
Security Improvements of JPEG Images Using Image De-Identification


Abstract
1. Introduction
2. Preliminaries
2.1. AES
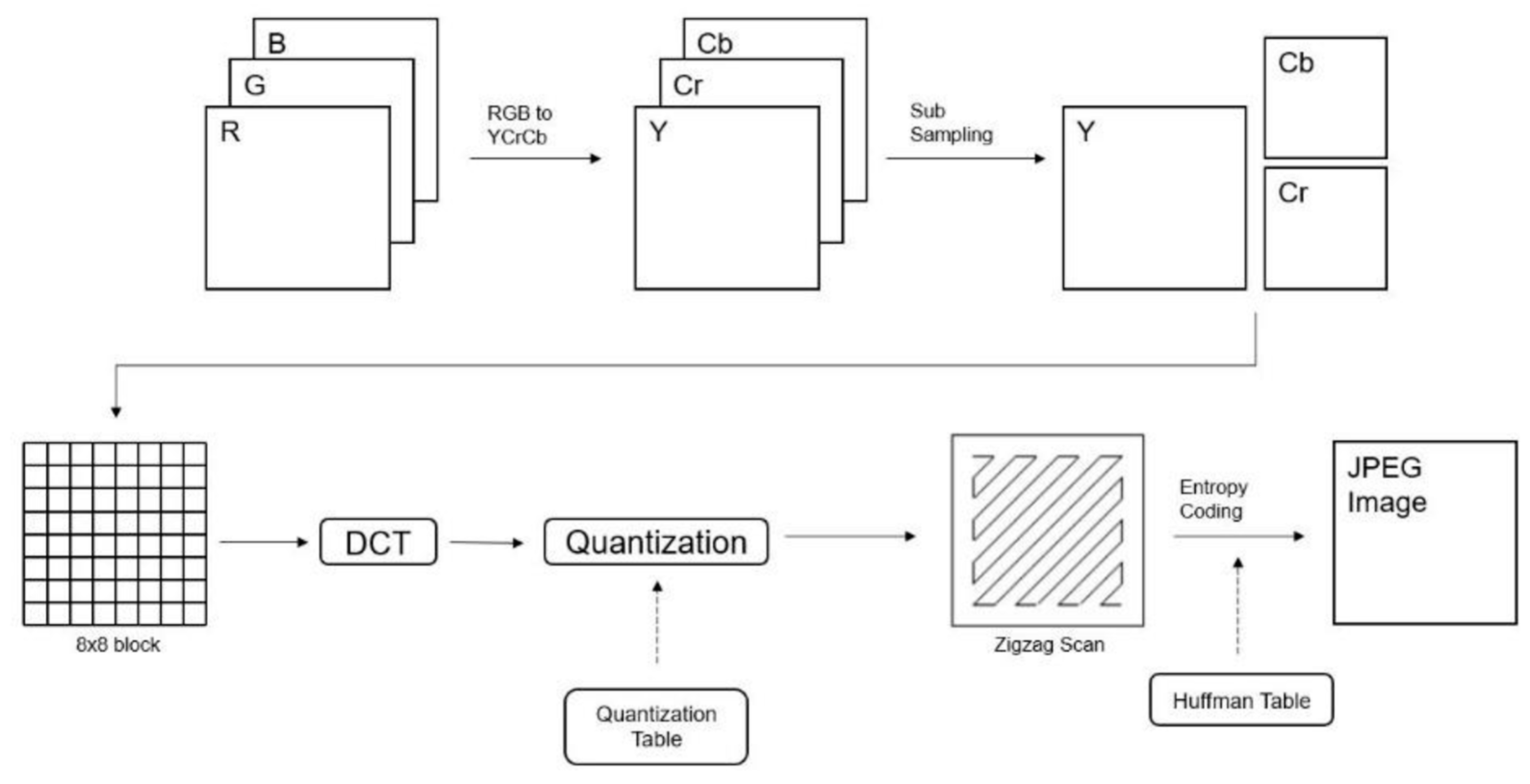
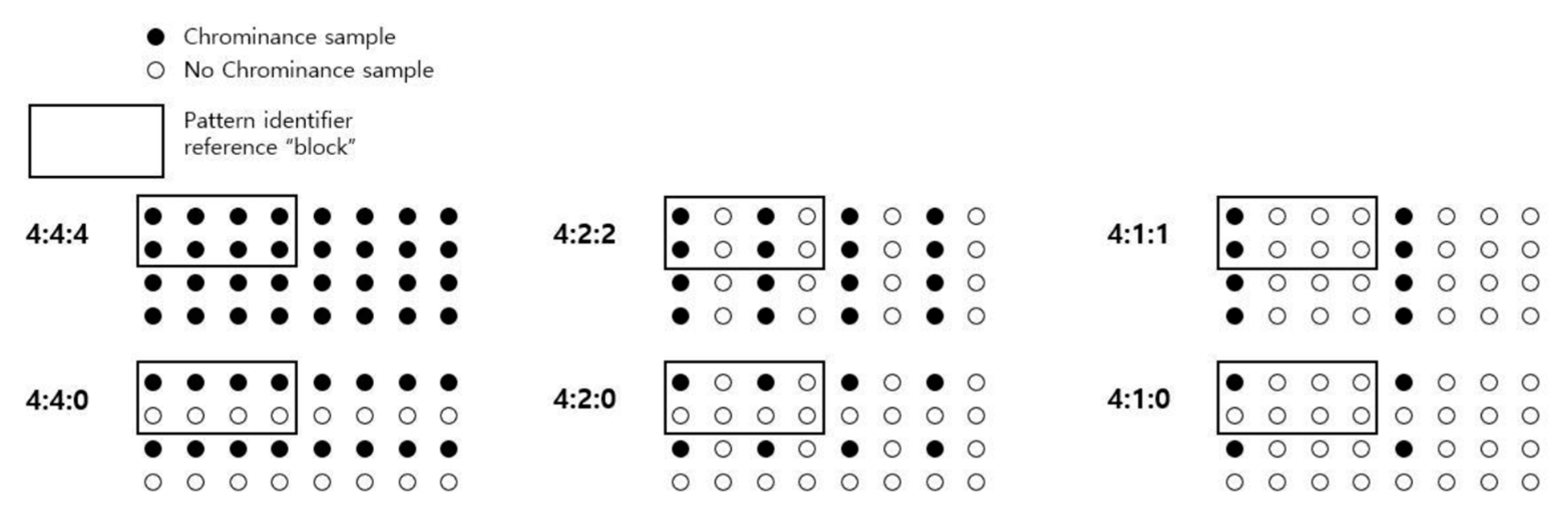
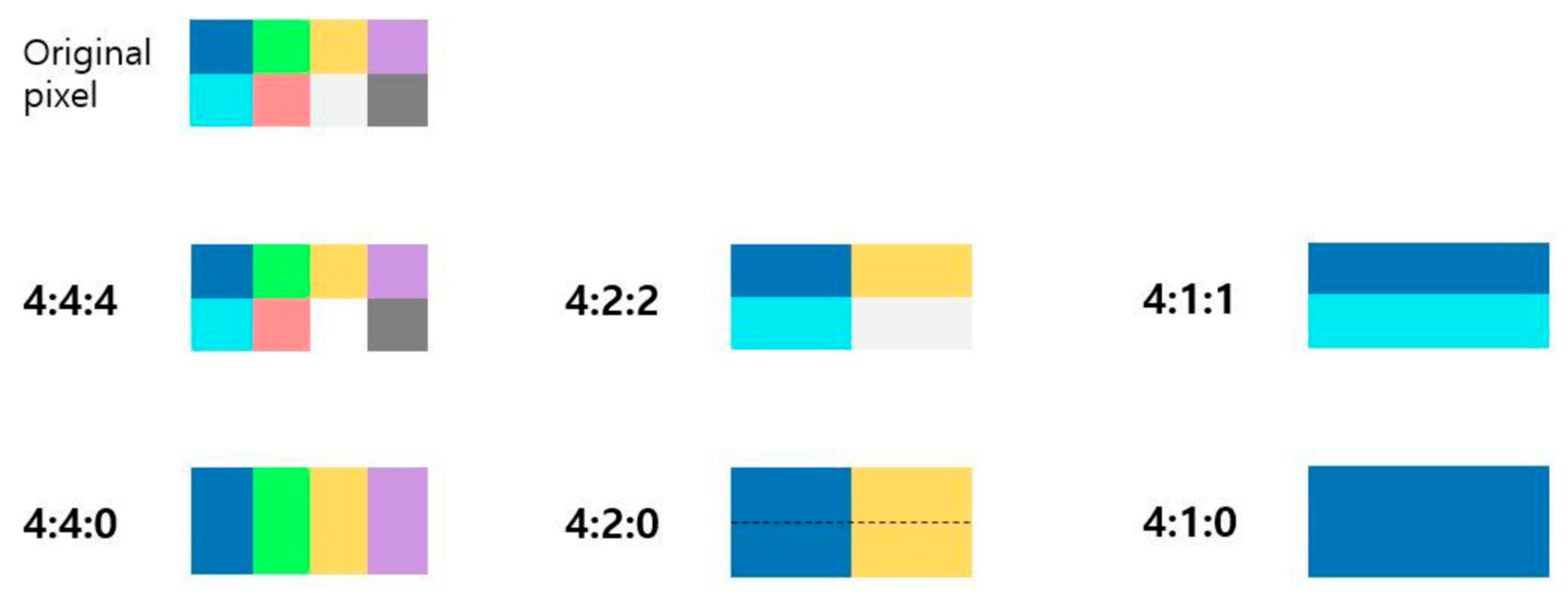
2.2. JPEG Compression
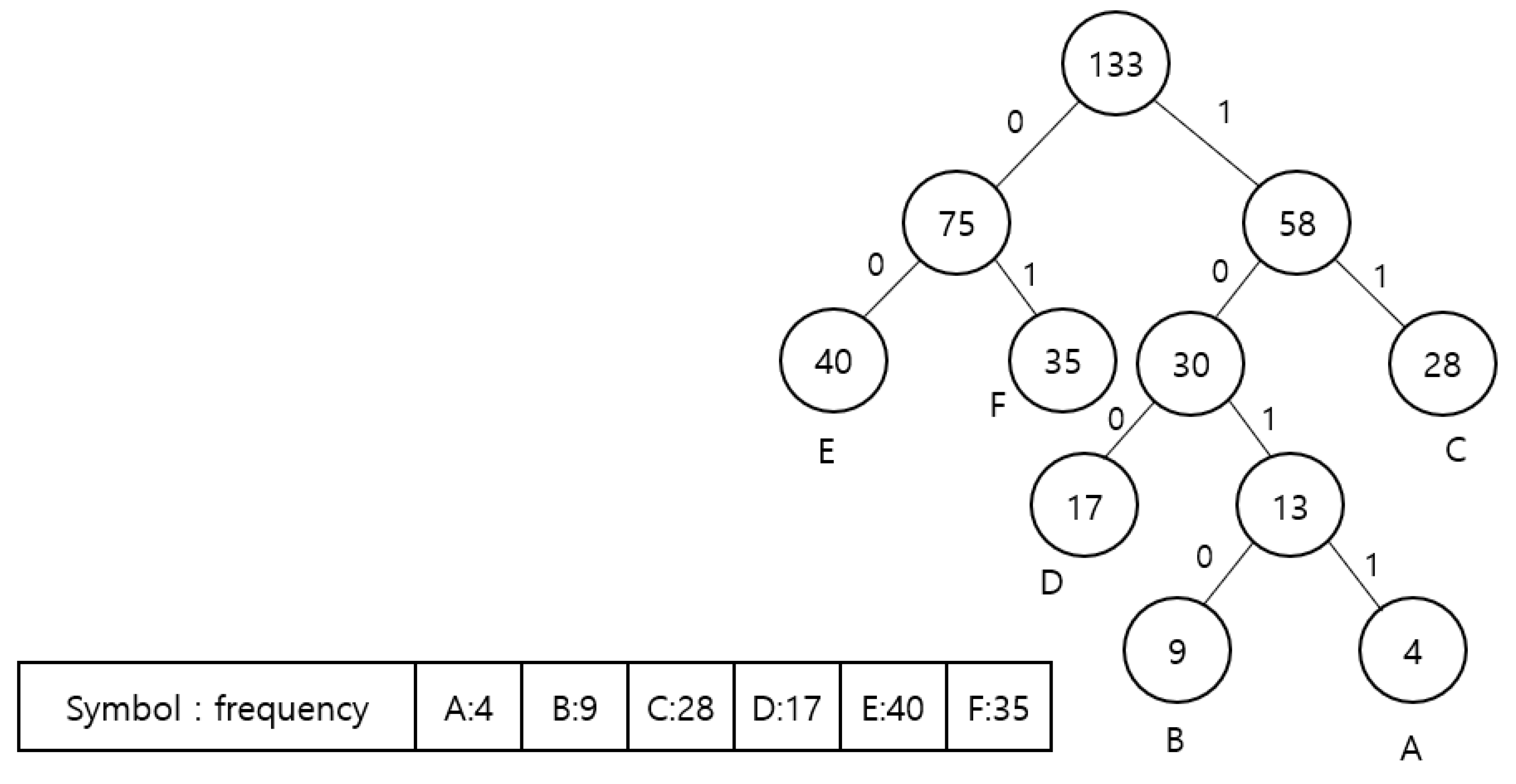
- Initialization: List all symbols according to their occurrence frequencies.
- Repeat the following steps until only one symbol remains.
- The parent node is produced by selecting two items with the least occurrence frequencies from the list as child nodes. Here, the value of the parent node is the sum of the child nodes.
- When creating a parent node, a weight of 0 is assigned to the edge of a node with a larger value, and a weight of 1 is assigned to the edge of a node with a smaller value.
- The child node with a larger value is placed on the left.
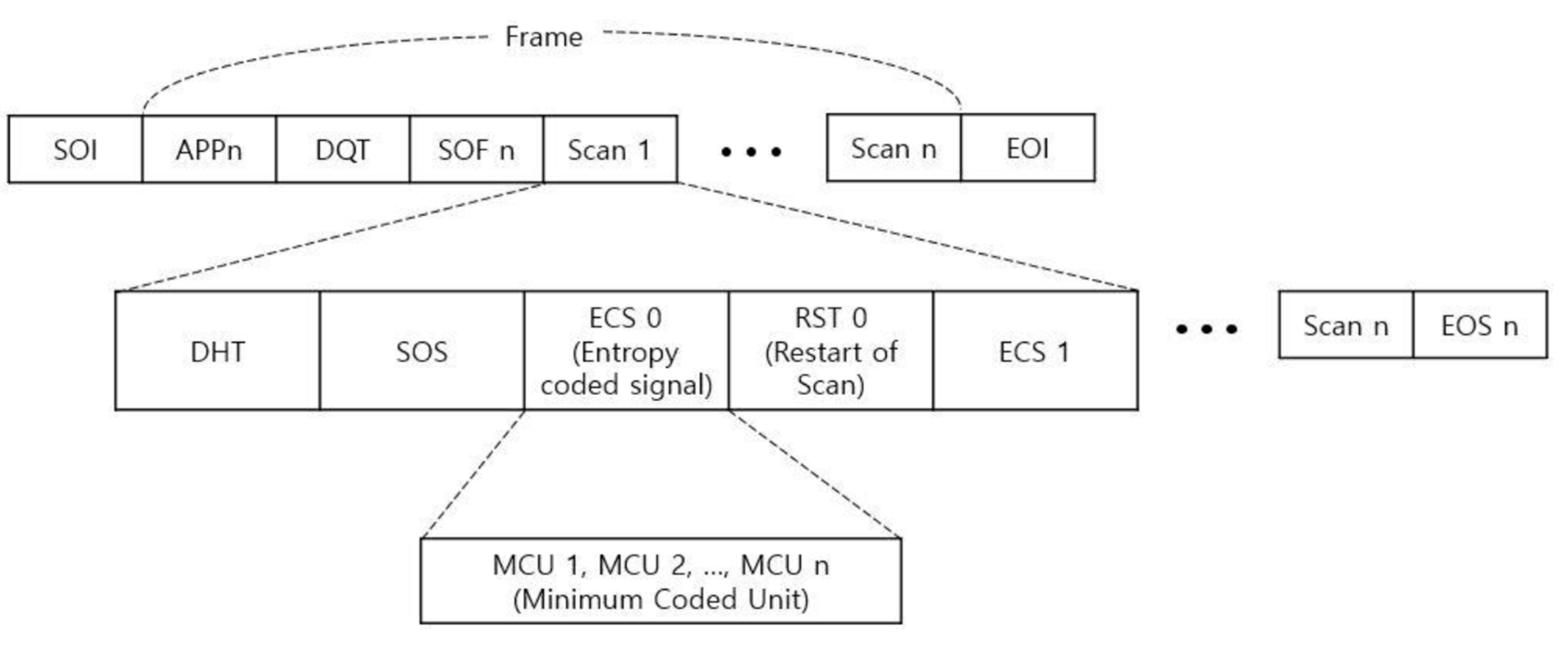
2.3. JPEG Header
3. Implementation
3.1. Experiment Environment
- Eclipse IDE 2021-03, JDK 11.0.5
- Intel i7-8700 CPU, 32GB Ram Desktop PC
- Windows 10 professional 64bit
- HxD [17] tool: for read and write binary data of images
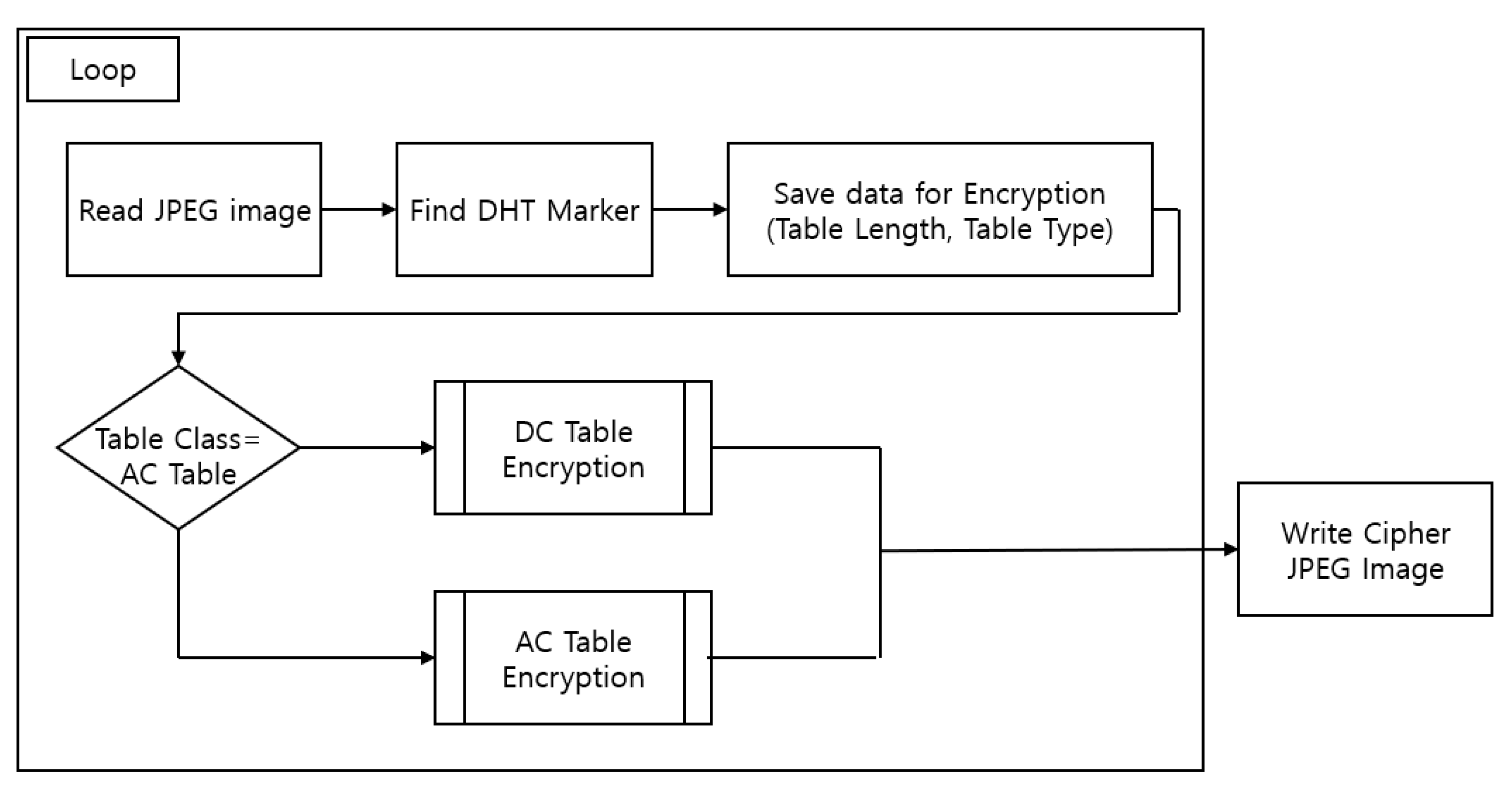
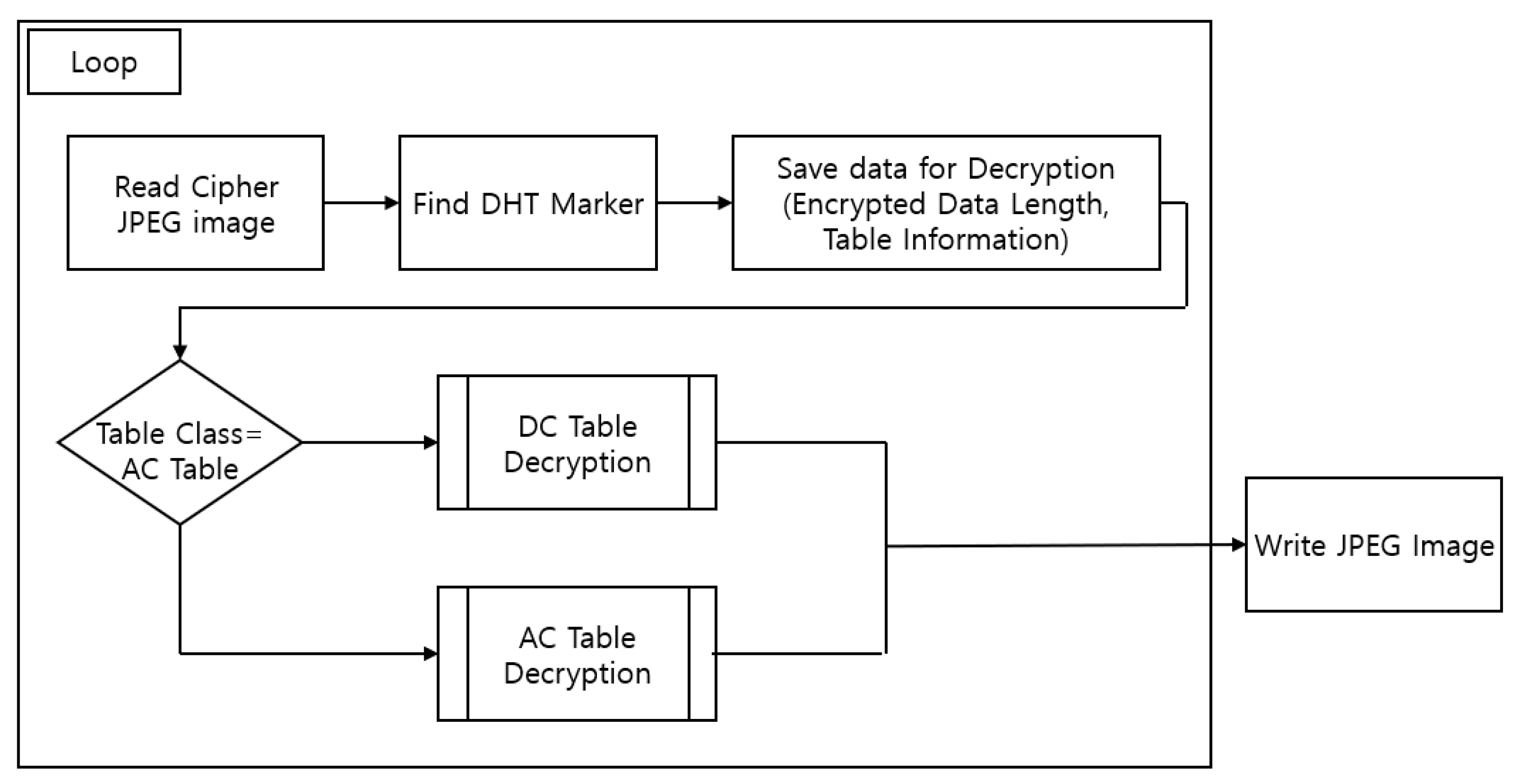
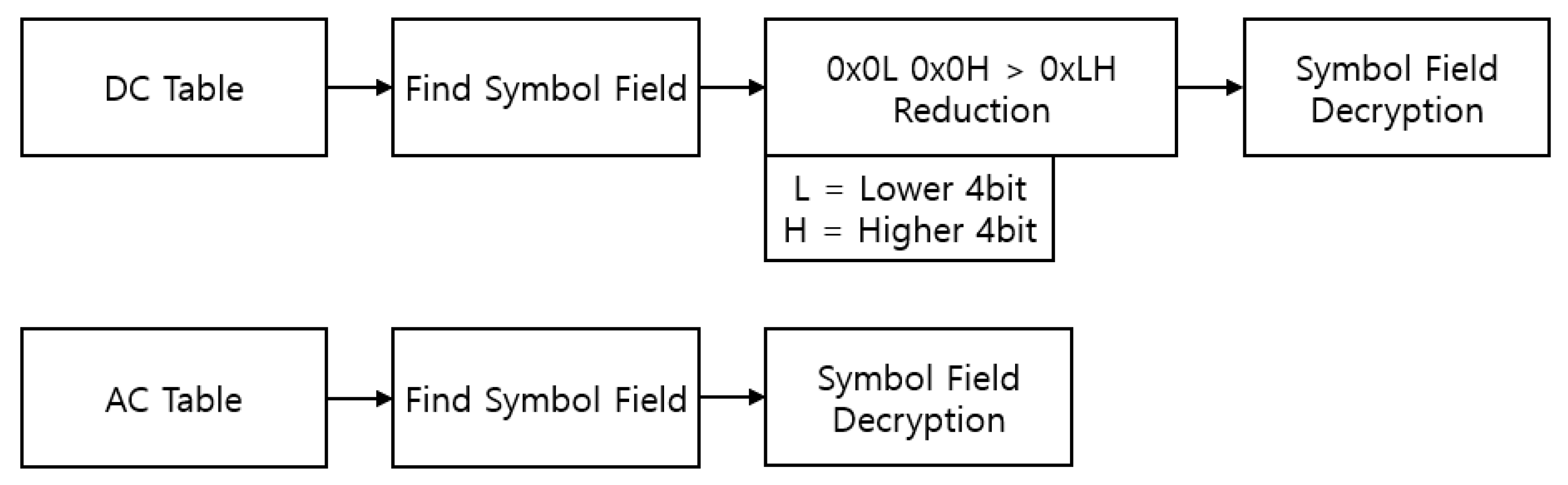
3.2. Overall Structure
- Find the DHT segment by locating the DHT marker in the read JPEG image.
- Check the classification information in the table. Then, if it is a DC table, an algorithm for encrypting the DC table is performed, and if it is an AC table, an algorithm for encrypting the AC table is used.
- After encrypting all four tables following the procedure described above, print the DHT-encrypted JPEG image.
- Find the DHT segment by locating the DHT marker in the encrypted JPEG image.
- Perform a decryption algorithm suitable for each table after checking the size information of the encrypted data in front of the DHT marker and the table classification information. Information containing the length of the encrypted data is deleted.
- The four tables are decrypted in the same way as above, and the image is printed.
3.3. Result
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kim, D.-G.; Lee, H. Overview on personal information de-identification based on big data. Rev. Korean Soc. Internet Inf. 2015, 16, 15–22. [Google Scholar]
- Zeghid, M.; Machhout, M.; Khriji, L.; Baganne, A.; Tourki, R. A Modified AES Based Algorithm for Image Encryption. Int. J. Comput. Sci. Eng. 2007, 1, 745–750. [Google Scholar]
- Singh, A.; Agarwal, P.; Chand, M. Image Encryption and Analysis using Dynamic AES. In Proceedings of the IEEE International Conference on Optimization and Applications (ICOA), Kenitra, Morocco, 25–26 April 2019. [Google Scholar]
- Daemen, J.; Rijmen, V. The Design pf Rijndael: The Advanced Encryption Standard (AES); Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Dworkin, M.J.; Barker, E.B.; Nechvatal, J.R.; Foti, J.; Bassham, L.E.; Roback, E.; Dray, J.F., Jr. Advanced Encryption Standard (AES); Federal Inf. Process. Stds. (NIST FIPS)—197; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2001. [Google Scholar]
- Ehrsam, W.F.; Meyer, C.H.; Smith, J.L.; Tuchman, W.L. Message Verification and Transmission Error Detection by Block Chaining. U.S. Patent US4074066A, 14 February 1978. [Google Scholar]
- Joint Photographic Experts Group. JPEG Homepage. Available online: https://jpeg.org/jpeg/index.html (accessed on 10 November 2021).
- ISO/IEC 10918-1; Information Technology—Digital Compression and Coding of Continuous-Tone Still Images: Requirements and Guidelines. ISO: Geneva, Switzerland, 1994.
- Wallace, G.K. The JPEG still picture compression standard. IEEE Trans. Consum. Electron. 1992, 38, 18–34. [Google Scholar] [CrossRef]
- Kerr, D.A. Chrominance Subsampling in Digital Images. 2012. Available online: http://www.dougkerr.net/Pumpkin/articles/Subsampling.pdf (accessed on 9 November 2021).
- Ahmed, N.; Rao, K.R. Discrete Cosine Transform. IEEE Trans. Comput. 1974, C-23, 90–93. [Google Scholar] [CrossRef]
- Sherlock, B.G. A Model for JPEG Quantization. In Proceedings of the ICSIPNN ‘94. International Conference on Speech, Image Processing and Neural Networks, Hong Kong, China, 13–16 April 1994. [Google Scholar]
- Huffman, D.A. A method for the construction of minimum redundancy codes. Proc. IRE 1952, 40, 1098–1101. [Google Scholar] [CrossRef]
- Information Technology—Digital Compression and Coding of Continuous-Tone Still Images: JPEG File Interchange Format (JFIF); IT-T.871; ITU-T: Geneva, Switzerland, 2011.
- Pennebaker, W.B.; Mitchell, J.L. JPEG: Still Image Data Compression Standard, 1993rd ed.; Springer: Berlin/Heidelberg, Germany, 1993. [Google Scholar]
- Razak, S.A. Analysis of DQT and DHT in JPEG Files. IJITCS 2013, 10, 1–11. [Google Scholar]
- Hörz, M. Hexeditor (HxD) Ver. 2.5.0.0. 2021. Available online: https://mh-nexus.de/en/hxd/ (accessed on 1 August 2022).
- Wu, S.W.; Gersho, A. Rate-constrained picture-adaptive quantization for JPEG baseline coders. In Proceedings of the 1993 IEEE International Conference on Acoustics, Speech, and Signal Processing, Minneapolis, MN, USA, 27–30 April 1993. [Google Scholar]
- Pareek, N.K. Image encryption using chaotic logistic map. Sci. Image Vis. Comput. 2006, 24, 926–934. [Google Scholar] [CrossRef]
- Peng, Y.; Fu, C.; Cao, G.; Song, W.; Chen, J.; Sham, C.-W. JPEG-compatible Joint Image Compression and Encryption Algorithm with File Size Preservation. ACM Trans. Multimed. Comput. Commun. Appl. 2024, 20, 1–20. [Google Scholar] [CrossRef]
- Zhu, S.; Deng, X.; Zhang, W.; Zhu, C. Secure image encryption scheme based on a new robust chaotic map and strong S-box. Math. Comput. Simul. 2023, 207, 323–346. [Google Scholar] [CrossRef]
- Yuan, Y.; He, H.; Mao, Y.Y.N.; Chen, F.; Ali, M. JPEG image encryption with grouping coefficients based on entropy coding. J. Vis. Commun. Image Represent. 2023, 97, 103975. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Frequency | Symbol | After Coding |
|---|---|---|
| 40 | E | 00 |
| 35 | F | 01 |
| 28 | C | 11 |
| 17 | D | 100 |
| 9 | B | 1010 |
| 4 | A | 1011 |
| Field | Marker | DHT Length | Table Class | Table Number | Huffman Code | Symbol |
|---|---|---|---|---|---|---|
| Length (Byte) | 2 | 2 | 0.5 | 0.5 | 16 | No fix Length |
| Data | 0xFF 0xC4 | - | 0 or 1 | 0 or 1 | … | Original Data |
| Field | Encrypted Data Length | Marker | DHT Length | Table Class | Table Number | Huffman Code | Symbol |
|---|---|---|---|---|---|---|---|
| Length (Byte) | 1 | 2 | 2 | 0.5 | 0.5 | 16 | No fix Length |
| Data | 0xFF 0xC4 | - | 0 or 1 | 0 or 1 | … | Encrypted Data |
| JPEG Image Size (Byte) | Encryption Speed (ms) | Decryption Speed (ms) | Encrypted Image Size (Byte) |
|---|---|---|---|
| A (202,692) | 2.148 | 2.207 | 202,764 |
| B (363,325) | 1.301 | 1.251 | 363,397 |
| C (399,029) | 2.178 | 2.315 | 399,097 |
| Scheme | Image Size (in Pixel) | Average Encryption |
|---|---|---|
| Ref. [2] | 256 × 256 | 31.75 ms |
| 200 × 320 | 29.25 ms | |
| Ref. [19] | 256 × 256 | 0.33~0.39 s |
| 512 × 512 | 0.38~0.40 s | |
| 1024 × 1024 | 6.26~6.32 s | |
| 2048 × 2048 | 25.15~25.32 s | |
| Ref. [20] | 512 × 512 | 19.27 ms |
| Proposed Method | 512 × 336 (A) 1419 × 1001 (B) 1280 × 960 (C) | 2.148 ms 1.301 ms 2.178 ms |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kang, H.-S.; Cha, S.; Kim, S.-R. Security Improvements of JPEG Images Using Image De-Identification. Electronics 2024, 13, 1332. https://doi.org/10.3390/electronics13071332
Kang H-S, Cha S, Kim S-R. Security Improvements of JPEG Images Using Image De-Identification. Electronics. 2024; 13(7):1332. https://doi.org/10.3390/electronics13071332
Chicago/Turabian StyleKang, Ho-Seok, Seongjun Cha, and Sung-Ryul Kim. 2024. "Security Improvements of JPEG Images Using Image De-Identification" Electronics 13, no. 7: 1332. https://doi.org/10.3390/electronics13071332
APA StyleKang, H.-S., Cha, S., & Kim, S.-R. (2024). Security Improvements of JPEG Images Using Image De-Identification. Electronics, 13(7), 1332. https://doi.org/10.3390/electronics13071332