Abstract
In producing English-Chinese bilingual maps, it is usually necessary to translate English place names into Chinese. However, pipeline-based methods for translating place names splits the place name translation task into multiple sub-tasks, carries the risk of error propagation, resulting in lower efficiency and poorer accuracy. Meanwhile, there is relatively little research on place name joint translation. In this regard, the study proposes an English-Chinese place name joint translation method based on prompt learning and knowledge graph enhancement. This method aims to improve the accuracy of English-Chinese place name translation. The proposed method is divided into two parts: The first part is the construction of prompt word template for place name translation. For the translation task of place names, the study first analyzes the characteristics of the transliteration of specific names and the semantic translation of generic names, constructing prompt word templates for the joint translation of ordinary place names. Then, based on the prompt words for ordinary place name translation, it takes into account the translation characteristics of the derived parts in derived place names, constructing a prompt word template for the joint translation of derived place names. Ultimately, leveraging the powerful contextual learning ability of LLM (Large Language Models), it achieves the joint translation of English and Chinese place names. The second part is the construction of the ontology of place name translation knowledge graph. To retrieve relevant knowledge about the input place names, the study designs an ontology for a knowledge graph of place names translation aimed at the English-Chinese place name translation task, combining the needs of English-Chinese place name translation and the semantic relationships between place names. This enhances the contextual information of the input place names and improves the performance of large language models in the English-Chinese place name translation task. Experiments have shown that compared to traditional pipeline-based place name translation methods, the place name translation method proposed in the study has improved performance by 21.26% in ordinary place name translation and an average of 27.70% in the field of derived place name translation. In bilingual map production, the method effectively improves the efficiency and accuracy of toponymic translation. Simultaneously providing reference for place name translation tasks in other languages.
1. Introduction
The translation of place names is the process of converting the names of geographical entities from the source language to the target language. English place names usually have two parts: a specific name that distinguishes between similar geographical names and a generic name that describes the type of place name [1]. Unlike general text translation, in translating English into Chinese place names, the strategy usually involves a “free translation of the generic name and transliteration of the specific name” [2]. For example, when translating the English place name “Palms Restaurant” into Chinese, the specific name “Palms” should be transliterated as “帕姆斯”, and the generic name “Restaurant” should be translated as “餐厅”. Furthermore, the derivation of place names is a common method of naming geographical entities [3], and there are many derived place names in the place name data. In the translation process, for original and derived place names with obvious derivation relationships, the semantic association between derived place names and original place names in the source language should be maintained [3,4]. For example, in place names with a completely derived derivation relationship like “Jackson Park” and “Jackson Park Road”, the derived part “Jackson Park” in both names should be translated as “杰克逊公园”, and “Jackson Park” and “Jackson Park Road” should be translated as “杰克逊公园” and “杰克逊公园路”, respectively. In English–Chinese place name translation, the combined translation of generic and specific names helps reduce error propagation during the translation process. At the same time, consistency in the translation of derived place names enhances the accuracy of place name translation. However, currently, the joint translation of English–Chinese place names based on prompt learning has not yet been explored. Therefore, the study aims to improve the efficiency and accuracy of English–Chinese place name translation by prompt learning and knowledge graph enhancement. This provides an efficient and well-performing machine translation tool for English–Chinese place name translation. The main challenges faced in the study are the following:
(1) How to design prompts to achieve the combined translation of generic names and specific names by integrating the characteristics of phonetic translation of ordinary place names and the semantic translation of generic names.
(2) How to design prompts to achieve accurate translation of derived place names based on the characteristics of derived place names.
(3) How to design the ontology structure of a knowledge graph in relation to place name translation tasks.
By addressing the above issues, the main contributions of the study are as follows:
(1) Construction of a template for prompts in the translation of ordinary place names. In the English-Chinese place name translation task, the study constructs a template for prompts in the translation of ordinary place names by selecting the letter sequences of place name words and the category information of place names, based on the characteristics of phonetic translation of specific names and semantic translation of generic names. This enables the combined translation of generic names and specific names.
(2) Construction of prompts for the translation of derived place names. Based on the prompts for the translation of ordinary place names, the study combines specific translation strategies for derived place names, selecting information such as derived place name discrimination, derived parts, and native place name categories to construct a template for prompts in the translation of derived place names. This enhances the accuracy of the translation of derived place names.
(3) Design of the ontology for the knowledge graph of place name translation. In response to the needs of the English-Chinese place name translation task and the semantic relationships in place name derivation, the study designs the ontology structure for the knowledge graph of place name translation. This ontology structure is then used to build the knowledge graph of place name translation, enhancing the contextual information of input English place names.
The structure of the article is as follows: Section 2 introduces the research status in the fields of machine translation based on prompt learning, place name translation, and knowledge graph enhancement. Section 3 introduces an English–Chinese place name translation method based on prompt learning and knowledge graph enhancement, which is mainly divided into place name translation prompt template construction and construction of the knowledge graph ontology for place name translation. Section 4 introduces the experiment of ordinary place name translation and derived place name translation. Section 5 summarizes the achievements of the study, the existing shortcomings, and prospects.
2. Related Work
To produce English–Chinese place names more efficiently, machine translation of English–Chinese place names has been a popular topic among place name translators. English-Chinese place name translation based on prompt learning and knowledge graph enhancement mainly involves the fields of machine translation based on prompt learning, place name translation, and knowledge graph enhancement. Regarding this, researchers have conducted a lot of research work.
- (1)
- Machine translation based on prompt learning
With the emergence of the transformer model, the field of natural language processing has entered the era of large language models. The transformer model [5] is a language model based on self-attention mechanisms, capable of parallel computation and capturing long-term dependencies, laying the foundation for training large-scale data and capturing complex language structures. Building on this technology, researchers have utilized vast amounts of text data to train larger language models through self-supervised training, such as GPT-3, GPT-4, LLaMa [6], and Chatglm [7]. With the impressive performance of LLM in various natural language processing tasks, many researchers have applied large language models to machine translation tasks. Large language models, unlike traditional machine translation systems, use end-to-end learning (mapping the system’s input to output through a single model) to understand language correspondences, resulting in stronger translation capabilities [8].
Large language models mainly stimulate machine translation capabilities through methods such as contextual learning, prompt learning, and instruction fine-tuning [9]. Radford et al. (2019) [10] first demonstrated through research that prompt learning has great potential in the field of text generation (such as machine translation and summarization). Subsequently, many researchers have worked on improving machine translation using LLM, focusing on prompt optimization and model fine-tuning. In terms of prompt optimization (enhancing the performance of large models by adjusting prompts), Jiang et al. (2024) [11] showed that correct prompts and contextual information can improve the performance of ChatGPT in machine translation tasks. In the area of few-shot prompting (prompt composed of a small number of examples), Chen Yufeng (2023) [12] and Moslem et al. (2023) [13] demonstrated that retrieving similar translation examples from the source language input as prompts can effectively improve machine translation results. In addition to using the source language context as prompts, Harritxu et al. (2024) [14] also considered the target language context as prompts, enhancing machine translation performance. In terms of model fine-tuning, Zhang et al. (2023) [15] compared the performance of zero-shot (do not provide any examples), few-shot, and QLoRA fine-tuning (model quantization fine-tuning technology) in machine translation tasks, showing that QLoRA fine-tuning has higher performance than the other two methods. Haoran et al. (2024) [16] studied the limits of using human-generated data for full fine-tuning in machine translation with medium-sized language models. They used the CPO (Contrastive Preference Optimization) method to help these models perform as well as large language models.
- (2)
- Place name translation
In the field of place name translation, researchers mainly use pipeline-based methods for place name translation. This method divides the translation process of place names into subtasks, such as the transliteration of specific names and the free translation of generic names, and finally combines the translation results of all subtasks into the translation result of place names (as shown in Figure 1). Researchers have conducted a lot of research on this.
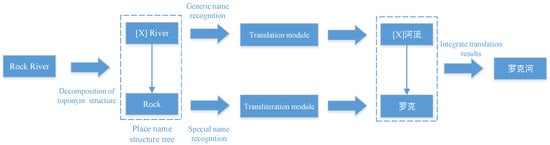
Figure 1.
Example of pipeline-based place name translation. In Figure, the input place name ‘Rock River’ is first decomposed using a place name decomposition algorithm to constructing a geographical name structure tree, followed by the identification of generic and specific names. Then, the generic name part and the specific name part are translated using the modules for free translation and transliteration, respectively. Finally, the translation results of each part are integrated into the final translation result.
(1) In the aspect of distinguishing between generic and specific names, Yan et al. (2021) [17] proposed a method that uses a structure tree for place names. It builds a structure tree by analyzing the relationships between place name words and decomposing place name phrases. Furthermore, the place names are represented as a structure tree with place name words and place name patterns (words with high co-occurrence frequency) as nodes. Then, it classifies the tree nodes to differentiate between generic and specific names.
(2) In terms of specific name transliteration, Zhao et al. (2016) [18] used a Russian–Chinese phonetic transcription table and the forward maximum matching principle to transcribe Russian–Chinese place names. Addressing the issues of phonetic generation and syllable division, Yan et al. (2019) [19] tackled phonetic generation and syllable division in English–Chinese name transliteration. They used an encoder–decoder model to treat phonetic generation as translating English words into Chinese characters. Their method, based on recurrent neural networks, achieved syllable segmentation using the minimum entropy principle. On this basis, Wang et al. (2020) [20] improved phonetic segmentation for proper name transliteration. They used a bidirectional maximum matching method to resolve cross-type ambiguities. Additionally, they enhanced the transliteration results with prior knowledge.
(3) In terms of integrating the translation results of generic names and specific names, Mao et al. [21] use an attention-based transliteration replacer to integrate transliteration and translation results. This replacer identifies specific names (usually represented as <UNK> in the translation vocabulary) based on the attention mechanism between the input place names and their preliminary translation results and then replaces the ‘<UNK>’ characters in the translation results with the corresponding transliteration model translation results of the input words. This ultimately achieves the integration of transliteration and translation results. Based on the place name structure tree, Ren et al. [22] use a nested translation method to combine the translation results of each node in a place name structure tree, achieving the final translation. This approach is applied to translate English and Arabic place names into Chinese.
- (3)
- Geographical name knowledge graph
With the development of knowledge engineering technology, geographical knowledge graphs have gradually become a hot topic among geographical researchers. A knowledge graph is a graphical representation of structured knowledge from the real world, in which nodes represent entities of interest, and edges represent relationships between those entities [23]. The construction of knowledge graphs is mainly divided into two approaches: top-down and bottom-up. The construction of domain knowledge graphs primarily adopts the top-down method, which is mainly divided into steps such as ontology construction, knowledge extraction, and entity filling [24]. An ontology is a conceptual specification [25], and its construction is crucial in the development of domain knowledge graphs. The construction of an ontology mainly includes the definition of relationships, attributes, and concepts [26].
In the field of place name translation, researchers express the place name knowledge involved in the place name translation task as a knowledge graph, thereby using the place name knowledge graph to enhance the efficiency of the place name translation task. In the field of translating place names derived from English, Liu Hanyou (2022) [4] proposed an English–Chinese-derived place name translation method based on a derived place name knowledge graph. This method uses geostatistics to build a knowledge graph of place names and then uses this information as nodes in a structure tree to translate the place names. In the field of translating Spanish place names, Wei Xuelu (2023) [27] proposed a method for transliterating Spanish-specific names based on knowledge graphs. This method combines the characteristics of Spanish place names and their transliteration rules to construct a knowledge graph for Spanish specific name transliteration. Furthermore, it enhances the syllable segmentation and optimization effects in the transliteration process of Spanish-specific names through knowledge retrieval and reasoning.
Currently, in the field of machine translation, large language models perform well in machine translation tasks compared to traditional machine translation models. To retain the knowledge from pre-training tasks in machine translation, researchers mainly use “prompt learning + fine-tuning” for optimization. In the field of place name translation, a pipeline approach is mainly adopted, separating the transliteration and translation processes of place names. This method carries the risk of error propagation. However, research on the joint translation of generic names and specific names is still in its infancy. In response, the study combines prompt learning methods with knowledge graph enhancement to leverage the world knowledge of large language models for the translation of English and Chinese place names, improving the effectiveness of English–Chinese place name translation.
3. Materials and Methods
Place names contain not only geographical environmental characteristics but also human environmental characteristics [28]. The human geographical information contained in English place names is widely available on the internet. To retain the local geographical information of English-speaking countries, the study uses a large language model with internet world knowledge to learn the mapping of English place names to Chinese place names through prompt learning [29]. In this regard, the study uses the large language model ChatGLM [7] based on the GLM (General Language Model) [30] framework as the language model for place name translation. This large language model is an open-source conversational language model that supports bilingual questions and answers in Chinese and English. In natural language understanding and generation tasks, the GLM framework outperforms traditional models such as Bart [31] and UniLM. At the same time, in order to save computing power costs, the study used Lora fine-tuning [32] for model training.
To further enhance the accuracy of place name translation, the study adopts a knowledge graph enhancement method to enrich the contextual information of place name translations. This method first retrieves relevant information about the place names to be translated from the place name translation knowledge graph through knowledge retrieval. The construction of the geographic name translation knowledge graph mainly extracts relevant entities, attributes, relationships, and other knowledge data from the geographic database based on the ontology structure, and is built through entity filling. Then, it slot-fills this information into a manually defined prompt template. Finally, it inputs the instantiated place name translation template into the large language model to generate translation results (as shown in Figure 2). In this regard, the study constructs both the prompt template for place name translation and the ontology of the place name translation graph.
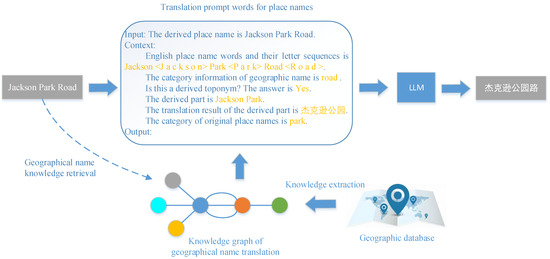
Figure 2.
English Chinese place name translation based on knowledge graph enhancement and prompt learning. In the figure, the English place name ‘Jackson Park Road’ is first retrieved through a knowledge search from the place name translation knowledge graph to obtain relevant place name information. Then, a prompt is generated using the place name translation prompt template as contextual information for the input place name. Finally, a large language model is used to generate the Chinese place name ‘杰克逊公园路’.
3.1. Construction of Prompt Words for Place Name Translation
In order to improve the accuracy of translating place names from English to Chinese, the study constructs templates to translate ordinary place names and derived place names by analyzing the characteristics of these names and combining them with the corresponding translation strategies, using manually defined prompt word templates.
3.1.1. Template for Translating Ordinary Place Names
In the process of translating ordinary place names, specific names and generic names have different translation strategies. To achieve the joint translation of generic names and specific names, the study combines the characteristics of generic name free translation and specific name transliteration to construct specific name translation prompts and generic name translation prompts (the specific usage example is shown in Table 1).

Table 1.
Prompt for joint translation of generic and specific names.
(1) Translation prompt for special names. From a linguistic perspective, the phonetic transcription of English-specific names is related to the pronunciation of the English-specific names, which in turn is related to the letter sequences that make up the specific names [33,34]. Therefore, the phonetic transcription of English-specific names is related to those letter sequences. For the phonetic transcription of English-specific names, the study selects the letter sequences of place names as the prompt for phonetic transcription. To indicate the affiliation between place names and their letter sequences, each letter sequence of a place name is marked with special characters ‘<’ and ‘>’. These characters serve as the beginning and ending symbols of the sequence. Each letter sequence is placed to the right of its corresponding place name (as shown in Formula (1), specific example are shown in Table 1).
In Equation (1), is a manually defined template for transliteration prompts, consisting of fixed prompts and variable placeholders ( and ). L represents the function that maps words to a sequence of letters. represents the i-th place name word. is the letter sequence that represents the i-th place name word. N represents the number of words contained in an English place name. is the prompt word for transliterating specific names.
(2) Translation prompt for generic names. In the semantic translation of English generic names, the semantic translation is related not only to the semantics of the generic name itself but also to the contextual information of the place-name category. In the process of translating place names, the category information of place names helps to eliminate the ambiguity of generic names [22,35]. For example, in the Australian place name ‘Poatina Golf Course’, the generic name ‘Course’ can mean road, site, etc. Since the place name category is ‘Golf Course’, it can be determined that the meaning of ‘Course’ should be site. From the perspective of the semantic association of place names, specific names have the function of distinguishing similar place names [18,36], and have a weaker semantic association with place name categories, while generic names have the function of describing place name categories and have a stronger semantic association with place name categories [37]. In the process of translating generic names, place name category information has the function of eliminating the ambiguity of generic names. Therefore, the study selects the category information of place names as the prompt for the semantic translation of generic names (as shown in Formula (2), specific example are shown in C Table 1).
In Equation (2), is a manually defined template for generic name translation, consisting of fixed prompts and variable placeholders (C). C represents the category of English place names. represents the prompt words for generic name translation.
3.1.2. Template for Translating Derived Place Names
Compared to ordinary place names, derived place names contain derived parts that originate from their original place names. These derived parts embody the geographical connection between derived place names and original place names. In the process of translating place names from English to Chinese, it is important to avoid severing the semantic relationship of geographical connections between derived place names and original place names in the target language. Based on the ordinary place name translation prompts, the study selects prompt words for derived place name discrimination, derived parts, and original place name categories from the perspective of the characteristics of derived place names and their linguistic associations to jointly construct a template for translating derived place names (specific usage examples of the derived place name translation template are shown in Table 2).
Table 2.
Translation prompt words for derived place names.
(1) Derived place name discrimination information prompt. In the process of place name translation, ordinary place names and derived place names have different translation strategies. To enable large language models to distinguish between the translation strategies of the two types of place names, it is necessary to identify the place name to be translated as a derived place name. The study selects the derived place name discrimination results as the prompt words for the derived place name category.
In the above formula, represents template of prompts consisting of fixed prompt words and derived place names for discrimination results.
(2) Prompt words for derived parts. Compared to ordinary place names, derived place names contain derived parts that originate from their original place names. These derived parts embody the geographical connection between the derived place names and the original place names [3,4]. Therefore, the accuracy of translating derived place names mainly depends on the accurate translation of the derived parts. In this regard, the study directly selects the derived parts of the source language and target language as prompts for translating derived place names.
In the above formula, represents template of prompts consisting of fixed prompt words and derived part. represents the derived part of the source language. represents the derived part of the target language.
(3) Prompt words for original place names category. In the derivational relationship of place names, there is also a certain semantic correlation between the derived part and the original place name category [4,38]. For example, the derived place name ‘Riverview Park Walking Trail’ has a generic name derivational relationship with the original place name category ‘river’, which is ‘North Branch Chicago River’. The derived part ‘Riverview’ has a certain semantic association with the place name category ‘river’. Therefore, the study selects the category information of the original place name as the translation template for the derived place name.
In the above formula, represents template of prompts consisting of fixed prompt words and original place names category. represents the original place names category of the source language.
3.2. Construction of the Ontology of Place Name Translation
In order to enable large language models to acquire facts related to place names and enhance the contextual information of place name translation, the study combines a designed template for place name translation prompts with the semantic associations of derived place names to create an ontology [4,39,40] for a place name translation knowledge graph. The construction of the place name translation ontology mainly includes the design of concepts, relationships, and attributes.
(i) Concept definition. In the data of place names to be translated, place names can be roughly divided into ordinary place names and derived place names, among which ordinary place names include original place names that have a derivational relationship with derived place names. Among the various derived place names, there are various parts derived from original place name words, mainly including specific name-derived parts, generic name-derived parts, and completely derived parts. In this regard, the study selects ordinary place names, derived place names, original place names, specific name-derived parts, generic name-derived parts, and completely derived parts as concepts for the place name translation knowledge graph (as shown in Figure 3).
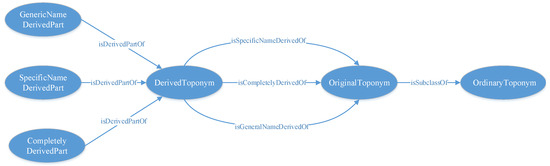
Figure 3.
Design of Concepts and Relationships. In Figure 3, circles represent concepts and lines represent relationships. The direction of various relationships is unidirectional. Relationships represent a certain association between two types of entities. Concepts represent an abstract description of a certain type of entity.
(ii) Definition of relationships. Derived place names and their original place names mainly include three types of semantic relationships: completely derived relationships, generic name-derived relationships, and specific name-derived relationships. Among them, original place names have an inclusion-semantic relationship with ordinary place names. At the same time, various derived place names have a derived part semantic relationship with their derived parts. In this regard, the study has designed five types of relationships: ‘isCompletelyDerivedOf’, ‘isSpecificNameDerivedOf’, ‘isGeneralNameDerivedOf’, ‘isDerivedPartOf’, and ‘isSubclassOf’ (as show in Figure 3).
(iii) Definition of attributes. This knowledge graph is primarily aimed at the English–Chinese translation tasks of place names. Therefore, the study selects the target language name as attributes for each concept, the data attribute domain being each concept, and the range being ‘xsd: language’. At the same time, considering the importance of the category information of place names in the process of place name translation for the correct translation of generic names, the study also considers the category information of place names as data attributes for derived place names, original place names, and ordinary place names (as shown in Table 3).
Table 3.
Definition of attributes.
4. Discussion
The experimental data were sourced from the Australian and American place name data on the Geoname official website, with a total of 30,069 English place name data. The English–Chinese place name translation supervision dataset was provided by the “Global Geographic Information Resource Construction and Maintenance Update” research group of the China Academy of Surveying and Mapping. The experiment is mainly divided into the prompt-based translation of ordinary place names and derived place names. The experimental environment and parameters for these two parts are shown in Table 4. In addition, the Bart model has an epoch of 40 and a batch size of 32, while the LLM model has an epoch of 15 and a batch size of 4. All experimental indicators are Rouge-1, Rouge-2, Rouge-L, and Bleu-2 (as shown in Equations (6)–(9)).
Table 4.
Experimental environment and model parameters.
In Formulas (6)–(9), S represents the reference text. represents . represents . represents the number of matches in the candidate summary. represents the number of appearing in the reference summary. represents the length of the longest common sequence. refers to the precision of n-grams. refers to the weight of n-grams. c represents the length of the machine translation. r represents the length of the reference translation.
- (1)
- Translation of ordinary place names
The translation experiment of ordinary place names used 20,000 Australian–English–Chinese place name translation data. The experimental data were used to construct the training set, validation set, and test set in an 8:1:1 ratio. In the experiment, the study used the traditional pipeline-style place name translation method as the control group, selected word sequences, and place name categories from different locations as prompt words for comparative experiments. At the same time, the performance of different language models in the translation task of ordinary place names was compared, mainly including the traditional pre-trained Bart [31] language model and the large language model Chatglm [7]. In order to compare the accuracy of place name translation between the experimental groups, Bleu was selected as the comprehensive evaluation indicator for this experiment. The experimental results are shown in Table 5.
Table 5.
Translation experiment of ordinary place names.
In Table 5, the experimental groups and showed that adding word letter sequences to the right of place name words improved the English–Chinese place name translation effect by 3.27%. The experimental groups and showed that adding place name category prompt words improved the English–Chinese place name translation effect by 2.62%. and indicate that the method of using word sequences located on the right side of words as place name prefixes has better place name translation performance compared to using the entire word letter sequence as a place name prefix. The experimental groups and demonstrate that compared to traditional pre-trained models, large language models have higher performance in place name translation tasks. Compared with other experimental groups, indicates that the place name translation method based on prompt learning has better performance than the pipeline-based place name translation method, with the best performance achieved by using place name categories and word letter sequences located on the right side of words. The example of the English–Chinese translation effect of place names in the bilingual map field is shown in Table 6 and Figure 4.
Table 6.
Translation results of ordinary place names.
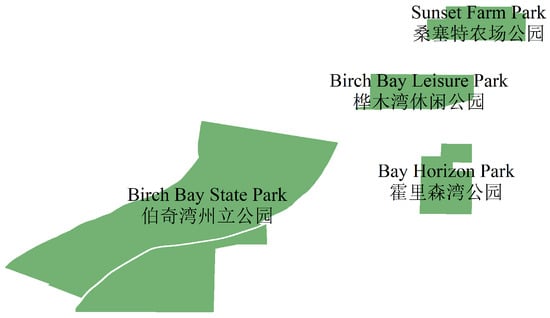
Figure 4.
Translation results of ordinary place name entities.
- (2)
- Derived place name translation experiment
The derived place name translation experiment used 10,069 American place name data points. The ratio of positive to negative case data points is 1:1, with positive case data being derived from place name data and negative case data being ordinary place name data. The experimental dataset is constructed with a ratio of 7:1.5:1.5 for the training set, validation set, and testing set. In this experiment, the method of selecting place name categories and word letter sequence information as prompt words were used as the control group, and prompt words composed of different derived place name-related information were compared and studied. To compare the performance of place name translation among different experimental groups, Bleu was selected as the comprehensive evaluation index for each experimental group in this experiment. The experimental results are shown in Table 7.
Table 7.
Derived place name translation experiment.
In Table 7, the experiments of and show that compared to traditional pipeline-based derived place name translation methods, the method based on large language models has a performance improvement of 23.83%. Compared with the group, other experimental groups showed that adding derived place name-related information as prompt words can improve the translation effect of derived place names by an average of 27.70%. In multiple experiments, the experimental group showed the best performance, with both derived parts, derived part translation results, derived place name recognition information, original place name category information, and other prompt words, demonstrating the best performance in derived place name translation tasks. Overall, the experimental group using derived part-related information as prompt words performed slightly better in derived place name translation tasks than the experimental group using original place name-related information as prompt words. The former has a slightly higher average performance than the latter by 0.39%. Among the experimental groups, the experimental group that utilized derived part translation results, derived place name discrimination information, and place name categories had the relatively best performance. The experiment shows that the method of using derived place name-related information as prompt words and original place name category information in the study can effectively improve the translation performance of derived place names. The example of the English–Chinese translation effect of place names in the bilingual map field is shown in Table 8 and Figure 5.
Table 8.
Translation results of derived place names.
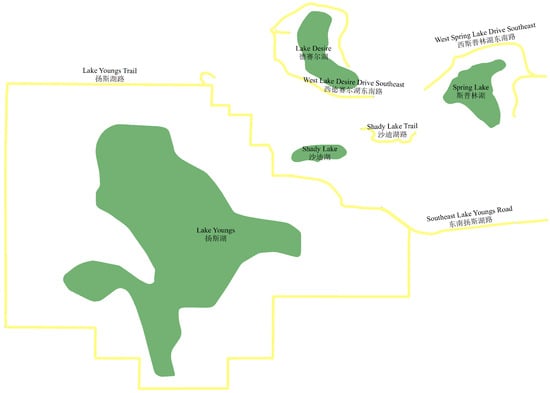
Figure 5.
Translation results of derived place name entities.
5. Conclusions
In order to improve the accuracy of English–Chinese place name translation, the study proposes a place name translation method based on prompt learning and knowledge graph enhancement. Experiments have shown that this method effectively improves the performance of English–Chinese place name translation. It helps to enhance the accuracy and efficiency of the translation quality of geographical names in the field of bilingual map production and provides a reference for the translation of place names between other alphabet-based languages (such as French, German, Russian, etc.) and Chinese. However, in the process of translating place names between English and Chinese, the translation of place name words also needs to refer to existing translation results, as well as consider local customs, mineral resources, myths and legends, religion, and other cultural and geographical information. In addition, the transliteration prompts studied in the study are only applicable to languages that can break words into multiple-letter sequences. The performance of place name translation between other languages and Chinese has not yet been explored. In this regard, in the future, efforts will be made to improve the accuracy of place name translation through few-shot learning, chain-of-thought prompting, and the integration of local cultural and geographical information into place name knowledge maps. For other languages, We will explore how to construct transliteration prompts for place names that are not based on alphabetic systems. Based on this, the performance of other large language models (such as Bloom, GPT-4, etc.) should be explored in the task of place name translation.
Author Contributions
Conceptualization, Hanyou Liu; methodology, Hanyou Liu; validation, Hanyou Liu; formal analysis, Hanyou Liu; investigation, Hanyou Liu; resources, Hanyou Liu and Xi Mao; data curation, Hanyou Liu; writing—original draft preparation, Hanyou Liu; writing—review and editing, Hanyou Liu; visualization, Hanyou Liu; supervision, Xi Mao; project administration, Xi Mao; funding acquisition, Xi Mao. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Key Research and Development Program of China (2023YFF0611901) and the Exploration of Global Intelligent Positioning of Multilingual Place Names (AR2412).
Data Availability Statement
Data will be made available on request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Zhang, C.; Zhang, X.; Ji, L.; Wang, H. Relation Mapping Between Generic Terms of Place Names and Geographical Feature Types. Geomat. Inf. Sci. Wuhan Univ. 2011, 36, 857–861. [Google Scholar]
- GB/T 17693.1-2008; Transformation Guidelines of Geographical Names from Foreign Languages into Chinese–English. The General Administration of Quality Supervision, Inspection and Quarantine of the People’s Republic of China, the Standardization Administration of China: Beijing, China, 2008.
- Huo, B. Exploration of Derived Place Names and Their Translation Methods. China Terminol. 2016, 18, 5–8. [Google Scholar] [CrossRef]
- Liu, H. Automatic Recognition and Translation Method for English Derived Place Names for Global Mapping. Master’s Thesis, Liaoning Technical University, Liaoning, China, 2022. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2023, arXiv:1706.03762. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and Efficient Foundation Language Models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Zeng, A.; Xu, B.; Wang, B.; Zhang, C.; Yin, D.; Rojas, D.; Feng, G.; Zhao, H.; Lai, H.; Yu, H.; et al. ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools. arXiv 2024, arXiv:2406.12793. [Google Scholar]
- Cui, Y. Application and Research of Large Models in Natural Language Processing. China Sci. Technol. J. Database Ind. A 2023, 57–61. [Google Scholar]
- Zhu, W.; Zhou, H.; Gao, C.; Liu, S.; Huang, S. Research Development of Machine translation and Large Language Model. In Proceedings of the 22nd Chinese National Conference on Computational Linguistics, Harbin, China, 3–5 August 2023; Available online: https://aclanthology.org/2023.ccl-2.3 (accessed on 3 March 2025).
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models are Unsupervised Multitask Learners. 2019. Available online: https://api.semanticscholar.org/CorpusID:160025533 (accessed on 3 March 2025).
- Jiang, Z.; Zhang, Z. Can ChatGPT Rival Neural Machine Translation? A Comparative Study. arXiv 2024, arXiv:2401.05176. [Google Scholar]
- Chen, Y. Enhancing Machine Translation through Advanced In-Context Learning: A Methodological Strategy for GPT-4 Improvement. arXiv 2023, arXiv:2311.10765. [Google Scholar]
- Moslem, Y.; Haque, R.; Way, A. Adaptive Machine Translation with Large Language Models. arXiv 2023, arXiv:2301.13294. [Google Scholar]
- Gete, H.; Etchegoyhen, T. Promoting Target Data in Context-aware Neural Machine Translation. arXiv 2024, arXiv:2402.06342. [Google Scholar]
- Zhang, X.; Rajabi, N.; Duh, K.; Koehn, P. Machine Translation with Large Language Models: Prompting, Few-shot Learning, and Fine-tuning with QLoRA. In Proceedings of the Eighth Conference on Machine Translation, Singapore, 6–7 December 2023; Association for Computational Linguistics: Singapore, 2023. [Google Scholar] [CrossRef]
- Xu, H.; Sharaf, A.; Chen, Y.; Tan, W.; Shen, L.; Durme, B.V.; Murray, K.; Kim, Y.J. Contrastive Preference Optimization: Pushing the Boundaries of LLM Performance in Machine Translation. arXiv 2024, arXiv:2401.08417. [Google Scholar]
- Yan, W.; Mao, X.; Qian, S.; Ma, W.; Yin, H.; Liu, D. Research on Distinguishing Common and Proper Names in Machine Translation of Foreign Language Place Names. Surv. Geogr. Inf. 2021, 46, 118–121. [Google Scholar] [CrossRef]
- Zhao, Y.; Liu, X.; Song, H.; Wu, Z.; Ma, S. A Fast Transliteration Method for Russian Place Names. Surv. Spat. Geogr. Inf. 2016, 39, 47–49+55. [Google Scholar] [CrossRef]
- Yan, W.; Liu, D.; Mao, X.; Ma, W.; Yin, H. Research on the Transliteration Technology of Place Names in Machine Learning. Geod. Geomat. 2019, 44, 87–92. [Google Scholar] [CrossRef]
- Wang, C.; Wang, J.; Mao, X.; Ma, W. English place name transliteration technology combining deep learning with prior knowledge. Surv. Sci. 2020, 45, 182–188. [Google Scholar] [CrossRef]
- Xi, M.; Wen, Y.; Weijun, M.; Hongmei, Y. Attention based English Place Name Machine Translation Technology. Surv. Sci. 2019, 44, 296–300+316. [Google Scholar] [CrossRef]
- Ren, H.; Mao, X.; Ma, W.; Wang, J.; Wang, L. An English-Chinese Machine Translation and Evaluation Method for Geographical Names. ISPRS Int. J. Geo-Inf. 2020, 9, 139. [Google Scholar] [CrossRef]
- Sheth, A.; Padhee, S.; Gyrard, A. Knowledge Graphs and Knowledge Networks: The Story in Brief. IEEE Internet Comput. 2019, 23, 67–75. [Google Scholar] [CrossRef]
- Cheng, N. Research on Knowledge Graph Construction Method of Basic Geo-entities Relationships. Geospat. Inf. 2024, 22, 20–24. [Google Scholar] [CrossRef]
- Gruber, T.R. A translation approach to portable ontology specifications. Knowl. Acquis. 1993, 5, 199–220. [Google Scholar] [CrossRef]
- Hao, X.; Ji, Z.; Li, X.; Yin, L.; Liu, L.; Sun, M.; Liu, Q.; Yang, R. Construction and Application of a Knowledge Graph. Remote Sens. 2021, 13, 2511. [Google Scholar] [CrossRef]
- Wei, X. Research on the Transliteration Method of Spanish Place Names Based on Knowledge Graph. Master’s Thesis, Beijing Jianzhu University, Beijing, China, 2023. [Google Scholar]
- Ying, W.; Ying, H. Research on the Chinese Translation of English Place Names from the Perspective of Functional Equivalence Theory. Engl. Teach. 2019, 19, 100–102. [Google Scholar]
- Liu, P.; Yuan, W.; Fu, J.; Jiang, Z.; Hayashi, H.; Neubig, G. Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing. ACM Comput. Surv. 2023, 55, 195. [Google Scholar] [CrossRef]
- Du, Z.; Qian, Y.; Liu, X.; Ding, M.; Qiu, J.; Yang, Z.; Tang, J. GLM: General Language Model Pretraining with Autoregressive Blank Infilling. arXiv 2022, arXiv:2103.10360. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020. [Google Scholar] [CrossRef]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. LoRA: Low-Rank Adaptation of Large Language Models. arXiv 2021, arXiv:2106.09685. [Google Scholar]
- Kessler, B.; Treiman, R. The Relationship between Sound and Letter in English Monosyllabia. J. Mem. Lang. 2001, 44, 592–617. [Google Scholar] [CrossRef]
- Gibson, E.J.; Pick, A.; Osser, H.; Hammond, M. The Role of Grapheme-Phoneme Correspondence in the Perception of Words. Am. J. Psychol. 1962, 75, 554–570. [Google Scholar] [CrossRef]
- Chen, K.; Lin, X.; Yuan, Y.; Li, R.; Liu, Y. Representation and Management of Type Information in Digital Gazetteers. Geogr. Geogr. Inf. Sci. 2009, 25, 6–11. [Google Scholar]
- Ubaydullayeva, M. Semantic Peculiarities of Proper Nouns in English and Uzbek. Acad. Res. Mod. Sci. 2024, 3, 65–67. [Google Scholar] [CrossRef][Green Version]
- Gan, C. Matching Algorithm for Chinese Place Names by Similarity in Consideration of Semantics of General Names for Places. Acta Geod. Cartogr. Sin. 2014, 43, 404–410. [Google Scholar] [CrossRef]
- Liu, H.; Mao, X. Recognition of Derived Semantic Relationships in Geographic Entity Generic Names. Preprints 2024. [Google Scholar] [CrossRef]
- Liu, Y.; Li, L.; Shen, H.; Yang, H.; Luo, F. A Co-Citation and Cluster Analysis of Scientometrics of Geographic Information Ontology. ISPRS Int. J. Geo-Inf. 2018, 7, 120. [Google Scholar] [CrossRef]
- Wu, Y.; Hu, W.; Li, C.; Yang, J.; Li, Z.; Yin, Q.; Xia, A.; Dang, F. Knowledge Graph Based Approach to Cyberspace Geographic Mapping Construction. Comput. Sci. 2024, 51, 321–328. [Google Scholar] [CrossRef]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Published by MDPI on behalf of the International Society for Photogrammetry and Remote Sensing. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).