Abstract
In the domain of multi-label classification, label correlations play a crucial role in enhancing prediction precision. However, traditional methods heavily depend on ground-truth label sets, which can be incompletely tagged due to the diverse backgrounds of annotators and the significant cost associated with procuring extensive labeled datasets. To address these challenges, this paper introduces a novel multi-label classification method called updating Correlation-enhanced Feature Learning (uCeFL), which extracts label correlations directly from the data instances, circumventing the dependency on potentially incomplete label sets. uCeFL initially computes a revised label matrix by multiplying the incomplete label matrix with the label correlations extracted from the data matrix. This revised matrix is then utilized to enrich the original data features, enabling a neural network to learn correlation-enhanced representations that capture intricate relationships between data features, labels, and their interactions. Notably, label correlations are not static; they are dynamically updated during the neural network’s training process. Extensive experiments carried out on various datasets emphasize the effectiveness of the proposed approach. By leveraging label correlations within data instances, along with the hierarchical learning capabilities of neural networks, it offers a significant improvement in multi-label classification, even in scenarios with incomplete labels.
Keywords:
multi-label classification; incompletely tagged label sets; label correlations; neural network learning MSC:
68T07
1. Introduction
Given the widespread occurrence of multi-label issues, researchers have introduced various multi-label classification techniques across diverse domains [1,2,3,4]. Unlike traditional single-label classification tasks [5,6], the semantic polysemy associated with multi-label data contributes to the complexity of these challenges. Specifically, as the number of categorical labels proliferates exponentially, the challenge of selecting an apt label set for novel data intensifies significantly [7].
Multi-label sample data consists of a wide array of category labels, many of which exhibit either direct or indirect relationships with each other. For instance, consider two illustrative images: one featuring a pyramid alongside a camel and the other displaying a pyramid situated in a desert. Initially, the camel and the desert in these two images may appear unrelated at a cursory glance. However, upon deeper examination of the contextual relationships inherent within these images, it becomes evident that there is an indirect correlation between the labels “camel” and “desert”. This observation is noteworthy as the terms “camel” and “desert” typically evoke a direct association in real-world scenarios. Research indicates that leveraging these label correlations, especially in scenarios with numerous category labels, can significantly reduce the complexity of classification problems and enhance classifier performance. The investigation of label correlations thus fuels the progress of multi-label classification, constituting a crucial research direction in this field [8,9].
Multi-label classification methods primarily categorize into four key strategies that capitalize on label correlations:
(1) Implicit exploitation of label dependencies, which involves partitioning a multi-label dataset into subsets based on labels and individually learning the data features within each subset. The representative method is label powerset (LP) [10], a simple method that treats each label subset in a training set as a single new label to construct a single-label classification problem. Although LP considers label correlations, it may produce a large number of classes, each with only a few examples. To solve the problem of insufficient training samples of new labels generated by LP, Read proposed pruned problem transformation (PPT) [11], which clips label subsets whose frequencies are much less than a threshold to smaller label subsets with slightly higher frequencies. Random k-Labelsets (RAkEL) [12] is an ensemble algorithm based on LP, which randomly selects m non-repetitive label subset combinations composed of k labels from an original set of category labels, and trains an LP classifier on the data of each label subset. Multiple LP classifiers vote for the prediction results. Parameters k and m are set artificially. RAkEL degenerates to a BR algorithm when = 1 and = and LP when = and = 1. RAkEL considers correlations between labels while avoiding the drawbacks of LP. However, for the best results, it requires a large number of datasets, as well as cross-testing of input parameters such as subset size and threshold. It is difficult to find the optimal parameters without sufficient training samples.
(2) Incorporating label correlations as prior knowledge during the training of classification models, thereby leveraging pre-existing relationships between labels. Wang et al. [13] proposed a subspace learning algorithm based on label sparse coding for feature extraction. This implies the exploitation of label correlations to annotate different images with the same label and appropriate weights. Zhang and Zhou [7] used label correlations to find a projection matrix that maximizes correlations between data features and labels in the dimensionally reduced feature space. Wang et al. [14] calculated the cosine similarity between category labels and constrained the learning of the objective function with the similarity matrix to obtain a Green’s function enhanced by the label correlations.
(3) Concurrent discovery of label correlations during the training process of the multi-label model, allowing for dynamic exploitation of inter-label relationships. Huang et al. [15] assumed that label correlations are local because sample sets share different label correlations, few of which apply globally. To encode the local effects of label correlations, they derived an LOC code to enhance the feature representation of each sample and combined the global discriminant fit and local correlation sensitivity in a unified framework. Xu et al. [9] captured label correlations by a low-rank structure and introduced a low-rank constraint of the label correlation matrix in the model learning process. Gu et al. [16] used a normal distribution of matrix variables on the vector of classifiers to model label correlations and minimized the label correlation regularized loss of label ranking based on a subset of features. Ji et al. [17] proposed a general framework to extract shared structures, within which a binary classifier was constructed for each label. Unlike traditional binary classifiers, all binary classifiers were defined on both the original data space and low-dimensional shared structures to capture label correlations.
(4) Augmenting the original feature space with a label space, thereby enriching the data with additional information stemming from label correlations. Read et al. introduced classifier chains (CCs) [18], constructing a binary classifier for each label, whose result is used to expand the feature space of the next classifier. However, the order of construction affects classification performance. Montañes et al. proposed dependent binary relevance (DBR) [19], which learns a binary classifier for each label, each employing − 1 features made up of other labels to expand the original feature space. Learning the label-expanded feature space, its binary classifiers can discover label correlations by themselves. However, the number of classifiers is proportional to the label length.
The aforementioned approaches primarily derive label correlations from the label sets available in the training data. However, these label sets are often incomplete, which is mainly attributed to the diverse backgrounds of grassroots users annotating data features [20] and the high cost associated with extracting a significant number of labeled samples for large-scale tasks [21]. Consequently, the accuracy of label correlations can suffer when labels are missing.
In the context of multi-label learning, a single instance is simultaneously associated with multiple class labels, and each label is determined by unique features specific to that instance. Since the amount of data feature information varies across objects corresponding to different category labels, the importance of labels within the same instance also differs. Nevertheless, the binary value (0 or 1) assigned to a label in a tagged label set merely signifies the presence or absence of the feature represented by label on data . This approach fails to capture the significance of the specific feature corresponding to label . As a result, relying solely on the given label matrix to derive label correlations may lead to distorted classification results.
Taking into account the aforementioned challenges, a novel multi-label learning architecture known as updating Correlation-enhanced Feature Learning (uCeFL) is introduced in this paper, specifically tailored for multi-label classification tasks. This approach harnesses label information to enrich the features of the original data, echoing the principles outlined in point 4 of the previous discussion. Notably, rather than merely incorporating the given labels directly into the expanded feature space, uCeFL enriches the data feature space by utilizing labels completed through label correlation. This label correlation is extracted from the data matrix, ensuring resilience against missing labels. This innovative approach effectively circumvents the challenges posed by incomplete label matrices, resulting in more precise and robust multi-label classification.
uCeFL employs a covariance matrix to efficiently capture the distinct features of each subset of data affiliated with individual category labels. Through the comparison of covariance matrices within an dimensional space, it accurately quantifies the correlation among these labels. It is universally acknowledged that the covariance between two variables increases as their interaction intensifies, and a covariance matrix comprehensively characterizes the interactions among all variables. The similarity between two covariance matrices suggests that their respective characteristic variables exhibit comparable distributions. Since category labels serve as abstract representations of interrelated data features, it is logically justifiable to express the correlation among labels through the similarity of covariance matrices pertaining to categorical data features. By deriving label relationships directly from the data, uCeFL effectively mitigates any potential interference caused by incomplete labels.
Regarding the intricate new data structure that is expanded with complete labels, this paper refrains from making any assumptions. However, since real-world data often reside in a low-dimensional manifold embedded within a high-dimensional space, the new data structure can be characterized as a nonlinear manifold. Multi-layer neural networks excel at simulating such nonlinear manifold structures without relying on hypotheses. They can acquire high-level data features by learning the hierarchical structure. Therefore, this paper utilizes a neural network to efficiently learn the multi-label data with increased dimensions, obtaining the fundamental variables that explain the enhanced data features. Label correlations are not merely considered as prior knowledge; rather, they are dynamically updated throughout the neural network training process, which ensures that our neural network continuously optimizes the label correlation, ultimately leading to more accurate and refined predictions.
Moreover, to emphasize the effectiveness of uCeFL, this paper introduces a variant named Correlation-enhanced Feature Learning (CeFL). This approach solely treats label correlations as prior knowledge, serving as a static input to the neural network throughout the entire training process. This input remains constant, ensuring consistency and stability.
Distinct from numerous existing methods, uCeFL distinguishes itself as being significantly more intuitive and comprehensible. Rigorous experiments spanning seven diverse databases have unequivocally established its superiority. Moreover, the label correlations inherently extracted from the data effectively capture the varying degrees of importance ascribed to each label, thereby reflecting the intricate relationships and interactions among the distinct features represented by these labels.
In essence, the key contributions of this article are outlined as follows:
- Our method distinguishes itself from the preponderance of multi-label correlation learning algorithms by directly extracting label correlations from the data itself, thereby enhancing their precision beyond those derived solely from pre-assigned labels.
- We introduce a revised label matrix, obtained by multiplying the incomplete label matrix with the captured label correlation, which serves to enrich the original data’s feature representation. A multi-layer neural network is then employed to learn the correlation-enhanced features that encapsulate intricate relationships among data features, labels, and their interconnections.
- Leveraging the high-level semantic features extracted by the multi-layer neural network, our uCeFL approach re-evaluates the label correlation, facilitating continuous updates of these correlations throughout the neural network’s learning trajectory. This approach effectively captures the label propagation effects, ensuring a comprehensive and accurate representation of the label space.
The remainder of this work is structured as follows. Section 2 provides the related work, exploring the existing literature and prior studies pertinent to our investigation. Section 3 delves into the uCeFL approach, offering a comprehensive explanation of the methodologies utilized and the architecture adopted in our research. Additionally, an introduction to CeFL is also provided. Section 4 presents the experimental results and discusses the outcomes obtained through rigorous testing and validation. Finally, Section 5 outlines our conclusions and future work, summarizing the key findings of our study and highlighting potential avenues for further exploration.
2. The Related Work
Among the various multi-label classification algorithms, classifier chains (CC) [18] occupy a significant position as a noteworthy approach. However, a major limitation of CC lies in its sequential nature, where each classifier’s prediction heavily depends on the output of its predecessor. This sequential dependency often leads to error accumulation and propagation, adversely affecting the overall prediction accuracy. To mitigate this limitation, dependent binary relevance (DBR) [19] methods have emerged as a promising alternative. DBR constructs independent binary classifiers for each label, incorporating features relevant to other labels to enrich the input data space. This allows classifiers to independently capture and utilize label dependencies.
However, traditional binary classifiers may not fully realize the potential of DBR when dealing with specific multi-label loss functions. To enhance DBR’s performance, various optimization algorithms have been proposed. Rauber et al. [22] introduced a recursive approach that leverages DBR’s initial predictions as a starting point. This method iteratively improves predictions through feedback, aiming to boost accuracy by continuously modeling label dependencies. Alternatively, Zhang et al. [23] proposed a DBR pruning technique based on Phi coefficients, which evaluates label-task relevance, optimizes the model structure, reduces costs, and demonstrates practical effectiveness. Furthermore, the RDBR algorithm [24], a novel approach within decision tree methods, generates crucial intermediate values for constructing DP matrices. While it offers a unique perspective, ensemble methods still provide superior diversity and robustness.
With the progress of multi-label classification research, researchers have increasingly focused on two key directions: label-specific feature learning and label dependency modeling. These approaches aim to learn the most suitable feature representation for each category and utilize label correlations to improve classification performance.
Label-specific feature learning aims to extract features closely related to the label from the data to improve classification performance. Zhang et al. [25] employed clustering techniques to delve into the inherent patterns of the feature space. However, this clustering approach was executed in a label-specific manner, overlooking the potential interplay between different class labels. ML-DFL, introduced by Zhang et al. [26], relies on a novel spectral clustering algorithm known as Spectral Instance Alignment (SIA). This method excels in capturing the latent patterns between positive and negative instances for each label. In another pursuit, RFS-LIFT [27] endeavors to select a refined set of label-specific features generated by LIFT, leveraging the fuzzy rough set framework. Concurrently, [28] introduced an efficient multi-label feature selection technique grounded in an information-theoretic label selection approach. This method identifies a subset of labels that significantly influence feature importance, enabling an effective output of a tailored feature subset. Nonetheless, a significant oversight among these methodologies is the lack of consideration for label correlations, which could potentially bolster their performance even further.
Label dependency modeling is another crucial research direction in multi-label classification, focusing on capturing and utilizing dependencies between labels. Loza et al. [29] tackle label dependencies in multi-label classification. They propose using rules to represent dependencies and introduce two rule-learning approaches: a bootstrapped stacking method that learns separate rulesets for each label and an algorithm that reincorporates predicted labels for learning subsequent rules. Both methods make dependencies explicit in rules and employ standard techniques to ensure rule usefulness. Li et al. [30] proposed the A-GCN, which leverages popular Graph Convolutional Networks with an adaptive label correlation graph to model label dependencies. Wang et al. [31] leverage Bayesian networks (BNs) to model the intricate correlations among labels and introduce a novel BN-based classifier chain method (BNCC). They utilize conditional entropy to capture the dependencies between labels, transforming the labels into nodes in a Bayesian Network (BN). The strength of these dependencies is represented by the weights of the edges. Furthermore, they devise a novel scoring function to evaluate the quality of the BN structure and employ a heuristic algorithm to refine and optimize the BN. Ultimately, through the application of topological sorting on the optimized BN’s nodes, a label order is derived, which serves as the foundation for constructing the classifier chain model.
Rather than focusing solely on label-specific features or label correlation modeling, some studies have also attempted to combine these two techniques to achieve better classification results. Zhan et al. [32] present LIFTACE, a multi-label learning method that leverages clustering ensemble techniques to generate label-specific features while accounting for label correlations, thus enhancing LIFT’s learning prowess. Zhang et al. [33] integrate partial least squares discriminant analysis (PLS-DA) with an -norm penalty, effectively capturing the intricate relationships between variables and labels while simultaneously reducing feature dimensionality. In another study, Liu et al. [34] employ partial least squares (PLS) to identify a latent shared space that bridges both data and label variable spaces, laying the foundation for an efficacious learning model. Ma et al. [35] introduce a label-specific dual graph neural network (LDGN) that harnesses categorical insights to derive label-tailored representations from documents. Central to its approach is a dual Graph Convolution Network (GCN) that comprehensively models the intricate and adaptive interactions among these representations, leveraging both statistical label co-occurrences and dynamic reconstruction graphs in a synergistic fashion.
Although numerous methods have been investigated to incorporate label-specific features and label correlations, many algorithms extract these features within the original feature space, which may not be the most effective approach. Therefore, this paper utilizes a neural network framework to map the correlation-augmented feature space into an embedded feature space. This approach captures the intricate interplay between label-specific features, labels, and their interactions while continuously optimizing label correlations. Ultimately, this leads to more accurate and refined predictions.
3. Algorithm Description
A multi-label classification problem can be defined as follows: be a training dataset consisting of N instances, where each instance is associated with possible category labels (). Each instance is represented by a feature vector containing attribute values. The corresponding label set for is denoted by a binary vector , where indicates that the instance belongs to label , and otherwise.
The training dataset can be further represented as data matrix and label matrix . The goal of this paper is to leverage the information contained in and to predict the label sets for unlabeled data points.
3.1. Motivation
Category labels serve as concise representations of intrinsic features, and the coexistence of various features within a sample indicates underlying interdependencies among those labels. Therefore, to attain accurate predictions for data samples’ labels, it is crucial to consider label correlations that possess substantial informational worth. Akin to numerous multi-label classification methodologies, such as CC and DBR, our research explicitly utilizes labels as data attributes. However, the distinction lies in our introduction of innovative approaches that harness label correlations inherent in the data itself rather than merely relying solely on ground-truth labels.
This paper first constructs the label-expanded feature vector , which is utilized instead of the data vector to train the model. Obviously, contains more distinguishable information than , and therefore, training with can achieve better classification performance. However, in multi-label problems, sample data with different category labels may share the same labels, suggesting that indirect relationships may exist between labels. This means that solely studying the combination may not be sufficient, especially when there are missing labels in , as , the components of , contains only the tagged labels of the corresponding instance; that is, can only indicate direct correlations between labels.
To fully leverage labels (including both direct and indirect relationships), this paper introduces a label correlation matrix . This matrix is used to transform the original labels into , effectively completing label sets with missing labels by utilizing a matrix [36]. Furthermore, by capturing varying degrees of importance among labels, the transformed labels enable a stronger association between data points with similar characteristics. Conventionally, the label matrix is defined using the normalized cosine similarity, as described in Equation (1):
where and are category labels, with corresponding row vectors and in label matrix . There are many approaches to improve the performance of multi-label classification using a label correlation matrix computed by cosine similarity [37,38]. However, as the amount of data increases and the data types become increasingly diverse, it is difficult to obtain the complete label information of each instance, which results in unreliable label correlations.
Assume that the sample data points and are accompanied by their corresponding label vectors and , respectively. These label vectors are defined as
which implies that comprises labels and , while solely contains . When assessing label correlations via cosine similarity with the original label vectors, it can be deduced that label is related to label , whereas label seems to be completely separate. However, the accuracy of label correlations derived from cosine similarity is compromised in scenarios where, despite possessing features indicative of label , this label is absent from the label vector . Consequently, it becomes imperative to rely on the data matrix, rather than the label matrix, for calculating label correlations whenever missing labels are encountered.
3.2. The Proposed CeFL
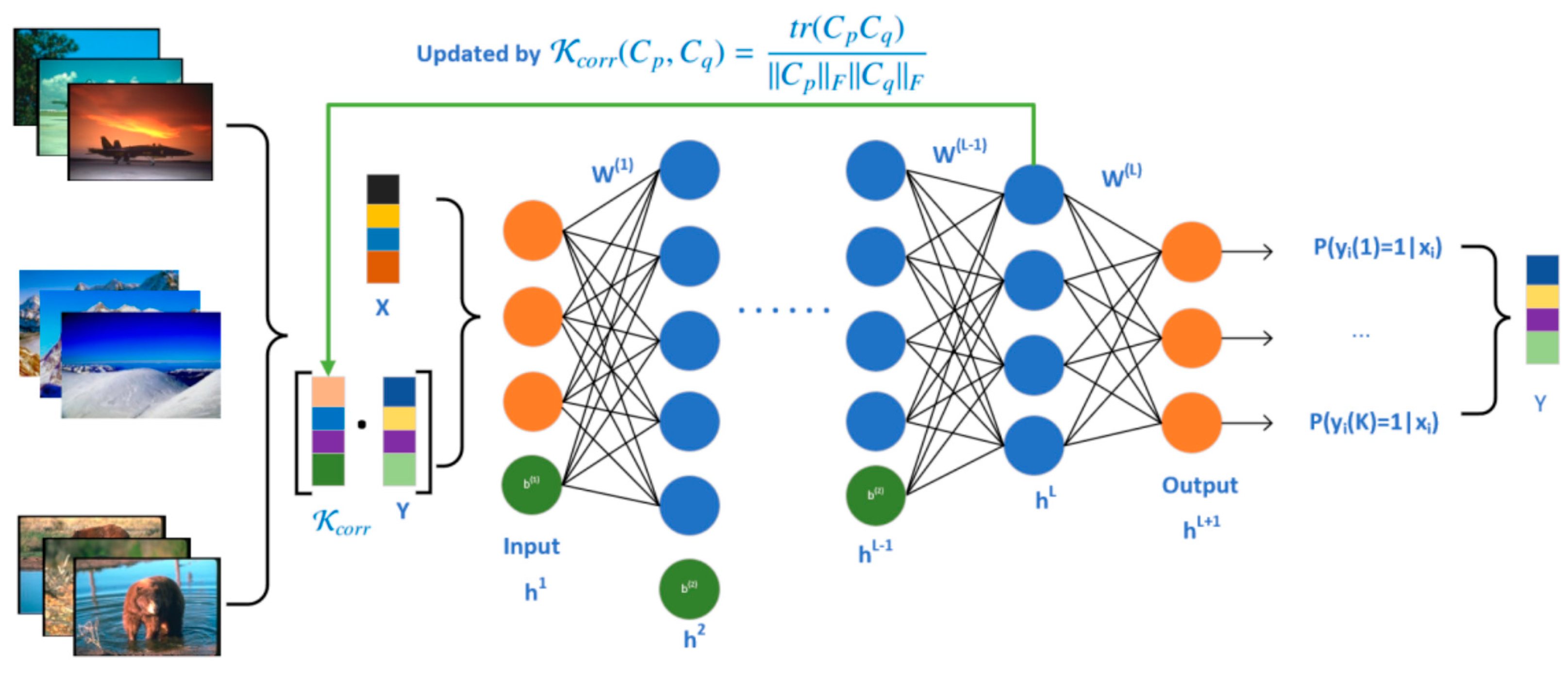
Motivated by the desire to enrich the data with supplementary information derived from label correlations and to minimize the influence of missing labels by relying on the data matrix for the computation of these correlations, this paper introduces a novel multi-label learning architecture termed updating Correlation-enhanced Feature Learning (uCeFL). This innovative approach is schematically represented in Figure 1. Subsequently, a detailed explanation of the architecture is provided as follows.
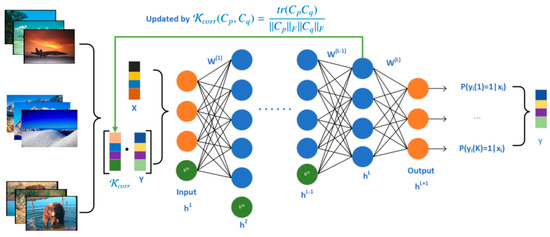
Figure 1.
The proposed architecture of uCeFL.
Let denotes a sample subset with label in the original dataset D, where is the number of samples in the subset. The covariance matrix similarity coefficient in Equation (2) is used to obtain a more accurate relationship between labels p and q from the data:
is the matrix trace, and is the Frobenius norm, , where is the correlation matrix distance [39], which becomes zero if the covariance matrices are equal up to a scaling factor and 1 if they differ to a maximum extent. and are the covariance matrices of sets and , respectively. The covariance matrix is actually a point on the Riemannian manifold, so can be calculated by the log-Euclidean metric [40], i.e., logarithmically mapping the points from the Riemannian manifold to the Euclidean space and calculating their correlation.
Without prior assumptions on the data distribution, the covariance matrix provides a natural representation for a dataset with any type of features and with an arbitrary number of samples, which can effectively distinguish data subsets with different category labels by encoding the feature-related information specific to each object class. The higher the degree of feature overlap between two subsets, the closer the relationship between the category labels and the greater the value of Equation (2). If the label matrix is used directly to calculate the label correlations, the feature overlap between sample sets cannot be truly represented, while the label correlation may be distorted to some extent when labels are missing. In short, by utilizing a covariance matrix to model the data subset, the issue of label correlation calculation can be resolved, even in datasets with incomplete labeling. Consequently, the label-expanded feature vector is updated to , where represents the revised label information.
As the feature space becomes larger, the data structure becomes more complicated, and this paper uses the multi-layer neural network to study the label-enhanced dataset because the neural network can simulate the nonlinear manifold structure of the data with no assumptions. If there are L + 1 layers in the neural network, for feature , the output in the -th layer is calculated as Equation (3):
where the first layer is the input layer, and the input is also the output of this layer. The symbol denotes the connection parameter between layers and + 1, while represents the bias term; both of these parameters are learned at the subsequent layer (i.e., layer + 1). Additionally, signifies the activation function employed in the hidden layer, which can be a sigmoid function or any other nonlinear function. To address the multi-label problem, softmax regression, trained via batch gradient descent, is utilized. The objective function of this model is described by Equation (4):
wherer each output item in layer L + 1 is the probability that label is assigned to data , is a tradeoff parameter, and is the row vector of matrix (i.e., ).
By utilizing a neural network with concealed layers, the process of acquiring label-expanded data features becomes layered and structured. This hierarchical learning approach ensures that the high-level semantic features of the data are extracted efficiently and accurately. These high-level features represent a fusion of three distinct types of relationships: relationships among data features, relationships connecting labels with data features, and pure relationships between labels. This fusion of relationships results in features that are highly informative and beneficial for subsequent studies of classification models.
As the learning process continues, the augmented features fed into the network are continuously updated with the aid of learned parameters and . This updating process ensures that the network adapts to the evolving data distribution and captures the most relevant features for classification. Specifically, after each iteration, a feedforward pass is performed. This pass computes the output for each subset (where k ranges from 1 to K) using the updated parameters and learned during that iteration. This output represents the network’s understanding of the data based on the current set of parameters. Subsequently, the covariance matrix similarity coefficient is recalculated. This coefficient measures the similarity between different subsets of data based on their covariance matrices. It captures the underlying relationships among the data (or labels) and is crucial for the next iteration, where it will be used to further refine the learning process. By iteratively updating the network parameters, recalculating the covariance matrix similarity coefficient, and performing feedforward passes, the neural network gradually learns to extract meaningful high-level semantic features from the label-expanded data. This process enables the network to adapt to complex datasets and produce accurate classification results.
Based on the preceding analysis, the optimization of the uCeFL can be achieved through gradient descent, and the corresponding pseudo code is outlined in Algorithm 1. Additionally, a variation called CeFL is presented, which is described thoroughly in Algorithm 2. CeFL relies solely on Equation (2) to compute the correlation matrix of the original dataset, thus negating the need for frequent updates of the extended features. However, it must be emphasized that if remains static, the procedural steps outlined in Algorithm 2 may not fully capture the label propagation effects and the inherent neural network benefits exhibited by uCeFL.
| Algorithm 1: uCeFL |
| Input: , ; Output: . 1. with appropriate values; 2. FirstFlag = true; 3. for each label k do 4. Construct the subset of training data associated with label k as ; 5. end for 6. for t = 1, 2, … T do 7. for each label k do 8. if FirstFlag = false then 9. ; 10. ; 11. ; 12. else 13. ; 14. FirstFlag = false; 15. end if 16. Compute covariance matrix of each ; 17. end for 18. Calculate the Covariance Matrix Similarity Coefficient by Equation (2); 19. Train the neural network using as input, then update and ; 20. if or then 21. Turn to return; 22. end if 23. end for 24. return Parameters and . |
| Algorithm 2: CeFL |
| Input: Training data matrix , label matrix , network layer number , iterative number , convergence error ; Output: Parameters and . 1. Initialize and with appropriate values; 2. for each label do 3. Construct the subset of training data associated with label as ; 4. Compute the covariance matrix of matrix ; 5. end for 6. Calculate the Covariance Matrix Similarity Coefficient by Equation (2); 7. for do 8. Train the neural network using as input, then update and ; 9. if or then 10. Turn to return; 11. end if 12. end for 13. return Parameters and . |
4. Experiments
To validate the efficacy of CeFL and uCeFL, seven diverse multi-label datasets spanning domains such as music, biology, images, and text were carefully selected. Table 1 concisely outlines the essential characteristics of these datasets. Most of these datasets can be conveniently downloaded from Mulan (http://mulan.sourceforge.net/datasets.html (accessed on 15 February 2024)), with the exception of the education dataset, which is obtainable from Yahoo [7] (https://www.lamda.nju.edu.cn/code_MDDM.ashx (accessed on 20 February 2024)). Cardinality indicates the average number of labels per instance, while attributes refer to the fact that all features belong to one of two categories: nominal or numeric. To assess the performance of our methods, they were benchmarked against established approaches such as ML-KNN [41], TRAM [42], LLFS-DL [43], and LCFM [44]. Notably, the use of a label-expanded feature space as the basis for training inputs is a commonality shared by our approaches and LLFS-DL. This common ground facilitated meaningful comparisons and the evaluation of the relative strengths of each method.

Table 1.
Characteristics of the datasets used in the experiments.
ML-KNN was developed from traditional k-nearest neighbor (KNN) problem transformation methods. For each test instance, its k-nearest neighbors are found in the training set. Based on statistical information from these neighbors, such as the number belonging to the same label category, the maximum a posteriori (MAP) principle is employed to determine the label set of the test instance. Although ML-KNN does not consider label correlation, it often outperforms many multi-label approaches.
TRAM examines the intricate composition of label concepts, considering the varying degrees of typicality that individual examples exhibit with respect to specific labels. Initially, TRAM builds a similarity matrix by determining the -nearest neighbor relationships for all samples, labeled and unlabeled, within the dataset. This step aims to capture the inherent connections and similarities among the data points. Subsequently, TRAM transforms the transductive multi-label learning challenge into an optimization problem, where the focus is on refining the definition and representation of label concept combinations for each multi-label instance through the optimization process. Leveraging the estimated label concept combination details, TRAM then utilizes the label concept combinations of labeled samples, coupled with their corresponding ground-truth labels, to solve an optimization function that admits a closed-form solution. The objective of this optimization is to derive a transformation matrix , which will serve as a crucial tool in assigning labels to unlabeled samples in subsequent stages.
LLFS-DL utilizes the label matrix as additional features to augment the feature space and supposes that each class label is only determined by a subset of relevant features from a given dataset. Unlike DBR, LLFS-DL does not directly increase the dimension of data features to learn a model. Instead, it solves a variation of the -norm regularization, incorporating both second-order and high-order label correlations in a sparse stacking manner to improve multi-label classification.
LCFM aims to address label prediction when labels are missing, a goal similar to ours. It combines global and local label features to learn correlations and restore missing labels. The approach utilizes sparse Lasso regression and regularization for featureselection, optimizing the model through binary cross-entropy loss and the APG algorithm.
4.1. Experimental Criteria
In the experiments, six performance metrics [45] were chosen to evaluate the performance of several multi-label classification approaches. Let be the test dataset, be the trained model, and be the number of labels. The indicators are defined as follows.
- HammingLoss is an example-based multi-label classification evaluation criterion that indicates the proportion of misclassified instances in two scenarios: when predicted labels do not belong to the instance, and when labels belonging to the instance are not predicted,where indicates the symmetric difference between the predicted and actual label vectors for each instance.
- SubsetAccuracy is a measure of classification accuracy. It considers a classification to be correct when the set of predicted labels exactly matches the set of true labels, and incorrect otherwise. Specifically, SubsetAccuracy calculates the proportion of instances in the test set that are fully and accurately classified,where is the indicator function. This metric provides a holistic view of the performance of a classification model with respect to predicting entire sets of labels, rather than just individual labels.
- Accuracy is the ratio of correctly predicted labels to the total number of predicted labels:
- F1Measure is a comprehensive evaluation index that combines precision and recall, and is also referred to as the comprehensive classification rate. The precision rate measures how many of the predicted labels are actually correct,The recall rate is the ratio of correctly predicted positive labels to the total number of actual positive labels,The F1Measure isThese evaluation metrics are example-based. We also consider label-based evaluation metrics, which are widely used in the literature. Let , , , and represent the number of true positives, true negatives, false positives, and false negatives, respectively, for label .
- MacroF1Measure is the arithmetic average value of the F1Measure of all labels.
- MicroF1Measure sums the Precisionj and Recallj of all labels before calculating the F1measure.For all these metrics except HammingLoss, a larger value indicates better classifier performance.
4.2. Implementation Details
The experiment was conducted on a computer that was equipped with an Intel(R) Core(TM) i7-10510U CPU running at 1.80GHz (base clock speed) up to 2.30 GHz (turbo boost speed), and had 16.0 GB of RAM. The MATLAB software version used for the experiment was R2018a, and the experiment was performed in a Microsoft Windows 10 operating system environment.
For the four comparison methods, default settings were applied. The CeFL and uCeFL approaches encounter a similar challenge to the LLSF-DL algorithm, which is the absence of initial label assignments for the test samples, and this obstacle hinders the utilization of a neural network. To align with the input space of , certain existing methods were employed to provide initial predictions for the test data . Specifically, KNN was adopted to annotate each test instance with the label set identical to that of the nearest training instance, with set to 1.
When calculating , both our algorithms need to input it into a logistic function first before expanding the attribute space. For the five nominal datasets of corel5k, enron, education, genbase, and medical, each item of must continue to be reset to 0 or 1. The strategy is to set it to 1 when the item is greater than the average and otherwise to 0.
The neural network in this work is comprised of two hidden layers. The first layer had 300 neurons, while the second layer had 120 neurons. Both hidden layers employed a sigmoid activation function. The network underwent training via the LBFGS method, which was implemented with the minFunc (gradient descent toolbox). The regularization parameter in Equation (4) was assigned a value of 0.0002.
4.3. Performance Comparison and Discussion
In the experiment, 10-fold cross-validation was performed on each dataset to evaluate the performance of each algorithm. For each experiment, 1/4 of the dataset was randomly selected as test data, and the remaining data was used for training. To assess the effectiveness of uCeFL in scenarios with incomplete labels, the observed labels were randomly removed from the training data at a preset missing rate that ranged from 0 to 0.6, incremented in steps of 0.2. Also, to prevent empty classes or instances without positive labels, at least one instance was retained for each class label, and each instance was ensured to have at least one positive class label.
The average performance of 10 iterations was used to evaluate the performance of each algorithm. Table 2, Table 3, Table 4, Table 5, Table 6, Table 7 and Table 8 display the experimental results (including the standard deviation) of the six evaluation indicators for each algorithm on the seven datasets. The symbol ↓ signifies that the smaller the value of an indicator, the better the performance, whereas ↑ indicates that a larger value signifies better performance. The optimal results within each row are highlighted in bold.
Table 2.
Comparison results (mean ± std) of six approaches over the emotions dataset.
Table 3.
Comparison results (mean ± std) of six approaches over the scene dataset.
Table 4.
Comparison results (mean ± std) of six approaches over the corel5k dataset.
Table 5.
Comparison results (mean ± std) of six approaches over the enron dataset.
Table 6.
Comparison results (mean ± std) of six approaches over the education dataset.
Table 7.
Comparison results (mean ± std) of six approaches over the genbase dataset.
Table 8.
Comparison results (mean ± std) of six approaches over the medical dataset.
The experimental results indicate that the following conclusions can be drawn:
- Overall, uCeFL was obviously competitive with the comparison approaches, especially on the emotions, genbase, medical, and corel5k datasets, where uCeFL performed best, regardless of the loss rate.
- When the label is not missing, TRAM performs relatively well on the three scene, enron, and education databases, and its performance on the other four datasets is also quite competitive. However, it is crucial to note that in the step of deriving the transformation matrix P, there is a significant reliance on the sample ground-truth labels. If labels are missing in the dataset, the accuracy of the obtained transformation matrix P may be compromised, potentially leading to inaccuracies in the labeling of unlabeled samples. Consequently, as the rate of missing labels increases, the overall performance of the system declines accordingly.
- ML-KNN only performed well on the scene dataset, and its performance was optimal when the missing rate was 0.2. ML-KNN utilizes the label information of the k-nearest neighbors of the test data to estimate the label set, but it does not take into account label correlation. Therefore, poor label annotation performance is possible when some class labels of the training data are missing.
- Similar to our approaches, the label space is augmented in LLSF-DL with the feature space as additional features. LLSF-DL removes unnecessary dependency relationships by identifying the sparsity coefficient of the label space . However, it may disregard correct indirect relationships resulting from labels that are not subject to sparsity coefficient consideration, which could be a reason why its performance is not ideal.
- Compared to LCFM, which tackles missing labels by integrating both global and local label-specific features, our method leverages neural networks with hidden layers. This facilitates hierarchical learning of label-expanded data features and adeptly extracts high-level semantic features from the data. These features capture three distinct relationships: between data features, between labels and data features, and among labels. Experimental results confirm that these features offer significant benefits for the development of subsequent classification models.
- At the end of each round of training, uCeFL performs a feedforward process to extract high-level features from the input data. Label correlations are then recalculated to update the input for the next round of training. Therefore, uCeFL not only takes the label correlations as prior knowledge but also continuously improves them during the learning process of the classification model. The experimental results show that uCeFL works better than CeFL, which demonstrates the effectiveness of using neural networks with hidden layers for feature learning.
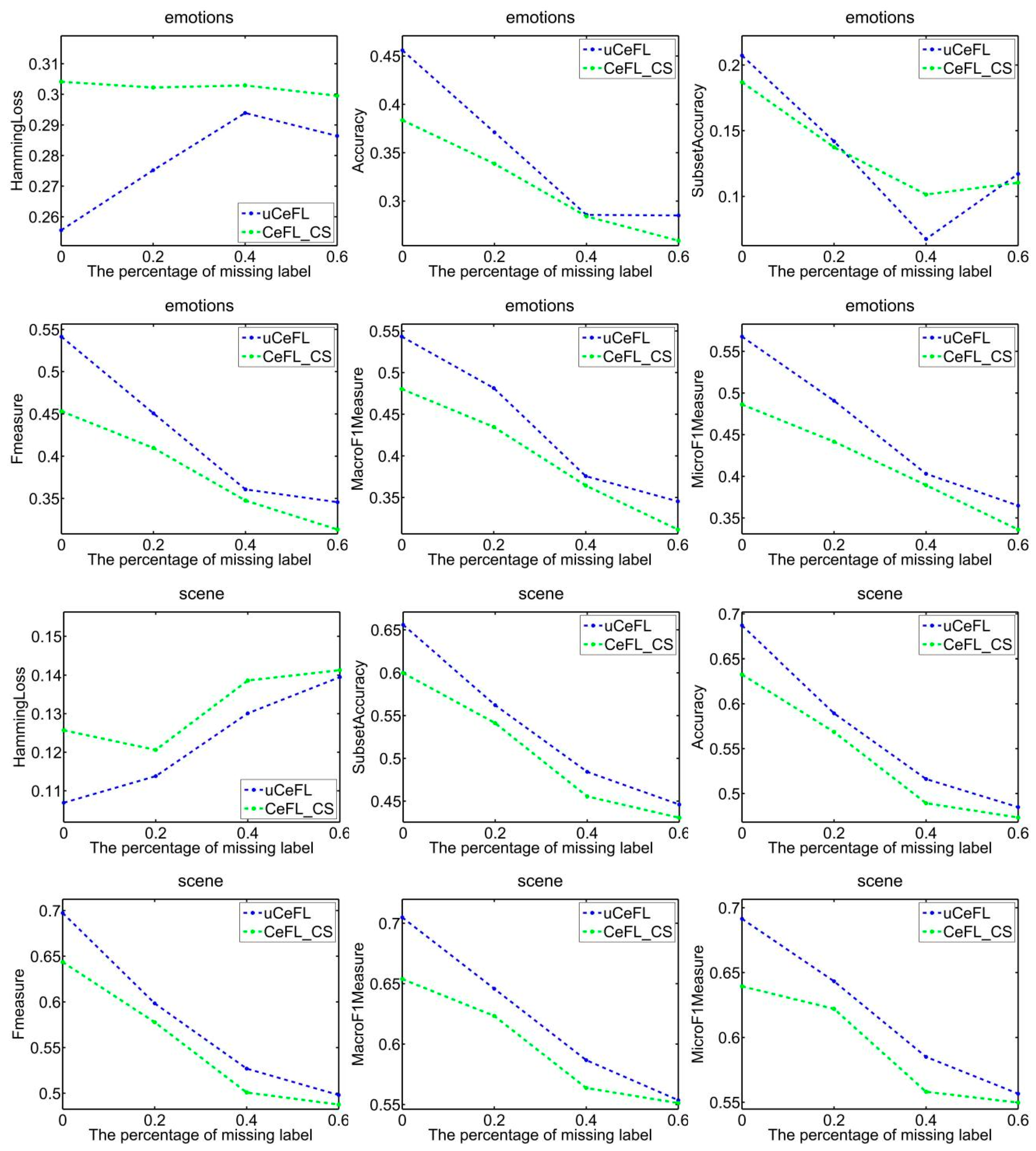
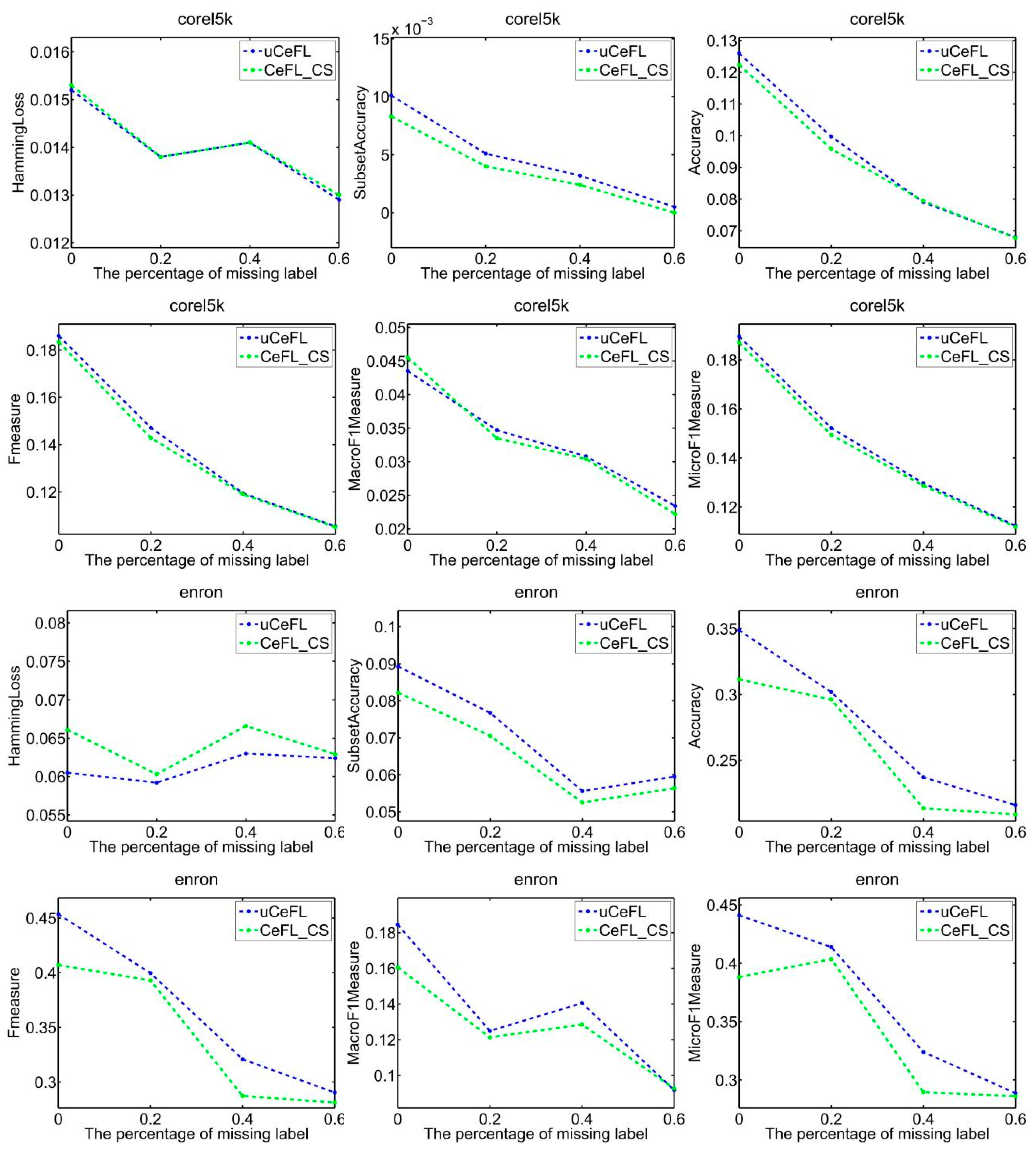
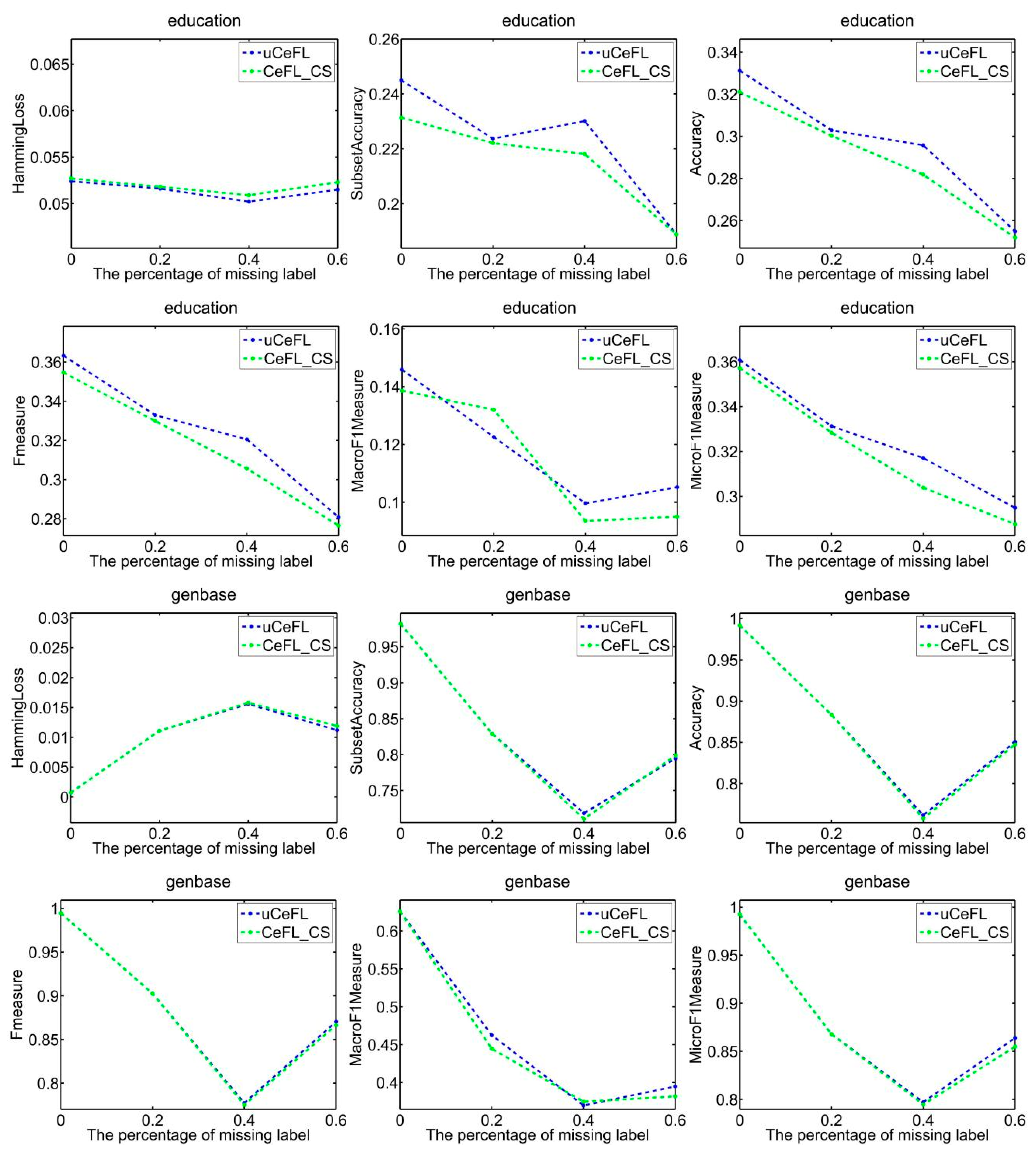
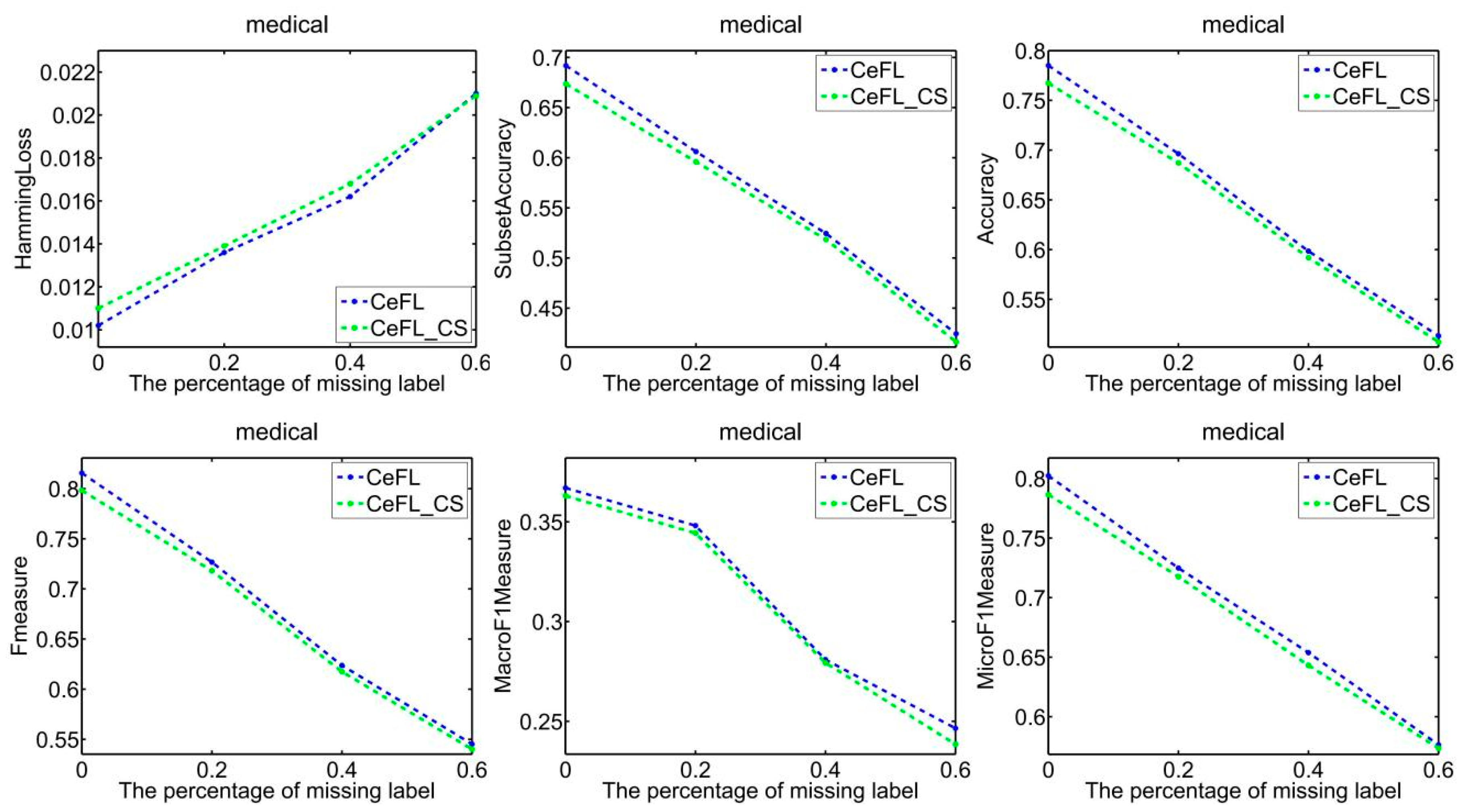
To demonstrate the efficacy of extracting label correlations directly from the data, a random division of the data into testing and training sets was made, with 1/3 designated for testing and the remaining portion for training. Subsequently, two techniques were employed to compute label correlations: the cosine similarity (CeFL_CS) and the covariance matrix similarity coefficient (uCeFL). Figure 2, Figure 3, Figure 4 and Figure 5 offer a comparative analysis of these techniques across diverse datasets. Notably, the results underscore the potential of extracting label correlations from the data, particularly in scenarios where a substantial proportion of class labels for the training data are missing, resulting in impressive performance.
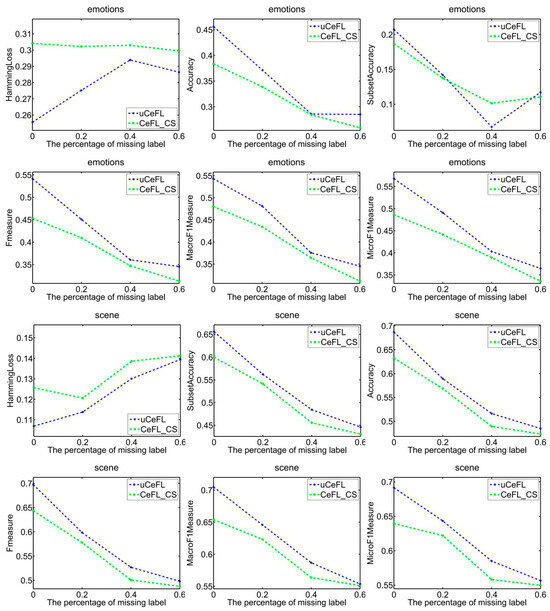
Figure 2.
Performance comparison between two similarity methods on the emotions and scene datasets.
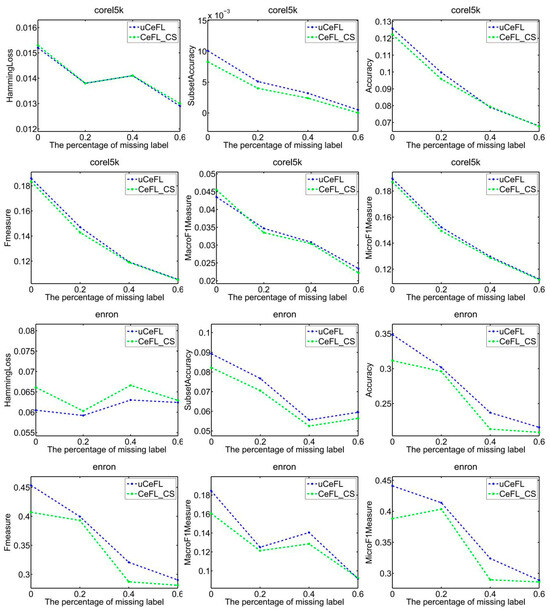
Figure 3.
Performance comparison between two similarity methods on the corel5k and enron datasets.
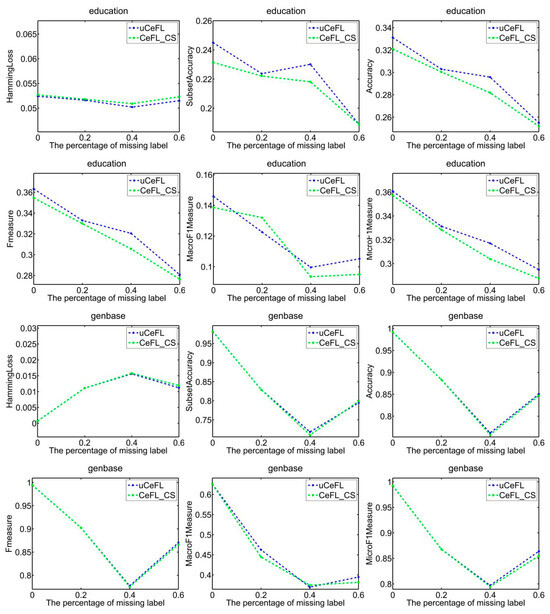
Figure 4.
Performance comparison between two similarity methods on the education and genbase datasets.
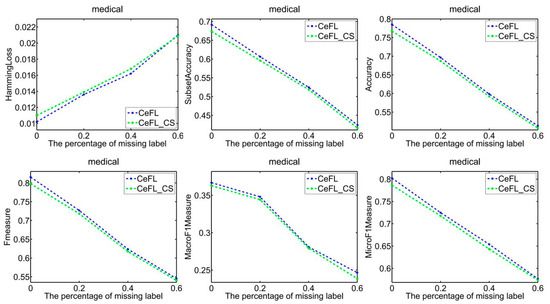
Figure 5.
Performance comparison between two similarity methods on the medical dataset.
5. Conclusions and Future Works
In summary, the uCeFL methodology proposed in this paper has incontrovertibly established its superiority in tackling multi-label classification tasks, especially when dealing with missing labels. By directly extracting label correlations from the data instances, uCeFL avoids reliance on potentially incomplete label sets. The method first computes a refined label matrix by multiplying the incomplete label matrix with the label correlations obtained from the data matrix. This refined matrix then augments the original data features, enabling a neural network to learn correlation-enhanced representations that capture the intricate interplay between data features, labels, and their interactions. Importantly, uCeFL does not treat label correlations as static, predefined knowledge. Instead, it iteratively updates the label correlations during the training process, further optimizing its performance. This is achieved through a feedforward mechanism implemented at the end of each training iteration, where high-level features of the input data are extracted, and the label correlations are recalculated to refine the input for the next iteration. This iterative refinement allows uCeFL to adapt to the changing nature of the data and label correlations, ultimately resulting in superior classification outcomes. The experimental results across a range of datasets highlight the competitiveness of uCeFL. Notably, it outperforms other comparative approaches, especially on datasets related to emotions, enron, genbase, and medical, where it achieves optimal performance regardless of the label missing rate.
Future research will consider the following aspects:
- This paper employed a covariance matrix to represent the dataset comprising category labels and derived label correlations through the calculation of a covariance matrix similarity coefficient. However, computing these correlations becomes challenging when dealing with a substantial data volume. The issue of efficiently acquiring label correlations in a big-data environment demands further exploration.
- Moreover, the paper only concentrated on one-to-one label correlations. To accurately capture the actual label correlations, further research is needed, encompassing investigations into both local and global correlations.
- The presence of multi-label data introduces the curse of dimensionality. Future aims can explore the relationship between labels and features to identify a more discriminative subspace.
Author Contributions
Z.Z.: Conceptualization, Methodology, Software, Writing—original draft. X.Z.: Data curation, Writing—review & editing. Y.Y.: Software. X.D.: Validation. S.L.: Writing—review & editing. All authors have read and agreed to the published version of the manuscript.
Funding
This work was financially supported by the Qingmiao Plan of Chengdu Technological University (No. QM2023054) and the Doctoral Fundation Program of Chengdu Technological University (No. 2019RC019).
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
No author associated with this paper has disclosed any potential or pertinent conflicts of interest that may be perceived as having a bearing on the work presented.
References
- Shu, X.; Qiu, J. Speed up kernel dependence maximization for multi-label feature extraction. J. Vis. Commun. Image Represent. 2017, 49, 361–370. [Google Scholar] [CrossRef]
- Du, J.; Chen, Q.; Peng, Y.; Xiang, Y.; Tao, C.; Lu, Z. Ml-net: Multi-label classification of biomedical texts with deep neural networks. J. Am. Med. Inform. Assoc. 2019, 26, 1279–1285. [Google Scholar] [CrossRef]
- Wang, T.; Liu, L.; Liu, N.; Zhang, H.; Zhang, L.; Feng, S. A multi-label text classification method via dynamic semantic representation model and deep neural network. Appl. Intell. 2020, 50, 2339–2351. [Google Scholar] [CrossRef]
- Tang, R.; Yu, Z.; Ma, Y.; Wu, Y.; Chen, Y.-P.P.; Wong, L.; Li, J. Genetic source completeness of hiv-1 circulating recombinant forms (crfs) predicted by multi-label learning. Bioinformatics 2020, 37, 750–758. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Z.; Waqas, J. Intrinsic structure based feature transform for image classification. J. Vis. Commun. Image Represent. 2016, 38, 735–744. [Google Scholar] [CrossRef]
- Gou, J.; Song, J.; Ou, W.; Zeng, S.; Yuan, Y.; Du, L. Representation-based classification methods with enhanced linear reconstruction measures for face recognition. Comput. Electr. Eng. 2019, 79, 106451. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhou, Z.-H. Multilabel dimensionality reduction via dependence maximization. ACM Trans. Knowl. Discov. Data 2010, 4, 1–21. [Google Scholar] [CrossRef]
- Li, Y.-K.; Zhang, M.-L. Enhancing binary relevance for multi-label learning with controlled label correlations exploitation. In Pacific Rim International Conference on Artificial Intelligence; Springer: Cham, Switzerland, 2014; pp. 91–103. [Google Scholar] [CrossRef]
- Xu, L.; Wang, Z.; Shen, Z.; Wang, Y.; Chen, E. Learning low-rank label correlations for multi-label classification with missing labels. In Proceedings of the 2014 IEEE International Conference on data Mining, Shenzhen, China, 14–17 December 2014; IEEE: New York, NY, USA, 2014; pp. 1067–1072. [Google Scholar] [CrossRef]
- Tsoumakas, G.; Katakis, I. Multi-label classification: An overview. Int. J. Data Warehous. Min. 2007, 3, 1–13. [Google Scholar] [CrossRef]
- Read, J.; Pfahringer, B.; Holmes, G. Multi-label classification using ensembles of pruned sets. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; IEEE: New York, NY, USA, 2008; pp. 995–1000. [Google Scholar] [CrossRef]
- Tsoumakas, G.; Vlahavas, I. Random k-labelsets: An ensemble method for multilabel classification. In European Conference on Machine Learning; Springer: Berlin/Heidelberg, Germany, 2007; pp. 406–417. [Google Scholar] [CrossRef]
- Wang, C.; Yan, S.; Zhang, L.; Zhang, H.-J. Multi-label sparse coding for automatic image annotation. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: New York, NY, USA, 2009; pp. 1643–1650. [Google Scholar] [CrossRef]
- Wang, H.; Huang, H.; Ding, C. Image annotation using multi-label correlated green’s function. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 27 September–4 October 2009; IEEE: New York, NY, USA, 2009; pp. 2029–2034. [Google Scholar] [CrossRef]
- Huang, S.-J.; Zhou, Z.-H. Multi-label learning by exploiting label correlations locally. In Proceedings of the AAAI Conference on Artificial Intelligence, Toronto, ON, USA, 22–26 July 2012; Volume 26. [Google Scholar] [CrossRef]
- Gu, Q.; Li, Z.; Han, J. Correlated multi-label feature selection. In Proceedings of the 20th ACM International Conference on Information and Knowledge Management, Glasgow UK, 24–28 October 2011; pp. 1087–1096. [Google Scholar] [CrossRef]
- Ji, S.; Tang, L.; Yu, S.; Ye, J. Extracting shared subspace for multi-label classification. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 381–389. [Google Scholar] [CrossRef]
- Read, J.; Pfahringer, B.; Holmes, G.; Frank, E. Classifier chains for multi-label classification. Mach. Learn. 2011, 85, 333–359. [Google Scholar] [CrossRef]
- Montañes, E.; Senge, R.; Barranquero, J.; Quevedo, J.R.; del Coz, J.J.; Hüllermeier, E. Dependent binary relevance models for multi-label classification. Pattern Recognit. 2014, 47, 1494–1508. [Google Scholar] [CrossRef]
- Huang, J.; Qin, F.; Zheng, X.; Cheng, Z.; Yuan, Z.; Zhang, W.; Huang, Q. Improving multi-label classification with missing labels by learning label-specific features. Inf. Sci. 2019, 492, 124–146. [Google Scholar] [CrossRef]
- Zhu, P.; Xu, Q.; Hu, Q.; Zhang, C.; Zhao, H. Multi-label featureselection with missing labels. Pattern Recognit. 2018, 74, 488–502. [Google Scholar] [CrossRef]
- Rauber, T.W.; Mello, L.H.; Rocha, V.F.; Luchi, D.; Varejão, F.M. Recursive dependent binary relevance model for multi-label classification. In Advances in Artificial Intelligence–IBERAMIA 2014: 14th Ibero-American Conference on AI, Santiago de Chile, Chile, 24–27 November 2014; Proceedings 14; Springer: Cham, Switzerland, 2014; pp. 206–217. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, Y.; Cai, Z. Correlation-based pruning of dependent binary relevance models for multi-label classification. In Proceedings of the 2015 IEEE 14th International Conference on Cognitive Informatics & Cognitive Computing (ICCICC), Beijing, China, 6–8 July 2015; IEEE: New York, NY, USA, 2015. [Google Scholar] [CrossRef]
- Rauber, T.W.; Rocha, V.F.; Mello, L.H.S.; Varejao, F.M. Decision template multi-label classification based on recursive dependent binary relevance. In Proceedings of the 2016 IEEE Congress on Evolutionary Computation (CEC), Vancouver, BC, Canada, 24–29 July 2016; IEEE: New York, NY, USA, 2016; pp. 2402–2408. [Google Scholar] [CrossRef]
- Zhang, M.L.; Wu, L. Lift: Multi-label learning with label-specific features. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 107–120. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.-J.; Fang, M.; Li, X. Multi-label learning with discriminative features for each label. Neurocomputing 2015, 154, 305–316. [Google Scholar] [CrossRef]
- Xu, S.; Yang, X.; Yu, H.; Yu, D.-J.; Yang, J.; Tsang, E.C. Multi-label learning with label-specific feature reduction. Knowl. Based Syst. 2016, 104, 52–61. [Google Scholar] [CrossRef]
- Lee, J.; Kim, D.-W. Efficient multi-label feature selection using entropy-based label selection. Entropy 2016, 18, 405. [Google Scholar] [CrossRef]
- Mencía, E.L.; Janssen, F. Learning rules for multi-label classification: A stacking and a separate-and-conquer approach. Mach. Learn. 2016, 105, 77–126. [Google Scholar] [CrossRef]
- Li, Q.; Peng, X.; Qiao, Y.; Peng, Q. Learning label correlations for multi-label image recognition with graph networks. Pattern Recognit. Lett. 2020, 138, 378–384. [Google Scholar] [CrossRef]
- RWang, R.; Ye, S.; Li, K.; Kwong, S. Bayesian network based label correlation analysis for multi-label classifier chain. Inf. Sci. 2020, 554, 256–275. [Google Scholar] [CrossRef]
- Zhan, W.; Zhang, M.-L. Multi-label learning with label-specific features via clustering ensemble. In Proceedings of the 2017 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Tokyo, Japan, 19–21 October 2017; IEEE: New York, NY, USA, 2017; pp. 129–136. [Google Scholar] [CrossRef]
- Zhang, J.; Li, C.; Cao, D.; Lin, Y.; Su, S.; Dai, L.; Li, S. Multi-label learning with label-specific features by resolving label correlations. Knowl. Based Syst. 2018, 159, 148–157. [Google Scholar] [CrossRef]
- Liu, H.; Ma, Z.; Han, J.; Chen, Z.; Zheng, Z. Regularized partial least squares for multi-label learning. Int. J. Mach. Learn. Cybern. 2018, 9, 335–346. [Google Scholar] [CrossRef]
- Ma, Q.; Yuan, C.; Zhou, W.; Hu, S. Label-specific dual graph neural network for multi-label text classification. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Bangkok, Thailand, 1–6 August 2021; Volume 1, pp. 3855–3864. [Google Scholar] [CrossRef]
- Fu, B.; Xu, G.; Wang, Z.; Cao, L. Leveraging supervised label dependency propagation for multi-label learning. In Proceedings of the 2013 IEEE 13th International Conference on Data Mining, Dallas, TX, USA, 7–10 December 2013; IEEE: New York, NY, USA, 2013; pp. 1061–1066. [Google Scholar] [CrossRef]
- Wang, H.; Ding, C.; Huang, H. Multi-label linear discriminant analysis. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2010; pp. 126–139. [Google Scholar] [CrossRef]
- Cai, X.; Nie, F.; Cai, W.; Huang, H. New graph structured sparsity model for multi-label image annotations. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 801–808. [Google Scholar] [CrossRef]
- Herdin, M.; Czink, N.; Ozcelik, H.; Bonek, E. Correlation matrix distance, a meaningful measure for evaluation of non-stationary mimo channels. In Proceedings of the 2005 IEEE 61st Vehicular Technology Conference, Stockholm, Sweden, 30 May–1 June 2005; IEEE: New York, NY, USA, 2005; Volume 1, pp. 136–140. [Google Scholar] [CrossRef]
- Arsigny, V.; Fillard, P.; Pennec, X.; Ayache, N. Geometric means in a novel vector space structure on symmetric positive-definite matrices. SIAM J. Matrix Anal. Appl. 2007, 29, 328–347. [Google Scholar] [CrossRef]
- Zhang, M.-L.; Zhou, Z.-H. Ml-knn: A lazy learning approach to multi-label learning. Pattern Recognit. 2007, 40, 2038–2048. [Google Scholar] [CrossRef]
- Kong, X.; Ng, M.K.; Zhou, Z.-H. Transductive multilabel learning via label set propagation. IEEE Trans. Knowl. Data Eng. 2011, 25, 704–719. [Google Scholar] [CrossRef]
- Huang, J.; Li, G.; Huang, Q.; Wu, X. Learning label-specific features and class-dependent labels for multi-label classification. IEEE Trans. Knowl. Data Eng. 2016, 28, 3309–3323. [Google Scholar] [CrossRef]
- Yu, Y.; Zhou, Z.; Zheng, X.; Gou, J.; Ou, W.; Yuan, F. Enhancing label correlations in multi-label classification through global-local label specific feature learning to fill missing labels. Comput. Electr. Eng. 2024, 113, 109037. [Google Scholar] [CrossRef]
- Zhang, M.-L.; Zhou, Z.-H. A review on multi-label learning algorithms. IEEE Trans. Knowl. Data Eng. 2013, 26, 1819–1837. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).