
Unified Generative Data Augmentation for Efficient Solar Panel Soiling Localization

 ,
, 
Abstract
1. Introduction
- We introduce three novel data augmentation techniques that generate diverse solar panel and soiling types, addressing the limitations of existing datasets.
- We generate three distinct datasets—Naïve, Realistic, and Translucent—using these techniques, ensuring that the augmented images are free from visual artifacts and reflect real-world soiling conditions.
- We compare the performance of the segmentation model trained with each dataset, using solar panel image data collected at Chungbuk National University, South Korea, acquired from 22 March 2023 to 1 May 2023. Through this experiment, we can confirm the segmentation model’s usability in actual solar power plants. Specifically, our proposed method improves the Jaccard Index of the public dataset SPSI by 14.59%.
2. Related Work
2.1. Classification-Based Solar Panel Analysis
2.2. Localization-Based Solar Panel Analysis
3. Materials and Methods
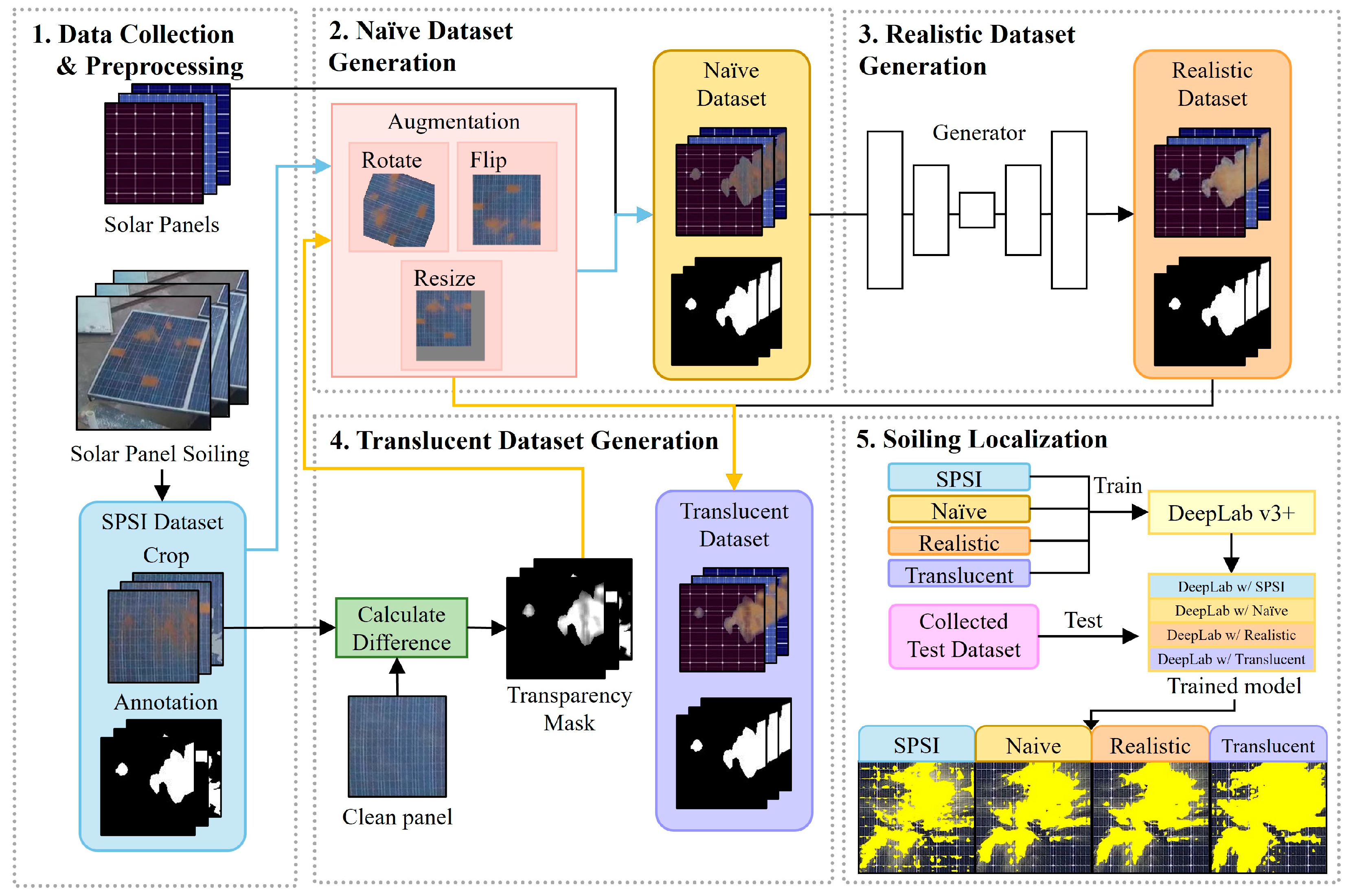
3.1. Overview
3.2. Data Collection
3.3. Preprocessing
3.4. Dataset Augmentation
3.4.1. Naïve Dataset Augmentation
3.4.2. Realistic Dataset Augmentation
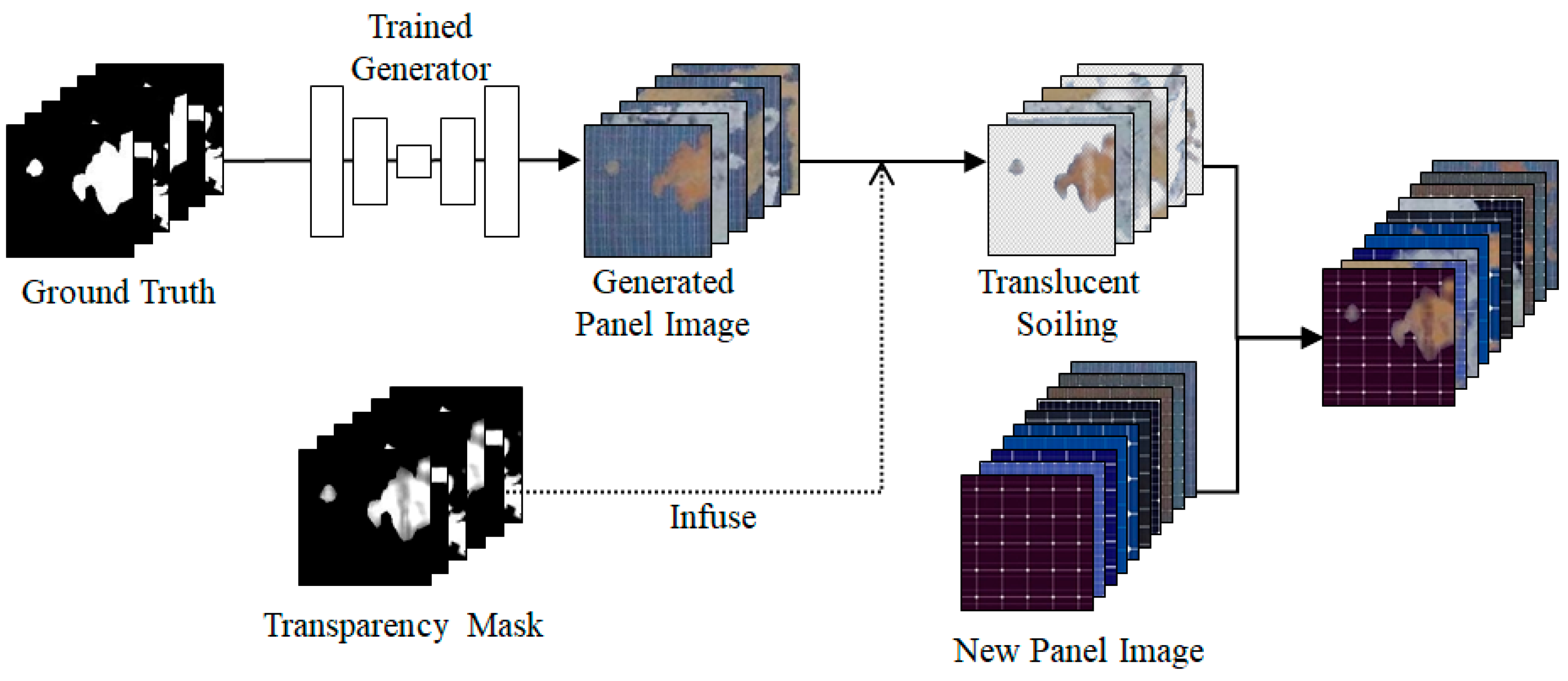
3.4.3. Translucent Dataset Augmentation
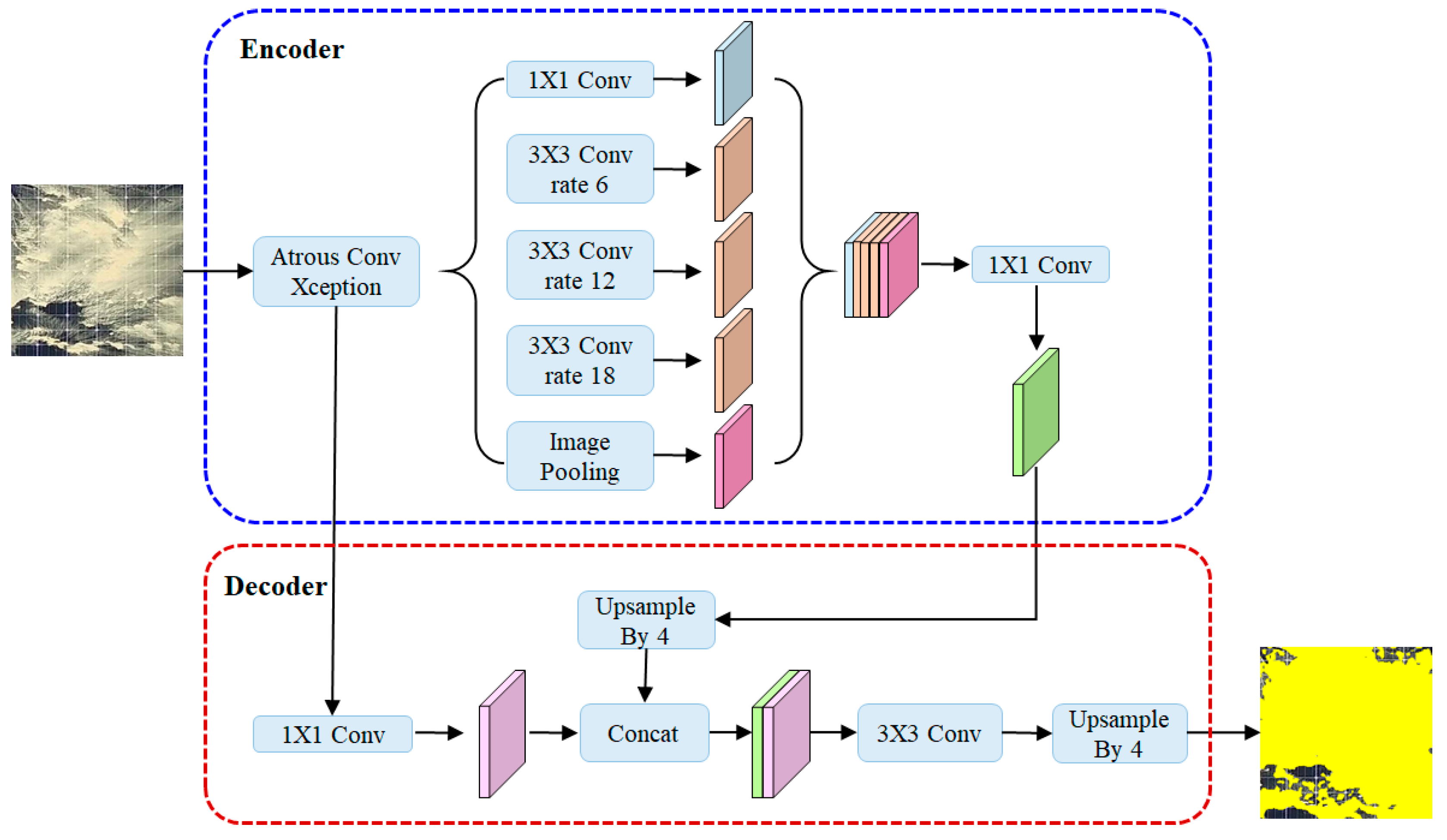
3.5. Soiling Localization
4. Results
4.1. Implementation Detail
4.2. Performance Evaluation Metric
4.3. Experimental Results
4.3.1. Qualitative Analysis
4.3.2. Quantitative Analysis
5. Discussions and Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

Appendix B
- SPSI dataset: This dataset suffers from an imbalance issue regarding the shapes of solar panels and soiling. The SPSI dataset exclusively uses only one type of panel. Consequently, when training a segmentation model with the SPSI dataset, the model overfits the specific panel. The overfitted segmentation model incorrectly identifies the panel cell boundaries as soiling when identifying soiling on different types of solar panels. Additionally, the soiling in the SPSI dataset shows limited diversity in shapes. Among a total of 45,754 solar panel soiling images, there are only 84 images with unique soiling shapes.
- Naïve dataset: We first applied traditional data augmentation methods, such as rotation, resizing, and flipping, to the SPSI dataset. We then copied pixels of the soiling area in each solar panel image and pasted them into the different types of solar panel images. As a result, we obtained an augmented dataset, called the Naïve Dataset, that contains various solar panel types and soiling shapes. However, the Naïve Dataset contains visual artifacts stemming from directly replicating existing solar panel patterns from the SPSI dataset.
- Realistic dataset: To address the issue of visual artifacts that arise in the Naïve dataset, we employed Pix2Pix, which provides a powerful image-to-image translation in specific areas, utilizing mask images. Specifically, we utilized mask images, which represent the soiling areas in the solar panel images, to train Pix2Pix. We then generated a Realistic dataset by using the pre-trained Pix2Pix. While the Realistic dataset excludes visual artifacts, it cannot consider translucent soiling. Translucent soiling is common in the wild, and it impacts solar power generation. Therefore, it is essential to augment solar panel images including translucent soiling.
- Translucent dataset: To generate translucent soiling images, we propose a new method to generate masks that incorporate information about soiling transparency. Specifically, transparency masks were formulated based on the RGB distance between the clean and soiled panels. RGB distance measures color dissimilarity between two images by calculating each pixel’s Euclidean distance in the RGB color space. The calculated RGB distance was then normalized to create a transparency mask. This generated transparency mask was infused into the solar panel image output from the Pix2Pix generator, resulting in the generation of a dataset (simply, Translucent dataset) that contains solar panel images with translucent soiling.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Number | Panel | Visual Artifacts | Translucent |
|---|---|---|---|---|
| SPSI | 29,190 | 1 | - | - |
| Naïve | 42,840 | 10 | O | X |
| Realistic | 42,840 | 10 | X | X |
| Translucent | 42,840 | 10 | X | O |

References
- Mehta, S.; Azad, A.P.; Chemmengath, S.A.; Raykar, V.; Kalyanaraman, S. DeepSolarEye: Power Loss Prediction and Weakly Supervised Soiling Localization via Fully Convolutional Networks for Solar Panels. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018. [Google Scholar]
- Umirzakova, S.; Ahmad, S.; Mardieva, S.; Muksimova, S.; Whangbo, T.K. Deep learning-driven diagnosis: A multi-task approach for segmenting stroke and Bell’s Palsy. Pattern Recognit. 2023, 144, 109866. [Google Scholar] [CrossRef]
- Umirzakova, S.; Whangbo, T.K. Detailed feature extraction network-based fine-grained face segmentation. Knowl. Based Syst. 2022, 250, 109036. [Google Scholar] [CrossRef]
- Baek, J.-H.; Oh, J. –H. Research on Improving Abandonment Detection Accuracy with Object Detection and Tracking Technology. J. Big Data Serv. 2024, 2, 47–60. [Google Scholar] [CrossRef]
- Aghaei, M.; Leva, S.; Grimaccia, F. PV Power Plant Inspection by Image Mosaicing Techniques for IR Real-Time Images. In Proceedings of the 2016 IEEE 43rd Photovoltaic Specialists Conference (PVSC), Portland, OR, USA, 5–10 June 2016; pp. 3100–3105. [Google Scholar]
- Akram, M.W.; Li, G.; Jin, Y.; Chen, X.; Zhu, C.; Ahmad, A. Automatic detection of photovoltaic module defects in infrared images with isolated and develop-model transfer deep learning. Sol. Energy 2020, 198, 175–186. [Google Scholar] [CrossRef]
- Li, X.; Yang, Q.; Lou, Z.; Yan, W. Deep Learning based module defect analysis for large-scale photovoltaic farms. IEEE Trans. Energy Convers. 2019, 34, 520–529. [Google Scholar] [CrossRef]
- Dunderdale, C.; Brettenny, W.; Clohessy, C.; van Dyk, E.E. Photovoltaic defect classification through Thermal Infrared Imaging using a machine learning approach. Prog. Photovolt. Res. Appl. 2019, 28, 177–188. [Google Scholar] [CrossRef]
- Aghaei, M.; Gandelli, A.; Grimaccia, F.; Leva, S.; Zich, R.E. IR Real-Time Analyses for PV System Monitoring by Digital Image Processing Techniques. In Proceedings of the 2015 International Conference on Event-Based Control, Communication, and Signal Processing (EBCCSP), Krakow, Poland, 17–19 June 2015; pp. 1–6. [Google Scholar]
- Wang, J.; Zhao, B.; Yao, X. PV Abnormal Shading Detection Based on Convolutional Neural Network. In Proceedings of the 2020 Chinese Control and Decision Conference (CCDC), Hefei, China, 22–24 August 2020; pp. 1580–1583. [Google Scholar]
- Dev, S.; Nautiyal, A.; Lee, Y.H.; Winkler, S. CloudSegNet: A deep network for nychthemeron cloud image segmentation. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1814–1818. [Google Scholar] [CrossRef]
- Ozturk, O.; Hangun, B.; Eyecioglu, O. Detecting Snow Layer on Solar Panels Using Deep Learning. In Proceedings of the 2021 10th International Conference on Renewable Energy Research and Application (ICRERA), Istanbul, Turkey, 26–29 September 2021; pp. 434–438. [Google Scholar] [CrossRef]
- Ghiasi, G.; Cui, Y.; Srinivas, A.; Qian, R.; Lin, T.Y.; Cubuk, E.D.; Le, Q.V.; Zoph, B. Simple Copy-Paste Is a Strong Data Augmentation Method for Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 2918–2928. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Li, B.; Delpha, C.; Diallo, D.; Migan-Dubois, A. Application of artificial neural networks to photovoltaic fault detection and diagnosis: A Review. Renew. Sustain. Energy Rev. 2021, 138, 110512. [Google Scholar] [CrossRef]
- Stock Photos, Royalty-Free Images, Graphics, Vectors & Videos. Available online: https://stock.adobe.com/ (accessed on 18 July 2024).
- Labelmeai/Labelme: Image Polygonal Annotation with Python (Polygon, Rectangle, Circle, Line, Point and Image-Level Flag Annotation). Available online: https://github.com/wkentaro/labelme#installation (accessed on 18 July 2024).
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 1–9. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Panchanan, S.; Dastgeer, G.; Dutta, S.; Hu, M.; Lee, S.-U.; Im, J.; Seok, I.S. Cerium-based halide perovskite derivatives: A promising alternative for lead-free narrowband UV photodetection. Matter 2024, 7, 3949–3969. [Google Scholar] [CrossRef]
- Nisar, S.; Ajmal, S.; Dastgeer, G.; Zafar, M.S.; Rabani, I.; Zulfiqar, M.W.; Souwaileh, A.A. Chemically doped-graphene FET photodetector enhancement via controlled carrier modulation with an iron(III)-chloride. Diam. Relat. Mater. 2024, 145, 111089. [Google Scholar] [CrossRef]
- CVAT-ai/cvat: Annotate Better with CVAT, the Industry-Leading Data Engine for Machine Learning. Used and Trusted by Teams at Any Scale, for Data of Any Scale. Available online: https://github.com/opencv/cvat (accessed on 18 July 2024).














| Type | Formula | Number |
|---|---|---|
| Unique soiling image in SPSI dataset | - | 84 |
| Copy-Paste without augmentation | 84 types of soiling × 9 panel image | 756 |
| Copy-Paste with augmentation | 84 types × 50 times augmentation × 10 panels | 42,000 |
| Total | - | 42,840 |
| Parameter | Value |
|---|---|
| Backbone | Exception |
| Optimizer | SGD |
| Learning rate | 0.01 |
| Epoch | 100 |
| Batch size | 4 |
| Dataset | Training | Validation | Test | Total |
|---|---|---|---|---|
| SPSI | 20,433 | 5838 | 2919 | 29,190 |
| Naïve | 29,987 | 8568 | 4285 | 42,840 |
| Realistic | ||||
| Translucent |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Go, S.-E.; Kim, J.-H.; Chuluunsaikhan, T.; Choi, W.-S.; Choi, S.-H.; Nasridinov, A. Unified Generative Data Augmentation for Efficient Solar Panel Soiling Localization. Electronics 2024, 13, 4859. https://doi.org/10.3390/electronics13244859
Go S-E, Kim J-H, Chuluunsaikhan T, Choi W-S, Choi S-H, Nasridinov A. Unified Generative Data Augmentation for Efficient Solar Panel Soiling Localization. Electronics. 2024; 13(24):4859. https://doi.org/10.3390/electronics13244859
Chicago/Turabian StyleGo, Seung-Eun, Jeong-Hun Kim, Tserenpurev Chuluunsaikhan, Woo-Seok Choi, Sang-Hyun Choi, and Aziz Nasridinov. 2024. "Unified Generative Data Augmentation for Efficient Solar Panel Soiling Localization" Electronics 13, no. 24: 4859. https://doi.org/10.3390/electronics13244859
APA StyleGo, S.-E., Kim, J.-H., Chuluunsaikhan, T., Choi, W.-S., Choi, S.-H., & Nasridinov, A. (2024). Unified Generative Data Augmentation for Efficient Solar Panel Soiling Localization. Electronics, 13(24), 4859. https://doi.org/10.3390/electronics13244859