
Optimal Harvesting of Stochastically Fluctuating Populations Driven by a Generalized Logistic SDE Growth Model


Abstract
:1. Introduction
2. Optimal Policy with Variable Effort
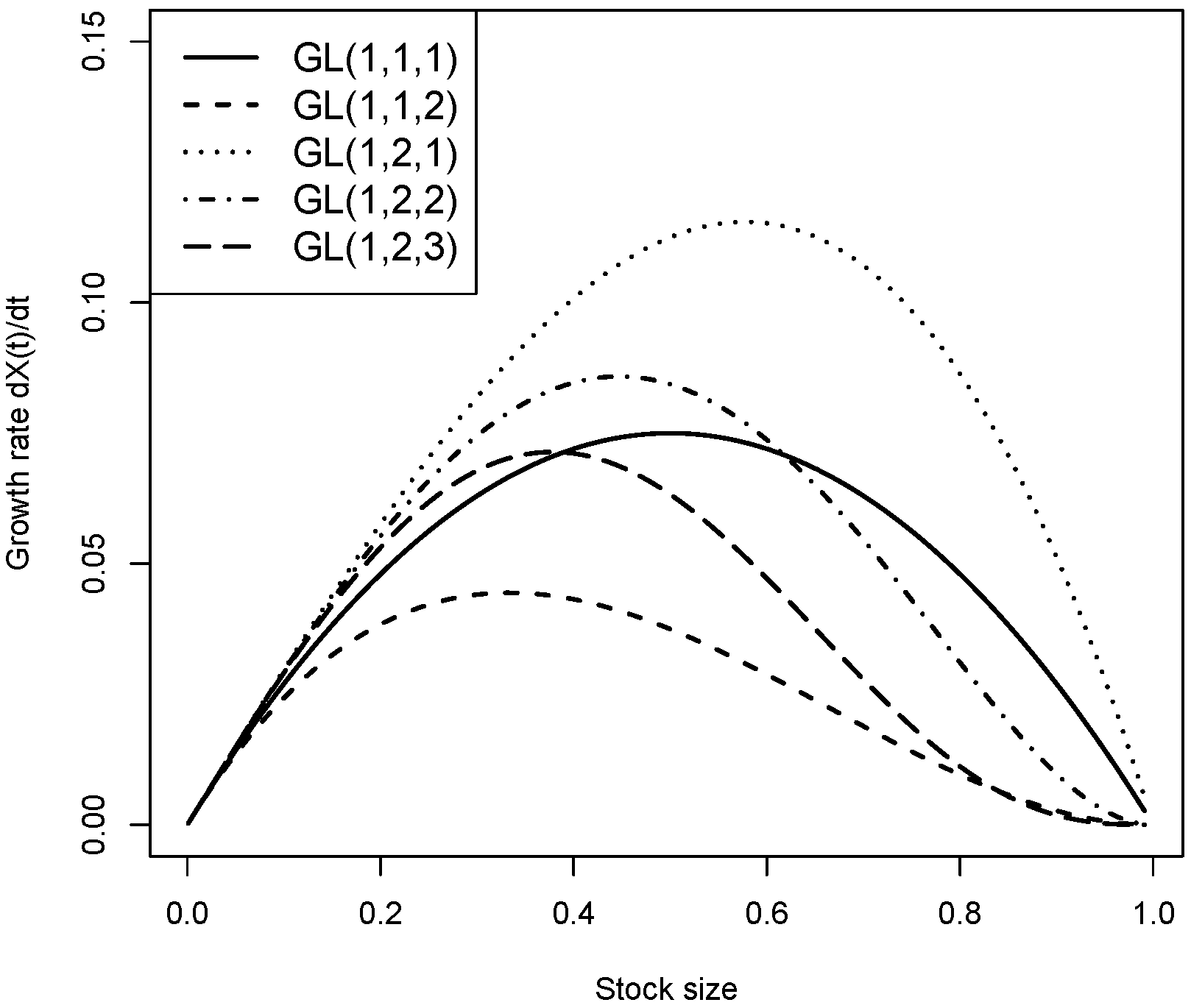
2.1. Generalized Logistic Growth Model
2.2. Optimal Policy
2.3. Domain Discretization and Finite Difference Approximation
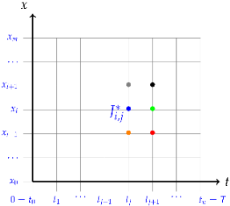
2.4. Numerical Solution
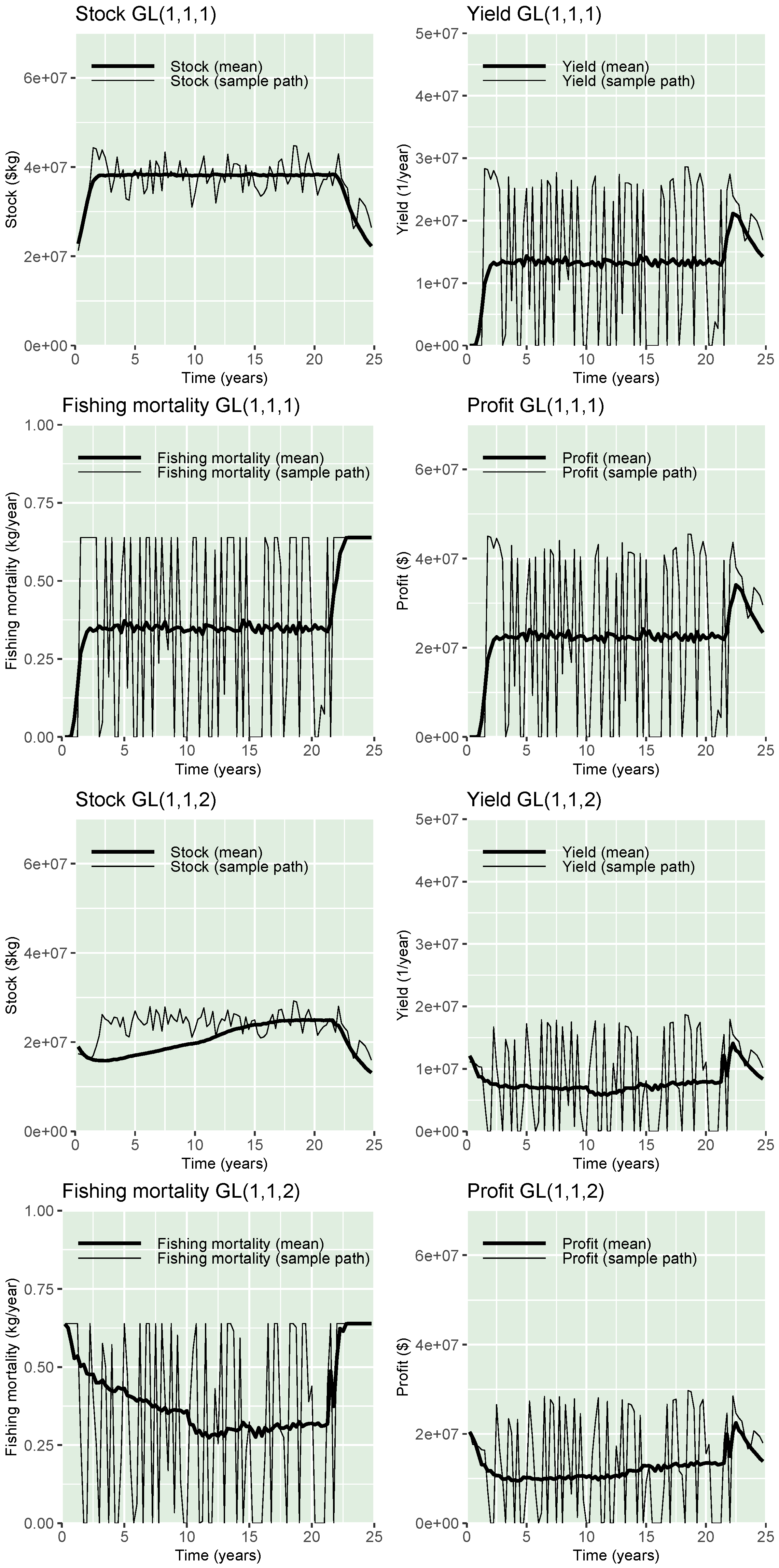
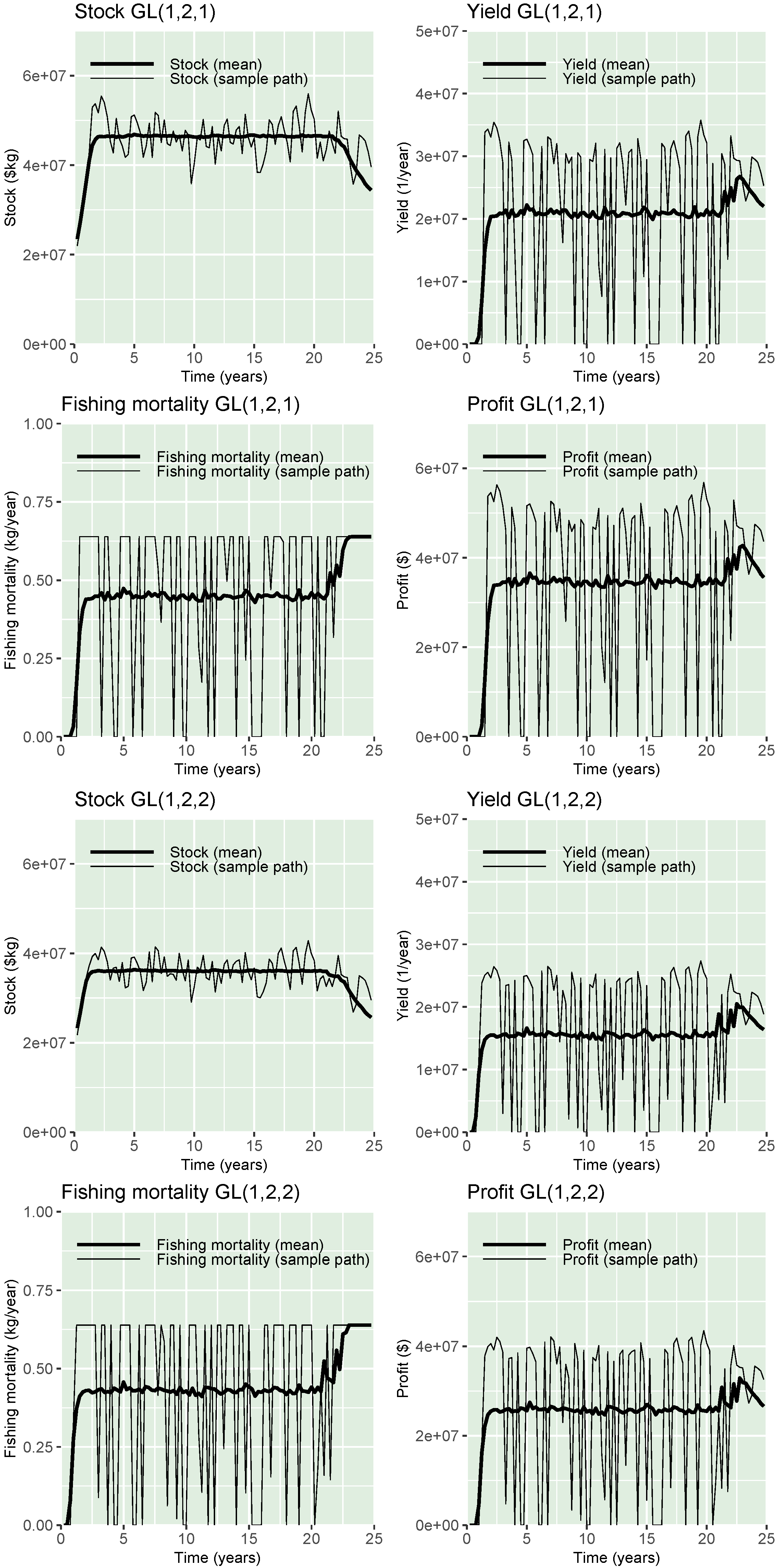
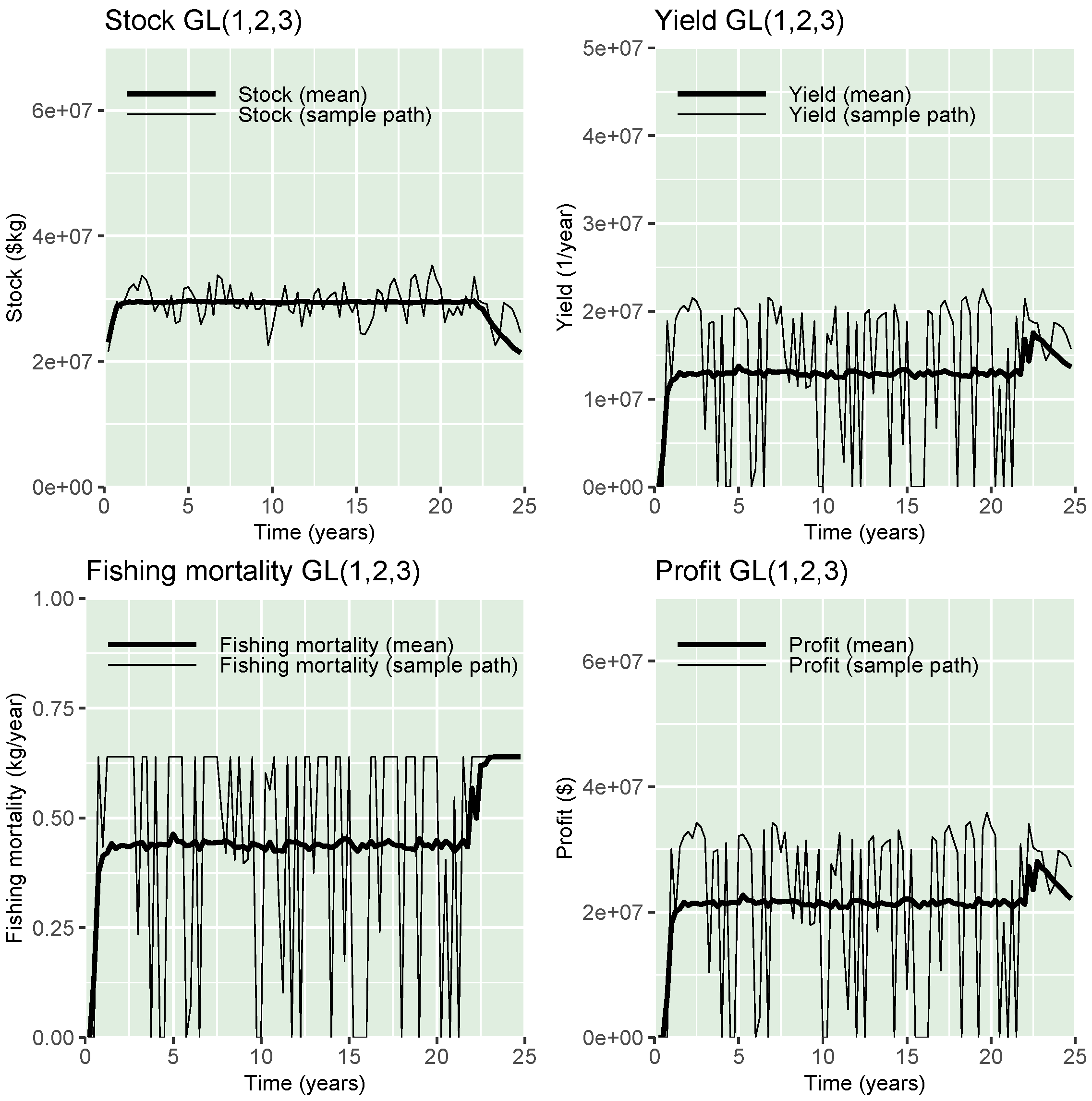
3. Results
Sensitivity Analysis
4. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
- (A)
- is a small positive quantity;
- (B)
- ;
- (C)
- ;
- (D)
- ;
- (E)
- is known;
- (F)
- during time interval , the control is constant.
References
- Beddington, J.R.; May, R.M. Harvesting natural populations in a randomly fluctuating environment. Science 1977, 197, 463–465. [Google Scholar] [CrossRef] [PubMed]
- Clark, C.W. Mathematical Bioeconomics: The Optimal Management of Renewable Resources, 2nd ed.; Wiley: New York, NY, USA, 1990. [Google Scholar]
- Alvarez, L.H.R.; Sheep, L.A. Optimal harvesting of stochastically fluctuating populations. J. Math. Biol. 1998, 37, 155–177. [Google Scholar] [CrossRef]
- Alvarez, L.H.R. On the option interpretation of rational harvesting planning. J. Math. Biol. 2000, 40, 383–405. [Google Scholar] [CrossRef]
- Alvarez, L.H.R. Singular stochastic control in the presence of a state-dependent yield structure. Stoch. Process. Their Appl. 2000, 86, 323–343. [Google Scholar] [CrossRef]
- Brites, N.M.; Braumann, C.A. Harvesting in a Random Varying Environment: Optimal, Stepwise and Sustainable Policies for the Gompertz Model. Stat. Optim. Inf. Comput. 2019, 7, 533–544. [Google Scholar] [CrossRef]
- Brites, N.M.; Braumann, C.A. Harvesting optimization with stochastic differential equations models: Is the optimal enemy of the good? Stoch. Model. 2021, 0, 1–19. [Google Scholar] [CrossRef]
- Brites, N.M.; Braumann, C.A. Profit optimization of stochastically fluctuating populations: The effects of Allee effects. Optimization 2022, 1–12. [Google Scholar] [CrossRef]
- Brites, N.M.; Braumann, C.A. Fisheries management in random environments: Comparison of harvesting policies for the logistic model. Fish. Res. 2017, 195, 238–246. [Google Scholar] [CrossRef]
- Brites, N.M.; Braumann, C.A. Fisheries management in randomly varying environments: Comparison of constant, variable and penalized efforts policies for the Gompertz model. Fish. Res. 2019, 216, 196–203. [Google Scholar] [CrossRef]
- Brites, N.M.; Braumann, C.A. Stochastic differential equations harvesting policies: Allee effects, logistic-like growth and profit optimization. Appl. Stoch. Model. Bus. Ind. 2020, 36, 825–835. [Google Scholar] [CrossRef]
- Brites, N.M.; Braumann, C.A. Harvesting Policies with Stepwise Effort and Logistic Growth in a Random Environment. In Current Trends in Dynamical Systems in Biology and Natural Sciences; Aguiar, M., Braumann, C., Kooi, B.W., Pugliese, A., Stollenwerk, N., Venturino, E., Eds.; Springer: Cham, Switzerland, 2020; pp. 95–110. [Google Scholar] [CrossRef]
- Shah, M.A.; Sharma, U. Optimal harvesting policies for a generalized Gordon–Schaefer model in randomly varying environment. Appl. Stoch. Model. Bus. Ind. 2003, 19, 43–49. [Google Scholar] [CrossRef]
- Tsoularis, A.; Wallace, J. Analysis of logistic growth models. Math. Biosci. 2002, 179, 21–55. [Google Scholar] [CrossRef]
- Verhulst, P.F. Notice sur la loi que la population poursuit dans son accroissement. Corresp. Math. Phys. 1838, 10, 113–121. [Google Scholar]
- Braumann, C.A. Stochastic differential equation models of fisheries in an uncertain world: Extinction probabilities, optimal fishing effort, and parameter estimation. In Proceedings of the Mathematics in Biology and Medicine, Bari, Italy, 18–22 July 1985; Capasso, V., Grosso, E., Paveri-Fontana, S.L., Eds.; Springer: Berlin, Germany, 1985; pp. 201–206. [Google Scholar]
- Braumann, C.A. Introduction to Stochastic Differential Equations with Applications to Modelling in Biology and Finance; John Wiley & Sons, Inc.: New York, NY, USA, 2019. [Google Scholar]
- Kamien, M.I.; Schwartz, N.L. Dynamic Optimization; North-Holland, The Netherlands, 1993. [Google Scholar]
- Fleming, W.H.; Soner, H.M. Controlled Markov Processes and Viscosity Solutions; Springer: New York, NY, USA, 2006. [Google Scholar]
- Touzi, N. Optimal Stochastic Control, Stochastic Target Problems, and Backward SDE; Springer: New York, NY, USA, 2013. [Google Scholar]
- Hanson, F.B.; Ryan, D. Optimal harvesting with both population and price dynamics. Math. Biosci. 1998, 148, 129–146. [Google Scholar] [CrossRef]
- LeVeque, R.J. Finite Difference Methods for Ordinary and Partial Differential Equations; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2007. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Description | Value | Unit |
|---|---|---|---|
| r | Intrinsic growth rate | ||
| K | Carrying capacity | kg | |
| q | Catchability coefficient | ||
| Minimum fishing effort | 0 | SFU | |
| Maximum fishing effort | SFU | ||
| Strength of environmental fluctuations | |||
| x | Initial population size | K | kg |
| Discount factor | |||
| Linear price coefficient | |||
| Quadratic price coefficient | 0 | ||
| Linear cost coefficient | |||
| Quadratic cost coefficient | |||
| T | Time horizon | 25 | year |
| n | Number of time sub-intervals | 100 | |
| Maximum stock size | kg | ||
| m | Number of sub-intervals for the space state (b) | 100 |
| Model Representation | J* | SD |
|---|---|---|
| 374.148 | 32.351 | |
| 214.864 | 32.205 | |
| 565.456 | 38.365 | |
| 432.174 | 30.185 | |
| 366.377 | 25.182 |
| Parameter | Value | J* | SD | Parameter | Value | J* | SD |
|---|---|---|---|---|---|---|---|
| 366.377 | 25.182 | 366.377 | 25.182 | ||||
| 183.553 | 14.512 | 362.629 | 25.107 | ||||
| 126.953 | 11.153 | 187.007 | 13.932 | ||||
| 366.377 | 25.182 | 366.377 | 25.182 | ||||
| 366.355 | 25.181 | 354.345 | 49.656 | ||||
| 364.146 | 25.048 | 270.540 | 81.259 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Brites, N.M. Optimal Harvesting of Stochastically Fluctuating Populations Driven by a Generalized Logistic SDE Growth Model. Mathematics 2022, 10, 3098. https://doi.org/10.3390/math10173098
Brites NM. Optimal Harvesting of Stochastically Fluctuating Populations Driven by a Generalized Logistic SDE Growth Model. Mathematics. 2022; 10(17):3098. https://doi.org/10.3390/math10173098
Chicago/Turabian StyleBrites, Nuno M. 2022. "Optimal Harvesting of Stochastically Fluctuating Populations Driven by a Generalized Logistic SDE Growth Model" Mathematics 10, no. 17: 3098. https://doi.org/10.3390/math10173098
APA StyleBrites, N. M. (2022). Optimal Harvesting of Stochastically Fluctuating Populations Driven by a Generalized Logistic SDE Growth Model. Mathematics, 10(17), 3098. https://doi.org/10.3390/math10173098