
Three-Branch Random Forest Intrusion Detection Model


Abstract
1. Introduction
2. Related Work and Background Work
2.1. Intrusion Detection Based on Machine Learning
- SVM
- 2.
- Naive Bayes
- 3.
- Decision tree
- 4.
- K-means clustering
- 5.
- Association Rules
- 6.
- Self-Organizing Map Neural Network
- 7.
- Deep Belief Network
- 8.
- Convolutional Neural Network
- 9.
- Recurrent Neural Network
- 10.
- AdaBoost
- 11.
- XGBoost
2.2. Related Work with Machine Learning
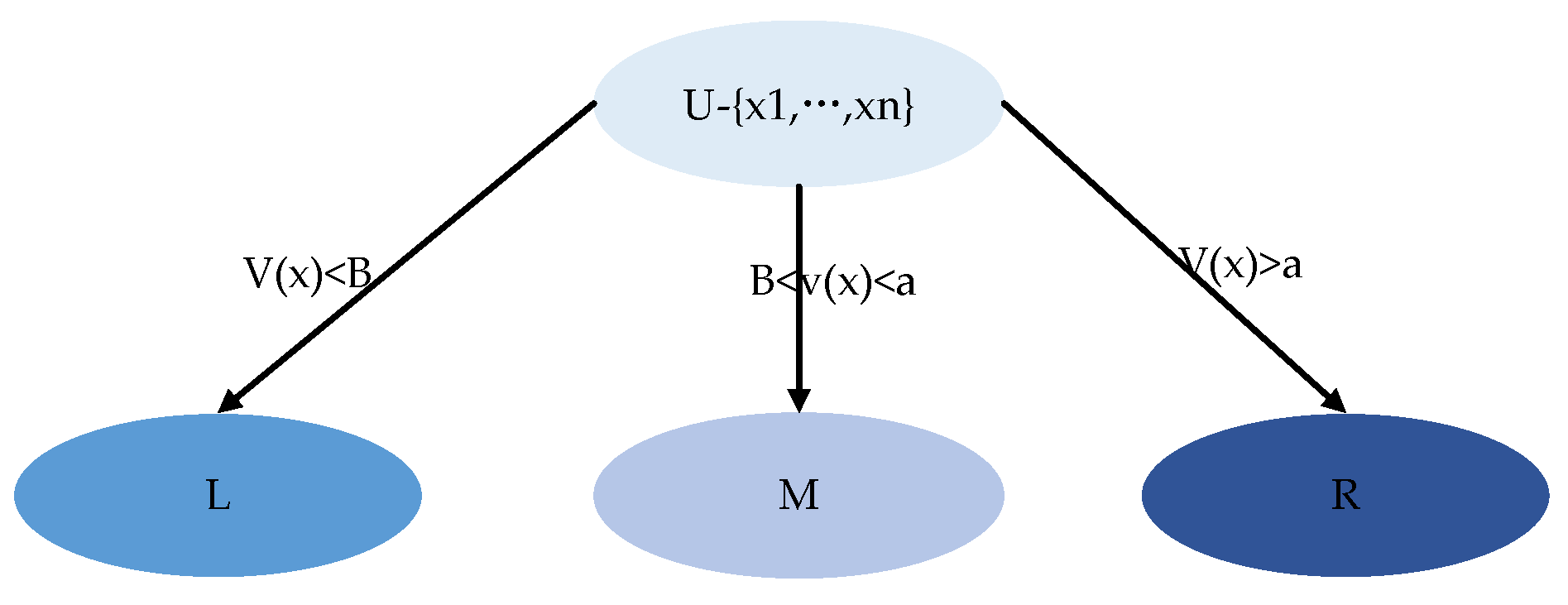
2.3. Three-Branch Decision Making Based on an Evaluation Function
- Three decisions:
- If , ;
- If , ;
- If , [36].
- Three-branch decision making based on evaluation function:
- If , it belongs to domain;
- If , it belongs to the domain;
- If , it belongs to domain.
2.4. Random Forest
- Set the training set size as . For each tree, training samples are randomly and put back from the training as the training set of the tree. Repeat times to generate the training sample set of group.
- If the sample dimension of each feature is , specify a constant <<, (usually ) and randomly select features from the features.
- Use features to maximize the growth of each tree, and there is no pruning process.
- The final integration is obtained by integrating the prediction results of all trees.
2.5. Related Work with Non-ML Techniques
- Reference [44] proposed a method combining multiple criteria linear programming (MCLP) and particle swarm optimization (POS). The main idea of MCLP is to seek to minimize and separate the sum of all overlaps of hyperplanes and maximize the sum of distances from points to the separation hyperplane [45]. However, the algorithm easily affects performance due to improper parameter selection and adjustment in the implementation process, so it is proposed to apply particle swarm optimization to parameter adjustment. Its advantages are less computation and the ability to find the global optimum. POS algorithm updates the velocity and position of each particle iteratively according to its own experience (pbest) and the best experience of all particles (gbest) and finally stops the iteration to obtain the best MCLP parameters. The experimental results also show that compared with a single MCLP model, the method in this paper effectively improves the detection accuracy and reduces the detection time. However, this method requires high data and does not consider the impact of too high dataset dimensions.
- Reference [46] proposed an intrusion detection model based on ant colony optimization (ACO) for feature selection. In this paper, features are regarded as nodes in the ACO algorithm, and the connection between nodes represents the next feature selection. Then, the graph is searched for the optimal feature subset through ant colony traversal. Finally, the optimal feature subset is obtained by applying the transformation rules and pheromone update rules of the ACO algorithm. Experimental results show that the algorithm achieves higher detection rates. However, when the data and distribution are uneven, the results of this method may be affected.
2.6. Correlation Comparison Algorithm
2.7. Problem Description
- The traditional machine learning algorithm has blind spots and has a certain tendency. Try to apply the integrated learning idea, and a single model is integrated to generate a stable model with excellent performance in all aspects;
- The attributes of the intrusion detection dataset are not unique, and different attributes have different effects on the classification results. Therefore, a method is adopted to calculate the importance of different attributes to increase the probability that the attributes with higher importance are selected;
- Most of the traditional attribute importance measurement methods directly delete the attributes with low importance, which to some extent leads to the loss of information. Therefore, a method needs to be adopted to judge and select the attributes with different importance.
3. Three-Branch Random Forest Intrusion Detection Model
3.1. IDTSRF Intrusion Detection Model Framework
- 4.
- A hierarchical sampling of the original dataset in proportion;
- 5.
- Because the dataset contains continuous attributes, according to the characteristics of different attributes, the data are discretized using equal distance dispersion or equal frequency dispersion to obtain the dataset required by the experiment;
- 6.
- Self-service sampling is performed on the dataset to generate data subsets and off-package data;
- 7.
- Set the evaluation function of the attribute based on the attribute importance of decision boundary entropy (), give the value of threshold value to , and divide the attributes in all data subsets into a positive domain, boundary domain or negative domain, respectively;
- 8.
- Select attributes according to three attribute selection rules (see Section 3.3);
- 9.
- The GINI index is selected as the criteria for node division of the decision tree to generate a tree;
- 10.
- The majority voting method is adopted to integrate the results to get the final integration;
- 11.
- To verify the effectiveness of the algorithm, test data are input into the integration to verify the effectiveness of the algorithm.
3.2. Decision Boundary Entropy and Attribute Importance
3.3. Randomized Three-Branch Decision of Attributes
- If , randomly select attributes from the positive field as attribute subsets;
- If , randomly select attributes as attribute subset from positive domain and boundary domain [43];
- If , randomly select attributes from the positive domain and boundary domain, and randomly select attributes from the negative domain to form an attribute subset [43].
3.4. Three-Branch Attribute Selection random forest Algorithm
| Algorithm1: Three-branch attribute selection random forest algorithm |
| Three-branch attribute selection random forest algorithm Input: Decision tables , Three attribute selection thresholds , Attribute randomness Output: TSRF (Forest) 1 For 2 3 Initialization 4 For do 5 Calculate according to formula (2) 6 If then 7 8 Else 9 If then 10 11 Else 12 13 End if 14 End if 15 End for 16 If 17 Randomly select attributes from the positive field to form attribute set 18 Else 19 If 20 Randomly select attributes from positive domain and boundary domain to form attribute set 21 Else 22 Select attributes from the positive domain and boundary domain, and attribute structural sets from the negative domain 23 End if 24 End if 25 Dataset with attribute 26 End for 27 Training decision tree according to 28 Comprehensive results |
3.5. Data Set and Experimental Environment
3.6. Subsection Data Preprocessing
3.7. Subsection Random Selection of Three Attributes
3.7.1. Parameter Selection Experiment
3.7.2. Parameter Value Determination and Attribute Random Selection
- |POS| = 1, so , does not meet rule 1);
- , , so rule 2 is not satisfied.
- Since , which meets rule 3, attributes are finally randomly selected from the positive domain and boundary domain, and attributes are randomly selected from the negative domain to form an attribute subset. data subsets containing 7 attributes are obtained, and these data subsets are trained to generate decision trees. Finally, the data outside the package is input into all decision trees, and the majority voting method is used to synthesize the results to get the final integration.
4. Evaluation Results and Discussion
4.1. Subsection Evaluation Index
4.2. Algorithm Comparison Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yange, T.S.; Onyekware, O.; Abdulmuminu, Y.M. A Data Analytics System for Network Intrusion Detection Using Decision Tree. J. Comput. Sci. Appl. 2020, 8, 21–29. [Google Scholar]
- Hassan, E.; Saleh, M.; Ahmed, A. Network Intrusion Detection Approach using Machine Learning Based on Decision Tree Algorithm. J. Eng. Appl. Sci. 2020, 7, 1. [Google Scholar] [CrossRef]
- Bhati, B.S.; Rai, C.S. Analysis of Support Vector Machine-based Intrusion Detection Techniques. Arab. J. Sci. Eng. 2020, 45, 2371–2383. [Google Scholar] [CrossRef]
- Shi, Q.; Kang, J.; Wang, R.; Yi, H.; Lin, Y.; Wang, J. A Framework of Intrusion Detection System based on Bayesian Network in IoT. Int. J. Perform. Eng. 2018, 14, 2280–2288. [Google Scholar] [CrossRef][Green Version]
- Prasath, M.K.; Perumal, B. A meta-heuristic Bayesian network classification for intrusion detection. Int. J. Netw. Manag. 2019, 29, e2047. [Google Scholar] [CrossRef]
- Xu, G. Research on K-Nearest Neighbor High Speed Matching Algorithm in Network Intrusion Detection. Netinfo Secur. 2020, 20, 71–80. [Google Scholar]
- Chao, D.; Gang, Z.; Liu, Y.; Zhang, D.L. The detection of network intrusion based on improved AdaBoost algorithm. J. Sichuan Univ. (Nat. Sci.Ed.) 2015, 52, 1225–1229. [Google Scholar]
- Zhang, K.; Liao, G. Network intrusion detection method based on improving Bagging-SVM integration diversity. J. Northeast. Norm. Univ. (Nat. Sci.Ed.) 2020, 52, 53–59. [Google Scholar]
- Li, B.; Zhang, Y. Research on Self-adaptive Intrusion Detection Based on Semi-Supervised Ensemble Learning. Electr. Autom. 2021, 43, 101–104. [Google Scholar]
- Jiang, F.; Zhang, Y.Q.; Du, J.W.; Liu, G.Z.; Sui, Y.F. Approximate Reducts-based Ensemble Learning Algorithm and Its Application in Intrusion Detection. J. Beijing Univ. Technol. 2016, 42, 877–885. [Google Scholar]
- Xia, J.M.; Li, C.; Tan, L.; Zhou, G. Improved Random Forest Classifier Network Intrusion Detection Method. Comput. Eng. Des. 2019, 40, 2146–2150. [Google Scholar]
- Zhang, L.; Zhang, J.; Sang, Y. Intrusion Detection Algorithm Based on Random Forest and Artificial Immunity. Computer Engineering 2020, 46, 146–152. [Google Scholar]
- Qiao, J.; Li, J.; Chen, C.; Chen, Y.; Lv, Y. Network Intrusion Detection Method Based on Random Forest. Comput. Eng. Appl. 2020, 56, 82–88. [Google Scholar]
- Qiao, N.; Li, Z.; Zhao, G. Intrusion Detection Model of Internet of Things Based on XGBoost-RF. J. Chin. Comput. Syst. 2022, 43, 152–158. [Google Scholar]
- Liang, B.; Wang, L.; Liu, Y. Attribute Reduction Based On Improved Information Entropy. J. Intell. Fuzzy Syst. 2019, 36, 709–718. [Google Scholar] [CrossRef]
- Ayşegül, A.U.; Murat, D. Generalized Textural Rough Sets: Rough Set Models Over Two Universes. Inf. Sci. 2020, 521, 398–421. [Google Scholar]
- Zhang, P.; Li, T.; Wang, G.; Luo, C.; Chen, H.; Zhang, J.; Wang, D.; Yu, Z. Multi-Source Information Fusion Based On Rough Set Theory: A Review. Inf. Fusion 2021, 68, 85–117. [Google Scholar] [CrossRef]
- An, S.; Hu, Q.; Wang, C. Probability granular distance-based fuzzy rough set model. Appl. Soft Comput. 2021, 102, 107064. [Google Scholar] [CrossRef]
- Han, S.E. Topological Properties of Locally Finite Covering Rough Sets And K-Topological Rough Set Structures. Soft Comput. 2021, 25, 6865–6877. [Google Scholar] [CrossRef]
- Liu, J.; Bai, M.; Jiang, N.; Yu, D. A novel measure of attribute significance with complexity weight. Appl. Soft Comput. 2019, 82, 105543. [Google Scholar] [CrossRef]
- Yao, Y. Three-Way Decision: An Interpretation of Rules in Rough Set Theory; Rough Sets and Knowledge Technology Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Yao, Y. Three-way decisions with probabilistic rough sets. Inf. Sci. Int. J. 2010, 180, 341–353. [Google Scholar] [CrossRef]
- Yao, Y. The superiority of three-way decisions in probabilistic rough set models. Inf. Sci. 2011, 181, 1080–1096. [Google Scholar] [CrossRef]
- Rajadurai, H.; Gandhi, U.D. Naive Bayes and deep learning model for wireless intrusion detection systems. Int. J. Eng. Syst. Model. Simul. 2021, 12, 111–119. [Google Scholar] [CrossRef]
- Xu, J.; Han, D.; Li, K.C.; Jiang, H. A K-means algorithm based on characteristics of density applied to network intrusion detection. Comput. Sci. Inf. Syst. 2020, 17, 665–687. [Google Scholar] [CrossRef]
- Liu, J.; Liu, P.; Pei, S.; Tian, C. Design and Implementation of Network Anomaly Detection System Based on Association Rules. Cyber Secur. Data Gov. 2020, 39, 14–22. [Google Scholar] [CrossRef]
- Jia, W.; Zhang, F.; Tong, B.; Wan, C. Application of Self-Organizing Mapping Neural Network in Intrusion Detection. Comput. Eng. Appl. 2009, 45, 115–117. [Google Scholar]
- Sohn, I. Deep belief network based intrusion detection techniques: A survey. Expert Syst. Appl. 2021, 167, 114170. [Google Scholar] [CrossRef]
- Wang, H.; Cao, Z.; Hong, B. A network intrusion detection system based on convolutional Neural Network. J. Intell. Fuzzy Syst. 2020, 38, 7623–7637. [Google Scholar] [CrossRef]
- Sun, X. Intrusion Detection Method Based on Recurrent Neural Network. Master’s Thesis, Tianjin University, Tianjin, China, 2020. [Google Scholar] [CrossRef]
- Rodríguez, J.J.; Kuncheva, L.I.; Alonso, C.J. Rotation forest: A new classifier ensemble method. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1619–1630. [Google Scholar] [CrossRef]
- Yulianto, A.; Sukarno, P.; Suwastika, N.A. Improving AdaBoost-based Intrusion Detection System (IDS) Performance on CIC IDS 2017 Dataset. J. Phys. Conf. Ser. 2019, 1192, 012018. [Google Scholar] [CrossRef]
- Dhaliwal, S.S.; Nahid, A.A.; Abbas, R. Effective Intrusion Detection System Using XGBoost. Information 2018, 9, 149. [Google Scholar] [CrossRef]
- Resende, P.A.A.; Drummond, A.C. A Survey of Random Forest Based Methods for Intrusion Detection Systems. ACM Comput. Surv. (CSUR) 2018, 51, 1–36. [Google Scholar] [CrossRef]
- Wang, L.; Gu, C. Overview of Machine Learning Methods for Intrusion Detection. J. Shanghai Univ. Electr. Power 2021, 37, 591–596. [Google Scholar]
- Yang, C.; Zhang, Q.; Zhao, F. Hierarchical Three-Way Decisions with Intuitionistic Fuzzy Numbers in Multi-Granularity Spaces. IEEE Access 2019, 7, 24362–24375. [Google Scholar] [CrossRef]
- Wu, Q.; Huang, S. Intrusion Detection Algorithm Combining Convolutional Neural Network and Three-Branch Decision. Comput. Eng. Appl. 2022, 58, 119–127. [Google Scholar]
- Du, X.; Li, Y. Intrusion Detection Algorithm Based on Deep Belief Network and Three Branch Decision. J. Nanjing Univ. (Nat. Sci.) 2021, 57, 272–278. [Google Scholar]
- Zhang, S.; Li, Y. Intrusion Detection Method Based on Denoising Autoencoder and Three-way Decisions. Comput. Sci. 2021, 48, 345–351. [Google Scholar]
- Hassan, M.; Butt, M.A.; Zaman, M. An Ensemble Random Forest Algorithm for Privacy Preserving Distributed Medical Data Mining. Int. J. E-Health Med. Commun. (IJEHMC) 2021, 12, 23. [Google Scholar] [CrossRef]
- Zong, F.; Zeng, M.; He, Z.; Yuan, Y. Bus-Car Mode Identification: Traffic Condition–Based Random-Forests Method. J. Transp.Eng. Part A Syst. 2020, 146, 04020113. [Google Scholar] [CrossRef]
- Zhang, P.; Jin, Y.F.; Yin, Z.Y.; Yang, Y. Random Forest based artificial intelligent model for predicting failure envelopes of caisson foundations in sand. Appl. Ocean. Res. 2020, 101, 102223. [Google Scholar] [CrossRef]
- Zhang, C.; Ren, J.; Liu, F.; Li, X.; Liu, S. Three-way selection Random Forest algorithm based on decision boundary entropy. Appl. Intell. 2022, 52, 13384–13397. [Google Scholar] [CrossRef]
- Bamakan SM, H.; Amiri, B.; Mirzabagheri, M.; Shi, Y. A New Intrusion Detection Approach using PSO based Multiple Criteria Linear Programming. Procedia Comput. Sci. 2015, 55, 231–237. [Google Scholar]
- Shi, Y.; Tian, Y.; Kou, G.; Peng, Y.; Li, J. Optimization Based Data Mining: Theory and Applications: Theory and Applications; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Aghdam, M.H.; Kabiri, P. Feature Selection for Intrusion Detection System Using Ant Colony Optimization. Int. J. Netw. Secur. 2016, 18, 420–432. [Google Scholar]
- Jiang, F.; Yu, X.; Du, J.; Gong, D.; Zhang, Y.; Peng, Y. Ensemble learning based on approximate reducts and bootstrap sampling. Inf. Sci. 2021, 547, 797–813. [Google Scholar] [CrossRef]
- Meng, Q.; Zheng, S.; Cai, Y. Deep Learning SDN Intrusion Detection Scheme Based on TW-Pooling. J. Adv. Comput. Intell. Intell. Inform. 2019, 23, 396–401. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Introduce | |
|---|---|---|
| IDTSRF | The advantage is that different attributes in the dataset have different effects on the results. Therefore, attribute importance measurement method based on decision boundary is adopted to select attributes and finally the attribute subset training decision tree integrated random forest model is obtained. | The disadvantage is that this method has better detection effect on small datasets at present. The next step will be to study this. |
| Random Forest | The advantage is that the idea of ensemble learning is adopted, which improves the accuracy of a single algorithm, is more stable, and does not easily fall into over fitting. | The disadvantage is that the calculation cost is high, requiring more time and space. |
| XGBoost | The advantage is that the regular term is introduced to reduce the complexity of the model, support parallel processing and high flexibility, and reverse pruning from bottom to top makes the model not easily fall into the optimal solution. | The disadvantage is that more model parameters lead to complex parameter adjustment, which is difficult to deal with with ultra-high dimensional data. |
| AdaBoost | The advantage is that different classifiers can be used as weak classifiers, and weak classifiers can be cascaded to fully consider the weight of each classifier. | The disadvantage is that the data imbalance easily affects the classification accuracy of the model and consumes time. |
| CNN | The advantage is that the shared convolution kernel can better handle high-dimensional data and can automatically extract features. | The disadvantage is that with the deepening of the network layer, the time is also extended, and the pooling layer loses a lot of useful information when compressing features. |
| SVM | The advantage is that the learning effects is good on small samples, and it can solve high-dimensional problems well, with good generalization. | The disadvantage is that it supports two classifications. When the sample size is too high, the calculation increases, which consumes a lot of memory and time. |
| Naive Bayesian | The advantages are excellent performance on small datasets, and it can handle multi-classification tasks and simple algorithms for implementation. | The disadvantage is that prior probabilities and assumptions need to be known while attributes are relatively independent, which affects the classification effect. |
| Decision Tree | The advantage is that the nominal and numerical data can be processed at the same time and the model training is fast and efficient. | The disadvantage is that it is easy to overfit, and the classification results are easily affected by the distribution of the number of samples, so the decision tree needs to be trained after data processing. |
| K-means | The advantages are fast convergence speed and simple parameters. | The disadvantage is that it easily falls into the local optimum, the K value and the center point are not easy to determine, and the data types are limited to seek the mean value. |
| Association Rules | The advantage is that it is not limited by the amount of data and can find the relationship between data in a large amount of data with a wide range of applications. | The disadvantage is that the analysis takes a long time, takes a large amount of memory, and does not take into account the different importance of attributes. |
| SOM | The advantage is that the visualization effect is good and is not easily affected by the initial parameter selection. | The disadvantage is that there is no definite objective function and the computational complexity is high. |
| DBN | The advantage is good flexibility. | The disadvantage is that it can only deal with one-dimensional data and easily falls into local optimum. |
| RNN | The advantage is that previous information is considered, which is suitable for processing sequential data. | The disadvantages are high video memory occupation, difficult training, gradient disappearance, and gradient explosion. |
| Data Type | Training Set | Test Set |
|---|---|---|
| Normal | 67,334 | 9711 |
| DoS | 45,927 | 7458 |
| Probe | 11,656 | 2421 |
| R2L | 995 | 2754 |
| U2L | 52 | 200 |
| Total | 125,973 | 22,544 |
| Attribute No | Attribute Importance |
|---|---|
| duration | 0.0 |
| protocol_type | 0.0 |
| service | |
| flag | 0.0 |
| src_bytes | |
| count | |
| diff_srv_rate | |
| dst_host_count | |
| dst_host_serror_rate |
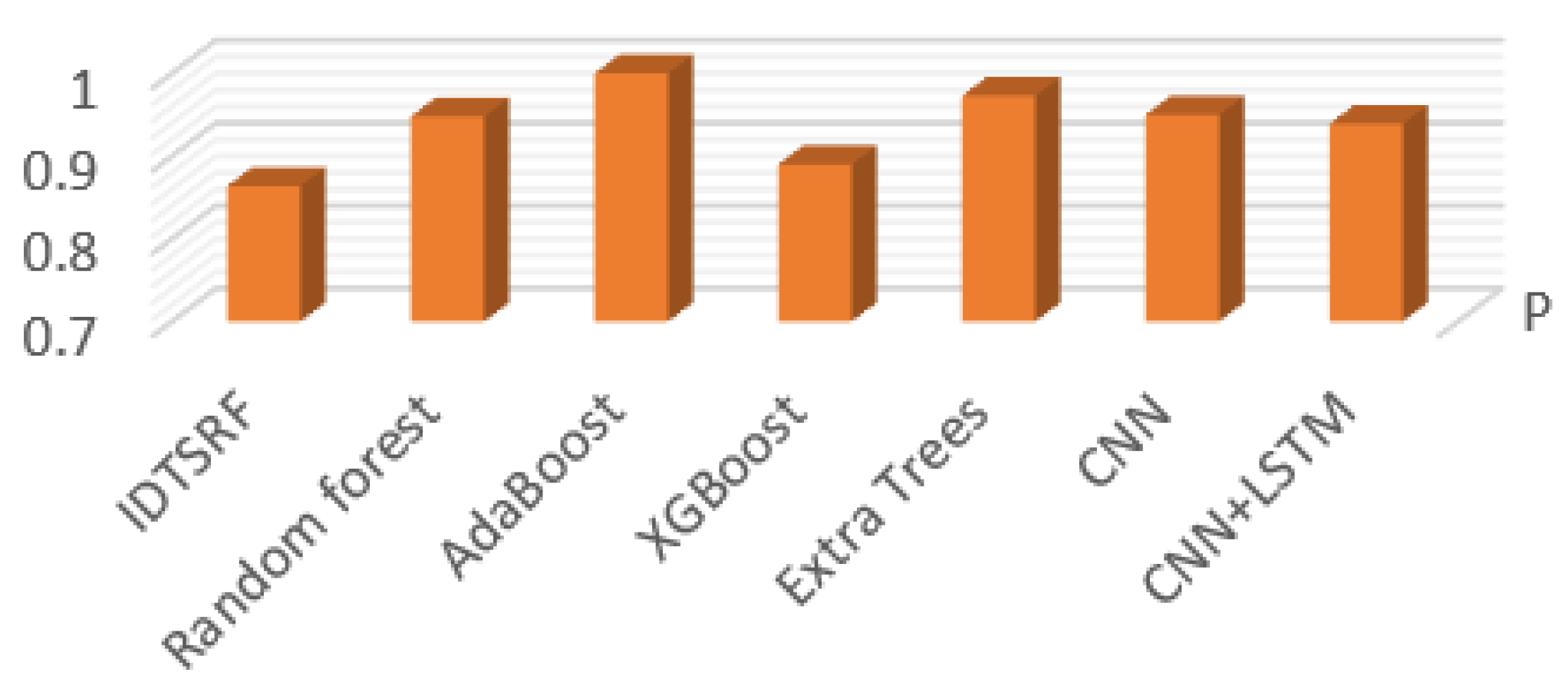
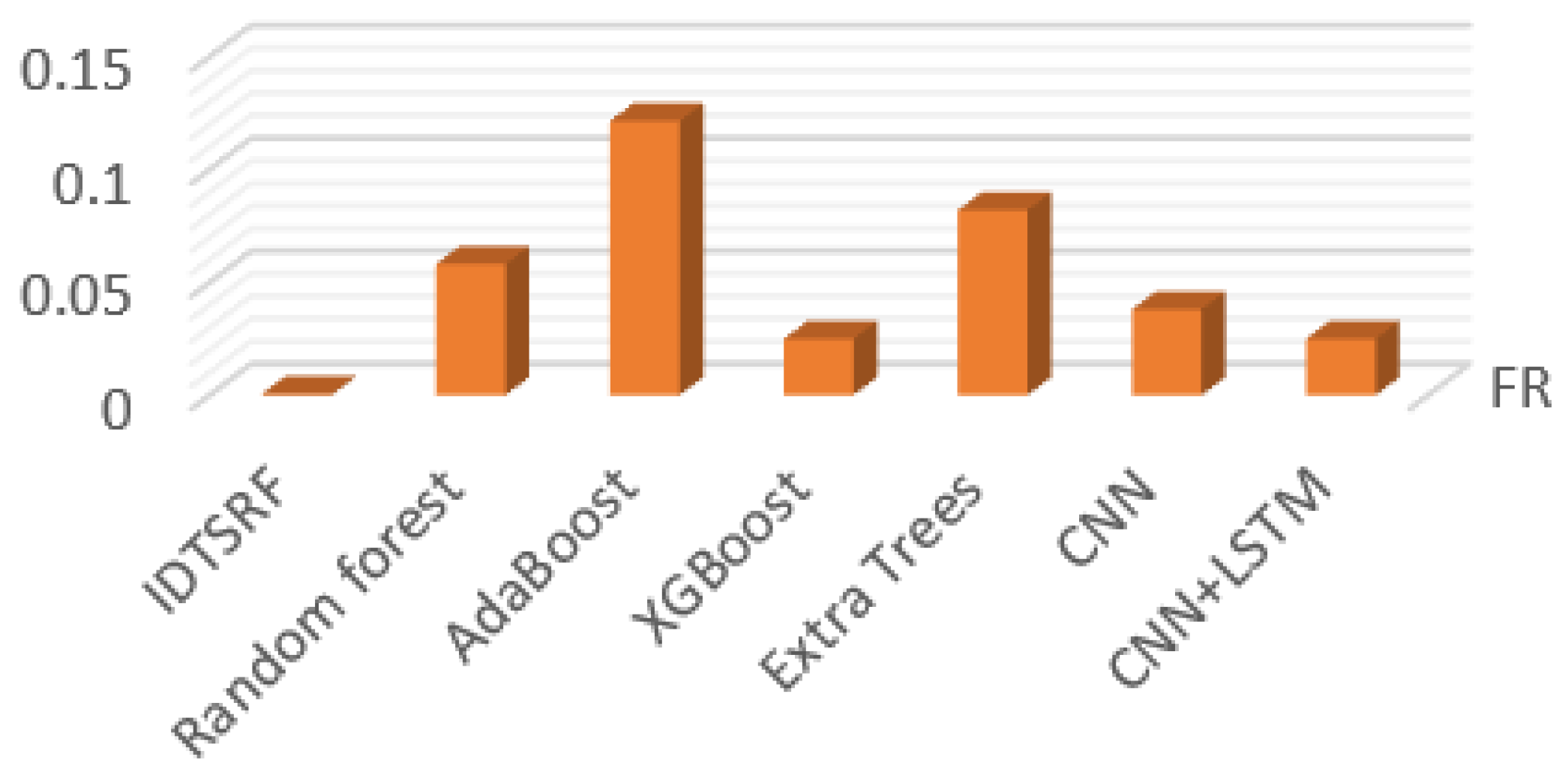
| FP | FR | P | R | F1 | |
|---|---|---|---|---|---|
| IDTSRF | 0.1363 | 0.0006 | 0.8637 | 0.9994 | 0.9533 |
| Random forest | 0.052 | 0.0581 | 0.948 | 0.9419 | 0.9438 |
| AdaBoost | 0 | 0.1215 | 1 | 0.8785 | 0.9126 |
| XGBoost | 0.11 | 0.025 | 0.89 | 0.975 | 0.931 |
| Extra Trees | 0.027 | 0.082 | 0.973 | 0.918 | 0.945 |
| CNN | 0.05 | 0.038 | 0.95 | 0.962 | 0.9583 |
| CNN + LSTM | 0.061 | 0.025 | 0.939 | 0.975 | 0.957 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, C.; Wang, W.; Liu, L.; Ren, J.; Wang, L. Three-Branch Random Forest Intrusion Detection Model. Mathematics 2022, 10, 4460. https://doi.org/10.3390/math10234460
Zhang C, Wang W, Liu L, Ren J, Wang L. Three-Branch Random Forest Intrusion Detection Model. Mathematics. 2022; 10(23):4460. https://doi.org/10.3390/math10234460
Chicago/Turabian StyleZhang, Chunying, Wenjie Wang, Lu Liu, Jing Ren, and Liya Wang. 2022. "Three-Branch Random Forest Intrusion Detection Model" Mathematics 10, no. 23: 4460. https://doi.org/10.3390/math10234460
APA StyleZhang, C., Wang, W., Liu, L., Ren, J., & Wang, L. (2022). Three-Branch Random Forest Intrusion Detection Model. Mathematics, 10(23), 4460. https://doi.org/10.3390/math10234460