1. Introduction
Since the mid-1960s, the research community emphasised the importance of monitoring computer systems in order to detect intrusive and malicious activities. Currently, security attacks have become more sophisticated and difficult to detect due to the advancement in network technologies, the prevalence of encryption and the fact that applications are emerging at an extremely rapid pace. On average, more than 4100 new apps are released daily on the Apple App Store and Google Play Store combined [
1], making the task of distinguishing between beginning and intrusive traffic in order to detect new security attacks, such as zero-day attacks, a challenging issue, especially for the traditional techniques of detecting intrusions that depend on pre-existing knowledge of the attack, such as signature-based methods, thus making them obsolete [
2,
3,
4].
The intrusion detection system (IDS) plays an essential role in discovering potential security threats and violations. Its main function is to continuously monitor computer and network systems for signs of intrusive activities, and it is an integral part of the defence-in-depth security paradigm. Generally, intrusion detection systems are categorised based on their data source, detection technique, deployment architecture, deployment applications, anomaly type and defence mechanism [
5,
6,
7]. A network anomaly detection system (NADS) is a type of anomaly-based IDS that applies machine learning (ML) and artificial intelligence (AI) techniques on network traffic in order to learn how to distinguish between anomalous and normal traffic [
5].
The effectiveness of an IDS is measured by several metrics and is often dependent on whether a supervised or an unsupervised model is used, as well as whether a binary classification model or a multi-classification model is used [
8]. Often, the false alarm rate (FAR) and the true alarm rate (TAR) are used to measure the performance of the IDS in detecting security attacks. The former refers to the percentage of benign events that are falsely identified as malicious, while the latter refers to the percentage of malicious events correctly flagged as threats. A perfect IDS has an FAR percentage of zero and a TAR of 100%; meaning that, the IDS identifies all anomalous and normal activities correctly without any misclassification. However, realistically, this goal is hard to achieve, if not impossible [
7].
Similarly, the performance of an NADS is dependent on its ability to correctly classify unseen traffic from previously seen traffic, which is referred to as generalisation error. Ultimately, this is a factor of the quality of the dataset, the output of the features engineering stage and the selected anomaly detection algorithm [
6].
Intrusion and anomaly detection systems face various challenges that researchers are ceaselessly trying to address. These open issues have been extensively identified in several surveys [
6,
7,
9,
10]. The lack of standard datasets that are reliable, realistic and publicly available is considered one of the major open issues for IDS/NADS. Having inaccurately labelled datasets with poorly diversified attack scenarios in addition to noisy, irrelevant and incomplete data can badly affect the credibility of the dataset. Additionally, the utilisation of different evaluation metrics makes the process of comparing different techniques impossible. Furthermore, designing an effective IDS/NADS has become a more complex task to address due to the increased complexity of network systems, as well as attack techniques. Moreover, the real-time detection of anomalous traffic is a major challenge due to the huge increase in traffic volume and speed of modern computer networks [
11]. In addition to the aforementioned challenges, detecting unknown attacks has proven to be a challenging issue for several reasons as follows:
Firstly, anomaly-based intrusion detection techniques are dependent on the conceptualisation of normality (i.e., what constitutes a normal or legitimate profile), which is a very challenging issue by itself.
Secondly, defining an inclusive profile of normal traffic is usually not feasible due to the complex similarities between normal and anomalous traffic.
Thirdly, the rapid change of anomalous behaviours either by introducing completely new attacks or enhancing already existing attacks requires a dynamically adaptable solution, which can greatly impact the performance of IDS/NADS and, at the same time, is not an easy task.
Finally, the prevalent utilisation of encryption in network traffic and applications in addition to the rapid increase in ransomware attacks create further challenges for the current intrusion and anomaly detection techniques.
In the current era of emerging attacks and advanced persistent threats (APTs), the ability to detect unknown attacks that the IDS/NADS has never encountered before has become a necessary feature for any intrusion detection technique. Over the past 10 years, several works in the literature have tried to address the issue of detecting unknown attacks. Nonetheless, we found that many of the proposed techniques lack rigorous evaluation, either empirical or formal; most importantly, they present an inconsistent definition of what constitutes an unknown attack, where the majority of works incorrectly referred to unknown attacks as unseen instances in the traditional ML sense—that is, a seen class, but unseen instance. Evidently, this is a flawed way to approach the problem. The authors identify this as an additional open research issue that is worth investigating. Here, the authors aim to address the issue of detecting unknown attacks by proposing a standard categorisation for what constitutes an unknown attack. This includes both the unknown category and the subcategory of security attacks. Then, the proposed categorisation is used to test the ability of previously proposed NADS models that employ both deep and shallow artificial neural network (ANN) classifiers to detect unknown attacks under the proposed categorisation.
The rest of the paper is organised as follows:
Section 2 highlights the state-of-the-art in the literature in terms of detecting unknown attacks.
Section 3 presents the research methodology including the proposed categorisation for unknown attacks.
Section 4 discusses the dataset selection process and the experimental analysis of the research problem.
Section 5 presents the comparative analysis results. Finally, in
Section 6, the paper is concluded, and future work is presented.
2. Literature Review
This section highlights the papers that aimed to address the issue of detecting modern unknown network intrusions in the past 10 years, as well as several recently proposed novel anomaly-based intrusion detection models.
Kukiełka and Kotulski (2010a) proposed an IDS classifier based on a multi-layer perceptron (MLP) model with the aim of detecting new types of attacks that were not defined in the knowledge discovery and data mining (KDD99) dataset. The model was trained to identify 22 types of attacks and was tested on a modified dataset, which included 14 new types of attacks that were manually generated using the Metasploit Framework [
12]. Nonetheless, all the newly generated attacks were new variants of the buffer overflow attack, which the model was already trained to identify; therefore, they were not truly new attacks. In addition, the proposed model was not able to detect the attacks until it was trained on a new feature (i.e., the “longest string sent”) that was specifically added to allow the model to identify the new variants. This implies that the model had to be trained manually to recognise such attacks.
Kukiełka and Kotulski (2010b, 2014) continued to improve on their previously proposed model in [
12] by experimenting with the support vector machine (SVM) ML algorithm [
13,
14]. Similarly, the model had to be trained manually to detect new attacks by adding new features. The model performed poorly in cases in which the attack pattern highly resembled normal traffic (e.g., SNMP get and guess attacks), thus rendering the proposed model inapplicable.
Bao et al. (2015) highlighted the lack of a well-defined methodology to detect new attacks and proposed a general reasoning methodology to infer new attacks from their factors. The authors assumed that each attack consists of several basic factors that occur in a specific pattern and that some attacks share similar factors. Based on the aforementioned assumption, they proposed a forward deduction method that utilises strong relevant logic to infer new attacks. Finally, the authors defined six factors to identify new attacks, which are the attacker goals, methods and resources in addition to the target resources, authentication methods and countermeasures [
15]. The proposed method was not analysed nor evaluated; moreover, the defined factors are not sufficient to detect modern attacks such as APTs. In addition, the authors did not provide an exact definition for what constitutes a new attack, nor a specific scope for which the proposed method can be used (network attacks, OS attacks, software vulnerabilities, etc.).
Bao et al. (2016) presented an evaluation for their previously proposed methodology in [
15], focusing on the detection of unknown attacks on cryptographic protocols [
16]. The authors utilised two basic mutual authentication protocols to demonstrate potential attacks on cryptography-based protocols in order to validate the proposed methodology. Nevertheless, the proposed method did not provide a rigorous evaluation other than the common manual testing of cryptographic functions.
Ajjouri et al. (2016) proposed a distributed hierarchical agent-based IDS architecture to learn new patterns of security attacks using the case-based reasoning technique [
17]. The proposed technique relies on detecting new attacks by learning from the similarities with known attacks. The proposed architecture was neither evaluated empirically nor formally, which makes it unverifiable.
Sellami et al. (2017) proposed cloud, agent and anomaly-based IDS. The proposed model works by pushing an agent to the device trying to connect to the cloud service provider (CSP). This agent acts as an IDS or an intrusion prevention system (IPS). Once the user is successfully authenticated, the behaviour is compared to a predefined normal profile to detect potential anomalies by calculating the projection distance between the observed behaviour and the predefined normal behaviour. An anomaly event is triggered only when this distance is greater than a certain threshold [
18]. The proposed model resembles the ordinary agent-anomaly-based IDS. In addition, the model’s ability to detect new attacks is merely based on the definition of anomaly-based IDS and was presented without empirical evaluation.
Aljawarneh et al. (2017) proposed a hybrid anomaly-based IDS that uses seven classifiers, namely J48, Meta Pagging, RandomTree, REPTree, AdaBoostM1, DecisionStump and naive Bayes (NB), in a voting-based ensemble learning model to improve the detection accuracy of said classifiers [
19]. The proposed model utilises mutual information-based feature selection to reduce the number of features selected to train the model. The authors approached the problem as both a binary classification and multi-class classification problem using the NSL-KDD dataset and compared their results with J48, SVM and NB. The proposed model showed improved results when comparing the three algorithms under both classification problems (i.e., binary and multi-class).
Meira (2018) presented an experimental study into the detection of unknown attacks using unsupervised learning techniques. The study relied on the hypothesis that unknown attacks will appear as outliers. Four algorithms were evaluated—autoencoder neural network, K-means, K-nearest neighbour (k-NN) and isolation forest—using two datasets (i.e., NSL-KDD and ISCX-IDS). The datasets were processed to separate the normal traffic for training and the abnormal traffic for testing. The results showed that all algorithms performed poorly in terms of precision. The recall value was higher when compared with the precision [
20]. The proposed technique utilises a one-class classification model, which means that the classifier only learns the normal traffic, and any variation in testing is considered an anomaly. Several attacks can share similar characteristics with normal traffic; therefore, these will be misclassified, which is evident from the poor precision.
Amato et al. (2018) proposed the use of an MLP classifier on the KDD99 dataset and explored the use of KNIME software for features selection and data preprocessing [
21]. Although the authors stated that the proposed model is capable of identifying new types of security attacks without retraining the entire network, their work did not provide any experimental or theoretical analysis to support this.
Ahmad et al. (2018) addressed the efficiency issue of using machine learning algorithms, namely SVM, random forest (RF) and extreme learning machine (ELM), to handle large datasets in training intrusion detection classifiers [
22]. The authors evaluated the algorithms on the NSL-KDD dataset using two splits: 90% and 80% for the training set, with 10% and 20% for the testing set, respectively. Their results suggested that ELM has better performance when presented with large data, while SVM performed the best with relatively small data.
Santikellur et al. (2019) proposed and evaluated the use of a new multi-layer network-based IDS to improve the detection rate of modern network attacks. The proposed system implements a hierarchical architecture of multiple machine learning models optimised using evolutionary computing algorithms organised into a two-layer architecture. The first layer consists of several variants of three binomial classifiers (i.e., AdaBoost, ANN and NB), while the second layer has a decision tree (DT) multi-class classifier [
23]. The authors evaluated the system using the CIC-IDS-2017 dataset. Although the authors stated that the proposed approach can significantly improve the detection rate of modern unknown attacks, they did not evaluate the system performance when faced with an unknown attack.
Qureshi et al. (2019a) studied the performance of using a random neural network (RNN) classifier to detect anomalous traffic in the IoT environment [
24]. The authors compared the proposed model with seven other machine learning algorithms using the NSL-KDD dataset and evaluated its performance using the full features and selected features based on the feature-selection techniques highlighted in [
25]. The results showed that the proposed model greatly outperformed the other models in terms of precision and accuracy.
Qureshi et al. (2019b) proposed a hybrid anomaly-based intrusion detection model using RNN with the artificial bee colony (ABC) algorithm to find the optimal weights for the neurons [
26]. The authors empirically evaluated the proposed model using the NSL-KDD dataset and under multiple learning rates. The results reported better performance measures for the proposed model when compared with traditional RNN models utilising the gradient descent algorithm.
Khare et al. (2020) proposed a hybrid model that combines the spider monkey optimisation (SMO) algorithm to reduce the dataset dimensionality with a deep neural network (DNN) classifier [
27]. The proposed model showed a 3.3% improvement in the F1-score over a standalone DNN model with significantly reduced training time using the KDD99 dataset.
Khraisat et al. (2020) proposed a hybrid two-layer model that combines signature-based IDS with anomaly-based IDS with the aim of detecting known and unknown attacks [
28]. The model uses the signature-based IDS to detect known attacks and then feeds the unknown signatures to the anomaly-based IDS to detect the unknown attacks.
Tang et al. (2020) proposed a deep learning IDS for SDN using binary DNN and gated recurrent neural network (GRU-RNN) classifiers [
29]. The proposed model demonstrated better results in terms of the F1-measure when compared with the NB, DT and SVM classifiers using the NSL-KDD dataset.
Kim et al. (2020) designed a convolutional neural network (CNN) model to detect denial of service (DoS) attacks [
30]. The authors utilised the KDD99 and the CSE-CIC-IDS-2018 datasets to train and test the model, where the comma separated value-based datasets were transformed into multidimensional vectors and then encoded into RGB and greyscale images to create new image-based datasets. The proposed design was applied as both a binary and multi-class classifier and then compared against an RNN-based classifier.
Jo et al. (2020) devised three field-to-pixel-based preprocessing techniques to transfer packet-based datasets into image-based datasets for IDS evaluation [
31]. The proposed methods were used to transfer the NSL-KDD dataset into greyscale images and tested using a CNN-based model against known and unknown attacks.
In conclusion, it is apparent that, although many researchers have tried to address the issue of detecting unknown attacks [
12,
13,
14,
15,
16,
17,
18,
20,
21,
23,
28,
29,
31], the proposed techniques either lacked rigorous analysis and evaluation [
15,
16,
17,
21] or had a flawed definition of unknown attacks [
12,
13,
14,
18,
23]. The lack of a complete solution for the problem demonstrates the need for further research in this area.
Table 1 summarises the related work and highlights its limitations.
3. Research Methodology
In this section, the research problem and methodology are identified and stated. Additionally, the new categorisation of unknown attacks is proposed, justified and explained.
In this study, the researchers started by surveying the literature from the past 10 years for studies that focused on detecting unknown security attacks. Thereafter, they found a need for the proposal of a standard categorisation of unknown attacks. Then, several common datasets that have been extensively used by the research community were studied and analysed with the goal of identifying which of them could be used to study unknown attacks under the proposed categorisation. Furthermore, two datasets and two ANN models were selected, and a series of experiments were conducted to study whether modern anomaly-based intrusion detection models are capable of detecting unknown attacks under the proposed categorisation. The research problem was addressed as both a binary classification and multi-class classification problem, which ensures that the results are more comprehensive.
3.1. Problem Statement
Security attacks are becoming more targeted and less general, with an epidemic escalation in attack complexity [
32]. Attackers are currently relying more on unknown attack techniques that resemble normal traffic and are fragmented, encrypted or obfuscated to avoid detection by traditional intrusion detection systems [
33]. This is evident from the study of the statistics of the common techniques used in cyber-attacks published in monthly reports [
34].
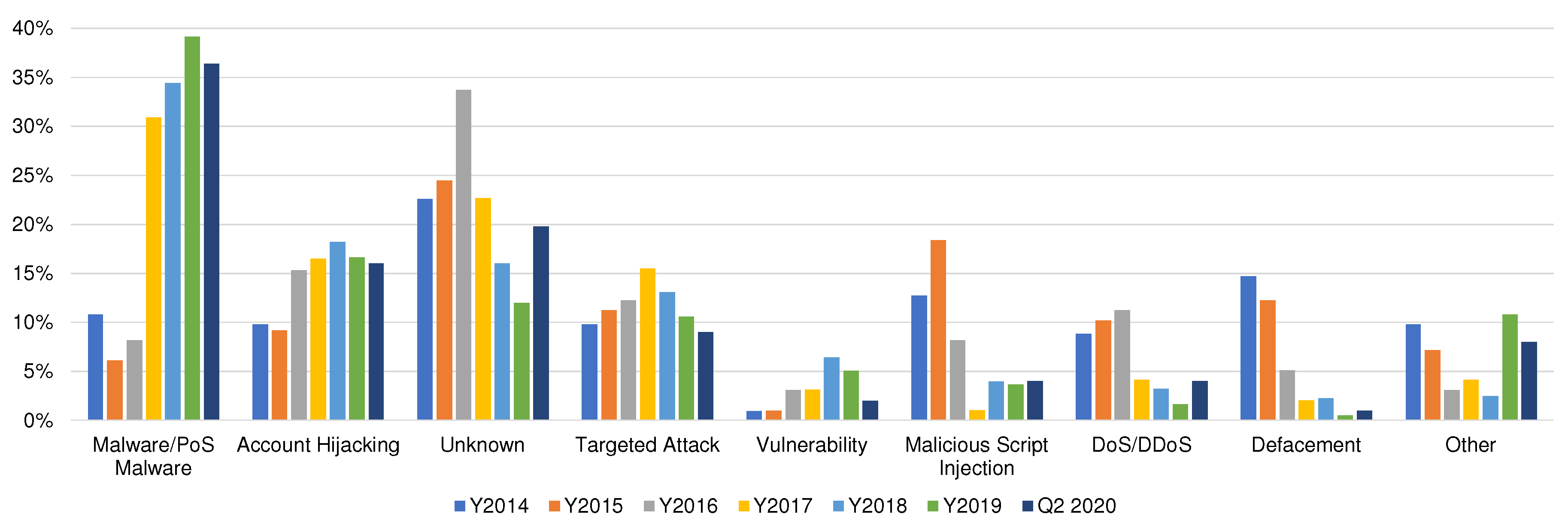
Figure 1 shows the distribution of the attack techniques from 2014 to Q2 2020. When comparing the top attack techniques over the past six years, two conclusions can be drawn: firstly, unknown techniques were the dominant attack vector for the years 2014–2016 and displayed a steady increase in the that period; secondly, unknown techniques witnessed a noticeable decrease in the period from 2017 to 2019. One might argue that this decrease is merely a result of attackers relying on easier attack vectors such as account hijacking, in addition to the rise of cyber-crime as a motivation behind security attacks from 62.3% in 2014 to 85.82% ending Q2 in 2020, which explains the prominent inflation in the number of malware-related attacks in the same period (i.e., 2017–2019). In addition, unknown attacks were the third most common kinds of security attacks in the Middle East and North Africa (MENA) region in March 2019 [
35].
When considering the different IDS types based on detection techniques and their ability to handle unknown attacks, signature-based IDS is inherently incapable of detecting either completely new attacks or any new variation of existing attacks. This is due to its design, where an attack is identified by matching it to a well-known signature. On the other hand, anomaly-based IDS is designed to learn normal behaviour and flags any variation as anomalous behaviour. This design makes the NADS more suitable for detecting unknown attacks. Nonetheless, it still suffers from several issues: fundamentally, it is not straightforward to define normal traffic, and there is a great intersection between the boundaries of normal and anomalous behaviour, making it a challenging task for NADS to detect unknown attacks. Conversely, specification-based IDS manually defines the characteristics of a specific network protocol and identifies any variation as an anomaly; thus, it is able to detect both known and unknown attacks. This technique is susceptible to enormous errors since not all applications strictly adhere to protocol specifications.
From the literature review, the researchers found that there is an apparent lack of a constant definition of what constitutes an unknown attack. We aimed to address this issue by proposing a standard categorisation to define an unknown attack and then studying the ability of modern ML models to detect unknown attacks under the proposed categorisation. In this study, the researchers focused on shallow and deep supervised ANN models in NADS.
3.2. Unknown Attacks
In this paper, the researchers propose a new categorisation of unknown attacks, comprising the unknown attack category and unknown attack subcategory:
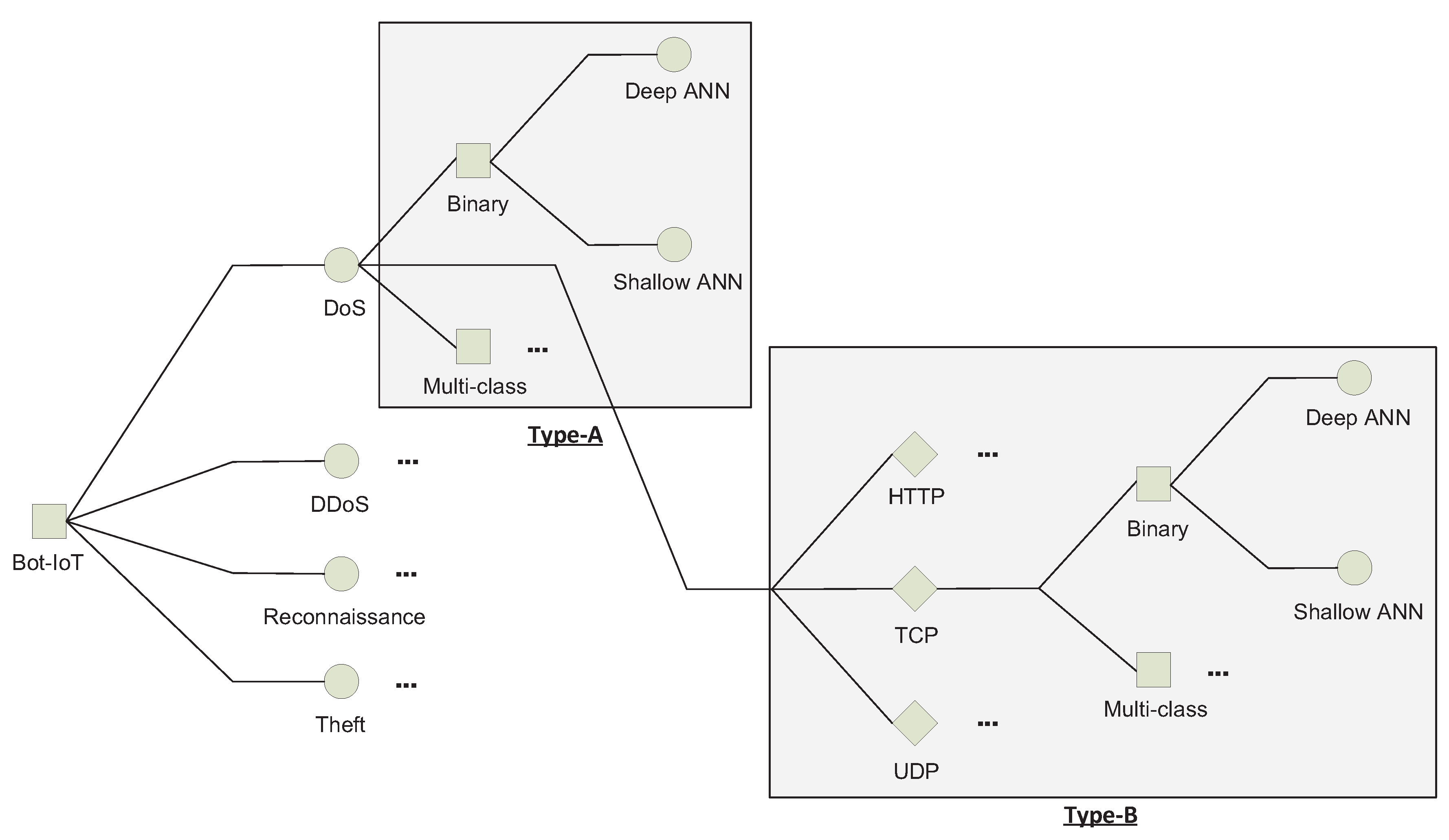
Unknown attack category: In terms of supervised machine learning, an unknown attack category refers to a completely new class label that the classifier has not encountered before in the training set; for example, if the classifier was not trained on DoS attacks and encountered DoS attacks in the testing set. The authors refer to this type of unknown attacks as Type-A.
Unknown attack subcategory: This refers to a semi-new class label (i.e., a subclass); for example, if the classifier was indeed trained on detecting some DoS attack types, such as HTTP flooding, but encountered session initiation protocol (SIP) DoS attacks in the testing, which were not available in the training set yet share some characteristics with other DoS attacks present in the training set. The authors refer to this type of unknown attacks as Type-B.
The rationale behind the two-type proposed categorisation for unknown attacks detection is that anomaly-based classification requires the model to be trained on one or more datasets; however, having an all-inclusive dataset that contains all types of known attacks is not realistic. Moreover, unknown attacks are constantly ranked among the top attack distribution techniques since 2014 as shown in
Figure 1. Furthermore, the proposed categorisation is consistent with how attacks are generally categorised in the real-world. For example: DoS attacks can occur from different types of intrusive activities, namely volumetric, resource exhaustion and application layer attacks. Meanwhile, each type of said attack constitutes multiple sub-types of the same attack. Internet control message protocol (ICMP), transmission control protocol (TCP), user datagram protocol (UDP) and internet protocol security (IPSec) flood attacks are examples of sub-types of DoS volumetric attacks. Additionally, having a consistent categorisation of unknown attacks helps to alleviate the confusion currently present in the literature; several researchers have incorrectly referred to new instances in a testing dataset or previously seen anomalies as unknown attacks. This categorisation provides a standard metric for evaluating works on unknown attack detection, which is currently lacking, as stated in [
10].
4. Comparative Analysis
This section presents the comparative analysis to empirically study the ability of a modern NADS that utilises shallow and deep supervised ANN models to detect Type-A and Type-B unknown attacks under the proposed categorisation. Ninety-two experiments were conducted on two datasets (i.e., UNSW-NB15 and Bot-IoT) using deep and shallow ANN classifiers. With each experiment, both binary and multi-class supervised classifiers were built to identify the ability of the model to detect Type-A and Type-B of each attack class in the UNSW-NB15 and Bot-IoT datasets. Then, the accuracy, F1-score and classification error rate of unknown attack detection were calculated for each attack class for Type-A and for each subclass for Type-B. The results are presented and discussed in the
Section 5.
4.1. Dataset Selection
The first stage of building an anomaly-based IDS includes the selection of a suitable dataset, which is used to train and evaluate the performance of the detection model [
10]. The dataset has to be collected from a real network and correctly represent both benign and malicious network traffic to be representative. In nature, a true representative dataset is not balanced, because in reality, malicious traffic constitutes a small percentage of the overall traffic, which creates a challenge for the design of an accurate ML model [
36].
Several datasets are available for evaluating IDS. Each dataset has its unique characteristics that make it suitable for certain types of research problems while unsuitable for others [
36]. In order to find the correct datasets for this study, the researchers surveyed the most common and widely used datasets to indicate whether each dataset has both attack class and subclass labels, thus making it suitable for the study of unknown attacks. The results are shown in
Table 2.
In this study, the authors utilised two datasets: the UNSW-NB15 and the Bot-IoT datasets. Both datasets were generated by the same research laboratory using the same platform (i.e., Ixia PerfectStorm traffic generator), thus ensuring comparable results even though only Type-A unknown attacks can be generated from the UNSW-NB15 dataset. Moreover, they contain modern realistic network traffic with many benign and malicious attack types, as well as being validated and extensively studied by the research community. Furthermore, having both a network dataset and an IoT dataset ensures that the results can be generalised on both types of networks.
As described in
Table 2, UNSW-NB15 has two labels, Category and Label, where the former is a multi-class label that hosts 10 classes, namely Analysis, Backdoors, DoS, Exploits, Fuzzers, Generic, Reconnaissance, Shellcode, Worms and Benign, whilst the latter is a binary class label with the value “0” indicating a benign instance and “1” an attack. The benign traffic constitutes 87% of the entire dataset, leaving 13% of the dataset as attack traffic distributed amongst the nine attack categories. Clearly, the dataset is not balanced; nonetheless, the real network traffic is not balanced either, as benign traffic is the predominant type of traffic [
36].
On the other hand, the Bot-IoT has three labels; Attack, Category and Subcategory. The first is a binary class label with the value “0” indicating normal traffic and “1” attack traffic. The second is a multi-class label with four attack classes; DDoS, DoS, Reconnaissance and Theft, in addition to Normal. The third label is also a multi-class label, which contains seven attack classes: HTTP, TCP, UDP, Data Exfiltration, Keylogging, OS Fingerprint and Service Scan, in addition to the Normal class. In contrast with UNSW-NB15, the benign traffic in the Bot-IoT dataset constitutes less than 1% (i.e., 0.01%) of the entire traffic; therefore, subsampling had to take place. We used stratified sampling with a maximum cut of 9543 samples in order to include all the benign traffic and ensure a uniform distribution of the other attack labels.
Table 3 shows the number of instances in the Bot-IoT before and after applying subsampling. It is worth mentioning that the Bot-IoT dataset has a smaller set, with 5% of the full dataset but with more features. In this work, the full dataset was used.
4.2. Feature Engineering
Feature engineering involves the creation of a set of features from the collected network traffic to be used by the ML model to classify the traffic. This stage includes four major tasks: feature generation, feature selection, feature conversion and feature normalisation [
10]. In feature generation, a collection of features is created from the raw captured network traffic. In feature selection, a subset from the generated features is selected to train the model. Association rules’ mining, principal component analysis (PCA) and independent component analysis (ICA) are some of the techniques used in this stage [
5]. Both tasks can greatly impact the overall performance of the ML model; general, poorly generated or selected features will result in a poorly performing model. In feature conversion, the format of the data is converted to be suitable for the selected algorithm (e.g., converting textual features into numerical features). Some ML libraries often perform this stage implicitly when needed. Finally, in feature normalisation, a function is used to scale the numerical values into a specific interval (e.g., [0–1]).
After the two datasets (i.e., UNSW-NB15 and Bot-IoT) were selected, they underwent several data preprocessing steps. The authors applied the same data preprocessing steps used in [
46] to cleanse both datasets. Both datasets are published as multiple CSV files; therefore, the first step was to merge each dataset file into a single CSV file, then remove duplicate instances. The second step was to transform textual features into numerical values. In UNSW-NB15, three features were encoded (i.e., protocol, state and service), and in Bot-IoT, three features were also encoded (i.e., protocol, state and flags). The third step was to remove statistically insignificant features. In UNSW-NB15, the source and destination IP address features were removed, while in the Bot-IoT, 10 features where removed, namely packet sequence ID, timestamp, source/destination IP address, source/destination MAC address, source/destination country code, and source/destination organisationally unique identifier (OUI). In the fourth step, missing values were replaced with zero, then the numerical features where normalised into the interval [0, 1] using max-min normalisation. Finally, dataset instances were randomly shuffled.
4.3. Experimental Analysis
In this study, ninety-two experiments were conducted to test the ability of modern shallow and deep ANN models to detect unknown attacks under the proposed categorisation. Mainly, the experiments were divided into two parts: the first part involved testing the ability of shallow and deep multi-layer feed forward ANN models to detect unknown attacks of Type-A and Type-B under binary classification, whilst the second part involved the same test, but under multi-class classification.
Approaching the problem as both a binary and multi-class supervised classification problem ensured that the results were more representative. When testing for Type-A attacks, both datasets were used (i.e., UNSW-NB15 and Bot-IoT); however, only Bot-IoT was used to test Type-B attacks. In the literature, an ANN model with one/two hidden layers is referred to as a shallow model, whereas a model with two or more hidden layers is considered a deep structural model [
7,
47]. The general configurations for the shallow and deep ANN classifiers were proposed in [
46,
48], respectively, as shown in
Table 4.
Over the years, several ML algorithms have been utilised to build classification models for IDS/NADS, including but not limited to ANN, DT, K-means, k-NN, NB, RF and SVM. The use of these algorithms has been extensively studied in the literature [
8,
10,
49,
50], with each algorithm having its strengths, weaknesses and special requirements, thus making it suitable for certain types of applications. ANN models have been gaining remarkable recognition in the field of intrusion detection due to their uncanny ability to handle high-dimensional data and big data datasets [
46,
48,
49,
50]. It has been shown that ANN models outperform other ML models such as SVM, NB and RF [
50]. Notably, the computational complexity and model performance increases with the number of ANN layers; therefore, deep ANN models have been shown to outperform shallow ANN models. In this study, the researchers opted to examine the performance of both deep and shallow ANN models at detecting unknown attacks in order to present representative results.
In this study, generating the testing sets is considered to be the most important step because it represents the basis for the evaluation of the proposed categorisation of unknown attacks; therefore, the first step in each experiment was to generate the training, validation and testing sets from each dataset. The testing sets were generated based on the class for Type-A attacks and subclasses for Type-B attacks in each dataset.
The procedure for generating the testing, training and validation sets for the binary classification model starts by defining a set of distinct attack classes for Type-A or subclasses for Type-B, which were extracted from the original dataset (e.g., DoS, DDoS, Reconnaissance and Theft for Type-A in the Bot-IoT dataset and Data Exfiltration, Keylogging, OS Fingerprint, Service Scan, HTTP, TCP and UDP for Type-B). Thereafter, all the instances of each class or subclass (based on the unknown attack type being generated) in the set were recursively extracted and saved as the testing set for that type of attack; meaning that the testing set only contains one class, which represents the unknown attack. Then, the remaining instances were split into training and validation sets using a fixed seed to ensure uniformity across all splits, with ratios of 0.9 and 0.1, respectively. This ensured that the testing set contained only one class of unknown attack and each corresponding training and validation set contained all the other benign and attack classes (except for that unknown attack).
For example, the testing set for the DoS attack of Type-A contained all the instances with a class label equal to DoS and nothing else, whilst the training and validation sets contained all the other instances in which the class label was not DoS. Following the same logic, the testing set for the UDP DoS attack of Type-B contained all the instances in which their class label was DoS and the subclass label was UDP and nothing else, whereas the training and validation sets contained all the other instances in which the class and subclass label were not DoS and UDP, respectively. Since the generated sets were used to evaluate binary classification models, both the class and subclass labels were removed, leaving only the binary class label. Conversely, when generating sets for evaluating multi-class classification models, the binary class label was removed, and the class label was kept for Type-A and the subclass label for Type-B. The procedure for generating the testing, training and validation sets is fully described in Procedure 1.
The procedure takes two variables as input:
D and
C. Variable
D represents the dataset dimensions, while variable
C holds the set of distinct attack classes or subclasses. The output is multiple subsets (i.e., training, testing and validation). The number of generated subsets depends on the size of variable
C, which is the number of distinct attack classes or subclasses. In Lines 1-29, the procedure loops through each class or subclass in variable
C. In Line 2, a copy of the original dataset is made. In Lines 3–5, the output subsets are initialised. In Lines 6–27, the procedure loops thorough each instance in the input dataset. In Lines 7–10, the procedure verifies if the attack class of the current instance matches the one in the outer loop, and if so, it will be added to the testing subset and removed from the temporary dataset. Lines 11–14 verify whether the attack subclass matches the subclass of the outer loop. In this case, the instance will be appended to the testing subset. Lines 15–26, confirm the problem type, namely binary classification and multi-class classification of Type-A or Type-B. In case it is a binary classification problem, both attack and sub-attack labels are dropped, and only the binary label is stored. Conversely, the binary and the sub-attack labels are dropped when it is a Type-A multi-class problem, whereas the binary and the attack labels are both dropped if it is a Type-B multi-class problem. Finally, in Line 28, a function is called to split the temporary dataset into training and validation subsets using the stratified random split method with 90% for training and 10% for validation. The function is based-on a pseudo-random function, which uses a fixed seed to ensure the repeatability.
| Procedure 1 Generate testing, training and validation sets for unknown attacks. |
Input: D, dataset of size
Input: [], set of size l; Type-A or Type-B
Output: Testing subsets of size
Output: Training subsets of size
Output: Validation subsets of size
- Ensure:
- Ensure:
- 1:
for all
do - 2:
- 3:
- 4:
- 5:
- 6:
for all
do - 7:
if Type-A and d.class == c then - 8:
+= d - 9:
-= d - 10:
end if - 11:
if Type-B and d.subclass == c then - 12:
+= d - 13:
-= d - 14:
end if - 15:
if BinaryClass then - 16:
del
- 17:
del
- 18:
end if - 19:
if MultiClass and Type-A then - 20:
del
- 21:
del
- 22:
end if - 23:
if MultiClass and Type-B then - 24:
del
- 25:
del
- 26:
end if - 27:
end for - 28:
StratifiedRandomSplit(, 0.9, 1586512076128) - 29:
end for - 30:
Function StratifiedRandomSplit(l, r, s): - 31:
return from l using stratified random sampling with seed s - 32:
End Function
|
As previously described in
Table 2, the UNSW-NB15 dataset has nine attack classes and no subclasses; therefore, only unknown attacks of Type-A were generated. For each of the nine attack classes, four models were built, trained and tested, two of which were shallow and deep binary classification models, and the other two were multi-class classification models, resulting in a total of 36 models. On the other hand, the Bot-IoT has both class and subclass labels; thus, both Type-A and Type-B testing sets were generated. Four Type-A attack classes and 10 Type-B attack subclasses were found; therefore, 16 binary classification models were built, in addition to 40 multi-class classification models. Overall, ninety-two models were used to evaluate the ability of shallow and deep ANN classifiers to detect unknown attacks under the proposed categorisation.
Figure 2 illustrates the process of generating the subsets and the associated ML models.
5. Results
In this section, the results are presented and discussed for each dataset. Each model was trained, validated and tested 30 times, and the overall average value for all the runs is reported. This was done to ensure that the results were as accurate as possible. The accuracy, F1-score and classification error rate values were then used as the evaluation metrics to measure the model’s ability to correctly classify unknown attacks. The accuracy in Equation (
1) is an evaluation metric that measures the ratio of the correctly classified instances to the total number of instances. The F1-score in Equation (
2) estimates the model’s ability to correctly classify instances as a weighted average of the precision and recall. The classification error rate in Equation (
3) measures the ratio of the misclassified instances to the total number of instances. A higher accuracy and F1 value imply better performance, while a higher classification error rate value implies poor performance.
Most importantly, the definition of “correctly classified” should be properly set and explained. For the binary classification models, the classification was considered correct (i.e., true) if the instance in the testing set was classified as an attack; otherwise, it was considered a misclassification (i.e., false). This is consistent with regular machine learning generalisation error measurements.
Conversely, when working with multi-class classification models, one cannot simply apply the same concept nor follow the norms of machine learning generalisation error measurements, because the class in the testing set is not present in the training set. Therefore, the model has never learned to classify the class in the first place, and thus, it is an unknown class/attack. Consequently, for multi-class Type-A models, if the instance is classified as benign, it is considered a misclassification; otherwise, it is considered correct. The logic behind this is that the classifier was able to correctly identify it as an attack, but placed it into an incorrect category because it was never trained to learn that class. This is analogous to a child who has just started learning about animals and who broadly knows cats, dogs, birds and fishes. Then, he/she is presented with a picture of a horse and asked to classify it. If he/she says that it is an animal, then surely his/her response could be construed as correct given that he/she does not know any better. On the other hand, with multi-class Type-B models, the predication is considered correct only if the model assigns the instance a subclass from within its parent class. The logic behind this is that the model was able to approximate the subclass to the closest correct one; thus, this is considered correct classification. Returning to the previous analogy, if the same child also gained knowledge about a few breeds of dog—for example, poodle and bulldog—and then was presented with a picture of a German shepherd, if he/she were able to classify it as a dog, then he/she would be considered to be correct; otherwise, his/her classification would be clearly incorrect.
In
Table 5, the results of the binary classification models using the UNSW-NB15 dataset are summarised. They show that both the shallow and deep models were able to detect four out of the nine Type-A unknown attacks (i.e., Analysis, DoS, Exploits and Shellcode) with a marginal classification error rate and high accuracy and F1-score values, which is reasonable given that it is a binary classifier. On the other hand, the shallow classifiers were completely unable to detect three types of unknown attacks, namely Worms, Backdoors and Generic attacks, with a 100.00% classification error rate and zero accuracy and F1-score. When compared with their corresponding deep classifiers, both Worms and Backdoors attacks were detected with minimal error rate (i.e., 2.87% and 0.77%, respectively). The classification error rate for the Generic attacks class was still high (i.e., 68.87%) with poor accuracy (i.e., 31.13%) and a poor F1-score value (i.e., 47.48%) using the deep classifier, suggesting that for Backdoors and Worms classes, the deep models suffered from over-fitting, which is a common issue with ANN models. Interestingly, with regard to the Fuzzers and the Reconnaissance classes, the deep classifiers performed poorly in comparison with the shallow classifier, with classification error rates of 67.63% and 40.85% as opposed to 8.33% and 17.09%, respectively. It is clear from the experimental result that neither the deep nor the shallow models were able to detect all types of unknown attacks with high accuracy and F1-score values while maintaining a marginal classification error rate.
In
Table 6, the results of the multi-class classification models using the UNSW-NB15 dataset are shown, and they clearly indicate that the shallow classifiers were unable to detect all of the unknown attacks with a high classification error rate and low accuracy and F1-score values, except for the Worms attack, in which both accuracy and F1-score values were high (98.85% and 99.42, respectively) and the classification error rate was significantly low (i.e., 1.15%); this is as it should be, as shallow classifiers are known to yield good results with smaller datasets [
47]. On the other hand, the deep multi-class classifiers were able to detect four out of the nine unknown attacks with a minimal classification error rate (<
), namely Analysis, DoS, Shellcode and Worms attacks. As regards the remaining attacks, the classification error rate was considerably high (between 43–95%). Interestingly, the deep classifiers performed poorly in comparison with shallow classifiers under the Generic and the Worms attacks, with classification error rates of 76.67% and 9.77% as opposed to 43.35% and 1.15%, respectively.
From these results, one could conclude that shallow multi-class classifiers are ineffective at detecting unknown attacks, with an overall weighted average classification error rate of 55.57%. Conversely, although the deep multi-class classifiers were able to detect several unknown attacks with a marginal classification error rate and an overall weighted average classification error rate of 28.28%, the fact that several other unknown attacks were missed with considerably high classification error rates and low accuracy and F1-score means that they are not a suitable solution. Furthermore, because the shallow classifiers outperformed their respective deep classifiers in terms of accuracy and F1-score when detecting several unknown attacks, one cannot simply exclude shallow classifiers and only rely on deep classifiers.
The results for the Bot-IoT dataset using binary classification models under Type-A unknown attacks are summarised in
Table 7. Both shallow and deep models showed a negligible classification error rate for the DDoS class (<
). Conversely, for the remaining classes, the classification error rate ranged from 12.43% up to 85.97% with a weighted average of 20.60% for the shallow models and 49.94% for the deep classifiers. Comparing these results with those obtained using the UNSW-NB15 dataset, there was clearly a noticeable improvement in the overall classification error rate, accuracy and F1-score; however, when comparing the generalisation error metrics for the same classes (i.e., DoS and Reconnaissance) from both datasets, the classification error rate was considerably higher in both datasets.
Table 8 shows the results for the Bot-IoT dataset using the multi-class models for Type-A attacks. The shallow classifiers showed negligible classification error rates across all attack classes (<
), high accuracy (>
) and high F1-score (>
), whilst the deep models showed considerable classification error rates (>
) for all classes except DDoS (<
). This can be explained by the fact that shallow models outperform deep classifiers with smaller datasets as ANN models tend to stick to local optima.
For Type-B unknown attacks, the results were convergent for both binary and multi-class models with an overall weighted average classification error rate of around 25% for the shallow models and 22.5% for the deep models. Interestingly, DoS and DDoS classes showed the lowest error rates amongst all attack classes, except for the DDoS HTTP class, which showed the highest error rate under both shallow (>
) and deep (>
) classifiers.
Table 9 and
Table 10 summarise the results for binary and multi-class Type-B unknown attacks using the Bot-IoT dataset, respectively.
When taking into consideration the high overall weighted average classification error rate from all experiments (50.09%), it is obvious that neither shallow nor deep models can be considered a viable solution for the detection of unknown attacks under the proposed categorisation. This supports our research proposal, as the current common classifiers were not able to detect unknown attacks with an acceptable generalisation error metrics.
6. Conclusions
An intrusion detection system is an effective tool for detecting potential security threats and violations. Nonetheless, detecting unknown attacks has proven to be a challenging issue due to the constant growth of new attacks. Detecting unknown attacks is an open research area. The literature lacks a consistent definition of what constitutes an unknown attack. In this work, the authors proposed a new categorisation to define unknown attacks as Type-A of unknown attacks, which represents a completely new category of attacks, and Type-B, which represents unknown attacks within already known categories of attacks. Then, the authors provided an experimental evaluation using modern shallow and deep ANN models and two benchmark datasets that are commonly used in IDS research. A total of 92 different models were tested, and the results showed that they were incapable of detecting several classes of unknown attacks, as well as exhibiting a significant overall error rate of around 50%, which suggests the need for innovative approaches and techniques to address this problem. Machine learning (ML) classification algorithms, supervised and unsupervised alike, are used to handle problems with predefined classes of data at the model creation time. Whether the data are labelled or not, the number of overall classes, which represents the number of attack categories in our domain here, is fixed at the model creation time during the learning stage. Classifying, with high accuracy, the unknown security attacks that do not exist during the ML model creation requires a different approach.
As a future work, the authors are planning to:
Evaluate the performance of hybrid supervised and unsupervised anomaly-based ML models in detecting unknowns attacks.
Examine whether the lightweight ML classifiers are capable of detecting unknown attacks in the IoT environment.
Study the ability of discovering an adversarial attack that might result in misled prediction as a type of unknown attack.






{kind=link}
{kind=link}