

Learning Heterogeneous Graph Embedding with Metapath-Based Aggregation for Link Prediction
Abstract
1. Introduction
- •
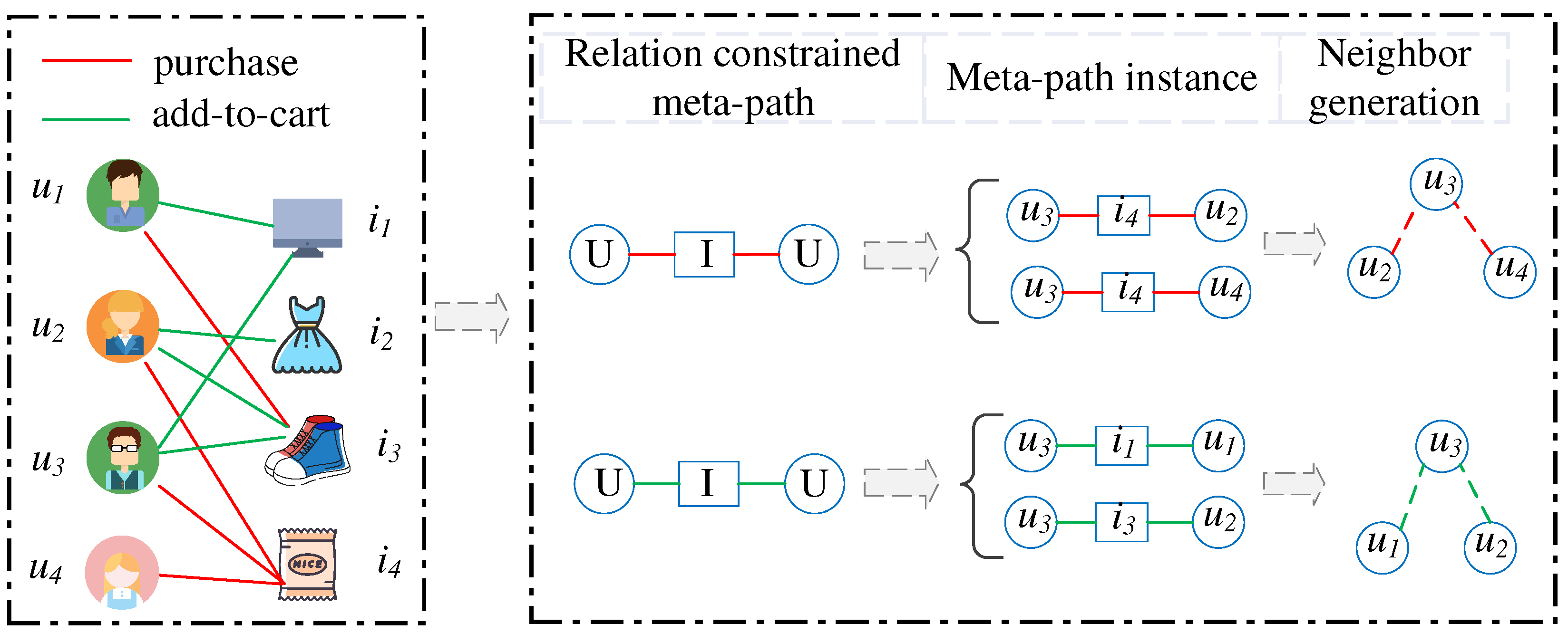
- Novel definition: We propose a novel definition of metapath, i.e., relation-constrained metapath. Then, each relation constrained metapath instance has a specific meaning and can clearly describe the relations between nodes.
- •
- Multiview modeling: We design two levels of metapath-guided aggregation methods, which aggregates from the intrapath on the instance level and the interpath on the semantic level, respectively. This method is more conducive to node aggregation and improves the accuracy of nodes representations.
- •
- Multifaceted experiments: We perform a suite of experiments on three datasets. The results demonstrate the effectiveness of the proposed model compared to the baseline model. In addition, we validate that our model can alleviate cold-start problem to a certain extent.
2. Related Work
3. Preliminaries
3.1. Definitions
3.2. Problem Definition
3.3. Notations
4. The Proposed Method
4.1. Instantiating Paths and Generating Neighbors
4.1.1. Random Walk-Based Metapath Instance and Neighbour Generation
4.1.2. Relation-Constrained Metapath Instance and Neighbor Generation
4.2. Node Aggregation
4.2.1. Intrapath Aggregation
Random Walk-Based Intrapath Aggregation
Relation Constrained Metapath-Guided Intrapath Aggregation
4.2.2. Interpath Aggregation
4.3. Model Optimization
| Algorithm 1: The proposed model. |
|
| Output: Embeddings of all nodes. Initialize all the model parameters Generate random walk based path instances and neighbors according to Section 4.1.1; Generate relation-constrained metapath instances and neighbors according to Section 4.1.2; |
 |
4.4. Classifier for Link Prediction
5. Simulation Experiment and Results Analysis
- RQ1: How do different hyperparameters affect the final performance?
- RQ2: How does the proposed method perform compared with other state-of-the-art baselines on the task of link prediction?
- RQ3: How does the proposed method perform on cold-start scenarios compared to baselines?
5.1. Datasets
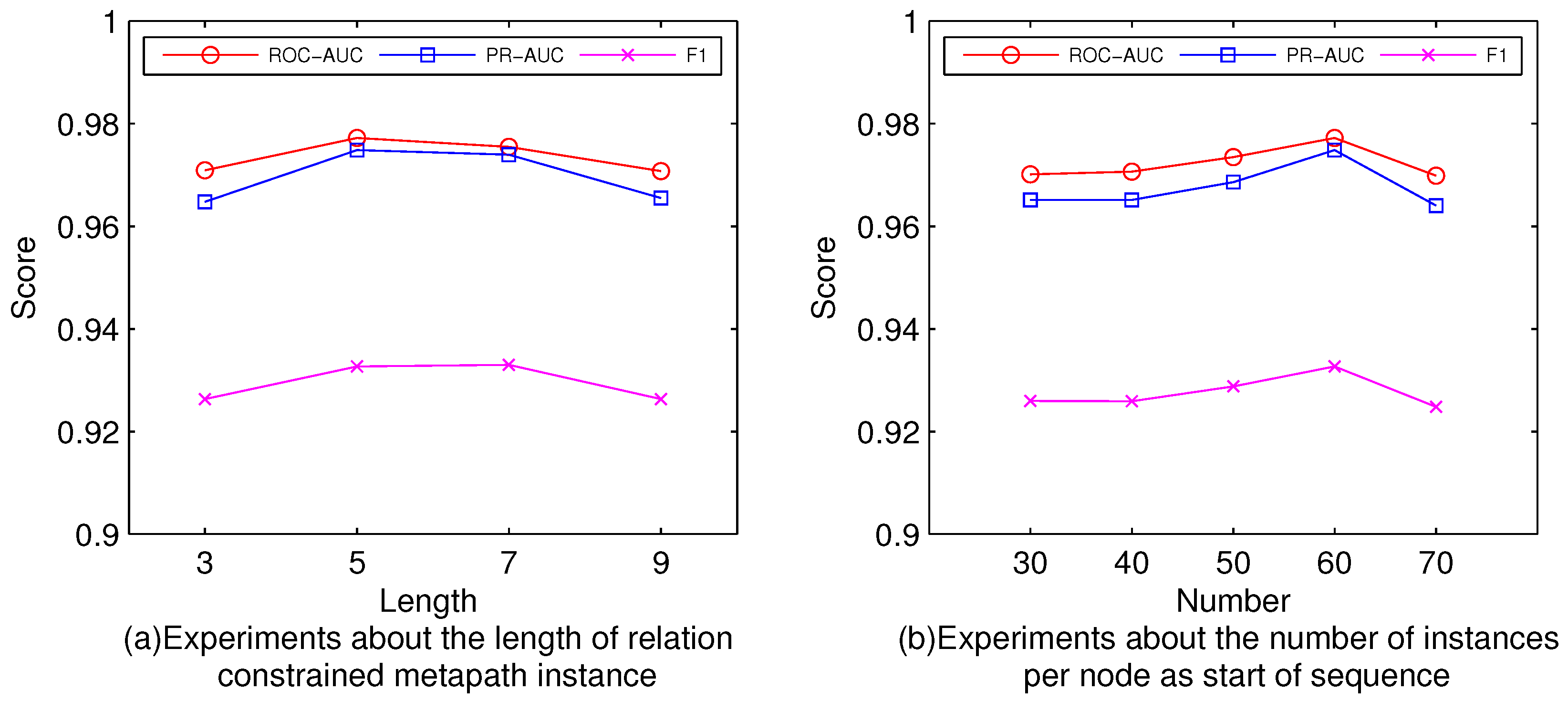
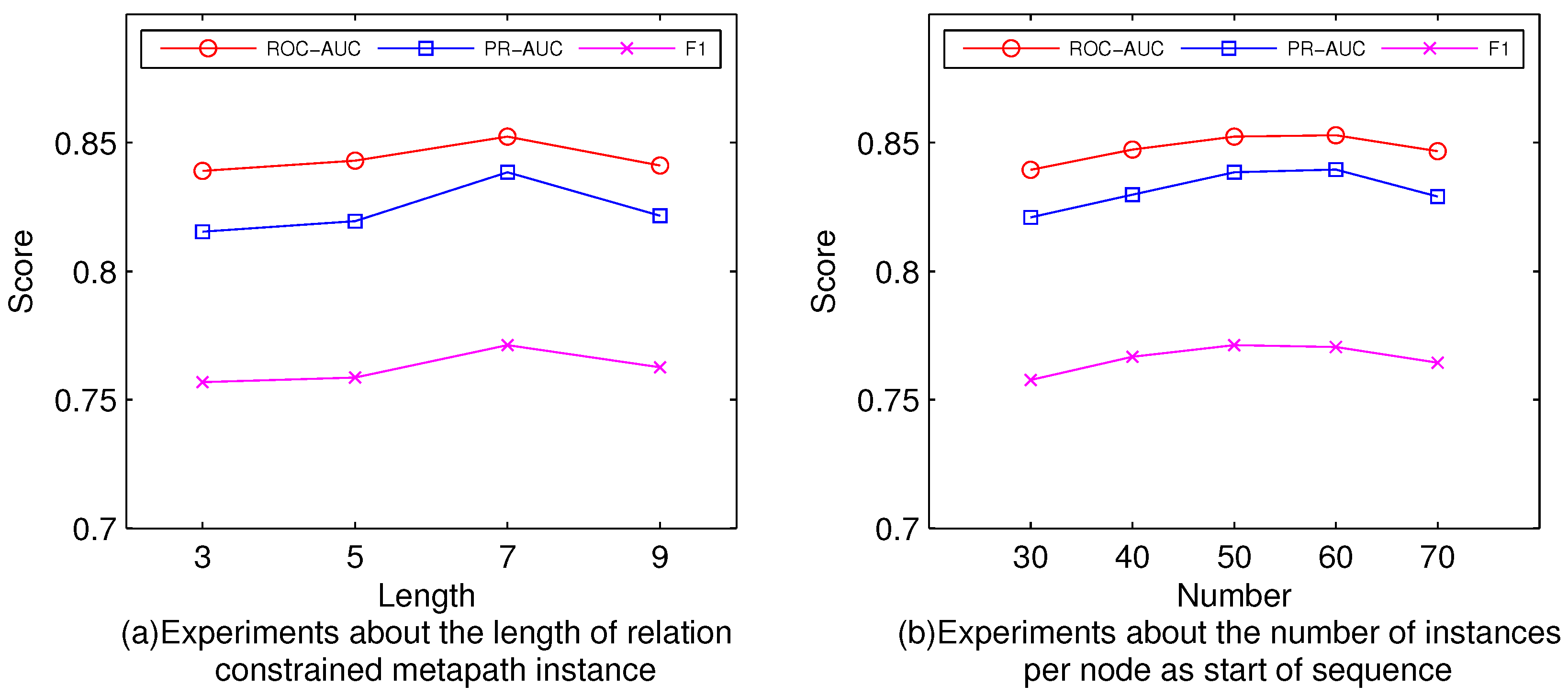
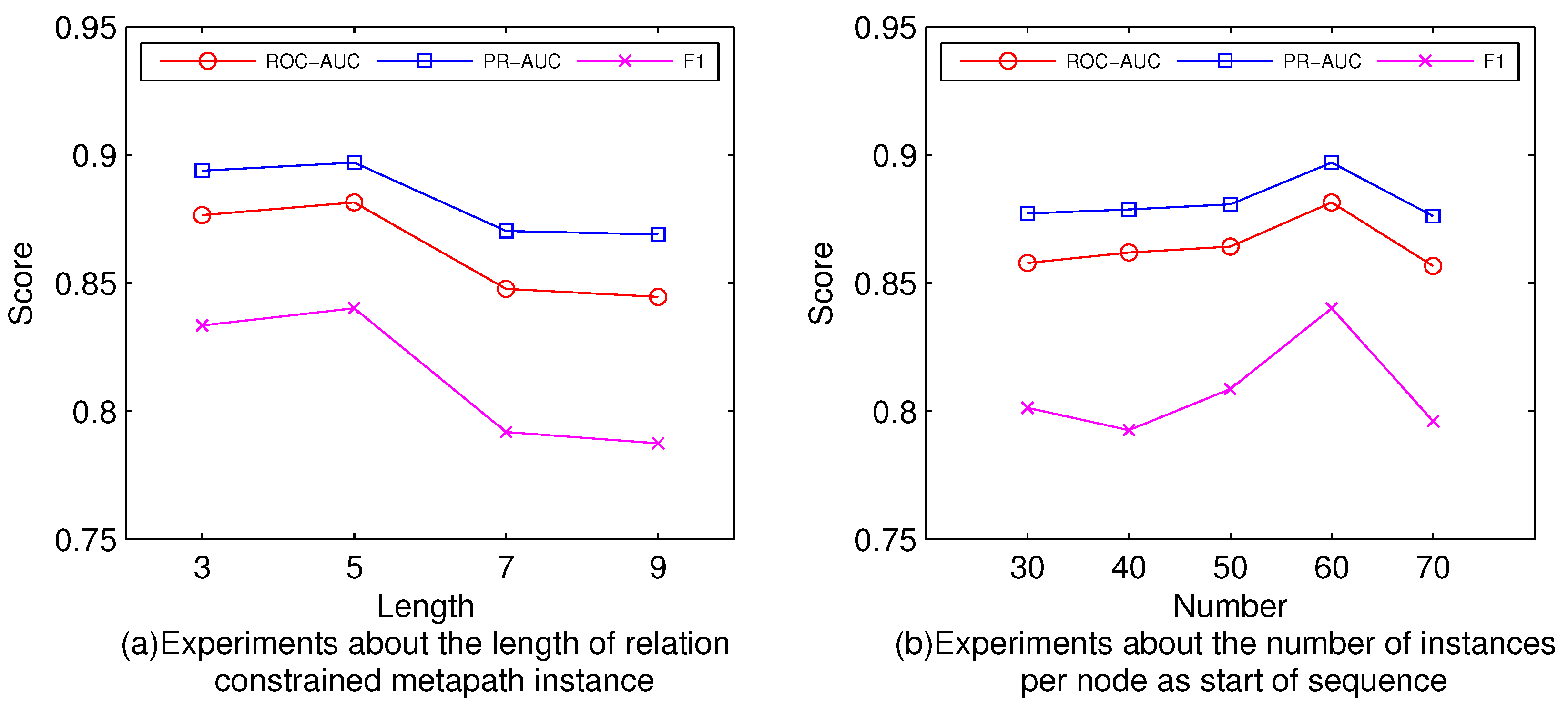
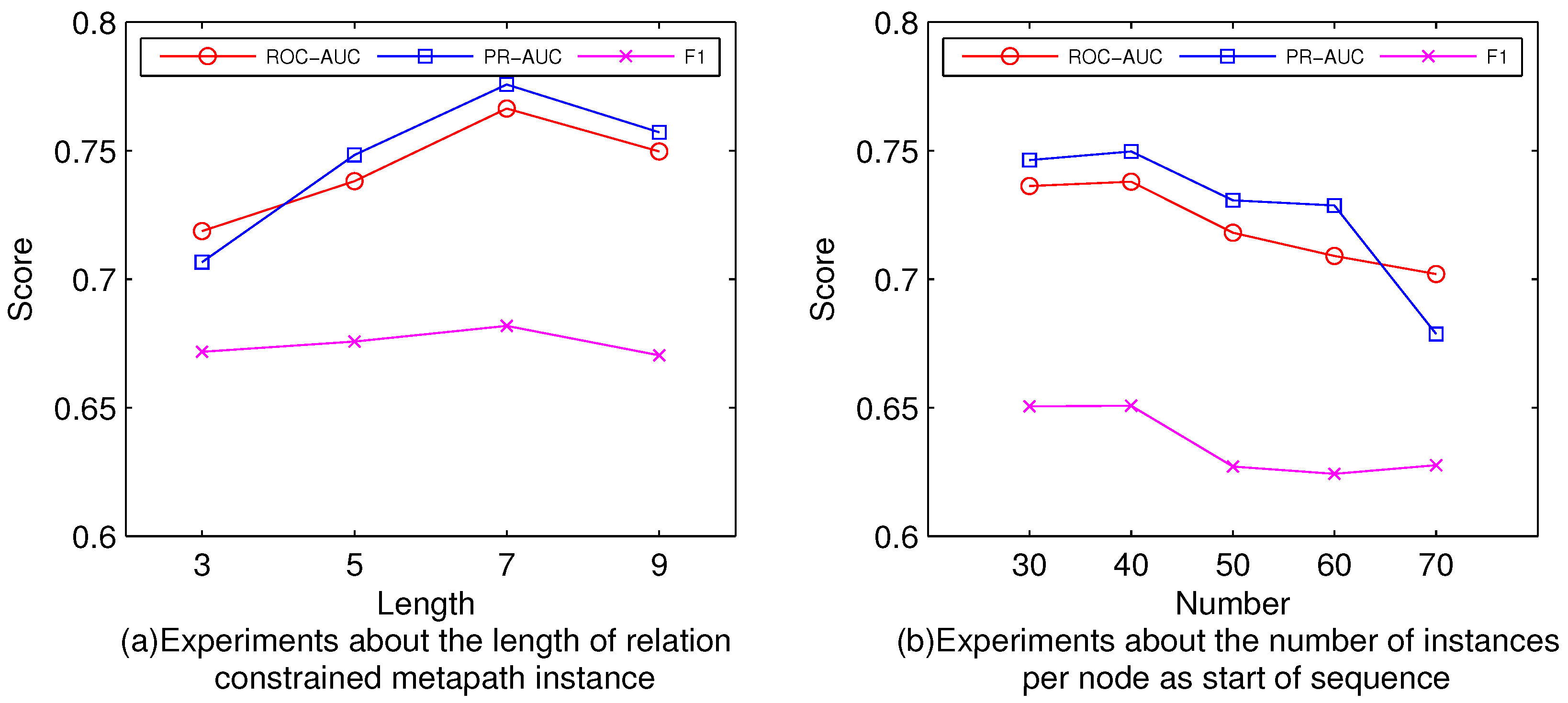
5.2. Parameters Experiments (RQ1)
5.3. Baselines
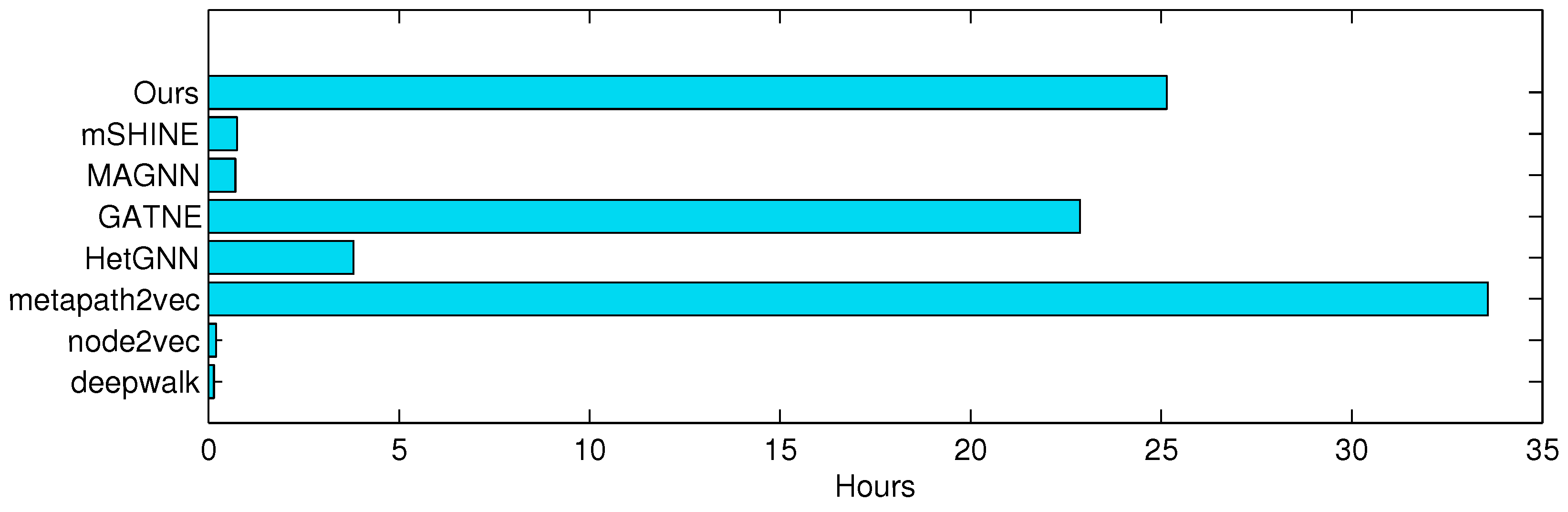
5.4. Contrastive Experiment Results and Discussion (RQ2)
5.5. Cold-Start Experiment (RQ3)
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, B.; Zhou, M.; Zhang, S.; Yang, M.; Lian, D.; Huang, Z. BSAL: A Framework of Bi-component Structure and Attribute Learning for Link Prediction. In Proceedings of the SIGIR’22: The 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2022; Amigó, E., Castells, P., Gonzalo, J., Carterette, B., Culpepper, J.S., Kazai, G., Eds.; ACM: New York, NY, USA, 2022; pp. 2053–2058. [Google Scholar] [CrossRef]
- Yadati, N.; Nitin, V.; Nimishakavi, M.; Yadav, P.; Louis, A.; Talukdar, P. NHP: Neural Hypergraph Link Prediction. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, CIKM’20, Online, 19–23 October 2020; pp. 1705–1714. [Google Scholar]
- Han, J.; Tao, Q.; Tang, Y.; Xia, Y. DH-HGCN: Dual Homogeneity Hypergraph Convolutional Network for Multiple Social Recommendations. In Proceedings of the SIGIR’22: The 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2022; Amigó, E., Castells, P., Gonzalo, J., Carterette, B., Culpepper, J.S., Kazai, G., Eds.; ACM: New York, NY, USA, 2022; pp. 2190–2194. [Google Scholar] [CrossRef]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 701–710. [Google Scholar]
- Tang, J.; Qu, M.; Wang, M.; Zhang, M.; Yan, J.; Mei, Q. LINE: Large-Scale Information Network Embedding. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 1067–1077. [Google Scholar] [CrossRef]
- Grover, A.; Leskovec, J. Node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Huang, T.; Dong, Y.; Ding, M.; Yang, Z.; Feng, W.; Wang, X.; Tang, J. Mixgcf: An improved training method for graph neural network-based recommender systems. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Long Beach, CA, USA, 6–10 August 2021; pp. 665–674. [Google Scholar]
- Yu, J.; Yin, H.; Li, J.; Wang, Q.; Hung, N.Q.V.; Zhang, X. Self-supervised multi-channel hypergraph convolutional network for social recommendation. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 413–424. [Google Scholar]
- Chen, W.; Feng, F.; Wang, Q.; He, X.; Song, C.; Ling, G.; Zhang, Y. CatGCN: Graph Convolutional Networks with Categorical Node Features. IEEE Trans. Knowl. Data Eng. 2021. [Google Scholar] [CrossRef]
- Kang, J.; Zhu, Y.; Xia, Y.; Luo, J.; Tong, H. RawlsGCN: Towards Rawlsian Difference Principle on Graph Convolutional Network. In Proceedings of the WWW’22: The ACM Web Conference 2022, Lyon, France, 25–29 April 2022; Laforest, F., Troncy, R., Simperl, E., Agarwal, D., Gionis, A., Herman, I., Médini, L., Eds.; ACM: New York, NY, USA, 2022; pp. 1214–1225. [Google Scholar] [CrossRef]
- Luo, D.; Bian, Y.; Yan, Y.; Liu, X.; Huan, J.; Zhang, X. Local Community Detection in Multiple Networks. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, 6–10 July 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 266–274. [Google Scholar] [CrossRef]
- Luo, X.; Wu, J.; Beheshti, A.; Yang, J.; Zhang, X.; Wang, Y.; Xue, S. ComGA: Community-Aware Attributed Graph Anomaly Detection. In Proceedings of the WSDM’22: The Fifteenth ACM International Conference on Web Search and Data Mining, Virtual Event/Tempe, AZ, USA, 21–25 February 2022; Candan, K.S., Liu, H., Akoglu, L., Dong, X.L., Tang, J., Eds.; ACM: New York, NY, USA, 2022; pp. 657–665. [Google Scholar] [CrossRef]
- Gao, H.; Wang, Z.; Ji, S. Large-Scale Learnable Graph Convolutional Networks. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD 2018, London, UK, 19–23 August 2018; Guo, Y., Farooq, F., Eds.; ACM: New York, NY, USA, 2018; pp. 1416–1424. [Google Scholar] [CrossRef]
- You, J.; Gomes-Selman, J.M.; Ying, R.; Leskovec, J. Identity-aware graph neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 10737–10745. [Google Scholar]
- Fu, X.; Zhang, J.; Meng, Z.; King, I. MAGNN: Metapath Aggregated Graph Neural Network for Heterogeneous Graph Embedding. In Proceedings of the WWW’20: The Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; Huang, Y., King, I., Liu, T., van Steen, M., Eds.; ACM: New York, NY, USA, 2020; pp. 2331–2341. [Google Scholar] [CrossRef]
- Sun, Y.; Han, J.; Yan, X.; Yu, P.S.; Wu, T. PathSim: Meta Path-Based Top-K Similarity Search in Heterogeneous Information Networks. Proc. VLDB Endow. 2011, 4, 992–1003. [Google Scholar] [CrossRef]
- Guan, W.; Jiao, F.; Song, X.; Wen, H.; Yeh, C.; Chang, X. Personalized Fashion Compatibility Modeling via Metapath-guided Heterogeneous Graph Learning. In Proceedings of the SIGIR’22: The 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2022; Amigó, E., Castells, P., Gonzalo, J., Carterette, B., Culpepper, J.S., Kazai, G., Eds.; ACM: New York, NY, USA, 2022; pp. 482–491. [Google Scholar] [CrossRef]
- Wang, X.; Liu, N.; Han, H.; Shi, C. Self-supervised Heterogeneous Graph Neural Network with Co-contrastive Learning. In Proceedings of the KDD’21: The 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Virtual Event, Singapore, 14–18 August 2021; Zhu, F., Ooi, B.C., Miao, C., Eds.; ACM: New York, NY, USA, 2021; pp. 1726–1736. [Google Scholar] [CrossRef]
- Zheng, J.; Ma, Q.; Gu, H.; Zheng, Z. Multi-view Denoising Graph Auto-Encoders on Heterogeneous Information Networks for Cold-start Recommendation. In Proceedings of the KDD’21: The 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Virtual Event, Singapore, 14–18 August 2021; Zhu, F., Ooi, B.C., Miao, C., Eds.; ACM: New York, NY, USA, 2021; pp. 2338–2348. [Google Scholar] [CrossRef]
- Dong, Y.; Chawla, N.V.; Swami, A. metapath2vec: Scalable representation learning for heterogeneous networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, USA, 13–17 August 2017; pp. 135–144. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Zhang, C.; Song, D.; Huang, C.; Swami, A.; Chawla, N.V. Heterogeneous Graph Neural Network. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD’19, Anchorage, AK, USA, 4–8 August 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 793–803. [Google Scholar] [CrossRef]
- Wang, X.; Ji, H.; Shi, C.; Wang, B.; Ye, Y.; Cui, P.; Yu, P.S. Heterogeneous Graph Attention Network. In Proceedings of the World Wide Web Conference, WWW’19, San Francisco, CA, USA, 13–17 May 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 2022–2032. [Google Scholar] [CrossRef]
- Cen, Y.; Zou, X.; Zhang, J.; Yang, H.; Zhou, J.; Tang, J. Representation learning for attributed multiplex heterogeneous network. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 1358–1368. [Google Scholar]
- Martínez, V.; Berzal, F.; Cubero, J.C. A survey of link prediction in complex networks. ACM Comput. Surv. (CSUR) 2016, 49, 1–33. [Google Scholar] [CrossRef]
- Lü, L.; Zhou, T. Link prediction in complex networks: A survey. Phys. A Stat. Mech. Its Appl. 2011, 390, 1150–1170. [Google Scholar] [CrossRef]
- Amara, A.; Taieb, M.A.H.; Aouicha, M.B. Cross-network representation learning for anchor users on multiplex heterogeneous social network. Appl. Soft Comput. 2022, 118, 108461. [Google Scholar] [CrossRef]
- Zitnik, M.; Leskovec, J. Predicting multicellular function through multi-layer tissue networks. Bioinformatics 2017, 33, i190–i198. [Google Scholar] [CrossRef] [PubMed]
- Daud, N.N.; Ab Hamid, S.H.; Saadoon, M.; Sahran, F.; Anuar, N.B. Applications of link prediction in social networks: A review. J. Netw. Comput. Appl. 2020, 166, 102716. [Google Scholar] [CrossRef]
- Chiluka, N.; Andrade, N.; Pouwelse, J. A link prediction approach to recommendations in large-scale user-generated content systems. In Proceedings of the European Conference on Information Retrieval, Dublin, Ireland, 18–21 April 2011; pp. 189–200. [Google Scholar]
- Kumar, A.; Singh, S.S.; Singh, K.; Biswas, B. Link prediction techniques, applications, and performance: A survey. Phys. A Stat. Mech. Its Appl. 2020, 553, 124289. [Google Scholar] [CrossRef]
- Negi, S.; Chaudhury, S. Link prediction in heterogeneous social networks. In Proceedings of the 25th ACM International on Conference on Information and Knowledge Management, Indianapolis, IN, USA, 24–28 October 2016; pp. 609–617. [Google Scholar]
- Mishra, S.; Singh, S.S.; Kumar, A.; Biswas, B. HOPLP- MUL: Link prediction in multiplex networks based on higher order paths and layer fusion. Appl. Intell. 2022, 53, 3415–3443. [Google Scholar] [CrossRef]
- Mishra, S.; Singh, S.S.; Kumar, A.; Biswas, B. MNERLP-MUL: Merged node and edge relevance based link prediction in multiplex networks. J. Comput. Sci. 2022, 60, 101606. [Google Scholar] [CrossRef]
- Chen, C.; Liu, Y.Y. A survey on hyperlink prediction. arXiv 2022, arXiv:2207.02911. [Google Scholar]
- He, R.; McAuley, J. Ups and downs: Modeling the visual evolution of fashion trends with one-class collaborative filtering. In Proceedings of the 25th International Conference on World Wide Web, Montreal, QC, USA, 11–15 April 2016; pp. 507–517. [Google Scholar]
- McAuley, J.; Targett, C.; Shi, Q.; Van Den Hengel, A. Image-based recommendations on styles and substitutes. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; pp. 43–52. [Google Scholar]
- Tang, L.; Liu, H. Uncovering cross-dimension group structures in multi-dimensional networks. In Proceedings of the SDM Workshop on Analysis of Dynamic Networks; 2009; pp. 568–575. Available online: https://www.public.asu.edu/huanliu/papers/sdm-adn09.pdf (accessed on 17 January 2023).
- Zhang, X.; Chen, L. mSHINE: A Multiple-meta-paths simultaneous learning framework for heterogeneous information network embedding. IEEE Trans. Knowl. Data Eng. 2020. [Google Scholar] [CrossRef]
- Li, Y.; Jin, Y.; Song, G.; Zhu, Z.; Shi, C.; Wang, Y. GraphMSE: Efficient Meta-path Selection in Semantically Aligned Feature Space for Graph Neural Networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; pp. 4206–4214. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations | Definitions |
|---|---|
| User type, item type | |
| A user , an item | |
| Node set, edge set | |
| S | A set of relation-constrained metapath |
| v | A node |
| d | The dimension of feature representation of nodes |
| The feature representation of node | |
| Node type set, edge type set | |
| A metapath, the length of metapath | |
| A relation-constrained metapath | |
| The matrix including all nodes features in the sequence, the matrix after linear transformation | |
| The matrix representation after linear transformation | |
| The length of sequence | |
| L | The number of negative samples per training sample |
| Dataset | #Nodes | #Edges | #Types of Nodes | #Types of Edges |
|---|---|---|---|---|
| Amazon | 10,166 | 148,865 | 1 | 2 |
| YouTube | 2000 | 1,310,617 | 1 | 5 |
| Ali | 33,969 | 132,500 | 2 | 4 |
| 10,000 | 331,899 | 1 | 4 |
| Dataset | Model | ROC-AUC | PR-AUC | F1 |
|---|---|---|---|---|
| Amazon | Deepwalk | 94.20 | 94.03 | 87.38 |
| node2vec | 94.47 | 94.30 | 87.88 | |
| metapath2vec | 94.15 | 94.01 | 87.48 | |
| HetGNN | 95.85 | 94.71 | 88.06 | |
| GATNE | 96.28 | 96.31 | 92.12 | |
| MAGNN | 87.86 | 87.23 | 85.67 | |
| mSHINE | 79.10 | 80.67 | 73.57 | |
| Ours | 97.72 | 97.48 | 93.26 | |
| YouTube | Deepwalk | 71.11 | 70.04 | 65.52 |
| node2vec | 71.21 | 70.32 | 65.36 | |
| metapath2vec | 70.98 | 70.02 | 65.34 | |
| HetGNN | 80.05 | 79.18 | 73.32 | |
| GATNE | 82.29 | 81.81 | 74.63 | |
| MAGNN | 75.16 | 74.69 | 70.13 | |
| mSHINE | 66.53 | 63.11 | 62.55 | |
| Ours | 85.23 | 83.85 | 77.13 | |
| Ali | Deepwalk | 69.56 | 37.07 | 36.25 |
| node2vec | 62.84 | 46.93 | 47.01 | |
| metapath2vec | 79.09 | 78.59 | 71.76 | |
| HetGNN | 79.95 | 78.24 | 75.37 | |
| GATNE | 82.87 | 85.26 | 76.13 | |
| MAGNN | 63.86 | 65.15 | 62.36 | |
| mSHINE | 41.07 | 53.04 | 52.43 | |
| Ours | 88.14 | 89.69 | 84.01 | |
| Deepwalk | 69.42 | 72.58 | 62.68 | |
| node2vec | 69.9 | 73.04 | 63.12 | |
| metapath2vec | 69.35 | 72.61 | 62.7 | |
| HetGNN | 72.36 | 75.28 | 69.71 | |
| GATNE | 72.4 | 74.4 | 65.89 | |
| MAGNN | 69.85 | 74.24 | 64.38 | |
| mSHINE | 67.17 | 70.85 | 63.98 | |
| Ours | 76.87 | 77.67 | 68.18 |
| Metric | GATNE | Ours |
|---|---|---|
| ROC-AUC | 85.16 | 88.25 |
| PR-AUC | 86.90 | 89.64 |
| F1 | 78.27 | 81.72 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, C.; Li, K.; Wang, S.; Zhou, B.; Wang, L.; Sun, F. Learning Heterogeneous Graph Embedding with Metapath-Based Aggregation for Link Prediction. Mathematics 2023, 11, 578. https://doi.org/10.3390/math11030578
Zhang C, Li K, Wang S, Zhou B, Wang L, Sun F. Learning Heterogeneous Graph Embedding with Metapath-Based Aggregation for Link Prediction. Mathematics. 2023; 11(3):578. https://doi.org/10.3390/math11030578
Chicago/Turabian StyleZhang, Chengdong, Keke Li, Shaoqing Wang, Bin Zhou, Lei Wang, and Fuzhen Sun. 2023. "Learning Heterogeneous Graph Embedding with Metapath-Based Aggregation for Link Prediction" Mathematics 11, no. 3: 578. https://doi.org/10.3390/math11030578
APA StyleZhang, C., Li, K., Wang, S., Zhou, B., Wang, L., & Sun, F. (2023). Learning Heterogeneous Graph Embedding with Metapath-Based Aggregation for Link Prediction. Mathematics, 11(3), 578. https://doi.org/10.3390/math11030578