1. Introduction
After over a decade of development, the global tally of massive open online courses (MOOCs) has surpassed 10,000 courses, attracting over a billion users. MOOCs have emerged as a significant knowledge source for students worldwide. Nevertheless, a notable limitation is that most MOOC content is recorded in a single language, creating a barrier for non-native speakers who struggle to fully grasp the nuances of many outstanding courses. While modern algorithms facilitate audio and subtitle language translations, the majority of current scene text translation methods overlook the significance of stylized transfer when translating elements like writing on a board or PPT slides in MOOC videos. Consequently, this oversight can result in issues like text overlap, blurriness, and mismatched background colors in the translated text, ultimately impeding the comprehension and effective communication of MOOC content to non-native speakers.
To cater to learners from diverse regions and linguistic backgrounds, the textual content featured in MOOC videos should undergo meticulous language conversion. Cross-lingual refers to the phenomenon or technology where the input text and the output text are in different languages.This intricate process encompasses not just text translation, but also cultural adaptation, aiming to facilitate effective communication and comprehension of the material across a wide array of cultures. Considering the global outreach of MOOC videos, it becomes imperative for MOOC production teams to guarantee that their video content resonates accurately with learners hailing from different linguistic and cultural backgrounds. Achieving this demands not just the expertise of proficient translators adept in various languages for manual translation and proofreading, but also a committed video processing team tasked with seamlessly integrating the translated text at precise timestamps within the video. Consequently, the manual creation of multilingual MOOC videos proves to be a time-consuming, labor-intensive, costly, and often inefficient endeavor. Existing research has consistently demonstrated that manual annotation is prohibitively costly [
1,
2].
Text style transfer strives to substitute the original text in an image with text that bears a particular style. The primary obstacles it encounters encompass diverse elements like language, font, color, direction, stroke size, and spatial perspective. Significantly, cross-language text style transfer poses extraordinary challenges for models in extracting features and producing high-quality images, primarily because of the distinct glyph shapes inherent to different languages, such as Chinese and English. Moreover, directly applying the existing text style transfer methods to MOOC videos poses challenges for several reasons. Firstly, the majority of font generation research concentrates on languages that share similar characteristics, such as Chinese, Japanese, and Korean. Stylized translated text, on the other hand, relies on the mutual conversion between Chinese and English for style migration, despite their vastly different glyph structures. Secondly, while font generation primarily focuses on individual characters, stylized translated text aims to transform entire paragraphs. Lastly, font generation tasks prioritize specific elements like character strokes, font thickness, and glyph structure. To minimize interference from fonts and background colors, datasets predominantly feature high-contrast color schemes, such as white backgrounds with black text, or vice versa.
Major Challenges
The task of text language transfer in MOOC videos, as addressed in this paper, primarily faces three major challenges: language diversity, readability, and complex backgrounds. These challenges specifically impact the design of scene transfer algorithms for MOOC videos in the following three aspects:
Language Diversity: Most existing font generation research has focused on languages with similar characteristics, such as Chinese, Japanese, and Korean. In contrast, MOOC videos often require style transfer between languages with vastly different glyph structures, such as Chinese and English. This disparity complicates feature extraction and style adaptation.
Complex Backgrounds: MOOC videos often feature text embedded in complex backgrounds, such as blackboards or PPT slides. Existing methods, typically trained on high-contrast datasets (e.g., white text on black backgrounds), struggle to maintain text clarity and style consistency in such environments.
Readability: Preserving the original text’s color integrity during style transfer is crucial for visual quality. However, existing methods often fail to maintain color consistency, leading to issues like mismatched background colors or distorted text appearance.
To address these challenges, this paper introduces a character-level style transfer algorithm grounded in an attention mechanism, specifically targeting the prevalent issue of subpar image quality in current cross-language text style transfers. Our algorithm adeptly handles the demanding task of style transfer across diverse languages, a challenge that has proven elusive for many existing algorithms. To bolster the efficacy of the style transfer, we propose an imposed sequential attention (IS-attention) mechanism to pinpoint the precise location of text within the image. These positional data then serve as a guide to oversee the style transfer outcome for each individual character. Furthermore, we devised a novel color loss function that preserves the uniformity of text color throughout the style transfer process. By integrating this loss function, our algorithm ensures a more faithful retention of the original text’s color integrity during image generation, elevating the overall visual quality of the output. Experimental findings underscored the effectiveness of our proposed character-level style transfer algorithm, leveraged by the attention mechanism. It adeptly mitigates issues like text blurring and color discrepancies, ultimately yielding images of superior quality.
2. Related Work
The text style transfer algorithm, as an offshoot of style transfer algorithms, can be traced back to the inception of its parent field. The origins of style transfer algorithms date to the 1990s, a time when neural networks had yet to gain prominence. In this era, researchers frequently resorted to non-parametric techniques [
3]. They meticulously described various image features by conducting in-depth analyses of images’ textural features and using statistical models and mathematical formulas. Despite achieving certain results, this approach presented significant challenges: (1) slow generation speed and inefficient processing; (2) labor-intensive feature description, limiting practical applications; and (3) extracted features tended to be superficial, inadequately capturing the deeper meanings conveyed by images. Ideally, a robust style transfer algorithm should efficiently extract high-level features from the target image, ensuring a clean separation of image content and style [
4].
The remarkable advancements achieved by deep convolutional neural networks (CNNs) [
5] in the ImageNet large-scale visual recognition challenge paved the way for innovations in the field. Notably, Simonyan et al. introduced the renowned VGG network, which claimed victory in the ILSVRC2014 localization task and secured second place in the classification task. Leveraging the widespread adoption of CNNs, Gatys et al. [
6,
7,
8] built on this foundation and presented a CNN-based image transfer algorithm. This algorithm employs the VGG network to extract multi-layer features from both style and target images. The deeper the network extracts features, the more abstract and semantically rich they become. Gatys et al. emphasized that CNNs can effectively separate and articulate the content and style features extracted from images.
Despite breaking traditional boundaries in image style transfer, Gatys’s algorithm faced limitations due to its reliance on iterating over every pixel in the image, often demanding hundreds of iterations for convergence. Furthermore, the extracted high-dimensional features occasionally lost crucial underlying image information, resulting in content distortion and unpredictable errors in the stylized images. Subsequent scholars [
9,
10,
11] delved deeper into Gatys’s algorithm and proposed various methods to address the convergence issues stemming from pixel-based iteration.
Huang et al. [
12] made a groundbreaking achievement by enabling real-time conversion of arbitrary styles. Through rigorous experimentation, they established that instance normalization (IN) could standardize a style by normalizing feature statistics. They introduced adaptive instance normalization, which adjusts the affine parameters of IN to alter the standardization of feature statistics, thereby generating a variety of styles. Huang’s paper presented comprehensive experimental results, affirming the efficacy of adaptive instance normalization in style transfer and offering a novel approach for multi-style transfer.
The emergence of generative adversarial networks (GANs) [
13] marked a seismic shift in the realm of image generation. GANs consist of two neural networks: a generator that learns the data distribution and produces images, and a discriminator that distinguishes between real and generated images. Through a competitive mechanism, GANs yield more realistic and diverse imagery. The advent of GANs ushered in a new era of image generation, sparking numerous GAN-based style transfer studies [
14,
15,
16,
17] and paving the way for future research.
NVIDIA’s introduction of StyleGAN [
18] represented a significant milestone, achieving unsupervised separation of high-level attributes and utilizing latent space mapping to decouple input variables. Subsequently, StyleGAN2 [
19] considered the “blistering” phenomenon observed in StyleGAN’s output images, revealing disruptions in information flow between feature maps during normalization with adaptive instance normalization. StyleGAN3 [
20] further identified issues related to image positioning and feature adhesion in StyleGAN2 images, introducing an optimization strategy to address aliasing caused by point-wise non-linearity. This innovation allowed image translation, rotation, and other invariances, significantly elevating the quality of the generated images.
As the application of GANs in image style transfer has gradually matured, numerous scholars have shifted their focus to a crucial subtask within this domain: font generation. Font generation tasks typically involve languages with extensive character sets and intricate character structures, such as Chinese and Korean, posing higher demands than standard image style transfer tasks. This is due to the significant structural differences between various Chinese characters, where even minor errors can profoundly impact the overall appearance of the font. The common approach to this task is typically based on the encoder–decoder architecture, with strong constraints imposed on the output characters [
21,
22].
To address the limitations of learning and outputting only a single target font style at a time, as well as the limited migration effects for more stylized fonts, Tian [
23] introduced the zi2zi model. Meanwhile, ZiGAN [
24] further enhanced the zi2zi model by incorporating the CycleGAN framework. This addition of an extra encoder–decoder allows for mapping the generated styled font back to the original standard font, significantly improving the quality of the generated font shapes. Moreover, the discriminator incorporates a CAM (Class Activation Map) to sharpen the model’s focus on local information. FUNIT [
25] employs a network to extract the glyph features of standard characters and another network to capture the unique style of stylized characters. These two types of features are then fused together, enabling the reconstruction of Chinese characters with unchanged glyphs but an entirely new style. SC-Font [
26] incorporates semantic information at the stroke level as auxiliary data, gradually integrating it into the main UNet structure to ensure the stroke stability of the generated images. AGIS-Net [
27] utilizes two independent decoders to process the fused features: one decoder is dedicated to generating the basic glyph, while the other decoder is responsible for further rendering more delicate style details based on the previously generated glyph.
DM-Font [
4] underscores the importance of emphasizing local text features rather than overall morphology for font generation. Through meticulous observations of the glyphic structures of Chinese, Japanese, and Korean characters, the authors discovered that these scripts are governed by radicals and proposed the innovative concept of “component reuse”. They maintain that by meticulously manipulating these components, it is theoretically feasible to synthesize any character. Kong [
28] introduced an attention mechanism to oversee the accuracy of component generation during the text generation process. Meanwhile, Xie [
29] put forth the DG-Font model, arguing that styled fonts can be achieved by applying traditional transformations to standard fonts. This approach offers a novel perspective on font generation, emphasizing the potential of traditional techniques in creating unique and stylish fonts.
However, text style transfer differs from font generation tasks: (1) Font generation tasks typically involve the use of the same or similar languages, such as Chinese, Japanese, and Korean. (2) Font generation tasks aim to generate individual characters, whereas stylized translation text targets a segment of text. (3) Font generation tasks place greater emphasis on the stroke connections, thickness, and glyphic structure of characters. To minimize the influence of font color and background color, datasets often adopt a white background with black text or other color schemes with high contrast. Addressing these issues, Wu L [
30] designed SRNet (Style Retention Network), the first attempt to solve the problem of text editing in natural scene images. The algorithm consists of three modules: a text transformation module, a style background restoration module, and a fusion module. The text transformation module changes the text content, converting the source image to the target text, while preserving the original text. The style background restoration module erases the original text and fills the text area with appropriate textures. The fusion module combines information from the first two modules and generates the edited text image. SRNet’s architecture ensures that the original style of the content image is maintained, while replacing the text content, achieving a visual effect consistent with the original text image. Yang [
31] built upon the SRNet architecture and proposed the CSTN (Content Shape Transformation Network) module to address curved and irregular text in stylized images. This module utilizes N reference points to model the geometric transformation of text. Krishnan [
32] introduced self-supervision to decouple background and foreground text in stylized images, enabling the one-time transfer of a source style to new content.
In MOOC scenarios, scene text editing faces significant challenges, particularly in cross-language text style transfer. Current methods, often based on single large models, struggle with readability and are typically integrated approaches involving background separation, image fusion, and style transfer. While these methods work well for ordinary scenes like street views or menus, MOOC scenarios present unique challenges due to fixed shooting angles and dense text stacking, such as in PPTs, which can lead to text overlaps after translation.
Cross-language text style transfer is further complicated by the structural differences between languages, such as the complex strokes of Chinese characters versus the simpler shapes of English letters. Most existing research has focused on holistic style transfer, which can degrade the quality of individual characters. Additionally, GAN-based methods often impose simplistic style constraints, leading to an overpowered discriminator that hinders the generator’s ability to update parameters effectively. These limitations highlight the need for more robust solutions tailored to the specific demands of MOOC scenarios.
3. Method
The main objective of cross-language text style transfer is to acquire the style embodied by a text in a styled image of one language via convolutional neural networks and transpose it onto text in another language. Nonetheless, several obstacles arise during this endeavor: Defining and recognizing style itself proves to be intricate; Given the substantial disparities in glyph structures among different languages, preserving a text’s inherent structural traits during style transfer is imperative; Translated texts might exhibit varying word lengths, posing a challenge in automatically resizing the text to prevent it from spilling over the image boundaries; Ensuring color parity between the original and output images remains an unresolved concern during style transfer. To tackle these obstacles, this study employs advanced techniques like generative adversarial networks (GANs), attention mechanisms, and latent space mapping, culminating in a network model adept at pinpointing textual positions within images. This model adeptly extracts pertinent features from designated locations and processes each character’s traits independently, facilitating meticulous character-level style transfer and color coordination. This methodology preserves the text’s structural coherence, while seamlessly transferring cross-language text styles and maintaining color harmony between the source and output images.
3.1. Text Style Transfer Networks
The cross-language text style transfer network presented in this paper is essentially an image generation GAN. The generator component employs an encoder–decoder framework, which efficiently processes input images and translates them into a sequence of feature representations. During the encoding phase, the model utilizes multiple layers of convolution operations to extract crucial feature information from the image, while during the decoding phase, this information is leveraged to progressively recreate the image, ultimately producing an output image with a distinctive style. The encoder–decoder framework guarantees comprehensive extraction of image features and facilitates the transfer of image styles.
This study incorporates the style module from StyleGAN. By integrating this module, we achieve decoupling and infusion of style features. This module seamlessly blends the characteristics of the style image with the text features, ensuring that the generated image preserves the original text information, while embodying the desired style attributes. To elevate the quality of the generated images even further, we introduce an attention mechanism into the discriminator. This mechanism predicts the location of each text within the generated image. Subsequently, the predicted text positions are employed to extract corresponding style and text features, enabling character-level supervision. Thus, the discriminator, equipped with an attention mechanism, aims to oversee the style and text features of each text, thereby enhancing its discriminatory capabilities. The adversarial training between the generator and discriminator of the GAN then serves to direct the generator towards producing images of superior quality. The specific architectural details of the model are shown in
Figure 1.
It is worth noting that AdaIN components play a crucial role in both the encoding and decoding stages of the network. A style vector is introduced into each upsampling convolution block’s AdaIN component, which then integrates it into every layer of feature maps, facilitating feature fusion. The calculation formula of AdaIN is shown in Equation (1). Distinguishing it from other normalization techniques, the statistics
and
are derived from an intermediate vector. AdaIN receives a combined feature map comprising both style and text features. Through analysis of this combined map, we ascertain the statistics
and
, employing a normalization formula to seamlessly integrate the style vector into the feature map. The style encoding is denoted as
, and the content encoding is represented as y, both of which have a dimensionality of 256.
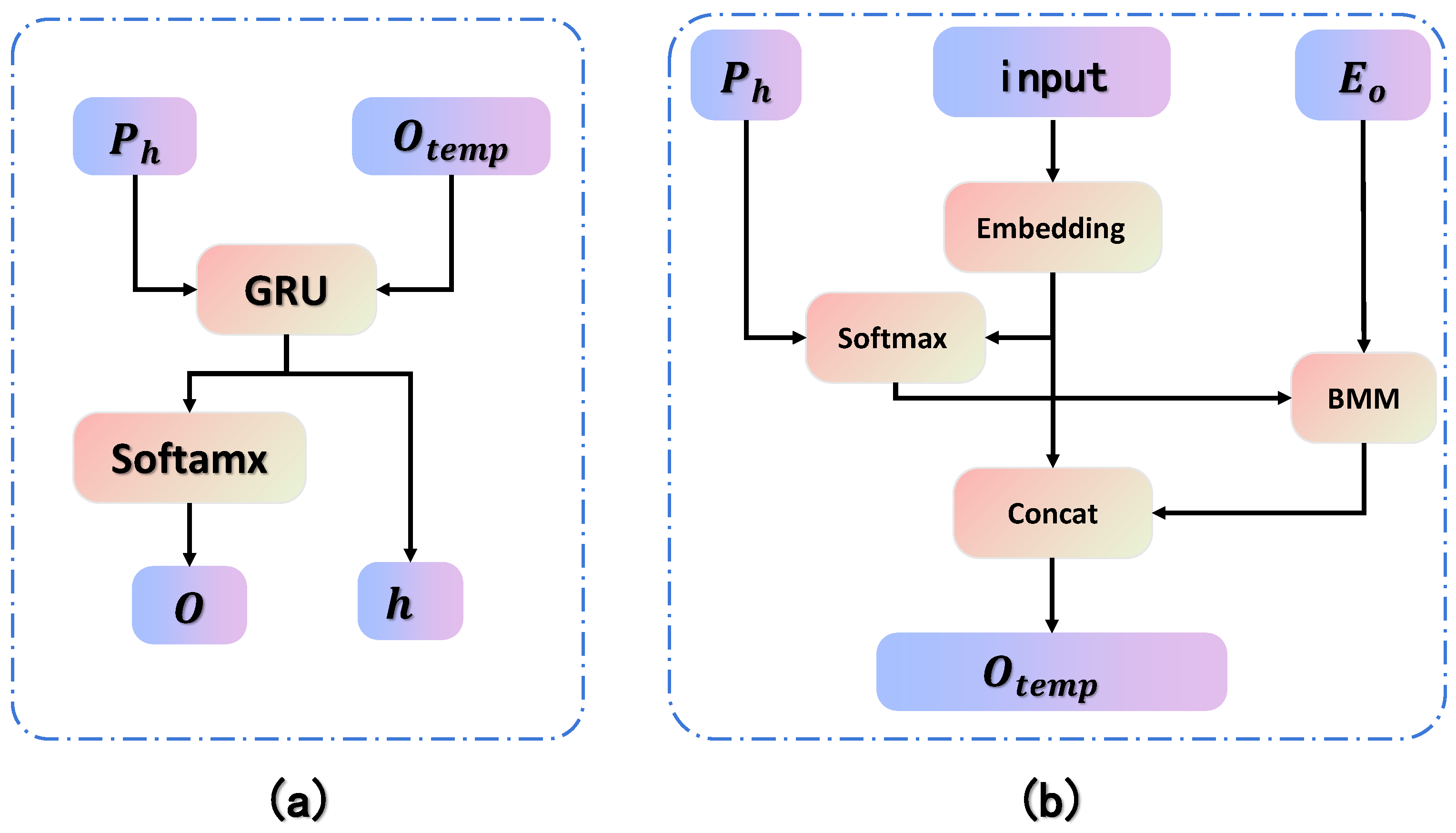
3.2. Imposed Sequential Attention
Prior to implementing the attention mechanism, corresponding data preparation is required. The first step involves using an encoder to extract features from the input image and output a feature map of the generated image. Assuming the parameters of the feature map are , a dimension transformation is applied to set , converting the feature map of the generated image into L C-dimensional vectors , denoted as . The second step involves preparing the text sequence vector for the generated image. Assuming a text sequence is represented as , where n denotes the length of the text sequence and t denotes the text. Next, the corresponding index numbers for the words in the vocabulary are found, such as the index number of the word t in the vocabulary being ′t3′. This generates the corresponding text vector . Finally, start and end symbols are added to the text vector t, with index numbers corresponding to 0 and 1 in the vocabulary, resulting in the text vector, denoted as . The third step involves using a vector of all zeros as the hidden state of the encoder in its final step, denoted as .
The three aforementioned pieces of data,
,
, and
, are inputted into the attention mechanism to initiate the first time-step computation process. The attention mechanism mainly consists of two steps. The first step focuses on calculating weighting parameters to determine which elements of
have a greater impact on the current word
. The weights for
are generated using a combination of
and
. After completing the aforementioned data preparation, the specific computational steps for the strong temporal attention mechanism unfold as follows: Initially, the attention scores between the hidden layer variables are computed. Utilizing the vector embedding operation as in Equation (
2), word embedding is conducted to yield the
vector. Next,
and
are concatenated, followed by applying a
function to derive
as in Equation (
3). Subsequently,
and
are multiplied to generate
, as outlined in Equation (
4). In the final step,
and
are aggregated, and a fully connected layer facilitates a dimensional transformation to produce
, as defined in Equation (
5), where ⊙ indicates element-wise multiplication.
The following represents the central procedure of the method introduced in this paper: imposing temporal constraints on the encoder output of the attention mechanism. By doing so, we compel the algorithm to systematically review every component of the text within the writing sequence, encompassing elements like the radicals of Chinese characters and all the letters of the English alphabet. Our primary approach involves utilizing a GRU network to model the output of each writing time step, effectively constraining and refining both the hidden layer state and the prediction outcomes. The specific process begins by utilizing prevh, acquired from the preceding step, as the input hidden state. Additionally, the output vector outt from the attention mechanism serves as the temporal input. Subsequently, the GRU network model is employed to generate the new output and hidden state. Within the two-step operation of the attention mechanism, the input data eo, ph, and in are leveraged to compute the prediction results and the hidden layer parameters of the attention mechanism through the formulas mentioned earlier. Upon completion of the first time step, ph undergoes an update in the subsequent time step. Here, the hidden layer outcome hidden in the previous time step is adopted as phid, allowing the continuation of the same process until all time steps have been finalized.
In
Figure 2, the input data are represented by the brown area, the blue area depicts the process of learning parameters, the green area signifies operations that require no parameter learning, and the yellow section displays the output results. In the initial phase of the attention mechanism, a correlation connection is established between the input data to guarantee a precise one-to-one correspondence between the text sequence and its corresponding feature map. This ensures the extraction of feature maps for each individual text within the sequence, facilitating effective transfer and supervision of text structural information. Referring to the discriminator network shown in
Figure 1, subsequent to the extraction of feature maps for each text, this study proceeds to analyze these features to ascertain the accuracy of style transfer and color consistency.
3.3. Loss Function
The
serves as a specifically designed loss function tailored for the attention mechanism. In this chapter, the algorithm leverages an attention mechanism to extract a feature map of each text present within the image. However, the attention mechanism’s output extends beyond merely the feature map; crucially, it offers the probability of predicting the type of text the current time step corresponds to. The cross-entropy loss function effectively quantifies the difference between the predicted result and the actual result. Its calculation formula is outlined in Equation (7), where CLS represents the cross-entropy loss function,
signifies the predicted text probability result derived from the attention mechanism, and
designates the target text sequence.
is the color loss function designated for each text element within the image, aiming to maintain color consistency throughout the generated image. The computational approach involves the attention mechanism generating a corresponding feature map for each textual region within the image. Subsequently, a convolutional neural network is applied to each text feature map, tasked with predicting the RGB value for each text region based on the extracted features. To guarantee the precision of the prediction outcomes, a cross-entropy loss function is employed to quantify the discrepancy between the predicted and target results. The calculation formula is detailed in Equation (8), where
signifies the predicted RGB value, and
denotes the desired RGB value.
stands for the font loss function, sharing similarities in design concept with
. In the experiments detailed in this paper, we curated a comprehensive dataset encompassing 172 distinct font files, serving as the primary source for textual styling in style images. The task of predicting the font file associated with a given text is tantamount to predicting its stylistic attributes. The core process involves leveraging the attention mechanism to meticulously extract a feature map for each textual region within the image. These feature maps encapsulate the pivotal characteristics of the text, serving as the basis for subsequent font type predictions. Subsequently, these extracted feature maps are employed and a font classifier is deployed to ascertain the font type corresponding to each textual region. By contrasting the prediction outcomes with the authentic font types, the font loss is determined, thereby strengthening the constraints on style transfer. The computational formula for this process is outlined in Equation (9).
calculates the difference between the text features of
and the text features of
. During style transfer, it is necessary for the text features of the generated image
and the text image
to remain consistent. Therefore,
aims to ensure that the text features in the image are preserved during the feature fusion process and are not destroyed. The calculation process involves re-extracting the text features of the generated image
and the text image
using a text feature extractor, and then utilizing the L1 loss function to calculate the difference between the text features. Here,
represents the text features of
, and
represents the text features of
. The calculation formula is shown in Equation (10).
The adversarial loss aims to assist the generator G in synthesizing a realistic image that is indistinguishable from real samples, while making the discriminator D be unable to distinguish between the generated image and the real sample, as shown in Equation (11).
Lastly, the loss function of the entire network is divided into two parts: the generator G and the discriminator D, as shown in Equations (12) and (13).
Based on the aforementioned model framework and loss function settings, this paper improved upon the classic GNN training method and designed a training procedure specifically tailored for video scene text images. This training procedure ensures the convergence of the generative network’s output, while minimizing the two proposed loss functions, namely and . The detailed steps of the training process are outlined in Algorithm 1.
| Algorithm 1: Pseudo-code for cross-lingual text style transfer algorithm. |
- 1
Initialize networks and sample , ,
from training set M. - 2
for
to
T
do - 3
for to K do - 4
Freeze G - 5
Compute , , and . - 6
Generate output . - 7
Calculate via Equation ( 13) - 8
Update D by . - 9
end - 10
for to K do - 11
Freeze D parameters (no backpropagation). - 12
Compute , , and . - 13
Generate output . - 14
Calculate via Equation ( 12) - 15
Update generator G via backpropagation. - 16
end - 17
Return G.
|
4. Experiments
In this section, the experimental results are showcased, validating the robust scene text editing abilities of our model. Moreover, comparisons between our methodology and alternative approaches are offered to illustrate the superior effectiveness of our method. Furthermore, an ablation study was conducted to further assess our technique. Before detailing the experiment, it is necessary to elucidate the objectives of this study. The method proposed herein aims to address the issues of language diversity, readability, and complex backgrounds present in current MOOC videos. Specifically, regarding language diversity, the output text language differs from the input text language, while retaining similar stylistic characteristics, such as the thickness of strokes and the curvature of edges in handwriting. In terms of background complexity, we hoped for the output text and background colors to align with the input text and background colors. As for readability, we ensure that the output text is devoid of blurring, typos, and other such imperfections. Notably, these aspects can be evaluated using metrics such as FID, SSIM, and LPIPS, which assess style similarity.
4.1. Experimental Settings
Cross-lingual Synthesis Dataset for Chinese and English: A synthetic dataset, produced by the SRNet-Datagen open-source project and provided by Youdao Company, was chosen to create paired data sharing the same style but featuring distinct texts. The image style predominantly relies on 172 font files, incorporating randomized text and background colors; the latter are primarily drawn from a palette of 50 solid colors. Additionally, random blurring was applied to mimic the effects of real-world conditions on image clarity. Consequently, a training dataset comprising 50,000 images and a test dataset comprising 2000 images were generated.
Real-world Dataset: The ICDAR2013 [
33] and ICDAR2019-LSVT [
34] datasets, sourced from street scenes and primarily designed for detecting and recognizing horizontal text in natural environments, were utilized. Each image in these datasets boasts detailed text labels, with annotations provided by rectangular bounding boxes. Notably, every image encompasses one or multiple text boxes. However, due to the absence of corresponding target images in these datasets and the impracticalities of manually creating them, a subset of 2000 images was carefully chosen exclusively for testing in this study. The network proposed in this study was trained for 50 epochs on the aforementioned dataset, with mixed training conducted in each epoch. During the training process, Chinese and English samples were alternately selected. For instance, when training for English-to-Chinese translation, English words were sampled from the dataset, and the corresponding translated Chinese handwritten characters were set as the output, and vice versa. The training was performed on a hardware configuration comprising an Intel Core i9-13900K processor (manufacturer: Intel, Santa Clara, CA, USA), an NVIDIA RTX 4090 GPU (manufacturer: NVIDIA, Santa Clara, CA, USA) with 24GB of memory, and 128GB of DDR5 RAM. The implementation was based on the PyTorch toolkit (version 1.2.0) with Python 3.8. The seed size configured in this study was set to 256. In addition, the Adam optimizer was employed to train our model, with
as 0.5 and
as 0.999, until the output stabilized throughout the training phase. The learning rate was fixed at
and the batch size was consistently maintained at 8. The specific parameters of the neural network involved in this project are listed in table below. We primarily employed three metrics to evaluate the success of our approach: IS (Inception Score), LPIPS (Learned Perceptual Image Patch Similarity), and FID (Fréchet Inception Distance). IS is used to assess the quality and diversity of generated images, though it has limitations in evaluating realism. LPIPS measures the perceptual similarity between generated and target images, making it suitable for assessing details and structural fidelity. FID evaluates the distribution distance between generated and real images in feature space, providing a comprehensive assessment of both quality and diversity.The specific details and scale parameters of the model are shown in
Table 1 and
Table 2.
4.2. Results and Analysis
Cross-lingual Style Transfer. To assess the efficacy of our proposed algorithm in achieving cross-lingual style transfer, this section exhibits the experimental outcomes of our cross-lingual text style transfer module. We also benchmark the image generation capabilities of our algorithm against SRNet [
30] as a reference point. Precisely, four distinct language pairs were established for style transfer in our experiments: Chinese to Chinese, English to English, Chinese to English, and English to Chinese. Furthermore, to demonstrate the algorithm’s robustness in handling scenarios where the word counts in the style image and the text image diverge, we intentionally varied the word counts across different languages.
From a quantitative standpoint, the method introduced in this paper exhibited significantly improved readability of text after undergoing style transfer, when juxtaposed with the baseline approach. Additionally, given that this study involves cross-language style transfer—necessitating that the input text for target style differs linguistically from the content text—our proposed method remained impressively resilient to linguistic disparities. As an illustration, refer to the second row of
Figure 3, where the baseline method incorrectly incorporated Chinese characters even though the intended content is exclusively in English. Conversely, our method not only accurately reproduced the intended textual content but also maintained the defining attributes of the target style, including text color and stroke thickness, among others. Remarkably, in certain experimental outcomes, the method adeptly replicated the curvature traits of the text strokes. Notably, in the third row of
Figure 3, the curvature of the rendered Chinese characters bears a striking resemblance to that of the English source text, a similarity that is discernible even to the casual observer.
Intra-lingual Style Transfer To further evaluate the results of style transfer within the same language, we set the MOSTEL [
35] algorithm as a comparison method in this section and present the style transfer effects from English to English. As shown in
Figure 4, we compared the results of our proposed algorithm with those of MOSTEL on the English dataset.
It should be noted that there have been few works on cross-language text style transfer, and some of them did not publish their code. Therefore, we selected the SRnet method, which published its source code, to compare between different languages. We also chose MOSTEL as a comparative method for style transfer within the same language. The above comparison methods maintain the same configuration during the training process. As can be seen in
Figure 4, the edited text structure is regular; the font remains consistent with the previous one, the background texture is more reasonable, and the overall feeling is similar to the real image. The quantitative comparison in
Table 3 shows that our method outperformed the comparison methods in all indicators.
Compared to the chosen baseline method, the approach presented in this paper exhibited noteworthy advantages in text clarity, correctness, foreground contrast, and image signal-to-noise ratio. By amalgamating these outcomes with those from prior cross-language model experiments, it is unequivocally evident that the enhancements introduced in this study were remarkably effective. Furthermore,
Table 3 encapsulates the quantitative findings from the intra-language experiments. Among all the experimental data in the tested dataset, our method emerged as the top performer across all three metrics for image similarity and quality assessment. Remarkably, our approach achieved a substantial lead in the FID metric, which came as a pleasant surprise. We further scrutinized the range of improvements suggested in this paper via ablation experiments.
4.3. Results of Scene Text Style Transfer
To further validate the effectiveness of the algorithm, a relevant real-world dataset was adopted as the test set to verify the generalization ability of the algorithm. In particular, considering that the real-world dataset lacked corresponding target images and it was difficult to manually create them for training, the real dataset was only used for testing during the training process. The results are shown in
Figure 5. We performed cross-language style transfer experiments focusing on real-world scene texts within images. The outcomes revealed that our approach effectively transferred attributes like text color and stroke thickness from the reference style image. Notably, the results presented in the fourth row of
Figure 5 show that our method adeptly captured and reproduced the connected writing patterns inherent in the input style text. This finding underscores the role of our algorithm’s robust temporal attention mechanism, which considered the image traits of the transitions between various text elements during the training phase. Undoubtedly, this constitutes a promising outcome.
The statistical results of this experiment are presented in
Table 4, and in this section, we elaborate on the experimental findings. In practical, real-world experiments, the dataset lacked labeled target text specifically for migration purposes. To evaluate the stylistic consistency, we computed FID and IS metrics by comparing the migrated text with the original style text input images (marked as
S-r). It is important to note that the experimental results depicted in
Figure 5 are associated with
, which may explain why these outcomes were marginally less impressive when compared to the benchmarks in
Table 4. Despite this, the results unequivocally demonstrated that our method notably surpassed the baseline approach in the field of scene text style transfer. This serves as additional proof of the remarkable generalization capabilities of the method introduced in this paper.
Furthermore, we conducted additional tests by employing the input text content
as the benchmark for the target image, denoted as C-ref. This particular metric served to primarily ascertain the correctness of the text generated by our method. Referring to
Table 4, it becomes evident that our approach excelled among the comparative methods in terms of textual accuracy, aligning seamlessly with the outcomes presented in
Figure 3,
Figure 4 and
Figure 5.
4.4. Ablation Study
To assess the influence of the color constraints introduced in this paper on the ultimate outcomes,
Figure 6 distinctly presents effect diagrams of the text style transfer, comparing scenarios with and without the application of color constraints.
Upon analyzing the ablation experimental results related to color constraints, it becomes evident that the algorithm without the inclusion of color constraints struggled to accurately capture color information during the transfer process, leading to color confusion in the resulting diagrams. Furthermore, in cases where the color information of the generated image is pale, the text font structure could not be fully rendered, significantly compromising the quality of the generated image. In conclusion, the integration of color constraints significantly boosted the algorithm’s capacity to learn color features, thereby effectively enhancing the quality of text style transfer.
Apart from the previously mentioned ablation experiments focusing on color constraints, this paper further conducted ablation studies on the attention mechanisms, text-level style loss, and content encoder loss functions. The outcomes of these ablation experiments are summarized in
Table 5, which utilized three widely recognized style transfer quality evaluation metrics: IS, LPIPS, and FID, to quantitatively assess the effectiveness of the ablation studies.
Through a comparative analysis of the results in
Table 5, the following conclusions can be drawn: The absence of color constraints significantly impacted the IS, LPIPS, and FID metrics, indicating that without color constraints, the consistency between generated images and target images was notably reduced. This suggests that the generated images were highly dependent on color and sensitive to color recognition. In the cases of missing character-level style constraints and text constraints, the FID metric was also affected to some extent, demonstrating that FID is sensitive to text-related features and struggles to generate results consistent with the target image when text information is lacking. Notably, the results without the attention mechanism were worse across all three metrics compared to those without color constraints, highlighting that relying solely on the attention mechanism, without additional technical support, can weaken the overall performance of the algorithm.
4.5. MOOC Applications
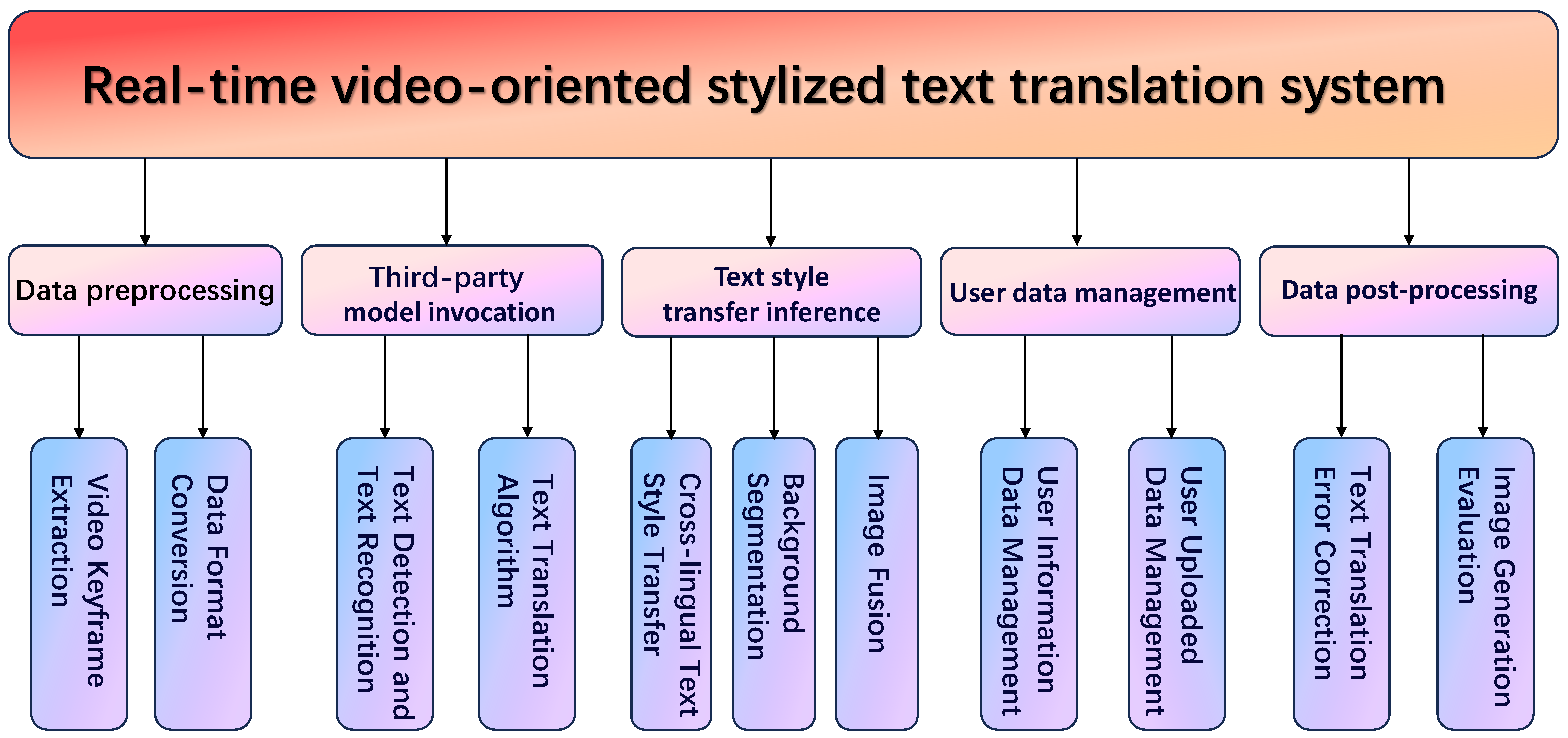
Leveraging the proposed text migration methodology, along with established models like text detection, this paper introduces a system tailored for MOOC-specific scene text language migration. This comprehensive system comprises five primary modules: data preprocessing, third-party model inference invocation, cross-language text style transfer inference, data post-processing, and video keyframe extraction, which identifies crucial frames within MOOCs and pinpoints the timestamps where text alterations occur.
The system also incorporates third-party model inferences, specifically utilizing PaddleOCR’s [
37] text detection and recognition models alongside machine translation algorithms. PaddleOCR employs a two-pronged approach, initially employing a text detection algorithm to ascertain the precise coordinates of styled images. The end result of this meticulously designed system is exemplified in
Figure 7, showcasing its efficacy and precision in MOOC-related text migrations.
5. System
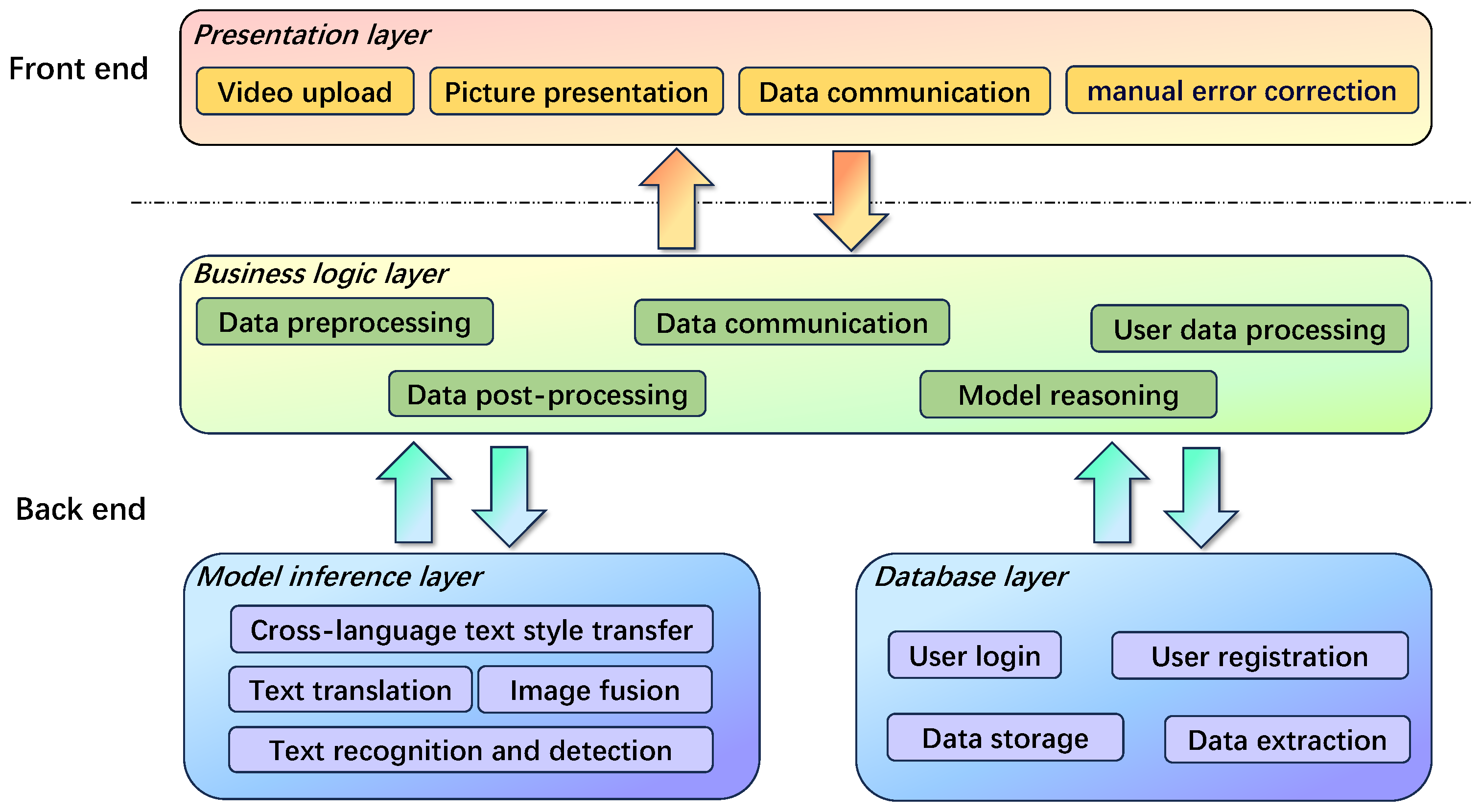
This section delves deeply into and introduces the logical flow of the real-time stylized translation text system for videos. The system achieves efficient processing and stylized translation of video content through four carefully designed core steps, successfully applying advanced algorithms to practical scenarios. Leveraging an existing front-end and back-end technology stack, we successfully built a feature-complete, visually interfaced real-time stylized translation text system for videos. This system not only fully realizes its core functions but also incorporates intuitive and user-friendly function buttons and operational interfaces, enabling users to easily operate and manage the process, thereby greatly enhancing user experience and system practicality.
5.1. System Logical Flow
For the specific optimization algorithm in the MOOC scenario, there are three key components: video keyframe extraction, background separation, and cross-language text style transfer. Other components are implemented using third-party open-source algorithms. The logical flow of the system is divided into four main steps:
(1) The front-end interface uploads a video, sends the video file to the back end, and the back end sends the video to the video keyframe extraction module to extract a sequence of keyframes from the video. (2) Text detection is performed on the keyframe sequence to detect the location coordinates of the text in the image. These coordinates are used to extract the corresponding text image as the style image. Then, a text detection algorithm is used to recognize the text information in the text image. Finally, the text is translated through a text translation module into the corresponding language, generating a content image. (3) The text style transfer module and background extraction module process in parallel. The content image and style image are input into the cross-language style transfer module to achieve style transfer for the content image. The background separation module extracts the background image by erasing the text information from the style image. (4) The image fusion module is responsible for fusing the background image and the style-transferred image to produce the output result image. Finally, the resulting image is returned to the video frame based on the text position determined by text detection.
5.2. System Overall Design
The system is designed based on a B/S architecture, utilizing front-end–back-end separation technology to complete the overall development. As shown in
Figure 8, the front end employs technologies such as H5, Vue, and AntDesign to build an intuitive and interactive user interface. Additionally, Ajax technology is used to implement asynchronous operations, ensuring efficient and smooth data transmission between the front end and back end. The back end is divided into three layers: the business logic layer, the model inference layer, and the database layer. The business logic layer primarily uses Python (version 3.8) and Java (Java 21) languages to handle the business logic, including data preprocessing, model inference invocation, and user data management functions. The model inference layer mainly relies on deep learning frameworks such as PyTorch (version 1.2.0) and Paddle (version 2.1.0), leveraging their rich functional libraries and GPU acceleration technology to efficiently process data and perform calculations. In the database layer, technologies such as SpringBoot, Aop, Mybatis, and Jdbc are used to handle database creation, maintenance, storage, connection, and session management tasks, enabling user registration, login, and data storage functionalities.
5.3. System Function Design
This section focuses on the back-end part of the system, which is mainly divided into five modules, as shown in
Figure 9: data preprocessing, third-party model inference invocation, a cross-language text style transfer inference module, data post-processing, and user data management. Data preprocessing includes video keyframe extraction, background separation algorithms, and data format conversion. Video keyframe extraction is responsible for extracting keyframes from videos and detecting time nodes where text changes in the video. The background separation algorithm erases text traces from the detected text images, preserving non-text areas. Data format conversion involves unifying images to the size required for model inference, normalizing the data, and converting it into tensor operations.
Third-party model inference invocation includes PaddleOCR’s text detection and text recognition models, as well as machine translation algorithms. PaddleOCR’s text detection and text recognition model mainly adopts a two-stage method. First, a text detection algorithm is used to obtain the coordinate positions of style images. Then, the coordinate information is utilized to crop out the style images for text recognition, to identify the content of the text in the current style image. Machine translation translates the currently recognized text content into the corresponding language, such as from Chinese to English, and finally generates a content image in the translated language.
The cross-language style transfer inference algorithm applies text stylization to the content image in the translated language, maintaining the visual appearance of the style image. An image fusion algorithm is then used to fuse the background image with the stylized image, outputting the final result image. The data post-processing module is divided into result image quality assessment and text translation quality assessment. It mainly relies on manual methods to judge whether the results meet subjective human visual quality standards and whether the machine-translated content is accurate. Finally, post-processing is used to implement error correction for the entire system.
User data management is used to manage all user information and data, including user identity information, uploaded video data, and subsequently compiled video data.
5.4. System Interface Diagram
This section presents the most crucial aspects of the implementation of the front-end interface: After logging in through the user interface, users can access the video upload interface. They can select the video file to be uploaded and click the “Open” button directly to upload the video to the front-end interface. The front-end interface sends the video data to the back-end business logic layer and utilizes the data preprocessing module to extract keyframes from the video. Upon completing the parsing of the entire video file, the back end saves the user data, such as uploaded video files and extracted keyframe sequences, by combining user information through user data management in the business logic layer. Finally, the back end returns the keyframes to the front-end interface to display the result. Users can flip through the keyframe sequence using the “Previous” and “Next” buttons, making it convenient for them to observe the keyframes.
When the current keyframe is selected, the system navigates to the image recognition interface. The business logic layer invokes third-party models for inference. It first locates the text in the keyframe through text detection and recognizes the text content. Then, it translates the text using a text translation algorithm. Lastly, it utilizes the text position information obtained during text detection to return the translated text to the original image. The “User Data Management” in the back end saves the output image and sends it to the front-end interface for display. This allows users to easily observe whether the text translation results are correct. When a translation error is found, it can be manually corrected through the text box above, and the changes can be saved by clicking the “Save” button. The “Previous” and “Next” buttons are used to navigate through the text in the current video frame.
After invoking the third-party models, the text style transfer inference model in the back-end business logic layer inputs the prepared data into the cross-language text style transfer, background separation, and image fusion models for inference. Finally, it returns the final result image.
This system demonstrates the process of cross-language text stylization in the simplest way. It not only combines machine translation with text detection and recognition technology to support image content recognition and translation, but also utilizes current text style transfer technology to automatically return the translated text in stylized images to the video frame.
Nevertheless, the current system exhibits several limitations that warrant further refinement. Firstly, the inherent disparities in pronunciation duration and rhythm between Chinese and English lead to challenges in subtitle alignment within MOOC videos. Enforced alignment may cause certain subtitle segments to transition too rapidly, potentially disrupting user engagement. Secondly, the approach adopted in this study necessitates the superimposition of generated cross-language text over the original PPT, which can inadvertently mask transient elements such as symbols or underlines present in the original content. Lastly, the system’s processing time for an entire video remains notably lengthy, highlighting the need for optimization to enhance efficiency.
6. Conclusions
This paper centers on the migration of stylized content from online course videos and texts, including PowerPoint presentations, within MOOC applications. Addressing the limitations of existing methods, we introduced several groundbreaking measures, such as an imposed temporal attention mechanism and color constraint loss. Our approach delivered impressive results in the cross-language style transfer dataset compiled for this study, surpassing the current state-of-the-art (SOTA) methods in numerous comparative metrics. Moreover, our method proved its efficacy in various real-world text editing scenarios, consistently showing notable advantages in experimental outcomes. Through ablation studies, we comprehensively validated the effectiveness of each proposed innovation. Ultimately, our methodology has been tentatively integrated into text translation for MOOC settings, significantly contributing to the global advancement of MOOCs.
Future Work
The current system is not without its imperfections and still requires enhancements to the algorithms and technical capabilities to achieve optimal performance: First, OCR accuracy is dependent on the language/script, and while current OCR algorithms perform well on printed fonts, further optimization of multilingual OCR models is needed. Second, subtitles, incorrect matches, or unnecessary line breaks in PPTs may lead to semantic segmentation. We are exploring solutions based on large models, but no significant progress has been made yet. Third, the current algorithm does not specifically handle cross-language scenarios, resulting in poor readability and inconsistent style in generated fonts, as demonstrated in the experimental section. Fourth, complex backgrounds may cause OCR algorithms to fail in detecting text, but MOOC videos typically use solid-color backgrounds to enhance contrast, making this issue rare in practice. Resolution significantly impacts video processing results, and we require the original video resolution to be at least 1080p. Fifth, when there is a significant difference in the length of content before and after translation, layout issues may arise. In the project implementation, we prioritized the readability of generated text, partially sacrificing layout neatness. When processing large datasets, excessively long videos or too many PPT slides can increase the computation time. However, actual tests showed that computation time increases linearly with video length, and the system typically processes a MOOC video within two to five minutes, which is considered acceptable.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}