1. Introduction
The primary focus in information retrieval lies in developing models that are both effective and efficient, aligning with the information-seeking needs expressed by users through unstructured queries. That process is conducted via information retrieval models separated into three categories, set-theoretic, algebraic, and probabilistic; moreover, numerous hybrid models have been developed, integrating a complexity that spans multiple scientific domains beyond the scope of classical approaches [
1].
One of the previously mentioned areas pertains to the field of graph theory. The inception of graph-theoretic models for information retrieval can be traced back to approximately 1957, as highlighted by Firth [
2]. Subsequently, numerous graphical formalisms have been applied to represent textual data in the format of these graphs. Blanco and Lioma [
3] introduced two distinct aspects of co-occurrence text graphs. The first aspect involves an undirected structure, where an edge connects two nodes (terms) if they are found within a specified window of terms. Term weights are computed using a methodology similar to TextRank [
4], a variant of PageRank [
5], or with a degree-based metric known as TextLink. The second aspect entails a directed co-occurrence graph incorporating grammatical constraints, expressed through part-of-speech (PoS) tagging.
Classical information retrieval models generate sparse document representations, giving rise to the concept of “Sparse Retrieval”. However, the evolution of information retrieval has integrated machine learning algorithms to generate document vectors containing term scores learned from the documents, akin to traditional term frequency. This integration of machine learning, primarily based on neural networks, has led to the emergence of Neural Information Retrieval [
6].
Previously, models were trained on documents to learn sparse vector representations. However, with the advent of transformers and attention mechanisms in 2017 [
7], models with dense vector representations have become prevalent in the literature. Consequently, depending on the shape of the document vectors, the retrieval method can be categorized as “learned sparse” [
8,
9,
10,
11,
12] or “dense” [
13,
14,
15]. Many dense retrieval models leverage representations derived from BERT [
16], which may introduce latency issues in delivering final results. Hence, it is common practice to employ a two-stage pipeline comprising an initial ranking stage followed by a re-ranking stage. A sparse model, such as the BM25, is commonly implemented as a first-stage ranker.
This study adopts the methodology introduced by Kalogeropoulos et al. [
17] and seeks to augment the extension of the Set-Based model [
18,
19] proposed by them. The primary objective of this research is to introduce a robust initial ranking approach, integrating graphs with the set-based model, enriched with word and node vector representations, commonly referred to as embeddings. In a general sense, embeddings are real-valued vectors containing semantic or structural information about the term. Each document will be represented as a graph, a structure exploitable for various tasks, including keyword detection, summarization, and classification.
Another contribution of our work is that, besides addressing the information retrieval aspect, it also tackles the text classification task, which involves organizing text documents into predetermined categories or classes. The primary objective is to automatically assign a label or category to a given piece of text based on its content. This task holds significance for various applications, including spam detection, sentiment analysis, and topic modeling. Textual data can be represented as numerical features, which will serve as input for machine learning algorithms. Common techniques encompass bag-of-words representations such as tf-idf (Term Frequency–Inverse Document Frequency) and word embeddings. These embeddings can be generated either through contextualized pretrained models like BERT [
16] or from count-based models such as Word2Vec or GloVe [
20,
21].
The foundation of the graph-based extension of the set-based model’s [
17] scheme rests on the assumption that every term in a document shares an equal bidirectional relationship with all others, creating a complete graph for each document. Terms are depicted as nodes and their connections as edges in this graph. However, linguistically, it is evident that the initial hypothesis is overly simplistic. Therefore, it becomes crucial to limit the relationships within a document, which will be considered in our experimental evaluation.
A similar method, known as Graph of Words (GoW), waws proposed by Rousseau and Vazirgiannis [
22]. They proposed a degree-based evaluation scheme based on the BM25 model [
23,
24], which implements an overlapping sliding window to limit the correlation of terms in a sentence on the graph creation process. Their graph algorithm is implemented with minor variations on multiple applications. The implementation of directed graphs proved beneficial in applications like document summarization or phrasal indexing.
Furthermore, when addressing the keyword detection problem, they [
25] employed core decomposition [
26]. The identification of document keywords was achieved by preserving nodes within the main core of each textual graph. Subsequently, the authors introduced techniques for estimating crucial nodes by considering dense subgraphs beyond the main core. In their initial exploration, they concentrated on dense cores or trusses [
27], ultimately suggesting a node ranking based on the sum of core numbers to which each neighbor belongs for a given node [
28]. These methods have the ability to isolate significant components within a large graph, often as dense subgraphs. Therefore, they can be applied as edge removal techniques, and they are also useful in tasks like identifying important nodes.
The remainder of this paper is structured into five sections. The second section (
Section 2) will delve into a theoretical analysis of significant methods and models that are pertinent to this study. Specifically, it will encompass discussions on the basic set-based model, its graph extensions, graph decomposition techniques, and embedding methodologies.
The third section (
Section 3) will outline the contributions of the paper to ranking and classification tasks. Following this, the fourth section (
Section 4) will delve into the results obtained from the proposed approach.
Concluding remarks, limitations, and future directions will be addressed in the fifth and final section (
Section 5).
2. Preliminaries and Methods
This section outlines the baseline and introduces some novel concepts proposed by Kalogeropoulos et al. [
17]. Prior to delving into the proposed model, it is imperative to elucidate and grasp the functioning of the simple set-based model along with its extension.
2.1. Set-Based Model
The set-based model is a combination of set theory with an algebraic influence on the way weights are computed. It introduces the concept of term sets, where if each term in a particular set exists in a text, then the text is defined as containing that set. Initially, the sets may appear to be very large, but in practice, this is not the case; it is proportional to the size of the query. Thus, a model is created with high accuracy in combination with the cost of equivalent efficient models.
Every term that appears in any document of the collection belongs to the collection’s vocabulary V. Every subset of the vocabulary constitutes a set of terms n in size, where n is the number of terms it contains. A vocabulary of size m can potentially generate sets of terms. Naturally, several of these sets may not exist in any document of the collection. For this reason, the frequency of appearance of each set of terms in the texts, denoted as and defined as the cardinality of the set of documents for each term set, is the frequency of its occurrence.
The model decreases the number of term sets even more, by considering only the frequent sets in the termset creation process. A set of terms is called frequent if the number of occurrences of it is greater than a minimum threshold set by the model creator. Therefore, the Apriori algorithm is implemented for the process of term set creation in the simplest form of the model [
29]. The Apriori algorithm is a popular algorithm used for association rule mining in data mining and machine learning. By considering the text as a transaction database and the terms as an item, the algorithm can discover frequent itemsets from the database. It is important to notice that in our approach, we implemented the Eclat algorithm [
30] as it will result in similar itemsets with lower time complexity.
The model utilizes, as previously mentioned, term sets as structural elements for representing text queries. Specifically, each text and query is represented as a vector that includes the weight of each set in that particular text or query. The term sets are determined by the terms of the query. The calculation of the weight for each frequent term set is influenced by the number of occurrences of the entire set in the text, the rarity of the set in the collection texts, and the size of the referenced text. Naturally, a set that appears in many texts has less semantic value than a rarer one. Additionally, large texts may contain more than one term set from the query, which, if not addressed, could provide an advantage in the retrieval process. Therefore, an algebraic weight calculation scheme similar to the Vector Space Model (tf-idf) is followed (Equation (
1) and (
2)). Notably, the reference is to sets of terms rather than individual terms of the query. Thus, the term frequency is replaced by the set frequency
for text
j and set
, and similarly, the inverse document frequency in the collection pertains to the corresponding set
. The variable
N represents the total number of texts, while
expresses the number of texts in which the set
appears.
Finally, the document (
) and query (
) vectors are formed with a size of at most
elements, where
n is the number of unique terms that the query contains (Equation (
3)).
It is imperative to notice that a collection-wise termset calculation would be non-realistic, since it is computationally expensive because the lexicon size
N is vastly larger than the number of query terms (
). As the set-based model dictates, the ranking scheme is expressed as the ordered cosine similarity between the collection documents and the query.
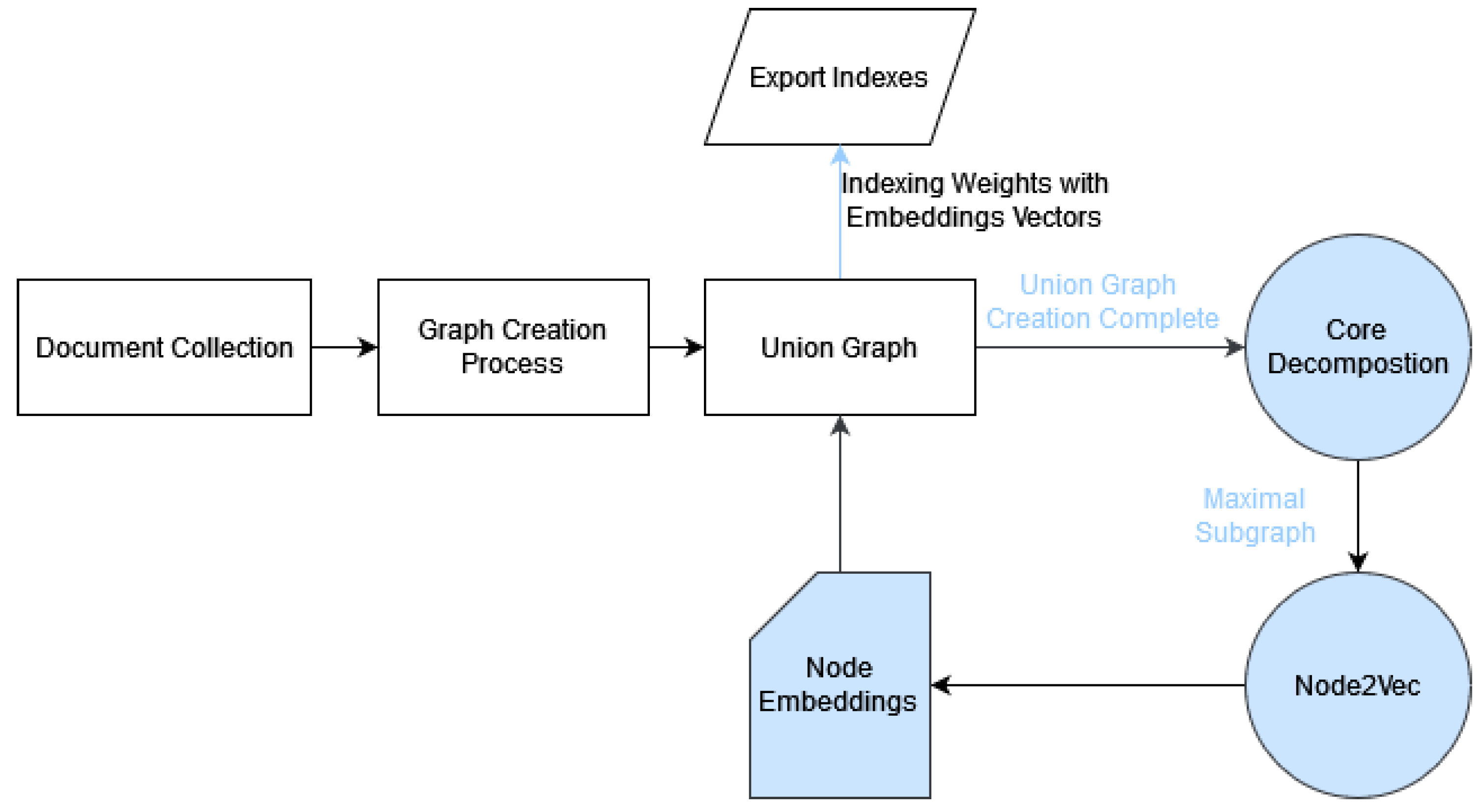
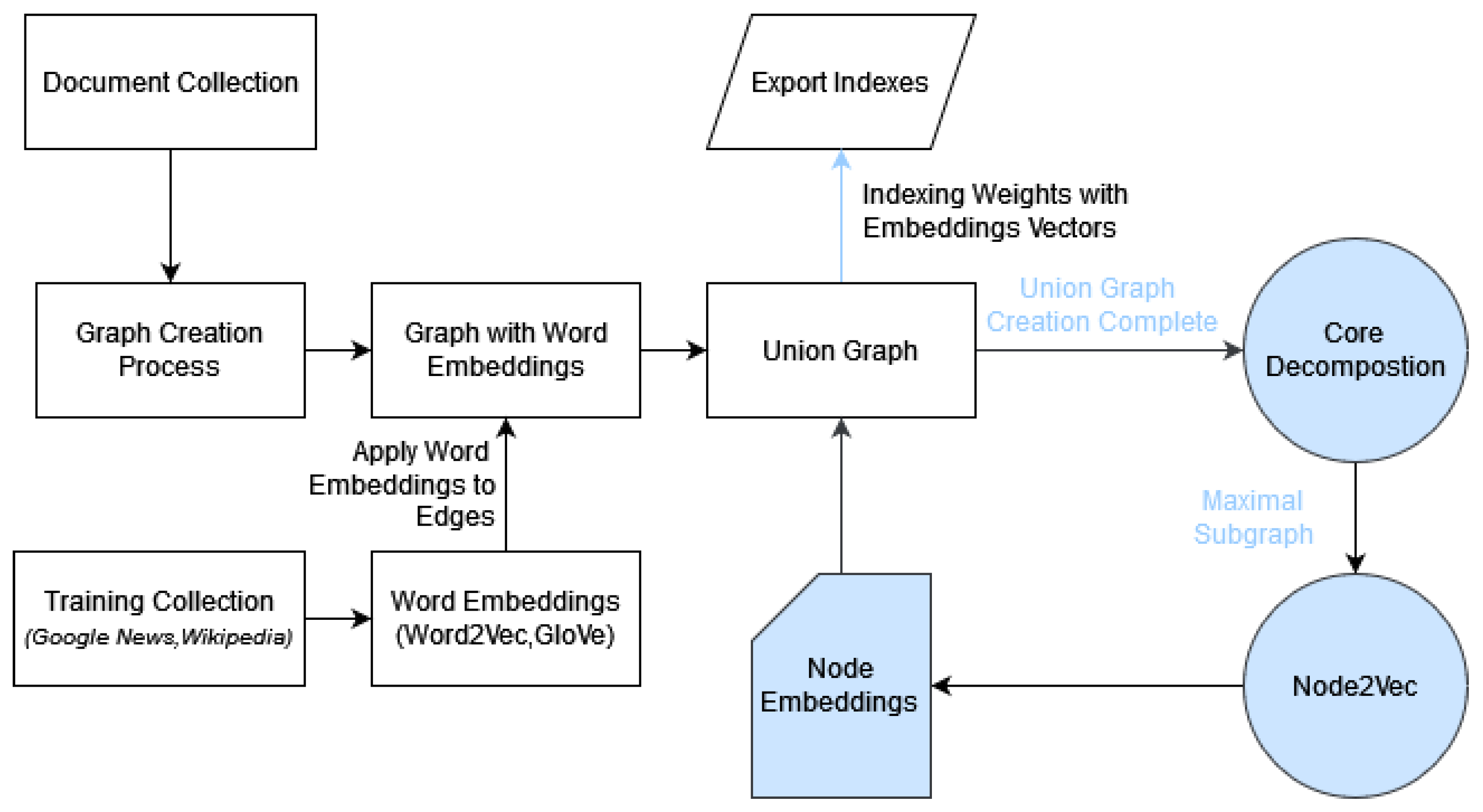
2.2. Core Decomposition
Core Decomposition was proposed by Seidman [
26] and is used in many applications of important node estimation, or subgraph mining.
Let be a graph, and let be its subgraph. The k-core (order k) of graph G is a subgraph S where each node has a degree greater than k. The set of all k-core cores constitutes the core decomposition of graph G. The decomposition based on core numbers (K-core decomposition) has been proposed as a tool for studying graphs, aiming to identify vertices of particular significance that exert a more substantial influence on the graph. The absence of these vertices could potentially lead to issues with connectivity.
Qualitatively describing the above definition, we observe that a subgraph has the order K if and only if every node within it has a degree greater than or equal to K. Meanwhile, a node has a core number of K if it belongs to the K-core but not to the (K + 1)-core. In graphs with weighted edges, the degree order of a node is the sum of the weights of its edges. For small values of K, the K-core tends to be large, and its cohesion increases as K grows.
2.3. Graphs and Set-Based Model
Kalogeropoulos et al. [
17] proposed a novel extension to the simple set-based model (GSB), which accumulates structural information about the text and the collection using graphs.
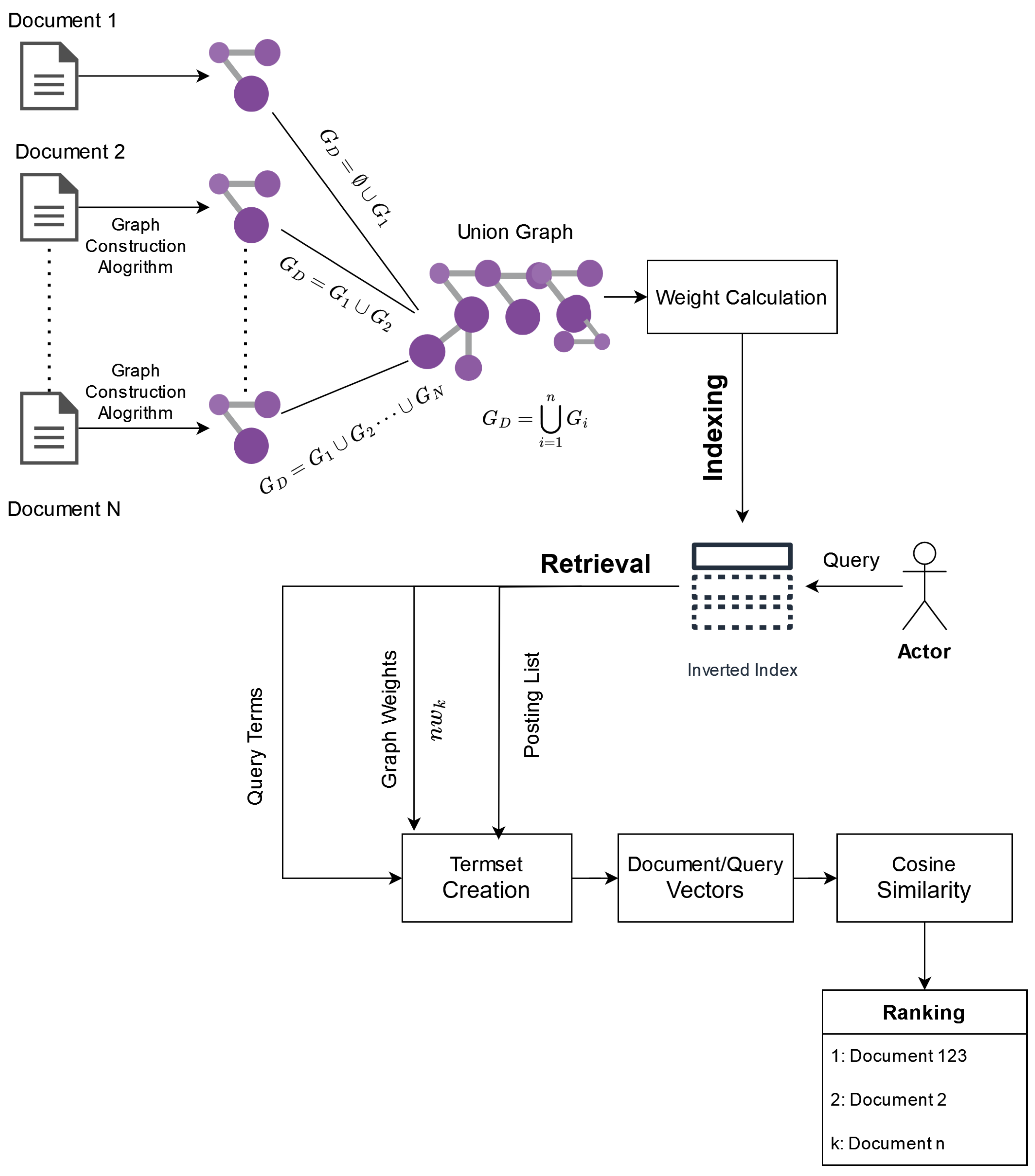
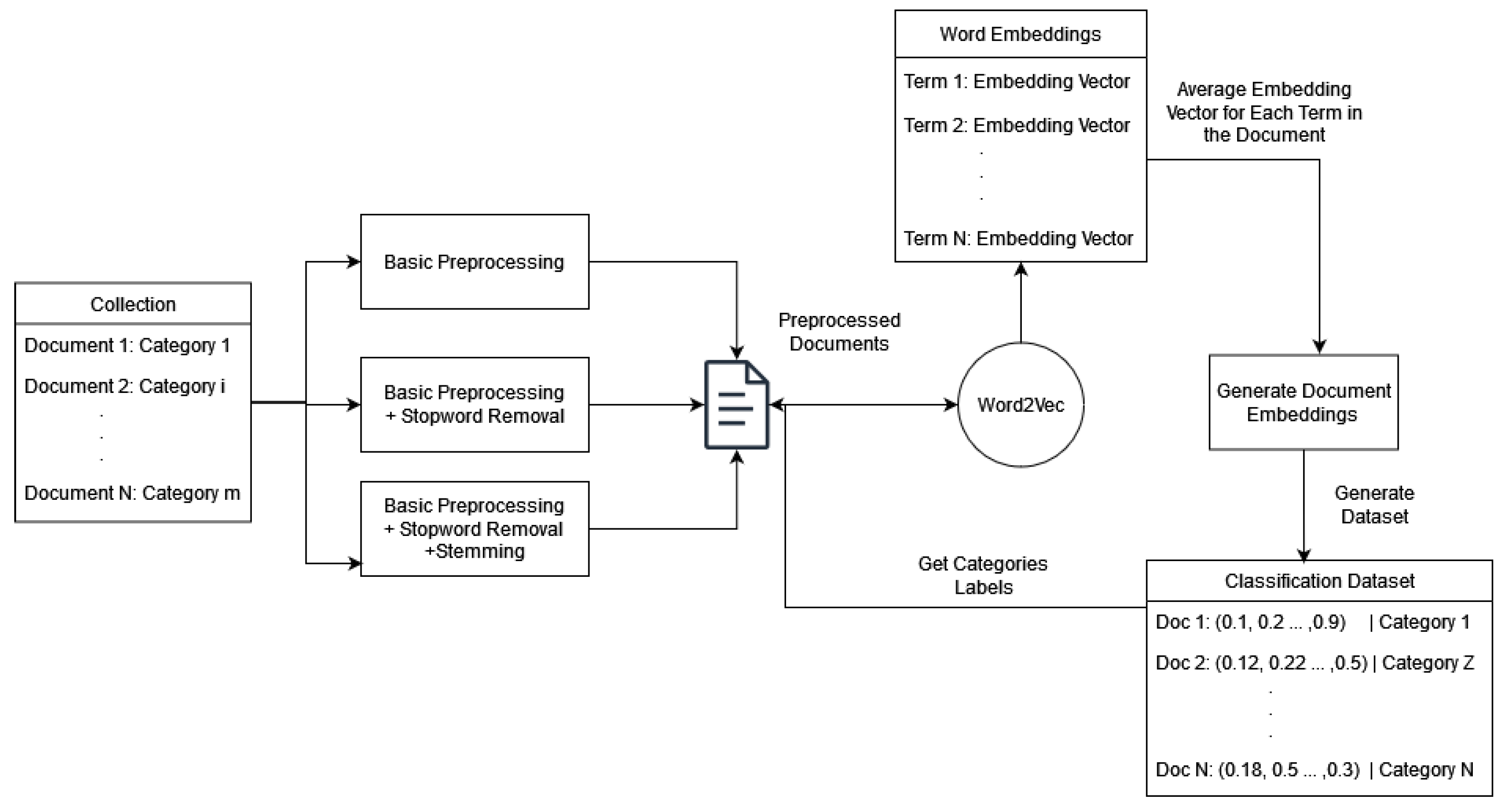
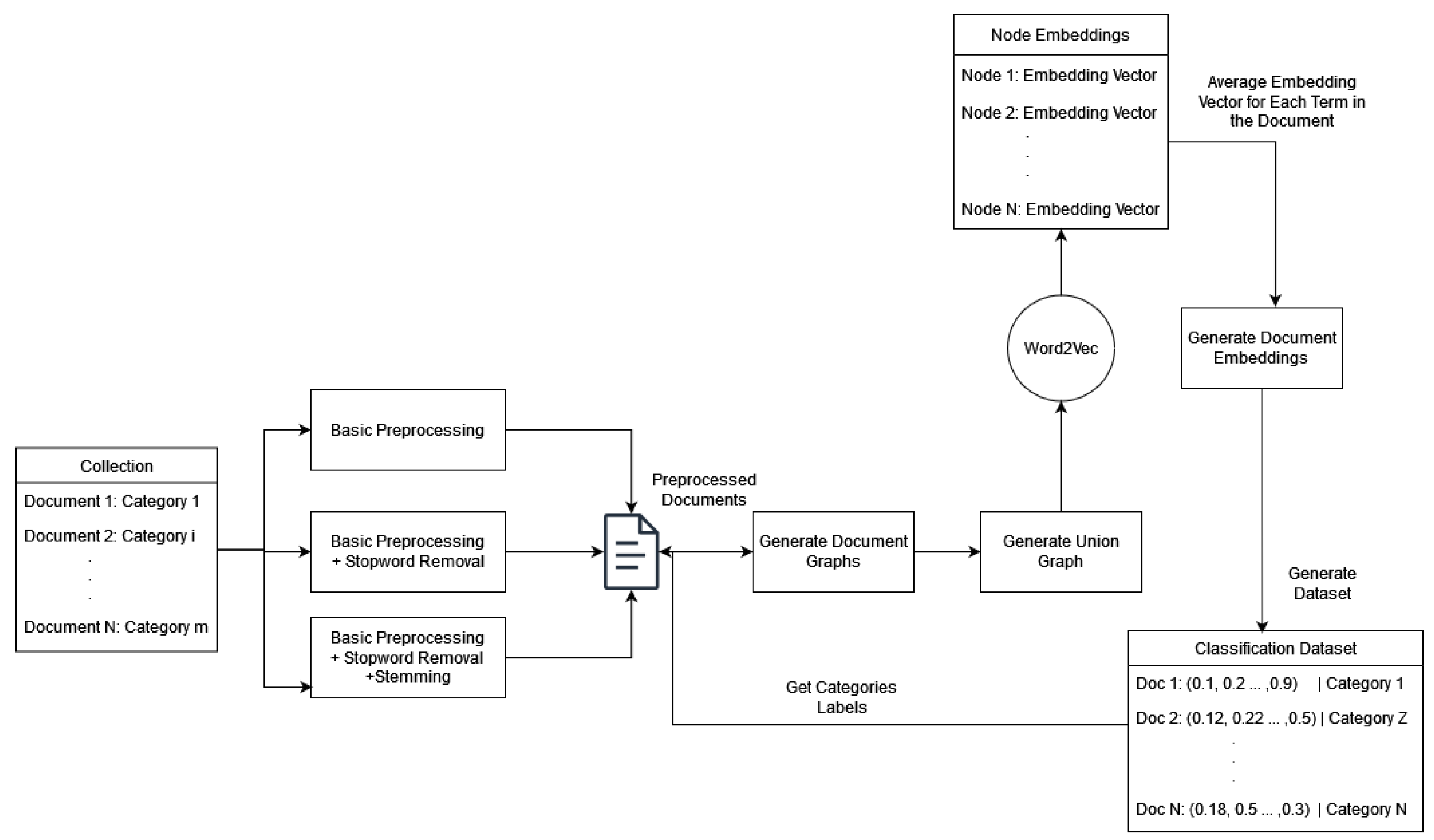
Figure 1 illustrates the model architecture. At first, their approach considers a fully connected graph (complete graph) for each document that, in the most naive approach, is combined in a collection-wide graph. Each node represents a document term, and the edge weight among terms is calculated multiplicatively by the nodes’ respective term frequency.
To elaborate further, the document graph referred to as the Rational Path Graph is a co-occurrence graph characterized by two types of edges: in-edges and out-edges. An in-edge is a self-loop on a node N with a weight equal to and the out-edge is an edge between two nodes N, M with weight , where or is the term frequency of the respective term in the document.
They introduced the graph union operation [
31] as a graph merge method. That operator (Equation (
5)) will accumulate all document graphs into one graph. Each term is considered a node, and the resulting edge weight is calculated by the sum of the weights that the edge has in every graph that exists.
Thereafter, for each node/term, a graph derived from the union is calculated (Equation (
6)) and indexed. It is important to note that the parallelization of the graph construction and union and the weight parallelisation are feasible tasks.
The aforementioned weights will be implemented on the set-based weighting scheme, with the variable
. That variable is the product of the
weights for every term
k that the termset contains.
The is a compilation of the sum of the out-edges related to node k (), the weight of the self-loop (), and the number of the node’s k neighbors ().
However, unlike the naive approach, they include a level of document graph processing before the graph union operation. At first, a running method can be used to reduce the number of edges, keeping only the important ones, which are expressed by the respective edge weight. Therefore, the model removes edges to an extent that is less than the percentage of the average edge weight. Furthermore, following the work of Rousseau and Vazirgiannis [
25] and Tixier et al. [
28], they amplify the keyword-related edges by an importance variable
h. Such keywords have been located that implement methods and algorithms that include core decomposition. This process assists the model in identifying and handling noisy data, without any performance loss. On the contrary, the ranking process in many cases supersedes the simple set-based model.
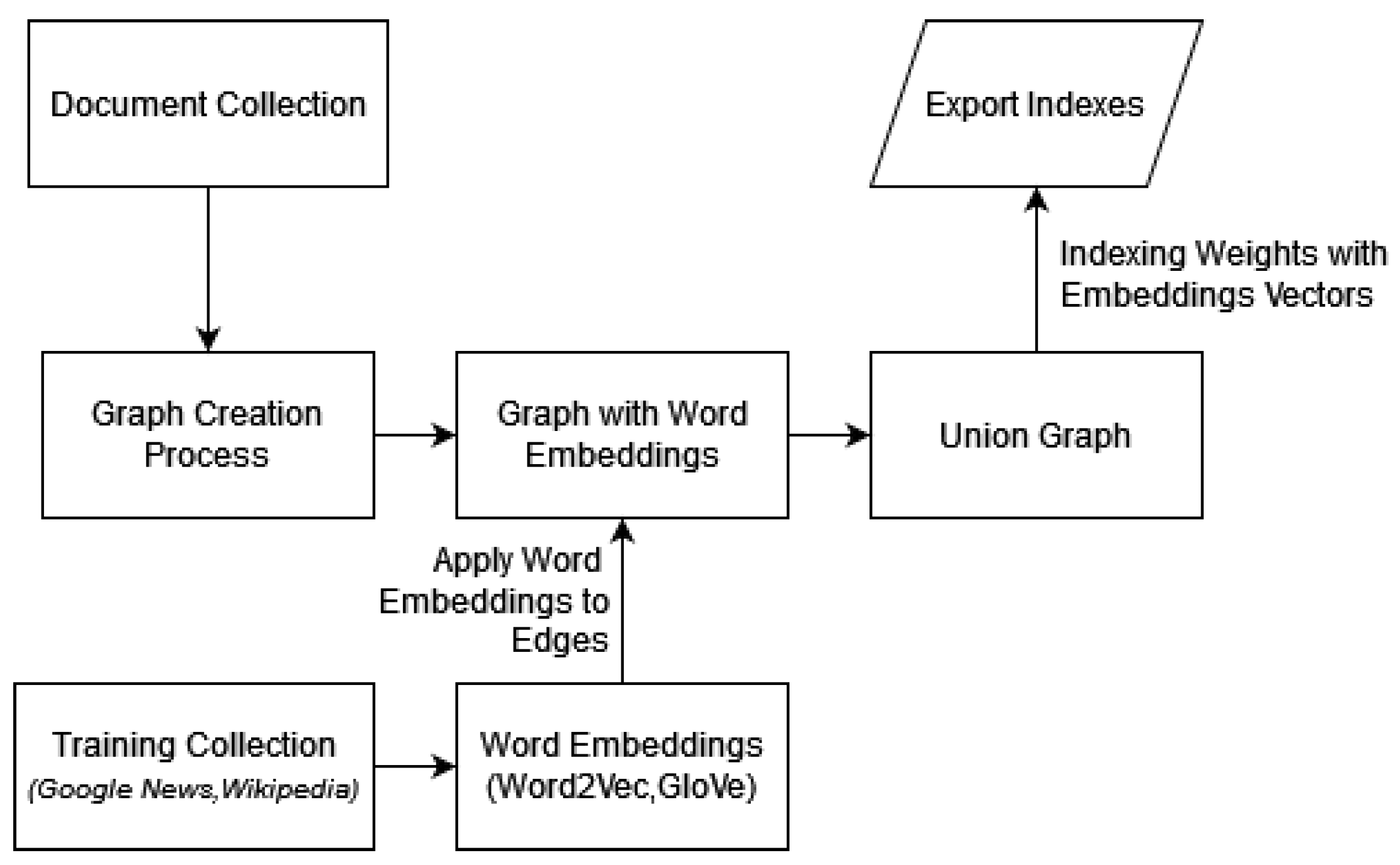
2.4. Word Embeddings
Word2Vec [
20] efficiently captures semantic relationships by mapping words to high-dimensional vector spaces. The fundamental idea behind Word2Vec is that it learns distributed representations for words based on their contextual usage in a given corpus. The model is trained to predict the likelihood of words appearing together in a given context, enabling it to create dense vectors where words with similar meanings or contexts are geometrically closer. This not only preserves semantic relationships but also allows mathematical operations on word vectors to produce intriguing results, such as analogies.
Node2Vec [
32] is a powerful graph embedding algorithm designed to represent nodes in a network as continuous vectors in a multi-dimensional space. Developed to capture intricate structural and semantic relationships within graphs, Node2Vec extends the concept of Word2Vec to network data. It navigates through the graph by employing a flexible biased random walk strategy, allowing it to balance between exploring local neighbourhoods and jumping to more distant nodes. This nuanced exploration approach enables Node2Vec to generate embeddings that preserve the network’s topology and community structure.
GloVe [
21] is designed to transform words into continuous vector representations, capturing the semantic relationships between them based on their co-occurrence patterns in a given corpus. The underlying principle involves constructing a word–word co-occurrence matrix from the corpus, followed by training the model to learn word embeddings. The objective function of GloVe is carefully crafted to maximize the dot product of word vectors for frequently co-occurring words while minimizing it for those that rarely co-occur.
4. Experiments
This section consider the results of our experiments regarding the two aforementioned tasks on multiple collections.
Table 1 shows the collection name, size, and task that each collection was used for to evaluate the ranking and classification aspect. Those experiments aim to determine the ranking performance of our approach versus the complete extension of the set-based model, as well as the set-based model itself, while being a competent document classification method.
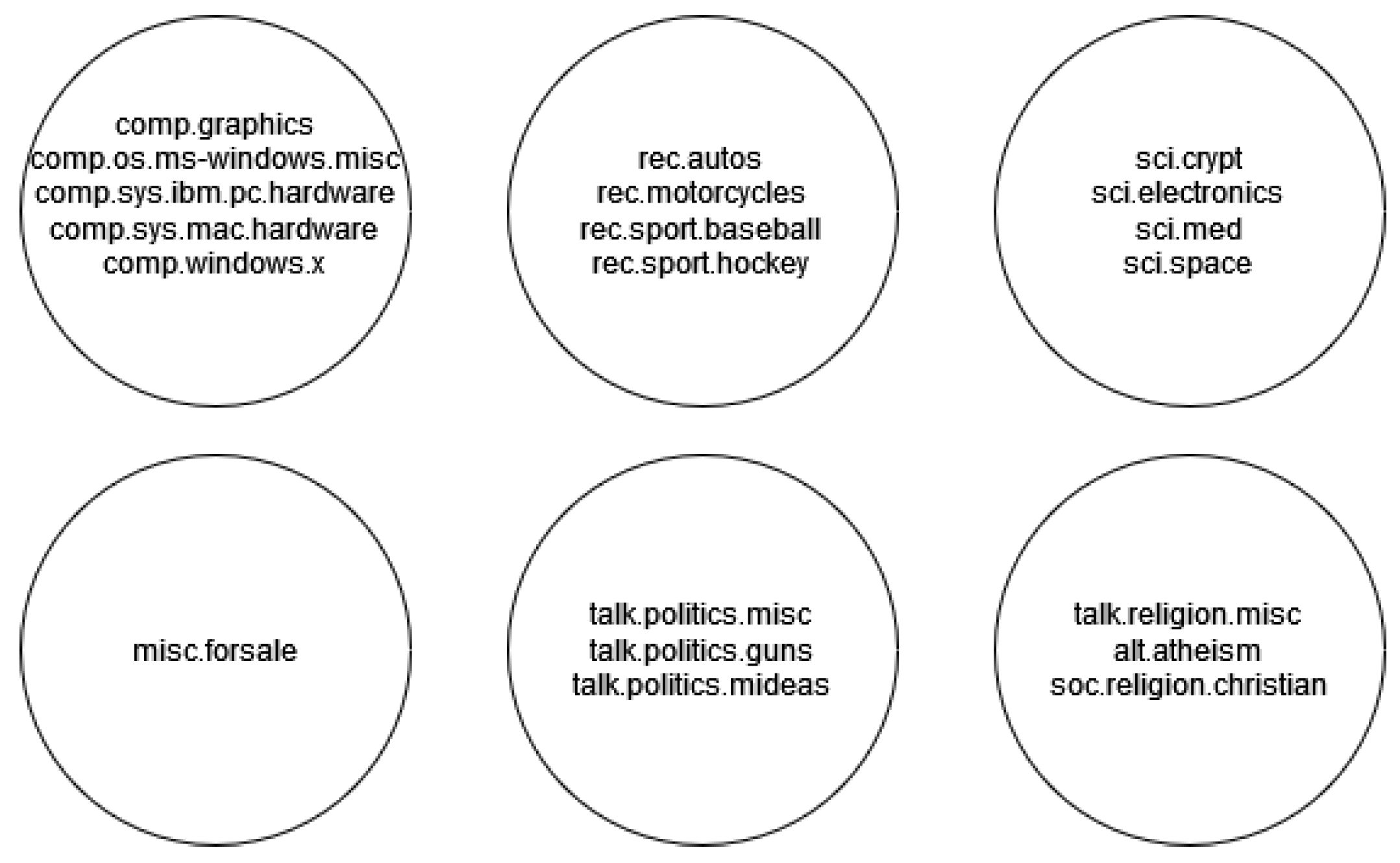
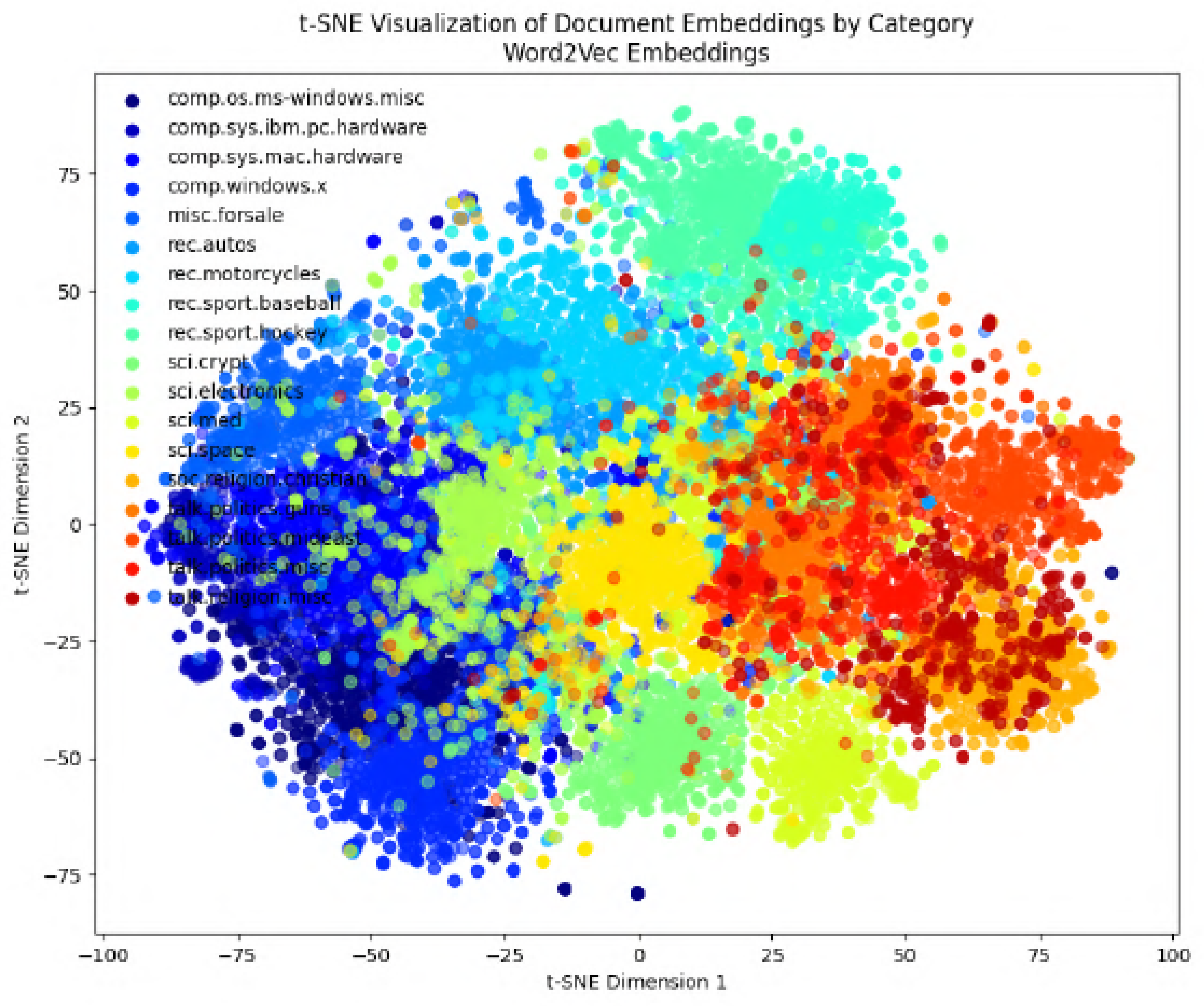
The Cystic Fibrosis collection contains 1.239 abstracts regarding the disease. The collection is accompanied by 100 queries with respective expert-derived relevant document lists, which can be used to assess the ranking performance. The 20newsgroups collection contains 20 different categories. However, in our experiments, we tried to make our data set be balanced or fairly balanced; thus, two categories were omitted. It is important to notice here that the 20 labels can be merged into larger groups (
Figure 7), thus creating dependencies among classes and rendering the task even more difficult.
The BBC News collection is a balanced five-category collection and the Spam/Ham Emails collection is an imbalanced binary collection, which will be used for the classification task. That way, we can estimate the performance on standard and difficult multi-class issues without disregarding the more simple binary task.
4.1. Models’ Performance on Ranking
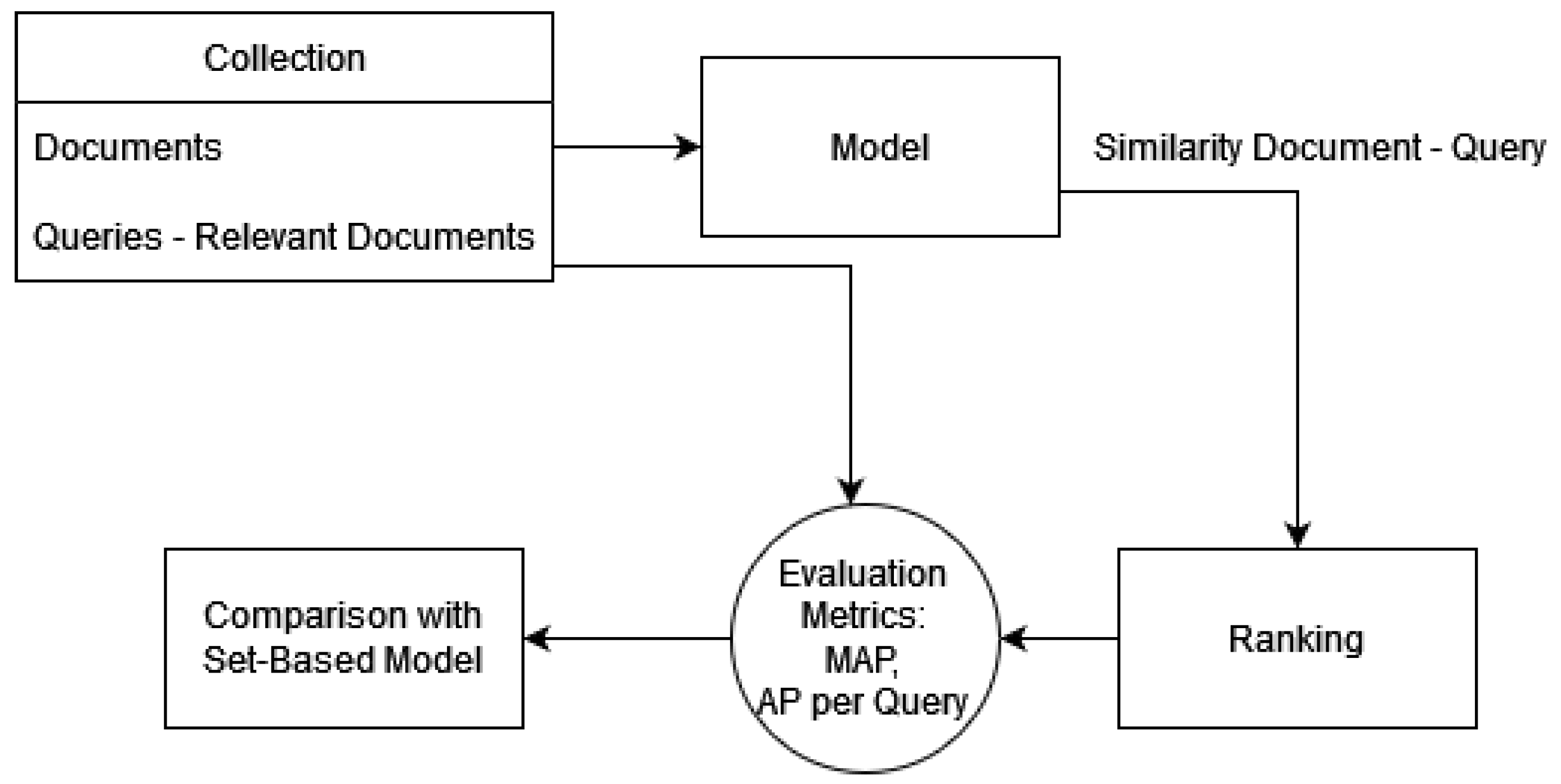
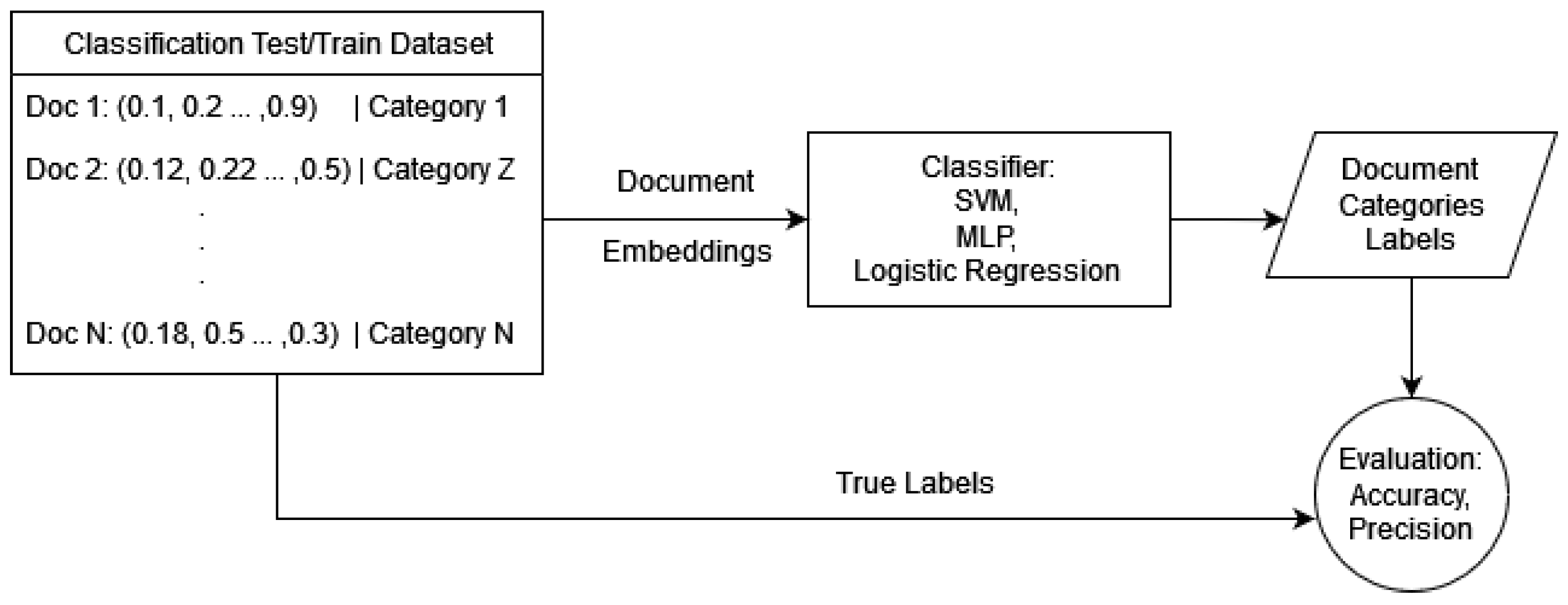
In this subsection, we evaluate the performance of the proposed embedding method on a classical information retrieval application as depicted in
Figure 8. Given a collection of documents, alongside the respective queries and relevant documents, we will apply each model separately. For each query–document pair, a similarity function will be implemented, resulting in a ranking that will be evaluated by employing the appropriate metrics (Average Precision per query and Mean Average Precision). The CF collection contains 100 queries on which our model will offer rankings. We will estimate the average precision of each approach and compare it with that of the simple set-based model, creating a metric that will express the number of queries each method supersedes in the set-based model. That method of validation will render the set-based model as our baseline, as shown in
Figure 8.
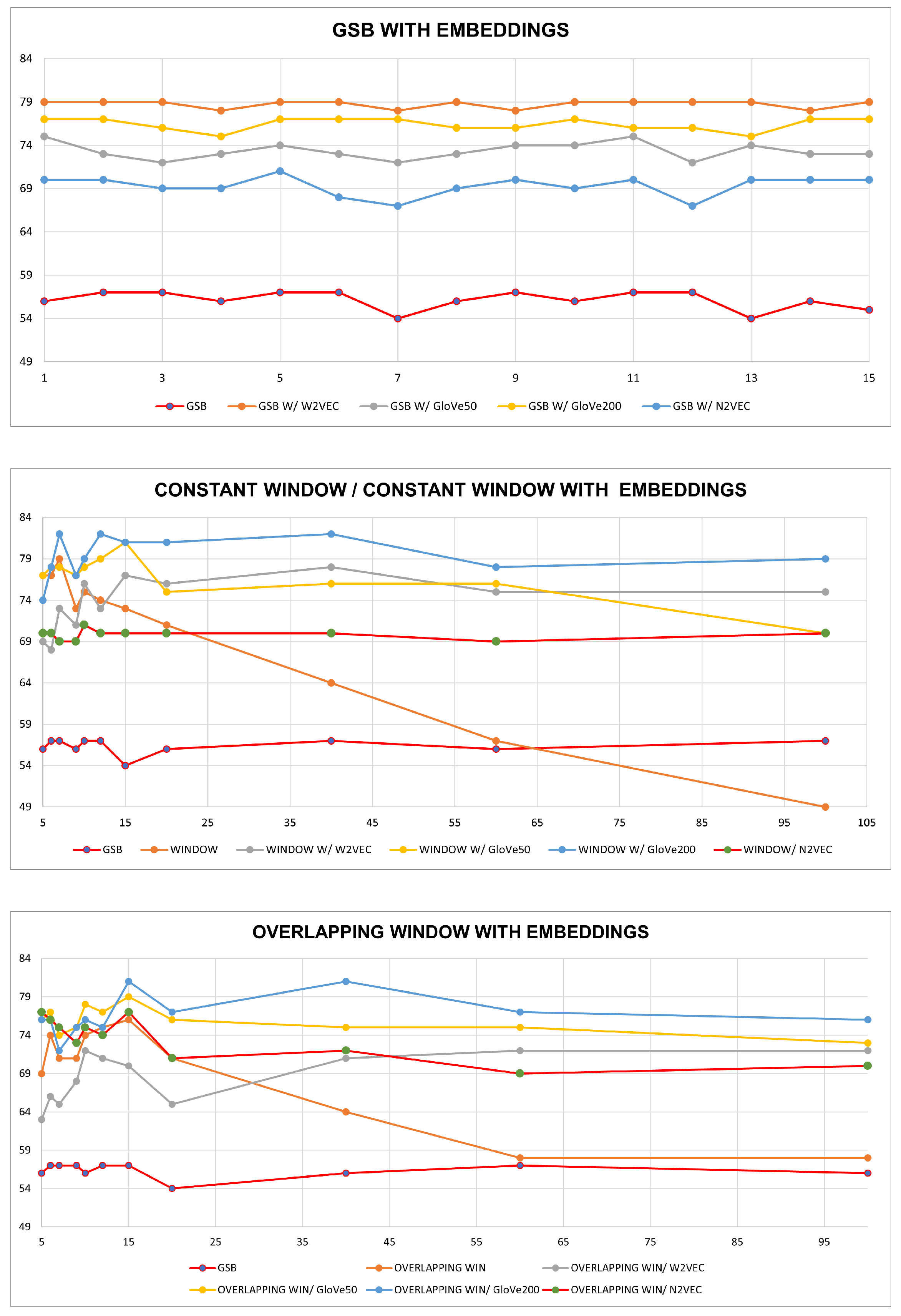
First, we will evaluate the performance of the complete case [
17] augmented with embeddings of Node2Vec, Word2Vec, and GloVe with embedding vector sizes of 50 and 200. Immediately, we can notice a substantial performance improvement versus the simple model. The best embedding technique in this approach seems to be the Word2Vec one, as shown in
Figure 9.
At this point, instead of a pruning method, we will apply our graph creation algorithm on non-overlapping text segments—windows. We can notice a slight performance increase when implementing GloVe vectors. However, the most important observation lies in the stability of the performance regardless of the window size. This shows that our windowed approach is window-agnostic, which was a drawback of the simple model.
Finally, if we allow the text segments to overlap, we can notice a performance drop in the general model. However, the general stability of the model is increased. The GloVe vectors in this case also yield the best results.
Table 2 depicts the best-noted results in each case.
The complete extension is highly amplified by inducing embeddings on the edges. Although the overall highest performance on the windowed options is slightly impacted by our approach, the stability of each model’s precision is greatly improved, as mentioned in the above figures.
Table 3 provides a concise overview of several state-of-the-art models, categorised based on their underlying principles. More information about BERT-based models and other variants of them can be found in the literature [
15,
35]. The first section of the table includes vector-space-probabilistic models, followed by BERT-based models in the second section, and graph-based models in the final section. We will compare the performance of the models in those categories in a later table. It is noteworthy that models like BM25, GoW, or GSB can be utilized as first-stage rankers. Contextual embeddings extracted from BERT are frequently employed as representations in both dense and sparse approaches. Later on, we will compare models from each category with our proposed methods.
In
Table 4, we present a comparison of the Mean Average Precision (MAP) for each model concerning the 100 queries contained within the Cystic Fibrosis collection. The performance of the set-based model is enhanced through the incorporation of graphs, leading to the graph-based extension. This extension effectively captures structural information, particularly with the inclusion of windows. The results for the windowed case closely resemble those of the BM25 model (and in some queries improve it). The BM25 model is widely recognized as a foundational model that is frequently utilized for re-ranking purposes in the initial stage. Moreover, our approach is close to (and in some queries an improvement on) the colBERT model and, in conjunction with it, can yield better results, as observed in preliminary experiments (these experiments are the subject of future work). Overall, this outcome suggests that our approach could be effectively employed as a first-stage model alongside dense retrieval models.
4.2. Text Classification Performance
In this section, we present the results of our classification model trained on the dataset. We evaluate the performance of the model using various metrics and analyze its effectiveness in accurately predicting the target classes. The design of the experiment is depicted in
Figure 10.
In
Table 5,
Table 6 and
Table 7, we can observe that the Word2Vec embeddings are slightly better against the Node2Vec (
Table 8,
Table 9 and
Table 10) in some cases, and Doc2vec (
Table 11,
Table 12 and
Table 13) falls short as an embedding technique in the classification task; however, in general, the Node2Vec approach yields results that are competitive with those of Word2Vec. Therefore, we can conclude that our graph creation algorithm can be implemented and perform competitively on classification tasks, such as topic modeling. Furthermore, in each of the columns of the following tables, the preprocessing is more aggressive from left to right, as explained before. Regarding the preprocessing aspect of the textual data, we can conclude that a stemming/lemmatization process deteriorates the performance of the model due to the information loss that occurs. On the other hand, a stopword removal phase seems to increase the classifiers’ performance.
From
Table 5,
Table 6,
Table 7,
Table 8,
Table 9,
Table 10,
Table 11,
Table 12 and
Table 13, we can conclude that the Multilayer Perceptron (MLP) outperforms the rest of the classifiers on every task at hand. For the hard multi-class problem, the Node2Vec results dominates slightly amongst the embedding techniques. However, on easier tasks such as a simple multi-class or a binary classification case, Word2Vec yields better results as the number of classes dwindles. Eventually, Doc2Vec cannot compete equally with the under-discussion models and techniques with a substantial performance loss with respect to the Word2Vec–Node2Vec comparison.
In terms of computational performance, it is evident that Doc2Vec can generate the required document vectors more efficiently than the Word2Vec model. This efficiency stems from the fact that Doc2Vec does not require the vector aggregations that the basic Word2Vec model needs to compute in order to merge term vectors into a single document vector. On the other hand, the Node2Vec model inherently involves computationally intensive tasks [
32]. Initially, it must calculate transition probabilities for each node, followed by computing the necessary paths. This process inherently introduces computational complexity, which can be mitigated through pruning or subgraph mining techniques such as core decomposition, as implemented in this paper. Furthermore, akin to Word2Vec, Node2Vec also needs to transform term–node vectors into document vectors through aggregation, thereby potentially compromising the model’s efficiency.
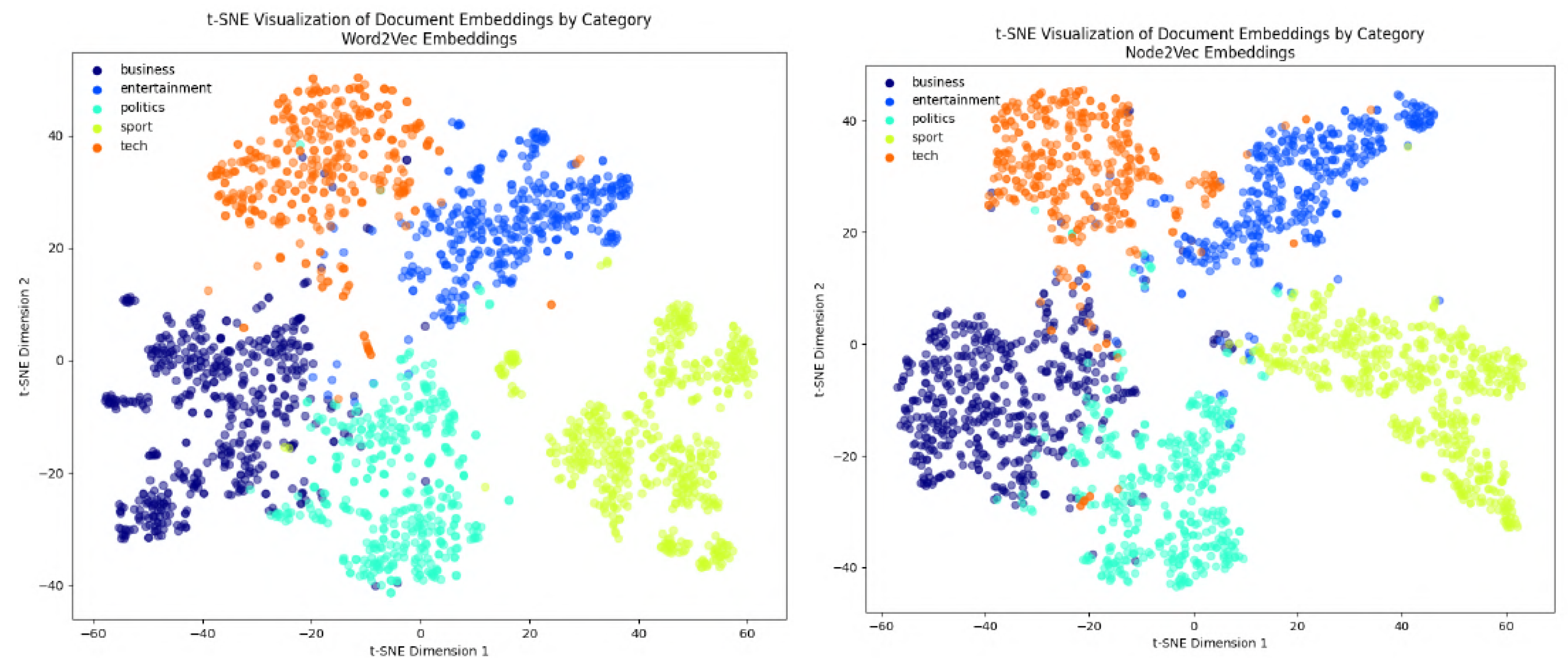
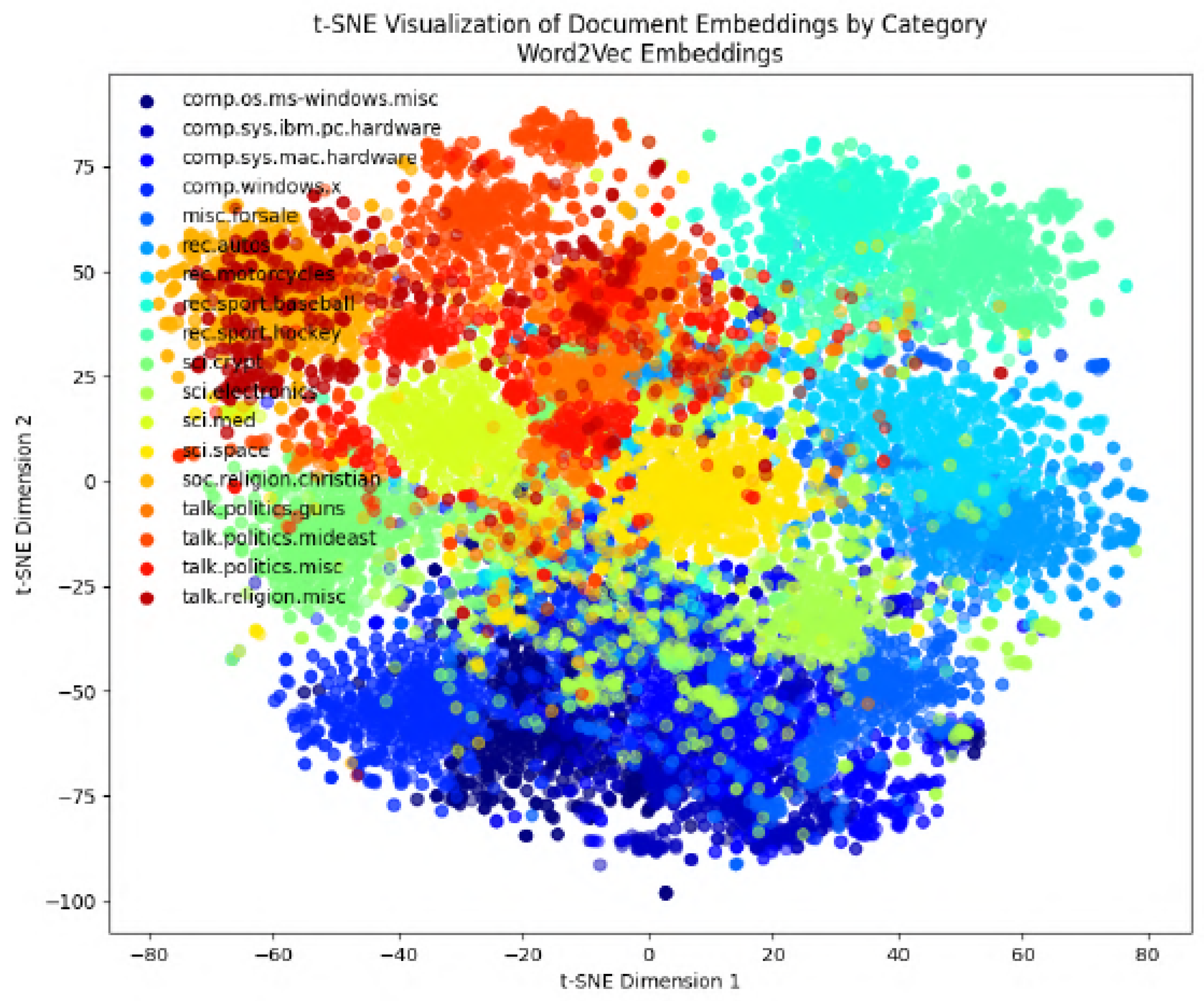
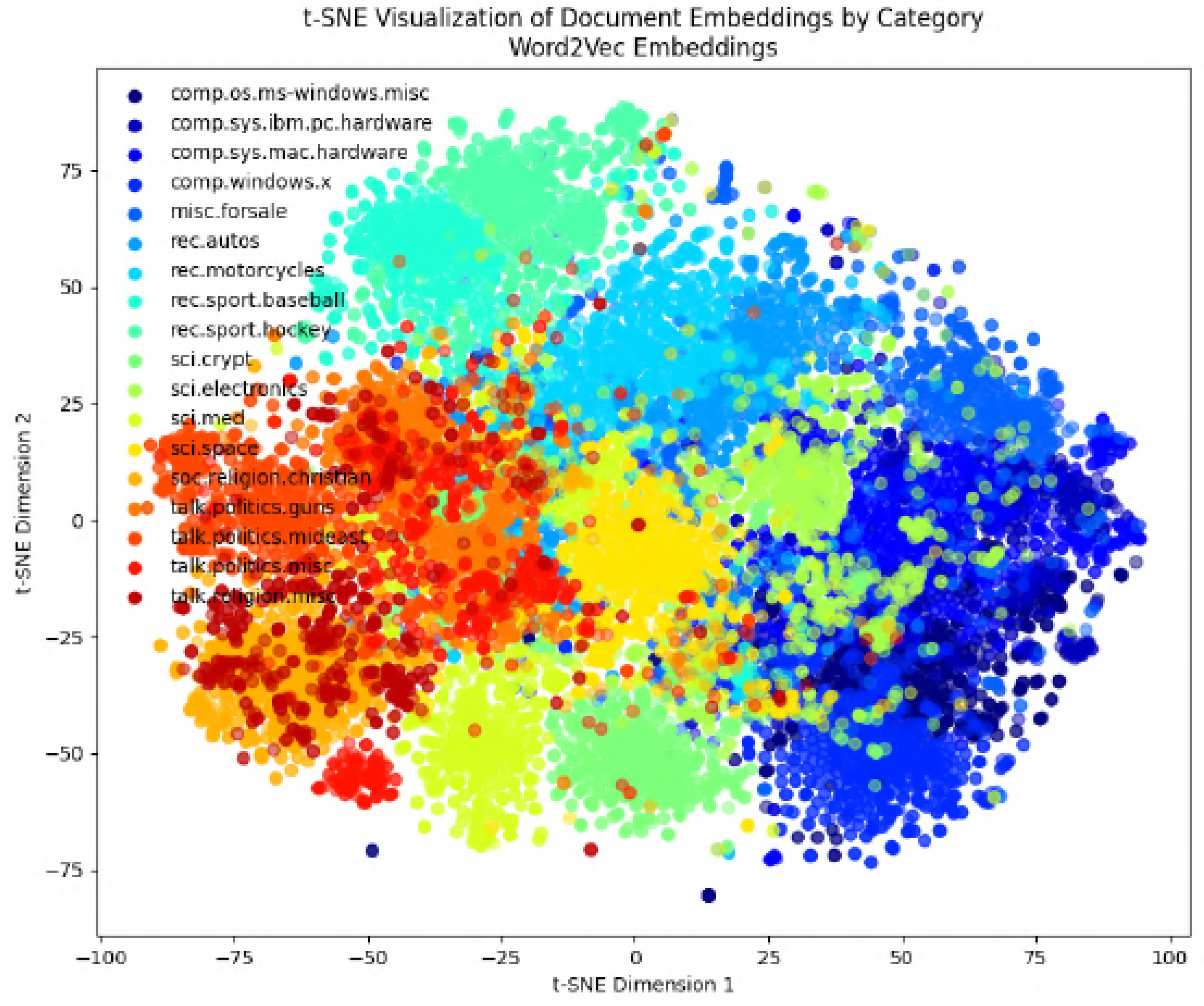
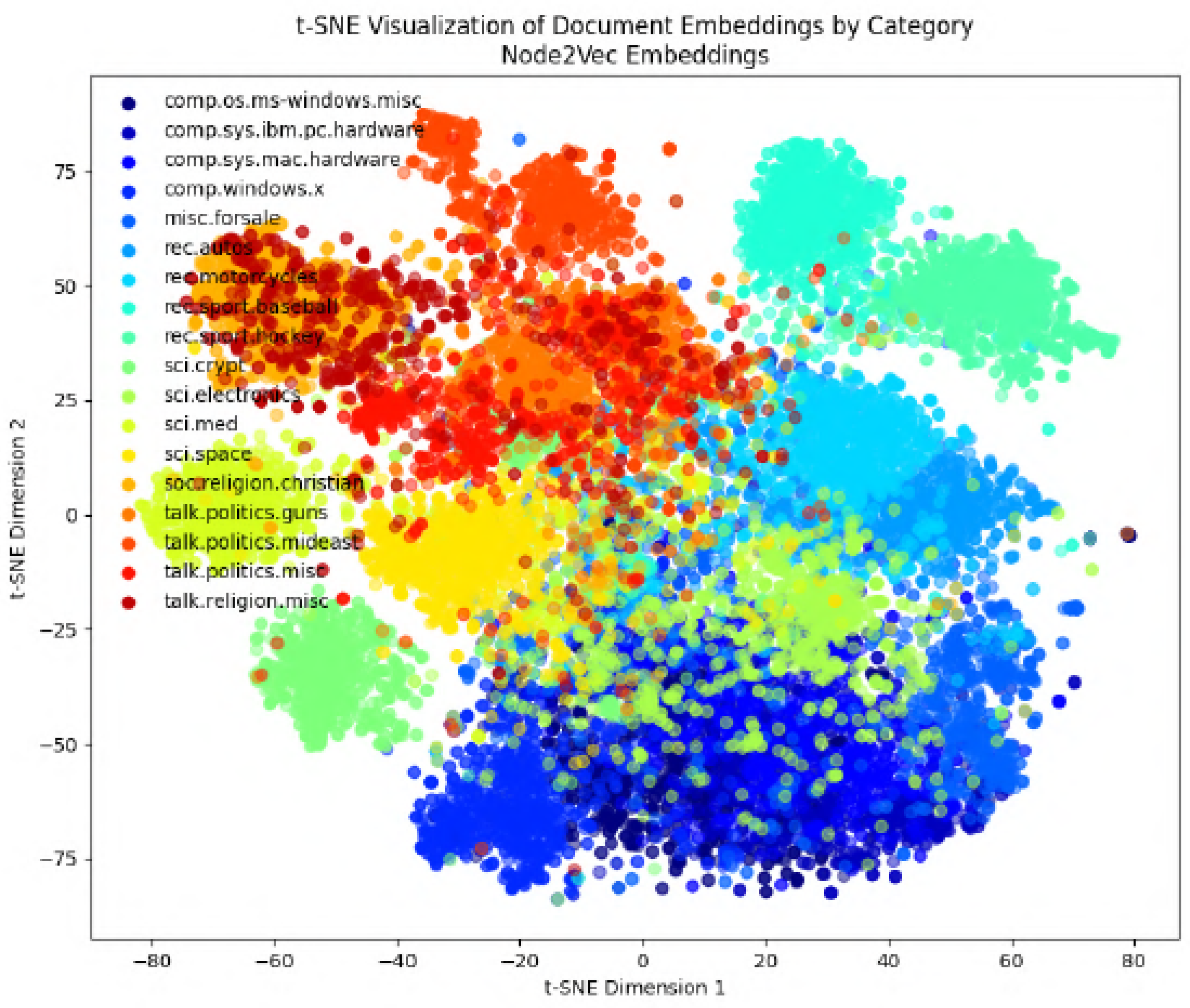
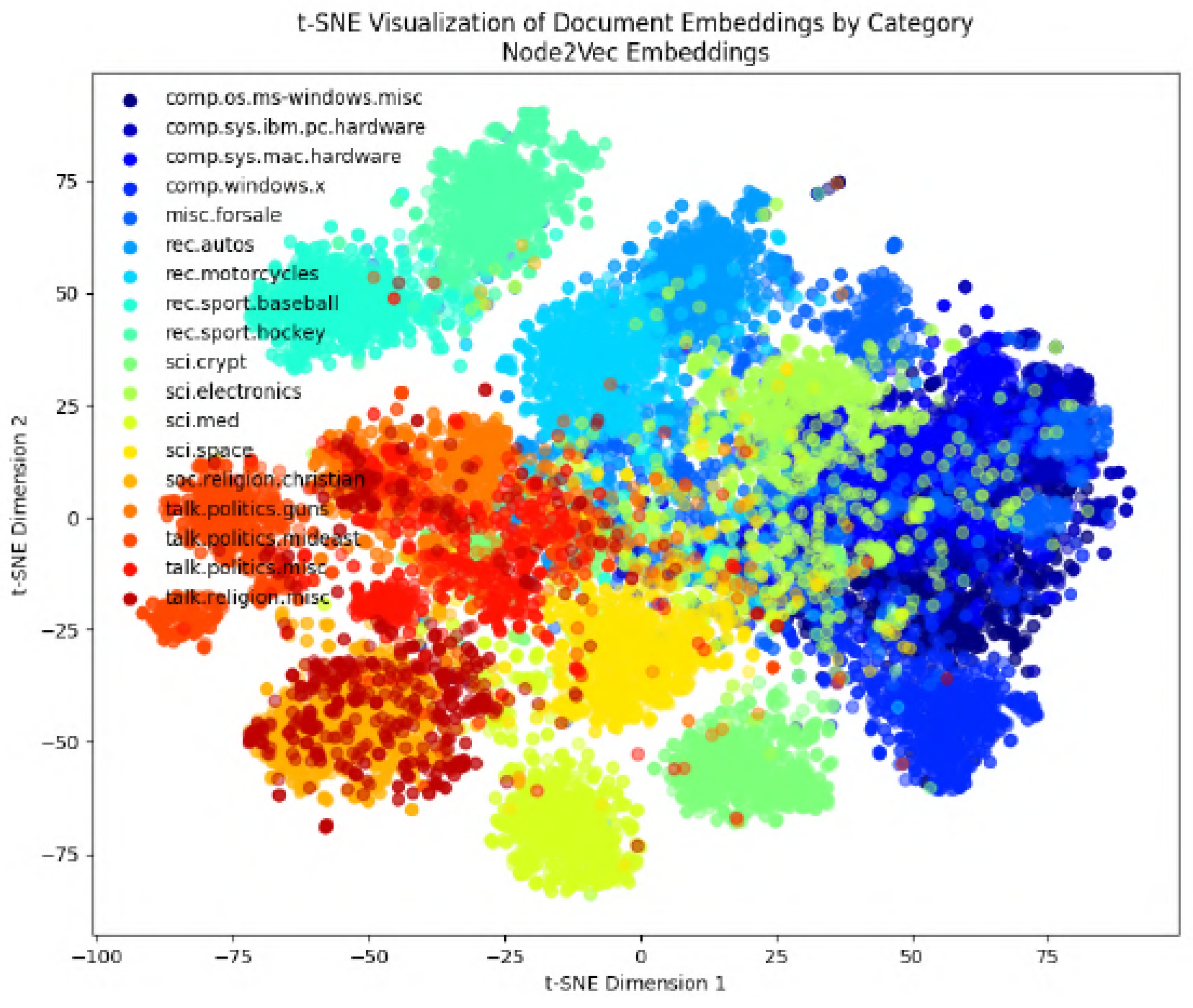
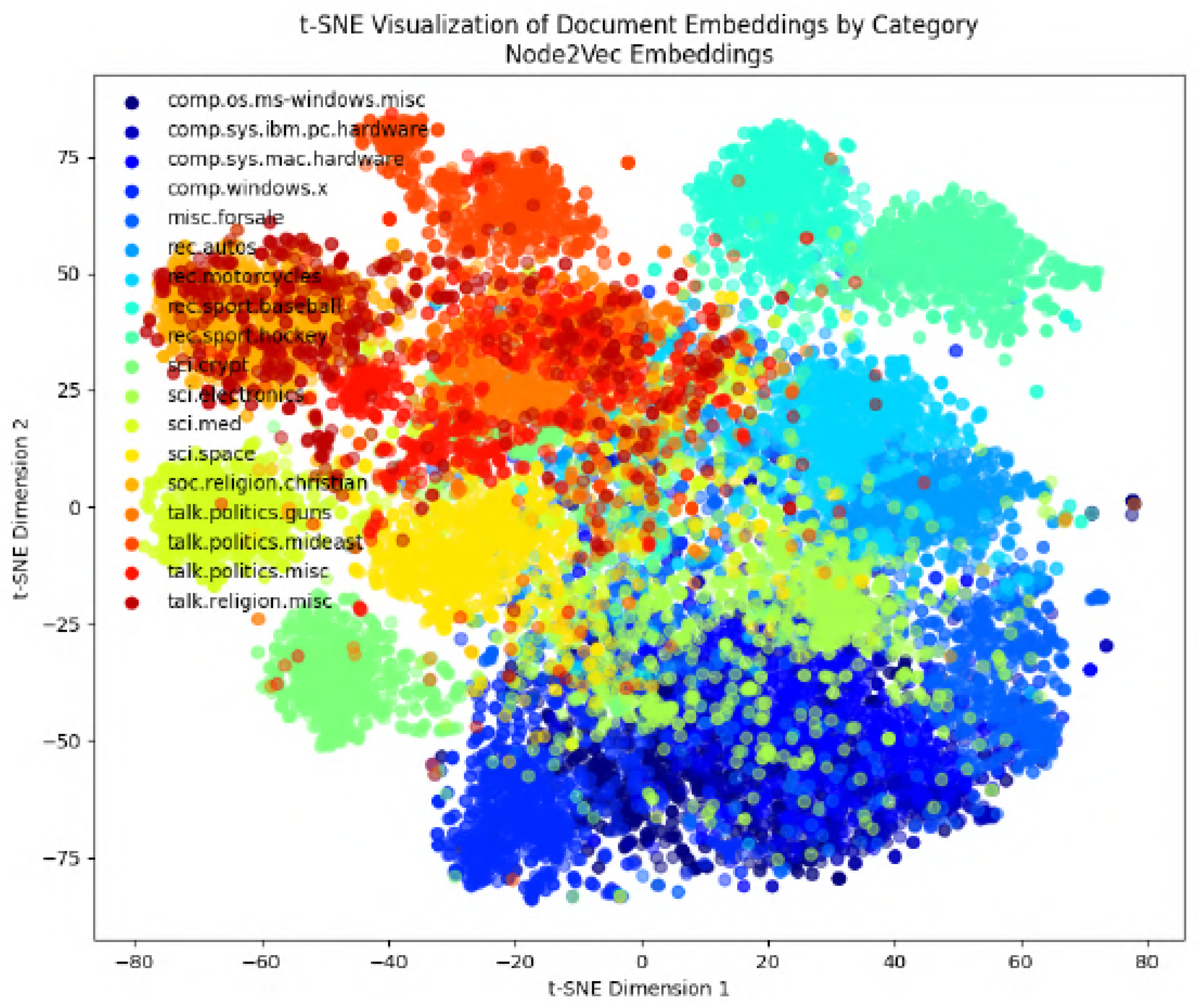
In the following figures, we will delve into the Word2Vec and Node2Vec methodologies through visualization, employing t-SNE, a potent technique for dimensionality reduction and data visualization.
Figure 11,
Figure 12,
Figure 13,
Figure 14,
Figure 15,
Figure 16 and
Figure 17 illustrate documents in a two-dimensional space, with each colored according to its respective class under different preprocessing techniques. Notably, we observe that Node2Vec yields more distinct clusters in this space. A similar trend is apparent in the BBC collection, as depicted in the figure.
5. Conclusions and Future Work
In this paper, we proposed an initial ranking approach that can be implemented as a first-stage ranker in reranking schemes or, in some cases, as a standalone ranker. The model offers structures that can be exploited in various domains, such as in classification. In conclusion, the proposed extensions notably enhance the graph-based extension of the set-based model. The inclusion of text segments as windows for pruning has notably boosted the performance of the ranking model, particularly for larger window sizes, while the integration of embeddings ensures result stability, particularly for large window sizes. Therefore, the proposed model exhibits capability in addressing ranking tasks, whether as a standalone model or as a first-stage ranker.
Additionally, the proposed method contains intermediate structures that can be implemented for various tasks. The main task we explored in this paper was that of classifying documents into categories. We observed that the proposed graph methods contain information capable of categorizing documents on a binary problem, as well as on multiple classification problems regardless of the number of categories, leveraging node embeddings. Therefore, we offer a model that is capable of tackling the two main tasks of information retrieval and data mining.
The existence of an intermediate structure creates an increase in time and space complexity in the model’s indexing stage. However, if the model is applied to an information retrieval task, document graphs and the collection union graph can be disregarded after the indexing phase. Although, to fully acknowledge the models’ advantages, it is recommended that such structures be stored in appropriate databases (e.g., Neo4j [
38]).
Another important aspect to consider pertains to the absence of embeddings. Despite the abundance of pretrained embeddings, we cannot guarantee the presence of a representation for every term, nor can we ensure its quality. The quality of embedding vectors is not solely determined by the model that generates them; rather, it is context-dependent. Consequently, there may be instances where fine-tuning or even training the model from scratch becomes necessary. While this process can increase computational complexity, such cases are rare.
In future research, a focal point of its direction should elaborate on the window aspect of the model, exploring linguistically sound window options that will also capture the notion of a paragraph. The windowed algorithm creates cliques connected with bridge edges. Such edges contain nodes that are important for graph cohesion. Exploratory research about the importance of those nodes in the document, as well as their role inside the text (i.e., keywords or stopwords), should be conducted as a keyword- or stopword-detection problem that can be applied in summarization tasks. Furthermore, for the computational aspect, the model contains algorithms that can be parallelized or computed for distributed implementation frameworks such as Apache Spark [
39]. Finally, the collection union graph can be implemented as an online indexer. Each node can contain a label, which will store any information needed by the model to form a knowledge graph-like structure. When an edge information is changed, the respective nodes will recalculate the necessary weights.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}