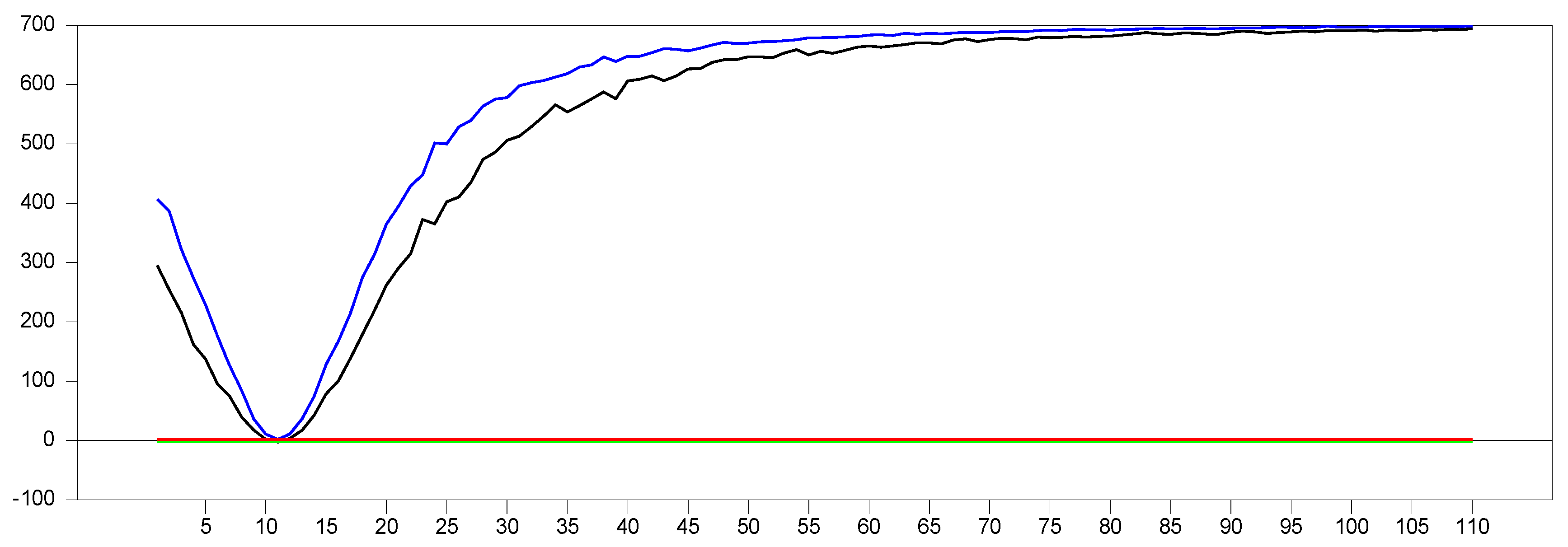
Each 10,000-point interval corresponds to a factor loading of
. After
, the parameters become equal, marking the turning point in
Figure 17, where the estimated parameter values for the original factor variable and the proxy converge, effectively remedying the CSD. The same pattern is observed in the CCE estimation. We subtracted the parameter value of
from the original factor’s parameter value within the same factor loading range.
Figure 19 below summarizes the results of the Monte Carlo study.
These two simulation results shed light on an issue. From
Figure 19, we can see that the difference between the parameters ranges from −0.04 to 0.06 until the factor loading reaches
, after which the difference becomes nearly zero, and it finally reaches 0.0 at
, as shown in
Figure 18. The difference obtained using the
parameter in
Figure 18 is quite large compared to the CCE estimator for the factor loading range
, where the CCE estimator consistently performs better. However, after
, the performance of the
proxy improves. Moreover, based on
Figure 13,
Figure 14 and
Figure 15, we observe that the
proxy performs better in small samples with
. These results suggest that there is a transformation that remedies CSD more effectively than the CCE estimator for small samples, particularly for factor loadings in the range
. However, we also recognize that while
or
is necessary for remedying CSD, they are not sufficient without incorporating
. Using
and
(as in the CCE estimator) together remedies CSD across all factor loadings but introduces a negative significant
test result, indicating that some CSD remains in the estimation process in panel unit root testing. Based on the simulation results from the original factor variable, we identified the behavior of an effective proxy with respect to the
test. Any proxy that meets these criteria can be used as an efficient proxy for factor variables.
In
Figure 20, we demonstrate that as the factor loadings increase in 0.1 increments, [
27]’s CCE estimator, denoted as
, and our proposed estimator,
, become equal, meaning
. Starting from a factor loading of 0.0 and increasing to 10.0, we find that at a factor loading of 1.0,
and
are approximately equal. At this point, the
test shows very low dependence when using our proposed estimator.
Based on the arguments and simulations presented, we propose a new estimator that may prove to be more efficient in small sample sizes. Our newly proposed method is outlined as follows:
Step 1. Run the below regression:
Step 2. Estimate the
and
from Equation (20), and compute the new variable:
Step 3. Use this new variable as a dependent variable and obtain the panel unit root test:
In the first step, we remove the CSD effect from residual term
with [
27]’s CCE method. Now, we are left with more CS independent data. However, still, some CSD prevails as we showed in the above simulations. In the second step, we impose some more CSD into the dependent variable by adding the
variable into the filtered dependent variable. And in the final stage, we use
as a proxy, which is indirectly equal to
. Therefore, we use [
8]’s method and Proposition 1 together. Our simulation results are given in
Figure 21,
Figure 22 and
Figure 23.
The newly proposed estimator behaves similarly to the CCE estimator for . All characteristics, such as the decrease in test values as the dimension increases and the narrowing of the band, follow the same pattern. However, while the lower bound of the test aligns in both methods, the upper bound converges more slowly than in the CCE estimator. This slower convergence of the upper bound makes the new estimator perform better than the CCE estimator in terms of the test.
In the second step, we increase the
dimension again to assess its impact. The results of these simulations are shown in
Figure 22 below. The new proxy method exhibits very similar behavior to the original factor variable for
, further supporting its effectiveness as a good proxy. In particular, for small
dimensions (
to
), the method performs as well as the original factor. However, for low levels of CSD, such as
, this method does not remedy CSD, which can be seen as a favorable characteristic. Similarly to the CCE estimator, the
test shows a negative sign, indicating that the method introduces some CSD. Additionally, as
increases, the upper and lower bounds of the computed values converge to those of the CCE estimator. As
grows, the
test results follow the same trend as the CCE estimator. For instance, with
and
0, the lower bound of the
test reaches 10.0, while the upper bound also becomes closer to the CCE estimator. This convergence is a positive attribute for deriving the asymptotic properties of the new estimator, showing that as
and
approach infinity, the new test aligns with the same asymptotic properties. The following simulation results are obtained for
.
From
Figure 23, we can clearly observe that for
and
, the newly proposed method closely approximates the original factor variable. These simulation results indicate that our proposed method performs similarly to the original factor as
increases while
is fixed. Additionally, we conducted simulations for two scenarios: one where both
and
approach infinity, and another where
is fixed and
is large.
Figure 24 shows that as
and
approach infinity, the new method converges toward the CCE method in remedying CSD.
However, when
is fixed and
approaches infinity, the newly proposed method serves as a better proxy for the original variable. The results for this case are presented in
Figure 25.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}