Abstract
This article is concerned with an original approach to generative classification of spatiotemporal areal (or lattice) data based on implementation of spatial weighting to Hidden Markov Models (HMMs). In the framework of this approach data model at each areal unit is specified by conditionally independent Gaussian observations and first-order Markov chain for labels and call it local HMM. The proposed classification is based on modification of conventional HMM by the implementation of spatially weighted estimators of local HMMs parameters. We focus on classification rules based on Bayes discriminant function (BDF) with plugged in the spatially weighted parameter estimators obtained from the labeled training sample. For each local HMM, the estimators of regression coefficients and variances and two types of transition probabilities are used in two levels (higher and lower) of spatial weighting. The average accuracy rate (ACC) and balanced accuracy rate (BAC), computed from confusion matrices evaluated from a test sample, are used as performance measures of classifiers. The proposed methodology is illustrated for simulated data and for real dataset, i.e., annual death rate data collected by the Institute of Hygiene of the Republic of Lithuania from the 60 municipalities in the period from 2001 to 2019. Critical comparison of proposed classifiers is done. The experimental results showed that classifiers based on HMM with higher level of spatial weighting in majority cases have advantage in spatial–temporal consistency and classification accuracy over one with lower level of spatial weighting.
Keywords:
Markov chain; transition probabilities; Bayes discriminant function; confusion matrix; spatial weights MSC:
62H30; 62C10; 62M05
1. Introduction
This article is concerned with a generative approach (see, e.g., [1]) to supervised classification of spatiotemporal data collected at fixed areal units (sites, locations) and specified by HMMs with continuous observations in each class (state) and traditionally invoked conditional independence assumption for observation distribution and Markov assumption for label transition probabilities (see, e.g., [2]). That is an extension to the basic HMM when observation may be signified by continuous real value instead of discrete value. We focus on the models that describes the process of randomly generating an unobservable class label (state) sequences from the first-order Markov chain and generating an Gaussian observation from each class to produce an observable sequence from single probabilistic distribution [3,4]. Unlike the conventional conditional density HMM, the proposed HMMs consider the temporal information of each areal unit obtain the most possible sequence of label by the incorporating the spatial information through spatial weights. It should be noted that HMM with spatial weighting have been successfully used in land-cover classification [5]. Shekhar [6], Atkinson [7], Tang et al. [8] extended pixel-based geostatistically weighted classifiers to object-based image classifications. Kadhem, Hewson, and Kaimi [9] developed Poisson HMM to model spatial dependence in network. However, only the cases with geostatistical models of observation based on spatial covariances or semivariograms are considered there.
Comprehensive literature survey on state-of-the-art advances in spatiotemporal data analysis is proposed by Ali Hamdi et al. [10]. Systematic review of methods in spatial deep learning is reported by Mishra et al. [11]. It should be noted that in the environmental agricultural and other research, data are often collected across space and through time. The spatiotemporal data are usually recorded at regular time intervals (time lags) and at irregular stations (areas) in compact area (see, e.g., [12,13]). Modeling and prediction of a such type of data has been studied by the numerous authors (see, e.g., [14,15,16,17]). Often before analyzing spatiotemporal datasets, spatiotemporal discretization (or aggregation) is applied. The discretization is useful to summarize information and help in extracting features within a spatiotemporal range rather than measuring a single point [18]. Compared with the general classification problem, spatial classification needs to consider the location information of the data and the interaction among feature and label variables at every time moment. There are currently a variety of ways to achieve the classification goal, but one of the most effective one is to use the BDF. The generative approach to spatial classification is studied by numerous authors (see, e.g., [19,20,21,22]). The approach to Bayesian classification of Gaussian Markov Random Fields (GMRF) observation on the lattice has been developed by Dreižienė and Dučinskas [23,24,25], and generative classification method for geostatistical spatiotemporal Gaussian model is introduced by Karaliutė and Dučinskas [26,27].
Novelty of our approach lies in the incorporation of spatial weights in HMM parameter estimation from labeled training sample and using plug-in BDF for classification (decoding) of the test observation. This enables us to enrich and generalize the existed generative classification methods of spatiotemporal data modeled by HMM.
Our approach is aimed at situation when BDF is implemented for data that are collected at fixed areal units (or sites as they are also known) over the fixed sequential time periods. At the beginning, for each local HMM, the maximum likelihood estimators of regression coefficients and variances and two types of transition probabilities estimators are derived from labeled training sample.
Furthermore, HMM parameter estimators in two spatial weighting levels are plugged in BDF. Two levels of spatial weighting are specified as follows:
- lower level called as partial spatial weighting (PSW) indicates that parameter estimators of Gaussian component are spatially weighted when transition probability estimators remain unweighted;
- higher level called as complete spatial weighting (CSW) comprise the cases with spatially weighted estimators of Gaussian parameters and transition probabilities.
Performance measure of the classifier are chosen to be the ACC and BAC evaluated from the confusion matrices for a test sample. The proposed methodology is illustrated for simulated data and for real dataset, i.e., annual death rate data collected by the Institute of Hygiene of the Republic of Lithuania from the 60 municipalities in the period from 2001 to 2019. Presented critical comparison of proposed classifier by the introduced criteria with existing ones can aid in the selection of proper classification rules of spatiotemporal areal data.
The experimental results showed that proposed HMM in CSW level in majority cases have advantage in classification accuracy over HMM in PCW level by both performance measures.
In order to carry out the study, this paper is organized as follows. First, Section 2 introduces the HMM for spatial–temporal Gaussian data. Next, Section 3 introduces Bayesian classification based on HMM, while Section 4 compares them by two criteria via simulation. In Section 5, we offer a real application of our approach of classification of annual death rate data collected by the Institute of Hygiene of the Republic of Lithuania from the 60 municipalities in the period from 2001 to 2019. Finally, conclusions and comments are made in the last section.
2. HMM for Spatiotemporal Data
Formally, we identify the set of possible labels of classes (e.g., diseases, land cover labels, etc.) as across n areal units over T years in the time series. Let be a set of n nonoverlapping areal units (AUs). Assume that S is endowed with a neighborhood system , where denotes the collection of areas that are neighbors of area . Usually, the neighborhood could be defined to be those areas with which area shares a common border. For each area unit , data consist of feature variable observation (further simply observation) and label observed at consecutive time periods at . Let denote number of elements in the set .
Furthermore, use the following notation , for and .
In this study, we assume that for , the model of observation conditional on is
where is deterministic spatiotemporal mean and errors are independent normally distributed random variables with zero mean and finite variance .
In what follows with an insignificant loss of generality, we focus on the linear independent of time mean , where is the vector of an explanatory variables and is a q-dimensional vector of parameters, . That choice is motivated by considering only the cases when explanatory variables represent only the spatial coordinates or their functions.
Then design matrix for observation vector has the form
Conditional distribution of conditional on is T dimensional Gaussian, i.e.,
where and is identity matrix.
Denote by and the vectors of observations and class labels associated ith AU over T temporal periods.
As it follows, denote the realized values of random variables and by and , respectively.
It is known that the label sequence Y constitutes a first-order Markov chain, and the observed sequence Z is only related to the corresponding class label sequence, assuming that the label of the observation is only related to the last year’s label. Hence, dependence between Y and Z constitutes a first-order HMM. Label variable Y for ith AU is specified by transition probabilities matrix where for . An obvious extension to the basic HMM model is to allow continuous observation space instead of a finite number of discrete symbols. In this model, the emission probabilities matrix cannot be described as a simple matrix of point probabilities but rather as a complete probability density function (PDF) over the continuous observation space for each state. Therefore, the values emission probabilities must be replaced with a conditional PDF of , given class label , is denoted by . The conditional distributions can in principle be arbitrary but usually they are restricted to be simple parametric distributions, like Gaussians. The set of all possible values of parameters of above conditional densities is denoted by . The last component of HMM is called an initial label distribution over classes and is denoted by , where , . Specify the HMM parameter set for ith AU by , .
The HMM allows us to talk about both observed events that we meet in the input and hidden events that we think of as causal factors in our probabilistic model. A first-order HMM instantiates two simplifying assumptions.
First, Markov Assumption: as with a first-order Markov chain, the probability of a particular state depends only on the previous state: .
Second, Output Independence: the probability of an output observation oi depends only on the class that produced the observation qi and not on any other states or any other observations: .
The goal of HMMs is to infer the most likely Y by giving the observed variables Z.
Then, under HMM independence assumption, the conditional distribution of given and , is Gaussian, i.e.,
Recall that for HMM, each label realization produces only a single observation. Thus, the sequence of labels and the sequence of observations have the same length.
Given this one-to-one mapping and the Markov assumptions, for a particular hidden state sequence and an observation sequence , the conditional likelihood of the observation sequence is
where denotes PDF of univariate Gaussian distribution .
Given an and an observation and label sequences (i.e., labeled training sample is known), the likelihood has the following form where .
Specify a matrix of spatial weights with if and elswhere.
Define an augmented likelihood
where and .
Then, the criterion for Bayes classification rule is .
In the HMM and machine learning context, this problem is called as decoding problem.
3. Bayesian Classification Based on HMM
Under the assumption that the HMM is completely specified given labeled training sample , it is that known BDF minimizing the total probability of misclassification of is formed by the log-ratio of augmented conditional likelihoods of distributions (see [28]) specified in Equation (2), that is,
So, BDF classifies the observation in following way: class label takes value 1 if , and 0 otherwise.
Definition 1.
Probability of correct classification (PCC) incurred by given is defined as
where denotes Heaviside step function, and denotes the PDF of Gaussian distribution .
Lemma 1.
Under the above HMM, the BDF defined in Equation (3) has the form
with PCC
where and , and , is the standard Gaussian distribution function.
Proof of Lemma 1.
Substituting these expressions directly in Equation (3), we obtain closed-form expression for BDF presented in Equation (4).
Under the assumptions described above and formula (4), it follows that given , the conditional distribution of is Gaussian distribution with mean and variance , .
Consequently, using the properties of Gaussian distribution, we complete the proof of Lemma 1. □
So, it is obvious from Equation (5) that depends only the one label realization of training sample, i.e., . The PCC and its plug-in versions are one of the natural performance measures to the BDF similar as the mean squared prediction error (MSPE) for the universal kriging predictor (see [29]). MSPE and its plug-in versions are usually used for spatial sampling design criterion for prediction (see [30]). These facts strengthen the motivation for the deriving an explicit expression of the PCC for any of spatial classification procedures.
However, in practical applications, all statistical parameters , , , of populations are rarely known.
Then, the estimators of unknown parameters , are derived by the maximum likelihood (ML) method by maximizing and , by maximizing . In classical HMM context, it is also called the learning problem.
Hence, we obtain the estimators of local HMM parameters:
ML estimator of regression parameters ; and bias-adjusted ML estimator of variance .
ML estimators of transition probabilities
where is the indicator of event A.
It should be noted that we do not care about initial label distributions and consider it fixed, since it does not presented in BDF expression Equation (4).
In this study, we propose two types of the transition probability estimators for the ith AU:
- (M1)
- and
- (M2)
- andwhere and denote label persistence rate and change rate, respectively.
For greater interpretability, we impose the following popular for the areal data spatial weights
We propose the following spatial weighting procedures for local model parameter estimators
Replacing parameters with their estimators for BDF, we introduce four plug-in BDFs (PBDF):
- 1.
- partial spatial weighting level with inserted M1 type transition probability estimators and denote it by (PSW1);
- 2.
- partial spatial weighting level with inserted M2 type transition probability estimators and denote it by (PSW2);
- 3.
- complete spatial weighting level with inserted M1 type transition probability estimators and denote it by (CSW1);
- 4.
- complete spatial weighting level with inserted M2 type transition probability estimators and denote it by (CSW2).
They differ on the type and level of the incorporated spatiotemporal information.
Performance criteria of the generative classifier based on PBDF is evaluated by confusion matrix formed for test data and that records the results of correctly and incorrectly recognized test observations of each class.
That procedure is realized via partitioning the observed data into training and testing sets. Then, classifier being designed on the training data and its accuracy being validated on the test data. In this paper, our focus is on using T temporal observations for training and the observations at time moment are used for testing.
Label prediction in areal unit at time moment based on PBDF is given by .
The form of the confusion matrix that will be applied for the assessment of the proposed classifier performances is shown in Table 1.

Table 1.
Confusion matrix for ith AU.
Define , for .
Traditionally, the most commonly used empirical measure of classifier performance is called accuracy rate that shows the percentage of correctly classified test data is given by the formula
However, in practice, situations with significant disbalance between the majority and minority class examples frequently occur (see, e.g., [31,32,33]). Then, the evaluation of the classifiers’ performance must be carried out using specific metrics to take the class distribution into account. In this article, we also used other performance evaluation measures based on confusion matrix usually called Balanced Accuracy (see, e.g., [31,34]) and is specified by the formula
Below, we applied the Receiver Operator Characteristic (ROC) chart [35] that allows to visualize the trade-off between sensitivity (true positive rate), i.e., and 1-specificity (false positive rate), i.e., for any confusion matrix corresponding to selected PBDF.
4. Simulation Study
To conduct the critical comparison of four proposed classifiers, we begin with some simulation studies that based on spatial layout of AUs distributed in . Data collected in each locations followed the follows HMM with and normally distributed observations and like first order trend surface model, i.e., the first explanatory variable is constant equal 1, these second and third explanatory variables are x and y coordinates. Define the imbalance ratio for training sample by assuming that it is constant for all .
Spatial sampling set illustrated by the graph with 20 vertices is depicted in Figure 1. The neighborhood system is specified by the graph edges.
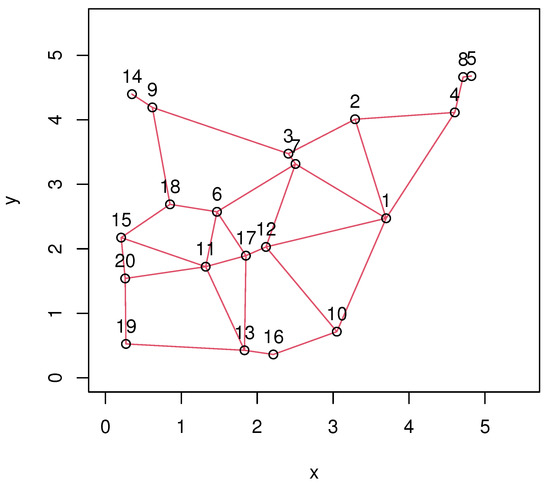
Figure 1.
Spatial sampling set .
For all 20 AUs, spatially weighted estimates of Gaussian distribution parameters and transition probabilities are presented in Table 2.
Table 2.
Spatially weighted estimators of the HMM parameters for 20 AUs .
Conditional distribution of given is Bernoully with parameter , i.e., . Hence, it is obvious that .
At first, we generate simulation runs (replications) for test label by the Bernoulli distribution described above and corresponding conditional Gaussian observation.
Furthermore, we compute performance measures ACC and BAC for each AUs and present their spatially averaged values in Table 3.
Table 3.
Averaged performance of classifiers based on PBDF for simulated data.
As we can see from Table 3, classifiers based on HMM with CSW level of spatial weighting in majority cases have an advantage over one with PSW level of spatial weighting by ACC as well as BAC performance measures for various values.
Estimation method M1 has advantage against M2 for smaller values of . However, M2 ensures greater classification accuracy for .
5. Real Data Example
The numerical analysis of annual death rate data collected by the Institute of Hygiene of the Republic of Lithuania from the 60 municipalities in the period from 2001 to 2019 is carried out.
Crude death rate for each municipality measured in units per one hundred thousand population is considered as variable Z. We consider two label variables: one is specified by the threshold mortality index due to acute cardiovascular event (ACE) and other is specified by the threshold mortality index due to diseases of the circulatory system (CSD).
Cases with index values less than threshold have label value equal 0 and have label value equal 1. Here, we consider the case with constant mean, i.e., , with .
Then, for
Numerical illustrations are performed on 60 areas in two dimensional areas that are depicted in Figure 2.
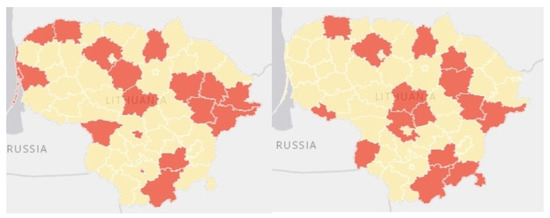
Figure 2.
Classified Lithuanian municipalities in 2018 (left) and 2019 (right). Yellow color areas indicate municipalities with low level of mortality due to ACE (with label value 0) and red areas indicates municipalities with high level of mortality due to ACE (with label value 1).
Data in the period from 2001 to 2018 () are used for training and remaining data (period 2019) are used for testing. Hence, and , i.e., we consider observations for training and 60 for testing. Here, values are calculated for testing data by changing the thresholds in specification of the mortality levels.
The values of performance measures for the proposed classifiers specified in Equations (6) and (7) are presented in Table 4.
Table 4.
Performance measures of classifiers based on PBDF for real data.
As it might be seen from Table 4, classifiers based on HMM with CSW level of spatial weighting in majority cases have an advantage over one with PSW level of spatial weighting by ACC as well BAC performance measures for various values. The similar trend is detected for CSD disease case. Exceptions to this rule is depicted in the table by bold figures.
ROC plot of is presented in Figure 3 visualizes the classifier performances with induced by different classifiers. Depicted points represent four considered classifiers and a random classifier. It is easy to check that the area under the curve in the ROC plot is equal the performance measure BAC.
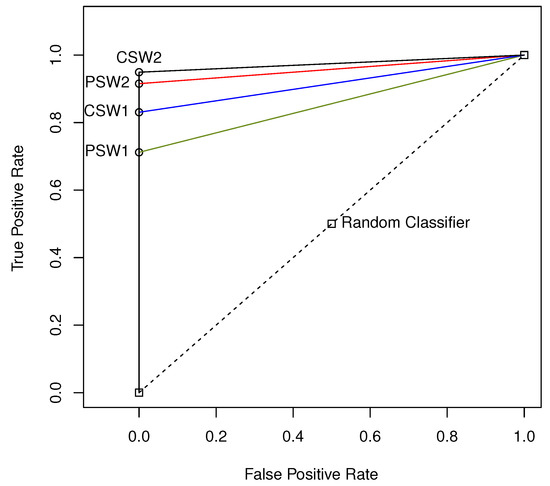
Figure 3.
ROC plots for the problems with class label variables ACE with .
6. Conclusions
In this paper, we developed the novel supervised generative approach to Bayesian classification of areal Gaussian data based on HMM implementing spatial weighting in several levels. A real data study has been conducted, and critical comparison of the performance of the classifiers with decision threshold values induced by different spatial autocorrelation indexes are performed.
The proposed methodology has several attractive features that make it compare favorably against other approaches to generative supervised spatial classification based on HMM.
First, the method is applicable to HMM with discrete and continuous observation on regular and irregular areal units.
Second, the approach provides an easily interpretable methods of spatial weighting for the local HMM parameters.
Third, proposed classification methodology can be easily specified in terms of undirected and directed graphs.
The obtained results with simulated and real data showed that the spatial weighting level significantly influenced the performance of proposed classifiers.
Based on the calculation results, the suggestions for the selection of transition probabilities estimation method is presented.
It should be also noted that derived closed form PCC could be essentially used in specifying theoretical values of model parameters.
There are several reasons for further research. First, there is further scope for exploring techniques supervising classification due to HMM of spatiotemporal Gaussian data to multiclass case. Second, future research may also include implementation of the proposed classification technique in the context of other continuous non-Gaussian models of observations. Third, in future research, it is reasonable to consider second-order Markov chain model for labels instead of first-order Markov chain. That will enable us to incorporate more information on stochastic temporal dependence.
Presented critical comparison of the performances of classifiers with different level of incorporated spatial information and types of parameter estimators can aid in the selection of proper classification rules of spatiotemporal areal data specified by HMM with Gaussian or other continuous observations.
Author Contributions
Conceptualization, K.D.; methodology, M.K. and K.D.; software, M.K.; data curation, M.K.; formal analysis, L.Š.-V.; writing—original draft preparation, M.K. and L.Š.-V.; writing—review and editing, M.K. and L.Š.-V.; visualization, M.K.; supervision, K.D. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Publicly available datasets were analyzed in this study. This data can be found here: the Institute of Hygiene of the Republic of Lithuania https://stat.hi.lt/ (accessed on 1 January 2020).
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| HMM | Hidden Markov Model |
| BDF | Bayes discriminant function |
| ACC | Average accuracy rate |
| BAC | Balanced accuracy rate |
| PSW | Partial spatial weighting |
| CSW | Complete spatial weighting |
| AU | Areal unit |
| Probability density function | |
| PCC | Probability of correct classification |
| MSPE | Mean squared prediction error |
| ML | Maximum likelihood |
| PBDF | Plug-in Bayes discriminant function |
| ROC | Receiver Operator Characteristic |
| ACE | Acute cardiovascular event |
References
- Ng, A.Y.; Jordan, M.I. On Discriminative vs. Generative Classifiers: A comparison of logistic regression and naive Bayes. NIPS Neural Inf. Process. Syst. 2001, 14, 33. [Google Scholar]
- Zuanetti, D.A.; Milan, L.A. Second-order autoregressive Hidden Markov Model. Braz. J. Probab. Stat. 2017, 31, 653–665. [Google Scholar] [CrossRef]
- Bryan, J.D.; Levinson, S.E. Autoregressive Hidden Markov Model and the Speech Signal. Procedia Comput. Sci. 2015, 61, 328–333. [Google Scholar] [CrossRef]
- Nguyen, L. Continuous Observation Hidden Markov Model. Rev. Kasmera 2016, 44, 65–149. [Google Scholar]
- Gong, W.; Fang, S.; Yang, G.; Ge, M. Using a Hidden Markov Model for Improving the Spatial-Temporal Consistency of Time Series Land Cover Classification. Int. J. Geo-Inf. 2017, 6, 292. [Google Scholar] [CrossRef]
- Shekhar, S.; Schrater, P.R.; Vatsavai, R.R.; Wu, W.; Chawla, S. Spatial contextual classification and prediction models for mining geospatial data. IEEE Trans. Multimed. 2002, 4, 174–188. [Google Scholar]
- Atkinson, P.M.; Lewis, P. Geostatistical classification for remote sensing: An introduction. Comput. Geosci. 2000, 26, 361–371. [Google Scholar] [CrossRef]
- Tang, Y.; Jing, L.; Li, H.; Atkinson, P.M. A multiple-point spatially weighted k-NN method for object-based classification. Int. J. Appl. Earth Obs. Geoinf. 2016, 52, 263–274. [Google Scholar] [CrossRef]
- Kadhem, S.K.; Hewson, P.; Kaimi, I. Using hidden Markov models to model spatial dependence in a network. Aust. N. Z. J. Stat. 2018, 60, 423–446. [Google Scholar] [CrossRef]
- Hamdi, A.; Shaban, K.; Erradi, A.; Mohamed, A.; Rumi, S.K.; Salim, F.D. Spatiotemporal data mining: A survey on challenges and open problems. Artif. Intell. Rev. 2022, 55, 1441–1488. [Google Scholar] [CrossRef]
- Mishra, B.; Dahal, A.; LuinteL, N.; Shahi, T.B.; Panthi, S.; Pariyar, S.; Ghimire, B.R. Methods in the spatial deep learning: Current status and future direction. Spat. Inf. Res. 2022, 30, 215–232. [Google Scholar] [CrossRef]
- Demel, S.S.; Du, J. Spatio-temporal models for some data sets in continuous space and discrete time. Stat. Sin. 2015, 25, 81–98. [Google Scholar]
- Haslett, J.; Raftery, A.E. Space-Time Modelling with Long Memory Dependence: Assessing Ireland’s Wind Power Resource. Appl. Stat. 1989, 38, 1–50. [Google Scholar] [CrossRef]
- Blangiardo, M.; Cameletti, M. Spatial and Spatio-Temporal Bayesian Models with R-INLA; Wiley, John Wiley & Sons: Hoboken, NJ, USA, 2015; pp. 235–258. [Google Scholar]
- Blangiardo, M.; Cameletti, M.; Baio, G.; Rue, H. Spatial and spatio-temporal models with R-INLA. Spat. Spatio-Temporal Epidemiol. 2013, 7, 39–55. [Google Scholar] [CrossRef] [PubMed]
- Cressie, N.; Wikle, C.K. Statistics for Spatio-Temporal Data; Wiley: Hoboken, NJ, USA, 2011. [Google Scholar]
- Fontanella, L.; Ippoliti, L.; Martin, R.J.S. Trivisonno. Interpolation of spatial and spatio-temporal Gaussian fields using Gaussian Markov random fields. Adv. Data Anal. Classif. 2008, 2, 63–79. [Google Scholar] [CrossRef]
- Giannotti, F.; Pedreschi, D. Mobility, Data Mining and Privacy: Geographic Knowledge Discovery; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Berrett, C.; Calder, C.A. Bayesian spatial binary classification. Spat. Stat. 2016, 16, 72–102. [Google Scholar] [CrossRef]
- Dučinskas, K. Approximation of the expected error rate in classification of the Gaussian random field observations. Stat. Probab. Lett. 2009, 79, 138–144. [Google Scholar] [CrossRef]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Sensoy, M.; Kaplan, L.; Cerutti, F.; Saleki, M. Uncertainty-Aware Deep Classifiers Using Generative Models. Proc. Aaai Conf. Artif. Intell. 2020, 34, 5620–5627. [Google Scholar] [CrossRef]
- Dreižienė, L.; Dučinskas, K. Comparison of spatial linear mixed models for ecological data based on the correct classification rates. Spat. Stat. 2020, 35, 100395. [Google Scholar] [CrossRef]
- Dučinskas, K.; Dreižienė, L. Risks of Classification of the Gaussian Markov Random Field Observations. J. Classif. 2018, 35, 422–436. [Google Scholar] [CrossRef]
- Dučinskas, K.; Dreižienė, L. Performance Evaluations of Gaussian Spatial Data Classifiers Based on Hybrid Actual Error Rate Estimators. Aust. J. Stat. 2020, 49, 27–34. [Google Scholar] [CrossRef]
- Karaliutė, M.; Dučinskas, K. Classification of Gaussian spatio-temporal data with stationary separable covariances. Nonlinear Anal. Model. Control 2021, 26, 363–374. [Google Scholar] [CrossRef]
- Karaliutė, M.; Dučinskas, K. Supervised linear classification of Gaussian spatio-temporal data. Liet. Mat. Rinkinys. Proc. Lith. Math. Soc. 2021, 62, 9–15. [Google Scholar] [CrossRef]
- McLachlan, G.J. Discriminant Analysis and Statistical Pattern Recognition; Wiley: New York, NY, USA, 2004. [Google Scholar]
- Diggle, P.J.; Ribeiko, P.J.; Christensen, O.F. An introduction to model-based geostatistics. Spat. Stat. Comput. Methods Lect. Notes Stat. 2003, 173, 43–86. [Google Scholar]
- Zhu, Z.; Stein, M.L. Spatial sampling design for prediction with estimated parameters. J. Agric. Biol. Environ. Stat. 2006, 11, 24–44. [Google Scholar] [CrossRef]
- López, V.; Fernández, A.; García, S.; Palade, V. Herrera, F. An insight into classification with imbalanced data: Empirical results and current trends on using data intrinsic characteristics. Inf. Sci. 2013, 250, 113–141. [Google Scholar] [CrossRef]
- Orriols-Puig, A.E. Bernadó-Mansilla, Evolutionary rule-based systems for imbalanced datasets. Soft Comput. 2009, 13, 213–225. [Google Scholar] [CrossRef]
- Ortigosa-Hernández, J.; Inza, I.; Lozano, J.A. Measuring the class-imbalance extent of multi-class problems. Pattern Recognit. Lett. 2017, 98, 32–38. [Google Scholar] [CrossRef]
- Soleymani, R.; Granger, E.; Fumera, G. F-measure curves: A tool to visualize classifier performance under imbalance. Pattern Recognit. 2020, 100, 107146. [Google Scholar] [CrossRef]
- Scaccia, L.; Martin, R.J. Testing axial symmetry and separability of lattice processes. J. Stat. Plan. Inference 2005, 131, 19–39. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).