Abstract
A challenge in association rules’ mining is effectively reducing the time and space complexity in association rules mining with predefined minimum support and confidence thresholds from huge transaction databases. In this paper, we propose an efficient method based on the topology space of the itemset for mining associate rules from transaction databases. To do so, we deduce a binary relation on itemset, and construct a topology space of itemset based on the binary relation and the quotient lattice of the topology according to transactions of itemsets. Furthermore, we prove that all closed itemsets are included in the quotient lattice of the topology, and generators or minimal generators of every closed itemset can be easily obtained from an element of the quotient lattice. Formally, the topology on itemset represents more general associative relationship among items of transaction databases, the quotient lattice of the topology displays the hierarchical structures on all itemsets, and provide us a method to approximate any template of the itemset. Accordingly, we provide efficient algorithms to generate Min-Max association rules or reduce generalized association rules based on the lower approximation and the upper approximation of a template, respectively. The experiment results demonstrate that the proposed method is an alternative and efficient method to generate or reduce association rules from transaction databases.
Keywords:
knowledge discovery in database (KDD); frequent itemsets; closed itemsets; association rules; the topology for itemsets MSC:
68W99
1. Introduction
In knowledge discovery in database (KDD), association rules mining (ARM) from transaction databases proposed in [1,2] have received considerable attention and wide applications, such as medical diagnosis [3,4], marketing planning [5,6], etc. ARM can be formally explained as follows: Let be a transaction database, where U a non-empty finite set of transactions, A a non-empty finite set of items, each transaction decides a mapping , i.e., for any item , the transaction has (or has not) the item if (or ), each subset of A is called as an itemset. An association rule describing the co-occurrence relation among items is an implication in the form , where itemsets and of A such that are called as antecedent and consequent, respectively. Theoretically, ARM from a transaction database is a NP-hard problem because itemsets and are selected from (powerset of A), in real world practices, the existed mining methods usually extract a large number of association rules which are difficult to handle; many kinds of association rules or mining methods have been proposed to generate association rules, although these mining methods are different, their processing is nearly the same, i.e., how to evaluate usefulness of association rules and how to select the antecedent and consequent of association rules.
Quality measures are used to evaluate the usefulness of association rules, and various measures have been provided to discover significant and specific association rules. In a transaction database , for any , denote , is the absence of , then the following quality measures can be defined
- Support [1,2]: ;
- Confidence [1,2]: ;
- Netconfidence [7]: ;
- Conviction [8]: ;
- Added value [9]: ;
- Accuracy [9]: ;
- Interestingness [10]: ;
- Comprehensibility [10]: ;
- Lift [11]: .
By combining with several quality measures to form fitness functions, ARM is transformed into optimization problems, and various optimal algorithms can be used to extract interesting or valid association rules from . In [12], schema constraints and the opportunistic confidence constraint are enforced to mine generalized association rules in the analyzed data. In [13], confidence, comprehensibility, and interestingness are considered as a multi-objective problem, and the particle swarm optimization algorithm is proposed to extract the best rules. In [10], support, comprehensibility and interestingness are considered as a multi-objective problem, and a Pareto-based genetic algorithm is used to extract some useful and interesting rules from any market-basket type database. In [14], Shafer’s theory of evidence is used as two information measures for the quality evaluation of the set of frequent itemset (or frequent pattern). In [15], off-the-shelf constraint programming techniques are employed for modeling and solving a wide variety of constraint-based frequent itemsets. In [16], based on exclusive causal-leverage measure, a data mining algorithm is developed to mine the causal relation between drugs and their associated adverse drug reactions. In [17], the particle swarm optimization algorithm are provided to improve computational efficiency as well as to automatically determine suitable support and confidence threshold values of association rules. In [18], grammar-guided genetic programming models are proposed to deal with the association rule mining problem under a multi-objective perspective. In [19], a new multi-objective evolutionary model, which maximizes the comprehensibility, interestingness and performance of the objectives, is presented to mine a set of quantitative association rules with a good trade-off between interpretability and accuracy. In [20], a principal components analysis is applied to a set of measures that evaluate quantitative association rules’ quality; the QARGA algorithm is provided to find out quantitative association rules from a wide variety of datasets. In [21], a new confidence degree of association rules and a discrete bi-level parametric programming are proposed to extract association rules from huge databases. In [22], redundancy analysis, sampling and multivariate statistical analysis are provided to ascertain the discovered rules and discard the non-significant rules. In [23], a systematic assessment of various numerical association rule mining methods and a meta-study of thirty numerical association rule mining algorithms are provided. The authors investigate how far the discretization techniques have been used in the numerical association rule mining methods. In [24], a multi-objective particle swarm optimization is proposed using an adaptive archive grid based on the Pareto optimal strategy for numerical association rule mining. In [25,26,27,28], these papers adopt the idea of parallelization and improves the Apriori algorithm based on the MapReduce model.
By analyzing associative relation among items, suitable itemsets can be selected to generate association rules. The most widely used itemsets are frequent itemsets and closed itemsets [15,29,30,31,32], an itemset is frequent if its support is not less than the minimum support value, an itemset is closed if and only if no proper superset of the itemset has the same support as the itemset. In [33], frequent itemsets are employed to construct taxonomy over items, and a breadth-first search is adopted to enumerate all frequent itemsets. Closed frequent itemsets can be used to uniquely determine the set of all frequent itemsets and applied to generate a condensed set of association rules [34,35,36]. Formally, all closed itemsets of can be constructed as a closed itemset lattice, and CHARM-L algorithm is proposed to explicitly generate the frequent closed itemset lattice [37]. In [38], the parent-child relation of the closed itemset lattice has been exploited, and the cross-level closed itemset lattice is constructed to mine the most relevant minimal cross-level association rules. In [39], an efficient post-processing method is presented to prune redundant rules by virtue of the property of Galois connection, which inherently constrains rules with respect to objects. At present, itemsets have been widely investigated [40,41], and various itemsets and their generating algorithms for specific association rules mining have been proposed, such as expressive generalized itemsets [42], free itemsets [43], disjunction-free itemsets [44,45], non-derivable itemsets [46,47], disjunctive closed itemsets [48], etc. In fact, we notice that frequent itemsets or closed itemsets are rooted to the co-occurrence relation among items; from the mathematical point of view, topology may be a more suitable tool to express the relation among items, because a topology for the set is used to express a relation among subsets, subsets of the set are granulated as members of the topology, and the topology for the set is generated by its topology base; this means that the base for the topology is the basic relation among elements of the set. Topology-based pattern mining has been widely investigated in the rough set theory and knowledge model, such as in [49]; a nested topology on a crisp set of reference is provided to interpret a fuzzy subset; the approach provides us a unified framework for most of the fuzzy thresholding algorithms. In [50], the lower and upper approximations of the rough set theory are shown as pre-topological invariants and dual to each other, and the corresponding generalized topological closure via the upper approximation is constructed. In [51], the knowledge representation and reasoning method are proposed for identity-based spatial change; the change process is presented by a multistage graph, the binary relation model for identity change is defined, and qualitative reasoning for and combining with topological relations are investigated.
In this paper, we analyze topology and the topology base for items, express more general associative relations among items and extract useful association rules based on the topology and the base; all of these are inspired by our previous works on the formal concept analysis; in [52], we proposed a novel method based on the topology for attributes of a formal context to generate all formal concepts, the topology for attributes has been used to explain the associative relation among attributes of the formal context, and the formal concept lattice can be constructed by the topology for attributes based on an equivalent relation. In [53], we used the topology for attributes of multi-valued information systems to generate Min-Max association rules. In this paper, we construct the topology for the set of items of a transaction database, which can be used to explain more general associative relation among items; moreover, we prove that frequent itemsets, closed itemsets and closed frequent itemsets are included in the topology for the set of items, provide two kinds of lattice on the topology to display the hierarchical structures on itemsets, and propose efficient algorithms based on the base for the topology to generate or reduce many kinds of association rules.
The organization of this paper is as follows: In Section 2, we briefly review some basic notions used in association rules mining. In Section 3, we present the topology for the set of items and lattices on itemsets of a transactional database, in which some important properties of the topology, the quotient lattice and minimal generators of closed frequent itemsets, are provided. In Section 4, we propose several algorithms to generate or reduce association rules, and analyze confidences of generalized association rules. In Section 5, we choose zoo, mushroom, connect-4 and chess as transactional databases to show the proposed method in generating association rules. We conclude the paper in Section 6.
2. Preliminaries
In the section, we briefly review some basic concepts used in frequent itemsets, closed itemsets or association rules mining; several concepts are also widely used in rough sets and formal concept analysis. For a uniform expression, we adopt the following set-to-set mapping in a transaction database , denote and as power sets of U and A, respectively, then we have
Based on and , we can rewrite the support of an itemset and the confidence of an association rule , as follows:
and also make us define closed itemsets and their generator concisely, i.e., is a closed itemset if and only if , an itemset is a generator of the closed itemset if and only if and , furthermore, is a minimal generator of if and only if such that . Formally, and are also analyzed in rough sets and formal concept analysis [50,54,55,56,57], and the following properties of and are obviously, for any and , (1) If , then ; (2) If , then ; (3) ; (4) , . In [52], we use and to induce a reflexive and transitive relation on the set of attributes from a formal context, the topology for attributes are constructed by using the relation, then the formal concepts are analyzed in the the topology for attributes. Here, we provide the same results in a transaction database.
Definition 1.
For any transactional database , τ and γ decide a point-to-set mapping from A to , i.e., for any , is
Intuitively, the point-to-set mapping C represents a co-occurrence relation among items, i.e., the following binary relation on A can be decided by the mapping, C. For any ,
In [52], we have proved that the binary relation on A is reflexive and transitive, and is an approximation space. For any subset of A, denote and , then and are generalized upper approximation and lower approximation of , especially if is an equivalent relation; and are Pawlak’s upper approximation and lower approximation [55]. More important, we have the following theorem.
Theorem 1
([52]). For any transactional database .
- 1 .
- is a topology for A;
- 2 .
- For any , ;
- 3 .
- is a base for the topology .
The theorem means that the topology for A has a simple expression, i.e., , we use the following example to explain the above mentioned concepts and results; the example was initially used to analyze the concept “to-be-a-fruit” [58].
Example 1.

Let a fruit data be , where a chestnut (), an olive (), a pepper (), a strawberry (), an orange (), a tomato ()} and to-grow-on-trees (), to-be-sweet (), to-be-raw-edible (), to-yield-juice (), to-have-a-skin ()} be used to understand the concept “to-be-a-fruit” (shown in Table 1). According to Definition 1, we have , , and , e.g., for , it means that and are co-occurrence in Table 1, i.e., a fruit is “to-be-sweet”, it must be “to-be-raw-edible”. The binary relation on is shown in Table 2.
Table 1.
A transactional database .
Table 2.
The binary relation on A.
Based on Theorem 1 and the mapping C, we have , e.g., the member is obtained by
According to Table 2, we can find that on A is not symmetric generally, e.g., but , hence, members of the topology for the set of items are not Pawlak’s lower approximation in practice. According to Table 1, we can obtain the support of each member in the topology for A, e.g., for , we have or . If we fix minimum support , then members such as and are frequent itemsets, which can be used to generate association rules, e.g., we can generate association rules “” and “”; confidences of them are
In A of the fruit data , “” is “to-grow-on-trees implies to-be-raw-edible”, “” is “to-be-raw-edible implies to-grow-on-trees”, by considering their confidences, “” is more confident than “” due to .
From Example 1, we notice that members of the topology for the set of items are itemsets, which is generated by the co-occurrence relation among items. In existed ARM methods, frequent itemsets or closed itemsets are always used to mine association rules, one problem is “can we use members of the topology for the set of items to mine all useful and needful association rules”. The problem will be solved in the next section.
3. Lattice Structures on the Topology for the Set of Items
In this section, we use set inclusion to construct lattice structures on the topology for the set of items, one is constructed on the topology itself, another is constructed on quotient set of the topology , then we analyze minimal elements and minimal generators of closed itemsets in the lattice structures, which are useful information in ARM.
3.1. The Lattice on the Topology
Formally, the topology for the set of items is a proper subset of the power set of A—theoretically, the power set of A naturally forms a power set lattice; however, its proper subset may be not a lattice. Here, we use the set inclusion to construct lattice on the topology for the set of items and analyze hierarchical structure of members of the topology.
It is obvious that is an poset by set inclusion, i.e., for any
On the poset , we define
For any , we have and ; hence, there exists and such that and , according to Theorem 1, and , we have
this means that we rewrite Similarly, we rewrite , this means that is a lattice.
Furthermore, for any subset , we denote
then, one can easily prove that and , and is also a complete lattice, e.g., in Example 1, we have , due to , and due to . The complete lattice of Example 1 is shown in Figure 1.
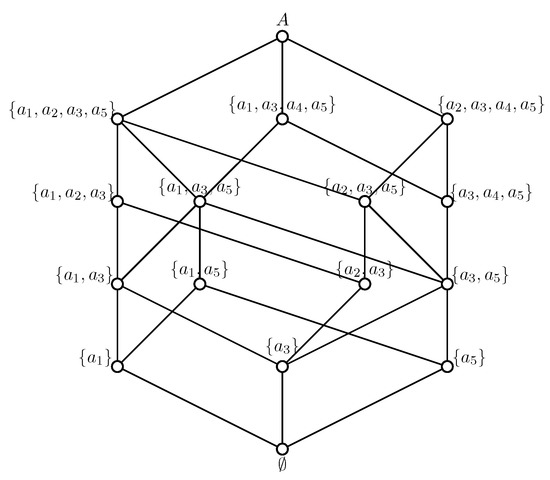
Figure 1.
The lattice of the topology of Example 1.
From up to down, the complete lattice provides us hierarchical information among members of the topology, intuitively, hierarchical information means that any member of is contained in its upper hierarchical members, and there are common transactions in the member of and its upper hierarchical members; such information can be used to generate association rules, i.e., suppose that is an upper hierarchical member of , then, we have the following association rule
in which, and , e.g., in Figure 1, itemset is an up hierarchical member of itemset , according to Table 1, we have with and . with and . In A of the fruit data , “” is “to-have-a-skin implies to-be-raw-edible”, “” is “to-grow-on-trees and to-be-raw-edible implies to-have-a-skin”; obviously, “to-have-a-skin implies to-be-raw-edible” is more confident and useful than “to-grow-on-trees and to-be-raw-edible implies to-have-a-skin” due to .
3.2. The Lattice on the Quotient Set of the Topology
To fast mine association rules with high support and confidence from the topology for the set of items, we construct another lattice structure on the topology in the subsection; then, we analyze minimal elements and minimal generators of closed itemsets in the lattice, which can help us to fast generate association rules with high support and confidence.
For any , we define a binary relation on the topology for the set of items, as follows
It is obvious that is an equivalent relation on the topology , and an quotient set of the topology can be decided by the equivalent relation, i.e., ; each equivalent class in is consisted of members of with the same support . According to the property of the topology, we have is in if and are in . On the other hand, according to property of the set-to-set mapping , for any and , , we have , i.e., each equivalent class in is closed for the ∪ operation, hence, we have the following theorem.
Theorem 2.
For each equivalent class in , is a union semi-lattice.
The maximum element of each equivalent class in is important. Formally, we denote the maximum element of as , then we confirm that is a closed itemset and each member T of is a generator of , in fact, suppose that T is a generator of a closed itemset , according to the set-to-set mapping and Definition 1; we have
this means that is a member of the topology for the set of items and , hence, .
Corollary 1.
For any transactional database and each equivalent class in , (1) all closed itemsets of A are in ; (2) is a closed itemset; (3) and , is a generator of .
Because is a proper subset of powerset of A and the existed methods search closed itemsets in powerset of A, the corollary means that we can reduce the searching range of closed itemsets in the topology for the set of items. On the other hand, frequent itemsets own the downward closed property, i.e., any subset of a frequent itemset is still frequent; hence, we can use closed frequent itemsetsto obtain its all frequent itemsets, any subset of a closed frequent itemset is a frequent itemset. The following corollaries help us to obtain minimal generators of closed itemsets, which is useful information in ARM.
In each union semi-lattice , we denote minimal members of as .
Corollary 2.
For any , if there exists no such that , then is a minimal generator of such that and .
In Example 1, we can easily check , in which, , due to for any , , is a minimal generator of , and .
For , if there exists such that , we denote , is an poset by set inclusion, i.e., , if and only if , minimal elements of is denoted by
Corollary 3.
For , is a minimal generator of , where is a generator of .
In Example 1, , due to , and is a minimal generator of , and .
From the algebraic point of view, we can construct a lattice structure on the quotient set of the topology , i.e., for any , we define and , one can easily check that operators ∨ and ∧ on are well defined, and we have the following theorem.
Theorem 3
([52]). is a complete lattice, in which the maximum and minimum elements are and , respectively.
In Example 1, , the lattice of Example 1 is shown in Figure 2.
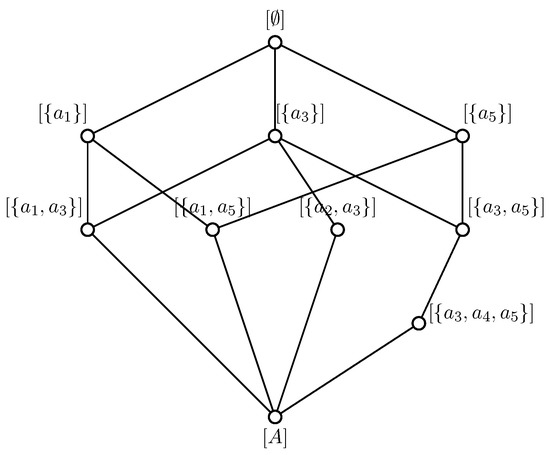
Figure 2.
The complete lattice of Example 1.
4. Association Rules Mining from the Quotient Set of the Topology
In summary, we can confirm the follows facts about itemsets of a transactional database based on the above mentioned results:
- 1.
- The topology for the set of items is a complete lattice and displays a hierarchical structure on some itemsets, it can be generated by the base ; generally, each is an itemset and can more fast generate closed itemsets than single items in the existed methods;
- 2.
- All closed itemsets are included in the topology , moreover, a closed itemset is the maximum element of an equivalent class ;
- 3.
- Each itemsets in has the same support; moreover, generators and minimal generators of a closed itemset can be obtained from ;
- 4.
- The complete lattice displays the hierarchical structures on closed itemsets.
Inspired by rough set theory, each equivalent class in can be understood as a granular knowledge on the set of itemsets of ; on the one hand, each granular knowledge can be used to mine association rules because it includes a closed itemset. On the other hand, all granular knowledge can be also used to approximate any itemset , i.e.,
- 1.
- The lower approximation of :
- 2.
- The upper approximation of :
It is obvious that for any itemset , and are in the topology for the set of items, if , then the itemset is in ; furthermore, supports of , and are such that
such as in Example 1, for itemset , , , and . Formally, the lower approximation and the upper approximation of an itemset provide us an alternative method to mine generalized association rules or reduce association rules. All of these will be discussed in the rest of the section.
4.1. Min-Max Association Rules Mining
In the subsection, we provide an useful method to mine Min-Max association rules from closed frequent itemsets; here, an association rule is called as a Min-Max association rule if and only if there does not exist an association rule with the same quality measures as the association rule, but with a more specific antecedent part and a more general consequent part. Because closed itemsets are in equivalent classes of , we propose Algorithm 1 to generate all Min-Max association rules with confidence from equivalent classes of .
| Algorithm 1 Min-Max association rules mining from closed itemsets |
|
The pseudocode provided in Algorithm 1, is responsible for mining Min-Max association rules from closed itemsets. Step (1) generates the base , step (2) generates the topology , step (3) generates the equivalent class , step (4) generates the minimum of .
Example 2.
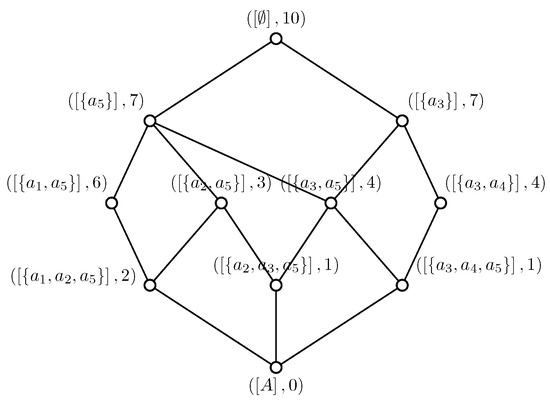
A transactional database is shown in Table 3. According to Definition 1, we obtain , , , and , i.e., the base for the topology for the set of items is , the co-occurrence relation among items decided by Equation (1) is shown in Table 4. The topology for the set of items generated by and the quotient set of the topology are
Table 3.
A transactional database .
Table 4.
A binary relation on A.
The complete lattice is shown in Figure 3, in which, each equivalent class is with its support, e.g., means . Closed itemset and minimal generators of each equivalent class are shown in Table 5; accordingly, Min-Max association rules with confidence generated from each equivalent class are shown in Table 6.
Figure 3.
The complete lattice of Example 2.
Table 5.
Closed itemset and minimal generators of each equivalent class.
Table 6.
Min-Max association rules with support s and confidence .
In Table 6, is generated by a minimal generator of , is generated by generator of , which are association rules with confidence ; however, they are not Min-Max association rules with confidence , only is Min-Max association rules with confidence . Generally, there are many association rules with confidence generated from each equivalent class; however, Min-Max association rules with confidence must be generated by , and , i.e., the advantage of our method is that searching minimal generator is limited in but not in all subsets of .
According to the hierarchical structures on closed itemsets displayed in the complete lattice , we provide Algorithm 2 to generate Min-Max association rules with high support and confidence from a fixed itemset.
| Algorithm 2: Min-Max association rules mining from a fixed itemset |
|
The pseudocode provided in Algorithm 2 is responsible for mining Min-Max association rules from a fixed itemsets. Step (1) generates , step (2) generates the set of equivalent classes, and step (4) generates the Min-Max association rules.
In Example 2, several fixed itemsets and their lower approximations are shown in Table 7, the corresponding Min-Max association rules generated by the itemsets are shown in Table 8.
Table 7.
Itemsets and their lower approximations of Example 2.
Table 8.
Min-Max association rules generated by the itemsets.
Finally, advantages of Algorithms 1 and 2 can be summarized as follows:
- 1.
- Min-Max association rules are always mined from closed itemsets, in this paper, we prove that closed itemsets are maximum elements of equivalent classes, i.e., equivalent classes can be used to mine Min-Max association rules with confidence 1;
- 2.
- The shortest length antecedents of Min-Max association rules are searched from minimal members of equivalent classes, i.e., and ; in this paper, searching minimal generators are in smaller scope than in all subsets of closed itemsets;
- 3.
- Lower approximations and their minimal generators help us to fast mine Min-Max association rules from a fixed itemset.
4.2. Generalized Association Rules Based on the Lower Approximation
Generalized association rules are important extension of association rules. By using taxonomy over items of transactional databases, generalized items are aggregated according to different granularity levels. In practice, generalized itemsets provide a high level view of the patterns hidden in the analyzed data and a high level abstraction of the mined knowledge in different application domains [12,30,59,60]. In this paper, each equivalent class in is understood as a granular knowledge on the set of itemsets; it can also be considered as a kind of generalized itemsets. Accordingly, we provide an alternative method to mine generalized association rules based on the lower approximation of any itemset, and analyze the changing confidence of generalized association rules. Formally, for any association rule , we propose the following three kinds of generalized association rules of based on the lower approximation:
- 1.
- Generalized antecedent association rule (GAR): ;
- 2.
- Generalized conclusion association rule (GCR): ;
- 3.
- Generalized antecedent and conclusion association rule (GACR): .
It is obvious that if , then and ; if , then and ; if , then , and .
Corollary 4.
For any association rule , , and .
- 1 .
- ;
- 2 .
- ;
- 3 .
- If , then ;
- 4 .
- If , then .
Proof.
Based on and , (1) and (2) can be easily proved. For (3) and (4), due to and , we have = , by , if , then . If , then . □
Corollary 5.
Let , and . 1) If , then ; 2) If , then .
Based on , and , , and of association rule have the following redundant rules with the same confidence and the same support:
- 1.
- Redundant association rule of GAR: ;
- 2.
- Redundant association rule of GCR: ;
- 3.
- Redundant association rule of GACR: .
Accordingly, we provide Algorithm 3 to mine generalized association rules of any association rule and its corresponding redundant association rules.
| Algorithm 3: Mining generalized association rules and redundant association rules based on the lower approximation |
|
The pseudocode provided in Algorithm 3 is responsible for mining generalized association rules and redundant association rules based on the lower approximation. Step (1) generates and , step (2) generates and , step (4) generates association rules.
4.3. Generalized Association Rules Based on the Upper Approximation
Similarly, for any association rule , we propose the following three kinds of generalized association rules of based on the upper approximation:
- 1.
- Generalized antecedent association rule (gar): ;
- 2.
- Generalized conclusion association rule (gcr): ;
- 3.
- Generalized antecedent and conclusion association rule (gacr): .
It is obvious that if , then ; if , then ; if , and then .
Corollary 6.
For , , and .
- 1 .
- ;
- 2 .
- 3 .
- If , then ;
- 4 .
- If , then .
Proof.
Based on and , (1) and (2) can be easily proved. For (3) and (4), due to and , we have
i.e., . If , then , i.e., . If , then , i.e., . □
Corollary 7.
Let , and . (1) If , then ; (2) If , then .
Based on , and , , and of association rule have the following redundant rules with the same confidence and support:
- 1.
- Redundant association rule of gar: ;
- 2.
- Redundant association rule of gcr: ;
- 3.
- Redundant association rule of gacr: .
Accordingly, we provide Algorithm 4 to mine generalized association rules of and corresponding redundant association rules.
The pseudocode provided in Algorithm 4, is responsible for mining generalized association rules and redundant association rules based on the upper approximation. Step (1) generates and , step (2) generates and , step (4) generates association rules, and step (5) generates redundant association rules.
| Algorithm 4 Mining generalized association rules and redundant association rules based on the upper approximation |
|
5. Example Analysis
Experiments were made to compare the execution time, memory usage and numbers of association rules of the Apriori [1,61] algorithms and our method. They were implemented on a Thinkpad X1 laptop with Intel i5 Core Duo (2 × 2.4 GHz), 4 GB of RAM and running Windows 10. The algorithms were coded in Matlab 2015b. Four databases from the UCI databases [62] were used for the experiments, of which the features are shown in Table 9.
Table 9.
Dataset characteristics.
5.1. The Execution Time
Experiments were made to compare the execution time of the algorithms Apriori and ours.The minConf was set to 50%. The results of the four databases for various minSup values are shown in Figure 4, Figure 5, Figure 6 and Figure 7, which shows that the execution of our algorithm was faster than Apriori in all cases. For example, given , for the Chess database, the mining time of Apriori and ours were 3035.53(s) and 507.33(s), respectively. The time ratio is . Besides, as the minSup is decreased, the time ratio is reduced also. For example, consider the Connect database with set at 98%, 96% and 94%, the speed up of the time ratio were 91.93%, 7.26% and 1.56%, respectively. The results demonstrate that the execution time of mining rules from ours was more efficient than Apriori.

Figure 4.
Execution time of the two algorithms in Chess dataset for various minSup values.
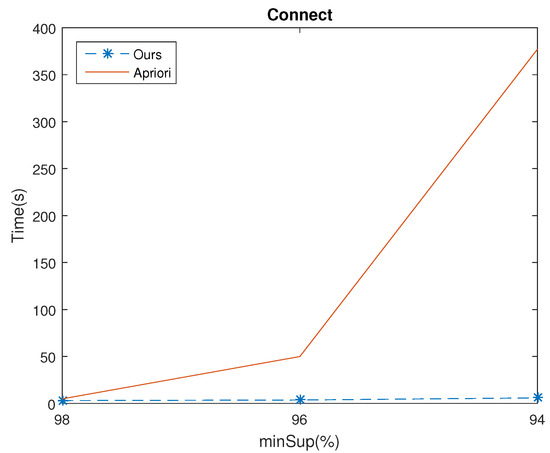
Figure 5.
Execution time of the two algorithms in Connect dataset for various minSup values.
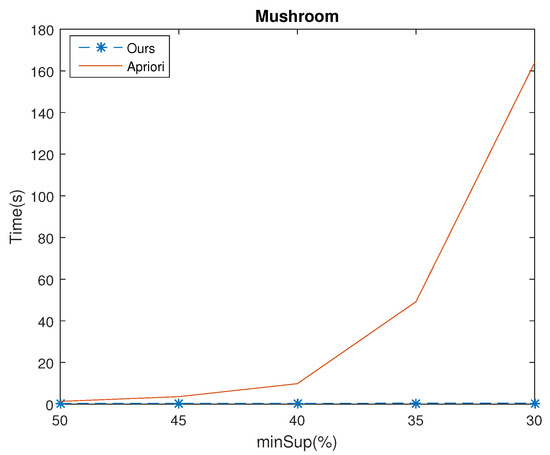
Figure 6.
Execution time of the two algorithms in Mushroom dataset for various minSup values.
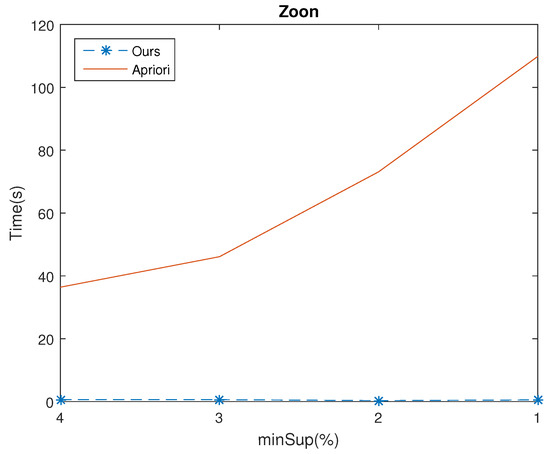
Figure 7.
Execution time of the two algorithms in Zoon dataset for various minSup values.
5.2. The Memory Usage
Experiments were made with the same databases and same parameters as the execution time experiments. The results show that the Apriori algorithm consumed more memory than ours in almost all cases, which are shown if Figure 8, Figure 9, Figure 10 and Figure 11. For example, given , for Chess database, the memory usage of Apriori and ours were 672 (Mb) and 136.54 (Mb), respectively. The time ratio is . Moreover, when we decrease the , the time ratio will reduce as well. For example, consider the Connect database with set at 98%, 96% and 94%, the speed up of the time ratio were 87.55%, 75.84% and 9.18%, respectively.
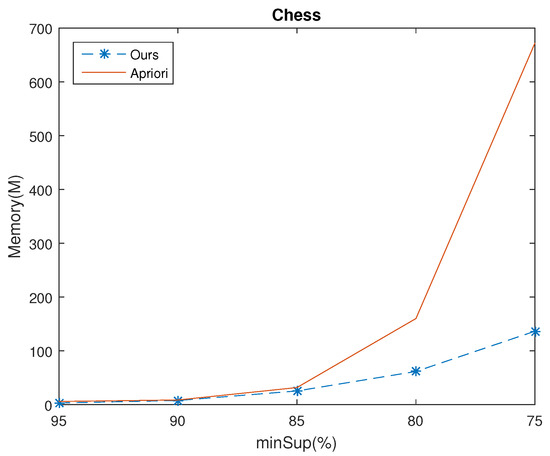
Figure 8.
Memory usage of the two algorithms in Chess dataset for various minSup values.
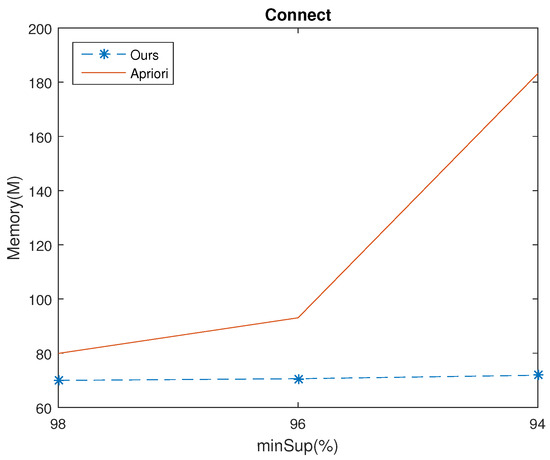
Figure 9.
Memory usage of the two algorithms in Connect dataset for various minSup values.
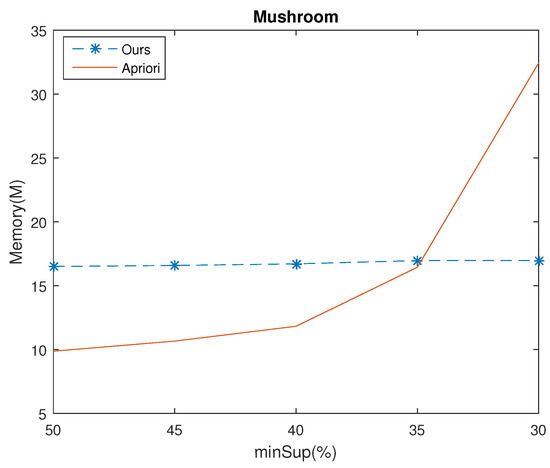
Figure 10.
Memory usage of the two algorithms in Mushroom dataset for various minSup values.
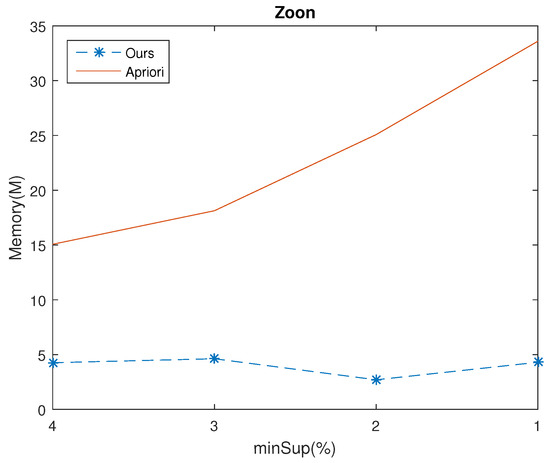
Figure 11.
Memory usage of the two algorithms in Zoon dataset for various minSup values.
5.3. Numbers of Rules
We compare the numbers of association rules of Apriori with ours with the same databases and same parameters as the execution time experiments in Table 10. The results demonstrate that the numbers of ours is always smaller than those of Apriori. For example, given , for Chess database, the number of rules of Apriori and ours were 2,336,556 and 253,836, respectively. The time ratio is . For our algorithm generating Min-Max association rules, the numbers of rules of ours is smaller than Apriori.
Table 10.
Number of rules of Apriori and Ours.
In this section, some examples are provided to show our method in association rules mining; transactional databases come from [62] and their characteristics are shown in Table 9. The Zoo database is initially used for classification of animals; in this paper, association rules among attributes of animals are considered, in which Min-Max association rules with confidence and confidence will be shown, respectively. For mushroom database, connect-4 and chess, the topology, basis for the topology and equivalent classes with thresholds of support are obtained, and Min-Max association rules and generalized association rules are generated. Because the Reliable basis used to retrieve and reduce association rules in [63] is similar to our method, our results are compared with the method based on the Reliable basis limited in the number of Min-Max association rules and redundant rules.
Example 3.
In the Zoo database, there are 101 objects (animals) and 17 attributes (15 boolean, 2 numeric). Here, we discover association rules among 15 boolean attributes of animals, i.e., hair (), feathers (), eggs (), milk (), airborne (), aquatic (), predator (), toothed (), backbone (), breathes (), venomous (), fins (), tail (), domestic () and catsize ().
According to Definition 1, 15 bases are generated (shown in Table A1 of Appendix A). Members of topology and equivalent classes with are shown in Table A2 of Appendix A. Equivalent classes used to generate association rules with confidence are shown in Table A3 of Appendix A. According to Table A3, 7 Min-Max association rules with and confidence are generated (shown in Table A4 of Appendix A), in which (rule 4) is considered redundant of (rule 5) and (rule 6) due to , , and ; i.e., we use less conditions to achieve more results by with the same support and confidence. Furthermore, some Min-Max association rules generated in the quotient lattice of the topology with and confidence are shown in Table A5 of Appendix A, in which the Min-Max association rule and can be considered as a GAR of , respectively.
Example 4.
The mushroom database consists of a database with 8124 objects (mushrooms) and 22 nominally valued attributes. Here, we convert 22 nominally valued attributes as 126 boolean attributes and generate 111 bases. Change of bases with different is shown in Figure A1 of Appendix A. Members of topology, equivalent classes and its generating time by using different bases are shown in Figure A2 of Appendix A.
Table A6 of Appendix A shows Min-Max association rules with and . Compared with results in [63], rules 1–8 and 11 are same with [63], and rules 9, 10, 12 and 13 are new rules, in which rule 8 can be considered as a redundant rule of rules 9 and 10, rule 11 being a redundant rule of rules 12 and 13.
Table A7 of Appendix A show Min-Max association rules with and , in which rules 1–25 are also generated in [63]; rules 26-41 are new rules.
Table A8 of Appendix A shows comparative results, in which means the number of all approximate rules in [63], Min-Max () and Reliable () means number and reduction ratio of Min-Max basis rules and reliable basis rules generated by Min-Max approximate basis, Min-Max exact basis, reliable approximate basis and reliable exact basis in [63]. means the number of all rules generated in the quotient lattice , N-Min-Max () means the number and reduction ratio of Min-Max association rules generated in , the reduction ratio is calculated as or . In Table A8, it can be noticed that the association rules used to obtain a reduction in the quotient lattice are less than in [63], such as for , 2528 association rules are used to obtain reduction. The lower and confidence c is corresponding to more generated association rules and higher reduction ratio in the quotient lattice , such as for and confidence , 1825 rules are generated and the reduction ratio is 0.77.
Example 5.
In the connect-4 database, the number of reduction association rules with confidence and compared with in [63] are shown in Table A9 of Appendix A. For template and rule ,
Accordingly, Table A10 shows the association rule of the template and generalized association rules in the connect-4 database.
In the chess database, the number of reduction association rules with confidence and compared with in [63] are shown in Table A11 of Appendix A. For template and rule ,
Accordingly, Table A12 shows the association rule of the template and generalized association rules in the chess database.
6. Conclusions
Association rules are often generated by frequent itemsets or closed itemsets from transactional databases. In order to obtain these itemsets, many methods have been proposed. In this article, for representing more general associative relations, which are among the items of transaction databases, the topology on itemset of a transactional database can been constructed. The topology on itemset includes frequent itemsets and closed itemsets. The topology on itemset includes frequent itemsets and closed itemsets, which has been proved. Most important of all, the basis of the topology can be used to generate the topology on the itemset, which deduced from the transactional database. Using the basis of the topology can efficiently avoid scanning databases many times in extracting association rules. The quotient lattice of the topology displays the hierarchical structures on all itemsets, because every closed itemset and its generators or minimal generators are limited in an element of the quotient lattice, valid Min-Max association rules can be easily generated in the element. Because the quotient lattice of the topology provides granular concepts to approximate any template of itemset, reductant association rules can be easily generated by granular concepts. The experiment demonstrates that association rules mining using topology for itemset is an efficient method.
Author Contributions
Conceptualization, Z.P.; methodology, Z.P. and B.L.; validation, C.Z. and F.H.; Writing—original draft, B.L.; Writing—review and editing, Z.P., formal analysis, Z.P. and B.L.; All authors have read and agreed to the published version of the manuscript.
Funding
This work has been partially supported by Talent introduction project of Xihua University (Z202104) and the Opening Project of Intelligent Policing Key Laboratory of Sichuan Province (Grant no. ZNJW2022KFMS004, ZNJW2022KFQN002, ZNJW2023KFQN007).
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
Table A1.
Basis of Zoo database.
Table A1.
Basis of Zoo database.
| Attributes | |||||
|---|---|---|---|---|---|
| Basis | |||||
| Attributes | |||||
| Basis | |||||
| Attributes | |||||
| Basis |
Table A2.
Members of topology and equivalent classes with .
Table A2.
Members of topology and equivalent classes with .
| c | 0 | |||
|---|---|---|---|---|
| Members of topology | 4159 | 98 | 54 | 11 |
| Equivalent classes | 237 | 75 | 44 | 11 |
Table A3.
Equivalent classes used to generate association rules with and confidence .
Table A3.
Equivalent classes used to generate association rules with and confidence .
| Equivalent Classes | |||
|---|---|---|---|
| 2 | |||
| 2 | |||
| 1 | |||
| 1 | |||
| 1 | |||
| 1 | |||
| 2 | |||
| 1 | |||
| 2 | |||
| 3 | |||
| 2 | , | ||
| 1 | |||
| 1 | |||
| 1 | |||
| 1 | |||
| 1 | |||
| 1 | |||
| 1 | |||
| 2 | |||
| 1 | |||
| 2 | |||
| 2 |
Table A4.
All Min-Max association rules with and .
Table A4.
All Min-Max association rules with and .
| Numbers | Rule |
|---|---|
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 |
Table A5.
Some Min-Max association rules with and .
Table A5.
Some Min-Max association rules with and .
| Numbers | Rule |
|---|---|
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | |
| 9 | |
| 10 | |
| 11 | |
| 12 | |
| 13 | |
| 14 | |
| 15 |

Figure A1.
Change of bases in the mushroom database corresponding to .

Figure A2.
Members of topology, equivalent classes and its generating time in the mushroom database corresponding to bases.
Table A6.
All Min-Max association rules in the mushroom database with and .
Table A6.
All Min-Max association rules in the mushroom database with and .
| N | Rule |
|---|---|
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | |
| 9 | |
| 10 | |
| 11 | |
| 12 | |
| 13 |
Table A7.
Min-Max association rules with and .
Table A7.
Min-Max association rules with and .
| Numbers | Rule |
|---|---|
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | |
| 9 | |
| 10 | |
| 11 | |
| 12 | |
| 13 | |
| 14 | |
| 15 | |
| 16 | |
| 17 | |
| 18 | |
| 19 | |
| 20 | |
| 21 | |
| 22 | |
| 23 | |
| 24 | |
| 25 | |
| 26 | |
| 27 | |
| 28 | |
| 29 | |
| 30 | |
| 31 | |
| 32 | |
| 33 | |
| 34 | |
| 35 | |
| 36 | |
| 37 | |
| 38 | |
| 39 | |
| 40 | |
| 41 |
Table A8.
The number of approximate rules and reduction in the mushroom database with confidence .
Table A8.
The number of approximate rules and reduction in the mushroom database with confidence .
| Min-Max () | Reliable () | N-Min-Max () | |||
|---|---|---|---|---|---|
| 0.4 | 2528 | (465, 0.82) | (361, 0.86) | 1825 | (420, 0.77) |
| 0.5 | 835 | (175, 0.79) | (135, 0.84) | 514 | (190, 0.63) |
| 0.6 | 228 | (59, 0.74) | (52, 0.77) | 136 | (65, 0.52) |
| 0.7 | 161 | (39, 0.74) | (34, 0.79) | 90 | (41, 0.54) |
| Average | 0.77 | 0.82 | 0.62 |
Table A9.
Number of approximate rules and reduction in the connect-4 database with confidence .
Table A9.
Number of approximate rules and reduction in the connect-4 database with confidence .
| Min-Max () | Reliable () | N-Min-Max () | |||
|---|---|---|---|---|---|
| 0.94 | 199,560 | (49,407, 0.75) | (10,220, 0.95) | 88,116 | () |
| 0.95 | 77,206 | (24,794, 0.68) | (5245, 0.93) | 39,768 | (4731, 0.88) |
| 0.96 | 26,856 | (11,452, 0.57) | (2538, 0.91) | 16,356 | (2535, 0.85) |
| 0.97 | 7895 | (4439, 0.44) | (1214, 0.85) | 5690 | (1294, 0.77) |
| Average | 0.61 | 0.91 | 0.85 |
Table A10.
Templates, association rules and generalized association rules in the connect-4 database.
Table A10.
Templates, association rules and generalized association rules in the connect-4 database.
| Template 1 | |
|---|---|
| Reduction of | |
| Rule 1 | |
Table A11.
The number of approximate rules and reduction in the chess database with confidence .
Table A11.
The number of approximate rules and reduction in the chess database with confidence .
| Min-Max () | Reliable () | N-Min-Max () | |||
|---|---|---|---|---|---|
| 0.90 | 10,614 | (8371, 0.21) | (2483, 0.77) | 9230 | () |
| 0.91 | 5785 | (5050, 0.13) | (1571, 0.73) | 5354 | (1357, 0.75) |
| 0.93 | 2338 | (1948, 0.17) | (688, 0.71) | 2110 | (648, 0.69) |
| 0.95 | 468 | (459, 0.02) | (196, 0.58) | 466 | (195, 0.58) |
| Average | 0.13 | 0.70 | 0.70 |
Table A12.
Templates, association rules and generalized association rules in the chess database.
Table A12.
Templates, association rules and generalized association rules in the chess database.
| Template 1 | |
|---|---|
| Rule 1 | |
References
- Agrawal, R.; Imieliński, T.; Swami, A. Mining Association Rules between Sets of Items in Large Databases. In Proceedings of the 1993 ACM SIGMOD International Conference on Management of Data, Washington, DC, USA, 25–28 May 1993; Association for Computing Machinery: New York, NY, USA, 1993; pp. 207–216. [Google Scholar]
- Agrawal, R.; Srikant, R. Fast Algorithms for Mining Association Rules in Large Databases. In Proceedings of the 20th International Conference on Very Large Data Bases, Santiago de Chile, Chile, 12–15 September 1994; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1994; pp. 487–499. [Google Scholar]
- Thamer, M.B.; El-Sappagh, S.; El-Shishtawy, T. A Semantic Approach for Extracting Medical Association Rules. Int. J. Intell. Eng. Syst. 2020, 13, 280–292. [Google Scholar] [CrossRef]
- Razzak, M.I.; Imran, M.; Xu, G. Big data analytics for preventive medicine. Neural Comput. Appl. 2020, 32, 4417–4451. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.N.; Dwivedi, A.D. Precise Marketing Data Mining Method of E-Commerce Platform Based on Association Rules. Mob. Netw. Appl. 2022. [Google Scholar] [CrossRef]
- Reddy, R.V.; Venkateswara Rao, K.; Kameswara Rao, M.; Deepak Kumar, B.P. A Review on Stock Market Analysis Using Association Rule Mining. In Cybernetics, Cognition and Machine Learning Applications; Gunjan, V.K., Suganthan, P.N., Haase, J., Kumar, A., Eds.; Springer Nature Singapore: Singapore, 2023; pp. 171–183. [Google Scholar]
- Ahn, K.I.; Kim, J.Y. Efficient Mining of Frequent Itemsets and a Measure of Interest for Association Rule Mining. J. Inf. Knowl. Manag. 2004, 3, 245–257. [Google Scholar] [CrossRef]
- Brin, S.; Motwani, R.; Ullman, J.D.; Tsur, S. Dynamic itemset counting and implication rules for market basket data. In Proceedings of the 1997 ACM SIGMOD International Conference on Management of Data, Tucson, AZ, USA, 13–15 May 1997; ACM: New York, NY, USA, 1997; pp. 255–264. [Google Scholar]
- Geng, L.; Hamilton, H.J. Interestingness measures for data mining: A survey. ACM Comput. Surv. 2006, 38, 9. [Google Scholar] [CrossRef]
- Ghosh, A.; Nath, B. Multi-objective rule mining using genetic algorithms. Inf. Sci. 2004, 163, 123–133. [Google Scholar] [CrossRef]
- Silverstein, C.; Brin, S.; Motwani, R. Beyond market baskets: Generalizing association rules to dependence rules. Data Min. Knowl. Discov. 1998, 2, 39–68. [Google Scholar] [CrossRef]
- Baralis, E.; Cagliero, L.; Cerquitelli, T.; Garza, P. Generalized association rule mining with constraints. Inf. Sci. 2012, 194, 68–84. [Google Scholar] [CrossRef]
- Beiranvand, V.; Mobasher-Kashani, M.; Bakar, A.A. Multi-objective PSO algorithm for mining numerical association rules without a priori discretization. Expert Syst. Appl. 2014, 41, 4259–4273. [Google Scholar] [CrossRef]
- Guil, F.; Marín, R. A Theory of Evidence-based method for assessing frequent patterns. Expert Syst. Appl. 2013, 40, 3121–3127. [Google Scholar] [CrossRef]
- Guns, T.; Nijssen, S.; De Raedt, L. Itemset Mining: A Constraint Programming Perspective. Artif. Intell. 2011, 175, 1951–1983. [Google Scholar] [CrossRef]
- Ji, Y.; Ying, H.; Tran, J.; Dews, P.; Mansour, A.; Massanari, R.M. A Method for Mining Infrequent Causal Associations and Its Application in Finding Adverse Drug Reaction Signal Pairs. IEEE Trans. Knowl. Data Eng. 2013, 25, 721–733. [Google Scholar] [CrossRef]
- Kuo, R.J.; Chao, C.M.; Chiu, Y.T. Application of particle swarm optimization to association rule mining. Appl. Soft Comput. 2011, 11, 326–336. [Google Scholar] [CrossRef]
- Luna, J.M.; Romero, J.R.; Ventura, S. Grammar-based multi-objective algorithms for mining association rules. Data Knowl. Eng. 2013, 86, 19–37. [Google Scholar] [CrossRef]
- Rodríguez, D.M.; Rosete, A.; Alcalá-Fdez, J.; Herrera, F. QAR-CIP-NSGA-II: A new multi-objective evolutionary algorithm to mine quantitative association rules. Inf. Sci. 2014, 258, 1–28. [Google Scholar]
- Martínez-Ballesteros, M.; Martínez-Álvarez, F.; Lora, A.T.; Riquelme, J.C. Selecting the best measures to discover quantitative association rules. Neurocomputing 2014, 126, 3–14. [Google Scholar] [CrossRef]
- Pei, Z. Extracting association rules based on intuitionistic fuzzy special sets. In Proceedings of the FUZZ-IEEE, Hong Kong, China, 1–6 June 2008; pp. 873–878. [Google Scholar]
- Shaharanee, I.N.M.; Hadzic, F.; Dillon, T.S. Interestingness measures for association rules based on statistical validity. Knowl. Based Syst. 2011, 24, 386–392. [Google Scholar] [CrossRef]
- Kaushik, M.; Sharma, R.; Peious, S.A.; Shahin, M.; Yahia, S.B.; Draheim, D. A Systematic Assessment of Numerical Association Rule Mining Methods. SN Comput. Sci. 2021, 2, 348. [Google Scholar] [CrossRef]
- Kuo, R.J.; Gosumolo, M.; Zulvia, F.E. Multi-objective particle swarm optimization algorithm using adaptive archive grid for numerical association rule mining. Neural Comput. Appl. 2019, 31, 3559–3572. [Google Scholar] [CrossRef]
- Wang, H.B.; Gao, Y.J. Research on parallelization of Apriori algorithm in association rule mining. Procedia Comput. Sci. 2021, 183, 641–647. [Google Scholar] [CrossRef]
- Bazai, S.U.; Jang-Jaccard, J. In-Memory Data Anonymization Using Scalable and High Performance RDD Design. Electronics 2020, 9, 1732. [Google Scholar] [CrossRef]
- Bazai, S.U.; Jang-Jaccard, J.; Alavizadeh, H. A Novel Hybrid Approach for Multi-Dimensional Data Anonymization for Apache Spark. ACM Trans. Priv. Secur. 2021, 25, 1–25. [Google Scholar] [CrossRef]
- Bazai, S.U.; Jang-Jaccard, J.; Alavizadeh, H. Scalable, High-Performance, and Generalized Subtree Data Anonymization Approach for Apache Spark. Electronics 2021, 10, 589. [Google Scholar] [CrossRef]
- Calders, T.; Dexters, N.; Gillis, J.J.M.; Goethals, B. Mining frequent itemsets in a stream. Inf. Syst. 2014, 39, 233–255. [Google Scholar] [CrossRef]
- Han, J.; Cheng, H.; Xin, D.; Yan, X. Frequent pattern mining: Current status and future directions. Data Min. Knowl. Discov. 2007, 15, 55–86. [Google Scholar] [CrossRef]
- Pei, J.; Han, J.; Mao, R. CLOSET: An Efficient Algorithm for Mining Frequent Closed Itemsets. In Proceedings of the ACM SIGMOD Workshop on Research Issues in Data Mining and Knowledge Discovery, Dallas, TX, USA, 14 May 2000; pp. 21–30. [Google Scholar]
- Wang, J.; Han, J.; Pei, J. CLOSET+: Searching for the best strategies for mining frequent closed itemsets. In Proceedings of the KDD, Washington, DC, USA, 24–27 August 2003; Getoor, L., Senator, T.E., Domingos, P.M., Faloutsos, C., Eds.; ACM: New York, NY, USA, 2003; pp. 236–245. [Google Scholar]
- O’Sullivan, D.; Smyth, B.; Wilson, D.C.; McDonald, K.; Smeaton, A. Improving the Quality of the Personalized Electronic Program Guide. User Model. User-Adapt. Interact. 2004, 14, 5–36. [Google Scholar] [CrossRef]
- Kryszkiewicz, M.; Rybinski, H.; Gajek, M. Dataless Transitions Between Concise Representations of Frequent Patterns. J. Intell. Inf. Syst. 2004, 22, 41–70. [Google Scholar] [CrossRef]
- Pasquier, N.; Bastide, Y.; Taouil, R.; Lakhal, L. Efficient mining of association rules using closed itemset lattices. Inf. Syst. 1999, 24, 25–46. [Google Scholar] [CrossRef]
- Zaki, M.J. Scalable algorithms for association mining. IEEE Trans. Knowl. Data Eng. 2000, 12, 372–390. [Google Scholar] [CrossRef]
- Zaki, M.J.; Hsaio, C.J. Efficient Algorithms for Mining Closed Itemsets and Their Lattice Structure. IEEE Trans. Knowl. Data Eng. 2005, 17, 462–478. [Google Scholar] [CrossRef]
- Hashem, T.; Ahmed, C.F.; Samiullah, M.; Akther, S.; Jeong, B.S.; Jeon, S. An efficient approach for mining cross-level closed itemsets and minimal association rules using closed itemset lattices. Expert Syst. Appl. 2014, 41, 2914–2938. [Google Scholar] [CrossRef]
- Liu, H.; Liu, L.; Zhang, H. A fast pruning redundant rule method using Galois connection. Appl. Soft Comput. 2011, 11, 130–137. [Google Scholar] [CrossRef]
- Cagliero, L.; Cerquitelli, T.; Garza, P.; Grimaudo, L. Misleading Generalized Itemset discovery. Expert Syst. Appl. 2014, 41, 1400–1410. [Google Scholar] [CrossRef]
- Cagliero, L.; Garza, P. Itemset generalization with cardinality-based constraints. Inf. Sci. 2013, 244, 161–174. [Google Scholar] [CrossRef]
- Baralis, E.; Cagliero, L.; Cerquitelli, T.; D’Elia, V.; Garza, P. Expressive generalized itemsets. Inf. Sci. 2014, 278, 327–343. [Google Scholar] [CrossRef]
- Boulicaut, J.F.; Bykowski, A.; Rigotti, C. Free-sets: A condensed representation of boolean data for the approximation of frequency queries. Data Min. Knowl. Discov. 2003, 7, 5–22. [Google Scholar] [CrossRef]
- Bykowski, A.; Rigotti, C. DBC: A condensed representation of frequent patterns for efficient mining. Inf. Syst. 2003, 28, 949–977. [Google Scholar] [CrossRef]
- Chiang, D.A.; Wang, Y.F.; Wang, Y.H.; Chen, Z.Y.; Hsu, M.H. Mining disjunctive consequent association rules. Appl. Soft Comput. 2011, 11, 2129–2133. [Google Scholar] [CrossRef]
- Calders, T.; Goethals, B. Non-derivable itemset mining. Data Min. Knowl. Discov. 2007, 14, 171–206. [Google Scholar] [CrossRef]
- Li, H.; Chen, H. Mining non-derivable frequent itemsets over data stream. Data Knowl. Eng. 2009, 68, 481–498. [Google Scholar] [CrossRef]
- Hamrouni, T.; Yahia, S.B.; Nguifo, E.M. Sweeping the disjunctive search space towards mining new exact concise representations of frequent itemsets. Data Knowl. Eng. 2009, 68, 1091–1111. [Google Scholar] [CrossRef]
- Barrenechea, E.; Sola, H.B.; Campión, M.J.; Induráin, E.; Knoblauch, V. Topological interpretations of fuzzy subsets. A unified approach for fuzzy thresholding algorithms. Knowl. Based Syst. 2013, 54, 163–171. [Google Scholar] [CrossRef]
- Syau, Y.R.; Lin, E.B. Neighborhood systems and covering approximation spaces. Knowl. Based Syst. 2014, 66, 61–67. [Google Scholar] [CrossRef]
- Wang, S.; Liu, D. Knowledge representation and reasoning for qualitative spatial change. Knowl. Based Syst. 2012, 30, 161–171. [Google Scholar] [CrossRef]
- Pei, Z.; Ruan, D.; Meng, D.; Liu, Z. Formal concept analysis based on the topology for attributes of a formal context. Inf. Sci. 2013, 236, 66–82. [Google Scholar] [CrossRef]
- Zhang, Y.; Pei, Z.; Shi, P. Association rule mining based on topology for attributes of multi-valued information systems. Int. J. Innov. Comput. Inf. Control. Ijicic 2013, 9, 1679–1690. [Google Scholar]
- Ganter, B.; Wille, R. Formal Concept Analysis: Mathematical Foundations; Springer: Berlin/Heidelberg, Germany, 1999. [Google Scholar]
- Pawlak, Z.; Skowron, A. Rough sets and Boolean reasoning. Inf. Sci. 2007, 177, 41–73. [Google Scholar] [CrossRef]
- Qin, K.; Yang, J.; Pei, Z. Generalized rough sets based on reflexive and transitive relations. Inf. Sci. 2008, 178, 4138–4141. [Google Scholar] [CrossRef]
- Zhang, H.P.; Ouyang, Y.; Wang, Z. Note on “Generalized rough sets based on reflexive and transitive relations”. Inf. Sci. 2009, 179, 471–473. [Google Scholar] [CrossRef]
- Freund, M. On the notion of concept I. Artif. Intell. 2008, 172, 570–590. [Google Scholar] [CrossRef]
- Srikant, R.; Agrawal, R. Mining Generalized Association Rules. In Proceedings of the 21st International Conference on Very Large Databases, Zurich, Switzerland, 11–15 September 1995; pp. 407–419. [Google Scholar]
- Wu, C.M.; Huang, Y.F. Generalized association rule mining using an efficient data structure. Expert Syst. Appl. 2011, 38, 7277–7290. [Google Scholar] [CrossRef]
- Apriori Algorithm. Available online: http://www.mathworks.com/matlabcentral/fileexchange/42541-association-rules/ (accessed on 1 September 2022).
- UCI Machine Learning Repository. Available online: http://archive.ics.uci.edu/ml/ (accessed on 1 September 2022).
- Xu, Y.; Li, Y.; Shaw, G. Reliable representations for association rules. Data Knowl. Eng. 2011, 70, 555–575. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).