Abstract
Knowledge management within organizations allows to support a global business strategy and represents a systemic and organized attempt to use knowledge within an organization to improve its performance. The objective of this research is to study and analyze knowledge management through Bayesian networks with machine learning techniques, for which a model is made to identify and quantify the various factors that affect the correct management of knowledge in an organization, allowing you to generate value. As a case study, a technology-based services company in Mexico City is analyzed. The evidence found shows the optimal and non-optimal management of knowledge management, and its various factors, through the causality of the variables, allowing us to more adequately capture the interrelationship to manage it. The results show that the most relevant factors for having adequate knowledge management are information management, relational capital, intellectual capital, quality and risk management, and technology assimilation.
1. Introduction
At present, knowledge management in a company is an essential element to ensure its sustainability. Through it, organizations generate value and create intangible assets. Therefore, properly managing data to obtain information, as well as disseminating it systematically and efficiently to transform it into useful knowledge that can be quickly incorporated into decision-making and strategies, represents a competitive advantage that allows generating innovative actions.
Nevertheless, innovation is no accident. There is a process, a way of doing things, that leads to the generation of new ideas, concepts, and more efficient solutions. Innovation pursues the generation of new products/services, new production, commercialization, or organizational processes; that is, new solutions based on knowledge.
Knowledge depends on the context and implies an understanding of how something works, and fundamentally involves interrelations and behavior [1,2]. Therefore, knowledge management is essentially about getting the right knowledge to the right person at the right moment. This does not seem so complex; however, it implies a strong link to corporate strategy, understanding where and in what ways knowledge exists, along with creating processes that consider all organizational functions and ensuring that initiatives are accepted and supported by the members of the organization [3]. An analysis of knowledge is associated with various learning processes, which is why it focuses on how it can be identified and exploited.
Therefore, companies are transformed into companies based on knowledge supported by open innovation, in which internal and external agents participate in the process of innovating and improving the competitive possibilities of the organization.
The innovation capacity of companies entails developing new types of knowledge, which can come from both the internal environment (human talent) and the external environment (market, clients, suppliers, and consultants, among others). In this context, knowledge management and open innovation have a very close relationship that generate value for the organization.
Open innovation allows companies to use internal and external knowledge to accelerate innovation [4]. In other words, this means sharing knowledge and information about different problems and looking to people or organizations outside the company for solutions and new ideas [5]. This approach allows companies to grow with less infrastructure, be more agile, efficient, and responsive to the dynamics of increasingly competitive markets [6].
However, there is no exact open innovation formula for each company; rather, each one must customize its model to be as successful as possible according to the resources available [7]. This model streamlines the generation of results, reduces innovation costs, offers new business opportunities, increases the efficiency of the use of knowledge, encourages the development of new innovative products or services, and strengthens the ecosystem in which the company is immersed.
Based on the above, the objective of this research is to study and analyze knowledge management in a technology-based firm to predict what decisions must be made to generate innovation. For this, the research seeks to elucidate which are the most significant processes, factors, and value generators that must be considered when making decisions. The study is carried out from the structure of a Bayesian network, using machine learning techniques that allow obtaining a predictive model of knowledge management that is more in line with the company.
The questions that guide this research, based on a case study, are the following: What are the key factors for optimal knowledge management in the firm? How can a technology-based company improve the management of its knowledge to make better decisions in the protection of its product/service?
The present work is organized in three sections: The first section addresses the theoretical framework where the importance of knowledge management in organizations is conceptualized and highlighted, as well as the importance of open innovation for the generation of this; it also presents the various theories that have studied this topic. The second section presents the methodology for the analysis and construction of the model through machine learning (ML) techniques. The third section presents the results, the discussion, and conclusions.
1.1. Relevance between Knowledge Management and Open Innovation
For Davenport and Prusak [8] and Koenig and Neveroski [9], knowledge is an evolutionary combination of experience, values, contextual information, experience, and knowledge that provides a framework for evaluating and incorporating new experiences and information. This knowledge is generally embodied in documents or repositories and organization routines, processes, practices, and standards.
According to the above, knowledge is dynamic since it is created in social interactions between individuals and organizations. Knowledge is context-specific because it depends on a particular time and space [1,10]; that is, knowledge is about meaning, which implies that, for it to make sense, users of such knowledge must understand, and have experience with, the context or surrounding conditions and influences in which the knowledge is generated and used [11].
Organizational knowledge can be defined as a set of intangibles, resources, and the capabilities of individuals, groups, and organizations, which have quality and strategic idiosyncrasy; this forces the organization to know how to manage, motivate, and develop, from the human level or the knowledgeable person, without leaving aside the importance of technologies as catalysts or tools, and even more, the environmental context in which the knowledge processes are developed [12].
Knowledge management (KM) is the constant process of identifying, finding, classifying, projecting, presenting, and using, in a more efficient way, the knowledge and experience of the business accumulated in the organization [13,14]; thus, it represents a series of actions aimed at the knowledge evaluation that is generated within and for the organization, with special emphasis on allowing it to be more competitive [15].
The management of knowledge is an essential element and a strategic resource that is directly linked to the productivity, innovation, and competitiveness of organizations. To understand how knowledge is created in the organization, it is necessary to resort to epistemology to distinguish between the two types of knowledge: tacit and explicit.
The organization itself cannot create knowledge; it creates it with people, with their talent. To generate that knowledge, it must be shared with others, it must be disseminated and amplified at the group level to form a spiral that through different ontological levels becomes one of the keys that creates it in the organization [16,17]. Knowledge is generated through learning processes, in various instances, with mechanisms of internalization and externalization.
For Fearnley and Horder [18], knowledge management is a constant process to capture the collective experience of an organization; that is, the collective use of knowledge, experience, and competencies available internally and externally. Thus, knowledge represents the most valuable strategic resource in the organization, and is a systematic process of generation, dissemination, exchange, use, and improvement of individual and organizational knowledge, valuable for its contribution to innovation and competitiveness of the organization.
Following the above, knowledge management has tactical and operational perspectives relative to the planning, implementation, operation, and supervision of all activities and programs related to the knowledge required for its adequate management [19].
Knowledge management and information management are not the same, despite being closely related concepts. Information is the raw material to generate knowledge. It is very important to distinguish one from the other; information is the raw material of knowledge to the extent that it is understood and applied in practice [20,21]. Knowledge is both informative memory and the process of construction of mental representation; therefore, it is the result of information acquisition and cognitive action. For Fernández [20], the differences between the two terms are from form, content, meaning, and use.
According to Rajalakshmi and Banu [21] and Dorji and Kirikova [22] (p. 3), the data are facts or un-interpreted symbols, such as numbers, characters, words, signals, and signs, which do not provide any meaning. Once the data is properly analyzed and organized, and it is possible to understand and provide meaning; thus, the data will become information. When interpreting data, employees must make a decision based on their experience, observation, culture, and educational background to provide contextual meaning to it; that is, employees interpret data using their knowledge to make this information understandable, thus providing meaning [23,24]. Once users understand it and can justify what are the characteristics, problems, and suggestions that are required to solve problems in the activities and organizational work systems, it becomes knowledge. Information is the input of knowledge and it is always received through the senses; that is, it requires human interaction. Learning is the process of integrating new information from existing information. Therefore, knowledge must be able to interpret data, elaborate information, and learn from elaborated information [22]. Thus, knowledge is information that has been understood, evaluated, and appropriated by the user [25]. Knowledge is a high-value form of information that is ready to be applied to decisions and actions [19] (Table 1).

Table 1.
From information management to knowledge management.
Marchiori [31] and Choo [32] addresses these differences by stating that information management (IM) has as a goal to optimize the usefulness and contribution of information resources to achieve the objectives of the organization. However, according to Gold et al. [33] and Koentjoro and Gunawan [34], effective knowledge management, from the perspective of organizational capabilities, suggests a knowledge infrastructure that should include five key elements: (1) technology, the systems, tools, and technologies properly designed and implemented for the needs of the organization; (2) structure; (3) organizational culture, i.e., that which influences the way people interact, the context within which knowledge is created, the resistance they have to certain changes, and, ultimately, the way knowledge is shared or not; (4) a knowledge process architecture of acquisition, conversion, application, and protection; and (5) leadership [35,36].
Knowledge management is the process of purchase, localization, organization, storing, exploiting, and applying the information and data created in an organization, which includes individual information or tacit knowledge, as well as general and known information or explicit knowledge [20] (Table 1).
According to Sveiby [37,38,39] and Hannu and Sveiby [40], unlike information, knowledge is intrinsic to people, and its generation occurs as part of the process of interaction between them. Information—quantitative and qualitative—is a fundamental part of knowledge; managing it correctly is a necessary condition if we want to carry out quality knowledge management.
Knowledge management includes (1) defining the way information and knowledge are acquired and shared within the organization and (2) how it is disseminated outside. It is important to mention that ideas are formed through a deep interaction between people and tacit and explicit knowledge—in environments that have the conditions to allow the creation of knowledge—and this, in turn, will be reflected in the generation of value and innovation (Table 1).
Knowledge is the cognition or recognition of the know-what—the capacity to act—the know-how, and the know-why—understanding—that resides within the mind of persons. The purpose of knowledge is to create or increase value for the enterprise, all its stakeholders, and increase the quality of life [24,25] (p. 50). The difference between knowledge management and information management is that knowledge management centers on people, while information management centers on processes. Knowledge management creates ideal conditions for individuals to learn using another person’s information and experience [41,42].
Both data and information management and knowledge management are key factors for the organization. They give structure, order, and support to the different dynamics and processes, creating value and competitive advantages for the organization.
Therefore, the essential elements that precede the creation and acquisition of knowledge begin with the capture of data from the external and internal environment and it is structuring for the corresponding transformation into information, which, in turn, is potentially convertible into knowledge by people when it is assimilated. Therefore, an organization must carry out such a distinction to have the opportunity to capture the key data to be structured and put into consideration among the members of the organization, to generate value [43], either by influencing decision making or triggering innovation processes. However, this is a complex process, where contextual, use, evaluation, and interpretation variants are combined.
Several factors are crucial to the process of implementation of a knowledge management system (KMS). According to Asiedu [44], it depends on each firm, but it is necessary to design a KMS in a manner that integrates human and technology factors during the whole process.
Knowledge management is a critical driver of competitive advantages because it improves the capacity of organizations to innovate, differentiating themselves from their competitors [45].
Innovation must be a constant and dynamic process within the organization, for which it requires various sources of knowledge and interactions. These interactions take place internally and externally between different actors in the environment. That allows the firm to generate new knowledge, which constitutes the basis for the construction of organizational competencies [46]. One of these strategies that the firm has implemented is open innovation. For which knowledge is its center.
Open innovation has been conceptualized as a distributed innovation process based on purposively managed knowledge flows across organizational boundaries. It provides insights into how firms can harness inflows and outflows of knowledge to improve the highest possible value of their innovative potential [47].
However, the ability of open innovation to promote the recognition of the value of the data and new internal or external information, and to assimilate it and apply it, is directly linked to the absorptive capacity of the firm. Absorption capacity is conceptualized as a set of routines and processes through which companies acquire, assimilate, transform, and exploit knowledge to produce a dynamic organizational capacity. Therefore, this capacity to absorb knowledge is key to understanding the support provided by open innovation. It is based on external knowledge [48].
1.2. Bayesian Networks Through Machine Learning
Machine learning is a branch of artificial intelligence that allows a system to learn from data. As machine learning algorithms learn from the training data, it will produce more accurate predictive models. The learning of Bayesian networks consists of inducing a model, structure, and associated parameters from data. This can naturally be divided into two parts: (1) structural learning, which involves obtaining the structure or topology of the network; and (2) parametric learning—given the structure, obtain the associated probabilities [49].
The purpose of machine learning techniques is to automatically recognize complex patterns in a data set, allowing therefore for inference or prediction in new data sets [50]. For their part, Bayesian modeling is broadly adopted for designing algorithms for learning from data [51]. It arises at the intersection of statistics, which seeks to learn relationships from data and computer science, with an emphasis on efficient computer algorithms [50]. In this way, Bayesian networks are statistical tools that emerged in the field of artificial intelligence, which allow us to face research situations with many variables where there are complex relationships in which uncertainty intervenes. Pearl [52,53] is the pioneer in the application of probabilistic methods in understanding intelligent systems, both natural and artificial, especially in Bayesian networks.
All of them have had a transformative impact on many disciplines, from statistics to artificial intelligence, and are the foundation of the recent emergence of Bayesian cognitive science; also, it has applications in many fields such as medicine, finance, environment, and economics, among others.
Bayesian networks (BNs) provide a straightforward mathematical language to express the relations between variables clearly [54]. The advantage of a BN is that it can incorporate several variables, and all nodes and probability tables can be interpreted concerning the domain; uncertainty is also managed, providing an explanatory environment that facilitates decision-making. BNs have complete knowledge of the state of the system and can make observations (obtain evidence) and update the probabilities of the rest of the system [55]. Thus, a BN allows handling a model to characterize causality in terms of the conditional probabilities in which the conditional independencies of a variable are represented. These independencies simplify the representation of knowledge (fewer parameters) and reasoning (propagation of probabilities).
Other methods, such as neural networks, also produce good results, however, databases with many instances are required, and they do not consider the uncertainty and knowledge of the experts. Alternatively, the classical or frequentist model does not allow estimates in complex models or small sample sizes [56,57,58,59].
2. Materials and Methods
The present research is mixed—qualitative (descriptive) and quantitative. A model is built to identify the main processes in efficient knowledge management that can lead a company to generate value. Our case study is a technology-based company in the financial sector, located in Mexico City. The case study company oversees managing people′s retirement funds all over México. The instrument used to collect the information was by interviewing key people in the company and a focus group of experts.
For the design of the model, the methodology of Bayesian networks (BNs) was applied, which allows the incorporation of expert opinion and available statistics into the model.
These experts as external agents participated in the open innovation process by contributing their expertise to make better decisions in knowledge management to improve the processes of the company case study.
The use of Bayesian networks in this study is justified since the networks carry probabilistic and causal information. There are variants in some fields within the social sciences and economics, where some of these models are known as path diagrams or SEM structural equation models, as well as in artificial intelligence—such models are known as Bayesian networks.
The capabilities for bidirectional inferences, such as rapid prediction and diagnosis, debugging, and reconfiguration, combined with a rigorous probabilistic basis, have made Bayesian networks the method of choice for uncertain reasoning in artificial intelligence and expert systems, replacing the schemes above based on ad hoc rules [60]. The most important aspect of Bayesian networks is that they are direct representations of the world, not of reasoning processes.
Bayesian networks are used to represent knowledge in reasoning methods, analysis of financial system debtors, and sales prediction, among others; they are based on the theory of probability, such that the value of the unobserved variables can be predicted and the results obtained from the observed variables can be explained. The use of Bayesian networks allows us to learn about dependency relationships and combine knowledge with new data [59].
Thanks to the modeling power of Bayesian networks, they could be used to generate more and better models of the functioning of organizations [61].
An expert is a person whose experience and knowledge of the operation allows it to make credible-enough assumptions about how the operations of the company affect the profile of the company. Initially, their opinion can be used as a surrogate for the data and can provide valuable information on a company’s operations that is difficult to capture from the data alone.
The experts selected for the design and estimation of the Bayesian network are recognized collaborators of companies and knowledge management consultancies from various industries and researchers who have experience and information on the variables that influence the analyzed process. The degree of confidence in the expert′s information also affects the a priori probabilities. Bayesian analysis formalizes this concept: the subsequent densities consider to a lesser or greater degree the information of the beliefs, depending on the confidence that is had about it. In this work, to quantify the network, the opinions of knowledge management experts from different industries were consulted and the prior probabilities for each node were defined.
BNs are dynamic models that allow the incorporation of information collected over time into the model and the evaluation of results. In a BN, the variables (nodes) are defined and the causal relationships between them are called the influence relationships between variables [61]. Bayesian models are used to solve problems from both a descriptive and a predictive perspective. As a descriptive method, they focus on discovering the dependency/independence relationships. As for the predictive function, it is circumscribed to Bayesian techniques as classification methods.
Bayesian methods are one of the most widely used techniques in artificial intelligence, machine learning, and data mining problems. This is because they are valid and practical methods to make inferences from with the available data, which implies inducing probabilistic models that, once calculated, can be used with other data mining techniques [62].
For the construction of the interrelations model, it is necessary to know, in detail, the variables involved in the generation of knowledge in the case study company, and its causality (Figure 1).
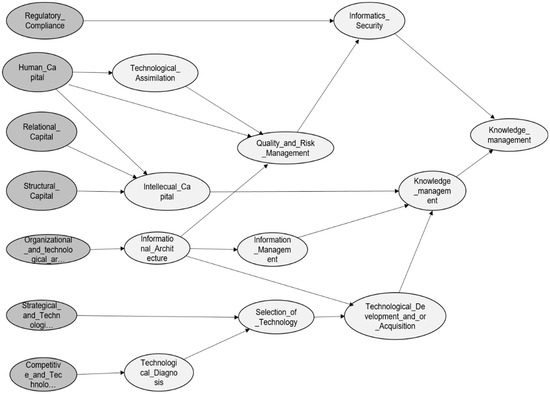
Figure 1.
Scheme of the knowledge management model: variables and nodes.
To validate the knowledge management model, the technology management model validated by Terán-Bustamante et al. [63] was considered. The knowledge management model for the technology-based company consist of 17 variables (Table 2).
Table 2.
Definition of the variables and nodes.
Following a structure-based learning approach, the model was configured as a Bayesian network. Then, 500 instances were generated using GENIE software (Figure 1 and Table 1). The next step was to select the most relevant variables for the classification, based on the Relief algorithm. The algorithm assigns a weight to each variable depending on its classification capability. It first selects random instances from the training data set and for each one finds the closest instance of the same class and the opposite class. The weight of the attribute is determined based on its ability to distinguish the closest instance of the same class from the other. Thus, it receives the highest weight if it can differentiate between classes. Once the weights are assigned, the algorithm selects the variables that exceed a certain threshold [64].
The data set was then classified through three algorithms: Naive Bayes (NB), Support Vector Machines (SVM), and Neural Network (NNA). This was done to validate the results obtained when modeling through the Bayesian networks. The Knowledge Management variable was considered as a class in the data set [65].
Then, the association rules were determined through the CN2 algorithm, which is a classification technique designed for the efficient induction of rules simply and understandably [66]; also shown are the variables that are frequently grouped to obtain a result, based on the association rules. This was done to discover interesting relationships between the variables in the databases, to identify the solid rules discovered in the databases using some measures of interest, and to provide clarity on how inferences were made [67].
3. Results
As already mentioned, the case study refers to the company responsible for managing the retirement funds of workers in Mexico. The company was established to create a business model to safeguard the information on the contributions of the Mexican workers to the retirement fund. By 2020, it managed 67.7 million accounts [68]. For this reason, the main objective of its constitution is the management of information and the individualization of accounts of each worker. At the same time, it generates information for the decision-making of the various actors: for the government, to improvement or create social policies; for retirement fund managers (AFORE)—banks and insurers—to improve their investment strategies and attract customers; and for workers, to make better decisions regarding the management of their retirement fund account.
The processing of operations is done in batches in large volumes. The interaction with the data is through files, through massive downloads and uploads of information.
The most relevant variables for classification, where the class is the knowledge management variable, according to the Relief algorithm, assigns scores to the variables according to their correlation with the class. In this way, the variables that have the greatest influence on the Knowledge Management variable are determined (Table 3).
Table 3.
Most relevant variables in knowledge management.
Information management is the most relevant variable, which means that is the first process in which the company must focus its efforts on optimal knowledge management. The firm is required to establish the appropriate means for the people involved in its collection, organization, storage, recovery, and use to be transformed, both individually and collectively, into knowledge.
The second relevant variable is relational capital, which focuses on recognizing the value of new information, on the collaboration that the company has with the various actors in its environment, for the generation of knowledge flows with an open innovation strategy. This will allow the identification of knowledge that generates value for the company with the variable Intellectual Capital. However, under the relevance of the information that the company manages, it must always consider the Quality and Risk Management variable. For this, it needs to have the necessary technological tools to protect it. The fifth variable, assimilation of knowledge that involves absorption capacity, reflects the organization’s ability to interpret and understand external knowledge with existing knowledge structures (Table 3).
The data obtained were classified through several algorithms, where those that obtained the best results were Naive Bayes, Neural Network, and SVM. The best result obtained is the model generated with Bayes’ networks (Table 4), as expected, since the model was generated utilizing Bayes’ networks. The three algorithms have similar values; however, the best value for the area under the curve was obtained by Naive Bayes (Figure 2). In the area under the curve (AUC) graph, the number of true positives or hits on the ordinate axis (“y” axis) and the total hits or total positives in the abscissa axis (“x” axis) are shown (Table 4).
Table 4.
Performance evaluation of the algorithms.
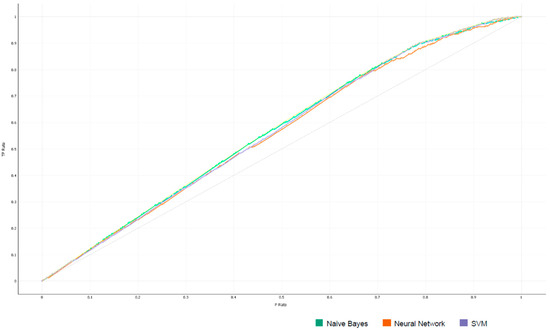
Figure 2.
The lift curve of the models evaluated for knowledge management.
Another representation of the evaluation of the models applied for the classification is presented through a Venn diagram. It shows in parenthesis the number of hits of each model for the data set under study (see Figure 3); it is observed that Naïve Bayes is the model best evaluated by the number of hits obtained.
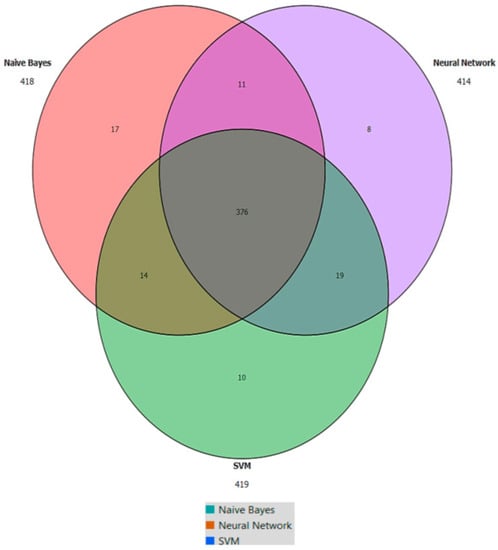
Figure 3.
Venn diagram.
Through a nomogram, a predictive model is made for the diverse processes—the variables—where the values and the importance of the variables in the classification of the data set become evident. This allows for the visual representation of the effects of the variation of the variables in the probabilities of the class “Knowledge Management”. In this representation, the required values are shown for each variable if it is desired to have 80% of the probabilities of achieving knowledge management at the HIGH level (Figure 4). To test the validity of the predictive model, it must have three properties applied to it, which are (1) calibration—the agreement between the predicted probabilities of the model and the real incidence of an event; (2) discrimination—the ability to distinguish between different events; and (3) utility—applicability in the practice of the predictive model (Figure 2).

Figure 4.
Nomogram that indicates the values of the variables to reach the objective determined by the class.
Based on the induction rules, the items or variables that appear together frequently have been determined to obtain the result in terms of the Knowledge Management variable, according to their values listed below. The support percentage is the minimum proportion of data instances that the set of items must have to generate the set of grouped variables (Table 5).
Table 5.
Sets of variables.
Additionally, a tree diagram is shown, where it can be seen how the variables influence Knowledge Management. A decision tree is a type of supervised learning algorithm that can be used in classification problems. The image below (Figure 5) shows a series of division rules, starting at the top of the tree. The classification tree is used to predict the response (Information Management) located in the parent node, and the proportion of the variables that have a positive value (expressed as a percentage). Interpreting the results of this classification tree, when moving to the right side of the parent node, the results are shown in the path of the branches of the tree to the right and downwards; the proportions that each variable has to achieve the objective; and the variable (Information Management) reaching the value “OPTIMAL”.
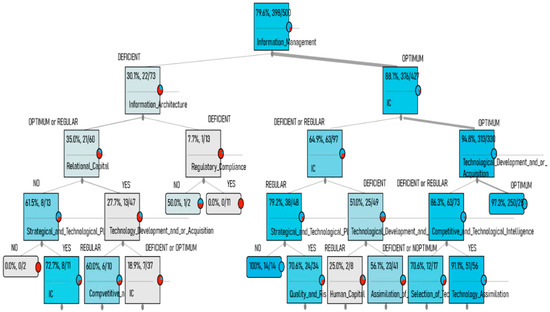
Figure 5.
Decision tree for the knowledge management model.
4. Discussion
Intending to clarify how the target class (Information Management) is predicted, below we present the induction rules generated through the CN2 Rule Inducer algorithm (Table 6). We show how the algorithm has reasoned to arrive at the results delivered. The rules have a logic structure: “If” the variable has a given value, then the class “Knowledge Management”. In this case, the combinations of variables that allow obtaining a HIGH value for the Knowledge Management variable are presented with the probability indicated in the right column. With an optimum level of information management, development, acquisition of technology, and intellectual capital, there will be optimal knowledge management with a probability of 97%.
Table 6.
Inference rules.
According to the evidence found, the key elements for optimal knowledge management in a technology-based company are information management together with the processes and systems that make use of it, resulting in very important assets in the organization. The proper management of information has allowed the organization to give its clients confidence by providing confidentiality and proper handling of sensitive information. This has been essential to maintaining the levels of competitiveness, profitability, legal compliance, and business image necessary to achieve the objectives of the organization and to ensure economic benefits. The information and how it is managed has turned out to be a very valuable asset for the organization, which has allowed it to generate knowledge. This management, together with the assimilation of technology, has allowed the case study organization to generate organizational capacities, share information and knowledge within the organization, and assess how it is disseminated internally and externally.
The precision reached by the evaluated models (CA) indicates that the Naive Bayes and SVM algorithms could be applied to other cases in which it is sought to determine the probabilities of achieving an optimal value for knowledge management. This can be set based on the training and testing process of the algorithms used, where the data sets are divided into training data and test data. In this way, the results of the models are validated against the test data with repetitive iterations.
Finally, during the decision-making process, each company selects an optimal action according to its strategies, as well as selecting the optimal actions taken to achieve the objectives [69].
Future work could test the application of the proposed models to other case studies, considering other variables or combinations between them, to study problems that include increasing changes in the organization.
5. Conclusions
Knowledge management is a systematic process of generation, dissemination, exchange, use, and improvement of valuable individual and organizational knowledge for the generation of value to the organization. This includes defining how data, information, and knowledge are acquired and shared within the organization and how it is disseminated abroad; that is, knowledge management is an effort to increase the use and transfer of knowledge in the organization. In other words, it is connecting and sharing. The various forms to do this include encouraging communication, offering opportunities to learn, and promoting the sharing of appropriate knowledge objects or artifacts, their relation, and external collaboration, among others. In a technology-based company whose mission is to safeguard the data and contributions for its retirement pension, a key element is knowledge management. Accordingly, an organization must acquire the ability to make useful knowledge. Research shows that information management together with processes and systems are very important assets in an organization. It includes the confidentiality, integrity, and availability of sensitive information that is essential to maintain the levels of competitiveness, profitability, legality, and image of the organization. This ensures competitive advantages, where intellectual capital is understood simply as the knowledge that can be translated into extraction and creation of value.
The use of the Bayesian network model through machine learning techniques will allow us to identify the different variables that generate the most value in knowledge management.
An effective design of a Bayesian network is based on the decomposition of a problem domain into a set of causal or conditional propositions about the domain, which implies full knowledge of each of the processes involved in the origin of a product or service.
Bayesian networks allows an analysis of scenarios if the network is running, such as the effect of the data entered within one or more nodes propagated throughout the network, in all directions, updating the distribution of the nodes; consequently, it provides timely information to the user. This allows generating higher explicit probability distribution functions at each node to determine the required probabilities that provide important information about how the variables are related; it also allows adjusting the probabilities a posteriori to the data of each function, for better decision-making on knowledge management—for all nodes.
Through knowledge management, flows of information and shared knowledge can be generated, such as the case of experts that allow the transfer of outsourced knowledge at an intra-organizational level and resulting in open innovation processes that generate value for the company.
The open innovation model represents a key factor in improving knowledge management and thus generating innovation, with implications both for the internal processes carried out in each organization and for the collaborative relationships that are established.
The present research has both practical and strategic implications for future research, through the model that was developed with machine learning tools, Bayesian networks, and for open innovation through the collaboration of experts. This will allow the company to make better decisions in the management of data, information, and knowledge. At the same time, through its absorption capacity to generate knowledge, a company can generate more innovation and be more competitive. However, the empirical results of some research show that not all open innovation activities have a positive effect on the results related to innovation [70]. Besides the above, there is the limitation that the sample comes from a single organization, which limits the generality of the results. In this context, an exploratory model is proposed that integrates the key factors found through the collaboration of experts and the applied machine learning methodology. For future research, it is proposed to generate more cases of knowledge management models in companies from different sectors supported by open innovation and artificial intelligence.
Author Contributions
Conceptualization, A.T.-B.; data curation, A.T.-B. and A.M.-V.; formal analysis, A.T.-B. and A.M.-V.; investigation, A.T.-B., A.M.-V. and G.D.-A.; methodology, A.T.-B., A.M.-V. and G.D.-A.; project administration, A.T.-B.; writing—original draft, A.T.-B.; writing—review and editing, A.T.-B. and A.M.-V. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Conflicts of Interest
The authors declare no conflict of interest
References
- Nonaka, I.; Teece, D.J. (Eds.) Managing Industrial Knowledge: Creation, Transfer, and Utilization; Sage Publications Ltd.: New York, NY, USA, 2001. [Google Scholar]
- Teece, D. Human Capital, Capabilities, and the Firm: Literati, Numerati, and Entrepreneurs in the Twenty-First-Century Enterprise. In The Oxford Handbook of Human Capital; Burton-Jones, A.J.-C., Ed.; OUP Oxford: Oxford, UK, 2011. [Google Scholar]
- Hajric, E. Knowledge Management System and Practices. A Theoretical and Practical Guide for Knowledge Management in Your Organization; Helpjuice: Jacksonville, FL, USA, 2018. [Google Scholar]
- Chesbrough, H.; Vanhaverbeke, W.; West, J. (Eds.) Open Innovation: Researching a New Paradigm; Oxford University Press: Oxford, UK, 2006. [Google Scholar]
- Chesbrough, H. The future of open innovation: The future of open innovation is more extensive, more collaborative, and more engaged with a wider variety of participants. Res. Technol. Manag. 2017, 60, 35–38. [Google Scholar] [CrossRef]
- Ellen, E.; Bogers, M.; Chesbrough, H. Exploring open innovation in the digital age: A maturity model and future research directions. R&D Manag. 2020, 50, 161–168. [Google Scholar]
- Chesbrough, H.; Bogers, M. Explicating Open Innovation: Clarifying an Emerging Paradigm for Understanding Innovation. In New Frontiers in Open Innovation; Chesbrough, H., Vanhaverbeke, W., West, J., Eds.; Oxford University Press: New York, NY, USA, 2014; pp. 3–28. Available online: https://ssrn.com/abstract=2427233 (accessed on 16 January 2021).
- Davenport, T.H.; Prusak, L. Working Knowledge: How Organizations Manage What They Know; Harvard Business School Press: Boston, MA, USA, 1998. [Google Scholar]
- Koenig, M.; Neveroski, K. The Origins and Development of Knowledge Management. J. Inform. Knowl. Manag. 2008, 7, 243–254. [Google Scholar] [CrossRef]
- von Hayek, F.A. The use of knowledge in society. Am. Econ. Rev. 1945, 35, 519–530. [Google Scholar] [CrossRef]
- Nonaka, I.; Takeuchi, H. The Knowledge-Creating Company: How Japanese Companies Create the Dynamics of Innovation; Oxford University Press: New York, NY, USA, 1995. [Google Scholar]
- Bueno, E. Dirección del Conocimiento en las Organizaciones; Documento. Núm 16; AECA: Madrid, Spain, 2004. [Google Scholar]
- Lahaba, Y.N.; Santos, M.L. La gestión del conocimiento: Una nueva perspectiva en la gerencia de las organizaciones. Acimed 2001, 9, 121–126. [Google Scholar]
- Solleiro, J.L.; Escalante, F.; Herrera, A.; Castañón, R.; Luna, K.; Sánchez, G.; González, E. Gestión del conocimiento en Centros de Investigación y Desarrollo de México, Brasil y Chile; FLACSO México; Centro Internacional de Investigaciones para el Desarrollo: Avenida, Brasil, 2010. [Google Scholar]
- Bryson, J.M.; Berry, F.S.; Yang, K. The state of public strategic management research: A selective literature review and set of future directions. Am. Rev. Public Adm. 2010, 40, 495–521. [Google Scholar] [CrossRef]
- Guillen, I.; Montoya, T.; Rendón, M.; Montaño, L. Aprendizaje y cultura en las organizaciones: Un acercamiento al caso mexicano. Adm. Organ. 2002, 4, 53–83. [Google Scholar]
- Ekboir, J.; Dutrénit, G.; Martínez, G.; Torres, A.; Vera-Cruz, A. Successful Organizational Learning in the Management of Agricultural Research and Innovation the Mexican Produce Foundations; Research Report; IFPRI (International Food Policy Research Institute): Washington, DC, USA, 2009; p. 153. [Google Scholar]
- Fearnley, P.; Horder, M. What is knowledge management? Knowledge Management in the Oil and Gas Industry. In London Conference Proceedings Notes; IGI Global: London, UK, 1997. [Google Scholar]
- Solleiro, J.L.; Terán-Bustamante, A. Buenas Prácticas de Gestión de la Innovación en Centros de Investigación Tecnológica; Universidad Autónoma de México e Instituto de Investigaciones Eléctricas: Mexico City, México, 2012. [Google Scholar]
- Fernández, V. Gestión del Conocimiento versus Gestión de la Información. Investig. Bibliotecol. 2006, 20, 42–62. [Google Scholar] [CrossRef][Green Version]
- Rajalakshmi, S.; Banu, R.W. Analysis of Tacit Knowledge Sharing and Codification in Higher Education. In Proceedings of the 2012 International Conference on Computer Communication and Informatics, Coimbatore, India, 10–12 January 2012. [Google Scholar]
- Dorji, S.; Kirikova, M. Data, Information, and Knowledge Modeling in Work System Networks; Faculty of Computer Science and Information Technology, Institute of Applied Computer Systems, Kalku 1, Riga Technical University: Riga, Latvia, 2012. [Google Scholar]
- Liew, A. DIKIW: Data, information, knowledge, intelligence, wisdom, and their interrelationships. Bus. Manag Dynam. 2013, 2, 49. [Google Scholar]
- Liew, A. Data, information, knowledge, and their interrelationships. J. Knowl. Manag. Prac. 2007, 7, 2. [Google Scholar]
- Zins, C. Conceptual approaches for defining data, information, and knowledge. J. Am. Soc. Inform. Sci. Technol. 2007, 58, 479–493. [Google Scholar] [CrossRef]
- Davenport, T.; Long, D.; Beers, M. Successful Knowledge Management Projects. Sloan Manag. Rev. 1998, 39, 43–57. [Google Scholar]
- Manzano, O.; González, Y. La gestión del conocimiento como generador de valor agregado en las organizaciones: Análisis de un sector empresarial. Libre Empresa 2011, 8, 69–80. [Google Scholar]
- Plaz, R. Gestión del conocimiento: Una visión integradora del aprendizaje organizacional. MadrI + D51. 2003, 7, 51–58. [Google Scholar]
- Plaz, R.; González, N. La gestión del conocimiento organizativo: Dinámicas de agregación de valor en la organización. Econ. Ind. 2005, 357, 41–54. [Google Scholar]
- Choo, P. Innovation and Knowledge Creation: How are these Concepts Related? Int. J. Inform. Manag. 2006, 26, 302–312. [Google Scholar]
- Marchiori, D.; Mendes, L. Knowledge management, and total quality management: Foundations, intellectual structures, insights regarding the evolution of the literature. Total Qual. Manag. Bus. Excell. 2020, 31, 1135–1169. [Google Scholar] [CrossRef]
- Choo, C.W. Information Management for the Intelligent Organization, 3rd ed.; Information Today Inc.: Medford, NJ, USA, 2001. [Google Scholar]
- Gold, A.H.; Malhotra, A.; Segars, A.H. Knowledge management: An organizational capabilities perspective. J. Manag. Inform. Syst. 2001, 18, 185–214. [Google Scholar] [CrossRef]
- Koentjoro, S.; Gunawan, S. Managing Knowledge, Dynamic Capabilities, Innovative Performance, and Creating Sustainable Competitive Advantage in Family Companies: A Case Study of a Family Company in Indonesia. J. Open Innov. Technol. Mark. Complex. 2020, 6, 90. [Google Scholar] [CrossRef]
- Chung-Jen, C.; Huang, J.; Hsiao, Y. Knowledge management and innovativeness. Int. J. Manpow. 2010, 31, 848–870. [Google Scholar] [CrossRef]
- Lee, V.-H.; Leong, L.-Y.; Hew, T.-S.; Ooi, K.-B. Knowledge management: A key determinant in advancing technological innovation? J. Knowl. Manag. 2013, 17, 848–872. [Google Scholar] [CrossRef]
- Sveiby, K.E. The New Organizational Wealth: Managing and Measuring Knowledge-Based Assets; Berrett-Koehler: San Francisco, CA, USA, 1997. [Google Scholar]
- Sveiby, K.E. A knowledge-based theory of the firm to guide in strategy formulation. J. Intellect. Cap. 2001, 2, 44–358. [Google Scholar] [CrossRef]
- Sveiby, K.E. The Intangible Assets Monitor. J. Hum. Resour. Costing Account. 1997, 2, 73–97. [Google Scholar] [CrossRef]
- Hannu, R.; Sveiby, K.E. Are Turn to Practice. In The Routledge Companion to Intellectual Capital; Guthrie, J., Dumay, J., Ricceri, F., Nielsen, C., Eds.; The Routledge Companion to Intellectual Capital; Routledge: London, UK, 2017. [Google Scholar] [CrossRef]
- McInerney, C.R.; Koenig, M.E. Knowledge management (KM) processes in organizations: Theoretical foundations and practice. Synthesis Lectures on Information Concepts. Retr. Serv. 2011, 3, 1–96. [Google Scholar]
- Luga, V.; Kifor, C.V. Information and knowledge management and their inter-relationship within lean organizations. Sci. Bull. Nicolae Balcescu Land Forces Acad. 2014, 19, 31. [Google Scholar]
- Durant-Law, G.Y.; Byrne, P. The Tardis Knowledge Productivity System. Australian Government. 2007. Available online: http://www.durantlaw.info/sites/durantlaw.info/files/TARDIS%20Manual.pdf (accessed on 16 January 2021).
- Asiedu, E. A Critical Review on the Various Factors that Influence Successful Implementation of Knowledge Management Projects within Organizations. Int. J. Econ. 2015, 4, 7. [Google Scholar] [CrossRef]
- Omotayo, F. Knowledge Management as an important tool in Organisational Management: A Review of Literature. Libr. Philos. Prac. 2015, 1, 1–23. [Google Scholar]
- Mugellesi Dow, R.; Pallaschke, S. Managing knowledge for spacecraft operations at ESOC. J. Knowl. Manag. 2010, 14, 659–677. [Google Scholar] [CrossRef]
- Chesbrough, H.; Bogers, M. Explicating Open Innovation: Clarifying an Emerging Paradigm for Understanding Innovation. In Open Innovation: New Frontiers and Applications; Chesbrough, H., Vanhaverbeke, W., West, J., Eds.; Oxford University Press: Oxford, UK, 2014. [Google Scholar] [CrossRef]
- Zahra, S.A.; George, G. Absorptive capacity: A review, reconceptualization, and extension. Acad. Manag. Rev. 2002, 27, 185–203. [Google Scholar] [CrossRef]
- Deo, R.C. Machine learning in medicine. Circulation 2015, 132, 1920–1930. [Google Scholar] [CrossRef]
- Duda, R.O.; Hart, P.E. DG Stork Pattern Classification; John Wiely and Sons, Inc.: Hoboken, NJ, USA, 2001. [Google Scholar]
- Bernardo, J.M.; Smith, A.F. Bayesian Theory; Wiley Series in Probability and Mathematical Statistics; John Wiley & Sons: Hoboken, NJ, USA, 2009; Volume 405. [Google Scholar]
- Pearl, J. Reverend Bayes on Inference Engines: A Distributed Hierarchical Approach; Cognitive Systems Laboratory, School of Engineering and Applied Science, University of California: Los Angeles, CA, USA, 1982; pp. 133–136. [Google Scholar]
- Pearl, J. Fusion, Propagation, and Structuring in BAYESIAN Networks; University of California, Computer Science Department: Los Angeles, CA, USA, 1985. [Google Scholar]
- Rivera, M.M. El Papel de las Redes Bayesianas en la Toma de Decisiones. 2011. Available online: http://www.urosario.edu.co/Administracion/documentos/investigacion/laboratorio/miller_2_3.pdf (accessed on 16 January 2021).
- Koshi, T.; Noble, J. Bayesian Networks an Introduction; Wiley Series in Probability and Statistics; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2009. [Google Scholar]
- Clark, J.S. Why environmental scientists are becoming Bayesians. Ecol. Lett. 2005, 8, 2–14. [Google Scholar] [CrossRef]
- Bolker, B. Ecological Models and Data in R; Princeton University Press: Princeton, NJ, USA, 2008. [Google Scholar]
- Gelman, A.; Carlin, J.B.; Stern, H.S.; Dunson, D.B.; Vehtari, A.; Rubin, D.B. Bayesian Data Analysis, 3rd ed.; Chapman and Hall/CRC Press: New York, NY, USA, 2013. [Google Scholar]
- Ruiz-Benito, P.; Andivia, E.; Archambeaou, J.; Astigarraga, J.; Barrientos, R.; Cruz-Alonso, V.; Florencio, M.; Gómez, D.; Martínez-Baroja, L.; Quiles, P.; et al. Ventajas de la estadística bayesiana frente a la frecuentista: ¿por qué nos resistimos a usarla? Ecosistemas 2018, 27, 136–139. [Google Scholar] [CrossRef]
- Pearl, J. Bayesian networks, causal inference, and knowledge discovery. UCLA Cognitive Systems Laboratory. Tech. Rep. 2001, 1–9. Available online: ftp://pike.cs.ucla.edu/pub/stat_ser/R281.ps (accessed on 16 January 2021).
- Kjærulff, U.B.; Madsen, A.L. Probabilistic Networks. Bayesian Networks and Influence Diagrams: A Guide to Construction and Analysis; Springer: Berlin, Germany, 2008; pp. 63–106. [Google Scholar] [CrossRef]
- Beltrán, M.; Muñoz, A.; Muñoz, Á. Redes Bayesianas aplicadas a problemas de credit scoring. Una aplicación práctica. Cuad. Econ. 2014, 37, 73–86. [Google Scholar] [CrossRef]
- Terán-Bustamante, A.; Davila, G.; Castañon, R. Management of Technology and Innovation: A Bayesian Network Model. Ecoo. Teória Práct. 2019, 50, 63–100. [Google Scholar] [CrossRef]
- García, C.A. Selección de Instancias y Atributos en Conjuntos de Datos Mediante Algoritmos Sobre Grafos; Universidad de Sevilla: Sevilla, Spain, 2012; Available online: https://idus.us.es/bitstream/handle/11441/15361/O_Tesis-PROV25.pdf;jsessionid=45ADCE0BADE3179EDE0B60EAF9989776?sequence=1 (accessed on 16 January 2021).
- Huete, J.F. Sistemas Expertos Probabilísticos: Modelos Gráficos. 1998. Available online: https://ruidera.uclm.es/xmlui/handle/10578/6097 (accessed on 16 January 2021).
- Lavrač, N.; Kavšek, B.; Flach, P.; Todorovski, L. Subgroup discovery with CN2-SD. J. Mach. Learn. Res. 2004, 5, 153–188. [Google Scholar]
- López Puga, J. Modelos Predictivos en Actitudes Emprendedoras: Análisis Comparativo de las Condiciones de Ejecución de las Redes Bayesianas y la Regresión Logística. Master’s Thesis, Universidad de Almería, Almería, Spain, 2011. [Google Scholar]
- CONSAR. Información estadística. Cuentas Administradas por las Afores. México. (Cifras al cierre de Noviembre de 2020). 2020. Available online: https://www.consar.gob.mx/gobmx/aplicativo/siset/CuadroInicial.aspx?md=5 (accessed on 16 January 2021).
- Wang, Y.; Ye, Z.; Wan, P.; Zhao, J. A survey of dynamic spectrum allocation based on reinforcement learning algorithms in cognitive radio networks. Artif. Intell. Rev. 2019, 51, 493–506. [Google Scholar] [CrossRef]
- Kim, H.; Park, Y. The effects of open innovation activity on performance of SMEs: The case of Korea. Int. J. Technol. Manag. 2010, 52, 236–256. [Google Scholar] [CrossRef]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).