Abstract
Quasi-Monte Carlo (QMC) methods have been successfully used for the estimation of numerical integrations arising in many applications. In most QMC methods, low-discrepancy sequences have been used, such as digital nets and lattice rules. In this paper, we derive the convergence rates of order of some improved discrepancies, such as centered -discrepancy, wrap-around -discrepancy, and mixture discrepancy, and propose a randomized QMC method based on a uniform design constructed by the mixture discrepancy and Baker’s transformation. Moreover, the numerical results show that the proposed method has better approximation than the Monte Carlo method and many other QMC methods, especially when the number of dimensions is less than 10.
MSC:
65D30; 62K15
1. Introduction
Consider the problem of numerical integration of the function over the s-dimensional unit cube ,
In practice, for most functions, the integral (1) cannot be solved analytically. Therefore, we have to solve these integrals numerically, that is, we want to find an algorithm that allows us to approximate the true value of the integral to any given level of precision. For one-dimensional integration, there are many classical quadrature rules available, such as the trapezoidal rule, the Simpson rule, or the Gauss rule [1]. However, for high dimensions, if the classical quadrature rules are still used to compute an -approximation, then the computational complexity increases exponentially with s, which is called the “curse of dimensionality”.
The constraints of classical quadrature rules have prompted the development of probabilistic methods, in which the integral is interpreted as the expected value of the integrand evaluated at a uniformly distributed random variable over an s-dimensional unit cube. These methods were first proposed and applied by Fermi et al. [2], and named as the Monte Carlo (MC) method. The MC method is based on the central limit theorem, and the convergence rate of order is independent of the dimension s. Although the MC method is simple and conventional, its convergence rate is too slow in many applications, and the convergence rate is in the sense of probability.
To reduce the approximation error, Richtmyer [3] proposed a quasi-Monte Carlo (QMC) method, whose convergence rate is of the order of . Compared with the MC method, a QMC method utilizes a carefully selected deterministic point set instead of the random points in the MC method. Usually, low-discrepancy sequences are chosen for the deterministic point sets, which have two main research lines, that is, digital nets and lattice rules. The Halton sequence [4] and Sobol sequence [5] are two widely used representatives of digital sequences. Faure [6], Niederreiter [7], Tezuka [8] further developed new construction methods based on Sobol sequences. Joe and Kuo [9] presented a construction method of Sobol sequences with better two-dimensional projection uniformity. On the other hand, Korobov [10,11] and Hlawka [12] proposed a construction method for low-discrepancy sequences based on lattice rules, which is also one of the deterministic methods for construction of uniform designs, which was proposed by Fang [13] and Fang and Wang [14]. A point set is called a low-discrepancy point set if its discrepancy is small, and similarly is called a uniform design if its design points are uniformly scattered on , that is, has a minimum discrepancy.
Since the points in a QMC method are deterministic, it is difficult to get an estimate of the approximation error. Therefore, randomized quasi-Monte Carlo (RQMC) methods have been considered. The earliest randomization method is random shift modulo 1, which was proposed by Cranley and Patterson [15] for standard lattice rules. Tuffin [16] and Morohosi [17] suggested that RQMC methods can be used for other low discrepancy point sets. After that, Owen [18,19] proposed a randomization method named Scrambling for the digital network. Moreover, Matoušek [20] proposed a randomization method of random linear Scrambling that requires less storage space. In addition, Wang and Hickernell [21] proposed a method for randomized Halton sequences.
All these QMC or RQMC methods are seeking for point sets with better uniformity as a way to reduce the error in estimating the integrals, and to allow that the estimations converge the true values at a faster rate. The most common uniformity criterion is the star discrepancy, and a number of papers have derived its order of convergence on different point sets [22]. Besides the star discrepancy, there are many improved discrepancies to measure the uniformity, such as centered -discrepancy (CD, [23]), wrap-around -discrepancy (WD, [24]), mixture discrepancy (MD, [25]). Those discrepancies play a key role in the theory of uniform designs. More details of those discrepancies can refer to Fang et al. [26]. However, there has no theoretical result of the convergence rates of order of those improved discrepancies. In this paper, we derive the convergence orders of those discrepancies.
Moreover, we also propose a RQMC method which combine the uniform design with the Baker’s transformation. It will be shown that the proposed RQMC method has better approximation than MC methods and many other QMC methods. The remainder of this paper is organized as follows. Section 2 briefly introduces some theoretical results of Monte Carlo numerical integration, and then focuses on the two types of low-discrepancy sets and sequences used in quasi-Monte Carlo and some uniformity criteria. Section 3 derives the theoretical results of the convergence rates of the improved uniformity criteria and proposes an improved RQMC method. Section 4 gives some numerical experimental comparisons among the MC and three different RQMC methods. The conclusion is addressed in Section 5. The detailed proofs can be found in the Appendix A.
2. Preliminaries
For estimating the integral (1), one can select an n-point sequence and use
to approximate . The MC method randomly selects a sequence , which includes the independent vectors uniformly distributed over . It can be know that is an unbiased estimator, and , where . If , by the central limit theorem, we know that the integration error of the MC method has a convergence rate of order in probability. Noted that the convergence rate of the MC method is independent of the dimensionality of the integration problem, while such a convergence rate may be too slow in many cases. There are many variance-reduction techniques proposed by Glasserman [27] and Hammersley et al. [28], such as importance sampling, stratified sampling, control variable method, dual variable method, for improving the efficiency of the MC method. However, those methods have no effect on the convergence rate of the MC method. Bakhvalov [29] also proved that for general square integrable functions, the convergence rate of the MC method cannot be further improved.
A QMC method replaces the independent random points in the MC method by a deterministic low-discrepancy sequence . For a QMC method, the convergence rate of the estimated error of the QMC method can be obtained through the Koksma-Hlawka inequality,
where is the total variation of the function f in the sense of Hardy and Krause, is the star discrepancy. Such the inequality was first shown by Koksma [30] for the one-dimensional case, and was extended by Hlawka [31] for arbitrary dimensions. The Koksma-Hlawka inequality divides the upper bound of the integral error into two irrelevant parts, the total variation of the function and the star discrepancy of the selected point set. In this way, for a certain function f, if is bounded, then one may choose a point set such that its star discrepancy as small as possible and that we can minimize the upper bound.
The star discrepancy plays a very important role in the quasi-Monte Carlo method, but it also has shortcomings. First, its calculation is complicated, which cannot be calculated in polynomial time; secondly, it is not rotation and reflection invariance. In order to overcome these shortcomings of star discrepancy, Hickernell [23,24] used the tool of reproducing kernel Hilbert space to propose some generalized -discrepancies. Among them, the CD and WD have been popularly used. Moreover, Zhou et al. [25] proposed the mixture discrepancy to measure the uniformity of a point set and showed that such a uniformity criterion has more reasonable properties comparing with the CD and WD.
Define the local projection discrepancy for the factor indexed by u as
where is a design with n runs and s factors on , and is a set used for indexing the factors of interst, is the projection of x and onto respectively. is a pre-define region for all . A generalized -discrepancy is defined in terms of all of these local projection discrepancies as follows:
For a generalized -discrepancy, Hickernell [32] gave the generalized Koksma-Hlawka inequality, which extends the star discrepancy and the total variation in the sense of Hardy-Krause to the generalized -discrepancy and the variation in the general norm sense. Based on different , we can define different discrepancy, such as the CD, WD, and MD.
(1) Centered -discrepancy. For any , let denote the vertex closest to x, and define in one dimension be the region between points x and , the region in any dimension is the kronecker product of the region in one dimension, that is,
From (4) and (5), Hickernell [23] gave the square expression of CD as follows.
From the definition of the centered -discrepancy, it can be seen that it has good reflection and rotation invariance.
(2) Wrap-around -discrepancy. Both the star-discrepancy and the centered -discrepancy require one or more corner points of the unit cube in definition of . A natural extension is to fall inside of the unit cube and not to involve any corner point of the unit cube, which leads to the so-called wrap-around -discrepancy. The region of WD, , is determined by two independent points , and the corresponding local discrepancy are defined as
respectively. The wrap-around -discrepancy is defined as follows
Then the expression of the squared WD value can be written as
Similarly, the WD also has good reflection and rotation invariance, and satisfies the generalized Koksma-Hlawka inequality.
(3) Mixture discrepancy. Although the CD and WD overcome the most of shortcomings of the star discrepancy, they still have some shortcomings. For example, CD does not perform well in high dimensions, and in some cases, the design with repeated points has a small CD. The coordinate drift of the WD in some dimensions does not change the discrepancy value, which may cause some unreasonable phenomena. Therefore, a natural idea is to mix the two kinds of discrepancies to avoid their respective shortcomings while keeping their goodness. such as the discrepancy proposed by Zhou et al. [25]. The mixture discrepancy modifies the definition of the regions in CD and WD. The regions of mixture discrepancy and local discrepancies are defined as follows:
The mixture discrepancy is defined as
Zhou et al. [25] derived the expression of the squared MD as follow:
and showed that the MD has all the good properties of CD and WD and overcomes the shortcomings.
3. Convergence Rates of Order of the Three Discrepancies
In the previous section we introduced the three improved discrepancies for measuring the uniformity of a point set in . Based on any of the three improved discrepancies, we can search the uniform design , and use (2) to approximate the integral (1). Based on the generalized Koksma-Hlawka inequality, it is easily known that the approximated error converges to zero if the CD, WD, or MD of converges to zero. There exist many theoretical results for the star discrepancy in the Koksma-Hlawka inequality (3). For example, the convergence rate of order of the star discrepancy is , see [33]. In this section, we obtain the theoretical result of the convergence rate of order of the three popularly used discrepancies, CD, WD, and MD.
For the three improved uniformity criteria, we can obtain the upper bounds of their local discrepancy functions. Let , be a set indexing factors of interest. Without loss of generality, we also use u as the dimension of the subset u, and as the unit cube corresponding to the u dimensions. For a positive integer n, denote , , is a set of , where , . For the two vectors and , denote , , where is a vector in , and .
Theorem 1.
Let r and h be positive integers such that , where η satisfies . Denote , each is an integer, . Then for any we have
where
where is the inner product of and .
From Theorem 1, and Lemmas A3 and A4 in the Appendix A, the order of the three discrepancy can be obtained as follows.
Theorem 2.
Define be the fractional part of the real number t. There exists an integral vector such that the point set has the discrepancy
where ≃ indicates that they are asymptotically equivalent, is a constant related with the number of dimensions s.
From Theorem 2, we can easily know that all the convergence rates of order of CD, WD, and MD are . When s is not large, the convergence rate of order becomes , where is a small positive number. Therefore, the convergence rates of order of CD, WD, and MD is similar as that of the star discrepancy. Moreover, Fang et al. [26] showed that the three improved discrepancies are better than the star discrepancy. Then, we can use the three improved discrepancies in practical applications. For example, we can construct uniform designs under any of the three improved discrepancies for approximating the integral (1). Here, the MD is the most recommended one.
4. Randomized Uniform Design
We know that a sequence should be uniformly distributed modulo one to satisfy our purpose of approximating the integral of a Riemann integrable function arbitrarily closely with a QMC algorithm using the first N points of this sequence. In practice, however, it is never possible for us to use a finite set of points to be uniformly distributed modulo one. Nevertheless, it is still recommended to use point sets whose empirical distribution is close to uniform distribution modulo one [22]. In fact, a sequence is uniformly distributed modulo one if and only if its discrepancy converges to zero as number of points approaches infinity [1].
From Theorem 2, we can construct a QMC method based on uniform design with an empirical distribution close to uniform distribution modulo one. However, the QMC method also has some disadvantages compared with the MC method [22], and it was shown that the randomization of a uniform design obtained by the good lattice point method can improve its space-filling property [34]. In this section, we consider another randomization method of uniform designs based on the Baker’s transformation. It has good space-filling property comparing with other methods.
First we need to construct a uniform design. Generally, most existing uniform designs are obtained by a numerical search, and it can be defined as the optimization problem to find a design such that: where is the searching space and D is a given uniformity criterion. We always choose as the U-type design space, and the uniformity criterion can be one of the three improved uniformity criteria. A U-type design means that each level occurs the same time in each factor. Here, we use the threshold-accepting algorithm and the MD as the uniformity criterion to construct uniform designs, and denote this method as UD method. The general procedure of the threshold-accepting algorithm for construction of uniform design is as follow. Choose an initial design as the design at Step 0; at Step t, find another design in the neighborhood of , if the acceptance criterion is satisfied, let be the design at Step t, continue this procedure until some stopping rule is satisfied. In our procedure, the criterion is chosen as the difference between the MD of the new design and that of the design at Step t.
Then, we randomize the design obtained by the UD method to obtain a randomized uniform design, and denote this method as the RUD method. Such the algorithm is as follows.
- (1)
- Denote the design obtained by the UD method as , where ;
- (2)
- are s samples drawn from with equal probability with replacement;
- (3)
- Randomly generate n uniformly distributed independent s-dimensional vectors on , each element in the vector is also independent;
- (4)
- Obtained the RUD as , where and .
Furthermore, Hickernell [35] performed the Baker’s transformation on the uniform design obtained by the good lattice point method, and obtained that the convergence rate of the estimated integral error can reach under a certain smoothness assumption. Therefore, we perform Baker’s transformation on the design obtained by the RUD method to obtain a RUD after transformation, which is denoted as BRUD method. The Baker’s transformation has a simple form. When considering the one-dimensional case, it is a mapping of . The specific expression is as follows:
Since Baker’s transformation is a one-dimensional transformation, so we consider a multidimensional quadrature rule based on applying the Baker’s transformation in each coordinate.
5. Numerical Experimemts
In this section, we firstly evaluate the proposed BRUD method by integrating the following three test functions over .
- (1)
- (2)
- (3)
where is the independent normal density function with mean and variance . The three test functions have different degrees of nonlinearity. The true value of the integral of over can be obtained exactly. By the independence of the integration function, we can use the s-th power of the one-dimensional integral to get the result of the s-dimensional integral, which can be obtained by the value of the normal distribution function, for example, using the norm.cdf function in python or the pnorm function in R.
We compare the performances of the following methods, i.e., Monte Carlo method, Scrambling Sobol sequence (Sobel), UD method, RUD method, and BRUD method. We set the dimension s as in {2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, 25, 30, 35, 40, 45, 50}, and the runs n as {50, 100, 300, 500, 1000, 2000, 3000, 5000, 10,000}. Except for the UD method, we repeat experiments on each setting for times, and take the median as the integral estimate.
For the integration of , Figure 1 shows the median approximation error for all runs in each dimension. For better presentation, we consider the approximate error on a scale, and add the comparison of the estimated standard deviation of the BRUD, RUD and Sobel method with MC method. We can see that the original UD method is inferior to MC method when the dimension is greater than 10, and the BRUD method obtains a consistent smaller error at all dimension than the MC, UD, and RUD methods, and shows a significant advantage compared with Sobol method when . In addition, BRUD method outperforms MC, RUD and Sobel method in terms of standard deviation, especially in the low dimensions. In order to compare the convergence speed of different methods, the approximation error of integration of in five dimension for each runs is shown in Figure 2, and it is smoothed by using the locally weighted regression for better presentation. The reference lines in Figure 2 are given at from top to bottom. In the five-dimensional case, both the Sobol and BRUD methods can nearly achieve the convergence rate of order , and the BRUD method has a slight advantage.
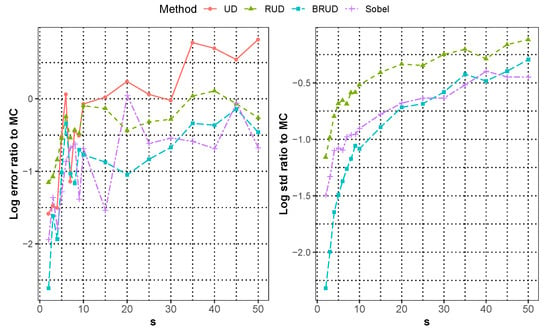
Figure 1.
The median approximation error of integration of over all runs for different dimension.
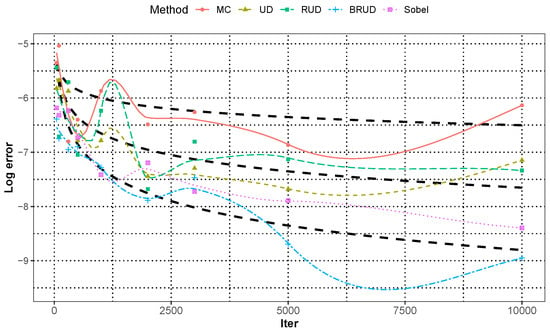
Figure 2.
The approximation error of integration 1 for each runs in dimension with locally weighted regression.
Now consider the integral of the functions and , which are multimodal mixed normal functions. Since they have different means and small variances, they are more concentrated around those means in higher dimensions, which may lead to a poor estimate by using the MC method. Moreover, for , when n is 10,000 and , the relative error of the estimated value of the MC or QMC methods is large enough, and the dimension of the integral that can be effectively estimated will decrease. Therefore, we only present the approximation errors of the integral that yield meaningful estimates.
Figure 3 and Figure 4 show the median approximation errors of integration of and for all runs in each dimension, and Figure 5 and Figure 6 show the approximation error of integration of and when the dimension for each run, respectively. In these two cases, all methods are worse than the previous case of that of . In general, BRUD method is still the best method among these methods. For , only when the dimension is greater than or equal to 15, it is inferior to the MC method. For , all methods are inferior to the MC method in about 6 dimensions. In addition, the convergence rates of the Sobol and BRUD methods are also worse than the previous case, and most of the convergence rates are between and for . In Figure 6, the MC method shows significantly better result at the number of iterations more than 5000 in comparison with all other methods. This anomaly is due to the non-smoothness of the function. Moreover, the standard deviation of the MC method is much larger compared to the error at this time, which can produce better results due to randomness. In this case, the BRUD method still has a smaller standard deviation and more stable results.
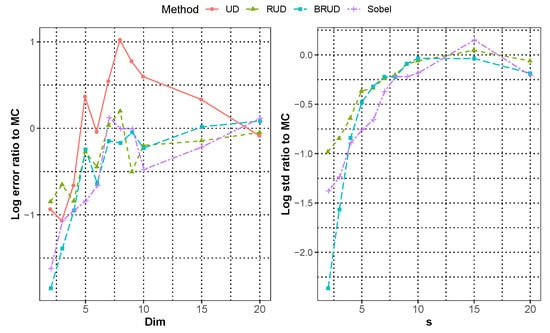
Figure 3.
The median approximation error of integration 2 over all runs for dimension 20.
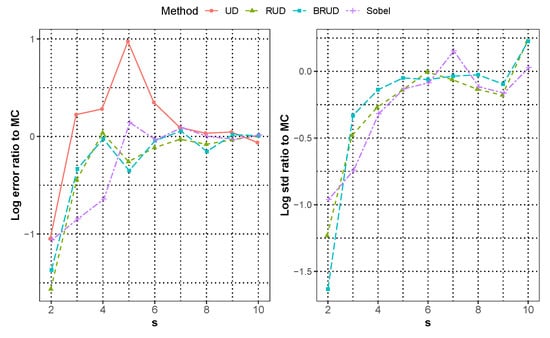
Figure 4.
The median approximation error of integration 3 over all runs for dimension 10.
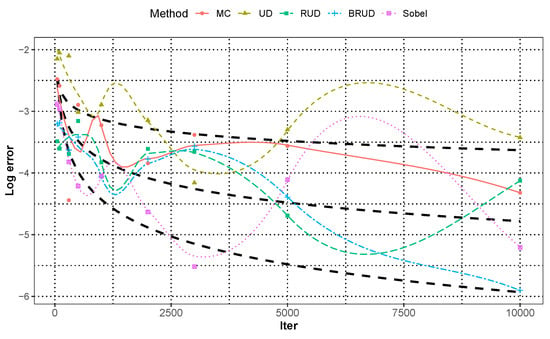
Figure 5.
The approximation error of integration 2 for each runs in dimension with Locally Weighted Regression.
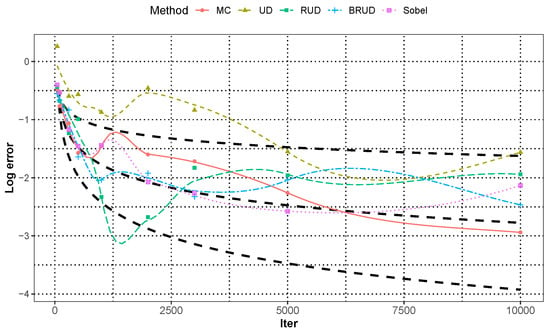
Figure 6.
The approximation error of integration 3 for each runs in dimension with Locally Weighted Regression.
In addition, we consider a complex test function from [36] for comparison,
This function integrates to 1 over . The parameter acts like a product weighht , and we choose .
In this case, the function is a product of , where is the degree 6 Bernoulli polynomial and is the degree 5 Euler polynomial. It is a sufficiently smooth function, but differs from the previous functions in that it is non-separable and has a product parameter . Figure 7 and Figure 8 show the performance of different methods for the integration of . The BRUD method and Sobel method still perform well in terms of the estimation error, standard deviation, and convergence rate of order, and the BRUD method has a significant advantage in low dimensions, but the Sobel method is superior in high dimensions.
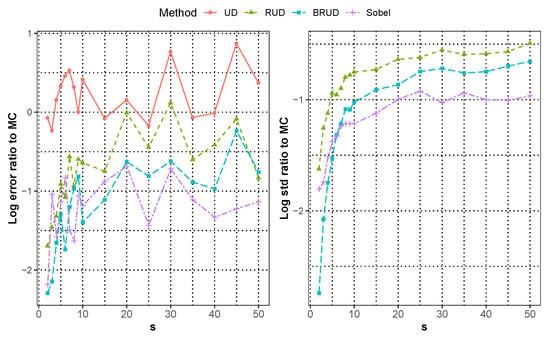
Figure 7.
The median approximation error of integration of over all runs for different dimension.
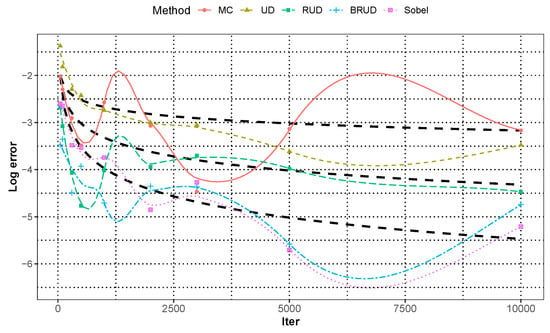
Figure 8.
The approximation error of integration of for each runs in dimension with Locally Weighted Regression.
From the numerical experimental results, the BRUD method has better results and shows faster convergence rates than other methods for functions with sufficient smoothness or lower dimensionality, where the effect of function smoothness on the convergence rate is a bit more significant. The requirement for smoothness condition in [35] is that the mixed partial derivatives of the integrand of order two or less in each coordinate be square integrable. All QMC methods are less effective compared to MC methods when the dimension of the function becomes higher or when the function is very non-smooth. The BRUD method is much better than other QMC methods in low dimensions, although it is not as good as other QMC methods in some high dimensional cases.
6. Conclusions
In this paper, we theoretically derive the order of convergence rate of the centered -discrepancy, wrap-around -discrepancy and mixture discrepancy. Using the uniform design obtained from the numerical search by MD, we propose a randomized quasi-Monte Carlo method based on randomization and the Baker’s transformation. Numerical studies show that, the proposed method has a great advantage over the Monte Carlo method and other quasi-Monte Carlo methods in terms of estimation error and standard deviation, especially for the dimension .
Author Contributions
Methodology, Y.H.; writing—original draft preparation, Y.H.; writing—review and editing, Y.Z.; supervision, Y.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (11871288 and 12131001), the Fundamental Research Funds for the Central Universities, LPMC, and KLMDASR.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
For proving the theorems, we first give the following Lemmas.
Lemma A1
(Vinogradov’s Lemma, [33]). Let r be a positive integer, and let , Δ be the real numbers satisfying . Then there exists a periodic function with period 1 such that:
(1) , if ,
(2) , if and ,
(3) , if ,
(4) has a Fourier expansion
where denotes a sum except , and .
Lemma A2.
Let n, l be the integer . Then and .
Proof.
Since , we have . Similarly, The lemma is proved. □
Lemma A3.
Let be an integral vector and q an integer , If and q are mutually prime, , then for any positive integer r,
Proof.
Lemma A4
([37], Chap. 2). Let be a set of integers such that their great common divisor is not divisible by p. Then the number of solutions of the congruence is at most s.
Lemma A5.
There exists an integral vector such that
Proof.
Let , where a is an integer. Let
Then by Lemma A4,
Hence there exists an integer a such that The lemma is proved. □
Proof of Theorem 1.
(a) First consider CD. For any projection , suppose that , where satisfies . Let , then
For , we construct two auxiliary functions and by Lemma A1 satisfying , and define them as follows,
where , are obtained by taking different parameters in Lemma A1. For brevity, we only show the parameters required to construct these 4 functions, as follows,
Moreover, by Lemma A1 we know that has the Fourier expansion in which . By Lemma A2,
where , and we use to denote a number satisfying but not always with the same value. Then we have
By Lemma A2, . Note that . Then using to instead of , we obtain a similar estimation of the lower bound. Combining them, we have
Next, suppose that there are t components of satisfying and the rest satisfying . Define , where if , and otherwise. Then
Finally, suppose that there are t components of satisfying and the rest satisfying . Define , where if and otherwise. Then
and
Therefore
(b) Consider WD. First suppose that , where , satisfy . Let . Then .
For , without loss of generality, let , then . We construct two auxiliary functions and by Lemma A1 satisfying , and define them as follows,
where are obtained by taking different parameters in Lemma A1. We only show the parameters required to construct these 4 functions, as follows,
Moreover, by Lemma A1 we know that has the Fourier expansion in which By Lemma A2
where , and we use to denote a number satisfying but not always with the same value. Then we have
By Lemma A2, . Note that . Then using to instead of , we obtain a similar estimation of the lower bound. combining them, we have
Next, without loss of generality, suppose that all elements of vector are greater than 0. Suppose that there are t components of satisfying , and the rest satisfying . Define vector , where if , and otherwise. Then
Finally, suppose that there are t components of equal to 1 and the rest are not greater than . Then the problem is reduced to the dimensional case. For any , define the vectors and as follows,
Therefore If there are some elements of are less than 0, we have Then,
(c) Consider MD. First suppose that , whose elements , satisfy Let . Then
For , without loss of generality, let , then . We construct two auxiliary functions and by Lemma A1 satisfying , and define them as follows,
where are obtained by taking different parameters in Lemma A1. And the parameters required to construct these 8 functions are as follows.
Moreover, by Lemma A1 we know that has the Fourier expansion
in which denotes a sum except , and
By Lemma A2
where , and we use to denote a number satisfying . Then we have
By Lemma A2, we have and
Then using to instead of , we obtain a similar estimation of the upper bound, and
Next, suppose that there are t components of equal to 0 or 1, and the rest are in . Then the problem is reduced to the dimensional case. For any , define four vector by replacing with 0 when or replacing with 1 when respectively, that is:
Therefore
Finally, suppose that there are t components of equal to 0 or 1, and the rest are in , Then the problem is reduced to the dimensional case. For the preceding and any , similarly define four vectors and obtain the following inequalities,
Hence
The theorem is proved. □
Proof of Theorem 2.
Let a satisfying Lemma A4. Then by Lemmas A3 and A4,
Take and in Lemma A1, then we have
and
Hence from the definition of it follows that Similarly, we have The proof of the theorem is finished. □
References
- Leobacher, G.; Pillichshammer, F. Introduction to Quasi-Monte Carlo Integration and Applications; Birkhuser: Basel, Switzerland, 2014. [Google Scholar]
- Metropolis, N. The beginning of the monte-carlo method. In Los Alamos Sci. 1987, 125–130. [Google Scholar]
- Richtmyer, R.D. The evaluation of definite integrals and a quasi-monte carlo method based on the properties of algebraic numbers. Differ. Equ. 1951.
- Halton, J.H. On the efficiency of certain quasi-random sequences of points in evaluating multi-dimensional integrals. Numer. Math. 1960, 2, 84–90. [Google Scholar] [CrossRef]
- Sobol, I.M. The distribution of points in a cube and the approximate evaluation of integrals. USSR Comput. Math. Math. Phys. 1969, 7, 784–802. [Google Scholar] [CrossRef]
- Faure, H. Discrépance des suites associées à un systéme de numération. Acta Arith. 1982, 41, 337–351. [Google Scholar] [CrossRef]
- Collings, B.J.; Niederreiter, H. Random number generation and quasi-monte carlo methods. J. Am. Stat. Assoc. 1993, 699. [Google Scholar] [CrossRef]
- Shu, T. Uniform Random Numbers: Theory and Practice; Springer: Berlin/Heidelberg, Germany, 1995. [Google Scholar]
- Joe, S.; Kuo, F.Y. Constructing sobol’ sequences with better two-dimensional projections. SIAM J. Sci. Comput. 2008, 30, 2635–2654. [Google Scholar] [CrossRef]
- Korobov, N.M. The approximate computation of multiple integrals. Dokl. Akad. Nauk. SSSR 1959, 124, 1207–1210. [Google Scholar]
- Korobov, N.M. Properties and calculation of optimal coefficients. Dokl. Akad. Nauk. 1960, 132, 1009–1012. [Google Scholar]
- Hlawka, E. Zur angenäherten berechnung mehrfacher integrale. Monatshefte Math. 1962, 66, 140–151. [Google Scholar] [CrossRef]
- Fang, K.T. The uniform design: Application of number-theoretic methods in experimental design. Acta Math. Appl. Sin. 1980, 3, 9. [Google Scholar]
- Wang, Y.; Fang, K.T. A note on uniform distribution and experimental design. Kexue Tongbao 1981, 26, 485–489. [Google Scholar]
- Patterson, R. Randomization of number theoretic methods for multiple integration. Siam J. Numer. Anal. 1976, 13, 904–914. [Google Scholar]
- Tuffin, B. On the use of low discrepancy sequences in monte carlo methods. Monte Carlo Methods Appl. 1998, 4, 87–90. [Google Scholar] [CrossRef]
- Morohosi, H.; Fushimi, M. A Practical Approach to the Error Estimation of Quasi-Monte Carlo Integrations. In Monte-Carlo and Quasi-Monte Carlo Methods; Springer: Berlin/Heidelberg, Germany, 1998. [Google Scholar]
- Owen, A.B. Scrambling sobol’ and niederreiter-xing points. J. Complex. 1998, 14, 466–489. [Google Scholar] [CrossRef]
- Owen, A.B.; Niederreiter, H.; Shiue, J.S. Randomly permuted (t,m,s)-nets and (t,s)-sequences. In Monte Carlo and Quasi-Monte Carlo Methods in Scientific Computing; Springer: New York, NY, USA, 1995. [Google Scholar]
- Matoušek, J. On the l2-discrepancy for anchored boxes. J. Complex. 1998, 14, 527–556. [Google Scholar]
- Wang, X.; Hickernell, F.J. Randomized halton sequences. Math. Comput. Model. 2000, 32, 887–899. [Google Scholar] [CrossRef]
- Dick, J.; Pillichshammer, F. Digital Nets and Sequences: Discrepancy Theory and Quasi-Monte Carlo Integration; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar]
- Hickernell, F.J. A generalized discrepancy and quadrature error bound. Math. Comput. 1998, 67, 299–322. [Google Scholar] [CrossRef]
- Hickernell, F.J. Lattice rules: How well do they measure up? In Random and Quasi-Random Point Sets; Hellekalek, P., Larcher, G., Eds.; Springer: Berlin/Heidelberg, Germany, 1998; pp. 106–166. [Google Scholar]
- Zhou, Y.D.; Fang, K.T.; Ning, J.H. Mixture discrepancy for quasi-random point sets. J. Complex. 2013, 29, 283–301. [Google Scholar] [CrossRef]
- Fang, K.T.; Liu, M.Q.; Qin, H.; Zhou, Y. Theory and Application of Uniform Experimental Designs; Springer and Science Press: Singapore, 2018. [Google Scholar]
- Glasserman, P. Monte Carlo Methods in Financial Engineering; Springer: New York, NY, USA, 2003. [Google Scholar]
- Hammersley, J.M.; Handscomb, D.C. Monte Carlo Methods; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Bakhvalov, N.S. On the approximate calculation of multiple integrals. J. Complex. 2015, 31, 502–516. [Google Scholar] [CrossRef]
- Koksma, J.F. A general theorem from the theory of uniform distribution modulo 1. Banks Filip Saidak Mayumi 1942, 7–11. [Google Scholar]
- Hlawka, E. Funktionen von beschränkter variatiou in der theorie der gleichverteilung. Ann. Mat. Pura Appl. 1961, 54, 325–333. [Google Scholar] [CrossRef]
- Hickernell, F.J.; Liu, M. Uniform designs limit aliasing. Biometrika 2002, 89, 893–904. [Google Scholar] [CrossRef]
- Hua, L.K.; Wang, Y. Applications of Number Theory to Numerical Analysis; Springer: Berlin, Germany; Science Press: Beijing, China, 1981. [Google Scholar]
- L’Ecuyer, P.; Lemieux, C. Recent advances in randomized quasi-monte carlo methods. Modeling Uncertainty; Springer: New York, NY, USA, 2002; pp. 419–474. [Google Scholar]
- Hickernell, F.J. Obtaining O(n−2+ϵ) convergence for lattice quadrature rules. In Monte Carlo and Quasi-Monte Carlo Methods; Springer: Berlin/Heidelberg, Germany, 2000; pp. 274–289. [Google Scholar]
- Dick, J.; Nuyens, D.; Pillichshammer, F. Lattice rules for nonperiodic smooth integrands. Numer. Math. 2014, 126, 259–291. [Google Scholar] [CrossRef]
- Hua, L.K. Introduction to Number Theory; Science Press: Beijing, China, 1956. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).