Abstract
Relation classification is a significant task within the field of natural language processing. Its objective is to extract and identify relations between two entities in a given text. Within the scope of this paper, we construct an artificial dataset (CS13K) for relation classification in the realm of cybersecurity and propose two models for processing such tasks. For any sentence containing two target entities, we first locate the entities and fine-tune the pre-trained BERT model. Next, we utilize graph attention networks to iteratively update word nodes and relation nodes. A new relation classification model is constructed by concatenating the updated vectors of word nodes and relation nodes. Our proposed model achieved exceptional performance on the SemEval-2010 task 8 dataset, surpassing previous approaches with a remarkable F1 value of 92.3%. Additionally, we propose the integration of a ranking-based voting mechanism into the existing model. Our best results are an F1 value of 92.5% on the SemEval-2010 task 8 dataset and a value 94.6% on the CS13K dataset. These findings highlight the effectiveness of our proposed models in tackling relation classification tasks.
MSC:
68T50
1. Introduction
In light of the dynamic evolution of the cybersecurity field and the exponential expansion of cybersecurity data, traditional analysis methods became inadequate to fulfill the demands of the cybersecurity industry. Considering how to timely and accurately analyze and process massive amounts of data, extract key elements and relations, and mine potential valuable information emerged as pressing issues that require immediate resolution. The use of natural language processing technology can help cybersecurity experts quickly and accurately process and analyze large amounts of cybersecurity data and textual information, thereby better understanding and applying cybersecurity knowledge. Therefore, scholars attempted to leverage natural language processing techniques, including named entity recognition [1], relation extraction [2], and attribute extraction [3]; as well as mathematical representation methods, including quantization [4], dimensionality reduction [5], and interpolation [6,7]; as means of identifying, analyzing, defending against, and mitigating various cybersecurity attacks.
Relation classification is a classical problem within the domain of relation extraction and a crucial task in natural language processing (NLP). It primary objective is to identify the pre-defined relations between two target entities in a given sentence and represent these relations as triples with “subject, predicate, object” forms, which serve as foundational data sources for constructing knowledge graphs. BERT [8,9], which is a Transformer-based bidirectional language model, demonstrated impressive performance across diverse NLP tasks. Unlike conventional unidirectional language models, BERT stands out as it is trained in both left-to-right and right-to-left directions. This enables BERT to capture contextual information effectively, resulting in dynamic word vectors that adapt to the context, thereby capturing contextual semantics more effectively. The model attained state-of-the-art outcomes in various classification and sequence labeling tasks and was adopted and applied in various fields, including relation extraction, question answering, text representation, and natural language inference [8,10].
Graph Neural Networks (GNNs) are types of neural network specifically designed to handle graph-structured data. Due to their ability to handle data with arbitrary topology, GNNs found extensive applications in diverse fields, such as graph classification, node classification, relation prediction, object tracking, etc. [11]. Compared to traditional graph-based methods, GNNs can directly learn the representations of nodes and graphs from their topological structures. Meanwhile, Graph Attention Networks (GATs) integrate GNNs and attention mechanisms. In the GATs model, relationships between nodes are captured through attention weights, which are subsequently employed to perform weighted aggregation of the features of neighboring nodes. This process, in turn, updates the nodes’ representations, enhancing the model’s expressive power.
In this paper, we constructed a cybersecurity dataset named CS13K specifically for relation classification tasks using manual annotation. Given that the relation classification task requires high position information for the two entities, we inserted special markers before and after the target entities to identify their positions and transmit the information to the BERT model. Next, we located the positions of the two target entities within the output embeddings of the BERT model, allowing the model to capture the semantics of the sentence and the semantics of the entities in a simultaneous manner. Based on this method, we used GATs to iteratively update word nodes and relation nodes, and constructed a new GATs-based relation classification model (Bert-GAT). Furthermore, based on the work in the literature [12], we introduced a voting mechanism in the Bert–GAT and the R-Bert models, and constructed a new ensemble model called Bert–Vote, which was specifically tailored for relation classification tasks. In summary, the key contributions of this paper are:
- (1)
- Based on our current understanding, the CS13K dataset we constructed is the first manually annotated text dataset for relation classification in the field of cybersecurity.
- (2)
- To encode the entities and sentences, we inserted special marker symbols before and after the target entities to identify their positions, and utilized the BERT pre-training model. Additionally, we iteratively updated word nodes and relation nodes using GATs, resulting in the development of a novel relation classification model, named Bert–GAT. The proposed model attained a remarkable state-of-the-art performance, obtaining an F1 score of 92.3% on the SemEval-2010 task 8 dataset and a 94.1% score on the CS13K dataset.
- (3)
- We employed an ensemble learning approach to construct a new relation classification model, known as Bert–Vote, which achieved a state-of-the-art performance of 92.5% in terms of F1 score on the SemEval-2010 task 8 dataset, as well as a 94.6% score on the CS13K dataset.
The remaining content of this paper is organized as follows: Section 2 discusses related work in terms of relation classification datasets, relation classification tasks, graph neural networks, and voting mechanisms; Section 3 provides a detailed introduction to the proposed cybersecurity relation classification dataset and relation classification model; in Section 4, the experiments and evaluation are presented and Section 5 provides the conclusions and future works of the article.
2. Related Work
In this section, we will conduct a comprehensive review of previous work on relation classification datasets, relation classification tasks, GNNs, voting mechanisms, and other related research, providing a comprehensive overview of these studies.
2.1. Relation Classification Datasets
Relation classification is a highly challenging problem in NLP. In recent years, significant progress was made in relation classification tasks in various fields. Common relation classification datasets include SemEval 2010 Task 8, DDRel, FewRel, TACRED, and MATRES [13,14,15]. SemEval 2010 Task 8 is a dataset for multi-dimensional relation classification in the general domain. DDRel is a dataset for interpersonal relation classification in binary dialogues. FewRel is a relation classification dataset containing 100 categories and 7836 sentences constructed from Wikipedia. The TACRED dataset contains approximately 90,000 sentences from news articles, each of which contains information about the relations between two entities. These relations are divided into 42 different types, such as “author”, “organization member”, “birthplace”, etc. The MATRES dataset contains nearly 1000 news articles, with over 2000 events annotated with temporal relations to other events. This dataset has high annotation accuracy, and provides an important foundation for research on time relation recognition and event extraction. Although significant progress was made in relation classification in general domains, it has been slow in the field of cybersecurity. This issue is largely because the data in the field of cybersecurity are highly specialized, and there is a lack of open-source datasets for relation classification. Furthermore, existing publicly available datasets are of poor data quality, which has become one of the main obstacles in research on relation classification tasks in cybersecurity, particularly in the development of deep learning-based relation classification algorithms. Therefore, building a relation classification dataset that is as close to real-world situations as possible is crucial for promoting research in the field of cybersecurity.
2.2. Relation Classification
In current studies on relation classification, the main methods can be classified into three distinct categories: feature-, kernel-, and neural network-based approaches. Among them, feature-based methods excessively rely on expert knowledge, face difficulties in feature selection, and have poor transferability to new domains. In contrast, kernel-based methods have the advantage of automatically extracting a multitude of useful features, which can be obtained from syntax trees or strings, avoiding the trouble of manually constructing the feature space. Bunescu et al. [16] proposed a relation extraction kernel based on the shortest path between two entities by comparing the number of identical nodes in the paths. Culotta et al. [17] obtained a tree kernel by weighting and summing common subtrees, migrated the tree kernel to dependency trees, and then added syntactic parsing information, significantly improving the classification accuracy. The problem with these methods is that their recall rate is relatively low; therefore, many scholars subsequently focused on improving the recall rate.
Although neural network-based relation classification methods have constraints, such as high model complexity or the need for large-scale training corpus, they are still the most effective relation classification methods currently available, and scholars are still focusing on optimizing and improving the model’s generalization ability. Liu et al. [18] were pioneers in utilizing neural networks to automatically extract features for relation classification, proposing a relation classification method based on convolutional neural networks (CNN). The network architecture consists of a single convolutional layer, followed by a fully connected layer, and a softmax layer, with a relatively simple structure. Based on this approach, scholars successively proposed many CNN-based improved methods [19,20]. Socher et al. [21] first attempted to use recursive neural networks to solve relation classification problems, and other scholars used recurrent neural networks to solve relation classification problems. Thang et al. [22] integrated CNN and RNN in their approach, utilizing both models to perform relation classification to identify connections between two entities, and then using a voting mechanism to filter out the final relation classification result, where the CNN and RNN voting weights can be adjusted. Recently, some scholars attempted to introduce the BERT model into relation classification tasks and combined it with information about target entities to handle relation classification problems, proposing the R-BERT model, which effectively integrates text features and semantic features of sentences, achieving an F1 value of 89.25% on the SemEval2010 task 8 relation classification dataset [12]. By constructing a heterogeneous graph to model entities and relations, the RIFRE model achieves outstanding performance in the joint extraction of entities and relations [23]. The CorefBERT model uses entity recognizers and coreference resolvers as two important components. The entity recognizer first identifies entities in the text and marks them, and then embeds their representations into the BERT model. The coreference resolver uses the output of the entity recognizer to determine to which entity each reference refers, and then embeds their representations into the BERT model. Finally, the model uses these embeddings to perform relation classification tasks, achieving an F1 value of 89.2% [24]. In the QA model, the input text is initially encoded using a bidirectional LSTM. Subsequently, an attention mechanism is employed to identify and select potential relation segments between the two entities of interest. Following that method, a span prediction layer is utilized to predict whether these segments contain a relation. During the prediction process, the model simultaneously predicts the label of each relation and the starting and ending positions of the relation text segment, enabling direct prediction of the relation text segment without the need for manual feature extraction [25]. The writing style and format of the translation should adhere to the conventions of academic papers written in English, and there should be no grammatical errors.
2.3. GNNs
In the research on GNNs, Xie et al. [26] proposed a method that uses sentence nodes and entity nodes as the basic units of the heterogeneous GNNs and captures the neighborhood information between relation nodes and sentence nodes. The advantage of this method is its ability to capture diverse data from various types of nodes and integrate them into a common node classification task. Sahu et al. [27] introduced a method for cross-sentence relation extraction, which utilizes document-level GNNs, considering the dependency relations between sentences as edges and capturing the interaction between sentences by constructing a document-level graph model, thus achieving accurate and effective cross-sentence relation extraction results. Mandya et al. [28] introduced a graph convolutional neural network model that incorporates multi-dependency subgraphs for relation extraction tasks in sentences. The model can capture semantic information from different parts of the sentence and fuse it to improve the efficiency and accuracy of relation extraction. Zhao et al. [29] proposed a new entity-pair-based graph neural network model called EPGNN. EPGNN uses GNNs to model the relations between entities and uses a combination of semantic features and graph topology features for relation classification. Compared to traditional feature-based methods, GNNs can handle complex relations between nodes and edges and use graph structural information to extract more accurate features.
2.4. Voting Mechanisms
The voting mechanism is a commonly used model ensemble method that combines the predictions of multiple models to improve the accuracy and robustness of the model. In classification problems, the voting mechanism is typically used to determine the ultimate classification outcome of each sample, with the basic idea of selecting the class with the most votes or highest scores as the sample’s classification label. Mushtaq et al. [30] used a range of machine learning algorithms to train and optimize multiple biomedical features, and then integrated the output results of these algorithms using the voting mechanism to improve the accuracy of diabetes prediction. Bhati et al. [31] introduced a new voting-based ensemble method for intrusion detection systems (IDS). This method uses multiple separate IDS models, each of which is trained using different feature subsets and classifiers. Next, by voting on the results of each model, the outcomes of the conducted experiments showed that this method can significantly improve the performance of IDS. Khan et al. [32] constructed an IoT network intrusion detection method based on a voting classifier, which is composed of multiple classifiers to form a voting ensemble model, with each classifier using different feature sets and algorithms for training. When a new data sample is input into the system, each classifier generates a prediction result, which is then determined using the voting mechanism to achieve the final classification result. By employing this approach, different classifiers can be integrated to enhance the accuracy of intrusion detection. Maheshwari et al. [33] introduced a refined ensemble model that employs weighted voting for the purpose of detecting and mitigating DDoS attacks in SDN environments. The ensemble model consists of multiple base classifiers, each of which classifies data and then merges their classification results into a final classification result. The authors also introduced an optimized weighted voting strategy to enhance the accuracy and robustness of the model.
3. Methodology
In this section, we will offer a comprehensive introduction to the cybersecurity dataset that we constructed. Moreover, we will provide an in-depth elucidation of the architecture underlying our relation classification model.
3.1. Dataset
To advance research on relation classification tasks in the field of cybersecurity, we collected data from over 440 publicly available security reports and manually constructed a cybersecurity relation classification dataset, which is named CS13K. Each security report was published by internationally recognized security firms or government agencies, including cybersecurity blogs, research papers, and technical documents. The reports were analyzed, extracted, and annotated by multiple doctoral students from the Cybersecurity Institute, who possess good domain knowledge in the field of cybersecurity. The CS13K dataset comprises 12 relation types, namely belongTo, cause, exploits, hasAttackLocation, hasAttackTime, hasCharacteristics, hasVulnerability, indicates, mitigates, targets, use, and associate. The dataset contains 13,027 sentences, each of which includes two entities and the relation type between them.
The relations in the dataset exhibit directionality, meaning that relation(entity1, entity2) and relation(entity2, entity1) are distinct. Therefore, in this task, it is necessary not only to predict the relations between entities, but also to predict the direction of the relations. Hence, there are 24 relation types in the actual relation classification dataset. Table 1 shows examples of the exploits and hasVulnerability relation types. exploits(e1, e2) and exploits(e2, e1) represent two distinct relation types. For each sentence containing the target entities e1 and e2, we marked the entities with special symbols.

Table 1.
Examples of CS13K dataset.
The statistical characteristics of the CS13K dataset are shown in Table 2. For training purposes, we utilized 11,500 samples, while 1527 samples were reserved for testing.
Table 2.
Relation types in CS13K dataset and their statistical characteristics.
We validated the effectiveness of the relation classification model using the CS13K dataset and conducted comparative evaluations with the SemEval-2010 Task 8 dataset. The evaluation metric employed for these comparisons was the macro-averaged F1 score.
3.2. Relation Classification Models
In order to ensure that the model effectively incorporated the positional information of these two entities, for any sentence containing two target entities, we inserted special markers “$” at the initial and final positions of the first entity, entity 1, and “#” at the initial and final positions of the second entity, entity 2. In addition, at the beginning of each sentence, we included the token “[CLS]”, and at the end, we append the token “[SEP]”. Based on the work in the literature [12], we used the BERT model to encode each word in the sentence. Assuming that entity 1 was embedded as a vector from to and entity 2 was embedded as a vector from to , we obtain the mean vector of entity 1 by averaging the vectors from to , and similarly, we obtained the mean vector of entity 2 by averaging the vectors from to , where . Similarly, we embedded each pre-defined relation label as a high-dimensional vector with the same dimension as the entity vectors using a relation encoder, where .
Building on the work of [9,21], we denoted all entity nodes as and all relation nodes as . We treated entity nodes and relation nodes as neighbors and updated their node representations through a message-passing mechanism. We incorporated a multi-head attention mechanism to augment the model’s capability to attend and concentrate on node features. For each attention head , we first constructed the query matrix , key matrix , and value matrix :
where , , and are trainable weight parameters.
Next, we calculated the attention weights.
where is the dimension of the key matrix .
Next, we utilized the attention weights to update the nodes and obtain the output of each attention head.
We concatenated the outputs of all attention heads, , together, and then multiplied the concatenated output vector by the weight matrix to obtain the final multi-head attention output.
where is a trainable weight parameter, , is a neighbor of node , and is the attention weight between the entity node and the relation node .
A gating mechanism was used to calculate weight vectors for each node and edge, enabling the model to maintain its non-linear capacity.
where is a trainable weight parameter and is the final output of node representation. We simplify the above node update process as follows:
where GAT refers to the mechanism employed to update the node , are all the neighboring nodes of the entity node , and is the updated node representation of the node .
The exchange in information between entity nodes and relation nodes can be illustrated as the message-passing process:
where is the node representation before the update, is the updated node representation of , and is the final entity node representation.
Similarly, based on the update of entity nodes, the update process of relation nodes can be represented as:
where is the representation of the relation node before the update and is the updated representation of . When the model contains multiple layers of GAT, the node update process of other layers is similar.
After obtaining the updated entity nodes and relation nodes, we applied a Dropout layer and introduce a fully connected layer in the model architecture to obtain output vectors for entity nodes, as well as for relation nodes. Finally, we concatenated , , and , and added a fully connected layer to obtain . We then applied a Softmax classification layer for the final relation classification. This process is represented as follows:
where and are trainable parameters. We denoted the relation classification model that used special marker symbols for entity tagging and iteratively updated the word nodes and relation nodes using graph neural networks as the Bert–GAT model. Figure 1 illustrates the model architecture.
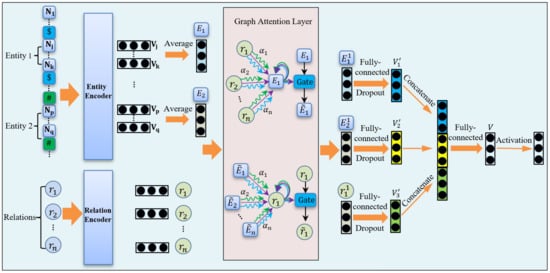
Figure 1.
Bert–GAT model.
In addition, given that voting mechanisms can fully utilize the advantages of multiple models, thus enabling them to complement each other and enhance the robustness and generalization ability of the models, we introduced a new relation classification model called Bert–Vote. It was based on a ranking-based voting mechanism that combined the strengths of Bert–GAT and R-Bert models to determine the final classification result, aiming to achieve better performance in relation classification.
Specifically, for all sentences that comprise two target entities, the Bert–GAT and R-Bert models calculated the probability of the sentence belonging to any pre-defined relations. Firstly, we sorted the predicted results of the R-Bert and Bert–GAT models in descending order of probability and select the top three as candidate results, forming a candidate result list. We supposed that the anticipated candidate outcomes of the R-Bert and Bert–GAT models were A, B, C and B, D, E, respectively. Subsequently, the combined candidate result list was A, B, C, D, E. Secondly, we compared the candidate results of the R-Bert and Bert–GAT models. For each candidate result, we checked whether it existed in the candidate results of the other model. If it did exist, both models had the same prediction result; if it did not exist, the prediction outcomes of the two models were different. For the results predicted by both models, their probabilities were added to obtain the integrated result. For the results predicted by only one model, they were directly taken as the integrated result. Finally, we designated the type associated with the highest probability as the final classification result.
In the above process, we denoted the probabilities calculated via the Bert–GAT model as , and similarly, we denoted the probabilities predicted using the R-Bert model as . We integrated and by allocating a voting weight to each model, which can be adjusted according to the classifier’s performance.
where the probability of a sentence being classified as a certain type of relation by the Bert–Vote model is denoted as > 0 is an adjustable parameter. Figure 2 depicts the architecture of the Bert–Vote model.
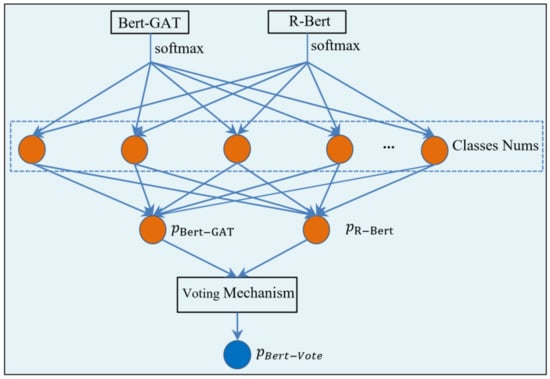
Figure 2.
Schematic diagram of Bert–Vote model.
In addition, to compare them with the Bert–Vote model, we referred to the models that use a simple weighted voting mechanism as W-Vote and A-Vote. The W-Vote model selected the class with the maximum probability value among the predicted results of Bert–GAT and R-Bert as the final prediction result. In contrast, A-Vote performed weighted addition on the predicted results of Bert–GAT and R-Bert, before selecting the type with the maximum average probability value as the final prediction result.
4. Experiments and Evaluation
In this section, we will separately assess the effectiveness of the Bert–GAT and Bert–Vote models on the general dataset SemEval-2010 Task 8, and verify the performance of the two models on the cybersecurity dataset CS13K.
4.1. Experimental Settings and Evaluating Metrics
For the dataset of SemEval-2010 Task 8, we employ the Macro F1 value as the evaluation metric and the official scoring script to assess our model’s performance on the relation classification task. The dataset includes nine pre-defined semantic relation types, along with one manually defined relation type called “Other”. It contains a total of 10,717 sentences, which are further split into 8000 sentences for training purposes and 2717 sentences for testing purposes. The official scoring script calculates the Macro F1 score for the nine pre-defined actual relations and considers directionality. On the cybersecurity dataset CS13K, besides reporting the Macro F1 value, we also report the precision and recall values for a more comprehensive evaluation of the model’s performance. Table 3 showcases the key parameter settings for the Bert–GAT model.
Table 3.
Key parameter settings.
4.2. Comparison with Other Models
On the dataset of SemEval-2010 Task 8, we conducted comparisons between our models and other baseline models, including RNN, CNN, Bi-LSTM, Att-Pooling-CNN, R-BERT, SPOT, and RIFRE. Macro F1 was used as the evaluation metric for all methods, and the results of these comparisons are presented in Table 4. It is noticeable that both the Bert–GAT model and Bert–Vote model exhibited superior performance compared to all baseline models, as indicated via the F1 score. Specifically, the Bert–GAT model achieved an F1 score of 92.3% on the dataset of SemEval-2010 Task 8, exhibiting a 3.0% increase compared to the R-BERT model. This finding suggests that by inserting special tokens before and after the target entities and using GATs to iteratively update the word nodes and relation nodes, the model excels at capturing intricate relationships within the text, leading to improved classification results.
Table 4.
Results of relation classification tasks based on SemEval-2010 Task 8 dataset.
On the dataset of SemEval-2010 Task 8, the F1 scores of the W-Vote and A-Vote models are 91.6% and 92.1%, respectively. This result may be due to the fact that the simple weighted voting mechanism cannot accurately capture the complex relationship between models, and cannot effectively combine the strengths of the Bert–GAT and R-Bert models. In contrast, the Bert–Vote model achieved an F1 score of 92.5%, surpassing the F1 score of the R-Bert model by 3.2% and the F1 score of the Bert–GAT model by 0.2%. This finding indicates that the ranking-based voting mechanism can increase the diversity of candidate results and enable models to complement each other, thereby improving the performance of relation classification.
4.3. Relation Classification in Cybersecurity
Furthermore, we performed relation classification experiments on the CS13K dataset utilizing the Bert–GAT and Bert–Vote models, and compared their performance to that of the baseline R-BERT model. The outcomes are presented in Table 5. Table 5 reveals that the F1 scores of the Bert–GAT and Bert–Vote models on the CS13K dataset are 94.1% and 94.6%, respectively, which both outperform the R-BERT model. Compared to the outcomes on the SemEval-2010 Task 8, the classification accuracies of the two models slightly improved. This result may be due to the fact that the CS13K dataset was constructed by domain experts who have in-depth knowledge and experience in the field. Through careful data annotation, they were able to better control data quality, effectively reducing noise and redundant information in the dataset. As a result, the models’ classification accuracy experienced notable improvement.
Table 5.
Relation classification results on CS13K dataset.
In addition, we reported the Precision, Recall, and F1 scores of the Bert–GAT model for each specific relation type, which are displayed in Table 6. By analyzing the Precision, Recall, and F1 scores for each distinct relation type, we can gain a deeper understanding of the model’s classification performance under different relations. We found that the model exhibited different precision and recall rates in different relation types. For example, relations such as “cause(e2, e1)” and “hasCharacteristics(e2, e1)” had relatively high precision and recall rates, while the relation “associate(e2, e1)” had a relatively low one. This result suggests that the model’s classification ability varies under different relation types, possibly due to differences in sample quality and features among different relations in the dataset.
Table 6.
Results for different relation types in CS13K dataset.
4.4. Ablation Experiments
To examine the influence of individual components on the model’s performance, we conducted a series of experiments to investigate the influence of various factors on the performance of our relation classification model. During the experiments, we set all parameters, except for the component being tested to their optimal values.
To verify the influence of GATs on the performance of the model, we conducted four groups of experiments with GATs layers set to 0, 1, 2, and 3, respectively. The 0 layer indicates the removal of the GATs layer in the model to verify the influence of adding GATs layers on the model’s relation classification performance. The 1, 2, and 3 layers are used to assess the influence of the number of GATs layers on the performance of the model. We denote the settings with GATs layers set to 0, 1, 2, and 3 as Bert–GAT-layer-0, Bert–GAT-layer-1, Bert–GAT-layer-2, and Bert–GAT-layer-3, respectively.
The multi-head attention mechanism allows the capture of multiple interactions and dependencies among different neighboring nodes, thus enhancing the model’s performance. However, the appropriate number of attention heads may vary depending on the dataset and task. Therefore, we investigated the influence of different numbers of attention heads on the model’s effectiveness. In our experiments, we varied the number of attention heads used, specifically setting it to 0, 2, 4, 8, and 12, which we denote as Bert–GAT-head-0, Bert–GAT-head-2, Bert–GAT-head-4, Bert–GAT-head-8, and Bert–GAT-head-12, respectively. Here, Bert–GAT-head-0 refers to the configuration where the multi-head attention mechanism is removed.
In addition, we examined the impact of padding methods on the model’s performance. One option is to process all sentences at a constant length, and we selected 512 as the length. If a sentence is shorter than 512, it is padded with zeros. We denote this method as Bert–GAT-padding-512. Another option is to use dynamic padding for each batch of sentences, where the padded length is equal to the maximum length of sentences in the batch. We denote this method as Bert–GAT-Dynamic-padding.
Meanwhile, we investigated the impact of the entity itself on the relation classification performance. We removed the special symbols ‘$’ and ‘#’ used to mark entities in the sentences and replaced both Entity1 and Entity2 with “[UNK]”. We denote this method as Bert–GAT-UNK.
Finally, in order to further evaluate the performance of our proposed relation classification model under different BERT variants, we conducted comparative experiments with lightweight BERT models, such as DistillBERT, TinyBERT, and ALBERT. These lightweight BERT models reduce model complexity by reducing embedding dimensions, parameter sizes, or utilizing parameter-sharing schemes. We evaluated these models using the same experimental settings, and employed F1 score as the evaluation metric.
Table 7 presents the outcomes of the ablation experiments. Indeed, the number of layers in the GATs exhibits a substantial influence on the performance of the model, as evident from our observations. On the dataset of SemEval-2010 Task 8, when the number of layers in the GATs is 0, there is a 2.9% decrease in the F1 score compared to when the number of layers is 2, and a 3.8% decrease in the score for the CS13K dataset. As the number of layers in the GATs increases, we observe an improvement in the model’s classification performance. When the number of layers is greater than 1, the model’s performance tends to stabilize.
Table 7.
Influence of different components on the model performance.
The inclusion of the multi-head attention mechanism also contributes to the improvement of the model’s performance to some extent. Within a certain range, increasing the number of attention heads leads to improved model performance, and the best performance is achieved when the number of heads is 8. This trend is observed in both the SemEval-2010 Task 8 and CS13K datasets.
The padding method also has a certain impact on the model’s performance. Using the dynamic padding method leads to slightly better results than using constant padding. This result may be due to the burden imposed on the model when the sentence length is too long. In addition, the meaning of the entities themselves has a significant impact on the model’s performance. When Entity1 and Entity2 in the sentence are replaced with “[UNK]”, the model’s classification performance decreases significantly compared to the optimal results.
As shown in Table 8, the performance and convergence time differences among DistillBERT, TinyBERT, and ALBERT can be attributed to their architectural variances and parameter settings. DistillBERT and TinyBERT achieve a balance between performance and model size reduction, while ALBERT sacrifices some performance for a more compact parameter configuration. In contrast, our Bert–GAT model combines the strengths of BERT, resulting in enhanced relational modeling capabilities.
Table 8.
Performance of lighter BERT-based models.
4.5. LIME Explanations for Relation Classification Results
We employed LIME to explain the relation classification results for both general text and cybersecurity text. Table 9 showcases examples of a general domain text and a cybersecurity domain text, along with their corresponding explanations obtained through as shown LIME in Figure 3. These explanations highlight the impact of different words on the classification results.
Table 9.
Examples of Texts and Relations.
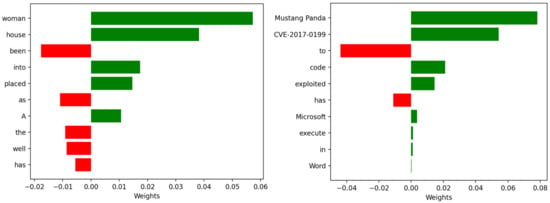
Figure 3.
Weights Distribution of General Text (left) and Cybersecurity Text (right).
Specifically, LIME computes the weights of each word in the relation classification results, contributing to our understanding of the model’s decision-making process. In Figure 3, we use green markers to indicate words that have a positive influence on the classification results, while red markers indicate words that have a negative influence. These visualizations provide an intuitive way of comprehending the model’s decision-making process in relation classification to some extent.
5. Conclusions and Future Works
This paper focuses on investigating the task of relation classification in the field of cybersecurity, which involves discerning the relations between entities from texts. To address this issue, we first constructed a manually annotated cybersecurity dataset called CS13K, and proposed two new relation classification models: Bert-GAT and Bert-Vote. Experimental results showed that Bert-GAT attained an impressive F1 value of 92.3% on the SemEval-2010 task 8 dataset and a 94.1% value on the CS13K dataset, which verified the effectiveness of special entity position tags and the introduction of GATs in dealing with relation classification problems. We introduced a ranking-based voting mechanism in the Bert–Vote model, which achieved the best performance of 92.5% on the SemEval-2010 task 8 dataset and a 94.6% value on the CS13K dataset. This result demonstrates that the method based on the voting mechanism can integrate different classifier results to enhance the performance of the relation classification models. While our proposed models showed impressive performance, there is still room for further improvement. Future research can explore techniques to optimize these models, such as experimenting with different architectures or exploring diverse GNNs models to enhance the encoding of node representations.
Author Contributions
Conceptualization, Z.S. and H.L.; methodology, Z.S. and C.P.; software, Z.S.; validation, D.Z.; formal analysis, H.L. and C.P.; investigation, Z.S.; writing—original draft preparation, Z.S.; writing—review and editing, C.P. and D.Z.; visualization, Z.S.; supervision, H.L.; funding acquisition, H.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (Grant no. 61771001).
Data Availability Statement
Publicly available datasets were analyzed in this research. The SemEval-2010 task 8 dataset can be found here (https://huggingface.co/datasets/sem_eval_2010_task_8; accessed on 1 January 2023). The CS13K dataset that supports the findings of this study is available from the corresponding author upon reasonable request.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Wang, X.; Liu, X.; Ao, S.; Li, N.; Jiang, Z.; Xu, Z.; Xiong, Z.; Xiong, M.; Zhang, X. Dnrti: A large-scale dataset for named entity recognition in threat intelligence. In Proceedings of the 2020 IEEE 19th International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Guangzhou, China, 29 December 2020–1 January 2021; pp. 1842–1848. [Google Scholar]
- Wang, Y.; Wang, Y.; Peng, Z.; Zhang, F.; Yang, F. A Concise Relation Extraction Method Based on the Fusion of Sequential and Structural Features Using ERNIE. Mathematics 2023, 11, 1439. [Google Scholar] [CrossRef]
- Shen, G.; Qin, Y.; Wang, W.; Yu, M.; Guo, C. Distant Supervision for Relations Extraction via Deep Residual Learning and Multi-instance Attention in Cybersecurity. In Proceedings of the Security and Privacy in New Computing Environments: Third EAI International Conference, SPNCE 2020, Lyngby, Denmark, 6–7 August 2020; Proceedings 3. Springer: Berlin/Heidelberg, Germany, 2021; pp. 151–161. [Google Scholar]
- Li, H.; Hu, K.; Zhao, D. The Golden Quantizer in Complex Dimension Two. IEEE Commun. Lett. 2021, 25, 3249–3252. [Google Scholar] [CrossRef]
- Peng, Z.; Li, H.; Zhao, D.; Pan, C. Reducing the Dimensionality of SPD Matrices with Neural Networks in BCI. Mathematics 2023, 11, 1570. [Google Scholar] [CrossRef]
- Li, H.; Qin, X.; Zhao, D. An improved empirical mode decomposition method based on the cubic trigonometric B-spline interpolation algorithm. Appl. Math. Comput. 2018, 332, 406–419. [Google Scholar] [CrossRef]
- Li, H.; Gao, Z.; Zhao, D. Least squares solutions of the matrix equation AXB+ CYD= E with the least norm for symmetric arrowhead matrices. Appl. Math. Comput. 2014, 226, 719–724. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Xiong, H.; Yan, Z.; Zhao, H.; Huang, Z.; Xue, Y. Triplet Contrastive Learning for Aspect Level Sentiment Classification. Mathematics 2022, 10, 4099. [Google Scholar] [CrossRef]
- Joshi, M.; Chen, D.; Liu, Y. Spanbert: Improving pre-training by representing and predicting spans. Trans. Assoc. Comput. Linguist. 2020, 8, 64–77. [Google Scholar] [CrossRef]
- Velickovic, P.; Cucurull, G.; Casanova, A. Graph attention networks. Stat 2017, 1050, 10-48550. [Google Scholar]
- Wu, S.; He, Y. Enriching pre-trained language model with entity information for relation classification. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 2361–2364. [Google Scholar]
- Jia, Q.; Huang, H.; Zhu, K.Q. Ddrel: A new dataset for interpersonal relation classification in dyadic dialogues. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; pp. 13125–13133. [Google Scholar]
- Hendrickx, I.; Kim, S.N.; Kozareva, Z.; Nakov, P. Semeval-2010 task 8: Multi-way classification of semantic relations between pairs of nominals. arXiv 2019, arXiv:1911.10422. [Google Scholar]
- Han, X.; Zhu, H.; Yu, P.; Wang, Z.; Yao, Y.; Liu, Z.; Sun, M. Fewrel: A large-scale supervised few-shot relation classification dataset with state-of-the-art evaluation. arXiv 2018, arXiv:1810.10147. [Google Scholar]
- Bunescu, R.; Mooney, R. A shortest path dependency kernel for relation extraction. In Proceedings of the Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing, Vancouver, BC, Canada, 6–8 October 2005; pp. 724–731. [Google Scholar]
- Culotta, A.; Sorensen, J. Dependency tree kernels for relation extraction. In Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics, Barcelona, Spain, 21–26 July 2004; pp. 423–429. [Google Scholar]
- Sekine, S. On-demand information extraction. In Proceedings of the COLING/ACL 2006 Main Conference Poster Sessions, Sydney, Australia, 17–18 July 2006; pp. 731–738. [Google Scholar]
- Qin, P.; Xu, W.; Guo, J. An empirical convolutional neural network approach for semantic relation classification. Neurocomputing 2016, 190, 1–9. [Google Scholar] [CrossRef]
- Liu, Y.; Wei, F.; Li, S.; Ji, H.; Zhou, M.; Wang, H. A dependency-based neural network for relation classification. arXiv 2015, arXiv:1507.04646. [Google Scholar]
- Zhang, D.; Wang, D. Relation classification via recurrent neural network. arXiv 2015, arXiv:1508.01006. [Google Scholar]
- Nguyen, T.H.; Grishman, R. Combining neural networks and log-linear models to improve relation extraction. arXiv 2015, arXiv:1511.05926. [Google Scholar]
- Zhao, K.; Xu, H.; Cheng, Y.; Li, X.; Gao, K. Representation iterative fusion based on heterogeneous graph neural network for joint entity and relation extraction. Knowl.-Based Syst. 2021, 219, 106888. [Google Scholar] [CrossRef]
- Li, J.; Katsis, Y.; Baldwin, T.; Kim, H.C.; Bartko, A.; McAuley, J.; Hsu, C.N. SPOT: Knowledge-Enhanced Language Representations for Information Extraction. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, Atlanta, GA, USA, 17–21 October 2022; pp. 1124–1134. [Google Scholar]
- Cohen, A.D.; Rosenman, S.; Goldberg, Y. Relation classification as two-way span-prediction. arXiv 2020, arXiv:2010.04829. [Google Scholar]
- Xie, Y.; Xu, H.; Li, J.; Yang, C.; Gao, K. Heterogeneous graph neural networks for noisy few-shot relation classification. Knowl.-Based Syst. 2020, 194, 105548. [Google Scholar] [CrossRef]
- Sahu, S.K.; Christopoulou, F.; Miwa, M.; Ananiadou, S. Inter-sentence relation extraction with document-level graph convolutional neural network. arXiv 2019, arXiv:1906.04684. [Google Scholar]
- Mandya, A.; Bollegala, D.; Coenen, F. Graph Convolution over Multiple Dependency Sub-graphs for Relation Extraction. In Proceedings of the COLING, International Committee on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 6424–6435. [Google Scholar]
- Zhao, Y.; Wan, H.; Gao, J.; Lin, Y. Improving relation classification by entity pair graph. In Proceedings of the Asian Conference on Machine Learning, Nagoya, Japan, 17–19 November 2019; pp. 1156–1171. [Google Scholar]
- Mushtaq, Z.; Ramzan, M.F.; Ali, S.; Baseer, S.; Samad, A.; Husnain, M. Voting classification-based diabetes mellitus prediction using hypertuned machine-learning techniques. Mob. Inf. Syst. 2022, 2022, 1–16. [Google Scholar] [CrossRef]
- Bhati, N.S.; Khari, M. A new ensemble based approach for intrusion detection system using voting. J. Intell. Fuzzy Syst. 2022, 42, 969–979. [Google Scholar] [CrossRef]
- Khan, M.A.; Khan Khattk, M.A. Voting classifier-based intrusion detection for iot networks. In Advances on Smart and Soft Computing: Proceedings of the ICACIn 2021; Springer: Singapore, 2022; pp. 313–328. [Google Scholar]
- Maheshwari, A.; Mehraj, B.; Khan, M.S.; Idrisi, M.S. An optimized weighted voting based ensemble model for DDoS attack detection and mitigation in SDN environment. Microprocess. Microsyst. 2022, 89, 104412. [Google Scholar] [CrossRef]
- Socher, R.; Huval, B.; Manning, C.D.; Ng, A.Y. Semantic compositionality through recursive matrix-vector spaces. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Jeju, Republic of Korea, 12–14 July 2012; pp. 1201–1211. [Google Scholar]
- Zhang, S.; Zheng, D.; Hu, X.; Yang, M. Bidirectional long short-term memory networks for relation classification. In Proceedings of the 29th Pacific Asia Conference on Language, Information and Computation, Shanghai, China, 30 October–1 November 2015; pp. 73–78. [Google Scholar]
- Zeng, D.; Liu, K.; Lai, S.; Zhou, G.; Zhao, J. Relation classification via convolutional deep neural network. In Proceedings of the COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers, Dublin, Ireland, 23–29 August 2014; pp. 2335–2344. [Google Scholar]
- Yu, M.; Gormley, M.; Dredze, M. Factor-based compositional embedding models. In Proceedings of the NIPS Workshop on Learning Semantics, Montreal, QC, Canada, 8–13 December 2014; pp. 95–101. [Google Scholar]
- Santos CN, D.; Xiang, B.; Zhou, B. Classifying relations by ranking with convolutional neural networks. arXiv 2015, arXiv:1504.06580. [Google Scholar]
- Lee, J.; Seo, S.; Choi, Y.S. Semantic relation classification via bidirectional lstm networks with entity-aware attention using latent entity typing. Symmetry 2019, 11, 785. [Google Scholar] [CrossRef]
- Wang, L.; Cao, Z.; De Melo, G.; Liu, Z. Relation classification via multi-level attention cnns. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 1298–1307. [Google Scholar]
- Peters, M.E.; Neumann, M.; Logan, R.L., IV; Schwartz, R.; Joshi, V.; Singh, S.; Smith, N.A. Knowledge enhanced contextual word representations. arXiv 2019, arXiv:1909.04164. [Google Scholar]
- Soares, L.B.; FitzGerald, N.; Ling, J.; Kwiatkowski, T. Matching the blanks: Distributional similarity for relation learning. arXiv 2019, arXiv:1906.03158. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).