The experiments of this study are designed as follows. We first introduce a general evaluation framework to systematically evaluate the applicability of head/tail breaks to an arbitrary flow analytics method. Next, we conduct tests with standard algorithms from three representative families of methods for spatial flow analysis, namely flowAMOEBA [
10] for flow clustering, Louvain [
5] for network community detection, and the weighted PageRank [
8] for network centrality measurement. The experiment data include travel flow data, cellphone call flow data, and synthetic flow data. The test environment is a laptop of the following specifications: OS: Windows 10; Model: Surface Book 2; CPU: Intel Core i7-8650U; RAM: 16 GB.
4.1. Evaluation Framework
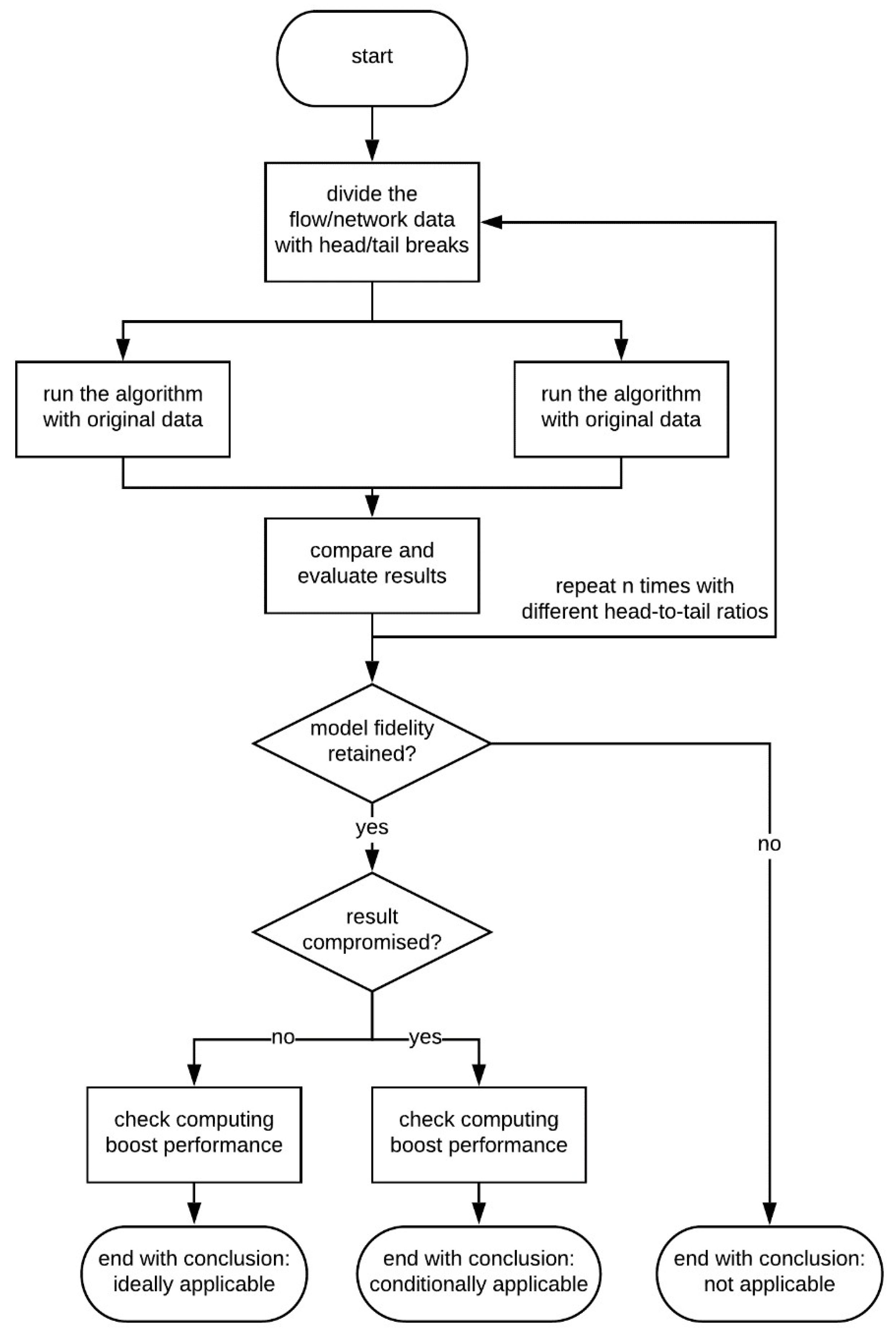
We design an evaluation framework to test the applicability of head/tail breaks to any flow analytics algorithm. As shown in
Figure 2, the process begins with splitting the flow data into two parts with head/tail breaks. There are at least two options to set the breakpoint: based on a specific flow value (e.g., mean) or on a preset head-to-tail ratio. The next step is to run the algorithm with the original data and with the “head” part only, respectively. Then we record the computing time and algorithm results of each test and repeat the process with different head-to-tail ratios. Even though the main purpose of head/tail break data reduction is to boost the computational efficiency of the algorithm, the bottom line is that model fidelity has to be maintained, i.e., the algorithm ought to produce results that are fundamentally consistent with results generated on the original data. The actual way to carry out this step varies according to the type of algorithm. For instance, a clustering algorithm should retain a similar number of clusters, while a ranking algorithm should keep most ranks consistent. If it fails, the whole evaluation process ends with the conclusion that head/tail breaks do not apply innocuously to this particular algorithm, and it becomes meaningless to record the computing performance.
Nevertheless, the assessment of model fidelity may indicate the original results are not perfectly preserved. In practice, it is possible that the quality of results is compromised after applying the head/tail breaks, but the loss in quality is still deemed acceptable to retain model fidelity. It is also possible the results are well kept under certain conditions. Therefore, it is necessary to further examine the results to establish the degree to which result quality may be compromised or the ideal computational conditions. We advocate selecting sample results to conduct an in-depth evaluation with means like geovisualization and possibly expert knowledge.
If the model fidelity is maintained, the last step is to check the computing performance boost and find the optimal head-to-tail ratio that balances result quality and speedup. We do not set a fixed threshold on the computing boost because it is subjective to the user whether the speedup is satisfactory.
4.2. Experiment 1. Flow Clustering Method: FlowAMOEBA
We first test with a flow clustering method called flowAMOEBA [
10]. It is a data-driven and bottom-up spatial statistic method for identifying spatial flow clusters of extremely high- or low-value, e.g., anomalously large number of travelers between two regions. This method is an ideal choice to test the effectiveness of head/tail breaks. It includes an iterative process to spatially search clusters of extreme value, which takes a long time to compute even for a relatively small dataset. The algorithm of flowAMOEBA is briefly summarized as follows.
- (a)
Identify the neighbor flows of each flow based on the contiguity of both endpoints. For example, the state-to-state migration flow from California to North Carolina can be seen as a flow that is neighbor of the migration flow from California to South Carolina, as they share the same origin while their destinations are contiguous.
- (b)
Select an arbitrary flow as the seed of a cluster and calculate its
statistic [
25,
26] with Equation (1). The classical
statistic is used to measure the concentration of high or low values at a given location
i. The
value of the seed flow is taken as the starting point of an iterative cluster-expanding process. The spatial weight
is set as 1 if flow
j neighbors flow
i, otherwise 0.
N is the total number of flows.
is the value of flow
j.
is the mean value of all flows.
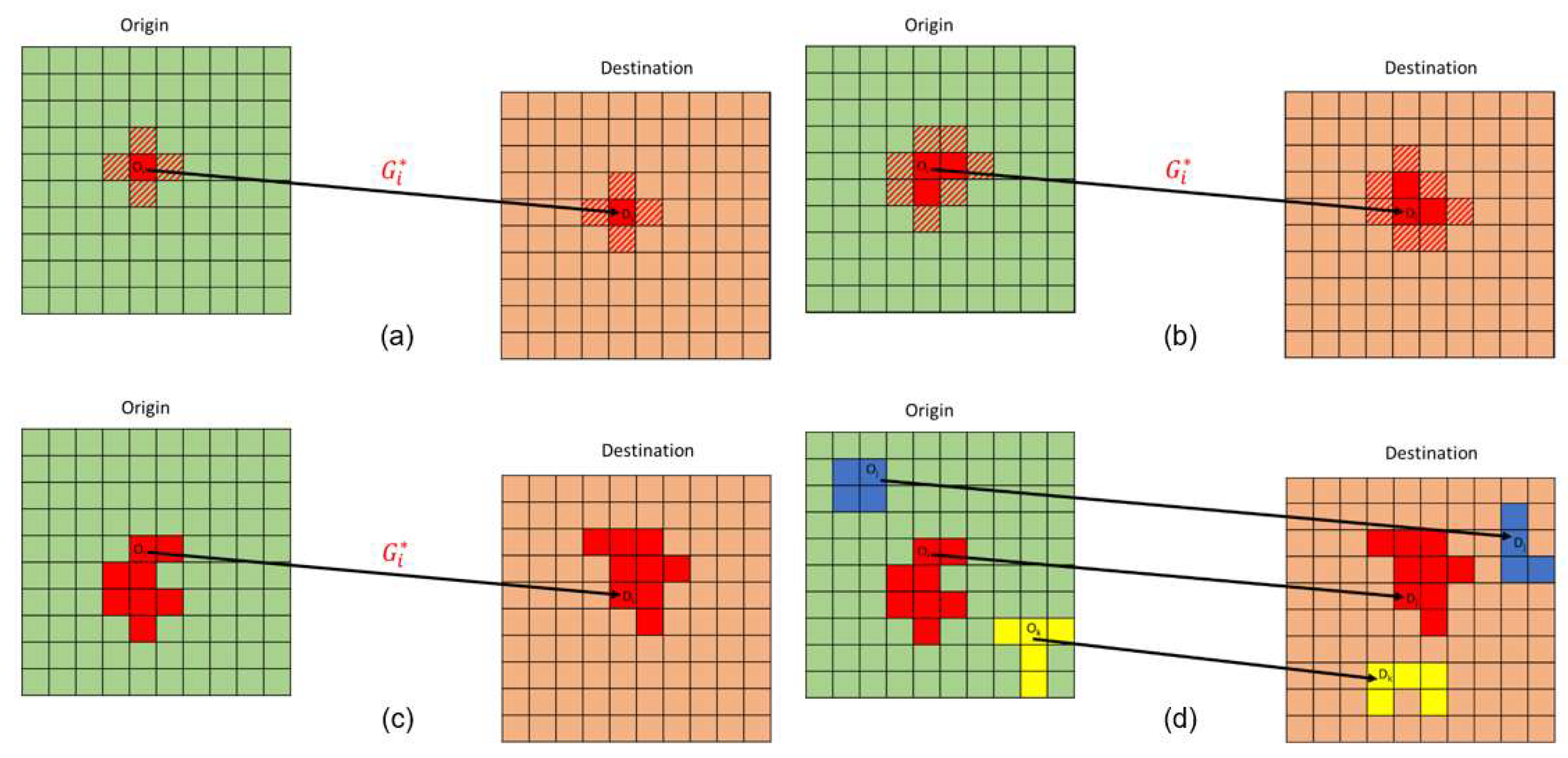
Figure 3a shows the selected seed flow and its
value, while the grid cells filled with red stripe lines represent the origins and destinations of flow
i’s neighbors.
- (c)
Traverse the neighbor flows of the seed one by one and include the ones that can increase the overall
value to the cluster.
Figure 3b shows that some of flow
i’s neighbors (between solid-filled red grid cells) are selected to merge with the seed as a larger cluster. The algorithm will continue the attempt to absorb more flows through discrimination of the neighbors of the newly joined flows (between the grid cells filled with red stripe lines) with the same criterion.
- (d)
Stop the search-and-expand process once the
value cannot increase anymore. By then, the flow cluster reaches a stable stage and no more flow neighbors can join.
Figure 3c depicts the stable status of the flow cluster regarding seed flow
i.
- (e)
Repeat the previous three steps and until every flow has served as seed. Collect all flow clusters at their stable stage.
Figure 3d illustrates the identified flow clusters originated from different seeds. Conduct a 1000-time Monte-Carlo simulations by randomly permutating the flow values. Preserve the flow clusters that pass the statistical significance level, e.g., 0.01, as the final outcome.
However, the demands of big flow data analysis do not spare the computational capability and efficiency of flowAMOEBA. The most time-consuming part is the iterative search-and-expand process starting from each seed flow. This process is mutually independent from the start at each seed, which means parallel computing techniques can readily be incorporated, similar to how Widener et al. [
27] accelerated the original AMOEBA method [
28]. Nevertheless, the speedup of flowAMOEBA brought by parallel computing is still underwhelming even with highly capable infrastructure. Here we demonstrate that by applying the head/tail breaks we can achieve a much faster computation without compromising the flow clustering results.
We conduct a test with a flow dataset on inter-city travel in China acquired from Baidu Map Inc. The dataset represents the number of people traveling from one of the 36 cities in Northeast China to one of the 300 cities in the rest of the country at the prefecture-city level on April 1st, 2017. In total, there are 147,416 travelers on that day, encapsulated in 5719 non-zero city-to-city flows. The highest flow value is 4585, which corresponds to the number of travelers from Shenyang (the largest city in Northeast China) to Beijing on that day. The dataset follows a typical heavy-tailed distribution as most flows bear a small value. In total, 96 percent of the flows have a value less than 100, and 80 percent have a value less than 15.
The original computing time is close to 10,419 s or nearly 3 h, of which only 15.8 s were spent on the first step, a task not suitable for multi-core computing. The rest of the steps, including the search-and-expand process from each seed and the 1000-time Monte-Carlo simulations, are ideal for parallel computing. Although we did not conduct this experiment with a highly capable computing infrastructure, the theoretically fastest parallel computing time with 1000 computing cores for the task on hand is about 26.2 s, according to Amdahl’s law [
29].
The way we apply head/tail breaks is to preselect some of the highest-value flows, or only the “head” part, as seed flows in the second step. Considering that flowAMOEBA aims at identifying clusters of flows with anomalously high absolute value, it is meaningless to start the computation with those low-value flows which have no chance of being part of a flow cluster. On the other hand, picking a low-value flow as the seed leads to a lengthy expansion process. Since the algorithm keeps searching for relatively higher-value flows to merge with, a humble starting point means more flows would satisfy the criterion, i.e., increasing the overall value. In turn, a large number of flows to join the cluster leads to many more directions for the next search-and-expand step, and so on.
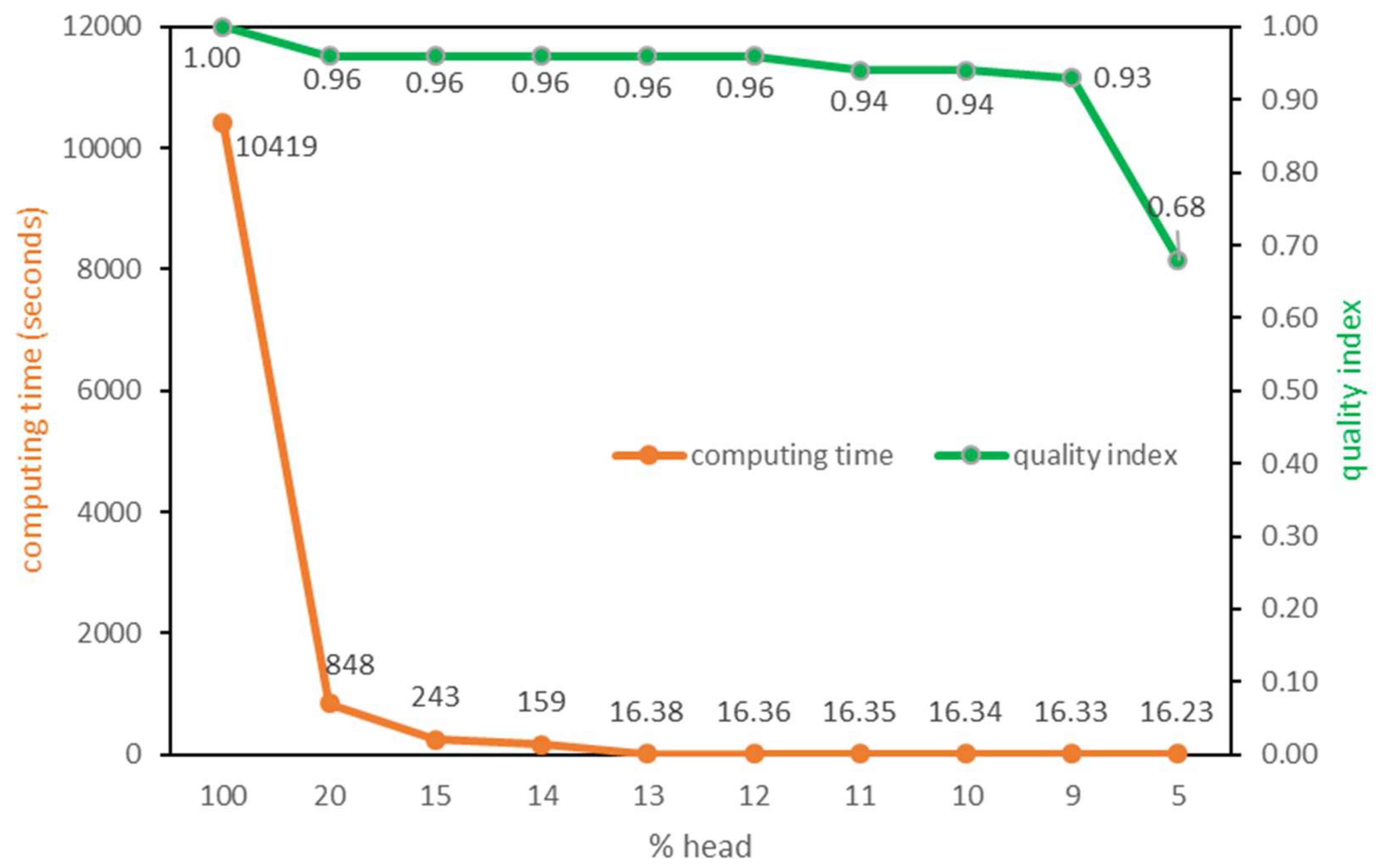
As
Figure 4 shows, a series of experiments have been conducted with different breakpoint values. The leftmost starting point denotes the situation when taking the entire dataset into the computing, or without applying head/tail breaks. The computing time decreases dramatically by applying the head/tail breaks to restrict seed flows selection. If selecting the top 20 percent as seeds, the computing time decreases to 848 s. Furthermore, it takes only slightly over four minutes if selecting the top 15 percent as seeds. The computing time keeps diving as the head-to-tail ratio drops. A relatively stable status is reached when the top 13 percent of flows are selected as seeds, since then the computing time stays about 16 s. Considering that 15.8 s are spent on the first step to identify flow neighbors, the actual computing time since the second step has been reduced to less than one second with the help of data reduction by head/tail breaks.
The improvement of the computation is only meaningful with no or very minor compromise of the quality of the results. To evaluate the model fidelity, we design a quality index
QI by incorporating the number of detected clusters and the total flow value of the detected clusters, calculated as Equation (2):
where
NC is the number of detected flow clusters;
VC is the total flow value, or the total number of travelers in this example, of the detected clusters. The numerator corresponds to the result by applying head/tail breaks to the seed selection, while the denominator is the result on the whole dataset.
Referring to
Figure 4, the quality index remains at a high level in most tests. However, when selecting only the top 5 percent of flows as seeds, the quality index collapses to 0.68. Taking both the computation and the result quality into account, the plausible optimal breakpoint falls at the 13:87 head-to-tail ratio, where the computing time is close to the minimum and the quality index stays above 0.95.
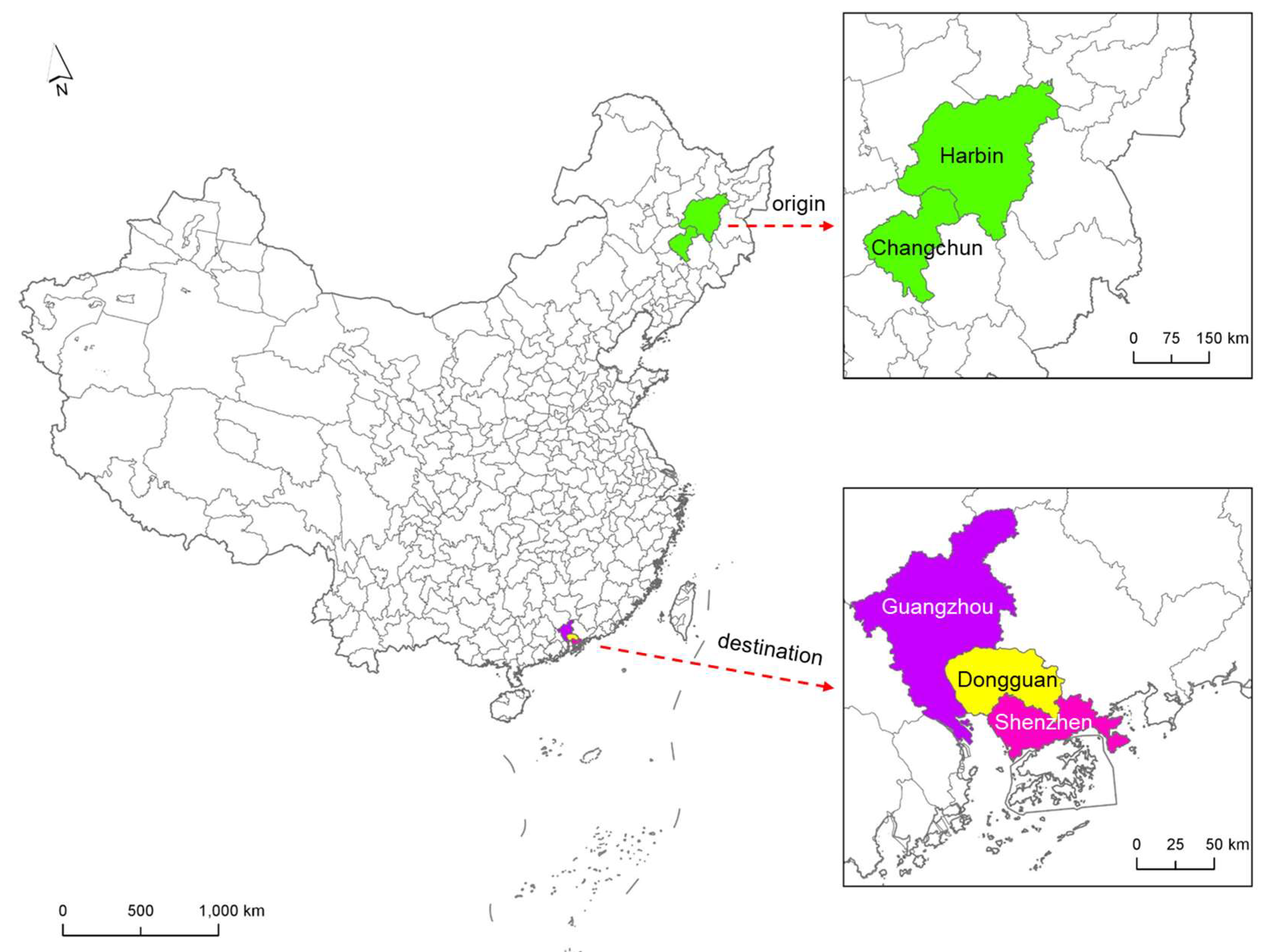
We further examine the differences that head/tail breaks bring to the flowAMOEBA results, which might not be reflected in the quality index. The original result contains 28 flow clusters capturing 81,044 travelers, while the result after applying head/tail breaks at the 13:87 head-to-tail breakpoint contains 27 clusters that capture 81,072 travelers. Through careful comparison of the detail of these two sets of results, we find that the latter includes an additional flow that connects two separate flow clusters in the original result as one bigger cluster. As shown in
Figure 5, the original result has two separate clusters between these two regions: Harbin-Changchun to Guangzhou, and Harbin-Changchun to Shenzhen. Instead, the result after applying the head/tail break includes an extra flow from Harbin to Dongguan. Because of the contiguity relationship, this extra flow helps merge the two separate clusters of the original solution as one. Therefore, the number of detected clusters decreases by one, and the total flow value of the clusters increases by 28, which is the value of the additional flow. A possible reason behind this change is that the flow from Harbin to Dongguan barely passes the threshold set by the head/tail breaks to qualify as a seed flow. The search-and-expand process starting from this flow can easily include the nearby flows of higher value and pass the significance test. On the contrary, this same flow is likely to join a cluster through a search-and-expand process that started from a low-value flow, which leaves the cluster a lower chance to pass the significance test.
This further examination of the result differences reveals a fact that a similarity-based quality index cannot convey. The cluster “missing” after applying head/tail breaks is due to the inclusion of an extra flow. This slight difference of the results after applying head/tail breaks to flowAMOEBA falls short of implying the result quality is compromised. On the other hand, the improvement on the computing time is so large that computing time is much less than the theoretically fastest scenario with 1000 computing cores in parallel.
4.3. Experiment 2. Network Community Detection Method: Louvain
As stated earlier, spatial flows can be regarded as the edges of a network. Head/tail breaks and network community detection methods can be a great combination [
16]. In the second experiment, we conduct a test with the Louvain method [
5], which is a widely-adopted algorithm to extract community structures from large networks. The reasons for selecting Louvain are twofold: the method itself is well-accepted in both industry and academia, and it weighs the weight and direction of edges (flows) to detect communities. The Louvain algorithm is one of the fastest modularity-based algorithms that suit large networks. It is built on the modularity index calculated as Equation (3), which is a scalar value between −1 and 1 that measures the density of edges inside communities as compared to edges between communities [
5].
where
is the weight of edge (flow) between
i and
j;
is the sum of edge (flow) weights attached to node
i, respectively;
m is the sum of all edge (flow) weights in the network;
is the community that includes node
i;
equals 1 if
u =
v, and 0 otherwise.
The algorithm initializes each node as its own community. In the first step, each node is switched from its current community to one of its neighbors’ community. The switch is confirmed if it helps increase the modularity value. This process is applied repeatedly for all nodes until no further improvement can be achieved, in other words, a local maximum of the modularity is reached. The second step is to define a new coarse-grained network, whose nodes are the communities found in the first step. The edge weights between the new nodes are the sum of the edge weights between the lower-level nodes of each community. These two steps are repeated until no further modularity-increasing reassignments of communities can be found.
We apply head/tail breaks to Louvain to reduce the input data to the “head” part of the distribution only. We test with a large cellphone call flow dataset in the Beijing-Tianjin-Hebei (BTH) urban agglomeration in China in November 2017. Each flow event represents a cellphone call made from one location to another. They are aggregated to the basic spatial units as one-kilometer-by-one-kilometer grid cells. After aggregation, the dataset consists of 45 million flows that connect 177,608 grid cells. The dataset is extremely heavy-tailed: a flow value of 5 or more places a dyad in the top 10.8% of the entire dataset. We test with a series of head/tail breaks to record the computing times while evaluating the results. Because the Louvain algorithm assigns every grid cell to a community, many resulting communities end up with one or just a few cells. To evaluate the result quality, we focus on the meaningful big communities while ignoring the noisy small ones. Since the definition of big communities can be arbitrary, we pick out the 100 largest communities of every test to have consistent cross-comparisons. Specifically, we compare the population sizes of these communities and their spatial patterns through visualization. We adopt the publicly available population data from
www.worldpop.org to count the population within the communities, specifically we use the 2015 Asia population dataset in 1 km resolution.
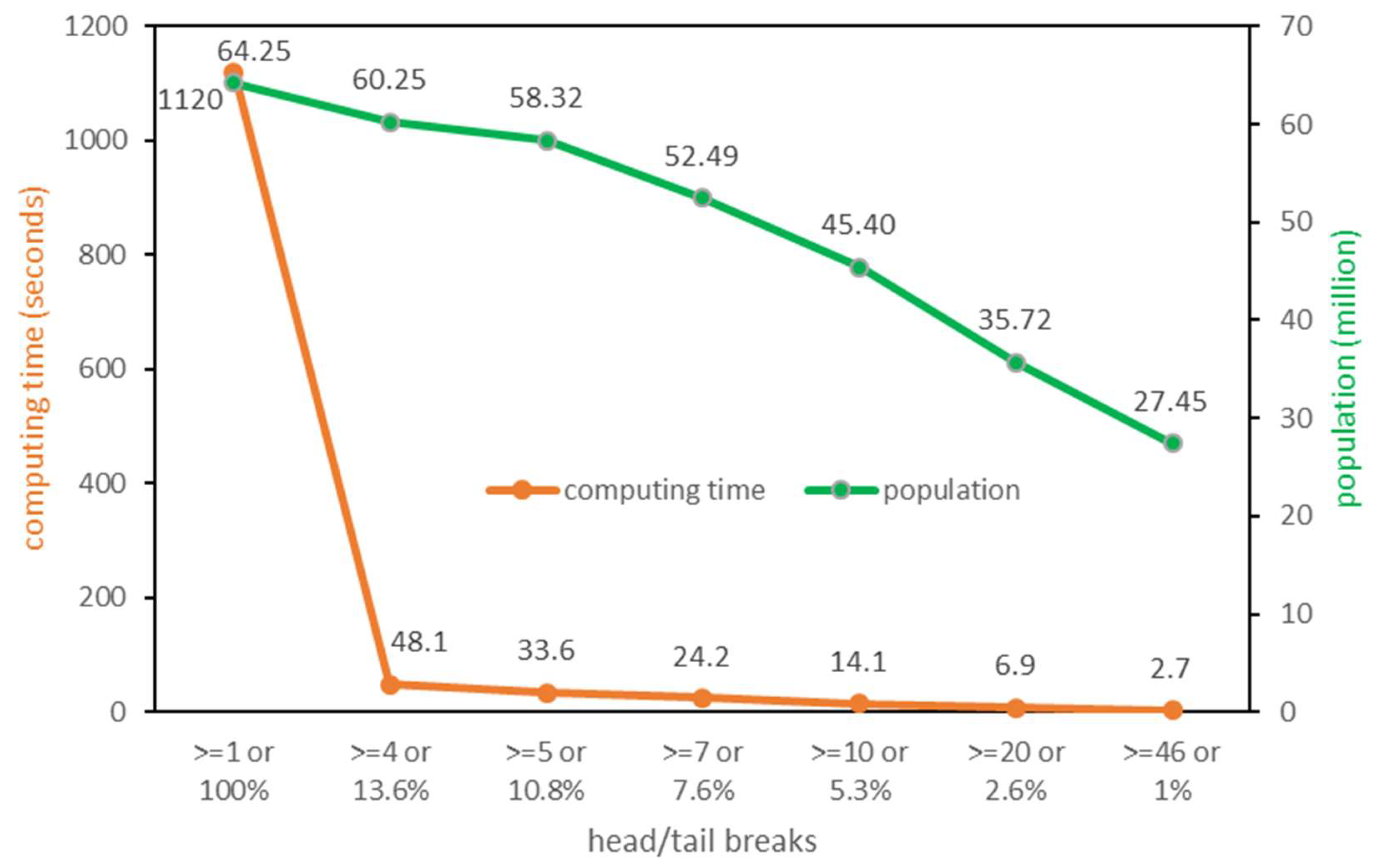
Figure 6 summarizes the test results. The original computing time is 1120 s without applying head/tail breaks. It is decreased to 48.1 s by selecting the flows with value equal or larger than 4, or the top 13.6%, as input data. The computing time can be further shrunk with lower head-to-tail ratio. For instance, it would take less than half a minute to process only the top 1% as the input data.
On the other hand, the total population of the 100 largest communities of each test has decreased to some extent as the head-to-tail ratio lowers. Taking the top 10.8% flows as the input data, the algorithm keeps a population of 58.32 million in the 100 largest generated communities. Although the shrinking of community sizes is expected, the degree of shrinking is conservative as 90.8% of the original population are kept.
To further examine the effect of applying head/tail breaks on the results, we visualize three sets of detected communities as well as the population density in the study area as
Figure 7. Only the 100 largest communities of each test are visualized with a qualitative color scheme, while the rest of the grid cells are hidden as noise. The colors differentiate the communities of the same map, but there is no correspondence relationship of the same color across the maps. Several observations can be made.
First, all the tests can extract at least a hundred unique communities at a granularity commensurate with counties. Most detected communities are consistent with the predefined county boundaries, with a few exceptions that are formed by multiple neighboring counties. Second, applying head/tail breaks to selectively reduce the input data would shrink the spatial extent of the retained communities within the BTH urban agglomeration. Comparing with the population density map in
Figure 7d, we see that the shrunk communities preserve the most populous core regions, while losing the peripheral grid cells. Relating back to the chart in
Figure 6, it can be concluded that the significant shrinking of communities’ spatial extent on the map does not lead to a proportional decrease of the population encompassed by these communities. In other words, the results obtained with head/tail breaks preserve the most meaningful parts of the community structures. Last but not least, head/tail breaks can help extract communities at lower hierarchical level. In
Figure 7a, Beijing (with red outline) consists of a few communities and Tianjin (with turquoise outline) is detected as a single large community. By applying head/tail breaks, both megacities can be decomposed into a number of smaller communities that correspond to the city districts. This change probably results from the data reduction produced by the head/tail breaks that filter out the low-value flows that serve as the weak links between city districts. With only the “head” part as the input data, the algorithm is better positioned to extract the spatially compact communities with strong internal cohesion.
To sum up, through this series of experiments with the classical Louvain algorithm, we found that the data reduction method of head/tail breaks can significantly boost the computation on large flow/network dataset. The computing time keeps decreasing as the head-to-tail ratio is set lower. However, beyond a certain point, it becomes less appealing to save a few extra seconds at the expense of degraded geographic representation of communities. The plausible optimal threshold of flow value in this case falls between 4 and 5, corresponding to the top 13.6% and 10.8% as the “head”, respectively.
4.4. Experiment 3. Network Centrality Algorithm: PageRank
In this section, we test a well-known network centrality algorithm, namely weighted PageRank (WPR; [
8]), which is a link analysis method to measure centrality of nodes in a graph. By considering the importance of links, the WPR is an extension of the original PageRank algorithm developed by Google to rank the relative importance of website pages [
30]. As spatial flows between locations can be represented by directed and weighted edges (links) of a network dataset, WPR has been used to measure the relative attractiveness or importance of locations in spatial interaction contexts involving various spatial flows [
6,
7]. The WPR algorithm follows an iterative process by which the WPR value of each node is continuously calculated until convergence is reached. For a node
in a network of
nodes, the WPR value of
is computed as follows:
where
is the residual probability which is fixed by an empirically estimated value 0.85;
is the set of nodes that have outbound links to
;
is the weight (or flow value) of an outbound link from
to
. During calculating, the first term
in Equation (4) is fixed and thus
, which means the WPR value for a node in question is dependent on a sum of the weighted WPR values of all other nodes that have outbound links to this node. The weighting term is the weight (
) of an outbound link normalized by the sum of weights for all outbound links from a node
. Firstly, due to the normalization, weighting becomes relative and the absolute flow values (link weights) become not meaningful to the final WPR values anymore, which hypothetically contradicts the basic assumption of head/tail breaks that the links (flows) with larger weights carry more value in the results of analysis. Second, according to the fundamental assumption of the WPR algorithm that more important nodes (higher WPR values) are likely to receive a larger number of links from other nodes that are also important, link distribution instead of weight distribution plays a major role in affecting WPR values. That is, the concentration of incoming links (e.g., larger node in-degree) causes larger sizes of
and
, and thus larger WPR values. The above hypotheses are tested empirically as follows.
To empirically test the applicability of the head/tail breaks to the weighted PageRank algorithm, the break is applied to the mean value of the weight distribution so that the links with lower weight values are removed from the networks. In a related work, Jiang [
6] applied head/tail breaks to handle the heavy-tailed WPR values, which is different from what we are testing here: using head/tail breaks to select link values (reduce input data) and see if the WPR values can be retained. Therefore, the model fidelity can be evaluated by the degree to which the ranking of WPR values of nodes can be preserved in the reduced network, compared to that of the original network. Specifically, a preservation ratio for the top-
% nodes with the highest WPR values between the reduced and the original networks is defined as:
where
is the number of nodes preserved in the top-
% ranked nodes for the reduced network, compared to the number
of top-
ranked nodes of the original network. By varying the value of
, comparison of results can be evaluated for different top-
% ranked nodes.
We test with the same cellphone call flow dataset for the Beijing-Tianjin-Hebei (BTH) urban agglomeration used in Experiment 2.
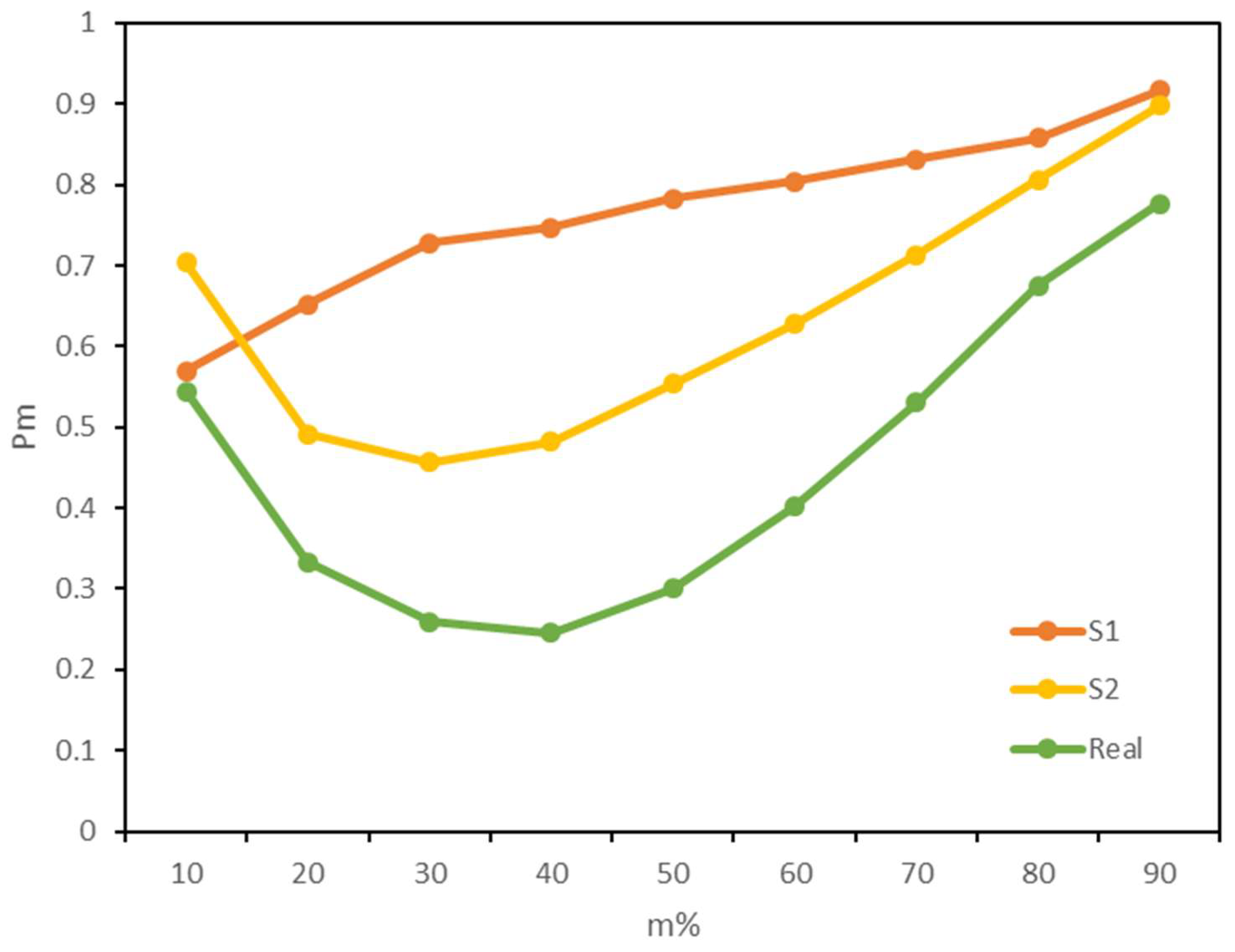
Figure 8 shows the preservation ratios for this dataset (Real) for a range of top-
% ranked nodes. It exhibits rather lower preservation ratios over the entire range of
%. Specifically, only half of the top 10% ranked nodes are preserved, and then the preservation ratio decreases at the lowest for
%=40% and increases again for
% = 50% and higher, which portrays a nonmonotonic trend. As expected, the computing time is reduced from 314 s to 22 s after the head/tail break. However, the performance gain is meaningless given the loss of model fidelity in general. This finding supports our first hypothesis about the contradiction between the weighted PageRank’s relative weighting scheme and the assumption of applying head/tail breaks for data reduction.
To further confirm our finding, two synthetic datasets are designed as benchmarks to remove the sensitivity due to the choice of test data. The two synthetic datasets are specified as follows. First, a random directed network is created with 100 nodes and 1000 edges that are randomly distributed following a uniform distribution. The edge weights are generated by following a Zipf distribution [
31] to allow the application of the head/tail break and are assigned to edges randomly. Second, another random directed network is created with 100 nodes and 1000 edges. The edge weights are also generated from a Zipf distribution, but larger weights are assigned to outbound links of nodes that have higher degree. Since the two datasets are random networks, 30 runs are conducted to control for the effects of randomness.
The preservation ratios for the synthetic datasets 1 and 2 (S1 and S2 in
Figure 8) both show a general loss of model fidelity. For S1, half of the top 10% ranked nodes are preserved, 13 of the top 20% nodes, and this ratio is monotonically increasing as m% increases. This is simply because more nodes can be preserved with a larger number of top-m% nodes considered, which is true especially when m > 50 for all three datasets. For S2, more top-10% nodes are preserved, but the preservation ratio decreases first and then increases at 30%, which portrays a similar overall pattern as the Real dataset. The larger ratio of preservation for top-10% nodes can be attributed to the assignment of weights according to the in-degree of nodes, in which case better connected nodes have larger weights thus their links have a higher chance to be kept. It verifies the second hypothesis that the WPR algorithm values the flow (link) distribution more than the flow value (weight) distribution.
In sum, the results of WPR algorithm are severely compromised after applying head/tail breaks for all three datasets tested and the model fidelity is hardly retained in any sensible way. Although conditions where the weight distribution matches the link distribution of nodes could potentially enhance the preservation of original WPR results, the capacity is in fact very limited (for top-10% nodes) in our findings. The empirical tests with three datasets support that the emphasis of weighted PageRank algorithm on relative weighting and link distribution violates the assumption of head/tail breaks and thus renders this algorithm a poor choice for this data reduction technique.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}