Abstract
Seasonal autoregressive (SAR) models have many applications in different fields, such as economics and finance. It is well known in the literature that these models are nonlinear in their coefficients and that their Bayesian analysis is complicated. Accordingly, choosing the best subset of these models is a challenging task. Therefore, in this paper, we tackled this problem by introducing a Bayesian method for selecting the most promising subset of the SAR models. In particular, we introduced latent variables for the SAR model lags, assumed model errors to be normally distributed, and adopted and modified the stochastic search variable selection (SSVS) procedure for the SAR models. Thus, we derived full conditional posterior distributions of the SAR model parameters in the closed form, and we then introduced the Gibbs sampler, along with SSVS, to present an efficient algorithm for the Bayesian subset selection of the SAR models. In this work, we employed mixture–normal, inverse gamma, and Bernoulli priors for the SAR model coefficients, variance, and latent variables, respectively. Moreover, we introduced a simulation study and a real-world application to evaluate the accuracy of the proposed algorithm.
MSC:
62F15
1. Introduction
Seasonal autoregressive (SAR) time series models are widely used in different fields such as economics and finance to fit and forecast time series that are characterized by seasonality [1]. As it is well known, time series modeling starts with the specification of the model order, followed by estimation, diagnostic checks, and forecasting [2]. Therefore, the model specification phase is important, since all other modeling phases depend on its accuracy. In most real-world applications, the number of time series lags incorporated in a proposed time series model for an underlying time series is unknown, and this number of time series lags in this case is known as the model order, which needs to be specified or estimated based on the given time series data and its assumed probability distribution [3].
Although the time series model order is usually unknown, a maximum value of this order can be assumed, and different methods can be introduced to select the best subset to have a parsimonious model. Traditional subset selection methods include information criteria, such as the Akaike information criterion (AIC) [4] and the corrected AIC (AIC) [5]. These traditional selection methods use exhaustive searches based on parameter estimation and order selection. Many researchers have used these methods for subset selection in autoregressive (AR) time series models, including McClave [6], Penm and Terrell [7], Thanoon [8], Sarkar and Kanjilal [9].
However, it is very computationally expensive to apply these traditional methods to complicated models with high orders, such as the SAR models and other time series models with multiple seasonalities [10,11]. Accordingly, other subset selection procedures based on Markov chain Monte Carlo (MCMC) methods have been proposed for reducing the computational cost and efficiently selecting the best subset of time series models. Some researchers have adopted the stochastic search variable selection (SSVS) procedure, which was introduced by George and McCulloch [12], for selecting the best subset of linear regression models to be applied to the subset selection of time series models. Chen [13] proposed the Gibbs sampler, along with the SSVS procedure, to select the best subset of AR models. This work has been extended by different researchers to other time series models. So et al. [14] extended it for the subset selection of AR models with exogenous variables, and Chen et al. [15] extended it for the subset selection of threshold ARMA models.
On the other hand, the Bayesian analysis of the SAR model is complicated, because the likelihood function is a nonlinear function of the SAR model coefficients, and, accordingly, its posterior density is analytically intractable. Different approaches have been introduced to facilitate this analysis, including Markov chain Monte Carlo (MCMC)-based approximations [16]. Barnett et al. [17,18] applied MCMC methods to estimate SAR and ARMA models based on sampling functions for partial autocorrelations. Ismail [19,20] applied the Gibbs sampler to introduce the Bayesian analysis of SAR and SMA models. Ismail and Amin [16] applied the Gibbs sampler to present the Bayesian estimation of seasonal ARMA (SARMA) models, and, recently, Amin [1] used the same approach to introduce the Bayesian prediction of SARMA models. For modeling time series with multiple seasonalities, Amin and Ismail [21] and Amin [22,23] applied the Gibbs sampler to introduce the Bayesian estimation of double SAR, SMA, and SARMA models. Recently, Amin [24,25] applied the Gibbs sampler to introduce the Bayesian analysis of double and triple SAR models.
From a real-world application perspective, it is crucial to introduce an efficient Bayesian method for selecting the best subset of the SAR models, with the aim to obtain a parsimonious SAR model. However, most of the existing work has focused only on the Bayesian estimation and the prediction of SAR processes, and none of them has tried to tackle this problem of selecting the best subset of the SAR models. Therefore, in this paper, we aim to fill this gap and enrich real-world applications of the SAR models by introducing a Bayesian method for subset selection of these models based on modifying the SSVS procedure and adopting the Gibbs sampler. In particular, we first introduce latent variables for the nonseasonal and seasonal SAR model lags, assume that the SAR model errors are normally distributed, and employ mixture–normal, inverse gamma, and Bernoulli priors for the SAR model coefficients, variance, and latent variables, respectively. We then derive full conditional posteriors of the SAR model parameters in the closed form, and we apply the Gibbs sampler, along with SSVS, to develop an efficient algorithm for the best subset selection of the SAR models. In order to evaluate the performance of the proposed algorithm, we conduct a simulation study and a real-world application.
The remainder of this paper is organized as follows: We summarize the SAR models and related Bayesian concepts in Section 2. We then introduce the posterior analysis and proposed algorithm for the Bayesian best subset selection of the SAR models in Section 3. In Section 4, we present and discuss simulations and the real-world application of the proposed Bayesian subset selection algorithm. Finally, we conclude this work in Section 5.
2. Seasonal Autoregressive (SAR) Models and Bayesian Concepts
A mean deleted time series is generated by a seasonal autoregressive model of order and , and is designated as SAR if it satisfies [2]:
where the SAR errors are assumed to follow a normal distribution with a mean zero and variance of , s is the seasonal period, and B is an operator defined as . and are the nonseasonal and seasonal autoregressive polynomials with orders and , respectively. Also, and are the nonseasonal and seasonal autoregressive coefficients, respectively.
We can expand the SAR model (1) and write it as follows:
With the objective of simplifying the Bayesian analysis, we write the SAR model (2) in a matrix notation as follows:
where , , and is an matrix, i.e., , with the row defined as:
and is the coefficient vector, which is defined as the following:
The products of the coefficients, i.e., , are part of the SAR model, and, accordingly, this model is a nonlinear function of and , thereby leading to complications in its Bayesian analysis.
As we mentioned in the introduction, one of the main challenges of time series analysis is specifying the value of the SAR model order and , since these values are unknown and depend on the stochastic structure of the time series under study. Thus, we assume that the maximum value of the SAR model order is known, and we adopt and modify the SSVS procedure for the Bayesian best subset selection of the SAR model. Accordingly, we first introduce a latent variable for each coefficient of the SAR model, i.e., for , where equals to one when the corresponding time series lag to is selected, and it equals to zero otherwise. We then represent the prior distribution on each SAR model coefficient using a mixture–normal distribution that is defined as:
and
Thus, the prior distribution of and can be presented as a multivariate normal distribution that is defined as follows:
where , is a diagonal matrix, i.e., with if and if , and is a prior correlation matrix. Here, is specified in such a way to be a scaling of the prior covariance matrix to satisfy the prior specification in (6). In particular, we chose to be small, and, therefore, the s associated with would likely be close to zero. In addition, we chose to be large enough to make highly greater than ; thus, the associated with would tend to have a high variation and likely be away from zero, and the corresponding time series lags were selected as the best subset SAR model. For more information about setting these constants in the SSVS procedure, we refer to George and McCulloch [12].
As a prior distribution of , we specify an inverse gamma distribution that is defined as:
Using the marginal distribution of the s given in (7), we can write the joint prior distribution of as:
It is worth noting that the uniform prior of , i.e., , is a special case, since each time series lag has the same probability to be selected.
The likelihood function of the SAR model (3) with normally distributed errors can be presented as:
3. Bayesian Subset Selection of the SAR Models
The introduction of the Bayesian subset selection of the SAR models is based on posterior analysis; however, the joint posterior (12) of the SAR model parameters is a nonlinear function of the coefficients and . Accordingly, this joint posterior is analytically intractable, and, thus, the marginal posterior of each parameter cannot be analytically derived in closed forms. One of the solutions that can be applied to tackle this problem and ease the Bayesian subset selection of the SAR models is introducing the Gibbs sampler to approximate the required marginal posteriors of these models. In this section, we first derive the conditional posterior distributions of the SAR model as a requirement to employ the Gibbs sampler, and we then introduce our proposed algorithm for the Bayesian subset selection of the SAR models.
3.1. Conditional Posteriors of the SAR Models
As we introduced in our previous work [1,10], deriving the conditional posterior of each SAR model parameter can be simply done from the joint posterior (12) by first combining related terms to that parameter and then integrating out all unrelated terms. Following the same approach, we derive here the full conditional posteriors of the SAR parameters, i.e., , , , and , that are required to adopt the Gibbs sampler, along with SSVS for selecting the best subset of the SAR models.
We rewrite the SAR model (3) as the following:
We substitute (13) in the joint posterior (12), and we then complete the square in the exponent with respect to and integrate out all unrelated terms to obtain the conditional posterior of given , , and to be , where:
where is a matrix with the element , and is a matrix with the row .
In the same way, we rewrite the SAR model (3) as the following:
We substitute (15) in the joint posterior (12), and we then complete the square in the exponent with respect to and integrate out all unrelated terms to obtain the conditional posterior of given , and to be , where:
where is an matrix with the element , and L is an matrix with the row .
Moreover, from the joint posterior (12), we easily derive the conditional posterior of given , and to be an inverse gamma , where .
Now, in order to simplify the deriving conditional posteriors of latent variables, we need to first simplify the notations. In particular, for the latent variable in the vector, we refer to other latent variables as . In addition, for the latent variable vector, we refer to other latent variable vectors as . Accordingly, we derive the conditional posterior of each latent variable given , , , , and to be a Bernoulli distribution with a probability that is defined as follows:
where , and .
3.2. Proposed Algorithm for Bayesian Subset Selection of the SAR Models
Based on the work of the previous subsection, the required conditional posteriors of the SAR parameters are available, and we are accordingly able to adopt the SSVS and Gibbs sampler to propose an algorithm for the Bayesian subset selection of the SAR models.
We can implement our proposed algorithm for the Bayesian subset selection of the SAR models in the following steps:
- 1.
- Set a maximum value for the SAR model order as (, ).
- 2.
- Apply the OLS method to estimate the SAR()() model, and set these estimates as initial values for the Gibbs Sampler—.
- 3.
- Set the Gibbs sampler simulation design, which includes the number of simulations, burn-in, and thinning.
- 4.
- Set r as the current simulation and simulate the conditional posteriors as the following:
- , .
- , .
In this simulation, the generated values together construct the value of the Markov chain, i.e., . - 5.
- Repeat step (4) until all the required Gibbs sampler simulations have been conducted.
- 6.
- Apply the burn-in and thinning processes for the simulated Markov chain and monitor the convergence using autocorrelations, Raftery and Lewis diagnostics [26], and Geweke diagnostics [27]. For more information about these convergence diagnostics, see LeSage [28] and Amin [1,10].
- 7.
- Once the convergence of the simulated Markov chain is confirmed, select the best SAR subset that corresponds to a value of latent variables with the highest frequency in the simulated Markov chain, and also (whenever it is needed) compute the Bayesian estimates of the SAR parameters directly using the sample averages of these simulation outputs.
4. Simulations and Real Application
In this section, we introduce a simulation study and a real-world application for the proposed Bayesian algorithm for selecting the best subset selection for the SAR models, wherein we aim to evaluate its accuracy and applicability.
4.1. Simulation Study
We performed simulations from four SAR models using a simulation design that is presented in Table 1. The parameters of these SAR models were selected to cover different seasonality patterns, without any bias to select specific models or parameters. In particular, the first two SAR models are examples of SAR(2)(1), the third SAR model is an example of SAR(1)(2), and the fourth SAR model is an example of SAR(2)(2).

Table 1.
Simulation design.
We first generated 1,000 time series from each SAR model with different sizes, from 100 to 500 with an increment of 100, and we then applied the proposed Bayesian algorithm for selecting the best subset of the SAR model, as described in Section 3.2.
We set the Gibbs sampler simulation design as follows:
The number of Gibbs sampler simulations equaled 11,000, the burn-in equaled 1000, and thinning level equaled 10. In addition, we set the maximum order value of the SAR model (2) to be three, i.e., . Using Gibbs sampler draws, we computed the frequency values for each latent variable to find the best subset of the SAR model as a value with the highest frequency. Also, whenever it is needed, we can easily compute Bayesian estimates of the SAR model parameters as the following summary statistics: mean, standard deviation, and (, ) percentiles of draws as a 95% credible interval. We evaluated the accuracy of our proposed Bayesian algorithm for the best subset selection of the SAR models by simply computing the percentage of correctly selected best subset SAR models. In addition, for the sake of comparison, we used the traditional subset selection methods, including the AIC and AIC, to select the best subset of the simulated SAR models and also computed their percentage of correctly selected best subset SAR models. We can illustrate in some detail how our proposed algorithm works for the best subset selection of the SAR models by presenting all the results of the Gibbs sampler draws for only one time series of size generated from Model I. For this generated time series, we display the Bayesian subset selection results in Table 2 and the estimation results in Table 3.
Table 2.
Bayesian subset selection results for one time series generated from Model I.
Table 3.
Bayesian estimates results for one time series generated from Model I.
As can be seen from Table 2, for the nonseasonal latent variables , the values had the highest frequency among all the possible values, with a percentage of about 71.4%, and, for the seasonal latent variables , the values had the highest frequency, with a percentage of about 60%. Therefore, for this generated time series, the algorithm selected SAR(2)(1) as the best subset, which was the same as the true SAR model used to generate the time series, which highlights the accuracy of our proposed algorithm for the subset selection of SAR models. On the other hand, even though the estimation of the SAR models was not our objective in this work, the Bayesian estimates of the SAR parameters presented in Table 3 were very close to their true values in the simulated SAR models.
All of these results were only based on the time series generated from Model I, and, in the following, we present and discuss all the simulation study results. Since our objective in this work was the Bayesian best subset selection of the SAR models, we only display the simulation results for the Bayesian subset selection of all the simulated SAR models, and the Bayesian estimation results are not of our interest here. In particular, in Table 4, we show the percentage of correctly selected best subset SAR models using our proposed Bayesian algorithm and the traditional subset selection methods, i.e., the AIC and AIC.
Table 4.
Percentage of correctly selected best subset SAR models for the simulation study.
From Table 4, we can state general conclusions:
- First, for our proposed algorithm, the larger the size of the time series, the higher the percentage of correctly selected subset SAR models that were obtained, which implies that the proposed Bayesian subset selection is a consistent estimator of the best subset of the SAR models. However, this was not the case for the traditional subset selection methods, where the simulation results showed that they are inconsistent estimators.
- Second, for small time series sizes, i.e., , our proposed algorithm had comparable accuracy to those of the traditional subset selection methods. However, once the time series size became larger, our proposed algorithm had substantially higher accuracy than those of the traditional subset selection methods. For instance, when the time series size , our proposed algorithm had a percentage of correctly selected subset SAR models of at least 93%, compared to 75% at most for the traditional subset selection methods.
- Third, the accuracy of our proposed algorithm was almost the same across all the simulated SAR models, which indicates the robustness of our proposed algorithm against the different stochastic behaviors of time series exhibiting seasonal patterns.
In general, all these simulation results confirm that the traditional subset selection methods do not completely fail to select the best subset of SAR models, but they are inconsistent estimators, and their best subset selection was achieved mostly with a low accuracy. On the other hand, the proposed Bayesian algorithm for the subset selection of the SAR models was a consistent estimator with a high accuracy of best subset selection.
4.2. Real Application
In this subsection, we evaluate the applicability of our proposed Bayesian subset selection algorithm to real-time series. We conducted the Bayesian subset selection of the SAR models with real-world time series exhibiting seasonal patterns. This real-time series that we considered in our application is the monthly Federal Reserve Board (FRB) production index, with data starting from January 1948 to December 1978. For more details about this time series, see, for example, Amin [1].
We present the FRB production index time series in Table 5 and visualize this real-time series in Figure 1. As can be seen from Figure 1a, the FRB production index is nonstationary. We tried to stationarize the time series by applying the first (nonseasonal) difference, as visualized in Figure 1a, but still, the differenced time series was not stationary in the seasonal component. Accordingly, we employed both nonseasonal and seasonal differences to stationarize it, as visualized in Figure 1c. Therefore, we applied our proposed algorithm of Bayesian subset selection to the stationary differenced FRB production index, not the nonstationary raw data, with the same Gibbs sampler setting used in our simulation study.
Table 5.
FRB production index time series.
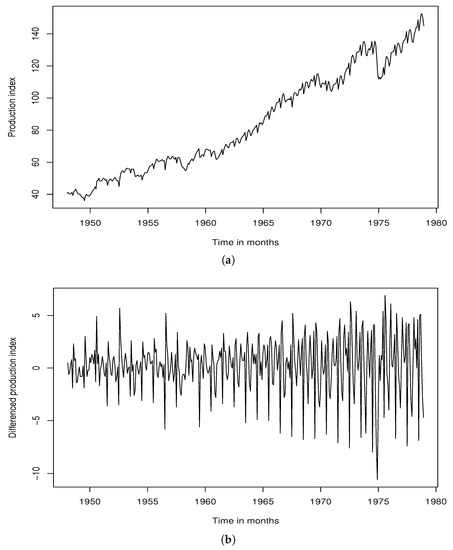
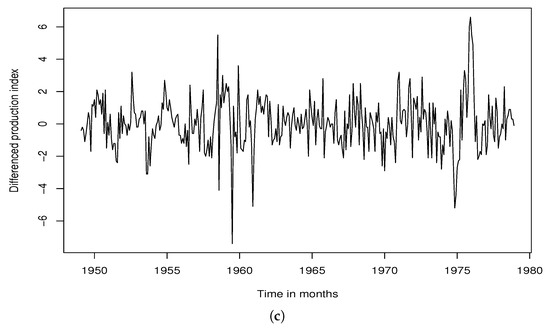
Figure 1.
Plots of FRB production index time series. (a) FRB production index. (b) Nonseasonal differenced FRB production index. (c) Nonseasonal and seasonal differenced FRB production index.
We present the Bayesian subset selection results of the SAR models for the differenced FRB production index in Table 6, and we also display the estimation results in Table 7. As can be seen from Table 6, for the nonseasonal latent variables , the values had the highest frequency among all the possible values with a percentage of about 45.3%. For the seasonal latent variables , the values had the highest frequency with a percentage of about 37.5%, but another set of values had a very similar frequency with a percentage of about 36%. Thus, in this case, we had to look at the estimation results to check the significance of the SAR model coefficients using the 95% credible interval to decide between these two subsets of the SAR model. As we can see from Table 7, for the nonseasonal AR coefficients, only the first coefficient, i.e., , was significant, and all other nonseasonal AR coefficients were insignificant. On the other hand, for the seasonal AR coefficients, the first three coefficients, i.e., , , and , were significant, which supported the selection of , not . Therefore, for the differenced FRB production index, the SAR(1)(3) was selected as the best subset of the SAR model. For the sake of comparison, we also applied the AIC and AIC to select the best subset, and the results show that both methods selected the same subset, SAR(2)(4), which was very close to our algorithm selection.
Table 6.
Bayesian subset selection results for the differenced FRB production index.
Table 7.
Bayesian estimates results for the differenced FRB production index.
5. Conclusions
In this paper, we developed a Bayesian subset selection of the SAR models based on the SSVS procedure and Gibbs sampler. By introducing latent variables for the nonseasonal and seasonal SAR model lags, we adopted and modified the SSVS procedure to select the best subset SAR model. We employed mixture–normal, inverse gamma, and Bernoulli priors for the SAR model coefficients, variance, and latent variables, respectively. By deriving full conditional posteriors of the SAR model parameters in the closed form, we introduced the Gibbs sampler along with SSVS to present an efficient algorithm for the subset selection of the SAR models. We performed a simulation study and a real application to evaluate the accuracy of the proposed algorithm, and the results of the simulation study confirmed its accuracy, while the results of the real application showed its applicability to select the best subset of the SAR model for real time series with seasonality. As part of future work, we plan to extend this work to select the best subset of time series models with multiple seasonalities, as introduced in [11], and also to select the best subset of multivariate autoregressive models, i.e., vector autoregressive models.
Author Contributions
Methodology, A.A.A.; Validation, A.A.A.; Writing—original draft, A.A.A.; Writing—review & editing, W.E., Y.T. and C.C.; Supervision, C.C.; Project administration, W.E.; Funding acquisition, W.E. and Y.T. All authors have read and agreed to the published version of the manuscript.
Funding
The study was funded by the Researchers Supporting Project number (RSPD2023R488), King Saud University, Riyadh, Saudi Arabia.
Data Availability Statement
All the datasets used in this paper are available for download (https://aymanamin.rbind.io/publication/2023-sar_subsetselection/), and they are accessed on 24 June 2023.
Acknowledgments
The authors are thankful to the editor and reviewers for their valuable suggestions that improved the paper. The study was funded by the Researchers Supporting Project number (RSPD2023R488), King Saud University, Riyadh, Saudi Arabia; and the authors thank King Saud University for the financial support.
Conflicts of Interest
The authors declare that they have no conflict of interest.
References
- Amin, A.A. Gibbs Sampling for Bayesian Prediction of SARMA Processes. Pak. J. Stat. Oper. Res. 2019, 15, 397–418. [Google Scholar] [CrossRef]
- Box, G.E.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Amin, A.A. Sensitivity to prior specification in Bayesian identification of autoregressive time series models. Pak. J. Stat. Oper. Res. 2017, 13, 699–713. [Google Scholar] [CrossRef]
- Akaike, H. A new look at the statistical model identification. IEEE Trans. Autom. Control. 1974, 19, 716–723. [Google Scholar] [CrossRef]
- Hurvich, C.M.; Tsai, C.L. Regression and time series model selection in small samples. Biometrika 1989, 76, 297–307. [Google Scholar] [CrossRef]
- McClave, J.T. Estimating the order of autoregressive models: The max X2 method. J. Am. Stat. Assoc. 1978, 73, 122–128. [Google Scholar]
- Penm, J.H.; Terrell, R. On the recursive fitting of subset autoregressions. J. Time Ser. Anal. 1982, 3, 43–59. [Google Scholar] [CrossRef]
- Thanoon, B. Subset threshold autoregression with applications. J. Time Ser. Anal. 1990, 11, 75–87. [Google Scholar] [CrossRef]
- Sarkar, A.; Kanjilal, P. On a method of identification of best subset model from full ar-model. Commun. Stat.-Theory Methods 1995, 24, 1551–1567. [Google Scholar] [CrossRef]
- Amin, A.A. Bayesian analysis of double seasonal autoregressive models. Sankhya B 2020, 82, 328–352. [Google Scholar] [CrossRef]
- Amin, A.A. Gibbs sampling for Bayesian estimation of triple seasonal autoregressive models. Commun. Stat.-Theory Methods 2022. [Google Scholar] [CrossRef]
- George, E.I.; McCulloch, R.E. Variable selection via Gibbs sampling. J. Am. Stat. Assoc. 1993, 88, 881–889. [Google Scholar] [CrossRef]
- Chen, C.W. Subset selection of autoregressive time series models. J. Forecast. 1999, 18, 505–516. [Google Scholar] [CrossRef]
- So, M.K.; Chen, C.W.; Liu, F.C. Best subset selection of autoregressive models with exogenous variables and generalized autoregressive conditional heteroscedasticity errors. J. R. Stat. Soc. Ser. (Appl. Stat.) 2006, 55, 201–224. [Google Scholar] [CrossRef]
- Chen, C.W.; Liu, F.C.; Gerlach, R. Bayesian subset selection for threshold autoregressive moving-average models. Comput. Stat. 2011, 26, 1–30. [Google Scholar] [CrossRef]
- Ismail, M.A.; Amin, A.A. Gibbs Sampling For SARMA Models. Pak. J. Stat. 2014, 30, 153–168. [Google Scholar]
- Barnett, G.; Kohn, R.; Sheather, S. Bayesian estimation of an autoregressive model using Markov chain Monte Carlo. J. Econom. 1996, 74, 237–254. [Google Scholar] [CrossRef]
- Barnett, G.; Kohn, R.; Sheather, S. Robust Bayesian Estimation Of Autoregressive–Moving-Average Models. J. Time Ser. Anal. 1997, 18, 11–28. [Google Scholar] [CrossRef]
- Ismail, M.A. Bayesian Analysis of Seasonal Autoregressive Models. J. Appl. Stat. Sci. 2003, 12, 123–136. [Google Scholar]
- Ismail, M.A. Bayesian Analysis of the Seasonal Moving Average Model: A Gibbs Sampling Approach. Jpn. J. Appl. Stat. 2003, 32, 61–75. [Google Scholar] [CrossRef]
- Amin, A.A.; Ismail, M.A. Gibbs Sampling for Double Seasonal Autoregressive Models. Commun. Stat. Appl. Methods 2015, 22, 557–573. [Google Scholar] [CrossRef]
- Amin, A.A. Bayesian Inference for Double Seasonal Moving Average Models: A Gibbs Sampling Approach. Pak. J. Stat. Oper. Res. 2017, 13, 483–499. [Google Scholar] [CrossRef]
- Amin, A.A. Gibbs Sampling for Double Seasonal ARMA Models. In Proceedings of the 29th Annual International Conference on Statistics and Computer Modeling in Human and Social Sciences, Cairo, Egypt, 28–30 March 2017. [Google Scholar]
- Amin, A.A. Full Bayesian analysis of double seasonal autoregressive models with real applications. J. Appl. Stat. 2023, 1–21. [Google Scholar] [CrossRef]
- Amin, A.A. Bayesian Inference of Triple Seasonal Autoregressive Models. Pak. J. Stat. Oper. Res. 2022, 18, 853–865. [Google Scholar] [CrossRef]
- Raftery, A.E.; Lewis, S.M. The number of iterations, convergence diagnostics and generic Metropolis algorithms. Pract. Markov Chain. Monte Carlo 1995, 7, 763–773. [Google Scholar]
- Geweke, J. Evaluating the accuracy of sampling-based approaches to the calculations of posterior moments. Bayesian Stat. 1992, 4, 641–649. [Google Scholar]
- LeSage, J.P. Applied Econometrics Using MATLAB; Technical Report; Department of Economics, University of Toronto: Toronto, ON, Canada, 1999. [Google Scholar]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).