1. Introduction
With the emergence of mobile device location-based services, such as the Internet of Things (IoT) and Machine Type Communication (MTC), location-based services (LBS) have been attracting intensive attention recently. As one of the most popular wireless positioning technologies, the Global Navigation Satellite System (GNSS) has achieved great success in outdoor open-scene positioning. However, GNSS becomes infeasible for indoor scenarios due to the signal strength attenuation and multi-path effects [
1]. Thus, it is imperative to develop efficient indoor positioning schemes to meet the requirements of numerous and booming indoor location-aware applications, such as indoor emergency rescue, smart factory asset management and tracking, mobile medical services, virtual reality games, etc.
Traditional positioning methods can be roughly categorized as geometry-based and feature-matching-based methods [
2]. The geometry-based methods, such as Angle of Arrival (AOA), Angle of Departure (AOD), Time Difference of Arrival (TDOA), and Multi-Round Trip Time (Multi-RTT), rely on the measurement of positioning information and estimation of the target location. Feature matching-based methods are mainly regarded as fingerprint recognition methods, which have also received widespread attention in positioning technology in the era of 5G and beyond [
3]. Specifically, the primary approach of fingerprint recognition is based on the Received Signal Strength (RSS) or Channel State Information (CSI) [
4].
Recently, the 3rd Generation Partnership Project (3GPP) emphasized the importance of the LBS in 5G networks, and in 3GPP Rel-16, it ultimately established the direction of 5G positioning enhancement [
5]. Specifically, the New Radio (NR) specification includes reference signals introduced for positioning. These signals include the Positioning Reference Signal (PRS) for the downlink and the Sounding Reference Signal (SRS) for the uplink. Based on these signals, 3GPP Rel-16 has introduced a number of advanced positioning schemes suitable for 5G NR, including angle-based positioning schemes based on downlink AOD or uplink AOA, downlink TDOA, uplink TDOA, and Multi-RTT.
Although these methods can provide high positioning accuracy, they heavily depend on the availability of line-of-sight (LOS) components [
6]. Unfortunately, in many indoor scenarios, such as the industrial environment, there could be many obstacles that can cause signal refraction, reflection, and diffraction, which leads to poor performance under some specific scenarios [
7]. Hence, it is imperative to explore efficient techniques to improve the positioning performance in heavy non-line-of-sight (NLOS) scenarios for the 5G system and beyond.
In order to achieve higher positioning accuracy, the standardization work of 3GPP Rel-18 is introducing Carrier Phase Positioning (CPP) technology. The carrier phase information of a signal contains distance information between the signal receiver and transmitter, which can be used to accurately calculate the user’s position. CPP technology has been widely applied in GNSS, enabling centimeter or even millimeter-level positioning accuracy [
8]. However, the low power of the GNSS signals can be blocked and discontinuous in indoor scenarios. Due to the high power of cellular network signals and their resistance to environmental interference, carrier phase positioning based on cellular signals is not limited to outdoor environments, and because the carrier phase contains the distance between the signal receiver and transmitter, it can be used to precisely calculate targets’ position [
1]. Compared to satellite-based CPP, using CPP in indoor scenarios can achieve similar positioning accuracy and lower positioning latency. In the measurement of the carrier phase from the Positioning Reference Signal (PRS), the estimated value of the Channel Frequency Response (CFR) is first used to obtain the Channel Impulse Response (CIR) by an Inverse Discrete Fourier Transform (IDFT). Then, based on certain criteria, the first path of arrival is determined from the CIR, and the phase is calculated to obtain the carrier phase measurement value. Therefore, the CIR signal can be considered as the original information of the carrier phase to distinguish multipath characteristics and can potentially be used for accurate and pervasive indoor positioning [
9]. In addition, CSI can be also obtained from CFR, which is the sampled version of CFR at the granularity of the subcarrier level [
9].
Meanwhile, in recent years, Artificial Intelligence (AI) has experienced rapid development and widespread applications in positioning fields due to their outstanding performance [
10]. 3GPP also studied AI-based positioning enhancement for indoor scenarios [
11]. The AI-based solutions can potentially overcome the limitations and difficulties of traditional positioning methods, and numerical results show that deep supervised learning with CIR information can greatly improve positioning accuracy compared with traditional methods [
12].
Motivated by the high performance of AI and its wide application, some research has regarded CSI as image information and finds a mapping from CSI measurements to the coordinates of the target terminals by using deep learning; these learning-based methods achieved higher positioning accuracy than traditional positioning methods [
13,
14]. Meanwhile, In CSI-based or CIR-based fingerprinting approaches, AI models are able to learn the knowledge of fingerprint features offline based on the dataset of labeled fingerprints [
4]. However, obtaining a large amount of labeled data is difficult and rather costly due to the need for experts’ time and experience. Moreover, low-quality labeled data can adversely affect the performance of deep models. To address these issues, Deep Semi-Supervised Learning (DSSL) has been recently considered to improve learning performance by exploring potential patterns from unlabeled samples.
When carefully examining the similarity of image processing and the underlying indoor location, we can find that both image processing and CIR positioning are based on feature recognition, thereby realizing the perception and understanding of user location, and obtaining position features of User Equipments (UEs) in a specific area. They also have similar feedback mechanisms in the process of model training through generating loss values when using a neural network. These observations inspire us to exploit an adapted DSSL method to handle indoor positioning tasks. Although various methods, such as the
Model, Temporal Ensembling [
15], and Mean Teacher [
16], have shown advantages for image classification, some modifications have to be made based on the data type and target format for positioning tasks. In this paper, we develop an Adapted Mean Teacher (AMT) model under the DSSL paradigm for indoor positioning using CIR fingerprints, which is inspired by the inherent similarity between image processing and indoor positioning, and the efficiency of the consistency regularization method. Additionally, the 5G Advanced has set high requirements for future positioning accuracy, aiming to achieve centimeter-level precision. Based on the scenario of a 5G new radio, we aim to apply the machine learning method to indoor positioning to meet the development needs of 5G Advanced. The main contributions of this paper can be summarized as follows:
We mathematically present the CIR estimation for building a CIR-based fingerprint dataset according to the 5G NR standard.
A tailored neural network based on Residual Network (ResNet) is designed to extract position features of CIR fingerprints to predict the position of users. In a supervised learning manner with abundant label data, it achieves sub-meter level accuracy with a mean error of 31 cm.
We propose efficient implicit random augmentation methods for CIR data by borrowing the idea of data augmentation in image processing tasks. Experiments on adding augmentation methods in the training process show that our proposed method can achieve higher accuracy in both supervised and semi-supervised learning methods.
We propose an AMT model to handle fingerprint indoor positioning tasks and possess a superior positioning performance than reference algorithms, achieving a sub-meter level accuracy.
The rest of this paper is organized as follows.
Section 2 presents the related works for positioning methods and existing DSSL methods.
Section 3 presents the scenario and system model.
Section 4 elaborates the proposed AMT model, and in
Section 5, we provide a detailed description of the CNN structure. We present simulation results as well as discussions in
Section 6 and finally conclude the paper in
Section 7.
2. Related Works
Positioning technology has been developing for decades. During this time, various location technologies have emerged. To summarize the previous technical work, in this section, we start by summarizing positioning techniques based on the common metrics of positioning. We then review recent research advancements in wireless positioning systems, which contain a detailed explanation of positioning technology for 5G cellular networks related to the paper’s topic. Additionally, we provide an overview of AI-based indoor positioning methods and DSSL-based indoor positioning schemes.
2.1. Positioning Techniques Based on Common Measurements
Indoor positioning is a challenging problem that has been extensively investigated, resulting in the development of various technologies such as WiFi, Bluetooth, Ultra-Wideband (UWB), geomagnetism, sound/ultrasound, or Pedestrian Dead Reckoning (PDR) [
8,
17]. Though a number of facilities can be used for positioning, in traditional positioning schemes for both cellular and non-cellular positioning systems, some universal signal measurements are used. In this section, we introduce positioning methods based on common measurements such as RSS, AOA, and TDOA.
The RSS-based approach [
18] is a simple and commonly used method for indoor positioning, which involves measuring the strength of the received signal. By using signal propagation models with the knowledge of the transmission power or power at a reference point, it is possible to estimate the absolute distance between the two devices based on the RSS value. In the device-based positioning, RSS positioning requires the use of trilateration or N-point lateration [
19]. This involves using the RSS at the UE to estimate the precise distance between a UE and three or more signal sources. Subsequently, basic geometry and trigonometry are applied to determine the location of the device relative to the reference points.
The AOA-based methods [
20] make use of antenna arrays on the receiver side to determine the angle that the transmitted signal arrives at the receiver. This is achieved by calculating the TDOA at each element of the antenna array. While AOA can provide an accurate estimation for short distances between the transmitter and receiver, it requires more complex hardware and precise calibration compared with RSS techniques. Additionally, the accuracy of the AOA-based positioning decreases as the distance between the transmitter and receiver increases, as even a small error in the angle calculation can result in a significant error in the actual location estimation. Furthermore, in an indoor environment with multipath effects, obtaining the LOS condition for AOA-based positioning can be challenging.
The TDOA-based methods [
21] use the differences in signal propagation time measured at the receivers from different transmitters. To accurately determine the location of the receiver, the TDOAs from at least three transmitters are required. This allows for the calculation of the receiver’s position as the intersection of three or more hyperboloids [
21]. Solving the system of hyperbola equations can be achieved through methods such as linear regression or by linearizing the equation using Taylor-series expansion.
However, all of the aforementioned existing methods heavily depend on LOS scenarios, and in other scenarios, such as urban streets and indoor scenarios, the complex signal propagation paths will lead to unreliable positioning results.
2.2. Wireless Positioning Systems
Wireless positioning technology can be categorized based on the scope of service, including positioning systems for Wireless Wide Area Network (WWAN) and Wireless Local Area Network (WLAN)/Personal Area Network (PAN). The WLAN/PAN includes WiFi positioning systems, Bluetooth positioning systems, and UWB positioning systems, while the WWAN includes GNSS and cellular network positioning systems.
WiFi-based positioning technologies mainly consist of four types, including positioning methods based on RSS, fingerprinting, AOA, and TOA. Different from traditional RSS-based WiFi positioning systems, the use of deep learning methods has been widely applied to explore the numerical features of signals in RSSI positioning. Dai et al. [
22] used a multi-layer neural network (MLNN) to provide localization services in RSS-based indoor localization, which combined the RSS signal-transforming section, raw data-denoising section, and node-locating section to form a deep architecture. By using the deep architecture, the predicted locations of UE can be attained without using a radio pathloss model or comparing with a radio map. Hoang et al. [
23] emphasized the superiority of RNN in dealing with location nonlinearly because the mapping from RSS to UE’s location is nonlinear. In this work, the authors provided a complete study of several RNN architectures for WiFi RSS fingerprint positioning. Research on WiFi fingerprint positioning typically utilizes the CSI or RSS signals obtained from WiFi signals [
24]. The CSI-based method provides more detailed signal propagation characteristics, resulting in better positioning accuracy compared to RSS [
25]. However, the acquisition of CSI requires the cooperation of WiFi access points (APs), which is limited by the practical deployment of devices. To overcome this obstacle, Gao et al. [
26] proposed a CSI fingerprinting-based positioning approach named CRISLoc, which obtains the packets in the air passively, while a joint clustering and outlier detection method is used to find altered APs. By applying CRISLoc, the accuracy of CSI fingerprinting-based localization can reach a sub-meter level. The RSS-based WiFi fingerprint positioning technology is often heavily influenced by noisy environments; recent studies have begun to utilize advanced deep-learning models to address these issues. Chen et al. [
27] proposed an LF-DLSTM framework to alleviate the noise effect and attain stable features from the raw noisy RSS data. Additionally, in traditional AOA WiFi positioning systems, a limited number of antennas in WiFi devices can result in limited AOA resolution. In order to achieve more accurate and robust positioning, recent research has focused on developing new methods. Yang et al. [
28] worked out the relationships among different AoAs of different APs, and proposed a novel co-localization method between multiple APs to achieve a real-time and accurate localization system. For TOF-based WiFi positioning, the positioning performance of the TOF-based WiFi system is largely limited by the WiFi channel bandwidth because of the low resolution of TOF, and recent research has utilized multipath to increase time resolution [
29]. While the use of WIFI technology for positioning facilities can achieve centimeter-level accuracy in many studies, the coverage range is limited to a 10 m level, which results in extremely high deployment costs when attempting to cover large areas.
The Bluetooth positioning system is a common short-distance wireless communication technology primarily used for PAN. In the latest release of Bluetooth 5.1, the version has added measurements of AOA and AOD, integrating the results with RSS to provide sub-meter positioning accuracy [
30]. However, Bluetooth positioning faces serious multipath interference issues. The accuracy of positioning is difficult to further improve, and there are limitations on coverage range, making it challenging to deploy over large areas [
31].
UWB positioning technology is characterized by high positioning accuracy, high rating, and strong resistance to multipath interference [
32]. Current recent research has mainly focused on how to reduce the impact of non-line-of-sight (NLOS) paths in high NLOS scenarios when applying UWB positioning to decrease positioning errors. Poulose et al. [
33] applied LSTM networks in UWB localization in indoor scenarios to migrate the negative effects from both NLOS conditions and TOA errors. Compared to the conventional method, it can reduce the mean position error to 7 cm. Although UWB has a high positioning accuracy, the high cost of base stations and tags for UWB positioning makes it not a universally applicable positioning solution.
For positioning systems in WWAN, Assist-Global Positioning System (A-GPS) technology is widely used in the location services of smartphones. It leverages cellular mobile communication networks to broadcast GNSS information and its auxiliary data, thereby assisting UEs in shortening the satellite’s initial search time and improving location accuracy during satellite navigation [
34]. The GNSS signal can be easily blocked, and recent research has attempted to enhance GPS using the UWB systems. Gao et al. [
35] proposed an RCP scheme that evaluates the positioning performance by generating a dataset in real urban scenarios. Experimental results show that this scheme can robustly resist adverse effects on positioning performance.
Positioning technologies in cellular networks have evolved from 2G to 5G, and now to 5G NR and 5G-Advanced. In 5G NR and 5G-Advanced, the requirement for positioning accuracy has reached to centimeter level, leading to a significant focus on research based on CSI and CPP. Meanwhile, some studies have emphasized machine learning and fingerprint recognition. Zhang et al. [
36] developed a novel Attention-Aided Residual Convolutional Neural Network (AAresCNN) for CSI-based indoor positioning, achieving a state-of-the-art performance on public datasets. Ruan et al. [
37] proposed a novel positioning system, iPOS, using commercial 5G-NR CSI fingerprints for indoor positioning, incorporating CSI pre-processing and feature reconstruction modules. In the current development of 5G-Advanced, Tedeschini et al. [
38] utilized CIR to extract position-related features and enhance positioning accuracy through cooperative deep learning, combined with NLOS recognition. Unlike other positioning systems, cellular network positioning does not require additional infrastructures and can achieve centimeter-level accuracy, which significantly reduces positioning costs. The use of CSI and CPP as measurement values, along with machine learning positioning strategies, demonstrates advancements in both 3GPP standards and recent research.
2.3. DSSL Methods for Indoor Positioning
In recent years, deep learning algorithms have shown great potential in solving complex positioning problems, and DSSL methods have been emerging as a promising approach to deal with the challenges of limited labeled data in positioning problems by leveraging both labeled and unlabeled data to train deep learning models.
The branches of DSSL mainly include pseudo-label methods [
39], deep generative methods [
40], graph-based methods [
41], consistency regularize methods [
15,
16] and hybrid methods [
42]. Currently, research on DSSL mainly focuses on the image classification task.
For DSSL methods applied in image classification tasks, each branch has advanced algorithms capable of achieving high accuracy. Regarding the pseudo-labeling method, using the high-confidence model’s predictions as pseudo labels for unlabeled samples is a common approach known as self-training. Ref. [
39] proposed a simple and efficient training framework for neural networks. The model is first trained in a usual supervised manner; this trained model is used to attain predictions from unlabeled data. The crossentropy loss is used in the process of obtaining predictions from unlabeled samples, and when we obtain soft labels, the model’s highest confidence predictions are viewed as pseudo labels.
Consistency regularization is a technique that typically involves using a single model to make multiple predictions with different input noise or model parameters each time. It aims to obtain a similar prediction result under different noisy inputs and parameters, thereby improving the generalization of the model. From certain perspectives, using consistency regularization can also be observed as generating pseudo-labels. However, it focuses on obtaining accurate labels by regularizing the distance between outputs and supervised training, which is fundamentally different from the pseudo-labeling method. Ref. [
15] proposed two training frameworks, named
Model and Temporal Ensembling, respectively. During each epoch of training with the
Model, the same batch of unlabeled samples is processed by the same model twice after adding random perturbations. Some inconsistencies in the two predictions will exist because of the different perturbations, so the
Model uses a consistency loss function to minimize the disparity between the two predicted outputs. Temporal Ensembling makes some improvements to the
Model. Due to the fact that the
Model requires two rounds of inference at each step, it slows down the inference speed. To overcome this defect, the Temporal Ensembling model only needs one round of inference, while one prediction is obtained by calculating the moving average of a historical output over a certain period of time. Another prediction is generated by the current output. By combining the loss items of two predictions as a loss function, the inconsistency in the two predictions decreases.
Mean Teacher [
16] is an improved method for Temporal Ensembling, and it consists of a teacher model and a student model. The student model resembles the
Model, while the teacher model shares the same structure as the student model but incorporates Exponential Moving Average (EMA) of the student weights. This allows Mean Teacher to enforce a consistency constraint between the predictions of the student and teacher models. Results from [
16] indicate that Mean Teacher performs superiorly in test accuracy compared to Temporal Ensembling, while it also allows for training with fewer labels.
DSSL-based indoor positioning is often considered as a regression problem rather than a classification problem, and previous research on DSSL for indoor positioning mainly focuses on pseudo-label methods [
43], deep generative methods [
44], and graph-based methods [
45]. The idea of the pseudo-label method in [
43] is to pretrain the initial model with labeled data and use the trained model to predict unlabeled data, treating the predictions as pseudo-labels. The advantage of this method is its simplicity and strong operability, which is needless to deploy additional models. Whereas in actual positioning scenarios, the target distributions of labeled data and unlabeled data are often inconsistent, and using the same model parameters directly on different distributed data will reduce the positioning accuracy. In [
44], the author discussed a semi-supervised indoor positioning scenario based on the Generative Adversarial Network (GAN) by using CSI data, which consists of a generator and a discriminator and aims to generate new CSI that similar to labeled data. Results of using GAN for semi-supervised positioning have confirmed its effectiveness under a few labeled input. However, using explicit data augmentation methods to improve the performance of positioning may increase the computing power burden of the device and consume a large amount of memory when facing the massive data demand. Moreover, when the labeled data are highly resembled, overfitting can be caused by a deep generative method. Moreover, the consistency regularization method as an effective DSSL method achieves a good balance between accuracy and memory occupation. In [
46], the ladder network, the first attempt at consistency regularization, was used for indoor positioning using CSI, which is inspired by a deep denoising AutoEncoder. It predicts whether each input has noise, using denoising functions and the unsupervised denoising square to generate consistency loss, and aligns with the supervised learning loss to obtain more accurate user coordinates.
The advanced consistency regularization methods after the Ladder Network, such as the Model, Temporal Ensembling, and Mean Teacher, have been proposed to improve accuracy without requiring additional data by regulating the consistency loss between noisy inputs to reduce overfitting and enhance the generalization of neural networks. However, these methods have not been really well used yet, and how to efficiently apply them to the positioning field still remains outstanding.
4. Semi-Supervised Learning Based on Mean Teacher Model
The concept of consistency regularization is that even if the input is perturbed, the network can still generate an output consistent with the output before perturbating and punishing inconsistent items. Specifically, consistency is based on the comparison of output space distributions, which is referred to as an approximate result or an output vector with a small distance from distribution. Consistency regularization is mainly applied to the teacher–student structure, with a consistency constraint defined as:
where
is the student’s prediction of input
,
is the teacher’s prediction of input
.
is the distance function between two vectors. Different consistency regularization methods differ in the way they generate consistency constraints. For example, the
Model [
15] generates consistency a constraintbetween two predictions of the same model by adding different noises to inputs, and the Temporal Ensembling [
15] generates constraint between the training prediction of the current epoch and EMA prediction from the last epoch. As for the Mean Teacher, it averages model weights instead of predictions. Specifically, the teacher model uses the EMA weights of the student model and then generates a constraint between the teacher model’s prediction and the student model’s prediction. The consistency constraint of the Mean Teacher can be defined as
where
,
represent different perturbations for input.
There are several techniques to improve the performance of the consistency regularization method. One strategy is to carefully select input perturbations instead of adding additive or multiplicative noises. Another one is to carefully consider the teacher model instead of copying the student model [
16].
4.1. AMT for Indoor Positioning
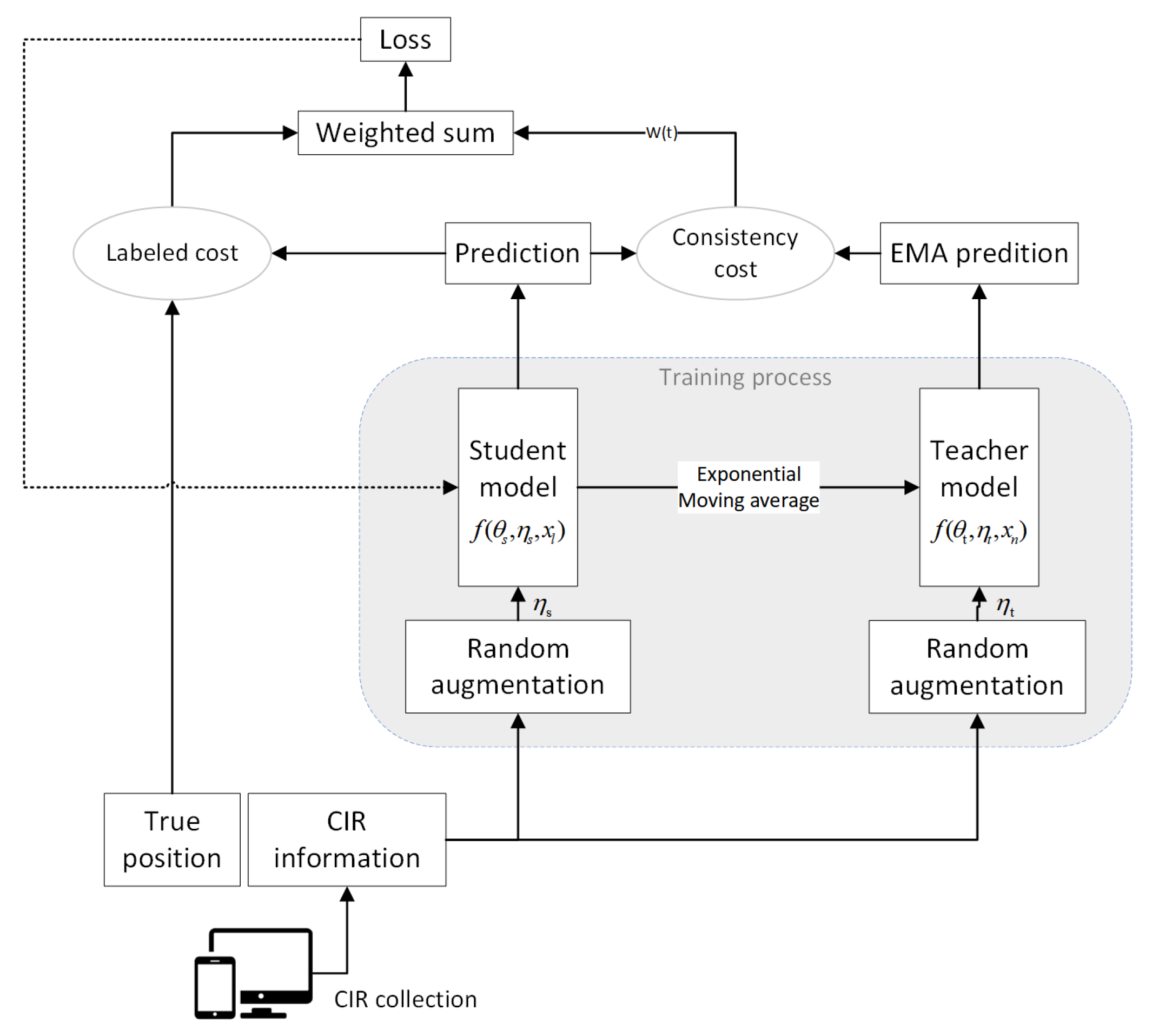
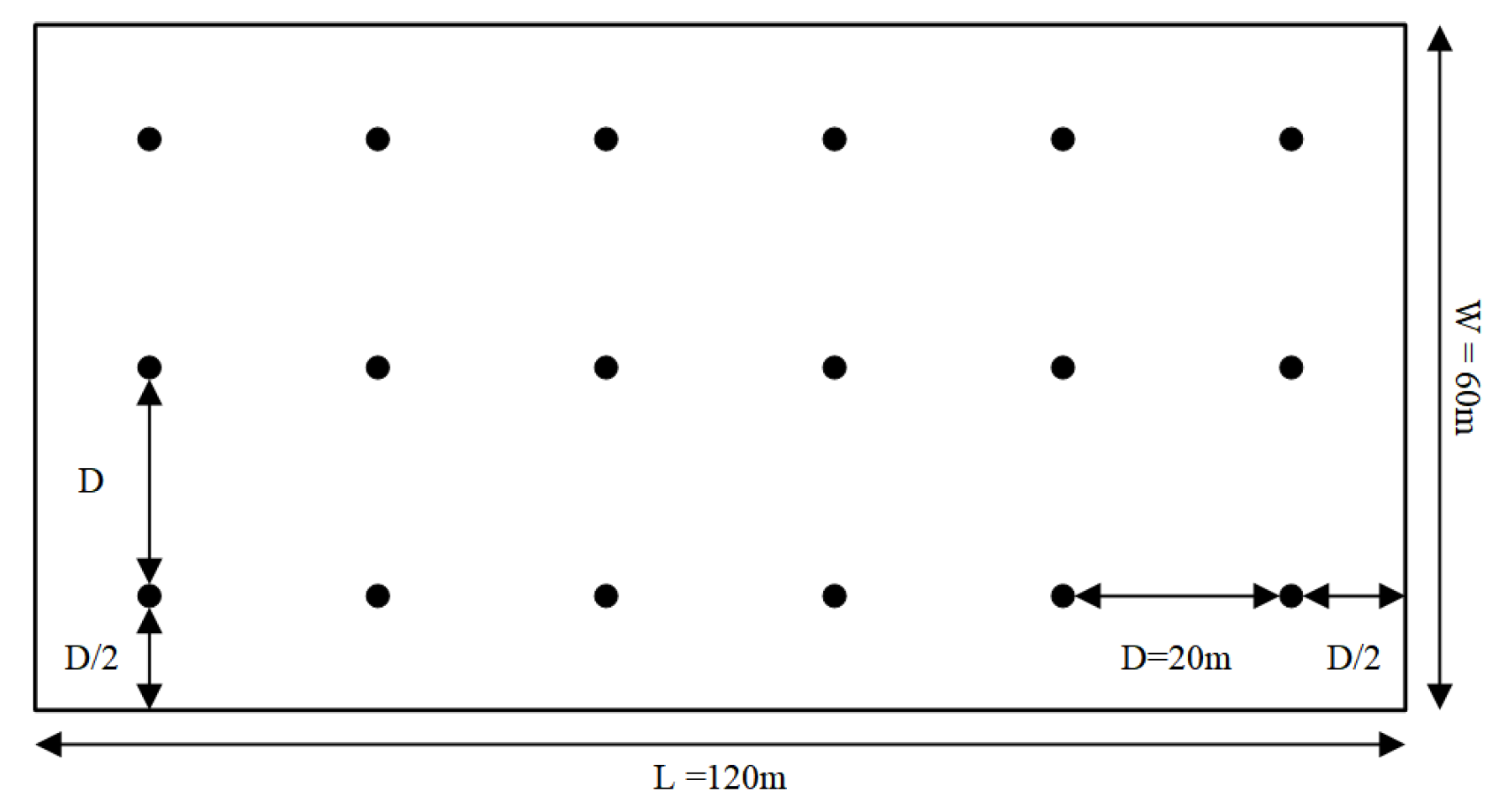
The AMT ensembles the teacher and student model, aiming to train a better teacher model from the student model without additional training. In this paper, the teacher and student models use the same network structure, which can be considered as a self-ensemble method. The framework of the proposed AMT is shown in
Figure 2.
The labeled data are denoted as
, where
L represents the total number of labeled samples. The unlabeled data are expressed as
, where
U represents the total number of unlabeled samples. The total dataset is presented as
, and
. The random signal perturbations (data augmentation) for the teacher and student models are denoted as
and
, respectively, and the weights of the two neural networks are denoted as
and
, respectively. Then, the predictions of the teacher and student models are expressed as
and
, respectively, where they use the identical input
x with a fixed proportion of labeled and unlabeled data, and both teacher and student models use the same network structure
. We first input two CIR data streams, and use different random augmentations for each stream, and then predict UEs’ position using the two models. During training steps, the two models interact, with the teacher model
using the EMA weights of the student model. In more detail, at the end of the
kth step, the weights of the teacher model
are updated using the EMA weights of the student model, and the weight update function of the teacher model is given by
where
represents the smoothing coefficient hyper-parameter.
Instead of regulating the consistency loss of the image classification task in the original Mean Teacher method, we measure the consistency of the users’ predicted coordinates. Therefore, we set the distance function
as the smooth L1 loss between the batch outputs of data streams instead of the cross-entropy loss. The advantage of using the smooth L1 loss is that the loss can be updated more smoothly, and it is the combination of the L1 and L2 loss with the benefits of both approaches. The specific formula can be expressed as
Using the distance Function (9), we define the loss function for the student model, updating in a minibatch as the weighted sum of the labeled loss of the student model and the consistency loss, which is namely the distance between student and teacher model’s prediction. The loss function is
where
represents the current training epoch,
is a coefficient that represents the maximum ramp-up length,
linearly increases from 0 to 1, and
is the unsupervised weight ramp-up function that controls the weight of the unsupervised loss, which increases linearly to 1 over a certain number of epochs. The mild increase in training is important to assist the model in adapting to the increased training interference caused by the unlabeled data and prevent any degradation in performance. In this paper, we use a Gaussian ramp-up function with
. Additionally,
is the constant that controls the maximum loss for unsupervised training and is calculated as
, where
is a coefficient that represents a maximum weight value for unsupervised training.
At each training step, the student model learns from the teacher model by minimizing the . Through this approach, we can achieve consistency in regularization.
4.2. Data Augmentation
To help models learn abstract patterns in data without being affected by minor changes, the concept of implicit data augmentation has been proposed. The model should tend to provide consistent output for similar data points. In classification tasks, the consistent output refers to the same classification, while in regression tasks, consistent output refers to output vectors that are close in distance. To achieve this goal, minor changes are typically implemented by adding noise or data perturbation. Many regularization techniques rely on this concept, such as the dropout used in neural network models.
In image classification tasks, consistency regularization methods often add random noise to the data in the data augmentation process. Some techniques, such as flipping, resizing, and random cropping can be used to increase the variety of images. The original Mean Teacher method used random translations and horizontal flips as part of its data augmentation strategy [
16]. The rationale behind these approaches is that the model’s softmax output usually cannot provide accurate predictions beyond the training data. To alleviate this problem, noise can be added to the model during the inference time to generate more accurate predictions. This method is used in the Pseudo-Ensemble Agreement [
48] and has demonstrated excellent performance. Thus, a teacher model injected with noise can be inferred to generate more precise targets than that not injected with noise. Therefore, implicit data augmentation, namely data perturbation, aims to provide accurate predictions by generating new predictions beyond labeled data and adding randomness to prevent overfitting.
4.2.1. Implicit Data Augmentation for CIR
General positioning methods map geometric information to user positions using measurement quantities such as power, time, and angle, then estimate user position through geometric estimation methods. Power, time, and angle features are common physical measurements, each with varying accessibility, complexity, and accuracy. As shown in the estimation of Formulas (2) and (3) for CIR, the three types of information can be well reflected in CIR. Therefore, we infer that power, time, and angle should be extracted as the main useful positioning features as AI positioning methods for using CIR. However, precise angle-based positioning typically relies on the angle difference between multiple antennas on the same device in MIMO communication. In our settings, the number of sampled antennas is insufficient, so we will mainly focus on the power and time of arrival features in AI positioning for using CIR. Inspired by the concept of data augmentation in image classification, we perturb CIR input by adding random noise to critical positioning features, namely the power and time of arrival.
4.2.2. Random Amplitude Scaling
As RSS-based fingerprint positioning systems are commonly used, their fundamental limitation is their inability to capture multipath effects [
9]. To fully characterize each path, the wireless communication propagation channel is modeled as a time-linear filter called CIR. CIR is similar to the RSS sequence, but it has a finer frequency resolution and equally higher time resolution to distinguish multipath components. Therefore, we can reasonably infer that CIR has a high power feature for effective positioning, and augmentation can be effectively performed by perturbing the power characteristics of CIR.
The received power measured at a fixed frequency is proportional to the amplitude of the channel frequency response (CFR) [
9]. Similarly, in CIR, we infer that the amplitude information is highly relevant to the received power, and different amplitude represents different LOS/NLOS environment distributions. Thus, we propose a random amplitude scaling in training steps to perturb partial LOS/NLOS distribution in the indoor environment, aiming to provide accurate predictions outside the training data. The amplitude of the CIR received by antenna
u of UE
n from transmitter antenna
s can be expressed as:
The scaling size is represented as a positive random number , where , with a being the maximum scaling size. Then, the random scaling amplitude can be expressed as . Note that the same scaling on the time series of CIR should be performed to ensure that the shape of the amplitude remains unchanged and to avoid destroying effective positioning features.
4.2.3. Random Temporal Shifting
The time feature is a conventional positioning physical measurement. It can obtain a highly accurate position under LOS conditions. In the positioning situations, there are two conventional time-of-arrival estimation techniques based on CIR; one method is to convert CFR to CIR through the inverse Fourier transform and select the index time of the first peak as the estimated time of arrival. A series of super-resolution techniques are used for estimation; the most commonly used technique is MUSIC algorithm [
49]. The other method is based on cross-correlation techniques such as matched filtering [
50]. Therefore, we believe that adding perturbations to the time characteristics can randomly shift the overall multipath information of CIR forward or backward, thereby perturbing the index of the first peak. Setting the random perturbation constant as
, where
, and for the UE
n, the continuous CIR information affected by a delay perturbation can be written as:
where * represents the convolution operation, and
is the translation coefficient with a maximum translation size of
b.
5. Convolutional Neural Network for Indoor Positioning
For CIR samples, the structure and dimension of the CIR input are similar to image input, so AI methods used for image processing are considered as our positioning schemes. The most commonly used neural network models for image processing are based on the CNN and self-attention mechanism. Although the concept of deep neural networks is stacking neural networks together, which is observed as a simple process, the performance of these networks can vary greatly due to different network architectures and choices of hyperparameters.
With regard to the models based on CNN, there are several mainstream network structures. AlexNet [
51] introduced the concept of deep CNNs and addressed the vanishing gradient problem by utilizing the Rectified Linear Unit (ReLU) activation function while it employed a dropout regularization to prevent overfitting. GoogLeNet [
52] further advances the field with its inception module architecture, which allows for the simultaneous use of different-sized convolutional kernels and pooling layers, enabling the extraction of features at multiple scales. On the other hand, ResNet [
53] introduces the concept of residual learning. It addresses the degradation problem that arises when deep neural networks suffer from a diminishing performance with increasing depth. By employing skip connections, ResNet allows for the direct flow of input to the output layer, facilitating the learning of residual mappings.
The self-attention mechanism [
54] focuses on the correlation of vectors in input sequences, and it was first used for semantic comprehension. When applying the self-attention to image processing tasks, images are divided into small parts and input as sequences. The most typically used model is the Vision Transformer (ViT) [
55]. ViT is an effective tool for handling large images and complex visual scenes. This model can also enhance its performance through pre-training.
To effectively extract features for positioning, we consider a ResNet structure as the basic model for AMT. It is applied in both student and teacher models. The ResNet has several advantages, including its extremely deep network structure, which enhances the network’s ability for feature extraction. Additionally, it introduces the residual blocks, which prevent network degradation, gradient vanishing, or gradient explosion in deeper networks.
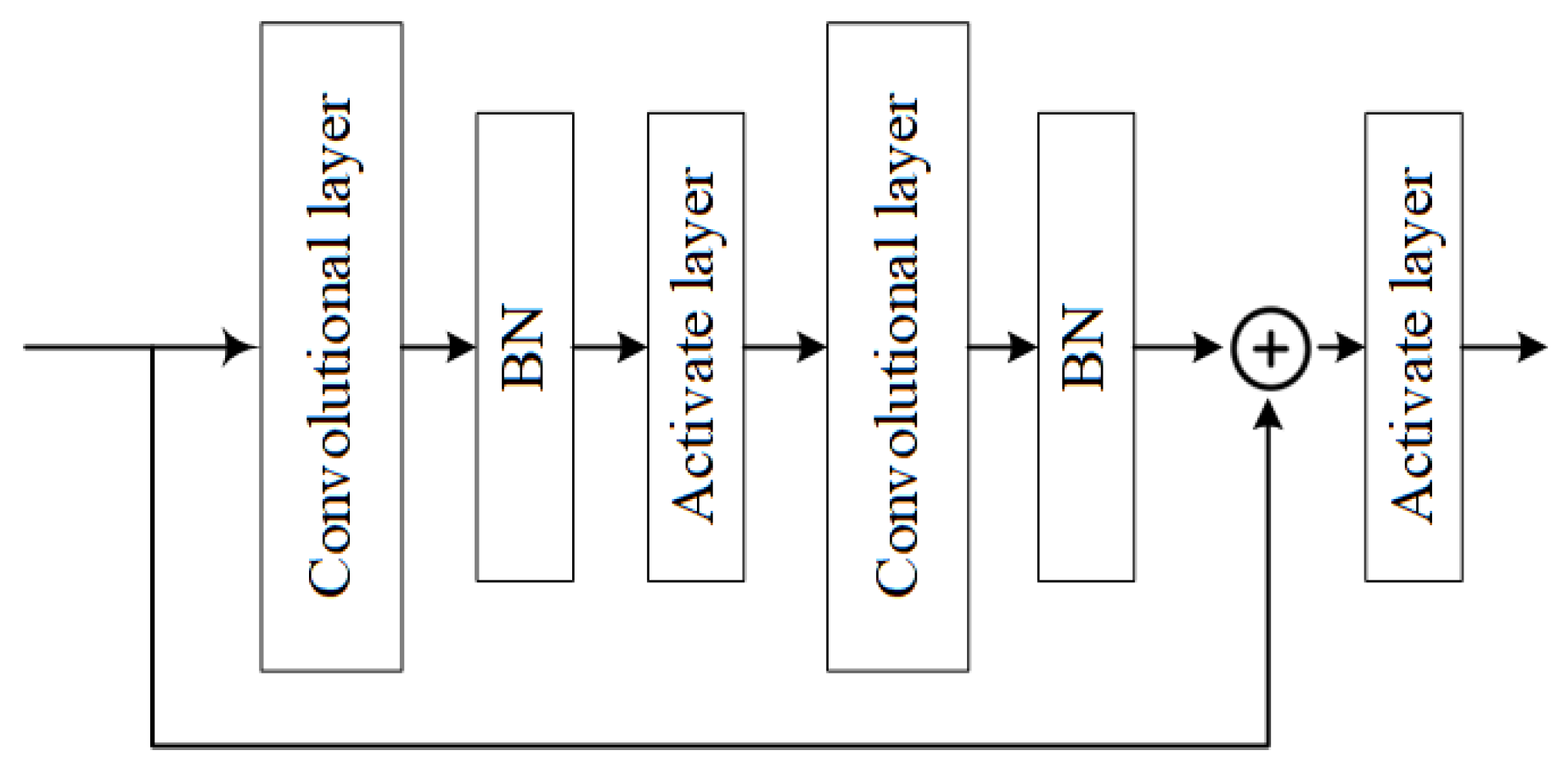
5.1. Residual Network
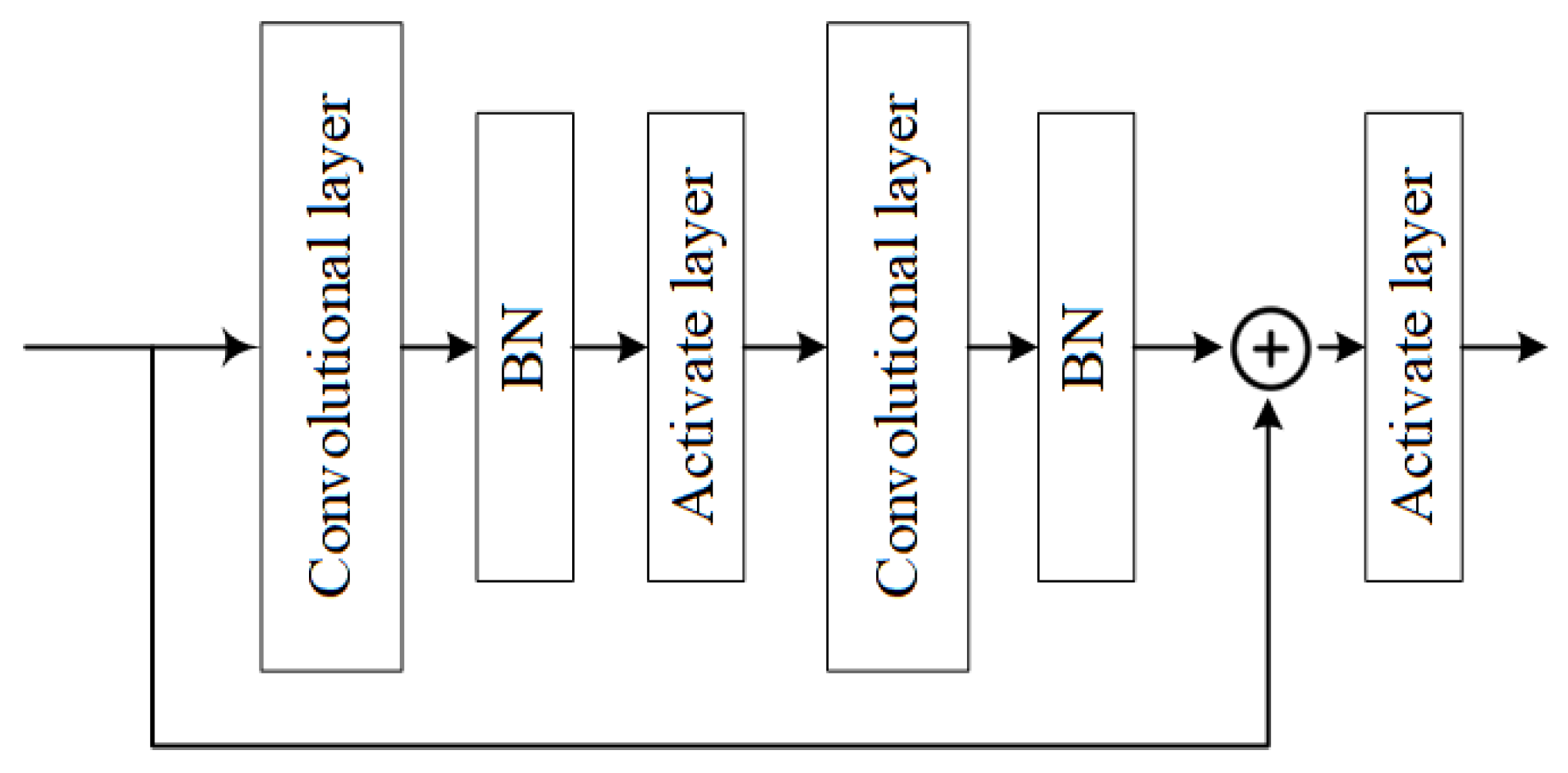
ResNet features two main types of residual blocks: the basic block and the bottleneck block. The basic block consists of two 3 × 3 convolutional layers and a residual connection with a stride of 1, while the bottleneck block includes a 1 × 1 convolutional layer, a 3 × 3 convolutional layer, another 1 × 1 convolutional layer, and a residual connection. The 1 × 1 convolutional layer in the bottleneck block is primarily used to decrease the dimension of the feature map, thereby reducing the computation and parameter count.
In this paper, we consider a basic block of residual blocks. The structure of residual blocks is shown in
Figure 3. The core of ResNet’s residual blocks lies in its residual connection, which adds the output of the previous layer to the current layer’s output, enabling the current layer to incorporate information from the previous layer. This design effectively alleviates the problem of gradients vanishing, making the model easier to train and optimize.
The ResNet consists of residual blocks that are based on the convolutional layer. For the purpose of accelerating the model convergence speed and improving model performance, we added BN and activation function layers between convolutional layers in the residual structure of ResNet. The Batch Normalization (BN) layer normalizes the input of each layer in a deep neural network for each batch, which stabilizes the input distribution of each layer and accelerates model convergence speed. Assuming the input after augmentation is
x, for a layer with multiple input dimensions, the BN operation [
56] for each dimension can be expressed as:
where
and
present the expectation and variance of the input mini-batch respectively, and
is a small coefficient to prevent the denominator from being zero, which approximates to 0.
Alternatively, the activation function layer, ReLU function, is used in the structure due to its simplicity and non-linearity. This function is added after the BN operation to effectively mitigate the gradient vanishing problem and enhances the model’s performance. The activation function can be mathematically presented as
5.2. CNN-Based Regression Positioning Method
In the previous research about classification-based fingerprint positioning, the area was divided into small grids, and the fingerprints were mapped to the reference point (RP) in the grid [
57,
58]; however, this approach is not suitable for large areas because of the extensive number of classes it needs to be divided into, and this will greatly increase the model complexity in deep learning-based fingerprint positioning. Meanwhile, a straightforward classification method of fingerprint positioning first defines RPs by collecting features at different points and then finding the similarity between the target feature and different RPs. This heavily depends on the number and density of RPs because of the limited training space; it is hard to reach sub-meter level accuracy in large areas. In contrast, the regression method can overcome the discontinuity of RPs and has the potential to reach higher accuracy, while it is also insensitive to the size of areas. From these concerns, we use the regression method rather than the classification.
7. Conclusions
In this paper, we proposed an effective DSSL framework for InF-DH scenarios named AMT, which solves the problem of inaccurate positioning caused by inadequately labeled samples for fingerprint positioning. In the DSSL framework, we operate AMT by assigning the EMA weights of the student model to the teacher model and regularizing the consistency loss of two models. Additionally, we have also proposed novel implicit random augmentation methods in terms of amplitude and temporal features of CIR data in AMT to enhance the performance of neural networks. By adding random perturbation to these critical positioning features in the training process, continuous new data can be generated artificially from existing data.
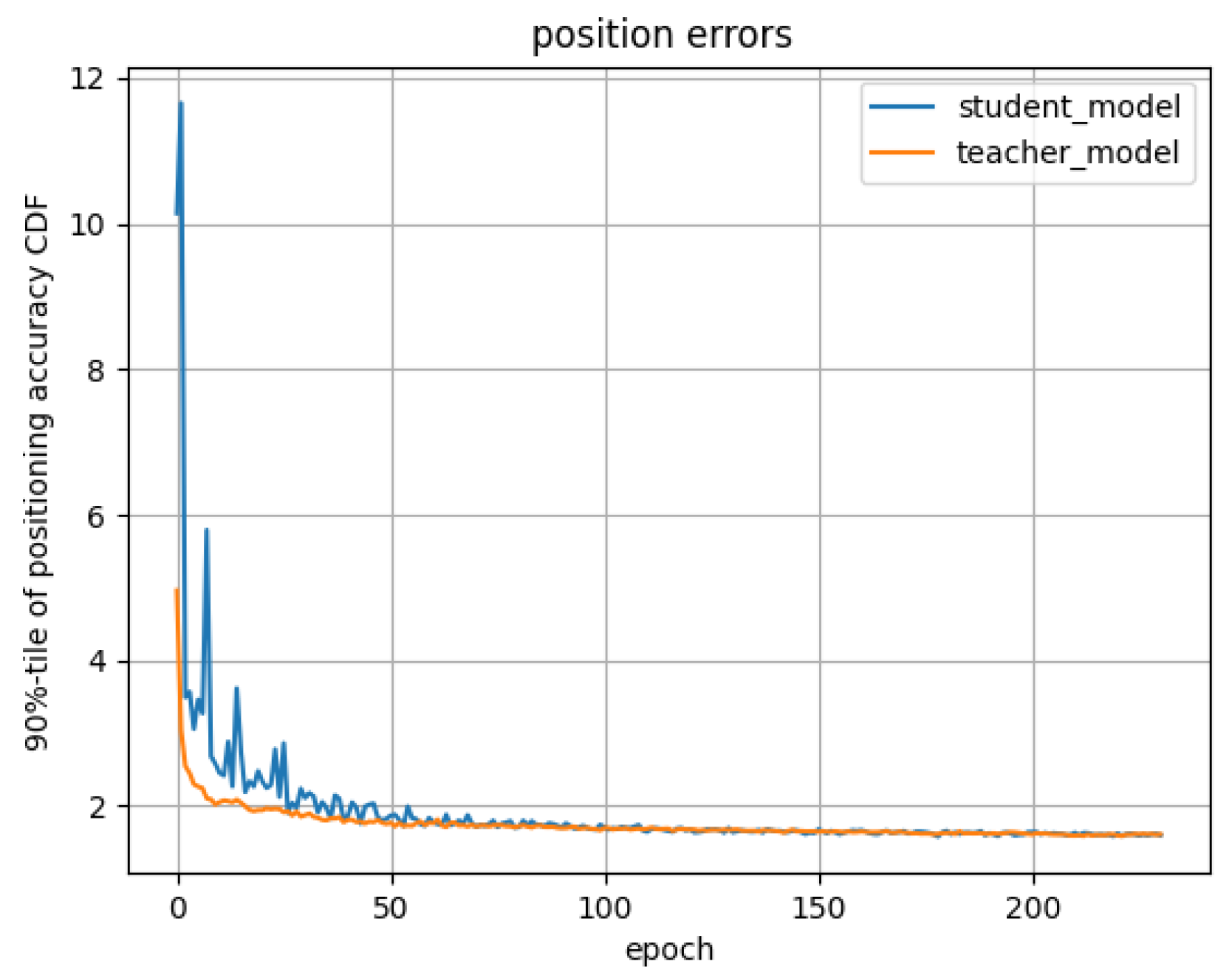
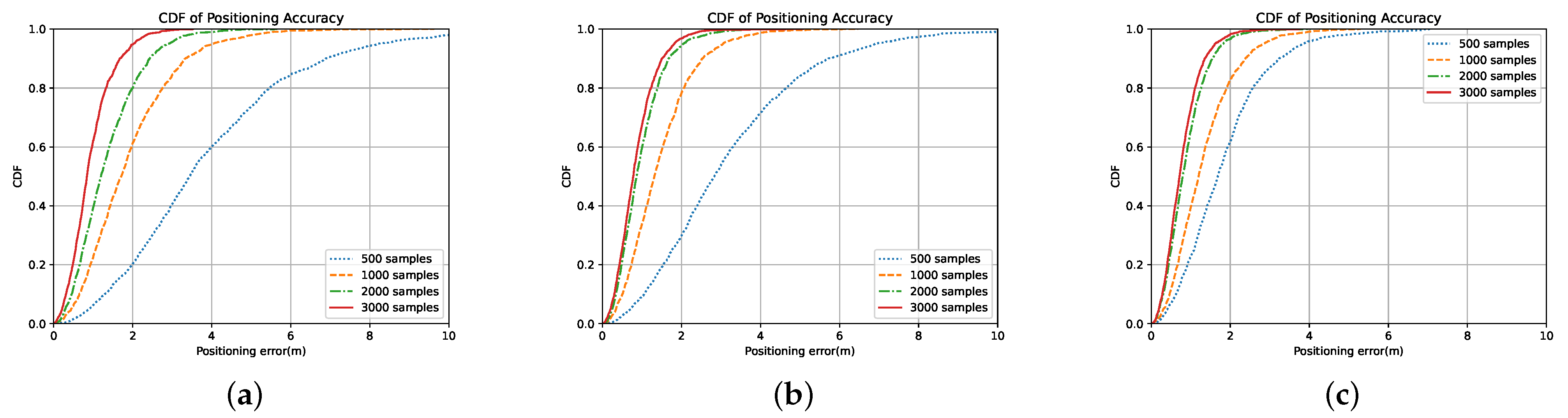
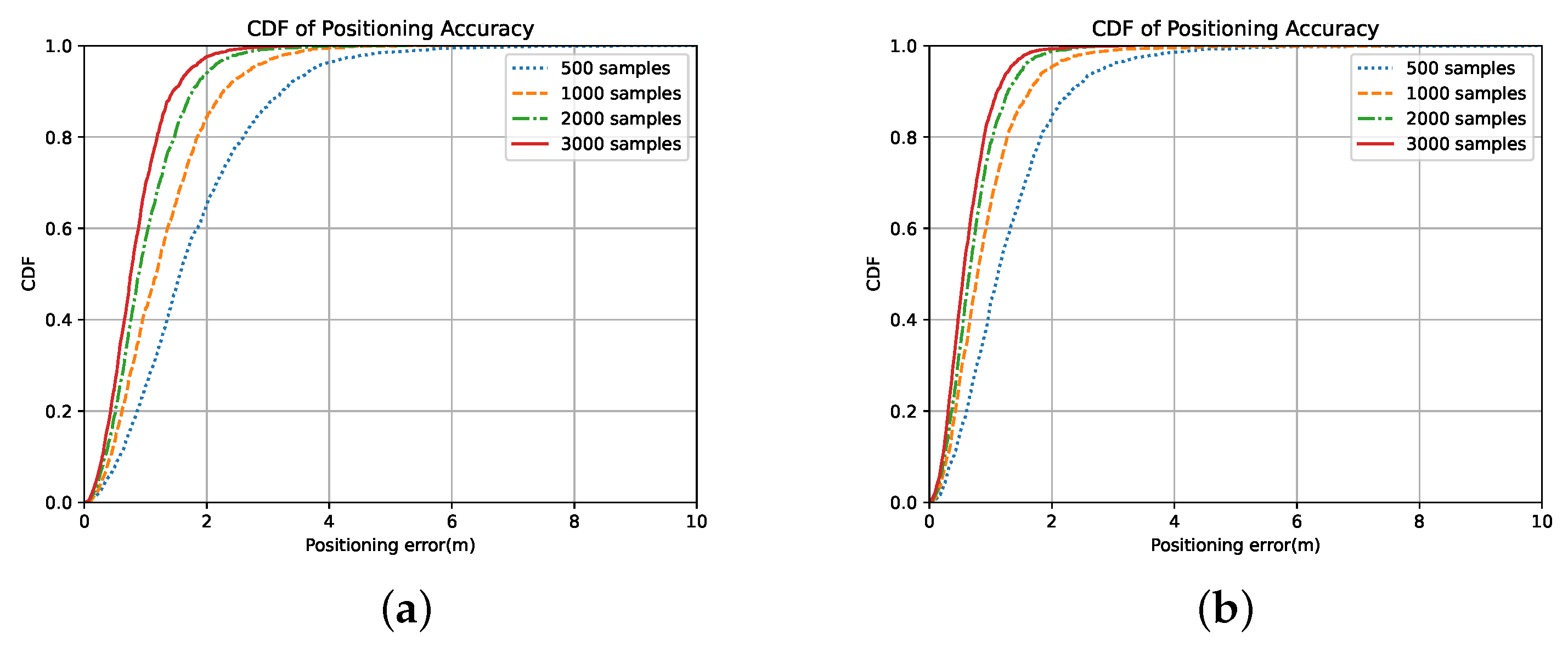
From conducting the simulation, we conclude that the deep-learning method has a superior performance compared with the estimation method in the heavy NLOS scenario, which can achieve a sub-meter level accuracy, and using CIR for deep learning-based positioning can achieve a higher positioning accuracy than using other measurements proposed in the 5G NR standard. By analyzing the performances of the DSSL methods, the numerical results show that using regularization in consistency loss improves the neural network’s ability to resist perturbation, which helps learn effective features in unlabeled data, especially in the case of small samples. Meanwhile, the interaction in model weights for consistency regularization methods improves the convergence of neural networks. Additionally, results also show the robustness of AMT by using different numbers of labeled data, and its performance gain in the smaller samples is more obvious.
By using AMT, we find the inherent similarity between image processing and indoor positioning, and we also verify the effectiveness of image processing methods when applying them to the positioning field. However, the work does not involve using the angle feature for positioning because of the single receiving antenna set in the dataset. Since multiple receiving antennas can bring more channel information for positioning, we plan to explore the generalization of our proposed method in multiple-receiver situations in future studies.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}