1. Introduction
Automatic loading of multiple logs requires visuomotor control of a crane manipulator in a complex environment. This involves challenges in collecting and interpreting visual information for grasping and crane motion planning to handle obstacles, grapple-pile dynamics, and external conditions. While improvements in efficiency and automation are important for the forestry industry’s role in sustainability, these pose major challenges due to the unstructured and harsh outdoor environment. Rough terrain with various obstacles, shaking, wear and tear of equipment, and exposure to light, weather, and seasonal conditions pose different challenges compared to the environment of conventional robot control, in particular for vision-based systems. A forwarder spends most of its time picking up logs [
1], and it is crucial for high efficiency that it be able to lift multiple logs with each grasp without exceeding the maximum lift capacity of the crane. This requires detailed and unobstructed information about the piles and the environment, and makes data collection, segmentation, and crane control significant challenges that must be addressed in order to enable reliable and robust autonomous forwarding.
Driven by the global trend of big data and the progress in machine learning, the forestry industry is experiencing an increase in the collection and availability of large amounts of data. Harvest areas can be scanned from the air and the ground, and both ground and trees can be segmented [
2,
3], allowing detailed terrain maps to be created for path planning [
4], among other things. Harvesters are increasingly being equipped with high-precision positioning systems, and are able to store the geospatial information of the felled logs [
5] as well as the travelled paths. This opens up possibilities for autonomous forwarding and increased efficiency in forestry. Removing the operator from the vehicle additionally relaxes the economic, ergonomic, and design constraints. While fully autonomous forwarding is a challenge, more imminent scenarios include operator assistance, remote-controlled machines, or partially autonomous functions.
The process of grasping logs in forestry is related to the general field of robotic grasping, which has been extensively explored in recent years [
6,
7,
8]. However, there are differences that make log grasping a special case, most notably regarding grasping multiple objects, the unstructured forest environment, the electro-hydraulic crane actuation, the system size, and exposure to the elements. For the specific application of log grasping and autonomous forwarding, there are good solutions for crane motion planning and control [
9,
10] without considering grapple–log interaction or surrounding obstacles. Reinforcement learning (RL) control has proven to be effective for the same task in simulations, grasping a single log with known pose [
11]. However, transferring such joint-level RL control to a real system is a problem due to simulation bias when the electro-hydraulic circuit [
12,
13] has not been precisely modelled. Dhakate et al. [
14] shows how joints can be modelled and the dynamics learned using RL to enable Cartesian control. Actuator dynamics are specific to each machine, non-intuitive for humans, and difficult to interface with other control systems or human operators for shared control of crane operation [
15]. Cartesian control, on the other hand, can be seen as a common interface, which is more intuitive and interfaces more easily with other systems. Considering the grapple, logs, and obstacles, there is a need for visual input to take their configurations and interactions into account. Logs may be partially overlapped or interlocked, and successful grasps may depend on small geometric details that affect the interaction between the grapple and the logs. At the same time, the terrain and obstacles, such as trees and rocks, make the grasping task more than a grasp-pose estimation problem, additionally involving a crane control problem with grasp dynamics and path planning. While there are methods for log detection [
16,
17], varying conditions and occlusion make real-time segmentation difficult and hinder continuous crane and grasping control. There are, however, promising experiments in which segmentation has been used to identify grasp poses. La Hera et al. [
18] shows sparks of early autonomous forwarding in practice, picking single logs along a path on flat ground in concept machine experiments. Ayoub et al. [
19] developed a grasp planning algorithm which was successfully tested on a physical crane to grasp single or multiple logs on flat ground. In this approach, logs are segmented and modelled in a simulator to produce depth-camera images, from which a grasp pose is generated by a convolutional neural network (CNN).
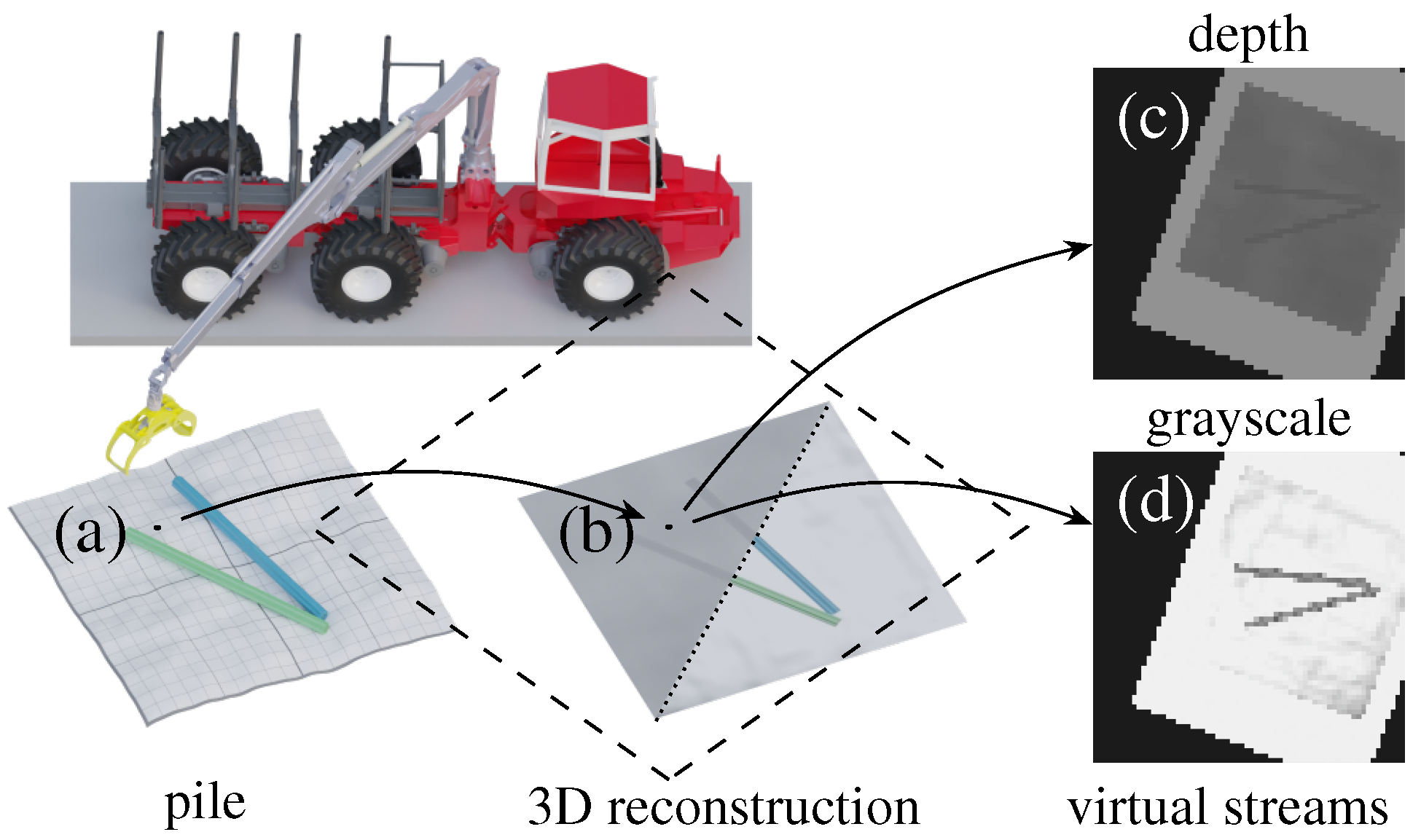
Visual information for continuous crane and grasping control should provide a good overview and be unobstructed, including occlusion by the crane and grapple. It would be beneficial to collect visual data during moments with good visibility or to combine data from different times and perspectives. Another option would be to separate segmentation and control, using specialised systems for each. Considering this, we define a
virtual camera as a sensor that generates a stream of 2D data originating from a 3D reconstruction; see
Figure 1.
To address the challenge of collecting and using visual data for control in challenging forest environments, we explore using reinforcement learning and virtual visual servoing for multi-log grasping. We utilise Cartesian control to simplify the typical reinforcement learning problems of simulation-to-reality (sim-to-real) transfer and interfacing with other control systems or human operators. To address the issue of occlusion in visual servoing for crane control, we utilise a virtual camera, allowing the underlying 3D reconstruction data to be captured where there is no obstruction. This enables data from different times or perspectives to be combined and removes the need for real-time segmentation, allowing more time and computational resources for this task. We train agents using multibody dynamics with frictional contacts, with a reward signal designed to provide dense feedback from the camera data. In addition, we investigate ways to gain insight into learned behaviours, with a focus on the use of image data.
2. Method
To test control from 3D reconstructed data using virtual cameras, we train an agent to grasp multiple logs using model-free RL. Application in practice would require segmenting logs and removing disturbing background from real image data [
16,
17]. Here, we work with piles generated to match such corresponding output. We generate log piles and simulate a forwarder using multibody dynamics with frictional contacts using the AGX Dynamics physics engine [
20].
2.1. Piles and Virtual Camera
We used Perlin noise [
21] to generate uneven terrain as
m
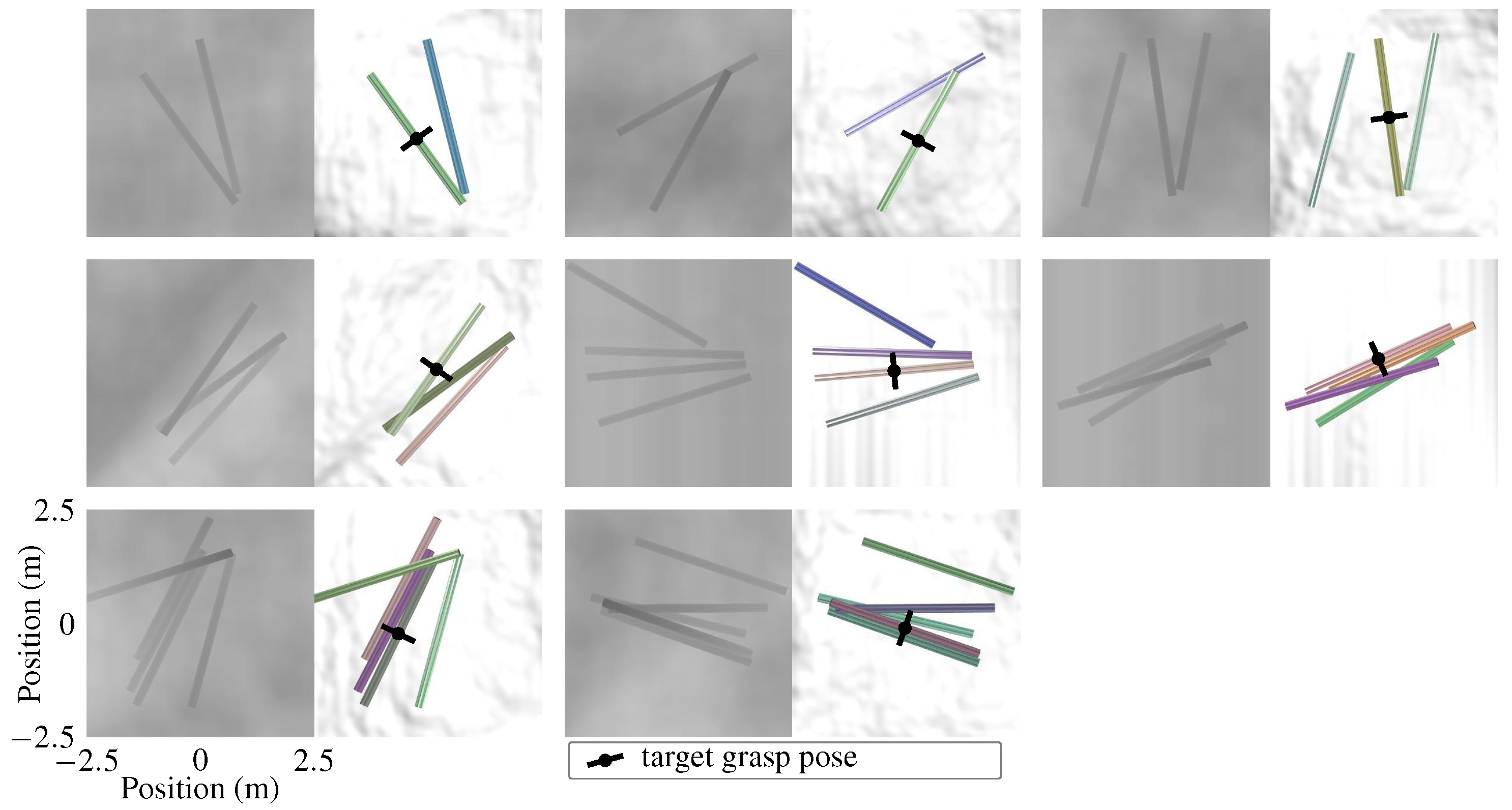
patches, and formed disordered piles with 2–5 logs by stacking logs vertically with random displacements and rotations in the horizontal plane, then letting them fall to the ground. To emulate output from log segmentation, the ground was coloured in a uniform bright colour, then colour and depth (RGB-D) images were generated using an orthographic camera placed straight above the pile, as seen in
Figure 2. The displacement components and rotation for the logs were sampled from Gaussian distributions centred around zero with
m and
rad, determined empirically to achieve varying and challenging piles. To make logs less prone to rolling, they were modelled by two overlapping square cuboids with a relative rotation of
. We delimit ourselves to fixed-sized and shaped logs, using cuboids that are 3.5 m long and
m thick to emulate logs with a diameter of 0.2 m and a mass of 112 kg. Cases where the logs did not relax quickly were discarded by comparing the mean log speed to a small threshold
m/s within 10 s. The target grasp pose was set according to the position and orientation of the log closest to the combined log centre of mass position which was not occluded by any other log; see
Figure 2.
The aim of the virtual camera was to imitate the output of a real camera as if mounted on the grapple while using segmented 3D reconstructed data; see
Figure 1. The relative position
and orientation
of the pile and the virtual camera were used to transform the RGB-D data to a virtual camera output stream. To reduce the dimensionality of the camera data, the RGB data were converted to greyscale. The RGB colours of the logs were sampled from small (
) Gaussian variations around grey. This ensured that all logs were similar in greyscale, emphasising that logs must not be individually segmented.
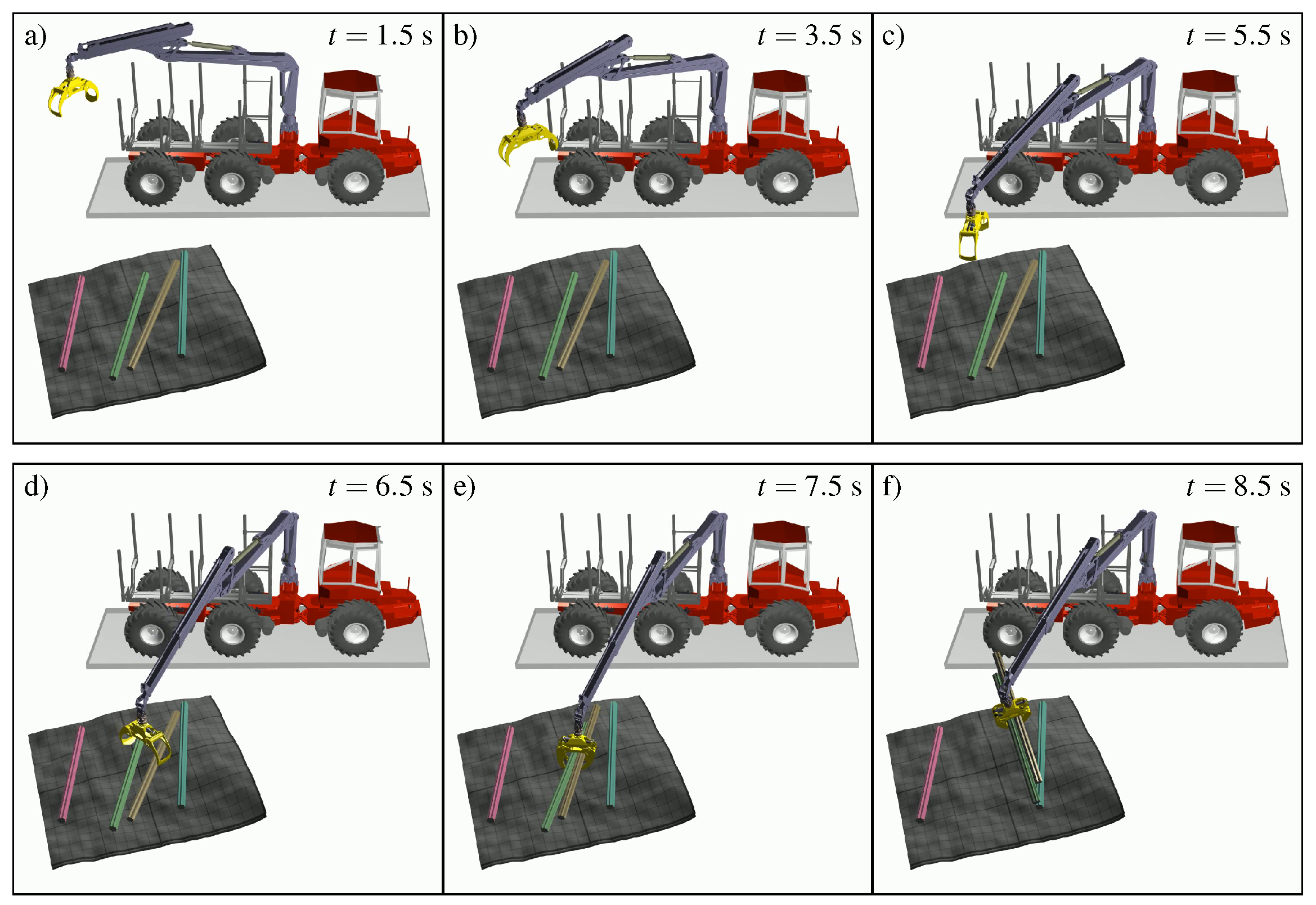
The orthographic camera lacks perspective, and is simply specified by its resolution and physical size. We set the resolution to pixels; to mimic a field-of-view, we varied the camera size depending on the z-component of . This was done by defining the camera sizes and at some far (5 m) and near (0 m) distances and using linear interpolation in between. A virtual camera is not limited to obeying the constraints of physics, as a real camera is. This flexibility allows for the exploration of scenarios that may be challenging or unattainable to replicate in the physical world. We explored m and m in order to retain an overview during the grasp moment, when the grapple is close to the pile. While the RGB sensor data was independent of the distance to the pile, the depth sensor data were rescaled to match the output of a real depth camera. A major difference between a virtual camera and a physical one is that the underlying data of the virtual camera do not update after grasping. We investigated how important the different observables were to the agent’s behaviour at different stages of the grasping cycle.
2.2. Crane Control and Calibration
The crane is a
Cranab FC12 (Cranab AB) mounted on an
Xt28 (eXtractor AB) pendulum arms concept forwarder; see
Figure 3. It consists of 21 bodies and 26 joints, of which 6 are actuated. The
pillar is connected to the
base, and can rotate by an actuated hinge (a). From the pillar, the
main boom is connected with a hinge (b) and a piston that provides hydraulic power. The
outer boom similarly connects (c) from the main boom, and the
telescope can extend (d) from the outer boom, powered by a piston. The end-effector consists of a
rotator and a
grapple. The rotator has one actuated hinge (e) for rotating the grapple and two hinges (g–h) that allow the grapple to swing. The grapple opens and closes (f), powered by a piston. To speed up simulations, the mesh geometry of the grapple was replaced by a similar simplified geometry made up of nine boxes, while the original geometry was retained for visuals.
Joint range and force limits were calibrated using data from the manufacturer [
22], though these were not experimentally confirmed. Joint range limits were set using the maximum reach of the crane and illustrations/images of different configurations, while force limits were set guided by data of the lift capacity at some discrete crane configurations. The lowest lift capacity, at the 8 m full extension, was 9.7 kN. As the logs weigh 112 kg, this lift capacity is enough to easily lift five logs even at full extension. To model the friction in the rotator hinges, we used weak lock constraints and tuned the force limits and compliance until the damping of the swinging of the grapple appeared physical and agreeable with video material. The crane weighs 1630 kg, while the rotator and grapple weigh 249 kg together.
We implemented
Cartesian control; thus, from a desired crane-tip velocity
in Cartesian world frame coordinates, the corresponding target velocity of each joint is calculated with inverse kinematics [
23]. As an alternative to joint-level control, Cartesian control is becoming increasingly common in commercial forest machines [
24]. Actuator dynamics are specific to each machine design, whereas Cartesian control can be seen as a layer of abstraction, exposing a common interface. This increases generality and simplifies implementation and sim-to-real transfer, removing the need for precise modelling of the electro-hydraulic crane actuation. In addition, it simplifies combining control with human operators or other control systems [
15], e.g., for obstacle avoidance.
The Cartesian control problem for the described crane, with four degrees of freedom to control the three components of the crane-tip velocity, is an under-determined system. Thus, there is no inverse to the Jacobian describing how the crane-tip velocity is affected by the velocity of each joint given some crane configuration, i.e., there can be (infinitely) many joint velocity solutions for a single crane-tip velocity. This issue was addressed by defining a pseudo-inverse, with weights for prioritising motion in different joints. We defined these as functions of the articulation of each joint, which are approximately constant but decrease to 10% near the range limits. This makes the system solvable, with solutions mostly within the physical limits of the actuators.
To simplify the modelling and avoid slowing down simulations, we modelled the crane hydraulics using kinematic constraints instead of hydraulic and electric circuit simulations. For each actuator, the force/torque was determined as a solution of the multibody dynamics equation while considering the provided limits on joint ranges and motor force. To mimic the relatively slow motion of the hydraulics, the requested joint velocities were restricted by clipping in the range of m/s (rad/s).
2.3. Reinforcement Learning Control
Reinforcement learning is a machine learning method in which an agent learns through trial and error. It has proven successful in complex control problems with high-dimensional observations such as visual data where otherwise conventional control systems have struggled. The agent selects an
action based on a
state and its
observation of it. A
reward signal is used to guide the learning towards desired state–action mappings [
25]. RL has led to many impressive results, especially in games [
26], though it has yet to be widely used in real-world applications. Compared to classical control methods, its main strengths are in complex planning tasks with long horizons and many degrees of freedom.
2.3.1. Observation and Action
The observation space consists of the virtual camera output and sixteen scalar values concerning the crane, grapple, and target configurations. The camera data are 64 × 64 pixels with two channels. To maintain the idea of Cartesian control as a high-level interface, we chose not to include joint observations of the crane, i.e., the angles/speed of the joints (a–d) in
Figure 3. Instead, we used the grapple’s relative position, velocity, and speed with respect to the target. Details regarding the rotator and grapple are provided, along with the angles and angular speed for the rotation, swing (two directions), and grapple opening. Furthermore, to compensate for the lack of joint observations and not deprive the agent of all haptic sense, we provide a virtual load cell in the rotator. This measures the grapple–load weight, which is normalised by subtracting and dividing by the empty grapple weight. In practice, the crane configuration and the pressure in the hydraulic cylinder of the main boom could provide such force estimates. Angle and speed observations for the grapple and rotator joints were scaled to
using their respective limits, while other observations were clipped to
to encompass the full range of the typical relative grapple position components. The relative rotation of the grapple to the target angle was
not included as one of the observations. The motivation behind this was to create a dense dependence on the camera data containing information on the angles of all logs compared to the grapple. We suggest that this increases the ability of the agent to analyse the camera data, which simplifies the learning process.
The action consists of five scalar values, where three represent the velocity components of the desired crane-tip velocity and the other two represent rotating and opening/closing the grapple.
2.3.2. Reward
We designed a reward function
that combines a sparse term related to overall success or failure with dense terms to aid learning from image data. The sparse term
is designed to become the dominant term, with the others intended to aid learning without overly biasing the final behaviour. The relative contributions to the accumulated reward depend on the learned behaviour, and cannot be immediately inferred. For the trained agent, they are
,
, and
, respectively.
We used zero-centred Gaussian functions for scaling, denoting these as
for some measure
x, or
for short. The first term,
, is awarded only when the agent has achieved the target objective of grasping one or several logs and lifting them a sufficient height off the ground:
where
is the proximity of the grapple to the centre of mass of the logs in the grapple,
m, and
is the number of logs in the grapple.
The second term in Equation (
2),
, is a dense reward designed to help the agent consistently learn to grasp logs:
where
scales with the vertical tilt of the grapple,
,
is the number action steps, and
is any of three stages. Stage 1 provides an increasing reward for proximity to the target position, aligning with the target angle, and opening the grapple; Stage 2 provides an increasing reward for closing the grapple; and Stage 3 is activated when the grapple has closed around at least one log, with an increasing reward for lifting the grapple. We believe that the use of a dense reward term is vital for learning appropriate grapple angles from image data, where the dense reward greatly increases the feedback as to which grapple angle the image data represents. The third term in Equation (
2) is a penalty for excessive energy use, which is proportional to the sum of the power of the actuators.
2.3.3. Curriculum
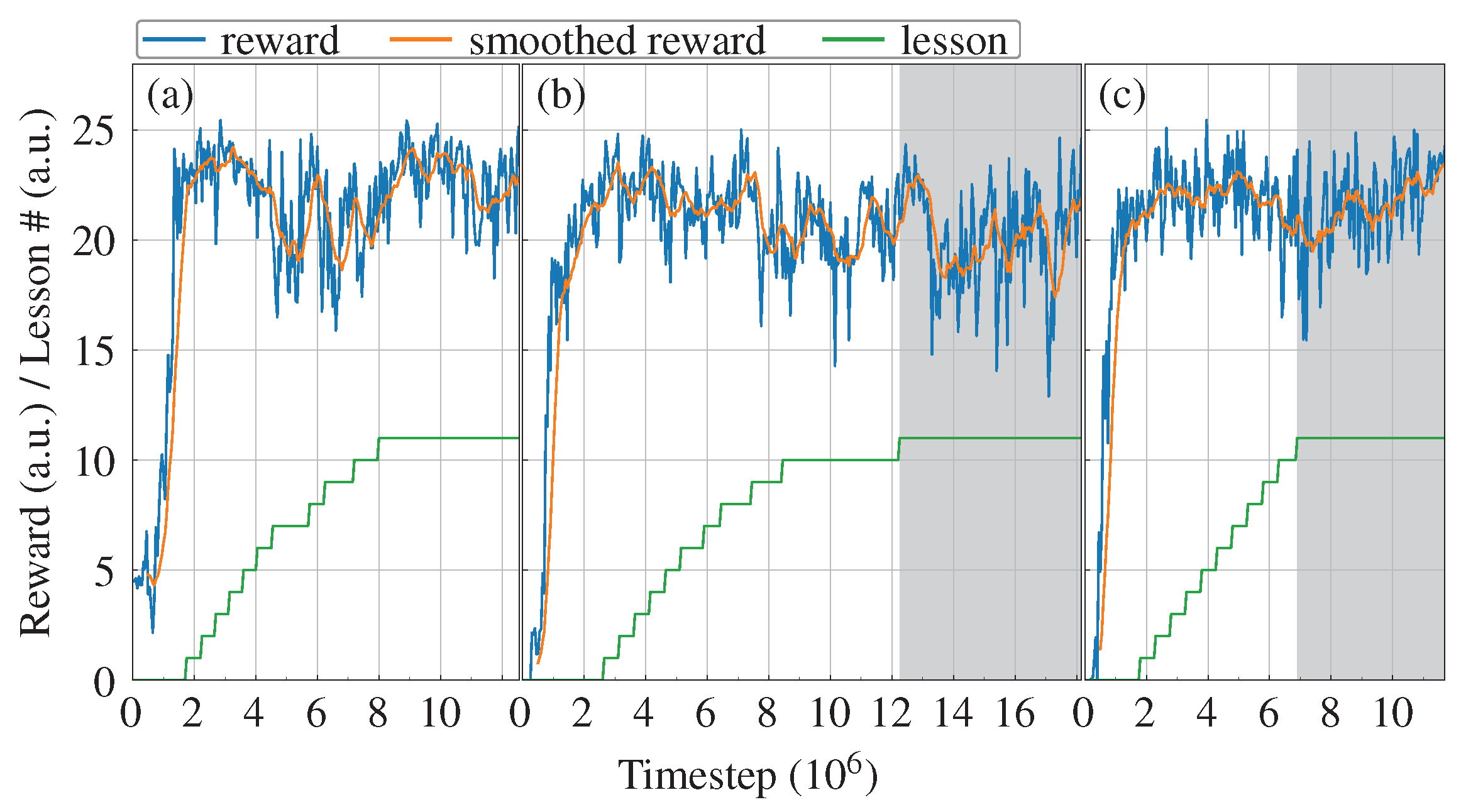
Each episode of the RL task features a pile placed according to a function, with a difficulty parameter determining the challenge level. To speed up the simulations, we kept the vehicle in the same configuration and placed the pile in relation to it. For , the pile was always placed just below the starting position of the grapple, while for it was placed with random rotation at challenging positions on either side of the vehicle at varying heights m. For intermediate difficulty levels, a linear interpolation of the two cases was used, allowing the challenge of the task to be smoothly adjusted. Collisions between the vehicle and the crane/piles were disabled, as piles can overlap with the vehicle, especially during the curriculum.
The curriculum consisted of lessons, during which we adjusted the difficulty parameter in increments of . Twenty evaluation episodes were conducted every 50,000 steps, and progress to the next lesson was determined by the mean accumulated reward of the past evaluation episodes compared to a threshold. The threshold was empirically determined and set to 21 to allow progress through the curriculum on a regular basis. In addition to varying the target position, we modified the criterion for target success. As the lessons became more challenging, we required the logs to be raised higher above the ground, from 0.25 m for to 1.1 m for .
2.3.4. RL Algorithm and Network
We used the Stable-Baselines3 [
27] RL library with the
model-free on-policy algorithm PPO [
28]. While this setup can enable learning in complex environments, it tends to be sample-inefficient. Unlike model-based methods, it does not build an internal model of the environment, instead learning a mapping from states to actions in order to maximise the expected accumulated discounted reward. After each policy update in PPO, new data must be acquired using the new policy.
The input data for our RL agent consisted of sixteen floating-point numbers and two channels of images. The images pass through a CNN feature extractor network, and the resulting vector is concatenated with the other observations. The concatenated input is then fed into two fully connected neural networks, one to predict the value function and the other to generate the action.
We carried out training using eight environments with a maximum episode length of 10 s, a simulation frequency of 60 Hz, and a control frequency of 20 Hz. A number of hyperparameters, such as the batch size, learning rate, and network parameters, were varied to find the agents with the best performance. The best model was trained using a batch size of 1600, a learning rate of 0.00025, and a feature extractor CNN with (8, 8, 8) filters of sizes [8, 4, 3] and strides [4, 2, 1], and 64 output features. The fully connected networks have two hidden layers of size (64, 64), with tanh activation functions. A summary of the hyperparameters can be found in
Table 1.
4. Conclusions
We conclude that using a virtual camera stream from 3D reconstructed data is a viable setup for multi-log grasping, with the agent able to use the camera data for grasping despite the underlying data not updating during the grasp as a real camera would. The agent learns to pick logs with 95% accuracy, using the camera when steering the crane tip as well as when rotating and closing the grapple. The Cartesian control simplifies domain adaption for deploying the RL agent on a real machine. Using a virtual camera allows for collecting visual information when the view is not occluded, combining data from different times or perspectives, and working with processed data to avoid real-time segmentation. This enables solutions to problems related to segmentation, occlusion, season, weather, and light conditions in applications in unstructured forest environments.
The grasping agent has a modular design that is interoperable with any method for crane control that takes the crane-tip target velocity as input. This includes existing methods for time-optimal trajectory planning and control [
9] and semi-autonomous shared control [
15], with the possibility of introducing geofences around the machine and other known objects. This interoperability is important to ensure the safety and productivity of the automated system, e.g., through human monitoring of planned motion with the possibility of intervening by manually adjusting the speed and direction of the crane-tip motion. The implication is that automatic loading can be introduced as an assistive system well before the system is sufficiently mature for autonomous control.
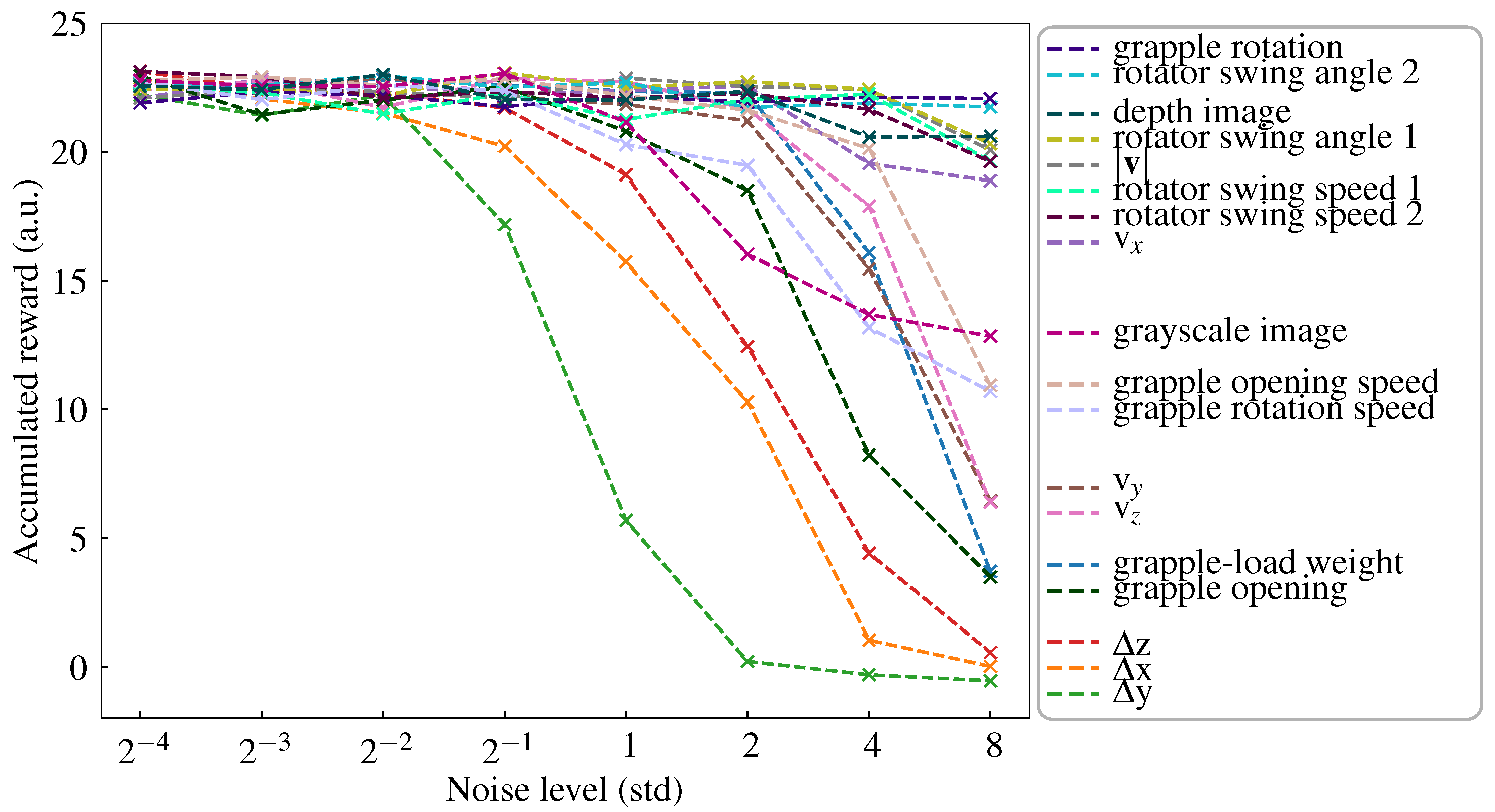
Our observation ablation/augmentation study provides insights into the inner workings of the agent, showing how a dense dependence on camera data is important for allowing the agent to utilise vision and how the agent uses features of the camera data that are not captured by the target angle alone. Our observation noise study reveals the importance of each observation, indicating that the grapple–load weight is a vital observation and that the greyscale camera is more important for the trained agent than the depth camera. Additionally, the study results show that the grapple rotating action is controlled by the camera data and rotation speed, and does not involve the rotation angle itself.
Possible future work involves improvements in RL methods and training to achieve master-level performance, the inclusion of models for optimal grasp poses, the inclusion of log diversity in terms of size and shape, and transfer of the learned skills to a real machine. Transfer tests of the learned skills to a real machine will involve integration with a log segmentation algorithm such as the one described in [
17] and interfacing with a crane control system that takes the crane-tip velocity as an input. In addition to RGB-D sensing, the test system will need to be equipped with sensors for the grapple’s orientation and opening as well as an estimator for the load weight.






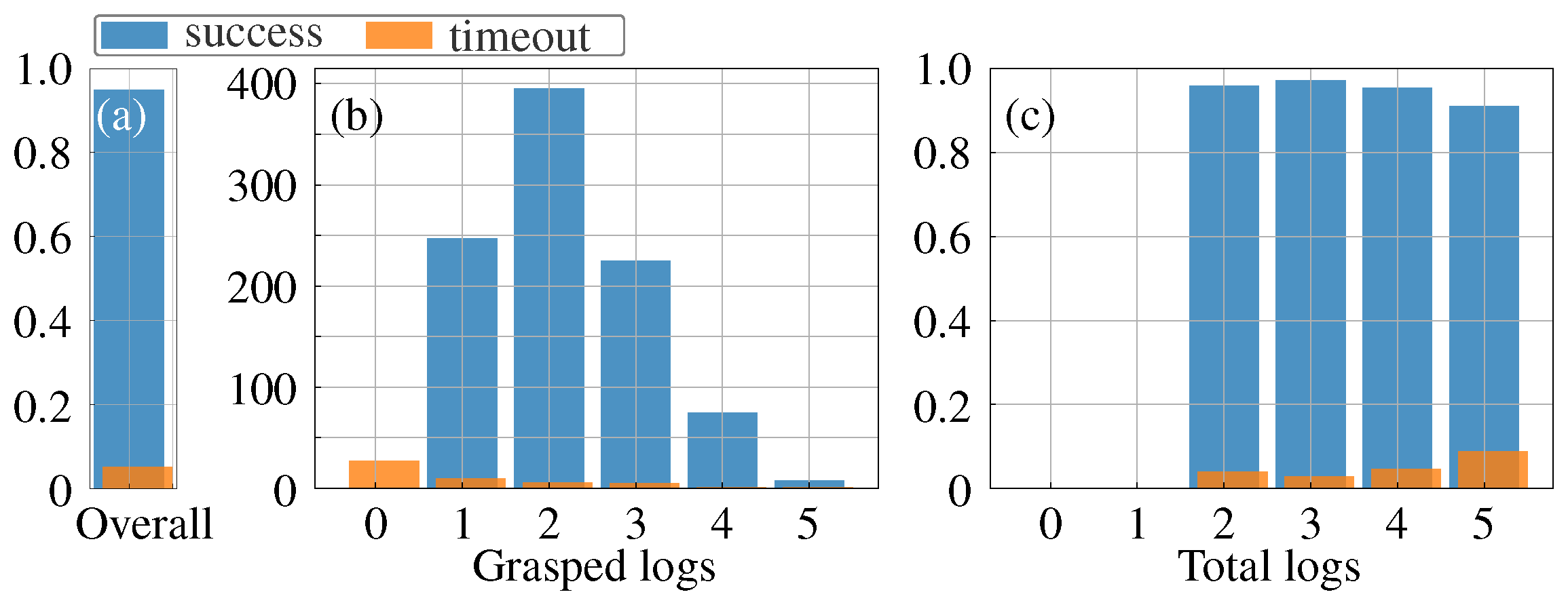




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}