Abstract
This paper studies variable selection for the data set, which has heavy-tailed distribution and high correlations within blocks of covariates. Motivated by econometric and financial studies, we consider using quantile regression to model the heavy-tailed distribution data. Considering the case where the covariates are high dimensional and there are high correlations within blocks, we use the latent factor model to reduce the correlations between the covariates and use the conquer to obtain the estimators of quantile regression coefficients, and we propose a consistency strategy named factor-augmented regularized variable selection for quantile regression (Farvsqr). By principal component analysis, we can obtain the latent factors and idiosyncratic components; then, we use both as predictors instead of the covariates with high correlations. Farvsqr transforms the problem from variable selection with highly correlated covariates to that with weakly correlated ones for quantile regression. Variable selection consistency is obtained under mild conditions. Simulation study and real data application demonstrate that our method is better than the common regularized M-estimation LASSO.
MSC:
62H25; 62F12
1. Introduction
Along with the continuous development of data collection and storage technology, data sets that present high dimensions and high correlations within blocks of variables can cause some new research problems in economics, finance, genomics, statistics, machine learning, etc. Because for such data, we need to make a variable selection in highly correlated variables.
There has been significant research into variable selection methods, and many variable selection methods have been developed, such as the regularized M-estimation method, which includes the LASSO [1], SCAD [2], elastic net [3], and the Dantzig selector [4]. There are many references to the regularized M-estimation method’s theoretical properties and algorithmic studies, including [5,6,7,8,9,10,11,12,13,14].
Most existing variable selection methods assume that the covariates are cross-sectionally weakly correlated, even, and serially independent. However, these assumptions are easily invalid in the data sets, which present high dimensions and high correlations within blocks of covariates, such as economic and financial data sets. For example, economics studies [15,16,17] show a strong correlation within blocks of covariates. In order to deal with the problem, Fan et al. proposed factor-adjusted variable selection for mean regression [18].
However, mean regression cannot simultaneously fit the skew and heavy-tailed data; mean regression is not robust against the outliers. Koenker and Bassett [19] proposed quantile regression (QR) to model the relationship between the response y and the covariates . Compared to the mean regression, QR has two significant advantages: (i) QR can be used to model the entire conditional distribution of y given , and thus, it provides insightful information about the relationship between y and . The conditional distribution function of Y given is . For , the th conditional quantile of Y given is defined as . (ii) QR is robust against outliers and can be used to model the response in which distribution is skewed or heavy-tailed without correct error assumption. These two advantages make QR an appealing method to reflect data information that is difficult for the mean regression. The researchers can refer to Koenker [20] and Koenker et al. [21] for a comprehensive overview of methods, theory, computation, and many extensions of QR.
Ando and Tsay [22] proposed factor-augmented predictors for quantile regression, but the model did not contain the idiosyncratic components of the covariates, so it will cause an information loss of explanatory variables. So, we refer to Fan et al. [18] and propose the factor-augmented regularized variable selection (Farvsqr) for quantile regression to overcome the problems caused by the correlations within the covariates. As usual, let us assume that the i-th observation covariates follow an approximate factor model,
where is a vector of latent factors, is a loading matrix, and is a vector of idiosyncratic components or errors which are independent of .
The factor model has become one of the most popular and powerful tools in multivariate statistics and deeply impacted biology [23,24,25], economics, and finance [15,16,26]. Chamberlain and Rothschild [27] first proposed using principal component analysis (PCA) to solve the approximate factor model’s latent factors and loading matrix. Subsequently, much literature explores the factor model using the PCA method [28,29,30,31,32]. In our paper, we will use the PCA to obtain the estimators of , , and .
The process of Farvsqr is first to estimate model (1) and obtain the independent or low-correlated estimators of and . Then, we replace the high correlation covariates with the estimators and . The second step is to solve a common regularized loss function. In this paper, we study Farvsqr by giving the specific parameter-solving process and the theoretical properties. Moreover, both simulation and real data application studies are presented.
The main contribution of our paper is to generalize the factor-adjusted regularized variable selection of mean regression to the quantile regression to accommodate the skew and heavy-tailed data. Section 2 introduces the smoothed quantile regression and the approximate factor models. Section 3 introduces the variable selection methodology of Farvsqr. Section 4 presents the general theoretical results. Section 5 provides simulation studies, and Section 6 applies our model to the Quarterly Database for Macroeconomic Research (FRED-QD).
2. Quantile Regression and Approximate Factor Model
2.1. Notations
Now, we will give some notations that will be used throughout the paper. Let denote the identity matrix; denotes the zero matrix; and denote the zero vector and one vector in , respectively. For a matrix , let denote its max norm, while and denote its Frobenius and induced p-norms, respectively. Let denote the minimum eigenvalue of if it is symmetric. For , and , define , , . For a vector and , define to be its subvector. Let ∇ and be the gradient and Hessian operators. For and , define and . Let denote the normal distribution with mean and covariance matrix .
2.2. Regularized M-Estimator for Quantile Regression
This subsection will begin with high-dimensional regression problems with heavy-tailed data. Let be the response vector, , be the p-dimensional vectors of the explanatory variables. Let be the design matrix and be the response vector. Let be the matrix including n samples of the p-dimensional vector.
In this paper, we will fit the heavy-tailed data with quantile regression. Let be the conditional cumulative distribution function of given . Under the linear quantile regression assumption, the th conditional quantile function is defined as
where the quantile , is the true coefficients of the quantile regression that changes with the quantile . For the convenience of writing, we will omit the given in the following.
Under the linear quantile regression assumption, the common regression coefficient estimator at a given can be given as [19]
where is the check function, is the indicator function, and is the quantile. However, as we know, the check function is not differentiable, which is very different from other widely used objective functions. The non-differentiable has two obvious disadvantages: (i) theoretical analysis of the estimator is very difficult; and (ii) gradient-based optimization methods cannot be used. So, He et al. [33] proposed a smoothed quantile regression for large-scale inference, which is denoted as conquer (convolution-type smoothed quantile regression). He et al. [33] concluded that the conquer method could improve estimation accuracy and computational efficiency for fitting large-scale linear quantile regression models rather than by minimizing the check function (3). So, in our paper, we will use the conquer to estimate the quantile regression. The estimator is given by
where , is a symmetric and non-negative kernel function in which the integral is 1, and h is the bandwidth. Referring to He et al. [33], we have the definition:
The conquer function is twice continuously differentiable relative to ; the gradient matrix and hessian matrix are as follows:
When is a sparse vector, it is common to estimate through the regularized M-estimator as the following:
We expect that the estimator of (5) satisfies two formulas: for some norm and as . Zhao and Yu [9] studied the LASSO estimator for a sparse linear model and showed that there exists an irrepresentable condition that is sufficient and almost necessary for two formulas when we assume . Let and denote the submatrices of , which are the first l and the rest of the columns, respectively. Then, the irrepresentable condition is:
where , but when the explanatory variables strongly correlate with the blocks, the irrepresentable condition will be easily invalid [18].
2.3. Approximate Factor Model
When there exist strong correlations between the covariates , in order to estimate the parameters , the common method is the latent factor model. There are many papers in the literature that studied the latent factor model in econometrics and statistics [15,16,18,30,34].
As usual, let us assume that follows the approximate factor model (1). As we know, the are the only observed variables; we need to estimate . Generally, it is assumed that k is independent of n [18]. Let be the latent factors matrix, and is the errors matrix. Then, Equation (1) can be written in a matrix as the following:
Here, we need to note that have a strong correlation within the blocks, not including the intercept, so the matrix form of the latent factor model is but not . We impose the basic assumption for the latent factor model to identify the model as Assumption 1 [18].
Assumption 1.
Assume that , is diagonal, and all the eigenvalues of are bounded away from 0 and ∞ as .
3. Factor-Augmented Regularized Variable Selection
3.1. Methodology
Let , and . With the approximate factor model (7), we have , so we can obtain:
where . So, the regularized variable selection (5) can be written as:
We need to estimate the coefficient of , namely , so we consider as the nuisance parameter. Now, let us consider a new estimator without the constraint ,
From Equation (10), we can see that the vector can be considered as the new explanatory variables. In other words, we lift the covariate space from to with the latent factor model, and the highly dependent covariates are replaced by weakly dependent .
We have the following lemma, whose proof is given in Appendix A:
Lemma 1.
Consider the model (2), let , and . If , then
By the latent factor model, has a much weaker correlation than . So, we can calculate the estimators by the following two steps:
- Let be the design matrix with strong cross-section correlations. Fit the approximate factor model (7), and the estimators of , and are denoted as and . This paper will use the principal component analysis (PCA) to estimate all the parameters in the latent factor model. Regarding PCA, the references such as Bai [28] and Fan et al. [18,30] are available. More specifically, the columns of are the eigenvectors of corresponding to the top k eigenvalues, .
- Define and . Then, is obtained from the first entries of the estimator vector of .where is the i-th row of the matrix .
We call the above two-step method as the factor-augmented regularized variable selection for quantile regression (Farvsqr). We successfully changed the quantile variable selection with highly correlated covariates in (5) to quantile variable selection with weakly correlated or uncorrelated ones by the latent factor model in (12). Formula (12) is a convex function that can be minimized via the method conquer proposed by He et al. [33].
3.2. Selection Method of
Throughout all the study, the tuning parameter is selected by 10-fold cross-validation. First, we are given an equally spaced sequence of size 50 with the range from 0.05 to 2, which is the value range of . Second, the samples are divided into 10 pieces, nine of which are used as training sets and one of which is used as the test set. Third, for each value of , calculate the estimators of the model (12) using the training sets, then predict the test set, and select the which obtains the minimum value of the mean square error on the test set.
4. Theoretical Analysis
In this section, we will give the theoretical guarantees of the estimator from Formula (12) under the condition of the LASSO penalty. As the description before, is the first elements of . Here, let . When the explanatory variables can be fitted well by the approximate factor model (7), then we can use the true augmented explanatory variables to solve the objective function
where . However, is not observable, so we need to use its estimator to solve the objective function
Assumption 2.
. For some constants and , we have .
Assumption 3.
Let . It is assumed that and such that
Assumption 4.
for some constant . In addition, there exists nonsingular matrix , and such that for , we have and .
Theorem 1.
Suppose Assumptions 2–4 hold. Define and
If , then, we have and .
5. Simulation Study
In this section, we will assess the performance of the method proposed by this paper through simulation. We compare Farvsqr with LASSO and SCAD under different simulation data.
We generate the response from the model , where the true coefficients are set to be , and the error part is following three models:
- (i)
- ;
- (ii)
- ;
- (iii)
- .
The covariates are generated from one of the following two models:
- (i)
- Factor model. with . Factors are generated from a stationary model with . The -th entry of is set to be when and when . We draw , and from the i.i.d. standard normal distribution.
- (ii)
- Equal correlated case. We draw from i.i.d. , where has diagonal elements 1 and off-diagonal elements 0.4.
For the factor model, in order to comprehensively evaluate the Farvsqr, given the quantile , we compare the influence of the different sample sizes and the explanatory variable’s dimensionality under different error distributions. We use the estimation error, namely , average model size, percentage of true positives (TP) for , percentage of true negatives (TN) for , and the elapsed time to compare the Farvsqr and LASSO. The percentage of TP and TN are defined as follows:
We compare the model performance of Farvsqr with LASSO under different error distributions and explanatory variable relationships; for each situation, we simulate 500 replications.
- Influence of sample size
We compare the model with the fixed explanatory variable’s dimensionality ; the sample size is set to be , and respectively. For each sample size, we simulate 500 replications and calculate the average estimation error, average model size, TP, TN, and elapsed time. The results are presented in Table 1, Table 2 and Table 3. From the results, we can see that under three different error distributions, for each and n, the average estimation error of Farvsqr is smaller than that for LASSO. For example, when of normal distribution, the average estimation errors of Farvsqr and LASSO are 0.127 and 2.586, respectively. As for the average model size, almost all the values of Farvsqr are smaller than those of LASSO, except for . For TP, all the scenarios are the same for Farvsqr and LASSO, so we can say that both can select the true non-zero variables. For elapsed time, all the values of Farvsqr are smaller than those of LASSO, so we can say that our method is more efficient. From all of the above, we can say that Farvsqr is better than LASSO. For every quantile , as the number of samples increases, the estimation error gradually decreases for Farvsqr, but for LASSO, the impact of sample size is not obvious. It may be that for the factor model, LASSO is not approximate, so although the sample size becomes larger, it cannot change the defects of LASSO method.

Table 1.
The comparison for with the factor model.
Table 2.
The comparison for with the factor model.
Table 3.
The comparison for with the factor model.
- Influence of explanatory variable’s dimensionality
We compare the model with a fixed sample size ; the explanatory variable’s dimensionality is set to be , and 600, respectively. For each explanatory variable’s dimensionality, we simulate 500 replications and calculate the average estimation error, average model size, TP, TN, and elapsed time. The results are presented in Table 4, Table 5 and Table 6. From the results, we can see that under three different error distributions, for each and p, the average estimation error of Farvsqr is smaller than that of LASSO. For example, when of normal distribution, the average estimation errors of Farvsqr and LASSO are 0.124 and 2.059, respectively. As for the average model size, all the values of Farvsqr are smaller than those for LASSO. For TP, all the scenarios are the same for Farvsqr and LASSO, so we can say that both can select the true non-zero variables. For TN, all the values of Farvsqr are bigger than those of LASSO, so we can say that LASSO prefers to select redundant variables. For elapsed time, all the values of Farvsqr are smaller than those of LASSO, so we can say that our method is more efficient. From all of the above, we can say that Farvsqr is better than LASSO. For every quantile , as the dimension increases, the average estimation error also increases, which is consistent with common sense, however, the increase in range of Farvsqr is smaller than that for LASSO. For example, when normal distribution, the values of Farvsqr are 0.124 and 0.158, respectively, for and , the relative increase is ; as for LASSO, the relative increase is , so we can say that LASSO is vulnerable to the increase of variable dimension.
Table 4.
The comparison for with the factor model.
Table 5.
The comparison for with the factor model.
Table 6.
The comparison for with the factor model.
- Equal correlated case
We also compare our model with LASSO under different sample sizes and explanatory variable’s dimensionality situation for the equal correlated case. By simulating 500 replications, we calculate the average estimation error, average model size, TP, TN, and elapsed time. The results are presented in Table 7, Table 8, Table 9, Table 10, Table 11 and Table 12. From all the tables, we can see that essentially all the elapsed time of Farvsqr is shorter than LASSO; at the same time, the estimation error is slightly larger for most situations. For the fixed explanatory variable’s dimensionality , as the number of samples increases, the elapsed time gradually decreases for Farvsqr and LASSO, but the relative increase is more significant for LASSO. For example, when for , the elapsed time of two methods for are 0.687 and 1.099, respectively, and the elapsed time of two methods for are 1.965 and 3.856, respectively, and the relative increase is for Farvsqr. As for LASSO, the relative increase is . So, we can say that the efficiency of LASSO is easily affected by the sample size, and it is not appropriate for the large sample data. So, we can say that Farvsqr pays less cost for the similar correlated case.
Table 7.
The comparison for with the equal correlated case.
Table 8.
The comparison for with the equal correlated case.
Table 9.
The comparison for with the equal correlated case.
Table 10.
The comparison for with the equal correlation.
Table 11.
The comparison for with the equal correlation.
Table 12.
The comparison for with the equal correlation.
From all the results above, we can draw the following conclusions:
- (i)
- When the covariates are high dimensional and high correlations within blocks, namely, the covariates are generated from the factor model, our method Farvsqr is better than LASSO from all the evaluating indicators, including the average estimation error, average model size, TP, TN, and elapsed time.
- (ii)
- For the factor model, the parameter estimation accuracy of LASSO is easily affected by the increase of the explanatory variable’s dimension.
- (iii)
- For the equal correlated case, the Farvsqr pays less cost.
- (iv)
- For all the different scenarios, the efficiency of the LASSO is easily affected by the sample size.
In order to illustrate further that our method is better for the data which is high dimensional and high correlations within blocks, we compare our method with SCAD also, and we found the same conclusions as LASSO. Here, we just give the results under normal distribution. Table 13 and Table 14 are, respectively, for the fixed explanatory variable’s dimensionality and sample size. We need to know here that the Farvsqr method is first to replace the highly dependent covariates by weakly dependent or uncorrelated ones by the latent factor model; then, we minimize (12) with LASSO or SCAD. However, LASSO and SCAD directly minimize Formula (5) in which the covariates are highly correlated.
Table 13.
The comparison for with the factor model between Farvsqr and SCAD.
Table 14.
The comparison for with the factor model between Farvsqr and SCAD.
6. Real Data Application
In this section, we will use the season U.S. macroeconomic variables in the FRED-QD database [17]. The dataset includes 247 dimensions, and the covariates in the FRED-QD data set are strongly correlated. We choose 88 data points which are complete observation samples from the first quarter of 2000 to the last quarter of 2021. The FRED-QD is a quarterly economic database updated by the Federal Reserve Bank of St. Louis, which is publicly available at http://research.stlouisfed.org/econ/mccracken/sel/ (accessed on 28 June 2022). The detailed information about the data can be found on the website. In this paper, we choose the variable GDP as the response and the other 246 variables as the explanatory variables. The density distribution of the response of our data is as shown in Figure 1. We compare the proposed Farvsqr with LASSO in variable selection, estimation, and elapsed time. The estimation performance is evaluated by the , which is defined as:
where is the observed value at the time i, is the predicted value, and is the sample mean. We model the data given the quantile . We evaluate the model from the , model size, and elapsed time.
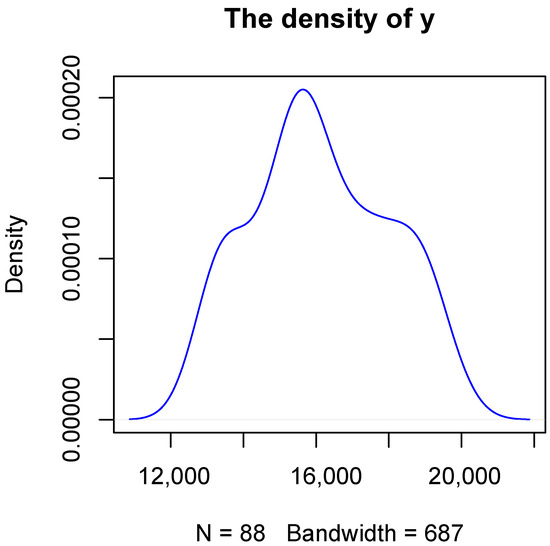
Figure 1.
The density of the response.
The results are presented in Table 15. From the result, we can see that the model sizes of Farvsqr are 18, 19, 38, and 38 for the quantile and , respectively; however, the model sizes of LASSO are 241, 176, 207, and 222 for the quantile and , respectively. The LASSO prefers to choose more related variables. For instance, for and , all LASSO models include both Real PCE expenditures: durable goods, Real PCE: services, Real PCE: nondurable goods, Real gross private domestic investment, Real private fixed investment, Real gross private domestic investment: fixed investment: nonresidential: equipment, and Real private fixed investment: nonresidential because of the strong correlation between them. Moreover, all LASSO models also include both Number of civilians unemployed for less than 5 weeks, Number of civilians unemployed from 5 to 14 weeks, and Number of civilians unemployed from 15 to 26 weeks because of the strong correlation between them. Many other related variables are included by LASSO. The elapsed times of Farvsqr are 7.6209, 8.2036, 8.3589, and 8.3493 for the quantile and respectively, while the elapsed times of LASSO are 9.8736, 13.8031, 10.6616, and 10.1012 for the quantile and , respectively; so we can say that the algorithm efficiency of LASSO for our real data is much lower than that of Farvsqr. It may be because LASSO selects too many redundant explanatory variables, which not only affects the estimation accuracy of the model but also affects the efficiency of the algorithm. For the , Farvsqr is better than LASSO except for . So, we can see that Farvsqr is more suitable for this data set. Furthermore, we can say that for the data set with strong correlation between explanatory variables, Farvsqr is more suitable for use.
Table 15.
The results of the real data.
7. Conclusions
In this paper, we are aimed at the data set, which has heavy-tailed distribution, high dimension, and high correlations within the blocks of the covariates. By generalizing the factor-adjusted regularized variable selection for mean regression to the quantile regression, we proposed the method of factor-augmented regularized variable selection for quantile regression ( Farvsqr). In order to analyze the theoretical analysis and improve estimation accuracy and computational efficiency for fitting large-scale linear quantile regression models, we use the convolution-type smoothed quantile regression to estimate the quantile regression coefficients. The paper gives the theoretical result of the estimators. At the same time, from the simulation and the real data analysis, we can see that our method is better than LASSO. In the future, we will continue to study the missing data variable selection for quantile regression with the high correlations within the blocks of the covariates.
Author Contributions
Conceptualization, M.T.; methodology, Y.Z.; software, Q.W.; validation, Y.Z. and Q.W.; formal analysis, M.T.; investigation, M.T.; resources, M.T.; data curation, Y.Z.; writing—original draft preparation, Y.Z.; writing—review and editing, M.T.; visualization, M.T.; supervision, M.T.; project administration, M.T.; funding acquisition, M.T. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Fundamental Research Funds for the Central Universities and the Research Funds of Renmin University of China (22XNL016).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The researchers can download the FRED-QD database from the website http://research.stlouisfed.org/econ/mccracken/sel/ (accessed on 28 June 2022).
Acknowledgments
The authors would like to thank for Liwen Xu for some helpful suggestions.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| QR | Quantile Regression |
| Conquer | Convolution-type Smoothed Quantile Regression) |
| PCA | Principal Component Analysis |
Appendix A
Appendix A.1. Proof of Lemma 1
Let and . Note that
and . So the conclusion can be proved by
Appendix A.2. Proof of Theorem 1
In order to proof the theorem 1, let us introduce the Lemma A1 from Fan et al. [18] first. When we assume that the last k variables are not penalized, let be a convex function, and be the sparse sub-vector of interest. Then, and are estimated by
Let . Then, we can obtain the Lemma A1 as follows:
Assumption A1
(Smoothness). and there exist such that whenever and ;
Assumption A2
(Restricted strong convexity). There exist such that and ;
Assumption A3
(Irrepresentable condition). for some ;
Lemma A1.
Under Assumptions A1–A3, if
then and
Next, we will give the proof of the Theorem 1.
Proof of Theorem 1.
As we know, . From Assumption 4, we know that is nonsingular and . Let . So, we can see that and . So, and for any norm.
Then, we can change to study and the objective function in order to study the theoretical properties of . We will give the Theorem A1 which means all the assumptions in Lemma A1 are fulfilled.
Let and be the th row of and , respectively. We can see that , . Hence . From the properties of the vector norm, we can obtain . In addition, let . From Lemma A1, we can obtain that Theorem 1 is true. □
Theorem A1.
Based on all the Assumptions 2–4, define , then
Proof.
(i) , then
For any and , we have
By the Cauchy–Schwarz inequality and , so for , we have . Plugging this result back to (A1), we can obtain
(ii) For any , we have
With , we can obtain
From Assumption 4, we know that . By Jensen’s inequality, , we have
So
Let , then we can obtain
And
So
(iii) The third conclusion can be obtained easily from (A4). Since for any symmetric matrix B, is satisfied. We can obtain , and thus
(iv)
From the conclusion (ii) and (A2), we can obtain that
On the other hand, we can take . By Assumption 4, , and we have
From Formula (A3), we can obtain . As a result,
By combining these estimates, we have
Therefore, . □
References
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B Stat. Methodol. 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Fan, J.; Li, R. Variable selection via nonconcave penalized likelihood and its oracle properties. J. Am. Stat. Assoc. 2001, 96, 1348–1360. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B Stat. Methodol. 2005, 67, 301–320. [Google Scholar] [CrossRef]
- Candes, E.; Tao, T. The Dantzig selector: Statistical estimation when p is much larger than n. Ann. Stat. 2007, 35, 2313–2351. [Google Scholar]
- Donoho, D.L.; Elad, M. Optimally sparse representation in general (nonorthogonal) dictionaries via l1 minimization. Proc. Natl. Acad. Sci. USA 2003, 100, 2197–2202. [Google Scholar] [CrossRef]
- Fan, J.; Peng, H. On non-concave penalized likelihood with diverging number of parameters. Ann. Stat. 2004, 32, 928–961. [Google Scholar] [CrossRef]
- Efron, B.; Hastie, T.; Johnstone, I.; Tibshirani, R. Least angle regression. Ann. Stat. 2004, 32, 407–499. [Google Scholar] [CrossRef]
- Meinshausen, N.; Bühlmann, P. High-dimensional graphs and variable selection with the lasso. Ann. Stat. 2006, 34, 1436–1462. [Google Scholar] [CrossRef]
- Zhao, P.L.; Yu, B. On model selection consistency of Lasso. J. Mach. Learn. Res. 2006, 7, 2541–2563. [Google Scholar]
- Fan, J.; Lv, J. Sure independence screening for ultrahigh dimensional feature space. J. R. Stat. Soc. Ser. B Stat. Methodol. 2008, 70, 849–911. [Google Scholar] [CrossRef] [PubMed]
- Zou, H.; Li, R. One-step sparse estimates in nonconcave penalized likelihood models. Ann. Stat. 2008, 36, 1509–1533. [Google Scholar]
- Bickel, P.J.; Ritov, Y.A.; Tsybakov, A.B. Simultaneous analysis of lasso and dantzig selector. Ann. Stat. 2009, 37, 1705–1732. [Google Scholar] [CrossRef]
- Wainwright, M.J. Sharp thresholds for high-dimensional and noisy sparsity recovery using-constrained quadratic programming (lasso) quadratic programming (Lasso). IEEE Trans. Inform. Theory 2009, 55, 2183–2202. [Google Scholar] [CrossRef]
- Zhang, C.H. Nearly unbiased variable selection under minimax concave penalty. Ann. Stat. 2010, 38, 894–942. [Google Scholar] [CrossRef]
- Stock, J.; Watson, M. Forecasting using principal components from a large number of predictors. J. Am. Stat. Assoc. 2002, 97, 1167–1179. [Google Scholar] [CrossRef]
- Bai, J.; Ng, S. Determining the number of factors in approximate factor models. Econometrica 2002, 70, 191–221. [Google Scholar] [CrossRef]
- McCracken, M.; Ng, S. FRED-QD: A Quarterly Database for Macroeconomic Research; Federal Reserve Bank of St. Louis: St. Louis, MO, USA, 2021. [Google Scholar]
- Fan, J.; Ke, Y.; Wang, K. Factor-Adjusted Regularized Model Selection. J. Econom. 2020, 216, 71–85. [Google Scholar] [CrossRef]
- Koenker, R.; Bassett, G. Regression quantiles. Econometrica 1978, 46, 33–50. [Google Scholar] [CrossRef]
- Koenker, R. Quantile Regression; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Koenker, R.; Chernozhukov, V.; He, X.; Peng, L. Handbook of Quantile Regression; CRC Press: New York, NY, USA, 2017. [Google Scholar]
- Ando, T.; Tsay, R.S. Quantile regression models with factor-augmented predictors and information criterion. Econom. J. 2011, 14, 1–24. [Google Scholar] [CrossRef]
- Hirzel, A.H.; Hausser, J.; Chessel, D.; Perrin, N. Ecological-niche factor analysis: How to compute habitat-suitability maps without absence data? Ecology 2002, 83, 2027–2036. [Google Scholar] [CrossRef]
- Hochreiter, S.; Clevert, D.A.; Obermayer, K. A new summarization method for affymetrix probe level data. Bioinformatics 2006, 22, 943–949. [Google Scholar] [CrossRef] [PubMed]
- Gonalves, K.; Silva, A. Bayesian quantile factor models. arXiv 2020, arXiv:2002.07242. [Google Scholar]
- Chang, J.; Guo, B.; Yao, Q. High dimensional stochastic regression with latent factors, endogeneity and nonlinearity. J. Econom. 2015, 189, 297–312. [Google Scholar] [CrossRef]
- Chamberlain, G.; Rothschild, M. Arbitrage, factor structure, and mean–variance analysis on large asset markets. Econometrica 1982, 51, 1305–1324. [Google Scholar] [CrossRef]
- Bai, J. Inferential theory for factor models of large dimensions. Econometrica 2003, 71, 135–171. [Google Scholar] [CrossRef]
- Lam, C.; Yao, Q. Factor modeling for high-dimensional time series: Inference for the number of factors. Ann. Stat. 2012, 40, 694–726. [Google Scholar] [CrossRef]
- Fan, J.; Liao, Y.; Mincheva, M. Large covariance estimation by thresholding principal orthogonal complements. J. R. Stat. Soc. Ser. (Stat. Methodol.) 2013, 75, 603–680. [Google Scholar] [CrossRef] [PubMed]
- Fan, J.; Liu, H.; Wang, W. Large covariance estimation through elliptical factor models. Ann. Stat. 2018, 46, 1383–1414. [Google Scholar] [CrossRef]
- Ando, T.; Bai, J. Quantile co-movement in financial markets: A panel quantile model with unobserved heterogeneity. J. Am. Stat. Assoc. 2020, 115, 266–279. [Google Scholar] [CrossRef]
- He, X.; Pan, X.; Tan, K.M.; Zhou, W.X. Smoothed quantile regression with large-scale inference. J. Econom. 2021; in press. [Google Scholar] [CrossRef]
- Forni, M.; Hallin, M.; Lippi, L. The generalized dynamic factor model: One-sided estimation and forecasting. J. Am. Stat. Assoc. 2005, 100, 830–840. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).