


Enhancing the Resilience of a Federated Learning Global Model Using Client Model Benchmark Validation

 ,
,  , ,
, ,
Abstract
1. Introduction
- Privacy and security refer to how private data in FL are protected from leakage. It is vital to protect the privacy of FL data and model parameters since they are regarded as sensitive information belonging to their owners. This includes preventing the unlawful use of data that can identify individuals or households. The data includes names, ages, genders, face photos, and fingerprints. Commitment to privacy protection is a critical aspect in establishing the reliability of an FL system. This is due to regulatory and legal restrictions, as well as the value of the data.
- Robustness and Resilience refers to the ability of FL to retain stability under harsh conditions, particularly those caused by attackers. This is critical since the real-world situations in which FL systems operate are often complicated and unpredictable. Robustness is an important aspect that determines the performance of FL systems in real applications. A lack of robustness may result in unanticipated or detrimental system behaviors, weakening trustworthiness.
- Fairness and Trust is the term for a set of guiding ideals and moral obligations that demand that FL systems be free from bias, partiality, or discrimination against individuals or groups. This is accomplished by virtue of three different aspects of fairness: attribute fairness, which guarantees similar predictions for similar individuals or keeps the model unaffected by sensitive characteristics like gender or age; performance fairness, which guarantees a uniform distribution of accuracy across clients; and contribution fairness, which rewards clients based on their contributions to the system. These guidelines are essential for advancing reliable and moral FL models that successfully fulfill their stated goals.
- Explainability is the degree to which people can understand and provide an explanation for the choices made or the results obtained by an FL system is known as. This idea basically consists of two parts: post hoc explainability, which is creating external mechanisms to clarify the choices the FL system makes to determine whether the system’s results can be explained, and ante hoc explainability, which concentrates on the transparency and understandability built into the FL system design to determine whether each process within the system is explainable. Explainability is essential for an FL system since it builds user trust. Additionally, it encourages more fruitful communication between domain specialists and FL systems, especially in industries like banking and healthcare. This increased comprehension enables the system to produce more reliable and compliant decisions.
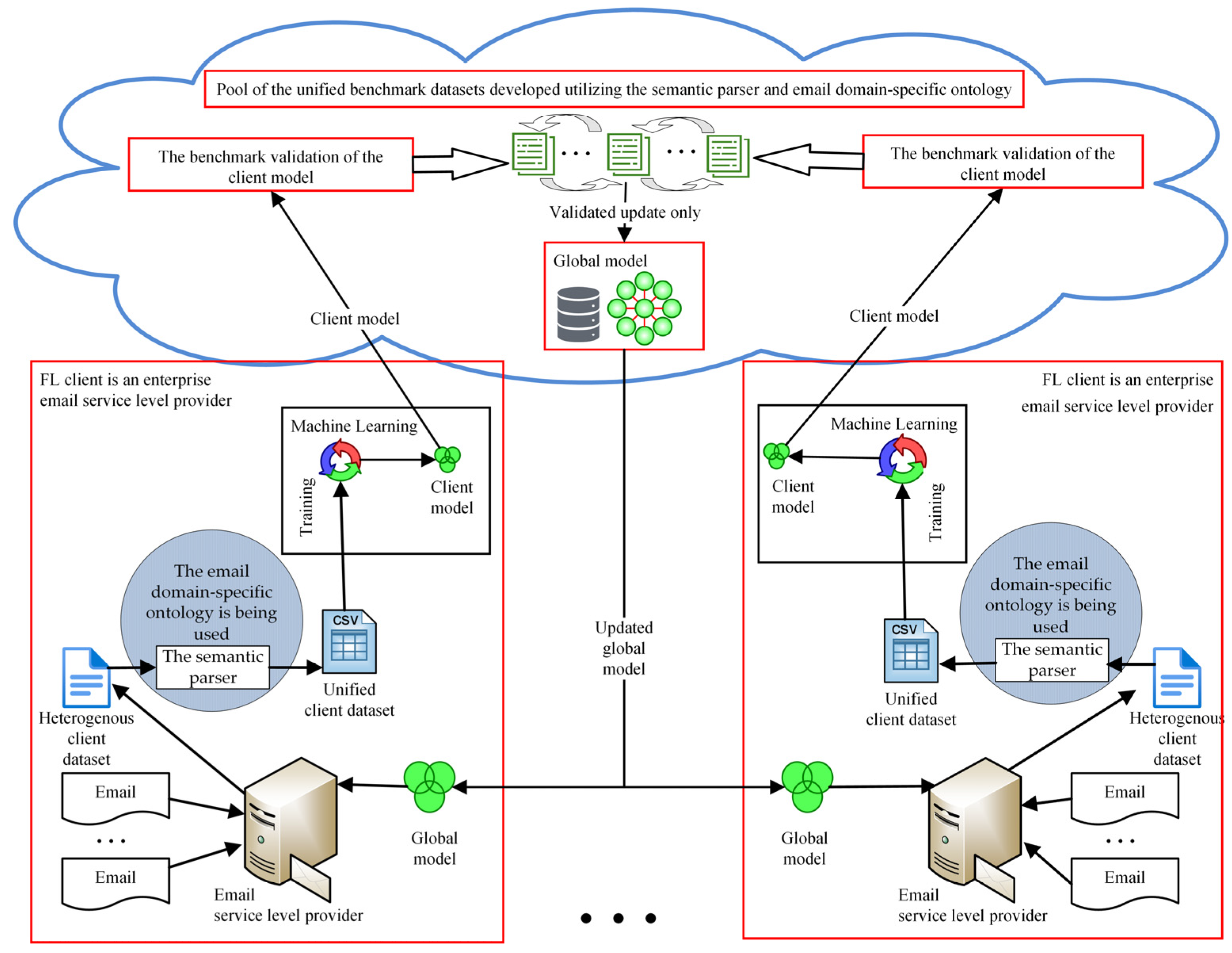
- The novelty of the proposed approach to improving the resilience of a global federated learning model is based on the evaluation of the client model using benchmark validation to detect malicious or trustless clients. An update of the client model that exhibits an appropriate benchmark validation score may be used to update the global model. This will protect the global model against a Byzantine attack.
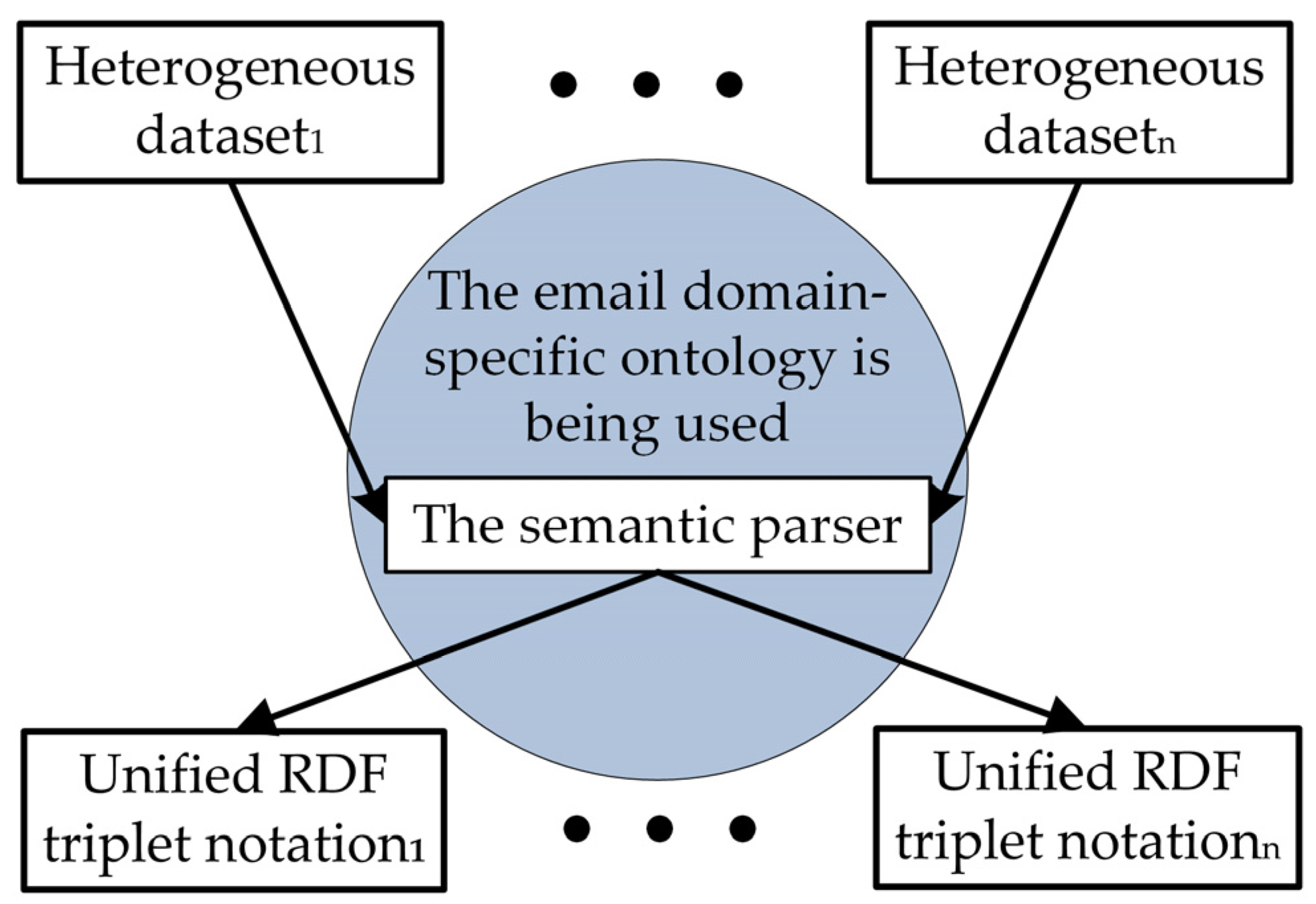
- By giving meaning to an email’s metadata, the email domain-specific ontology made it possible to make datasets for email benchmark corpuses and participant updates that were all in the same format and had all the same features.
2. Related Work
2.1. Privacy and Security
2.2. Robustness and Resiliency
2.3. Fairness and Trust
2.4. Summary of Related Work
- Statistical heterogeneity difficulty arises from the nonidentically distributed nature of data, as each client has a distinct sample of data that often reflects distinct qualities, patterns, or statistical characteristics;
- The robust and resiliency approach proposed by the other authors is to use Byzantine-robust aggregation rules, which essentially compare the clients’ local model updates and remove statistical outliers before applying them to the global model;
- One of the biggest shortcomings of robustness and resiliency is that an attacker can create an adaptable attack by changing the aggregation rule;
- As stated in [20], for the learning task, the service provider manually gathers a small clean training dataset known as the root dataset. Like how a client maintains a local model, the server maintains a model (referred to as the server model) for the root dataset. The server changes the global model in each iteration considering both the local model updates from the clients and its own server model update.
3. Proposed Approach
3.1. Resolving Statistical Heterogeneity and Privacy Challenges
3.2. Resolving Robustness and Resiliency Challenges
4. Experimental Settings and Results
4.1. Dataset Selection
4.1.1. SpamAssasin
4.1.2. CDMC2010
4.1.3. ENRON-SPAM
4.1.4. TREC07p
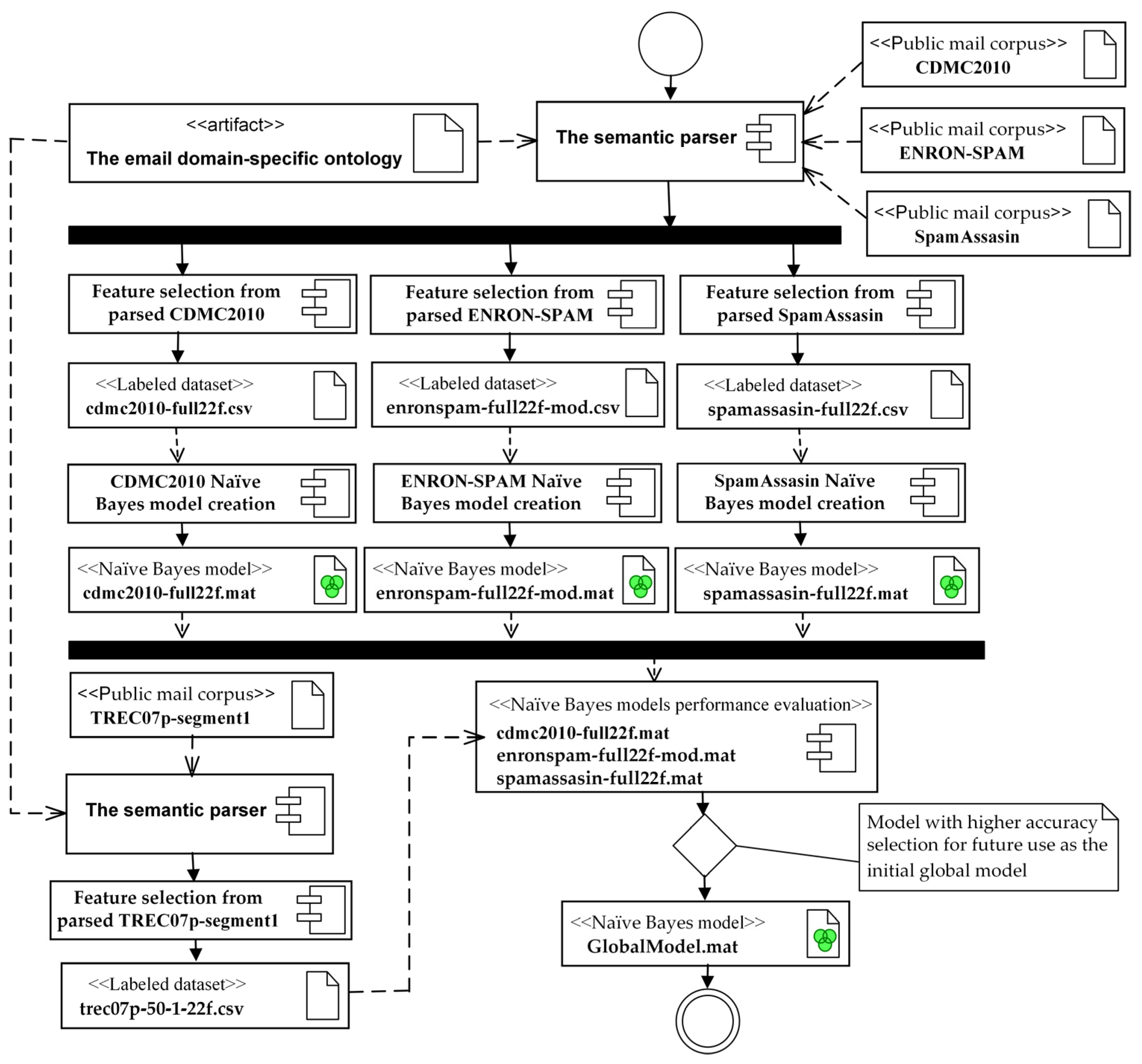
4.1.5. Assessment of Dataset and Preliminary Global Model Development
| Algorithm 1. The pseudo-code of the initial global model creation. |
| Input: Datasets: CDMC2010, ENRON-SPAM, SpamAssasin, TREC07p-segment1. Creation:
Compacted models cdmc2010-full22f.mat, enronspam-full22f-mod.mat, spamassasin-full22f.mat, GlobalModel.mat End the initial global model creation algorithm |
4.2. Evaluation of Model Resilience: Experimental Results of the Proposed Approach
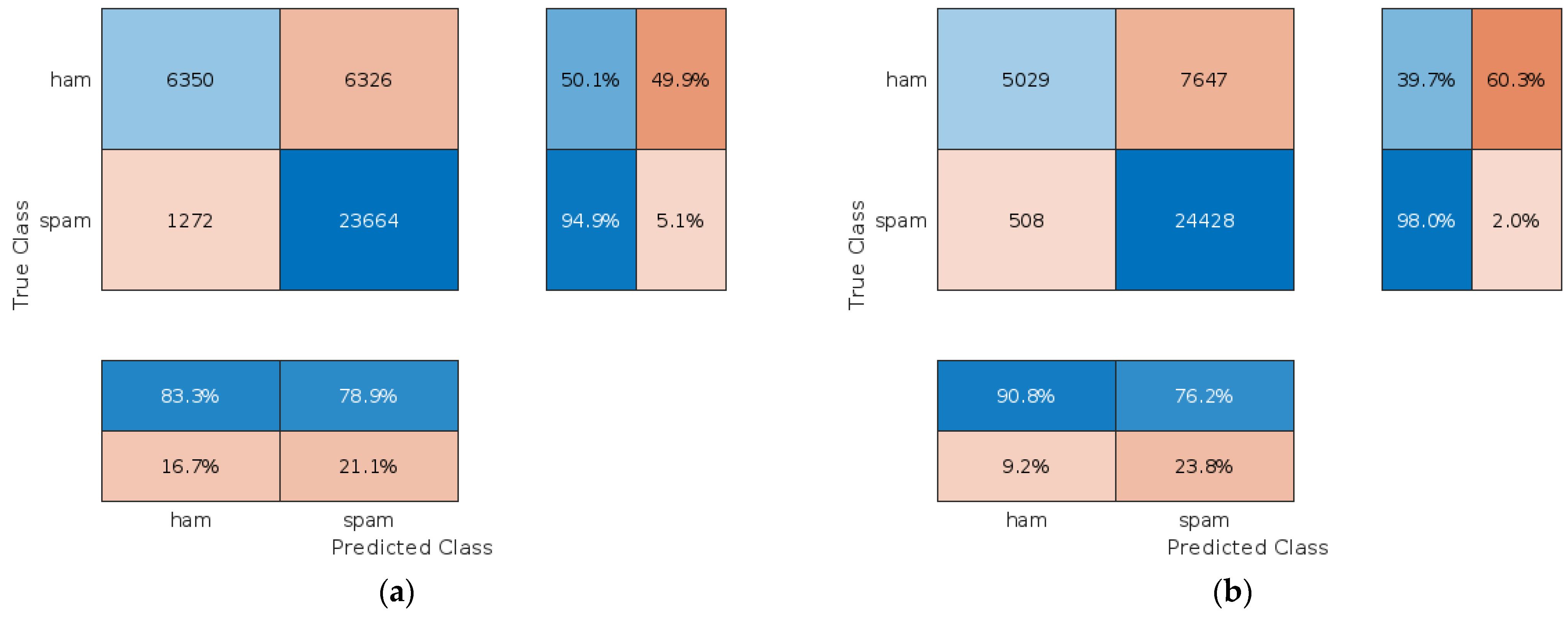
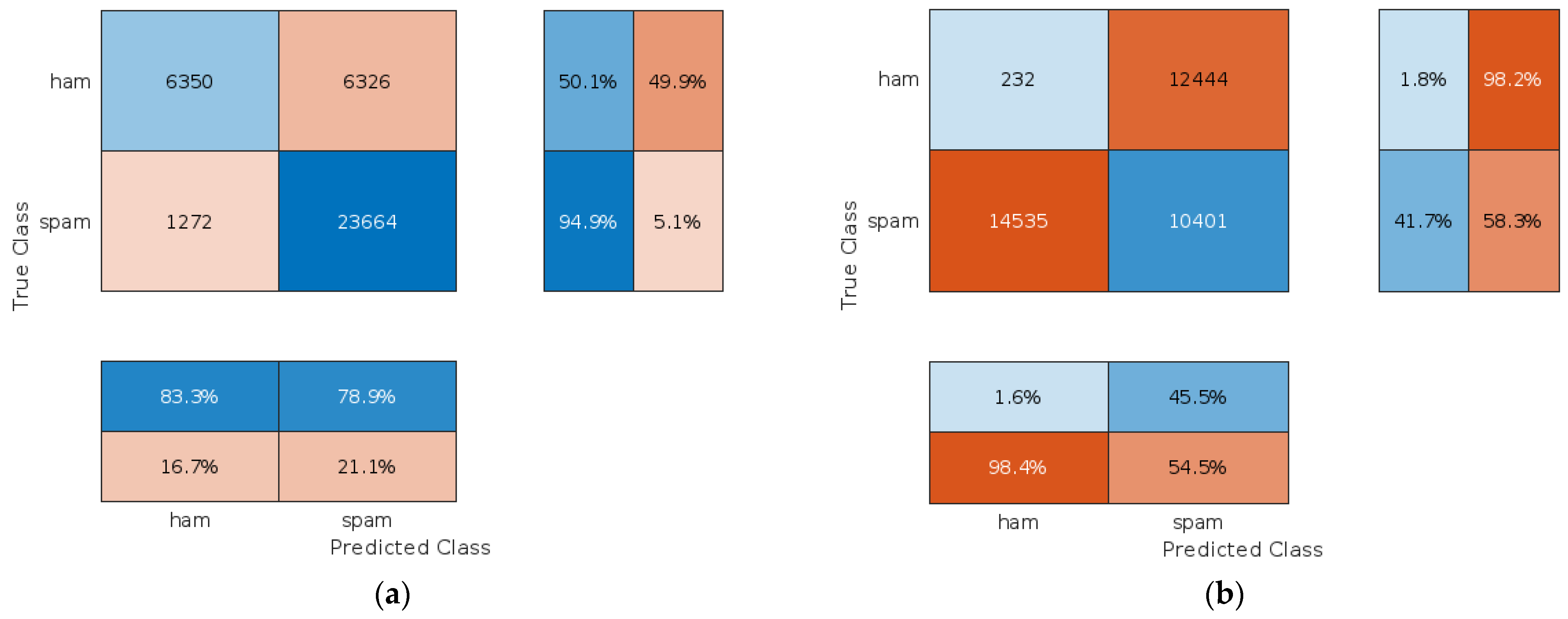
4.2.1. Assessment of the Proposed Approach When Clients Are Trustworthy
| Algorithm 2. The pseudo-code for the validation of the client model update. |
|
4.2.2. Assessment of the Proposed Approach When Clients Are Malicious
4.2.3. Assessment of the Proposed Approach to Protect Against Backdoor and Model Inversion Attacks
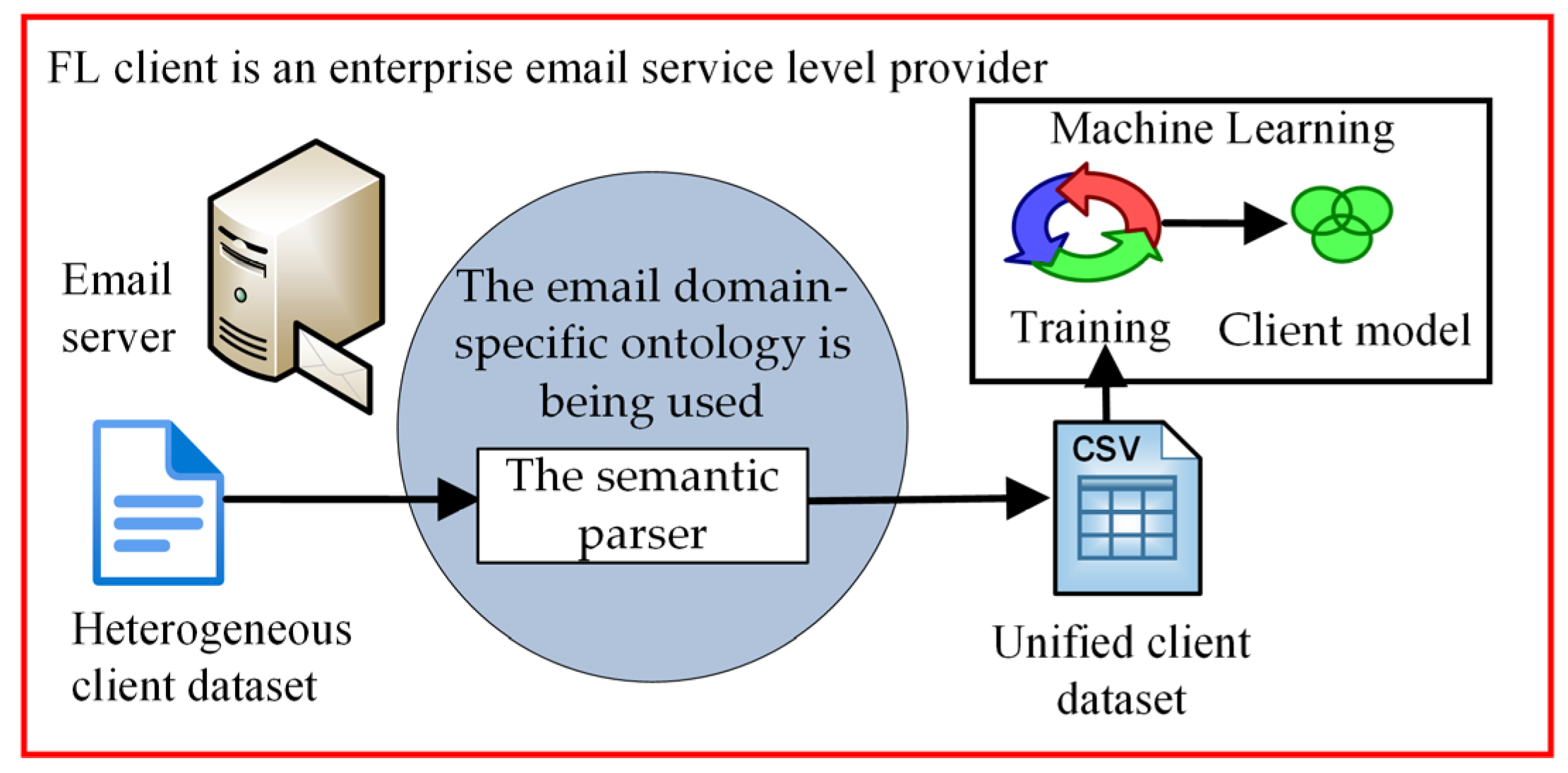
- We employ email domain-specific ontology that excludes any potentially sensitive information from email messages and instead concentrates on their metadata, which includes technical elements that show how an email travels from sender to recipient;
- To ensure that updates from malicious or trustless clients do not compromise a global FL model’s resilience, client models are evaluated using benchmark validation prior to making any updates;
- It is possible to use the semantic representation of the email message’s metadata for the classification of encrypted email messages without knowing of the decryption key. The S/MIME email encryption standard cryptographically protects only the body of the messages, whereas the header fields remain in plaintext because the SMTP servers need to deliver the message correctly. In such a case, only the metadata of the attached files and links to external resources cannot be extracted and populated. That is, classification is possible on the SMTP servers of the service provider without compromising the confidentiality of the final user’s data.
5. Discussion
6. Conclusions
- This article presents an investigation of the issues associated with email classification, along with a new strategy to improve resilience that is based on benchmark validation;
- Federated learning, the email domain-specific ontology, the semantic parser, and benchmark datasets derived from publicly available email corpuses are incorporated into the approach that was suggested;
- Using the email domain-specific ontology to extract metadata from an email message enables the creation of datasets with identical features derived from the benchmark email corpora and model updates provided by the client. This approach enables the utilization of benchmark models to verify the accuracy of client model updates;
- Meanwhile, the semantic parser serves to safeguard the confidentiality of email messages because only email message metadata are used.
- All client models have their performance metrics collected during the client model benchmark validation. In our experiment, the F1 score and the MCC were the primary metrics used to assess the client model and its applicability to update the global model.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Qi, P.; Chiaro, D.; Guzzo, A.; Ianni, M.; Fortino, G.; Piccialli, P. Model aggregation techniques in federated learning: A comprehensive survey. Future Gener. Comput. Syst. 2024, 150, 272–293. [Google Scholar] [CrossRef]
- Mothukuri, V.; Parizi, M.R.; Pouriyeh, S.; Huang, Y.; Dehghantanha, A.; Srivastava, G. A survey on security and privacy of federated learning. Future Gener. Comput. Syst. 2021, 115, 619–640. [Google Scholar] [CrossRef]
- Zhang, Y.; Zeng, D.; Luo, J.; Fu, X.; Chen, G.; Xu, Z.; King, I. A Survey of Trustworthy Federated Learning: Issues, Solutions, and Challenges. ACM Trans. Intell. Syst. Technol. 2024, 15, 1–47. [Google Scholar] [CrossRef]
- Zhang, Y.; Sun, R.; Shen, L.; Bai, G.; Xue, M.; Meng, M.H.; Li, X.; Ko, R.; Nepal, S. Privacy-Preserving and Fairness-Aware Federated Learning for Critical Infrastructure Protection and Resilience. In Proceedings of the ACM Web Conference 2024 (WWW ’24), Singapore, 13–17 May 2024; Association for Computing Machinery: New York, NY, USA, 2024; pp. 2986–2997. [Google Scholar] [CrossRef]
- Yazdinejad, A.; Dehghantanha, A.; Karimipour, H.; Srivastava, G.; Parizi, R.M. A Robust Privacy-Preserving Federated Learning Model Against Model Poisoning Attacks. IEEE Trans. Inf. Forensics Secur. 2024, 19, 6693–6708. [Google Scholar] [CrossRef]
- Chen, J.; Yan, H.; Liu, Z.; Zhang, M.; Xiong, Z.; Yu, S. When Federated Learning Meets Privacy-Preserving Computation. ACM Comput. Surv. 2024, 56, 319. [Google Scholar] [CrossRef]
- Jagarlamudi, G.K.; Yazdinejad, A.; Parizi, R.M.; Pouriyeh, S. Exploring privacy measurement in federated learning. J. Supercomput. 2024, 80, 10511–10551. [Google Scholar] [CrossRef]
- Wang, Y.; Su, Z.; Pan, Y.; Luan, T.H.; Li, R.; Yu, S. Social-Aware Clustered Federated Learning with Customized Privacy Preservation. IEEE/ACM Trans. Netw. 2024, 32, 3654–3668. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated Learning: Challenges, Methods, and Future Directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Zheng, Y.; Lai, S.; Liu, Y.; Yuan, X.; Yi, X.; Wang, C. Aggregation Service for Federated Learning: An Efficient, Secure, and More Resilient Realization. IEEE Trans. Dependable Secur. Comput. 2023, 20, 988–1001. [Google Scholar] [CrossRef]
- Shabbir, A.; Manzoor, H.U.; Ahmed, R.A.; Halim, Z. Resilience of Federated Learning Against False Data Injection Attacks in Energy Forecasting. In Proceedings of the 2024 International Conference on Green Energy, Computing and Sustainable Technology (GECOST). Miri Sarawak, Malaysia, 17–19 January 2024; pp. 245–249. [Google Scholar] [CrossRef]
- Reisizadeh, A.; Tziotis, I.; Hassani, H.; Mokhtari, A.; Pedarsani, R. Straggler-Resilient Federated Learning: Leveraging the Interplay Between Statistical Accuracy and System Heterogeneity. IEEE J. Sel. Areas Inf. Theory 2022, 3, 197–205. [Google Scholar] [CrossRef]
- Imteaj, A.; Khan, I.; Khazaei, J.; Amini, M.H. FedResilience: A Federated Learning Application to Improve Resilience of Resource-Constrained Critical Infrastructures. Electronics 2021, 10, 1917. [Google Scholar] [CrossRef]
- Yamany, W.; Keshk, M.; Moustafa, N.; Turnbull, B. Swarm Optimization-Based Federated Learning for the Cyber Resilience of Internet of Things Systems Against Adversarial Attacks. IEEE Trans. Consum. Electron. 2024, 70, 1359–1369. [Google Scholar] [CrossRef]
- So, J.; Güler, B.; Avestimehr, A.S. Byzantine-Resilient Secure Federated Learning. IEEE J. Sel. Areas Commun. 2021, 39, 2168–2181. [Google Scholar] [CrossRef]
- Tao, Y.; Cui, S.; Xu, W.; Yin, H.; Yu, D.; Liang, W.; Cheng, X. Byzantine-Resilient Federated Learning at Edge. IEEE Trans. Comput. 2023, 72, 2600–2614. [Google Scholar] [CrossRef]
- Rjoub, G.; Wahab, O.A.; Bentahar, J.; Cohen, R.; Bataineh, A.S. Trust-Augmented Deep Reinforcement Learning for Federated Learning Client Selection. Inf. Syst. Front. 2024, 26, 1261–1278. [Google Scholar] [CrossRef]
- Rjoub, G.; Wahab, O.A.; Bentahar, J.; Bataineh, A. Trust-driven reinforcement selection strategy for federated learning on IoT devices. Computing 2024, 106, 1273–1295. [Google Scholar] [CrossRef]
- Sánchez, P.M.S.; Celdrán, A.H.; Xie, N.; Bovet, G.; Pérez, G.M.; Stiller, B. FederatedTrust: A solution for trustworthy federated learning. Future Gener. Comput. Syst. 2024, 152, 83–98. [Google Scholar] [CrossRef]
- Cao, X.; Fang, M.; Liu, J.; Gong, N.Z. FLTrust: Byzantine-robust Federated Learning via Trust Bootstrapping. In Proceedings of the 2021 Network and Distributed System Security (NDSS) Symposium, San Diego, CA, USA, 21–25 February 2021. [Google Scholar] [CrossRef]
- Ji, S.; Tan, Y.; Saravirta, T.; Yang, Z.; Liu, Y.; Vasankari, L.; Pan, S.; Long, G.; Walid, A. Emerging trends in federated learning: From model fusion to federated X learning. Int. J. Mach. Learn. Cybern. 2024, 15, 3769–3790. [Google Scholar] [CrossRef]
- Tang, Z.; Chu, X.; Ran, R.Y.; Lee, S.; Shi, S.; Zhang, Y.; Wang, Y.; Liang, A.Q.; Avestimehr, S.; He, C. Fedml parrot: A scalable federated learning system via heterogeneity-aware scheduling on sequential and hierarchical training. arXiv 2023, arXiv:2303.01778. [Google Scholar]
- Venčkauskas, A.; Toldinas, J.; Morkevičius, N.; Sanfilippo, F. Email Domain-specific Ontology and Metadata Dataset. Mendeley Data 2024. [Google Scholar] [CrossRef]
- Venčkauskas, A.; Toldinas, J.; Morkevičius, N.; Sanfilippo, F. An Email Cyber Threat Intelligence Method Using Domain Ontology and Machine Learning. Electronics 2024, 13, 2716. [Google Scholar] [CrossRef]
- Sikandar, H.S.; Waheed, H.; Tahir, S.; Malik, S.U.R.; Rafique, W. A Detailed Survey on Federated Learning Attacks and Defenses. Electronics 2023, 12, 260. [Google Scholar] [CrossRef]
- Lyu, L.; Yu, H.; Ma, X.; Chen, C.; Sun, L.; Zhao, J. Privacy and Robustness in Federated Learning: Attacks and Defenses. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 8726–8746. [Google Scholar] [CrossRef] [PubMed]
- Herath, C.; Rahulamathavan, Y.; Liu, X. Recursive Euclidean Distance-based Robust Aggregation Technique for Federated Learning. In Proceedings of the 2023 IEEE IAS Global Conference on Emerging Technologies (GlobConET), London, UK, 19–21 May 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Ozdayi, M.S.; Kantarcioglu, M.; Gel, Y.R. Defending against Backdoors in Federated Learning with Robust Learning Rate. In Proceedings of the 2021 AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 9268–9276. [Google Scholar] [CrossRef]
- Gencturk, M.; Sinaci, A.A.; Cicekli, N.K. BOFRF: A Novel Boosting-Based Federated Random Forest Algorithm on Horizontally Partitioned Data. IEEE Access 2022, 10, 89835–89851. [Google Scholar] [CrossRef]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef]
- Kaur, N.; Singh, H. An empirical assessment of threshold techniques to discriminate the fault status of software. J. King Saud Univ. Comput. Inf. Sci. 2022, 34, 6339–6353. [Google Scholar] [CrossRef]
- Spamassassin. Available online: https://spamassassin.apache.org/old/publiccorpus/ (accessed on 20 December 2024).
- CDMC2010. ICONIP 2010: 17th International Conference on Neural Information Processing. Available online: http://www.wikicfp.com/cfp/servlet/event.showcfp?eventid=10627©ownerid=5571 (accessed on 20 December 2024).
- Metsis, V.; Androutsopoulos, I.; Paliouras, G. Spam Filtering with Naive Bayes-Which Naive Bayes? In Proceedings of the 2006 Third Conference on Email and Anti-Spam CEAS, Mountain View, CA, USA, 27–28 July 2006; Volume 17, pp. 28–69. [Google Scholar]
- Klimt, B.; Yang, Y. The Enron Corpus: A New Dataset for Email Classification Research. In Proceedings of the Machine Learning: ECML 2004, Pisa, Italy, 20–24 September 2004; Boulicaut, J.-F., Esposito, F., Giannotti, F., Pedreschi, D., Eds.; Springer: Berlin/Heidelberg, Germany, 2004; pp. 217–226. [Google Scholar]
- Cormack, G.V. TREC 2007 Spam Track Overview Conference. In Proceedings of the 2007 Text Retrieval Conference, Gaithersburg, MD, USA, 6–9 November 2007; Available online: https://api.semanticscholar.org/CorpusID:2848551 (accessed on 20 December 2024).
- Choosing the Right Classification Model. Available online: https://www.mathworks.com/campaigns/offers/next/choosing-the-best-machine-learning-classification-model-and-avoiding-overfitting.html (accessed on 20 December 2024).
- Zhou, Z.; Zhu, J.; Yu, F.; Li, X.; Peng, X.; Liu, T.; Han, B. Model Inversion Attacks: A Survey of Approaches and Countermeasures. arXiv 2024, arXiv:2411.10023. Available online: https://arxiv.org/abs/2411.10023 (accessed on 27 February 2025).
- Parikh, R.; Dupuy, C.; Gupta, R. Canary Extraction in Natural Language Understanding Models. arXiv 2022, arXiv:2203.13920. Available online: https://arxiv.org/abs/2203.13920 (accessed on 27 February 2025).
- Abad, G.; Paguada, S.; Ersoy, O.; Picek, S.; Ramírez-Durán, V.J.; Urbieta, A. Sniper Backdoor: Single Client Targeted Backdoor Attack in Federated Learning. arXiv 2023, arXiv:2203.08689. Available online: https://arxiv.org/abs/2203.08689 (accessed on 27 February 2025).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Privacy Security | Robustness Resilience | Fairness Trust | Advantages | Disadvantages |
|---|---|---|---|---|---|
| Yazdinejad et al. [5] | Additive Homomorphic Encryption (AHE) | Byzantine-tolerant gradient aggregation | An efficiency score | An efficiency score that combines privacy, accuracy, and computational efficiency | Computational and communication overhead due to the complexity of the proposed PPFL architecture |
| Wang et al. [8] | Customizable privacy protection | Hierarchical SCFL framework | Low-cost, feasible, and customized FL services by using the social attributes of the users’ | Participants in FL must form social connections | |
| Zheng et al. [10] | Integration between secure aggregation and quantization-based model compression | FL services with lightweight, secure, and resilient aggregation | Minimally trusted hardware | The suggested approach may manage client dropouts while maintaining the confidentiality of their secret keys, preventing them from directly participating in subsequent rounds | The proposed system only assumes minimally trusted hardware with integrity guarantees |
| Imteaj et al. [13] | On-device learning without sharing any data | Improve the resilience of critical infrastructures through early prediction | The proposed FL-based strategy consists of a local CIA that acts as an intelligent decision-making agent. The FedResilience algorithm provides prediction tasks for potential outages | Privacy was not guaranteed by the partial work that was made possible to gather from agents with limited resources. | |
| So et al. [15] | Use of stochastic quantization | Robust gradient descent approach | A single-server Byzantine-resilient secure aggregation framework is suggested for secure FL | A single server for model update aggregation is not faulty tolerant | |
| Rjoub et al. [17] | Privacy-preserving machine learning | Deep reinforcement learning | A transfer learning mechanism was incorporated to compensate for possible learning deficiencies in some servers and address data shortages in certain regions | The relatively high computation time Cyberattacks could be launched against many parts of the proposed solution. | |
| Sánchez et al. [19] | Perturbation | Poisoning and Inference | Federation | A novel taxonomy created with the main building blocks—privacy, robustness, fairness, explainability, accountability, and federation FederatedTrust computes global and partial trustworthiness scores by aggregating metrics and pillars | The real-world deployment of FederatedTrust may present challenges such as resource consumption, data leakage, governance, compliance, and scalability |
| Cao et al. [20] | Byzantine-robust FL method called FLTrust | The service provider manually logs in and collects a small clean training dataset (called the root dataset) for the learning task The defense is performed on the server side | The root dataset must be clean from poisoning The proposed method is effective once the root dataset distribution does not deviate too much from the overall training data distribution to ensure integrity |
| Feature | Description | Example |
|---|---|---|
| SENT_TS | Sent timestamp assigned by the originator server | 1030019517000 |
| CONT_SUBTYPE | Subtype part of the Content-Type header field | html |
| CONT_PARAM | Parameter part of the Content-Type header field | charset = “iso-8859-1” |
| FROM_P | Display-namepart of the From email address | CNET News.com Daily Dispatch |
| FROM_U | Local part of the From email address | Online#3.20777.51-8J4zgE1Uu7_vxsRR.1 |
| FROM_D | Domain part of the From email address | newsletter.online.com |
| TO_U | Local-part part of the first To email address | update |
| TO_D | Domain part of the first To email address | list.theregister.co.uk |
| REPLY_P | Display-name part of the Reply-to email address | Daily Dilbert |
| REPLY_U | Local-part part of the Reply-to email address | 2.21122.29-GYdCgEWAHESJ.1 |
| REPLY_D | Domain part of the Reply-to email address | ummail4.unitedmedia.com |
| SENDER_U | Local-part part of the Sender email address | shifty |
| SENDER_D | Domain part of the Sender email address | spit.gen.nz |
| OMTA_FROM_H | Host name extracted from the From-domain part of the Received field at the originator SMTP server | r-smtp |
| OMTA_BY_D | Host domain extracted from the By-domain part of the Received field at the originator SMTP server | siteprotect.com |
| OMTA_TS | Timestamp at the SMTP server of the originator | 1030149730000 |
| DMTA_NR | Delivery SMTP server’s hop number | 4 |
| DMTA_FROM_H | Host name extracted from the From-domain part of the Received field at the delivery SMTP’s server | sunu422 |
| DMTA_BY_D | Host domain extracted from the By-domain part of the Received field at the originator SMTP server | bph.ruhr-uni-bochum.de |
| DMTA_TS | Timestamp at the delivery SMTP server | 1030018641000 |
| DMTA_DELAY | Delay of the message (in milliseconds) at the originator SMTP server | 7000 |
| URL1_HOST | Host of the first URL in the message’s body | www.ktu.lt |
| Dataset | File Name | The Number of Records | The Percentage of All Records | The Number of SPAM Records | The Percent of SPAM Records | The Number of HAM Records | The Percent of HAM Records |
|---|---|---|---|---|---|---|---|
| CDMC2010 | cdmc2010-full22f.csv | 4279 | 100% | 1331 | 31.11% | 2948 | 68.89% |
| ENRON-SPAM | enronspam-full22f-mod.csv | 48,490 | 100% | 31,369 | 64.69% | 17,121 | 35.31% |
| SpamAssasin | spamassasin-full22f.csv | 5961 | 100% | 1816 | 30.46% | 4145 | 69.54% |
| TREC07p -full | Not used | 75,225 | 100% | 50,008 | 66.48% | 25,217 | 33.52% |
| TREC07p-segment1 | trec07p-50-1-22f.csv | 37,612 | 50% | 24,936 | 66.30% | 12,676 | 33.70% |
| TREC07p-segment2 | trec07p-50-2-22f.csv | 37,612 | 50% | 25,071 | 66.66% | 12,541 | 33.34% |
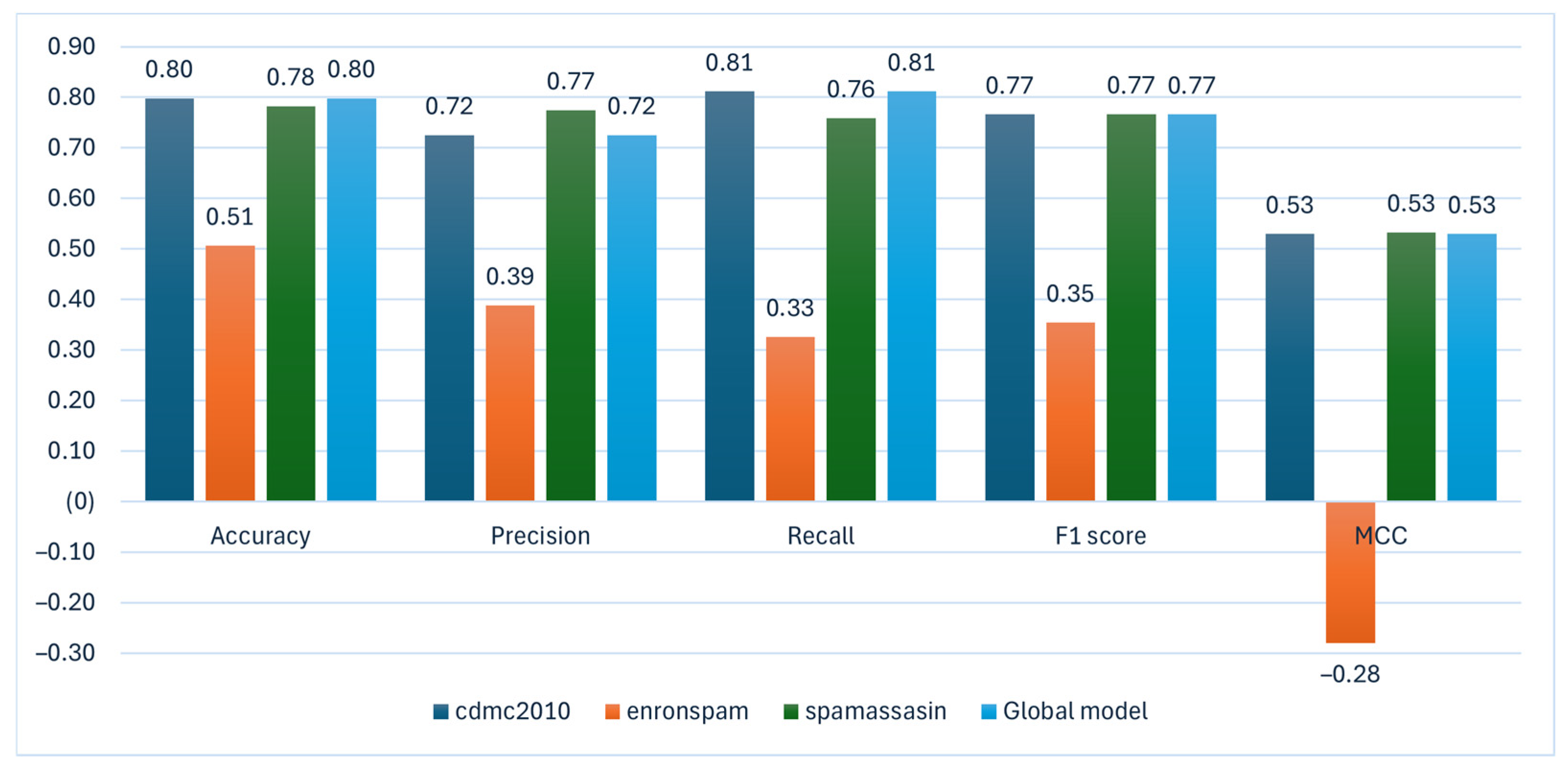
| Model | The Number of Training Records | Accuracy | Precision | Recall | F1 Score | MCC |
|---|---|---|---|---|---|---|
| cdmc2010 | 4279 | 0.80 | 0.72 | 0.81 | 0.77 | 0.53 |
| enronspam | 48,490 | 0.51 | 0.39 | 0.33 | 0.35 | −0.28 |
| spamassasin | 5961 | 0.78 | 0.77 | 0.76 | 0.77 | 0.53 |
| Global model | 0.80 | 0.72 | 0.81 | 0.77 | 0.53 |
| File Name of the Client Updates | The Number of Records | The Number of SPAM Records | The Percentage of SPAM Records. | The Number of HAM Records | The Percentage of HAM Records |
|---|---|---|---|---|---|
| CL4K01.csv | 4096 | 2709 | 66.14% | 1387 | 33.86% |
| CL4K02.csv | 4096 | 2733 | 66.72% | 1363 | 33.28% |
| CL4K03.csv | 4096 | 2705 | 66.04% | 1391 | 33.96% |
| CL4K04.csv | 4096 | 2761 | 67.41% | 1335 | 32.59% |
| CL4K05.csv | 4096 | 2782 | 67.92% | 1314 | 32.08% |
| CL4K06.csv | 4096 | 2719 | 66.38% | 1377 | 33.62% |
| CL4K07.csv | 4096 | 2728 | 66.60% | 1368 | 33.40% |
| CL4K08.csv | 4096 | 2707 | 66.09% | 1389 | 33.91% |
| CL4K09.csv | 4096 | 2717 | 66.33% | 1379 | 33.67% |
| CL4K10.csv | 748 | 510 | 68.18% | 238 | 31.82% |
| In total | 37,612 | 25,071 | 66.66% | 12,541 | 33.34% |
| Client Model | F1 Score | ||||
|---|---|---|---|---|---|
| cdmc2010 | Enronspam | Spamassasin | TREC07p Segment1 | AVERAGE | |
| CL4K01 | 0.6280 | 0.6033 | 0.6528 | 0.9700 | 0.7135 |
| CL4K02 | 0.6396 | 0.6054 | 0.6786 | 0.9704 | 0.7235 |
| CL4K03 | 0.6257 | 0.5932 | 0.6522 | 0.9615 | 0.7081 |
| CL4K04. | 0.6378 | 0.6020 | 0.6670 | 0.9698 | 0.7192 |
| CL4K05 | 0.6232 | 0.6036 | 0.6529 | 0.9681 | 0.7120 |
| CL4K06 | 0.6204 | 0.6003 | 0.6450 | 0.9628 | 0.7071 |
| CL4K07 | 0.6143 | 0.6042 | 0.6398 | 0.9669 | 0.7063 |
| CL4K08 | 0.6232 | 0.6036 | 0.6485 | 0.9608 | 0.7090 |
| CL4K09 | 0.6324 | 0.6027 | 0.6581 | 0.9641 | 0.7143 |
| CL4K10 | 0.6132 | 0.3366 | 0.6657 | 0.9825 | 0.6495 |
| Client Model Update | MCC | ||||
|---|---|---|---|---|---|
| cdmc2010 | Enronspam | Spamassasin | TREC07p Segment1 | AVERAGE | |
| CL4K01 | 0.1635 | 0.1691 | 0.2431 | 0.9401 | 0.3789 |
| CL4K02 | 0.1968 | 0.1758 | 0.3128 | 0.9409 | 0.4066 |
| CL4K03 | 0.1457 | 0.1486 | 0.2312 | 0.9230 | 0.3622 |
| CL4K04. | 0.1822 | 0.1736 | 0.2776 | 0.9396 | 0.3933 |
| CL4K05 | 0.1431 | 0.1703 | 0.2389 | 0.9362 | 0.3721 |
| CL4K06 | 0.1309 | 0.1603 | 0.2097 | 0.9257 | 0.3566 |
| CL4K07 | 0.1202 | 0.1720 | 0.1997 | 0.9338 | 0.3564 |
| CL4K08 | 0.1431 | 0.1700 | 0.2247 | 0.9216 | 0.3649 |
| CL4K09 | 0.1657 | 0.1675 | 0.2511 | 0.9282 | 0.3781 |
| CL4K10 | 0.2253 | −0.3042 | 0.3314 | 0.9650 | 0.3044 |
| File Name of the Client Updates | The Number of Records | The Number of SPAM Records | The Percentage of SPAM Records. | The Number of HAM Records | The Percentage of HAM Records |
|---|---|---|---|---|---|
| CL4KM01.csv | 4096 | 1387 | 33.86% | 2709 | 66.14% |
| CL4KM02.csv | 4096 | 1363 | 33.28% | 2733 | 66.72% |
| CL4KM03.csv | 4096 | 1391 | 33.96% | 2705 | 66.04% |
| CL4KM04.csv | 4096 | 1335 | 32.59% | 2761 | 67.41% |
| CL4KM05.csv | 4096 | 1314 | 32.08% | 2782 | 67.92% |
| CL4KM06.csv | 4096 | 1377 | 33.62% | 2719 | 66.38% |
| CL4KM07.csv | 4096 | 1368 | 33.40% | 2728 | 66.60% |
| CL4KM08.csv | 4096 | 1389 | 33.91% | 2707 | 66.09% |
| CL4KM09.csv | 4096 | 1379 | 33.67% | 2717 | 66.33% |
| CL4KM10.csv | 748 | 238 | 31.82% | 510 | 68.18% |
| In total | 37,612 | 12,541 | 33.34% | 25,071 | 66.66% |
| Client Model Update | F1 Score | ||||
|---|---|---|---|---|---|
| cdmc2010 | Enronspam | Spamassasin | TREC07p Segment1 | AVERAGE | |
| CL4KM01 | 0.4237 | 0.3904 | 0.3436 | 0.2263 | 0.3460 |
| CL4KM02 | 0.5775 | 0.6789 | 0.5230 | 0.7082 | 0.6219 |
| CL4KM03 | 0.5281 | 0.0005 | 0.5315 | 0.6643 | 0.4311 |
| CL4KM04. | 0.4759 | 0.9994 | 0.4280 | 0.3364 | 0.5599 |
| CL4KM05 | 0.4759 | 0.9994 | 0.4280 | 0.3364 | 0.5599 |
| CL4KM06 | 0.3909 | 0.9990 | 0.4160 | 0.3385 | 0.5361 |
| CL4KM07 | 0.4650 | 0.9990 | 0.4164 | 0.3376 | 0.5545 |
| CL4KM08 | 0.3957 | 0.9991 | 0.4223 | 0.3383 | 0.5388 |
| CL4KM09 | 0.4639 | 0.9990 | 0.4176 | 0.3359 | 0.5541 |
| CL4KM10 | 0.6132 | 0.3366 | 0.6657 | 0.9825 | 0.6495 |
| Client Model Update | MCC | ||||
|---|---|---|---|---|---|
| cdmc2010 | Enronspam | Spamassasin | TREC07p Segment1 | AVERAGE | |
| CL4KM01 | −0.0395 | −0.0602 | −0.1060 | −0.5465 | −0.1881 |
| CL4KM02 | −0.0108 | 0.5578 | 0.006 | 0.3163 | 0.2173 |
| CL4KM03 | 0.0216 | −0.9988 | 0.0509 | 0.3275 | −0.1497 |
| CL4KM04. | −0.0161 | 0.9987 | −0.0548 | −0.3222 | 0.1514 |
| CL4KM05 | −0.0161 | 0.9987 | −0.0548 | −0.3222 | 0.1514 |
| CL4KM06 | −0.0871 | 0.9981 | −0.0735 | −0.3204 | 0.1293 |
| CL4KM07 | −0.0237 | 0.9980 | −0.0677 | −0.3212 | 0.1464 |
| CL4KM08 | −0.0825 | 0.9982 | −0.0658 | −0.3206 | 0.1323 |
| CL4KM09 | −0.0252 | 0.9981 | −0.0685 | −0.3243 | 0.1450 |
| CL4KM10 | 0.2253 | −0.3042 | 0.3314 | 0.365 | 0.1544 |
| Research | Approach | Performance Metrics | Algorithm | Validation | F1 | MCC |
|---|---|---|---|---|---|---|
| Yazdinejad et al. [5] | Additive Homomorphic Encryption (AHE) | Target accuracy, other label accuracy, overall Accuracy | Detecting anomalies by comparing local gradients’ cosine similarity with benign gradients | The server-held validation dataset | – | – |
| Wang et al. [8] | Customizable privacy protection | Accuracy | A distributed federation game with transferable utility | – | – | – |
| Zheng et al. [10] | Integration between secure aggregation and quantization-based model compression | Accuracy | Empowering Federated Learning with secure and efficient aggregation | The cloud server only learns the aggregate model update without knowing individual model updates | – | – |
| Imteaj et al. [13] | On-device learning without sharing any data | Accuracy | FedResilience algorithm | The server initializes a global model | – | – |
| So et al. [15] | Use of Stochastic Quantization | Accuracy | The multi-Krum algorithm in a quantized stochastic gradient setting | Single-server solution for Byzantine-resilient secure federated learning | – | – |
| Rjoub et al. [17] | Privacy-preserving machine learning | Precision, Recall, F1 score | Deep reinforcement learning (DRL) scheduling algorithm | The server aggregates parameters to derive a global aggregate model | + | – |
| Proposed | Integrates FL, email domain ontology, a semantic parser, and a collection of benchmark datasets from heterogeneous email corpuses | Accuracy, Precision, Recall, F1 score, MCC | Naïve Bayes classifier | Enhanced global model resilience through client model benchmark validation on the cloud | + | + |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Venčkauskas, A.; Toldinas, J.; Morkevičius, N.; Serkovas, E.; Krištaponis, M. Enhancing the Resilience of a Federated Learning Global Model Using Client Model Benchmark Validation. Electronics 2025, 14, 1215. https://doi.org/10.3390/electronics14061215
Venčkauskas A, Toldinas J, Morkevičius N, Serkovas E, Krištaponis M. Enhancing the Resilience of a Federated Learning Global Model Using Client Model Benchmark Validation. Electronics. 2025; 14(6):1215. https://doi.org/10.3390/electronics14061215
Chicago/Turabian StyleVenčkauskas, Algimantas, Jevgenijus Toldinas, Nerijus Morkevičius, Ernestas Serkovas, and Modestas Krištaponis. 2025. "Enhancing the Resilience of a Federated Learning Global Model Using Client Model Benchmark Validation" Electronics 14, no. 6: 1215. https://doi.org/10.3390/electronics14061215
APA StyleVenčkauskas, A., Toldinas, J., Morkevičius, N., Serkovas, E., & Krištaponis, M. (2025). Enhancing the Resilience of a Federated Learning Global Model Using Client Model Benchmark Validation. Electronics, 14(6), 1215. https://doi.org/10.3390/electronics14061215