Abstract
Based on the idea of integral averaging and function extension, an extended Kantorovich-type neural network operator is constructed, and its error estimate of approximating continuous functions is obtained by using the modulus of continuity. Furthermore, by introducing the normalization factor, the approximation property of the new version of the extended Kantorovich-type neural network (normalized extended Kantorovich-type neural network) operator is obtained in . The numerical examples show that this newly proposed neural network operator has a better approximation performance than the classical one, especially at the endpoints of a compact interval.
Keywords:
neural networks; Kantorovich-type operator; approximation; modulus of continuity; Lp space MSC:
41A30; 41A25; 47A58
1. Introduction
Neural networks are broadly applied in various applications, such as visual recognition, healthcare, astronomical physics, geology, cybersecurity, and many more. As the most widely used neural networks, feedforward neural networks (FNNs) have been thoroughly studied because of their universal approximation capabilities. Theoretically, any continuous function on a compact set can be approximated by FNNs to an arbitrary desired degree provided that the number of neurons is sufficiently large. Further, some upper bounds of the approximation error for FNNs in the uniform metric and metric have been studied in [1,2,3,4,5], and so on.
FNNs with one hidden layer can be mathematically expressed as
where for are the thresholds, are the connection weights, are the coefficients, is the inner product of and , and is the activation function.
NN operators and their approximation properties have attracted a lot of attention since the 1990s. Cardaliaguet and Euvrard [6] first introduced NN operators to approximate the unit operator. Since then, different types of NN operators were constructed, and their approximation properties were widely investigated. A lot of impressed results concerning the convergence of NN operators as well as the complexity of approximation have been achieved ([6,7,8,9,10,11,12,13,14,15,16,17], etc.). Traditional operators provide references for NN operators in many aspects, such as the construction, the way of discussing approximation properties, and the practical applications. They are both related and different in approximation performance and practical applications. Taking the classical Bernstein operator as an example, it is usually used to approximate continuous functions, while NN operators can be utilized to approximate a broad class of functions, such as integrable functions; Bernstein operators are valuable tools in computer-aided geometric design, while NN operators are used for a wider range of applications, such as machine learning. Moreover, different from classical operators, one remarkable feature of NN operators is that they are nonlinear. It is worth mentioning that the main advantage of using NN operators as approximation tools is that the NN operators can be viewed as FNNs with multiple layers, while all the components in the NN operators are known, such as the coefficients, the weights, and the thresholds, in order to approximate the target function. The constructions of NN operators and related discussions have formed an important part of the fundamental theories of artificial neural networks, which were introduced in order to simulate human brain activities.
Next, we are going to review some NN operators and their approximation properties. Let be the space of continuous functions on . The approximation properties of NN operator ,
has been studied in [12,18,19], where will be defined in Section 2, , equipped with the uniform norm . The symbol denotes the greatest integer not exceeding x, while denotes the smallest integer greater than or equal to x.
In applications, the values of would have some errors due to the time-jitter or offset of the input signals, while more information is usually known around a point than precisely at that point. In approximation theory, constructing a Kantorovich-type operator to reduce the “time-jitter or offset“ errors is a well-known method. This kind of operator is also very useful in areas such as signal processing. To achieve this, we replace single function values by an average of f on a small interval around , namely the mean, .
In [13], the authors used a similar idea and constructed a Kantorovich-type neural network operator in , and the related estimates are given therein. If we consider the one-dimension case of , then the NN operator degenerates to ,
It was proved in [13] that convergences to in various functional spaces.
In [9], the authors extended the continuous function f on to the function
and discovered that, after constructing Kantorovich-type operators, the approximation rate of the constructed NN operator to the target function was significantly improved.
A natural question is, what happens if we combine the idea of function extension with that of integral averaging? In this paper, we investigate the approximation effects, including the convergence properties and quantitative estimates, of our newly constructed NN operator, called the extended Kantorovich-type NN operator, regarding this question. A numerical example shows that this type of neural network operator has a better approximation performance than , especially at the endpoints of a compact interval.
The remaining part of this paper is organized as follows. In Section 2, we propose two new types of NN operators, the extended Kantorovich-type NN operator (EKNNO) and the normalized extended Kantorovich-type NN operator (NEKNNO), and investigate their basic properties and the operator-dependent activation function. In Section 3, we establish the approximation theorems of the EKNNO and NEKNNO for continuous functions, including the convergence theorems and quantitative estimates, using the modulus of continuity. This section also demonstrates a numerical example and its results, which verify the validity of the theoretical results and the potential superiority of these operators. In Section 4, we further establish and prove the approximation properties of the EKNNO in the Lebesgue space, as well as the convergence results and the approximation rate of the NEKNNO. The conclusions are included in Section 5.
2. Extended Neural Network Operators of Kantorovich Type
In this section, we explain how to construct two extended neural network operators of a Kantorovich type—EKNNO and NEKNNO.
The activation function plays a significant role in the approximation properties of neural networks. In many fundamental NN models, the activation function is usually taken to be a sigmoid function ([20]), which is defined below.
A function is called sigmoid ([20]) if
For example, the well-known Logistic function is a typical sigmoid type, which is defined by .
Next, we write , a combination of the translations of that was first proposed by Chen and Cao [8]:
We assume in this paper that the sigmoid-type function is nondecreasing on , such that , and it is centrosymmetric with respect to the point . For example, the Logistic function is exactly the sigmoid-type function that satisfies these conditions, i.e.,
The function , which is often called the “bell-shaped function” (a name given by Cardaliaguet and Euvrard [6]), has been discussed in many papers. It has some important properties, and we cite part of them from [11] here, which are related to the research presented in this paper.
Using the definition of the Fourier transformation ([21]) and the Poisson summation formula ([9,22]), we have Theorem 1.
Theorem 1.
Assume that is type and centrosymmetric with respect to the point , is defined by (2). If there exist constants and such that
then we have
where is the Fourier transformation of .
Throughout the paper, C refers to a positive constant whose value may vary under different circumstances.
Remark 1.
If is taken as the function in Theorem 1, it was proved in [8,22] that for all , we have , that is, Equality (3) can be simply written as .
Inspired by the idea of integral averaging and function extension, we propose the first new operator—the extended Kantorovich-type NN operator (EKNNO)—as follows.
Definition 1.
Let , is defined by (2). Denote
Assume , and is defined as in (1). Then, EKNNO is defined by
The EKNNO has several key characteristics. First, we replace by the integral averaging to remove the effect of time-jitter. Second, we extend the traditional function f defined on interval to on to have better approximation abilities, especially around the endpoints . Further, we introduce a parameter A into the activation function , which serves as a flexible quantity used to fine tune the approximation ability of the operator.
Based on Definition 1, by introducing the normalization factor, we further construct the normalized version of the extended NN operator (NEKNNO) as follows.
Normalization allows us to further discuss the approximation performance of NN operators in the integrable function space.
Compared with , has the following properties.
Theorem 2.
Assume is defined as in Definition 2. Then, for , we have
(I) .
(II) Denote the unitary constant function on , i.e., . Then,
Proof.
For arbitrary , we have
similarly
Notice that for arbitrary , if , then
The Proof of (II) is straightforward because
Theorem 2 is proved. □
To obtain the error estimates of the operators and , we need the following lemmas.
Lemma 1.
Proof.
For any , set , and then . Further, for any , denote . Then, for sufficiently large , by the definition of and Theorem 1, we have
□
Lemma 2.
Let be defined as in 4. For any , , the following inequality holds:
Proof.
For all , it is easy to see that
Further, we can fix a specific such that ; therefore,
which completes the proof of Lemma 2. □
3. Degree of the Approximation by and in
The main aim of this section is to prove the convergence theorem as well as the quantitative approximation theorem of operators and to functions . For the EKNNO , Theorem 3 can be established.
Theorem 3.
Assume that the function satisfies the condition in Theorem 1, and then for , there exists a constant such that
where .
The symbol in Theorem 3 denotes the modulus of continuity of f [23], defined by
Proof.
In view of Theorem 1,
then
Now, we estimate separately.
For , we have . By the definition of and the property that , we have:
Similarly,
and
While for ,
then
Furthermore, because
thus
while
Therefore,
Combining the above estimates together, we have
□
Remark 2.
For a fixed A, the terms , and are approaching 0 when ; consequently,
for some constant . Especially, if we choose , we have
Remark 3.
Taking the activation function , then in this case. Following the similar (but more simple) procedure, we have
when
Remark 4.

Notice that in Theorem 3, we set
Figure 1.
Comparison of the Order.
In approximation theory, Theorem 3 is called a direct theorem of approximation by the operators, which gives the upper bound of the approximation. The direct theorems of the Kantorovich-types operators were investigated in much of the literature, see, for example, [24,25], etc.
The results on the upper bound imply the convergence of the NN operators to the target function and also provide a quantitative measurement of how accurately the target function can be approximated.
As for the NEKNNO , we have the following theorem.
Theorem 4.
Assume that is bounded on and continuous at , then
Furthermore, if , we have
Proof.
f is continuous at ⇔ For any , there exists a , such that for arbitrary , it holds . While for and , we have
then
Notice that for sufficiently large .
Remark 5.
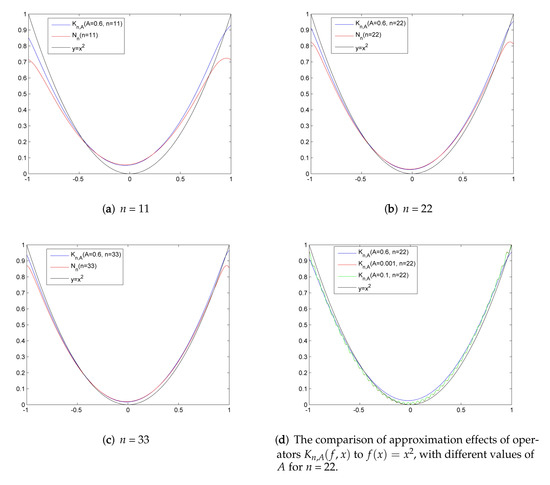
In Figure 2, we compare the approximation efficiency of the NEKNNO and when both approximate to the quadratic function on , while parameters n and A vary. It is very clear to see from Figure 2a–c that the NEKNNO has a better approximation performance, especially at the endpoints. At the same time, the change in the parameter A in Figure 2d obviously affects the approximation efficiency of the NEKNNO at the endpoints. Then, whether the optimal solution of A exists or not is an open question worth discussing.
Figure 2.
The comparison of approximation effects of operators and .
4. Degree of the Approximation by NEKNNO and EKNNO in
Now, consider the efficiency of the approximation of f by proposed operators EKNNO and NEKNNO in the Lebesgue space , where
equipped with the norm
We first give Lemma 3.
Lemma 3.
For any functions , the following inequality holds:
Proof.
By the definition of , Theorem 2, Lemma 2, and applying Jenson’s inequality due to the convexity of , we have
In view of Theorem 1, we obtain
Therefore,
This completes the proof of Lemma 3. □
Utilizing Lemma 3, we can prove the convergence of in .
Theorem 5.
Assume that , then
Proof.
It is well-known that is dense in . Let . Then, for any , there exists a function such that . By Lemma 3 and (14),
Therefore, for sufficiently large , we have
Theorem 5 is proved. □
Next, we consider . We need Lemma 4, whose proof is similar to that of Lemma 3.
Lemma 4.
For any functions , the following inequality holds:
Now, we can establish the approximation theorem of in space.
Theorem 6.
Let denote the set of all functions that are differentiable and have continuous derivatives on . Then, for , , the following inequality holds:
where , and
Proof.
Let , and . By Minkowski’s inequality,
In view of Lemma 4,
Therefore,
According to the definition of and , we have
By Jensen’s inequality, Hölder’s inequality, and Lemma 2,
For , , according to the Lagrange mean value theorem, we have
Therefore,
Let . We have
Remark 6.
If we take as the activation function, then we have
Consequently,
Choosing appropriate with and leads to
If we define g as the Steklov mean function of f, that is,
where , then g is absolutely continuous and f related. The upper bound of can be estimated by using the modulus of smoothness in space. We will derive this type of estimate in future work.
5. Conclusions
In this paper, we propose two types of NN operators, the EKNNO and NEKNNO, which can be regarded as feedforward neural networks with multiple layers. We construct the EKNNO and NEKNNO using the following ideas: (1) integral averaging leads to a Kantorovich-type NN operator for removing time-jitters; (2) a function extension improves the EKNNO’s and NEKNNO’s approximation abilities, especially at the endpoints of a compact interval; (3) the introduction of a flexible parameter A can fine tune the approximation ability of the operators; and (4) normalization allows us to further discuss the approximation performance of the NEKNNO in an integrable function space. All these features combined provide a better approximation performance. We further prove the convergence of these operators as well as attain the quantitative estimates, while in the latter some important approximation tools, such as the modulus of continuity and the idea of K-functional, are utilized. Numerical examples are used to verify the validity of the theoretical results and some potential superiorities of our NN operators.
However, in this paper, we only considered the direct theorems of the NN operators, and the target function is univariate. The converse results and higher dimensional case will be investigated in our future work. Moreover, we use the sigmoid-type function as the activation function in our paper, while many other activation functions, such as ReLU and some other variations of ReLU (such as LeakReLU, PReLu, ELU, SELU, etc.) are widely used in the machine learning and deep learning fields. It is worth exploring if the similar construction of an NN can work well with different activation functions.
In conclusion, we utilize methods and tools in approximation theory to obtain some interesting results in the field of neural networks, which may lead to more applications in neural networks.
Author Contributions
Conceptualization, writing—review and editing, visualization, C.X.; conceptualization, formal analysis, writing—review and editing Y.Z.; conceptualization, writing—review and editing X.W.; conceptualization, writing—review and editing P.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Natural Science Foundation of China under grant number 11671213, 11601110 and the Natural Science and Engineering Research Council of Canada under number RGPIN-2019-05917.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The study did not report any data.
Acknowledgments
The authors would like to thank the Anonymous Reviewers, Academic Editor, and the Journal Editor for their important comments.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of the data; in the writing of the manuscript; or in the decision to publish the results.
Abbreviations
The following abbreviations are used in this manuscript:
| NN | neural network |
| FNNs | feedforward neural networks |
| EKNNO | extended Kantorovich-type neural network operator |
| NEKNNO | normalized extended Kantorovich-type neural network operator |
References
- Barron, A.R. Universal approximation bounds for superpositions of a sigmoidal function. IEEE Trans. Inform. Theory 1993, 39, 930–945. [Google Scholar] [CrossRef]
- Cao, F.L.; Xu, Z.B.; Li, Y.M. Pointwise approximation for neural networks. Lect. Notes Comput. Sci. 2005, 3496, 39–44. [Google Scholar]
- Cao, F.L.; Xie, T.F.; Xu, Z.B. The estimate for approximation error of neural networks: A constructive approach. Neurocomput. 2008, 71, 626–630. [Google Scholar] [CrossRef]
- Cao, F.L.; Zhang, R. The errors of approximation for feedforward neural networks in the Lp metric. Math. Comput. Model. 2009, 49, 1563–1572. [Google Scholar] [CrossRef]
- Chui, C.K.; Li, X. Approximation by ridge functions and neural networks with one hidden layer. J. Approx. Theory 1992, 70, 131–141. [Google Scholar] [CrossRef]
- Cardaliaguet, P.; Euvrard, G. Approximation of a function and its derivative with a neural network. Neural Netw. 1992, 5, 207–220. [Google Scholar] [CrossRef]
- Cantarini, M.; Coroianu, L.; Costarelli, D.; Gal, S.G.; Vinti, G. Inverse Result of Approximation for the Max-Product Neural Network Operators of the Kantorovich Type and Their Saturation Order. Mathematics 2022, 10, 63. [Google Scholar] [CrossRef]
- Chen, Z.X.; Cao, F.L. The approximation operators with sigmoidal functions. Comput. Math. Appl. 2009, 58, 758–765. [Google Scholar] [CrossRef]
- Chen, Z.X.; Cao, F.L.; Zhao, J.W. The construction and approximation of some neural networks operators. Appl. Math.-A J. Chin. Univ. 2012, 27, 69–77. [Google Scholar] [CrossRef]
- Chen, Z.X.; Cao, F.L. Scattered data approximation by neural network operators. Neurocomputing 2016, 190, 237–242. [Google Scholar] [CrossRef]
- Costarelli, D.; Spigler, R. Approximation results for neural network operators activated by sigmoidal functions. Neural Netw. 2013, 44, 101–106. [Google Scholar] [CrossRef] [PubMed]
- Costarelli, D.; Spigler, R. Multivariate neural network operators with sigmoidal activation functions. Neural Netw. 2013, 48, 72–77. [Google Scholar] [CrossRef] [PubMed]
- Costarelli, D.; Spigler, R. Convergence of a family of neural network operators of the Kantorovich type. J. Approx. Theory 2014, 185, 80–90. [Google Scholar] [CrossRef]
- Costarelli, D.; Vinti, G. Quantitative estimates involving K-functionals for neural network-type operators. Appl. Anal. 2019, 98, 2639–2647. [Google Scholar] [CrossRef]
- Qian, Y.Y.; Yu, D.S. Neural network interpolation operators activated by smooth ramp functions. Anal. Appl. 2022, 20, 791–813. [Google Scholar] [CrossRef]
- Yu, D.S.; Zhou, P. Approximation by neural network operators activated by smooth ramp functions. Acta Math. Sin. (Chin. Ed.) 2016, 59, 623–638. [Google Scholar]
- Zhao, Y.; Yu, D.S. Learning rates of neural network estimators via the new FNNs operators. In Proceedings of the 2014 International Joint Conference on Neural Networks (IJCNN), Beijing, China, 6–11 July 2014. [Google Scholar] [CrossRef]
- Anastassiou, G.A. Univariate hyperbolic tangent neural network approximation. Math. Comput. Model. 2011, 53, 1111–1132. [Google Scholar] [CrossRef]
- Anastassiou, G.A. Intelligent Systems: Approximation by Artificial Neural Networks, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Cybenko, G. Approximation by superpositions of a sigmoidal function. Math. Control. Signals Syst. 1989, 27, 303–314. [Google Scholar] [CrossRef]
- Zygmund, A.; Fefferman, R. Trigonometric Series, 3rd ed.; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Zhang, Z.; Liu, K.; Zhu, L.; Chen, Y. The new approximation operators with sigmoidal functions. Appl. Math. Comput. 2013, 42, 455–468. [Google Scholar] [CrossRef]
- DeVore, R.A.; Lorentz, G.G. Constructive Approximation, 1st ed.; Springer: Berlin/Heidelberg, Germany, 1992. [Google Scholar]
- Heshamuddin, M.; Rao, N.; Lamichhane, B.P.; Kiliçman, A.; Ayman-Mursaleen, M. On one- and two-dimensional α-Stancu-Schurer- Kantorovich operators and their approximation properties. Mathematics 2022, 10, 3227. [Google Scholar] [CrossRef]
- Rao, N.; Malik, P.; RaniPradeep, M. Blending type Approximations by Kantorovich variant of α-Baskakov operators. Palest. J. Math 2022, 11, 402–413. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).