
Real-Time Spatial Queries for Moving Objects Using Storm Topology

 ,
,
Abstract
:1. Introduction
- We propose a distributed index based on a Storm topology for moving objects and then implement range queries and continuous KNN (CKNN) queries using this distributed index. In this way, the pressure of updating data streams in stand-alone nodes can be relieved, and real-time updating for moving objects can be realized.
- We design a spatial join algorithm using Storm for moving object streams. Experiments show that a quadtree-based index outperforms other types as the secondary index for distributed querying and updating.
2. Related Work and Background
2.1. Related Work
2.1.1. Spatial Index for Moving Objects
2.1.2. U-Grid and P-Grid
2.1.3. Spatial Querying on a Distributed Platform
2.2. Technological Background
2.2.1. Distributed Streaming Processing Framework
2.2.2. Storm Topology Programming Paradigm
3. Problem Setting and Semantic Information
3.1. Problem Setting
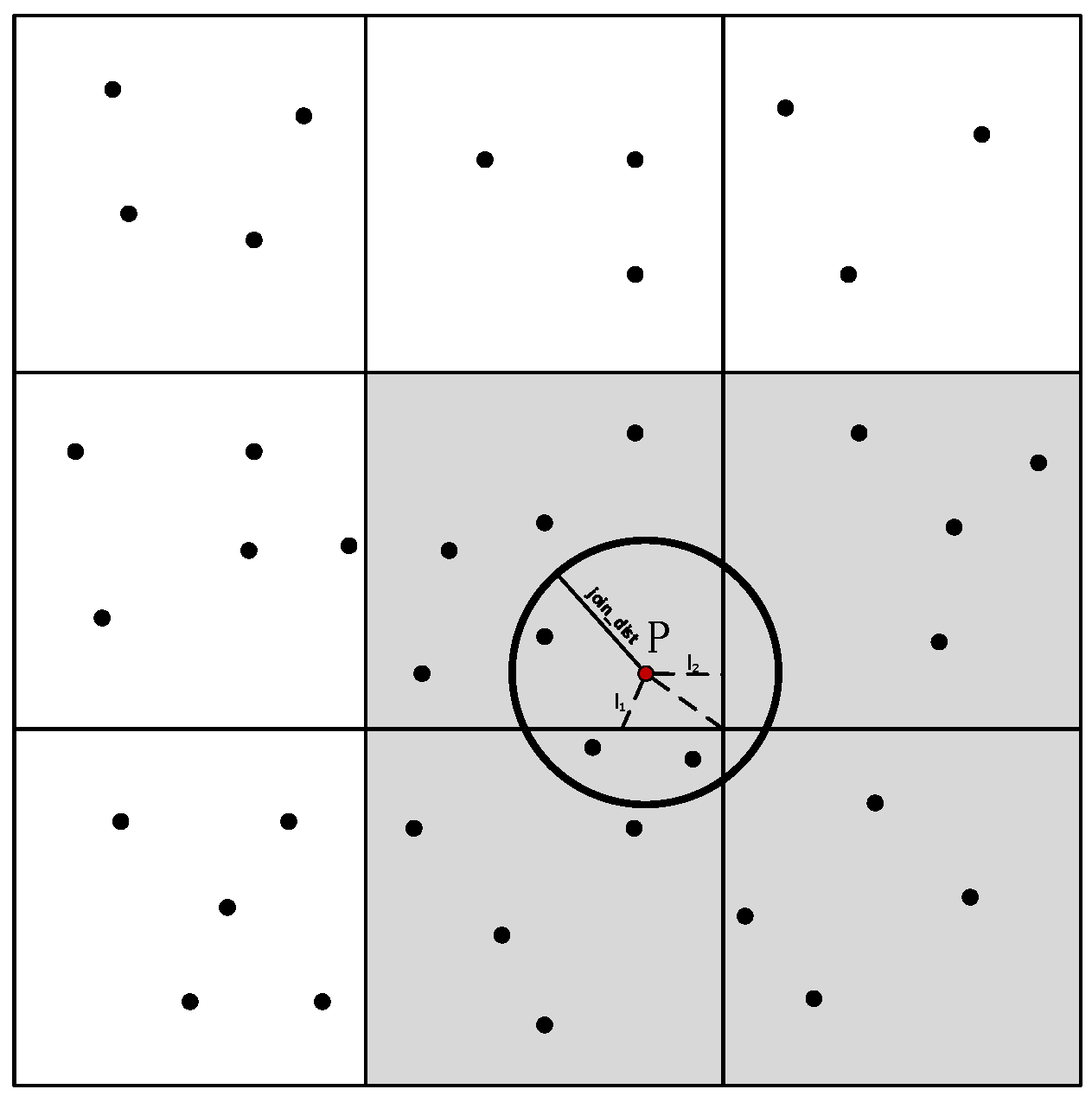
3.2. Semantic Information
4. Structure and Algorithms for Spatial Data in a Storm Topology
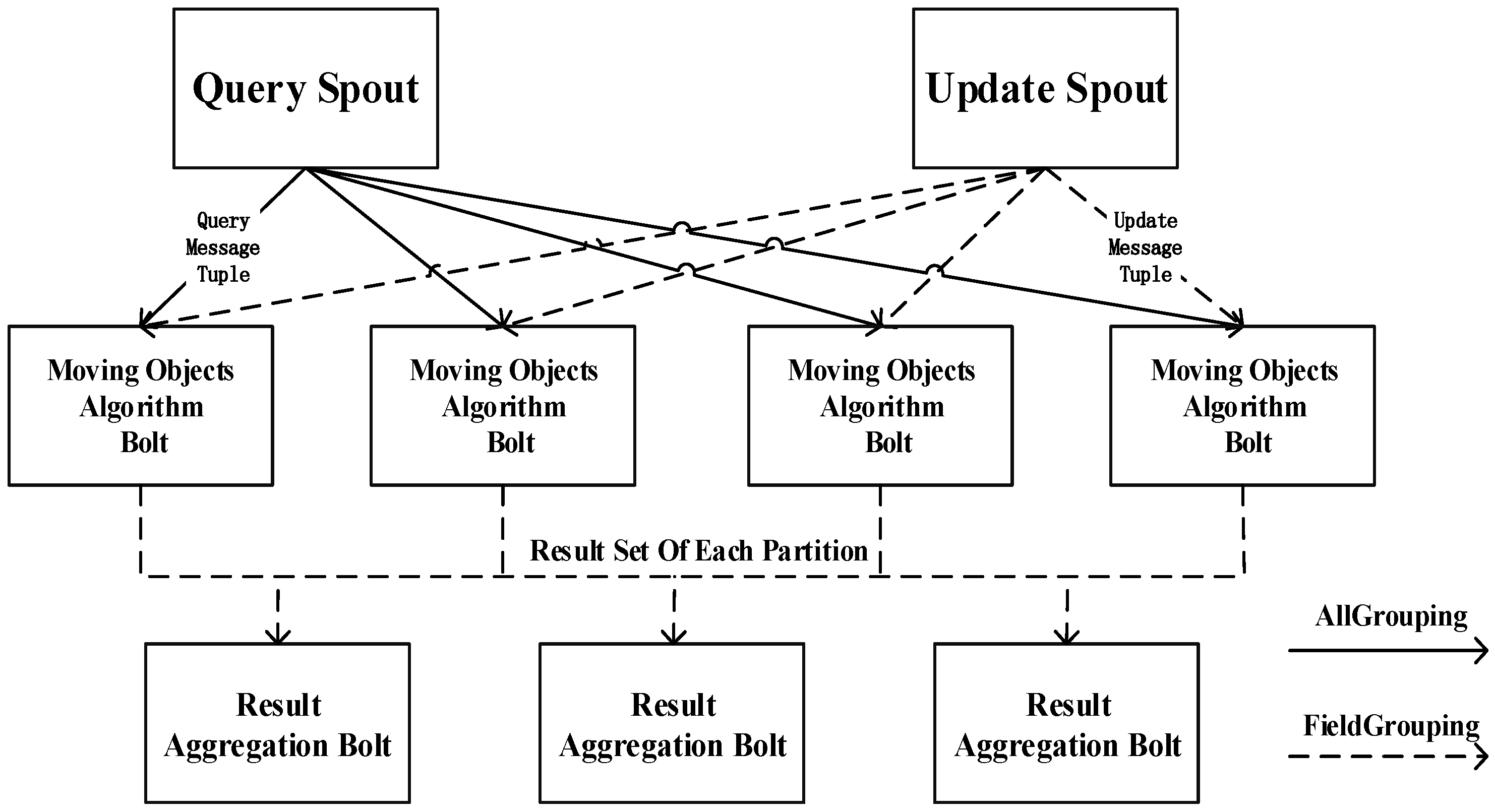
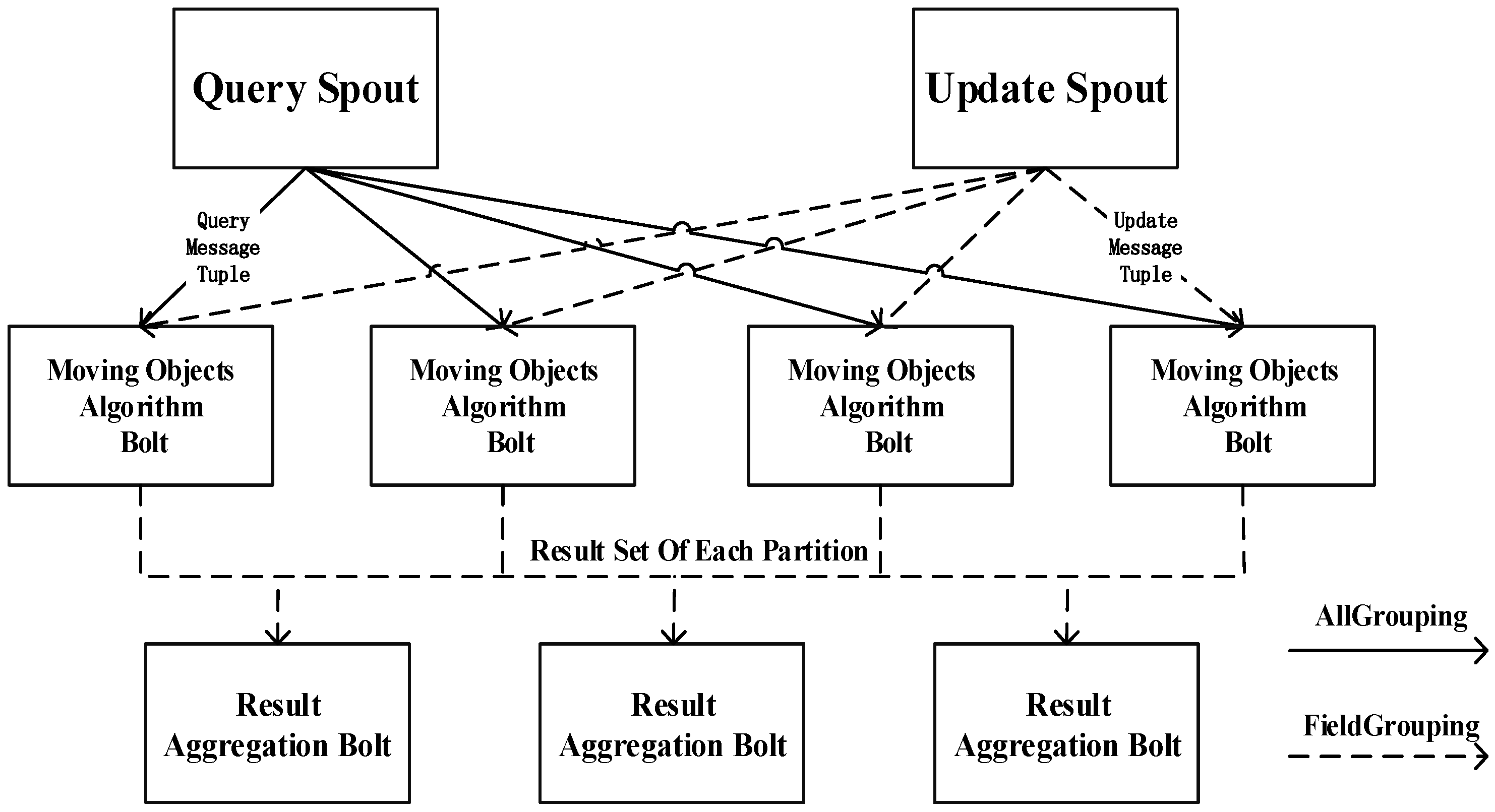
4.1. Storm Topology Algorithm for a Single Dataset
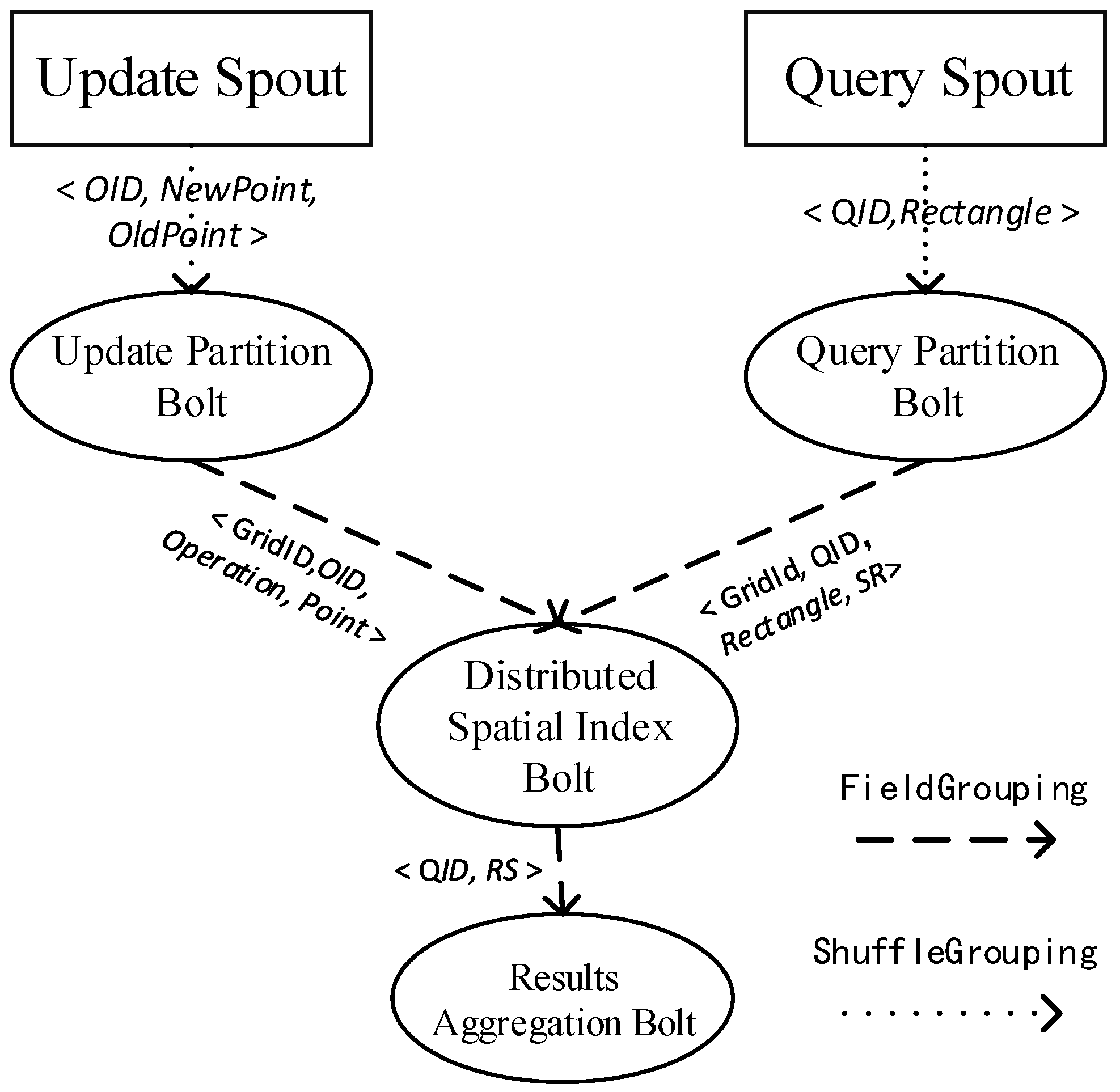
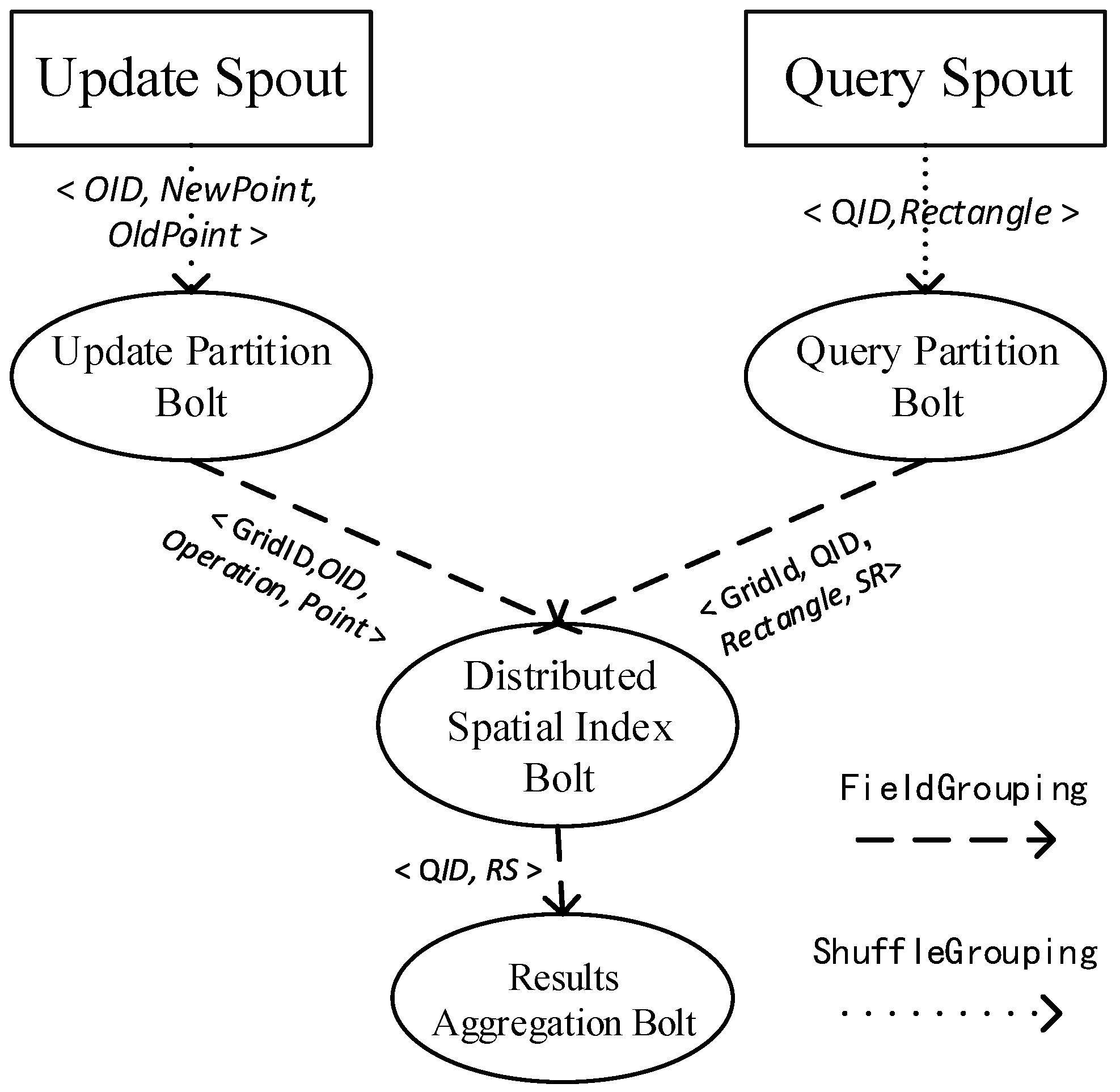
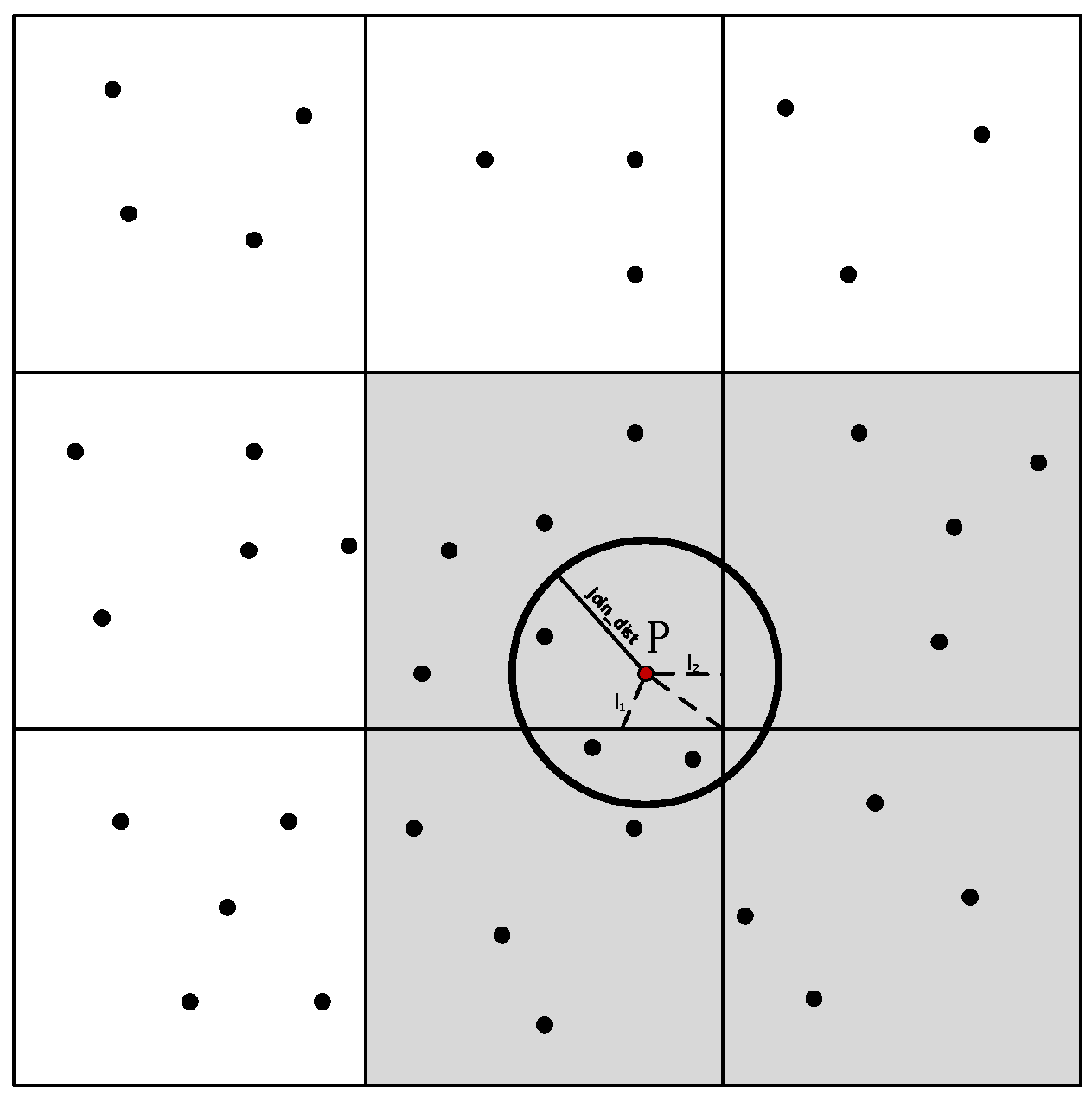
4.2. Spatial Joins for Moving Objects in a Storm Topology
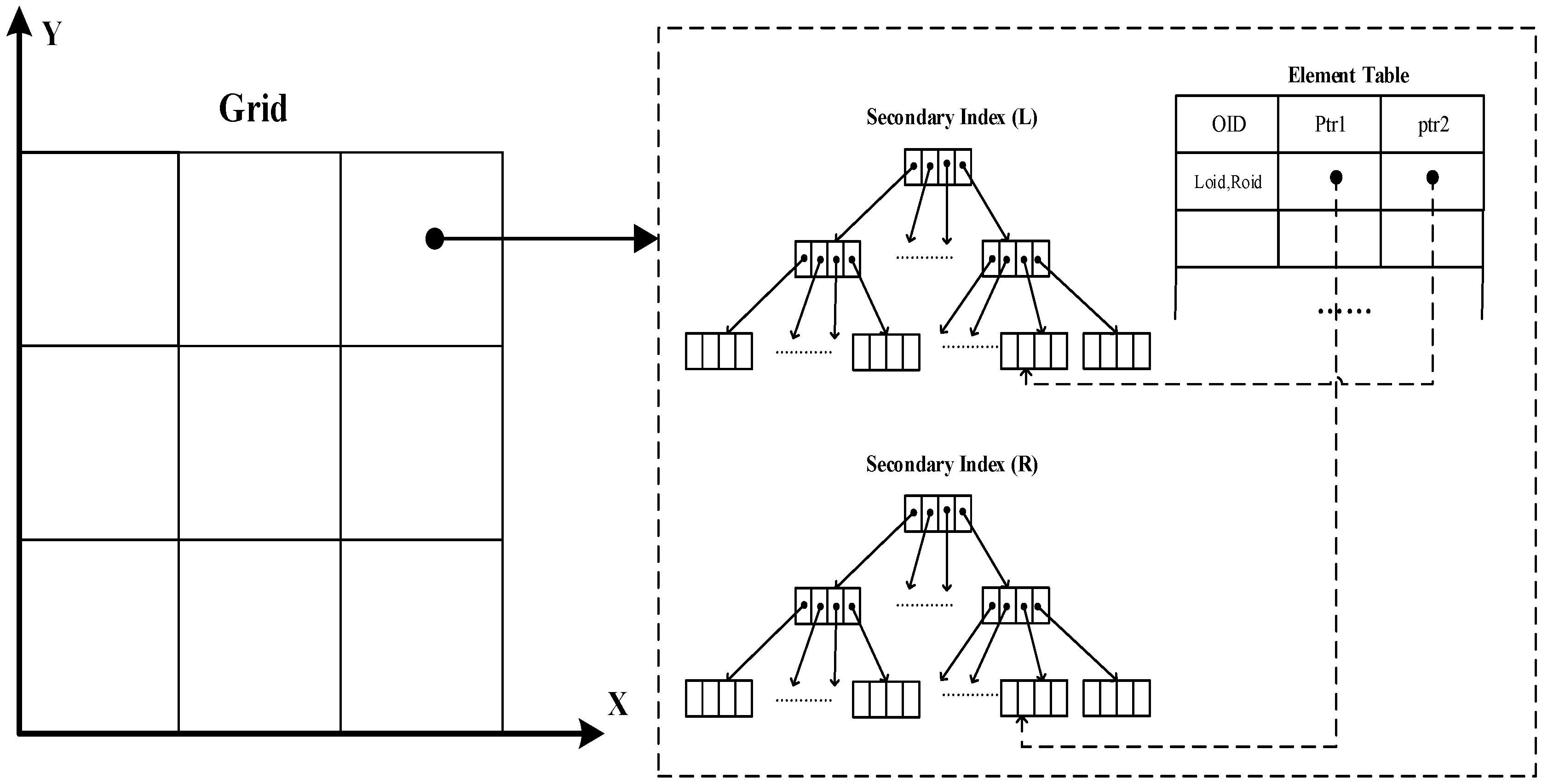
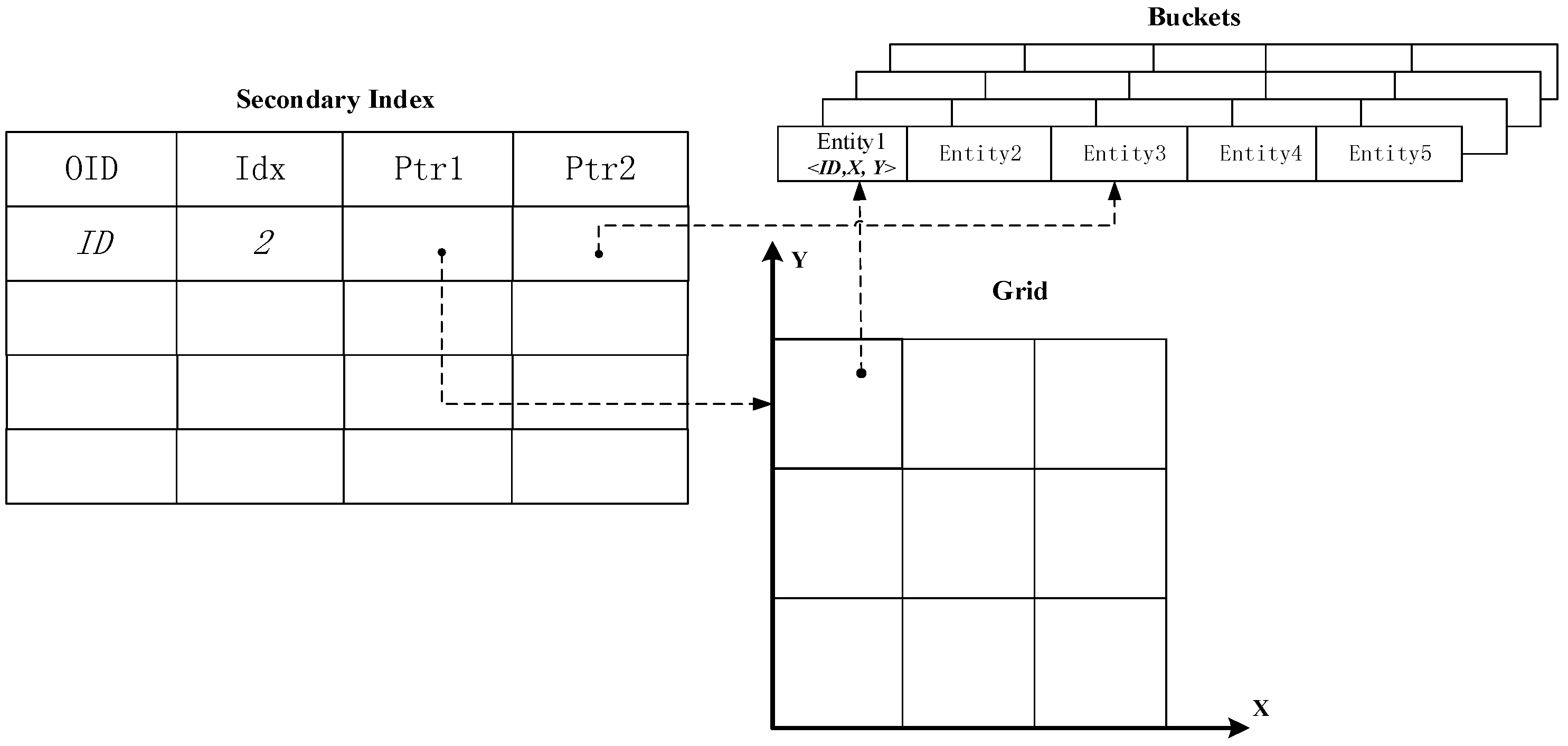
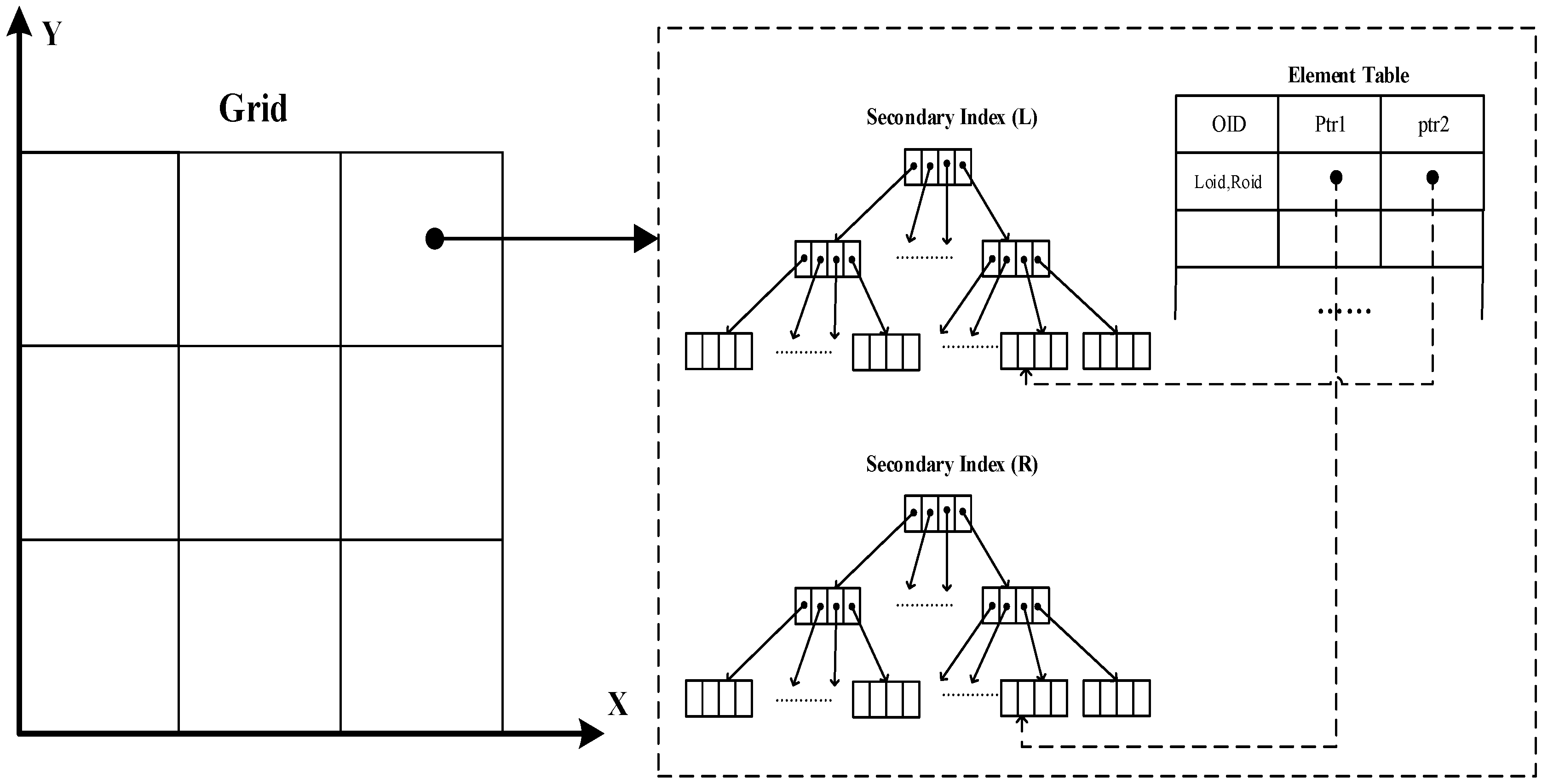
4.2.1. Data Structure
4.2.2. Update Partition Bolt
| Algorithm 1: UpdatePartBolt (Tuple UpdateMessage) | |
| 1. | OldCC←GetOldCC(JoinDistance, UpdateMessage.OldPoint) |
| 2. | NewCC←GetOldCC(JoinDistance, UpdateMessage.NewPoint) |
| 3. | OldACList←GetOldACList(Grid, oldCC) |
| 4. | NewACList←GetNewACList(Grid, newCC) |
| 5. | foreach Cell in OldACList |
| 6. | if Cell In NewACList then |
| 7. | emit(CellId, UpdateOperation, Point) |
| 8. | else |
| 9. | emit(CellId, DeleteOperation, Point) |
| 10. | end if-then |
| 11. | end-foreach |
| 12. | foreach Cell in NewACList then |
| 13. | if not in OldACList then |
| 14. | emit(CellID, DeleteOperation,Point) |
| 15. | end if-then |
| 16. | end-foreach |
4.2.3. Query Partition Bolt
| Algorithm 2: QueryPartBolt (Tuple QueryMessage) | |
| 1. | AffectQueryCellList←CalculateByRange(QueryMessage.Range) |
| 2. | foreach Cell in AffectQueryCellList |
| 3. | if cell PartialCovered by Range then |
| 4. | emit (CellID, SR:Intersect) |
| 5. | end-if |
| 6. | if Cell TotalCovered by Range then |
| 7. | emit(CellID, SR:Contain) |
| 8. | end-if |
| 9. | end-foreach |
4.2.4. Distributed Spatial Index Bolt
| Algorithm 3: SpatialIndexBolt(Tuple Message) | |
| 1. | Cell←FindCellByID(Message.CellId) |
| 2. | if Message from QueryPartBolt then |
| 3. | if Message.SR = contain then |
| 4. | foreach Pair in Cell.RS |
| 5. | emit Pair |
| 6. | end-foreach |
| 7. | end if-then |
| 8. | if Message.SR = Intersect then |
| 9. | foreach Pair in Cell.RS |
| 10. | if Pair.Point1∈Message.Range&Pair.Point2∈Message.Range then |
| 11. | emit Pair |
| 12. | end if-then |
| 13. | end-foreach |
| 14. | if Message from UpdatePartBolt then |
| 15. | foreach SpatialIndex In cell.SI |
| 16. | if Message.Point∈SpatialIndex then |
| 17. | SpatialIndex.Operate(Message.Point, Message.Operate) |
| 18. | else |
| 19. | PairList←SpatialIndex(Message.Point, JoinDistance) |
| 20. | update Cell.RS by PairList |
| 21. | end if-then |
| 22. | end-foreach |
| 23. | end if-then |
4.2.5. Results Aggregation Bolt
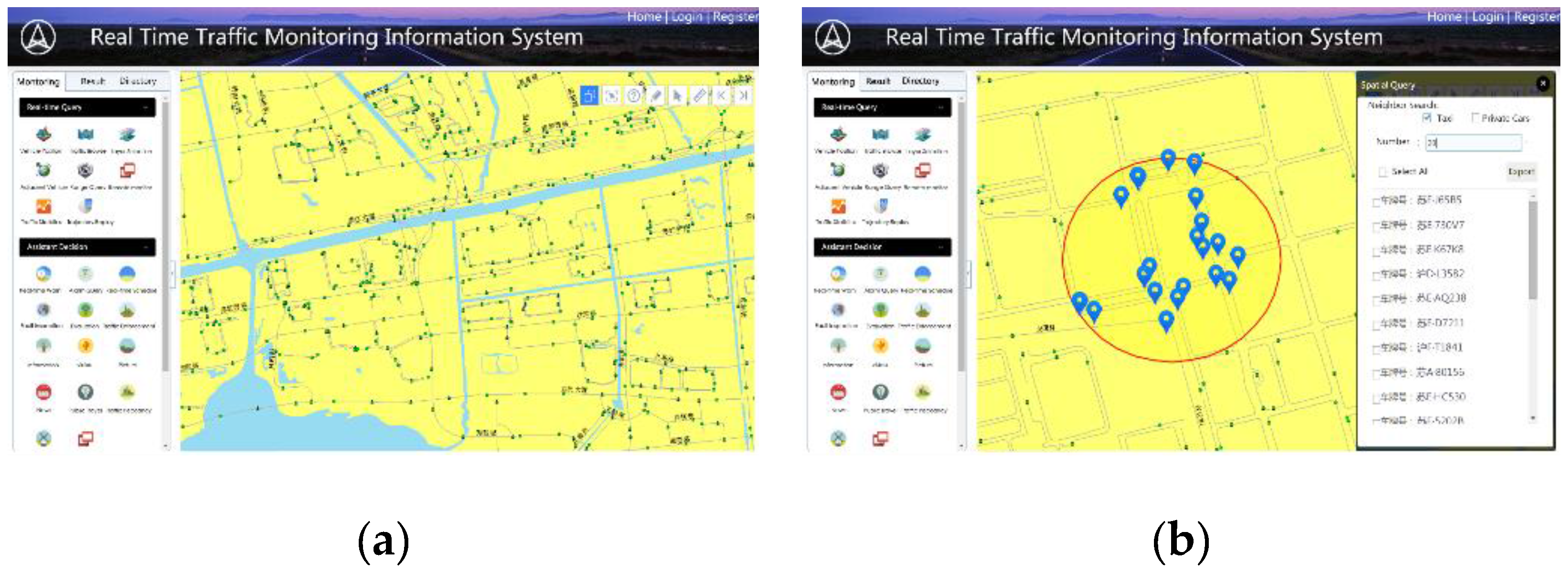
5. Experimental Study
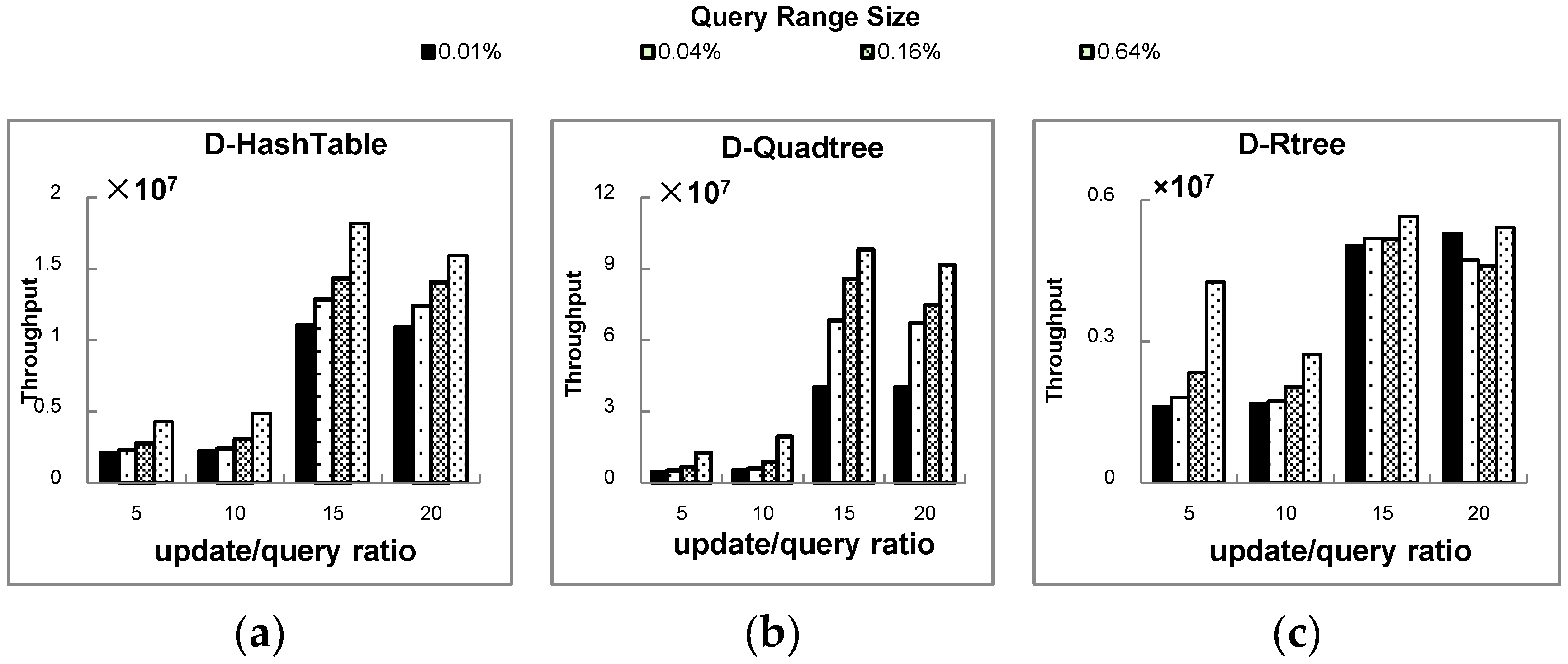
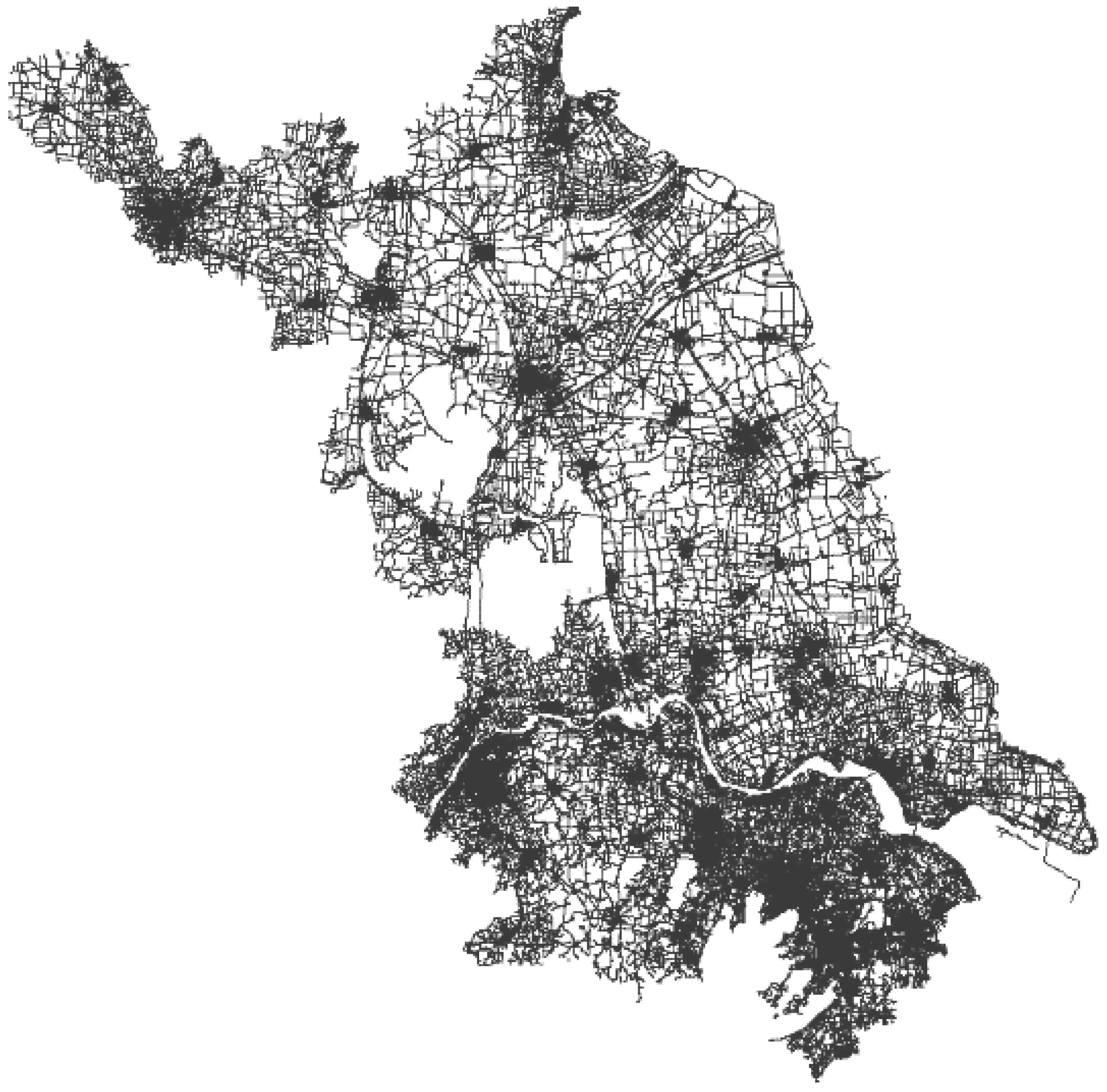
5.1. Experimental Setting and Workloads
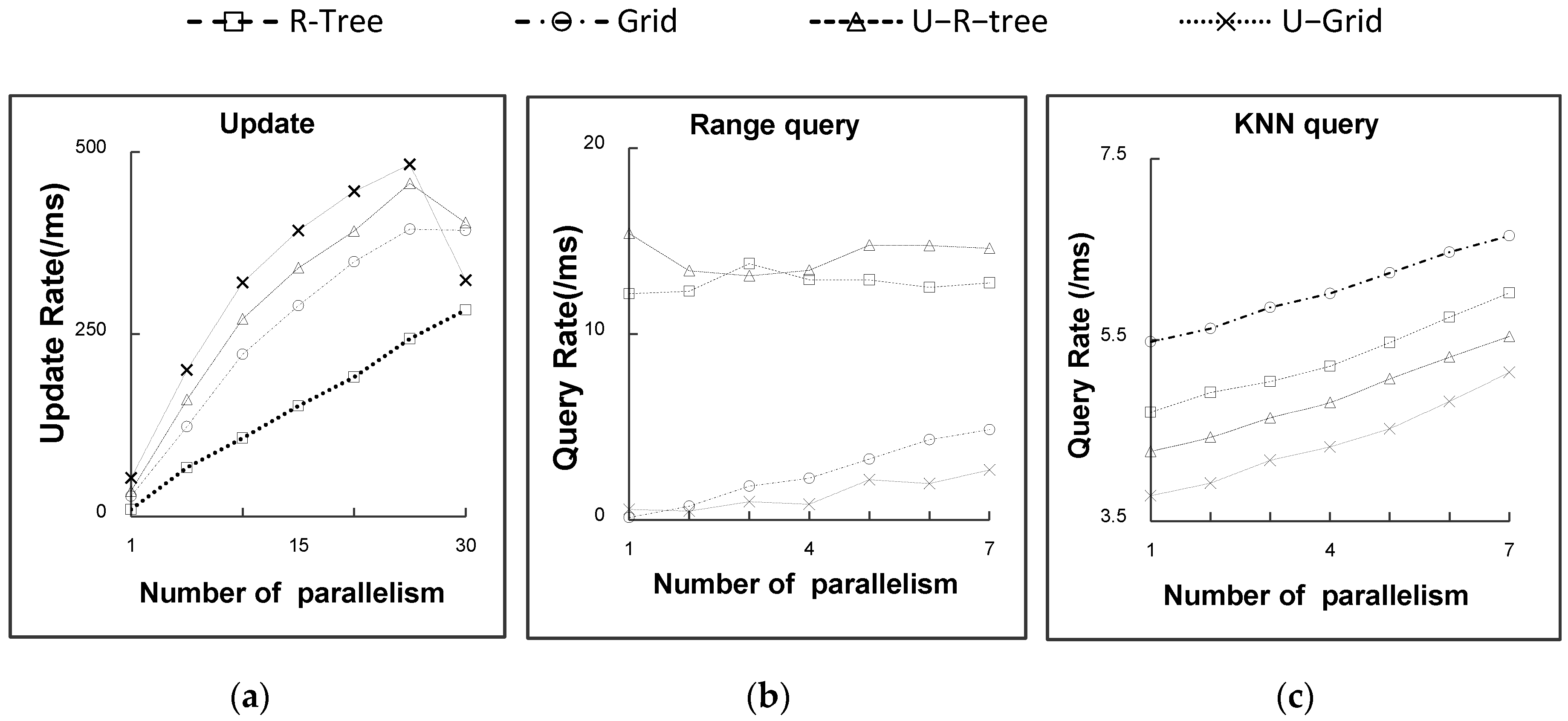
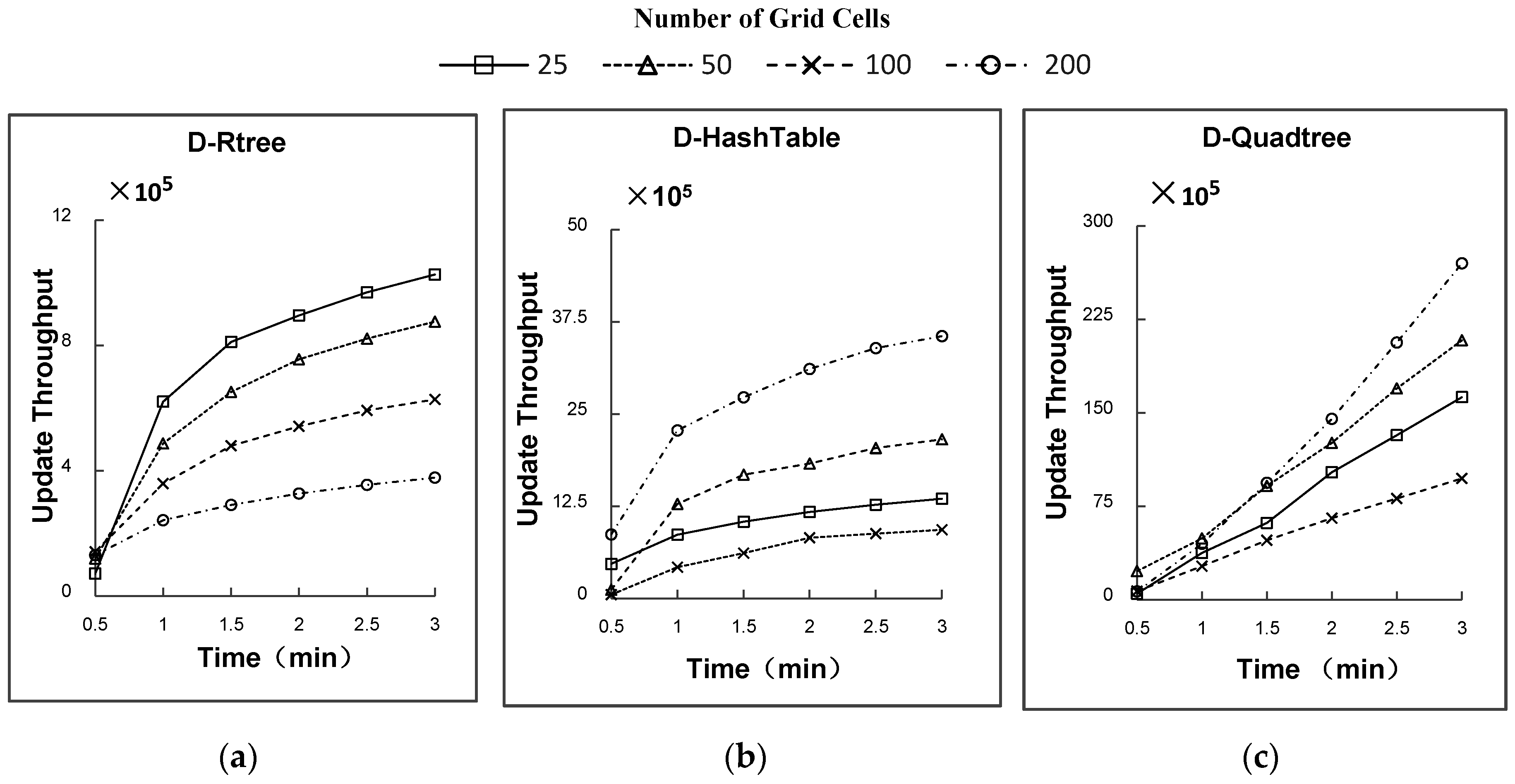
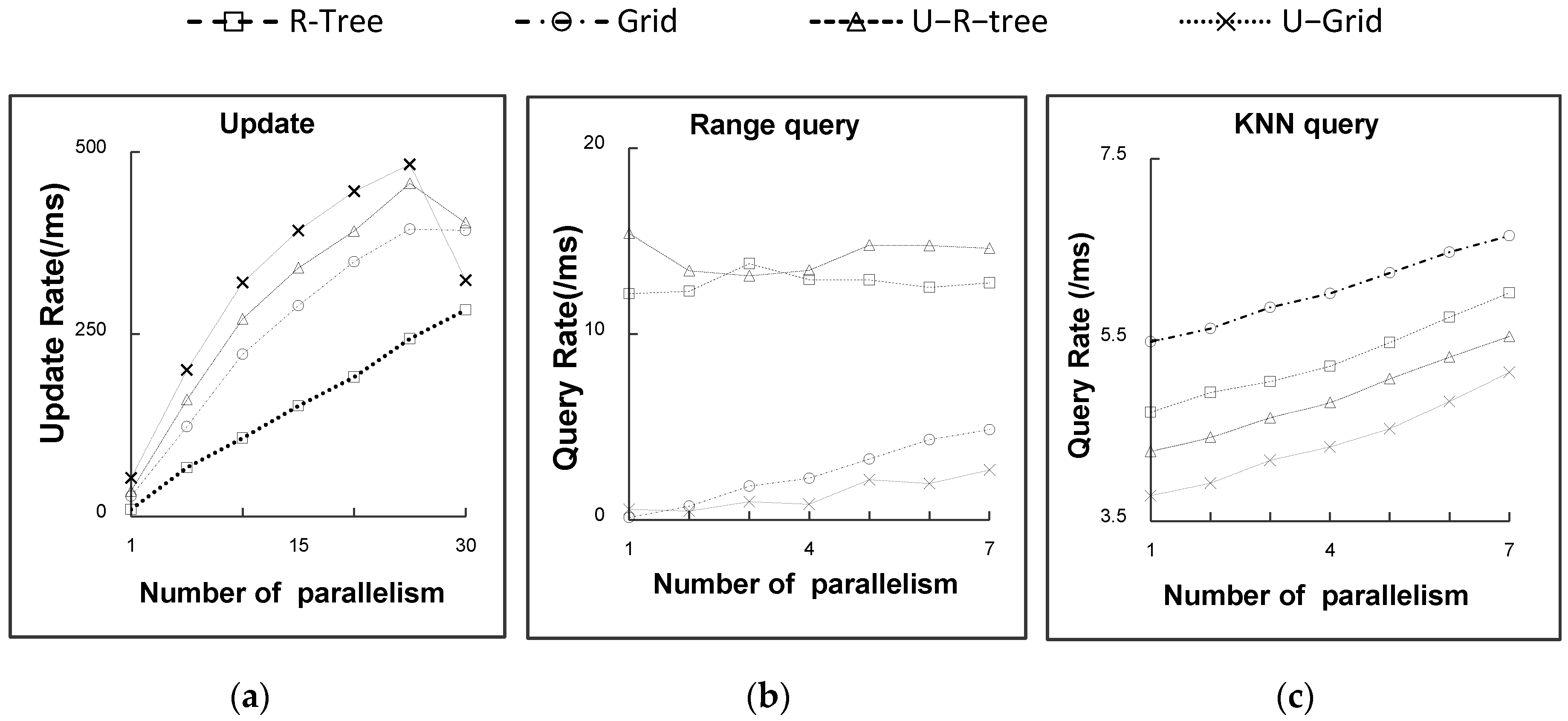
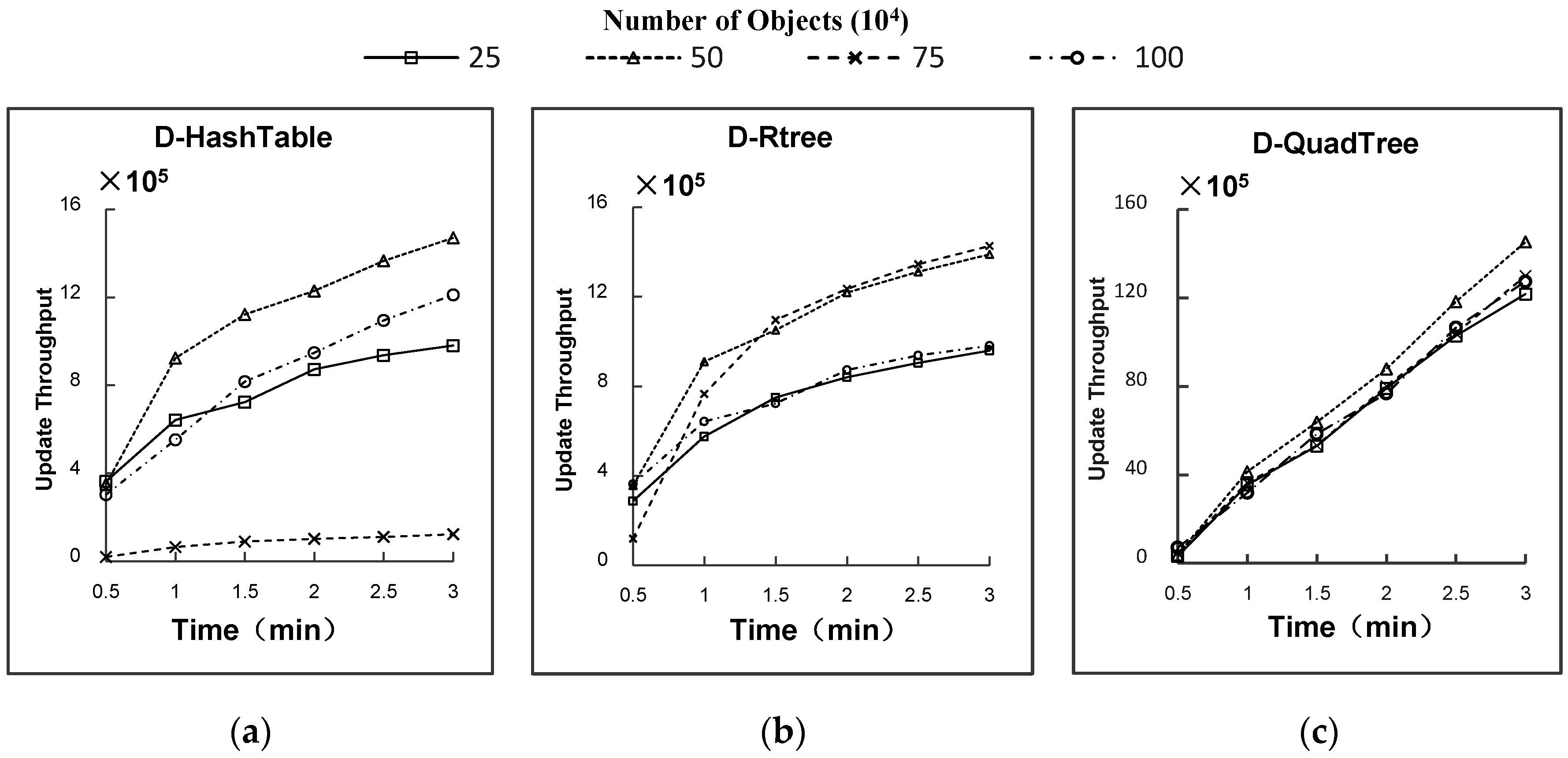
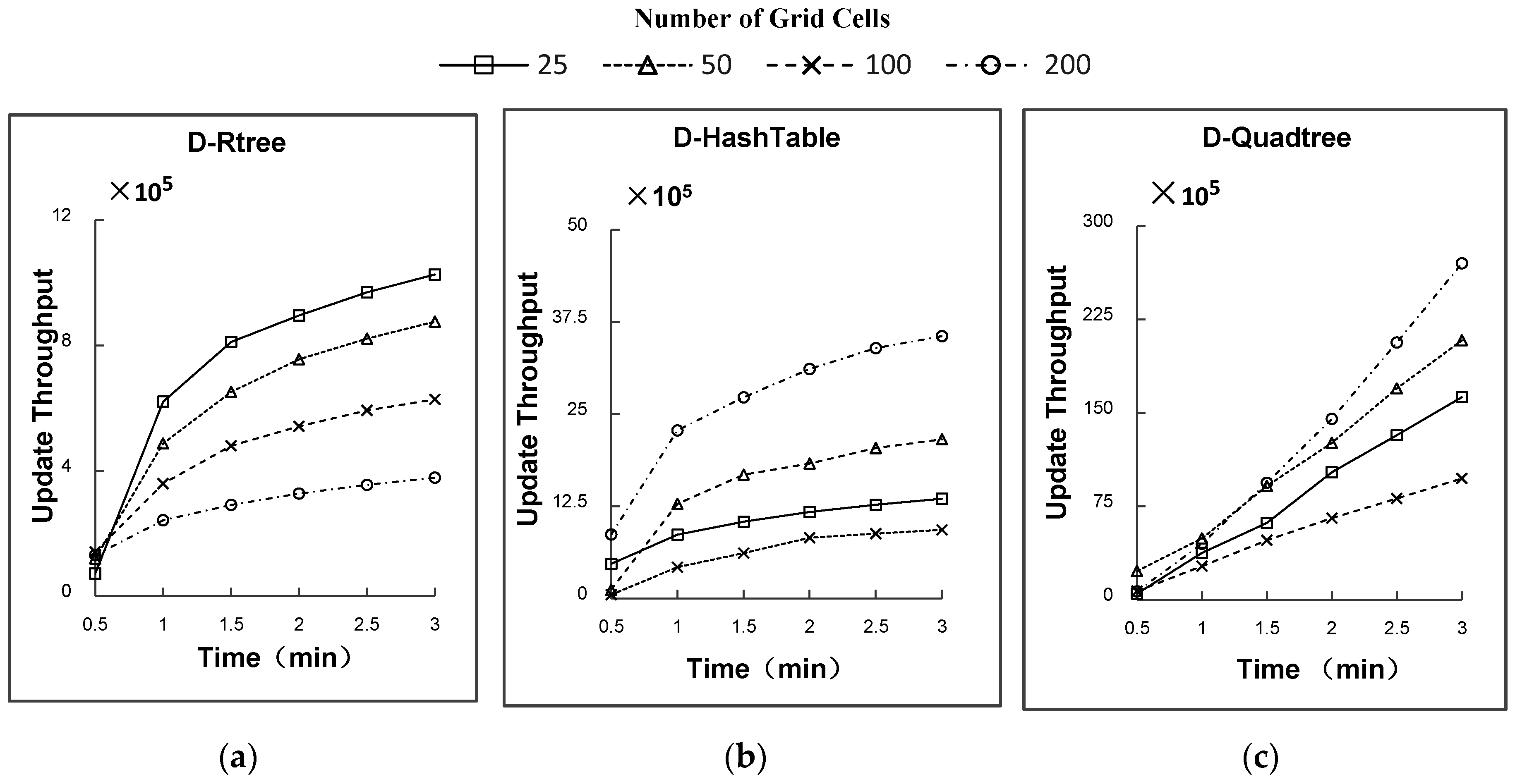
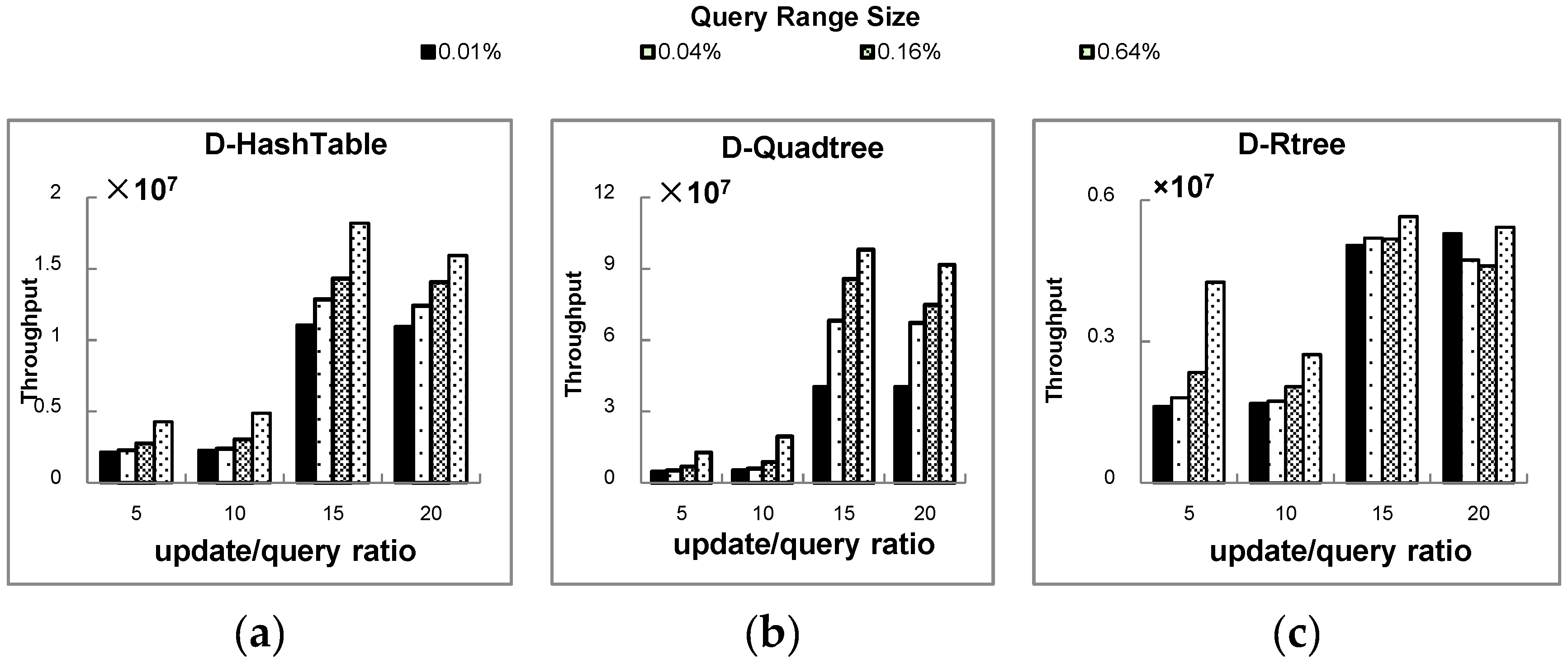
5.2. Experimental Results
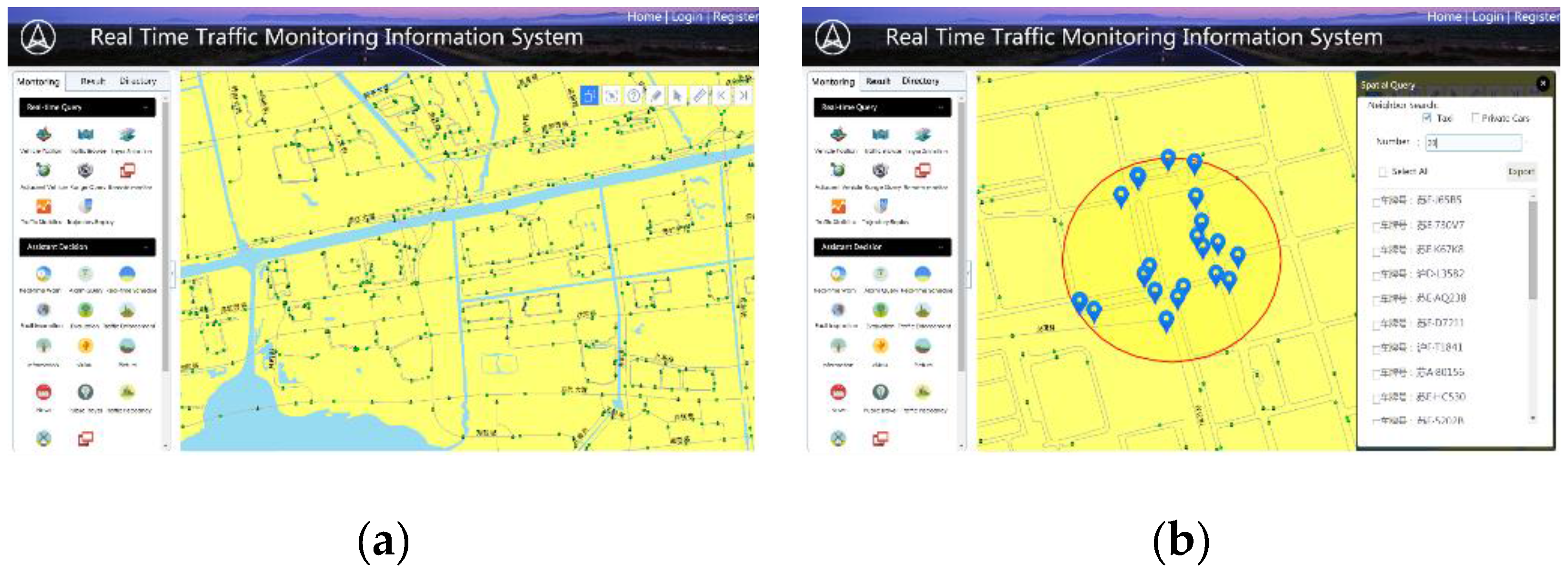
6. Conclusions and Applications
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Huang, X.; Zhao, Y.; Yang, J.; Zhang, C.; Ma, C.; Ye, X. TrajGraph: A graph-based visual analytics approach to studying urban network centralities using taxi trajectory data. Vis. Comput. Graph. 2016, 22, 160–169. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Liu, Z.; Liao, H. Improving the performance of GIS polygon overlay computation with MapReduce for spatial big data processing. Clust. Comput. 2015, 18, 507–516. [Google Scholar] [CrossRef]
- You, S.J.; Zhang, L.G. Large-scale spatial join query processing in cloud. In Proceedings of the IEEE International Conference on Data Engineering Workshops, Seoul, Korea, 13–17 April 2015.
- Fast Data: The Next Step after Big Data. Available online: http://www.infoworld.com/article/2608040 (accessed on 13 September 2016).
- Stojanović, D.N.; Turanjanin, J. Processing big trajectory and Twitter data streams using Apache STORM. In Proceedings of the 12th International Conference on Telecommunication in Modern Satellite, Cable and Broadcasting Services (TELSIKS), Niš, Serbia, 14–17 October 2015.
- Zhao, S.; Chandrashekar, M.; Lee, Y. Real-time network anomaly detection system using machine learning. In Proceedings of the 11th International Conference on the Design of Reliable Communication Networks, Kansas City, MO, USA, 24–27 March 2015.
- Iwerks, G.S.; Samet, H.; Smith, K.P. Maintenance of K-nn and spatial join queries on continuously moving points. ACM Trans. Database Syst. 2006, 31, 485–536. [Google Scholar] [CrossRef]
- Park, K. An efficient scalable spatial data search for location-aware mobile services. J. Inf. Sci. Eng. 2015, 31, 165–178. [Google Scholar]
- Kwon, D.; Lee, S. Indexing the current positions of moving objects using the lazy update R-tree. In Proceedings of the Third International Conference on Mobile Data Management, Singapore, Singapore, 8–10 January 2002.
- Pfoser, D.; Jensen, C.S.; Theodoridis, Y. Novel approaches to the indexing of moving object trajectories. In Proceedings of the 26th VLDB Conference, Cairo, Egypt, 10–14 September 2000.
- Xu, J.; Guting, R.H.; Zheng, Y. The TM-RTree an index on generic moving objects for range queries. Geoinformatica 2015, 19, 487–524. [Google Scholar] [CrossRef]
- Tao, Y.; Papadias, D.; Sun, J. The TPR-tree: An optimized spatio-temporal access method for predictive queries. In Proceedings of the 29th International Conference on Very Large Data Bases, Berlin, Germany, 9–12 September 2003.
- Tao, Y.; Papadiasa, D. MV3R-Tree: A Spatio-Temporal Access Method for Timestamp and Interval Queries Dept; Hong Kong University: Hong Kong, China, 2000. [Google Scholar]
- Jensen, C.S.; Lin, D.; Ooi, B.C. Query and update efficient B ± Tree based indexing of moving objects. In Proceedings of the 30th VLDB Conference, Toronto, ON, Canada, 31 August–3 September 2004.
- Šaltenis, S.; Jense, C.S.; Leutenegger, S.T. Indexing the positions of continuously moving objects. In Proceedings of the ACM SIGMOD International Conference on Management of Data, New York, NY, USA, 16–18 May 2000.
- Chen, N.; Shou, L.D.; Chen, G. Adaptive indexing of moving objects with highly variable update frequencies. J. Comput. Sci. Technol. 2008, 23, 998–1014. [Google Scholar] [CrossRef]
- Wu, W.; Tan, K. ISEE: Efficient continuous K-nearest-neighbor monitoring over moving objects. In Proceedings of the 19th International Conference on Scientific and Statistical Database Management, Banff, AB, Canada, 9–11 July 2007.
- Šidlauskas, D.; Ross, K.A.; Jensen, C.S. Thread-level parallel indexing of update intensive moving-object workloads. In Proceedings of the 12th International Symposium on Spatial and Temporal Databases, Minneapolis, MN, USA, 24–26 August 2011.
- Deng, Z.; Wu, X.; Wang, L. Parallel processing of dynamic continuous queries over streaming data flows. IEEE Trans. Parallel Distrib. Syst. 2015, 82, 834–846. [Google Scholar] [CrossRef]
- Xiong, D.; Marble, D.F. Strategies for real-time spatial analysis using massively parallel SIMD computers: An application to urban traffic flow analysis. Int. J. Geogr. Inf. Syst. 1996, 10, 769–789. [Google Scholar] [CrossRef]
- Šidlauskas, D.; Šaltenis, S.; Jensen, C.S. Trees or grids? Indexing moving objects in main memory. In Proceedings of the 17th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 4–6 November 2009.
- Lee, M.L.; Hsu, W.; Jense, C.S. Supporting frequent updates in R-trees: A bottom-up approach. In Proceedings of the 29th International Conference on Very Large Data Bases, Berlin, Germany, 12–13 September 2003.
- Šidlauskas, D.; Šaltenis, S.; Jensen, C.S. Processing of extreme moving-object update and query workloads in main memory. VLDB J. 2014, 23, 817–841. [Google Scholar] [CrossRef]
- You, S.; Zhang, J.; Le, G. Spatial join query processing in cloud: Analyzing design choices and performance comparisons. In Proceedings of the International Conference on Parallel Processing Workshops, Beijing, China, 16–19 August 2015.
- Zhang, S.; Han, J.; Liu, Z. SJMR: Parallelizing spatial join with MapReduce on clusters. In Proceedings of the IEEE International Conference on Cluster Computing & Workshops, New Orleans, LA, USA, 31 August–4 September 2009.
- Lu, W.; Shen, Y.; Chen, S. Efficient processing of k nearest neighbor joins using MapReduce. Proc. VLDB Endow. 2012. [Google Scholar] [CrossRef]
- Akdogan, A.; Demiryurek, U.; Banaeikashani, F.; Shahabi, C. Voronoi-based geospatial query processing with MapReduce. In Proceedings of the IEEE Second International Conference on Cloud Computing Technology & Science, Indianapolis, Indiana, IN, USA, 15–19 November 2010.
- Zhong, Y.Q.; Han, J.Z.; Zhang, T.Y. Towards parallel spatial query processing for big spatial data. In Proceedings of the Parallel & Distributed Processing Symposium Workshops & PhD Forum, Shanghai, China, 21–25 May 2012.
- Aji, A.; Wang, F.; Vo, H. Hadoop-GIS: A high performance spatial data warehousing system over MapReduce. Proc. VLDB Endow. 2013. [Google Scholar] [CrossRef]
- Eldawy, A.; Mokbel, M.F. A demonstration of SpatialHadoop: An efficient MapReduce framework for spatial data. Proc. VLDB Endow. 2013. [Google Scholar] [CrossRef]
- Yu, J.; Wu, J.; Sarwat, M. A demonstration of GeoSpark: A cluster computing framework for processing big spatial data. In Proceedings of the IEEE International Conference on Data Engineering, Helsinki, Finland, 16–25 May 2016.
- Baig, F.; Mehrotra, M.; Wang, F. SparkGIS: Efficient comparison and evaluation of algorithm results in tissue image analysis studies. In VLDB Workshops; Big-O(Q) and DMAH: Waikoloa, HI, USA, 2015; pp. 134–146. [Google Scholar]
- Xie, D.; Li, F.; Li, G. Simba: Efficient in memory spatial analytics. In Proceedings of the 2016 International Conference on Management of Data, San Francisco, CA, USA, 26 June–1 July 2016.
- Allen, S.T.; Jankowski, M.; Pathirana, P. Basic Storm concepts. In Storm Applied: Strategies for Real-Time Event Processing; Manning Publications: Shelter Island, NY, USA, 2015; pp. 17–29. [Google Scholar]
- MouRatidis, K.; Papadias, D.; Hadjieleftheriou, M. Conceptual partitioning: An efficient method for continuous nearest neighbor monitoring. In Proceedings of the ACM SIGMOD International Conference on Management of Data, New York, USA, 13–16 June 2005.
- Dittrich, J.; Blunschi, L.; Salles, M.A. Movies: Indexing moving objects by shooting index images. Geoinformatica 2011, 15, 727–767. [Google Scholar] [CrossRef]
- Bentley, J.L.; Friedman, J.H. Data structures for range searching. ACM Comput. Surv. 1979, 11, 397–409. [Google Scholar] [CrossRef]
- Wang, H.; Zimmermann, R. Processing of continuous location-based range queries on moving objects in road networks. IEEE Trans. Knowl. Data Eng. 2011, 23, 1065–1078. [Google Scholar] [CrossRef]
- Tauheed, F.; Heinis, T.; Ailamaki, A. Thermal-join: A scalable spatial join for dynamic workloads. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Melbourne, Australia, 9–16 July 2015.
- Corral, A.; Torres, M.; Vassilakopoulos, M. Predictive join processing between regions and moving object. In Proceedings of the 12th East European Conference, Pori, Finland, 5–9 September 2008.
- Ward, G.D.; He, Z.; Zhang, R. Real-time continuous intersection joins over large sets of moving objects using graphic processing units. VLDB J. 2014, 23, 965–985. [Google Scholar] [CrossRef]
- Kalashnikov, D.V.; Prabhakar, S.; Hamrusch, S.E. Main memory evaluation of monitoring queries over moving objects. Distrib. Parallel Databases 2004, 15, 117–135. [Google Scholar] [CrossRef]
- Gedik, B.; Liu, L. MobiEyes: Distributed processing of continuously moving queries on moving objects in a mobile system. In Advances in Database Technology—EDBT 2004; Springer: Philadelphia, PA, USA, 2004; Volume 2992, pp. 67–87. [Google Scholar]
- Zhang, R.; Qi, J.Z.; Lin, D. A highly optimized algorithm for continuous intersection join queries over moving objects. VLDB J. 2012, 21, 561–586. [Google Scholar] [CrossRef]
- Mokbel, M.F.; Xiong, X.; Aref, W.G. PLACE: A query processor for handling real-time spatio-temporal data streams. In Proceedings of the 30th International Conference on Very Large Data Bases, Toronto, ON, Canada, 29 August–3 September 2004.
- Xiong, X.P.; Mokbel, M.F.; Aref, W.G. SEA-CNN: Scalable processing of continuous k-nearest neighbor queries in spatio-temporal databases. In Proceedings of the 21st International Conference on Data Engineering, Tokyo, Japan, 5–8 April 2005.
- Brinkhoff, T. A framework for generating network-based moving objects. Geoinformatica 2002, 6, 153–180. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Storm | S4 | Spark Streaming | Samza |
|---|---|---|---|---|
| Time | 2011 | 2010 | 2012 | 2013 |
| Grain | Single Record | Single Record | Micro-batching | Single Record |
| Data Model | Tuple | Event | Object | Object |
| Routing | User-defined | By Key | / | Depends on Kafka |
| State Management | Not Built In | Stateful | Dedicated DStream | Stateful Operations |
| Latency | Very Low | Low | Medium | Low |
| Throughput | Low | Low | High | High |
| Maturity | High | Low | High | Medium |
| Intermediate Result Storage | Local Memory | Local Memory | Local Memory or File System | Kafka |
| Guarantees | At Least Once | None | Exactly Once | At Least Once |
| Parameter | Value |
|---|---|
| Number of objects, 106 | 1 |
| Update ratio, M/S | 0.7 |
| Query selectivity | 0.5% |
| K in nearest neighbor analysis | 100 |
| Nodes | 232237895 |
| Monitored region (km2) | Jiangsu Province, 511 × 494 |
| Parameter | Value |
|---|---|
| Number of objects, 106 | 0.25, 0.5, 0.75, 1 |
| Query/update ratio | 5%, 10%, 15%, 20% |
| Query selectivity | 0.01%, 0.04%, 0.16%, 0.64% |
| Monitored region (km2) | Jiangsu Province, 511 × 494 |
| Nodes | 232237895 |
| Update ratio, M/S | 0.7 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, F.; Zheng, Y.; Xu, D.; Du, Z.; Wang, Y.; Liu, R.; Ye, X. Real-Time Spatial Queries for Moving Objects Using Storm Topology. ISPRS Int. J. Geo-Inf. 2016, 5, 178. https://doi.org/10.3390/ijgi5100178
Zhang F, Zheng Y, Xu D, Du Z, Wang Y, Liu R, Ye X. Real-Time Spatial Queries for Moving Objects Using Storm Topology. ISPRS International Journal of Geo-Information. 2016; 5(10):178. https://doi.org/10.3390/ijgi5100178
Chicago/Turabian StyleZhang, Feng, Ye Zheng, Dengping Xu, Zhenhong Du, Yingzhi Wang, Renyi Liu, and Xinyue Ye. 2016. "Real-Time Spatial Queries for Moving Objects Using Storm Topology" ISPRS International Journal of Geo-Information 5, no. 10: 178. https://doi.org/10.3390/ijgi5100178
APA StyleZhang, F., Zheng, Y., Xu, D., Du, Z., Wang, Y., Liu, R., & Ye, X. (2016). Real-Time Spatial Queries for Moving Objects Using Storm Topology. ISPRS International Journal of Geo-Information, 5(10), 178. https://doi.org/10.3390/ijgi5100178