Abstract
The use of commercial off-the-shelf smart devices in digital signage for sentient spaces is emerging as a promising solution within smart city environments. In such scenarios, these devices are often required to execute resource-intensive applications despite limited local computational capacity. Although cloud and fog infrastructures have been proposed to offload demanding workloads, they are not always suitable due to privacy and security concerns. As a result, executing sentient space applications directly on smart devices may exceed their processing capabilities. To address this limitation, state-of-the-art solutions have introduced load balancing techniques for smart devices. However, these approaches typically rely on centralized coordination or require extensive system profiling, making them unsuitable for sentient spaces, where device availability is intermittent and cooperative behavior must remain lightweight, adaptive, and decentralized. This paper proposes a distributed load balancing strategy tailored for sentient spaces that operate without reliance on cloud or fog infrastructures. The approach is based on reactive cooperation among neighboring devices and employs a local feasibility-check mechanism to determine when to offload computation and which neighboring devices are available to process it. The proposed solution is evaluated in a laboratory setting that emulates a real-world sentient space scenario within a commercial mall. Experimental results show the effectiveness of the proposed approach in maintaining real-time performance and mitigating local computational overload without relying on centralized infrastructure. Even under dynamic operating conditions, the system achieves a load balancing execution time of 5 ms on an ARM Cortex-A53 processor integrated in an AMD Zynq UltraScale+ platform.
1. Introduction
The use of commercial off-the-shelf smart devices in digital signage for sentient spaces (i.e., environments that sense and react to human presence and context through embedded intelligence) represents an increasingly valuable approach in the context of smart city applications [1]. Imagine a network of smart totems equipped with sensors, processing components, and actuators, capable of gathering visual intelligence on approaching individuals to deliver personalized information in real time. These smart devices can analyze individuals using age estimation, gender identification, and language recognition algorithms, dynamically optimizing the content delivery process. These devices can be modeled as computing nodes within a distributed system [2]. However, the underlying algorithms associated with the gathering of visual intelligence are known to be computationally intensive [3], often requiring significant local processing capabilities to ensure timely execution.
The traditional mobile cloud computing approach, typically adopted to relieve computing nodes from heavy workloads by offloading tasks to remote cloud servers [4], is not always feasible in this context. The mobile cloud computing approach may expose sensitive personal data to security vulnerabilities and is subject to variable latency depending on internet connectivity [5]. To reduce latency, fog computing has been introduced, allowing processing to be offloaded to nearby servers located closer to the data source [6]. However, fog computing still relies on centralized intermediate nodes, which may continue to pose privacy concerns, particularly in scenarios involving sensitive user profiling data.
To address these limitations, a certain degree of pre-processing must be performed directly on the computing node before transmitting summarized information to any back-end system. For instance, rather than sending full video streams, a computing node should report only extracted features such as age, gender, and language once recognition is complete. This approach of pre-processing on the computing node requires the computing node to execute computationally intensive, real-time video and audio processing algorithms whenever individuals appear within its field of view or are in close proximity to the device sensors. In such conditions, there is a risk of missing task deadlines due to limited local processing capabilities. Consequently, there is a need for alternative strategies based on distributed processing. These strategies must be capable of operating under real-time constraints while also preserving user privacy and adapting to the dynamic and decentralized nature of sentient spaces [1].
State-of-the-art research has proposed various load balancing strategies targeting edge and distributed environments [7,8,9,10,11,12,13]. However, these approaches often rely on centralized coordination, cost-based optimization, or require extensive system profiling, making them less suitable for dynamic scenarios like sentient spaces, where node availability is intermittent and the system requires low-overhead solutions.
In this paper, we propose a distributed load balancing approach for computing nodes operating within a sentient space. The proposed approach provides two key contributions:
- A load balancing algorithm based on local feasibility checks and reactive cooperation with neighboring nodes;
- A cooperation infrastructure among neighboring nodes, which enables two key phases:
- –
- Discovering neighboring nodes that are available to support a node in computation when its local workload risks violating the application deadline;
- –
- Performing task offloading among nodes without relying on a centralized intermediate node, laying the foundation for a communication framework that does not share sensitive data with third-party elements.
The proposed approach is validated in a laboratory setting that emulates a real-world sentient space scenario in a commercial mall, involving five computing nodes. Load balancing is triggered whenever local processing exceeds a predefined latency threshold. Experimental results show that the proposed solution effectively maintains real-time response requirements under varying crowd conditions and computational workloads, showing its ability to adapt to dynamic scenarios and operate in a fully decentralized manner.
2. Related Works
Different load balancing strategies have been proposed in recent years to address the challenges of task allocation in edge and distributed computing environments. These approaches generally aim to improve system responsiveness, reduce service latency, or increase resource utilization by dynamically distributing workloads across computing nodes.
However, in order to be applicable to sentient spaces, these approaches must meet specific requirements. In sentient spaces (namely, physical environments augmented with distributed sensing, processing, and actuation capabilities that enable them to perceive and react to human presence and contextual changes):
- Requirement R1—Nodes may operate in loosely connected and dynamically varying groups, where central coordination is not always feasible and neighbor availability can fluctuate significantly [1]. This implies that the load balancing strategy must explicitly account for such conditions by incorporating mechanisms for neighbor awareness and dynamic discovery of available resources.
- Requirement R2—Nodes are typically resource-constrained, imposing computational limitations that restrict their ability to process workloads locally. This implies that the load balancing strategy must be lightweight, avoiding complex optimization techniques or computationally intensive models.
The work in [7] introduced a workload allocation mechanism for edge computing in smart grids, aimed at minimizing service delay by combining resource allocation and task distribution. Their algorithm integrates particle swarm optimization and semi-definite programming for intra-node and inter-node optimization, respectively. The work in [8] proposed a dynamic resource allocation approach for load balancing in fog computing environments. Their approach leverages static service partitioning and dynamic service migration to balance workloads. In both works, the formulations assume relatively stable computing node availability and do not address the challenge of intermittently available neighbors, failing to satisfy Requirement R1.
The work in [9] proposes a traffic load allocation scheme for drone-assisted fog networks, aiming to minimize wireless latency through optimized drone placement and user association. The work in [14] addresses task offloading and resource allocation in mobile edge computing systems using a quantum particle swarm optimization algorithm, with the objective of minimizing overall task completion time while satisfying resource constraints. While both solutions address dynamic node deployment, they rely on centralized optimization and do not incorporate decentralized, reactive behavior based on feasibility assessments. As such, these approaches are not well-suited to sentient space scenarios, where nodes may be isolated in small groups and unable to perform centralized optimization. Moreover, the proposed methods are not lightweight, requiring significant computational power for decision-making.
The work in [10] proposes a five-layer mist–fog–cloud architecture for IoT scenarios, leveraging Software-Defined Networking to optimize data transmission and resource allocation through centralized load balancing. While this architecture enhances Quality-of-Service and energy efficiency, it relies on the presence of fog infrastructure and centralized orchestration, making it unsuitable for sentient spaces where fog nodes may be absent and node availability is dynamic and decentralized.
In vehicular and mobile edge computing domains, researchers have explored deep learning-based schedulers (e.g., [11]) and reinforcement learning approaches for task distribution (e.g., [12]), yielding promising results for dynamic and predictive load balancing. However, these approaches often require extensive training and system-wide profiling, making them less suitable for reactive and lightweight load balancing solutions in scenarios with uncertain node participation, such as those found in sentient spaces.
The work in [13] proposes a distributed load balancing strategy that reacts to system dynamics and leverages local resource information. However, their distributed solution relies on solving a cost-minimization optimization problem using linear programming techniques at each node. While effective in controlled scenarios, such optimization is computationally intensive, and it is impractical for the constrained hardware platforms typically deployed in sentient spaces.
The approach proposed in this paper aims to overcome the previous limitations in providing a load balancing strategy designed for dynamic environments such as sentient spaces. Similar to the work in [13], the proposed approach adopts a reactive and distributed load balancing mechanism that leverages local interactions and node-specific status information. Unlike [13], the proposed solution replaces optimization-based decision-making with lightweight feasibility checks, reducing computational complexity and making the approach suitable for resource-constrained nodes in sentient spaces, where decisions must be made rapidly due to their impact on real-time constraints.
Table 1 presents a comparison between relevant works in the literature and the proposed approach, with respect to their load balancing architecture (centralized, distributed, or AI-based), trigger type (reactive, proactive, or predictive), decision strategy, and whether they address the requirements R1 and R2. With respect to R2, the related works generally do not report latency or runtime overhead figures in a way that allows a fair, quantitative comparison, as their evaluation is typically conducted in simulation and without explicit timing results. For this reason, instead of presenting absolute numbers, we classify each approach as “lightweight” or not, providing a qualitative indication of whether the decision mechanism is suitable for use in resource-constrained nodes.

Table 1.
Comparison of load balancing approaches.
Unlike the rest of the works, the proposed approach introduces a distributed load balancing strategy explicitly designed for dynamic environments. It ensures that offloading is triggered only when needed and is guided by a lightweight feasibility assessment rather than continuous cost optimization (addressing requirement R2). Furthermore, the proposed approach operates in a distributed manner without requiring full knowledge of the system state or centralized control. By explicitly accounting for dynamic neighbor availability (addressing requirement R1) and prioritizing feasibility in terms of meeting task deadlines over generalized resource optimization, the proposed solution offers a practical and robust alternative tailored to resource-constrained nodes in sentient spaces.
3. The Proposed Approach
The reference scenario is that of sentient spaces within a commercial mall, where a set of nodes is deployed to support digital advertising, user interaction services, and video surveillance functionalities. While this specific use case drives the experimental validation, the proposed approach is not limited to commercial environments and can be applied more broadly to other sentient space scenarios, such as smart campuses, transportation hubs, or public service areas, where distributed, real-time processing and dynamic cooperation among nodes are required.
The proposed approach is designed for a context where
- Nodes are primarily intended for advertising and user assistance applications;
- Nodes are continuously powered (i.e., not battery-constrained), and energy consumption is not considered a limiting factor;
- Not all nodes can directly communicate with each other; instead, localized groups of nodes may form communication clusters, reflecting real-world conditions where physical separation (e.g., walls, layout zones) limits connectivity within the commercial mall;
- All tasks are associated with soft real-time deadlines, where deadline violations may degrade the overall quality of service [15].
It is important to clarify that, although commercial malls are typically equipped with Wi-Fi coverage throughout the entire area, this infrastructure is not used when sensitive information must be exchanged between nodes. Specifically, for privacy and security reasons, such information is required to remain local and must not be transmitted over shared wireless networks. Therefore, while mall-wide Wi-Fi may be available, it is bypassed in scenarios involving personal data (this design choice is motivated by compliance with data protection principles such as data minimization and local processing, as outlined in the General Data Protection Regulation (GDPR), Regulation (EU) 2016/679).
- Underlying Principle
The underlying principle of the proposed approach is to allow each node to anticipate situations in which its local workload may exceed its real-time processing capabilities, potentially leading to deadline violations. When such a condition is detected, the node evaluates whether nearby peers have previously announced their availability to assist with workload sharing. If that is the case, the node performs a feasibility-based task offloading.
The proposed solution consists of two main components:
- A load balancing algorithm based on local feasibility checks and reactive cooperation with neighboring nodes;
- A cooperation infrastructure among neighboring nodes that enables the discovery of nodes available to support computation when the local workload risks violating the application deadline, and the execution of task offloading to achieve load balancing through workload sharing among neighbors.
The following subsections present the system and execution model (Section 3.1), the load balancing algorithm (Section 3.2), and the cooperation infrastructure among nodes (Section 3.3).
3.1. System and Execution Model
This subsection first presents the system model (Section 3.1.1), which introduces the formalism adopted to describe the sentient space as a distributed system. It then describes the execution model (Section 3.1.2), detailing how each node of the sentient space executes the application. Finally, it discusses the rationale of application execution (Section 3.1.3).
3.1.1. System Model
We consider a distributed system composed of a set of identical nodes (see Figure 1a). Nodes are interconnected in a peer-to-peer manner through generic communication links, forming a decentralized architecture with no central coordinator. The specific link technology is abstracted here and detailed later in Section 3.3. The set of nodes is defined as follows:
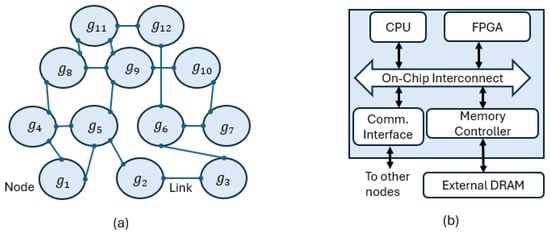
Figure 1.
(a) Decentralized peer-to-peer topology composed of identical nodes , representing the distributed system. (b) Internal architecture of a node, showing processing units (CPU and FPGA), on-chip interconnect, memory subsystem, and communication interface used to connect directly to other nodes in the topology shown in (a).
Each node contains a processor, which can be multicore, and an FPGA (see Figure 1b). The FPGA can host hardware accelerators to support the processor in task execution or, alternatively, additional processors to execute tasks isolated from those running on the main processor.
Both the processor and the FPGA are integrated on the same chip and share a DRAM main memory, accessed through an on-chip memory controller. A communication interface connects the node to its directly linked peers in the decentralized topology of Figure 1a. This architecture is representative of several commercially available Systems-on-Chip (SoCs), such as the AMD/Xilinx Zynq UltraScale+ [16], Microchip Polarfire SoC [17], Achronix Speedster SoC [18], and Intel Agilex SoCs [19]. The main memory size typically ranges in the order of a few gigabytes.
The distributed system executes a set of applications:
At system bootstrap, according to its role in the sentient space, each node is configured to execute exactly one application, which remains fixed throughout the system runtime. Multiple nodes may be configured to independently execute instances of the same application. We formally define a mapping function:
such that, for each node , the function returns the application assigned to that node, namely .
Each application is composed of a set of tasks:
At runtime, due to variable input conditions on the corresponding node (e.g., the number of people detected by sensors), each task may release multiple jobs. We define the multiplicity vector for as follows:
where denotes the number of jobs released by task during a single activation of application on its associated node.
It is worth noting that the multiplicity vector may vary at each activation, as it depends on input conditions. In particular, for one or more tasks, the corresponding multiplicity may also be zero, indicating that the task is not required for that specific activation.
Let denote the k-th job released by task . The complete set of jobs to be scheduled on the related node during one activation of application is as follows:
Each application is associated with a relative deadline , which represents the maximum allowable time to complete all jobs in during one activation of the application. Deadline violations are tolerated under soft real-time constraints but may degrade service quality.
While dependencies may exist among tasks in (e.g., data produced by one task may be consumed by another), we assume that all jobs released by the same task are independent once generated. Specifically, for each task , the set of jobs are considered self-contained units of work that can be executed in parallel and potentially distributed across available compute resources. This assumption is motivated by the nature of sentient space applications, which typically involve processing multiple heterogeneous inputs such as images, audio streams, or sensor readings. When multiple jobs are released by the same task, they generally correspond to different input instances (e.g., distinct people detected in different camera frames or separate audio utterances), and thus they can be processed in parallel without introducing inter-job dependencies.
Conversely, jobs released by different tasks in the same (e.g., and with ) are not assumed to be mutually independent, as their execution order may be implicitly constrained by the application structure. This assumption is motivated by the fact that, in typical sentient space applications, tasks are often organized in processing pipelines where the output of one task constitutes the input for the next (e.g., face detection precedes age estimation, or audio transcription precedes language classification). Such inter-task dependencies prevent arbitrary reordering or parallelization across different tasks. Consequently, only intra-task job sets are eligible for parallel execution and offloading.
3.1.2. Execution Model
Assuming that node is responsible for executing application (i.e., ), the goal of the proposed approach is to determine a spatial scheduling that assigns each job to an execution resource such that
where is the total execution time of the job on the assigned execution resource. The possible execution resources that can be assigned to each job are as follows:
- the local CPU of node , with worst-case observed execution time ;
- the local FPGA of node , with worst-case observed execution time ;
- if the job is parallelizable and therefore offloadable, the FPGA of a remote node , with worst-case observed execution time , provided that has previously announced its availability and that is the communication time required to transfer job data between local node and remote node.
The spatial scheduling is determined through a load balancing algorithm, detailed in Section 3.2.
We assume that the communication overhead , i.e., the time required to transfer job data between nodes for workload sharing (i.e., for the cooperation), is independent of the specific source and destination nodes. This assumption is reasonable in sentient space scenarios, where exchanged data primarily consists of images of bounded size. We also assume that the execution time is the same on both local and remote nodes, since all nodes are equipped with identical FPGA hardware and implement the same accelerator structure capable of executing the workloads in the task set. Once a resource (e.g., an FPGA) is assigned to a job, it is reserved for the entire duration of the application instance and is not reused within the same scheduling round. This static reservation model simplifies coordination and eliminates the risk of dynamic contention during execution.
3.1.3. Application-Layer Dependency Management
The application executed by node is structured as a pipeline of dependent tasks, generating jobs. Each job associated with task is activated only after its required inputs have been produced by preceding tasks. As detailed in Section 3.1.2, we distinguish between intra-task and inter-task job sets. The inter-task job set and its associated dependencies are enforced by the application logic, while the load balancing algorithm takes as input the complete job set and, for intra-task job sets, provides the possibility to offload jobs to other nodes.
The load balancer is invoked once per activation of application , after all inputs have been acquired and the complete job set has been defined. includes all the jobs that need to be executed during the current activation of application , across all tasks . The load balancing algorithm operates on the entire , and computes a feasible job-to-resource assignment such that the cumulative execution time does not exceed the application deadline .
This approach enables the system to make a global scheduling decision before execution begins. During execution, the application :
- follows the correct order of task activation, based on the known task dependencies;
- executes each job on the resource assigned to it by the load balancing algorithm.
The assignment of execution resources is based on a cooperation mechanism: nodes periodically publish their availability using a binary flag, indicating whether they are currently able to accept additional jobs. Only FPGA resources are considered for remote execution, as CPU resources are reserved for local workloads. Details on the communication technology used to publish availability are discussed in Section 3.3.
3.2. Load Balancing Algorithm
The proposed algorithm is reported in pseudo-code in Algorithm 1 and is designed to be executed on each node .
The algorithm takes as input the job set , the application deadline , the execution times of each job both on the CPU () and on the FPGA (), and the communication time between nodes. This communication time accounts for the transfer of input data required when offloading a job to another node. To enable such cooperation, it is assumed that each node has the instruction code of all applications deployed in the sentient space. This assumption is not restrictive, as the considered node model (Figure 1) is equipped with several gigabytes of main memory. The algorithm also receives as input the set of currently available neighboring nodes (Line 3).
The algorithm is executed at the beginning of each application instance on every node, restarting from scratch at each invocation.
Initially, the algorithm computes the total execution time on the CPU of all jobs belonging to the local application, stored in (Line 5). If is within the application deadline, the node announces the availability of its FPGA to neighboring nodes (Line 7) and schedules all jobs on its local CPU (Line 8).
If exceeds the deadline, the algorithm initializes with (Line 10) and uses the binary variable FPGA_used to indicate whether the local FPGA is currently available. The algorithm then iterates over all tasks and their corresponding jobs (Lines 12–13). For each job, if the local FPGA is available and its execution time is shorter than the CPU time (Line 15), the algorithm computes the gain and assigns the job to the local FPGA (Line 17). The accumulated execution time is updated accordingly (Line 19). If the updated is within the deadline, the algorithm immediately approves the schedule and terminates. This early exit mechanism increases responsiveness by avoiding unnecessary checks once a feasible schedule has been found. If the local FPGA is not available (e.g., already in use by another job or another node), the algorithm checks whether any neighboring node offers its FPGA resources. It first computes , the sum of the remote FPGA execution time () and the communication time () (Line 24). If this time is lower than the (Line 25), the algorithm iterates over the set of available neighboring nodes (Line 28). As soon as a node with an available FPGA is found, the job is assigned to that node (Line 29), is updated (Line 30), and is compared again with the deadline. If the updated time meets the deadline, the algorithm exits immediately; otherwise, it proceeds to the next job. If no feasible schedule can be found after all iterations, the algorithm returns an infeasible status and falls back to best-effort CPU execution (Line 42).
It is worth noting that, while the triggering condition acts as a strict feasibility check, it remains robust in the considered reference scenario (a sentient space in a commercial mall). This is because the proposed approach relies on worst-case observed execution times, and the deadlines involved are in the range of seconds (as will be discussed in Section 4), whereas typical execution time fluctuations are limited to microseconds or a few milliseconds. Hence, the risk of triggering unnecessary offloading due to transient peaks is considered negligible.
| Algorithm 1 Load Balancing Algorithm |
|
3.3. Cooperation Infrastructure
In the context of the load balancing algorithm described in Algorithm 1, communication plays a critical role in two specific phases:
- Neighbor discovery and FPGA availability: announcing FPGA availability to other nodes (Line 7) and identifying neighboring nodes with available FPGA resources (Line 27);
- Task offloading: transmitting the necessary data to selected neighboring nodes once they are involved in the scheduling process.
This section proposes a cooperation infrastructure designed to ensure that these two phases are properly implemented while meeting the specific requirements of a sentient space:
- (i)
- When two computing nodes need to exchange sensitive information, communication must not involve any third-party intermediaries in order to preserve data privacy. Conversely, for non-sensitive information, the involvement of third-party nodes may be acceptable.
- (ii)
- In the context of task offloading, data exchanged in sentient spaces often includes information extracted from video frames, images, or audio recordings, potentially reaching sizes of several megabytes. Therefore, the communication technology must provide sufficient bandwidth to support such data transfers within the soft real-time deadlines typical of these environments. Deadlines in sentient space applications commonly range from 0.1 s to 1.5 s [20,21].
- (iii)
- Nodes are often nomadic and may be deployed in diverse and dynamically changing physical locations throughout the environment.
To satisfy requirement (iii), we focus exclusively on wireless communication technologies. Table 2 compares several wireless communication technologies in terms of operating frequency, communication range, and data transmission speed. To meet requirement (ii), Wi-Fi technologies are considered the most suitable, as they provide high data transmission rates and low latency. With respect to requirement (i) and the associated communication protocols, we distinguish between the neighbor discovery and FPGA availability phase and the task offloading phase.
Table 2.
Comparison of wireless communication technologies.
3.3.1. Neighbor Discovery and FPGA Availability
Neighbor discovery and FPGA availability announcements are performed using standard Wi-Fi technology, which allows nodes to publish and subscribe to availability information over an existing infrastructure network.
At the transport layer, the Transmission Control Protocol (TCP) is adopted, as it ensures reliable and ordered data delivery through acknowledgment and retransmission mechanisms. This reliability is essential for maintaining the correctness of availability information.
At the application layer, the Message Queuing Telemetry Transport (MQTT) protocol is employed. MQTT is a lightweight publish/subscribe communication protocol well-suited for resource-constrained environments. It enables nodes to broadcast their availability to support computational offloading by publishing intent-to-help messages to predefined topics. Each node operates as an MQTT client and subscribes to these topics to receive updates from other nodes within Wi-Fi range.
In the proposed cooperation infrastructure, one of the participating nodes acts as the MQTT broker, managing all published messages and maintaining the current availability status of neighboring nodes. Since standard Wi-Fi supports multi-party communication through a shared access point, this architecture ensures reliable message distribution even in dynamic deployments. MQTT messages are small, often just a few bytes, yet sufficiently expressive to convey availability and acceptance conditions for offloaded tasks. This approach provides a lightweight, scalable, and decoupled coordination mechanism, enabling reactive and efficient load balancing without centralized infrastructure.
3.3.2. Task Offloading
Task offloading is carried out using Wi-Fi Direct, which enables direct peer-to-peer communication between nodes without the involvement of intermediate access points, thereby preserving privacy and reducing latency.
At the transport layer, TCP is again adopted to ensure reliable and ordered delivery of data, which is crucial for transferring computational inputs and results, such as image frames or feature maps.
At the application layer, HTTP is used as the communication protocol for task offloading. HTTP offers a stateless and persistent connection model, broad platform support, and standard port usage, simplifying integration and firewall traversal. Although FTP also operates over TCP, HTTP provides faster session establishment and is better suited for integration with Wi-Fi Direct peer-to-peer links. Consequently, HTTP is employed to transmit input data and receive computation results between nodes during the task offloading phase.
4. Experimental Activities
The proposed approach is validated in a laboratory setting that emulates a commercial mall sentient space scenario [22], involving different computing nodes, where load balancing is triggered whenever local processing exceeds the predefined latency threshold.
The nodes consist of informative totem nodes and roof nodes. Figure 2 shows their placement within the selected commercial mall. The area is divided into three main sections, referred to as spaces, separated by walls. Spaces 1 and 2 each contain one totem with four sides, with a screen installed on each side. In both spaces, four roof nodes are mounted on the ceiling around each totem, positioned on its four sides, and execute video surveillance tasks. The objective of each totem is to deliver customized advertising on its screens based on the characteristics of individuals approaching it. Space 3 contains three totems, each with four screens, and one roof node. As in Spaces 1 and 2, the totems in Space 3 deliver customized advertising on their screens, while the roof node performs video surveillance.
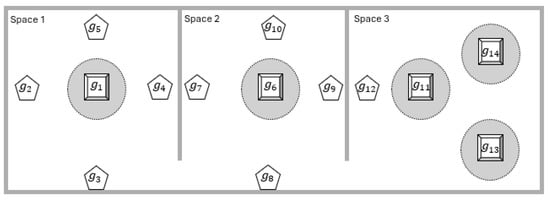
Figure 2.
Physical layout of the considered commercial mall. The mall is divided into three spaces. Spaces 1 and 2 each contain a Totem node (square shape), labeled and , surrounded by a Totem area (dotted circle) and four Roof nodes (pentagon shape). Space 3 contains three Totem nodes, labeled , , and , and one Roof node.
The customized advertisement on the totem must be generated within one second from the moment individuals appear in front of the screen, in accordance with human-computer interaction guidelines that recommend sub-second system response to preserve user attention and engagement [20,21].
The goal of the experimental activity is to show how the proposed load balancer enables the totem (in different scenarios) to operate correctly while meeting the one-second deadline, even in high-demand scenarios where individuals are present on all four sides. This is achieved by leveraging nearby nodes (either roof nodes or other totems) to offload computation when needed. It is worth noting that the proposed approach is applicable to scenarios involving node types different from those used in the experimental activity.
This section is organized as follows: Section 4.1 describes the hardware and software details of the totem and roof nodes. Section 4.2 presents the characterization of workload execution on the totem. Section 4.3 evaluates how the response time of the overall totem activity, in two different scenarios (Space 1 and Space 3 of Figure 2), remains within the one-second deadline as the number of people around the totem increases. Finally, Section 4.4 discusses the obtained results in relation to state-of-the-art works.
4.1. System Composition
This section describes the hardware and software configuration of the totem and roof nodes used in the experimental setup.
4.1.1. Informative Totem Node Architecture
From a hardware perspective, each informative totem is built around a Zynq UltraScale+ platform [16], which is connected to four screens to enable the system to process targets from four directions. Each screen is paired with a dedicated camera, resulting in a total of four cameras per totem. Additionally, each totem is equipped with four microphones, one for each side. The totem node also integrates two Pmod WiFi modules [23], enabling both standard Wi-Fi and Wi-Fi Direct communication with other nodes. This configuration reflects a typical setup in commercial malls, where a single processing platform manages the functionality of an entire totem [24]. The Zynq UltraScale+ platform resembles the node architecture considered in the proposed sentient space (see Figure 1b), where the CPU consists of a quad-core ARM Cortex-A53, while the FPGA fabric corresponds to an Artix-7 device. Inside the FPGA, there are two Xilinx DPU hardware accelerators [25], which are able to execute convolutional neural networks. The SoC architecture of the informative totem is reported in Figure 3.
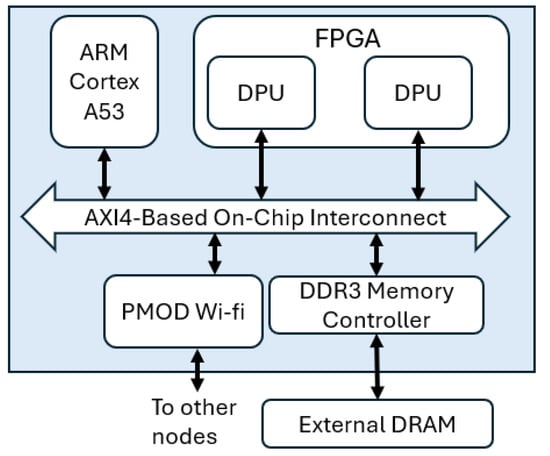
Figure 3.
Instance of the node architecture used in the experimental activity for both Totem and Roof nodes, based on the Zynq UltraScale+ platform. The SoC integrates an ARM Cortex-A53 processor and an FPGA hosting two Deep Learning Processing Units (DPUs), interconnected via an AXI4-based on-chip interconnect. Two PMOD Wi-Fi modules enable both standard Wi-Fi and Wi-Fi Direct communication with other nodes, while an external DDR3 DRAM is shared through a memory controller.
The informative totem executes an application composed of several tasks, as shown in Figure 4a, which depicts the task graph of the application. For each individual approaching the totem from any side, three main tasks are performed: Idiom Recognition (IR), which executes one job per side and processes audio inputs from the microphones; and Age Estimation (AE) and Gender Classification (GC), which each execute one job per individual and process visual inputs from the cameras. The outputs of these tasks are then forwarded to the Content Selection (CS) task, which determines the most appropriate advertisement to display on the screen corresponding to the individual position. CS executes one job per side of the totem. In Figure 4a, the tasks highlighted in light blue represent those that can be offloaded to other nodes, whereas the dark grey tasks are always executed locally. This assumption does not limit the general applicability of the proposed load balancing strategy. Should additional tasks become offloadable (for example, IR), the load balancer would continue to operate effectively, adapting to the updated configuration and producing results different from those presented in this work.
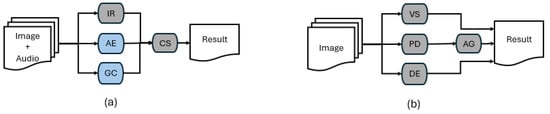
Figure 4.
Task pipelines for (a) Totem node and (b) Roof node. Tasks highlighted in blue correspond to offloadable components of the workload, while tasks in gray are executed locally and are not offloadable.
The IR module performs automatic language identification using speech processing techniques. The module operates by recording audio in real time and applying a speech-to-text mechanism based on machine learning. The Vosk API [26] is used to generate a transcript of the spoken input, supported by lightweight language models pre-trained on large datasets. A keyword detection algorithm is then applied to identify predefined language-specific hot words from the transcript. In the current implementation, the system is configured to recognize the English word “hello” and the Italian word “ciao” as part of its IR task. Upon activation, the totem invites individuals to greet it using their native language, enabling a more natural and engaging interaction while triggering the IR task execution. The IR module runs on the quad-core ARM Cortex-A53 processor included in the Zynq UltraScale+ platform.
The AE and GC modules are implemented using two independent convolutional neural networks, both based on the VGG-Face architecture [27], a variant of the VGG16 model known for its effective performance in face-related tasks. The AE module estimates the individual’s age from the captured facial image, whereas the GC module classifies gender. Both tasks rely on deep feature extraction and classification layers trained on annotated facial datasets. The AE and GC modules can be executed either on the quad-core ARM Cortex-A53 processor or one of the DPU accelerators on the FPGA fabric of the Zynq UltraScale+ platform.
The CS module operates as a lightweight lookup mechanism that receives the recognized age, gender, and idiom as input and returns the most appropriate advertisement content to be displayed on the screen. It is executed on the quad-core ARM Cortex-A53 processor.
All tasks described are executed on top of the operating system PetaLinux [28]. The operating system also executes an MQTT broker. Overall, the tasks of the application executed on the informative totem node can be processed on the node CPU, while some of them can also be executed on its local FPGA. This configuration aligns with the expected node architecture required to apply the proposed load balancing strategy.
4.1.2. Roof Node Architecture
Each roof node integrates two hardware platforms: a custom platform based on an NVIDIA Jetson Nano [29] and a Xilinx Zynq UltraScale+ device. The two boards are interconnected via Ethernet and are both connected to a camera. The Zynq UltraScale+ is also equipped with two Pmod WiFi modules, identical to those used in the totem nodes, enabling both standard Wi-Fi and Wi-Fi Direct communication with other nodes. On the FPGA, two DPU accelerators are instantiated, identical to those used in the totem node (see Figure 3).
The roof node executes an application composed of several tasks, as shown in Figure 4b. Specifically, it performs video surveillance analysis (VS) (not detailed in this work), as well as People Detection (PD), Alarm Generation (AG), and Density Estimation (DE). In Figure 4b, all tasks are highlighted in dark gray, indicating that they are always executed locally (i.e., they are not offloadable to other nodes). This configuration has been selected to emphasize how the roof nodes support the totems in providing timely responses to users. More complex scenarios are supported by the proposed load balancer; for instance, the DE task could generate multiple jobs depending on the input. It is worth noting that the VS task is executed entirely on the NVIDIA Jetson Nano and is not involved in the load balancing process.
The PD task is based on a convolutional neural network for real-time person detection and event recognition. The implementation is based on YOLOv5 and is executed on the NVIDIA Jetson Nano platform, together with the VS tasks. The PD module detects two types of events: the presence of a person within the totem area (defined as a circular region surrounding the totem, as shown in Figure 2), and the presence of a person in front of a specific side of the totem. These events correspond to the generation of two alarms, referred to as Alarm Area and Alarm Front, respectively, both indicated with the task AG in Figure 4b. Alarms are sent to the totem node using MQTT over a specific topic.
The DE task is implemented using a convolutional neural network designed to estimate the crowd density in the monitored area. The model processes the video stream to generate density maps representing the spatial distribution of individuals. The DE task can be executed either on the quad-core ARM Cortex A53 or on one of the DPU accelerators implemented on the FPGA fabric of the Zynq UltraScale+ device.
The Jetson Nano platform runs a custom Linux distribution, while the Zynq UltraScale+ device operates with the PetaLinux operating system. Each roof node also runs an MQTT client to publish event notifications to the network. It can be observed that, apart from the presence of the NVIDIA Jetson Nano, the architecture of the roof node is the same as that of the totem node.
4.1.3. Roof–Totem Interaction
In order to describe the interaction between the roof and totem nodes, this section focuses on one of the totems shown in Figure 2. The analysis also concentrates on one side of the selected totem, and its interaction with a roof node. The totem-roof interaction is depicted in Figure 5.
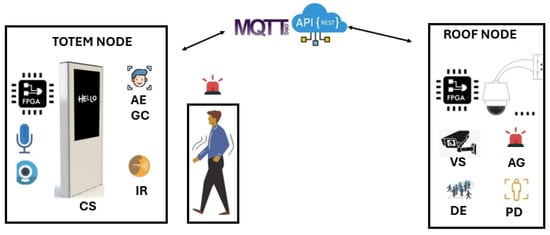
Figure 5.
Interaction between Totem and Roof nodes in the proposed system. The Totem node performs Idiom Recognition (IR), Age Estimation (AE), Gender Classification (GC), and Content Selection (CS), while the Roof node executes Video Surveillance (VS), People Detection (PD), Density Estimation (DE), and Alarm Generation (AG). Nodes exchange information via MQTT and REST-based APIs over standard Wi-Fi or Wi-Fi Direct, enabling cooperative task execution.
Suppose three individuals are walking within the commercial mall, inside Space 1. While the individuals are located outside the totem area, the screen of the totem remains powered off. When the individuals enter the totem area, the roof node detects it through the PD task and triggers an Alarm Area message to the totem node through the AG task. In response, the totem powers on the screen and displays a welcome message. When the individuals move directly in front of the totem, the roof node triggers an Alarm Front through the AG task, prompting the totem to request that the individuals greet in their language. At this point, the execution of the tasks described in Figure 4a begins. For each of the three individuals positioned in front of the totem screen, the totem performs AE and GC jobs. The IR task continues execution until a language is successfully identified or until a predefined timeout is reached, at which point the process is terminated. The results from these three tasks are forwarded to the CS module, which selects the appropriate advertisement to display on the screen. This entire process must be completed within one second in order to maintain user attention. The following section presents the characterization of the tasks executed by the totem.
4.2. Characterization of Workloads
This section provides a characterization of the workloads associated with the tasks executed on the totem node. The measured response times for each task are reported in Table 3. Specifically, the columns labeled GC and AE indicate the time required to execute a single job of the GC and AE tasks on a DPU core. It is worth noting that for each person standing in front of the totem, one AE job and one GC job are generated. The OS column reports the average response time for operating system management tasks, while the CS column refers to the time required to display an advertisement on a single screen. The columns labeled “Send to Roof” and “Receive from Roof” represent the transmission and reception times between the totem and the roof node during offloading, assuming a WiFi bandwidth of 2 Mb/s and camera image sizes of 4 KB. The 2 Mb/s bandwidth value was obtained through 100 repeated measurements with the PMOD WiFi module in our laboratory setup, and corresponds to the lowest observed throughput (typical values ranged between 2 and 2.3 Mb/s). Within this controlled setting, the throughput did not exhibit significant fluctuations, packet loss, or jitter. By adopting the minimum observed value in the feasibility model, the reported communication times are conservative estimates, ensuring robustness of the evaluation.
Table 3.
Response time of each task executed on the totem node.
In addition, the MQTT broadcast latency was measured over 100 trials, resulting in an average of 1.8 ms with low variability, which we also used as a fixed parameter in the experimental analysis. This latency, however, is not included in the load balancer execution time, since the availability check (line 27 of Algorithm 1) is performed locally in a few microseconds. If a node announces its availability while the load balancer is executing, it is considered in the next application instance, thus ensuring that MQTT latency does not contribute to the scheduling overhead.
Based on these characterized values, it is possible to evaluate the timing performance of the totem in executing the task pipeline under different conditions, particularly as the number of people and the number of active sides of the totem vary. Table 4 reports the total response time required to execute the pipeline shown in Figure 4a, for various input configurations. The first column of Table 4 (“Sides”) indicates the active sides of the totem from which people approach, using the notation N–S–E–W for north, south, east, and west. The second column reports the number of people approaching the totem, while the following columns define the number of jobs associated with each task in the pipeline.
Table 4.
Response time as a function of the number of people and active sides of the totem, with the totem executing all the pipeline. Cells in green indicate response time within the = 1.1 s; red cells indicate deadline violations.
In the first four rows, individuals approach from a single side (north), and the results show that the totem can sustain the execution of the full processing pipeline for up to three people while meeting the deadline s, with an accepted variation of 0.1 s. When four people approach simultaneously from one side, the system exceeds the . The fifth row shows that the totem can support two individuals approaching from two different sides (north and south) while still meeting the . However, the last two rows show that when one person approaches from each of three or four sides, the total response time exceeds the constraint, resulting in a deadline violation. Focusing on Table 4, we observe that, compared to the response time when a single individual approaches from one side of the totem (first row), a second individual approaching from the same side increases the response time by 32% (second row). In contrast, a second individual approaching from a different side increases the response time by 57% (fifth row). A third individual approaching from a third side increases the response time by 113% (sixth row), and a fourth individual approaching from the remaining side increases it by 169% (seventh row). The difference between the growth observed when a second individual approaches from the same side and the growth observed from a different side is due to the fact that, in the latter case, the totem must execute an additional job for both IR and CS, whereas for the same side, no additional IR or CS job is required.
These results highlight the importance of dynamic task offloading and load balancing to maintain responsiveness in scenarios involving multiple active sides of the totem.
4.3. Application of the Proposed Load Balancer
In this subsection, we show that by applying the proposed load balancer, the totem can operate correctly while meeting the one-second deadline, even in cases that are infeasible according to Table 4. The load balancing algorithm is executed exclusively on the totem node, which determines whether part of its computational workload can be redistributed to nearby nodes while still meeting soft real-time deadlines. However, the proposed approach is general enough to be applied to any node in the scenario (e.g., also to the roof nodes). When the load balancer executes on the totem, the roof nodes or other totems can make their FPGA-based DPU accelerators available for offloading jobs related to the AE and GC tasks. This configuration enables the execution of AE and GC either locally on the totem or remotely on the roof nodes/other totems. This design choice is motivated by the computational acceleration requirements of these tasks on the totem. Naturally, as the FPGA is a reconfigurable device, it can also host other accelerators if required by different applications.
The load balancer is evaluated in two scenarios: one with a single totem and four roof nodes (Spaces 1 and 2 in Figure 2), and one with three totems and a single roof node (Space 3 in Figure 2).
4.3.1. Scenario 1: One Totem and Four Roof Nodes
Focusing on the totem in Space 1 (or Space 2) in Figure 2, the totem node executes a set of tasks for each group of approaching individuals. The total processing time depends on the number of display sides from which people approach, denoted by .
The problem is formalized using the following parameters (we focus on Space 1):
- and are the applications executed by the system. is the informative totem node, and are the roof nodes. The mapping is defined as and .
- The application executes the following tasks: .
- The execution times of corresponding tasks part of are as follows:
- The communication overhead is , computed as the sum of the last two columns of Table 3.
By running the load balancing algorithm on one of the quad-core parts of ARM Cortex A53, the algorithm takes s. The total processing deadline is s (a variation of 0.1 s is accepted compared to the main requirement).
For each incoming workload, the totem node evaluates the total processing time . If the estimated time exceeds , the totem attempts to offload the jobs associated with the AE and GC tasks. The algorithm then checks which roof nodes have previously announced their availability and offloads the corresponding jobs accordingly.
Table 5 reports the response times observed under different workload conditions, varying the number of people approaching the totem and the number of active sides. The column Roof Nodes Required to Meet Deadline indicates the number of Roof Nodes that the totem actually used to stay within the application deadline. It is worth noting that in this case, each Roof Node is equipped with 1 DPU, differently from Figure 3. The case with 2 DPUs for each Roof node is detailed in the next experiment. The column “Response Time (no LB)” reports the processing time that would occur without applying the load balancing algorithm, while the last column shows the response time achieved with the proposed approach, demonstrating its effectiveness in ensuring soft real-time constraints.
Table 5.
Response time comparison with and without load balancing under varying conditions, for Scenario 1. Cells in green indicate response time within the = 1.1 s; red cells indicate deadline violations.
It is important to note that if a Roof Node does not publish an intent-to-help message, it is not considered by the totem (as shown in Line 27 of Algorithm 1). This reflects a realistic scenario in which not all neighboring nodes are always available to support workload sharing. For the experiments reported in Table 5, all four Roof Nodes published their availability, and the load balancer offloaded jobs only until the application deadline was satisfied.
Figure 6a shows the response time of the application on the totem for different numbers of people approaching from the same (north) side. The graph distinguishes between two cases, where the four roof nodes that allow offloading can make available either one or two DPUs. This impacts the number of people that totem can handle while meeting the deadline, with a maximum of six people when each roof node provides one DPU, and up to 10 people when each provides two DPUs. Figure 6b reports the response time of the application on totem for people approaching from all four sides. With one DPU available from each of the four roof nodes, it is possible to manage up to five people within the deadline, whereas with two DPUs available per node, up to eight people can be handled within the deadline. In the experiments reported in Figure 6a,b, the number of DPUs available on each Roof Node for offloading was controlled by adjusting the execution period of the DE task: nodes configured with a short DE period continuously executed density estimation and provided only one DPU, whereas nodes with a long DE period had idle intervals and could provide two DPUs.
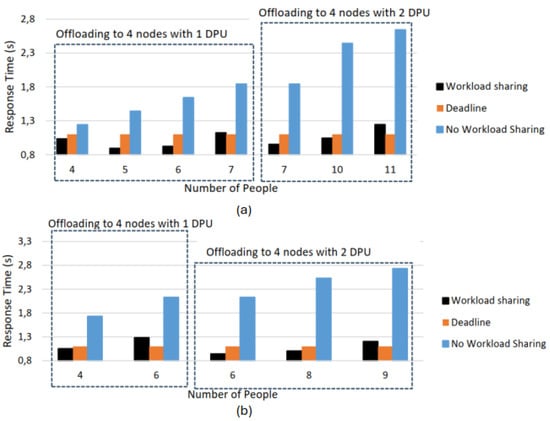
Figure 6.
Response time of totem for different numbers of people approaching from the north side only (a) and from all four sides (N, S, E, W) (b). Orange bars indicate the deadline of 1.1 s. Blue bars refer to the case where no offloading is possible, while black bars represent the case with offloading to four nodes. The two boxes distinguish between the cases where the four nodes make available 1 DPU and 2 DPUs, respectively.
4.3.2. Scenario 2: Three Totems and One Roof Node
Focusing on the totems in Space 3 of Figure 2, the totem nodes execute a set of tasks for each group of approaching individuals. In this scenario, there is one roof node, which is assumed to never announce its intent to help. This means that the totems must support each other. The roof node continues to execute application and trigger detection alarms, as discussed in Section 4.1.3.
The three totem nodes, labeled , , and , all execute application . Our analysis focuses on , with the goal of showing how the proposed load balancer helps keep within its deadline , while also highlighting some runtime actions that can be taken when the deadline would otherwise be missed. We analyze the case where people are approaching from all four sides of (N, S, E, and W). Figure 7 reports the response time for executing application on for different numbers of people approaching from these four sides. When cannot perform offloading, it cannot process four people from all four sides without missing the deadline (No Offloading case).
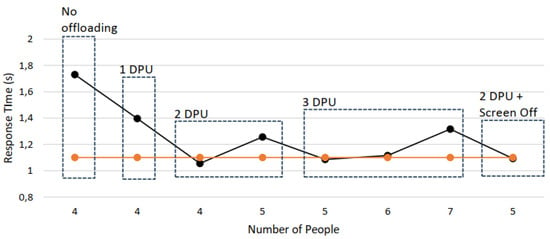
Figure 7.
Response time of totem for different numbers of people approaching from all four sides (N, S, E, W). No Offloading refers to the case where totems and are not available for offloading. 1 DPU, 2 DPU, and 3 DPU refer to cases where and make different numbers of DPUs available for offloading. 2 DPU + Screen Off refers to the case where the turns off one screen to reduce workload. The orange line represents the deadline.
When the other two totems ( and ) are available to offload jobs from , we first analyze the case where each makes available only one of the two DPUs they contain. This represents a situation in which the other totems are partially occupied with their own workloads. As shown in Figure 7 (1 DPU case), this configuration is insufficient to meet the deadline. Only when both totems make available the two DPUs (2 DPU case) can meet the deadline with four people approaching; however, the deadline is again missed if a fifth person approaches.
This suggests that, when people approach from all four sides of , it may be beneficial to reconfigure the FPGAs of and to host three DPUs instead of two. As shown in Figure 7 (3 DPU case), this would allow managing up to six people from all four sides of . Such FPGA reconfiguration could be performed via dynamic partial reconfiguration [30] under the control of a runtime manager.
As an alternative to increasing from two to three DPUs in the neighboring totems, the runtime manager could turn off one of the screens of to reduce its workload. In this case, reported as 2 DPU + Screen Off in Figure 7, people would not stop in front of the powered-off screen but would instead move toward the remaining three screens, allowing the system to stay within the deadline.
4.4. Discussion
4.4.1. Comparison with Related Work
The work in [9] provides only a simulation-based evaluation and does not report the execution time of the load balancing procedure. The approach in [10] has computational complexity and achieves millisecond-level end-to-end latency for sample transmissions. However, it relies on a fog-based centralized architecture, which is not compatible with the requirements of sentient spaces. In [11], the load balancing strategy is recomputed every two minutes, and the computational overhead is claimed to be negligible, but no explicit execution time is reported. Finally, [13] addresses the load balancing problem using linear programming (both centralized and distributed) and simulates networks of up to 30 nodes. The authors report an overhead for the load balancer based on measurements obtained with MATLAB 2015a under Linux on an Intel Xeon processor, showing a runtime of about 10 ms for a 5-node scenario. They also note that on embedded devices, the runtime may be significantly higher, although following a similar trend.
Differently from the aforementioned works, the proposed solution is validated in a laboratory setting that emulates a real-world sentient space scenario in a commercial mall, rather than relying exclusively on simulation. It achieves a measured load balancing execution time of 5 ms on an ARM Cortex-A53 processor, making it directly applicable to contexts with soft real-time requirements and satisfying Requirement R2 for sentient spaces (i.e., lightweight design). Moreover, because the load balancer is invoked before the execution of each application instance on a node, it can adapt to dynamic environments where the set of available neighboring nodes may change between two executions. The proposed cooperation infrastructure also enables a fully decentralized operation, fulfilling Requirement R1 for sentient spaces (i.e., dynamic variability and decentralized architecture). Table 5, and Figure 6 and Figure 7 highlight the effectiveness of the proposed approach in maintaining soft real-time constraints under varying workload conditions in dynamic environments.
4.4.2. Applicability, Scalability, and Limitations
Although the experimental validation focuses on a commercial mall environment, the proposed load balancing strategy is applicable to other types of sentient space scenarios where the core requirements (i.e., decentralized cooperation, dynamic node availability, soft real-time response, energy availability, and the management of sensitive information) align with the assumptions and design choices of the proposed approach. As such, the load balancing mechanism can be adapted with minimal modifications to the deployment logic and task structure. For instance, in airport terminals, nodes could assist with passenger information, queue monitoring, or gate navigation using localized sensing and computation, while avoiding the transmission of sensitive data over wide-area networks. In this case, the proposed approach would remain unchanged at the architectural level, while the application logic would involve tasks such as identity-blind people tracking, real-time occupancy estimation, or boarding group display selection [31]. On the other hand, in university campuses, nodes may support digital signage, crowd estimation, or interactive educational content [32]. Here, the task pipeline could include dynamic schedule display based on localized presence, or personalized announcements triggered by detected user profiles [33]. The load balancing mechanism would operate similarly, with the offloadable tasks tailored to the local services of each zone (e.g., classroom buildings vs. bar areas).
The scalability of the proposed approach can be examined from three complementary perspectives: (i) communication organization, (ii) task offloading assumptions, and (iii) wireless technology constraints. As point (i), although the cooperation mechanism is fully decentralized, the MQTT-based neighbor discovery phase requires one node in each connectivity group to act as an MQTT broker. In large-scale deployments, where nodes may be partitioned into multiple groups that cannot directly reach each other, each group must elect or assign its own broker. This architecture preserves the decentralized nature of the system, avoids a single point of failure, and enables the solution to scale across multiple disjoint groups of nodes. As point (ii), the current experimental validation assumes a constant communication overhead for task offloading. This assumption holds in the considered setting, where the exchanged data size is bounded and the wireless link is stable. However, in larger or more heterogeneous deployments, especially when involving nodes with different bandwidth capabilities, may become variable and potentially dominant in the total execution time. In such cases, the load balancing algorithm could be extended to explicitly account for communication time variability in its feasibility checks. As point (iii), the task offloading phase relies on Wi-Fi Direct for peer-to-peer transfers. While this choice preserves privacy by avoiding intermediate access points, Wi-Fi Direct connections are established between two peers at a time. Consequently, when a node needs to offload jobs to multiple peers, transmissions are serialized, which may limit scalability under high offloading demand. This constraint could be mitigated by exploring alternative wireless technologies or by introducing concurrent multi-link support in future work.
Regarding scalability, it is worth noting that the execution time of the load balancing algorithm itself is only affected by the number of neighboring nodes that have announced their availability at the time of scheduling, rather than by the total number of nodes in the group. Regarding robustness, the proposed approach inherently tolerates certain dynamic conditions. Task offloading is only attempted for nodes that have explicitly announced their availability, and if no feasible schedule can be found, the system defaults to local execution in a best-effort mode. These mechanisms allow the system to continue operating in the presence of temporary neighbor unavailability.
Future extensions could further improve robustness by incorporating additional metrics into the offloading decision process, such as the physical distance between nodes, periodic liveness verification to detect failures promptly, and historical data on node availability and communication latency. Such enhancements would enable more reliable offloading decisions in scenarios with intermittent connectivity, delayed message delivery, or partial node failures.
Regarding security, the decentralized and cooperative nature of the proposed approach introduces potential risks related to untrusted nodes and data interception. Untrusted nodes may attempt to mislead the load balancing process by falsely advertising availability or by sending incorrect or malicious data. Likewise, the use of wireless communication makes the system vulnerable to eavesdropping or tampering during data transmission. To address these risks, lightweight security mechanisms could be integrated without undermining the low-latency and decentralized objectives of the system. For example, blockchain-based anti-tampering techniques [34] could be used to maintain a tamper-resistant ledger of node activity and trust levels, while lightweight cryptography and intrusion detection systems, such as those developed for ad-hoc and wireless sensor networks (e.g., TAKS and TinyWIDS [35,36]), could protect sensitive communications and detect abnormal or malicious behaviors from neighboring nodes. The integration of such mechanisms would enable secure cooperation among nodes, ensuring data integrity and authenticity even in the presence of untrusted or compromised participants.
Finally, regarding energy consumption, the current version of the load balancer has a computational cost of only 5 ms on an ARM Cortex-A53 and is implemented as a set of nested loops iterating over tasks, their associated jobs, and the subset of neighboring nodes that have announced their availability. Its direct contribution to overall energy usage is therefore minimal compared to the cost of executing application tasks based on neural networks or performing wireless data transfers. Furthermore, since the proposed load balancer is executed once before each application instance, it allows all tasks to be executed on the CPU without involving the FPGA whenever the deadline is respected (Line 6 of Algorithm 1), avoiding unnecessary accelerator usage. In the experimental activities, this also enabled turning off the totem’s screen when no people were detected, as detailed in Section 4.1.3. The proposed approach can also be evolved to account for energy constraints, making the load balancer suitable for battery-operated nodes in sentient space scenarios. In such cases, the feasibility check could be extended to incorporate energy-awareness, prioritizing offloading decisions that minimize overall energy usage while still meeting application deadlines. Specifically, Algorithm 1 could be adapted to use an energy threshold in place of, or in addition to, a timing deadline, and the offloading decision condition would rely on an appropriate energy model. To preserve the lightweight nature of the system, such models should be kept simple, for example, by adopting the approach described in [37].
5. Conclusions and Future Work
This paper presented a distributed load balancing strategy tailored for sentient space scenarios, where nodes operate without centralized coordination and under soft real-time constraints. The proposed approach relies on a feasibility-based, reactive mechanism that offloads computationally intensive tasks only when local deadlines are at risk of being violated. A cooperation infrastructure based on Wi-Fi and lightweight communication protocols was designed to enable neighbor discovery and task offloading without involving third-party intermediaries, thus preserving data privacy.
The proposed solution was validated in a laboratory setting that emulates a real-world sentient space scenario in a commercial mall. Experimental results show that the approach maintains real-time response requirements under dynamic workloads, with a measured load balancing execution time of 5 ms on an ARM Cortex-A53 processor. This makes the solution directly applicable to soft real-time environments characterized by dynamic variability and intermittent node availability. Although the evaluation in this work focused on discrete workload states representative of typical arrival patterns in a commercial mall, the low execution time of the proposed load balancer (5 ms) makes it well-suited for deployment in scenarios with more rapidly changing conditions, including high-density situations.
Future work will extend the evaluation to explicitly model and test dynamic arrival patterns, leveraging empirical data on pedestrian flows in crowded environments. We also plan to investigate the efficient implementation of optimization-based strategies, such as the linear programming formulation proposed in [13], on embedded devices. Furthermore, we will extend the validation to larger and more heterogeneous networks, including additional types of nodes in a sentient space.
Author Contributions
Conceptualization, G.V. and L.P.; methodology, T.D.M., F.C., G.V. and L.P.; software, G.V.; validation, G.V., T.D.M., F.C. and L.P.; formal analysis, G.V.; investigation, G.V.; resources, T.D.M. and L.P.; data curation, G.V.; writing—original draft preparation, G.V.; writing—review and editing, G.V., F.C. and L.P.; visualization, G.V.; supervision, T.D.M. and L.P.; project administration, T.D.M. and L.P.; funding acquisition, T.D.M. and L.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the European Union’s ECSEL Joint Undertaking (FRACTAL project, grant number 877056) and by the European Union’s Horizon Europe programme (Resilient Trust project, grant number 101112282).
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
Correction Statement
This article has been republished with a minor correction to the Data Availability Statement. This change does not affect the scientific content of the article.
References
- Torrens, P.M. Smart and Sentient Retail High Streets. Smart Cities 2022, 5, 1670–1720. [Google Scholar] [CrossRef]
- van Steen, M.; Tanenbaum, A.S. Distributed Systems, 3rd ed.; Createspace Independent Publishing Platform: Scotts Valley, CA, USA, 2017; Available online: https://www.distributed-systems.net/index.php/books/ds3/ (accessed on 1 August 2025).
- Mehrabi, A.; Siekkinen, M.; Ylä-Jääski, A. Edge Computing Assisted Adaptive Mobile Video Streaming. IEEE Trans. Mob. Comput. 2019, 18, 787–800. [Google Scholar] [CrossRef]
- Sthapit, S.; Hopgood, J.R.; Robertson, N.M.; Thompson, J. Offloading to neighbouring nodes in smart camera network. In Proceedings of the 2016 24th European Signal Processing Conference (EUSIPCO), Budapest, Hungary, 29 August–2 September 2016; pp. 1823–1827. [Google Scholar] [CrossRef]
- Wu, H.; Knottenbelt, W.; Wolter, K. Analysis of the Energy-Response Time Tradeoff for Mobile Cloud Offloading Using Combined Metrics. In Proceedings of the 2015 27th International Teletraffic Congress, Ghent, Belgium, 8–10 September 2015; pp. 134–142. [Google Scholar] [CrossRef]
- Yi, S.; Li, C.; Li, Q. A Survey of Fog Computing: Concepts, Applications and Issues. In Proceedings of the 2015 Workshop on Mobile Big Data (Mobidata ’15), Hangzhou, China, 21 June 2015; pp. 37–42. [Google Scholar] [CrossRef]
- Niu, X.; Shao, S.; Xin, C.; Zhou, J.; Guo, S.; Chen, X.; Qi, F. Workload Allocation Mechanism for Minimum Service Delay in Edge Computing-Based Power Internet of Things. IEEE Access 2019, 7, 83771–83784. [Google Scholar] [CrossRef]
- Xu, X.; Fu, S.; Cai, Q.; Tian, W.; Liu, W.; Dou, W.; Sun, X.; Liu, A.X. Dynamic Resource Allocation for Load Balancing in Fog Environment. Wireless Commun. Mob. Comput. 2018, 2018, 6421607. [Google Scholar] [CrossRef]
- Fan, Q.; Ansari, N. Towards Traffic Load Balancing in Drone-Assisted Communications for IoT. IEEE Internet Things J. 2019, 6, 3633–3640. [Google Scholar] [CrossRef]
- Asif-Ur-Rahman, M.; Afsana, F.; Mahmud, M.; Kaiser, M.S.; Ahmed, M.R.; Kaiwartya, O.; James-Taylor, A. Toward a Heterogeneous Mist, Fog, and Cloud-Based Framework for the Internet of Healthcare Things. IEEE Internet Things J. 2019, 6, 4049–4062. [Google Scholar] [CrossRef]
- Li, J.; Luo, G.; Cheng, N.; Yuan, Q.; Wu, Z.; Gao, S.; Liu, Z. An End-to-End Load Balancer Based on Deep Learning for Vehicular Network Traffic Control. IEEE Internet Things J. 2019, 6, 953–966. [Google Scholar] [CrossRef]
- Lu, H.; Gu, C.; Luo, F.; Ding, W.; Liu, X. Optimization of lightweight task offloading strategy for mobile edge computing based on deep reinforcement learning. Future Gener. Comput. Syst. 2020, 102, 847–861. [Google Scholar] [CrossRef]
- Sthapit, S.; Thompson, J.; Robertson, N.M.; Hopgood, J.R. Computational Load Balancing on the Edge in Absence of Cloud and Fog. IEEE Trans. Mob. Comput. 2019, 18, 1499–1512. [Google Scholar] [CrossRef]
- Dong, S.; Xia, Y.; Kamruzzaman, J. Quantum Particle Swarm Optimization for Task Offloading in Mobile Edge Computing. IEEE Trans. Ind. Inform. 2023, 19, 9113–9122. [Google Scholar] [CrossRef]
- Ben Mabrouk, N.; Beauche, S.; Kuznetsova, E.; Georgantas, N.; Issarny, V. QoS-Aware Service Composition in Dynamic Service Oriented Environments. In Middleware 2009; Bacon, J.M., Cooper, B.F., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 123–142. [Google Scholar] [CrossRef]
- Xilinx. Zynq UltraScale+ Technical Reference Manual. Available online: https://docs.amd.com/r/en-US/ug1085-zynq-ultrascale-trm (accessed on 1 August 2025).
- Microchip. PolarFire SoC. Available online: https://github.com/polarfire-soc (accessed on 1 August 2025).
- Achronix. Speedster7t. Available online: https://www.achronix.com/product/speedster7t-fpgas (accessed on 1 August 2025).
- Intel. Agilex 7. Available online: https://iwave-global.com/product/agilex-7-r31b-r31c-soc-fpga-system-on-module/ (accessed on 1 August 2025).
- Miller, R.B. Response time in man-computer conversational transactions. In Proceedings of the Fall Joint Computer Conference, Part I (AFIPS ’68 (Fall, Part I)), New York, NY, USA, 9–11 December 1968; pp. 267–277. [Google Scholar] [CrossRef]
- VCCP. Challenger Series—Hacking the Attention Economy Morning Book. Available online: https://pages.vccp.com/hubfs/Challenger%20Series%20-%20Hacking%20the%20Attention%20Economy%20Morning%20Book.pdf?ref=denkalseenstrateeg.nl (accessed on 1 August 2025).
- Peretti, S.; Caruso, F.; Valente, G.; Pomante, L.; Di Mascio, T. Educating artificial intelligence following the child learning development trajectories. Behav. Inf. Technol. 2025. [Google Scholar] [CrossRef]
- Digilent. Pmod ESP32 Reference Manual. Available online: https://digilent.com/reference/pmod/pmodesp32/reference-manual?redirect=1 (accessed on 1 August 2025).
- Davies, N.; Clinch, S.; Alt, F. Pervasive Displays: Understanding the Future of Digital Signage; Synthesis Lectures on Mobile and Pervasive Computing; Springer: Cham, Switzerland, 2014; Volume 8, pp. 1–128. [Google Scholar] [CrossRef]
- Xilinx. DPU for Convolutional Neural Network. Available online: https://www.amd.com/en/products/adaptive-socs-and-fpgas/intellectual-property/dpu.html (accessed on 1 August 2025).
- Alpha Cephei. Vosk Speech Recognition Toolkit. Available online: https://alphacephei.com/vosk/ (accessed on 1 August 2025).
- Wan, L.; Liu, N.; Huo, H.; Fang, T. Face Recognition with Convolutional Neural Networks and subspace learning. In Proceedings of the 2017 2nd International Conference on Image, Vision and Computing (ICIVC), Chengdu, China, 2–4 June 2017; pp. 228–233. [Google Scholar] [CrossRef]
- AMD. PetaLinux Tools. Available online: https://www.amd.com/en/products/software/adaptive-socs-and-fpgas/embedded-software/petalinux-sdk.html (accessed on 1 August 2025).
- NVIDIA. Jetson Nano. Available online: https://www.nvidia.com/en-us/autonomous-machines/embedded-systems/jetson-nano/product-development/ (accessed on 1 August 2025).
- Valente, G.; Di Mascio, T.; Pomante, L.; D’Andrea, G. Dynamic Partial Reconfiguration Profitability for Real-Time Systems. IEEE Embed. Syst. Lett. 2021, 13, 102–105. [Google Scholar] [CrossRef]
- Stark, J. Digital Transformation of an Airport. In Digital Transformation of Industry: Continuing Change; Springer Nature: Cham, Switzerland, 2025; pp. 73–77. [Google Scholar] [CrossRef]
- She, J.; Crowcroft, J.; Fu, H.; Li, F. Convergence of interactive displays with smart mobile devices for effective advertising: A survey. ACM Trans. Multimedia Comput. Commun. Appl. 2014, 10, 1–16. [Google Scholar] [CrossRef]
- Clinch, S.; Mikusz, M.; Elhart, I.; Davies, N.; Langheinrich, M. Scheduling Content in Pervasive Display Systems. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2020, 3, 1–37. [Google Scholar] [CrossRef]
- Tiberti, W.; Carmenini, A.; Pomante, L.; Cassioli, D. A Lightweight Blockchain-based Technique for Anti-Tampering in Wireless Sensor Networks. In Proceedings of the 2020 23rd Euromicro Conference on Digital System Design (DSD), Kranj, Slovenia, 26–28 August 2020; pp. 577–582. [Google Scholar] [CrossRef]
- Tiberti, W.; Caruso, F.; Pomante, L.; Pugliese, M.; Santic, M.; Santucci, F. Development of an extended topology-based lightweight cryptographic scheme for IEEE 802.15.4 wireless sensor networks. Int. J. Distrib. Sens. Netw. 2020, 16, 1550147720951673. [Google Scholar] [CrossRef]
- Bozzi, L.; Di Giuseppe, L.; Pomante, L.; Pugliese, M.; Santic, M.; Santucci, F.; Tiberti, W. TinyWIDS: A WPM-based Intrusion Detection System for TinyOS2.x/802.15.4 Wireless Sensor Networks. In Proceedings of the Fifth Workshop on Cryptography and Security in Computing Systems (CS2’18), Manchester, UK, 24 January 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 13–16. [Google Scholar] [CrossRef]
- Liri, E.; Ramakrishnan, K.K.; Kar, K.; Lyon, G.; Sharma, P. Efficient and Lightweight Model-Predictive IoT Energy Management. ACM Trans. Internet Things 2025, 6, 1–32. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).