

EHFP-GAN: Edge-Enhanced Hierarchical Feature Pyramid Network for Damaged QR Code Reconstruction
 ,
,
Abstract
:1. Introduction
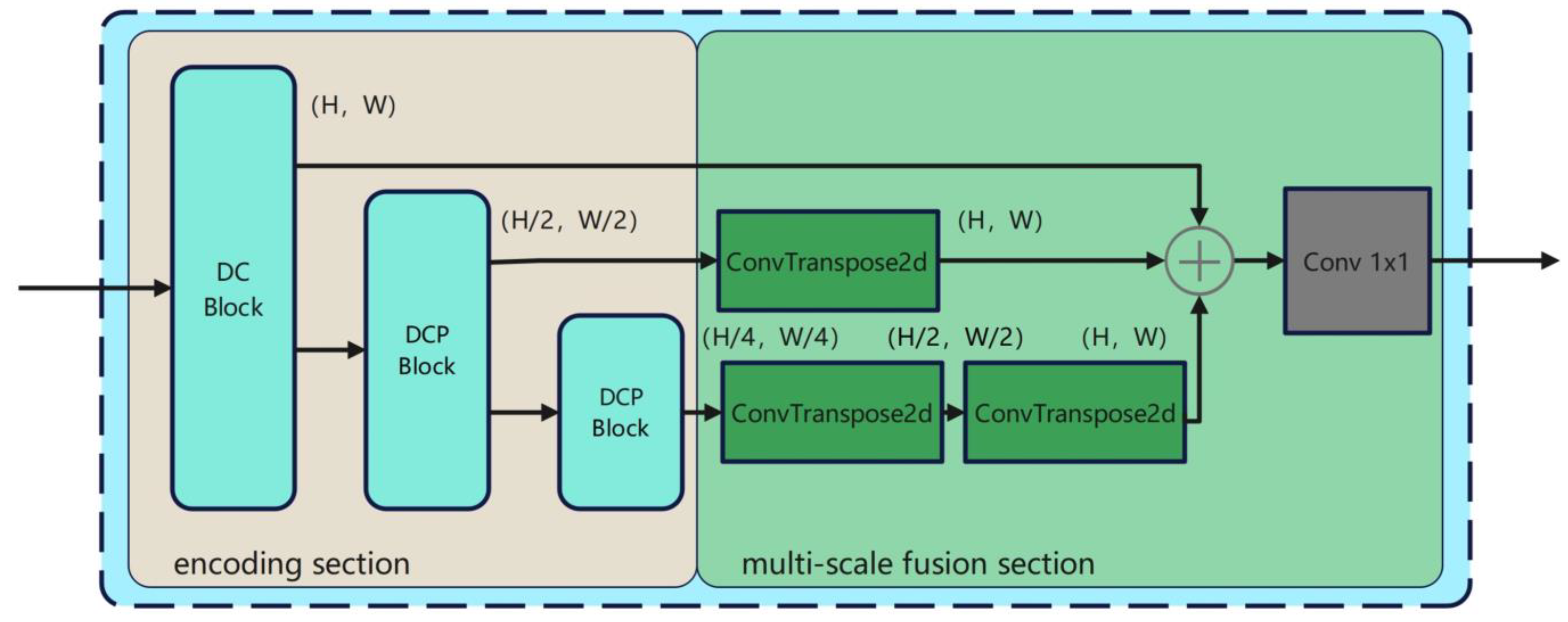
- We propose a multi-scale feature fusion module named the Hierarchical Feature Pyra-mid (HFP) Block, which seamlessly integrates into the network and enhances the model’s perception of global contextual information.
- We design and implement an edge-enhanced hierarchical feature pyramid GAN, named EHFP-GAN, built upon the foundation of the HFP Block. The EHFP-GAN focuses on restoring and reconstructing damaged QR code images.
- We demonstrate through comparative experiments with other advanced methods that the EHFP-GAN model achieves state-of-the-art improvements in QR code image quality, with a particularly notable enhancement in QR code recognizability.
2. Related Work
2.1. QR Code-Related Work
2.2. Image Inpainting Work
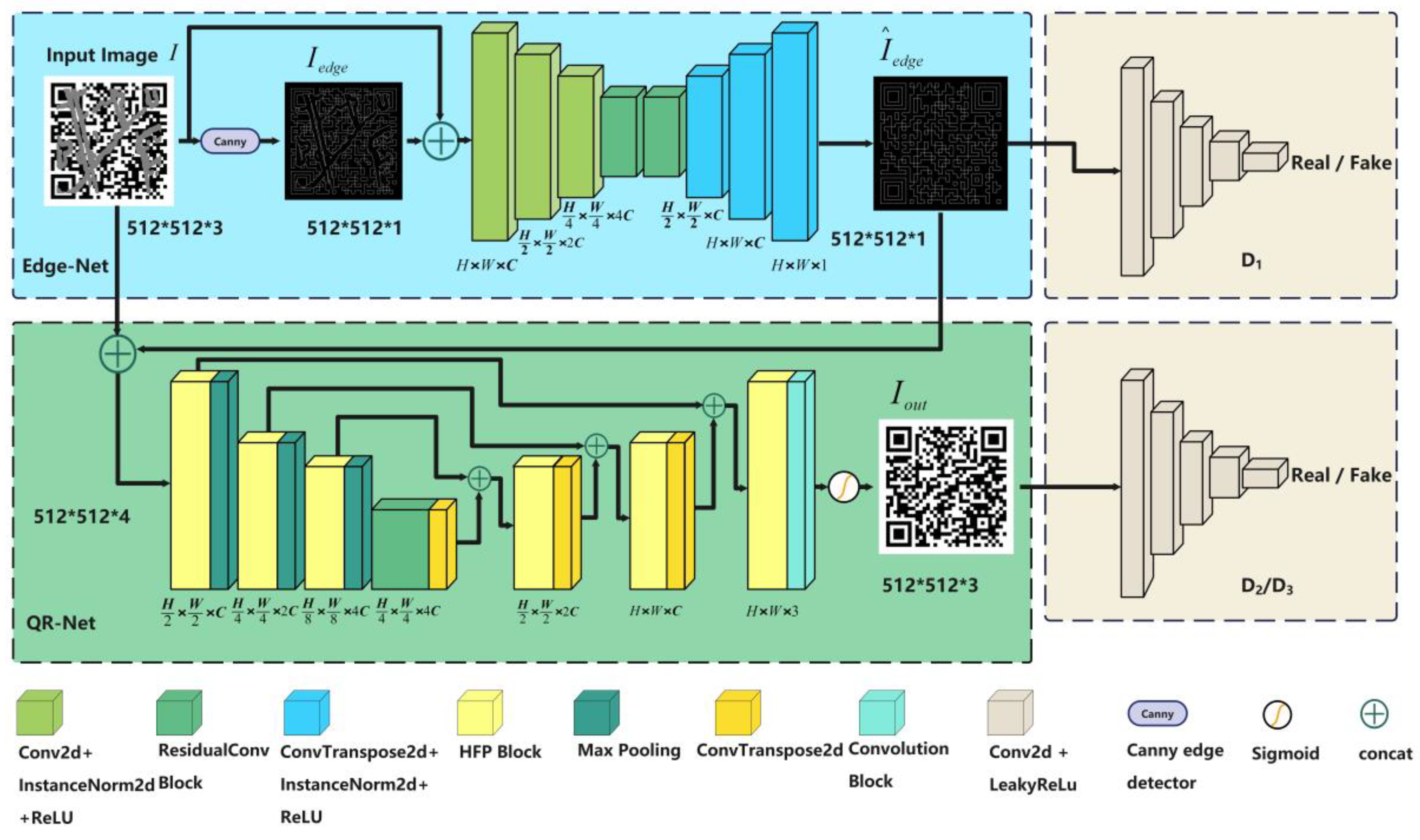
3. Methods
3.1. Edge Reconstruction Module
3.2. QR Code Reconstruction Module
3.3. Discriminators
3.4. Loss Functions
4. Experiments
4.1. Datasets
4.1.1. Original QR Code Images
4.1.2. Irregular Masks
4.1.3. Dataset Split
4.2. Training Configuration and Strategies
4.2.1. Staged Training Strategy
- Individual training of the edge reconstruction module. The optimizer updates only the parameters of this module. We utilize the Canny edge detection algorithm [18] to obtain the edge map A from the input image and edge map B from the target image. Edge map A is used as the input, and B serves as the supervisory signal for training. In this case, the loss function excludes the QR code loss, with the weight parameter set to zero. This ensures that the edge restoration module can accurately restore edge information.
- Individual training of the QR code reconstruction module. The optimizer updates only the parameters of this module. We also acquire edge maps B from the target image and concatenate them with the original input image along the channel dimension, using the complete loss function for training.
- Joint training of the entire model. The optimizer updates all parameters, while keeping the loss function unchanged. Following the phased training of the previous two steps, the individual modules have been pre-trained effectively, and this step aims to strengthen the collaborative effect between the two modules.
4.2.2. Training Parameter Settings
4.3. Evaluation Metrics
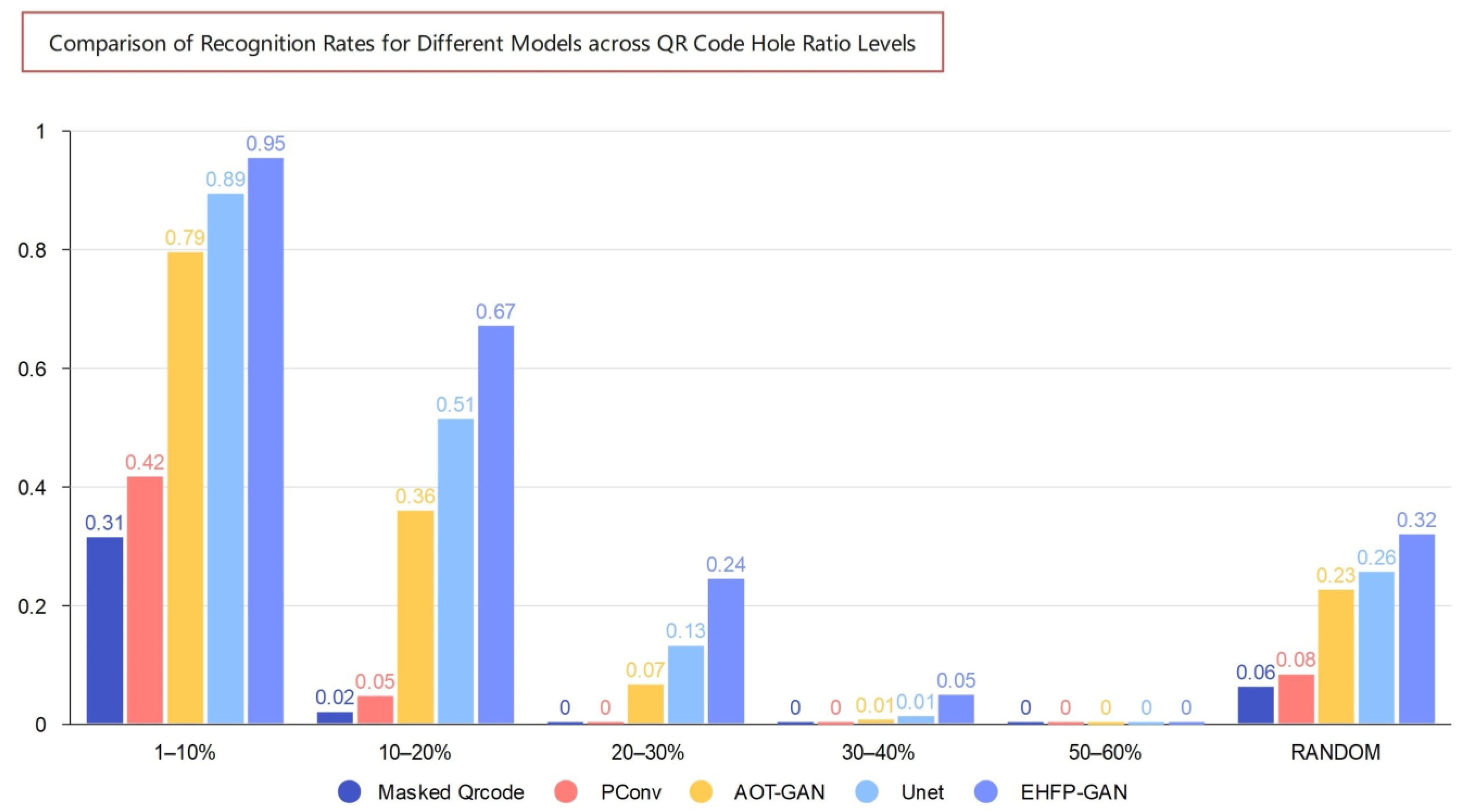
- The Recognition Rate (RR) is adopted as a key quantitative metric to evaluate the performance of QR code restoration methods. The RR is calculated as the number of restored QR code images that are correctly recognized, divided by the total number of damaged input images. A restored image is considered successfully recognized only if the QR decoder can extract its original embedded information without errors. The RR directly quantifies how well a method can recover damaged QR codes to be identifiable again. A higher RR indicates the method restores more damaged codes to be correctly recognized. Maximizing the RR is an important goal when optimizing solutions for QR code restoration.
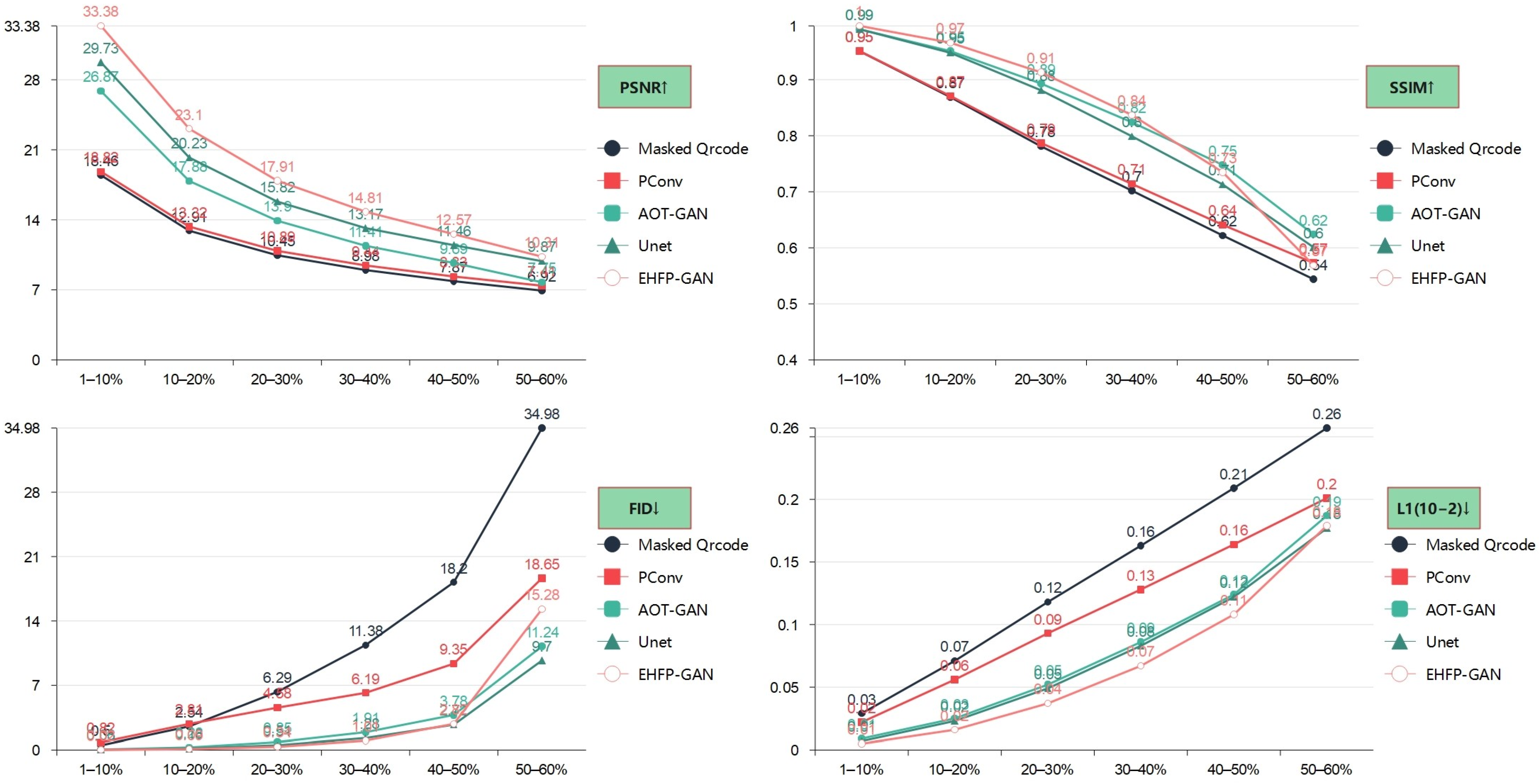
- Structural Similarity Index (SSIM) [34] compares the restored results with original images in terms of brightness, contrast, and structure.
- L1 Error is widely used to measure the average absolute error between restored and original images at the pixel level for evaluating reconstruction accuracy.
- Fréchet Inception Distance (FID) [36] evaluates the perceptual quality distance between generated and real images. Compared to traditional pixel-level metrics, FID focuses more on perceptual quality, consistent with human subjective evaluation.
- Peak Signal-to-Noise Ratio (PSNR) measures the image reconstruction accuracy by calculating the PSNR between restored and original images. It is commonly used to assess restoration quality.
4.4. Comparison Models
- Pconv [17]: Partial Convolutional Network aims to address color discrepancies both inside and outside of the holes. By incorporating partial convolutional layers, PConv effectively restores details and structure in damaged images.
- AOT-GAN [15]: A method based on learning aggregated contextual transformations and enhancing discriminators for high-resolution image restoration. AOT-GAN leverages a generative adversarial network framework to generate more authentic and intricate restoration outcomes.
- Unet [37]: A classical image segmentation network model featuring an encoder–decoder architecture. Unet performs well in image processing tasks, capturing contextual information between input and output by learning their mapping, thus achieving precise image restoration.
4.5. Experimental Results
4.5.1. Quantitative Comparisons
4.5.2. Qualitative Comparisons
4.5.3. Ablation Study
5. Discussion
- Real-world applications: Our QR code restoration method holds great potential for real-world applications. The ubiquity of QR codes in various industries, including retail, logistics, and advertising, underscores the importance of effective QR code restoration. Specifically, our approach can enhance the readability and visual quality of damaged QR codes, which are commonly encountered in practical scenarios. By restoring QR codes to their original state, our technology can facilitate seamless transactions, improve inventory management, and enhance user experiences in scanning codes.
- Impact on special QR codes: In contemporary applications, QR codes are increasingly diverse, often incorporating images and additional elements. While our study primarily focused on standard QR codes, there is a growing need to address specialized QR codes. Future research should expand our dataset to include these unique QR code variations, allowing our model to effectively restore a broader range of QR codes found in real-world contexts.
- Resource optimization: The demand for computational resources during model training and restoration is an important consideration, especially for real-time applications. We acknowledge the need to optimize algorithms and model structures to reduce computational resource requirements. This optimization will not only improve the real-time performance but also make our approach more accessible for a wide range of practical applications.
- External factors: Real-world environments are often subject to external factors such as changes in lighting conditions, which can interfere with restoration results. To address this, we propose the incorporation of image enhancement and preprocessing techniques that can mitigate the effects of external factors. These enhancements will contribute to our model’s robustness in real-world scenarios.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jiao, S.; Zou, W.; Li, X. QR code based noise-free optical encryption and decryption of a gray scale image. Opt. Commun. 2017, 387, 235–240. [Google Scholar] [CrossRef]
- Bai, H.; Zhou, G.; Hu, Y.; Sun, A.; Xu, X.; Liu, X.; Lu, C. Traceability technologies for farm animals and their products in China. Food Control 2017, 79, 35–43. [Google Scholar] [CrossRef]
- Tarjan, L.; Šenk, I.; Tegeltija, S.; Stankovski, S.; Ostojic, G. A readability analysis for QR code application in a traceability system. Comput. Electron. Agric. 2014, 109, 1–11. [Google Scholar] [CrossRef]
- Chen, R.; Zheng, Z.; Yu, Y.; Zhao, H.; Ren, J.; Tan, H.-Z. Fast Restoration for Out-of-Focus Blurred Images of QR Code With Edge Prior Information via Image Sensing. IEEE Sens. J. 2021, 21, 18222–18236. [Google Scholar] [CrossRef]
- Karrach, L.; Pivarčiová, E.; Bozek, P. Recognition of Perspective Distorted QR Codes with a Partially Damaged Finder Pattern in Real Scene Images. Appl. Sci. 2020, 10, 7814. [Google Scholar] [CrossRef]
- Fröschle, H.-K.; Gonzales-Barron, U.; McDonnell, K.; Ward, S. Investigation of the potential use of e-tracking and tracing of poultry using linear and 2D barcodes. Comput. Electron. Agric. 2009, 66, 126–132. [Google Scholar] [CrossRef]
- Chen, R.; Zheng, Z.; Pan, J.; Yu, Y.; Zhao, H.; Ren, J. Fast Blind Deblurring of QR Code Images Based on Adaptive Scale Control. Mob. Netw. Appl. 2021, 26, 2472–2487. [Google Scholar] [CrossRef]
- van Gennip, Y.; Athavale, P.; Gilles, J.; Choksi, R. A Regularization Approach to Blind Deblurring and Denoising of QR Barcodes. IEEE Trans. Image Process. 2015, 24, 2864–2873. [Google Scholar] [CrossRef] [PubMed]
- Wang, M.; Chen, K.; Lin, F. Multi-residual generative adversarial networks for QR code deblurring. In Proceedings of the International Conference on Electronic Information Technology (EIT 2022), Chengdu, China, 18–20 March 2022; pp. 589–594. [Google Scholar]
- Wang, B.; Xu, J.; Zhang, J.; Li, G.; Wang, X. Motion deblur of QR code based on generative adversative network. In Proceedings of the 2019 2nd International Conference on Algorithms, Computing and Artificial Intelligence, Sanya, China, 20–22 December 2019; pp. 166–170. [Google Scholar]
- Bertalmio, M.; Sapiro, G.; Caselles, V.; Ballester, C. Image inpainting. In Proceedings of the 27th Annual Conference on Computer Graphics and Interactive Techniques, New Orleans, LA, USA, 23–28 July 2000; pp. 417–424. [Google Scholar]
- Fanous, M.J.; Popescu, G. GANscan: Continuous scanning microscopy using deep learning deblurring. Light. Sci. Appl. 2022, 11, 265. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Wan, Z.; Zhang, B.; Chen, D.; Zhang, P.; Chen, D.; Liao, J.; Wen, F. Bringing old photos back to life. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2747–2757. [Google Scholar]
- Zeng, Y.; Fu, J.; Chao, H.; Guo, B. Aggregated Contextual Transformations for High-Resolution Image Inpainting. IEEE Trans. Vis. Comput. Graph. 2022, 29, 3266–3280. [Google Scholar] [CrossRef] [PubMed]
- Nazeri, K.; Ng, E.; Joseph, T.; Qureshi, F.Z.; Ebrahimi, M. Edgeconnect: Generative image inpainting with adversarial edge learning. arXiv 2019, arXiv:1901.00212. [Google Scholar]
- Liu, G.; Reda, F.A.; Shih, K.J.; Wang, T.-C.; Tao, A.; Catanzaro, B. Image inpainting for irregular holes using partial convolutions. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 85–100. [Google Scholar]
- Canny, J. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 6, 679–698. [Google Scholar] [CrossRef]
- Fan, Z.; Liu, Z.; Li, M. Research on QR Code Image Recognition. In Proceedings of the 2012 Second International Conference on Electric Information and Control Engineering-Volume 01, Washington, DC, USA, 6–8 April 2012; pp. 1189–1192. [Google Scholar]
- Gu, Y.; Zhang, W. QR code recognition based on image processing. In Proceedings of the International Conference on Information Science and Technology, Nanjing, China, 26–28 March 2011; pp. 733–736. [Google Scholar]
- Theljani, A.; Houichet, H.; Mohamed, A. An adaptive Cahn-Hilliard equation for enhanced edges in binary image inpainting. J. Algorithms Comput. Technol. 2020, 14, 1748302620941430. [Google Scholar] [CrossRef]
- Wakahara, T.; Yamamoto, N. Image processing of 2-dimensional barcode. In Proceedings of the 2011 14th International Conference on Network-Based Information Systems, Tirana, Albania, 7–9 September 2011; pp. 484–490. [Google Scholar]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Generative image inpainting with contextual attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5505–5514. [Google Scholar]
- Yang, C.; Lu, X.; Lin, Z.; Shechtman, E.; Wang, O.; Li, H. High-resolution image inpainting using multi-scale neural patch synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6721–6729. [Google Scholar]
- Telea, A. An image inpainting technique based on the fast marching method. J. Graph. Tools 2004, 9, 23–34. [Google Scholar] [CrossRef]
- Criminisi, A.; Perez, P.; Toyama, K. Region Filling and Object Removal by Exemplar-Based Image Inpainting. IEEE Trans. Image Process. 2004, 13, 1200–1212. [Google Scholar] [CrossRef] [PubMed]
- Reed, I.S.; Solomon, G. Polynomial Codes Over Certain Finite Fields. J. Soc. Ind. Appl. Math. 1960, 8, 300–304. [Google Scholar] [CrossRef]
- Shimobaba, T.; Endo, Y.; Hirayama, R.; Nagahama, Y.; Takahashi, T.; Nishitsuji, T.; Kakue, T.; Shiraki, A.; Takada, N.; Masuda, N.; et al. Autoencoder-based holographic image restoration. Appl. Opt. 2017, 56, F27–F30. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, V.-T.; Nguyen, A.-T.; Nguyen, V.-T.; Bui, H.-A. A real-time human tracking system using convolutional neural network and particle filter. In Intelligent Systems and Networks; Selected Articles from ICISN 2021, Vietnam, 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 411–417. [Google Scholar]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context encoders: Feature learning by inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2536–2544. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Wang, Z.; Simoncelli, E.P.; Bovik, A.C. Multiscale structural similarity for image quality assessment. In Proceedings of the Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, Pacific Grove, CA, USA, 9–12 November 2003; pp. 1398–1402. [Google Scholar]
- Wave, D. Information Capacity and Versions of the QR Code. 2022. Available online: https://www.qrcode.com/en/about/version.html (accessed on 4 October 2023).
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. arXiv 2017, arXiv:1706.08500. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. pp. 234–241. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Masking Rate | Masked Qrcode | PConv [17] | AOT-GAN [15] | Unet [37] | EHFP-GAN | |
|---|---|---|---|---|---|---|
| RR↑ | 1–10% | 31.45% | 41.65% | 79.45% | 89.3% | 95.35% |
| 10–20% | 2.00% | 4.65% | 35.9% | 51.4% | 67.05% | |
| 20–30% | 0.00% | 0.10% | 6.62% | 13.2% | 24.45% | |
| 30–40% | 0.00% | 0.05% | 0.70% | 1.25% | 4.85% | |
| 40–50% | 0.00% | 0.00% | 0.03% | 0.05% | 0.10% | |
| 50–60% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | |
| RANDOM | 6.22% | 8.33% | 22.56% | 25.61% | 31.94% | |
| PSNR↑ | 1–10% | 18.456 | 18.817 | 26.867 | 29.734 | 33.385 |
| 10–20% | 12.91 | 13.323 | 17.882 | 20.226 | 23.103 | |
| 20–30% | 10.451 | 10.892 | 13.905 | 15.818 | 17.905 | |
| 30–40% | 8.977 | 9.439 | 11.406 | 13.174 | 14.807 | |
| 40–50% | 7.866 | 8.333 | 9.689 | 11.465 | 12.569 | |
| 50–60% | 6.925 | 7.414 | 7.751 | 9.866 | 10.315 | |
| RANDOM | 10.921 | 11.321 | 14.532 | 16.703 | 18.591 | |
| SSIM↑ | 1–10% | 0.951 | 0.951 | 0.99 | 0.99 | 0.996 |
| 10–20% | 0.869 | 0.871 | 0.951 | 0.948 | 0.966 | |
| 20–30% | 0.781 | 0.787 | 0.893 | 0.881 | 0.913 | |
| 30–40% | 0.702 | 0.714 | 0.824 | 0.799 | 0.837 | |
| 40–50% | 0.622 | 0.641 | 0.748 | 0.713 | 0.735 | |
| 50–60% | 0.544 | 0.573 | 0.624 | 0.601 | 0.569 | |
| RANDOM | 0.746 | 0.755 | 0.838 | 0.823 | 0.837 | |
| FID↓ | 1–10% | 0.504 | 0.822 | 0.055 | 0.029 | 0.017 |
| 10–20% | 2.543 | 2.812 | 0.281 | 0.159 | 0.093 | |
| 20–30% | 6.295 | 4.575 | 0.85 | 0.512 | 0.34 | |
| 30–40% | 11.38 | 6.187 | 1.914 | 1.284 | 1.012 | |
| 40–50% | 18.201 | 9.354 | 3.784 | 2.724 | 2.817 | |
| 50–60% | 34.978 | 18.646 | 11.241 | 9.701 | 15.284 | |
| RANDOM | 10.46 | 5.64 | 2.545 | 1.831 | 2.452 | |
| L1(10−2)↓ | 1–10% | 0.029 | 0.022 | 0.009 | 0.007 | 0.005 |
| 10–20% | 0.071 | 0.056 | 0.025 | 0.023 | 0.016 | |
| 20–30% | 0.118 | 0.093 | 0.052 | 0.049 | 0.037 | |
| 30–40% | 0.163 | 0.128 | 0.086 | 0.083 | 0.067 | |
| 40–50% | 0.209 | 0.164 | 0.124 | 0.122 | 0.108 | |
| 50–60% | 0.257 | 0.201 | 0.187 | 0.177 | 0.179 | |
| RANDOM | 0.141 | 0.111 | 0.08 | 0.076 | 0.068 | |
| Edge-Net | HFP Block | DC Block | RR↑ | PSNR↑ | SSIM↑ | FID↓ | L1↓ |
|---|---|---|---|---|---|---|---|
| √ | 13.50% | 11.434 | 0.781 | 5.645 | 0.106 | ||
| √ | √ | 41.45% | 21.124 | 0.914 | 0.411 | 0.037 | |
| √ | 44.80% | 21.588 | 0.926 | 0.258 | 0.033 | ||
| √ | √ | 47.05% | 22.083 | 0.927 | 0.284 | 0.032 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, J.; Zhao, R.; Lin, Z.; Liu, S.; Zhu, R.; Zhang, Z.; Fu, Y.; Lu, J. EHFP-GAN: Edge-Enhanced Hierarchical Feature Pyramid Network for Damaged QR Code Reconstruction. Mathematics 2023, 11, 4349. https://doi.org/10.3390/math11204349
Zheng J, Zhao R, Lin Z, Liu S, Zhu R, Zhang Z, Fu Y, Lu J. EHFP-GAN: Edge-Enhanced Hierarchical Feature Pyramid Network for Damaged QR Code Reconstruction. Mathematics. 2023; 11(20):4349. https://doi.org/10.3390/math11204349
Chicago/Turabian StyleZheng, Jianhua, Ruolin Zhao, Zhongju Lin, Shuangyin Liu, Rong Zhu, Zihao Zhang, Yusha Fu, and Junde Lu. 2023. "EHFP-GAN: Edge-Enhanced Hierarchical Feature Pyramid Network for Damaged QR Code Reconstruction" Mathematics 11, no. 20: 4349. https://doi.org/10.3390/math11204349
APA StyleZheng, J., Zhao, R., Lin, Z., Liu, S., Zhu, R., Zhang, Z., Fu, Y., & Lu, J. (2023). EHFP-GAN: Edge-Enhanced Hierarchical Feature Pyramid Network for Damaged QR Code Reconstruction. Mathematics, 11(20), 4349. https://doi.org/10.3390/math11204349