1. Introduction
As science and technology advance, various sensors collect traffic flows (i.e., a kind of traffic statistic) accurately and in real-time [
1,
2,
3,
4,
5,
6]. Real-time traffic data records the time sequence information of the road and can describe the traffic status in more detail. The real-time traffic data can be shared with other companies and organizations and are subsequently utilized in intelligent transportation systems (ITS), such as traffic light control [
7], route planning [
8], autonomous driving [
9,
10], and forecasts of electric vehicle energy consumption [
11], ensuring these applications can provide more personalized services and timely respond to environmental changes. However, these traffic statistical data often contain individual sensitive information [
12], e.g., location information and vehicle status, which will lead to considerable threats to individual privacy. For example, according to the uniqueness of the individuals’ mobility trace [
13], an adversary can link back to the individuals’ ID information through some outside information when the trace information is published, and then the adversary may match the ID information with sensitive information to acquire individuals’ privacy.
To solve the issues of privacy leakage in data sharing, an insightful privacy protection model with strong theoretical support, called
-differential privacy, has been proposed in [
14]. It ensures that the outcomes of any analyses on neighboring datasets (i.e., two datasets that have only one data difference) are difficult to distinguish. Based on differential privacy, a lot of varietal schemes have been proposed for privacy protection [
15,
16,
17,
18,
19,
20,
21,
22]. However, most of them focus on either the user-level privacy on finite streams or the event-level privacy on infinite streams. However, applying these methods directly to protect real-time data often leads to inadequate protection or a notable reduction in data utility.
In view of this, Kellaris et al. [
23] have proposed a novel model of differential privacy named
w-event
-differential privacy (
w-event privacy for short). The
w-event privacy model fills the gap between the event-level and the user-level privacy, which can protect all events that happen at any successive
w timestamps without sacrificing too much data utility. Using
w-event privacy to protect the real-time data is a favorable option. The authors in [
23] have designed two schemes based on
w-event privacy, called budget distribution (BD) and budget absorption (BA), to protect any event sequence occurring at any successive
w timestamps (i.e., a sliding window of size
w).
Currently, numerous improved privacy-preserving schemes based on
w-event privacy for real-time data sharing have been proposed [
24,
25,
26,
27,
28,
29]. To improve the accuracy of the shared traffic flows, Wang et al. [
24] have proposed two schemes for privacy protection, i.e., RescueDP and E-RescueDP, which take into account data dynamics and can adaptively allocate privacy budgets for each section through proportional-integral-derivative control (PID control) or a recurrent neural network (RNN). Huo et al. [
25] have proposed an adaptive
w-event privacy for fog computing, which optimizes the prediction of E-RescueDP by using a long short-term memory. In contrast to the centralized differential privacy mentioned earlier, some
w-event privacy schemes for real-time data release, based on local differential privacy (abbreviated as LCD), have been developed without the need for establishing a trusted server, as discussed in [
27,
28,
29].
In this paper, we focus on sharing real-time traffic flows that are used to serve the intelligent transportation system continually. However, if the real-time traffic flows of each road section are shared with the public directly, it can cause serious privacy issues, such as the disclosure of whereabouts. To ensure the shared traffic flows are protected by strong privacy, enabling the sharing of traffic flows that adhere to w-event privacy is essential.
1.1. Motivation
Nevertheless, the prior schemes that focus on real-time data sharing under the protection of w-event privacy have shown limitations in data utility, specifically in terms of the quality of the shared data. Data utility is a vital metric for assessing the quality of the shared data.
First, privacy protection for raw data significantly reduces data utility. In BD and BA schemes [
23], they allocate an equivalent privacy budget for the traffic flows of each section. The LCD-based work in [
29] divides privacy budgeting to different processing steps to satisfy more limited privacy guarantees. However, the above schemes tend to result in allocating low privacy budgets to traffic flows, which in turn leads to excessive noise introduced into the shared traffic flows. An reasonable allocation of privacy budget is a promising way to solve the above issues. In RescueDP and E-RescueDP in [
24], an adaptive allocation is proposed, where the current raw traffic flows are replaced by the predicted traffic flows without consuming privacy budget. In any case, the more accurate the predicted traffic flows are, the more accurate the shared traffic flows also are. However, the calculation of predicted data in [
24] is based on the temporal correlation between data, which may not be the best way to predict traffic flows.
Second, the difference in the privacy budget allocated to each section can introduce large relative perturbation error. The sections with small traffic flow produce a large relative perturbation error in the
w-event privacy schemes, where the perturbation error is introduced by Laplace noise. To reduce the perturbation error, the mechanism for dynamic grouping in [
24] partitions the sections with small traffic flows into different groups, which is based on the similarity of traffic flows. Furthermore, to satisfy
w-event privacy, it uses the smallest privacy budget of the section as the privacy budget of all sections in the group. However, if the sections with a large different privacy budget are partitioned into the same group, it will cause a large perturbation error in all sections of the group. This will lead to a reduction in the accuracy of the shared traffic flows.
1.2. Contributions
Motivated by the above discussions, a scheme named DP-SCR is proposed in this paper to enhance the real-time traffic data sharing. In DP-SCR, we design an adaptive allocation of a privacy budget by using spatial correlation. Then, a novel dynamic clustering method based on k-means algorithm is developed, which takes the traffic flows and the difference in privacy budget into account. Finally, the proposed DP-SCR is proved to satisfy w-event privacy, providing a high level of privacy protection. This means that even if the attacker has background information about the user, they cannot obtain any additional information from the shared data.
Compared with the existing schemes that also satisfy w-event privacy, DP-SCR has the following three contributions:
In DP-SCR, we prove that the spatial characteristic of traffic flows provides a more remarkable correlation than other characteristics of traffic flows. Then, the designed spatial correlation prediction in DP-SCR is used to adaptively allocate the privacy budget for traffic flows. It significantly improves the accuracy of the shared traffic flows;
We design a novel dynamic clustering algorithm to aggregate the sections with similar traffic flow and privacy budget. It further improves the accuracy of the shared traffic flows by reducing the relative perturbation error caused by the small traffic flows.
The experimental results with real-world traffic datasets demonstrate that DP-SCR outperforms baseline w-event privacy schemes in terms of data utility for real-time data release. Also, these experiments validate that DP-SCR is robust to the changes of and w.
1.3. Organization
The rest of this paper is organized as follows. In
Section 2, some preliminary knowledge of the proposed scheme is described. Then, the main problems of the sharing of real-time traffic flows are stated in
Section 3. The construction of DP-SCR is established in
Section 4, consisting of the adaptive allocation of privacy budgets, dynamic clustering, approximation and perturbation. In
Section 5, we analyze the related performance of DP-SCR. The experiments are conducted to verify the high data utility of DP-SCR in
Section 6. Finally, the conclusions and future work of this paper can be derived in
Section 7.
2. Preliminaries
In this section, we review some basic preliminaries that are necessary for the rest of this paper, mainly including differential privacy,
w-event privacy and the characteristics of traffic flows. Some mathematical notations are summarized in
Table 1.
2.1. Differential Privacy
Let denote a set of datasets, and let Q be the query function. M represents the Laplace mechanism, and the set R denotes the range of .
Definition 1 (Neighboring datasets [
30])
. For two datasets and , if can be obtained from D by removing or adding any single record, D and are neighboring. Definition 2 (Sensitivity [
30])
. Assume Q: , then the sensitivity of Q with regard to iswhere D and represent any pair of neighboring datasets of . Definition 3 (Laplace mechanism [
30])
. For Q: , M adds noise into the results of , where the noise conforms to the Laplace distribution. Formally, for any dataset ,where ε denotes privacy budget indicating the privacy level of mechanism M. Definition 4 (Differential privacy [
31])
. For any neighboring dataset D and , and the set R, ifthe mechanism M satisfies ε-differential privacy (). Take the traffic flows of section k at timestamp i as an sample. The queried result of the traffic flows from is represented as , and the shared traffic flows after the processing of differential privacy can be rewritten as , where is the raw traffic data at timestamp i and is the query function for section k.
Theorem 1 (Sequential composition [
32])
. Assume that M includes a sequence of sub-mechanisms and each adds an independently random noise. If each mechanism satisfies -differential privacy, the mechanism M satisfies ()-differential privacy. According to the above definitions and Theorem 1, it is obvious that the smaller or the higher is, the larger the noise introduced. The privacy budget of M assigned to sub-mechanisms may be different.
2.2. w-Event Privacy
w-event privacy can protect all events that happen at any successive w timestamps. For a distinct description of w-event privacy, the traffic data are denoted as an infinite tuple , where represents the raw traffic data at timestamp t, and is the i-th element of S. Then a stream prefix of S at timestamp t is denoted as .
Definition 5 (
-neighboring [
23])
. Two stream prefixes and are w-neighboring, where w is a positive integer, if they satisfy the following conditions:- 1.
For each , with and , it holds that , are neighboring;
- 2.
For each , , , , when , and , it holds that ;
Definition 6 (
-event privacy [
23])
. Let and one set . For all w-neighboring stream prefixes , and all t, ifthe mechanism M satisfies w-event privacy. Theorem 2. Let stream prefix denote the input of M, and the output of M is . Suppose that the mechanism M includes t mechanisms , and each achieves -differential privacy. Then the mechanism M satisfies w-event privacy, if 2.3. Characteristics of Traffic Flows
Based on the analyses in
Section 1,the proposed DP-SCR mainly considers the spatial correlation between traffic flows.
Definition 7 (Spatial correlation [
33])
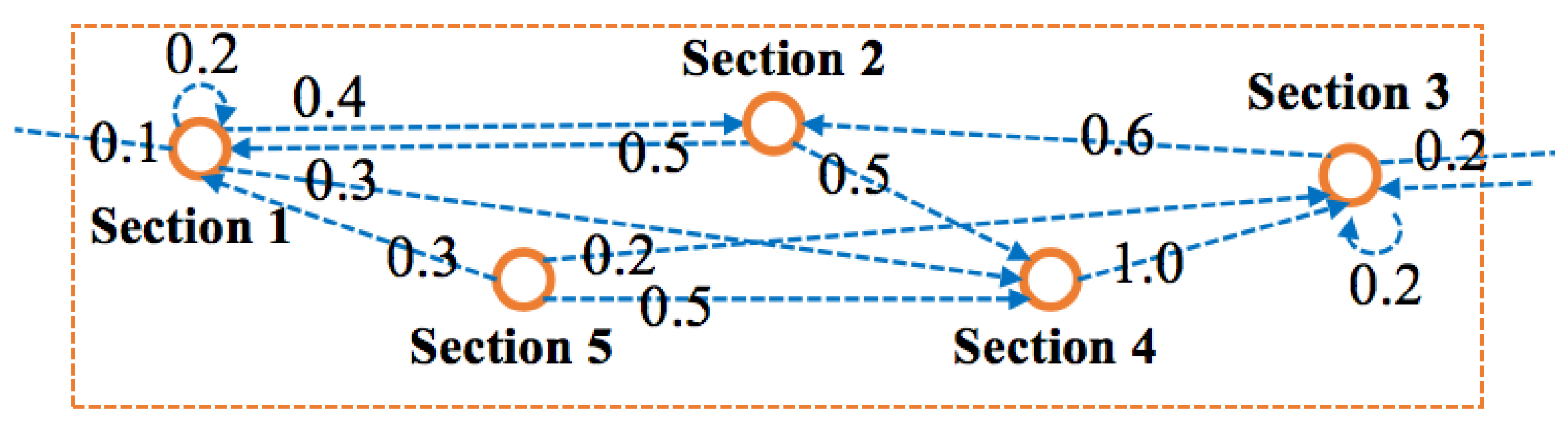
. A road network consists of multiple sections, and there exists a spatial correlation between sections. Formally, the algorithm denotes the spatial correlation between the traffic flows. The predicted traffic flow can be calculated by , where is the traffic parameter of section i at timestamp t. If the linked sections of section i are section j and section k, then , where consists of the shared traffic flow and some prior knowledge including the maximal speed limit , the predefined sampling period, and the road networks . The road networks link with all the sections and show the flow correlation between different sections. As shown in
Figure 1, it is a part of the road networks, where each numeric value represents the probability that the traffic flow of one section enters its linked (adjacent) sections.
For example, there are half traffic flows of
Section 5 that enter to
Section 4, so the probability is 0.5 and is denoted as
in this paper. Obviously, the flow of traffic on any section will either stay in the same section or enter to another section, so the probability of section
i satisfies the following relationship.
where
is a set includes section
i and its linked sections. The flow correlation is represented as
, where
is the set of all sections.
Mathematical notations: The mathematical notations and their semantic meanings used in this paper are summarized in
Table 1.
3. Problems Statement
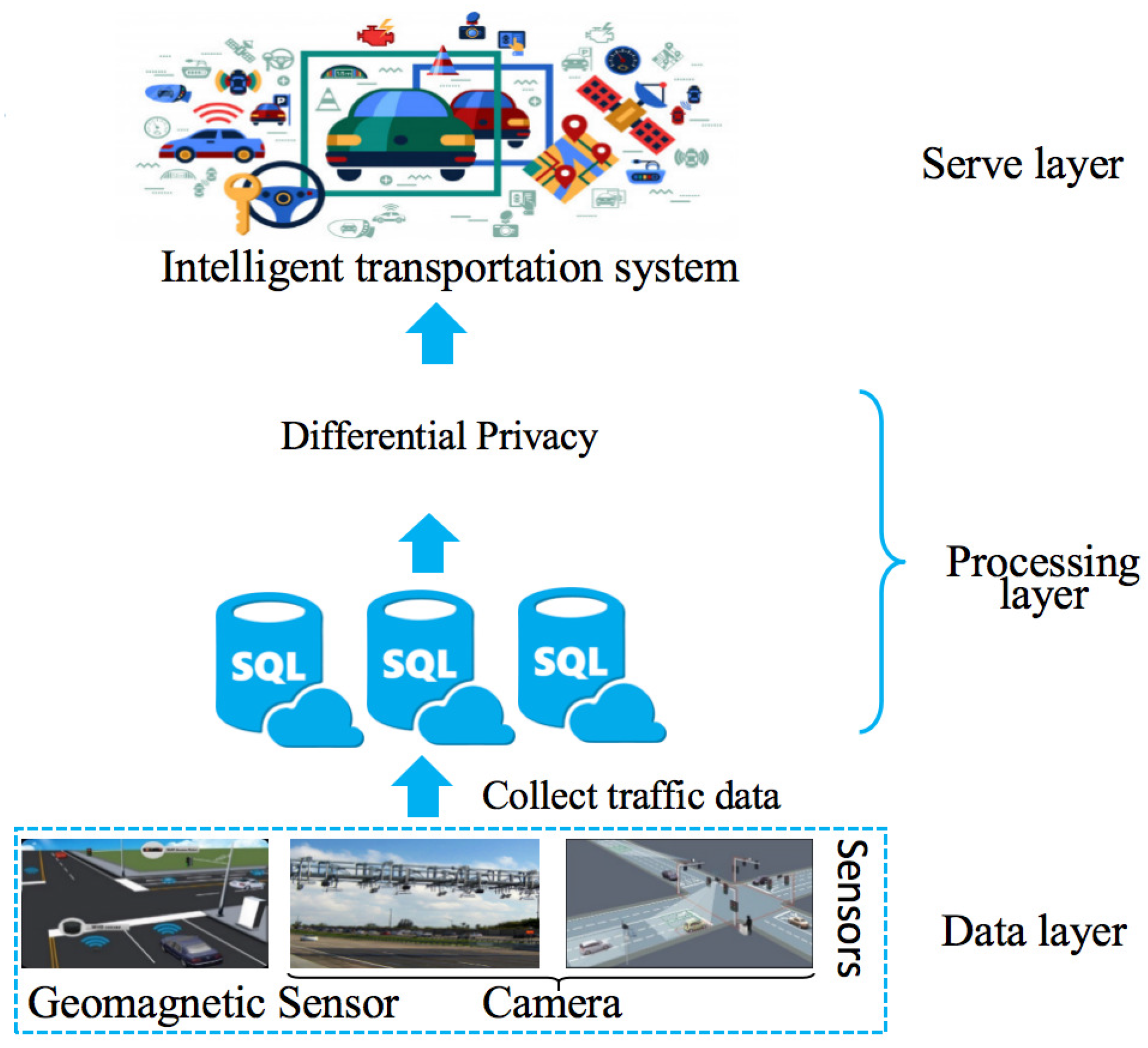
When real-time traffic flows are shared with the public, they may cause serious privacy issues. Therefore, in order to ensure the shared traffic flows with strong privacy protection, each section is required to satisfy
w-event privacy. As shown in
Figure 2, the traffic data are collected by various sensors and stored in the database. Then, the traffic flows for serving an intelligent transportation system will be processed to satisfy
w-event privacy, so that the shared flows can not leak the privacy of users. To be more specific, let
be the traffic flows of section
k and
be raw traffic data at timestamp
k. Then, we have
, where
n is the total number of sections at timestamp
t, and
is defined as the traffic flow of section
i at timestamp
k. In order to ensure the traffic flows are shared securely, the sanitized version of
, denoted by
, is used to replace
. Thus, the sanitized version of infinite time traffic flows at section
i is denoted as
.
In this paper, the problem concerning privacy protection is formally stated as follows.
Given an infinite time series of traffic flows , denote its sanitized version as . Then, a scheme is designed to make each infinite time section from , denoted as , which satisfies w-event privacy.
Since data utility is the main criterion for measuring the quality of a scheme, designing a mechanism to improve the data utility of the shared traffic flows is very meaningful. In this paper, the allocation of the privacy budget and the perturbation error will affect the accuracy of the shared traffic flows greatly. Therefore, the problem of the data utility can be described as follows.
(a) How to allocate the privacy budget reasonably. (b) How to reduce the absolute error (MAE) and relative error (MRE) of the shared traffic flows , where MAE and MRE are the representation of perturbation error.
4. The Design of DP-SCR
In this section, we propose a scheme, named DP-SCR, which satisfies
w-event privacy and provides high accuracy of traffic flows. The proposed DP-SCR can achieve the adaptive allocation of privacy budget, where the spatial correlation prediction is used to improve the budget allocation. Additionally, dynamic clustering is proposed to reduce the perturbation error caused by the small traffic flows. Finally, a novel approximation method and the perturbation method are used to deal with the no sampled sections and sampled sections in DP-SCR, respectively.
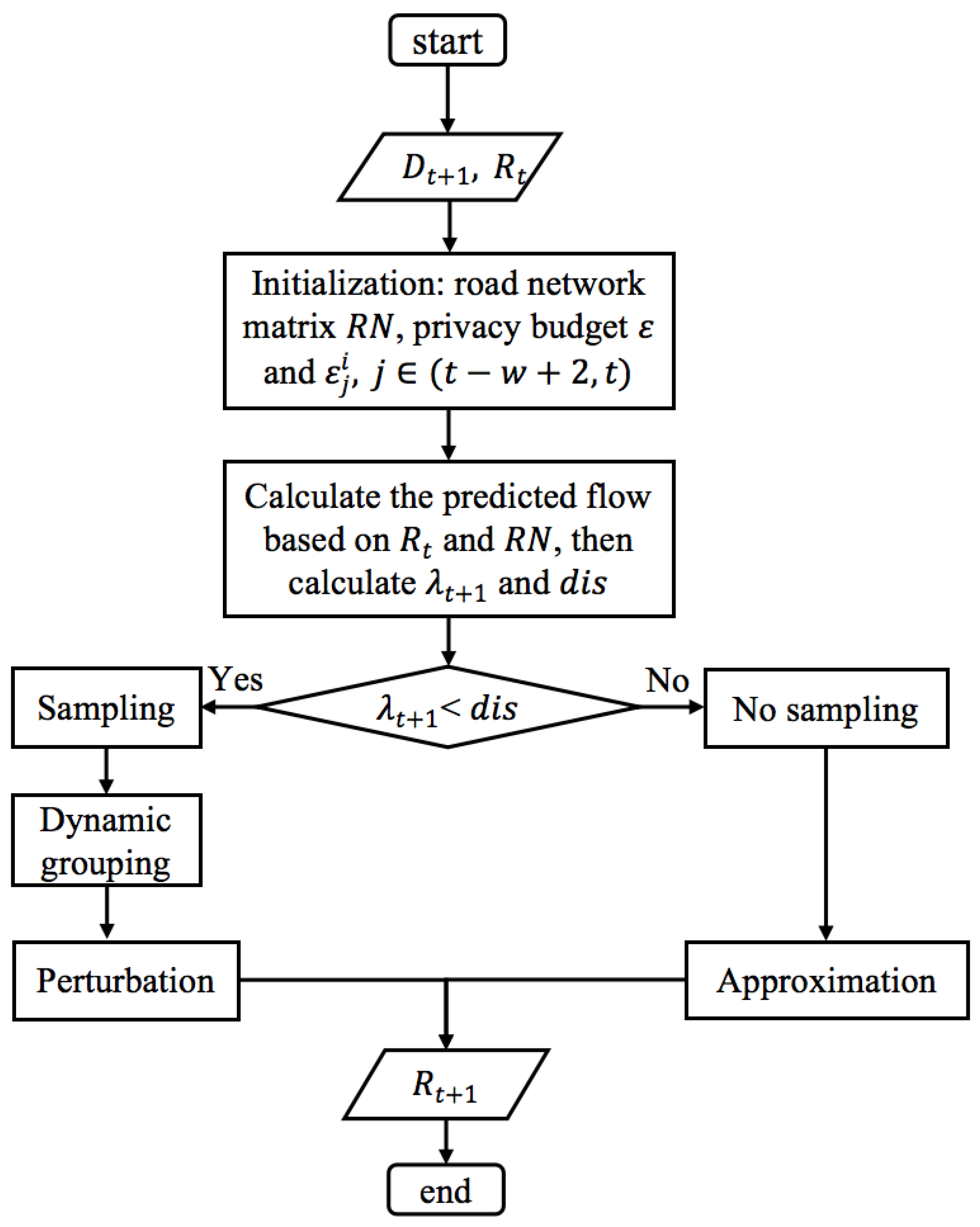
Figure 3 shows the flowchart of DP-SCR, where the sampling of sections is determined by
and
. The
is the dissimilarity between the predicted traffic flow and the last shared traffic flow, and
is perturbation error.
Algorithm 1 gives an overall description of the proposed DP-SCR. The main processes of DP-SCR are described in detail as follows.
| Algorithm 1: DP-SCR. |
Require: raw traffic data , the shared traffic flows , . Ensure: new shared traffic flows .
- 1:
Obtain traffic flows ; - 2:
for each section i at timestamp t do - 3:
Calculate the predicted traffic flow according to , and then calculate ; - 4:
Calculate the privacy budget for each section at timestamp t; - 5:
Sampling according to . - 6:
- 7:
For sampling points, do dynamic clustering for them at timestamp t + 1, and perturb their traffic flows by adopting Laplace mechanism; ( see Section 4.2 and Section 4.3) - 8:
For non-sampled points, approximate current traffic flows with the corresponding predicted traffic flows; ( see Section 4.3) - 9:
Obtain by combining the results at sampling points and the results at non-sampled points.
|
4.1. Adaptive Allocation of Privacy Budget
According to Theorems 1 and 2, if the sliding window size
w is too large, the privacy budget allocated for the sections at each timestamp is small, which will result in a large magnitude of noise. Sampling is a promising way to reduce noise. Because the non-sampled points do not consume any privacy budget, more privacy budget will be allocated for the sampling points. Towards this end, an adaptive allocation of the privacy budget is proposed in the literature [
24]. It adopts the temporal correlation to predict the value at the next timestamp, and the value is used for sampling, where the predicted value determines the quality of the sampling. Also, due to the spatial correlation between traffic flows, it can increase the accuracy of predicted traffic flows and make the sampling more reasonable.
Inspired by the above ideas, a mechanism for the adaptive allocation of the privacy budget based on spatial correlation is proposed in this paper. The mechanism includes three operations, which are described in detail as follows.
4.1.1. Spatial Correlation Prediction
In the phase of spatial correlation prediction, we note that
is the maximal speed limit of section
i, where the speed of all vehicles is assumed to be less than or equal to the maximum speed. The predefined
is the sampling period of raw traffic data. According to Equation (9) of the work [
34], the speed–flow relationship between
and
is
,
, where
is the average vehicle speed in section
i at timestamp
t,
is the maximum capacity of section
i, and
and
are scale factor corrections. It is obvious that the average vehicle speed is related to the shared traffic flows, the maximal speed limit of the section, and the predefined sampling period. However, the scale factors are hard to set artificially. Inspired by [
34], we design a novel spatial correlation algorithm
to calculate the predicted traffic flows of section
i. The goal of the method is to predict the traffic flow of section
i at timestamp
t + 1 based on
and the prior knowledge
,
and
. Specific processes are described in the following three steps:
Step 1: To calculate , we train a model to learning the relationship between and , and . Based on the trained model, we can obtain the average vehicle speed of each section at any timestamp by inputing the prior knowledge and the shared traffic flows.
Step 2: Based on the average speed of section
i and the sampling period
, the traffic outflow
of section
i is calculated by
Step 3: According to the actual situation, the predicted traffic flow (
) of section
i is the difference between the traffic outflow of section
i and the traffic inflows of its linked sections. For example, if section
j and section
k are the linked sections of section
i, the predicted traffic flow of section
i is represented as the following formula.
4.1.2. Calculation of Privacy Budget
In the calculation of the privacy budget, to satisfy w-event privacy, the total privacy budget of each section at any sliding window should be smaller than . Here, assume that all sections at the next timestamp are sampling points. Thus, the privacy budget of all sections at the next timestamp should be calculated.
Without loss of generality, let the current timestamp be
t; then, the privacy budget for section
i at timestamp
t + 1 is
. The remaining privacy budget
in the sliding window
is calculated by
. Additionally, the sampling interval is
, where
l is the last sampling point of section
i. Then, a scale factor
p, which determines how much privacy budget will be allocated for section
i at timestamp
t + 1, is calculated by
where
is defined as a scale factor varied in (0, 1], and
is the maximum portion of privacy budget allocated for each sampling point. In the end, the privacy budget allocated for section
i at timestamp
t + 1 is calculated by
where
is the maximum privacy budget allocated for each sampling point. Two constraints (i.e.,
and
) are aimed at striking a good balance between the data utility and privacy protection of traffic flows.
4.1.3. Sampling with the Predicted Traffic Flows
The perturbation error of section
i is
, and the dissimilarity between the predicted traffic flow and the last shared traffic flow is
, where
is the last shared traffic flow of section
i. If
, the traffic flow at timestamp
t + 1 is approximated by the predicted traffic flow. Then, the privacy budget of section
i is withdrawn, i.e., section
i at timestamp
t + 1 is a non-sampled point, and its privacy budget is zero. Otherwise, section
i at timestamp
t + 1 is a sampling point, and its privacy budget remains unchanged. The mechanism for the adaptive allocation of the privacy budget is formally presented in Algorithm 2.
| Algorithm 2: Adaptive allocation of privacy budget for section i at timestamp t + 1. |
Require: privacy budget , , , , and the traffic flows of section i and its linked sections at timestamp t. Ensure: the privacy budget of section i at timestamp t + 1.
- 1:
Assume that section i at timestamp t + 1 is sampling point, and calculate privacy budget for it, then obtain , where and ; - 2:
According to Spatial Correlation Prediction, calculate that is the predicted traffic flow of section i at timestamp t +1; - 3:
Calculate the dissimilarity between the predicted traffic flow and the last sharing ; - 4:
; - 5:
if then - 6:
section i at timestamp t + 1 is sampling point; - 7:
return ; - 8:
else - 9:
section i at timestamp t + 1 is non-sampled point; - 10:
return 0; - 11:
end if
|
4.2. Dynamic Clustering
As shown in the analyses in
Section 1, the sections with small traffic flow can cause large relative perturbation error in the
w-event privacy schemes. In this section, a dynamic clustering algorithm, i.e., bisecting
k-means, is adopted to reduce the perturbation error. Specifically, the sections with similar traffic flow and privacy budget will be aggregated together to resist noise via the dynamic clustering.
First, it is necessary to determine which sections have small traffic flow before clustering. Here, the noise resistance threshold is defined as , which reflects whether the traffic flows have sufficient capacity to resist noise. When the traffic flows are smaller than , they are classified as small traffic flows. Then, the sections with small traffic flows will be saved in the cluster .
Assume that the number of the sections with small traffic flow is n; then , , and , , where is the traffic flow of cluster , and is perturbation error. When , the cluster at timestamp t + 1 can be denoted as , . Also, the sum of the squared error () of is , where is the cluster center of . As is well known, the smaller the is, the more similar the traffic flows and privacy budget of sections are. Thus, the dynamic clustering is aimed at finding the smallest , which is described in Algorithm 3.
After dynamic clustering, suitable privacy budget should be allocated for each cluster in
. Without loss of generality,
is denoted as the total privacy budget for section
i at any successive
w timestamps. In order to ensure
, the privacy budget allocated for
is equal to
, and the privacy budget of the sections in
is also
, where
.
| Algorithm 3: Dynamic Clustering Algorithm at timestamp t + 1. |
Require: . Ensure: .
- 1:
Initialization: , . - 2:
if then - 3:
return ; - 4:
end if - 5:
while 1 do - 6:
; ; - 7:
for do - 8:
do 2- for in , then obtain new and ; - 9:
if and then - 10:
; (the clusters except and are from ) - 11:
if then - 12:
- 13:
end if - 14:
end if - 15:
end for - 16:
if then - 17:
; - 18:
else - 19:
return ; - 20:
end if - 21:
end while - 22:
The function of 2-means is as follows. - 23:
Function: =2-() - 24:
1: randomly select two objects from these k objects of as the initial cluster centers of the cluster A and the cluster B; - 25:
2: calculate the similarity (Euclidean distance) between each object and the cluster center; (The smaller the value is, the closer the similarity is) - 26:
3: all objects are divided into the cluster with closer similarity; - 27:
4: recalculate the cluster centers of the cluster A and the cluster B; - 28:
5: repeat step 2–step 4 until each cluster is not changing; - 29:
6: , and ; - 30:
7: return and . - 31:
end Function
|
4.3. Approximation and Perturbation
To ensure that each section satisfies
w-event privacy, the noise that conforms to Laplace distribution is injected into each sampling section. In [
24], it uses the last shared value to approximate non-sampled sections. Different from the approximation mechanism in [
24], we propose a novel approximation mechanism that takes the predicted value as the value of non-sampled sections. The predicted values are used to approximate the real value in this paper. However, there exists a dissimilarity
between the last shared values and the predicted values, so the predicted values are closer to the real traffic flows of the section than to its last shared value. In any case, the predicted values are calculated based on the shared traffic flow at the previous timestamp. Thus, it also can protect real values and prevent privacy leakage.
In the perturbation mechanism,
is the raw traffic data at timestamp
t + 1, and
is a cluster at timestamp
t + 1 consisting of
sections. As each vehicle can only appear in at most one section at each timestamp, the sensitivity of
Q (
) is 1. Then, the sanitized traffic flow of section
i at timestamp
t + 1 can be denoted as
If section , the sanitized traffic flows are . Otherwise, the sanitized traffic flows are .
6. Experimental Simulation and Evaluation
In this section, the related experiments are simulated on real-world datasets, and the performance of the proposed DP-SCR is compared with that of schemes E-RescueDP [
24], BD [
23] and BA [
23]. All our experiments are run in Matlab 2018a platform on PC with Intel(R) Core(TM) i5-4590 CPU @ 3.30 GHz, 4.00 G main memory, and 500 GB hard disk with the Microsoft Windows 7 operating system.
The datasets of our experiments include the vehicular mobility dataset and the street layout dataset. The vehicular mobility dataset is mainly based on the real data collected by the General Departmental Council of Val de Marne (94) in France (Downloaded at
http://vehicular-mobility-trace.github.io/ accessed on 2 March 2024). It comprises around 10,000 traces, over rush hour periods of two hours in the morning (7 a.m.–9 a.m.) and two hours in the evening (5 p.m.–7 p.m.). The real street layout of the Creteil roundabout area (sampled area) is obtained from the OpenStreetMap database, as shown in
Figure 6. Here, each 400-m road is served as one section.
Subsequently, a traffic flow dataset with 160 timestamps for each section is created, which is sampled every 85 s from the vehicular mobility dataset. Moreover, the traffic flow dataset contains vehicle numbers, vehicle coordinates on the two-dimensional plane (x and y coordinates in meters), vehicle speed (in meters per second), and vehicle id. The target section is randomly selected from the sections generated by function Q. In any case, to ensure the credibility of our experiments, all experiments involving the Laplace mechanism are conducted 100 times, and the average value of these 100 experiment results is represented by the points in the figures.
6.1. Data Utility of the Shared Traffic Flow
In this section, we conduct experiments for the designed adaptive allocation of privacy budget and dynamic clustering to evaluate the superiority in terms of data utility. The accuracy of the shared traffic flows reflects the data utility. The mean absolute error (
) and the mean relative error (
) are served as an accuracy metric. Moreover, the smaller the
and
are, the more accurate the traffic flows are. Let
be raw traffic flows, and let
be the sanitized traffic flows of section
i at successive
n timestamps before Filtering. Then, the formulas for the
and
, respectively, are
where
is the bound of small traffic flows, which is used to reduce the effect of excessively small traffic flows and is equal to 0.1% of
.
(1) Prediction accuracy evaluation for DP-SCR. The allocation for privacy budget affects the accuracy of the predicted traffic flows greatly. RescueDP and E-RescueDP are the baseline temporal-based schemes designed for the sharing of real-time data with w-event privacy. Due to the performance of E-RescueDP being better than that of RescueDP, we only compare our scheme with the preferable E-RescueDP in terms of the accuracy of prediction. In these experiments, the privacy budget is .
E-RescueDP is based on the temporal correlation with the Elman network [
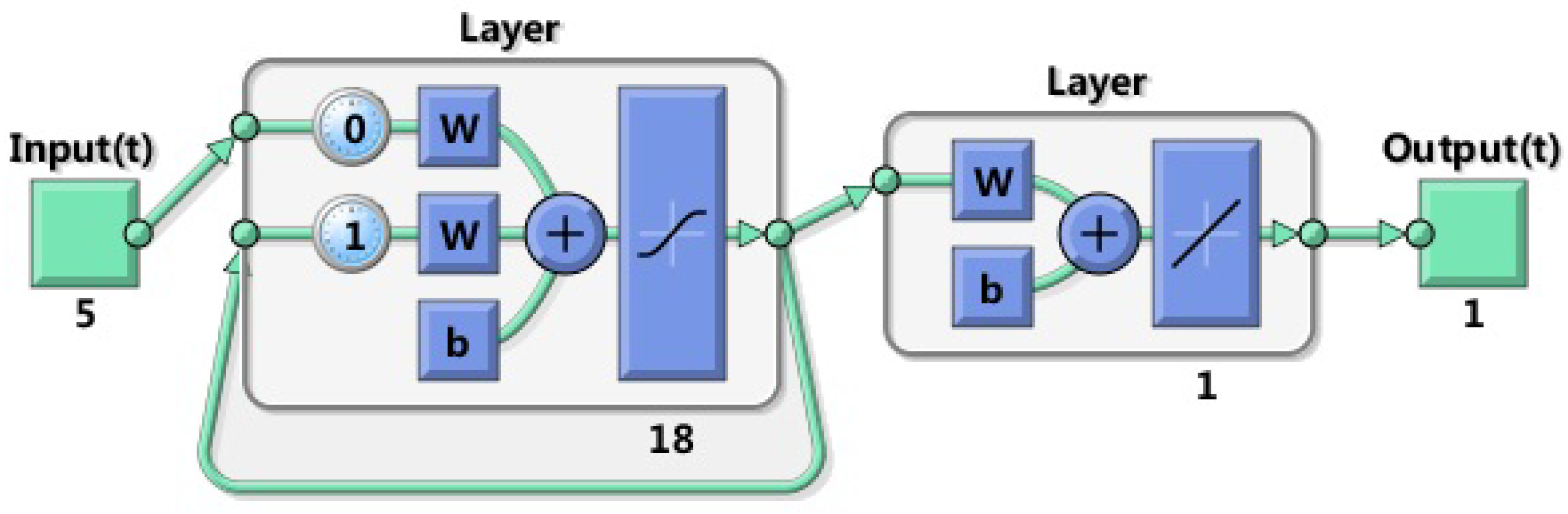
39] (an RNN algorithm). In the Elman network, the number of neurons is 5 in the input layer, 18 in the hidden layer and 1 in the output layer, respectively. The designed diagram of the Elman network is shown in
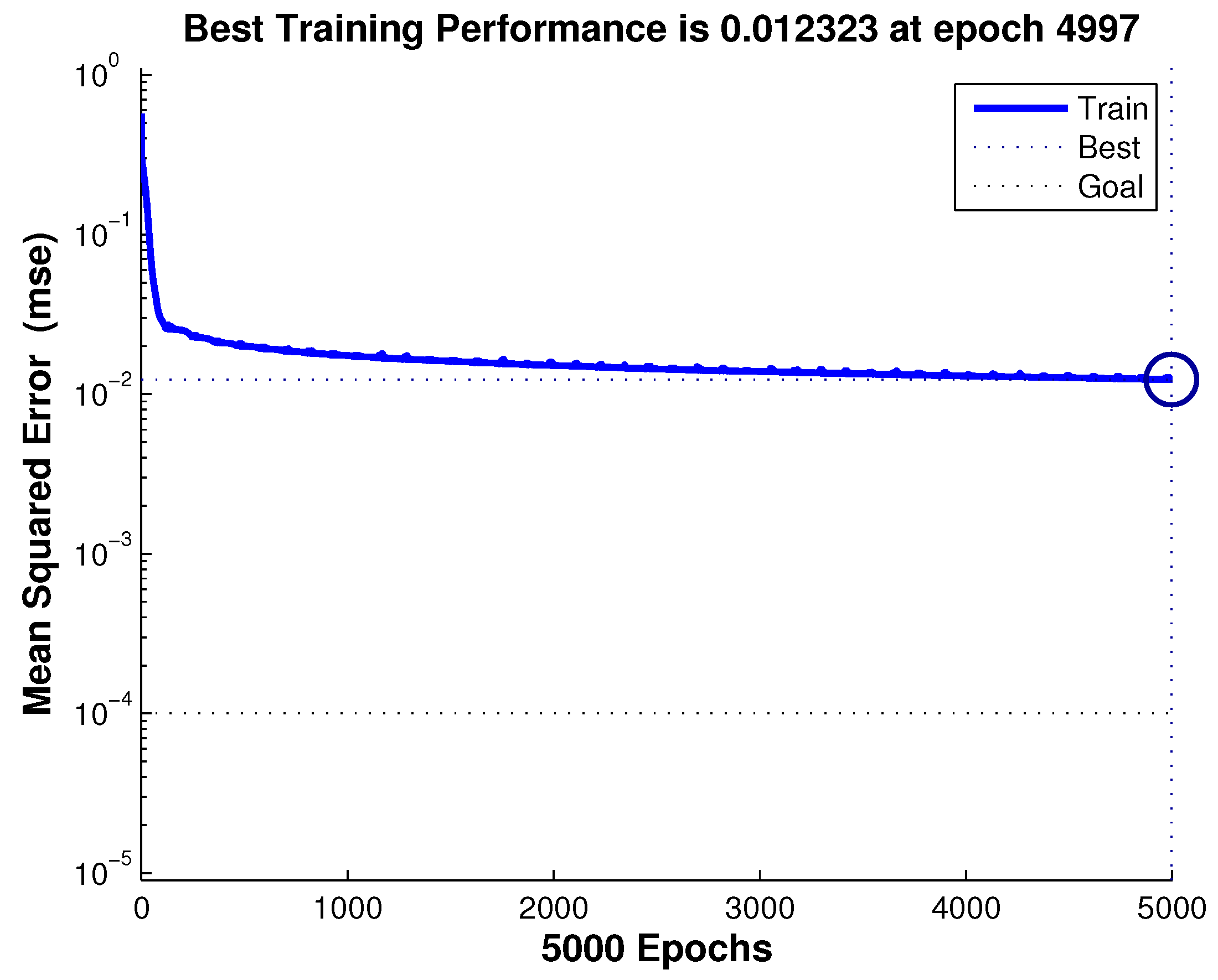
Figure 7. Moreover, the traffic flows at the first successive 80 timestamps of the target section is selected as the training sets, and the remaining traffic flows are taken as the testing sets. As depicted in
Figure 8, the blue line represents the training loss (i.e., mean squared error) of the Elman network during training. It is noteworthy that the training loss remains stable and is equal to 0.012323 at 4997 epochs. In
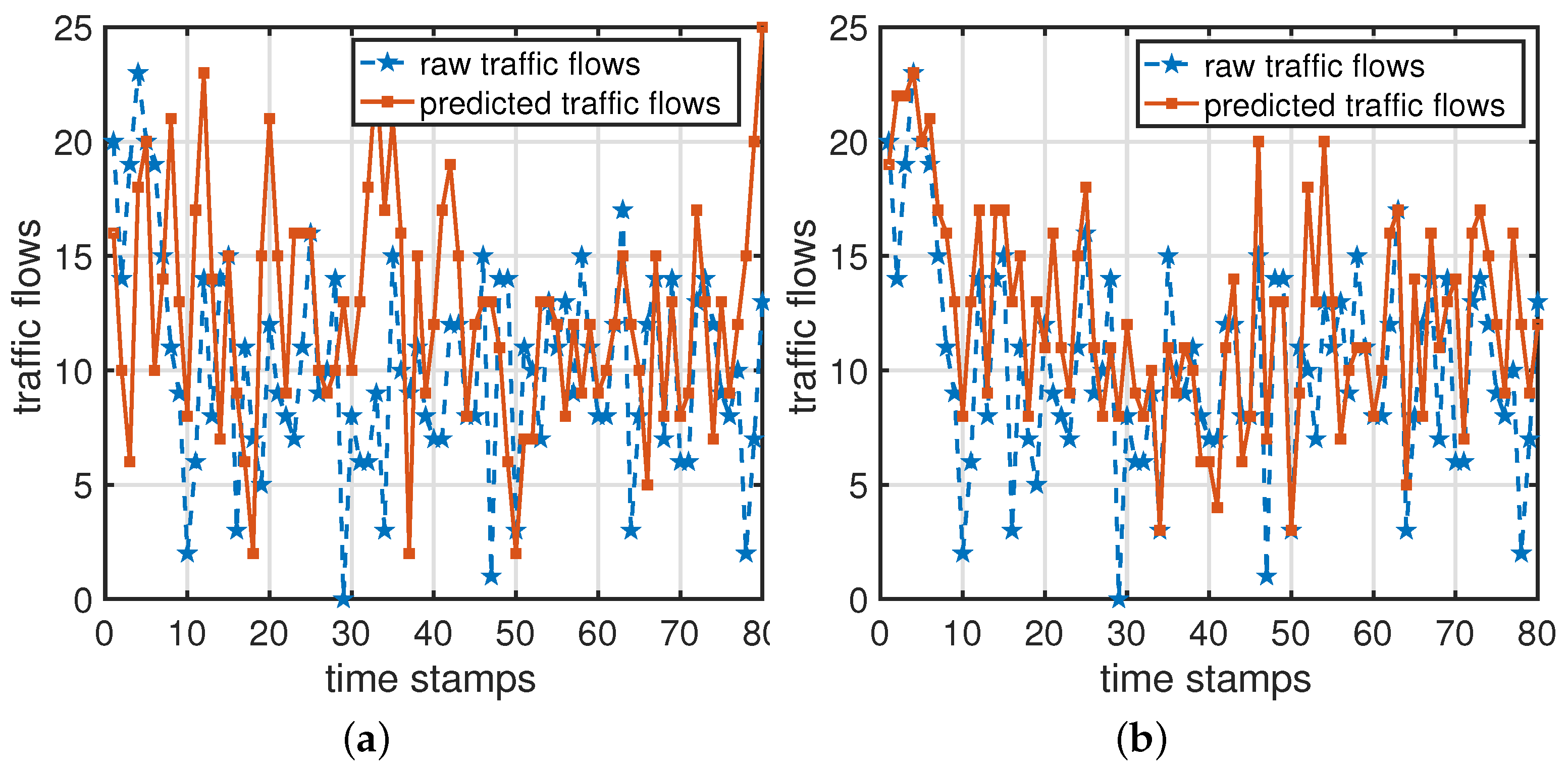
Figure 9, the blue dashed lines depict the raw traffic flows, while the orange solid lines represent the predicted traffic flows.
Figure 9a displays the predicted results in the E-RescueDP scheme. The results show that there are significant differences between the predicted results of E-RescueDP and the raw traffic flows, where the
and
in E-RescueDP are 5.0875 and 0.4881, respectively.
In the proposed DP-SCR, the traffic data of the above target section and its linked sections at the last 80 timestamps are selected as experimental data. For fair comparison, the model
is trained on Elman network also with the number of neurons is 18 in the hidden layer and 1 in the output layer, respectively. The number of neurons is 3 in the input layer, including the shared traffic flow, maximal speed limit, and sampling period. The prediction results of DP-SCR are shown in
Figure 9b, where the predicted traffic flows match the raw traffic flows well. Moreover, the
and
in DP-SCR are 3.1000 and 0.2680, respectively.
In summary, the predicted results in DP-SCR are more accurate than that in E-RescueDP, which means the data utility of the proposed scheme is higher.
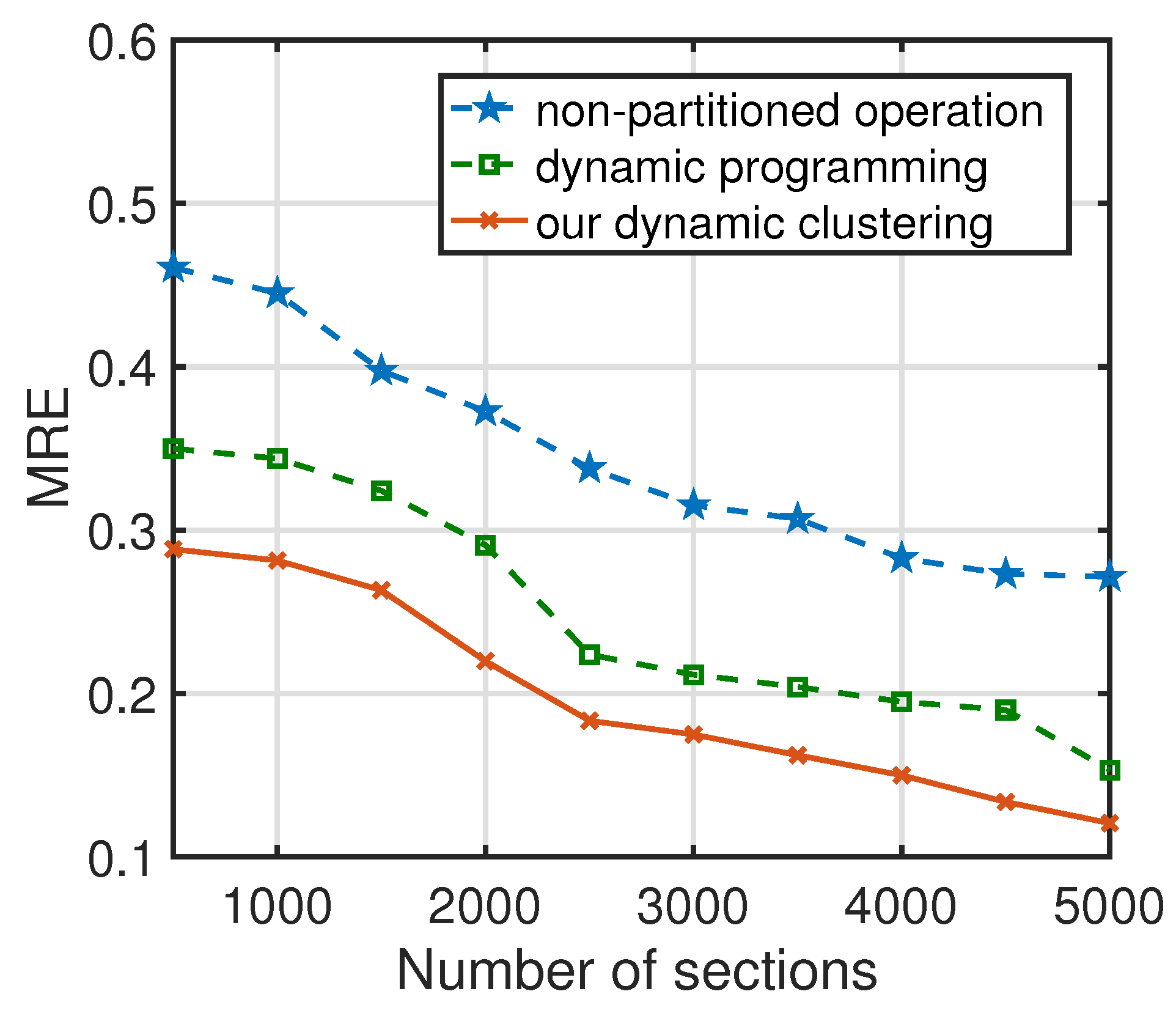
(2) Accuracy evaluation for dynamic clustering. The dynamic clustering based on bisecting
k-means is adopted to reduce the perturbation error caused by the small traffic flows, which will result in the loss of data utility. In the experiments on dynamic clustering, an experimental dataset based on real data is created, where the dataset includes 5000 sections with small traffic flows that are allocated with a random privacy budget. The
of the bisecting
k-means is compared with that of non-partitioned operation and dynamic programming, where the dynamic programming is the partitioned operation in [
24].
Figure 10 illustrates the
results of different strategies with different sections. It observes that the
of DP-SCR is smaller than that of other schemes, indicating the higher data utility of the shared traffic flows obtained by the dynamic clustering in DP-SCR compared to other partitioned operations.
6.2. Data Utility vs. Privacy Budget
In this section, the experiments about the
and
are conducted when
varies from 0.1 to 1.0. The
and
of DP-SCR are compared with those of schemes BA [
23], BD [
23], E-RescueDP [
24] and CLDP [
29]. BA and BD are baseline
w-event privacy schemes for the real-time data release, and CLDP is the baseline
w-event privacy scheme with local differential privacy.
Figure 11 compares
and
for the shared traffic flows with
changing, where
w is fixed and equal to 10. The results indicate that the
and
of DP-SCR with any privacy budget are significantly smaller than those of other schemes. Moreover, the
and
of BA, BD and LCDP decrease as
increases, and the magnitude of the decrease is also becoming smaller. The changes in the
and
of E-RescueDP and DP-SCR are little. There are three reasons for the above experimental results. First, BA, BD and CLDP allocate too small privacy budget for perturbation, which introduces more noise into the shared data. Second, the prediction of DP-SCR is more accurate than that of E-RescueDP, so the
and
of DP-SCR are smaller than those of E-RescueDP. Third, since the adaptive allocation of budget privacy is adopted in E-RescueDP and DP-SCR, providing more reasonable privacy budgets, the
and
of them are relatively stable when
changes.
6.3. Data Utility vs. Sliding Window Size
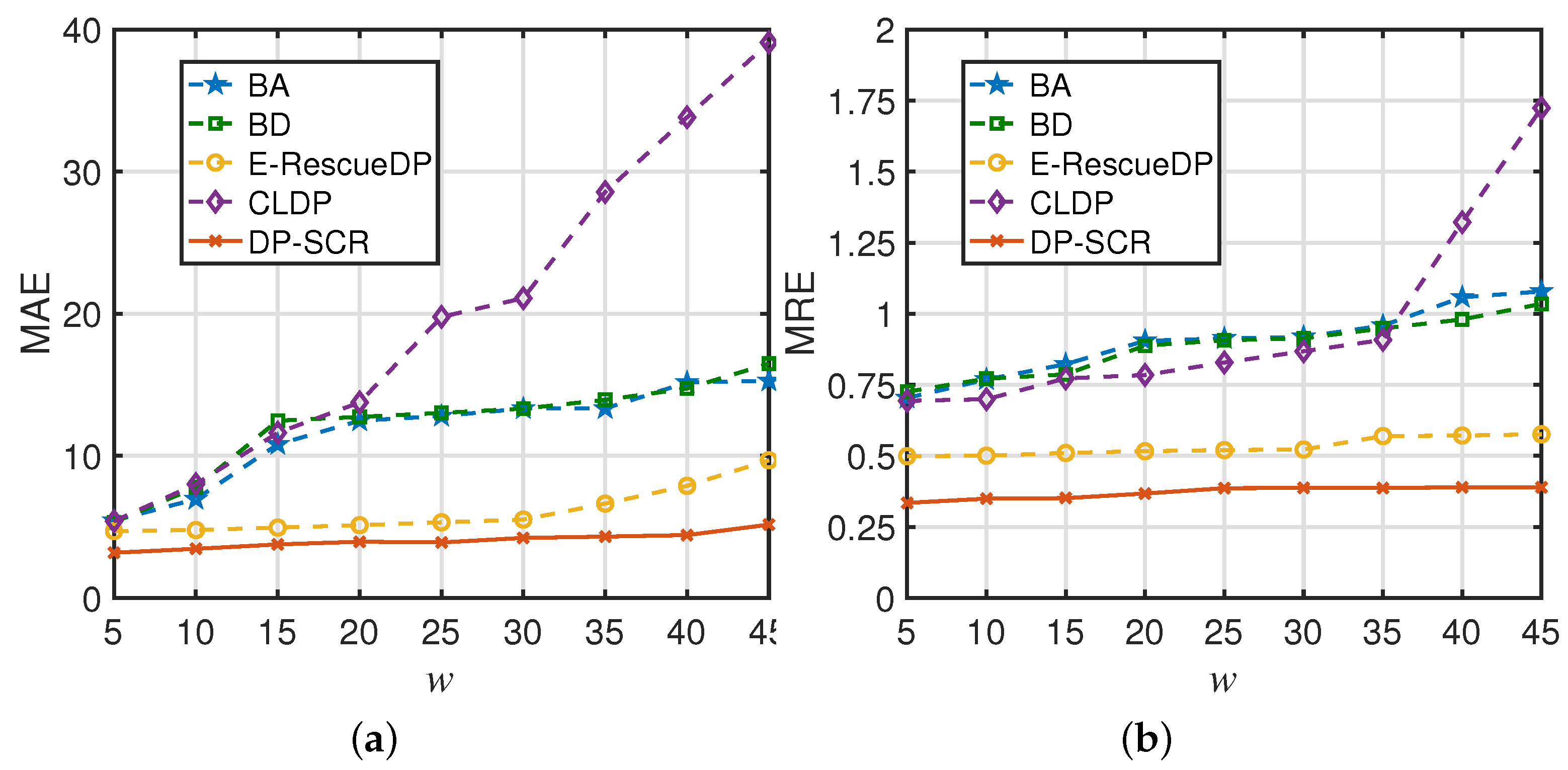
The data utility of DP-SCR is compared with that of schemes BA, BD, E-RescueDP and LCDP, where
w varies from 5 to 45. The results are shown in
Figure 12, where the
and
of DP-SCR are higher than those of other schemes. Also, the
and
of BA, BD and LCDP increase as
w increases, and the
and
of E-RescueDP and DP-SCR are relatively stable. This is because the adaptive allocation of privacy budget and dynamic processing improve the accuracy of the shared traffic flows and make them robust to the changes in
w.
7. Conclusions
In this paper, we propose a scheme, named DP-SCR, to ensure the sharing of real-time traffic flows with high data utility under privacy protection. DP-SCR consists of four key components: adaptive allocation of privacy budget, dynamic clustering, approximation and perturbation. In the proposed DP-SCR, we take advantage of the spatial correlation prediction and the novel clustering strategy to improve the accuracy of the shared traffic flows. Moreover, the results of the experiments on real-world datasets have also shown that the shared traffic flows in DP-SCR are more accurate than those in the existing baseline w-event privacy schemes. Also, in terms of privacy protection, DP-SCR has been proven to satisfy w-event privacy, which provides strong privacy protection to the shared traffic flows.
However, some aspects that still exist can be improved in future work. First, more characteristics of traffic flows may be considered together in prediction to improve the data utility. Second, genetic algorithms [
40] may be used to improve the accuracy of the spatial correlation prediction. Finally, other privacy-preserving methods such as secure data deduplication [
41], blockchain-based secure sharing scheme [
42] and federated learning [
43,
44] can be used to enhance the data utility and security.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}