Abstract
Data clustering is a process of arranging similar data in different groups based on certain characteristics and properties, and each group is considered as a cluster. In the last decades, several nature-inspired optimization algorithms proved to be efficient for several computing problems. Firefly algorithm is one of the nature-inspired metaheuristic optimization algorithms regarded as an optimization tool for many optimization issues in many different areas such as clustering. To overcome the issues of velocity, the firefly algorithm can be integrated with the popular particle swarm optimization algorithm. In this paper, two modified firefly algorithms, namely the crazy firefly algorithm and variable step size firefly algorithm, are hybridized individually with a standard particle swarm optimization algorithm and applied in the domain of clustering. The results obtained by the two planned hybrid algorithms have been compared with the existing hybridized firefly particle swarm optimization algorithm utilizing ten UCI Machine Learning Repository datasets and eight Shape sets for performance evaluation. In addition to this, two clustering validity measures, Compact-separated and David–Bouldin, have been used for analyzing the efficiency of these algorithms. The experimental results show that the two proposed hybrid algorithms outperform the existing hybrid firefly particle swarm optimization algorithm.
Keywords:
hybrid firefly particle swarm optimization algorithm; crazy firefly algorithm; variable step size firefly algorithm; compact-separated validity index; David–Bouldin validity index MSC:
68T10
1. Introduction
Clustering is a widely used unsupervised machine learning tool used to group data based on their similarity and dissimilarity properties [1]. The use of clustering technology is utilized for a wide range of application scenarios such as data mining, marketing, medicine, banking and finance, data science, machine learning, agriculture etc. In artificial intelligence and data mining, clustering data into meaningful clusters is a significant challenge. There are various aspects to influence the outcomes of clustering algorithms, such as the number of clusters that can be generated in a set of data, the standard and approach to clustering [2]. A variety of clustering techniques such as simulated annealing, k-means, k-medoids and fuzzy c-mean have been suggested to resolve data clustering problems. Such strategies are completely reliant on the initial solution; as a result, the chance of becoming easily stuck inside the local optima is high. Since these clustering algorithms are unable to handle the clustering job for large and complex datasets, several nature-inspired meta-heuristic optimization algorithms have been proposed to overcome the clustering problems by experimenting on several complex and high-dimensional datasets [3]. In the past few decades, to solve the data clustering problems, several evolutionary algorithms such as differential evolution algorithm and genetic algorithm along with several swarm intelligence algorithms such as particle swarm optimization, ant colony optimization, artificial bee colony optimization algorithms, firefly optimization have been applied.
In recent years, owing to its simplicity, effectiveness, robust and better performance, the firefly algorithm (FA) has gained more attention from many global optimization researchers. From the literature review, it is found that the limitations of FA can be overcome by hybridizing FA with different metaheuristic optimization algorithms. In addition to this, a strong balance between exploitation and exploration will be maintained [4]. The main purpose of this study is to build up an automatic superior data-clustering technique without prior knowledge regarding the characteristics of datasets. In this study two new modified FAs have been hybridized with particle swarm optimization algorithm (PSO). The results obtained by these two modified hybrid algorithms will be analyzed along with the existing hybrid firefly particle swarm optimization algorithm (HFAPSO). The two modified hybrid FAs include a hybrid crazy firefly algorithm particle swarm optimization algorithm (HCFAPSO) and a hybrid variable step size firefly algorithm (HVSFAPSO). In crazy FA, the searching diversity is well maintained by adding a craziness factor to the standard FA. So, it will perform better than the standard firefly algorithm [5]. In variable step size FA, a variable step size strategy is added to the standard FA to decrease the searching step size with the number of iterations; as a result, the detection, development and accuracy of the optimization can be improved. Furthermore, two cluster analysis validity measures, namely Davis–Bouldin (DB) and Compact-Separated (CS), have been used to check the validity of clustering solutions [6,7]. The experimental results are carried out based on ten UCI repository datasets and eight Shape sets to verify the better performance of proposed hybrid algorithms over other existing clustering algorithms. The traditional clustering algorithms are unable to handle the clustering task of high dimensional datasets; to overcome this problem many algorithms have been developed [8]. Sustainable automatic data clustering using a hybrid PSO algorithm with mutation was proposed by Sharma and Chhabra [9]. A novel sustainable hybrid clustering algorithm (HPSOM) has thus been developed by integrating PSO with a mutation operator for different network-generated datasets. In automatic data clustering, using the nature-inspired symbiotic organism search (SOS) algorithm, Zhou et al. [10] describe the need of SOS algorithms to overcome the clustering issues. The experimental results prove that the SOS algorithm outperforms other optimization algorithms with high accuracy and stability. Another clustering algorithm proposed by Rajah and Ezugwu [11] is a hybrid algorithm for automatic data clustering in which five novel hybrid symbiotic searching algorithms are used for automatic data clustering without having any primary information regarding the number of clusters. Researchers have identified the NP-difficult, automatic clustering issues; to overcome these issues a metaheuristic ant optimization algorithm has been proposed [12]. All the above-mentioned works demonstrate the need for studies on automatic data clustering problems and to perform certain improvements in data clustering tasks by developing two hybrid models with the help of swarm intelligence algorithms.
Most clustering approaches would require a clearly specified objective function. A Euclidean-based distance measure is chosen along with the two aforementioned validity indices utilized for computing the fitness function of each solution obtained. The majority of metaheuristic algorithms can manage noise or outlier identification related to the datasets and automatically split datasets into an ideal number of clusters. These algorithms start with a population of randomly generated individuals and try to optimize the population over a sequence of generations until the optimum solution is obtained. The proposed algorithms focus initially on searching for the best number of clusters and, after that, gradually move to globally optimal cluster centers. Two types of continuous fitness functions are designed on the basis of current clustering validation indices and the penalty functions designed for minimizing the amount of noise and to control the number of clusters [1]. The CS and DB validity index is used as fitness function to calculate the fitness of each firefly. The cluster center will be refined by the position firefly. The distance between two fireflies will be calculated using the Euclidean distance, where the position of firefly will be updated using the fitness parameter [3,4].
- Two variants of FA, namely crazy FA and variable step size FA, are hybridized individually with the standard PSO algorithm;
- The proposed hybrid algorithms are applied in an automatic data clustering task. The results obtained by the two planned hybrid algorithms have been compared with the existing HFAPSO;
- Ten UCI Machine Learning Repository datasets and eight Shape sets have been used for performance evaluation;
- Two clustering validity measures, CS and DB, have been used for analyzing the efficiency of these algorithms;
- The numerical result calculation is based on the CS as well as the DB validity index;
- The mean value and standard deviation for both the CS and DB validity index has been given;
- The main aim is to obtain the optimal clustering results.
The outline of this study is as follows: Section 2 gives an overview of related work. Section 3 describes the proposed methodology. Section 4 represents detailed knowledge regarding the results analysis. Section 5 presents a comparison study of HFASO, HCFAPSO and HVSFAPSO automatic clustering algorithms. Section 6 describes the findings of this work. Finally, Section 7 concludes the study with a concluding note and future research ideas.
2. Related Work
2.1. The Clustering Problem Description
In this research article, two different modified HFAPSO algorithms have been proposed to overcome the automatic data clustering issues. Automatic data clustering is adopted according to the method mentioned [13]. Let the data set given be be divided into clusters which are non-overlapping in nature, such that the dimension is . A cluster center (centroid) is allocated for every cluster, i.e., belongs to the centres of . For an l-dimensional data vector, the following mentioned criteria should be considered [3]:
In the initialization step of every hybrid clustering algorithm, the swarm size is defined as . Assume every member in the swarm size will be a D × l-dimensional vector and the , which is described as . The objective of the optimization process is performed by the proposed hybrid algorithms by using two performance measures: CS index and DB index for data clustering automatically by reducing the sum of distance between datasets and centres . The upper bound as well as the lower bound of the total number of groups in the Iwarm is represented like and , respectively. Here the is represented as and the is represented as . Generally, for the solution space, the lower boundary is and the upper boundary is . To overcome the automatic data clustering issues, the particle is calculated as Equation (4) [3]
Here, is a vector of randomized number which is distributed in a uniform manner returns a value ranging between 0 and 1.
2.2. The Clustering Validity Measures
In this study, we consider two different validity measures, CS index and DB index, to calculate the efficiency as well as the cluster quality and analyse the performance of the clustering algorithms.
2.2.1. Compact-Separated Index (CS Index)
The CS index calculates the ratio between the total sum of within-cluster scattering and the between-cluster separation. It has been observed that the CS index performs better while working for automatic data clustering with different sizes or densities and dimensions. Therefore, the CS validity measure can be evaluated like a fitness function, as the following mentioned in Equation (5) (Chou et al. [7]).
where denotes to the total number of data points in the cluster , the function represents to the distance between the intra-cluster scatter and the inter-cluster separation and represents to the distance between the datapoints to their centroid.
2.2.2. Davis–Bouldin Index (DB Index)
The DB index calculates automatic data cluster results with the help of estimating intra-cluster (mean distance of all the data points in a cluster from the centroid) to inter-cluster (distance in between two different centroids) distance. Like the CS index, lower values of the DB index will result in good compactness or separation, while the opposite is true for a high value. The DB index can be evaluated like a fitness function, as per the following Equation (6) [6]
is the distance between the data point to the centroid, whereas and are represented as the mean for all data points intra clusters of their distance in between data points and their centroids, and also the denoted as the inter-cluster distance in between two centroids.
2.3. Firefly Algorithm (FA)
The FA is a population-based, stochastic, meta-heuristic, nature-inspired, swarm-related algorithm proposed by Yang [13]. This refers to stochastic algorithms that attempt to search for a collection of solutions using a randomization method. The intensity of firefly is inversely proportional to the distance between two fireflies [13]
Every firefly has its own unique and special attractiveness which determines how intensely a firefly excites other swarm members. However, the attraction is still relative; this will differ along with distance . In between two different fireflies, and presented at locations and , respectively [13]
Firefly positions are the locations where the fireflies are present. Here, and are the positions where two different fireflies and presented.
The attractiveness function of the firefly is evaluated as follows.
The firefly that has the finest fitness value will be chosen to perform in the succeeding optimizing process. In the case of equal brightness, the firefly arbitrarily migrates. By applying the current position, the firefly adjusts its position. The movement of the firefly attracts another brighter firefly and will be evaluated (Yang [14]).
Algorithm 1 is data clustering using the FA algorithm. In this algorithm, the method by which clusters are encoded with FA algorithm is mentioned. Initially, every firefly and cluster centroid is initialized randomly. Then the fitness function is calculated as Equations (5) and (6). According to Equation (9), firefly attraction will be changed and the fireflies’ positions will be updated based on ranking; in addition to this, the current best solution will be updated.
| Algorithm 1. Pseudo code for FA |
| Start Initialized every firefly and random cluster centroid randomly; for ; Calculate the fitness function and as Equations (5) and (6) respectively and obtain the current best solution; As Equation (7) Intensity of light will be calculated; Define light absorption coefficient; while for ; for ; if Move towards as Equation (10) to refine cluster centers; end if According to Equation (9), attraction of fireflies changes with distance; New solution will be calculated and light intensity will be updated; end for end for Fireflies position will be updated based on ranking and the current best solution will be updated. End for end while End |
2.4. Particle Swarm Optimization Algorithm (PSO)
The PSO algorithm is a population oriented, stochastic, metaheuristic optimization algorithm based on the social behaviour of swarm or a group of individuals [15]. In this algorithm, the position as well as the velocity of each particle of swarm will be updated by using the objective function to achieve the best simulation results. The velocity as well as the position of every individual will be adjusted as Equations (11) and (12), respectively [16].
Here, is considered as the latest velocity of the particle, is taken as the inertia weight, is the present velocity of individual, and are personal and global acceleration coefficients respectively, and are two uniformly distributed independent random variables in the range between , is the earliest best position of ith particle, is the position of particle in the iteration, is represented as global best position of the population. is represented as the latest position of a particle.
2.5. Hybrid Firefly Particle Swarm Optimization Algorithm (HFAPSO)
The hybrid clustering algorithm has been designed by integrating the advantages of both PSO and FA algorithms. While creating a hybrid clustering model, two major problems may arise. The first problem is created by adding two or more separate techniques into a single design and the second is the calculation of the best solution by using the process of individual solution searching. Here in this hybrid algorithm, the designing process is carried out by combining FA and PSO. The FA algorithm has strong intensification ability, whereas the PSO algorithm has strong exploration ability [17]. The FA algorithm is good for local searching whereas the PSO algorithm is good for global search solutions. So, for hybridization purposes, the FA algorithm will be taken as the base searching algorithm and then the PSO algorithm will be integrated for finding the optimal solution. Both FA and PSO have their own advantages. By combining FA and PSO, an excellent hybrid optimization algorithm which can be used for automatic data clustering can be developed [17].
The clustering results and efficiency of the HFAPSO clustering algorithm can be determined by using the CS validity measure and DB validity measure. In addition, these performance measures will also help to select the best perfect number of clusters and are also needed for finding the finest partitioning for the selected clusters. While carrying out a further global search for the optimum solution, Firefly does not require any prior previous information of the local best position. Additionally, Firefly does not suffer from the problems with velocity startup and instability for high-velocity particles. The working of HFAPSO will begin with a randomly initializing process by defining the initial firefly population. Then the fitness value of every solution of the FA will be calculated by applying the CS measure and the DB measure. Thereafter the population will be modified by the help of FA operators. Consequently, a similar approach will be repeated in an iterative manner for PSO operators still in the first cycle of the calculation stage of HFAPSO design. PSO makes use of the finest solution provided by FA as its initial search population. The position as well as the velocity of the newly generated solutions by PSO will be updated. In estimation, the previous local best value as well as the previous global best value will be compared with the new population, and the particle will also be updated with the finest fitness values as the global best or best solution. Likewise, the CS and the DB measures have been used by PSO for measuring every solution’s ultimate fitness function. Then, it is used by HFAPSO to define the finest candidate solution and performs the required modifications. Ultimately, the finest solution will be evaluated, depending on the solution having the smallest CS index value or DB index value. The two stages of the HFAPSO algorithm will be repeated until the termination conditions are satisfied.
3. Proposed Methodology
3.1. Hybrid Crazy Firefly Particle Swarm Optimization Algorithm (HCFAPSO)
In swarm intelligence algorithms, birds, fish or fireflies can change their direction quickly. A term of craziness has been used in many swarm intelligence techniques to define the unexpected change of direction in optimization algorithm. The global searching ability of the traditional HFAPSO can be increased by introducing a craziness operator to the traditional FA, and this modification is considered as the best modification to obtain that each firefly must have a predefined probability of craziness for better diversification maintenance. The crazy FA will give superior results with higher convergence rate than the traditional FA. In addition to this this craziness operator will help to obtain improved exploration ability. Mathematically, the expression using craziness is as follows.
Here and are arbitrary parameters selected uniformly inside the interval of and respectively.
is represented as a predefined craziness probability [18]. Adding a crazy operator with the FA algorithm will improve the performance and the searching ability of the algorithm. For data clustering tasks, the crazy operator will give the best results. Therefore, in this hybrid automatic clustering algorithm, the crazy FA will be integrated with the PSO algorithm for finding better cluster results.
In Algorithm 2 the proposed HCFAPSO method for automatic data clustering is described properly. In this algorithm the stepwise procedure of the automatic data clustering using HCFAPSO is stated, in which the crazy FA algorithm is integrated with PSO algorithm. Whereas Figure 1 is the flowchart of the proposed HCFAPSO algorithm for automatic data clustering. In Figure 1 the working principle of the proposed HCFAPSO algorithm is described.
| Algorithm 2. Pseudo code for HCFAPSO |
| Start Initialize every firefly and random cluster centroid randomly; Evaluate fitness value; for ; Calculate the fitness function and as Equations (5) and (6) respectively and obtain the current best solution; if the current value of , then modify the current as best solution; ; end if end for while for ; for ; if Move towards as Equation (13); if ; will be the new solution; if ; Modify as new solution; end if end if end if Initialized randomly; Calculate the and position of every particle ; Evaluate fitness value by taking the function and ; if ; else if the fitness value is lesser than the overall best fitness value, then modify the new value as the global best value. ; Modify centroids of cluster following velocity and coordinates modifying Equations (11) and (12); end if end if end for end for end while End |
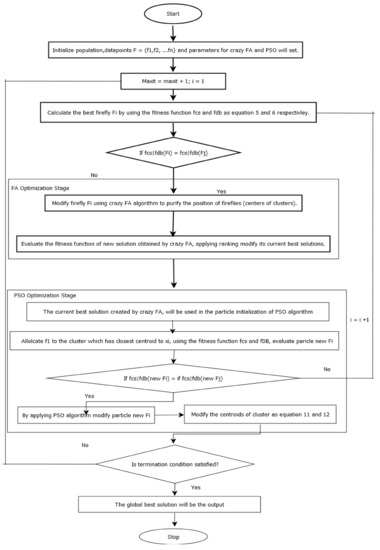
Figure 1.
Flowchart for HCFAPSO automatic clustering.
3.2. Hybrid Variable Step Size Firefly Particle Swarm Optimization Algorithm (HVSFAPSO)
The performance of standard FA can be improved by increasing the convergence speed [19]. To overcome the drawbacks of standard FA, the global exploration as well as the local exploitation should be maintained properly. For this purpose, the step size should be adjusted dynamically. In standard FA, the step size is constant and will not perfectly follow the searching process. In variable step size algorithms, the step size is considered as a variable. To maintain balance in between the identification and development capacity of firefly algorithms, initially step size should be a larger value. Subsequently, it decreases over iterations. Based on various searching space optimization issues, a large searching step size is needed if the definition space of the optimization target is large. Otherwise, a small searching step size is required, which will aid the algorithm’s ability to adapt to a variety of optimization issues [20].
Here = number of existing iterations and max generation = maximum number of iterations. For data clustering tasks, the variable step size FA will work better than the standard FA algorithm by adjusting the step size dynamically. Therefore, in this hybrid automatic clustering algorithm, the variable-step-size firefly algorithm will be integrated with the particle swarm optimization algorithm to obtain better cluster results.
Algorithm 3 is the proposed HVSFAPSO method for automatic data clustering. In Algorithm 3, the variable-step-size FA algorithm is hybridized with PSO for automatic data clustering; Figure 2 shows the flowchart for the proposed HVSFAPSO algorithm. The working principle of the automatic data clustering task is described in detail in Figure 2.
| Algorithm 3. Pseudo code for HVSFAPSO |
| Start Initialized every firefly and random cluster centroid randomly; Evaluate fitness value; for ; Calculate the fitness function and as Equations (5) and (6) respectively and obtain the current best solution; if the current value of , then modify the Current as best solution; ; end if end for while for ; for ; if Move towards as Equations (8) and (9); Set the value of step size as Equation (14) if ; will be the new solution; if; Modify as new solution; end if end if end if Initialized randomly; Calculate the and position of every particle ; Evaluate fitness value by taking the function and ; if ; else if the fitness value is lesser than the overall best fitness value, then modify the new value as the global best value. ; Modify centroids of cluster following velocity and coordinates modifying Equations (11)and (12); end if end if end for end for end while End |
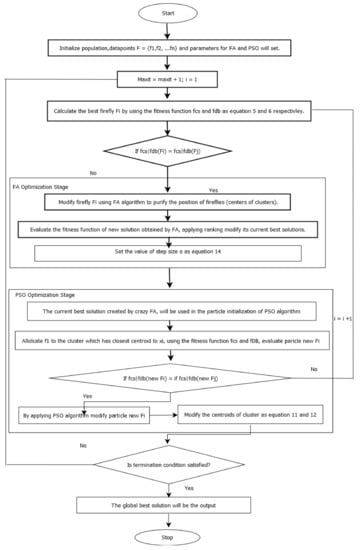
Figure 2.
Flow chart for HVSFAPSO automatic clustering.
4. Results Analysis
This section presents detailed information regarding the simulation experiments on automatic data clustering by using three hybrid algorithms and describes in detail the system configuration along with the design of the datasets; in addition to this, the results obtained will be discussed.
4.1. System Configuration
The experiments have been implemented on MATLAB by using a 1.80 GHz Intel(R) Core (TM) i5-8265U processor with 4.00 GB RAM on a Windows 10 operating system. The parameter setting for the HFAPSO implementation is given in Table 1. The parameter values of the firefly algorithm have already been explored in past studies [3,4,14,17]. From those works, the optimal range values have been chosen, rather than a specific fixed value to obtain better clustering results. The experiments have been conducted on HFAPSO by using 200 iterations with 25 population size for 20 independent runs. Furthermore, 10 UCI repository datasets and 8 Shape sets have been used for experimental purposes. The details regarding the datasets are mentioned in Table 2.

Table 1.
Parameter setting.
Table 2.
Characteristics of the eighteen datasets.
4.2. Datasets Design
Eighteen datasets used for experimental study were taken from the UCI Machine Learning Repository and Shape sets [21,22]. The detailed descriptions of the datasets have been mentioned in Table 2, including the number of data points, datasets’ dimensions and number of clusters. The experiments for the task of automatic data clustering have been performed by considering 200 iterations with 25 populations on 20 independent runs. The numerical result calculation is based on the CS validity index as well as the DB validity index, which are presented in Table 3. In the results table, the clustering results are given. The Best, Worst, Average, StDev represent the best clustering solution, worst clustering solution, average clustering solution and the standard deviation respectively [23].
Table 3.
Numerical results of HFAPSO based on CS and DB validity indices over 20 independent runs.
4.3. Results Discussion
In this section, the numerical results obtained by automatic data clustering for all three above mentioned hybrid algorithms by taking two validity indices: the CS index and the DB index, over 20 independent runs, have been discussed clearly. In Table 3 the results of the HFAPSO automatic data clustering algorithm for all datasets is clearly presented. The four decimal values are in bold, representing that they constitute the best value for this set. The main aim is to get quality results with less execution time to execute every algorithm to obtain the optimal clustering results. In Table 3, it is shown that CS index outperforms the DB index in some datasets: Spiral, Path based, Jain, Flame, Breast, R15, Leaves, and D31. Similarly, the DB index outperforms than CS index in some datasets, namely Iris, Yeast, Wine, Thyroid, Hepatitis, Heart, Glass, Compound, Wdbc, and Aggregation. In Figure 3, the execution times of HFAPSO for both the CS index and DB index are presented clearly. In the Figure 3 the blue bar represents the CS index whereas the orange bar represents the DB index. However, the figure shows that the CS index will take longer to execute in comparison to the DB index to obtain the clustering results. The clustering illustrations of each individual datasets of HFAPSO, HCFAPSO and HVSFAPSO automatic data clustering based on both CS index and DB index is presented in Figure 4 and Figure 5 respectively.
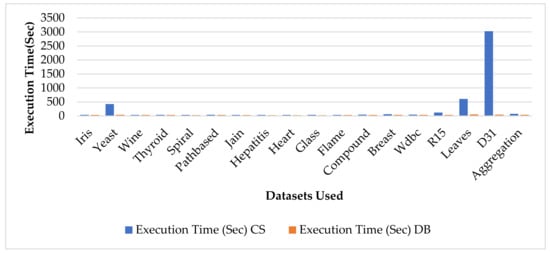
Figure 3.
Average execution time taken by HFAPSO on CS and DB indices for all the datasets used over 20 independent runs.
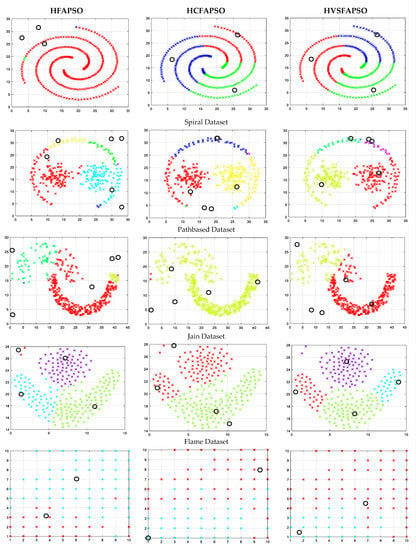
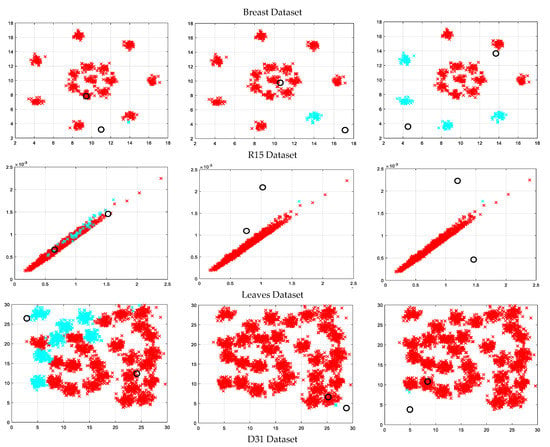
Figure 4.
Clustering illustrations for HFAPSO, HCFAPSO and HVSFAPSO clustering algorithms on some selected datasets based on CS index where the black hollow circle represents the number of clusters formed.
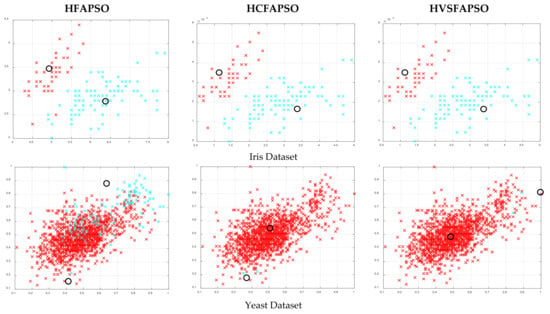
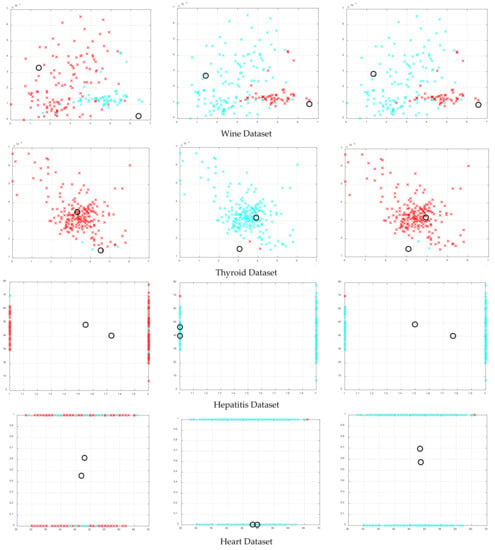
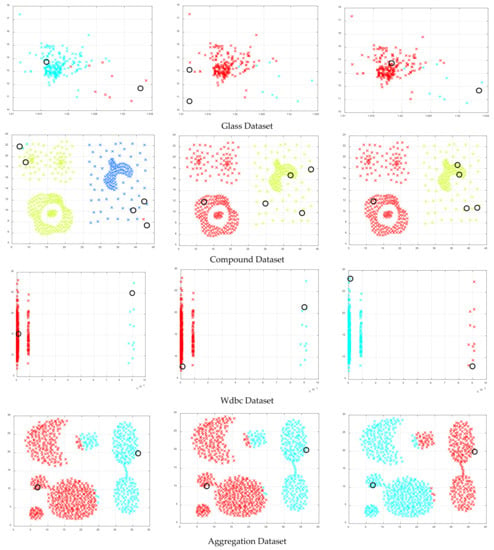
Figure 5.
Clustering illustrations for HFAPSO, HCFAPSO and HVSFAPSO clustering algorithms on some selected datasets based on DB index, where the black hollow circle represents the number of clusters formed.
In Table 4 the results of the HFAPSO automatic data clustering algorithm for all datasets is clearly presented. The four decimal values are in bold, representing that they constitute the best value. The main aim is to obtain quality results with less execution time to execute every algorithm to obtain the optimal clustering results. In Table 4 it is shown that the CS index outperforms the DB index in some datasets: Spiral, Path based, Flame, R15, Leaves, and D31. Similarly DB index outperforms than CS index in some datasets namely, Iris, Yeast, Wine, Thyroid, Jain, Hepatitis, Heart, Glass, Compound, Breast, Wdbc and Aggregation. In Figure 6 the execution time of HCFAPSO for both CS index and DB index is presented clearly. In the Figure 6 the blue bar represents the CS index whereas the orange bar represents the DB index. However, from the figure it shows that the CS index will take longer to execute in comparison to the DB index to obtain the clustering results. The clustering illustrations of each individual datasets of HFAPSO, HCFAPSO and HVSFAPSO automatic data clustering based on both CS index and DB index is presented in Figure 4 and Figure 5 respectively.
Table 4.
Numerical results of HCFAPSO based on CS and DB validity indices over 20 independent runs.
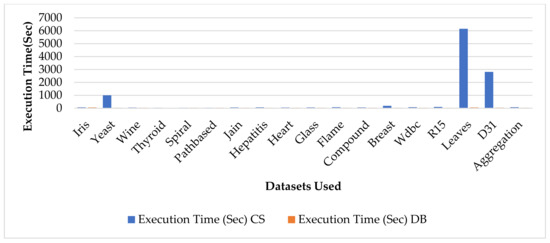
Figure 6.
Average execution time taken by HCFAPSO on CS and DB indices for all the datasets used over 20 independent runs.
In Table 5 the results of the HVSFAPSO Automatic data clustering algorithm for all datasets are clearly presented. The four decimal values are in bold, representing that they constitute the best value. The main aim is to obtain quality results with less execution time to execute every algorithm to obtain the optimal clustering results. In Table 5 it is shown that the CS index outperforms than DB index in some datasets: Spiral, Path based, Jain, Glass, Flame, Breast, R15, Leaves, and D31.Similarly the DB index outperforms than the CS index in some datasets, namely, Iris, Yeast, Wine, Thyroid, Hepatitis, Heart, Compound, Wdbc, Aggregation. In Figure 7 the execution time of HVSFAPSO for both CS index and DB index is presented clearly. In the Figure 7 the blue bar represents the CS index whereas the orange bar represents the DB index. However, from the figure it shows that the CS index will take longer to execute in comparison to the DB index to obtain the clustering results. The clustering illustrations of each individual datasets of of HFAPSO, HCFAPSO and HVSFAPSO automatic data clustering based on both the CS index and the DB index are presented in Figure 4 and Figure 5, respectively.
Table 5.
Numerical results for HVSFAPSO based on the CS and DB validity indices over 20 independent runs.
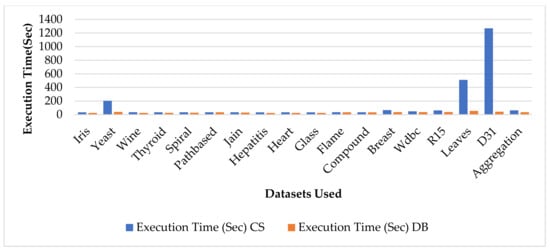
Figure 7.
Average execution time taken by HVSFAPSO on CS and DB indices for all the datasets used over 20 independent runs.
5. Comparison Study of HFASO, HCFAPSO and HVSFAPSO Automatic Clustering Algorithms
In this section the comparison results of three hybrid clustering algorithms have been discussed. In Table 6, the mean value and standard deviation for both CS and DB indexes have been given. The clustering illustration of all eighteen datasets for both CS index and DB index has been given in Figure 4 and Figure 5 respectively. The convergence curves for all three-hybrid algorithms for both the CS and DB indexes have been shown in Figure 8 and Figure 9, respectively.
Table 6.
Result Comparison of HFAPSO, HCFAPSO and HVSFAPSO for Automatic Clustering.
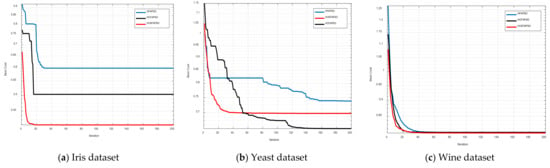
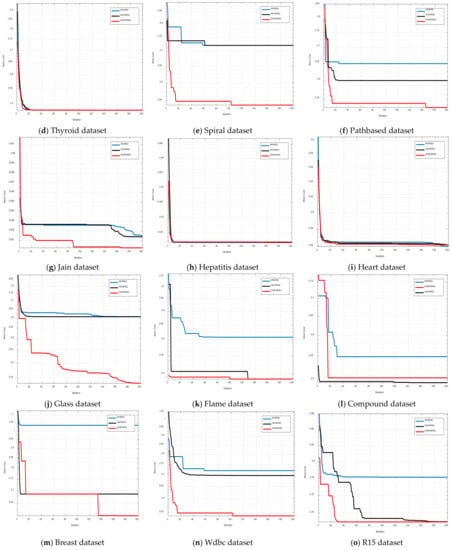
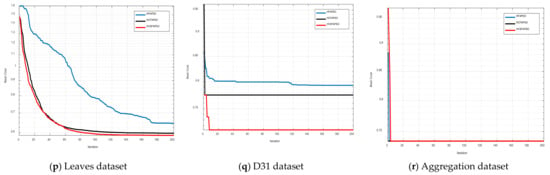
Figure 8.
Convergence curves for all used datasets on CS-index.
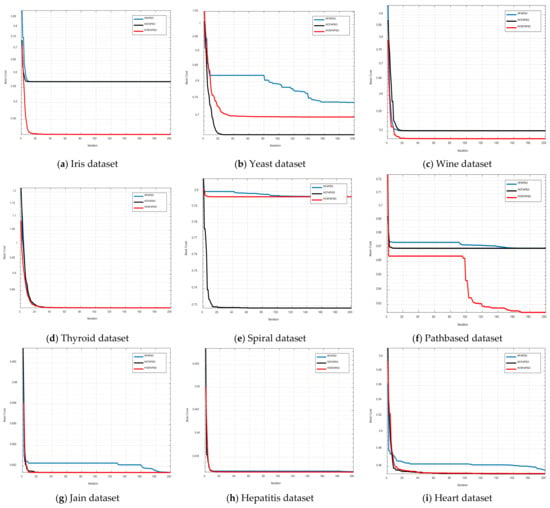
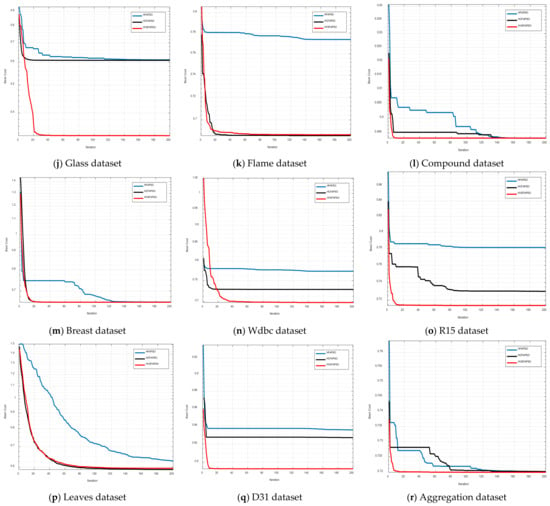
Figure 9.
Convergence curves for all used datasets on DB index.
The clustering illustrations for HFAPSO, HCFAPSO and HVSFAPSO on some selected datasets based on the CS index have been presented in Figure 4. For the Spiral dataset from the above figure, it shows that in using the FAPSO clustering algorithm, we have some outliers in the clustering, whereas both HCFAPSO and HVSFAPSO clustering algorithms give superior results with three perfect clusters and no outliers. For the Path-based dataset the HFAPSO clustering algorithm gives four clusters with few magenta and blue outliers and by using HCFAPSO clustering algorithm, three distinct clusters are found with very few outliers, whereas in HVSFAPSO, four clearly separated clusters are generated. For the Jain dataset, HCFAPSO and HVSFAPSO give good clustering in comparison to HFAPSO clustering algorithms. For the Flame dataset, both HCFAPSO and HVSFAPSO clustering algorithms are superior to the HFAPSO clustering algorithm, having two and four clear clusters, respectively. For the breast dataset, by using both HCFAPSO and HVSFAPSO clustering algorithms, better clustering results obtained than the existing HFAPSO clustering algorithm. For R15 dataset the HFAPSO clustering algorithm gives clusters with outliers, whereas by using both HCFAPSO and HVSFAPSO clustering algorithms, good clustering results are observed with no outliers. For the Leaves dataset both HFAPSO and HVSFAPSO clustering algorithms outperform the HFAPSO clustering algorithm with good clusters, having far fewer outliers which are not noticeable. Similarly, for D31 dataset both HCFAPSO and HVSFAPSO clustering algorithms outperform the HFAPSO clustering algorithm with one cluster each.
The clustering illustrations for HFAPSO, HCFAPSO and HVSFAPSO on some selected datasets based on the DB index have been presented in Figure 5. For Iris, Wine, Yeast, Thyroid, Hepatitis and Heart datasets, HCFAPSO and HVSFAPSO clustering algorithms outperform the HFAPSO clustering algorithm, having two clusters each with very few blue and red outliers which can be ignored. For the Compound dataset, the HCFAPSO and HVSFAPSO algorithm give superior results than the HFAPSO clustering algorithm having three clusters without outliers. The exception cases are Glass, Wdbc and Aggregation datasets, in which all three algorithms give good clustering results, having two clusters each, but for better clustering results, both HCFAPSO and HVSFAPSO clustering algorithms can be considered [24].
In Figure 8 and Figure 9 the equivalent graphical convergence comparison curves of the three hybrid clustering algorithms discussed above for eighteen datasets based on the CS index and DB index are presented, respectively. For both the CS index and the DB index, the HCFAPSO clustering algorithm and HVSFAPSO clustering algorithm give better convergence results than the existing HFAPSO clustering algorithm. However, the HVSFAPSO clustering algorithms converge faster and also give smoother convergence curves than HCFAPSO.
To further find a better experimental result, the Wilcoxon rank-sum test has been taken. In Table 7 the p-values for both CS and DB indexes are presented in pairwise analysis in terms of HCFAPSO vs. HFAPSO and HVSFAPSO vs. HFAPSO. The Wilcoxon rank-sum test also contrasts with the null hypothesis, which holds that two values are samples from continuous distributions with equal medians. Almost all values in Table 7 are less than 0.05, which shows significance level of 5%. This significance level provides better support over the null hypothesis and demonstrates the statistical importance of the proposed HCFAPSO and HVSFAPSO clustering results.
Table 7.
p-Values generated by using Wilcoxon rank-sum test for equal medians.
6. Discussions
- In this work, two hybrid algorithms have been proposed to automatically cluster datasets by exploring the FA and PSO. Those algorithms start with a population of randomly generated individuals and try to optimize the population over a sequence of generations until the optimum solution is obtained.
- The proposed algorithms initially focus on searching for the best number of clusters and gradually move to obtain the globally optimal cluster centers.
- Two types of continuous fitness functions are designed on the basis of current clustering validation indices and the penalty functions designed for minimizing the amount of noise and to control the number of clusters [1].
- The CS and DB validity indexes are used as fitness functions to calculate the fitness of each firefly. The cluster center has been changed by the position of each firefly. The distance between two fireflies has been calculated using the Euclidean distance, where the position of each firefly has been updated using the fitness parameter.
- The effectiveness of the proposed clustering strategy has shown its efficiency with respect to the convergence graph, mean value, standard deviation value and the p-value generated by the Wilcoxon rank-sum test in comparison with HFAPSO to establish its effectiveness.
7. Conclusions and Future Scope
In past, many traditional clustering algorithms have been designed by researchers, but these have been unable to solve complex real-time data clustering problems. Most clustering approaches would require a clearly specified objective function. Two modified hybrid automatic clustering algorithms, namely HCFAPSO and HVSFAPSO, have been proposed to overcome the data clustering issues in real time. Subsequently the performance analysis of both the proposed automatic clustering algorithms has been performed based on two validity indices: CS index and DB index [6,7]. The CS index proves itself the better clustering performance measure than the DB index, with little more execution time taken than the DB index. The results obtained using both the proposed algorithms have been compared with the existing HFAPSO automatic clustering algorithms. In terms of better convergence speed, better diversification, and ability to adapt to a variety of optimization issues, both the proposed modified automatic clustering algorithms will outperform the existing HFAPSO automatic data clustering algorithm. In addition to this, both the proposed HCFAPSO and HVSFAPSO automatic data clustering algorithms will give superior results to HFAPSO based on the optimal number of clusters. The proposed HCFAPSO and HVSFAPSO algorithms can be used efficiently to solve automatic data clustering issues. However, in certain problems a little more emphasis must be given to the proposed HVSFAPSO to obtain better results. In future, HCFAPSO and HVSFAPSO can be applied efficiently in different complex optimization areas for better performance.
Author Contributions
Conceptualization, M.B., A.S., D.M., P.K.M., J.S., P.N.S. and M.F.I.; data curation, M.B., A.S. and D.M.; formal analysis, M.B., A.S., D.M., P.K.M. and J.S.; funding acquisition, M.F.I. and J.S.; investigation, P.K.M., J.S., P.N.S. and M.F.I.; methodology, M.B., A.S., D.M., P.K.M., J.S. and P.N.S.; project administration, M.F.I., P.N.S. and J.S.; resources, M.F.I. and J.S.; software, M.B., A.S., D.M., P.K.M., J.S. and P.N.S.; supervision, J.S., P.N.S. and M.F.I.; validation A.S., D.M. and M.B. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by Sejong University Research fund.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Publicly available datasets were analyzed in this study.
Acknowledgments
Jana Shafi would like to thank the Deanship of Scientific Research, Prince Sattam bin Abdul Aziz University, for supporting this work.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Guan, C.; Yuen, K.K.F.; Coenen, F. Particle swarm Optimized Density-based Clustering and Classification: Supervised and unsupervised learning approaches. Swarm Evol. Comput. 2019, 44, 876–896. [Google Scholar] [CrossRef]
- Majhi, S.K.; Biswal, S. Optimal cluster analysis using hybrid K-Means and Ant Lion Optimizer. Karbala Int. J. Mod. Sci. 2018, 4, 347–360. [Google Scholar] [CrossRef]
- Agbaje, M.B.; Ezugwu, A.E.; Els, R. Automatic Data Clustering Using Hybrid Firefly Particle Swarm Optimization Algorithm. IEEE Access 2019, 7, 184963–184984. [Google Scholar] [CrossRef]
- Ezugwu, A.E.-S.; Agbaje, M.B.; Aljojo, N.; Els, R.; Chiroma, H.; Elaziz, M.A. A Comparative Performance Study of Hybrid Firefly Algorithms for Automatic Data Clustering. IEEE Access 2020, 8, 121089–121118. [Google Scholar] [CrossRef]
- Sarangi, S.K.; Panda, R.; Sarangi, A. Crazy firefly algorithm for function optimization. In Proceedings of the 2nd International Conference on Man and Machine Interfacing (MAMI), Bhubaneswar, India, 21–23 September 2017; pp. 1–5. [Google Scholar]
- Davies, D.L.; Bouldin, D.W. A Cluster Separation Measure. IEEE Trans. Pattern Anal. Mach. Intell. 1979, 1, 224–227. [Google Scholar] [CrossRef] [PubMed]
- Chou, C.-H.; Su, M.-C.; Lai, E. A new cluster validity measure and its application to image compression. Pattern Anal. Appl. 2004, 7, 205–220. [Google Scholar] [CrossRef]
- Deeb, H.; Sarangi, A.; Mishra, D.; Sarangi, S.K. Improved Black Hole optimization algorithm for data clustering. J. King Saud Univ. Comput. Inf. Sci. 2022, 34, 5020–5029. [Google Scholar] [CrossRef]
- Sharma, M.; Chhabra, J.K. Sustainable automatic data clustering using hybrid PSO algorithm with mutation. Sustain. Comput. Inform. Syst. 2019, 23, 144–157. [Google Scholar] [CrossRef]
- Zhou, Y.; Wu, H.; Luo, Q.; Abdel-Baset, M. Automatic data clustering using nature-inspired symbiotic organism search algorithm. Knowl.-Based Syst. 2019, 163, 546–557. [Google Scholar] [CrossRef]
- Rajah, V.; Ezugwu, A.E. Hybrid Symbiotic Organism Search algorithms for Automatic Data Clustering. In Proceedings of the Conference on Information Communications Technology and Society (ICTAS), Durban, South Africa, 9–10 March 2022; pp. 1–9. [Google Scholar]
- Pacheco, T.M.; Gonçalves, L.B.; Ströele, V.; Soares, S.S.R.F. An Ant Colony Optimization for Automatic Data Clustering Problem. In Proceedings of the 2018 IEEE Congress on Evolutionary Computation (CEC), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar]
- Yang, X.S. Firefly Algorithm, Nature-Inspired Metaheuristic Algorithms; Luniver Press: Cambridge, MA, USA, 2008; pp. 79–90. [Google Scholar]
- Yang, X.S. Firefly Algorithms for Multimodal Optimization. In Stochastic Algorithms: Foundations and Applications; Watanabe, O., Zeugmann, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; Volume 5792, pp. 169–178. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle Swarm Optimization. In Proceedings of the ICNN’95—International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; pp. 1942–1948. [Google Scholar]
- Eberhart, R.; Kennedy, J. A new optimizer using particle swarm theory. In Proceedings of the Sixth International Symposium on Micro Machine and Human Science, Nagoya, Japan, 4–6 October 1995; pp. 39–43. [Google Scholar]
- Xia, X.; Gui, L.; He, G.; Xie, C.; Wei, B.; Xing, Y.; Wu, R.; Tang, Y. A hybrid optimizer based on firefly algorithm and particle swarm optimization algorithm. J. Comput. Sci. 2018, 26, 488–500. [Google Scholar] [CrossRef]
- Samal, S.; Sarangi, S.K.; Sarangi, A. Analysis of Adaptive Mutation in Crazy Particle Swarm Optimization. In Proceedings of the 2020 International Conference on Computational Intelligence for Smart Power System and Sustainable Energy (CISPSSE), Keonjhar, India, 29–31 July 2020; pp. 1–5. [Google Scholar]
- Alhmouz, O.; Abrar, S.; Iqbal, N.; Zerguine, A. A Variable Step-Size Blind Equalization Algorithm Based on Particle Swarm Optimization. In Proceedings of the 14th International Wireless Communications & Mobile Computing Conference (IWCMC), Limassol, Cyprus, 25–29 June 2018; pp. 1357–1361. [Google Scholar]
- Zhao, J.; Chen, W.; Ye, J.; Wang, H.; Sun, H.; Lee, I. Firefly Algorithm Based on Level-Based Attracting and Variable Step Size. IEEE Access 2020, 8, 58700–58716. [Google Scholar] [CrossRef]
- Bache, K.; Lichman, M. UCI Machine Learning Repository; University of California, School of Information and Computer Science: Irvine, CA, USA, 2013. [Google Scholar]
- Clustering Basic Benchmark. Available online: http://cs.joensuu.fi/sipu/datasets/ (accessed on 25 November 2019).
- Samanta, S.R.; Mallick, P.K.; Pattnaik, P.K.; Mohanty, J.R.; Polkowski, Z. (Eds.) Cognitive Computing for Risk Management; Springer: Cham, Switzerland, 2022. [Google Scholar]
- Mukherjee, A.; Singh, A.K.; Mallick, P.K.; Samanta, S.R. Portfolio Optimization for US-Based Equity Instruments Using Monte-Carlo Simulation. In Cognitive Informatics and Soft Computing. Lecture Notes in Networks and Systems; Mallick, P.K., Bhoi, A.K., Barsocchi, P., de Albuquerque, V.H.C., Eds.; Springer: Singapore, 2022; Volume 375. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).