1. Introduction
The three-dimensional (3D) point cloud has become an important data source for reconstructing and understanding the real world because of its abundant geometry, shape and scale information. Among the many methods for obtaining 3D point clouds, airborne laser scanning (ALS) or light detection and ranging (LiDAR) are important technologies for obtaining high-precision and dense point clouds of large-scale ground scenes. Many applications of ALS point clouds have been explored, such as digital elevation model (DEM) generation [
1,
2], building reconstruction [
3,
4], road extraction [
5,
6], forest mapping [
7,
8], power line monitoring [
9,
10] and so on. For these applications, the basic and critical step is the classification of the 3D point cloud, which is also called semantic segmentation of the point cloud in the field of computer vision. It requires the assignment of semantic labels, such as ground, building and vegetation, to each point. Point cloud classification is very important for understanding scenes and the subsequent processing of point clouds. However, due to the unstructured and disordered characteristics of point clouds, especially in urban scenes with different object types and variable point densities, the accurate and efficient classification of ALS point clouds is still a challenging task.
Early research on ALS point cloud classification focused on extracting handcrafted features, such as eigenvalues [
11,
12], shape and geometry features [
13,
14,
15] and using traditional supervised classifiers, such as support vector machine (SVM) [
16,
17,
18], random forests [
19,
20], AdaBoost [
14,
21], Markov random field (MRF) [
22,
23,
24], conditional random field (CRF) [
25,
26] and so on. However, these traditional machine learning-based methods rely heavily on professional experience and have limited generalizability when applied to complex, large-scale scenes [
27]. In recent years, deep learning methods, especially the convolutional neural network (CNN), have achieved great success in two-dimensional (2D) image classification [
28,
29,
30] and semantic segmentation [
31,
32,
33] due to the implicit ability to learn high-dimensional features. Inspired by this major breakthrough, researchers have begun to use deep learning-based methods for 3D point classification. However, due to the unordered and unstructured characteristics of point clouds, CNN for image semantic segmentation cannot be applied directly to point cloud classification. Some works transform an irregular 3D point cloud into regular 2D images or 3D voxels, which can be classified by 2D CNN or 3D CNN [
34,
35,
36,
37]. However, this transformation leads to the loss of information. Some recent methods have tried to build a point-based CNN to classify irregular point clouds directly [
27,
38,
39,
40,
41,
42,
43,
44]. However, these methods are inefficient for learning multi-level point features. Some methods still need to input some low-level geometric features to improve the classification accuracy.
In this paper, we propose a novel, point-based CNN to classify ALS data. The method can directly take the raw 3D point cloud as an input. The local point features are learned efficiently by a convolution operation designed for unstructured points. Then, we build a classification network by stacking with multi-convolution layers, which is constructed based on the convolution operation. The network has the structure of encoder and decoder, which is similar to U-net, flexible and easy to expand. Multi-scale features are learned through a classification network and class labels are predicted for each point in an end-to-end fashion.
The main contributions of our method are summarized as follows.
- (1)
A new convolution operator is designed, which can directly learn local features from an irregular point cloud without transforming to images or voxels. This is more adaptable and efficient than the handcrafted features.
- (2)
A multi-scale CNN with an encoder and decoder structure is proposed. It can learn multi-level features directly from the point cloud and classify the ALS data in an end-to-end manner. The network is flexible and extensible.
- (3)
The proposed method demonstrates state-of-the-art performance on two ALS datasets: the ISPRS Vaihingen 3D labeling benchmark and the 2019 IEEE GRSS Data Fusion Contest dataset.
The remainder of this paper is organized as follows. In
Section 2, we briefly review the methods of ALS point cloud classification.
Section 3 gives a detailed introduction to the proposed method. In
Section 4, the performance of our method is evaluated, using two ALS datasets. We compare our results with other methods in
Section 5. Finally,
Section 6 presents some concluding remarks.
5. Discussion
As listed in
Table 4, the classification confusion matrix of our method was calculated to further evaluate the performance. According to
Table 4, our method performed well on low vegetation, impervious surface, car, roof and tree. Although power line and car categories had few points in the dataset, as shown in
Table 2, they still achieved high F1 scores, especially for the car category. This is due to the use of weighted cross-entropy loss function in the training. We achieved a bad F1 score for fence and shrub. According to the confusion matrix, a large number of points that originally belonged to the fence category were mistakenly classified as shrub, tree and low vegetation. Most of the false positive points that were incorrectly classified to fence were also shrub, tree, and low vegetation. Shrub was also confused with low vegetation, tree and fence. The confusion was mainly due to the similarity of topological and spectral characteristics among these categories.
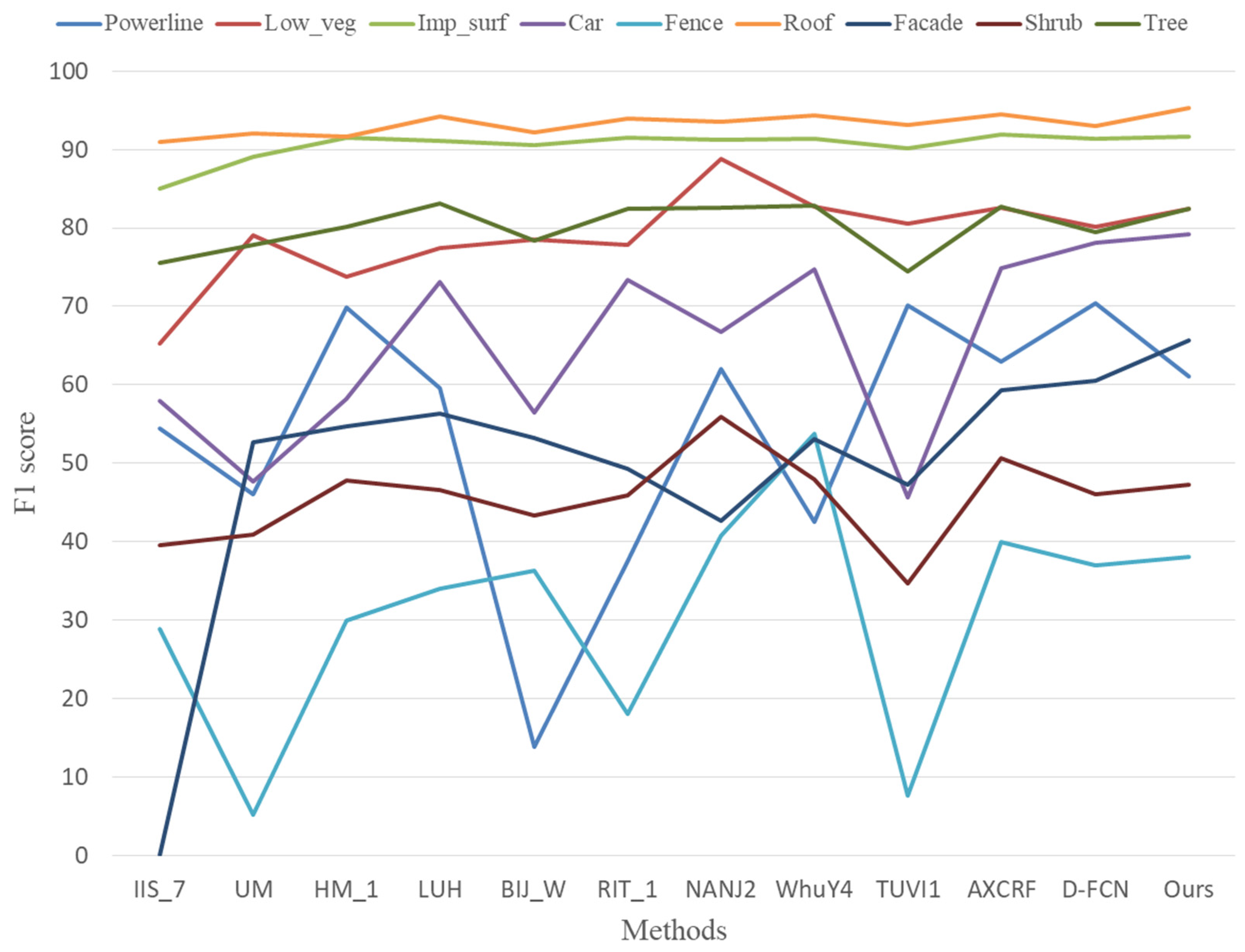
The performance comparison between our method and other methods on Vaihingen 3D test set is shown in
Table 5. The first two columns of
Table 5 show the OA and average F1 score (Avg.F1). The last nine columns show the F1 scores for each category. We refer to other methods according to the names posted on the website of contest. Readers are encouraged to review the website for further details. For Vaihingen 3D data, two accuracy measures—OA and Avg.F1—were used to evaluate the performance of different methods. However, the experiments showed that for unbalanced data, Avg.F1 is more important than OA. The pursuit of OA will lead to the neglect of minority categories due to the category imbalance of the dataset. It can also be seen from
Table 5 that almost all methods obtained OA above 80%, with little difference, but the Avg.F1 was quite different from the others. Therefore, when comparing the performance of different methods, we mainly focused on Avg.F1.
In
Table 5, IIS_7 [
60] used a supervoxel-based segmentation on point cloud and classified the segments by different machine learning algorithms with extracted spectral and geometric features. In UM [
61], a genetic algorithm was applied to obtain 3D semantic labeling based on point attributes, textural properties and geometric attributes. HM_1 extracted various, locality-based radiometric and geometric features and conducted a contextual classification, using a CRF-based classifier. LUH [
62] used two independent CRF to classify points and segments. In summary, IIS_7, UM, HM_1 and LUH are all traditional machine learning-based methods that use handcrafted features. The results of HM_1 and LUH methods were better than those of IIS_7 and UM, especially in Avg.F1. This is mainly because HM_1 and LUH used context information through the CRF model.
Other methods, including BIJ_W [
38], RIT_1 [
39], NANJ2 [
35], WhuY4 [
34], TUVI1 [
40], A-XCRF [
41], and D-FCN [
27], and ours are all deep learning-based methods. Some methods were introduced in
Section 2.2. In NANJ2 and WhuY4, the features of each point were extracted and transformed into 2D image. Then the classification of a point was transferred to the classification of its corresponding feature image to make full use of 2D CNN. It can be seen from
Table 5 that they obtained higher OA and Avg.F1 than traditional, machine-learning methods. This is mainly due to 2D CNN’s efficient learning of deep features. However, these methods still need to extract the local features of each point, and the transformation from 3D point cloud to 2D image may bring information loss. Other methods used point-based CNN, which directly work on irregular point clouds without transformation to 2D images. Among these methods, BIJ_W, RIT_1 and TUVI1 are based on PointNet or PointNet++. The OA and Avg.F1 of these methods are lower than NANJ2 and WhuY4, which are based on 2D CNN. This means that the shared MLP layers in PointNet and PointNet++ are still not sufficiently effective for learning point features. A-XCRF was designed to address the overfitting issues when training with a limited number of labeled points, so it achieved good performance on the Vaihingen 3D data, which is a small dataset.
As shown in
Table 5, our method ranked first with an Avg.F1 of 71.4%. In terms of individual categories, we achieved the highest F1 score on car, roof and facade. As we mainly used the Avg.F1 rather than OA to evaluate the performance of classification in hyperparameter tuning and model selection, the OA of our method was slightly lower and ranked only fourth overall. However, it was still comparable with the state-of-the-art methods. Although NANJ2 achieved the highest OA 0.6%, higher than our method, it got an unsatisfactory Avg.F1, which was 2.1% lower than our method. Compared with the methods based on traditional machine learning or 2D CNN, our method does not need to extract handcrafted features, but automatically learns features through a point-based convolution operator. The result showed that our method can successfully learn features from discrete point clouds and achieve the semantic label for each point in an end-to-end manner.
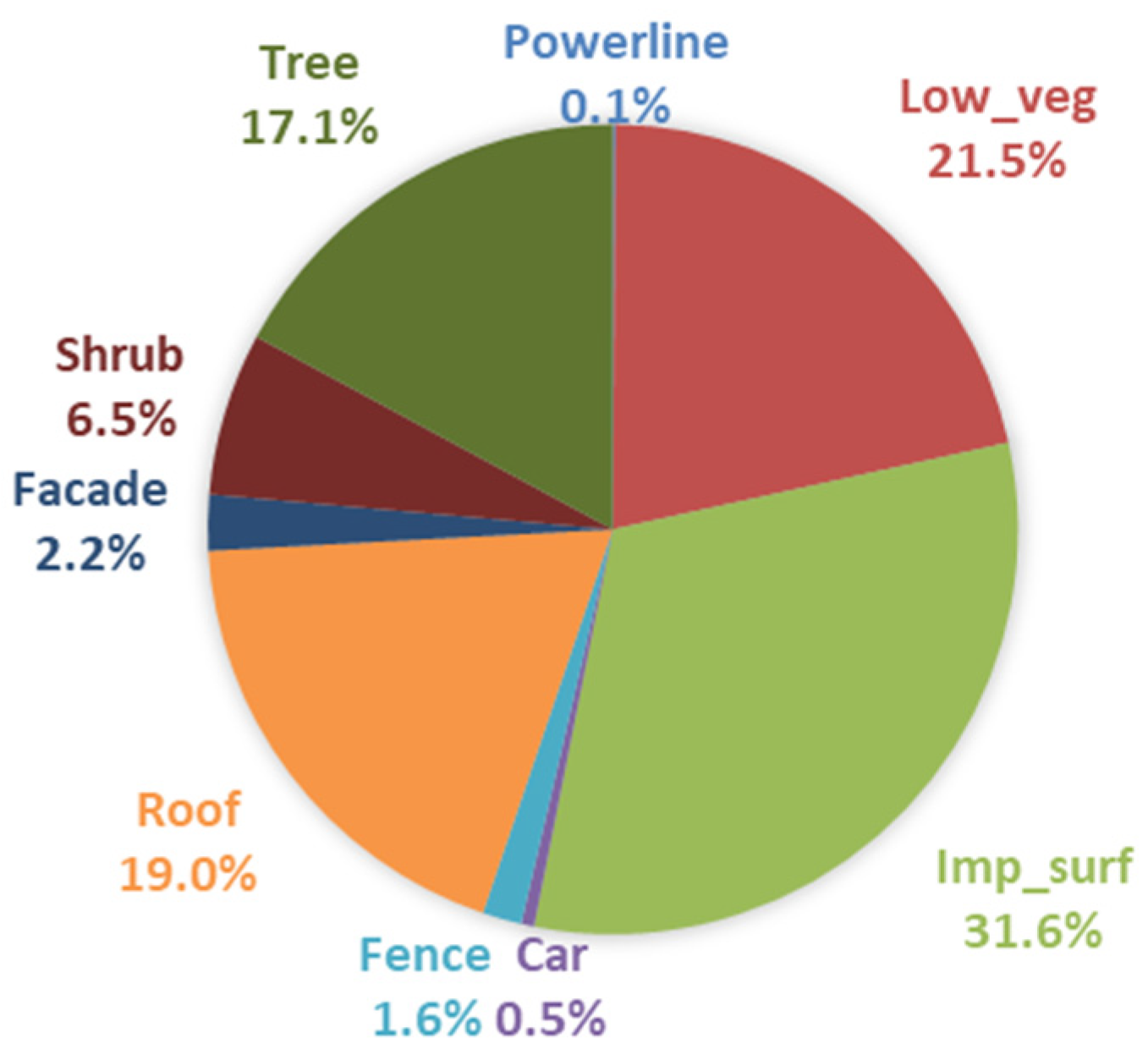
In order to analyze the performance of these methods in each category more intuitively,
Table 5 was transformed into
Figure 11. The number of points in each category of training set in
Table 2 were also converted into percentages, and then transformed into
Figure 12. Through the analysis of
Figure 11 and
Figure 12, we found that although the number of points in roof was not the largest, accounting for only 19% of the training set, all methods performed best on roof. Our method achieved the highest F1 score, which is 95.3%. All methods performed well on Imp_surf, which had the most points in the training set, and the F1 score was basically around 90%. They also had good performance on Low_veg and Tree, the F1 score basically reaching about 80%. These four categories had a large number of points in the training set, which enabled them to achieve higher classification accuracy. The experiments showed that, regardless of whether the method used was based on traditional machine learning or deep learning, higher classification accuracy could usually be obtained for those categories which accounted for a larger proportion in the training data. Surprisingly, although powerline and car accounted for a small proportion in the training set, some methods still performed well. The F1 score of our method on car was even close to 80%. The F1 score of most algorithms on facade was basically 60. The performance on fence and shrub was the worst. This is mainly because there were few points in these two categories, and their characteristics were very close to each other, which made it very difficult to distinguish them.
The classification confusion matrix for all the 10 tiles of DFC 3D test set is shown in
Table 6. We performed best on ground and high vegetation, which had the most points in the training set according to
Table 3. For water and bridge deck, although the number of points was very small in the training set, high IoU were still obtained. The water and bridge deck were mainly confused with the ground. According to
Table 6, some building points are wrongly classified as ground and high vegetation, and some points belonging to the ground and high vegetation are mistakenly classified as buildings. This led to a reduction in IoU in the building category. Through further analysis of the results, we could see that most points with incorrect classification were located near the boundaries of adjacent objects, rather than inside them. This means that our method has a good label consistency and low classification noise.
Table 7 shows the quantitative comparison of performance between our method and other methods on the DFC 3D dataset. The first two columns of
Table 7 show the OA and mIoU. The last five columns show the IoU for each category. As shown in
Table 7, our method ranked first on the contest website with an OA of 97.74% and mIoU of 0.9202. As far as a single category is concerned, our method performed best in terms of ground, high vegetation and building. Because there was no specific information about these methods, except the name on the competition website of the DFC 3D data, there was no way to know what methods they used and make further comparisons. Although the data of the DFC 3D dataset were much larger than those of the Vaihingen 3D dataset, our algorithm still performed well. This shows that our method is suitable for the classification of point cloud in complicated and large-scale scenes.



 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}