Abstract
Online detection devices, powered by artificial intelligence technologies, enable the comprehensive and continuous detection of high-speed railways (HSRs). However, the computation-intensive and latency-sensitive nature of these detection tasks often exceeds local processing capabilities. Mobile Edge Computing (MEC) emerges as a key solution in the railway Internet of Things (IoT) scenario to address these challenges. Nevertheless, the rapidly varying channel conditions in HSR scenarios pose significant challenges for efficient resource allocation. In this paper, a computation offloading system model for detection tasks in the railway IoT scenario is proposed. This system includes direct and relay transmission models, incorporating Non-Orthogonal Multiple Access (NOMA) technology. This paper focuses on the offloading strategy for subcarrier assignment, mode selection, relay power allocation, and computing resource management within this system to minimize the average delay ratio (the ratio of delay to the maximum tolerable delay). However, this optimization problem is a complex Mixed-Integer Non-Linear Programming (MINLP) problem. To address this, we present a low-complexity subcarrier allocation algorithm to reduce the dimensionality of decision-making actions. Furthermore, we propose an improved Deep Deterministic Policy Gradient (DDPG) algorithm that represents discrete variables using selection probabilities to handle the hybrid action space problem. Our results indicate that the proposed system model adapts well to the offloading issues of detection tasks in HSR scenarios, and the improved DDPG algorithm efficiently identifies optimal computation offloading strategies.
1. Introduction
1.1. Background
With the rapid development of communication and artificial intelligence technologies, new horizons for development in the field of rail transit operation and maintenance have emerged. Particularly for high-speed railways (HSRs), due to the fast velocities of high-speed trains, the high safety standards required, the complexity of the operational environment, the substantial passenger load, and the prolonged duration of high-speed travel, there is a significant safety risk [1] associated with the detection of high-speed rail vehicles. The detection process for high-speed trains still relies heavily on manual efforts, with routine checks constituting the bulk of maintenance activities, leading to high safety risks, elevated maintenance costs, and low efficiency. The deployment of online detection devices, big data analytics [2], and machine vision-based non-contact non-destructive testing techniques [3] could allow for the synchronous and continuous detection of the condition of rail transit vehicles and the status of railway lines without stopping, without sacrificing accuracy and comprehensiveness. However, these detection tasks are typically computation-intensive and latency-sensitive. Equipping each detection device with extensive computing power is clearly a high-cost and wasteful approach.
A railway Internet of Things (IoT) [4] system with integrated sensing, storage, and computing, based on mobile edge computing (MEC) [5], can effectively address this issue. Such an integrated system embeds certain edge computing nodes that provide the necessary computing power and memory capacity for detection tasks. Thus, by utilizing MEC, these detection tasks can be offloaded to edge servers for processing. This approach can offer low-latency computational services and life-cycle-long management [6] for detection tasks.
Although some progress has been made in the research on the allocation of communication and computing resources in MEC based on optimization methods [7,8] within traditional IoT environments, the channel conditions in railway scenarios are rapidly time-varying, particularly for HSR. Moreover, given the massive number of detection devices along the entire railway, the computing power and memory capacity [9] of edge servers may not always be sufficient to immediately serve every task. In short, in dynamic and resource-constrained environments, system and environmental parameters are constantly changing. Thus, finding an optimal allocation strategy for communication, computing, and memory resources for detection tasks quickly and effectively is challenging.
1.2. Related Work and Contribution
Numerous noteworthy studies have concentrated on investigating the issues of computation offloading and resource management within the domain of MEC. Optimization-based methods are the primary solutions for addressing this problem. Zhao et al. [10] aimed to minimize the system’s maximum delay by optimizing user beamforming vectors, BS beamforming matrices, and MEC server resource allocation while adhering to communication and computing budget constraints. Xu et al. [8] proposed a novel approach to optimize network throughput in HSR scenarios by admitting as many tasks as possible under delay constraints and multicasting the maximum number of computation results, considering the high mobility of trains and frequent handovers. They introduced a multi-group-shared Group Steiner tree model and an efficient heuristic algorithm to address the multicast routing problem, enhancing the quality of data services for passengers during long journeys. Deep Reinforcement Learning (DRL) is being increasingly applied in resource allocation problems. Jiang et al. [11] investigated the optimization of task execution, focusing on offloading decisions and resource assignments in MEC environments to reduce task latency, and used Q-learning to solve the problem. Chen et al. [12] explored energy efficiency in AR task offloading and resource allocation in single and multiple MEC system environments and proposed a multiagent deep reinforcement learning model for dynamic communication environments. Ale et al. [13] tackled the challenge of task offloading in environments with multiple IoT devices and edge servers, formulating the problem as a Markov decision process (MDP) and introducing a DRL algorithm for hybrid action spaces that involve both task partitioning and computational power allocation. Deng et al. [14] developed an autonomous system for the partial offloading of delay-sensitive tasks in multiuser IIoT MEC systems, employing the Deep Deterministic Policy Gradient (DDPG) to facilitate continuous offloading decisions and optimize system performance.
While research has explored computation offloading and resource allocation in MEC from diverse optimization perspectives, the majority of these research studies focus on quasi-static system settings and do not take into account the requirements for multiple resources by dynamic systems with time-varying conditions in high-speed contexts. In the dynamic sector of MEC for railway IoT, Xu et al. [5] crafted a hybrid DRL approach that synergizes a Double Deep Q-Network (DDQN) and DDPG to minimize computational costs by fine-tuning subcarrier assignment, offloading ratios, and resource distributions. Addressing HSR, Li et al. [15] developed a joint resource allocation and computation offloading scheme based on millimeter waves and matched game theory to curtail latency and bolster user capacity. To maximize throughput, Xu et al. [8] addressed the issue of maximizing network throughput in HSR scenarios by proposing an efficient heuristic algorithm for multicasting computation results in an MEC network. The approach considered the dynamic nature of HSRs, optimizing multicast tree construction and task admission under delay constraints to enhance data services for passengers. Lastly, Tian et al. [16] introduced a blockchain-enhanced, multi-hop transmission framework for MEC in smart rail systems, applying DRL to refine offloading paths and strategies for improved system performance.
With the development of communication technology, many technologies have become increasingly mature and applied in practice, such as millimeter wave and multiple-input multiple-output technologies [17]. The introduction of these technologies has also brought more possibilities to MEC. In particular, the Non-Orthogonal Multiple Access (NOMA) technology has brought about significant performance enhancements. Xu et al. [18] tackled the complex joint task offloading and resource allocation in NOMA-based HetNets for MEC, proposing an iterative solution to the combinatorial problem. Du et al. [19] studied cost-effective offloading in NOMA-enabled vehicular networks, developing a Vehicle Edge Computing (VEC) network model to address the cost minimization challenge through heuristic algorithms and deriving closed-form solutions for cloud-based optimizations. Du et al. [20] introduced a NOMA-assisted ultra-dense edge computing model optimized by DDPG to enhance spectrum utilization and reduce task execution delay and energy consumption in healthcare IoT, outperforming local computation and traditional offloading methods.
Although some of the aforementioned papers have applied MEC to railway scenarios, the impact of high-speed movement on communication is often overlooked. Moreover, detection devices may be deployed on trains or alongside tracks, adding uncertainty and complexity to the computation offloading problem. However, summarizing these issues and considering the specific environment of high-speed railway IoT for train vehicle and track detection, we propose a computation offloading strategy for detection tasks in railway IoT with integrated sensing, storage, and computing. In this paper, we consider the interference caused by high-speed movement. Our system supports two communication modes, direct communication and relay communication, to accommodate the uncertainty in device deployment. Additionally, the differences in device and relay transmission power open up possibilities for the introduction of NOMA technology. We incorporate NOMA technology on top of Orthogonal Frequency Division Multiplexing (OFDM) to enhance channel utilization. By selecting appropriate edge servers, we also mitigate data congestion on each server. Building upon the aforementioned system model, we adopt an improved DDPG algorithm in conjunction with a low-complexity channel allocation algorithm to optimize the configuration of communication and computational resources. This study has threefold specific contributions, as follows:
- To better accommodate detection devices deployed in different locations and environments in various types of railways, we proposed two transmission models, namely the direct transmission model and the relay transmission model. Furthermore, in the OFDM system, we introduced NOMA technology to increase channel capacity.
- Taking into account the limitation of computing resources and memory capacity, we allocated computing resources through server selection, combined with the order of arrival, while also ensuring that the task queue pending for each server does not exceed its memory capacity.
- We proposed an improved DDPG algorithm combined with a low-complexity subcarrier allocation algorithm to solve the optimization problem of communication and computing resource allocation.
The organization of the rest of this paper is as follows. Section 2 describes the model of the MEC system in a railway IoT system for detection tasks and optimization problem formulation. Section 3 proposes the subcarrier allocation algorithm and the improved DDPG algorithm. Section 4 presents and analyzes the simulation results. Section 5 concludes this paper.
2. System Model and Problem Formulation
In this section, we initially outline the network framework of MEC for detection tasks in the railway IoT with integrated sensing, storage, and computing. We then present two transmission models, the NOMA-based transmission model and the limited computing resource and memory capacity allocation model. Finally, we formulate an optimization problem to minimize the average delay ratio.
2.1. System Model
As shown in Figure 1, we consider an MEC system beside HSR to provide task offloading services for multiple detection devices. Within a certain range along the track, a Base Station (BS) is deployed beside the railway, forming a cell. Meanwhile, a communication relay is installed on the train. Near the BS, there is an MEC server installed. The MEC servers along the entire railway are interconnected via fiber optic links to form an edge computing network. To achieve multi-directional intelligent safety detection in HSR, detection devices incorporate onboard detection sensors and ground detection sensors. The detection devices in this system are equipped with the necessary capabilities for detection and communication but lack computing capacity. Thus, the various detection tasks need to be offloaded to MEC servers for processing. The detection devices have two transmission modes. One is direct transmission, in which the detection devices transmit the detection tasks directly to the BS. The other is relay transmission, in which the detection devices first send the tasks to the communication relay on the train, which then forwards them to the BS.
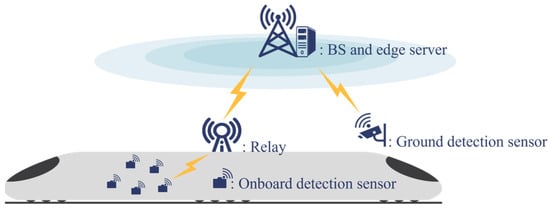
Figure 1.
MEC system for detection task in railway IoT.
We assume that, in a time slot, there are onboard devices and ground devices that have requests for task offloading. Therefore, a total of tasks need to be offloaded to the MEC, denoted by , where , represents the task from the onboard devices and represents the task from the ground devices. In a time slot, the task, , is represented by a quadruple , where is the data size of the task in bits, is the computation workload of the task in cycles/bit, is the maximum allowable delay for the task, and is the loaded data size for the task, including the data size of the neural network model to be loaded and the intermediate data generated during the calculation [21,22].
2.2. Direct Transmission Model
The detection devices directly transmit the tasks to the BS of the cell where the train is located, which is referred to as sensor-to-BS (S2B) data transmission. We assume that the transmission power of each detection device can be monitored before making decisions, and there will not be significant differences among the devices. This implies that the channel gain differences among different tasks during direct communication will not be too large. Thus, we adopt OFDM technology for the communication between ground devices and the BSs. Interference between subcarriers is negligible. At the same time, in the HSR environments, since the distance between trains exceeds 50 km, the interference between cells can be considered negligible.
However, for the detection tasks of onboard devices, namely , due to the high mobility of trains in the HSR environments, the transmitted signal will inevitably experience a Doppler shift, which leads to inter-channel interference (ICI) [23]. This interference can be considered a form of noise. Thus, the received Signal-to-Interference-plus-Noise Ratio (SINR) [24] of the detection task created by the onboard device can be expressed as:
where is the noise power, is the transmission power of the device, is the channel gain between the device and the BS, and is the ICI factor due to the Doppler effect [24], which is given by:
where and represent the velocity of the train and the speed of light, respectively. is the signal symbol duration. is the zero-order Bessel function of the first kind.
However, for the ground detection devices, namely , which are fixed as is the BS, there is no other interference. The received SINR of the task created by the ground device can be expressed as:
Assuming there are subcarriers in this OFDM system, denotes the variable of subcarrier allocated, where . When is 1, the task is offloaded to the BS via the subcarrier. Otherwise, is 0. Thus, the transmission rate for the task can be expressed as:
where is the subcarrier bandwidth.
2.3. Relay Transmission Model
In addition to direct transmission, the detection devices can also choose the relay transmission model. This is divided into two phases. First, the device transmits the task to the relay located in the middle of the train, namely the sensor-to-relay (S2R) phase. Then, it is forwarded from the relay to the BS, which is the relay-to-BS (R2B) phase. To enhance spectrum utilization, we adopt Co-time Co-frequency Full Duplex (CCFD) [25]. This technology allows a relay to transmit and receive data simultaneously on the same channel. However, the received and transmitted signals on the same subcarrier will inevitably interfere with each other.
When the task is in the S2R phase, the onboard devices and the relay are relatively stationary, whereas the channel between the ground devices and the relay rapidly changes due to the Doppler effect. Thus, the S2R phase is the opposite of the direct communication model. The interference received by ground tasks needs to include ICI, while the onboard tasks do not require it. Furthermore, the signal received by the relay will be interfered with by the transmitted signal, and existing self-interference (SI) cancellation technologies can already eliminate the interference from the transmitted signal to a great extent.
Thus, during the S2R phase, the received SINR [26] of the onboard device connected can be expressed as:
where is the channel gain between the onboard device and the relay, , and denotes the SI cancelation level [26].
However, at this time, the received SINR of the ground device connected can be expressed as:
where .
Thus, during the S2R phase, the transmission rate of the task can be expressed as:
When the task is in the R2B phase, the relay moves at high speed relative to the BS, which can result in ICI caused by the Doppler effect. Thus, the SINR during the R2B phase can be expressed as:
where is the transmission power allocated to the task and is the channel gain between the relay and the BS. During the R2B phase, the transmission rate of the task can be expressed as:
Since different subcarriers are allocated for the S2R and R2B transmission phases in the OFDM system, the relay can achieve full-duplex communication, which means it can receive and transmit at the same time. Thus, the transmission rate of the relay transmission model is determined by the slower phase and can be represented as:
2.4. NOMA-Based Transmission Model
When a task adopts the relay transmission model, the transmission power allocated by the relay often exceeds the transmission power of the device itself. Moreover, within a time slot, since the starting points of the tasks are all within the length range of the train and the transmission between the relay and the BS is often line-of-sight (LOS), the channel gain between the relay and the BS is always greater than that between the sensing device and the BS. As a result, the signal strength of the signal transmitted via the relay is higher than that of the signal from direct communication. Therefore, the NOMA-based transmission model [27] is viable. In this model, NOMA subcarriers can superimpose a group of signals with varying signal strengths. Signals in this group will interfere with one another. Successive Interference Cancellation (SIC) [28] technology can separate the signals in a group. SIC technology initially decodes the signal with the higher signal strength by treating the lower signal strength signal as interference. Then, it subtracts the decoded signal with high signal strength from the original signal. As a result, the remaining signal will be free of any additional interference.
After the relay transmission uses NOMA technology, the tasks uploaded in the R2B phase are considered signals with high signal strength. Thus, the interference they encounter needs to include the signal strength of the co-subcarrier signals. The transmission rate of the task using NOMA can be expressed as:
where is the signal strength of the co-subcarrier signals. denotes the variable that indicates whether a subcarrier is allocated to the R2B-NOMA channel. It should be noted that the subcarriers allocated to the R2B-NOMA channel can overlap with any subcarriers allocated to direct transmission channels. However, these subcarriers must not overlap with those allocated to the relay transmission channel because their signal strengths are similar.
NOMA technology can increase the relay’s transmission rate on top of the existing OFDM system without altering the other two channels. Therefore, the total transmission rate when tasks choose the relay transmission model can be expressed as:
2.5. Transmission Delay
For tasks using the direct transmission model, the transmission delay can be expressed as:
For tasks using the relay transmission model, the transmission delay can be expressed as:
For the task, which can choose either of the two transmission models, the transmission delay can be expressed as:
where is the model selection variable. When is 1, the task will use the direct transmission model. When is 0, the task will use the relay transmission model.
2.6. Computing Delay
We assume that the MEC servers communicate with each other via fiber optics, which allows us to neglect the delay. This means that a task can be processed by any server. However, considering the large volume of tasks generated by multiple trains within the entire railway range, deploying multiple servers near every base station along the entire railway is very expensive and wasteful. Thus, we consider the scenario where there is a limited number of MEC servers, meaning that not all tasks uploaded can be processed immediately. It is presumed that each server is limited to processing a single task concurrently. Additionally, the tasks within a time slot significantly outnumber the servers available to handle them.
In this system, there are MEC servers available in a time slot, denoted by . We use a tuple to describe the performance of an MEC server, where denotes the computational capability of the server and denotes the memory capacity of the server. Let denotes the variable of server allocation, where . When is 1, the task is processed on the server. Otherwise, is 0. For the task processing order on the same server, we adopt the First-Come First-Served (FCFS) principle. The system can control the allocation of communication resources to allow tasks with the smaller maximum allowable delay to reach the server first, thereby prioritizing their processing. Let denote the arrival order of the task, where , , . indicates that the task is the to arrive. The matrix composed of is denoted as . The matrix composed of is denoted as . Let matrix be the result of the cross product of matrices , , , denoted as , where , denote that on the server, the task is the in the queue to be processed.
Thus, the total delay of the task can be expressed as:
where denotes the total delay from the start of a time slot to the completion of the task at the position in the queue on the server, denotes the computing delay that a server computing task costs, . Specifically, both and are equal to 0.
In addition, the maximum queue length of tasks being processed on the server can be expressed as:
where denotes the total length of tasks on the server after the task arrives and denotes the length of tasks that have been processed so far.
2.7. Problem Formulation
We aim to minimize the average delay ratio through the joint optimization of communication and computational resources. The delay ratio refers to the proportion of the actual delay to the maximum allowable delay. Thus, we take the computation offloading strategy as the decision variable, with communication, computation, and memory resources as constraints, aiming to minimize the average delay ratio as the optimization objective. The problem formulation can be expressed as follows:
where constraint C1 denotes that the total sum of transmit power allocated to tasks using the relay transmission model cannot exceed the relay’s maximum transmission power. Constraint C2 denotes that tasks using OFDM cannot share a subcarrier. Constraint C3 denotes that subcarriers allocated to the NOMA system cannot overlap with those allocated to the R2B channel. Constraint C4 denotes that a task can only be allocated to one server and must be allocated to a server. Constraint C5 denotes that the total delay of a task cannot exceed the maximum tolerable delay. Constraint C6 denotes that the queue of tasks being processed and awaiting processing on the server cannot exceed the memory capacity of the server.
3. DDPG-Based Resource Allocation Algorithm
3.1. Subcarrier Allocation Algorithm
The performance of NOMA systems is affected by the difference in signal strengths between relayed and direct communications. A larger disparity in signal strength can yield better performance gains. Conversely, a minimal difference in signal strength can result in poor system performance and may even preclude the separation of the two signals. Therefore, we propose a low-complexity subcarrier matching strategy. This algorithm aims to reduce the likelihood of a small intensity gap between two signals, preventing the assignment of a relay communication signal with a lower intensity to a subcarrier of a direct communication signal with a higher intensity, which would make it impossible to decode and separate the two. While this algorithm may not be optimal, it allows NOMA technology to be stably compatible with the entire system. Employing this approach, the complex issue of allocating subcarriers in high dimensions can be simplified by distributing quantities of subcarriers. The step-by-step procedure for this method is outlined in the pseudocode as Algorithm 1.
| Algorithm 1: Subcarrier Allocation Algorithm |
| Input: |
| Output: |
|
|
|
|
|
Thus, the optimization problem of Equation (18) can be transformed into the following form:
where constraint C2 denotes that the aggregate sum of subcarriers assigned to all tasks must not surpass the total quantity of subcarriers at disposal, and constraint C3 denotes that the sum of subcarriers allocated to the R2B-NOMA channel cannot surpass the sum of subcarriers allocated to tasks using direct transmission models. All other constraints remain unchanged.
3.2. MDP Model
Since the problems of relay power allocation and server selection are non-convex, securing the optimal solution through conventional optimization techniques proves to be challenging. Thus, an MDP is introduced to effectively learn policies in complex environments. The aforementioned optimization problem can be formulated as an MDP, denoted as , where components align with the state space, action space, state transition matrix, reward function, and discount factor of the problem, in that order.
Observation: in time slot , the state space includes the basic information of the detection task and the data transmission rates between the sensors and BS, as well as between the sensors and the relay. In time slot , the state space can be expressed as follows:
where is the data size in time slot , is the computation workload in time slot , is the maximum allowable delay in time slot , represents the data size of the neural network model to be loaded and the intermediate data generated in time slot , is the power of the devices, is the data transmission rates between the sensors and BS, and is the data transmission rates between the sensors and the relay.
Action: in time slot , the action space includes communication and computation resource allocation strategies. In time slot , the action space can be expressed as follows:
where is the selected model, is the number of subcarriers allocated to the tasks, is the number of subcarriers allocated to the R2B-NOMA channel, is the power allocated to the task by the relay, and is the server selection strategy.
Reward: the objective of the joint optimization problem of computation offloading and resource allocation is to minimize the average delay ratio. However, the aim of training with reinforcement learning is to optimize the total accumulated reward over time. Concurrently, tasks that surpass the threshold of the maximum allowable delay will trigger a predefined penalty. Thus, the reward for the task in time slot can be expressed as follows:
where is the absolute value of the penalty.
Thus, the total reward in time slot can be expressed as follows:
3.3. Improved Deep Deterministic Policy Gradient Algorithm
Given that the action space comprises both continuous and discrete variables, the DDPG algorithm demonstrates commendable performance in addressing continuous action control problems.
The DDPG algorithm merges the aspects of actor–critic algorithms with deep learning techniques to enable effective policy learning in high-dimensional, continuous action spaces. The core of DDPG lies in learning a deterministic policy, which specifies the action to be taken in each state, along with a Q-function that estimates the expected returns. The architecture of the DDPG algorithm is shown in Figure 2.
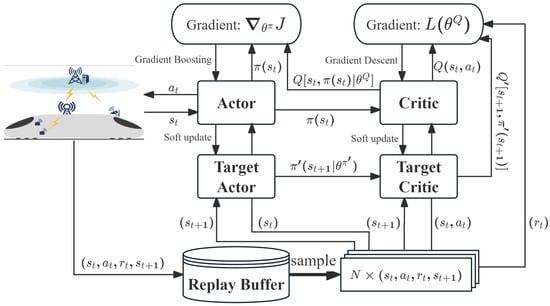
Figure 2.
The architecture of the DDPG algorithm.
The Q-function, which estimates the expected reward of taking an action in state , following a policy , is defined as , where are the parameters of the critic network. The expected return from the Q-function is computed as:
where the return is the sum of the immediate reward and the discounted future rewards, and is given by:
where is the discount factor that balances immediate and future rewards.
The objective of the critic network is to reduce the mean squared error, focusing on bringing the forecasted Q-values in line with the target Q-values as described by the following function:
where is the target value defined as:
where and represent the target critic and target actor networks, respectively.
The policy gradient for updating the actor network is derived from the critic network and is calculated using the sampled gradients of the Q-function with respect to the actions [14]:
Finally, the actor network is updated through gradient ascent using the policy gradient, adjusting the parameters in the direction that maximizes the Q-function:
where is the learning rate.
The pseudocode for the training process of the DDPG algorithm is presented in Algorithm 2.
| Algorithm 2: The Training Process of DDPG Algorithm |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
However, the DDPG algorithm does not perform well with certain discrete variables, especially those that represent the selection of indices. Therefore, we modified the architecture of the actor network, as shown in Figure 3. Actions and in the action space are exactly such discrete variables. Although for , which is a binary variable, the tanh function can effectively solve the binary classification problem. As for the variable , if the number of servers is more than two, this becomes a multi-class variable, and common activation functions struggle to address this issue. We process as follows:
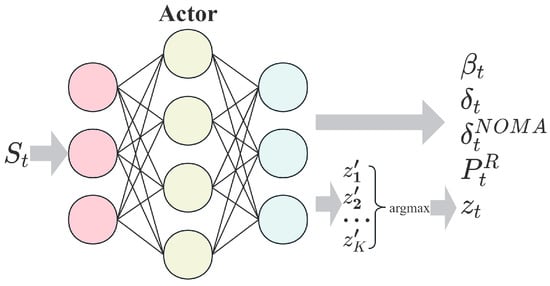
Figure 3.
The architecture of actor network.
We replace in the action space with , where is an matrix and represents the probability of choosing the server for the task. We select the server number with the highest probability as the choice strategy for the task, which can be expressed as .
The optimization problem represented by Equation (17) can be effectively addressed by improving the DDPG algorithm through the aforementioned approach for discrete variables, in conjunction with the channel allocation algorithm presented in Section 4.1.
4. Simulation Results and Discussion
In this section, we use simulation experiments to evaluate the system model proposed in Section 3 and the algorithm presented in Section 4. The simulation results are obtained using Python 3.7 and Tensorflow 2.11 on a machine powered by an Intel Core i5-13400F CPU with an NVIDIA GeForce RTX 4060Ti GPU.
4.1. Simulation Setting
In real-world train detection scenarios, the generation of detection tasks is cyclical and patterned. To demonstrate the effectiveness of the system model and algorithms, we set the task generation locations to be random yet confined within the length range of the train. This is because ground detection equipment only generates tasks when the train passes by. Furthermore, the parameters describing the tasks are also random. Specifically, the task data length follows a uniform distribution of [1, 4] Mbits, the computation workload follows a uniform distribution of [800, 1000] cycles/bit, the maximum allowable delay follows a uniform distribution of [1, 4] seconds, the loaded data size follows a uniform distribution of [15, 25] Mbits, and the power of the devices follows a uniform distribution of [0.1, 0.5] W [29]. For the entire railway system, the allocation of subcarrier numbers to each train, the number of available servers, and other parameter settings could be considered a queuing theory problem for optimization allocation. However, this is beyond the scope of this paper. Therefore, we assume that these parameters are pre-allocated and fixed. Specifically, the number of servers is set to 3, with computational capability of 7 GHz and maximum memory capacity of 128 Mbits. In addition, for the algorithm proposed in Section 4, the absolute value of the penalty is set to 5. Other determined parameters are provided in Table 1.

Table 1.
Simulation parameters.
We compare the proposed improved DDPG algorithms with standard DDPG as a benchmark algorithm, which was used in [31]. Then, we compare the system model proposed in Section 2 with three benchmark schemes as follows:
Full Direct Communication (FDC): As in the task offloading scheme for HSR described in [5], all detection tasks will be directly offloaded to the edge servers in this scheme.
Full Relay Communication (FRC): In this scheme, all detection tasks choose the relay communication model.
OFDM: In this scheme, no tasks will employ NOMA technology for transmission.
4.2. Result Analysis
In reinforcement learning algorithms, batch size is a critical hyperparameter. Smaller batch sizes can enhance generalization and facilitate the escape from local optima but may increase variance, affecting learning stability. Larger batch sizes provide more accurate gradient estimates, though they may lead to local optima and increased memory requirements. Figure 4 shows the influence of batch size on convergence. The calculation method of the reward is shown in Equation (23). The DDPG algorithm obtains rewards through interaction with the environment and learns to achieve higher rewards. Higher rewards also imply a lower average delay ratio. Despite the initial rapid increase and subsequent stabilization of the reward curves across four batch sizes, it indicates that our improved DDPG algorithm can learn a stable computation offloading policy. Notably, a batch size of 64 yields better rewards. Therefore, we set the batch size to 64 in subsequent simulations.
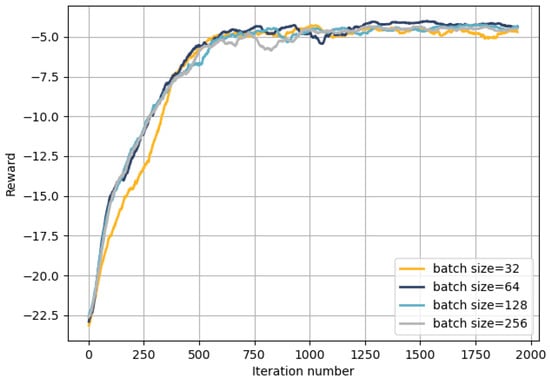
Figure 4.
Influence of batch size on convergence.
Additionally, the learning rate is a crucial hyperparameter. Figure 5 shows the impact of different learning rates on training outcomes. It can be observed from the figure that the convergence of the improved DDPG algorithm is highly sensitive to the learning rate. When the learning rate is too low, the training process converges to a local optimum. This is also the reason for the reward curve’s pattern of the initial increase followed by a decline, ultimately making it challenging to achieve satisfactory training outcomes. Conversely, when the learning rate is too high, the parameters fluctuate too violently during training, making it difficult to converge to a desirable solution and resulting in significant volatility. However, it is evident that setting the learning rate to 0.00001 leads to stable convergence and superior performance. Therefore, in subsequent simulations, we will set the learning rate to 0.00001.
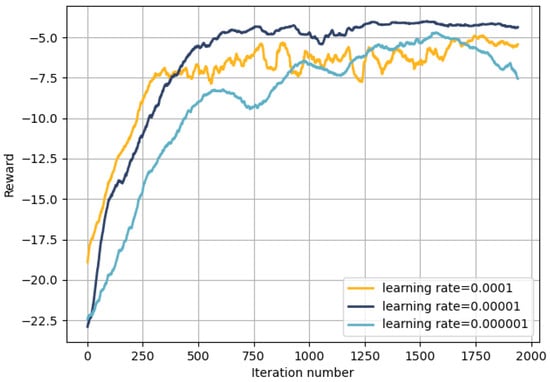
Figure 5.
Influence of learning rate on convergence.
Figure 6 shows the average delay ratio and success rate under different absolute values of penalty when the number of devices is 20 (high load). In Figure 6a, the average delay ratio increases with the increase in . However, when , the average delay ratio is not sensitive to changes in . Within a 300% variation range of , the average delay ratio only fluctuates by 2.27%. Due to the randomness of the simulation environment, these fluctuations are acceptable. In Figure 6b, the success rate also shows an increasing trend as increases. When , the success rate is also not sensitive to changes in . Within a 300% variation range of , the average delay ratio only fluctuates by 0.71%. By comparing these two figures, we can observe that when , our proposed algorithm sacrifices the success rate to achieve a lower average delay ratio, as the penalty strength is not sufficient. Although a larger reduces algorithm errors and leads to a higher success rate, when , disregarding the bias in the training effect, we can consider the training effect of the algorithm to be stable and not sensitive to changes in . However, when is too large, an increase in the number of tasks may cause the Q value to exceed the floating-point limit. Thus, setting as 5 is reasonable.
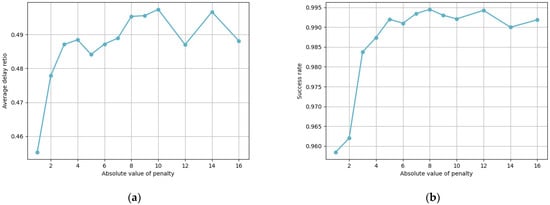
Figure 6.
Simulation results of penalty. (a) Average delay ratio against absolute value of penalty; (b) success rate against absolute value of penalty.
In Figure 7, we demonstrate the performance comparison of our proposed improved DDPG algorithm against the standard DDPG algorithms mentioned in Section 4.1 under both low- and high-load conditions by varying the number of onboard and ground sensors. In Figure 7a, the numbers of both types of sensors are set to 5, whereas in Figure 7b, they are set to 10. It was observed that under low-load conditions, all algorithms show good performance, with the improved DDPG slightly outperforming the others. However, under high-load conditions, the differences between algorithms became more pronounced. Compared to the standard DDPG, our improved DDPG algorithm is able to find more optimal offloading strategies. This indicates its efficacy in handling hybrid action space problems and higher-dimensional action spaces.
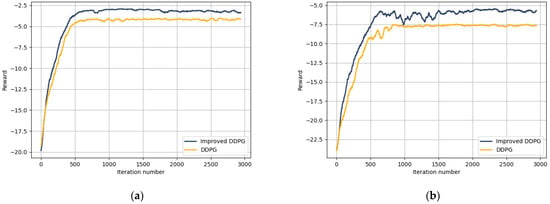
Figure 7.
Simulation results of different algorithms. (a) Comparison of algorithm (number of devices is 10); (b) comparison of algorithm (number of devices is 20).
Figure 8 illustrates the average delay ratio and completion rate for different schemes. In the HSR scenario, a lower delay means anomalies can be detected more quickly, allowing for more time to respond; a higher success rate ensures that no details are missed, enhancing the completeness and meticulousness of the detection. Overall, these two metrics reflect the contribution of different schemes to safety.
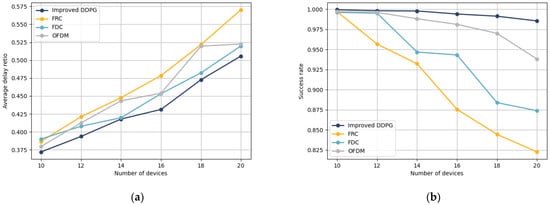
Figure 8.
Simulation results of different schemes. (a) Average delay ratio against the number of devices; (b) the success rate against the number of devices.
Figure 8a demonstrates the trend of the average delay ratio obtained by different schemes as the number of devices varies. It should be noted that the quantity of the two types of devices is identical here. It is clear that the average delay ratio for each algorithm increases with the number of devices. When compared to the FDC, OFDM, and FRC schemes mentioned in Section 4.1, our scheme proposed in Section 2 consistently achieves lower delay ratios, reducing it by 4.69%, 6.56%, and 11.84%, respectively. This is attributed to the different channel conditions and interference that ground and onboard sensors experience under various transmission modes. Comparing the FDT and FDR schemes, we can demonstrate that our proposed approach better adapts to detection-oriented scenarios in railway IoT. The combination of these two transmission models allows for a more suitable transmission model for each detection task. Furthermore, the comparison with the OFDM scheme demonstrates that the introduction of NOMA technology indeed increases channel capacity, resulting in higher overall transmission rates and lower delay ratios. In summary, our proposed computation offloading model consistently delivers superior performance across different task quantities.
Figure 8b demonstrates the success rate trends of different schemes as the number of devices varies in the simulation. With an increase in device quantity, the success rate of each scheme generally decreases. Compared with the FDC, OFDM, and FRC schemes mentioned in Section 4.1, the scheme we proposed in Section 2 consistently achieves a higher completion rate. Specifically, in high-load environments, the failure rate is reduced by 89.6%, 64.9%, and 96.7%, respectively. This also indicates that our proposed scheme can better adapt to detection tasks in railway IoT. Furthermore, comparing the FDC and OFDM schemes in Figure 7, it is evident that FDC shows a lower delay ratio, while OFDM achieves higher completion rates. This observation reinforces the notion that a faster transmission rate is not always preferable. The server queue is closely linked to the task arrival time, influenced by the transmission rate. Excessive speed may result in server queue backlogs that exceed memory capacity. Thus, our enhanced DDPG algorithm effectively allocates communication and computational resources.
5. Conclusions
This study explores the dynamic resource management problem in the scenario of railway IoT systems with integrated sensing, storage, and computing, specifically focusing on the computation offloading for detection tasks. By optimizing subcarrier allocation, transmission mode selection, relay power allocation, and server selection, the objective is to minimize the average delay ratio, which is the ratio between the delay and the maximum tolerable delay. To address this problem, a low-complexity subcarrier allocation algorithm is proposed to reduce the action space dimension. Furthermore, an improved DDPG algorithm is proposed, which represents discrete variables using selection probabilities to handle the hybrid action space problem. Through simulation experiments, the performance of the improved DDPG algorithm is evaluated against existing benchmark schemes and algorithms, some of which referenced existing literature. The results indicate that the MEC system proposed in this paper can achieve a lower average delay ratio and a higher completion rate, demonstrating significant advantages over other schemes and algorithms, especially under high-load conditions. This also means that HSR will have a more secure guarantee. The findings also highlight the adaptability of the proposed MEC system model for detection tasks in HSR environments.
Through simulation, our proposed MEC system demonstrates lower average latency ratios and higher completion rates compared to other literature. In addition, due to its excellent adaptability, our proposed MEC system could be compatible with various types of rail transportation. However, the ultimate goal is to deploy it in a real HSR environment. However, the deployment of edge servers and online monitoring equipment is a significant undertaking. Future work will focus on the practical deployment of MEC, particularly in dealing with real-world network conditions. We will further collect data and conduct performance tests on the proposed MEC system to analyze its potential applications in various rail transit scenarios. Future work will also include research on potential issues such as energy consumption and security.
Author Contributions
Research, Z.X.; conceptualization, Z.X. and Y.W.; algorithm design, Z.X. and Q.G.; simulation analysis, Q.G. and Z.X.; verification, J.Y. and Y.W.; writing—original draft preparation, Q.G. and Z.X.; writing—review and editing, J.Y. and Y.W.; supervision, J.Y. and Y.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
All data underlying the results are available as part of the article and no additional source data are required.
Acknowledgments
The authors would like to thank the editors and the reviewers for their valuable time and constructive comments.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Wang, J. Maintenance Scheduling at High-Speed Train Depots: An Optimization Approach. Reliab. Eng. Syst. Saf. 2024, 243, 109809. [Google Scholar] [CrossRef]
- Yang, N.; Chen, M. Design and Application of Big Data Technology Management for the Analysis System of High Speed Railway Operation Safety Rules. In Proceedings of the 2023 IEEE International Conference on Integrated Circuits and Communication Systems (ICICACS), Raichur, India, 24–25 February 2023; pp. 1–6. [Google Scholar]
- Sobhy, H.; Zohny, H.N.; Elhabiby, M. Railway Inspection Using Non-Contact Non-Destructive Techniques. Int. J. Eng. Appl. Sci. (IJEAS) 2020, 7. [Google Scholar] [CrossRef]
- Singh, P.; Elmi, Z.; Krishna Meriga, V.; Pasha, J.; Dulebenets, M.A. Internet of Things for Sustainable Railway Transportation: Past, Present, and Future. Clean. Logist. Supply Chain 2022, 4, 100065. [Google Scholar] [CrossRef]
- Xu, J.; Ai, B.; Chen, L.; Cui, Y.; Wang, N. Deep Reinforcement Learning for Computation and Communication Resource Allocation in Multiaccess MEC Assisted Railway IoT Networks. IEEE Trans. Intell. Transp. Syst. 2022, 23, 23797–23808. [Google Scholar] [CrossRef]
- Wang, Y.; Yang, S.; Ren, X.; Zhao, P.; Zhao, C.; Yang, X. IndustEdge: A Time-Sensitive Networking Enabled Edge-Cloud Collaborative Intelligent Platform for Smart Industry. IEEE Trans. Ind. Inform. 2022, 18, 2386–2398. [Google Scholar] [CrossRef]
- Li, Y.; Zhu, L.; Wu, J.; Wang, H.; Yu, F.R. Computation Resource Optimization for Large-Scale Intelligent Urban Rail Transit: A Mean-Field Game Approach. IEEE Trans. Veh. Technol. 2023, 72, 9868–9879. [Google Scholar] [CrossRef]
- Xu, J.; Wei, Z.; Yuan, X.; Qiao, Y.; Lyu, Z.; Han, J. Throughput Maximization for Result Multicasting by Admitting Delay-Aware Tasks in MEC Networks for High-Speed Railways. IEEE Trans. Veh. Technol. 2024, 73, 8765–8781. [Google Scholar] [CrossRef]
- Khan, K.; Pasricha, S.; Kim, R.G. A Survey of Resource Management for Processing-In-Memory and Near-Memory Processing Architectures. J. Low Power Electron. Appl. 2020, 10, 30. [Google Scholar] [CrossRef]
- Zhao, C.; Cai, Y.; Liu, A.; Zhao, M.; Hanzo, L. Mobile Edge Computing Meets mmWave Communications: Joint Beamforming and Resource Allocation for System Delay Minimization. IEEE Trans. Wirel. Commun. 2020, 19, 2382–2396. [Google Scholar] [CrossRef]
- Jiang, K.; Zhou, H.; Li, D.; Liu, X.; Xu, S. A Q-Learning Based Method for Energy-Efficient Computation Offloading in Mobile Edge Computing. In Proceedings of the 2020 29th International Conference on Computer Communications and Networks (ICCCN), Honolulu, HI, USA, 3–6 August 2020; pp. 1–7. [Google Scholar]
- Chen, X.; Liu, G. Energy-Efficient Task Offloading and Resource Allocation via Deep Reinforcement Learning for Augmented Reality in Mobile Edge Networks. IEEE Internet Things J. 2021, 8, 10843–10856. [Google Scholar] [CrossRef]
- Ale, L.; King, S.A.; Zhang, N.; Sattar, A.R.; Skandaraniyam, J. D3PG: Dirichlet DDPG for Task Partitioning and Offloading With Constrained Hybrid Action Space in Mobile-Edge Computing. IEEE Internet Things J. 2022, 9, 19260–19272. [Google Scholar] [CrossRef]
- Deng, X.; Yin, J.; Guan, P.; Xiong, N.N.; Zhang, L.; Mumtaz, S. Intelligent Delay-Aware Partial Computing Task Offloading for Multiuser Industrial Internet of Things Through Edge Computing. IEEE Internet Things J. 2023, 10, 2954–2966. [Google Scholar] [CrossRef]
- Li, L.; Niu, Y.; Mao, S.; Ai, B.; Zhong, Z.; Wang, N.; Chen, Y. Resource Allocation and Computation Offloading in a Millimeter-Wave Train-Ground Network. IEEE Trans. Veh. Technol. 2022, 71, 10615–10630. [Google Scholar] [CrossRef]
- Tian, L.; Li, M.; Si, P.; Yang, R.; Sun, Y.; Wang, Z. Design and Optimization in MEC-Based Intelligent Rail System by Integration of Distributed Multi-Hop Communication and Blockchain. Math. Probl. Eng. 2023, 2023, 8858263. [Google Scholar] [CrossRef]
- Xue, Q.; Wei, R.; Li, Z.; Liu, Y.; Xu, Y.; Chen, Q. Beamforming Design for Cooperative Double-RIS Aided mmWave MU-MIMO Communications. IEEE Trans. Green Commun. Netw. 2024; Early Access. [Google Scholar] [CrossRef]
- Xu, C.; Zheng, G.; Zhao, X. Energy-Minimization Task Offloading and Resource Allocation for Mobile Edge Computing in NOMA Heterogeneous Networks. IEEE Trans. Veh. Technol. 2020, 69, 16001–16016. [Google Scholar] [CrossRef]
- Du, J.; Sun, Y.; Zhang, N.; Xiong, Z.; Sun, A.; Ding, Z. Cost-Effective Task Offloading in NOMA-Enabled Vehicular Mobile Edge Computing. IEEE Syst. J. 2023, 17, 928–939. [Google Scholar] [CrossRef]
- Du, R.; Wang, J.; Gao, Y. Computing Offloading and Resource Scheduling Based on DDPG in Ultra-Dense Edge Computing Networks. J Supercomput. 2024, 80, 10275–10300. [Google Scholar] [CrossRef]
- Zhou, X.; Tian, Y.; Wang, X. MEC-DA: Memory-Efficient Collaborative Domain Adaptation for Mobile Edge Devices. IEEE Trans. Mob. Comput. 2024, 23, 3923–3937. [Google Scholar] [CrossRef]
- Wang, J.; Ge, M.; Ding, B.; Xu, Q.; Chen, S.; Kang, Y. NicePIM: Design Space Exploration for Processing-In-Memory DNN Accelerators With 3-D Stacked-DRAM. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2024, 43, 1456–1469. [Google Scholar] [CrossRef]
- Li, Y.; Cimini, L.J. Bounds on the Interchannel Interference of OFDM in Time-Varying Impairments. IEEE Trans. Commun. 2001, 49, 401–404. [Google Scholar] [CrossRef]
- Gao, M.; Ai, B.; Niu, Y.; Wu, W.; Yang, P.; Lyu, F.; Shen, X. Edge Caching and Content Delivery with Minimized Delay for Both High-Speed Train and Local Users. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar]
- Jiao, B.; Liu, S.; Lei, Y.; Ma, M. A Networking Solution on Uplink Channel of Co-Frequency and Co-Time System. China Commun. 2016, 13, 183–188. [Google Scholar] [CrossRef]
- Wang, Y.; Niu, Y.; Wu, H.; Ai, B.; Zhong, Z.; Wu, D.O.; Juhana, T. Relay Assisted Concurrent Scheduling to Overcome Blockage in Full-Duplex Millimeter Wave Small Cells. IEEE Access 2019, 7, 105755–105767. [Google Scholar] [CrossRef]
- Xue, J.; An, Y. Joint Task Offloading and Resource Allocation for Multi-Task Multi-Server NOMA-MEC Networks. IEEE Access 2021, 9, 16152–16163. [Google Scholar] [CrossRef]
- Wildemeersch, M.; Quek, T.Q.S.; Kountouris, M.; Rabbachin, A.; Slump, C.H. Successive Interference Cancellation in Heterogeneous Networks. IEEE Trans. Commun. 2014, 62, 4440–4453. [Google Scholar] [CrossRef]
- Zhong, A.; Li, Z.; Wu, D.; Tang, T.; Wang, R. Stochastic Peak Age of Information Guarantee for Cooperative Sensing in Internet of Everything. IEEE Internet Things J. 2023, 10, 15186–15196. [Google Scholar] [CrossRef]
- Maudet, S.; Andrieux, G.; Chevillon, R.; Diouris, J.-F. Practical Evaluation of Wi-Fi HaLow Performance. Internet Things 2023, 24, 100957. [Google Scholar] [CrossRef]
- Zhao, X.; Liu, M.; Li, M. Task Offloading Strategy and Scheduling Optimization for Internet of Vehicles Based on Deep Reinforcement Learning. Ad Hoc Netw. 2023, 147, 103193. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).