

DCP: Learning Accelerator Dataflow for Neural Networks via Propagation



Abstract
1. Introduction
2. Related Work
- Parallelism. Parallelism is about allocating the computation workload into the multiple HW processing units and letting these processing units perform the computation simultaneously. For DNN accelerators, the processing units are PEs, and they usually achieve parallelism via unrolling the loop nest of convolutional layers spatially.
- Computation order. Computation order is the temporal order of the dimensions to be performed in the multiple-dimensional computation task. Different computation orders can exploit different data movement patterns and reuse opportunities.
- Partitioning size. As there are many parameters to the DNN application and the buffer size of DNN accelerators is limited, accelerators with a multi-level memory hierarchy will partition these parameters and allocate them into buffers. In this process, the partitioning size will determine the data size of each tensor (input/output/weight) that needs to be present within the accelerator’s buffer.
3. Our Approach
3.1. Benchmarking Dataflow and DNN Layer
3.2. Training Predictor
3.3. Dataflow Code Optimization
4. Experiments
4.1. Experiment Settings
4.2. Per-Layer Dataflow Optimization
Layer-Wise Performance Analysis and Discussion
4.3. Per-Model Dataflow Optimization
4.4. Optimizing Dataflow for Multiple Objectives
4.5. Optimizing Dataflow for Unseen HW Settings
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Dataflow
Appendix A.1. Motivation
Appendix A.2. Expression
Appendix A.3. Example


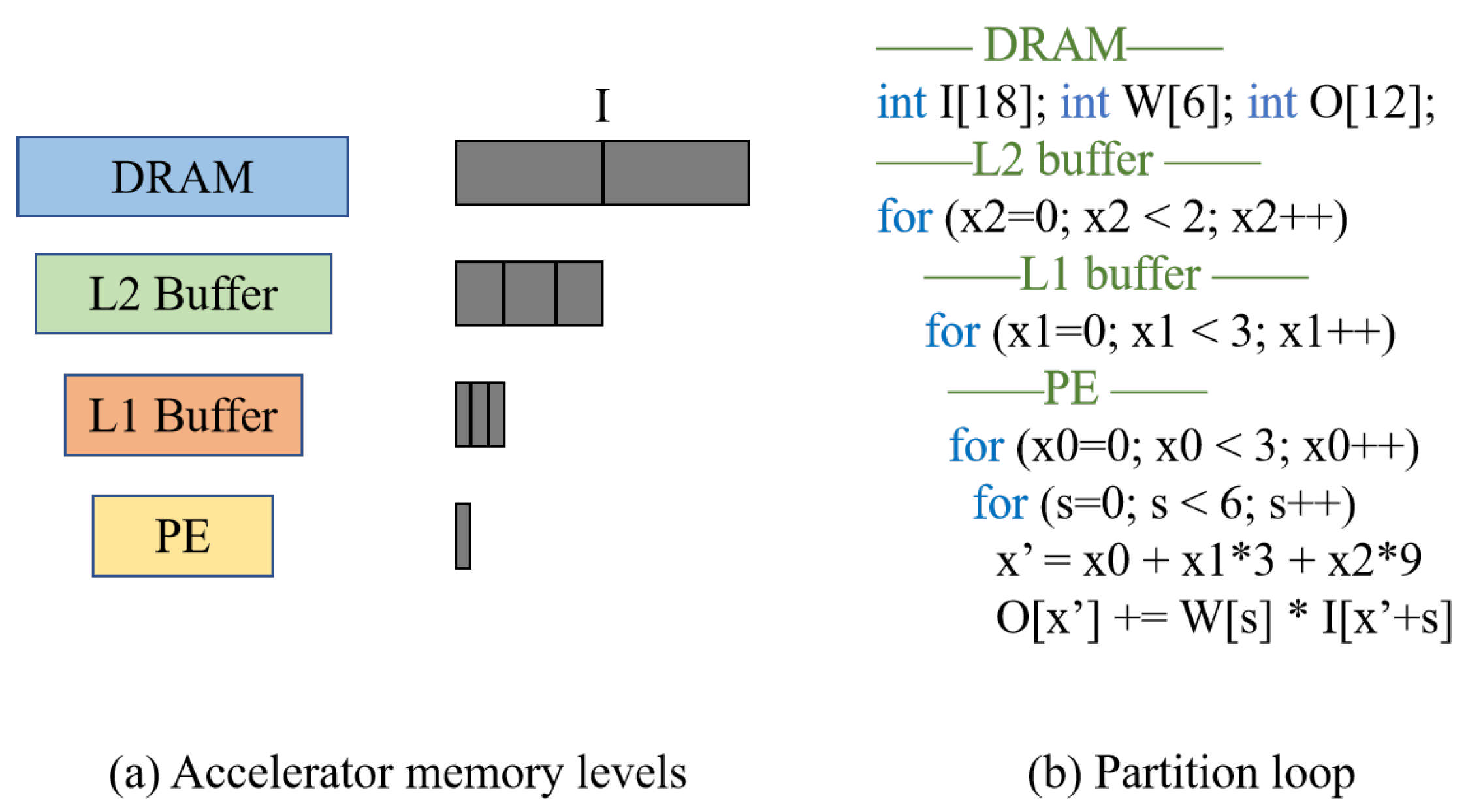
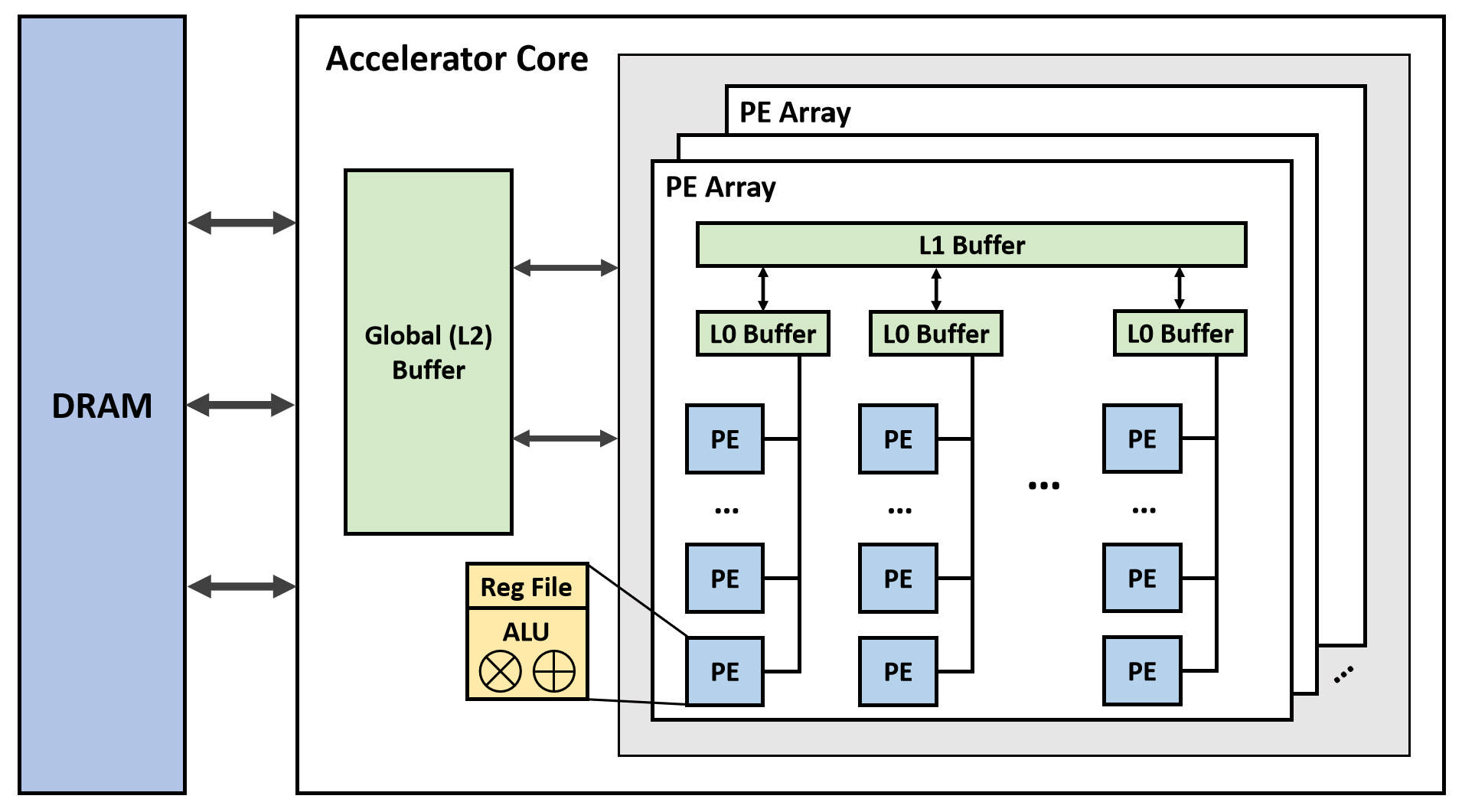
Appendix B. Tensorlib
Appendix B.1. Design Space
Appendix B.2. Example


Appendix B.3. Experiment
References
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. arXiv 2021, arXiv:2111.06377. [Google Scholar]
- Al-Qizwini, M.; Barjasteh, I.; Al-Qassab, H.; Radha, H. Deep learning algorithm for autonomous driving using GoogLeNet. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 89–96. [Google Scholar]
- Jumper, J.; Evans, R.; Pritzel, A.; Green, T.; Figurnov, M.; Ronneberger, O.; Tunyasuvunakool, K.; Bates, R.; Žídek, A.; Potapenko, A.; et al. Highly accurate protein structure prediction with AlphaFold. Nature 2021, 596, 583–589. [Google Scholar] [CrossRef]
- Tan, M.; Chen, B.; Pang, R.; Vasudevan, V.; Sandler, M.; Howard, A.; Le, Q.V. MnasNet: Platform-Aware Neural Architecture Search for Mobile. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 2815–2823. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the Computer Vision–ECCV, Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; pp. 122–138. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size. In Proceedings of the 2017 International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Chen, Y.H.; Krishna, T.; Emer, J.S.; Sze, V. Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks. IEEE J.-Solid-State Circuits 2017, 52, 127–138. [Google Scholar] [CrossRef]
- Chen, Y.H.; Yang, T.J.; Emer, J.; Sze, V. Eyeriss v2: A Flexible Accelerator for Emerging Deep Neural Networks on Mobile Devices. IEEE J. Emerg. Sel. Top. Circuits Syst. 2019, 9, 292–308. [Google Scholar] [CrossRef]
- NVDLA Deep Learning Accelerator. Available online: http://nvdla.org/primer.html (accessed on 15 March 2018).
- Du, Z.; Fasthuber, R.; Chen, T.; Ienne, P.; Li, L.; Luo, T.; Feng, X.; Chen, Y.; Temam, O. ShiDianNao: Shifting vision processing closer to the sensor. In Proceedings of the 2015 ACM/IEEE 42nd Annual International Symposium on Computer Architecture (ISCA), Portland, OR, USA, 13–17 June 2015; pp. 92–104. [Google Scholar]
- Jouppi, N.P.; Young, C.; Patil, N.; Patterson, D.; Agrawal, G.; Bajwa, R.; Bates, S.; Bhatia, S.; Boden, N.; Borchers, A.; et al. In-datacenter performance analysis of a tensor processing unit. In Proceedings of the 2017 ACM/IEEE 44th Annual International Symposium on Computer Architecture (ISCA), Toronto, ON, Canada, 24–28 June 2017; pp. 1–12. [Google Scholar]
- Parashar, A.; Rhu, M.; Mukkara, A.; Puglielli, A.; Venkatesan, R.; Khailany, B.; Emer, J.; Keckler, S.W.; Dally, W.J. SCNN: An accelerator for compressed-sparse convolutional neural networks. In Proceedings of the 2017 ACM/IEEE 44th Annual International Symposium on Computer Architecture (ISCA), Toronto, ON, Canada, 24–28 June 2017; pp. 27–40. [Google Scholar]
- Akhlaghi, V.; Yazdanbakhsh, A.; Samadi, K.; Gupta, R.K.; Esmaeilzadeh, H. SnaPEA: Predictive Early Activation for Reducing Computation in Deep Convolutional Neural Networks. In Proceedings of the 2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA), Los Angeles, CA, USA, 1–6 June 2018; pp. 662–673. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Kwon, H.; Samajdar, A.; Krishna, T. MAERI: Enabling Flexible Dataflow Mapping over DNN Accelerators via Reconfigurable Interconnects. SIGPLAN Not. 2018, 53, 461–475. [Google Scholar] [CrossRef]
- Yazdanbakhsh, A.; Angermüller, C.; Akin, B.; Zhou, Y.; Jones, A.; Hashemi, M.; Swersky, K.; Chatterjee, S.; Narayanaswami, R.; Laudon, J. Apollo: Transferable Architecture Exploration. arXiv 2021, arXiv:2102.01723. [Google Scholar]
- Kao, S.C.; Jeong, G.; Krishna, T. ConfuciuX: Autonomous Hardware Resource Assignment for DNN Accelerators using Reinforcement Learning. In Proceedings of the 2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Athens, Greece, 17–21 October 2020; pp. 622–636. [Google Scholar]
- Wang, J.; Guo, L.; Cong, J. AutoSA: A Polyhedral Compiler for High-Performance Systolic Arrays on FPGA. In Proceedings of the The 2021 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Virtual Event, USA, 28 February–2 March 2021; FPGA’21. pp. 93–104. [Google Scholar]
- Kao, S.C.; Krishna, T. GAMMA: Automating the HW Mapping of DNN Models on Accelerators via Genetic Algorithm. In Proceedings of the 39th International Conference on Computer-Aided Design, New York, NY, USA, 2–6 November 2020. ICCAD’20. [Google Scholar]
- Parashar, A.; Raina, P.; Shao, Y.S.; Chen, Y.H.; Ying, V.A.; Mukkara, A.; Venkatesan, R.; Khailany, B.; Keckler, S.W.; Emer, J. Timeloop: A Systematic Approach to DNN Accelerator Evaluation. In Proceedings of the 2019 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), Madison, WI, USA, 24–26 March 2019; pp. 304–315. [Google Scholar]
- Yang, X.; Gao, M.; Liu, Q.; Setter, J.; Pu, J.; Nayak, A.; Bell, S.; Cao, K.; Ha, H.; Raina, P.; et al. Interstellar: Using Halide’s Scheduling Language to Analyze DNN Accelerators. In Proceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems, Lausanne, Switzerland, 16–20 March 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 369–383. [Google Scholar]
- Kawamoto, R.; Taichi, M.; Kabuto, M.; Watanabe, D.; Izumi, S.; Yoshimoto, M.; Kawaguchi, H. A 1.15-TOPS 6.57-TOPS/W DNN Processor for Multi-Scale Object Detection. In Proceedings of the 2020 2nd IEEE International Conference on Artificial Intelligence Circuits and Systems (AICAS), Genova, Italy, 31 August–2 September 2020; pp. 203–207. [Google Scholar]
- Yamada, Y.; Sano, T.; Tanabe, Y.; Ishigaki, Y.; Hosoda, S.; Hyuga, F.; Moriya, A.; Hada, R.; Masuda, A.; Uchiyama, M.; et al. 7.2 A 20.5TOPS and 217.3GOPS/mm2 Multicore SoC with DNN Accelerator and Image Signal Processor Complying with ISO26262 for Automotive Applications. In Proceedings of the 2019 IEEE International Solid- State Circuits Conference-(ISSCC), San Francisco, CA, USA, 17–21 February 2019; pp. 132–134. [Google Scholar]
- Kawamoto, R.; Taichi, M.; Kabuto, M.; Watanabe, D.; Izumi, S.; Yoshimoto, M.; Kawaguchi, H.; Matsukawa, G.; Goto, T.; Kojima, M. A 1.15-TOPS 6.57-TOPS/W Neural Network Processor for Multi-Scale Object Detection with Reduced Convolutional Operations. IEEE J. Sel. Top. Signal Process. 2020, 14, 634–645. [Google Scholar] [CrossRef]
- Kwon, H.; Chatarasi, P.; Pellauer, M.; Parashar, A.; Sarkar, V.; Krishna, T. Understanding Reuse, Performance, and Hardware Cost of DNN Dataflow: A Data-Centric Approach. In Proceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture, Columbus, OH, USA, 12–16 October 2019; MICRO ’52. pp. 754–768. [Google Scholar]
- Fasfous, N.; Vemparala, M.R.; Frickenstein, A.; Valpreda, E.; Salihu, D.; Höfer, J.; Singh, A.; Nagaraja, N.S.; Voegel, H.J.; Vu Doan, N.A.; et al. AnaCoNGA: Analytical HW-CNN Co-Design Using Nested Genetic Algorithms. In Proceedings of the 2022 Design, Automation & Test in Europe Conference & Exhibition (DATE), Antwerp, Belgium, 14–23 March 2022; pp. 238–243. [Google Scholar]
- Lin, Y.; Yang, M.; Han, S. NAAS: Neural Accelerator Architecture Search. In Proceedings of the 2021 58th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 5–9 December 2021; pp. 1051–1056. [Google Scholar]
- Fasfous, N.; Vemparala, M.R.; Frickenstein, A.; Valpreda, E.; Salihu, D.; Höfer, J.; Singh, A.; Nagaraja, N.S.; Voegel, H.J.; Vu Doan, N.A.; et al. Auto-NBA: Efficient and Effective Search Over the Joint Space of Networks, Bitwidths, and Accelerators. In Proceedings of the 2021 38th International Conference on Machine Learning (ICML), Virtual Event, 18–24 July 2021; pp. 238–243. [Google Scholar]
- Choi, K.; Hong, D.; Yoon, H.; Yu, J.; Kim, Y.; Lee, J. DANCE: Differentiable Accelerator/Network Co-Exploration. In Proceedings of the 2021 58th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 5–9 December 2021; pp. 337–342. [Google Scholar]
- Li, Y.; Hao, C.; Zhang, X.; Liu, X.; Chen, Y.; Xiong, J.; Hwu, W.m.; Chen, D. EDD: Efficient Differentiable DNN Architecture and Implementation Co-search for Embedded AI Solutions. In Proceedings of the 2020 57th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 20–24 July 2020; pp. 1–6. [Google Scholar]
- Zhou, Y.; Dong, X.; Meng, T.; Tan, M.; Akin, B.; Peng, D.; Yazdanbakhsh, A.; Huang, D.; Narayanaswami, R.; Laudon, J. Towards the Co-design of Neural Networks and Accelerators. Proc. Mach. Learn. Syst. 2022, 4, 141–152. [Google Scholar]
- Abdelfattah, M.S.; Dudziak, L.; Chau, T.; Lee, R.; Kim, H.; Lane, N.D. Best of Both Worlds: AutoML Codesign of a CNN and its Hardware Accelerator. In Proceedings of the 2020 57th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 20–24 July 2020; pp. 1–6. [Google Scholar]
- Yang, L.; Yan, Z.; Li, M.; Kwon, H.; Lai, L.; Krishna, T.; Chandra, V.; Jiang, W.; Shi, Y. Co-Exploration of Neural Architectures and Heterogeneous ASIC Accelerator Designs Targeting Multiple Tasks. In Proceedings of the 2020 57th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 20–24 July 2020; pp. 1–6. [Google Scholar]
- Ding, M.; Huo, Y.; Lu, H.; Yang, L.; Wang, Z.; Lu, Z.; Wang, J.; Luo, P. Learning versatile neural architectures by propagating network codes. arXiv 2021, arXiv:2103.13253. [Google Scholar]
- Horowitz, M. 1.1 Computing’s energy problem (and what we can do about it). In Proceedings of the 2014 IEEE International Solid-State Circuits Conference Digest of Technical Papers (ISSCC), San Francisco, CA, USA, 9–13 February 2014; pp. 10–14. [Google Scholar]
- TORCHVISION. Available online: https://github.com/pytorch/vision/tree/v0.12.0-rc1 (accessed on 15 June 2022).
- Subakan, C.; Ravanelli, M.; Cornell, S.; Bronzi, M.; Zhong, J. Attention Is All You Need In Speech Separation. In Proceedings of the ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 21–25. [Google Scholar]
- Ramachandran, P.; Zoph, B.; Le, Q.V. Searching for Activation Functions. arXiv 2017, arXiv:1710.05941. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2015, arXiv:1412.6980. [Google Scholar]
- Goldberg, D.E. Genetic Algorithms in Search, Optimization and Machine Learning, 1st ed.; Addison-Wesley Longman Publishing Co., Inc.: Reading, MA, USA, 1989. [Google Scholar]
- Rapin, J.; Teytaud, O. Nevergrad-A Gradient-Free Optimization Platform. Available online: https://GitHub.com/FacebookResearch/Nevergrad (accessed on 15 December 2018).
- Marini, F.; Walczak, B. Particle swarm optimization (PSO). A tutorial. Chemom. Intell. Lab. Syst. 2015, 149, 153–165. [Google Scholar] [CrossRef]
- McMillan, C.; Grechanik, M.; Poshyvanyk, D.; Xie, Q.; Fu, C. Portfolio: Finding Relevant Functions and Their Usage. In Proceedings of the 33rd International Conference on Software Engineering, Honolulu, HI, USA, 21–28 May 2011; ICSE’11. pp. 111–120. [Google Scholar]
- Igel, C.; Suttorp, T.; Hansen, N. A Computational Efficient Covariance Matrix Update and a (1+1)-CMA for Evolution Strategies. In Proceedings of the 8th Annual Conference on Genetic and Evolutionary Computation, Seattle, WA, USA, 8–12 July 2006; GECCO’06. pp. 453–460. [Google Scholar]
- Hansen, N.; Niederberger, A.S.P.; Guzzella, L.; Koumoutsakos, P. A Method for Handling Uncertainty in Evolutionary Optimization With an Application to Feedback Control of Combustion. IEEE Trans. Evol. Comput. 2009, 13, 180–197. [Google Scholar] [CrossRef]
- Vodopija, A.; Tušar, T.; Filipič, B. Comparing Black-Box Differential Evolution and Classic Differential Evolution. In Proceedings of the Genetic and Evolutionary Computation Conference Companion, Kyoto, Japan, 15–19 July 2018; GECCO’18. pp. 1537–1544. [Google Scholar]
- Poláková, R.; Tvrdík, J.; Bujok, P. Adaptation of population size according to current population diversity in differential evolution. In Proceedings of the 2017 IEEE Symposium Series on Computational Intelligence (SSCI), Honolulu, HI, USA, 27 November–1 December 2017; pp. 1–8. [Google Scholar]
- Bergstra, J.; Bengio, Y. Random Search for Hyper-Parameter Optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Li, G.; Zhang, J.; Zhang, M.; Wu, R.; Cao, X.; Liu, W. Efficient depthwise separable convolution accelerator for classification and UAV object detection. Neurocomputing 2022, 490, 1–16. [Google Scholar] [CrossRef]
- Jia, L.; Luo, Z.; Lu, L.; Liang, Y. TensorLib: A Spatial Accelerator Generation Framework for Tensor Algebra. In Proceedings of the 2021 58th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 5–9 December 2021; pp. 865–870. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | MobileNet-V2 [16] | ResNet101 [14] | ViT [15] | Time Cost | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
EDP (Cycles × nJ) |
Latency (Cycles) |
Energy (nJ) |
EDP (Cycles × nJ) |
Latency (Cycles) |
Energy (nJ) |
EDP (Cycles × nJ) |
Latency (Cycles) |
Energy (nJ) | ||
| PSO [45] | 4945 s | |||||||||
| Portfolio [46] | 6010 s | |||||||||
| OnePlusOne [47] | 4756 s | |||||||||
| CMA [48] | 7529 s | |||||||||
| DE [49] | 4882 s | |||||||||
| TBPSA [50] | 4781 s | |||||||||
| pureGA [43] | 6662 s | |||||||||
| Random [51] | 4403 s | |||||||||
| GAMMA [21] | 5253 s | |||||||||
| DCP (Ours) | 3606 s | |||||||||
| Method | MobileNet-V2 [16] | ResNet101 [14] | ViT [15] | ||||||
|---|---|---|---|---|---|---|---|---|---|
|
EDP (Cycles × nJ) |
Latency (Cycles) |
Energy (nJ) |
EDP (Cycles × nJ) |
Latency (Cycles) |
Energy (nJ) |
EDP (Cycles × nJ) |
Latency (Cycles) |
Energy (nJ) | |
| NVDLA [9] | |||||||||
| Eyeriss [7] | |||||||||
| ShiDianNao [10] | |||||||||
| NAAS [29] | - | - | - | ||||||
| DCP (Ours) | |||||||||
| Target | Single Objective | Multiple Objective | |||||
|---|---|---|---|---|---|---|---|
| Latency | Energy | EDP | Latency + Energy | Latency + EDP | Energy + EDP | ||
| MobileNet-V2 [16] | Latency (cycles) | ||||||
| Energy (nJ) | |||||||
| EDP (cycles × nJ) | |||||||
| ResNet101 [14] | Latency (cycles) | ||||||
| Energy (nJ) | |||||||
| EDP (cycles × nJ) | |||||||
| ViT [15] | Latency (cycles) | ||||||
| Energy (nJ) | |||||||
| EDP (cycles × nJ) | |||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, P.; Shao, W.; Luo, P. DCP: Learning Accelerator Dataflow for Neural Networks via Propagation. Electronics 2025, 14, 3085. https://doi.org/10.3390/electronics14153085
Xu P, Shao W, Luo P. DCP: Learning Accelerator Dataflow for Neural Networks via Propagation. Electronics. 2025; 14(15):3085. https://doi.org/10.3390/electronics14153085
Chicago/Turabian StyleXu, Peng, Wenqi Shao, and Ping Luo. 2025. "DCP: Learning Accelerator Dataflow for Neural Networks via Propagation" Electronics 14, no. 15: 3085. https://doi.org/10.3390/electronics14153085
APA StyleXu, P., Shao, W., & Luo, P. (2025). DCP: Learning Accelerator Dataflow for Neural Networks via Propagation. Electronics, 14(15), 3085. https://doi.org/10.3390/electronics14153085